Introducción a las bases de datos
Anuncio

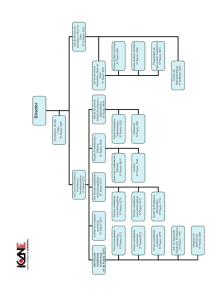
Introducción a las bases de datos Juan Ignacio Rodrı́guez de León Abstract Aplicaciones de los sistemas de bases de datos. Sistemas de bases de datos frente a sistemas de archivos. Visión de los datos. Modelos de datos. Lenguajes de bases de datos. Usuarios y administradores de la base de datos. Gestión de transacciones. Estructura de un sistema de bases de datos. Arquitecturas de aplicaciones. Historia de los sistemas de bases de datos. También se presenta un ejemplo de una aplicación de bases de datos: una empresa bancaria que cuenta con varias sucursales. Este ejemplo se usa como ejemplo de trabajo a lo largo de toda la asignatura. 1 Sistemas de bases de datos frente a sistemas de ficheros. Mantener la información en un sistema de ficheros presenta una serie de inconvenientes importantes, precisamente los que se intentan evitar con las sistemas de bases de datos: • Redundancia e inconsistencia de datos. La información puede estar duplicada en diferentes sitios, y codificada de diferentes maneras. Esta redundancia tiene como primera consecuencia mayores costes de almacenamiento y de acceso. Además, puede conducir a inconsistencias de datos. • LDificultad en el acceso a los datos. No existe otro método de acceso a los datos que los programas que se hayan implementado. • Aislamiento de los datos. Debido a que los datos están dispersos en varios ficheros, e incluso representados en distinto formatos, es difı́cil interrelacionarlos. • Problemas de integridad. Las restricciones que se deseen imponer a los datos deben hacerse por programa. Si existen varios programas (quizá incluso en varios lenguajes) hay que añadir el código de restricción a todos. En caso de tener que modificar o ampliar estas restricciones, el trabajo puede ser considerable. 1 1 SISTEMAS DE BASES DE DATOS FRENTE A SISTEMAS DE FICHEROS.2 • Problemas de atomicidad. En un sistema de archivos es difı́cil garantizar la atomicidad de las operaciones. • Anomalı́as en el acceso concurrente. Es complicado controlar el acceso concurrentes de diferentes usuarios y/o máquinas. • Problemas de seguridad. Seguridad no centralizada. Un sistema de base de datos es una colección de archivos interrelacionados y un conjunto de programas que permiten a los usuarios acceder y modificar esos archivos, intentando resolver los problemas descritos anteriormente. 1.1 Visión de los datos Uno de los principales objetivos de este sistema es proporcionar a los usuarios una visión abstracta de los datos, de forma que no deba de preocuparse por los detalles del almacenamiento de los datos. Esta simplificación de los detalles de almacenamiento y gestión de los datos se realizan en diversos niveles. Nivel Fı́sico En este nivel se describen en detalle las estructuras de datos que definen como se almacenan realmente los datos. Nivel lógico En este siguiente nivel, lo que se define es que datos se almacenan, ası́ como las relaciones entre los mismos. Este nivel permite describir la base de datos completa en base a un subconjunto de estructuras relativamente simples. Los usuarios a nivel lógico (Diseñadores y administradores de bases de datos) no necesitan preocuparse del nivel fı́sico. Nivel de vistas Este nivel completa, mediante la definición de vistas, las necesidades finales de acceso a los datos. La vista puede reorganizar la información del nivel lógico, ampliando, transformando o incluso reduciendo la información que se desea mostrar al usuario (Programadores y administradores de bases de datos) . Además de esconder los detalles del nivel lógico, las vistas proporcionan también un mecanismo de seguridad que evita los accesos a determinadas partes de la base de datos. Las bases de datos normalmente se ven modificadas a lo largo del tiempo. Se denomina ejemplar de la base de datos a la colección de información almacenada en la misma en un momento determinado. El diseño completo de la base de datos se llama esquema de la base de datos. Existen diferentes esquemas, de acuerdo con los niveles explicados anteriormente. Ası́, el esquema fı́sico describe el diseño final en el nivel fı́sico, mientras que el 2 MODELO DE DATOS 3 esquema lógico lo describe en el nivel lógico. Normalmente, es el esquema lógico el más importante, ya que afecta de manera importante a los programas de aplicación. El nivel fı́sico, aunque importante, puede ser alterado sin que las aplicaciones se vean afectadas. 2 Modelo de datos El modelo de datos es una colección de herramientas conceptuales que se utilizan para describir datos, incluyendo relaciones, semántica y restricciones de consistencia. Se estudiarán dos modelos de datos, el modelo entidad-relación y el relacional. Los diferentes modelos de datos que se han propuesto se clasifican en tres grupos: modelos lógicos basados en objetos, modelos lógicos basados en registros y modelos fı́sicos. 2.1 Modelo Entidad-Relación (E-R) Este modelo representa el mundo real mediante una colección de objetos básicos, que denomina entidades, y las relaciones entre estos objetos. Una entidad es cualquier cosa o parte del mundo que es distinguible del resto. Por ejemplo, en un sistema bancario, las personas y las cuentas bancarias se podrı́an interpretar como entidades. Las entidades se describen mediante una serie de atributos (por ejemplo, número de cuenta, saldo y fecha de alta pueden ser atributos de la entidad cuenta). Una relación es una asociación entre varias entidades (Por ejemplo, una relación impositor relaciona cada cliente con las cuentas que tenga abiertas). El conjunto de todas las entidades del mismo tipo se denomina conjunto de entidades, y el conjunto de todas las relaciones del mismo tipo se denominan conjunto de relaciones. La estructura lógica se representa mediante el diagrama Entidad-Relación o diagrama E-R, que consta de los siguientes componentes. sı́mbolos Rectángulos Elipses Rombos Lı́neas Representan Conjuntos de entidades Atributos Relaciones entre conjuntos de entidades Unen a los atributos con los conjuntos de entidades, y los conjuntos de entidades con las relaciones Además de representar entidades y relaciones, el modelo permite representar ciertas restricciones que los datos almacenados deben cumplir. Una restricción importante es la correspondencia de cardinalidad, que expresa el número de entidades con las que otra entidad se puede asociar a través de un conjunto de relaciones. El modelo E-R se estudiará con más detalles en el tema 2. 3 1.4 LENGUAJES DE BASE DE DATOS 2.2 4 Modelo relacional En el modelo relacional se utiliza un grupo de tablas para representar los datos y las relaciones entre ellos. Cada tabla está compuesta por varias columnas, y cada columna tiene su propio nombre, que debe ser único. Este modelo es un ejemplo de modelo basado en registros. Estos modelos se denominan ası́ porque la base de datos se estructura en registros de formato fijo, de diferentes tipos. Cada tabla contiene registros de un tipo particular. Cada tipo de registro define un número fijo de campos, donde cada campo representa un atributo. El modelo de datos relacional es el modelo más ampliamente usado, y la mayorı́a de los sistemas actuales se basan, parcial o totalmente, en el modelo relacional. Este modelo se estudiará con más detalle en los temas 3 al 7. Es habitual realizar primero un esquema E-R, situado en un nivel superior de abstracción, que luego es traducido al modelo relacional. En el Tema 2 se verá con más detalle este mecanismo de traducción. Por último, se ha de destacar que en el modelo relacional es posible crear esquemas que tengan, por ejemplo, información duplicada innecesariamente. El tema 7 se dedicará ı́ntegramente a evitar estos malos diseños. 3 1.4 Lenguajes de base de datos Un sistema de base de datos proporciona un lenguaje de definición de datos para especificar el esquema de la base de datos y un lenguaje de manipulación de datos para expresar las consultas y las modificaciones a la base de datos. En la práctica, los dos lenguajes no suelen ir por separado, sino que forman un único lenguaje, como por ejemplo en el lenguaje SQL, ampliamente utilizado. Lenguaje de definición de datos (LDD) sirve para especificar el esquema de la BD. El resultado de la compilación es un conjunto de tablas que se almacenan en un archivo especial llamado diccionario de datos o directorio de datos. El diccionario de datos almacena metadatos, es decir, datos acerca de los datos. La estructura de almacenamiento y los métodos usados se especifican mediante un conjunto de definiciones del lenguaje de almacenamiento y definición de datos. Lenguaje de manipulación de datos (LMD) permite acceder o manipular los datos organizados. Hay dos tipos: LMD procedimentales, que requieren que el usuario especifique que datos se necesitan y como obtenerlos, y LMD no procedimentales, que requiere que el usuario especifique que datos se necesitan, sin especificar como obtenerlos. La manipulación de la información almacenada en una base de datos contempla: 4 USUARIOS Y ADMINISTRADORES DE LA BASE DE DATOS 5 • La recuperación de la información almacenada • La inserción de información nueva • El borrado de información • La modificación de la información Una consulta es una instrucción para recuperar información, y la parte del LMD que implica recuperación de información se llama lenguaje de consultas. Existen varios lenguajes de consultas. En el tema 4 se estudiará SQL, el más extendido de todos. En el tema 5 se estudiarán otros. 3.1 Acceso a la base de datos desde programas de aplicación Los programas de aplicación se escriben normalmente en un lenguaje de programación de alto nivel (Cobol, C, C++, Java, Python, etc...), que denominaremos lenguaje anfitrión. Para acceder a la base de datos, las instrucciones LMD necesitan ser ejecutadas desde el lenguaje anfitrión. Hay dos maneras de hacerlo: • Mediante una API (Librerı́a de procedimientos) que se puede usar para enviar las instrucciones LMD y LDD a la base de datos, ası́ como recuperar los resultados. ODBC (Open Data Base Connectivity) es un ejemplo de API definida para permitir el acceso a la base de datos desde C. JDBC (Java Data Base Connectivity) es similar, pero utilizando Java como lenguaje anfitrión. • Extendiendo la sintaxis del lenguaje anfitrión para incorporar llamadas LMD dentro del programa del lenguaje anfitrión. Normalmente se realiza mediante un preprocesador. Si se utiliza esta técnica se dice que el lenguaje de consulta está embebido en el lenguaje anfitrión. 4 Usuarios y administradores de la base de datos Las personas que hacen uso de una base de datos pueden clasificarse en diferentes roles: 4.1 Usuarios • Usuarios normales: Usuarios no sofisticados, que interactúan con el sistema mediante la ejecución de programas especı́ficos escritos previamente. Normalmente la interfaz para este tipo de usuarios es del tipo de formularios e informes generados. 5 GESTIÓN DE TRANSACCIONES 6 • Programadores de aplicaciones: Profesionales informáticos que escriben los programas de aplicación que utilizan los usuarios. Para ello se suelen usar lenguajes convencionales, entornos de herramientas de desarrollo rápido de aplicaciones (RAD -Rapid Application Development-) o lenguajes de cuarta generación. • Usuarios sofisticados: Interactúan con el sistema sin usar aplicaciones especı́ficas, usando directamente el lenguaje de consultas. Los analistas que utilizan consultas para explotar los datos en la base de datos entran en esta categorı́a. • Usuarios especializados: son usuarios sofisticados que escriben aplicaciones de BD especializadas que no son adecuadas en el marco de procesamiento de datos tradicional. 4.2 Administrador de la base de datos Una de las ventajas de usar un un sistema gestor de base de datos es tener un control centralizado tanto de datos como de los programas que acceden a los datos. La persona que se encarga de manejar este control se denomina administrador de la base de datos. Sus funciones incluyen: • Definición de esquemas. • Definición de estructuras y métodos de accesos • Realizar las modificaciones de los esquemas y de la organización fı́sica, cuando sea necesario. • Conceder o revocar autorización a los usuarios para poder consultar, insertar, modificar o borrar los datos. • Mantenimientos rutinarios: copias de respaldo, comprobación de espacio ocupado en los discos, comprobaciones de rendimiento. 5 Gestión de transacciones Una de las grandes ventajas que proporciona el uso de un sistema gestor de base de datos es el de garantizar la atomicidad. La atomicidad es la garantı́a que nos da el sistema de que, ante la ejecución de una serie de operaciones, englobadas en una transacción, o bien se ejecutan todas las operaciones, o bien no se efectúa ninguna. En otras palabras, el conjunto de operaciones se hace entero o no se hace, no dejando ningún efecto sobre el sistema. La atomicidad nos permite realizar cambios en la base de datos garantizando la consistencia de los datos. la consistencia es la garantı́a de que determinadas reglas declaradas sean siempre verificadas después de la transacción, 6 ESTRUCTURA DE UN SISTEMA DE BASE DE DATOS 7 independientemente del resultado de la misma. Por ejemplo, en una transacción de fondos desde la cuenta A a la cuenta B, la regla de que A+B debe ser constante debe cumplirse tanto antes como después de la transacción (aunque durante la transacción si es posible que se produzcan inconsistencias). Otra caracterı́stica importante es la durabilidad. La durabilidad de una transacción garantiza que, en el instante en el que se finaliza la transacción, esta perdura a pesar de otras consecuencias. Por ejemplo, incluso en el caso de fallo en el disco duro, el sistema aún será capaz de recordar todas la transacciones que han sido realizadas en el sistema. La responsabilidad de asegurar la atomicidad y durabilidad recaen en una parte del sistema gestor de base de datos, concretamente en el componente de gestión de transacciones. En ausencia de fallos, toda transacción concluida es definitiva. En caso de fallo, el sistema debe realiza la recuperación de fallos, es decir, restaurar la base de datos al estado en que estaba antes de que ocurriera el fallo. Finalmente, otra caracterı́stica importante del sistema de transacciones es el aislamiento entre operaciones. El aislamiento es la garantı́a de que todas las transacciones que se estén realizando simultáneamente en el sistema son invisibles al resto los usuarios hasta que estas hayan concluido. Este aislamiento garantiza que los usuarios del sistema no observen los cambios intermedios. Es responsabilidad del gestor de control de concurrencia controlar la interacción entre las transacciones concurrentes. Estas cuatros caracterı́sticas de los sistemas gestores de bases de datos se suelen resumir con el acrónimo ACID, que corresponde con las iniciales en ingles (Atomicity, Consistency, Isolation, Durability). 6 Estructura de un sistema de base de datos Un SGBD se divide en módulos que se encargan de cada una de las responsabilidades del sistema completo. A grandes rasgos, estos módulos pueden agruparse en dos categorı́as, el gestor de almacenamiento y el procesador de consultas. El gestor de almacenamiento es importante porque las bases de datos requieren normalmente una gran cantidad de espacio, siendo ya relativamente normales bases de datos de varios Giga bytes, e incluso Terabytes. Debido a estos tamaños y a la diferencia de velocidades entre la memoria principal y la de disco, la estructuración correcta de los datos puede minimizar la necesidad de movimientos entre niveles de memoria y, consecuentemente, optimizar el rendimiento. El procesador de consultas es importante porque ayuda al SGBD a simplificar y facilitar el acceso a los datos. Las vistas de alto nivel ayudan a conseguir este objetivo. Es necesario traducir las actualizaciones y las consultas realizadas en lenguaje no procedimental (nivel lógico) en una se- 6 ESTRUCTURA DE UN SISTEMA DE BASE DE DATOS 8 cuencia de operaciones (en el nivel fı́sico). 6.1 Gestor de almacenamiento El gestor de almacenamiento es el módulo que proporciona la interfaz entre los datos de bajo nivel en la base de datos y los programas de aplicación y las consultas emitidas al sistema; por tanto, es n interprete de las instrucciones LMD a secuencias de órdenes de nivel inferior. También es responsable de la interacción con el sistema de ficheros. Ası́, el gestor de almacenamiento es responsable del almacenamiento, actualización y recuperación de los datos en la base de datos. Los componentes de gestor de almacenamiento incluyen: Gestor de autorización e integridad Comprueba que se satisfacen las restricciones de integridad y la autorización de los usuarios para acceder a los datos. Gestor de transacciones Asegura la consistencia de la base de datos, a pesar de los fallos en el sistema. También es responsable de que la ejecución de transacciones concurrentes ocurra sin conflictos. Gestor de archivos Gestiona la reserva de espacio de almacenamiento en disco, y las estructuras de datos usadas para almacenar la información. Gestor de memoria intermedia o caché Es responsable de traer los datos de disco hacia memoria principal, y de decidir que datos tratar en memoria caché. Este módulo es crı́tico para el rendimiento del sistema. El gestor de almacenamiento implementa varias estructuras de datos como parte de la implementación fı́sica del sistema: • Archivo de datos, que almacena la base de datos en si. • Diccionario de datos, que almacenan metadatos acerca de la estructura de la base de datos, en particular, el esquema. • Índices, que proporcionan acceso rápido a determinados datos. 6.2 Procesador de consultas Los componentes de este módulo son: Intérprete del LDD Interpreta las instrucciones del LLD y registra las definiciones en el diccionario de datos. 7 ARQUITECTURA DE APLICACIONES 9 Compilador del LMD Traduce las instrucciones del LMD en un lenguaje de consultas a un plan de evaluación, que consiste en instrucciones de bajo nivel que entiende el motor de evaluación de consultas. El compilador también puede producir y evaluar el coste de distintos planes alternativos, realizando ası́ una fase de optimización de la consulta. Motor de evaluación de consultas Ejecuta las instrucciones de bajo nivel generadas por el compilador de LMD. La figura 1 pretende mostrar estos componentes y sus conexiones. 7 Arquitectura de aplicaciones Las aplicaciones de Base de datos se dividen normalmente en dos o tres capas. En una arquitectura de dos capas, la aplicación se divide en un componente que reside en el cliente, que llama directamente a la funcionalidad del sistema de base de datos en el servidor mediante instrucciones de consultas, usando normalmente estándares como ODBC o JDBC. En una arquitectura de tres capas, existe un cliente muy ligero, que actúa simplemente como frontal, y que no llama directamente a la base de datos, sino que se comunica con un servidor de aplicaciones. Es este servidor de aplicaciones el que interactúa con la base de datos. La ventaja de este último esquema es que la implementación de la lógica de negocio se realiza en un único sitio, en la capa intermedia o servidor de aplicaciones, lo que facilita enormemente su mantenimiento. 7 ARQUITECTURA DE APLICACIONES 10 Figure 1: Componentes de un SGBD Programas de aplicación Interfaz de aplicaciones Compilador y enlazador Herramientas de consulta Herramientas de administración Consultas LMD Intérprete del LDD Código objeto de los programas de aplicación Compilador del LMD y organizador Motor de evaluación de Consultas Procesador de consultas Gestor de Memoria Intermedia (Caché) Gestor de archivos Gestor de autorización e integridad Gestor de transacciones Gestor de almacenamiento Diccionario de datos Índices Datos Datos estadísticos Almacenamiento en disco 8 8 PREGUNTAS HABITUALES 11 Preguntas habituales 1. ¿Cual de estos componentes no forma parte del Gestor de almacenamiento en un sistema gestor de base de datos. (a) Gestor de consultas (b) Gestor de autorización e integridad (c) Gestor de transacciones (d) Gestor de memoria intermedia 2. ¿A qué se refiere el término “Esquema de la base de datos” en un sistema de base de datos? (a) Al diseño completo de una base de datos (b) Al nivel fı́sico (c) Al nivel lógico (d) Al nivel vista 3. ¿Qué parte del lenguaje de base de datos se utiliza para especificar el esquema de la base de datos? (a) DML (b) DLL (c) DDL (d) EBD 4. ¿Cuál de estas afirmaciones es verdadera? (a) Un DML procedimental necesita que el usuario especifique que datos necesita pero no como obtenerlos. (b) Un DML procedimental necesita que el usuario especifique que datos necesita y como obtenerlos. (c) Un DML procedimental necesita que el usuario especifique que datos necesita mediante procedimientos. (d) Ninguna de ellas.