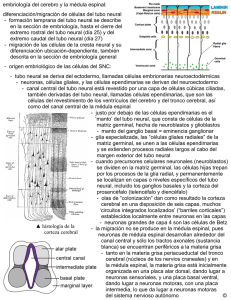
Flórez Revuelta, Francisco - RUA
Anuncio

Modelo de representación y
procesamiento de movimiento para
diseño de arquitecturas de tiempo real
especializadas
Francisco Flórez Revuelta
Tesis de Doctorado
Facultad:
Escuela Politécnica Superior
Director:
Dr. Juan Manuel García Chamizo
2001
Tesis Doctoral
Modelo de representación y
procesamiento de movimiento
para diseño de arquitecturas
de tiempo real especializadas
Francisco Flórez Revuelta
Tesis Doctoral
Modelo de representación y
procesamiento de movimiento
para diseño de arquitecturas
de tiempo real especializadas
presentada por:
Francisco Flórez Revuelta
dirigida por:
Dr. Juan Manuel García Chamizo
Programa de Doctorado
“Sistemas industriales, computación y reconocimiento
de formas”
Departamento de Tecnología Informática y
Computación
UNIVERSIDAD DE ALICANTE
Diciembre, 2001
Para la Ichi y
Mari Pulgui
AGRADECIMIENTOS
Al ponerme a escribir estas páginas me surgen algunas preguntas
para determinar quién me ayudó a realizar este trabajo. ¿Cuándo
comencé a escribir esta tesis? ¿Por qué este trabajo? ¿Cuándo di
con la solución? ¿Qué me llevó a ella? Ni yo mismo sé cuándo di
por iniciada la tesis. ¿Quizás cuando acabé los cursos de
doctorado? ¿Quizás al empezar el proyecto fin de carrera? Es
probable que antes. Muchas personas han pasado por mi lado
durante todo este tiempo. Tantas, importantes, que es muy fácil
dejar en el olvido a alguna.
En primer lugar, a mi mujer Icíar y mi hija María. Vuestro apoyo
y cariño es lo más importante, nada tiene valor sin ellos. Estos
últimos meses han sido de los más duros en mi vida, teniendo
que estar tanto tiempo separado de vosotras, sabiendo que
estabais disfrutando la una de la otra, llegando a casa para que
me contarais qué habíais hecho. A partir de ahora, volveréis a ser
el centro de mi vida. Os necesito. Os quiero.
A mis padres y a Nane. Podríamos decir que éste es el final de mi
etapa de estudiante. Sin vuestro esfuerzo y apoyo no hubiera
llegado a ningún lugar. Ahora me toca a mí, enseñar a María, los
valores que me inculcasteis y educarla como vosotros habéis
hecho conmigo. Os quiero.
Aunque en la portada aparece únicamente mi nombre, este
trabajo no sería el que es sin la ayuda, el apoyo, los consejos, las
AGRADECIMIENTOS
VIII
revisiones, las regañinas,... de Juanma. Has cumplido mucho
más allá de lo asociado con tu papel de tutor. Muchísimas
gracias.
A José Luis y Jero, compañeros de instituto, de universidad, de
piso, de trabajo,... Pero, ante todo, amigos. ¡Cuántos días juntos!
¡Cuántas vivencias! Recordaba hace poco, aquellos días del
verano del 93, contigo, Jero, y tu viejo 8086, descubriendo las
redes neuronales, intentando reconocer varias letras con una red
de propagación contraria. ¡Qué cosas! ¿No tendríamos nada más
que hacer?
A mis colaboradores en la etapa final del trabajo, Pepe y Antonio;
que me ayudaron en la realización de experimentos,
comprobación de resultados, redacción y verificación del
documento,...
A la gente del departamento, Paco, Andrés, Antonio, Ginés, Joan
Carles, Toni, María Teresa, Sergio, Javi, Paco Mora, Higinio, Dani;
por compartir conmigo trabajos, charlas, cafés, fútbol,...
A Ramón, Otto, Domingo, Sco, Faraón, Rosana y resto de gente
de i3a, con quienes compartí los inicios de esta tesis. Muchas de
las ideas de este trabajo, parten de conversaciones con vosotros.
A Rafa, Pablo, María José, Asun, Maribel, Cande, Andrés, Carlos,
Manolo, Tía Lola, María Dolores (sí, ya la acabé), Ángel, Marta,
Christian, Laura, Javi, Marta, José Manuel, Yoli, Josele, María
José, José Antonio, Mari, Ángel, Andrés, Rosa, Enrique,
Armando, José Manuel,...
A todos aquellos que dejo en el olvido.
A todos. Gracias.
Paco
Alicante, a 1 de Noviembre de 2001
RESUMEN
La investigación realizada aborda el problema del seguimiento de
objetos y análisis del movimiento en escenas. Este trabajo se
enmarca dentro del proyecto de investigación “Sistema de visión
para navegación autónoma” (CICYT TAP98-0333-C03-03). El
objetivo principal de este proyecto es el desarrollo de un
dispositivo de visión artificial para la ayuda a la navegación
autónoma.
Dado que se plantea la integración del módulo de procesamiento
de visión en el dispositivo, es necesario dotar a este último de
potencia computacional suficiente para procesar las imágenes a
frecuencia de video. Este hecho establece la necesidad de diseñar
arquitecturas de alto rendimiento, con capacidad de refinamiento
de la respuesta en función del tiempo disponible, especializadas
para los problemas de visión; todo ello con enfoque de
miniaturización y empotrabilidad. Para una mejor comprensión
del problema y cómo abordarlo, se han revisado numerosos
trabajos relacionados con él y se han considerado los diversos
enfoques de la visión activa.
Se ha propuesto el empleo de redes neuronales autoorganizativas para la representación de los objetos, por su
cualidad de preservadoras de la topología, lo que proporciona el
Grafo Preservador de la Topología ( GPT ). El mismo tiene alta
X
RESUMEN
capacidad expresiva, es sencillo de obtener, y resulta robusto. Se
aporta, asimismo, una técnica de síntesis de los objetos a partir
de dicha representación. Las características que se extraen del
GPT
simplifican
las
operaciones
de
clasificación
y
reconocimiento posteriores al evitar la alta complejidad de la
comparación entre grafos. Como ejemplo de aplicación de la
caracterización de los objetos, se propone un problema de
clasificación de formas a partir de su contorno.
El modelo de caracterización de los objetos permite refinar la
calidad de representación en función del tiempo disponible para
su cálculo, de modo que sirva como base para el diseño de
arquitecturas de visión de alto rendimiento que operen bajo
restricciones de tiempo real.
Se extiende la aplicación de los GPT
al tratamiento de
secuencias de imágenes y, más concretamente, al seguimiento de
objetos y análisis del movimiento. Debido al carácter dinámico de
estas redes, se modeliza la evolución de los objetos como las
modificaciones que sufre la red a lo largo de toda la secuencia,
entendiendo dichas modificaciones como variaciones en la
topología de la red de interconexión. La modelización del
movimiento como la dinámica de las neuronas, evita el problema
de correspondencia, uno de los más costosos en la mayoría de
técnicas de seguimiento de objetos. Para comprobar sus
prestaciones, se aplica al reconocimiento de gestos de la mano.
Aunque no ha sido destacado especialmente en la memoria, este
modelo permite la caracterización y seguimiento de múltiples
objetos presentes en la escena. Asimismo, se puede realizar el
seguimiento de un objeto que se disgregue en varias partes o que
se fusione.
La propuesta es suficientemente generalista para dar cobertura a
técnicas de tratamiento de una amplia diversidad de problemas
de visión; si bien, por cuestiones de extensión del trabajo, la
investigación se ha concretado en establecer la base conceptual
sobre la que después se materializarán las arquitecturas.
ABSTRACT
The research performed approaches the problems of tracking
objects and motion analysis in scenes. This work belongs to the
research project “Sistema de visión para navegación autónoma”
(CICYT TAP98-0333-C03-03). The main goal of this project is the
development of an artificial vision device for the aid to
autonomous navigation.
Since we are considering to integrate the vision processing
module into the device, it is necessary to give to this one enough
computational power to process the images at video rates. This
fact establishes the necessity to design high performance
architectures, with capacity of answer refinement of the answer
based on the availability of time, specialized for vision problems;
with miniaturization and empotrability approach. For a better
understanding of the problem and how to approach it, we have
reviewed a great deal of related works, considering the different
approaches of active vision.
We have proposed the use of self-organizing neural networks to
represent the objects, due to its quality of topology preservation,
which provides the Topology Preserving Graph ( GPT ). This one
has a high expresive capacity, it is simple to obtain and it is
robust. We contributed, also, a synthesis of synthesis of the
objects from this representation. Features that are extracted from
the GPT simplify the later operations of classification and
recognition, avoiding the high complexity of comparisons between
XII
ABSTRACT
graphs. As an example of the aplication of the characterization of
objects, we present the problem of shape classification from its
contour.
The model of characterization of the objects allows to refine the
quality of the representation based on the time available for its
calculation, so that it will be the basis for the design of high
performance realtime vision architectures.
We extend the application of the GPT to the processing of image
sequences and, particularly, to tracking objects and motion
analysis. Due to the dynamic character of these networks, we
model the evolution of the objects as the changes that the
network suffers throughout the sequence, understanding these
changes as variations in the topology of the interconnection
network. Modelling motion as neuron dynamics
avoids
correspondence problem, one of the most expensive in tracking
techniques. In order to verify the model, we apply it to the
problem of hand gesture recognition.
Although it has not been specially outstanding in this document,
this model allows the characterization and tracking of multiple
objects in the scene. Also, it can perform the tracking of an object
that disgregates in several parts or that merges.
The proposal is generalist enough to cover processing techniques
of a wide diversity of vision problems; although, by work
extension, the research has been focused in establishing the
conceptual basis on which the architectures will be developped.
CONTENIDO
AGRADECIMIENTOS................................................................................. VII
RESUMEN .......................................................................................................IX
ABSTRACT .....................................................................................................XI
CONTENIDO ...............................................................................................XIII
INDICE DE FIGURAS ................................................................................. XV
INDICE DE TABLAS .................................................................................. XIX
INTRODUCCIÓN: OBJETIVOS Y ESTADO DEL ARTE........................ 21
1.1 MOTIVACIÓN Y OBJETIVOS ....................................................................... 22
1.2 ESTADO DEL ARTE .................................................................................... 26
1.3 PROPUESTA DE SOLUCIÓN ......................................................................... 40
MODELOS NEURONALES DE REPRESENTACIÓN.............................. 45
2.1 REDES AUTO-ORGANIZATIVAS .................................................................. 46
2.2 GASES NEURONALES ................................................................................. 50
2.3 PRESERVACIÓN DE LA TOPOLOGÍA ............................................................ 57
2.4 INCORPORACIÓN DE RESTRICCIONES DE TIEMPO REAL .............................. 61
2.5 CONCLUSIONES......................................................................................... 69
XIV
CONTENIDO
REPRESENTACIÓN Y CARACTERIZACIÓN DE OBJETOS ............... 71
3.1 REPRESENTACIÓN DE UN OBJETO 2D CON UN GAS NEURONAL .................. 72
3.2 APLICACIÓN AL ANÁLISIS DE IMÁGENES ................................................... 75
3.3 APLICACIÓN A LA SÍNTESIS DE IMÁGENES ................................................. 92
3.4 EJEMPLO DE APLICACIÓN: CLASIFICACIÓN DE OBJETOS ............................ 94
3.5 CONCLUSIONES......................................................................................... 99
SEGUIMIENTO DE OBJETOS Y ANÁLISIS DEL MOVIMIENTO..... 103
4.1 SEGUIMIENTO DE OBJETOS...................................................................... 104
4.2 ANÁLISIS DEL MOVIMIENTO.................................................................... 108
4.3 EJEMPLO DE APLICACIÓN: RECONOCIMIENTO DE GESTOS ....................... 111
4.4 CONCLUSIONES....................................................................................... 124
CONCLUSIONES ......................................................................................... 127
5.1 APORTACIONES ...................................................................................... 128
5.2 LÍNEAS DE CONTINUACIÓN ..................................................................... 130
ESTUDIO DE LA PRESERVACIÓN DE LA TOPOLOGÍA................... 133
REFERENCIAS ............................................................................................ 143
INDICE DE FIGURAS
Figura 1.1.
Arquitecturas en malla.
31
Figura 2.1.
Inserción de neuronas durante el aprendizaje de la
Growing Cell Structure.
49
División de la red GCS en varias subredes al eliminar
neuronas.
50
Estados inicial, intermedio y final del aprendizaje de la
Neural Gas.
51
Estados inicial, intermedio y final del aprendizaje de la
Growing Neural Gas.
53
Figura 2.5.
Triangulación de Delaunay inducida
58
Figura 2.6.
Adaptación de diversos modelos auto-organizativos a un
espacio de entrada.
59
Comparación del error de cuantización entre mapas de
Kohonen y Neural Gas.
60
Figura 2.8.
Adaptación incompleta de la Neural Gas.
61
Figura 2.9.
Adaptación de la Growing Neural Gas con límites de
tiempo.
64
Adaptación de la Growing Neural Gas modificando el
número de patrones por iteración λ.
65
Adaptación de la Growing Neural Gas modificando el
número de neuronas insertadas por iteración.
67
Figura 2.2.
Figura 2.3.
Figura 2.4.
Figura 2.7.
Figura 2.10.
Figura 2.11.
INDICE DE FIGURAS
XVI
Figura 2.12.
Figura 3.1.
Figura 3.2.
Adaptación de la Growing Neural Gas completando la red
una vez finalizado el tiempo.
68
Descripción global del sistema de obtención del Grafo
Preservador de la Topología de un objeto.
74
Diferentes adaptaciones del gas neuronal a un mismo
objeto.
74
GPT del contorno de un objeto.
Figura 3.3.
Extracción del
Figura 3.4.
Obtención de los diversos contornos de un objeto.
76
Figura 3.5.
Curvaturas de los contornos.
79
Figura 3.6.
Simplificación
esquinas.
del
76
GPT∇ mediante la detección de
80
GPT mediante la obtención de aristas.
Figura 3.7.
Simplificación del
80
Figura 3.8.
Firmas.
81
Figura 3.9.
Códigos de cadena.
81
Figura 3.10.
Grafos Preservadores de la Topología de diversos objetos
bidimensionales.
83
Figura 3.11.
Representación de varios objetos.
83
Figura 3.12.
Subgrafos del
GPT.
86
Figura 3.13.
Histograma de vecindad.
Figura 3.14.
Contorno del
Figura 3.15.
Diagrama de Voronoi del contorno del
Figura 3.16.
Esqueletos.
Figura 3.17.
Síntesis a partir de un
Figura 3.18.
Sistema de clasificación de formas.
95
Figura 3.19.
Obtención y simplificación del grafo del contorno.
96
Figura 3.20.
Clasificación de los objetos a partir del
Figura 3.21.
Clasificación de los objetos según su firma.
100
Figura 3.22.
Clasificación de los objetos según su curvatura.
101
Figura 4.1.
Etapas del problema del análisis del movimiento.
104
Figura 4.2.
Posición del
Figura 4.3.
Grados de libertad de la mano.
88
GPT.
91
GPT.
92
92
GPT.
94
GPT.
GPT antes de la predicción.
98
107
112
INDICE DE FIGURAS
XVII
Figura 4.4.
Localizaciones típicas de los puntos de interés de la mano.
115
Figura 4.5.
Sistema de reconocimiento de gestos.
116
Figura 4.6.
Adaptación de la Growing Neural Gas a diferentes
posturas de la mano.
117
Figura 4.7.
Extracción del radio estándar de la palma.
118
Figura 4.8.
Adaptación dinámica de las Growing Neural Gas a un
gesto completo.
119
Figura 4.9.
Normalización de las trayectorias del gesto.
121
Figura 4.10.
Posturas de la mano inicial y final de cada uno de los
gestos.
123
Figura A.1.
Vecindades en el espacio de entrada y en la red.
134
Figura A.2.
Espacios de entrada.
136
Figura A.3.
Distancia geodésica.
137
-
INDICE DE TABLAS
Tabla 2.1.
Tabla 2.2.
Tabla 2.3.
Tabla 2.4.
Tabla 2.5.
Tabla 2.6.
Tabla 3.1.
Tiempos de aprendizaje de los diferentes modelos autoorganizativos.
60
Cálculo del producto topográfico de Neural Gas con
distintas tmax.
62
Cálculo del producto topográfico de Growing Neural Gas
con restricciones temporales.
63
Cálculo del producto topográfico de Growing Neural Gas
(variación 1).
65
Cálculo del producto topográfico de Growing Neural Gas
insertando diferente número de neuronas (variación 2).
66
Cálculo del producto topográfico de Growing Neural Gas
completando la red una vez finalizado el aprendizaje
(variación 3).
68
Longitud, diámetro
contornos.
78
y
longitud
normalizada
de
los
Tabla 3.2.
Momentos de los contornos.
82
Tabla 3.3.
Información extraída del número y longitud de las aristas.
87
Tabla 3.4.
Información extraída de las vecindades.
88
Tabla 3.5.
Momentos del
Tabla 4.1.
Tasa de acierto en el reconocimiento.
GPT.
90
124
XX
INDICE DE TABLAS
Tabla A.1.
Cálculo de la preservación de la topología (100 neuronas).
138
Tabla A.2.
Tiempos de aprendizaje de los diferentes modelos autoorganizativos.
139
Preservación de la topología de la Neural Gas deteniendo
su aprendizaje a los 12 segundos.
140
Preservación de la topología de la Neural Gas modificando
sus parámetros para que finalice a los 12 segundos.
141
Tabla A.3.
Tabla A.4.
Capítulo 1
INTRODUCCIÓN: OBJETIVOS Y
ESTADO DEL ARTE
El contexto de la investigación que se recoge en esta memoria
tiene aspectos de motivación particular, otros de interés del
grupo de investigación y, los más, de naturaleza científica,
relacionados con el problema que se aborda y con el estado del
conocimiento en la materia.
En este primer capítulo se realiza una introducción al problema
del seguimiento de objetos y análisis del movimiento. Para una
mejor comprensión del problema y cómo abordarlo, se han
revisado numerosos trabajos relacionados con él y se han
considerado los diversos enfoques de la visión por computador y
de la visión activa en particular. Se ha profundizado en las
arquitecturas específicas de visión, revisando, particularmente,
las dedicadas al seguimiento de objetos y análisis del movimiento.
El interés de que el procesamiento sea consecuente con las
restricciones temporales es la razón de que también se haya
revisado el estado del arte de las arquitecturas de tiempo real.
CAPÍTULO 1
22
La reflexión que constituye este capítulo se completa con una
propuesta, a grandes rasgos, de resolución del problema que se
plantea. El resto de la memoria aborda detalladamente dicha
solución.
1.1 MOTIVACIÓN Y OBJETIVOS
OBJETIVOS
1.1.1 PRESENTACIÓN
Este trabajo se enmarca dentro del proyecto de investigación
“Sistema de visión para navegación autónoma” parcialmente
subvencionado por la CICYT (TAP98-0333-C03-03). El objetivo
principal de este proyecto es el desarrollo de un dispositivo de
visión artificial para la ayuda a la navegación autónoma. Se
pretende dotar al sistema de capacidades perceptuales de bajo y
medio nivel para la extracción e interpretación de información
acerca del entorno. El dispositivo de visión se considera como un
periférico inteligente que, a partir de las imágenes captadas, debe
proporcionar información elaborada. El módulo de procesamiento
de imagen proporciona filtros y algoritmia para realizar
operaciones de morfología matemática, segmentación de la
imagen, extracción de contornos, cálculo de invariantes,
tratamiento de incertidumbre, identificación de obstáculos,...
Entre otras tareas, se aborda el análisis de secuencias de
imágenes.
Dado que se plantea la integración del módulo de procesamiento
de visión en el dispositivo, es necesario dotar a este último de
potencia computacional suficiente para procesar las imágenes a
frecuencia de video. Este hecho sugiere la necesidad de diseñar
arquitecturas de alto rendimiento especializadas para los
problemas de visión. Se tiene interés, asimismo, en el desarrollo
de modelos de procesamiento en tiempo real, que aporten
capacidad de refinamiento en la respuesta en función del tiempo
disponible.
El tratamiento del procesamiento de tiempo real, en este
proyecto, se ha tratado a dos niveles: uno, general, a nivel de
procesamiento hardware (Mora, 2001); y éste, más específico, del
desarrollo de estructuras de datos sencillas para representar los
INTRODUCCIÓN: OBJETIVOS Y ESTADO DEL ARTE
23
objetos, cuyo traslado al diseño de arquitecturas especializadas
sea fácil y cuyo modo de operación contribuya a la rapidez del
sistema. La integración de ambos trabajos constituirá el prototipo
de un sistema integral de procesamiento especializado en visión,
a los niveles bajo y medio, con capacidad de operación en tiempo
real, de altas prestaciones, derivadas de la flexibilidad de gestión
de las restricciones temporales a varios niveles; con enfoque de
miniaturización y empotrabilidad.
En lo que resta de este primer capítulo se realiza una descripción
del problema, marcando los objetivos con los que debería
culminarse el trabajo. Se pasa, a continuación a revisar trabajos
relacionados con las arquitecturas de visión y de tiempo real.
Finalmente, a partir de las conclusiones extraídas de lo anterior,
se presenta una propuesta de solución basada en el modelado
conexionista.
En el capítulo 2 se revisan las redes neuronales autoorganizativas, estudiando su capacidad de preservación de la
topología. Finalmente, se modifican estos modelos para dotarlos
de capacidad de operación bajo restricciones de tiempo real.
En el capítulo 3, se desarrolla la idea de emplear estas redes
preservadoras de la topología para la representación de los
objetos. Se presenta, asimismo, una técnica de síntesis de los
mismos a partir de dicha representación. Como ejemplo de
aplicación de la caracterización de los objetos, se propone un
problema de clasificación de formas a partir de su contorno.
En el capítulo 4 se extiende el uso del modelo desarrollado para
dotarlo de capacidad de representación del movimiento, de modo
que se permita el seguimiento de objetos y el análisis de su
movimiento. Para comprobar la bondad del modelo, se aplica al
reconocimiento de gestos de la mano.
Finalmente, en el capítulo 5 se presentan las principales
conclusiones del trabajo y se plantean las líneas futuras de
investigación que surgen de él.
CAPÍTULO 1
24
1.1.2 OBJETIVOS: DESCRIPCIÓN DEL PROBLEMA
PROBLEMA
La navegación de robots basada en información visual requiere el
análisis de imágenes, con el objetivo de realizar tareas de todo
tipo, como son la detección del movimiento o la localización y
seguimiento de objetos. Por ello, el objetivo principal de este
trabajo es el diseño de un modelo de representación de los
objetos de una escena, así como de la descripción de su evolución
a lo largo del tiempo. Este modelo será la base del desarrollo de
arquitecturas de tiempo real especializadas en visión, por lo que
debe aportar una estructura de datos eficiente, robusta y de
sencilla implantación. Aunque el ámbito de aplicación del modelo
es amplio, se ha particularizado, en este trabajo, para los
problemas de seguimiento de objetos y análisis de su movimiento.
Existen diversos factores que determinan la dificultad en la
resolución del problema de seguimiento de objetos. Un aspecto
fundamental al desarrollar estructuras de representación de los
objetos es su forma. Los objetos pueden estar constituidos por
puntos, aristas, curvas o poseer una morfología libre, con el
consiguiente incremento de complejidad.
Por otro lado, la dificultad en el seguimiento de los objetos,
vendrá dada, principalmente, por la conducta de evolución de los
mismos. Esta puede ser originada por:
• cambios morfológicos: los objetos pueden desde ser
rígidos a presentar modificaciones en su forma, tan
extremas como su posible disgregación en diversos
elementos;
• cambios fotométricos: modificaciones en parámetros,
tales como la iluminación, afecta a la apariencia visual
que se tiene del objeto;
• desplazamientos y giros.
Usualmente los sistemas de seguimiento de objetos han estado
restringidos a objetos rígidos. Sin embargo, en la naturaleza la
mayor parte de elementos en movimiento (el latido de un corazón,
los ejercicios de un atleta, los movimientos de las nubes,...) no
cumplen esta restricción. Por esto, en los últimos años existe un
INTRODUCCIÓN: OBJETIVOS Y ESTADO DEL ARTE
25
creciente interés en el seguimiento de objetos con otros modos de
movimiento (Kambhamettu et al., 1998).
El número de objetos a seguir también influye en el desarrollo de
sistemas de seguimiento. Trabajar con múltiples objetos conlleva
la iniciación de las estructuras de representación de cada uno
ellos en lugares adecuados de la escena o la posibilidad de
división de una estructura original para poder representarlos a
todos. Además, los objetos pueden tener algún tipo de relación,
de modo que los movimientos de unos estén en concordancia con
movimientos de otros, o ser independientes.
Las características del entorno afectan considerablemente al
funcionamiento de los sistemas desarrollados. Cambios en la
iluminación, presencia de sombras,... crean incertidumbre que
debe ser manejada correctamente. Esto debe llevar al desarrollo
de sistemas robustos, que aporten información redundante, de
modo que se posibilite eliminación de incertidumbre, con el
inconveniente de un mayor coste computacional. Igualmente, un
entorno con múltiples objetos en la escena puede dificultar
considerablemente el seguimiento, ya que pueden poseer
características visuales similares a las de las entidades objeto de
interés, pueden producir oclusiones,...
Por otro lado, el seguimiento de los objetos forma parte de una
tarea de más alto nivel, el análisis o reconocimiento del
movimiento. Dentro de éste existen dos vertientes principales: el
análisis del movimiento basado en el reconocimiento y el
reconocimiento basado en el movimiento. El primero de ellos está
determinado por las diversas instancias que el objeto toma a lo
largo de la secuencia. Por otro lado, el reconocimiento basado en
el movimiento se fundamenta en el análisis de las trayectorias
realizadas por el objeto o por partes determinadas del mismo, sin
prestar atención al reconocimiento del objeto en cada momento.
Es decir, se realiza un uso directo de la información relativa al
movimiento de los objetos.
Con todas estas consideraciones, el objetivo principal de este
trabajo se sustenta en otras metas intermedias, como son:
CAPÍTULO 1
26
• Desarrollo de un modelo de representación de la
topología de los objetos con alta capacidad expresiva,
sencillo de obtener, robusto,...
• El modelo debe aportar una caracterización de los
objetos con diferente calidad en la respuesta en función
del tiempo disponible para su cálculo, de modo que sirva
como base para el diseño de arquitecturas de visión de
alto rendimiento que operen bajo restricciones de tiempo
real.
• Desarrollo de un modelo de representación del
movimiento que realice de forma sencilla el seguimiento
de los objetos y aporte información relevante para el
análisis de su movimiento, ya sea basado en el
reconocimiento o basado en el movimiento.
Para evaluar la capacidad de representación de los objetos, se
propone un problema de clasificación extrayendo información de
los contornos de los objetos. Por otro lado, para comprobar el
funcionamiento del modelo en el tratamiento de secuencias de
imágenes se plantea una aplicación habitual del análisis del
movimiento: el reconocimiento de gestos de la mano.
1.2 ESTADO DEL ARTE
En este apartado se realiza una revisión de aquellos trabajos que
por tener un fin similar al de esta tesis, pudieran servir como
base de discusión para desarrollar una solución al problema a
resolver. Para ello, se ha realizado una primera introducción a los
problemas de visión por computador y, en particular, al de visión
activa. Posteriormente se especifican las diversas técnicas de
seguimiento de objetos y análisis del movimiento.
Con el objetivo de profundizar en el conocimiento de los aspectos
relacionados con las arquitecturas de tiempo real especializadas
en visión, se ha pasado a revisar los trabajos relacionados con
éstas.
INTRODUCCIÓN: OBJETIVOS Y ESTADO DEL ARTE
27
1.2.1 VISIÓN POR COMPUTADOR
El objetivo de la visión por computador es extraer información
relevante a partir de señal electromagnética del especto visible,
que pueda ser percibida por sistemas artificiales. Como el ámbito
de la visión es tan amplio, y también lo es la cantidad de tareas,
así como su naturaleza y grado de complejidad, es difícil
establecer una clasificación. En su defecto, usualmente estas
tareas son englobadas en tres niveles de procesamiento: visión de
bajo nivel, de nivel medio y de nivel alto.
Hasta mediados de los 80, el enfoque constructivista pretendía
reconstruir completamente el mundo, a diversos niveles de
abstracción, identificando los objetos y sus posiciones,
obteniendo sus formas a partir de sus colores, sus sombras, su
movimiento, visión estéreo,... Una vez realizada esta
reconstrucción tridimensional del entorno, se podían realizar las
tareas de reconocimiento e interpretación (Marr, 1982).
La realidad del modesto éxito obtenido incorporó objetividad y
orientó el planteamiento hacia el enfoque de la visión activa
(Aloimonos et al., 1988) (Bajcsy, 1988) (Ballard, 1991), en el que
el procesamiento de visión está dirigido a la tarea a realizar: el
sistema de visión no es un observador pasivo, sino que adquiere
las imágenes de forma inteligente.
Esto conlleva que los sistemas de visión activa, basándose en la
realimentación de resultados previos, poseen la capacidad de
controlar los parámetros del dispositivo de visión, tales como
zoom, enfoque,...; así como de variar la resolución o la frecuencia
de captura de imágenes. Asimismo, puede ocurrir que sin
modificar estos parámetros, sí se modifique el modo en el que la
imagen es procesada posteriormente.
Tal y como se expresa en (Escolano, 1997), en un sistema de
visión activa, la percepción debe estar guiada por la acción. Un
sistema de visión activa no pretende reconstruir el mundo, sino
enfocar su atención para conseguir aquellas propiedades de la
imagen que sean necesarias para realizar una tarea determinada,
obteniendo sistemas más eficientes.
28
CAPÍTULO 1
En particular, respecto del análisis del movimiento, los autores
coinciden en que éste consiste, en primer lugar, en el seguimiento
de uno o más objetos y, posteriormente, en la caracterización del
movimiento realizado, de modo que pueda ser extraída la
estructura del objeto o se pueda realizar un reconocimiento
basado en el movimiento (Cédras y Shah, 1995). Las áreas de
aplicación del análisis del movimiento son muy diversas y abarca
la interpretación de gestos, sistemas de vigilancia, navegación de
robots y vehículos, análisis de imágenes médicas, biomecánica,
compresión de imágenes, video-conferencia,...
Recientemente, la atención ha ido dirigida, principalmente, al
tratamiento de movimiento no-rígido (Kambhamettu et al., 1994)
(Aggarwal et al., 1998), y particularmente al del movimiento
elástico, esto es, al movimiento no-rígido cuya única restricción
es un cierto grado de continuidad.
Entre las técnicas empleadas en el seguimiento de objetos, donde
más trabajo se está realizando en la actualidad, desde el punto de
vista algorítmico, es en el desarrollo de modelos de
representación autónomos o activos, que son empleados
principalmente en el tratamiento de movimiento no-rígido: snakes
(Kass et al., 1988) (Terzopoulos y Szelinski, 1992), plantillas
deformables (Yuille y Hallinan, 1992) (Escolano, 1997), splines
activos (Curwen y Blake, 1992), superficies activas (Cohen et al.,
1992), cubos activos (Bro-Nielsen, 1994), rayos activos (Denzler y
Niemann, 1999), formas activas (Cootes y Taylor, 1992),...
El análisis del movimiento basado en modelos es más limitado, ya
que requiere un conocimiento previo de las características de los
objetos, de modo que se pueda realizar un seguimiento de líneas,
puntos, regiones, etc. que se adapten al modelo (Harris, 1992)
(Aggarwal y Cai, 1999).
Asimismo, se ha realizado un importante trabajo en la extracción
de características más o menos simples (puntos de interés,
esquinas, aristas,...) y su seguimiento en cada una de las
imágenes de la secuencia (Sethi y Jain, 1987) (Brady y Wang,
1992) (Smith et al., 1999), mediante un proceso de
correspondencia, el cual presenta bastantes problemas y un alto
coste computacional (Zhang, 1993).
INTRODUCCIÓN: OBJETIVOS Y ESTADO DEL ARTE
29
Otra técnica muy empleada es la del flujo óptico. Esto es, el
cálculo de la velocidad de cada uno de los puntos de la imagen
entre un par consecutivo de imágenes (Beauchemin y Barron,
1995).
Por último, existen sistemas que, mediante un proceso de
correlación, intentan encontrar regiones similares en cada una de
las imágenes, de modo que se pueda realizar su seguimiento
(Pratt, 1990) (Eklund et al, 1994).
La mayor parte de estos trabajos se interesan principalmente en
proporcionar algoritmos que resuelvan los problemas de visión,
prescindiendo de incorporar los aspectos de rendimiento,
estructuración, tecnológicos, etc. como objetivos de su
investigación. Las soluciones aportadas requieren, en muchos
casos, potencias computacionales difícilmente viables en la
actualidad.
1.2.2 ARQUITECTURAS PARA PROCESAMIENTO
PROCESAMIENTO DE IMAGEN
IMAGEN
La visión por computador es uno de los campos de aplicación
más importantes de la computación paralela (McColl, 1993). Sin
embargo, para usos modestos y, sobre todo con fines de
prototipado, algunos autores han profundizado en sistemas
monoprocesadores.
El uso de sistemas RISC en problemas de visión es ampliamente
estudiado en (Baglietto et al, 1996), concluyendo que hasta que
no se desarrollen compiladores específicos para programas de
tratamiento de imágenes que generen código optimizado para
estas tareas, y aumente la velocidad de procesamiento de estas
arquitecturas, no se podrá lograr un procesamiento en tiempo
real de las imágenes.
Se han desarrollado sistemas de seguimiento de objetos y
detección del movimiento empleando snakes sobre estaciones de
trabajo UNIX estándar (Denzler y Niemann, 1995), sistemas de
detección y seguimiento de objetos y personas sobre
computadores personales Pentium (Fayman et al., 1995)
(Haritaoglu et al., 1998),...
30
CAPÍTULO 1
Con el objetivo de acelerar las tareas que requieren una gran
velocidad de cálculo, en los últimos años se han desarrollado
diferentes tarjetas aceleradoras de procesamiento de imagen de
alto rendimiento, que ofrecen tasas de respuesta similares a la
frecuencia de video. Estos sistemas tratan, en su mayoría,
problemas de visión de bajo nivel.
Las arquitecturas paralelas empleadas en el tratamiento de
imagen se basan esencialmente sobre dos principios (Charot,
1993): el tratamiento segmentado y el paralelismo de datos.
En líneas generales, las arquitecturas SIMD son apropiadas para
el procesamiento a bajo nivel, donde redes de elementos de
procesamiento pueden realizar de forma paralela idénticas
operaciones sobre diversas zonas de la imagen. Los
requerimientos del procesamiento a nivel medio sugieren la
aplicación de computadores MIMD de grano fino, aunque
también son de aplicación sistemas SIMD. Por último, para el
procesamiento de alto nivel se requiere una estructura flexible y
control distribuido para los cálculos y las comunicaciones, por lo
que los computadores MIMD de grano grueso son los que mejor
se adaptan.
Sin embargo, esta clasificación no es generalizada ya que existen
problemas en los que no está claro el uso de una arquitectura
específica (Armstrong et al., 1998), e incluso se añaden nuevas
arquitecturas (Rehfuss y Hammerstrom, 1997) basadas en
modelos SFMD y SPMD para cubrir el hueco existente entre las
arquitecturas SIMD y MIMD. Asimismo, el uso de arquitecturas
híbridas SIMD/MIMD (Helman y Jájá, 1995) permite salvar las
desventajas de modelos SIMD o MIMD independientes.
Se han realizado diversos estudios comparativos del
comportamiento de las diversas arquitecturas ante determinados
problemas de visión: morfología matemática (Theys, 1996),
correlación entre imágenes (Armstrong et al., 1998), operaciones
a bajo y medio nivel (Persa y Jonker, 2000b), histogramas (Bader
y Jájá, 1994), operaciones a todos los niveles (Ratha y
Jain,1999),...
Se han empleado tanto procesadores SIMD de propósito general
para el tratamiento de problemas de visión como nuevos
INTRODUCCIÓN: OBJETIVOS Y ESTADO DEL ARTE
31
procesadores paralelos desarrollados específicamente para estas
tareas. El trabajo a este nivel ha ido encaminado principalmente
a establecer una red de interconexión entre los elementos de
procesamiento adecuada para resolver un problema dado.
Las arquitecturas en malla 2D operan sobre toda la imagen en
paralelo, dividiéndola en zonas y repartiéndolas entre los
diferentes procesadores. Si se posee una red de n x n
procesadores y una imagen de m x m puntos, esa división puede
ser realizada de dos formas (Figura 1.1):
1. La imagen se subdivide en ventanas de tamaño n x n, de
modo que de forma secuencial se barre toda la imagen.
2. Cada procesador se encarga de ventanas de la imagen de
tamaño m/n x m/n.
Figura 1.1. Arquitecturas en malla.
Existen multitud de sistemas de visión basados en esta
arquitectura, como son MPP de Goodyear (Strong, 1991) y su
evolución Blitzen (Blevins et al., 1990), DAP de ICL (Parkinson y
Litt, 1990), GAPP desarrollado por NCR (Cloud, 1988), MP-1
(Blank, 1990) y MP-2 (Tuck y Kim, 1993) de MasPar, CM-2 de
Thinking Machines (TMC, 1987), PAPRICA (Broggi et al., 1994a),
S3PE (Komuro et al.,1997),...
32
CAPÍTULO 1
En el caso de red de interconexión lineal, la imagen es dividida en
regiones que se asocian a cada uno de los procesadores, que
suelen corresponder a una columna o a una fila de la imagen a
procesar.
Entre los procesadores lineales de tratamiento de imagen se
encuentran CLIP7 (Fountain et al., 1988), SLAP (Fisher et al.,
1988), la Princeton Engine (Chin et al., 1988), la Sarnoff Engine
(Knight et al., 1992) y PAPRICA3 (Broggi et al., 1994b) diseñado
como evolución de PAPRICA. Diversas comparaciones del
comportamiento de otros procesadores lineales (IMAP-VISION,
SYMPHONIE, CNAPS, HDPP, SRC-PIM) ante diversas operaciones
sobre imágenes se pueden encontrar en (van der Molen y Jonker,
1998) (Le et al., 1998).
Otro modo de interconectar los elementos de procesamiento es
mediante una estructura toroidal o helicoidal. Un ejemplo de
arquitectura SIMD toroidal es el toro polimórfico de IBM (Li y
Maresca, 1989), cuyos nodos poseen una red interna
programable, por lo que, en ocasiones, es considerada un
multiprocesador reconfigurable (Bhandarkar y Arabnia, 1997).
Un sistema toroidal que conecta FPGA’s formando un toroide
para realizar el procesamiento de la imagen es la máquina
reconfigurable PARTS (Woodfill y von Herzen, 1997).
Arquitecturas de procesadores SIMD en hipercubo son empleadas
en la Connection Machine (Little et al., 1987) y VisTA (Sunwoo y
Aggarwal, 1991).
Una de las arquitecturas más empleada en tratamiento de
imagen son los procesadores piramidales. Una estructura en
pirámide establece diversos niveles de representación de las
imágenes, de modo que éstas puedan ser tratadas con baja
resolución,
empleando
pocos
datos,
para
proceder
posteriormente, si es necesario, a un refinamiento y verificación
de los resultados a una mayor resolución. Esto aporta diversas
ventajas (Camus, 1994) (Prewer, 1995) como son: reducción del
coste de procesamiento, extracción de características globales de
la imagen, reducción de la complejidad de la comunicación entre
los procesadores,... Sin embargo, también existen desventajas
como la dificultad para su implementación VLSI, lo que hace que
INTRODUCCIÓN: OBJETIVOS Y ESTADO DEL ARTE
33
en muchas ocasiones algoritmos piramidales sean ejecutados en
arquitecturas hipercubo.
Una de las primeras arquitecturas piramidales fue PCLIP
(Tanimoto, 1984). Otros ejemplos son: GAM (Schaefer et al.,
1987), SPHINX (Mérigot et al., 1986), la pirámide del EGPA
(Fritsch, 1986), SCOOP (Barad, 1988), WPM (Nudd et al., 1989),
PAPIA (Cantoni et al., 1991) y su evolución PAPIA2 (Biancardi et
al., 1992).
Aunque todas las topologías revisadas son ampliamente
utilizadas en visión por computador, no se ha probado que
alguna de ellas sea capaz de resolver todos los problemas de
visión. Recientemente, están apareciendo multiprocesadores
reconfigurables que permiten modificar la topología de su red de
interconexión, los cuales para ser factibles deben poseer las
siguientes propiedades (Bhandarkar y Arabnia, 1997):
• los nodos deben poseer en cada momento un grado de
conectividad razonable y la red debe mantener un
diámetro bajo, para que los enlaces de comunicación no
crezcan rápidamente,
• el hardware y el algoritmo de reconfiguración deben
tener una complejidad baja para no ralentizar el sistema.
Dentro de estos procesadores reconfigurables se encuentran
algunos de los ejemplos ya expuestos de otras arquitecturas
como CLIP7, el toro polimórfico y el sistema piramidal PAPIA2; así
como nuevos sistemas como RBA (Miller et al., 1988), PARBS
(Wang et al., 1991), CRAPS (Kao et al., 1993), RMA (Miller et al.,
1993), RMRN (Bhandarkar y Arabnia, 1997), VFE-200
(Mandelbaum et al., 1998).
Las arquitecturas MIMD de grano medio y grano grueso son
adecuadas para el tratamiento de imagen a nivel medio y alto, ya
que estos problemas requieren la ejecución asíncrona de
múltiples tareas cooperantes. Los transputers han sido muy
empleados como bloques constituyentes en una arquitectura
MIMD, dando lugar a sistemas como las cabezas KTH (Uhlin et
al., 1995) y Yorick 11-20 (Sharkey et al., 1993). Entre las
máquinas MIMD que emplean DSP’s como elementos de
34
CAPÍTULO 1
procesamiento se encuentran HMFV (Du et al., 1996), la cabeza
Yorick 5-5C (Sharkey et al., 1995), la cabeza PennEyes (Cahn von
Seelen, 1997). Por otro lado, se encuentran también las
máquinas de flujo de datos como DFCC (Quénot y Zavidovique,
1992).
Muchos de los problemas de visión requieren un particular modo
de operación (SIMD o MIMD) para su ejecución. Una deficiencia
de las máquinas MIMD típicas, en comparación con los SIMD, es
que no proveen soporte para coordinación y sincronización entre
conjuntos de procesadores, por lo que para simular operaciones
SIMD, la sobrecarga en la comunicación puede ser mayor que el
tiempo de procesamiento de tareas de bajo nivel. Por ello, una
máquina que permita cambiar dinámicamente entre ambos
modos de paralelismo se adaptará mejor a la resolución de un
mayor número de tareas de visión. Ejemplos de arquitecturas
híbridas son NETRA (Choudhary et al., 1993), PASM (Siegel et al.,
1996), APVIS (Kim et al., 1998) que hace uso del procesador
SIMD MPA, Execube (Kogge, 1994), MeshSP (I.C.E., 1995), GCN
(Jonker, 1993), GFLOPS (Houzet y et al., 1991).
Una máquina híbrida de propósito general ampliamente utilizada
en procesamiento de imagen es CM-5 (Leiserson et al., 1994) que
amplía las anteriores máquinas de Connection Machine,
dotándolas de modo de procesamiento SPMD. Se ha empleado
para el cálculo de la transformada de Hough (Baumann y Ranka,
1992), detección de contornos, aproximación lineal y
reconocimiento de objetos (Prasanna et al., 1993),... Splash2
(Ratha y Jain, 1997), construida con FPGA’s, ha sido utilizada en
tareas de visión a todos los niveles: convoluciones, segmentación
de textos y reconocimiento de huellas (Ratha y Jain, 1999).
MORRPH (Drayer et al., 1995) emplea, asimismo, una malla de
FPGA’s que puede funcionar como máquina SIMD, MIMD o
segmentada.
Entre las máquinas segmentadas empleadas para tratamiento de
imagen se encuentran MITE (Kimmel et al., 1985), PIPE (Kent et
al., 1985), Acadia (van der Wal et al., 2000). El uso de DSP’s
como elementos de procesamiento en máquinas segmentadas se
ha extendido, dando lugar a máquinas como GPIP (Heada et al.,
1988), ISHTAR (Shiohara et al., 1993).
INTRODUCCIÓN: OBJETIVOS Y ESTADO DEL ARTE
35
Dentro de esta categoría también pueden ser incluidas aquellas
máquinas, que por realizar tareas de visión a varios niveles,
desde bajo a alto nivel, combinan diversos módulos con
arquitecturas SIMD y/o MIMD. Estos sistemas tienen como
objetivo el realizar un reconocimiento o clasificación de los
objetos, un seguimiento de los mismos, determinación de la
estructura a partir del movimiento, etc. Dentro de este tipo de
máquinas, los sistemas PARADOX (Brady y Wang, 1992), del
Surrey Attentive Robot (Pretlove y Parker, 1993), IUA (Weems et
al, 1989) y su evolución IUA2 (Weems, 1993), Vision Engine
(Little et al., 1991), del Fraunhoffer Institut-IITB de Karlsruhe y
del ENSPS de Estrasburgo (Hirsch, 1993), ESCHeR (Kuniyoshi et
al., 1995); combinan un módulo SIMD, ya sea una arquitectura
desarrollada específicamente o una tarjeta aceleradora de
propósito especial, para el tratamiento de las imágenes a bajo
nivel y una red de transputers o DSP’s (módulo MIMD) para un
procesamiento a más alto nivel.
1.2.3 ARQUITECTURAS PARA SECUENCIAS
SECUENCIAS DE IMÁGENES
Dado que el análisis del movimiento y, por tanto, del seguimiento
de objetos, incorpora operaciones de visión por computador a
todos los niveles, desde el bajo nivel (filtrados, flujo óptico,
correlaciones,...), pasando por el medio (segmentación,
parametrización de trayectorias,...) y hasta llegar al alto nivel
(estructura a partir del movimiento, reconocimiento basado en el
movimiento,...); una amplia mayoría de las arquitecturas
diseñadas específicamente con estos objetivos comprenden
diversos módulos que combinan estructuras SIMD y MIMD.
Hasta el presente, es escaso el desarrollo de arquitecturas
específicas. Cuando el objetivo es el desarrollo de una
arquitectura para ser incorporada en un sistema con altas
restricciones temporales, suelen emplearse tarjetas comerciales
para la aceleración de las tareas de bajo nivel. En otros casos, se
emplean arquitecturas de visión segmentadas compuestas de
máquinas SIMD y MIMD. En el menor número de casos, se
desarrollan arquitecturas específicas para el seguimiento de
objetos.
36
CAPÍTULO 1
La mayor parte de las propuestas emplean métodos basados en el
cálculo del flujo óptico para la tarea de seguimiento de objetos.
Estos sistemas comprenden dos partes: a bajo nivel, se realiza el
cálculo del flujo óptico a partir de una secuencia de imágenes
siguiendo alguna de las diversas técnicas para su obtención
(Beauchemin y Barron, 1995). A alto nivel, a partir de dicho flujo
óptico se obtienen medidas como posición del objeto en
movimiento, tiempo y dirección de impacto,... que permiten el
análisis del movimiento. Estas arquitecturas suelen emplear
transputers o DSP’s para todos los niveles de procesamiento (Mae
et al., 1994) (Mittal et al., 1995) (Röwekamp et al., 1997). En
aquellas arquitecturas que tienen en consideración los diversos
niveles de procesamiento, no se desarrollan arquitecturas a bajo
nivel sino que se emplean tarjetas comerciales (Tucakov et al.,
1996) (Rougeaux y Kuniyoshi, 1997).
Asimismo, existen multitud de soluciones basadas en la
correspondencia entre puntos de interés. La mayor parte de estos
sistemas sigue la misma filosofía: un módulo SIMD realiza las
tareas de procesamiento a bajo nivel para mejorar la calidad de la
imagen y un módulo MIMD, formado por transputers o DSPs,
realiza la extracción y el seguimiento de los puntos o
características de interés. Estos características suelen ser aristas
(Rygol et al., 1992) (Balkenius y Kopp, 1996) (Asaad et al., 1996),
esquinas (Brady y Wang, 1992) (Beymer et al., 1997) o puntos
significativos del objeto (Persa y Jonker, 2000a).
Otros autores realizan el seguimiento de los objetos mediante el
reconocimiento de puntos o regiones, obtenidas mediante la
aplicación a la imagen de operaciones de bajo nivel, como pueden
ser diferencias, operaciones de morfología matemática,...
Mediante técnicas de correlación o de reconocimiento de patrones
se localizan los objetos en cada una de las imágenes, para
realizar su posterior seguimiento (Bertozzi y Broggi, 1998)
(Castrillón et al., 1998) (Hernández et al., 1999). No existen
muchos sistemas basados en estas técnicas, ya que son bastante
limitadas. Además, la productividad de las arquitecturas
desarrolladas no es muy elevada.
Por otro lado, apenas existen arquitecturas desarrolladas
siguiendo las técnicas de representaciones activas, resaltándose
este hecho en la literatura (Denzler y Niemann, 1995). En
INTRODUCCIÓN: OBJETIVOS Y ESTADO DEL ARTE
37
(Curwen y Blake, 1992) se presenta una solución de los
contornos dinámicos basados en splines, donde una red de
transputers realiza la predicción de la nueva posición del
contorno, así como su adaptación a la posición correcta.
Recientemente, se han propuesto computadores en rejilla (Case et
al., 2001). Estas arquitecturas están formadas por elementos de
procesamiento que pretenden representar un espacio ndimensional, de modo que cada uno de ellos está colocado en un
punto del espacio, conectados entre sí por canales de
comunicación bidireccionales formando una rejilla. Este sistema
ha sido empleado para realizar el seguimiento de objetos con
movimiento uniforme, marcando aquellos elementos de
procesamiento en los que está situado el objeto (Shende, 1991).
Mediante comunicaciones bidireccionales entre procesadores
vecinos se indica la nueva posición del objeto, de modo que la
secuencia de procesadores activados determina el movimiento
seguido por el objeto.
1.2.4 ARQUITECTURAS DE TIEM
TIEMPO
PO REAL
Estas arquitecturas previas realizan su operación a altas
velocidades, de modo que pueden operar bajo las restricciones
temporales que introduce tener que procesar las imágenes a
frecuencia de video. Sin embargo, se echa en falta que ajusten
sus respuestas en función del tiempo disponible. Por ello, en este
punto se revisan los trabajos relacionados con el desarrollo de
arquitecturas de tiempo real.
La característica fundamental que distingue el procesamiento en
tiempo real de otros tipos de procesamiento es la duración de las
operaciones y las consecuencias que se derivan de ello (Stankovic
y Ramamritham, 1990) (Butazzo1997).
Diversos autores (Ramamritham et al., 1990) (Stankovic, 1992)
(Niehaus, 1994) (Weems y Dropsho, 1994) (Krishna y Shin, 1997)
encuentran en lo anterior la mayor dificultad para el desarrollo
de procesadores específicos para tiempo real: el objetivo principal
en la mayoría de los diseños de procesadores actuales es
maximizar el rendimiento medio de las operaciones, tolerándose
retrasos importantes si los eventos que los producen son poco
38
CAPÍTULO 1
probables. En cambio, en los sistemas de tiempo real se deben
asegurar las cotas máximas de los tiempos de ejecución. Esto
significa que una varianza potencialmente grande en los
rendimientos del procesador sitúa al peor caso en una cota
demasiado baja, reduciendo la capacidad global del procesador
para tiempo real en aras de garantizar el resultado en un tiempo
predeterminado. En definitiva, los procesadores adecuados para
tareas de tiempo real necesitan de hardware de alto rendimiento
en el que los tiempos de respuesta, en el peor caso, se aproximen
al caso promedio (Tokhi, 1998).
Algunos ejemplos extraídos de los diseños de procesadores
existentes en los que la predecibilidad en los tiempos de
respuesta se ve perjudicada (Niehaus, 1994) (Hennessy y
Patterson, 1996) (Tokhi, 1999) son los siguientes: los
encaminamientos de datos condicionales, que dependen de que
se haya predicho el cauce correcto o no (Knieser y Papachristou,
1992); las instrucciones de latencia variable, dependientes de la
naturaleza de los operandos (Atkins, 1991); los coprocesadores
asíncronos que tienen tiempos de comunicación variable (TI,
1991); las traducciones de las direcciones de memoria, acceso a
datos e instrucciones, sufren variaciones en los tiempos debido al
uso de buffers (TLB —Table Lookaside Buffer), (DEC, 1992)
(Thomson y Ryan, 1994).
Las implicaciones de los sistemas de tiempo real en el nivel del
procesador se concretan en aportar soluciones con respecto a la
predecibilidad y a la reducción de la inestabilidad temporal en la
ejecución de sus operaciones. Sin embargo, a estos niveles se
deja pendiente el desarrollo de esquemas de control sobre esta
incertidumbre temporal, que proporcionen al diseñador y
programador, elementos de ayuda para satisfacer las demandas
impuestas por estos sistemas, sin tener que sacrificar el
rendimiento del mismo.
El reflejo de esta situación se sustancia en las líneas actuales de
investigación en el terreno de los sistemas de tiempo real (Son,
1995) donde predominan, sin lugar a dudas, las propuestas de
nivel alto y escasean las referidas a arquitecturas de
computadores:
INTRODUCCIÓN: OBJETIVOS Y ESTADO DEL ARTE
39
1. Métodos formales de especificación y verificación de
requerimientos (Hennessy y Reagan, 1991) (Nicollin y
Sifakis, 1991) (Nanda et al., 2000).
2. Herramientas y lenguajes de programación para soportar
el desarrollo de procesos predecibles cada vez más
potentes (Flex, RTC++, RT-Euclid,...) (Stoyenko, 1987)
(Bihari y Gopinath, 1991) (Kenny y Lin, 1991).
3. Sistemas operativos (Ready, 1986) (Holmes et al., 1987)
(Hull et al., 1996), entornos complejos y poco predecibles
como los sistemas distribuidos y multiprocesador
HARTOS (Kandlur et al., 1989), SPRING (Stankovic y
Ramamritham, 1991), CHAOSarc (Gheith y Schwan,
1993), Maruti-II (Son, 1995).
4. Redes de comunicaciones que soporten el tráfico de los
paquetes transmitidos en tiempo real (Ferrari, 1992)
(Chen y Cheng, 1997) (Rajkumar et al., 1997).
5. Bases de datos en tiempo real (Abbott, 1991) (Huang y
Stankovic, 1991).
1.2.5 CONCLUSIONES
Es de destacar que existe una gran divergencia entre la
investigación sobre movimiento en escenas y la orientada a
arquitecturas para visión y seguimiento de objetos. Mientras que
se han obtenido resultados prometedores usando las
representaciones activas, empleándolas sobre plataformas
computacionales de propósito general, apenas se han trasladado
a arquitecturas más especializadas.
Las arquitecturas están enfocadas, principalmente, al cálculo del
flujo óptico y al seguimiento de características como son esquinas
o aristas. Este hecho provoca que no existan apenas
arquitecturas para el análisis de movimiento no-rígido general
(elástico o fluido) que, como ya se comentó previamente, es el que
más se da en la naturaleza.
CAPÍTULO 1
40
Difícilmente se encuentran arquitecturas de análisis del
movimiento en las que los elementos de procesamiento guarden
una relación topológica con la secuencia de imágenes. En esos
casos, cada uno de dichos elementos suele realizar una operación
diferente sobre toda o parte de la imagen. Prácticamente la única
excepción es la de los computadores en rejilla, que representan el
espacio n-dimensional donde se mueve el objeto mediante una
malla de procesadores.
Por último, la mayor parte de las arquitecturas específicas de
visión están diseñadas para que operen con las fuertes
restricciones temporales que vienen dadas por la frecuencia de
video a la que hay que procesar la información, basándose, sobre
todo, en hardware y software de altas prestaciones. Sin embargo,
se echa en falta investigación orientada a hacer consideración de
las restricciones temporales con mayor flexibilidad y potencia,
como puede ser la obtención del resultado por refinamiento
sucesivo. De hecho, el trabajo realizado en el desarrollo de
arquitecturas de tiempo real no ha sido muy extendido, dejando
el tratamiento de las restricciones temporales para niveles
superiores.
1.3 PROPUESTA DE SOLUCIÓN
Tomando la idea de las representaciones activas, se va a
proponer un modelo de representación que adapte su topología
(elementos de procesamiento y red de interconexión) a la forma y
situación del objeto. La estructura de datos debe ser sencilla y
rápida de obtener, de modo que sirva de base al desarrollo de
arquitecturas de alto rendimiento. Por otro lado, si el proceso de
adaptación es iterativo, se podrán obtener representaciones
aproximadas de los objetos en función del tiempo disponible. A
continuación, se presenta la propuesta de solución de
construcción del modelo de representación.
Dado un objeto que presenta unas características geométricas en
cuanto a forma, posición,...; y una apariencia visual (color, tono
de gris, brillo, saturación,...), el problema de representación del
objeto va a consistir en la obtención de su apariencia geométrica
a partir de su apariencia visual.
INTRODUCCIÓN: OBJETIVOS Y ESTADO DEL ARTE
41
Para ello, dada una imagen, se realiza una transformación de la
misma, extrayendo la probabilidad de cada uno de los puntos de
pertenecer al objeto, basándose en el cumplimiento de una cierta
propiedad visual. Empleando esta función de transformación
como campo de potencial, se pretende que el modelo adapte su
topología al espacio de entrada determinado por el objeto. Este es
precisamente el comportamiento que tienen los modelos
neuronales auto-organizativos, donde su aprendizaje está
encaminado a la satisfacción de diversos objetivos (Fritzke, 1997),
principalmente: minimización del error, maximización de la
entropía, mapeado de características preservando su topología,
estimación de la función de densidad de un conjunto de señales y
división en clusters.
Si el espacio de entrada viene determinado por los puntos de la
imagen que pertenecen al objeto, estas redes permitirán
representarlo, minimizando el error de cuantización de sus
elementos de procesamiento y representando su geometría
mediante su red de interconexión. Sin embargo, como los
diferentes modelos auto-organizativos poseen diferente capacidad
de preservar la topología, se realizará un estudio para establecer
cual de ellos tiene un mejor funcionamiento.
Se define el Grafo Preservador de la Topología GPT = A ,C como
el grafo cuyos nodos están situados en los puntos asociados a
cada uno de los elementos de procesamiento, estableciendo una
arista entre aquellos nodos cuyos elementos de procesamiento
respectivos están conectados. Este grafo GPT realiza una
representación aproximada de la apariencia geométrica del
objeto.
Por lo tanto, el problema de obtención de la apariencia geométrica
del objeto, es el del cálculo de un Grafo Preservador de la
Topología GPT que lo represente. Este grafo puede ser empleado
como caracterizador de la forma del objeto, en procesos
posteriores de reconocimiento y/o clasificación. Como la
comparación entre grafos es muy costosa computacionalmente,
debería ser sencilla la extracción de características a partir de
éste, que permita mejorar los procesos de más alto nivel.
Si las propiedades del objeto varían con el tiempo, se presentarán
diferentes instancias del mismo, en sucesivas imágenes. Para
CAPÍTULO 1
42
facilitar el problema, se suelen incluir ciertas restricciones para
limitar la localización de un objeto o de alguna de sus partes
entre imágenes consecutivas de una secuencia. Cédras y Shah
(1995) establecen varias posibles limitaciones: uniformidad del
movimiento, velocidad máxima, suavidad del movimiento o
cambios pequeños en la velocidad, movimiento común,
correspondencia consistente, rigidez,... Escolano (1997) agrupa
todas éstas en dos: coherencia del movimiento y uniformidad del
movimiento.
De este modo, la arquitectura debe ser capaz de reconfigurar su
topología, de manera que para cada instancia del objeto, se
obtenga su representación correspondiente mediante un Grafo
Preservador de la Topología. Dado el carácter dinámico de los
modelos auto-organizativos, que no requieren comenzar el
aprendizaje cuando se introducen nuevos patrones, el
seguimiento de objetos va a consistir en la readaptación de la red
en cada una de las imágenes.
Por tanto, el problema del seguimiento de objetos se plantea como
la readaptación de la arquitectura, de modo que represente en
cada instante de tiempo la apariencia geométrica del objeto.
Se plantean dos formas de reconocer el movimiento:
• basado en el reconocimiento,
• basado en el movimiento.
Para el primero de ellos, se procede a reconocer cada una de las
instancias del objeto, a partir de su GPT o a partir de
características extraídas de éste. La secuencia de diferentes
instancias del objeto reconocidas determina el movimiento
realizado.
Para un análisis basado en el movimiento, se extrae información
sobre la dinámica que han seguido las diversas configuraciones
de la arquitectura. Para ello, se obtiene información de las
trayectorias seguidas por cada uno de los elementos de
procesamiento, entendidas como la sucesión de puntos de la
imagen asociados a cada uno de ellos. Dado que en todo
momento se tiene localizado a cada uno de estos elementos de
INTRODUCCIÓN: OBJETIVOS Y ESTADO DEL ARTE
43
procesamiento, se evita el problema de correspondencia, que es
uno de los más costosos de resolver.
El análisis del movimiento, por tanto, queda establecido por el
estudio de las diferentes apariencias geométricas que toma el
objeto, de modo que puede ser tratado desde dos puntos de vista:
mediante el reconocimiento de cada una de las instancias del
mismo, o mediante el estudio de la dinámica de readaptación de la
arquitectura.
Capítulo 2
MODELOS NEURONALES DE
REPRESENTACIÓN
En este capítulo se describe la red neuronal que va a ser
empleada para la modelización de los objetos. En primer lugar, se
realiza una introducción al conexionismo y una revisión de los
diferentes modelos neuronales con aprendizaje competitivo,
estudiando su capacidad de preservación de la topología. Una vez
estudiadas las propiedades de cada uno de ellos, se justifica la
utilización de los gases neuronales como redes caracterizadoras y
preservadoras de la topología, pasando a estudiarlas con más
detalle.
Dado que uno de los objetivos de este trabajo es la capacidad de
satisfacer restricciones de tiempo real, se aporta una
modificación de la dinámica de adaptación de los gases
neuronales para dotarlos de esta capacidad, estableciendo los
parámetros de aprendizaje acorde al tiempo disponible.
46
CAPÍTULO 2
2.1 REDES AUTO-ORGANIZATIVAS
2.1.1 INTRODUCCIÓN
La representación reducida de los datos con todas sus
interrelaciones es un problema importante en las ciencias de la
información. En este sentido, la situación de las neuronas de las
redes auto-organizativas juega un papel muy importante. Las
neuronas organizan su conectividad para optimizar la
distribución espacial de sus respuestas. Tienen la capacidad de
cambiar sus respuestas, de tal modo que la posición de la
neurona dentro de la red donde se obtiene la respuesta es
específica a cierta característica del conjunto de señales de
entrada. Se convierte la similitud en las señales de entrada en
proximidad de las neuronas excitadas: las neuronas con tareas
similares se comunican mediante caminos de conexiones más
cortos. Esta es una propiedad muy importante de este sistema
paralelo. Este proceso de ordenación o colocación de las
neuronas no se realiza moviendo las neuronas, sino que es un
conjunto de parámetros internos el que define la situación, los
cuales son modificados en el proceso auto-organizativo.
Las redes formadas mediante auto-organización son capaces de
describir relaciones topológicas entre las señales de entrada, de
modo que las relaciones de semejanza más importantes entre las
señales de entrada son convertidas en relaciones espaciales entre
las neuronas. Las redes suelen tener una o dos dimensiones, por
lo que la reducción de la dimensión de la entrada a la de la
situación de la neurona dentro del mapa puede ser vista como un
proceso de abstracción, de manera que el mapeado de las señales
de entrada se realiza según sus propiedades más importantes y
suprimiendo los detalles triviales. Además, si las señales de
entrada siguen una relación de orden, esta relación se verá
reflejada en el mapeado. Por tanto, se mantendrán en la
disposición topológica de la red los clusters o ramas que existan
en el espacio de las señales de entrada.
Existe un gran número de modelos neuronales autoorganizativos, algunos de los cuales serán estudiados a
continuación. La mayor parte de ellos poseen una topología y
funcionamiento básicos comunes, que se presentan a
continuación.
MODELOS NEURONALES DE REPRESENTACIÓN
47
Una red auto-organizativa A está formada por un conjunto de n
neuronas:
A = {c 1 ,c 2 ,…,c n }
(2.1)
donde cada una de las neuronas tiene asociado un vector de
referencia perteneciente al espacio de las señales de entrada V
w c ∈V
(2.2)
que indica la zona del espacio de entrada al cual esta neurona es
más receptiva.
Las neuronas están conectadas entre sí mediante conexiones de
vecindad que son simétricas y permiten establecer una relación
topológica entre las diferentes neuronas pertenecientes a la red
neuronal
C ⊂ A×A
(i , j )∈C ⇔ ( j , i )∈C
De modo que una neurona
topológicos N c :
(2.3)
c posee un conjunto de vecinos
N c = {i ∈ A (c , i ) ∈C }
(2.4)
El aprendizaje se realiza a partir de un conjunto de señales de
entrada n -dimensionales que son generadas siguiendo una
función de densidad de probabilidad
p ( ξ ), ξ ∈V
(2.5)
Para cada señal de entrada ξ , mediante un proceso competitivo
entre las n neuronas, se obtiene la neurona ganadora s (ξ )
definida como la neurona que posee el vector de referencia más
cercano a ξ
s ( ξ ) = arg min c∈A ξ − w c
(2.6)
CAPÍTULO 2
48
donde
⋅ representa, normalmente, la distancia euclídea.
Posteriormente, se produce un proceso de adaptación de los
vectores de referencia de todas o parte de las neuronas de la red
(dependiendo de la relación de vecindad) con el objetivo de
aproximar sus vectores de referencia a la señal de entrada
siguiendo la ley de Hebb:
∆w c = α ⋅ (w c − ξ )
donde
α
(2.7)
pondera el paso de adaptación.
Una vez finalizado el proceso auto-organizativo, se obtiene un
mapeado del espacio de las señales de entrada V en la red
neuronal A :
φW : V → A , ξ ∈V → φw (ξ )∈ A
donde
φw (ξ )
(2.8)
se obtiene a partir de la siguiente condición:
w φw (ξ ) − ξ = min c∈A ξ − w c
(2.9)
Aunque existe una amplia variedad de modelos autoorganizativos o con aprendizaje competitivo, únicamente se van
estudiar aquellos que se han considerado más relevantes, base de
las redes que se emplearán en este trabajo. Se puede encontrar
información sobre otros modelos auto-organizativos en (Fritzke,
1997) (Kohonen, 1995).
Se pueden diferenciar dos grandes grupos de modelos autoorganizativos desde el punto de vista estructural: aquellos que
tienen una dimensionalidad fija y topología de la red
preestablecida, y los que varían su dimensionalidad durante el
aprendizaje. Entre los primeros se encuentran los mapas autoorganizativos de Kohonen y las Growing Cell Structures. Entre los
segundos se encuentran la Neural Gas y la Growing Neural Gas.
En el modelo auto-organizativo, desarrollado por Kohonen (1995),
las neuronas están unidas entre sí formando una rejilla,
normalmente bidimensional. Tiene serias limitaciones a la hora
MODELOS NEURONALES DE REPRESENTACIÓN
49
de mapear el espacio de los vectores de entrada, ya que durante
el aprendizaje no puede variar la estructura de rejilla.
Han sido ampliamente utilizados desde entonces en multitud de
aplicaciones (Kohonen, 1995): compresión de imágenes
(Amerijckx et al., 1998), segmentación de objetos (Wu et al.,
2000), reconocimiento de formas (Iivarinen, 1998), etc.
2.1.2 GROWING CELL STRUCTURES
Este modelo desarrollado por Fritzke (1993a) posee una
estructura flexible, con un número variable de neuronas, y una
topología k-dimensional donde k es escogido arbitrariamente a
priori. Las neuronas están conectadas entre sí formando
hipertetraedros. En el caso más usual en el que la red es
bidimensional, las neuronas están unidas formando triángulos.
Figura 2.1. Inserción de neuronas durante el aprendizaje de la Growing Cell
Structure.
A partir de un número inicial mínimo de neuronas se procede al
aprendizaje, de modo que en aquellas zonas del espacio de los
vectores de entrada donde se produce un mayor error se añaden
nuevas neuronas con el fin de reducirlo, manteniendo siempre la
estructura de hipertetraedros (Figura 2.1). Asimismo, si se da el
caso de que una neurona ya no es necesaria, puede ser
eliminada, quitando también las conexiones que emanan de la
misma, con lo que puede ocurrir que la red neuronal se divida en
diversas subredes (Figura 2.2).
CAPÍTULO 2
50
Figura 2.2. División de la red GCS en varias subredes al eliminar neuronas.
Se ha demostrado que este modelo mejora el mapeado que
realizan los mapas auto-organizativos de Kohonen con respecto a
diferentes criterios (Fritzke, 1993b).
Esta red ha sido empleada en la clasificación de patrones (Cheng
y Zell, 2000a), compresión de imágenes (Fritzke, 1993c),
reconocimiento de gestos (Flórez et al.,2001),...
2.2 GASES NEURONALES
NEURONALES
Bajo este término
organizativos que:
se
engloban
diferentes
modelos
auto-
• realizan su proceso de adaptación según una función de
energía (espacio de los vectores de entrada), a diferencia
de los mapas auto-organizativos de Kohonen, en el que
viene determinado por la estructura de la red, y
• convergen rápidamente a errores de cuantización
pequeños, menores que los obtenidos con los modelos
anteriores.
Estos modelos pretenden evitar la restricción de los modelos
anteriores que requieren un conocimiento a priori sobre la
dimensión topológica del espacio de los vectores de entrada. Por
ello, no preestablecen ninguna topología de la red, sino que es
durante el aprendizaje cuando las neuronas se conectan o
desconectan reajustando su red de interconexión.
2.2.1 NEURAL GAS
Este modelo (Martinetz y Schulten, 1991) no establece a priori
ninguna topología de la red, conectando las dos neuronas más
MODELOS NEURONALES DE REPRESENTACIÓN
51
cercanas para cada uno de los patrones escogidos en el
aprendizaje. Posee la desventaja de tener que predeterminar el
tamaño de la red, es decir, el número de neuronas que posee
(Figura 2.3).
Ha sido empleada en la predicción de series temporales
(Martinetz et al., 1993), control de robots (Mataric, 2000),
clasificación de escritura (Atukorale y Suganthan, 1998),...
Figura 2.3. Estados inicial, intermedio y final del aprendizaje de la Neural Gas.
El algoritmo de aprendizaje es el siguiente:
1. Se inicializa el conjunto
A con n neuronas:
A = {c 1 ,c 2 ,...,c n }
(2.10)
con sus respectivos vectores de referencia establecidos
aleatoriamente, aunque suele seguirse la función de
densidad de probabilidad p (ξ ) .
Se crea el conjunto de conexiones como el conjunto vacío
C =φ
(2.11)
Se inicializa el parámetro que mide el tiempo:
t =0
2. Se genera una señal de entrada
(2.12)
ξ
según
p (ξ ) .
3. Se ordenan todos los elementos de A según su distancia
a ξ , encontrando la secuencia de índices i 0 , i 1 ,..., i n −1
(
)
CAPÍTULO 2
52
tal que w i es el vector de referencia más cercano a
0
w i es el vector de referencia más lejano.
ξ
y
n −1
4. Se adaptan los vectores de referencia según:
(
∆w i = ε (t ) ⋅ h λ (k i (ξ , A )) ⋅ ξ − w s 1
)
(2.13)
donde k i (ξ , A ) representa el índice k para el vector de
referencia w i dentro de la secuencia anterior, y:
(
ε (t ) = ε (ε
λ (t ) = λ0 λtmax λ0
0
tmax
h λ (k ) =
ε0
)
)
t tmax
t tmax
1
(2.14)
(2.15)
k λ (t )
(2.16)
5. Si la conexión entre las neuronas
entonces es creada
i0 e i1 no existe,
e
C = C ∪ {(i 0 ,i 1 )}
(2.17)
Se establece a 0 la edad de la conexión entre ellas
edad (i 0 ,i 1 ) = 0
(2.18)
6. Se incrementan las edades de todas las aristas que
emanan de i0
edad (i 0 , i ) = edad (i 0 ,i ) + 1 , ∀i ∈ N (i 0 )
(2.19)
7. Se eliminan todas las aristas cuya edad sea mayor que
una cierta edad máxima T (t ) donde:
(
T (t ) = T 0 T tmax T 0
)
t tmax
8. Se incrementa el parámetro temporal
(2.20)
MODELOS NEURONALES DE REPRESENTACIÓN
53
t =t +1
9. Si
(2.21)
t < tmax se continúa en el paso 2.
En resumen, la ordenación de las neuronas, según su distancia
al patrón de entrada, y la posterior modificación de sus vectores
de referencia, produce la expansión de las mismas dentro del
espacio de entrada. Posteriormente, mediante la inserción y
eliminación de aristas se establece una triangulación entre los
diversos elementos de procesamiento.
2.2.2 GROWING NEURAL GAS
A partir de los modelos de Neural Gas y de Growing Cell
Structures, Fritzke (1995) desarrolla el modelo de Growing Neural
Gas, en el que no se preestablece una topología de unión entre
las neuronas y en el que, a partir de un número inicial, nuevas
neuronas son insertadas (Figura 2.4).
Figura 2.4. Estados inicial, intermedio y final del aprendizaje de la Growing
Neural Gas.
Este modelo ha sido empleado en aplicaciones relacionadas con
la robótica (Marsland et al., 2000), la compresión de datos
(Bougrain y Alexandre, 1999), el reconocimiento de gestos
(Boehme et al., 1998),...
El algoritmo de aprendizaje es el siguiente:
1. Se crea el conjunto
y c2
A con únicamente dos neuronas c 1
A = {c 1 , c 2 }
(2.22)
CAPÍTULO 2
54
con sus respectivos vectores de referencia w 1 y w 2
inicializados aleatoriamente, siguiendo usualmente la
función de densidad de probabilidad p (ξ ) .
Se inicializa el conjunto de conexiones al conjunto vacío
C =φ
2. Se genera una señal de entrada
(2.23)
ξ
según
p (ξ ) .
3. Se localizan la neurona ganadora s 1 y la segunda
neurona más cercana s 2 obtenidas como
s 1 = arg min c∈A ξ − w c
(2.24)
s 2 = arg min c∈A −{s1 } ξ − w c
(2.25)
4. Si la conexión entre ambas neuronas
entonces es creada
s 1 y s 2 no existe,
C = C ∪ {(s 1 , s 2 )}
(2.26)
Se fija a 0 la edad de la conexión entre ellas
edad (s 1 , s 2 ) = 0
(2.27)
5. Se añade el cuadrado de la distancia existente entre la
señal de entrada y el vector de referencia de la neurona
ganadora a una variable de error local
∆E s1 = ξ − w s1
2
(2.28)
6. Se adaptan los vectores de referencia de la neurona
ganadora s 1 así como de todas sus neuronas vecinas.
Esta adaptación se pondera según ε1 y ε 2 .
(
∆w s1 = ε 1 ξ − w s1
)
(2.29)
MODELOS NEURONALES DE REPRESENTACIÓN
55
∆w i = ε 2 (ξ − w i ), ∀i ∈ N s1
(2.30)
7. Se incrementan las edades de todas las aristas que
emanan de s 1
edad (s 1 , i ) = edad (s 1 , i ) + 1 , ∀i ∈ N s1
(2.31)
8. Se eliminan todas las aristas cuya edad sea mayor que
una cierta cantidad edad max . Si al producirse la
eliminación una neurona se queda aislada, es decir, sin
aristas que salgan de ella, esta neurona es eliminada.
9. Cada cierto número λ de señales de entrada generadas
se inserta una neurona según el siguiente proceso:
− Se determina la neurona
acumulado:
q con el mayor error
q = arg max c∈A E c
− Se localiza la neurona
error acumulado:
f vecina de q con mayor
f = arg max c∈N q Ec
− Se inserta una nueva neurona
(w q + w f )
2
(2.33)
r entre f y q :
A = A ∪ {r }
wr =
(2.32)
(2.34)
(2.35)
− Se insertan nuevas conexiones entre la neurona r
y las neuronas f y q , eliminando la conexión que
existía entre éstas:
CAPÍTULO 2
56
C = C ∪ {(r , q ), (r , f
C = C − {(q , f
)}
(2.36)
)}
− Se decrece el error de las neuronas
fracción α :
f y q por una
∆E f = −αE f
(2.37)
∆E q = −αE q
− Se interpola el error de la neurona
errores de f y q :
Er =
(E f
+ Eq
)
2
r entre los
(2.38)
10. Se decrece el error de todas las neuronas
∆E c = − βE c , ∀c ∈ A
(2.39)
11. Si se cumple una determinada condición (tamaño
máximo de la red, error cuadrático medio,...) se finaliza
el proceso. Si no es así, se continúa con el paso 2.
En resumen, la adaptación de la red al espacio de los vectores de
entrada se produce en el paso 6. La inserción de conexiones (paso
4) entre la neurona ganadora y la segunda más cercana a la señal
de entrada induce finalmente una triangulación de Delaunay.
La eliminación de conexiones (paso 8) elimina las aristas que ya
no forman parte de dicha triangulación. Esto es realizado
eliminando las conexiones entre neuronas que ya no se
encuentran próximas o que tienen neuronas más cercanas, de
modo que la edad de dichas conexiones supera un umbral.
La acumulación del error (paso 5) permite identificar aquellas
zonas del espacio de los vectores de entrada donde es necesario
incrementar el número de neuronas para mejorar el mapeado.
MODELOS NEURONALES DE REPRESENTACIÓN
57
2.3 PRESERVACIÓN DE LA TOPOLOGÍA
TOPOLOGÍA
2.3.1 REDES PRESERVADORAS D
DE
E LA TOPOLOGÍA
El resultado final del proceso auto-organizativo o de aprendizaje
competitivo está estrechamente ligado al concepto de la
triangulación de Delaunay. La región de Voronoi de una neurona
está formada por todos los puntos del espacio de entrada para el
que ésta resulta la neurona ganadora. Por tanto, como resultado
final del aprendizaje competitivo se obtiene un grafo (red
neuronal), cuyos vértices son las neuronas de la red y cuyas
aristas son las conexiones entre las mismas, que representa la
triangulación
de
Delaunay
del
espacio
de
entrada
correspondiente a los vectores de referencia de las neuronas de la
red.
Aunque tradicionalmente se ha indicado que esta triangulación,
resultado del aprendizaje competitivo, preserva la topología del
espacio de entrada, (Martinetz y Schulten, 1994) introduce una
nueva terminología que restringe esta cualidad.
Se indica que el mapeado φw de V en A preserva la vecindad si
vectores de características similares, vectores cercanos en el
espacio de entrada V , son mapeados en neuronas cercanas de
A.
Asimismo, se señala que el mapeado inverso
φw−1 : A → V , c ∈ A → w c ∈V
(2.40)
preserva la vecindad si neuronas cercanas en A tienen
asociados vectores de características próximos dentro del espacio
de entrada.
Combinando ambas definiciones, se establece como Red
Preservadora de la Topología (RPT) a aquella red A cuyos
−1
mapeados φw y φw son preservadores de la vecindad.
De este modo, los mapas auto-organizativos de Kohonen no
serían preservadores de la topología como tradicionalmente han
sido considerados, ya que esto sólo ocurriría en el caso de que la
topología del mapa y del espacio de entrada coincidieran. Dado
58
CAPÍTULO 2
que la topología de la red es establecida a priori, desconociendo
posiblemente la topología del espacio de entrada, no se va a poder
−1
asegurar que los mapeados φw y φ w preserven la vecindad.
Las Growing Cell Structures de Fritzke tampoco son
preservadoras de la topología ya que la topología de la red está
establecida a priori (triángulos, tetraedros,...). Sin embargo, como
ya se indicó, sí que se mejora el funcionamiento respecto de los
mapas de Kohonen, debido a su capacidad de inserción y
eliminación de neuronas.
Por último, el grafo resultante del aprendizaje competitivo de las
Neural Gas y de las Growing Neural Gas, es una triangulación de
Delaunay inducida (Figura 2.5), subgrafo de la triangulación de
Delaunay, en el que únicamente se encuentran las aristas de la
triangulación de Delaunay cuyos puntos pertenezcan al espacio
de entrada V . En (Martinetz y Schulten, 1994) se demuestra que
estos modelos son Redes Preservadoras de la Topología.
Figura 2.5. (a) Triangulación de Delaunay, (b) Triangulación de Delaunay inducida
2.3.2 ESTUDIO DE LA PRESERVACIÓN
PRESERVACIÓN DE LA TOPOLOGÍA
TOPOLOGÍA DE LOS
MODELOS AUTO-ORGANIZATIVOS
ORGANIZATIVOS
La principal propiedad de los modelos auto-organizativos es la
extracción de la estructura esencial de los datos de entrada,
mediante la adaptación de la red de neuronas. En el caso de los
modelos cuya topología es establecida a priori, la dimensión
geométrica de la red suele ser de menor dimensión que el espacio
de entrada. Si esta dimensión es mucho menor, la red intenta
MODELOS NEURONALES DE REPRESENTACIÓN
59
aproximar la mayor dimensionalidad doblándose dentro del
espacio de entrada, sin preservar la topología del mismo.
Es por esto, que han surgido diferentes medidas que cuantifican
el grado de preservación de la topología (Bauer et al., 1999) para
determinar cuál debe ser la dimensionalidad correcta de la red: el
producto topográfico (Apéndice A), la medida ρ de Spearman, la
medida de Zrehen, la función topográfica o la medida de coste C.
En este trabajo, se ha empleado el producto topográfico que es,
de todas ellas, la que ha sido más ampliamente utilizada en la
literatura (Merkl et al., 1994) (Herbin, 1995) (Trautmann y
Denoeux, 1995).
Del estudio realizado (Apéndice A) se extrae que las redes que
mejor preservan la topología de los espacios de entrada son
aquellas cuya topología no está definida a priori (Figura 2.6), sino
que se adapta con el aprendizaje: las Neural Gas y las Growing
Neural Gas.
Kohonen
Growing Cell Structures
Neural Gas
Growing Neural Gas
Figura 2.6. Adaptación de diversos modelos auto-organizativos a un espacio de
entrada.
CAPÍTULO 2
60
Sólo en aquellos casos en los que el espacio de entrada tiene una
estructura similar a la topología predefinida de los mapas autoorganizativos, el producto topográfico es similar al de los otros
modelos. Esto es debido a que en el cálculo del producto
topográfico únicamente se considera la topología de la red, ya que
se asume que se ha realizado un correcto aprendizaje del espacio
de entrada y que, por tanto, se habrá obtenido una correcta
adaptación de la red. Sin embargo, en estos casos no es así, ya
que se observa que los mapas de Kohonen caracterizan peor el
espacio de entrada al producirse un mayor error de cuantización
(Figura 2.7).
Kohonen
Neural Gas
Figura 2.7. Comparación del error de cuantización entre mapas de Kohonen y
Neural Gas.
Las Neural Gas y las Growing Neural Gas tienen un
comportamiento similar, sin embargo, la complejidad del
aprendizaje de las Neural Gas es muy superior al de las Growing
Neural Gas, obteniendo unos tiempos de aprendizaje muy
superiores, por ejemplo, para el caso de una red con un número
final de 100 neuronas (Tabla 2.1). Esto es debido, principalmente,
al proceso de ordenación que hay que realizar por cada uno de
los patrones de entrada (paso 3 del aprendizaje de la Neural Gas).
Modelo auto-organizativo
Tiempo de aprendizaje (segundos)
Kohonen
38
Growing Cell Structure
9
Neural Gas
117
Growing Neural Gas
12
Tabla 2.1. Tiempos de aprendizaje de los diferentes modelos auto-organizativos.
MODELOS NEURONALES DE REPRESENTACIÓN
61
De hecho, si se interrumpiera el aprendizaje de la Neural Gas a
los 12 segundos, que es el tiempo en el que finalizan su
aprendizaje las Growing Neural Gas, ésta no habrá realizado,
siquiera, una aproximación al espacio de entrada, debido al
empleo de parámetros que decaen con el número de iteraciones
(Figura 2.8).
Figura 2.8. Adaptación incompleta de la Neural Gas.
Se puede concluir que aquellas redes auto-organizativas que
mejor preservan la topología de un espacio de entrada y que, por
tanto, van a servir para hacer una representación de los objetos,
son los gases neuronales. El empleo de cada uno de ellos vendrá
determinado por la aplicación. Por un lado, las Neural Gas
realizan una representación más próxima al objeto (Figura 2.6).
Por otro, las Growing Neural Gas tienen una menor complejidad
temporal y espacial, ya que al ir incrementando el número de
neuronas durante el aprendizaje, dicho espacio y elementos de
procesamiento pueden servir para otras tareas.
2.4 INCORPORACIÓN DE REST
RESTRICCIONES
RICCIONES DE TIEMPO REAL
En el caso que se está tratando, las restricciones temporales
determinarán el tiempo disponible para completar la adaptación
del modelo auto-organizativo. Si el proceso de aprendizaje de la
red no puede finalizar en dicho tiempo límite, la preservación de
la topología se verá afectada.
CAPÍTULO 2
62
2.4.1 NEURAL GAS PARA TIEMPO REAL
La elevada complejidad temporal de este modelo, en comparación
con los otros, provoca que ante un límite de tiempo para el
proceso de aprendizaje, la adaptación podría no haberse
completado. En ese caso, la preservación de la topología se ve
considerablemente afectada, debido al empleo de parámetros que
decaen con el número de iteraciones, provocando movimientos de
adaptación más bastos al principio del aprendizaje, para
posteriormente aproximarse de forma más suave. Si no se llega a
esta última fase, la red no logra representar con suficiente
fidelidad al objeto. Sin embargo, si el proceso adaptativo finaliza,
es el modelo que mejor preserva la topología del espacio de
entrada. Esto hace que se plantee en este punto, la posibilidad de
modificar los parámetros de aprendizaje de la Neural Gas para
lograr que el ajuste de la red finalice.
Para ello, la posibilidad inmediata es la de reducir el número de
iteraciones t max de modo que dé tiempo a finalizar la adaptación.
Por supuesto, esto conlleva la modificación de todos los
parámetros de aprendizaje que dependen de t max , provocando un
aprendizaje menos fino (Tabla 2.2).
Espacio de
entrada
tmax = 10000 tmax = 25000 tmax = 50000 tmax = 100000
(1 s.)
(3 s.)
(6 s.)
(12 s.)
Cuadrado
0.028831
0.007385
0.006957
0.006390
Círculo
0.028856
0.007847
0.006655
0.006207
Anillo
0.020108
0.004789
0.004028
0.003454
4 cuadros
0.035654
0.003764
0.003726
0.003690
Mano
0.033541
0.011564
0.010345
0.005739
Tabla 2.2. Cálculo del producto topográfico de Neural Gas con distintas tmax.
De la tabla se extrae que, aun reduciendo el número de patrones
presentados, la preservación de la topología que se logra con la
Neural Gas es mejor que la de lograda con la Growing Neural
Gas, a igualdad de tiempos de aprendizaje (últimas columnas de
MODELOS NEURONALES DE REPRESENTACIÓN
63
las tablas 2.2 y 2.3). Sin embargo, si se reduce t max
considerablemente, el número de patrones es insuficiente para
realizar una correcta adaptación de la red y la preservación de la
topología se ve claramente afectada.
2.4.2 GROWING NEURAL GAS PARA TIEMPO REAL
En el caso de la Growing Neural Gas la finalización del
aprendizaje suele venir determinado por la inserción de todas las
neuronas hasta obtener el tamaño máximo de la red. Si se desea
operar en tiempo real se incluirá la finalización del tiempo de
aprendizaje entre las diferentes condiciones de terminación del
mismo.
De este modo, si no existe tiempo suficiente para la finalización
del aprendizaje no se conseguirá insertar todas las neuronas y,
por tanto, completar la red. Esto provoca que la preservación de
la topología se vea afectada al realizar una peor aproximación de
la red al espacio de entrada (Tabla 2.3). Sin embargo, aunque la
adaptación es bastante buena (Figura 2.9), la red posee menos
neuronas
y
existen
aristas
que
conectan
neuronas
incorrectamente, de modo que no se establece una triangulación
adecuada.
Espacio
de
entrada
25% del tiempo
de aprendizaje
(3 s.)
50% del tiempo
de aprendizaje
(6 s.)
75% del tiempo
de aprendizaje
(9 s.)
100% del tiempo
de aprendizaje
(12 s.)
Cuadrado
0.016485
0.009796
0.00947
0.007785
Círculo
0.015197
0.010809
0.009112
0.007832
Anillo
0.013155
0.00717
0.006792
0.005030
4 cuadros
0.005537
0.00517
0.004711
0.004221
Mano
0.010262
0.009158
0.006435
0.00607
Tabla 2.3. Cálculo del producto topográfico de Growing Neural Gas con
restricciones temporales.
CAPÍTULO 2
64
25%
50%
75%
Figura 2.9. Adaptación de la Growing Neural Gas con límites de tiempo.
Sin embargo, si lo que se desea es obtener una red completa, con
todas sus neuronas, en un tiempo predeterminado, se debe
modificar el algoritmo de aprendizaje de la misma para acelerar
su finalización.
Hay diversas cuestiones que intervienen en la duración del
proceso adaptativo: el número de patrones de entrada λ por
iteración, el número de neuronas insertadas en cada iteración, la
posibilidad de eliminar neuronas,... Contemplando estas
posibilidades, se presentan, a continuación, tres modificaciones
del proceso de adaptación de la Growing Neural Gas para que se
pueda efectuar su aprendizaje bajo una restricción temporal:
• Elección de un menor número de señales de entrada por
iteración
• Inserción de varias neuronas por iteración
• Completado de la red una vez finalizado el aprendizaje
Estas tres técnicas no consideran la posibilidad que existe en el
aprendizaje de eliminación de neuronas (paso 8 del algoritmo
general), lo cual ralentizaría el aprendizaje y, por consiguiente,
podría no finalizar en el tiempo establecido.
VARIACIÓN 1: ELECCIÓN DE UN MENO
MENOR
R NÚMERO DE SEÑALES DE
ENTRADA POR ITERACIÓN
ITERACIÓN
Esta primera variación al algoritmo original de aprendizaje de la
Growing Neural Gas es similar a la empleada con la Neural Gas.
Dado que cada cierto número λ de señales de entrada se debe
MODELOS NEURONALES DE REPRESENTACIÓN
65
insertar una nueva neurona (paso 9), si se reduce este número,
cada neurona será insertada a intervalos menores de tiempo y,
por tanto, se tardará menos en completar el mapa.
Sin embargo, el elegir pocas señales de entrada por iteración
afecta a la adaptación de la red al espacio de entrada (Figura
2.10) y a la preservación de la topología de la misma. Este hecho
se observa en la Tabla 2.4 donde el producto topográfico se
distancia de 0, valor ideal, según disminuye λ .
λ=1000
λ=2500
λ=5000
Figura 2.10. Adaptación de la Growing Neural Gas modificando el número de
patrones por iteración λ.
Espacio de
entrada
λ = 1000
(1 s.)
λ = 2500
(3 s.)
λ = 5000
(6 s.)
λ = 10000
(12 s.)
Cuadrado
0.011742
0.008881
0.008465
0.007785
Círculo
0.010926
0.009457
0.008097
0.007832
Anillo
0.007538
0.005919
0.005193
0.00503
4 cuadros
0.005962
0.004772
0.004703
0.004221
Mano
0.008488
0.00709
0.006224
0.00607
Tabla 2.4. Cálculo del producto topográfico de Growing Neural Gas (variación 1).
Cuando el valor de λ es pequeño el aumentarlo provoca una
gran mejora en el producto topográfico. Según este número de
señales de entrada por iteración se acerca al número de puntos
del espacio de entrada el producto topográfico se estabiliza,
CAPÍTULO 2
66
mostrando un mayor tiempo de aprendizaje que no conlleva una
proporcional mejoría en la preservación de la topología.
Por otro lado, si el tiempo disponible para el aprendizaje es bajo
(1 segundo), el comportamiento de la red sigue siendo bueno. Al
contrario que la Neural Gas, que para finalizar en ese mismo
tiempo, por su mayor complejidad, requiere la presentación de un
número mucho menor de patrones, lo que perjudica claramente
al aprendizaje del espacio de entrada.
VARIACIÓN 2: INSERCIÓN DE VARIAS NEURONAS POR ITERACIÓN
ITERACIÓN
Existe un trabajo (Cheng y Zell, 2000b) en esta línea en el que se
establece una modificación del algoritmo de aprendizaje de la
GNG para insertar en cada iteración dos neuronas. Sin embargo,
no en todas las iteraciones, dependiendo de diversas
circunstancias, se insertan ambas neuronas, sino que puede
darse el caso de que sólo se inserte una de ellas y, por tanto, que
el aprendizaje no se acelere.
Para ello, en esta variación del algoritmo de aprendizaje de la
GNG permanece estable el número de señales de entrada λ ,
repitiéndose por cada iteración varias veces el paso 9 del
aprendizaje. De este modo, se asegura que el aprendizaje
finalizará en un tiempo determinado.
Espacio
de
entrada
Inserción de
1 neurona
(12 s.)
Inserción de
2 neuronas
(6 s.)
Inserción de
5 neuronas
(3 s.)
Inserción de
7 neuronas
(1.5 s.)
Inserción de
10 neuronas
(1 s.)
Cuadrado
0.007785
0.008524
0.008682
0.009134
0.009427
Círculo
0.007832
0.008055
0.008806
0.010069
0.010685
Anillo
0.00503
0.005381
0.006401
0.007660
0.008696
4 cuadros
0.004221
0.004571
0.0052
0.005402
0.006033
Mano
0.00607
0.006423
0.006923
0.007968
0.008416
Tabla 2.5. Cálculo del producto topográfico de Growing Neural Gas insertando
diferente número de neuronas (variación 2).
MODELOS NEURONALES DE REPRESENTACIÓN
67
Por supuesto, el realizar este aprendizaje más basto del espacio
de entrada (Figura 2.11) provoca que la preservación de la
topología se vea afectada (Tabla 2.5).
2 neuronas
5 neuronas
7 neuronas
10 neuronas
Figura 2.11. Adaptación de la Growing Neural Gas modificando el número de
neuronas insertadas por iteración.
VARIACIÓN 3: COMPLETADO DE LA RE
RED
D UNA VEZ FINALIZADO EL
APRENDIZAJE
APRENDIZAJE
En esta última variación se realiza un aprendizaje normal de la
red estableciendo un tiempo límite para la realización del mismo,
de modo que si no ha habido tiempo suficiente la red no estará
completa. Es en este punto, en el que se procede a efectuar la
inserción de las neuronas que resten para completar la red, de
modo similar a como se realiza en el paso 9 del aprendizaje.
Tras esta masiva inserción de neuronas, se realiza un proceso de
adaptación final de la red realizando únicamente los pasos 2 a 6
'
con un número λ de señales de entrada. De este modo, todas
estas neuronas que han sido creadas al final del aprendizaje
pueden adaptarse mejor al espacio de entrada. Esta inserción
final de neuronas y el proceso final de adaptación provoca que se
aumente el tiempo de aprendizaje, por lo que debe ser tenido en
CAPÍTULO 2
68
cuenta a la hora de establecer el tiempo límite en el cual la red
realiza la primera fase de aprendizaje normal.
La preservación de la topología, en este caso, se ve mucho más
afectada que con las variaciones anteriores (Figura 2.12). En este
caso, el producto topográfico es mucho mayor que en los casos
anteriores disponiendo del mismo tiempo para realizar el
aprendizaje (Tabla 2.6).
25%
50%
75%
Figura 2.12. Adaptación de la Growing Neural Gas completando la red una vez
finalizado el tiempo.
Espacio
de
entrada
25% del tiempo
de aprendizaje
(3 s.)
50% del tiempo
de aprendizaje
(6 s.)
75% del tiempo
de aprendizaje
(9 s.)
100% del tiempo
de aprendizaje
(12 s.)
Cuadrado
0.013381
0.011922
0.010735
0.007785
Círculo
0.013371
0.010869
0.009202
0.007832
Anillo
0.009024
0.008312
0.00741
0.005030
4 cuadros
0.006379
0.005976
0.005368
0.004221
Mano
0.009263
0.008198
0.007155
0.00607
Tabla 2.6. Cálculo del producto topográfico de Growing Neural Gas completando
la red una vez finalizado el aprendizaje (variación 3).
MODELOS NEURONALES DE REPRESENTACIÓN
69
2.5 CONCLUSIONES
En este capítulo se ha presentado el modelo conexionista que va
a proporcionar la representación de los objetos bidimensionales.
Para ello, se ha introducido el fundamento de comportamiento de
las redes neuronales auto-organizativas, las cuales tienen la
capacidad de adaptar su topología a un espacio de entrada, y se
ha realizado un estudio de la capacidad de preservación de la
topología de varios modelos auto-organizativos.
De este estudio, se desprende que los gases neuronales son los
que realizan una mejor representación de la topología de un
espacio de entrada. De hecho, son los únicos que poseen la
capacidad de división de la red durante el aprendizaje, de modo
que se pueden representar espacios no continuos. De éstos, la
Neural Gas realiza una mejor preservación a costa de una mayor
complejidad temporal y espacial.
Estos modelos son inherentemente paralelos, lo cual les hace
muy adecuados para tratar problemas de visión. Por otro lado, se
han modificado los algoritmos de aprendizaje correspondientes
para que puedan presentar una respuesta bajo restricciones de
tiempo real, estudiando como afecta este hecho a la preservación
de la topología.
El desarrollo de arquitecturas, tanto paralelas como de tiempo
real, a partir del modelo de representación presentado es
prácticamente inmediato. El empleo del conexionismo aporta alto
rendimiento en el procesamiento, mientras que el aprendizaje
iterativo y las modificaciones introducidas en el proceso autoorganizativo, introduce operatividad en tiempo real.
Capítulo 3
REPRESENTACIÓN Y
CARACTERIZACIÓN DE
OBJETOS
En este capítulo se estudia el caso particular de aplicación de la
Red Preservadora de la Topología aplicada al espacio
bidimensional, de modo que se realiza una representación de los
objetos de la escena mediante un gas neuronal. En caso de que
se
desee
obtener
una
representación
del
objeto,
independientemente del tiempo requerido, se empleará una
Neural Gas, que preserva mejor la topología de un espacio de
entrada. Si, por contra, existen restricciones temporales o
espaciales, se hará uso de una Growing Neural Gas.
Posteriormente, se estudia su aplicación al análisis de imágenes,
realizando simplificaciones del grafo (red) obtenido para un mejor
manejo de la información. Asimismo, se presentan diversas
características que pueden ser extraídas del grafo original.
CAPÍTULO 3
72
A continuación, se estudia la aplicación de la Red Preservadora
de la Topología a la síntesis de imágenes, aprovechando la
capacidad de compresión de la información que poseen los
modelos auto-organizativos.
Finalmente, se presenta un ejemplo de aplicación de la
adaptación de un gas neuronal a la forma de los objetos,
empleándolo para la clasificación de estos a partir de sus
contornos.
3.1 REPRESENTACIÓN DE UN OBJETO 2D CON UN GAS
NEURONAL
La capacidad de preservación de la topología que poseen los
gases neuronales va a ser empleada, particularmente en este
trabajo, para la representación de objetos bidimensionales.
Identificando los puntos de la imagen que pertenecen a los
objetos, se posibilita la adaptación de la red a este subespacio de
entrada, obteniendo una triangulación de Delaunay inducida por
el objeto.
[
]
Sea un objeto O = AG , AV que está definido por una apariencia
geométrica AG y una apariencia visual AV . La apariencia
geométrica AG viene dada por unos parámetros morfológicos
(deformaciones locales) y por unos parámetros posicionales
(traslación, rotación y escalado):
AG = [G M ,G P ]
(3.1)
La apariencia visual AV está establecida por un conjunto de
características del objeto como pueden ser el color, la textura, el
brillo,...
En (Escolano, 1997) se indica que dados un dominio soporte
S ⊆ R 2 , una función de intensidad de imagen I ( x , y ) ∈ R tal
que I : S → 0 , I max , y un objeto O , su campo de potencial
normalizado
ψ T (x , y ) = f T (I (x , y )) es la transformación
ψ T : S → [0 ,1 ] que asocia a cada punto (x , y ) ∈ S el grado de
cumplimiento de la propiedad visual T del objeto O por su
intensidad asociada I ( x , y ) .
[
]
REPRESENTACIÓN Y CARACTERIZACIÓN DE OBJETOS
73
Considerando:
• El espacio de las señales de entrada como el conjunto de
puntos de la imagen:
V =S
ξ = (x , y ) ∈ S
• La función de densidad de probabilidad en función del
campo de potencial normalizado obtenido para cada uno
de los puntos de la imagen:
p (ξ ) = p (x , y ) = ψ T (x , y )
se realiza el aprendizaje de un gas neuronal, ya sea una Neural
Gas o una Growing Neural Gas, siguiendo el algoritmo general o
cualquiera de sus variantes expuestas en el Capítulo 2. De modo
que, realizando este proceso, se obtiene la red neuronal que
preserva la topología del objeto O a partir de una cierta
propiedad T del mismo. Es decir, a partir de la apariencia visual
AV del objeto se consigue una aproximación a su apariencia
geométrica AG .
De ahora en adelante, se denominará Grafo Preservador de la
Topología al grafo no dirigido GPT = A ,C , definido por un
conjunto de vértices (neuronas) A y un conjunto de aristas C
que los conectan, que preserva la topología de un objeto a partir
del campo de potencial normalizado considerado.
En la Figura 3.1 se muestra una descripción global del sistema
de obtención del GPT de un objeto a partir de una escena, donde
se observa que se pueden obtener GPT
para diferentes
propiedades T de los objetos sin modificar el algoritmo de
aprendizaje de los gases neuronales, ya que obteniendo ψ T (x , y )
distintas, se provocan adaptaciones de la red para cada uno de
estos campos de potencial normalizados (Figura 3.2).
CAPÍTULO 3
74
Imagen
Cálculo del campo
de potencial
normalizado
ψ T (x , y )
Aprendizaje del gas
neuronal
GPT
Figura 3.1. Descripción global del sistema de obtención del Grafo Preservador de
la Topología de un objeto.
Figura 3.2. Diferentes adaptaciones del gas neuronal a un mismo objeto.
REPRESENTACIÓN Y CARACTERIZACIÓN DE OBJETOS
75
3.2 APLICACIÓN AL ANÁLISIS
ANÁLISIS DE IMÁGENES
Tal y como se expresa en (González y Woods, 1996) la
representación de una región u objeto admite dos posibilidades:
en términos de sus características externas (contorno) o en
términos
de
sus
características
internas
(superficie).
Generalmente, se elige una representación externa cuando el
objetivo principal se centra en las características de la forma y
una representación interna cuando el principal interés se centra
en propiedades como el color, la textura,...
Una vez se extrae de la escena el objeto, el siguiente paso es el de
descripción o caracterización del mismo. Las características
extraídas deben ser, en la medida de lo posible, invariantes a
modificaciones de tamaño, traslación y rotación; de modo que se
pueda llevar a cabo una correcta clasificación o reconocimiento
de los mismos al realizar una comparación con modelos
almacenados en una base de conocimiento.
A continuación, se indica el empleo del aprendizaje de los GPT
para extraer y caracterizar tanto contornos como superficies, así
como posibles características que se pueden obtener del mismo
que permitan mejorar reconocimientos posteriores.
3.2.1 EXTRACCIÓN Y CARACTERIZACIÓN
CARACTERIZACIÓN DE CONTORNOS
Como se ha expresado anteriormente, una forma de representar
los objetos es mediante su contorno. El contorno de un objeto
puede ser obtenido mediante un GPT eligiendo de forma
adecuada la propiedad visual T para la que se obtendrá el
campo de potencial normalizado ψ T de la escena.
Tomando T = ∇ como la función gradiente, el campo de
potencial normalizado ψ ∇ indica, para cada uno de los puntos de
la imagen I , si pertenece o no al contorno del objeto (Figura
3.3b).
A partir de este campo de potencial, se extrae el Grafo
Preservador de la Topología GPT ∇ que se adapta al contorno del
objeto (Figura 3.3d). En ocasiones, cuando el contorno del objeto
posee zonas con una curvatura importante, se crean aristas entre
neuronas que no se encuentran próximas en el contorno (Figura
CAPÍTULO 3
76
3.3c). Este problema es sencillo de resolver, eliminando del
obtenido todos los ciclos indeseados que se produzcan.
(a)
(b)
(c)
(d)
Figura 3.3. Extracción del
GPT ∇
GPT del contorno de un objeto.
El modelo es capaz de extraer, asimismo, los diversos contornos
que pueda tener un objeto (Figura 3.4), debido a la capacidad de
división que poseen los gases neuronales.
Figura 3.4. Obtención de los diversos contornos de un objeto.
REPRESENTACIÓN Y CARACTERIZACIÓN DE OBJETOS
77
Aunque, este GPT ∇ podría ser utilizado como característica del
objeto, es usual en la literatura encontrar diferentes
características que son extraídas de los contornos para facilitar
clasificaciones o reconocimientos posteriores (Loncaric, 1998)
(Sonka et al., 1998) (González y Woods, 1996). Entre éstas se
pueden encontrar algunos descriptores simples como su longitud,
su diámetro, códigos de cadena, curvatura, firmas, momentos,...
DIÁMETRO
Dado un GPT ∇ del contorno del objeto O , se obtiene su diámetro
como la distancia máxima existente entre dos vértices (neuronas)
cualesquiera del mismo:
(
diámetro (GPT ∇ ) = max i , j ∈A w i − w j
)
(3.2)
Esta medida es invariante a traslación y rotación, aunque no lo
es al escalado.
A partir del diámetro, otra característica que se puede obtener es
la orientación del eje mayor del contorno, que es la línea que
conecta ambos vértices.
LONGITUD
Dado un GPT ∇ del contorno del objeto O , se obtiene su longitud
como la suma de la longitud de todas las aristas que forman
parte del mismo:
long (GPT ∇ ) =
∑ wi − w j
∀ (i , j )∈C
(3.3)
Esta característica es invariante a traslación y rotación, pero no
lo es al escalado de los objetos. Con el objetivo de hacer
invariante esta medida también al escalado se ha transformado la
expresión anterior, normalizando la longitud del contorno con
respecto a su diámetro:
CAPÍTULO 3
78
long _ norm (GPT ∇ ) =
long (GPT ∇ )
diámetro (GPT ∇ )
(3.4)
En la Tabla 3.1 se presentan los diámetros y longitudes obtenidos
a partir del GPT ∇ calculados para algunos de los objetos que
están siendo cuestión de estudio. Para comprobar la efectividad
de la longitud normalizada como medida invariante de la forma
de los objetos, se han realizado tres instancias, a distintos
tamaños, de cada uno de los espacios de entrada.
Objeto
Longitud
Diámetro
Longitud normalizada
Cuadrado
319 / 639 / 1280
112 / 225 / 452
2.83 / 2.84 / 2.83
Círculo
274 / 551 / 1100
89 / 179 / 358
3.06 / 3.06 / 3.07
Mano
660 / 1320 / 2647
136 / 272 / 546
4.85 / 4.85 / 4.84
Tabla 3.1. Longitud, diámetro y longitud normalizada de los contornos.
CURVATURA
Dado un GPT ∇ del contorno del objeto O , la curvatura viene
dada por el ritmo de variación de su pendiente. Como se observa
en la Figura 3.5 la caracterización mediante curvatura del
contorno de los objetos es bastante inestable, debido a que el
GPT ∇ realiza una aproximación mediante rectas del contorno;
sin embargo, esto puede ser resuelto mediante alguna técnica de
suavizado.
Para poder utilizar la curvatura como característica clasificadora,
se debe tomar un mismo punto de partida en todos los casos.
Para ello, por ejemplo, se puede comenzar el cálculo de la
curvatura en el punto (neurona) que se encuentra más alejado
del centro de masas del grafo.
El análisis de las curvaturas en los diferentes puntos del
contorno permite dos modos de simplificación del mismo:
• detección de las esquinas del objeto y conexión de éstas,
• detección de las aristas o segmentos rectos del objeto.
REPRESENTACIÓN Y CARACTERIZACIÓN DE OBJETOS
79
Figura 3.5. Curvaturas de los contornos.
OBTENCIÓN DE ESQUINAS
Las esquinas son extraídas a partir de la función de curvatura del
objeto, detectando aquellos nodos donde la curvatura supera un
cierto umbral. Estas neuronas determinan las esquinas del objeto
y, mediante su conexión, se realiza una simplificación del GPT ∇
(Figura 3.6).
OBTENCIÓN DE ARISTAS
La detección de aristas se consigue estudiando la curvatura
acumulada entre neuronas sucesivas, de modo que cuando se
supera una cierta curvatura umbral, la primera y última neurona
de dicha sucesión determinan los extremos de la arista. Esta
simplificación es dependiente del punto de inicio, por lo que se ha
empleado la neurona con mayor curvatura como partida en la
búsqueda de aristas.
CAPÍTULO 3
80
Figura 3.6. Simplificación del GPT∇ mediante la detección de esquinas.
Figura 3.7. Simplificación del GPT mediante la obtención de aristas.
FIRMA
Dado un GPT ∇ del contorno del objeto O , su firma puede ser
calculada como la distancia de cada uno de sus vértices al centro
del grafo. Al igual que en el caso del cálculo de la curvatura, se
debe comenzar desde un mismo punto de partida. Si, además la
distancia es dividida entre la máxima distancia de un nodo del
GPT ∇ al centroide, se obtiene una medida invariante a
traslación, rotación y escalado (Figura 3.8).
CÓDIGOS DE CADENA
Los códigos de cadena se emplean para representar un contorno
mediante una sucesión de segmentos de dirección especificada.
Usualmente, esta representación se basa en segmentos de
conectividad cuatro u ocho. En el caso de la Figura 3.9 se ha
empleado conectividad ocho. Esta característica también depende
del punto de partida, aunque existen diversos criterios para
normalizar la cadena resultante (González y Woods, 1996).
REPRESENTACIÓN Y CARACTERIZACIÓN DE OBJETOS
Figura 3.8. Firmas.
Figura 3.9. Códigos de cadena.
81
CAPÍTULO 3
82
MOMENTOS
Los momentos son uno de los métodos más utilizados para
caracterizar contornos. Son calculados a partir de una
representación unidimensional de los contornos, como pueden
ser las curvaturas o las firmas.
Si se considera v como la función unidimensional elegida, k el
número de nodos del GPT ∇ , se obtiene el momento n-ésimo de v
como:
k
µ n (v ) =
∑ (v i − m )n
(3.5)
i =1
k
donde
k
m=
∑v i
(3.6)
i =1
k
En la Tabla 3.2 se representan los momentos de los contornos
calculados a partir de las firmas no normalizadas de los objetos.
Objeto
m
µ2
µ3
µ4
Cuadrado
92.78 / 92.90
103.61 / 105.49
525.07 / 524.27
21101 / 22000
Círculo
86.79 / 86.79
4,73 / 2.76
-5.20 / 0.82
50.39 / 15.46
Mano
90.04 / 87.62
1319.42 / 1394.14
-10277 / -9561
4048945 / 4575068
Tabla 3.2. Momentos de los contornos.
3.2.2 EXTRACCIÓN Y CARACTERIZACIÓN
SUPERFICIES
ERFICIES
CARACTERIZACIÓN DE SUP
La extracción del Grafo Preservador de la Topología GPT de la
superficie de un objeto se puede obtener tomando como
propiedad T para construir el campo de potencial cualquier
REPRESENTACIÓN Y CARACTERIZACIÓN DE OBJETOS
83
característica interna del objeto, como puede ser su textura, su
nivel de gris, su color, su saturación,...; así como combinaciones
de éstas.
Como resultado del aprendizaje del gas neuronal de este campo
de potencial, se obtiene un GPT que realiza una esqueletización
del objeto deseado (Figura 3.10).
Figura 3.10. Grafos Preservadores de la Topología de diversos objetos
bidimensionales.
Del mismo modo que
diversos contornos de
diversas partes de un
escena que posean los
T (Figura 3.11).
el modelo es capaz de representar los
un objeto, es posible caracterizar las
objeto, o varios objetos presentes en la
mismos valores para la propiedad visual
Figura 3.11. Representación de varios objetos.
CAPÍTULO 3
84
Si bien el Grafo Preservador de la Topología GPT caracteriza el
objeto, el empleo de éste para el reconocimiento o clasificación de
los objetos viene limitado por restricciones temporales. Esto es
debido a que la comparación entre grafos o cliques es un
problema que se ha demostrado que es NP, pero se desconoce si
es P o NP-completo (Fortin, 1996). Es por esto, que, a
continuación se introducen diversos subgrafos del GPT que
reducen el tiempo de comparación de los mismos al tener un
menor número de aristas.
Asimismo, al igual que se ha realizado con los contornos, se
presentan diversas características que pueden ser obtenidas del
GPT del objeto. Hay bastante trabajo realizado en este sentido,
que puede ser aprovechado, dado que la representación
establecida por el grafo está muy relacionada con estructuras de
geometría computacional.
SUBGRAFOS DEL GPT
Tal y como se ha expresado en el punto 2.3.1, el GPT establece
una triangulación de Delaunay inducida de los vértices del grafo.
En (Fortune, 1997) (O’Rourke y Toussaint, 1997) se establece la
siguiente relación entre grafos:
NNG ⊆ MST ⊆ RNG ⊆ GG ⊆ DT
donde NNG es el grafo de vecinos más cercanos, MST es el
árbol de expansión mínimo, RNG es el grafo de vecindad relativa,
GG es el grafo Gabriel y DT es la triangulación de Delaunay
(Figura 3.12).
GRAFO GABRIEL
El Grafo Gabriel GG es un subgrafo de la triangulación de
Delaunay establecida por el Grafo Preservador de la Topología
GPT que:
• posee su mismo conjunto de vértices A,
• posee aquellas aristas
( p ,q ) ∈ C
que cumplen que
REPRESENTACIÓN Y CARACTERIZACIÓN DE OBJETOS
85
§ p + q δ (p ,q ) ·
B¨
,
¸ ∩C = φ
2 ¹
© 2
donde
(3.7)
B (x ,r ) es un círculo de centro x y radio r , y
2
δ (p , q ) = ∑ w pi − w qi
i =1
esto es, los puntos p y q definen el diámetro de un
círculo que no es cruzado por ninguna otra arista.
En (Mou y Yeung, 1994) se presenta una red neuronal autoorganizativa, denominada Red Gabriel, que modifica durante el
aprendizaje las conexiones entre las neuronas de modo que se
obtenga el grafo Gabriel de las mismas. Sin embargo, los
ejemplos presentados no son muy representativos y el coste
computacional es elevado.
GRAFO DE VECINDAD RELATIVA
El grafo de vecindad relativa RNG es un subgrafo de la
triangulación de Delaunay establecida por el Grafo Preservador
de la Topología GPT que:
• posee su mismo conjunto de vértices A,
• posee aquellas aristas (p ,q ) ∈ C que cumplen que
Λ p ,q ∩C = φ , donde Λ p ,q = B (p ,δ (p ,q )) ∩ B (q ,δ (p ,q )) es
una luna o intersección entre dos círculos; esto es, no
existe ningún punto z que esté más cercano a p que q ,
y no existe ningún punto z que esté más cercano a q
que p .
ÁRBOL DE EXPANSIÓN MÍNIMO
El árbol de expansión mínimo MST es un subgrafo de la
triangulación de Delaunay establecida por el Grafo Preservador
de la Topología GPT que:
• posee su mismo conjunto de vértices A,
CAPÍTULO 3
86
• posee aquellas aristas (p ,q ) ∈ C que forman un árbol de
longitud total mínima, de entre todos los posibles árboles
que se pueden formar a partir del grafo GPT .
GRAFO DE VECINOS MÁS CERCANOS
El grafo de vecinos más cercanos NNG es un subgrafo de la
triangulación de Delaunay establecida por el Grafo Preservador
de la Topología GPT que:
• posee su mismo conjunto de vértices A,
• posee aquellas aristas
B (p ,δ (p ,q )) ∩C = φ .
( p ,q ) ∈ C
Figura 3.12. Subgrafos del
que cumplen que
GPT.
CARACTERIZACIÓN DE L
LA
A TOPOLOGÍA DEL GPT
Dentro de este apartado se incluyen todas aquellas medidas que
pueden ser obtenidas de la propia topología del Grafo Preservador
de la Topología. Esta información aporta datos sobre las
REPRESENTACIÓN Y CARACTERIZACIÓN DE OBJETOS
87
características morfológicas de los objetos. Entre ellas, se pueden
obtener:
• Número de aristas: un mayor número de aristas sugiere
una forma del objeto más compacta, ya que existe una
mayor capacidad de conexión (Tabla 3.3).
• Histograma de vecindad: obtención del número de
neuronas que poseen cada una de las vecindades. En la
Figura 3.13 se observa que las figuras más compactas
poseen unas vecindades más altas. Por otro lado, si el
objeto posee esquinas (cuadrado) o zonas muy estrechas
(los dedos de la mano) se generan neuronas con baja
vecindad.
• Medidas estadísticas de las vecindades: datos como la
vecindad media, la mediana, la desviación típica,...
aporta información similar a la del histograma de
vecindades (Tabla 3.4).
• Medidas estadísticas de las longitudes de las aristas: la
presencia en un GPT de aristas de menor longitud
sugiere la presencia de más aristas y, por tanto, una
forma compacta (Tabla 3.3).
• Número y tipos de polígonos: aunque el GPT debería
realizar una triangulación del espacio de entrada, al
estar inducida por el objeto, provoca que algunas de las
aristas de la triangulación de Delaunay desaparezcan y,
por tanto, se presenten líneas, así como otros polígonos.
Objeto
Nº de
aristas
Longitud
Media
Mediana
Desviación
típica
Cuadrado
258 / 258
17.67 / 17.63
17.46 / 17.49
1.88 / 1.91
Círculo
256 / 257
16.71 / 16.77
16.76 / 17.03
2.02 / 2.06
Anillo
226 / 227
17.17 / 17.17
17.00 / 17.12
2.06 / 2.09
Mano
228 / 228
19.07 / 19.06
18.87 / 18.97
2.25 / 2.26
Tabla 3.3. Información extraída del número y longitud de las aristas.
CAPÍTULO 3
88
Figura 3.13. Histograma de vecindad.
Objeto
Nº de
vecindades
Vecindad
media
Mediana
Desviación
típica
Cuadrado
516 / 516
5.16 / 5.16
6/6
1.20 / 1.22
Círculo
512 / 514
5.12 / 5.14
6/6
1.25 / 1.30
Anillo
454 / 452
4.54 / 4.52
4/4
1.27 / 1.26
Mano
456 / 456
4.56 / 4.56
4/4
1.18 / 1.17
Tabla 3.4. Información extraída de las vecindades.
MOMENTOS
Al igual que en el caso de los contornos, el cálculo de los
momentos de una superficie es uno de los métodos más
utilizados para su caracterización.
Dado un
GPT se define su momento de orden (p + q ) como:
m pq =
para
p ,q = 0 ,1 ,2 ,...
∑x p y q
∀ (x , y )∈A
(3.8)
REPRESENTACIÓN Y CARACTERIZACIÓN DE OBJETOS
89
Sus momentos centrales pueden ser expresados como:
µ pq =
∑ (x − x ) p (y − y )q
∀(x , y )∈A
(3.9)
donde
x =
m 10
m
, y = 01
m 00
m 00
(3.10)
Finalmente, los momentos centrales normalizados se definen
como:
η pq =
µ pq
µ00γ
(3.11)
donde
γ =
para
p +q
+1
2
(3.12)
p + q = 2 ,3 ,...
A partir de estos momentos, se pueden obtener un conjunto de
siete momentos invariantes (Hu, 1962):
φ1 = η20 + η02
(3.13)
φ 2 = (η20 − η02 )2 + 4η112
(3.14)
φ 3 = (η30 + 3η12 )2 + (3η21 − η03 )2
(3.15)
φ 4 = (η30 + η12 )2 + (η21 + η03 )2
(3.16)
CAPÍTULO 3
90
[ η30 + η12 )2 − 3 (η21 + η03 )2 ]+
φ 5 = (η30 − 3η12 )(η30 + η12 )(
[
+ (3η21 − η03 )(η21 + η03 ) 3 (η30 + η12 )2 − (η21 + η03 )2
]
φ6 = (η20 − η02 ) + [(η30 + η12 )2 − (η21 + η03 )2 ]+
+ 4η11 (η30 + η12 )(η21 + η03 )
[ η30 + η12 )2 − 3 (η21 + η03 )2 ]+
φ7 = (3η21 − η30 )(η30 + η12 )(
[
+ (3η12 − η30 )(η21 + η03 ) 3 (η30 + η12 )2 − (η21 + η03 )2
]
(3.17)
(3.18)
(3.19)
Estos momentos obtenidos a partir de los GPT son válidos para
la clasificación y reconocimiento de los objetos (Tabla 3.5).
Cuadrado
Círculo
Anillo
Mano
η 20
23.18 / 23.44
20.71 / 20.89
38.13 / 37.95
45.72 / 45.45
η02
21.70 / 21.32
18.35 / 18.64
36.24 / 36.33
23.92 / 23.98
η11
-0.12 / 0.13
0.22 / -0.26
0.01 / -0.05
1.23 / 1.58
η 30
-0.32 / -0.45
-0.75 / -0.15
-0.81 / 3.60
21.21 / 18.62
η12
-0.08 / -1.42
0.11 / 0.32
1.08 / 3.12
47.06 / 46.21
η21
-0.80 / 0.30
0.32 / 0.66
-0.34 / -0.42
-15.29 / -15.41
η03
0.94 / 1.02
1.15 / -0.30
-4.12 / -7.59
7.96 / 9.93
φ1
44.88 / 44.76
39.07 / 39. 53
74.37 / 74.29
69.63 / 69.43
φ2
2.26 / 4.56
5.77 / 5.35
3.59 / 2.61
481.66 / 471.06
φ3
2.42 / 25.86
4.64 / 3.44
32.32 / 246.48
27807 / 26042
φ4
0.18 / 5.24
2.57 / 0.15
19.98 / 109.40
4714.47 / 4232.51
φ5
-0.22 / 11.45
-4.00 / 0.04
337.05 / 2087.62
-31364862 / -28128226
φ6
0.23 / 2.36
-4.98 / -0.28
-37.62 / -20.84
97994 / 87341
φ7
0.09 / -39.30
5.15 / -0.13
358.62 / 1523.76
-32844276 / -25550254
Tabla 3.5. Momentos del
GPT.
REPRESENTACIÓN Y CARACTERIZACIÓN DE OBJETOS
91
EXTRACCIÓN DEL CONTORNO
CONTORNO DEL GPT
Dado un GPT de un objeto, se define su contorno como el
conjunto de aristas que pertenecen únicamente a un polígono.
Resultados de la aplicación de esta operación a varios objetos se
presentan en la Figura 3.14.
Figura 3.14. Contorno del
GPT.
ESQUELETIZACIÓN (EJE MEDIO
MEDIO)
Tal y como se ha explicado anteriormente el GPT establece una
esqueletización del objeto. Sin embargo, la representación del
objeto mediante un esqueleto más ampliamente utilizada es la
obtenida a partir de la transformada del eje medio, mucho más
simple que el resultado obtenido en este trabajo. Este esqueleto
viene definido por aquellos centros de círculos inscritos en el
objeto que no están incluidos completamente en otro círculo. El
resultado final presenta una figura estilizada del objeto.
Dado el gran número de trabajos que emplean la transformada
del eje medio, se ha planteado la obtención del eje medio del
objeto a partir de su GPT . Para ello, se calcula el diagrama de
Voronoi de las aristas que forman el contorno del grafo (Figura
3.15). Mediante la unión de aquellos puntos que son frontera
para tres o más regiones de Voronoi se obtiene el esqueleto del
objeto (Figura 3.16).
De igual modo, se puede operar con el
contorno del objeto.
GPT ∇ obtenido a partir del
CAPÍTULO 3
92
Figura 3.15. Diagrama de Voronoi del contorno del
GPT.
Figura 3.16. Esqueletos.
3.3 APLICACIÓN
PLICACIÓN A LA SÍNTESIS DE IMÁGENES
La capacidad de compresión de información de las redes
neuronales auto-organizativas se ve claramente demostrada en
este trabajo. La representación de un objeto bidimensional
mediante un GPT
extrae la información topológica más
importante para realizar el análisis de la forma del objeto.
REPRESENTACIÓN Y CARACTERIZACIÓN DE OBJETOS
93
En este punto, se plantea el problema inverso: ¿cómo generar la
forma del objeto a partir de su GPT ? Es decir, cómo aplicar este
trabajo a la síntesis de objetos.
Para ello, se procede siguiendo dos alternativas, dependiendo de
la información disponible en el momento de realizar la síntesis:
• Si en el momento de la adaptación del GPT se guarda
información asociada a cada neurona, relativa a la
distancia r al punto del contorno del objeto más cercano
a la misma; se procede a dibujar para cada una de las
neuronas un círculo con radio r .
• Si únicamente se dispone del GPT , sin información
adicional, se procede a dibujar círculos con centro en
cada una de las neuronas y con un radio r que está en
función del conjunto de aristas que salen de cada una de
ellas:
ri =
∑ wi −w j
∀j ∈N i
card (N i )
2
(3.20)
Asimismo, si se guarda información de la intensidad o color del
punto de la imagen que corresponde a cada una de las neuronas,
se puede dotar a cada uno de los círculos de dicho tono, de modo
que la síntesis posea la misma apariencia visual que el objeto real
(Figura 3.17). Para mejorar la calidad de la síntesis, eliminando el
efecto del dibujo de múltiples círculos, se realiza un filtrado
(mediana, erosión / dilatación,...).
Por supuesto, existen técnicas más complejas de sintetización de
objetos y de coloreado de los mismos, que podrían ser empleados;
las cuales se han dejado para trabajos posteriores.
CAPÍTULO 3
94
Figura 3.17. Síntesis a partir de un
GPT.
3.4 EJEMPLO DE APLICACIÓN: CLASIFICACIÓN DE
OBJETOS
En este punto, se aplica el modelo a la clasificación de objetos
según su estructura externa. Para ello, se realiza la adaptación
de una Growing Neural Gas al contorno de los objetos,
obteniendo una caracterización de su forma.
Se ha empleado una base de datos de 1100 imágenes de
contornos de peces utilizada en trabajos relacionados con la
REPRESENTACIÓN Y CARACTERIZACIÓN DE OBJETOS
95
búsqueda de similitud entre formas (Mokhtarian et al., 1996)
(Veltkamp y Hagedoorn, 1999). Cada uno de los ficheros contiene
un objeto representado por un número variable (entre 400 y
1600) de coordenadas x e y.
3.4.1 DESCRIPCIÓN GLOBAL DEL
DEL SISTEMA
El procedimiento a seguir es similar al presentado al inicio de
este capítulo. En primer lugar, se debe extraer el campo de
potencial normalizado ψ ∇ , es decir, la probabilidad de cada uno
de los puntos de pertenecer al contorno del objeto. Sin embargo,
este paso no es necesario en esta aplicación, ya que la base de
datos provee ya los contornos.
A continuación se procede a extraer el grafo preservador de la
topología del contorno del objeto, mediante la adaptación del gas
neuronal, en este caso una Growing Neural Gas.
Con esta estructura se puede actuar de dos modos: empleando el
propio grafo preservador de la topología como entrada al
clasificador, o extrayendo un vector de características a partir del
mismo (Figura 3.18). En este apartado, se abordarán ambas
posibilidades.
Imagen
Extracción del
contorno
ψ∇
Cálculo del Grafo
Preservador de la
Topología
GPT
Clasificación
Clase
GPT
Extracción de
características
Vector de
características
Clasificación
Clase
Figura 3.18. Sistema de clasificación de formas.
CAPÍTULO 3
96
La clasificación se va a realizar, igualmente, con una Growing
Neural Gas, pero en este caso con su empleo usual como
clasificadora de patrones.
3.4.2 OBTENCIÓN DEL GPT DEL CONTORNO
A partir del campo de potencial normalizado se realiza el
aprendizaje de la Growing Neural Gas, siguiendo el algoritmo del
punto 2.2.2 con ε 1 = 0.1 , ε 2 = 0.01 , λ = 10000 , α = 0 , β = 0 . En
este caso en particular, se educa la red con la condición de que
finalice la adaptación cuando posea 100 neuronas.
Debido a la complejidad de algunos de los contornos se producen
aristas indeseadas, que deben ser eliminadas para obtener una
representación adecuada (Figura 3.19). Para ello, se localiza un
ciclo que posea tantas aristas como neuronas posee la red. Se ha
observado que esta operación es muy costosa en determinados
casos, por lo que se está buscando algún tipo de solución, alguna
de las cuales se presenta en el capítulo de “Líneas de
continuación”.
Figura 3.19. Obtención y simplificación del grafo del contorno.
REPRESENTACIÓN Y CARACTERIZACIÓN DE OBJETOS
97
3.4.3 CLASIFICACIÓN DE CONTO
CONTORNOS A PARTIR DEL GPT
En este caso, la red neuronal clasificadora, una Growing Neural
Gas, tiene como entrada un grafo preservador de la topología, que
es, asimismo, otra Growing Neural Gas. Esta es una situación
que no se suele dar en la literatura, en la que la entrada a una
red neuronal sea otra red neuronal. Por ello, se debería continuar
con esta línea de trabajo para extraer posibles conclusiones que
llevaran al desarrollo de nuevos modelos.
El grafo obtenido en el paso previo es normalizado a traslación,
orientación y escalado, del siguiente modo:
• se obtiene su centro de masas situándolo en el origen de
coordenadas,
• se localiza la neurona más alejada al centroide, rotando
todo el grafo para situarla en la horizontal,
• se inscribe el contorno en un círculo de radio estándar
Se realiza el aprendizaje de la red clasificadora, que posee 200
neuronas, empleando los mismos parámetros que para la
extracción del contorno, con los 1100 GPT normalizados
obtenidos de los respectivos contornos; de modo que, finalmente,
cada una de las neuronas posee como vector de referencia el
contorno determinado por un GPT .
Una vez completado el aprendizaje de la red, se realiza un ciclo de
etiquetado, asociando cada uno de los patrones de entrada con la
neurona cuyo contorno es más similar.
En la Figura 3.20 se muestra el resultado de la clasificación de
diversos peces según este método: en la parte superior se
muestra los GPT
representantes de algunas neuronas,
asociando a éste diversos peces para los que dicha neurona es la
más cercana.
CAPÍTULO 3
98
Figura 3.20. Clasificación de los objetos a partir del
GPT.
3.4.4 CLASIFICACIÓN DE CONT
CONTORNOS
ORNOS A PARTIR DE
CARACTERÍSTICAS EXTRAÍDAS
EXTRAÍDAS DEL
GPT
La segunda alternativa en el empleo del GPT
como
caracterizador del contorno de los objetos, es la extracción de un
vector de características a partir del mismo, que reduzca la
dimensionalidad de los patrones de entrada y mejore la
caracterización. En este caso, se han probado dos de los métodos
presentados previamente: los análisis de firmas normalizadas y
de curvaturas. En ninguno de estos casos es necesario realizar
un proceso de transformación del GPT
original para
normalizarlo.
El tamaño de estos vectores de características es igual al número
de neuronas del GPT . En ambos casos, se observa que tras
realizar el aprendizaje de la red clasificadora, se obtienen como
vectores de referencia, funciones suavizadas de las firmas y
curvaturas (Figuras 3.21 y 3.22). En el primer caso no es un
problema, pero sí que se han encontrado dificultades en el caso
del análisis de curvaturas ya que las funciones son mucho más
REPRESENTACIÓN Y CARACTERIZACIÓN DE OBJETOS
99
fluctuantes entre valores positivos y negativos. Esto produce que
el suavizado lleve la mayor parte de los valores de las curvaturas
a cero. Sin embargo, los valores significativos (picos o valles) de la
función permiten realizar una correcta clasificación de los peces.
3.5 CONCLUSIONES
En este capítulo se ha demostrado la capacidad de
representación de objetos bidimensionales, mediante un gas
neuronal. Estableciendo una función de transformación
adecuada, el modelo es capaz de adaptarse tanto a las
características internas como externas del objeto, obteniendo lo
que se ha denominado Grafo Preservador de la Topología.
El modelo, por su propio método de adaptación, es capaz de
dividirse de modo que pueda extraer los múltiples contornos que
puede tener un objeto, así como caracterizar las diferentes partes
en las que pueda estar fragmentado.
Con el objetivo de facilitar y acelerar tareas de más alto nivel,
como clasificaciones y reconocimientos, se extraen características
de este grafo, como momentos, esqueletos, firmas,...
No sólo se obtienen resultados prometedores en el análisis de
objetos, sino que su aplicación a la síntesis de objetos ha sido
también satisfactoria. La triangulación de Delaunay establecida
por el modelo, permite una compresión de la información de la
morfología, a partir de la cual se consigue sintetizar
correctamente el objeto.
Para finalizar, se ha mostrado la capacidad de representación de
la forma de los objetos que posee el modelo. Para ello, se ha
extraído el contorno de los objetos mediante un GPT ,
empleándolo para la clasificación de los mismos. Se han
presentado dos posibles alternativas: la primera de ellas
novedosa, en cuanto a que el vector de características y el
clasificador son redes neuronales auto-organizativas del mismo
tipo; la segunda de ellas, usual, en la que se extraen
características del contorno, construyendo un vector que sirve de
entrada a la red clasificadora.
CAPÍTULO 3
100
Figura 3.21. Clasificación de los objetos según su firma.
REPRESENTACIÓN Y CARACTERIZACIÓN DE OBJETOS
Figura 3.22. Clasificación de los objetos según su curvatura.
101
Capítulo 4
SEGUIMIENTO DE OBJETOS
OBJETOS Y
ANÁLISIS DEL MOVIMIENTO
MOVIMIENTO
En este capítulo se extiende el empleo de los gases neuronales al
tratamiento de secuencias de imágenes, en particular para
resolver los problemas de seguimiento de objetos y análisis de su
movimiento. Aprovechando el carácter dinámico de las redes
neuronales auto-organizativas, que permite aprender nuevos
patrones de entrada sin tener que reiniciar el aprendizaje, se va a
modelar el movimiento de los objetos a partir de los cambios que
se producen en la red de interconexión entre los diferentes
elementos de procesamiento.
Haciendo uso de este modelo de representación, se plantea el
problema del reconocimiento de gestos de la mano. Este se
resuelve adaptando la red neuronal a la forma de la mano en
cada instante, y readaptándola para cada una de las posturas de
un gesto.
El proceso de seguimiento de objetos y análisis del movimiento
incorpora operaciones a varios niveles de procesamiento, tal y
como se muestra en la Figura 4.1.
CAPÍTULO 4
104
Imágenes
Segmentación
Extracción de
características
Análisis del
movimiento
Seguimiento
Operaciones de alto nivel
(estructura a partir del
movimiento, tiempo para
colisión,...)
Figura 4.1. Etapas del problema del análisis del movimiento.
4.1 SEGUIMIENTO DE OBJETOS
OBJETOS
El seguimiento de un objeto consiste en calcular la posición y
forma del mismo en cada una de las imágenes de una secuencia.
Como el problema general es muy complicado, se abordan
simplificaciones realistas o adecuadas a problemas concretos.
Para el movimiento elástico, en particular, se suelen tomar
algunas asunciones sobre la dinámica de los objetos (Sonka et
al., 1998):
• Velocidad restringida: si se asume que el objeto en
movimiento es muestreado a intervalos de tiempo dt , el
objeto se encontrará situado dentro de un círculo con
centro en su posición anterior y radio c max dt , donde
c max es la máxima velocidad que puede tomar el objeto.
• Aceleración pequeña: el cambio en la velocidad en un
tiempo dt está limitado.
• Movimiento común: todos los puntos del objeto se
mueven de forma similar.
Con estas consideraciones, se establece el movimiento de un
objeto como las variaciones que realiza un objeto, tanto en
posición como en forma, durante un periodo de tiempo:
[
]
M = [O (t )], t ∈ t 0 ,t f
(4.1)
con sus correspondientes apariencias geométricas y visuales
[
]
O (t ) = AG (t ), AV (t )
(4.2)
SEGUIMIENTO DE OBJETOS Y ANÁLISIS DEL MOVIMIENTO
105
Esto significa que el objeto puede variar su apariencia visual, por
ejemplo si se presentan cambios en la iluminación, por lo que la
arquitectura representativa debe ser capaz de soportar estas
variaciones.
El seguimiento de un objeto puede realizarse mediante la
obtención del Grafo Preservador de la Topología del objeto en
cada una de las imágenes, y para ello, se deberán tener en cuenta
las posibles modificaciones en la apariencia visual del objeto.
Siguiendo el esquema de aprendizaje de la morfología de un
objeto propuesta en el capítulo 3, el proceso de seguimiento
consta de las siguientes fases:
• cálculo de la función de transformación
• predicción de la nueva posición del
• readaptación del
ψT
,
GPT ,
GPT .
4.1.1 CÁLCULO DE LA FUNCIÓN DE TRANSFORMACIÓN
Dado que la apariencia visual del objeto puede variar con el
tiempo, es necesaria la modificación de la función de
transformación ψ T en cada instante, para realizar una correcta
segmentación del objeto a lo largo de toda la secuencia.
Para ello, se actualiza en cada una de las imágenes los valores de
la propiedad T que posee el objeto. Se extraen dichos valores de
las posiciones que poseen los nodos del GPT para la imagen
anterior:
ψ T (x , y ,t ) = f T (I (x , y ,t ),GPT (t − 1 ))
(4.3)
Por ejemplo, si la propiedad visual T es el nivel de gris, y la
función que segmenta el objeto f T es una umbralización, ésta
puede variar para cada una de las imágenes; calculando el nuevo
umbral a partir de los valores I (w i ) , para todos los nodos i del
GPT previo.
106
CAPÍTULO 4
De modo, que se varía de forma dinámica la función de
transformación que calcula la probabilidad de cada uno de los
puntos de pertenecer al objeto.
4.1.2 OBTENCIÓN
BTENCIÓN DEL GPT
Como resultado del paso anterior, a partir de una imagen I (t ) , se
calcula la correspondiente transformación ψ T (t ) . A partir de
ésta, se obtiene la representación del objeto, mediante la
adaptación del GPT .
Para el instante inicial t i se obtiene el GPT correspondiente de
forma directa. Sin embargo, dadas las características dinámicas
de las redes neuronales auto-organizativas, para las imágenes
posteriores, en lugar de partir de cero en el aprendizaje, se toma
la red previa como punto de inicio. Esto provoca que con una sola
iteración del mapa se consiga su readaptación a la nueva
posición del objeto.
PREDICCIÓN DE LA NUEVA
NUEVA POSICIÓN DEL GPT
Sin embargo, tal y como está presente en la mayor parte de
trabajos relacionados con seguimiento de objetos, es necesario
predecir la posición del nuevo mapa, previamente a esta
adaptación. Ese proceso facilita el aprendizaje ya que se realiza
una seudo-adaptación considerando los movimientos que están
desarrollando los diversos elementos de procesamiento.
Por ejemplo, en la Figura 4.2 se muestra el estado de un GPT
antes de realizar una predicción. Partiendo desde la
representación de la instancia previa del objeto, su readaptación
no será correcta, ya que es complicado que las neuronas vuelvan
a situarse en el dedo correspondiente. Más bien, se intentarán
readaptar de modo que, tras varias iteraciones, se obtenga una
nueva representación del objeto, sin que tenga relación la
posición que ocupa una neurona con la posición que ocupaba
previamente.
SEGUIMIENTO DE OBJETOS Y ANÁLISIS DEL MOVIMIENTO
Figura 4.2. Posición del
107
GPT antes de la predicción.
Existen diferentes mecanismos de predicción. Si la frecuencia de
muestreo de imágenes es alta en relación con la velocidad del
objeto, puede bastar una simple extrapolación, basada en las
posiciones previas de cada una de las neuronas
w ipred (t ) = 2 w i (t − 1 ) − w i (t − 2 )
Si se desea contar con un histórico de tres
siguiente expresión:
(4.4)
GPT se emplea la
w ipred (t ) = a + b + c
(4.5)
donde
a 0.5
b = − 1.5
c 1
−1
2
0
0.5 w i (t − 1 )
− 0.5 ⋅ w i (t − 2 )
0 w i (t − 3 )
(4.6)
READAPTACIÓN DEL GPT
pred
A partir del GPT
, se realiza el proceso de adaptación de la red
para la nueva posición y forma del objeto. El resultado final es
pred
función de la transformación ψ T (t ) y de GPT
(t ) .
La
proximidad
de
la
predicción
realizada
al
GPT
correspondiente, provoca, en muchos casos, que sea necesaria
una sola ejecución del bucle principal del algoritmo de
aprendizaje del gas neuronal para completar la readaptación.
CAPÍTULO 4
108
De este modo, la segmentación, representación y seguimiento del
objeto, se realiza en una única operación de adaptación del grafo.
4.2 ANÁLISIS DEL MOVIMIENTO
MOVIMIENTO
El análisis del movimiento comprende el
variaciones en posición y forma de los objetos.
estudio
de
las
El análisis del movimiento que realiza un objeto se aborda,
generalmente, mediante dos técnicas:
• Basado en el reconocimiento: donde el objeto es
reconocido en cada una de las imágenes de la secuencia.
De modo, que el movimiento viene determinado por las
diversas instancias que toma el objeto a lo largo del
tiempo.
• Basado en el movimiento: el análisis viene dado por las
trayectorias que toman determinados puntos del objeto.
Esta solución es menos costosa ya que se evita el
reconocimiento del objeto en cada imagen.
La arquitectura desarrollada basada en la adaptación dinámica
de GPT permite ambos modos de análisis.
El objeto puede ser reconocido a partir de su GPT . En el capítulo
3 se han introducido varias características que permiten
identificar las diferentes instancias de un objeto, de modo que se
pueda construir una cadena de formas y posiciones del mismo
para identificar el movimiento realizado.
Más interesante desde el punto de vista computacional, el modelo
aporta una herramienta de análisis basado en el movimiento muy
potente, ya que se evita el problema de correspondencia para
construir la trayectoria de los puntos de interés. Análogamente a
cuando se trabaja con marcadores, la determinación de las
trayectorias es inmediata, ya que únicamente hay que realizar un
seguimiento a los diferentes nodos del GPT .
SEGUIMIENTO DE OBJETOS Y ANÁLISIS DEL MOVIMIENTO
109
4.2.1 OBTENCIÓN DE LAS TRAY
TRAYECTORIAS
ECTORIAS
El movimiento de un objeto se interpreta como las trayectorias
seguidas por cada una de las neuronas del GPT :
M = [Tray i ], ∀i ∈ A
(4.7)
donde la trayectoria viene determinada por la sucesión de
posiciones de cada una de las neuronas a lo largo del mapa:
{
Tray i = w i t0 ,...,w i t f
}
(4.8)
El empleo de trayectorias directamente no suele proveer
información suficiente para abordar el reconocimiento del
movimiento, por lo que se acostumbra a realizar una
parametrización de las mismas.
En (Cédras y Shah, 1995) se presentan algunas propuestas de
parametrización. Una de las más utilizadas es el cálculo de sus
velocidades v x y v y , calculadas como:
v xt =
w x t − w x t −1
v yt =
∆t
w y t − w y t −1
∆t
(4.9)
Estas velocidades son invariantes a traslación, pero no a rotación
o escalado. Por otro lado, la velocidad y la dirección del
movimiento se determinan como:
vt =
(w
xt
− w x t −1
) + (w
2
yt
− w yt −1
w y − w y t −1
d t = arc tan t
wx −wx
t −1
t
)
2
(4.10)
(4.11)
Estas dos medidas son invariantes a traslación y rotación.
Además, la dirección es invariante a escalado. Sin embargo, es
muy sensible al ruido, debido al cálculo del arco tangente.
CAPÍTULO 4
110
Otra representación usual de las trayectorias es la curvatura
espacio-temporal κ , calculada como:
κ=
((w
A2 + B2 +C 2
) + (w 'y )2 + (t ' )2 ) 2
(4.12)
3
' 2
x
donde
A=
w 'y
t'
w 'y'
t ''
A=
t'
w 'x
t ''
w 'x'
A=
w 'x
w 'y
w 'x'
w 'y'
Normalmente, se emplea una discretización para calcular las
''
'
'
'
derivadas, por ejemplo, w x = w x − w x
y wx = wx −wx ,
t
t
t −1
t'
t
' ' t −1
asumiendo que ∆t es constante y, por tanto, t = 1 y t = 0 .
Esta representación tiene la ventaja que captura toda la
información sobre la trayectoria, sin necesitar dos medidas como
en los casos anteriores.
4.2.2 DESCOMPOSICIÓN DEL MO
MOVIMIENTO
VIMIENTO
El movimiento absoluto del objeto presenta dos componentes
(Allmen, 1991):
M = MC + MR
(4.13)
definidos como:
• Movimiento común: definido como el movimiento que
realiza el conjunto del objeto con respecto al observador,
de modo que todos sus elementos comparten dicho
movimiento. Principalmente determina traslaciones,
escalados y rotaciones del objeto.
• Movimiento relativo: definido como el movimiento de
cada uno de los elementos del objeto con respecto a los
otros. Este determina los cambios morfológicos del
objeto.
SEGUIMIENTO DE OBJETOS Y ANÁLISIS DEL MOVIMIENTO
111
En nuestro caso, el movimiento común va a considerarse como la
trayectoria que sigue el centroide del GPT :
{
M C = Tray c m = c mt ,...,c mt
0
f
}
(4.14)
Por otro lado, el movimiento relativo va a venir determinado por
los cambios de posición de cada una de las neuronas con
respecto a dicho centroide:
[
]
M R = Tray ic m , ∀i ∈ A
donde
{
Tray icm = w it − c mt ,...,w i t f − c mt
0
0
(4.15)
f
}
(4.16)
4.3 EJEMPLO DE APLICACIÓN: RECONOCIMIENTO DE
GESTOS
Para mostrar la potencia del modelo desarrollado, se va a tratar el
problema del reconocimiento de gestos de la mano. Esta es una
de las áreas donde más trabajo se está realizando como
aplicación del análisis del movimiento. Este es un problema
bastante completo dentro del movimiento no-rígido, siendo
además una de las más interesantes de resolver, debido a la
complejidad morfológica de la mano. El elevado número de grados
de libertad de la mano y los dedos (Figura 4.3) produce multitud
de posibles posiciones del objeto (mano) así como de oclusiones,
que dificultan considerablemente su seguimiento.
4.3.1 INTRODUCCIÓN
Si bien la comunicación oral puede considerarse como la más
importante, los gestos introducen una información adicional que
es muy importante para la expresión y comprensión humana. En
el caso de ausencia de voz, los gestos adquieren capital
importancia. Aunque los gestos son expresados con todo el
cuerpo, la mayoría de ellos están relacionados con la mano. Nos
comunicamos mediante gestos de la mano.
CAPÍTULO 4
112
Figura 4.3. Grados de libertad de la mano (Dorner, 1994).
Los movimientos de la mano tienen diferentes funciones (Cadoz,
1994):
• Semiótica: para comunicar información con significado.
En este caso los gestos están íntimamente relacionados
con el habla
• Ergótica: asociada con la noción de trabajo y la
capacidad de los humanos de manipular el mundo físico
con el objetivo de satisfacer determinadas necesidades.
Se incluyen operaciones para empujar, agarrar o soltar
objetos
• Epistémica: que permite a los humanos aprender del
entorno mediante la experiencia o exploración táctil
En este caso se centra la atención en la vertiente semiótica de los
gestos de la mano. Dentro del carácter lingüístico de éstos se
pueden destacar dos aspectos (McNeill, 1996): gesticulación y
lenguaje de signos.
SEGUIMIENTO DE OBJETOS Y ANÁLISIS DEL MOVIMIENTO
113
La gesticulación no puede ser considerada como “lenguaje” del
cuerpo, sino que complementa la comunicación oral. En el
lenguaje de signos cada uno de los gestos corresponde a un
concepto, aunque no tenga necesariamente una equivalencia con
palabras del lenguaje hablado. Ejemplos de lenguajes de signos
son el Lenguaje de Signos Americano (ASL) y el lenguaje de los
sordomudos.
Quek (1994) describe diferentes características de los gestos:
1. Los gestos están contenidos en movimientos que
comienzan desde una posición de descanso, continúan
con una fase de aumento sustancial de velocidad y que
finalizan volviendo a una posición de descanso.
2. La mano asume una configuración particular durante el
movimiento.
3. Lentos movimientos entre posiciones de descanso no son
gestos.
4. Los gestos de la mano deben estar limitados a un cierto
área del espacio.
5. Los gestos estáticos de la mano requieren un periodo
finito de tiempo para ser reconocidos.
6. Movimientos repetitivos de la mano pueden ser gestos.
Todo esto lleva a considerar (Huang y Pavlovic, 1995) los gestos
de la mano como:
• gestos estáticos: caracterizados por la postura que está
determinada por una configuración y orientación
particular de los dedos y la palma de la mano,
• gestos dinámicos: caracterizados por la configuración de
la mano en las posiciones inicial y final de descanso y
por su movimiento.
114
CAPÍTULO 4
4.3.2 TRABAJOS PREVIOS
Existen diferentes mecanismos para capturar elementos
importantes de la mano, pudiendo dividirlos en dos grandes
grupos: sistemas basados en visión y dispositivos mecánicos. No
hay ningún sistema que aporte todas las características deseadas
para la captura de información de la posición, postura y
movimiento de la mano, algunos son caros, otros molestos, otros
ambiguos en sus lecturas... Los sistemas basados en visión
tienen la ventaja de que no requieren que el usuario porte nada
sobre su cuerpo, pero tienen el problema de las oclusiones y de
los diferentes grados de iluminación. Por otro lado, los
dispositivos mecánicos no poseen estos inconvenientes pero son
molestos de usar. Los usuarios preferirán un sistema al cual no
tengan que prestar atención y que no les limite en su trabajo o
movimientos habituales.
Existen multitud de dispositivos mecánicos (Sturman, 1991) para
la extracción de la postura de la mano, algunos de los cuales
también permiten recuperar la posición y orientación de la
misma. Se han diseñado multitud de guantes con transductores
que determinan la posición de los dedos.
ANÁLISIS BASADO EN VI
VISIÓN
SIÓN
La generación de trayectorias de movimiento a partir de una
secuencia de imágenes implica, normalmente, la detección de
elementos en cada imagen, y la correspondencia de cada uno de
esos elementos de una imagen en la siguiente. Estos elementos
deben ser suficientemente diferenciables para su detección fácil y
deben ser estables en el tiempo para que puedan ser
correctamente seguidos. Podemos encontrarnos diferentes tipos
de elementos: aristas, esquinas, puntos de interés (Figura 4.4),
centroides, regiones...
Sin embargo, estos métodos conllevan la solución de varios
problemas complejos: segmentación de la mano en un entorno
complejo, seguimiento de la posición de la mano, reconocimiento
de las posturas de la mano y análisis del movimiento.
SEGUIMIENTO DE OBJETOS Y ANÁLISIS DEL MOVIMIENTO
115
Figura 4.4. Localizaciones típicas de los puntos de interés de la mano
(Sturman, 1991).
Para evitar el problema de segmentación, muchos de los sistemas
desarrollados emplean marcadores o guantes coloreados para
localizar fácilmente los puntos de interés. En otros casos, los
gestos son realizados frente un fondo homogéneo para extraer la
mano con una simple umbralización.
El resto de problemas son solucionados limitando el tamaño del
vocabulario de gestos a reconocer e, incluso, reconociendo
únicamente posturas estáticas de la mano.
Los sistemas de reconocimiento de gestos pueden ser clasificados
según la técnica empleada para la extracción y seguimiento de la
mano: análisis basados en modelos de la mano (Rehg y Kanade,
1993) (Shimada et al., 1998), análisis usando marcadores (Davis
y Shah, 1993) o guantes coloreados (Dorner, 1994), y análisis
basados en propiedades de la imagen (Starner y Pentland, 1995)
(Starner et al., 1998) (Campbell et al., 1996) (Triesch y von der
Malsburg, 1996). Relaciones más amplias de trabajos en este
campo se presentan en (Huang y Pavlovic, 1995) (Kohler y
Schröter, 1998).
CAPÍTULO 4
116
4.3.3 DESCRIPCIÓN GLOBAL DE
DEL
L SISTEMA PROPUESTO
Se propone un sistema de reconocimiento de gestos que emplea
una Growing Neural Gas para caracterizar la postura de la mano.
El gesto, determinado por las sucesivas posturas, es extraído a
partir de las trayectorias que siguen cada uno de los nodos.
Para reconocer el gesto, se realiza una normalización del GPT
para hacerlo invariante a traslación y escalado. Por otro lado, se
normalizan las trayectorias seguidas por los nodos para hacerlas
invariantes a rotaciones.
El esquema del sistema completo se muestra en la Figura 4.5.
CARACTERIZACIÓN DE LAS POSTURAS
Obtención del
Imágenes
de la mano
GPT
Normalización
a traslación y
escalado
CARACTERIZACIÓN DEL GESTO
Obtención de
las trayectorias
de los nodos
Normalización
a rotación
RECONOCIMIENTO DEL GESTO
Gesto
Reconocimiento
del gesto
Figura 4.5. Sistema de reconocimiento de gestos.
4.3.4 CARACTERIZACIÓN DE LA POSTURA DE LA MANO CON
UNA GNG
OBTENCIÓN DE LA GNG DE LA MANO
Dada una imagen I ∈ R
de la mano, se realiza la
transformación ψ T (x , y ) = T (I (x , y )) que asocia a cada uno de
2
SEGUIMIENTO DE OBJETOS Y ANÁLISIS DEL MOVIMIENTO
117
los puntos de la imagen su probabilidad de pertenecer a la mano,
según una propiedad T .
De modo que considerando ξ = (x , y ) y P ( ξ ) = ψ T (ξ ) , se aplica
el algoritmo de aprendizaje de la GNG a la imagen I , de modo
que la red adapta su topología, dando como resultado una
esqueletización de la mano.
Diversos resultados de la aplicación del algoritmo de aprendizaje
a varias posturas de la mano se presentan en la Figura 4.6.
Figura 4.6. Adaptación de la Growing Neural Gas a diferentes posturas de la
mano.
NORMALIZACIÓN DE LA GNG
Con el propósito de normalizar la red neuronal obtenida, se
realiza una transformación de la GNG para hacerla invariante a
traslación y escalado.
Se puede observar que las neuronas con un mayor número de
vecinas son aquellas que pertenecen a la palma. Por ello, se
CAPÍTULO 4
118
definen los subconjuntos A p
pertenecen o no a la palma:
y
A p como las neuronas que
A p = {n ∈ A / vecinas( n ) > κ }
(4.17)
Ap = A − Ap
(4.18)
donde κ se establece en función del número de neuronas totales
de la GNG.
Una vez encontradas las neuronas que forman parte de la palma,
se identifica el centro de la mano, como el centroide de estas
neuronas:
m 1 ,0 ( n ) m 0 ,1 ( n )
,n ∈ A p
C M = x C M , y C M =
,
m
(
n
)
m
(
n
)
0
0
0
0
,
,
(
)
(4.19)
A continuación, se procede a normalizar la mano, como sigue:
1. Se sitúa el centroide en el centro de la imagen.
2. Se escala la mano, de modo que la palma tenga un
tamaño fijo. Para ello, se obtiene la distancia media de
las neuronas más alejadas al centroide, estableciendo
esta distancia como radio estándar (Figura 4.7). En la
imagen, se representan con puntos blancos las neuronas
pertenecientes a la palma, y con puntos negros las
neuronas de los dedos.
Figura 4.7. Extracción del radio estándar de la palma.
SEGUIMIENTO DE OBJETOS Y ANÁLISIS DEL MOVIMIENTO
119
4.3.5 CARACTERIZACIÓN DE LO
LOS
S GESTOS DE LA MANO CON UNA
GNG
OBTENCIÓN DE LA GNG DEL GESTO
{
}
Sea M 1 , M 2 ,...,M f una secuencia de imágenes de la mano que
forman un gesto, donde M 1 es la postura inicial y M f es la
postura final del mismo.
Se realiza, como se explicó previamente, el aprendizaje de la GNG
para la postura inicial (imagen M 1 ), normalizando la red
obtenida. Posteriormente, se realiza el aprendizaje de la GNG
para la siguiente imagen, M 2 , partiendo de la red obtenida para
la imagen anterior. Por lo tanto, la adaptación a la nueva postura
será muy rápida, dado que únicamente es necesario realizar una
iteración al bucle principal de su algoritmo de aprendizaje. De
modo similar, se opera con el resto de imágenes, obteniendo para
cada una de ellas una GNG que no difiere en demasía de la
calculada previamente.
En la Figura 4.8 se muestran las sucesivas adaptaciones de una
GNG a un gesto realizado por la mano.
Figura 4.8. Adaptación dinámica de las Growing Neural Gas a un gesto completo.
CAPÍTULO 4
120
CARACTERIZACIÓN DEL GESTO
Dado un gesto y su secuencia de GNGs normalizados, se calcula
la trayectoria seguida por cada una de las neuronas. Por tanto,
para una neurona i se calcula su trayectoria T i realizada desde
la GNG inicial a la final. La trayectoria de cada neurona viene
dada por su posición en cada uno de los GNG normalizados:
{(
)(
) (
T i = x i1 , y i1 , x i2 , y i2 ,…, x i n , y i n
)}
(4.20)
Sin embargo, a la hora de reconocer un gesto únicamente se van
a considerar los puntos inicial y final de cada una de las
trayectorias. Esta simplificación ya fue realizada en (Davis y
Shah, 1994), rechazando la posible curvatura de las trayectorias,
dado que será mínima.
{
}
Por tanto, si G = T 1 , T 2 , ...,T n es un gesto a reconocer, cada
trayectoria T i es determinada por sus puntos inicial y final,
ti = ( x i , y i ) y ti = ( x i , yi ) .
o
o
o
f
f
f
A partir de esta definición del gesto, se establece el movimiento
común de la mano como el movimiento que realizan las neuronas
que pertenecen a la palma y, en particular, a la trayectoria que
sigue el centroide C M .
Por otro lado, se define el movimiento relativo de la mano como
los cambios morfológicos que sufre a lo largo del gesto,
determinados por los movimientos de cada una de las neuronas.
Sin embargo, dado que los cambios en la postura de la mano lo
determinan los dedos, únicamente van a ser consideradas las
trayectorias de aquellas neuronas que, en alguna ocasión
durante el gesto, no han pertenecido a la palma; es decir,
pertenecieron a los dedos.
En resumen, el movimiento común de la mano viene determinado
por los nodos pertenecientes a la palma, mientras que el
movimiento relativo viene determinado por las neuronas de los
dedos.
SEGUIMIENTO DE OBJETOS Y ANÁLISIS DEL MOVIMIENTO
121
NORMALIZACIÓN DE LO
LOS
S GESTOS
Con el propósito de normalizar el movimiento relativo de la mano
para hacerlo invariante a rotación, se extrae la dirección media de
las trayectorias seguidas por las neuronas de los dedos,
rotándolas para situar ésta en la vertical (Figura 4.9).
Figura 4.9. Normalización de las trayectorias del gesto.
De este modo, junto con la normalización realizada a cada una de
las posturas de la mano, se obtiene una representación del gesto
invariante a traslación, escalado y rotación.
4.3.6 RECONOCIMIENTO
El reconocimiento del gesto realizado, se efectúa comparando las
trayectorias del mismo con las de otros gestos que se encuentran
CAPÍTULO 4
122
{
en una base de datos, de modo que el patrón P = p 1 , p 2 , ..., p n'
más similar al gesto G es aquel que minimiza la expresión:
n
(
)
n'
(
)
n'
n
t i o − p j o + t i f − p j f + ∑ min t i o − p j o + t i f − p j f
∑ min
j =1
i =1 j =1
i =1
n + n'
}
(4.21)
Esto es, para cada una de las trayectorias del gesto G se calcula
su distancia a la trayectoria más similar del patrón P , obtenida
como la suma de las distancias entre los inicios y fines de ambas
trayectorias. Este proceso se repite para todas las trayectorias de
G . De igual modo, se realiza la operación en sentido contrario,
comparando cada una de la trayectorias de P con su
correspondiente en G . Por último, se calcula la distancia media
dividiendo entre el número total de trayectorias tomadas en
consideración.
4.3.7 EXPERIMENTACIÓN Y RES
RESULTADOS
ULTADOS
Para realizar los experimentos se ha diseñado un vocabulario de
12 gestos, algunos de los cuales tienen características similares.
En la Figura 4.10 se muestran los estados iniciales y finales de
cada uno de los gestos. Los gestos A a J comienzan con el puño
cerrado, mientras que los dos últimos gestos comienzan con la
palma extendida.
Los gestos han sido tomados con una resolución de 320 x 240
puntos y con 256 tonos de grises. Para evitar el problema de
segmentación, se han realizado los gestos frente un fondo oscuro,
de modo que el filtro ψ T es una función umbral:
0 , si I (x , y ) < umbral
ψ T (x , y ) =
1 , si I (x , y ) > umbral
(4.22)
La aplicación de este sistema a entornos más complejos, donde se
emplean cámaras en color o los fondos sean heterogéneos, se
reduce a encontrar la transformación adecuada para realizar una
correcta segmentación de la mano.
SEGUIMIENTO DE OBJETOS Y ANÁLISIS DEL MOVIMIENTO
123
Figura 4.10. Posturas de la mano inicial y final de cada uno de los gestos.
Para entrenar al sistema, se ha realizado cada uno de los gestos 5
veces. Posteriormente, se ha procedido a comprobar su
funcionamiento, realizando cada uno de los gestos en 20
ocasiones. En la tabla se presenta la tasa de acierto para cada
uno de ellos.
Como se observa, los gestos similares introducen cierta confusión
en el sistema, errando algunos de los reconocimientos. Dentro de
estos casos, se encuentran los gestos B y H; A, F e I. Asimismo, el
gesto D puede ser interpretado como C, si los dedos corazón y
anular no están muy separados.
CAPÍTULO 4
124
Gesto
Aciertos
Tasa de aciertos
A
20/20
100.00 %
B
18/20
90.00 %
C
19/20
95.00 %
D
19/20
95.00 %
E
20/20
100.00 %
F
20/20
100.00 %
G
20/20
100.00 %
H
19/20
95.00 %
I
19/20
95.00 %
J
20/20
100.00 %
K
20/20
100.00 %
L
19/20
95.00 %
Tasa media de acierto
233/240
97.08 %
Tabla 4.1. Tasa de acierto en el reconocimiento.
4.4 CONCLUSIONES
En este capítulo se ha desarrollado un modelo de representación
del movimiento, que aporta diversas ventajas con respecto a la
mayor parte de las técnicas existentes.
En primer lugar, las tres primeras etapas del problema del
análisis
del
movimiento
(segmentación,
extracción
de
características y seguimiento de objetos) se realizan en un único
proceso: la obtención del Grafo Preservador de la Topología del
objeto para cada una de las imágenes.
SEGUIMIENTO DE OBJETOS Y ANÁLISIS DEL MOVIMIENTO
125
Por otro lado, el modelo es capaz de adaptar su topología a las
diferentes evoluciones que puede tomar un objeto (ver punto
1.1.2):
• cambios morfológicos: mediante la obtención
movimiento relativo de cada una de las neuronas,
del
• cambios fotométricos: mediante el cálculo de la función
de transformación, dinámicamente para cada una de las
imágenes,
• desplazamientos y giros: los desplazamientos del objeto
vienen determinados por el movimiento común del Grafo
Preservador de la Topología; mientras que los giros los
determina la orientación de las neuronas con respecto al
centroide, que queda recogido en su movimiento relativo.
El análisis del movimiento se simplifica debido a que no es
necesario realizar un seguimiento de diferentes partes del objeto,
localizándolas en cada una de las imágenes (problema de
correspondencia). Este viene determinado por los diferentes
vectores de características de cada una de las neuronas.
Finalmente, el sistema de análisis de movimiento basado en la
adaptación de la Growing Neural Gas a las sucesivas posturas de
la mano, ha demostrado ser un buen método para caracterizar
los gestos. De hecho, la tasa de acierto es elevada incluso para
gestos que pueden ser confundidos con otros muy similares.
Capítulo 5
CONCLUSIONES
Se ha desarrollado un modelo de representación que, tomando
referencias de los trabajos basados en representaciones activas,
realiza la caracterización de objetos y el análisis de su
movimiento.
Como el objetivo que subyace es el desarrollo de arquitecturas
especializadas en visión, en movimiento, de tiempo real, se han
seguido planteamientos conexionistas por cuestiones de
paralelizabilidad y posibilidad de refinamiento progresivo de la
respuesta. Se entiende que este enfoque establece una diferencia
sustancial respecto de la práctica habitual en la investigación de
visión de nivel medio: en general, los problemas se abordan con
planteamientos puramente computacionales, con ignorancia de
los aspectos de implantación y de las características de los
computadores. El procesamiento se realiza, finalmente, sobre
sistemas potentes; casi sin consideraciones de especificidad que
permitan explotar las peculiaridades de la naturaleza de los
problemas de visión.
CAPÍTULO 5
128
Este trabajo, junto con (Mora, 2001), establece los primeros
pasos para el desarrollo de arquitecturas específicas de tiempo
real, no sólo dirigidas al análisis del movimiento, sino que deben
servir para tratar muchos otros aspectos de la visión de nivel
medio y bajo, algunos de los cuales ya han sido presentados en
esta memoria.
Tomando como base el comportamiento de los gases neuronales,
se adapta la topología de su red de interconexión a un espacio de
entrada definido por el objeto. El efecto que se consigue es doble:
por un lado, el Grafo Preservador de la Topología sirve como
estructura de datos reducida, pero rica en información; por otro,
se dota al modelo de capacidad de operación bajo restricciones de
tiempo real, previa modificación de sus algoritmos de aprendizaje.
Adicionalmente, debido al carácter dinámico de estas redes que
no necesitan reiniciar el aprendizaje al introducir nuevos
patrones, se modeliza el movimiento realizado por los objetos
como las deformaciones que sufre la red a lo largo de toda la
secuencia de imágenes.
Para poner de manifiesto las prestaciones de dicha metodología,
se ha propuesto resolver una instancia del problema del
reconocimiento de gestos, uno de los problemas considerado
complicado en el análisis del movimiento, debido al gran número
de grados de libertad que posee la mano humana, que conlleva
una gran variedad de estados morfológicos de la misma.
5.1 APORTACIONES
A continuación se presentan, de forma más ordenada, las
diversas aportaciones presentadas en esta trabajo:
• Se ha realizado un estudio de la capacidad de
preservación de la topología de objetos bidimensionales
por parte de diversos modelos neuronales autoorganizativos, comparando su comportamiento. Se ha
medido de forma empírica dicha capacidad, empleando
el producto topográfico. Se ha obtenido que los gases
neuronales, los modelos Neural Gas y Growing Neural
Gas, son los que mejor preservan la topología de un
espacio de entrada bidimensional.
CONCLUSIONES
129
• Se dota a los gases neuronales de capacidad de
funcionamiento bajo restricciones de tiempo real. Se han
introducido variantes a los procesos de aprendizaje para
que la adaptación pueda supeditarse a cotas de tiempo y
tener una medida de la calidad de respuesta.
• Se han empleado los resultados de las aportaciones
anteriores
para
la
representación
de
objetos
bidimensionales: la red de interconexión entre las
neuronas determina la morfología de los objetos,
obteniéndose un Grafo Preservador de la Topología. Se
obtiene una nueva aplicación de las redes neuronales
auto-organizativas, ya que usualmente han sido
empleadas como clasificadores de características, pero
no como las propias características de los objetos.
• Sin necesidad de modificar los algoritmos de aprendizaje
de los gases neuronales, sino modificando únicamente la
propiedad visual para la que es sensible la red; se puede
extraer tanto la representación externa (contorno) como
su representación interna.
• Se han extraído características del Grafo Preservador de
la Topología tanto al adaptarse a contornos, como a
superficies; de modo que operaciones de clasificación y
reconocimiento posteriores se vean simplificadas,
evitando la alta complejidad de la comparación entre
grafos.
• Dadas las capacidades de compresión de la información
y de preservación de la topología del GPT , se realiza la
síntesis de los objetos a partir del grafo. Se han
presentado diversas posibilidades, ya sea obteniendo
dicha
síntesis
contando
únicamente
con
la
representación del GPT o disponiendo de información
adicional, obtenida al calcularlo.
• Se ha extendido la aplicación de los GPT al tratamiento
de secuencias de imágenes y, más concretamente, al
seguimiento de objetos y análisis del movimiento. Debido
al carácter dinámico de estas redes, se ha modelizado la
evolución de los objetos como las modificaciones que
sufre la red a lo largo de toda la secuencia, entendiendo
CAPÍTULO 5
130
dichas modificaciones como variaciones en la topología
de la red de interconexión así como zona del espacio de
entrada para la que es sensible cada uno de los
elementos de procesamiento.
• La modelización del movimiento como la dinámica de las
neuronas, evita el problema de correspondencia, uno de
los más costosos en la mayoría de técnicas de
seguimiento de objetos.
• Aunque no ha sido destacado especialmente en la
memoria, este modelo permite la caracterización y
seguimiento de múltiples objetos presentes en la escena.
Asimismo, se puede realizar el seguimiento de un objeto
que se disgregue en varias partes o que se fusione.
Resumidamente, la investigación que se contiene en esta
memoria ha consistido en la aportación de estructuras de datos y
de métodos, desde el enfoque de proporcionar conocimiento para
cubrir los objetivos iniciales: establecer un marco de
modelización de arquitecturas especializadas para visión, con
capacidad de procesamiento en tiempo real, y suficientemente
generalista para dar cobertura a técnicas de tratamiento de una
amplia diversidad de problemas de visión.
Por cuestiones de extensión del trabajo, la investigación se ha
concretado en establecer la base conceptual sobre la que después
se materializarán las arquitecturas. La modelización se ha
particularizado para un par de problemas representativos: uno de
caracterización y otro de seguimiento.
5.2 LÍNEAS DE CONTINUACIÓN
CONTINUACIÓN
Dada la aplicación de las redes neuronales auto-organizativas
como caracterizadoras de los objetos, se espera que este trabajo
abra una nueva línea en el desarrollo de arquitecturas
especializadas en visión de nivel medio y bajo. Si bien en este
trabajo, se ha aplicado el modelo al problema del análisis del
movimiento, se debe realizar una generalización del mismo para
el tratamiento de otras operaciones de visión a todos los niveles.
Asimismo, se debe dotar al modelo de robustez para su aplicación
en entornos realistas, con presencia de ruido, oclusiones,...
CONCLUSIONES
131
Como ya se ha expresado en diversas ocasiones, este modelo
debe materializarse en el desarrollo de arquitecturas de tiempo
real especializadas, con características de miniaturización y
empotrabilidad; que muestren la potencia del prototipo
presentado en esta memoria.
Se deben estudiar algunas cuestiones que quedan al margen de
este trabajo, pero que se encuentran estrechamente ligadas:
• Desarrollo de nuevos modelos de representación,
tomando las ideas que se desprenden de esta tesis. En
particular, se está desarrollando una red en anillo
incremental, la Growing Ring Structure, que tomando el
algoritmo de aprendizaje de la Growing Cell Structure,
permite una adaptación a los contornos de los objetos
sin que se produzcan aristas indeseadas en zonas de
gran curvatura.
• Si existen varios objetos presentes en la escena, se
puede realizar el seguimiento de todos ellos adaptando
varios GPT simultáneamente. Esto puede producir
interacciones entre las diversas redes, lo que lleva a la
posible consideración de miscibilidad de los gases
neuronales.
• Desarrollo de sistemas robustos que permitan su empleo
en el tratamiento de escenas realistas.
• Diseño de arquitecturas de alto rendimiento, basadas en
el modelo presentado, para su integración en el
dispositivo de visión, con enfoque de miniaturización y
empotrabilidad.
Por último, en el tratamiento del reconocimiento de gestos, el
desarrollo de un modelo robusto ante entornos heterogéneos y el
desarrollo de nuevos filtros que permitan una buena
segmentación de las manos, permitirá su empleo en numerosas
aplicaciones, como son el reconocimiento de lenguaje de signos,
el desarrollo de video-fonos para sordomudos, el diseño de
nuevos interfaces hombre-máquina,...
APÉNDICE A
ESTUDIO DE LA
PRESERVACIÓN DE LA
TOPOLOGÍA
En este apéndice se muestra el estudio exhaustivo realizado de la
preservación de la topología de los cuatro modelos autoorganizativos introducidos en el punto 2.1, que poseen
características de aprendizaje diferentes.
PRODUCTO TOPOGRÁFICO
El producto topográfico (Bauer y Pawelzik, 1992), también
llamado en ocasiones “producto wavering” (Pawelzik, 1991), es
una buena medida de la preservación de la topología del espacio
de entrada por una red auto-organizativa. Esta medida ha sido
ampliamente utilizada en la literatura para la comparación de
modelos auto-organizativos (Merkl et al., 1994) (Herbin, 1995)
(Trautmann y Denoeux, 1995).
APÉNDICE A
134
La idea principal de esta medida es comparar la relación de
vecindad de dos neuronas con respecto a su posición en el mapa
por un lado ( Q 2 ( j ,k ) ) y según sus vectores de referencia por otro
( Q 1 ( j ,k ) ) (Figura A.1):
d V w j ,w n A ( j )
k
Q 1 ( j ,k ) =
d V w j ,w n V ( j )
k
(A.1)
(
j ,n kA ( j ))
Q 2 ( j ,k ) = A
d ( j ,n kV ( j ))
(A.2)
d
A
V
donde j es una neurona, w j es su vector de referencia, n K
indica la k vecina más cercana a j en el espacio de entrada V
V
A
según una medida de distancia d
y n K indica la k vecina más
A
cercana a j en la red A según una medida de distancia d .
Figura A.1. Vecindades en el espacio de entrada y en la red.
De esta definición, se extrae que Q 1 ( j ,k ) = Q 2 ( j ,k ) = 1 sólo si
las vecinas más cercanas de orden k en el espacio de entrada y
en la red coinciden. Sin embargo, estas medidas son muy
sensibles a pequeñas variaciones en el orden de vecindad de las
neuronas en ambos espacios. Para ello, se multiplican ambas
medidas para todos los órdenes de vecindad k , obteniendo
ESTUDIO DE LA PRESERVACIÓN DE LA TOPOLOGÍA
135
§ k
P1 ( j ,k ) = ¨¨ ∏Q 1 ( j ,l
© l =1
·
) ¸¸
¹
§ k
P2 ( j ,k ) = ¨¨ ∏Q 2 ( j ,l
© l =1
·
) ¸¸
¹
1
1
k
(A.3)
k
(A.4)
y
§ k
P3 ( j ,k ) = ¨¨ ∏Q 1 ( j ,l ) ⋅Q 2 ( j ,l
© l =1
·
) ¸¸
¹
1
2k
(A.5)
En el caso de que la dimensionalidad de la red y del espacio de
los vectores de entrada coincidan se tiene que P3 = 1 . Cualquier
desviación de dicho valor implica una disparidad en la
dimensionalidad de ambos espacios.
Para extender esta medida a todas las neuronas de la red y todos
los posibles órdenes de vecindad y, dado que sólo estamos
interesados en obtener desviaciones de dicha medida de 1, se
define el producto topográfico P como
P =
N N −1
1
∑ ∑log (P3 ( j ,k ))
N ( N − 1 ) j =1 k =1
(A.6)
MEDIDA DE LA PRESERVACIÓN D
DE
E LA TOPOLOGÍA DE LOS
LOS
DIFERENTES MODELOS AUTO
AUTO-ORGANIZATIVOS
Para obtener una medida de la capacidad de preservación de la
topología de los diferentes modelos auto-organizativos estudiados
se han realizado diversos experimentos, tomando un espacio de
entrada bidimensional (imágenes de 320x320 puntos), con
diferentes funciones de densidad de probabilidad (Figura A.2). El
cuadrado y el círculo son espacios de entrada con una topología
similar a la de los mapas auto-organizativos de Kohonen, que son
los que poseen una relación de vecindad más restringida de entre
todos los modelos; el anillo posee un hueco en su interior, por lo
APÉNDICE A
136
que será difícil que las redes con estructura preestablecida
preserven bien su topología; los cuatro cuadros separados
representan una función no continua, con lo que sólo aquellas
redes con capacidad de división podrán realizar un buen
aprendizaje; y la mano es un espacio más complejo de preservar
su topología, al tener concavidades y convexidades.
Figura A.2. Espacios de entrada.
Se ha realizado el aprendizaje de estos espacios de entrada con
los diferentes modelos auto-organizativos utilizando, para cada
uno de ellos, valores en sus parámetros empleados usualmente.
Para el aprendizaje de los mapas auto-organizativos se ha
empleado el algoritmo de (Kohonen, 1995) con t max = 100 ,
σ i = 5 , σ f = 1 , α i = 0.8 , α f = 0.1 .
Las Growing Cell Structures se han empleado según (Fritzke,
1993) con los parámetros ε b = 0.1 , ε n = 0.01 , α = 0 , λ = 10000 ,
η =0 .
Siguiendo el algoritmo mostrado en el punto 2.2.1 se ha educado
la Neural Gas con los siguientes parámetros: t max = 100 ,
λ0 = 100 ,
λtmax = 0.01 ,
ε 0 = 0.5 ,
ε tmax = 0.005 ,
T 0 = 20 ,
T t = 200 .
max
ESTUDIO DE LA PRESERVACIÓN DE LA TOPOLOGÍA
137
La Growing Neural Gas empleada sigue el algoritmo del punto
2.2.2 con ε 1 = 0.1 , ε 2 = 0.01 , λ = 10000 , α = 0 , β = 0 .
Se ha realizado el aprendizaje de redes que poseen 100 neuronas,
educando cinco redes de cada uno de los modelos y para cada
uno de los espacios de entrada. Una vez realizado este
aprendizaje se ha procedido al cálculo del producto topográfico,
con el objetivo de medir la preservación de la topología en cada
uno de los casos (Tabla A.1).
A diferencia del uso normal que se hace del producto topográfico
en la literatura en la que la distancia en el espacio de entrada
d V es la distancia euclídea entre dos puntos, en este trabajo se
emplea la distancia geodésica (Sonka et al., 1998), definida como
la longitud del mínimo camino que une ambos puntos dentro del
subespacio de entrada determinado por el objeto (Figura A.3). Si
V
no se puede establecer un camino entre ellos, d
=∞.
Figura A.3. Distancia geodésica.
APÉNDICE A
138
Espacio de entrada
Modelo
auto-organizativo
Producto
topográfico1
Error de
cuantización
Cuadrado
Kohonen
0.005914
4523614
Cuadrado
Growing Cell Structure
0.015628
1360265
Cuadrado
Neural Gas
0.005175
1176427
Cuadrado
Growing Neural Gas
0.007785
1286321
Círculo
Kohonen
0.004974
3841524
Círculo
Growing Cell Structure
0.015420
1103505
Círculo
Neural Gas
0.005331
954927
Círculo
Growing Neural Gas
0.007832
1039228
Anillo
Kohonen
Indeterminado
4262412
Anillo
Growing Cell Structure
0.017626
1306101
Anillo
Neural Gas
0.003718
1109236
Anillo
Growing Neural Gas
0.005030
1228092
4 cuadros
Kohonen
Indeterminado
7143062
4 cuadros
Growing Cell Structure
0.006417
1342739
4 cuadros
Neural Gas
0.002889
1123384
4 cuadros
Growing Neural Gas
0.004221
1276545
Mano
Kohonen
0.036150
8657777
Mano
Growing Cell Structure
0.021125
1939797
Mano
Neural Gas
0.003539
1556044
Mano
Growing Neural Gas
0.00607
1756100
Tabla A.1. Cálculo de la preservación de la topología (100 neuronas).
1 El valor “Indeterminado” del producto topográfico es debido a que
alguna neurona se encuentra fuera del espacio de entrada y, por tanto,
no se puede calcular la distancia de ésta a cualquier otra neurona.
ESTUDIO DE LA PRESERVACIÓN DE LA TOPOLOGÍA
139
Como se puede observar las redes que mejor preservan la
topología de los espacios de entrada son aquellas cuya topología
no está definida a priori, sino que se adapta con el aprendizaje:
las Neural Gas y las Growing Neural Gas. Sólo en aquellos casos
en los que el espacio de entrada tiene una estructura similar a la
topología predefinida de los mapas auto-organizativos, el
producto topográfico es similar al de los otros modelos. Esto es
debido a que en el cálculo del producto topográfico únicamente se
considera la topología de la red, ya que se considera que se ha
realizado un correcto aprendizaje del espacio de entrada y que,
por tanto, preservará la topología del mismo. Sin embargo, en
estos casos no es así, ya que los mapas de Kohonen caracterizan
peor el espacio de entrada al producirse un mayor error de
cuantización (Kohonen, 1995), calculado como:
E=
∑ wφ
∀ξ ∈V
2
w( ξ )
− ξ ⋅ p (ξ )
(A.7)
Las Neural Gas y las Growing Neural Gas tienen un
comportamiento similar ante diferentes espacios de entrada, sin
embargo, la complejidad del aprendizaje de las Neural Gas es
muy superior al de las Growing Neural Gas, debido al proceso de
ordenación de todos los vectores de referencia para cada uno de
los patrones de entrada ξ (paso 3 del aprendizaje), obteniendo
unos tiempos de aprendizaje muy superiores (Tabla A.2).
Modelo
auto-organizativo
Tiempo de
aprendizaje
(segundos)
Kohonen
38
Growing Cell Structure
9
Neural Gas
117
Growing Neural Gas
12
Tabla A.2. Tiempos de aprendizaje de los diferentes modelos auto-organizativos.
APÉNDICE A
140
En la Tabla A.3 se representa el producto topográfico de las
Neural Gas si se interrumpiera su aprendizaje a los 12 segundos,
que es el tiempo en el que finalizan su aprendizaje las Growing
Neural Gas. Como se observa, los resultados tanto en la
preservación de la topología como en el error de cuantización son
bastante peores, ya que no es capaz, en ese tiempo, de finalizar el
proceso de adaptación.
Espacio de
entrada
Modelo
auto-organizativo
Producto
topográfico
Error de
cuantización
Cuadrado
Neural Gas
0.089522
39323868
Cuadrado
Growing Neural Gas
0.007785
1286321
Círculo
Neural Gas
0.075313
30155116
Círculo
Growing Neural Gas
0.007832
1039228
Anillo
Neural Gas
Indeterminado
37848968
Anillo
Growing Neural Gas
0.005030
1228092
4 cuadros
Neural Gas
Indeterminado
101925872
4 cuadros
Growing Neural Gas
0.004221
1276545
Mano
Neural Gas
Indeterminado
62578424
Mano
Growing Neural Gas
0.00607
1756100
Tabla A.3. Preservación de la topología de la Neural Gas deteniendo su
aprendizaje a los 12 segundos.
Sin embargo, si se modifican los parámetros de la NG, por
ejemplo el número de patrones de entrada por iteración λ , para
que finalice su adaptación en esos 12 segundos, los resultados
del producto topográfico se siguen manteniendo cercanos a los
conseguidos con la GNG.
ESTUDIO DE LA PRESERVACIÓN DE LA TOPOLOGÍA
141
Espacio de
entrada
Modelo
auto-organizativo
Producto
topográfico
Error de
cuantización
Cuadrado
Neural Gas
0.006390
1210058
Cuadrado
Growing Neural Gas
0.007785
1286321
Círculo
Neural Gas
0.006207
974271
Círculo
Growing Neural Gas
0.007832
1039228
Anillo
Neural Gas
0.003454
1150331
Anillo
Growing Neural Gas
0.005030
1228092
4 cuadros
Neural Gas
0.003690
1194841
4 cuadros
Growing Neural Gas
0.004221
1276545
Mano
Neural Gas
0.005739
1668036
Mano
Growing Neural Gas
0.00607
1756100
Tabla A.4. Preservación de la topología de la Neural Gas modificando sus
parámetros para que finalice a los 12 segundos.
REFERENCIAS
(Abbott, 1991)
R. Abbott. Scheduling Real-Time Transactions: A Performance
Evaluation. Ph.D. Thesis, Princeton University, 1991.
(Aggarwal y Cai, 1999)
J.K. Aggarwal y Q. Cai. Human Motion Analysis: A Review.
Computer Vision and Image Understanding, 73(3):428-440, 1999.
(Aggarwal et al., 1998)
J.K. Aggarwal, Q. Cai, W. Liao y B. Sabata. Articulated and
Elastic Non-rigid Motion: A Review. Computer Vision and Image
Understanding, 70:142-156, 1998.
(Aloimonos et al., 1988)
Y. Aloimonos, I. Weiss y A. Bandopadhai. Active Vision.
International Journal of Computer Vision, 2:333-356, 1988.
(Amerijckx et al., 1998)
C. Amerijckx, M. Verleysen, P. Thissen, J.-D. Legat, Image
Compression by SelfOrganizing Kohonen Map, IEEE Trans. on
Neural Networks, 9(3):503-507, 1998.
144
REFERENCIAS
(Armstrong et al., 1998)
J.B. Armstrong, M. Maheswaran, M.D. Theys, H.J. Siegel, M.A.
Nichols y K.H. Casey. Parallel Image Correlation: Case Study to
examine Trade-Offs in Algorithm-to-Machine Mappings. The
Journal of Supercomputing, 12(1/2):7-35, 1998.
(Asaad et al., 1996)
S. Asaad, M. Bishay, D.M. Wilkes, and K. Kawamura. A LowCost, DSP-Based, Intelligent Vision System for Robotic
Applications. In Proceedings of the IEEE International Conference
on Robotics and Automation, Minneapolis, pp.1656-1661, 1996.
(Atukorale y Suganthan, 1998)
A.S. Atukorale y P.N. Suganthan. An Efficient Neural Gas
Network for Classification. In Proceedings of the International
Conference on Control, Automation, Robotics and Vision, Singapore
pp. 1152-1156, 1998.
(Bader y Jájá, 1994)
D.A. Bader y J. Jájá. Parallel
Algorithms for Image
Histogramming
and
Connected
Components
with
an
Experimental Study. Technical Report CS-TR-3384 and UMIACSTR-94-133, UMIACS and Electrical Engineering, University of
Maryland, 1994.
(Baglietto et al., 1996)
P. Baglietto, M. Maresca, M. Migliardi y N. Zingirian. Image
Processing on High Performance RISC Systems. Proceedings of
the IEEE, 84(7):917-930, 1996.
(Bajcsy, 1988)
R. Bajcsy. Active perception. Proceedings of the IEEE, 76:9961005, 1988.
(Balkenius y Kopp, 1996)
C. Balkenius y L. Kopp. Visual Tracking and Target Selection for
Mobile Robots. In Proceedings of the 1st Euromicro Workshop on
Advanced Mobile Robots, pp. 166-171, 1996.
(Ballard, 1991)
D.H. Ballard. Animate vision. Artificial Intelligence, 48:57-86,
1991.
REFERENCIAS
145
(Barad, 1988)
H.S. Barad. The SCOOP Pyramid: An Object-Oriented Prototype
of a Pyramid Architecture for Computer Vision. Technical Report
SIPI 115, Univ. of Southern California, 1988.
(Bauer y Pawelzik, 1992)
H-U. Bauer, K. Pawelzik. Quantifying the Neighborhood
Preservation of Self-Organizing Feature Maps. IEEE Transactions
on Neural Networks, 3(4):570-578, 1992.
(Bauer et al., 1999)
H-U. Bauer, M. Herrmann y T. Villmann. Neural Maps and
Topographic Vector Quantization. Neural Networks., 12(4-5):659676, 1999.
(Baumann y Ranka, 1992)
D. Baumann y S. Ranka. The Generalized Hough Transform on
an MIMD machine. Journal of Undergraduate Research in HighPerformance Computing, Volume 2, E.A. Bogucz y V.E. Weinman
(eds.), Northeast Parallel Architectures Center at Syracuse
University Technical Report SCCS-468, 1992.
(Beauchemin y Barron, 1995)
S.S. Beauchemin y J.L. Barron. The Computation of Optical Flow.
ACM Computing Surveys, 27(3):443-465, 1995.
(Bertozzi y Broggi, 1998)
M. Bertozzi y A. Broggi. GOLD: A Parallel Real-Time Stereo Vision
System for Generic Obstacle and Lane Detection. IEEE
Transactions on Image Processing, 7(1):62-81, 1998.
(Beymer et al, 1997)
D. Beymer, P. McLauchlan, B. Coifman y J. Malik. A Real-time
Computer Vision System for Measuring Traffic Parameters. In
Proceedings of the IEEE Conf. on Computer Vision and Pattern
Recognition, Puerto Rico, pp. 495-501, 1997.
(Bhandarkar y Arabnia, 1997)
S.M. Bhandarkar y H.R. Arabnia. Parallel Computer Vision on a
Reconfigurable Multiprocessor Network. IEEE Transactions on
Parallel and Distributed Systems, 8(3):292-309, 1997.
146
REFERENCIAS
(Biancardi et al., 1992)
A. Biancardi, V. Cantoni, M. Ferretti y M. Mosconi. The PAPIA2
Machine: Hardware and Software Architectures. In Proceedings of
the ERCIM Workshop on Parallel Architectures for Computer Vision,
Creta, pp. 120-141, 1992.
(Bihari y Gopinath, 1991)
T. Bihari y P. Gopinath. Real-Time concurrent C: A language for
programming dynamic real-time systems. Real-Time Systems,
2(4), 1991.
(Blank, 1990)
T. Blank. The MasPar MP-1 Architecture. In Proceedings of the
IEEE International Conference on Computer Architectures, San
Francisco, pp. 20-24, 1990.
(Blevins, 1990)
D.W. Blevins, E.W. Davis, R.A. Heaton y J.H. Reif. BLITZEN: A
Highly Integrated Massively Parallel Machine. Journal of Parallel
and Distributed Computing, 8(2):150-160, 1990.
(Boehme et al., 1998)
H.J. Boehme, A. Brakensiek, U.-D. Braumann, M. Krabbes, A.
Corradini y H.-M. Gross. Neural Networks for Gesture-based
Remote Control of a Mobile Robot. In Proceedings of the IEEE
World Congress on Computational Intelligence, Anchorage, 1:372377, 1998.
(Bougrain y Alexandre, 1999)
L. Bougrain y F. Alexandre. Unsupervised Connectionist
Clustering Algorithms for a better Supervised Prediction:
Application to a radio communication problem. In Proceedings of
the International Join Conference on Neural Networks,
Washington, 28:381-391, 1999.
(Brady y Wang, 1992)
M. Brady y H. Wang. Vision for mobile robots. Phil. Transactions
of the Royal Society of London B, 337:341-350, 1992.
(Bro-Nielsen, 1994)
M. Bro-Nielsen. Active nets and cubes. Technical report, Institute
of Mathematical Modeling, Technical Univ. of Denmark, 1994.
REFERENCIAS
147
(Broggi et al., 1994a)
A. Broggi, G. Conte, F. Gregoretti, C. Sansoé y L.M. Reyneri. The
PAPRICA Massively Parallel Processor. In Proceedings of the IEEE
International Conference on Massively Parallel Computing
Systems, pp. 16-30, 1994.
(Broggi et al., 1994b)
A. Broggi, G. Conte, G. Burzio, L. Lavagno, F. Gregoretti, C.
Sansoé y L.M. Reyneri. PAPRICA-3: A Real-Time Morphological
Image Processor. In Proceedings of the IEEE International
Conference on Image Processing, pp. 654-658, Austin, Texas,
1994.
(Buttazo, 1997)
G.C. Butazzo. Hard Real-Time Computing Systems. Predictable
Scheduling Algoritms and Applications. Kluwer Academic
Publishers. 1997.
(Cadoz, 1994)
C. Cadoz. Les réalités virtuelles. Dominos, Flamarion, 1994.
(Cahn von Seelen, 1997)
U.M. Cahn von Seelen. Performance Evaluation of an Active Vision
System. PhD Thesis, Univ. of Pennsylvania, 1997.
(Campbell et al., 1996)
L.W. Campbell, D.A. Becker, A. Azarbayejani, A.F. Bobick y A.
Pentland. Invariant features for 3-D gesture recognition. In
Proceedings of the 2nd International Workshop on Automatic Faceand Gesture Recognition, Killington, pp. 157-162, 1996.
(Camus, 1994)
T. Camus. Real-Time Optical Flow. PhD Thesis, Dept. of Computer
Science, Brown Univ., Providence, 1994.
(Cantoni et al., 1991)
V. Cantoni, V. Di Gesù, M. Ferretti, S. Levialdi, R. Negrini, R.
Stefanelli. The PAPIA System. Journal of VLSI Signal Processing,
2:195-217, 1991.
148
REFERENCIAS
(Case et al., 2001)
J. Case, D.S. Rajan y A.M. Shende. Lattice Computers for
Approximating Euclidean Space. Journal of the ACM, 48:110-144,
2001.
(Castrillón et al., 1998)
M. Castrillón, C. Guerra, J. Hernández, A. Domínguez, J. Isern,
J. Cabrera y F.M. Hernández. An Active Vision System integrating
Fast and Slow Processes. In Proceedings of the Symposium on
Intelligent Systems and Advanced Manufacturing, Boston, pp.
487-496, 1998.
(Cédras y Shah, 1995)
C. Cédras y M. Shah. Motion-based recognition: a survey. Image
and Vision Computing, 13(2):129-155, 1995.
(Charot, 1993)
F. Charot. Architectures parallèles spécialisées pour le traitement
d’image. Rapport de recherche nº 1978, INRIA, Rennes, France,
1993.
(Chen y Cheng, 1997)
X. Chen y A.M.K. Cheng. An Imprecise Algorithm for Real-Time
Compressed Image and Video Transmission. In Proceedings of the
6th International Conference on Computer Comunications and
Networks, 1997.
(Cheng y Zell, 2000a)
G. Cheng y A. Zell. Externally Growing Cell Structures for Pattern
Classification. In Proceedings of the ICSC Symposia on Neural
Computation, Berlin, pp. 233-239, 2000.
(Cheng y Zell, 2000b)
G. Cheng y A. Zell. Double Growing Neural Gas for Disease
Diagnosis. In Proceedings of Artificial Neural Networks in Medicine
and Biology Conference (ANNIMAB-1), pp. 309-314, Springer,
2000.
(Chin et al., 1988)
D. Chin, J. Passe, F. Bernard, H. Taylor y S. Knight. The
Princeton Engine: A Real-Time Video System Simulator. IEEE
Transactions on Consumer Electronics, 34(2):285-297, 1988.
REFERENCIAS
149
(Choudhary et al., 1993)
A.N. Choudhary, J.H. Patel y N. Ahuja. NETRA: A Hierarchical
and Partitionable Architecture for Computer Vision Systems.
IEEE Transactions on Parallel and Distributed Systems,
4(10):1092-1104, 1993.
(Cloud, 1988)
E.L. Cloud. The Geometric Arithmetic Parallel Processor. In
Frontiers of Parallel Computation, pp. 373-381, 1988.
(Cohen et al., 1992)
I. Cohen, L.D. Cohen y N. Ayache. Using deformable surface to
segment 3d images and infer differential structures. In Proc. of
the 2nd European Conference on Computer Vision, pp. 648-652,
1992.
(Cootes y Taylor, 1992)
T.F. Cootes y C.J. Taylor. Active shape models, smart snakes. In
Proc. of the British Machine Vision Conference, pp. 266-275, 1992.
(Curwen y Blake, 1992)
R. Curwen y A. Blake. Dynamic Contours: Real-time Active
Splines. In Active Vision, A. Blake y A. Yuille (eds.), The MIT
Press, 1992.
(Davis y Shah, 1993)
J. Davis y M. Shah. Gesture Recognition. Technical Report CSTR-93-11, Department of Computer Science, University of Central
Florida, 1993.
(Davis y Shah, 1994)
J. Davis y M. Shah. Recognizing Hand Gestures. In Proceedings of
the European Conference on Computer Vision ECCV’94,
Stockholm, Sweden, pp. 331-340, 1994.
(DEC, 1992)
Digital
Equipament
Corporation.
DECchip
21064-AA
Microprocessor Hardware Reference Manual. Maynard, 1ª ed.,
1992.
150
REFERENCIAS
(Denzler y Niemann, 1995)
J. Denzler y H. Niemann. Combination of Simple Vision Modules
for Robust Real-Time Motion Tracking. European Transactions on
Telecommunications, 5(3):275-286, 1995.
(Denzler y Niemann, 1999)
J. Denzler y H. Niemann. Active Rays: Polar-transformed Active
Contours for Real-Time Contour Tracking. Journal on Real-Time
Imaging, 5(3):203-213, 1999.
(Dorner, 1994)
B. Dorner. Chasing the colour glove: visual hand tracking.
Master’s Thesis, School of Computer Science, Simon Fraser
University, 1994.
(Drayer et al., 1995)
T.H. Drayer, W.E. King IV, J.G. Tront y R.W. Conners. A Modular
and Reprogrammable Real-time Processing Hardware, MORRPH.
In Proceedings of the IEEE Symposium on FPGA’s for Custom
Computing Machines (FCCM’95), pp. 11-19, 1995.
(Du et al., 1996)
F. Du, A. Izatt y C. Bandera. An MIMD Computing Platform for a
Hierarchical Foveal Machine Vision System. In Proceedings of the
1996 Conference on Computer Vision and Pattern recognition, pp.
720-725, 1996.
(Eklund et al., 1994)
M. W. Eklund, G. Ravichandran, M.M. Trivedi y S.B. Marapane.
Real-Time Visual Tracking Using Correlation Techniques. In
Proceedings of the 2nd IEEE Workshop on Applications of Computer
Vision, Florida, pp. 256-263, 1994.
(Escolano, 1997)
F. Escolano. Plantillas Deformables Extendidas: Modelización
Local Robusta y Caracterización Basada en Auto-Modelos para el
Reconocimiento y Tracking de Estructuras Geométricas Activas.
PhD Thesis, Univ. de Alicante, 1997.
(Fayman et al., 1995)
J.A. Fayman, E. Rivlin y H.I. Christensen. The Active Vision Shell.
Technical Report CIS9510, Computer Science Department,
Technion -- Israel Institute of Technology, Haifa, 1995.
REFERENCIAS
151
(Ferrari, 1992)
D. Ferrari. Real-Time Comunication in a Intranetwork. Journal of
High Speed Networks, 1992.
(Fisher et al., 1988)
A.I. Fisher, P.T. Hignam y T.E. Rockoff. Scan Line Array
Processors: Work in Progress. In Proceedings of the Image
Understanding Workshop, pp. 625-633, 1988.
(Flórez et al., 2001)
F. Flórez., J.M. García y F. Ibarra. Hand Gesture Recognition
based on Morphological Features. In Proceedings of the IX
Spanish Symposium on Pattern Recognition and Image Analysis,
Benicasim, II:7-12, 2001.
(Fortin, 1996)
S. Fortin. The Graph Isomorphism Problem. Technical Report TR96-20, Department of Computing Science, The University of
Alberta, Edmonton, Canada, 1996.
(Fortune, 1997)
S. Fortune. Voronoi Diagrams and Delaunay Triangulations. In
Discrete and Computational Geometry, J.E. Goodman, J.
O’Rourke (eds.), CRC Press LLC, Boca Raton, Florida, 1997.
(Fountain et al., 1988)
T.J. Fountain, K.N. Matthews y M.J. Duff. The CLIP7: A Image
Processor. IEEE Transactions on Pattern Analysis and Machine
Intelligence, 10(3):310-319, 1988.
(Fritsch, 1986)
G. Fritsch. General purpose pyramidal architectures. In
Pyramidal Systems for Computer Vision, V. Cantoni y S. Levialdi
(eds.), Springer-Verlag, Berlin, pp. 41-58, 1986.
(Fritzke, 1993a)
B. Fritzke. Growing Cell Structures – A Self-organizing Network
for Unsupervised and Supervised Learning. Technical Report TR93-026, International Computer Science Institute, Berkeley,
California, 1993.
152
REFERENCIAS
(Fritzke, 1993b)
B. Fritzke. Kohonen feature maps and growing cell structures – a
performance comparison. In Advances in Neural Information 5, L.
Giles, S. Hanson y J. Cowan (eds.), Morgan Kaufmann
Publishers, San Mateo, California, 1993.
(Fritzke, 1993c)
B. Fritzke. A Growing and Splitting Elastic Network for Vector
Quantization. In Neural Networks for Signal Processing 3 –
Proceedings of the 1993 IEEE Workshop, C.A. Kamm, S.Y. Kung,
B. Yoon, R. Chellappa y S. Kung (eds.), Piscataway, pp. 281-290,
1993.
(Fritzke, 1995)
B. Fritzke. A Growing Neural Gas Network Learns Topologies. In
Advances in Neural Information Processing Systems 7, G. Tesauro,
D.S. Touretzky y T.K. Leen (eds.), MIT Press, Cambridge, Mass.,
1995.
(Fritzke, 1997)
B. Fritzke. Some Competitive Learning Methods. Draft Paper,
System Biophysics, Institute for Neural Computation, RurhUniversität Bochum, 1997.
(Gheith y Schwan, 1993)
A. Gheith y K. Schwan. Chaos-arc: Kernel support for multiweight objects, invocations, and atomicity in real-time
applications. ACM Transactions on Computer Systems, 1993.
(González y Woods, 1996)
R.C. González y R.E.Woods. Tratamiento digital de imágenes.
Addison-Wesley Iberoamericana, S.A., Wilmington, Delaware,
1996.
(Haritaoglu et al., 1998)
I. Haritaoglu, D. Harwood y L.S. Davis. W4: Who? When? Where?
What? A Real Time System for Detecting and Tracking People. In
Proceedings of the International Conference on Automatic Face and
Gesture Recognition, pp. 222-227, 1998.
(Harris, 1992)
C. Harris. Tracking with Rigid Models. In Active Vision, A. Blake y
A. Yuille (eds.), The MIT Press, 1992.
REFERENCIAS
153
(Heada et al., 1988)
H. Heada, K. Kato, H. Matsushima, K. Kaneko y M. Ejiri. A
Multiprocessor System Utilizing Enhanced DSP’s For Image
Processing. In Proceedings of the International Conference on
Systolic Arrays, pp. 611-620, 1988.
(Helman y Jájá, 1995)
D. Helman y J. Jájá. Efficient Image Processing Algorithms on the
Scan Line Array Processor. IEEE Transactions on Pattern Analysis
and Machine Intelligence, 17(1):47-56, 1995.
(Hennessy y Patterson, 1996)
J.L. Hennessy y D.A. Patterson. Computer Architecture A
Quantitative Approach. Morgan Kaufmann Publishers Inc., 1996.
(Hennessy y Reagan, 1991)
M. Hennessy y T. Reagan. A Process Algebra for Timed Systems.
Technical Report 5/91, University of Sussex, 1991.
(Herbin, 1995)
S. Herbin. Graph Matching by Self-organizing Feature Maps, In
Proceedings of the International Conference on Artificial Neural
Networks, pp. 57-62, 1995.
(Hernández et al., 1999)
M. Hernández, J. Cabrera, M. Castrillón, A. Domínguez, C.
Guerra, D. Hernández y J. Isern. DESEO: An Active Vision
System for Detection, Tracking and Recognition. Lecture Notes in
Computer Science, 1542:379-391, 1999.
(Hirsch, 1993)
E. Hirsch. Parallel Architectures and Algorithms for Real Time
Computer Vision. In Parallel Algorithms for Digital Image
Processing, Computer Vision and Neural Networks, I. Pitas (ed.),
pp. 353-390, John Wiley & Sons, Ltd., 1993.
(Holmes et al., 1987])
V.P. Holmes, D. Harris, K. Piorkowski y G. Davidson. Hawk: An
operating system kernel for a real time embedded multiprocessor.
Technical Report Sandia National Laboratories, 1987.
154
REFERENCIAS
(Houzet et al., 1991)
D. Houzet, J.L. Basille y J.Y.Latil. GFLOPS: A General Flexible
Linearly Organized Parallel Structure for Images. In IEEE
ASAP’91 Conference, Barcelona, pp. 431-444, 1991.
(Hu, 1962)
M.K. Hu. Visual Pattern Recognition by Moment Invariants. IRE
Trans. Info. Theory, IT-8:179-187, 1962.
(Huang y Pavlovic, 1995)
T.S. Huang y V.I. Pavlovic. Hand Gesture Modelling, Analysis,
and Sinthesys. In Proceedings of the International Workshop on
Automatic Face-and Gesture Recognition, Zurich, pp. 73-79, 1995.
(Huang y Stankovic, 1991)
J. Huang y J. Stankovic. On using priority inheritance in RealTime Databases. In IEEE Real-Time Symposium, 1991.
(Hull et al., 1996)
D. Hull, W.C. Feng y J.W.S. Liu. Operating system support for
imprecise computations. Flexible Computation in Intelligent
Systems, 1996.
(I.C.E., 1995)
Integrated Computing Engines, Inc. The MeshSP Technical
Report. I.C.E., Inc., 1995.
(Iivarinen, 1998)
Jukka Iivarinen. Texture Segmentation and Shape Classification
with Histogram Techniques and Self-Organizing Maps. Acta
Polytechnica
Scandinavica,
Mathematics,
Computing
and
Management in Engineering Series, 95, 1998.
(Johansson, 1973)
G. Johansson. Visual perception of biological motion and a model
for its analysis. Perception and Psychophysics, 14(2):210-211,
1973.
(Jonker, 1993)
P.P. Jonker. An SIMD-MIMD Architecture for Image Procesing
and Pattern Recognition. In Proceedings of the IEEE International
Workshop on Computer Architectures for Machine Perception, New
Orleans, pp. 222-231, 1993.
REFERENCIAS
155
(Kambhamettu et al., 1998)
C. Kambhamettu, D.B. Goldgof, D. Terzopoulos y T.S. Huang.
Nonrigid motion analysis. In Deformable Models in Medical Image
Analysis, A. Singh, D. Goldgof y D. Terzopoulos (eds.), pp. 270284, 1998.
(Kandlur et al., 1989)
D.D. Kandlur, D.L. Kiskis y K.G. Shin. HARTOS: A distributed
real-time operating system. ACM SIGOPS Operating System
Review, 23(3), 1989.
(Kao et al., 1993)
T.W. Kao, S.J. Horng y Y.L. Wang. An O(1) time algorithm for
computing histogram and Hough transform on a cross-bridge
reconfigurable array of processors. IEEE Transactions on Systems,
Man and Cybernetics, 25:681-687, 1993.
(Kass et al., 1988)
M. Kass, A. Witkin y D. Terzopoulos. Snakes: Active contour
models. International Journal of Computer Vision, 1:321-331,
1988.
(Kenny y Lin, 1991)
K.B. Kenny y K.J. Lin. Building flexible real-time systems using
the flex language. IEEE Computer, 1991.
(Kent et al., 1985)
E.W. Kent, M.O. Shneier y R. Lumia. PIPE (pipelined Image
Processing Engine). Journal of Parallel and Distributed Computing,
2:50-78, 1985.
(Kim et al., 1998)
J.-M. Kim, Y. Kim, S.-D. Kim, T.-D. Han y S.-B. Yang. An
Adaptive Parallel Computer Vision System. International Journal
of Pattern Recognition and Artificial Intelligence, 12(3):311-334,
1998.
(Kimmel et al., 1985)
M. Kimmel, R. Jaffe, J. Manderville y M. Lavin. MITE: Morphic
Image Transform Engine, an architecture for reconfigurable
pipelines of neighborhood processes. In IEEE Computer Society
Workshop for Pattern Analysis and Image Database Management,
pp. 493-500, Miami Beach, 1985.
REFERENCIAS
156
(Knieser y Papachristou, 1992)
M.J. Knieser y C.A. Papachristou. Y-Pipe: A Conditional
Branching Scheme Without Pipeline Delays. In International
Symposium on Microarchitecture, 1992.
(Knight et al., 1992)
S. Knight, D.Chin, H. Taylor y J. Peters. The Sarnoff Engine: A
Massively Parallel Computer for High Definition System
Simulation. In Proceedings of Application Specific Array
Processors, pp. 342-357, 1992.
(Kogge, 1994)
P.M. Kogge. EXECUBE – a new architecture for scalable MPPs. In
1994 International Conference on Parallel Processing, pp. 77-84,
IEEE Computer Society Press, 1994.
(Kohler and Schröter, 1998)
M. Kohler y S. Schröter. A Survey of Video-based Gesture
Recognition – Stereo and Mono Systems. Research Report No.
693/1998, Fachbereich Informatik, Univesität Dortmund, 1998.
(Kohonen, 1995)
T. Kohonen. Self-Organizing
Heidelberg, 1995.
Maps.
Springer-Verlag,
Berlin
(Krishna y Shin, 1997)
C.M. Krishna y K.G: Shin. Real-Time Systems. New York:
McGraw-Hill, 1997.
(Kuniyoshi et al., 1995)
Y. Kuniyoshi, N. Kita, S. Rougeaux y T. Suehiro. Active stereo
vision system with foveated wide angle lenses. In Proceedings of
the 2nd Asian Conference on Computer Vision, Singapur, I:359363, 1995.
(Le et al., 1998)
T.M. Le, W.M. Snelgrove y S. Panchanathan. SIMD Processor
Arrays for Image and Video Processing: A Review. In Multimedia
Hardware Architectures, volume 3311 of SPIE Proceedings, S.
Panchanathan, F. Sijstermans y S.I. Sudharsanan (eds.), pp. 3041, 1998.
REFERENCIAS
157
(Leiserson et al., 1994)
C.E. Leiserson, Z.S. Abuhamdeh, D.C. Douglas, C.R. Feynman,
M.N. Ganmukhi, J.V. Hill, W.D. Hillis, B.C. Kuszmaul, M.A. St.
Pierre, D.S. Wells, M.C. Wong, S.-W. Yang y R. Zak. The Network
Architecture of the Connection Machine CM-5. Technical Report,
Thinking Machines Corporation, 1994.
(Li y Maresca, 1989)
H. Li y M. Maresca. Polymorphic Torus Network.
Transactions on Computers, 38(9):1345-1351, 1989.
IEEE
(Little et al., 1987)
J.J. Little, G. Blelloch y T. Cass. Parallel Algorithms for Computer
Vision on the Connection Machine. In Proceedings of the DARPA
Image Understanding Workshop, pp. 628-638, 1987.
(Little et al., 1991)
J.J. Little, R.A. Barman, S.J. Kingdom y J. Lu. Computational
Architectures for Responsive Vision: the Vision Engine. In
Proceedings of the International Workshop on Computer
Architectures for Machine Perception, pp. 233,240, 1991.
(Loncaric, 1998)
S. Loncaric. A Survey of Shape Analysis Tecniques. Pattern
Recognition, 31(8):983-1001, 1998.
(Mae et al., 1994)
Y. Mae, S. Yamamoto, Y. Shirai y J. Miura. Optical Flow Based
Realtime Object Tracking by Active Vision System. In Proceedings
of the 2nd Japan-France Congress on Mechatronics, 2:545-548,
1994.
(Mandelbaum et al., 1998)
R. Mandelbaum, M. Hansen, P. Burt y S. Baten. Vision for
Autonomous Mobility: Image Processing on the VFE-200. In
Proceedings of the IEEE International Symposium on Intelligent
Control, International. Symposium on Computational Intelligence in
Robotics and Automation, and Intelligent Systems and Semiotics,
Gaithersburg, 1998.
(Marr, 1982)
D. Marr. Vision. W.H. Freeman and Co. (eds.), San Francisco,
1982.
158
REFERENCIAS
(Marsland et al., 2000)
S. Marsland, U. Nehmzow y J. Shapiro. A Real-Time Novelty
Detector For A Mobile Robot. In EUREL Advanced Robotics
Conference, Salford, 2000.
(Martinetz y Schulten, 1991)
T. Martinetz y K. Schulten. A “Neural-Gas” Network Learns
Topologies. Artificial Neural Networks, T. Kohonen, K. Mäkisara,
O. Simula y J. Kangas (eds.), 1:397-402, 1991.
(Martinetz y Schulten, 1994)
T. Martinetz y K. Schulten. Topology Representing Networks.
Neural Networks, 7(3):507-522, 1994.
(Martinetz et al., 1993)
T. Martinetz, S.G. Berkovich y K.J. Schulten. “Neural-Gas”
Network for Vector Quantization and its Application to TimeSeries Prediction. IEEE Transactions on Neural Networks,
4(4):558-569, 1993.
(Mataric, 2000)
M. Mataric. Sensory-Motor Primitives as a Basis for Imitation:
Linking Perception to Action and Biology to Robotics. In Imitation
in Animals and Artifacts, C. Nehaniv y K. Dautenhahn (eds.), The
MIT Press, 2000.
(McColl, 1993)
W.F. McColl. Special Purpose Parallel Computing. Lectures on
Parallel Computation, Alan Gibbons y Paul Spirakis (eds.),
Cambridge International Series on Parallel Computation: 4,
Cambridge University Press, 1993.
(McNeill, 1995)
D. McNeill. Hand and mind: what gestures reveal about thoughts.
University of Chicago Press, 1995.
(Mérigot et al., 1986)
A. Mérigot, P. Clermont, J. Mehat, F. Devos y B. Zadovique. A
Pyramidal System for Image Processing. In Pyramidal Systems for
Computer Vision, V. Cantoni y S. Levialdi (eds.), Springer-Verlag,
Berlin, pp. 109-124, 1986.
REFERENCIAS
159
(Merkl et al., 1994)
D. Merkl, A.M. Tjoa y G. Kappel. A Self-Organizing Map that
Learns the Semantic Similarity of Reusable Software
Components, In Proceedings of the 5th Australian Conference on
Neural Networks, pp. 13-16, 1994.
(Miller et al., 1988)
R. Miller, V.K. Prasanna, D. Reisis y Q.F. Stout. Image
Computations on Reconfigurable VLSI Arrays. In Proceedings of
the IEEE Conference on Computer Vision and Pattern Recognition,
pp. 925-930, 1988.
(Miller et al., 1993)
R. Miller, V.K. Prasanna, D. Reisis y Q.F. Stout. Parallel
Computation on Reconfigurable Meshes. IEEE Transactions on
Computers, 42(6):678-692, 1993.
(Mittal et al., 1995)
A. Mittal, S. Banerjee, A. Valilaya y M. Balakrishnan. Real Time
Vision System for Collision Detection. Journal of Computer
Science and Automation, 25(1):174-208, 1995.
(Mokhtarian et al., 1996)
F. Mokhtarian, S. Abbasi y J. Kittler. Efficient and robust
retrieval by shape content through curvature scale space. In
Proceedings of the International Workshop on Image Databases
and MultiMedia Search, Amsterdam, pp. 35-42, 1996.
(Mora, 2001)
J. Mora. Unidades Aritméticas en coma flotante para Tiempo Real.
PhD Thesis, Universidad de Alicante, 2001.
(Mou y Yeung, 1994)
K.-L. Mou y D.-Y. Yeung. Gabriel Networks: Self-Organizing
Neural Networks for Adaptive Vector Quantization. In Proceedings
of the International Symposium on Speech, Image Processing and
Neural Networks, II:658-661, 1994.
(Nanda et al., 2000)
A. Nanda, K. Mak, K. Sugavanam y R. Sahoo. MemorIES: A
Programmable, Real-Time Hardware Emulation Tool for
Multiprocessor Server Design. SIGOPS Operating System Review,
34(5), 2000.
160
REFERENCIAS
(Nicollin y Sifakis, 1991)
X. Nicollin y J. Sifakis. The Algebra of Timed Process ATP: Theory
and Application. Technical Report RT-C26, Institut National
Polytechnique de Grenoble, 1991.
(Niehaus, 1994)
D. Niehaus. Program representation and Execution in Real-Time
Multiprocesor Systems. University of Massachusetts, 1994.
(Nudd et al., 1989)
G.R. Nudd, T.J. Atherton, R.M. Howarth, C.S. Clippingdale, N.D.
Francis, D.J. Kerbyson, R.A. Packwood, G.J. Vaudin y D.W.
Walton. WPM. A multiple-SIMD architecture for image
processing. In Proceedings of the Third International Conference on
Image Processing and its Applications, Coventry, pp. 161-165,
1989.
(O’Rourke y Toussaint, 1997)
J. O’Rourke y G.T. Toussaint. Pattern Recognition. In Discrete
and Computational Geometry, J.E. Goodman, J. O’Rourke (eds.),
CRC Press LLC, Boca Raton, Florida, 1997.
(Parkinson y Litt, 1990)
D. Parkinson y J. Litt (eds.). Massively Parallel Computing with
the DAP. MIT Press Research Monographs in Parallel and
Distributed
Computing,
The
MIT
Press,
Cambridge,
Massachussets, 1990.
(Pawelzik, 1991)
K. Pawelzik. Nichtlineare Dynamik und Hirnaktivität. Verlag Harri
Deutsch, 1991.
(Persa y Jonker, 2000a)
S. Persa y P. Jonker. Human-Computer Interaction using Real
Time 3D Hand Tracking. In Proceedings of the. 21st Symposium on
Information Theory in the Benelux, Wassenaar, pp. 71-75, 2000.
(Persa y Jonker, 2000b)
S. Persa y P. Jonker. Evaluation of Two Real Time Image
Processing Architectures. In Proceedings of the 6th Annual
Conference of the Advanced School for Computing and Imaging,
Lommel, 2000.
REFERENCIAS
161
(Prasanna et al., 1993)
V.K. Prasanna, C.-L. Wang y A.A. Khokhar. Low Level Vision
Processing on Connection Machine CM-5. In Proceedings of the
International Workshop on Computer Architectures for Machine
Perception, pp. 117-126, New Orleans, 1993.
(Pratt, 1990)
W.K. Pratt. Correlation techniques of image registration. Selected
Papers on Digital Image Processing, MS-17:243-248, 1990.
(Pretlove y Parker, 1993)
J.R.G. Pretlove y G.A. Parker. The Surrey Attentive Robot Vision
System. International Journal of Computer Vision, 7(1):89-107,
1993.
(Prewer, 1995)
D.
Prewer.
Connectionist
Pyramid
Powered
Perceptual
Organization: Visual Grouping with Hierarchal Structures of Neural
Network. Honours Report, Dept. of Computer Science, The Univ.
of Melbourne, 1995.
(Quek, 1994)
F. Quek. Toward a vision-based hand gesture interface. In
Proceedings of the ACM Symposium on Virtual Reality Software
and Technology , pp. 17-31, 1994.
(Quénot y Zavidovique, 1992)
The etca massively parallel data-flow functional computer for
real-time image processing. In IEEE International Conference on
Computer Design, Cambridge, pp. 492-495, 1992.
(Rajkumar et al., 1997)
R. Rajkumar, C. Lee, J.P. Lehozky y D.P. Siewiorek. A resource
Allocation Model for QoS Management. In Proceedings of the 18th
IEEE Real-Time Systems Symposium, 1997.
(Ramamritham et al., 1990)
K. Ramamritham, J.A. Stankovic y P.F. Shiah. Efficient
Scheduling Algorithms for Real-Time Multiprocessor Systems.
IEEE Transactions on Parallel and Distributed Systems, 1(2),
1990.
162
REFERENCIAS
(Ratha y Jain, 1997)
N.K. Ratha y A.K. Jain. FPGA-based Computing in Computer
Vision. In Proceedings of the 1997 Computer Architectures for
Machine Perception CAMP’97, pp. 128-137, 1997.
(Ratha y Jain, 1999)
N.K. Ratha y A.K. Jain. Computer Vision Algorithms on
Reconfigurable Logic Arrays. IEEE Transactions on Parallel and
Distributed Systems, 10(1):29-43, 1999.
(Ready, 1986)
J. Ready. Vrtx: A real-time operating system for embedded
microprocessor applications. IEEE Micro, 1986.
(Rehfuss y Hammerstrom, 1997)
S. Rehfuss y D. Hammerstrom. Comparing SFMD and SPMD
computation for on-chip multiprocessing of intermediate level
image understanding algorithms. In Proceedings of the 1997
Computer Architectures for Machine Perception CAMP’97,
Cambridge, pp. 2-11, 1997.
(Rehg y Kanade, 1993)
J.M. Rehg y T. Kanade. DigitEyes: Vision-Based Human Hand
Tracking. Technical Report CMU-CS-93-220, School of Computer
Science, Carnegie Mellon University, 1993.
(Rougeaux y Kuniyoshi, 1997)
S. Rougeaux e Y. Kuniyoshi. Robust Real-Time Tracking on an
Active Vision Head. In Proceedings of the International Conference
on Computer Vision and Pattern Recognition, pp. 1-6, 1997.
(Röwekamp et al., 1997)
T. Röwekamp, M. Platzner y L. Peters. Specialized Architectures
for Optical Flow Computation: A performance Comparison of
ASIC, DSP, and Multi-DSP. In Proceedings of the 8th International
Conference on Signal Processing Applications & Technology, San
Diego, 1997.
(Rygol et al., 1992)
M. Rygol, S. Pollard, C. Brown y J. Mayhew. A Parallel 3D Vision
System. In Active Vision, A. Blake y A. Yuille (eds.), The MIT
Press, 1992.
REFERENCIAS
163
(Schaefer et al., 1987)
D.H. Schaefer, P. Ho, J. Boyd y C. Vallejos. The GAM Pyramid. In
Parallel Computer Vision, L. Uhr (ed.), pp. 15-42, Academic Press,
1987.
(Sethi y Jain, 1987)
I.K. Sethi y R. Jain. Finding trajectories of feature points in a
monocular image sequence. IEEE Transactions on Pattern
Analisys and Machine Intelligence, 9(1):56-73, 1987.
(Sharkey et al., 1993)
P.M. Sharkey, D.W. Murray, S. Vandevelde, I.D. Reid y P.F.
McLauchlan. A Modular Head/Eye Platform for Real-Time
Reactive Vision. Mechatronics, 3(4):517-535, 1993.
(Sharkey et al., 1995)
P.M. Sharkey, D.W. Murray y P.F. McLauchlan. A mechatronic
approach to active vision systems. In 2nd International Conference
on Mechatronics and Machine Vision in Practice, Hong Kong, pp.
127-132, 1995.
(Shende, 1991)
A.M. Shende. Digital Analog Simulation of Uniform Motion in
Representations of Physical n-Space by Lattice-Work MIMD
Computer Architectures. PhD Thesis, State University of New York,
1991.
(Shimada et al., 1998)
N. Shimada, Y. Shirai, Y. Kuno y J. Miura. Hand Gesture
Estimation and Model Refinement using Monocular Camera Ambiguity Limitation by Inequality Constraints. In IEEE Proc. of
the 3rd International Conference on Automatic Face and Gesture
Recognition, Nara, pp. 268-273, 1998.
(Shiohara et al., 1993)
M. Shiohara, H. Egawa, S. Sasaki, M. Nagle, P. Sobey y M.V.
Srinivasan. Real-Time Optical Flow Processor ISHTAR. In
Proceedings of the Asian Conference on Computer Vision, Osaka,
pp. 790-793, 1993.
REFERENCIAS
164
(Siegel et al., 1996)
H.J. Siegel, T.D. Braun, H.G. Dietz, M.B. Bulaczewski, M.
Maheswaran, P.H. Pero, J.M. Siegel, J.J.E. So, M. Tan, M.D.
Theys y L. Wang. The PASM project: A study of reconfigurable
parallel computing. In Parallel Computing: Paradigms and
Applications, A.Y. Zomaya (ed.), pp. 78-114, International
Thomson Computer Press, London, 1996.
(Smith et al., 1999)
P. Smith, T. Drummond y R. Cipolla. Edge tracking for motion
segmentation and depth ordering. In Proceedings of the 10th
British Machine Vision Conference, Nottingham, 2:369-378, 1999.
(Son, 1995)
S.H. Son (ed.). Advances in Real-Time Systems. Prentice Hall,
1995.
(Sonka et al., 1998)
M. Sonka, V. Hlavac y R. Boyle. Image Processing, Analysis, and
Machine Vision (2nd edition). Brooks/Cole Publishing Company,
1998.
(Stankovic, 1992)
J. Stankovic. Real-Time
Massachusetts,1992.
Computing.
DCS,
University
of
(Stankovic y Ramamritham, 1990)
J. Stankovic y K. Ramamritham. What is predictability for realtime systems?. Journal of Real-Time Systems, 2, 1990.
(Stankovic y Ramamritham, 1991)
J. Stankovic y K. Ramamritham. The Spring kernel: a new
paradigm for real-time systems. IEEE Software, 1991.
(Starner y Pentland, 1995)
T. Starner y A. Pentland. Real-Time American Sign Language
Recognition from Video Using Hidden Markov Models. Technical
Report No. 375, Media Laboratory Perceptual Computing Section,
Massachussets Institute of Technology, 1995.
REFERENCIAS
165
(Starner et al., 1998)
T. Starner, J. Weaver y A. Pentland. A Real-Time American Sign
Language Recognition Using Desk and Wearable Computer Based
Video. Technical Report No. 466, Media Laboratory Perceptual
Computing Section, Massachussets Institute of Technology,
1998.
(Stoyenko, 1987)
A.D. Stoyenko. A schedulability analyzer for real-time Euclid. In
Proceedings of the 8th Real-Time Symposium, San Jose, 1987.
(Strong, 1991)
J.P.Strong. Computations on the Massively Parallel Processor at
the Goddard Space Flight Center. Proceedings of the IEEE,
79(4):548-558, 1991.
(Sturman, 1991)
D.J. Sturman. Whole-hand Input. PhD Thesis, School
Architecture and Planning, Massachussets Institute
Technology, 1991.
of
of
(Sunwoo y Aggarwal, 1991)
M.H. Sunwoo y J.K. Aggarwal. VisTA – An Image Understanding
Architecture. Parallel Architectures and Algorithms for Image
understanding, V.K. Prasanna Kumar (ed.), pp. 121-153,
Academic Press, 1991.
(Tanimoto, 1984)
S.L. Tanimoto. A Hierarchical Cellular Logic for Pyramid
Computers. Journal of Parallel and Distributed Computing, 1:105132, 1984.
(Terzopoulos y Szelinski, 1992)
D. Terzopoulos y R. Szelinski. Tracking with Kalman Snakes. In
Active Vision, A. Blake y A. Yuille (eds.), The MIT Press, 1992.
(Theys, 1996)
M.D. Theys. Programming Parallel Machines: An Image Morphology
Case Study and a Mixed-Mode Simulator. MSc Thesis, Purdue
Univ., 1996.
166
REFERENCIAS
(Thomson y Ryan, 1994)
T. Thomson y B. Ryan. PowerPC 620 Soars. Byte Magazine,
Noviembre, 1994.
(TI, 1991)
Texas Instruments, TMS320C4x User’s Guide, 1991.
(TMC, 1987)
Thinking Machines Corporation. Connection Machine Model CM2 Technical Summary. Technical Report HA87-4, 1987.
(Tokhi, 1998)
M.O. Tokhi. High performance Real-Time Computing Methods.
Shock and Vibration Digest, 30(5), 1998.
(Tokhi, 1999)
M.O. Tokhi. Special Issue on High performance Real-Time
Computing. Microprocessors and Microsystems, 23(6), 1999.
(Trautmann y Denoeux, 1995)
T. Trautmann y T. Denoeux. Comparison of dynamic feature map
models for environmental monitoring, In Proceedings of the
International Conference on Artificial Neural Networks, pp. 73-78,
1995.
(Triesch y von der Malsburg, 1996)
J. Triesch y C. von der Malsburg. Robust Classification of Hand
Postures against Complex Backgrounds. In Proceedings of the 2nd
International Workshop on Automatic Face-and Gesture
Recognition, Killington, pp. 170-175, 1996.
(Tucakov et al., 1996)
V. Tucakov, M. Sahota, D. Murray, A. Mackworth, J. Little, S.
Kingdon, C. Jennings y R. Barman. Spinoza: A Stereoscopic
Visually Guided Mobile Robots. In Proceedings of the 30th Hawaii
International Conference on System Sciences, 1996.
(Tuck y Kim, 1993)
R. Tuck y W. Kim. MasPar MP-2 PE Chip: A Totally Cool Hot
Chip. In IEEE 1993 Hot Chips Symposium, 1993.
REFERENCIAS
167
(Uhlin et al., 1995)
T. Uhlin, P. Nordlund, A. Maki y J.-O. Eklundh. Towards an
Active Visual Observer. In Proceedings of the International
Conference. on Computer Vision, Cambridge pp. 679-686, 1995.
(van der Molen y Jonker, 1998)
M.W. van der Molen y P. Jonker. A Comparison of Linear
Processor Arrays for Image Processing. M.Sc. Thesis, Faculty of
Applied Sciences, Delft University of Technology, 1998.
(van der Wal et al., 2000)
G. van der Wal, M. Hansen y M. Piacentino. The Acadia Vision
Processor. In IEEE proceedings of the International Workshop on
Computer Architecture for Machine Perception, Padua, 2000.
(Veltkamp y Hagedoorn, 1999)
R.C. Veltkamp y M. Hagedoorn. State-of-the-Art in Shape
Matching. Technical Report UU-CS-1999-27, Utrecht University, ,
1999.
(Wang et al., 1991)
B. Wang, G. Chen y H. Li. Configurational computation: A new
computation method on processor arrays with reconfigurable bus
system. In Proceedings of the 1991 International Conference on
Parallel Processing, III:42-48, CRC Press, 1991.
(Weems, 1993)
C. Weems. The Second Generation Image Understanding
Architecture and Beyond. Workshop on Computer Architectures for
Machine Perception, New Orleans, pp. 276-285, IEEE Computer
Society Press, 1993.
(Weems y Dropsho, 1994)
C. Weems y S. Dropsho. Real-Time: Computing: Implications for
General Microprocessors. University of Massachusetts, 1994.
(Weems et al., 1989)
C.C. Weems, S.P. Levitan, A.R. Hanson, E.M. Riseman, D.B. Shu
y J.G. Nash. The Image Understanding Architecture. International
Journal of Computer Vision, 2(3):251-282, 1989.
168
REFERENCIAS
(Woodfill y von Herzen, 1997)
J. Woodfill y B. von Herzen. Real-Time Stereo Vision on the
PARTS Reconfigurable Computer. In Proceedings of the IEEE
Symposium on Field-Programmable Custom Computing Maxhines,
Napa, pp. 242-250, 1997.
(Wu et al., 2000)
Y. Wu, Q. Liu y T.S. Huang. An Adaptive Self-Organizing Color
Segmentation Algorithm with Application to Robust Real-time
Human Hand Localization. In Proceedings of the IEEE Asian
Conference on Computer Vision, Taywan, pp. 1106-1111, 2000.
(Yuille y Hallinan, 1992)
A. Yuille y P. Hallinan. Deformable Templates. In Active Vision, A.
Blake y A. Yuille (eds.), The MIT Press, 1992.
(Zhang, 1993)
Z. Zhang. Le problème de la mise en correspondance: L’état de
l’art. Rapport de recherche nº 2146, Institut National de
Recherche en Informatique et en Automatique, 1993.