Métodos no supervisados Agrupamiento
Anuncio

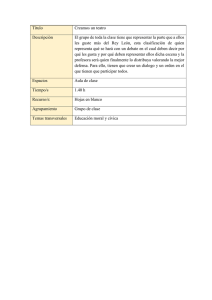
Clasificación de patrones
Abril 2005
Clasificación de patrones
Abril 2005
Agrupamiento (clustering)
Clasificación de patrones:
Métodos no supervisados
´
Los metodos
no supervisados (especialmente el clustering) se usan cuando:
Jordi Porta Zamorano
recopilar y clasificar a mano es costoso
´
Escuela Politecnica
Superior
Dept. de Lingü´ıstica Computacional
´
Universidad Autonoma
de Madrid
Real Academia Española
jordi.porta@uam.es
porta@rae.es
´ de los patrones cambia con el tiempo (o con el corpus)
la caracterizacion
por otro lado:
permite encontrar caracterizaciones utiles
para construir clasificadores
´
abril de 2005
el descubrimiento de grupos y subgrupos que revele la naturaleza de la estructura del problema
IULA-UPF
Page 1
Clasificación de patrones
Abril 2005
IULA-UPF
Page 2
Clasificación de patrones
Abril 2005
Agrupamiento: distancias
Agrupamiento: distancias
´
Las tecnicas
de agrupamiento se basan fundamentalmente en el concepto de similitud (o disimilitud)
entre ejemplos y agrupaciones. Muchas veces se utilizan m étricas (o distancias) para medir la similitud
´
´ usadas son:
entre ejemplos. Las metricas
mas
de Hamming: normalmente aplicada a vectores binarios, da el n umero
de componentes con valores
´
´
distancia de Minkowski: Se trata de una fam´
ılia de metricas
con la forma general:
Lq (~x, ~y ) = (
n
X
distintos.
H(~x, ~y ) = |{i |1 ≤ i ≤ n ∧ xi 6= yi }|
q 1/q
|xi − yi | )
P. ej.: La distancia de Hamming para los vectores (1, 0, 1, 0, 1) y (0, 1, 1, 1, 0) es 4.
i=1
de entre las que destacan las siguientes:
de Tanimoto: tambien aplicada a dos vectores binarios ~
x e ~y :
• Manhattan (o city block ) (q = 1):
L1 (~x, ~y ) =
n
X
T (S1 , S2 ) =
|xi − yi |
|S1 | + |S2 | − 2|S1 ∩ S2 |
|S1 | + |S2 | − |S1 ∩ S2 |
donde S1 son las componentes de ~
x con valor 1 y S2 las de ~y .
i=1
• Euclidea (q = 2):
...
v
u n
uX
L2 (~x, ~y ) = t (xi − yi )2
i=1
IULA-UPF
Page 3
IULA-UPF
Page 4
Clasificación de patrones
Abril 2005
Clasificación de patrones
Abril 2005
Agrupamiento: medidad de similitud
No siempre la medida de similitud es una distancia:
• distancia del coseno:
cos(~
x, ~y )
=
X
i
pP
xi · y i
pP
2
2
x
i i ·
i yi
Agrupamiento: evaluación
usada en recuperación de la información donde un documento se representa por un vector de
La calidad de un agrupamiento puede medirse con:
pesos
similitud intragrupo: normalmente la varianza de las similitudes de los elementos del agrupamiento
• Distancia simétrica de Kullback-Leibler :
KL(p||q)
=
X
i
pi
pi × log2
qi
disimilitud intergrupo: normalmente la disimilitud entre los centroides
• Distancia de χ2 :
´ a la comparacion
´ de rankings
• Distancia de edición: puede ser de aplicacion
• ...
IULA-UPF
Page 5
Clasificación de patrones
Abril 2005
IULA-UPF
Page 6
Clasificación de patrones
Abril 2005
Agrupamiento jerárquico
agrupamiento:
Agrupamiento: técnicas
crear un grupo con cada ejemplo
´ de un grupo do
while haya mas
´
´ usadas son las de agrupamiento jerárquico y las
Existen muchas tecnicas
de agrupamiento, las mas
´ similares y fusionarlos en uno
buscar los dos grupos mas
end while
de agrupamiento dinámico que a su vez pueden ser por reunión o separación.
´
´
Al igual que en los metodos
de clasificaci´
on supervisados, no existe una tecnica
de agrupamiento
´ universal.
de aplicacion
El algoritmo de agrupamiento admite tantas variantes como funciones de similitud puedan definirse.
´ populares para calcular la similitud entre dos agrupaciones son:
Los algoritmos mas
´
single-link : la m´
ınima de las distancias entre todos los pares de ejemplos de cada agrupaci on.
´
´
complete-link : la maxima
de las distancias entre todos los pares de ejemplos de cada agrupaci on.
´
group average: la media de las distancias entre todos los pares de ejemplos de cada agrupaci on.
IULA-UPF
Page 7
IULA-UPF
Page 8
Clasificación de patrones
Abril 2005
Clasificación de patrones
Abril 2005
COBWEB/CLASSIT
Agrupamiento dinámico
´ conocido como k -means o Iterative Distance-based Clustering. Necesita que se le proporTambien
cione a priori el numero
de grupos k . El algoritmo es el siguiente:
´
´
son dos sistemas de agrupamiento clasicos
COWEB funciona con atributos cualitativos y CLASSIT para cuantitativos
agrupamiento:
´
devuelve un arbol
en el que:
seleccionar al azar k ejemplos como centros iniciales de cada grupo;
• las hojas son ejemplos
repeat
asignar cada ejemplo al grupo con menor distancia a su centro;
• los nodos son agrupaciones
recalcular los nuevos centros de cada grupo;
´ de un nuevo ejemplo:
es un algoritmo incremental, la adicion
until los grupos sean estables
• queda absorvido por un nodo
´ denominados centroides pueden corresponderse con ejemplos
Los centros de cada grupo, tambien
´ del arbol
´
• provoca la restructuracion
(split/merge)
o no, en ese caso se les denomina prototipos.
´ de utilidad que mide cuanto
´ puede un agrupamiento predeci el valor de los atribsegun
´ una funcion
´
Los grupos se consideran estables cuando los ejemplos no cambian de grupo respecto la iteraci on
utos de sus ejemplos:
anterior.
Se pueden obtener agrupaciones jerarquizadas tomando k
= 2 y aplicando el mismo algoritmo de
P
l
p(Cl )
P P
i
j (p(ai
= vij |Cl )2 − p(ai = vij )2 )
k
en la que Cl son agrupaciones, ai atributos y vij los valores del atributo ai
manera recursiva sobre los ejemplos de cada grupo.
IULA-UPF
CU (C1 , . . . , Ck ) =
Page 9
IULA-UPF
Page 10