Pronósticos Electorales para Chile Este es el primer intento serio
Anuncio

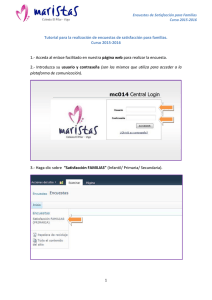
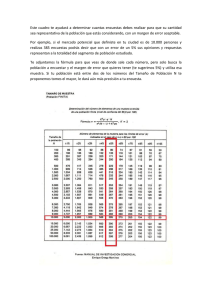
Pronósticos Electorales para Chile Este es el primer intento serio para hacer un pronóstico de una elección presidencial en Chile. Nunca antes se ha tratado de construir un instrumento para predecir resultados electorales antes que ocurran. Es un esfuerzo por tratar de entender lo que sucede en los meses previos a que se lleve a cabo una determinada elección. Es un experimento en tiempo real que intenta monitorear patrones y tendencias en las preferencias electorales de los chilenos. Hay que partir por lo que ya existe. Hasta el momento, hay una notable colección de literatura retrospectiva sobre comportamiento electoral. Académicos como David Altman, Alfredo Joignant, Carlos Huneeus, Miguel Ángel López, Mauricio Morales, Patricio Navia y Samuel Valenzuela entre otros han disectado el sistema político para explicarnos por qué unos ganan y otros pierden. Yo mismo escribí mi tesis de Máster sobre la elección de 2009/2010. Pero explicar resultados electorales en retrospectiva es una cosa, explicarlos antes que ocurran es otra cosa. Y en lo segundo, hay muy poco escrito. Hasta ahora, simplemente se han usado resultados de encuestas de manera descriptiva. Por ejemplo, es común que asesores de candidatos presidenciales dependan únicamente de encuestas para diseñar los itinerarios de sus candidatos. Sin encuestas, no tendrían cómo elegir las mejores estrategias para sus jefes. Pero este proceso tiene un problema fundamental. Las encuestas se equivocan. En estos casos los candidatos quedan a ciegas. Y si los puntos de referencia están mal, es imposible que los candidatos ganen sus batallas. Ejemplos sobran. Uno es Zalaquett en 2012, quien esperaba ganar en Santiago por un amplio margen de votos, pero que finalmente perdió. Si hubiera sabido que la carrera era más competitiva, de seguro habría apurado el trote para capturar esos pocos votos que le faltaron para ganar. Un segundo problema es la falta de puntos de referencia. Si las encuestadoras deciden no hacer encuestas los candidatos simplemente no tienen puntos de referencia. Obviamente cualquier candidatura seria tiene encuestas privadas, pero su utilidad es mayor cuando son públicas, y se puede medir su efecto en la gente. En esencia, el argumento aquí es que cuando pasa mucho tiempo entre encuestas, aumenta la probabilidad que candidatos tomen malas decisiones. La idea, entonces, es corregir estos errores, por medio de un modelo con puntos de referencia correctos para cada día por la duración de un ciclo electoral. El objetivo es usar las encuestas que sí se publican para crear pronósticos y simulaciones electorales sin sesgos. Si tomamos las encuestas en su estado natural esto es prácticamente imposible. El Cuadro 1 muestra este escenario, con resultados de encuestas que se hicieron entre Mayo y Diciembre de 2009. El Cuadro 1 muestra mucho ruido y poca señal. Si bien se ven una tendencia general, es porque los 4 candidatos que compitieron en esa elección ya estaban inscritos. Monitorear preferencias electorales antes que los candidatos se inscriban puede ser caótico. Para separar el ruido de la señal, se debe trazar tendencias. Una forma de hacer esto se muestra en el Cuadro 2. Es lo que hacen, entre otros, los grandes conglomerados de medios. El problema con el Cuadro 2 es que se presume que todas las encuestas son iguales. Simplemente se conecta una encuesta con la siguiente. Mi argumento, por el contrario, es que lo primero que se debe hacer es distinguir las buenas encuestas (las que entregan mucha señal y poco ruido) de las malas encuestas (las que entregan mucho ruido y poca señal). Para lograr esto, se debe ponderar a las encuestas buenas con un peso significativamente más alto. Esa es la premisa fundamental de pronósticos electorales. Para ayudar a explicar los que se hacen en Tresquintos, voy a usar el ciclo electoral de 2009. Sin embargo, me remito a ideas centrales. En otros artículos, como los enlaces en la página de Preguntas Frecuentes, explico detalles. (Lo que sigue puede ser largo, y en partes complejo. Se presume que el lector tiene conocimiento avanzado de estadística frecuentista, y una noción básica de estadística bayesiana). El primer paso, entonces, es recolectar la información que se va utilizar. En este caso, toda la información que se necesita viene de encuestas. Del caudal que se publica en los medios, se registran solo aquellas que reportan (1) las fechas de trabajo de campo, (2) la metodología de investigación y (3) el número de personas encuestadas. Una vez que se cuenta con esta información, se puebla una base de datos. En forma gráfica, sería similar a lo que muestra el Cuadro 1. El segundo paso es ponderar cada una de las encuestas de acuerdo a su peso en el grupo. Se presume que algunas encuestas entregan más y mejor información que otras. La idea es identificar y premiar a esas encuestas. Para esto se usan los datos recolectados en el primer paso. Una encuesta tiene un alto peso si (1) se hizo relativamente cerca de la elección, (2) la encuestadora de la cuál proviene tiene una buena reputación, y (3) tiene un alto número de personas encuestadas. Para calcular el peso temporal, se utiliza un período de semi-desintegración. Este es el lapso de tiempo que se considera antes que la encuesta se empieza a desintegrar, o bien comienza a perder capacidad predictiva. Para calcular el peso de la encuestadora se utiliza el ranking de encuestas, explicado en detalle aquí. Finalmente, para calcular el peso según el número de encuestados, simplemente se estima el margen de error con una confianza de 95%. El resultado se muestra en el Cuadro 3. El gráfico muestra lo que habría sido el pronóstico el 13 de Diciembre de 2009, si solo habría tomado en cuenta la ponderación del paso 2. Es decir, no se gráfica lo que reporta cada encuesta, más bien lo que se estima que reportaría cada encuesta si no tuviera sesgos. Por eso, la línea del Cuadro 3 es diferente a línea del Cuadro 2. No solo es un mejor indicador, pero reporta una estimación de intención de voto día a día. El tercer paso es reducir el error que pueda tener el pronóstico del paso 2. Para eso utilizo una lógica distinta. Pasó de inferencias frecuentistas a inferencias bayesianas. La idea tras esto es determinar la incertidumbre asociada a los pronósticos. La inferencia frecuentista solo nos permite saber la probabilidad de estar en lo correcto si tenemos suficiente información. Es decir, si nuestro N es grande podemos establecer la probabilidad de rechazar inferencias correctas (falsos positivos). Pero muchas veces la estadística frecuentista rechaza falsos positivos (o aprueba verdaderos negativos), sencillamente porque no contiene puntos de referencia reales. La estadística bayesiana, en cambio, inserta probabilidades anteriores (o a prioris) dentro de las inferencias. Expresa la probabilidad condicional de un evento A dado B en términos de la distribución de la probabilidad condicional del evento B dado A y la distribución de probabilidad marginal de sólo A. Bajando lo anterior a la elección de 2009, significa que por medio de inferencias bayesianas (utilizando información previa), evalúo la probabilidad de que mi pronóstico este mal. Es decir, en el modelo especifico neutralizar tendencias que no tienen fundamento. Esto sucede, por ejemplo, cuando una encuesta mala publica un resultado que en promedio es muy alto o muy bajo. El paso 4 es simular el paso 3, 100,000 veces. El Cuadro 4 muestra el resultado. El paso final es simplemente interpretar los datos. Aquí hago una diferencia semántica entre un pronóstico y una simulación. El pronóstico responde la pregunta "¿quién ganaría la elección si fuera hoy día?". La simulación, en cambio, responde la pregunta "¿quién ganaría la elección si fuera el 13 de Diciembre de 2009?" Los índices al final de las líneas del Cuadro 4 son pronósticos para el 13 de diciembre, por lo tanto son una simulación. Es importante notar que la última encuesta para la primera vuelta fue el 9 de Diciembre. Si se habría simulado la elección el 9 de Diciembre, habría sido un pronóstico. Pero como se busca predecir 4 días sin encuestas, es una simulación. Notar también que la área sombreada simboliza el intervalo de error. A medida que pasan más días sin encuestas, la área sombreada aumenta. Si se habría simulado la elección el 15 de Noviembre, el área sombreado sería más grande. La simulación es bastante acertada. Para Piñera el pronóstico fue 43,7% (en realidad fue 44,1%), para Frei el pronóstico fue 28,3% (en realidad fue 29,6%), para EnríquezOminami el pronóstico fue 22,6% (en realidad fue 20,1%), para Arrate el pronóstico fue 5,8% (en realidad fue 6,2%). Es decir, todos los pronósticos estuvieron dentro, o a alrededor, de 1% del resultado final--mucho mejor que cualquier encuestadora. Si miramos la distribución de probabilidades de voto para cada candidato usando la misma información, obtenemos lo que se muestra en el Cuadro 5. Allí vemos la probabilidad de voto para cada candidato. El eje horizontal es la probabilidad de obtener la votación que aparece en el eje vertical. Las barras tienen un ancho de 1%, y sumadas por cada candidato suman 100%. Por ejemplo, el 13 de diciembre Arrate tuvo una probabilidad de 50% de obtener entre 5% y 6% de los votos. Lo más interesante del Cuadro 5 son las probabilidades que tienen candidatos de empatar. Era evidente que Piñera iba obtener la mayoría relativa, y Arrate iba obtener la minoría relativa. La verdadera batalla estuvo entre Frei y Enríquez-Ominami. La distribución de resultados muestra la probabilidad de empates. La suma de las barras que se traslapan muestra esto. En este caso, de 100 elecciones, Frei y EnríquezOminami habrían empatado en 10 ocasiones. Esto es solo parte de la potencialidad de los pronósticos. Los resultados que vemos arriba demuestran que el modelo estuvo calibrado casi a la precisión. Es decir, es probable que las estimaciones hechas durante todo el periodo de campaña (entre Mayo y Diciembre de 2009, en este caso) también estén calibrados. Esto significa que los pronósticos hechos aquí entregan más y mejor información que cualquier encuestadora por sí sola. Los modelos fueron desarrollados junto a Stefan Bauchowitz. La manipulación de los datos y los cálculos estadísticos para las pronósticos se hicieron usando R. Para usuarios de MacOS X, se puede bajar aquí. Las estimaciones de probabilidades para las simulaciones se hicieron usando BUGS. Para usuarios de MacOS X, se puede bajar aquí. Más información sobre los modelos y el procesamiento de datos aquí. Para preguntas frecuentes, pinchar aquí.