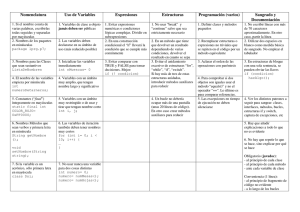
Inferencia de Tipos
Anuncio

Inferencia de Tipos
Paradigmas de Lenguajes de Programación
Primer cuatrimestre - 2008
Repasemos qué es “inferencia de tipos”
Dado un término U sin anotaciones de tipos, hallar un término M
tipable tal que:
1. Γ . M : σ para algún Γ y σ
2. Erase(M)=U
si U es tipable, y demostrar que no lo es en caso contrario.
Algunos ejemplos intuitivos
¿Qué tipo tienen...?
I
not False
I
1+2
I
Id (&&)
Axiomas y reglas de inferencia
x :σ∈Γ
(I-Var)
Γ.x :σ
(I-True)
Γ . true : Bool
(I-False)
Γ . false : Bool
(I-Zero)
Γ . 0 : Int
(Hasta acá son iguales que los axiomas y reglas de tipado.)
Reglas de inferencia
Γ ∪ {x : α} . e : β
(I-Abs)
Γ . λx.e : α → β
Γ . M : τ, S = MGU {τ =Int}
˙
(I-Succ)
S Γ . S (succ(M)) : S τ
Γ . M : τ, S = MGU {τ =Int}
˙
(I-Pred)
S Γ . S (pred(M)) : S τ
Γ.M : α, Γ0 .N : ρ, S = MGU({α=ρ
˙ → t}∪{σi =τ
˙ i /xi : σi ∈ Γ ∧ xi : τi ∈ Γ0 })
(I-App)
S Γ ∪ S Γ0 . S(M N) : S t
Extensiones
(I-Not)
Γ . not : Bool → Bool
(I-And)
Γ . && : Bool → Bool → Bool
(I-<)
Γ . < : Int → Int → Int
(I-+)
Γ . + : Int → Int → Int
(I-*)
Γ . ∗ : Int → Int → Int
(I-Id)
Γ . id : s → s
Tipado vs. Inferencia
Id es una constante polimórfica, una herramienta que nos
permiten las extensiones del lenguaje.
La regla de tipado para Id serı́a:
Γ . idσ : σ → σ
(T-Id)
Los términos que vamos a recibir van a venir sin anotaciones de
tipos en las constantes ni en las abstracciones (resultados de
Erase).
Al aplicar las reglas, las metavariables cuyos tipos no estén
definidos se van a reemplazar por variables de tipo frescas (es
decir, que no hayan sido usadas), y los términos polimórficos (en
esta clase Id y las abstracciones) se van a ir decorando.
Notación: vamos a denotar las variables de tipo con letras latinas, y las
metavariables con letras griegas.
Método del Árbol
Método del Árbol: paso por paso
1. Convencerse de que tipa (...o de que no tipa).
2. Convertir a notación prefija y hacer explı́citos todos los
paréntesis.
3. Construir el árbol de análisis sintáctico.
4. Aplicar las reglas sobre las hojas, indicando qué reglas,
unificaciones y sustituciones se aplican en cada paso.
5. Hacer lo mismo para los nodos internos a medida que sus
hijos queden resueltos.
6. Si se pudo tipar la raı́z, listo. Si no, indicar qué fue lo que falló.
Método del Árbol: más ejemplos
¿Qué tipo tienen...?
I
id not False
I
2 + True
I
λf.ff
¿Qué pasó?
¿Qué significa cuando Hugs dice “unification would give infinite
type”?
(O, para quien use ghc/ghci: “Occurs check: cannot construct the
infinite type: t = t − > t1”.)
Algoritmo PT (Principal Typing), o W
PT (x) = {x : t} . x : t, siendo t una variable de tipo fresca.
PT (succ(U)) : Si obtenemos del paso recursivo que:
PT (U) = Γ . M : τ
Construimos una sustitución que unifique τ con Int:
S = MGU{τ =Int}
˙
Entonces, devolvemos como resultado:
PT (succ(U)) = S Γ . S(succ(M)) : S τ
PT (pred(U)) : Si obtenemos del paso recursivo que:
PT (U) = Γ . M : τ
Construimos una sustitución que unifique τ con Int:
S = MGU{τ =Int}
˙
Entonces, devolvemos como resultado:
PT (pred(U)) = S Γ . S(pred(M)) : S τ
···
Algoritmo PT (continúa)
PT (UV ) : Si obtenemos de los pasos recursivos que:
PT (U) = Γ . M : τ
PT (V ) = Γ0 . N : ρ
(Asumimos que las variables de tipo de PT (U) y PT (V ) son disjuntas.)
Construimos una sustitución que unifique los contextos de tipado Γ y Γ0 :
S = MGU({α=β
˙ | x : α ∈ Γ ∧ x : β ∈ Γ0 } ∪ {τ =ρ
˙ → t}),
donde t es una variable de tipo fresca
Entonces, devolvemos como resultado:
PT (UV ) = SΓ ∪ SΓ0 . S(MN) : St
PT (λx.U) :
Si obtenemos del paso recursivo que:
PT (U) = Γ . M : ρ
Nos fijamos si habı́a información de tipado o no para la variable x.
Si x : τ ∈ Γ para algún τ :
PT (λx.U) = Γ − {x : τ } . λx : τ.M : τ → ρ
Si no:
PT (λx.U) = Γ . λx : s.M : s → ρ,
donde s es una variable de tipo fresca.
Algoritmo PT: extensiones
PT (not) = ∅ . not : Bool → Bool
PT (and) = ∅ . and : Bool → Bool → Bool
PT (<) = ∅. <: Int → Int → Bool
PT (+) = ∅ . + : Int → Int → Int
PT (∗) = ∅ . ∗ : Int → Int → Int
PT (Id) = ∅ . Idt : t → t siendo t una variable de tipo fresca.
En general, siempre que se quiera inferir el tipo de una constante
polimórfica, se usan variables de tipo frescas y se decora el término.
Para pensar...
¿Qué modificaciones habrı́a que hacerle al algoritmo si se
extendiera el lenguaje para contemplar pares hx, y i?
Para pensar...
Repasemos las reglas de tipado para pares:
Γ.M :σ Γ.N :τ
Γ. < M, N >: σ × τ
Γ.M :σ×τ
Γ . π1 (M) : σ
Γ.M :σ×τ
Γ . π2 (M) : τ
Nuevos casos para el algoritmo de inferencia:
PT (π1 (U)) :
Si la llamada recursiva devuelve PT (U) = Γ . M : σ
Construimos una sustitución que unifique σ con un par genérico s × t, con s y
t variables frescas.
S = Unify{σ =
˙ s ×t }
Finalmente:
PT (π1 (U)) = SΓ . S(π1 (M)) : Ss
El caso de π2 (U) es muy parecido...
Nuevos casos para el algoritmo de inferencia:
PT (< U, V >) :
Si las llamadas recursivas devuelven:
PT (U) = Γ . M : σ
PT (V ) = Γ0 . N : τ
Construimos una sustitución que unifique las variables libres de ambos
contextos:
S = Unify{α=β
˙ | x : α ∈ Γ ∧ x : β ∈ Γ0 }
Finalmente:
PT (< U, V >) = SΓ ∪ SΓ0 . S(< M, N >) : Sσ × Sτ
Para pensar ... (2)
Extender el algoritmo de inferencia visto en clase para que soporte
el tipado de un observador universal (case) de números naturales.
Su sintaxis es la siguiente:
M ::= ... | caseNat M of 0 → N ; Succ(x) → O
y su regla de tipado, la siguiente:
Γ . M : Nat
Γ.N :σ
Γ ∪ {x : Nat} . O : σ
Γ . caseNat M of 0 → N ; Succ(x) → O : σ
Ayuda: observar el parecido en la regla de tipado con un λ y
qué hace el algoritmo en ese caso.
Nuevos casos para el algoritmo de inferencia (2):
PT (caseNat U of 0 → V ; Succ(x) → W ) :
Si las llamadas recursivas devuelven:
PT (U) = Γ1 . M : σ, PT (V ) = Γ2 . N : τ, PT (W ) = Γ3 . O : ρ
Construimos una sustitución que unifique las variables libres de ambos
contextos, unifique los tipos de V y W, y unifique el tipo de U con nat. La
variable x debe tener tipo Nat sólo dentro del contexto de W, debe poder
aparecer libre en cualquier otro lado con otro tipo. Por ejemplo en:
caseNat (λy : Bool.Succ(0))x of 0 → 0 ; Succ(x) → x
S = Unify({τ =ρ}
˙
∪ {σ =Nat}∪
˙
{α=β
˙ | v : α ∈ Γi ∧ v : β ∈ Γj , 1 ≤ i, j ≤ 3, v 6= x}∪
{α=β
˙ | x : α ∈ Γi ∧ x : β ∈ Γj , 1 ≤ i, j ≤ 2})
Finalmente:
PT (caseNat U of 0 → V ; Succ(x) → W ) =
SΓ1 ∪ SΓ2 ∪ S(Γ3 − {x : α}) . S(caseNat M of 0 → N ; Succ(x) → O) : Sρ
Para pensar...(el último):
Asumimos que tenemos la constante polimórfica (==) : s → s,
pero no vale instanciar s en cualquier tipo, sólo vale para algunos.
¿Cómo se agregarı́a la clase de tipos Eq?
Ahora los juicios de tipado ahora son de la forma:
Γ . M : {σ1 , · · · , σm } ⇒ σ
Esto se lee: “M tiene tipo σ bajo contexto Γ si σ1 , · · · , σm tienen
la igualdad (==) definida”.
El axioma de inferencia de == queda ası́:
∅ . ==: {s} ⇒ s → s
Nuevos casos para el algoritmo de inferencia (el último):
El caso importante es el ==:
PT (==)= ∅. ==s : {s} ⇒ s → s, con s variable fresca
Ahora sı́ hay que modificar los casos que ya existı́an:
PT (x) = {x : t} . x : ∅ ⇒ t, siendo t una variable de tipo fresca.
Para las constantes que no son ==, simplemente se agrega el conjunto ∅ al
juicio de tipado.
En general para el resto de los casos, sigue todo igual y se unen los conjuntos
de Eq de los subtérminos y se les aplica la sustitución. Por ejemplo:
PT (UV ) :
PT (U) = Γ . M : {τ1 , · · · , τm } ⇒ τ
PT (V ) = Γ0 . N : {ρ1 , · · · , ρn } ⇒ ρ
S se define igual que antes.
PT (UV ) = SΓ ∪ SΓ0 . S(MN) : S({τ1 , · · · , τm } ∪ {ρ1 , · · · , ρn }) ⇒ St
Fin de la clase
¿?
¿? ¿?
¿?
¿? ¿? ¿? ¿?
¿?