Lectura crítica de estudios de diagnóstico
Anuncio

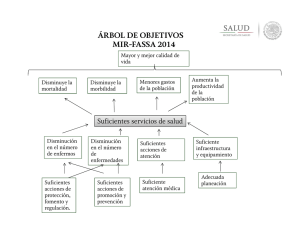
CAPÍTULO Lectura crítica de estudios de diagnóstico Ana Royuela Vicente, María Luisa Montes Ramírez y Antonio Jesús Martín Mateos Lectura crítica de la evidencia clínica, Capítulo 6, 87­99 • Definir la exactitud de una prueba diagnóstica. • Tratar los aspectos clave del diseño de los estudios de exactitud de una prueba diagnóstica. • Recoger los indicadores básicos del diagnóstico, sensibilidad, especificidad, valores predictivos y cocientes de probabilidades. • Reflexionar sobre el uso de las pruebas diagnósticas en la clínica. Introducción Según la Real Academia Española (RAE), el diagnóstico es el arte o acto de conocer la naturaleza de una enfermedad mediante la observación de sus síntomas y signos. Es el primer paso en la valoración del estado de un paciente, y solo desde un correcto diagnóstico podrá establecerse un tratamiento adecuado y un óptimo seguimiento posterior. Los estudios de diagnóstico suponen un interesante reto en la valoración de aquellos aspectos que los definen. Por un lado, no gozan de una metodología tan ampliamente desarrollada, conocida y estandarizada como otro tipo de estudios, como los estudios de tratamiento o las RS. Además, llevan asociada la dificultad de tener que presentar sus resultados siempre en forma de binomio. Cuando se hable de la sensibilidad en una prueba diagnóstica, tendrá que hablarse, ineludiblemente, también de su especificidad. El marco conceptual de evaluación de pruebas diagnósticas está evolucionando de manera sustancial en los últimos años. Ha pasado de considerarse un mero proceso de evaluación secuencial en fases (1) , mimetizando en mayor o menor medida las fases I a IV del EC, a constituir una evaluación más amplia, que engloba desde aspectos técnicos de factibilidad de la prueba, reproducibilidad y validez, hasta aspectos referentes a su impacto clínico y costes, teniendo en cuenta el contexto clínico donde se va a aplicar (2) . Por todo ello, se hace muy relevante comprender los aspectos más importantes del diseño de los estudios sobre diagnóstico, saber interpretar los resultados de un estudio sobre evaluación de pruebas diagnósticas y aplicar estos conocimientos a los diferentes escenarios clínicos en los que nos vemos envueltos diariamente. Escenario Francisco es un varón de 53 años con una infección por el virus de la inmunodeficiencia humana (VIH) de larga evolución. Ha recibido múltiples tratamientos antirretrovirales con respuestas parciales, pero desde hace 5 años recibe una pauta compleja con inhibidores de la proteasa que ha conseguido controlar la infección y recuperar parcialmente su inmunosupresión, manteniendo un recuento de linfocitos CD4+ de alrededor de 270 cél./μl. Acude a su revisión programada con el internista y le comenta que en el último mes tiene fiebre por las tardes de hasta 38°C, está más cansado de lo habitual y en la última semana ha comenzado a toser. Tras la anamnesis y exploración, su médico le explica que hay que descartar como primera posibilidad la tuberculosis pulmonar, y le solicita una radiografía de tórax y la recogida de muestras de esputo para el análisis microbiológico. Las pruebas no son concluyentes y, aunque las muestras de esputo se siembran para cultivo en medio de micobacterias, estos resultados tardarán 2 meses. Los síntomas empeoran y el inicio del tratamiento antituberculoso requiere modificar por completo la medicación antirretroviral, con el consiguiente riesgo de la pérdida del control de la infección por el VIH, por lo que la seguridad en el diagnóstico es muy importante. Se decide realizar una broncoscopia con toma de muestras y, tras comentar el caso con el microbiólogo, se propone realizar una prueba de detección de micobacterias mediante amplificación de ADN. Esta prueba es muy nueva, por lo que el internista busca información en PubMed y encuentra un artículo con referencias específicas para población infectada por el VIH. El resultado de la prueba de amplificación de ADN resulta positivo. • Las pruebas de detección de ADN de micobacterias en muestras de esputo, ¿tienen una buena rentabilidad diagnóstica en pacientes infectados por el VIH? • La positividad de la prueba de detección de ADN de micobacterias, ¿confirma el diagnóstico de Francisco con suficiente seguridad como para iniciar el tratamiento antituberculoso antes de saber los resultados del cultivo? Puntos clave de la lectura crítica de estudios de diagnóstico En el contexto de la práctica médica, una buena parte de nuestra labor consiste en diagnosticar, es decir, realizar mediciones e interpretar sus resultados. Cuando medimos, debemos tener en cuenta siempre la existencia de cierta variabilidad en la medición. Esta variabilidad es explicada, en parte, por las características de la población en la que se realiza, las características de la enfermedad que estamos midiendo y el propio proceso de medición. La variabilidad se divide en dos aspectos fundamentales: validez y reproducibilidad. La validez hace referencia al grado en que una medida se aproxima al valor real que se pretende medir; y la reproducibilidad se entiende como el grado en que una prueba diagnóstica produce los mismos resultados al aplicarse sobre el mismo sujeto. En este libro, se tratarán exclusivamente los puntos clave de los estudios sobre validez de pruebas diagnósticas. El primer punto que hay que tener en cuenta cuando leemos un estudio sobre validez de pruebas diagnósticas es el diseño del estudio. El diseño óptimo para evaluar la validez de una prueba diagnóstica es un estudio observacional transversal, donde, a una serie consecutiva de pacientes, de forma ciega e independiente se les aplica la prueba que hay que evaluar y una prueba de referencia o patrón de oro (del inglés, gold standard ), comparándose ambas clasificaciones. La selección de la muestra debe ser representativa de la población en la que posteriormente se utilizará la prueba y, por tanto, incluir un espectro de pacientes lo más parecido posible al del medio en que la prueba se pretenda usar (es decir, pacientes con enfermedad leve, moderada o grave, pacientes en etapa temprana y tardía de la enfermedad). Esto se consigue reclutando a una serie consecutiva de pacientes, para así minimizar el sesgo de selección. Posteriormente, todos los resultados deben confirmarse, tanto los positivos como los negativos, mediante una prueba de referencia o patrón de oro asumiendo que esta clasifica correctamente a los enfermos y a los no enfermos. La prueba de referencia es el criterio diagnóstico que define quién tiene «realmente» la enfermedad o condición de estudio. Es importante que ambas pruebas se realicen simultáneamente, pues cualquier lapso temporal entre ellas puede afectar a su resultado. Tanto la prueba que se va a evaluar como la de referencia deben ser aplicadas en todos los pacientes del estudio. El proceso de realización y evaluación de ambas pruebas, idealmente, debe ser ciego. Es decir, ambas pruebas deben realizarse e interpretarse sin conocer el resultado de la otra, y de forma independiente, es decir, la aplicación de la prueba de referencia no debe estar condicionada por los resultados de la prueba evaluada. En algunas situaciones, la prueba de referencia puede resultar invasiva o costosa, y pueden surgir reparos en la realización de la prueba de referencia a los pacientes con resultado negativo en la prueba que se va a evaluar. Una alternativa es seguir a los pacientes por un tiempo adecuado y evaluar así si son verdaderos negativos (VN). Otro de los puntos clave que hay que tener en cuenta en la lectura crítica de un artículo sobre evaluación de pruebas diagnósticas es el análisis de los resultados en ambas pruebas. Cuando el resultado de las pruebas es de carácter dicotómico (positivo o negativo), se puede realizar una clasificación cruzada de los resultados de ambas pruebas (la sometida a evaluación y la prueba de referencia) en forma de una tabla cruzada 2 × 2. A partir de la tabla cruzada, los resultados posibles son cuatro: la prueba ha dado un resultado positivo que ha sido confirmado por la prueba de referencia, con lo que se tratará de verdadero positivo (VP). Si el resultado de la prueba es negativo y se confirma la ausencia de enfermedad, se trata de un VN. Las situaciones en las que la prueba ha dado un resultado erróneo, es decir, un resultado no verificado por la prueba de referencia, tendremos falsos positivos (FP) o falsos negativos (FN), en función de si el resultado de la prueba fue positivo o negativo, respectivamente. En la tabla 6­ 1 (t0010) se representa una tabla de clasificación cruzada, y la notación contenida en sus cuatro celdas ayuda a explicar los cálculos de los índices de validez diagnóstica. Para medir el rendimiento diagnóstico de una prueba, se proponen distintas parejas de índices. Tabla 6­1 Clasificación cruzada 2 × 2 Prueba de referencia Presente Ausente Total VP a FP b a + b Negativo FN c VN d c + d Total b + d N Prueba que se va a evaluar Positivo a + c FN, falsos negativos; FP, falsos positivos; VN, verdaderos negativos; VP, verdaderos positivos. Sensibilidad y especificidad: son los índices más utilizados como índices de validez de las pruebas diagnósticas. Ambos se interpretan fácilmente, tomando valores entre 0 (prueba no válida) y 1 (prueba perfectamente válida). La sensibilidad se refiere a la probabilidad que tiene una prueba diagnóstica para proporcionar un resultado positivo entre los sujetos enfermos: Sens = a a+c La especificidad refleja la probabilidad que tiene una prueba diagnóstica de dar un resultado negativo entre los sujetos que no tienen la enfermedad: Esp = d b+d Cuando el objetivo es la detección de enfermedades graves y tratables, es necesaria una prueba muy sensible. Las pruebas que se aplican para cribado de enfermedades, por ejemplo, deben ser pruebas con alta sensibilidad. En cambio, con la especificidad se persigue la confirmación de los sujetos no enfermos. Es preferible una prueba muy específica cuando la enfermedad es grave, pero difícilmente tratable, y que un resultado falsamente positivo pueda tener una gran transcendencia, por ejemplo, un falso diagnóstico de VIH o de cáncer. En este sentido, se propone una regla nemotécnica que ayuda a valorar los resultados obtenidos en la sensibilidad y especificidad: SnNout recuerda que cuando una prueba diagnóstica tiene una sensibilidad elevada (sensitivity), los resultados negativos ayudan a descartar el diagnóstico con alta probabilidad (rule out). SpPin recuerda que si la prueba tiene alta especificidad (specificity), los resultados positivos son muy indicativos para confirmar el diagnóstico (rule in). Valores predictivos positivo y negativo: aunque los anteriores son los índices más recogidos en las publicaciones científicas de evaluación de prueba diagnóstica, no son índices útiles para la práctica, pues, en realidad, cuando se solicita una prueba, no se conoce si el paciente está enfermo o no. Lo que se quiere conocer es la probabilidad de estar enfermo a partir del resultado de la prueba. En este contexto de práctica clínica, parece más útil hablar de valores predictivos, es decir, la probabilidad de un diagnóstico cuando el resultado de la prueba es positivo o negativo. El valor predictivo positivo se refiere a la probabilidad de tener la enfermedad, dado que se ha observado un resultado positivo: VP+ = a a+b Con el valor predictivo negativo, se obtiene la probabilidad de no tener la enfermedad, dado que se ha observado un resultado negativo: VP− = d c+d Sin embargo, a pesar de su atractiva interpretación, no son unos índices adecuados para su uso como evaluación del rendimiento diagnóstico de una prueba, pues están muy influidos por la prevalencia de la condición que se está estudiando. Para una misma prueba diagnóstica, el aumento de la prevalencia aumenta el valor predictivo positivo y disminuye el valor predictivo negativo, y viceversa. Esto explica que una misma prueba se comporte de forma distinta según el ámbito en el que se aplique. Por tanto, el valor predictivo está relacionado con la aplicabilidad de la prueba. La probabilidad de que un paciente con prueba positiva esté realmente enfermo dependerá de la prevalencia de la enfermedad. Haz la prueba. En una población de 100.000 habitantes, hay una prevalencia de la enfermedad X del 1%. Tenemos una sensibilidad de la prueba diagnóstica del 90% y una especificidad del 90%. El 1% de 100.000 habitantes son 1.000 pacientes. Habrá, por tanto, 1.000 enfermos y 99.000 sanos. Si la sensibilidad de la prueba es del 90%, de los 1.000 pacientes enfermos, diagnostica correctamente a 900 (a). Si la especificidad de la prueba es del 90%, de los 99.000 sanos, diagnostica falsamente como enfermos a 9.900 (b). Por tanto, de los pacientes diagnosticados como enfermos 9.900 + 900 = 10.800 (a + b), solo 900 (a) son correctamente diagnosticados 900/10.800 (a/a + b), el 8,33%. Si haces estos mismos pasos variando la prevalencia, observarás cómo se va a ir modificando el porcentaje. Cocientes de probabilidad positivo y negativo: también denominados razones de verosimilitud o likelihood ratios (LR en la literatura inglesa). Son una pareja de índices menos populares que los anteriores, pero más útiles para interpretar y utilizar el resultado de una prueba diagnóstica (3) . El cociente de probabilidad positivo (CP+) refleja cuánto más frecuente es obtener un resultado positivo entre los enfermos que entre los no enfermos. Si la prueba fuera totalmente inútil para diagnosticar una enfermedad (piénsese en una moneda tirada al aire), el resultado positivo (p. ej., obtener una cara) se obtendría con la misma frecuencia en los enfermos que en los no enfermos, con lo que ese resultado positivo no aportaría ninguna información y el CP+ sería 1. Cuanto más frecuente sea el resultado positivo en los enfermos con respecto a los no enfermos, más información aporta ese resultado y, por tanto, mayor será el valor del CP+. De la misma forma, el cociente de probabilidad negativo (CP–) representa cuánto más frecuente es el resultado negativo entre los enfermos que entre los no enfermos. Si el resultado negativo (la cruz de la moneda de nuestro ejemplo) se obtuviera con la misma frecuencia en los enfermos y en los no enfermos, este resultado no contendría ninguna información (CP– igual a 1). Cuanto menos frecuente sea el resultado negativo en los enfermos con respecto a los no enfermos, más información aporta y menor será el valor del CP– (4) . Cociente de probabilidad positivo (CP+): cuánto más frecuente es obtener un resultado positivo entre los enfermos que entre los no enfermos: VP CP+ = V P +F N FP = sen 1−esp F P +V N Cociente de probabilidad negativo (CP–): cuánto más frecuente es obtener un resultado negativo entre los enfermos que entre los no enfermos: FN CP− = V P +F N VN = 1−sen esp F P +V N No te asustes con la fórmula; si lo piensas bien es muy fácil recordarla. Si conocemos la sensibilidad de la prueba y su especificidad, solo tienes que hacer un sencillo cálculo. Haz la prueba. Tenemos una prueba diagnóstica con una sensibilidad del 95% y una especificidad del 90%. Si te fijas bien en la fórmula anterior, el cociente de probabilidad positivo realmente es el cociente entre la sensibilidad y el «error» de la especificidad (1 – esp); si la especificidad es del 90%, hay un 10% de «error» en la especificidad, por tanto, nuestro ejemplo será 95/10 = 9,5. Para el cociente de probabilidad negativo, usaremos el «error» de la sensibilidad (1 – sen) y la especificidad, en nuestro ejemplo 5/90 = 0,055. Antes de realizar una prueba diagnóstica, la probabilidad de padecer la enfermedad en el estudio, denominada probabilidad a priori, coincide con la prevalencia para esa población de esa enfermedad o condición. Utilizando el conocido teorema de Bayes, se puede utilizar el valor del CP (positivo o negativo) del resultado de la prueba para actualizar la probabilidad a priori en probabilidad a posteriori (posprueba). Este cálculo puede obtenerse fácilmente gracias al nomograma desarrollado por Fagan en 1975 (5) ( fig. 6­1 (f0010) ). Trazando una línea de intersección entre la probabilidad a priori y el CP del resultado, se obtiene una probabilidad posprueba. Figura 6­1 Nomograma de Fagan. Si en lugar de un resultado dicotómico, la prueba que se va a evaluar proporciona resultados cuantitativos, los índices de validez diagnóstica deben obtenerse de una manera diferente, mediante la conocida curva ROC (receiver operating characteristic) (6) , escapando su descripción a los objetivos de este libro. Artículo Davis JL, Huang L, Worodria W, Masur H, Cattamanchi A, Huber C, et al. Nucleic acid amplification tests for diagnosis of smear­negative TB in a high HIV­prevalence setting: a prospective cohort study. PLoS One. 2011;6(1):e16321. Disponible en: http://www.plosone.org/article/info%3Adoi%2F10.1371%2Fjournal.pone.0016321 (http://www.plosone.org/article/info%253Adoi%252F10.1371%252Fjournal.pone.0016321) . Plantilla CASPe contestada para este artículo concreto En el cuadro 6­1 (b0010) se muestra la plantilla CASPe contestada para este artículo concreto. CUADRO 6­1 A) ¿Son válidos los resultados del estudio? Preguntas de eliminación 1. ¿Existió una comparación Sí ✓ No sé No con una prueba de referencia Se utilizó el cultivo en medio de micobacterias como el adecuada? patrón de oro, lo cual es correcto. PISTA: ¿es correcto el patrón Además, se utilizó un segundo patrón de oro incorporando criterios clínicos bien definidos en aquellos de oro? (no siempre se puede aplicar el mismo patrón de oro pacientes con cultivo negativo a todos los pacientes) 2. ¿Incluyó la muestra un espectro adecuado de pacientes? Sí ✓ No sé No PISTAS: Para evitar los sesgos de selección, se incluyeron todos los pacientes ingresados en el hospital de Kampala por – ¿Están adecuadamente descritos los pacientes y cómo tos de más de 2 semanas de duración de manera consecutiva. Los pacientes incluidos tenían la sospecha se seleccionaron? de enfermedad – Casi cualquier prueba distingue entre sanos y gravemente enfermos 3. ¿Existe una adecuada descripción de la prueba? Sí ✓ PISTAS: Se define con claridad qué es un resultado positivo, tanto – ¿Se define con claridad qué para la prueba de MTD como para la prueba secA1 PCR. Se especifica cómo realizar la prueba; no obstante, es un resultado positivo y qué No sé No es un resultado negativo? – ¿Se especifica la se remite al lector a otro original anterior donde la descripción fue más exhaustiva para la prueba de secA1 reproducibilidad de la prueba (este puede ser un punto clave en pruebas que dependen del observador, como las técnicas de imagen)? Preguntas detalladas 4. ¿Hubo evaluación Sí ✓ No sé No «ciega» de los resultados? Los investigadores se mantuvieron ciegos para los datos PISTA: ¿las personas que interpretaron la prueba conocían los resultados del clínicos y de la prueba de oro. Los resultados de las pruebas estudiadas solo se desvelaron cuando las muestras estuvieron clasificadas patrón de oro (y viceversa)? 5. ¿La decisión de realizar Sí ✓ No sé No el patrón de oro fue independiente del resultado de la prueba problema? Todas las muestras recogidas se procesaron tanto para el PISTAS: Considera si: cultivo (patrón de oro) como para las pruebas de estudio. Todas las muestras se clasificaron con los mismos criterios – Se incluyeron preferentemente los independientemente del resultado del cultivo resultados positivos en la prueba que se iba a evaluar – Se utilizaron diferentes patrones de oro en los positivos y en los negativos B) ¿Cuáles son los resultados? 6. ¿Se pueden calcular los cocientes de Sí ✓ probabilidad (likelihood ratios)? PISTAS: Test + No sé No Enfermos No enfermos a = 29 b = 7 – ¿Se han tenido en cuenta los pacientes con resultados «no concluyentes»? Test – c = 46 d = 129 Sensibilidad = a/(a + c) = 29/(29 + 46) = – ¿Se pueden calcular los cocientes de probabilidad para distintos niveles de la 38,7% (IC 95%: 27,6­50,6) Especifidad = d/(b + d) = 129/(129 + 7) = prueba, si procede? 94,9% (IC 95%: 89,7­97,9) CP+ = sens/(1 – esp) = 7,5 (IC 95%: 3,5­16,3) CP– = (1 – sens)/esp = 0,65 (IC 95%: 0,54­ 0,78) 7. ¿Cuál es la precisión de los resultados? Sí ✓ No sé No PISTA: hay que buscar o calcular los intervalos de confianza de los cocientes de Los intervalos de confianza de los cocientes de probabilidad son aceptables, pero probabilidad demasiado exactos Resultados para el cultivo y el método secA1 . C) ¿Son los resultados aplicables al escenario? 8. ¿Serán satisfactorias en el ámbito del escenario la reproducibilidad de la prueba y su interpretación? Sí No sé No ✓ El ámbito del estudio es completamente distinto al de Francisco, es población africana, con una incidencia de tuberculosis mucho más elevada que la nuestra, más joven, más inmunodeprimida y con una baja proporción de pacientes que reciben tratamiento antirretroviral PISTA: considera si el ámbito de la prueba es demasiado diferente al del escenario 9. ¿Es aceptable la prueba en este caso? Sí ✓ No sé No La prueba es factible en el medio de Francisco y los PISTA: considera la disponibilidad de la riesgos/molestias son mínimos. Los costes son moderados en nuestro medio, por lo que sí es aceptable prueba, los riesgos y molestias de la prueba y los costes 10. ¿Modificarán los Sí ✓ No sé No resultados de la prueba la decisión sobre cómo actuar? Dadas las dificultades tan importantes para tratar a Francisco con los tuberculostáticos, una prueba que excluya la infección es PISTAS: – Desde la perspectiva muy útil, a pesar de que la validación es en una población diferente. del escenario, si la actitud Si la prueba excluye, espera al resultado del cultivo, que tarda no va a cambiar, la unos 60 días, para definitivamente no tratar la tuberculosis prueba es (al menos) inútil – Considera el umbral de acción y la probabilidad de enfermedad antes y después de la prueba IC 95%, intervalo de confianza al 95%; MTD, Mycobacterium tuberculosis Direct; secA1 PCR, reacción en cadena de la polimerasa para la detección del gen secA1. Evaluación crítica del artículo propuesto (plantilla CASPe) Cómo citar este capítulo Royuela A., Montes M.L., Martín A.J.: Lectura crítica de estudios de diagnóstico. Cabello Juan B. Lectura crítica de la evidencia clínica . 2015. Elsevier Barcelona: pp. 87­99. Referencias 1. Sackett D.L., and Haynes R.B.: The architecture of diagnostic research. BMJ 2002 Mar 2; 324: pp. 539­541 Cross Ref (http://dx.doi.org/10.1136/bmj.324.7336.539) 2. Van den Bruel A., Cleemput I., Aertgeerts B., Ramaekers D., and Buntinx F.: The evaluation of diagnostic tests: evidence on technical and diagnostic accuracy, impact on patient outcome and cost­effectiveness is needed. J Clin Epidemiol 2007 Nov; 60: pp. 1116­ 1122 Cross Ref (http://dx.doi.org/10.1016/j.jclinepi.2007.03.015) 3. Jaeschke R., Guyatt G.H., and Sackett D.L.: Users’ guides to the medical literature. III. How to use an article about a diagnostic test. B. What are the results and will they help me in caring for my patients? The Evidence­Based Medicine Working Group . JAMA 1994 Mar 2; 271: pp. 703­707 Cross Ref (http://dx.doi.org/10.1001/jama.1994.03510330081039) 4. Abraira V.: Índices de rendimiento de las pruebas diagnósticas. SEMERGEN 2008; 28: pp. 193­194 5. Fagan T.J.: Letter: Nomogram for Bayes theorem. N Engl J Med 1975 Jul 31; 293: pp. 257 6. Hanley J.A., and McNeil B.J.: The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 1982 Apr; 143: pp. 29­36 Cross Ref (http://dx.doi.org/10.1148/radiology.143.1.7063747) Copyright © 2016 Elsevier, Inc. Todos los derechos reservados.