+ P( B) : P(A|B)
Anuncio
 : P(A|B)")
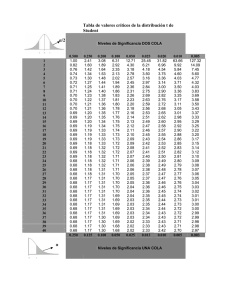
(16) Si A, B ∈ F y A ⊆ B, entonces P(A) ≤ P(B). Prueba Como A y B \ A son disjuntos, P(B) = P(A) + P(B \ A) ≥ P(A). ! Suele ser útil dibujar diagramas de Venn al trabajar con probabilidades. Por ejemplo, para ilustrar la igualdad (15) podemos dibujar el de la Figura 1.1 y observar que la probabilidad de A ∪ B es P(A) + P(B) − P(A ∩ B) porque esta última se cuenta dos veces en la suma P(A) + P(B). PROBABILIDAD BASICA P(A ∪ B) + P(A ∩ B) = P(A) + P(B) : y+!y y A B x x+!x P(A|B) = P(A ∩ B)/P(B) ; Fig. 1.1 Diagrama de Venn que ilustra la igualdad P(A ∪ B) = P(A) + P(B) − P(A ∩ B). si los Ai son una partición de Ω , ! 1 i de la suma P(B) = P(Ai ∩ B) es el sumando i P(B|Ai )P(Ai ) : F (x) X B p(0)+p(1)+p(2) DISTRIBUCIONES DE PROBABILIDAD (una variable) p(0)+p(1) p(0) nombre Binomial(n, p) 0 1 2 A1 función de masa (o densidad) x " # k 3 4 = n 5 p (1 − p)n−k p(k) k p(k) = exp(−λ) λ /k! Poisson(λ) k Geométrica(p) . . . pero la que cuenta sólo los j = k − 1 “fracasos hasta 1er éxito”, p(k) = p(1 − p)k−1 A2 A4 A3 media varianza np np(1 − p) λ λ 1/p (1 − p)/p2 (1/p) − 1 Uniforme(0,1) p(j) = p(1 − p)j "k−1# n p(k) = n−1 p (1 − p)k−n "j+n−1# n p(j) = n−1 p (1 − p)j f (x) = 1 , para 0 < x < 1 1/2 1/12 Exponencial(c) f (x) = c e−cx , para x > 0 1/c 1/c2 w/c w/c2 n 2n 0 1 µ σ2 Binomial Negativa(n, p) . . . y la que cuenta sólo los j = k − n “fracasos hasta el éxito n”, f (x) = Gamma(w, c) y la Gamma( n2 , 12 ) es la χ2n : Normal(0,1) Normal(µ, σ) . . . o Normal(µ, σ 2 ) : 1 w w−1 −cx e Γ(w) c x , para x > 0 √ f (z) = exp(−z 2 /2) / 2π X = σZ + µ , con Z ∼ Normal(0,1) A5 n(1 − p)/p2 n/p (n/p) − n La variable Y = eX = abZ , con a = eµ , b = eσ se llama entonces LogNormal; tiene E(Y ) = aeσ 2 /2 . DEFINICIONES CLAVE Función de distribución: FX (x) = P(X ≤ x) , para una X : Ω → R, FX (x1 , . . . , xn ) = P(Xi ≤ xi , i = 1, . . . , n) , para una X = (X1 , . . . , Xn ) : Ω → Rn , y la función de densidad es, en cada punto x = (x1 , . . . , xn ) ∈ Rn , ∂n fX (x) = FX (x) ∂x1 · · · ∂xn Varianza, covarianza y correlación: " " # # 2 σX = var(X) = E |X − µX |2 = E X 2 − µ2X cov(X, Y ) Coeficiente de correlación: ρX,Y = σX σY cov(X, Y ) = E ((X − µX )(Y − µY )) = E (XY ) − µX µY σY La recta de regresión de Y sobre X pasa por el punto de las medias y tiene pendiente = ρX,Y σX VARIABLES PIVOTE (para intervalos de confianza o contrastes de hipótesis) Notación usada y otros detalles generales: En cada caso, • µ, σ 2 designan a la media y varianza de ‘la población’: la v.a. X cuyos valores muestreamos, • x̄, s2 a la media y cuasi-varianza de la muestra, n al tamaño de ésta; • cuando hay dos muestras, sus tamaños son m, n y los subı́ndices A, B distinguen los estadı́sticos de ambas y los parámetros de las dos variables ‘observadas’. • En el caso de un IC con “desconfianza” (significance level) = α , los cuantiles de la variable pivote que correspondan al α elegido, producen, al despejar el parámetro, los extremos del intervalo buscado. • En el caso de un contraste de hipótesis, el parámetro viene dado por H0 , el nivel de significación decide qué cuantiles usar, y al despejar el estadı́stico resulta la frontera de la región de rechazo. Se fije o no a priori una región de rechazo, el p-valor que sale de los datos es la P, si H0 fuese cierta, de que la variable pivote Y se aleje de lo esperado tanto o más que el valor que producen los datos. x̄ − µ T = $ ∼ s 1/n Media: % td , con d = n − 1 si la X no difiere mucho de una Normal, ≈ N (0, 1) , si n es grande; √ 2 si se conoce σ, se usa en el lugar de s . Si la X es Poisson(λ) , x̄ estima λ = σ y podemos usar σ = x̄ X X √ en lugar de s ; en el caso de un contraste de hipótesis, el valor σX = λ0 dado por la hipótesis H0 . 2 2 Diferencia de dos medias: En % los mismos dos casos de antes, y si podemos suponer que σA = σB , 2 td , con d = m + n − 2 (x̄A − x̄B ) − (µA − µB ) (m − 1) sA + (n − 1) s2B $ T = . ∼ y con sp 2 = m+n−2 que es ≈ N (0, 1) si d grande, sp 1/m + 1/n Proporción, o la diferencia de dos de ellas: Ahora x̄ es la proporción muestral, y x̄(1 − x̄) estima σ 2 Z=$ x̄ − p x̄(1 − x̄)/n ≈ N (0, 1), Z=$ (x̄A − x̄B ) − (pA − pB ) x̄A (1 − x̄A )/m + x̄B (1 − x̄B )/n √ ≈ N (n, 2n) si n es grande. (n − 1) s2 ∼ χ2n−1 σ2 % n (f − e )2 ! fi son frecuencias observadas, i i 2 S= ∼ χd , donde e ei las frecuencias esperadas, i i=1 Varianza: S= ≈ N (0, 1) . n − 1 , d= n−1−r , (n − 1)(m − 1) , según los casos: si se estiman r parámetros, o en los otros dos casos vistos (tabla n × m). Pearson: LR: Para estimar Y − (α + βX) ∼ N (0, σ) , o contrastar la H0 : β = 0 , usando n datos (xi , yi ) : ! ! sy 2 β̂ = b = (yi − ȳ)(xi − x̄)/ (xi − x̄) = r s , * √ x sx n − 1 n−2 α̂ = a = ȳ − b x̄ ; es decir, ȳ = α̂ + β̂ x̄ , Si β = 0 , T = b = r ∼ tn−2 . sR 1 − r2 " # " n − 1 n − 1 σ̂ 2 = s2 = s2 − b2 s2x = 1 − r2 ) s2y . R n−2 y n−2 mini-TABLAS de: Normal(0,1) , y para S ∼ χ2n , del cocienteNormal(0,1) S/n (que esP∼=Exp p 1 si n = 2) Dan: • el valor (en %) de P(Z > z) para z ≥ 0 dado, si Z ∼ Normal(0,1); z • para p dado, el valor de t que cumple P(T > t) = p , si T ∼ Student tn ; • para p dado, los valores r0 , r1 que cumplen P(S/n < r0 ) = p = P(S/n > r1 ) , si S ∼ χ2n . Student tn , S ! Chi2n P=pP=p Student t Student t n Normal(0,1) Normal(0,1) P=p P=p z z z= 0. 1. t 2. 2 S2 ! Chi 50.0 15.9 2.30 .00 S ! Chi n n 48.0 14.7 2.00 .05 .10 46.0 13.6 1.80 P=p P=p P=p P=p .15 44.0 12.5 1.60 nr nr nr0 nr1 1 1.40 .20 0 42.1 11.5 40.1 10.6 1.20 .25 38.2 9.68 1.10 .30 36.3 8.85 0.94 .35 .40 34.5 8.08 0.82 32.6 7.35 0.71 .45 30.9 6.68 0.62 .50 29.1 6.06 0.54 .55 27.4 5.48 0.47 .60 25.8 4.95 0.40 .65 24.2 4.46 0.35 .70 22.7 4.01 0.30 .75 21.2 3.59 0.26 .80 19.8 3.22 0.22 .85 18.4 2.87 0.19 .90 .95 17.1 2.56 0.16 Para z mayores que 3 , . . . P(Z > z) ≈ 40% · e−z Con R: 2 /2 /z 100*(1-pnorm(z)) , P=p n p= n 3 4 5 6 7 8 9 10 11 12 13 14 15 16 18 20 30 40 50 60 120 600 5% 2.5% 1% 0.5% 2.35 2.13 2.02 1.94 1.89 1.86 1.83 1.81 1.80 1.78 1.77 1.76 1.75 1.75 1.73 1.72 1.70 1.68 1.68 1.67 1.66 1.65 3.18 2.78 2.57 2.45 2.36 2.31 2.26 2.23 2.20 2.18 2.16 2.14 2.13 2.12 2.10 2.09 2.04 2.02 2.01 2.00 1.98 1.96 4.54 3.75 3.36 3.14 3.00 2.90 2.82 2.76 2.72 2.68 2.65 2.62 2.60 2.58 2.55 2.53 2.46 2.42 2.40 2.39 2.36 2.33 5.84 4.60 4.03 3.71 3.50 3.36 3.25 3.17 3.11 3.05 3.01 2.98 2.95 2.92 2.88 2.85 2.75 2.70 2.68 2.66 2.62 2.58 ∞ 1.65 nr0 t 1.96 2.33 2.58 qt(1-p,n) , 1% P=p nr1 2.5% r0 =p= n 1 0.01 0.025 2 0.04 0.07 3 0.07 0.12 4 0.11 0.17 5 0.15 0.21 6 0.18 0.24 7 0.21 0.27 8 0.23 0.30 9 0.26 0.32 10 0.28 0.35 11 0.30 0.37 12 0.32 0.39 13 0.33 0.40 14 0.35 0.42 15 0.36 0.43 16 0.39 0.46 18 0.41 0.48 20 0.50 0.56 30 0.55 0.61 40 0.59 0.65 50 0.70 0.74 100 0.97 0.97 104 qchisq(p,n)/n , 5% 2.5% 1% r1 3.84 5.02 6.63 3.00 3.69 4.61 2.60 3.12 3.78 2.37 2.79 3.32 2.21 2.57 3.02 2.10 2.41 2.80 2.01 2.29 2.64 1.94 2.19 2.51 1.88 2.11 2.41 1.83 2.05 2.32 1.79 1.99 2.25 1.75 1.94 2.18 1.72 1.90 2.13 1.69 1.87 2.08 1.67 1.83 2.04 1.64 1.80 2.00 1.60 1.75 1.93 1.57 1.71 1.88 1.46 1.57 1.70 1.39 1.48 1.59 1.35 1.43 1.52 1.24 1.30 1.36 1.02 1.03 1.03 qchisq(1-p,n)/n