GENÉTICA MOLECULAR I Los mecanismos de herencia se
Anuncio

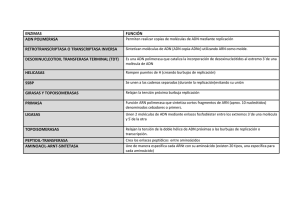
TEMA 14: GENÉTICA MOLECULAR I Los mecanismos de herencia se engloban dentro de la genética. La genética clásica se centra en el estudio de los descubrimientos de Mendel hasta el punto en que el concepto “Mendelismo” llegó a ser sinónimo de genética. Con los nuevos descubrimientos de la estructura del ADN y del código genético, se abrió una nueva rama de la genética conocida como genética molecular. Esta se ocupa de la naturaleza de los genes y de su expresión. 1. Flujo de información genética en los seres vivos 1.1. Los ácidos nucleicos como portadores de la información genética En un primer momento se descartó que el esqueleto azufre-fosfato fuese el responsable de la información genética. Durante muchos años existió la polémica de si el material genético estaba formado por proteínas o por ácidos nucleicos. Los ácidos nucleicos parecían moléculas demasiado simples para ello. A mediados del siglo XX se pensaba que los genes serían de naturaleza proteica. Pero los experimentos de Oswald, Avery, Colin McLeod y Maclyn McCarty demostraron que el portador de la herencia es el ADN. La historia se remonta a 1928, cuando un bacteriólogo inglés, Fred Griffith estudiaba, por encargo del Ministerio de Sanidad británico, la bacteria causante de la neumonía Diplococcus pneumoniae. Griffith observó que se presentaba en dos variantes: • Cepas S (con cápsula) y virulentas (smooth) • Cepas R (sin cápsula) y no virulentas (rough) Estas R carecen de alguna enzima para sintetizar dicha cápsula. Griffith inoculó a los ratones bacterias S muertas por calor y observó que esos sobrevivían, con lo que demostró que las cápsulas no eran las que provocaban la enfermedad. Pero, al infectar un ratón con una mezcla de bacterias S muertas por calor y de bacterias R vivas, el ratón inexplicablemente enfermaba y moría. Además, en su organismo podían aislarse bacterias S vivas. Algo había en los cadáveres de las bacterias S que había provocado la transformación de las R en S. Algún componente de las células S muertas había pasado establemente a las células R. Griffith le llamó principio transformante. Avery, McLeod y McCarty se propusieron encontrar cual era ese principio transformante que transmitía un carácter heredable. En 1943 publicaron el resultado de sus investigaciones atribuyendo al ADN ese papel. Demostraron que sólo los extractos de bacterias S muertas que contenían ADN eran capaces de producir dicha transformación. Por tanto era el ADN el que suministraba la información de cómo se sintetizaba la cápsula de polisacáridos que hace a estas bacterias resistentes a los fagocitos. Estos resultados fueron recibidos con escepticismo por parte de la comunidad científica. Muchos pensaron que se trataba de una peculiaridad de las bacterias. Fue necesario el experimento de Alfred Hershey y de Martha Chase, en 1952 para confirmar estas conclusiones. Trabajaron con un virus de ADN que infectaba a las bacterias, el bacteriófago T2. Para ello marcaron radiactivamente el ADN (P32) y las proteínas de la cápside (S35). Infectaron con este virus marcado un cultivo de la bacteria Escherichia coli. Tras dejar tiempo suficiente para que los virus infectaran las bacterias, agitaron el cultivo con una batidora doméstica para separar las cápsides vacías de los virus infectantes y finalmente las retiraron mediante centrifugación. Observaron que la radiactividad debida al S35 quedaba en las cápsides vacías, mientras que con el segundo cultivo constataron que el ADN radiactivo aparecía en el interior de las bacterias y, al cabo de un tiempo, en el interior de los nuevos virus descendientes. Así se demostró que era el ADN, y no las proteínas, la molécula que pasaba de una generación a otra y, por tanto, la que debe contener la información de cómo han de ser los organismos. Los experimentos de Avery sí habían convencido a Watson y Crick y se lanzaron a estudiar la estructura del ADN. 1 1.2. Dogma central de la biología molecular Aunque el mecanismo de replicación y transcripción tardaría algo en esclarecerse, todavía había una dificultad mayor: ¿Cómo se determina a partir de la información contenida en el ADN la secuencia de proteínas? Esto suponía una gran dificultad porque las proteínas están formadas por 20 aminoácidos diferentes. Para pasar del lenguaje del DNA al RNA bastaba una transcripción de los caracteres en la que T se sustituyera por U. Pero pasar de un mensaje expresado por combinación de 4 caracteres a otro expresado por combinación de 20 requiere un proceso de traducción. Para resolver el problema, Crick supuso que un RNA actuaría de molde intermediario formulando lo que se ha llamado el “dogma central de la biología molecular”, según el cual el flujo de la información sería: ADN → ARN → Proteínas Transcripción Traducción La información genética está codificada en el ADN y esta información pasa al ARN mensajero en el proceso de transcripción. El ARN transcrito va a ser leído en el proceso de traducción, para dar lugar a las proteínas. El proceso de transcripción, que se realiza en el núcleo (en eucariotas), consiste en la síntesis de una cadena de ARN a partir de una de las cadenas de la doble hélice de ADN que sirve como molde. La traducción consiste en la síntesis de cadenas polipeptídicas/proteínas a partir de una cadena de ARN mensajero que va a ser leída en los ribosomas. El dogma central satisfacía además la hipótesis un gen-una enzima, que había sido formulada anteriormente, según la cual una enzima es el producto de un gen. Este dogma admite excepciones: 2 • • Existe una enzima, la transcriptasa inversa, que es capaz de sintetizar ADN copiando la información contenida en un ARN. El papel biológico de esta enzima es fundamental en los virus con ARN. H. Temin recibió el Premio Nóbel en 1975 por sus descubrimientos en relación con la interacción entre los virus tumorales y el material genético en la célula, en particular por el descubrimiento de la transcripción inversa en virus ARN-ADN. Los virus bacteriófagos presentan autoduplicación del ARN gracias a la ARN replicasa y así el ARN puede actuar como molde y sintetizar otra molécula igual a él. El dogma central de la biología molecular quedaría de la siguiente manera: Replicación ADN ← → ADN Transcripción → ←Reversotra nscripción n Traducción ARN ←Replicació → ARN → Proteínas 1.3. Concepto de gen En 1865 Mendel utilizó el término factor hereditario para referirse a la información genética para un carácter que se transmitía de generación en generación. En 1948, Beadle y Tatum descubrieron que el material genético rige la producción de proteínas y propusieron la hipótesis un gen = una enzima. A partir de los años 40 se definía el gen como un punto de un cromosoma que determina un carácter. En 1960 se define como un gen = una proteína. Un gen es una porción de ADN que codifica una cadena polipeptídica, ya que no todas las proteínas son enzimas. Hoy se entiende por gen un fragmento de ADN que codifica un producto determinado, que puede ser una cadena polipeptídica (proteína) o un ARNt o ARNr. Los genes determinan la secuencia en que unos cuantos aminoácidos deben unirse para formar un polipéptido y finalmente una proteína. El gen es una unidad de información que sirve para dirigir y controlar la actividad de la célula. Desde el punto de vista mendeliano actúa como una unidad hereditaria, ya que cuando la célula se divide el gen transmite su mensaje a la descendencia. Desde el punto de vista molecular actúa como una unidad de transcripción. Cada gen puede existir en diversas formas llamadas alelos. El término alelo indica que un carácter puede representarse en dos o más formas alternativas. Ej. Color de ojos azul o castaño. De un mismo gen surgen diferentes alelos por mutaciones. Los puntos de un cromosoma ocupados por un gen reciben el nombre de locus (singular) o loci (plural). El conjunto de genes o material genético de un organismo constituye el genoma. En el caso de los virus serían las moléculas completas de ADN o ARN que llevan la información genética. Los genes de las células eucariotas normalmente presentan intrones sin información para la cadena polipeptídica, que separan los exones que poseen la información. En algunos virus se ha descubierto que una misma secuencia de nucleótidos puede contener dos informaciones, es decir, dos genes, según se empiece a leer por el primer nucleótido o por el segundo. Son los llamados genes solapados. La estructura de un gen presenta, además, una región promotora, un lugar de inicio de la transcripción y las señales que indican la finalización de la transcripción. 3 2. Replicación del ADN 2.1. Modelos de replicación El ADN se duplica sólo una vez en el transcurso de un ciclo celular. Para ello, las dos hebras del ADN han de separarse, después, a partir de desoxirribonucleótidos sueltos y siguiendo la complementariedad de bases, se forman dos hebras nuevas idénticas a las dos iniciales. Para explicar este proceso se propusieron tres hipótesis: • Hipótesis conservativa: Opina que tras la duplicación quedan, por un lado las dos hebras antiguas y por otro las dos nuevas. • Hipótesis semiconservativa: Fue propuesta por Watson y Crick. Sostiene que en cada molécula hija habrá una hebra antigua y otra nueva. • Hipótesis dispersiva: Supone que la doble hélice original se rompe y que al final las dos hijas tienen fragmentos antiguos y fragmentos nuevos. En 1953, Watson y Crick establecieron que la cadena de ADN puede servir como molde para una cadena complementaria ya que la doble hélice puede desenrollarse y las cadenas individuales atraer a sus bases complementarias proponiendo la hipótesis semiconservativa. Para confirmar la hipótesis semiconservativa, Messelson y Stahl, en 1957, cultivaron bacterias de Escherichia coli en un medio en el que la fuente de nitrógeno era N15 en vez del normal N14. Después las pasaron a un medio con N14 durante media hora, que es el tiempo necesario para que se duplique el ADN bacteriano. Se extrajo éste y se centrifugó. Luego, mediante rayos ultravioletas observaron que el ADN ocupaba una posición intermedia en el tubo de centrifugación. El ADN era híbrido N14-N15. Esto descarta la hipótesis conservativa, ya que para ello sería mitad pesado, mitad ligero. Al analizar la segunda generación, observaron que aparecían dos tipos de ADN, uno híbrido y otro ligero. Esto descarta la hipótesis dispersiva, ya que en ella siempre sería híbrido aunque cada vez más ligero. Messelson y Stahl completaron el experimento aislando una molécula de ADN híbrido y, al someterla a 80ºC consiguieron separar ambas cadenas observando que una era pesada y la otra ligera, quedando así demostrada la hipótesis semiconservativa. 4 2.2. Mecanismo general de replicación El mecanismo de replicación ocurre una sola vez en cada generación, durante la fase S del ciclo celular. Se pueden distinguir tres pasos: • Iniciación y separación de las cadenas • Formación de burbujas y horquillas de replicación • Final de la replicación 2.2.1. Iniciación y separación de las cadenas La duplicación se inicia en un punto que recibe el nombre de origen de la replicación y que está constituido por una secuencia de nucleótidos que actúa como señal de iniciación. En ecucariotas la iniciación se produce en varios puntos de ADN al mismo tiempo. En virus y bacterias existe un único punto de inicio. Actúan una serie de enzimas: • ADN polimerasas: Incorporan desoxirribonucleótidos a la cadena de ADN que se está sintetizando, utilizando una de las hebras de ADN como molde. Este proceso se produce siempre en dirección 5’→3’ • Helicasas: Rompen los enlaces de hidrógeno que existen entre las hebras desenrollando la doble hélice, quedando las dos hebras antiparalelas separadas para que puedan actuar como moldes para la síntesis de nuevas cadenas complementarias. • Topoisomerasas: Giran la molécula para evitar el superenrollamiento en el resto de la doble hélice. Las más conocidas son las girasas. • Proteínas SSB: Estabilizan las cadenas sencillas. Actúan conjuntamente con las helicasas. • Ligasas: Unen fragmentos de ADN adyacentes mediante enlaces fosfodiéster. En el proceso de replicación del ADN son las encargadas de unir los fragmentos de Okazaki. Los desoxirribonucleótidos tienen que estar activados, es decir, en sus formas trifosfato cargadas de energía: dATP, dTTP, dCTP, dGTP. 2.2.2. Formación de burbujas y horquillas de replicación La replicación es bidireccional, es decir, progresa en dos direcciones, separándose las dos cadenas mediante la acción de enzimas. La zona donde se produce la replicación se conoce como “burbuja de replicación”. A medida que avanza el proceso de replicación, en los extremos de la burbuja se forma una estructura en forma de “Y” conocida como “horquilla de replicación”. Ambas horquillas progresan en direcciones opuestas. Esto planteó un problema: Si en una horquilla una hebra crecía en dirección 5’→3’, la otra cadena debería hacerlo en dirección 3’→5’, y no se conoce ninguna ADN polimerasa que trabaje en esa dirección. La replicación sólo ocurre en un sentido, 5’→3’ y las dos cadenas de ADN son antiparalelas. • En la cadena 3’→5’ la síntesis es discontinua: Se realiza por medio de trozos o fragmentos de ADN que se forman de manera discontinua en dirección 5’→3’ y luego se unen. Estos fragmentos reciben el nombre de “fragmentos de Okazaki”, en honor al investigador que los descubrió en 1968. Cada fragmento está constituido por unos 40 – 50 nucleótidos de ARN y unos 1000 – 2000 de ADN que se forman de la siguiente manera: Una ARN polimerasa, que no necesita cebador, llamada primasa, sintetiza unos 40 nucleótidos de ARN en un punto que dista unos 1000 nucleótidos de la señal de iniciación, constituyendo el prímer. Luego, una ADN polimerasa III, utilizando al prímer como cebador, le añade nucleótidos en dirección 5’→3’, unos 1000. Este proceso se va repitiendo a medida que se van separando las dos hebras patrón. Una vez formado el ADN, se separan los ARN cebador y se unen los fragmentos de Okazaki formando la nueva hebra 5 cuya síntesis es discontinua, y como tarda más en crecer que la otra, también se le denomina hebra retardada. La ADN polimerasa I, con función exonucleasa, es la que retira los segmentos de ARN y luego, gracias a su función polimerasa, rellena los huecos con nucleótidos de ADN. • En la cadena 5’→3’ la síntesis es continua: Actúa la primasa fabricando un ARN cebador de unos 10 nucleótidos. La ADN polimerasa III, partiendo del prímer, comienza a sintetizar una larga cadena de ADN en dirección 5’→3’. A esta cadena se le conoce como hebra adelantada o conductora frente a la cadena retardada constituida por los fragmentos de Okazaki. 2.2.3. Final de la replicación Una ADN ligasa empalma entre sí los diferentes fragmentos de Okazaki. Se cree que una ADN polimerasa II termina la replicación. Existe un mecanismo de reparación de errores que corre a cargo de la enzima endonucleasa, que reconoce el fragmento mal replicado abriendo la hélice a su nivel para que actúen la ADN polimerasa, que lo coloca en su orden correcto, y la ligasa, que une los fragmentos. 6 2.2.4. Diferencias en la replicación de procariotas y eucariotas • • • • El ADN de eucariotas está fuertemente asociado a histonas. Durante la replicación, la cadena molde de la hebra conductora se queda con las histonas y ambas se enrollan sobre los octámeros antiguos. La hebra molde de la retardada y la retardada se arrollan sobre nuevos octámeros. El cromosoma eucariota es de mayor longitud que el bacteriano. La velocidad de replicación en procariotas es de unos 500 pares de bases / segundo, mientras que en eucariotas, seguramente debido a las histonas, es de 40 – 50 pb / s, lo que permite explicar por qué los procariotas tienen un solo punto de replicación y los eucariotas múltiples (60000 e mamíferos): es multifocal. Los fragmentos de Okazaki son más pequeños en eucariotas, de unos 100 – 200 nucleótidos y el proceso se lleva a cabo en la fase S de la interfase que dura de 6 a 8 horas. 2.3. Técnica PCR Muy relacionada con la replicación del ADN está la técnica de la PCR (Polymerase Chain Reaction) o Reacción en cadena de la polimerasa. Consiste en la replicación del ADN in vitro, o lo que es lo mismo, permite hacer fácil y rápidamente millones de copias de la molécula de ADN. La molécula de ADN que se va a copiar se calienta y desnaturaliza, separando las dos cadenas. Después, cada una de ellas se copia por la ADN polimerasa, que añade nucleótidos. Esta técnica requiere el conocimiento de las secuencias de nucleótidos del fragmento de ADN a replicar. Con ellas se sintetizarán pequeñas cadenas complementarias de 20 nucleótidos de ADN que actuarán como cebador para la ADN polimerasa. 1. Se introduce en una disolución que contiene ADN polimerasa el fragmento o fragmentos a replicar. 2. Se añaden desoxinucleótidos trifosfatos de las 4 bases y las moléculas del cebador sintetizadas. 3. Al calentar se separan las dos hebras complementarias. 4. Al enfriar, se unen los cebadores a las hebras simples, lo que es reconocido por la ADN polimerasa, que empieza a añadir nucleótidos, formando la hebra complementaria. 5. Calentando y enfriando alternativamente la solución se pueden obtener millones de copias de ADN en tiempos relativamente breves. La PCR revolucionó la biología y presenta grandes aplicaciones en áreas muy diversas, tanto de la Biología como de la Medicina (medicina forense, determinación o detección de ciertos tipos de cáncer,…), identificación de delincuentes y paternidades (huella genética). 3. Transcripción La transcripción es el paso de una secuencia de ADN a una secuencia de ARN, ya sea ARNm, ARNr o ARNt. Sólo se transcribe una de las dos cadenas de ADN. La ARN polimerasa cataliza la adición de ribonucleótidos por complementariedad de bases, uno a uno, al extremo 3’ de la cadena 7 de ARN en crecimiento. Esta enzima se mueve en dirección 3’→5’ respecto al ADN, sintetizando la nueva cadena complementaria de ribonucleótidos en dirección 5’→3’. Existen dos mecanismos diferentes según se trate de procariotas o eucariotas. 3.1. Mecanismo general de transcripción en procariotas En organismos procariotas sólo existe un tipo de enzima ARN polimerasa. Los ribonucleótidos tienen que estar en forma activa (ATP, GTP, CTP, UTP) y la transcripción se desarrolla en 4 etapas: Iniciación, Elongación, Finalización, Maduración. • • • • Iniciación: El ADN molde presenta un promotor (región concreta del ADN) que sirve para que la ARN polimerasa sepa donde se inicia la transcripción y cual de las dos cadenas se transcribe. En la región promotora se distinguen dos secuencias consenso: La secuencia – 10, situada en el extremo 3’, a 10 nucleótidos antes del inicio y es igual o parecida a TATAAT, y la secuencia – 35, situada a 35 nucleótidos del inicio, y que es igual o parecida a TTGACA. La ARN polimerasa ha de unirse al factor sigma (σ) para reconocer y asociarse al promotor. Una vez que se desenrolla una vuelta de hélice, se separa del factor σ. La hebra de ADN que se transcribe se denomina hebra patrón. Elongación: El proceso continúa a razón de unos 400 pb / s. A medida que la ARN polimerasa recorre la hebra de ADN patrón hacia su extremo 5’, se sintetiza una hebra de ARN en sentido 5’→3’. Por ejemplo: ADN: 3’…TACGCT…5’ ARN: 5’…AUGCGA…3’ Finalización: En el ADN molde también existen señales de finalización. Se produce cuando la ARN polimerasa llega a una secuencia llamada terminador, rica en bases G y C, seguida por una secuencia que se repite, generalmente TTTTT, que origina un bucle al final del ARN que favorece la separación y el ADN vuelve a formar la doble hélice. Secuencia palindrómica es aquella que se lee igual de izquierda a derecha que al contrario. Cuando se transcribe, las secuencias complementarias del ARN se aparean y forman un bucle intracatenario, lo que favorece la separación del ARN al ADN. “Dábale arroz a la zorra el abad” 5’ GAATTC 3’ 3’ CTTAAG 5’ Maduración: Si se sintetiza un ARNm no hay maduración puesto que los genes son continuos, en cambio, si es un ARNt o un ARNr, hay un tránscrito primario, que luego sufre un proceso de corte y empalme. 3.2. Mecanismo general de transcripción en eucariotas La síntesis de proteínas se realiza en los ribosomas, que están en el citoplasma. La información genética del ADN, que está en el núcleo, debe pasar al citoplasma, y lo hace a través de un intermediario, el ARNm. Este se sintetiza en el núcleo en unas fases similares a los procariotas, pero aquí intervienen varias ARN polimerasas y proteínas reguladoras, según el tipo de ARN que se va a sintetizar. Las ARN polimerasas dependen del tipo de ARN que se va a sintetizar. • ARN polimerasa I: Cataliza la síntesis de ARNr 28S, 18S y 5,8S. • ARN polimerasa II: Cataliza la síntesis de ARN heterogéneo nuclear. • ARN polimerasa III: Cataliza la síntesis de ARNt, ARNr 5S. La síntesis de ARN también la hay en mitocondrias y cloroplastos. En eucariotas todos los genes están fragmentados por lo que es necesario un proceso de maduración para que sea funcional. 8 En la síntesis de ARN mensajero se distinguen 4 etapas: Iniciación, elongación, finalización y maduración. • Iniciación: Una ARN polimerasa II reconoce y se une a una región del ADN llamada región promotora, que constituye la señal de inicio de la síntesis. Esta región promotora está constituida por tres secuencias consenso, la TATA, a 30 nucleótidos del inicio (caja TATA) y la CAAT a 80, y la – 120, rica en bases GC. • Elongación: Cuando la ARN polimerasa II está unida al promotor, cataliza la unión de los ribonucleótidos en la dirección 5’→3’. Cuando ya se le han unido unos 30 ribonucleótidos, se le añade al extremo 5’ una “caperuza” constituida por una metil–guanosín–trifosfato que sirve para proteger al ARNm del ataque de las nucleasas y marcará el inicio de la traducción. • Finalización: La síntesis continúa hasta llegar a la secuencia de finalización TTATTT. A continuación, la enzima poliA–polimerasa, le añade al extremo 3’ una cola de poli A constituida por unos 150 a 200 ribonucleótidos de adenina. El ARN formado es el heterogéneo nuclear o pre–mensajero. • Maduración: Los genes de eucariotas están fragmentados, y por tanto el pre–mensajero contiene secuencias sin información llamadas intrones y secuencias con información denominadas exones. Una enzima que actúa en el núcleo (la ribonucleoproteína pequeña nuclear o RNPpn) reconoce los intrones y los elimina y luego una ARN ligasa une o empalma los exones que luego serán traducidos. exón ADN 3’ Promotor Intrón E1 E2 E3 Terminador 5’ Transcripción 5’ 3’ E1 Caperuza E3 E2 ARNhn (pre–mensajero) cola poli A (AAAA…A) (m7–Gppp) Maduración (elimina intrones) 5’ E1 E2 E3 3’ ARNm Algunas setas como Amanita phaloides contienen sustancias que inhiben la transcripción en eucariotas, además de otras que afectan a la estructura del citoesqueleto, y de ahí su elevada peligrosidad. 3.3. Reversotranscripción La reversotranscripción es el paso de ARN a ADN, es decir, el paso de la información del ARN al ADN. Se conoce desde 1970. Es propia de los retrovirus gracias a poseer una enzima, la reversotranscriptasa, que se encarga de sintetizar ADN a partir de ARN. Los retrovirus, como el del SIDA, poseen un genoma constituido por una cadena de ARN sencilla que posee la información necesaria para construir nuevos virus. Cuando el retrovirus penetra en la célula, se despoja de la cápside proteica y quedan libres el ARN y la reversotranscriptasa. Este utiliza la cadena de ARN como molde para sintetizar una cadena de ADN copia (ADNc) con 9 secuencia complementaria, que forma un híbrido con la hebra de ARN. La enzima tiene también la función de degradar la hebra de ARN y de sintetizar otra cadena de ADN complementaria de la ADNc. Así se forma una doble hélice de ADN que se integra en el genoma de la célula hospedadora y así el virus se convierte en un provirus (virus de ADN) 4. Traducción: Biosíntesis de proteínas 4.1. El código genético Watson y Crick señalaron que la información genética del ADN estaba codificada y que la secuencia de nucleótidos debería especificar una secuencia de aminoácidos. Sin embargo, dado que existen 20 aminoácidos diferentes y tan solo 4 nucleótidos en el ADN, la correspondencia no puede ser 1 = 1. Si los nucleótidos se agrupan de 2 en 2, serían variaciones con repetición de 4 elementos tomados de dos en dos: 4 2 = 16 ( V42 ). Quedarían 4 aa sin codificar. Si se agrupan de 3 en 3: V43 = 4 3 = 64 . En este caso sobran aa. Hay 64 combinaciones posibles para 20 aa. Crick demostró que el código genético es un código de 3 nucleótidos que se llaman tripletes. Un triplete en el ADN recibe el nombre de codógeno, mientras que su complementario en el ARNm es el codón. ADN: ACGGTAACA Codógeno ARN: UGCCAUUGU codón Un triplete codifica para un aminoácido. La lectura es lineal, sin puntos ni comas. Sólo hay dos tipos de tripletes que no codifican aa: Los indicativos de iniciación y terminación. La señal de iniciación es AUG (metionina). La señal de terminación es UAG, UAA, UGA. La clave genética es la relación que existe entre la secuencia de nucleótidos del ARNm y la secuencia de aminoácidos. Su estudio fue iniciado por Severo Ochoa y concluido, años más tarde, por Nirenberg, que confirmaron la correspondencia entre tripletes y aminoácidos. En la clave se observa que, a veces, para un mismo aa existen varios tripletes, aunque generalmente sólo difieren en un nucleótido. Por eso se dice que el código genético está degenerado. Esta degeneración supone una ventaja ya que si se produjese un error en la copia de un nucleótido, el péptido sólo variaría un aminoácido, lo cual no es importante si este no forma parte del centro activo de la enzima. En cambio, si la clave no estuviese degenerada, habría 44 codones sin sentido, por lo que un error en la copia daría probablemente uno de estos codones y pararía la síntesis. Sólo la metionina y el triptófano vienen codificados por un solo triplete. 4.1.1. Características del código genético • Es universal, pues es utilizado por todos los organismos conocidos, salvo excepciones, como sucede en las mitocondrias vegetales, donde el codón CGC codifica triptófano en vez de arginina. Sólo algunos protozoos ciliados, mitocondrias y cloroplastos utilizan un código genético ligeramente diferente al universal. • • Está degenerado, es decir, es redundante ya que hay codones que significan lo mismo. Todos los tripletes se leen de la misma manera, en sentido 5’→3’. • Carece de solapamientos pues los tripletes se disponen uno a continuación del otro sin compartir ninguna base. 10 4.2. Mecanismo general de traducción La traducción es la biosíntesis de proteínas. Tiene lugar en los ribosomas libres o asociados al RER, por tanto se producen en el citoplasma. Para que se realice la traducción se requieren los siguientes pasos: activación de los aminoácidos, iniciación de la síntesis, alargamiento de la cadena y terminación de la síntesis. 4.2.1. Activación de los aminoácidos Para que los aa se sitúen en la posición correcta se necesita un intérprete, que es el ARNt, encargado de transportar los aa a su lugar correcto. Cada ARNt se une específicamente a un único aminoácido. Para cada aa existe una enzima, la aminoacil–ARNt–sintetasa que reconoce al ARNt con el que se ha de unir. La unión del aa al ARNt se realiza utilizando ATP y se forma un aminoacil–ARNt. El aa queda unido al extremo 3’ (COOH) del ARNt. La enzima queda libre para unirse a otro aa igual. 4.2.2. Iniciación de la síntesis El ARNm se une a la subunidad menor del ribosoma gracias a que su caperuza del extremo 5’ es reconocida por el ribosoma. Tras la caperuza hay una región que no se traduce, la llamada región líder, y a continuación está el triplete AUG que se traduce por el aa metionina, que suele ser retirado después. El triplete AUG atrae a un aminoacil – ARNt cuyo anticodón es UAC y que porta la metionina. Luego se une la subunidad mayor, formándose el complejo ribosomal. 4.2.3. Alargamiento de la cadena El complejo ribosomal, o complejo activo, tiene 2 centros de unión: El centro peptidil o centro P, donde se sitúa el primer aminoacil–ARNt y el centro aceptor o centro A, donde se colocan los nuevos aminoacil–ARNt. Al centro A llega el segundo aminoacil–ARNt. Los dos aa quedan enfrentados y se produce el enlace peptídico entre el –COOH del primer aa y el –NH2 del segundo. Esta unión está catalizada por una peptidil–transferasa y requiere GTP. En el ribosoma únicamente hay espacio para dos ARNt. Al producirse el enlace, el primer ARNt queda sin aa y abandona el sitio P. Entonces se produce la translocación ribosomal, pasando el dipeptidil–ARNt que estaba en el centro A al centro P, dejando el A vacío para recibir nuevos aminoacil–ARNt. 11 4.2.4. Terminación de la síntesis La síntesis finaliza cuando en el ARNm aparece un codón sin sentido: UAA, UAG, UGA, ya que no existe ningún ARNt que tenga su anticodón complementario a estos tres. Son reconocidos por los factores proteicos de liberación (FR), que necesitan GTP. Se instalan en el centro A y hacen que la peptidil–transferasa haga interaccionar el último –COOH con el agua. A continuación se separan el ARNm y las dos subunidades ribosomales. Generalmente, un mismo mensajero es traducido por varios ribosomas a la vez que se colocan en línea formando un polisoma. 4.2.5. Asociación de varias cadenas polipeptídicas para construir proteínas A medida que se va formando la cadena peptídico, esta va adquiriendo su estructura secundaria y terciaria, si la tiene, mediante los enlaces de hidrógeno y disulfuro,… Generalmente, la cadena formada ya es activa, pero a veces ha de unirse a algún ión, o eliminar algún aminoácido, que suele ser el aa iniciador metionina. Si la proteína está formada por más de una cadena peptídico, finalmente estas se unen entre sí. Algunos antibióticos alteran el proceso de traducción y se utilizan para combatir bacterias: La estreptomicina inhibe el inicio de la traducción y provoca errores en la lectura del ARNm. El cloranfenicol, la tetraciclina,… son inhibidores de la síntesis de proteínas. 12 5. Actividades 1) La secuencia de una cadena de ADN es: 5’ TACCAGGCTGCATGCGCATCGAC 3’ Escribe la cadena complementaria. 2) La secuencia de una cadena de ARN es: 5’ UCCGAUCGACGAUAUCUCUAGGU 3’ Escribe una cadena doble de ADN de la que se copió esta cadena de ARN indicando cual de las dos cadenas sencillas sirvió como molde. 3) Traduce los siguientes segmentos de ARNm: a) 3’ UUUUCGAGAUGUGAA 5’ b) 5’ AAAACCUAGAACCCA 3’ 4) Con esta hebra de ADN construye: 3’ TACGCAGTAC 5’ a) Su hebra complementaria b) El mensajero que se formaría c) El péptido codificado 5) Un ARNm tiene la siguiente secuencia: 5’ AUGAUUUUUACGGCAGCGGAGCACUAA 3’ a) Escribe el polipéptido en el que se traducirá este mensaje. b) Escribe la cadena de ADN de la que se copió el ARNm. 6) Un polipéptido está formado por los siguientes aa: Met – Leu – Pro – Thr – AS¡sn – Phe – Cys a) Escribe una cadena de ARNm de la que pueda traducirse dicho polipéptido b) ¿Es la cadena anterior la única, o puede haber más? c) ¿Cuántos ARNt tiene el aa Met? ¿Y el aa Cys? 7) En este segmento de la región promotora del ADN procariótico se observa una secuencia consenso a 10 nucleótidos del inicio de la transcripción. Encuéntrala e indica como será el principio del ARNm. 3’…TCT-TAT-AAT-ATC-GTA-GCA-TAC-AGC-TAG-AAC-GAT…5’ 8) 13 CÓDIGO GENÉTICO 14