GUIÓN DE LA PRÁCTICA 2
Anuncio

GUIÓN DE LA PRÁCTICA 2
1. Un poco de programación en R: sobre la varianza y la cuasivarianza muestral
Un ejemplo de cómo escribir una función en R: construyamos una función que calcule la varianza
muestral. Pinchar en File New R Script y escribir la función
varianza = function(x){n=length(x); v=sum((x-mean(x))^2)/n; v}
o igualmente
varianza = function(x){
n=length(x)
v=sum((x-mean(x))^2)/n
v # al final de una función de R hay que escribir el output de la función
}
y guardar el script como varianza.R. Antes de utilizar la función hay que cargarla en el
Workspace mediante:
source(‘varianza.R’)
Uso de la función en un ejemplo concreto:
x = seq(1,10)
varianza(x)
Calcular también la varianza usando la función de R var(x) y comparar ambos resultados. La
razón de la discrepancia observada es que en realidad var(x) calcula la cuasivarianza muestral y,
por tanto, var(x)=(n/(n-1))*varianza(x). El objeto de var(x) es corregir el sesgo que
presenta varianza(x).
2. Un experimento sencillo de simulación: cómo hacer iteraciones
v = rep(0,500)
for (i in 1:500){
v[i] = var(rnorm(20,mean=3,sd=2))
}
vM = mean(v)
Comparar este valor con la varianza de la población de la que muestreamos.
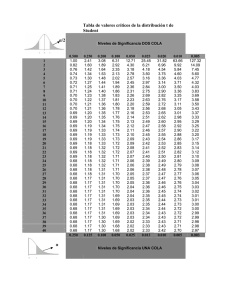
3. La dispersión de la media muestral disminuye cuando aumenta el tamaño de la muestra
Por tanto, la precisión de la media muestral, X , como estimador de la media poblacional, ,
también aumenta con el tamaño n de la muestra. Comprobémoslo:
t = seq(-3,9,0.01)
plot(t,dnorm(t,mean=3,sd=2),ylim=c(0,1),xlab='',ylab='',
type='l',lwd=0.3) # dibujo de la densidad que genera los datos
x = rep(0,300)
for (i in 1:300){
x[i] = mean(rnorm(20,mean=3,sd=2)) # media de cada muestra de tamaño 20
}
lines(density(x),col= 'red') # dibujo del estimador kernel de x
y = rep(0,300)
for (i in 1:300){
y[i] = mean(rnorm(50,mean=3,sd=2)) # media de cada muestra de tamaño 50
}
lines(density(y), col='blue') # dibujo del estimador kernel de y
2
. Con
n
los estimadores kernel estamos aproximando esta densidad. Observemos que, a medida que n
aumenta, cada vez hay más probabilidad concentrada en torno al verdadero valor de 3 .
La densidad de la media muestral X es la de una normal de media 3 y desviación típica
4. Ejercicio: comparar empíricamente el error que se comete al estimar la media de una normal
usando la media muestral, mean(x), y la mediana muestral, median(x).
Sugerencia para comenzar:
# Definimos una matriz en la que almacenar las muestras
# aleatorias y vectores en los que almacenar las
# correspondientes medias y medianas muestrales
medias.muestrales = rep(0,5000)
medianas.muestrales = rep(0,5000)
muestras = matrix(0,nrow=5000,ncol=100)
# Generamos las muestras y evaluamos las correspondientes
# medias y medianas
for (i in 1:5000){
muestras[i,] = rnorm(100,mean=1,sd=1)
medias.muestrales[i] = mean(muestras[i,])
medianas.muestrales[i] = median(muestras[i,])
}
#Calculamos los correspondientes errores cuadraticos medios
error.cuadratico.media = mean((medias.muestrales-1)^2)
error.cuadratico.mediana = mean((medianas.muestrales-1)^2)
Observación:
Como sabemos, el ECM “teórico” de la media muestral X es σ2/n (=1/100 en este caso). Puede
probarse que, denotando por la densidad de la N(0,1), el ECM de la mediana es
1
= 0.01570796, pero esta cantidad se estima con mucha
aproximadamente (para n grande)
2
4 (0)n
mayor variabilidad.
5. La función "apply"
apply(xx,MARGIN=2,FUN=median)
Aplica la función "median" (o la que se indique detrás de FUN=) a las columnas de la matriz xx. Si
MARGIN=1, la operación se aplica por filas.
Esto es útil, por ejemplo, para hacer simulaciones sin necesidad de usar "for".
Ejemplo:
xx = matrix(rnorm(5000),ncol=100,nrow=50)
medianas = apply(xx,MARGIN=2,FUN=median)
Probar a aplicar la función median directamente a la matrix xx para ver qué resultado se obtiene.