Análisis avanzado de datos
Anuncio

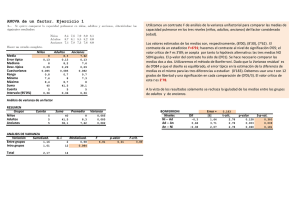
ANÁLISIS AVANZADO DE DATOS Analice la figura en la que aparecen los gráficos Box−Plot para la Variable producción, en dos cultivos A y B y a partir de ese análisis responda a las siguientes preguntas. 1.− El valor mediano es el mismo en ambos cultivos. 2.−La distribución de la variable producción en el cultivo A es simétrica. 3.−La variable producción en el cultivo A, presenta mayor dispersión que en el cultivo B. 4.−En el cultivo B el 25% de los datos toman valores entre 14 y 15 aproximadamente. 5.−Al menos el 25% de los datos del cultivo B son mayores que cualquiera (el 100%) de los datos del cultivo A. −−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−− 6.−La media aritmética no se ve afectada por los valores más extremos de la distribución. 7.−La suma de frecuencias absolutas coincide con el tamaño de la muestra. 8.−La frecuencia absoluta es un valor acotado entre cero y uno. 9.−La mediana está afectada por valores extremos de la variable. 10.−La desviación típica muestral sirve para valorar la dispersión de los datos en torno al valor central de la muestra. 11.−El error estándar de la media sirve para valorar la variabilidad de la media en el muestreo. 12.−La varianza es una medida de dispersión que presenta la ventaja de venir expresada en las mismas unidades que la variable. 13.−La desviación típica muestral y el error estándar de la media proporcionan la misma información, por eso es indiferente utilizar una u otra en una publicación científica. 14.−Cuando tenemos una distribución asimétrica utilizaremos la mediana en lugar de la media como medida de tendencia central. 15.−El coeficiente de variación es una medida de dispersión adimensional. 16.−En una distribución simétrica la media y la mediana coinciden. 17.−Una medida de tendencia central irá siempre acompañada de una medida de dispersión. 18.−Por riesgo tipo I entendemos la probabilidad de aceptar la hipótesis alternativa indebidamente. 19.−Por riesgo tipo II entendemos la probabilidad de rechazar la hipótesis nula indebidamente. 1 20.−Por potencia del contraste entendemos la probabilidad de aceptar la hipótesis nula cuando es verdadera. 21.−La potencia del contraste es 1−ð donde ð es la probabilidad de cometer un error de tipo II. 22.−En un contraste de comparación de medias la hipótesis nula depende del propósito del investigador. 23.−En un contraste para comparación de dos medias, la hipótesis nula es: Ho: x1 = x2 24.−En un contraste bilateral para comparación de dos medias, la hipótesis alternativa es: Ha: x1 = x2 La tabla siguiente muestra el análisis de la varianza para la comparación de la temperatura media del agua en cuatro semanas diferentes: SEMANA RESIDUAL DF SUM OF SQUARES 3 24 64,777 127,417 MEAN SQUARE 21,592 5,309 F−VALUE P−VALUE 4,067 0,181 Y las correspondientes medias para las semanas son Count 7 7 7 7 Mean 6,886 7,857 9,171 10,943 Std.Dev. 0,694 1,277 2,052 3,862 Std Error. 0,262 0,482 0,775 1,460 25.−La hipótesis nula es Ho: ð1= ð2 = ð3 = ð4 = ð5 26.− La hipótesis alternativa correspondiente es: Ha: ð1 = ð2 = ð3 =ð4 27.−El contraste es significativo. 28.−No es necesario realizar un contraste de hipótesis ya que las medias muestrales son claramente diferentes. 29.−Basándonos en el p−valor es claro que las diferencias observadas en la medias pueden ser debidas al azar. 30.−El contraste es altamente significativo. 31.−El p−valor de un contraste es la probabilidad de encontrar valores más extremos que los encontrados para nuestra muestra particular. 32.−Si el p−valor correspondiente a un contraste es menor de 0.5 rechazaremos la hipótesis nula. 33.−Rechazaremos la hipótesis nula si el p−valor es menor que el nivel de significación ð. 34.−En este caso aceptamos la hipótesis alternativa. 2 El gráfico siguiente muestra las medias de las semanas con los respectivos intervalos de confianza: 35.−El gráfico con los intervalos de confianza es una primera aproximación a la comparación de medias. 36.−Un intervalo de confianza para un nivel de significación, será tanto más preciso cuanta más amplitud tenga. 37.− Para que la estimación de un parámetro mediante un intervalo de confianza sea más precisa (diferencia entre el estimador y el verdadero parámetro poblacional más pequeña), podemos aumentar el nivel de confianza. 38.−Para que la estimación de un parámetro mediante un intervalo de confianza sea más precisa, podemos aumentar el nivel de significación. 39.−La precisión de la estimación aumenta con el tamaño muestral. 40.−En este caso, todos los intervalos se cruzan por lo que no se detectan diferencias claras en las semanas. 41.−La contradicción entre en ANOVA y el gráfico se debe a que este último no tiene en cuenta simultáneamente la información de todas las semanas. La tabla siguiente muestra el test LSD para la comparación de las medias. Mean diff. −0,971 −2,286 −4,057 −1,314 −3,086 −1,771 Crit.Diff 2,542 2,542 2,542 2,542 2,542 2,542 P−value 0,4380 0,0758 0,0031 0,2965 0,0194 0,1633 42.−Se detectan diferencias significativas entre todas las parejas salvo la (1,4) y la (2,4). 43.−Parece que hay una contradicción ya que si el ANOVA ha resultado significativo, todas las medias poblacionales son distintas. 44.−El ANOVA requiere que las poblaciones sean normales y homoscedasticas. 45.−El test LSD está protegido frente al riesgo tipo I por lo que se puede encontrar más diferencias de las que realmente existen en los datos. 46.−El test LSD para la comparación de medias por parejas es el más conservador. La tabla siguiente muestra el test de Bonferroni para la comparación de las medias por parejas: 1,2 1,3 1,4 2,3 Mean diff. −0,971 −2,286 −4,057 −1,314 Crit. Diff 3,541 3,541 3,541 3,541 P−value 0,4380 0,0758 0,0031 0,2965 3 2,4 3,4 −3,086 −1,771 3,541 3,541 0,0194 0,1633 Comparisons in this table are not significant unless the corresponding p−value is less than 0,0083. 47.−La prueba de Bonferroni permite llevar a cabo cualquier tipo de comparaciones por parejas, manteniendo el riesgo Tipo I por debajo de uno prefijado. 48.− La prueba de Bonferroni se puede utilizar con tamaños demuestras iguales o diferentes. 49.− Para este caso solamente se detectan diferencias significativas entre las semanas 1 y 4. 50.−Si utilizáramos la prueba de Tukey para la comparación de las semanas 1 y 2, el contraste sería no significativo. 51.−Si utilizáramos la prueba Tukey para la comparación de las semanas 1 y 4, el contraste sería significativo. 52.−No tenemos información suficiente para contestar las preguntas 50 y 51. 53.−Cuando intervienen en el contraste más de dos tratamientos los valores críticos de Tukey son mayores que los de Student para un mismo nivel de significación. 54.−Cuando intervienen en el contraste más de dos tratamientos los valores críticos de Bonferroni son mayores que los de Student para un mismo nivel de significación. 55.−Cuando intervienen en el contraste más de dos tratamientos los valores críticos de Bonferroni son menores que los de Tukey par un mismo nivel de significación. 56.− Si se comparan 4 grupos, es decir se pueden llevar a cabo 6 comparaciones por parejas, con un nivel de significación global de 0.05; el nivel de significación para cada comparación utilizando la aproximación de Bonferroni es 0.0083. Se desean comparar el porcentaje de mejora que producen 3 tipos de droga (A, B, C) en dos tipos de pacientes (esquizofrénicos y depresivos), para lo cual se realiza un diseño factorial con dos réplicas por casilla, obteniéndose los siguientes resultados para el Análisis de la varianza. Drogas Enfermedad D*E Residual DF SUM OF SQUARES 2 1 2 6 0,040 3,333E−5 0,086 0,005 MEAN SQUARE 0,20 3,333E−5 0,043 0,001 F−VALUE P−VALUE 26,130 0,043 56,130 0,0011 0,8417 0,0001 57.−En el análisis de la varianza de dos vías tenemos tres hipótesis a contrastar, dos para los efectos principales y una para la interacción. 58.−En general, el análisis de la varianza no detecta significación si la variabilidad entre grupos es más pequeña que la variabilidad dentro de los grupos. 59.−En principio se detectan diferencias significativas entre drogas pero no entre tipos de pacientes. 4 60.−Se detectan una interacción significativa entre drogas y tipos de pacientes. 61.−Si en un ANOVA de dos factores con interacción no se detectan diferencias entre los niveles de los factores principales pero se detecta interacción, la conclusión es que los factores no influyen en la respuesta. 62.− Si en un ANOVA de dos factores con interacción no se detectan diferencias entre los niveles de los factores principales pero se detecta interacción, la conclusión es que cada uno de los factores influye en la respuesta de manera diferente en cada uno de los niveles del otro factor. 63.−Si en un ANOVA dos factores con interacción se detecta una interacción significativa, las conclusiones obtenidas a partir de los contrastes para los factores principales pueden ser erróneas. 64.−En un ANOVA de dos factores con interacción sólo sacaremos conclusiones a partir de los contrastes para los factores principales si la interacción es significativa. 65.− En el ejemplo anterior, no podemos saber si hay diferencias entre enfermedades ya que éstas dependen de las drogas. 66.− Para que un experimento esté correctamente diseñado los tratamientos han de seleccionarse al azar sobre unidades experimentales homogéneas. 67.−La aleatorización puede introducir errores sistemáticos en las observaciones que aumentan el error experimental. 68.−Los modelos de diseño experimental tienen una parte controlada y una parte no controlada que mide la variabilidad intrínseca del material experimental. 69.−Para que un experimento esté diseñado es necesario que las unidades experimentales difieran de forma sistemática. 70.−La precisión de un diseño experimental es mayor cuanto más pequeño sea el tamaño muestral. 71.−Los diseños factoriales permiten controlar todas las combinaciones de niveles de los factores. 72.−El diseño en bloques permite controlar la variabilidad experimental procedente de la heterogeneidad de las observaciones. 73.−En un diseño factorial se prueban todas las combinaciones de niveles de los factores. 74.−El término de error en un modelo de diseño experimental recoge la variabilidad intrínseca de las unidades experimentales. 75.−Los efectos de los tratamientos se estiman a partir de las medias de las observaciones que recibieron cada uno de ellos. 76.−La parte que depende sólo de la unidad experimental se estima como la observación menos la media de tratamiento que se le aplicó. 77.−La normalidad de las poblaciones estudiadas no es necesaria par la aplicación correcta de los métodos de diseño experimental. 78.−Sólo es posible aislar la interacción cuando se prueban varias réplicas de cada tratamiento. 5 79.−Cuando existe interacción se dice que el modelo es aditivo. 80.−El modelo para un experimento con bloques al azar es xij = ð + ði + ðij 81.−El modelo para un experimento factorial con dos factores de variación considerando la interacción es xij = ð + ði + ðj + (ðð)ij + ðij 82.−La suma de cuadrados dentro de los grupos en el análisis de la varianza de 1 vía se calcula como: QE = 83.−La suma de cuadrados entre grupos mide la variabilidad controlada. 84.−La suma de cuadrados entre grupos mide la variabilidad no controlada en un análisis de la varianza. 85.−Todos los factores no controlados aumentan la variabilidad intrínseca de las observaciones y por tanto la variabilidad residual en el análisis de la varianza. 86.−Es más fácil detectar significación en las diferencias entre tratamientos cuanto mayor sea la variabilidad residual. 87.−Cuando dos factores no interactúan se dice que sus efectos son aditivos. 88.− En un gráfico de interacción, las líneas que representan a los niveles de uno de los factores son paralelas cuando la interacción resultó significativa en el análisis de la varianza. 89.−En un análisis de la varianza de dos vías con interacción se contrastan tres hipótesis distintas. 90.−Cuando en un experimento factorial se detecta interacción se dice que el modelo es multiplicativo. 6