Guía para el uso de R
Anuncio

Trabajo Práctico
Introducción al uso del R.
R es un programa estadístico de libre acceso con código abierto (que puede descargarse
en www.r-project.org), y como tal ofrece las siguientes ventajas:
1- Se instala sin una licencia en Windows, Linux o MacOS.
2- Casi TODO se puede hacer en este programa y lo que no se puede hacer se puede
programar para que lo haga y luego compartirlo para que otros lo usen (lo que se
conoce como inteligencia colectiva). Es decir, que es un programa que no tiene límites
en cuanto a lo que puede hacer, mientras que el resto de los programas estadísticos
hacen un número fijo de análisis estadísticos (los que ya están programados y en
general no se actualizan… o para actualizarlos hay que volver a pagar la licencia).
3- Existe MUCHA bibliografía actualmente que explica cómo se hacen los análisis en R,
mientras que para los otros programas tenemos el manual del programa y algún que
otro tutorial. Vea en el pdf “Instalacion basica de R...” en la carpeta DropBox de la
materia cómo descargar e instalar el R y el RStudio (otro programa que se usa como
interfaz entre R y el usuario).
La única desventaja que se podría pensar (que está relacionada con la ventaja 2) es que
las instrucciones al programa no se dan con botones, menúes desplegables y paneles ya
que como son infinitas las funciones que tiene serían infinitos los botones, menúes y
paneles que debería tener… por esto las instrucciones al programa se las da en forma
escrita. Esto es lo que desmoraliza a los principiantes que estamos acostumbrados a
buscar todo en botones, menúes o paneles. Sin embargo aunque esto pueda parecer más
lento y engorroso pensemos en el siguiente ejemplo:
Tenemos medida una variable X (cualquiera) a la que queremos calcular el promedio.
En el Infostat (por dar un ejemplo nada más) debemos hacer lo siguiente:
Ir al menú Estadística -> Medias resumen -> seleccionar la variable -> Aceptar -> elegir
“media” -> Aceptar
En R se debe escribir:
mean(X)
Como verá parece más fácil en R, el problema es que uno debe saber qué debe escribirle
al programa… El R no sólo es un programa, sino que también es un lenguaje (como el
Francés, el Inglés, etc). Y como todo lenguaje hay que aprenderlo…
Para pedir al R que haga algo se usan comandos (en courier new) y se agregan, entre
paréntesis y según cuál sea el comando, las especificaciones (sobre qué elemento aplicar
ese comando, qué método usar, etc). Por ejemplo, para mean(X) el comando es “mean”
(calcular el promedio) y entre paréntesis la especificación es X (la variable sobre la cual
quiero calcular el promedio). A medida que los comando se hacen más complejos dentro
del paréntesis habrá varias especificaciones, ver más adelante). A continuación hay
algunos ejemplos de símbolos y comandos que se necesitan para comenzar y las cosas
que deben tener en cuenta:
>
Este símbolo indica que R está listo para recibir instrucciones.
#
Este símbolo se usa para que R no tenga en cuenta lo que está escrito
después de él. Es muy útil para agregar notas o comentarios. Si una línea
comienza con #, R no leerá esa línea, por ejemplo, luego del comando
mean(X)uno puede escribir “# promedio de X ó anotar el resultado”.
setwd()
# Se usa para configurar el directorio de trabajo (ej. en qué carpeta va a
buscar el R, dentro de la computadora, los datos y planillas a las que se
haga referencia). Podría dar la siguiente instrucción
setwd("C:/Comunidades") para los análisis que hagamos en esta
materia. NO USE NUNCA espacios en los nombres de archivos, variables o
directorios. Tampoco debe usar los siguientes símbolos: £ $ % ^ & * ( ) # ?<
>/ | \ [ ] {
Observe la barra usada: puede usar “/” o doble barra invertida “\\”, pero esto
también puede depender si estamos trabajando bajo Windows, Linux u
MacOS
getwd()
# Muestra cuál es el directorio de trabajo.
dir()
# Muestra qué archivos tengo en esa carpeta.
ls()
# Muestra una “lista” de todos los elementos u objetos que se encuentran en
la memoria del R.
rm(list=ls()) # Esta instrucción la usamos para eliminar todos los objetos de la
memoria y así nos garantizarnos que R no tenga nada previamente
guardado.
= ó <-
# Sirven para crear ó definir un objeto. Por ejemplo con “x = 3” o “x <- 3”
se define un objeto que se llama x que es igual a 3. Los objetos pueden ser
varias cosas: valores, ecuaciones, vectores, matrices, salidas de análisis,
gráficos, etc. El poder de R se basa en que es un lenguaje basado en
objetos, ya veremos el porqué de esta afirmación.
Es una buena costumbre definir los objetos en mayúscula para que R no
confunda un objeto definido por nosotros con una de sus funciones. Por
ejemplo si el valor medio de x es 4, al definir mean <- 4, R no sabrá si
“mean” es 4 o es la función para calcular la media. Debido a que R es
sensible a las mayúsculas Mean y mean son cosas distintas. Finalmente
como todas las funciones (o la gran mayoría) fueron creadas usando
minúsculas si usamos mayúsculas para definir objetos y variables no
tendremos errores derivados de la confusión entre los objetos que creamos
nosotros y las que ya existen. Tenga en cuenta que R sobreescribirá objetos
si nosotros nombramos un nuevo objeto con el mismo nombre de un objeto
preexistente. Por ejemplo si uno crea el objeto x para que sea un 8 (x <- 8)
y luego escribe x <- x – 2, la próxima vez que escriba x, el R lo leerá
como un 6 y no ya como un 8.
?xx ??xx
# Muestra la ayuda de “xx”, donde “xx” es el comando que necesitamos
conocer cómo funciona. La primera instrucción realiza la búsqueda en las
ayudas de R de las cosas que tenemos instaladas en nuestra computadora.
La segunda realiza la búsqueda en la base de datos de R en Internet (las
tengamos o no instaladas en la computadora).
library() # Cargar los paquetes. Los paquetes son conjuntos de archivos que le
permiten al programa usar o no determinados comandos. Por eso,
dependiendo de lo que uno vaya a querer hacer necesita previamente
instalar el paquete necesario (el nombre del cual se debe indicar dentro de
los paréntesis). Con update.packages() se actualizan los paquetes. Ej.
library(vegan) carga el paquete vegan para análisis estadísticos de
comunidades como PCA, CA, CCA, RDA, etc.
read.table()
# Es la función que nos permite cargar una tabla de datos desde un
archivo de texto. Ej. read.table(Data.txt). Recordar que el R buscará
este archivo sólo dentro de la carpeta que fijamos como directorio de trabajo.
Data <- read.table("Data.txt", sep="\t", header=TRUE, row.names=1)
# Creará el objeto Data a partir del archivo Data.txt. Pero puede ser
necesario darle más especificaciones: sep="\t" indica que la separación
de las columnas del archivo de texto es una tabulación (también podría ser
un punto “.” o una coma “,”; header=TRUE indica que el archivo tiene una
fila que corresponde al nombre de las variables (si no tuviera se indica como
FALSE ó simplemente F); y row.names=1 indica que la primera columna
contiene el nombre de las unidades experimentales y no es parte de los
datos. Reemplazando en esta instrucción “Data.txt” por “clipboard”
creará Data a partir de los datos copiados en el portapapeles.
# Ej. para pegar datos copiados desde el Excel y generar un objeto Data:
Data <- read.table("clipboard", header = T, row.names = 1, sep =
"\t")
attach()
# Es la función que define objetos vectoriales con cada columna de un objeto
matriz. Ej. attach(Data)permitirá que el programa reconozca las variable
dentro de Data, es decir cada uno con el nombre de la columna. Por
ejemplo, si en nuestra tabla de datos tenemos valores de PH, Humedad y
Conductividad, luego de aplicar el comando podremos ver o hacer cálculos
con cada una de las variables por separado con sólo llamarlas por su
nombre. En caso de no hacerlo, en lugar de escribir PH uno debería escribir
Data$PH (la columna PH que está dentro del objeto Data) cada vez que
quisiera hacer algo con esa variable.
names()
# Devuelve los nombres de las columnas de una matriz o tabla de datos,
cuando esta fue “atachada” previamente. Ej. con: names(Data) devolverá
todos los nombres de las columnas de Data.
detach()
# Deshace todo lo realizado por la función attach(). Ej. detach(Data)
summary() # Devuelve un resumen estadístico. Ej. summary(Data) devolverá un
resumen estadístico de las variables (columnas) en Data. También sirve
para pedirle los resultados de análisis estadísticos que hayamos realizado
previamente.
as.factor()
# Define que una variable es un factor (variable categórica). Ej.
Data$Sp<-as.factor(Data$sp) especificamos que la variable Sp que
se encuentra dentro de la tabla Data es categórica.
as.integer()
# Define que una variable es un entero. Ej. Data$Abund <as.integer(Data$Abund)
as.numeric()
# Define que una variable es un número. Ej. Data$Vol <as.numeric(Data$Vol)
class()
# Devuelve el tipo de dato. Ej. class(Data$sp) nos devolverá como
resultado la palabra factor.
head()
# Devuelve los “encabezados” de una base de datos, es decir los nombres
de las variables de cada columna y las primeras 5 filas de datos. Ej.
head(Data)
plot()
# Crea un gráfico. Ej. plot(Data$Abund, Data$Vol) creará un gráfico
de dispersion con los datos Data$Abund y Data$Vol en los ejes X e Y.
Escriba ?plot para ver el resto de las opciones. También puede explorar la
función biplot()
hist()
# Crea un gráfico de histograma. También vea ?hist()
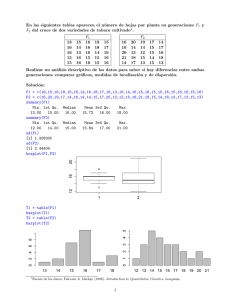
boxplot() # Crea un gráfico de cajas y bigotes. Vea ?boxplot()
windows() # Abre una ventana vacía, donde luego se dibujara el gráfico.
par(mfrow=c(1,2))
# Esta instrucción divide a windows()en 1 fila y 2 columnas
iguales donde R ubicará los próximos dos gráficos. par(mfrow=c(2,2))
dividirá a windows() en 2 filas y 2 columnas.
q()
# Cierra el R.
Otros comandos útiles que podrá explorar con “?”.
print()
mean()
sum()
write()
ncol()
cbind()
# Ej. write(x, file="Data00.txt")
Pruebas estadísticas útiles que podrá explorar con “?”.
t.test()
cor.test()
chisq.test()
fisher.test()
shapiro.test() # Realiza la prueba de Shapiro. Ej. shapiro.test(Data$Abund)
ks.test()
prop.test()
var.test()
levene.test # Necesita la librería o paquete car
wilcox.test
shapiro.test()
vegdist()
hclust() # Del paquete cluster
rda()
# Del paquete vegan. Para realiza el PCA y RDA.
cca()
# Del paquete vegan. Para ralizar el CA y CCA.
specnumber()
decostand()
cutree()
Ejercicios
Ahora para familiarizarse con el R realice los siguientes ejercicios.
Ej. 1. R como calculadora.
>
>
>
>
>
>
>
>
3+5
#Escriba “3+5” en la consola y luego aprete ENTER.
3^2
sqrt(9)
log(1)
exp(1)
factorial(3)
cos(pi)
0/0
Ej. 2. Generar secuencias de números con R.
>
>
>
>
1:7
seq(-1,10, 0.5)
seq(from= -1,to=10, by=0.5)
rep(1:6,2)
Ej. 3. Creando Objetos en R y trabajando con ellos.
a.
> X<-1:7 #¿Porque no devolvió el mismo resultado que en ejercicio anterior?
> X
#¿Entiende qué devuelve esta instrucción?
b.
> Y<-c(2,4,5.6,8)
> Y
> sum(Y)
> mean(Y)
> var(Y)
> min(Y)
> range(Y)
> median (Y)
> summary(Y)
c.
> Data3<-c(7,4,8,2,6,9,11,3,5)
> Data3[2]
> Data3[2:6]
> Data3[Data3>4]
Ej. 4. Creando Objetos tipo matrices en R
a.
> M<-matrix(c(2,3,5,7,11,13),ncol=2)
> M
b.
> Mx<-matrix(c(2,3,5,7,11,13),ncol=2,byrow=T)
> Mx
# Deduzca porqué M y Mx son distintas.
# Para extraer algunos elementos de la matriz
# Segunda columna de la matriz m:
> M[,2]
#Primera fila de la matriz m:
> M[1,]
Ej. 5. Gráficos con plot()
> Data5<-read.table("http://pbil.univlyon1.fr/R/donnees/myo.txt",h=T)
#Revisar los nombres de las columnas
> names(Data5)
> Data5$dose
> Data5$rep
> windows()
#Para que el gráfico lo realice en una ventana aparte
> plot(Data5) #Otra opción más concreta es plot(Data5$dose, Data5$rep)y
si previamente se uso attach(Data5) se puede escribir
directamente plot(dose, rep)
# Lo repetimos, pero editando la leyendas de los ejes.
> windows()
> plot(Data5$dose, Data5$rep, xlab="concentración de ouabina",
ylab="[ ] de noradrenalina")
# Agregamos una línea horizontal en el valor 0,6 y una vertical en 0,4 (sólo como
ejemplo).
> abline(h=0.6)
> abline(v=0.4)
# Otro gráfico interesante!
> windows()
> pairs(Data5)
Ej. 6. Importando datos desde el Excel.
# La forma más fácil y recomendada de importar datos desde el Excel es: (1) ingresar los
datos en una planilla Excel, (2) exportarla como texto (.txt) delimitado por tabulaciones (o
tab-delimited ascii file), (3) cerrar el archivo en el Excel, y (4) usar la función read.table
en el R para importar los datos.
# Para el punto (1) vamos a tratar de hacer las cosas de manera de que sea lo más
simple posible... Ingrese los datos de manera que las filas representes distintas
observaciones (ej. los casos, unidades experimentales, sitios, etc) y las columnas
representen las distintas variables. Si existen datos faltantes ingrese NA (en mayúscula)
para que luego el R los reconozca como datos faltantes (¡OJO! los valores iguales a cero
y los datos faltantes no son lo mismo...). Como se mencionó, no use para los nombres de
las variables los símbolos £, $, %, ^ , &, *, (, ), À, #, ?, , ,. ,<, >, /, |, \, ,[ ,] ,{, y }. Evite
también usar espacios en los nombres. Utilice nombres cortos y preferentemente escriba
la primera letra en mayúscula.
# Ingrese los datos de la tabla que se encuentra a continuación en una planilla Excel:
ID
Granja
Mes
Sexo
Largo
Peso
1
MO
07
1
75
25
2
MO
08
2
85
28
3
MO
11
1
91.6
30
4
MO
11
2
105.5
27
5
LM
08
1
76
23
6
LM
08
1
82
31
7
LM
11
2
90
33
8
LM
11
2
100.5
28
9
LM
11
1
102
30
# Guarde el archivo en la siguiente ruta "C:/Comunidades/TP00" con el nombre Datos6.txt
(Archivo → Guardar como → Texto delimitado con tabulaciones).
# Importe ahora Datos.txt en el R
> Data6 <- read.table(file = "C:/Comunidades/TP00/Datos6.txt",
header = TRUE, dec = ".") #Como ya sabe header = TRUE indica que la tabla
tiene encabezado, es decir que la primera fila corresponde al nombre de las variables y
dec = "." indica que el separador decimal es el punto ¡Atento! Que puede ser que deba
ser la coma, si es que la configuración regional indicó al Excel que el separador decimal
es la coma. Puede revisar esto abriendo Datos.txt en el block de notas).
> Data6
# Ahora, realice algunos gráficos con estos datos (use los comandos del Ej. 5).
Ej. 7. Análisis multivariados de los ensambles de peces de 30 sitios a lo largo del río
Doubs que se encuentra en las cercanías de la frontera entre Francia y Suiza (Verneaux
et al. 2003).
#Los datos de las abundancias de peces, las variables ambientales registradas y sus
coordenadas están disponibles en el paquete ade4. Debe instalarlo previamente.
install.packages("ade4")
library(ade4)
data(doubs)
doubs
# Podrá comprobar que doubs contiene varias tablas de datos
spe <- doubs$fish
# Abundancia de peces
env <- doubs$env
# Datos ambientales
spa <- doubs$xy
# Coordenadas geográficas
# Explore gráficamente los datos, por ejemplo los datos de las variables ambientales:
windows()
pairs(env)
Ej. 8. Cargue el paquete vegan y a partir de los datos doubs realice el ejercicio 4.3.1 de
la pág. 56 del libro Numerical Ecology with R (Borcard et al. 2011) y conteste:
¿Cuáles son los sitios más similares de acuerdo a sus características ambientales?
Ej. 9. A partir de los datos doubs realice el ejercicio 5.3.2.1 y 5.3.2.2 de la pág. 118 y 119
del libro Numerical Ecology with R (Borcard et al. 2011).
# Luego de “summary(env.pca, scaling=1)” escriba:
windows()
biplot(env.pca) # Para que muestre los resultados gráficamente.
Ej. 10. A partir de los datos doubs realice el ejercicio 5.4.2.1 de la pág. 133 del libro
Numerical Ecology with R (Borcard et al. 2011). No realice los análisis de la página 134,
continúe en la pág. 135.
Ej. 11. Usando los datos de presencia/ausencia de las distintas especies de roedores
Sigmodontinos de la provincia de Buenos Aires (Pardiñas et al. 2010, que son facilitados
por la materia) analice si puede identificar distintos ensambles de estos roedores en la
provincia y responda:
a) ¿Cuáles especies caracterizan a cada ensamble?
b) ¿Cuál es el ensamble con mayor riqueza de especies y cuál el de menor riqueza?
c) Ubique en el mapa A las áreas que presentan ensambles similares.
d) Plantee que aproximación metodológica usaría para analizar cuales son los factores
ambientales que estarían afectando en mayor medida la distribución de estos roedores en
la provincia de Buenos Aires y que datos necesitaría (y con que detalle) para realizar este
análisis.
Mapa A. Grilla de 0,5° de lado implementada por Pardiñas et al. (2010) para el análisis
biogeográfico de roedores Sigmodontinos de la provincia de Buenos Aires.