Contraste de hipótesis para una distribución normal Segundo ejemplo: distribución poblacional normal
Anuncio

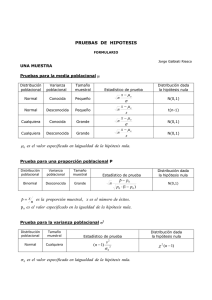
Vídeos docentes sobre Probabilidad y Teoría de la Decisión Contraste de hipótesis para una distribución normal F. J. Díez Vegas Dpto. Inteligencia Artificial. UNED fjdiez@dia.uned.es www.ia.uned.es/~fjdiez Segundo ejemplo: distribución poblacional normal X Objetivo: estudiar la relación entre la vitamina X y el síndrome Y X Hecho: la concentración de X en la sangre de personas sanas es 128 μg/cm3 (desviación estándar 20 μg/cm3) X Datos: análisis de sangre de 25 pacientes con el síndrome Y El promedio de la concentración de X es 117 μg/cm3 X Pregunta: ¿Hay asociación entre el déficit de vitamina X y la presencia del síndrome Y? (Sólo queremos averiguar si hay asociación. No pretendemos demostrar relación causal.) 1 Contraste de hipótesis (para este ejemplo) 1. Hipótesis experimental: HE = “μ < 128” 2. Hipótesis nula: H0 = “μ ≥ 128” 3. Tipo de distribución poblacional: normal (gaussiana) 4. Distribución poblacional, en el límite de la hipótesis nula: − 1 P( x | μ = 128) = e σ 2π ( x −μ )2 2σ 2 − 1 = e 20 2π ( x−128)2 2×202 P(x | μ=128) 0.025 0.02 0.015 0.01 0.005 0 50 100 150 200 250 x Distribución (poblacional) del nivel de X en sangre, X para el valor límite de la hipótesis nula 2 5. Tamaño de la muestra: n = 25 6. Distribución muestral para el estadístico X (promedio del nivel de X): distribución normal (gaussiana), con μ′ = μ = 128 σ′ = σ = n 20 =4 25 es decir, P( x | μ = 128) = − 1 e σ ′ 2π ( x −μ′)2 2σ ′2 = − 1 e 4 2π ( x −128)2 2×42 P(x | μ=128) 0.12 0.10 0.08 0.06 0.04 0.02 0 50 100 150 200 250 x Distribución (muestral) de X, el promedio de X para el valor límite de la hipótesis nula 3 Vista ampliada P(x | μ=128) 0.12 0.10 0.08 0.06 Resultado experimental 0.04 0.02 0 110 115 120 125 130 135 140 145 x Distribución (muestral) de X, el promedio de X para el valor límite de la hipótesis nula 7. Resultado experimental: xexp = 117 8. Valor p 1 p = P( x ≤ 117 | μ = 128) = 4 2π 117 ∫ − e ( x −128)2 2×42 d x = 0'003 −∞ 4 Vista ampliada P(x | μ=128) 0.02 Resultado experimental p = P( x ≤ 117 | μ = 128) 0 x 110 115 117 120 p = área bajo la curva Probabilidad de error tipo I (α) P(x) 0.12 Umbral de decisión 0.10 0.08 significativo Distribución de X según la hipótesis nula no significativo 0.06 0.04 0.02 0 100 Probabilidad de error tipo I 110 120 130 140 x 5 Probabilidad de error tipo II (β) P(x) 0.12 0.10 Distribución de X para personas enfermas Umbral de (muestra n=25) decisión 0.08 significativo Distribución de X para personas sanas (muestra n=25) no significativo 0.06 Probabilidad de error tipo II 0.04 0.02 0 100 110 120 130 140 x Nota: Sólo podríamos calcular la probabilidad de error tipo II si conociéramos la distribución de X para personas enfermas (que es precisamente lo que no conocemos) Ambos tipos de error son posibles P(x) 0.12 0.10 Distribución de X según HE 0.08 significativo Umbral de decisión Distribución de X según H0 no significativo 0.06 Probabilidad de error tipo II 0.04 0.02 0 100 Probabilidad de error tipo I 110 120 130 140 x 6 Compromiso entre ambos tipos de error P(x) 0.12 0.10 Distribución de X para muestras de personas enfermas (n=25) Umbral de decisión significativo Distribución de X para muestras de personas sanas (n=25) no significativo 0.08 0.06 0.04 0.02 0 100 Probabilidad de error tipo II Probabilidad de error tipo I 110 120 130 140 x Al intentar eliminar el error tipo II aumenta la probabilidad de error tipo I Tipos de error Significativo ( p < α): concluimos HE HE cierta (H0 falsa) HE falsa (H0 cierta) Acierto: nuevo conocimiento Error tipo I (α): conclusión errónea Acierto: No significativo ( p > α): Error tipo II (β): no concluimos nada no se concluye nada no se concluye nada ¿Es posible disminuir a la vez la probabilidad de error tipo I y la probabilidad de error tipo II? 7 Solución: aumentar el tamaño de la muestra P(x) 0.16 Distribución de X para muestras de personas enfermas (n=50) Umbral de decisión 0.14 0.12 Distribución de X para muestras de personas sanas (n=50) significativo no significativo 0.10 0.08 0.06 0.04 Probabilidad de error tipo II Probabilidad de error tipo I 0.02 0 100 110 120 130 140 x Así conseguimos dismunuir simultáneamente las probabilidades de los dos tipos de error 8