Ranking de Encuestadoras Uno de los objetivos de Tresquintos es
Anuncio

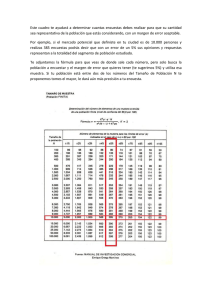
Ranking de Encuestadoras Uno de los objetivos de Tresquintos es analizar encuestas de opinión pública. Una forma de analizar encuestas es tender inferencias cada vez que una encuestadora publica una encuesta nueva. Otra forma de analizar encuestas es tender inferencias en base a múltiples encuestas, de una serie de encuestadoras distintas. Los que conocen el terreno de la opinión pública en Chile sabrán que la segunda forma no es nada de fácil. Las encuestas difieren en varios aspectos. Tienen diferencias significativas en sus ‘fechas de trabajo de campo’, ‘diseños metodológicos’ y ‘tamaños de muestra’. Durante la campaña presidencial de 2009 hubo un par de sitios que intentaron tender inferencias en base a múltiples encuestas, al ponderar varias de ellas en un indicador único que intentaba representar el valor real de la intención de voto para cada candidato. El sitio TodoPolítica solo consideró las 4 encuestas más recientes. Promedió el valor de la última encuesta con las 3 anteriores en una regresión local para generar su indicador único. El sitio Vota 2009 de La Tercera tuvo una aproximación similar. Ponderó todas las encuestas con una media aritmética para dar con su propio indicador único. En ambos casos, encuestadoras y encuestas fueron comparadas par a par. En el caso de TodoPolítica, las encuestas presenciales que entrevistaron a más de 1,000 personas con un margen de error de 3,0% fueron consideradas igual de relevantes que las encuestas telefónicas que entrevistaron a 600 personas con un margen de error de 4,5%. En el caso de Vota2009, las encuestas que se realizaron durante fines de 2008 (más de un año antes de la elección!) fueron consideradas igual de relevantes que las encuestas que fueron realizadas a fines de 2009 (menos de un mes antes de la elección!). Comparar encuestadoras y sus encuestas involucra un proceso metodológico complejo. Justamente porque todas las encuestas difieren, las respectivas proporciones de intención de voto que reportan tienden a ser distintos. Por ejemplo, podemos anticipar proporciones diferentes dependiendo si las encuestas son presenciales o telefónicas, o si los entrevistados son seleccionados por cuota o de forma aleatoria. Incluso si todas las encuestadoras tuvieran las mismas características particulares, es probable que observáramos diferencias en sus respectivas encuestas. Para crear un indicador único sin sesgo, es importante partir de la base que todas las encuestadoras tienen características particulares distintas y todas sus encuestas introducen error en sus predicciones. El primer paso, entonces, es asignarles mayor peso en el indicador único a las encuestadoras que tienen encuestas que introducen menos error en sus predicciones. Es decir, crear un Ranking de Encuestadoras. Para determinar que encuestadora tiene menos error, observé las encuestas que sondearon intención de voto para la primera vuelta de la elección presidencial de 2009. En total, consideré 12 encuestadoras: CEP CERC Direct Media El Mercurio-Opina Giro País (Subjetiva) Imaginacción IPSOS La Segunda (UDD) La Tercera MORI TNS-Time UDP Para rankear a encuestadoras, se debe partir desde un punto mínimo de homogeneidad entre las encuestadoras. Es decir, se debe seleccionar datos que en esencia estén midiendo lo mismo. Por ejemplo, no todas las encuestas reportan el porcentaje de encuestados que se declara registrado para votar. La encuestadora CERC excluye nulos, blancos y abstenciones. Es decir, la intención de voto por candidato suma 100%. Otras encuestadoras, en cambio, sí reportan nulos, blancos, abstenciones, por lo cual los votos válidos suman menos de 100%. Para homogeneizar las encuestadoras, normalicé los datos de todas las encuestas a 100%. Si suponemos que todas las encuestadoras diseñan sus encuestas metodológicamente bien, deberíamos esperar que aquellas con un menor margen de error (o un mayor número de encuestados) tengan una mejor capacidad predictiva. Sin embargo, el siguiente cuadro muestra que no hay una asociación entre margen de error y capacidad predictiva. Algunas encuestadoras con un bajo margen de error fallaron más que encuestadoras con un alto margen de error. Por ejemplo, la encuestadora con el margen de error más bajo (Ipsos, con 2,5%) tuvo la octava (de doce) mejor predicción de intención de voto para Piñera. Eso es suficiente evidencia para sostener que el margen de error no es la única fuente de error en las encuestas. Si el margen de error fuera la única fuente de error de las encuestas, todas las encuestas tendrían una predicción correcta, dentro de su margen de error. En esencia, esto significa que las encuestadoras introducen un error natural a partir de su particulares procesos metodológicos. Para medir el error de cualquier encuesta, propongo aislar sus fuentes de error en una parte provista por la encuestadora y una parte no provista por la encuestadora: ERROR REAL = Error Reportado + Error-No-Forzado Ahora bien, en vez de mirar el error de cada encuesta en las predicciones de cada candidato, decidí fijar un parámetro de estimación. Esto se justifica porque es común que una encuesta reporte una predicción correcta para un candidato, pero falle significativamente en su predicción para otros candidatos. Por ejemplo, MORI hizo la segunda mejor predicción de votación para Piñera, pero tuvo mayor error que el resto de las encuestadoras en la predicción de votación para los otros candidatos. En este caso el parámetro de estimación más importante es el que mide la diferencia en votación entre los dos candidatos con más preferencias. Esto tiene sentido porque a menudo sabemos quién es el favorito, pero no sabemos por cuánto. En elecciones competitivas esta distancia es crucial. Si ambos candidatos giran en torno al 50% de las preferencias, lo importante es conocer la distancia entre ambos. Por ejemplo, en 2009, todas las encuestas reportaron a Piñera como favorito, pero todas con distancias superiores diferentes por sobre Frei. Error Reportado El primer paso es estimar el Error Reportado. Esta es la diferencia entre la predicción del parámetro de cada encuesta y el parámetro real. Es la forma más básica de medir el error de una encuesta. El siguiente cuadro muestra el error reportado para el parámetro de estimación. La columna ‘Parámetro Estimado’ es la predicción del parámetro (la diferencia entre Piñera y Frei). La columna ‘Error Parámetro’ es la diferencia entre parámetro estimado y el parámetro real. La columna ‘Error Reportado’ es el valor absoluto de ‘Error Parámetro’. El índice de mayor interés es ‘Error Reportado’, que muestra la distancia absoluta del parámetro estimado de cada encuesta y el parámetro real (en este caso 14,5%). El promedio de error reportado de todas las encuestas fue de 3,7%. Esto significa que en general las encuestas hicieron buenas predicciones, haciendo una estimación relativamente cercana al resultado de la elección. De todas las encuestas La Segunda/UDD tuvo el error reportado más bajo (0,05%) con una predicción de 14%, mientras que ICSO-UDP tuvo el error reportado más alto (7,9%) con una predicción de 6,6%. Error-No-Forzado El segundo paso es estimar el Error-No-Forzado. Esta es la diferencia entre el error reportado y el margen de error. Es lo que el margen de error no explica en el error reportado de la encuesta. El siguiente cuadro muestra el error-no-forzado para el parámetro de estimación. La columna ‘Error Reportado’ es el valor absoluto de ‘Error Parámetro’. La columna ‘Margen de Error’ muestra el margen de error que reporta la encuesta. La columna ‘Error-No-Forzado’ es la diferencia entre el error reportado y el margen de error. El índice de mayor interés aquí es ‘Error-No-Forzado’, que muestra el error que tiene una encuesta, que no puede ser explicado por su margen de error. Un índice negativo significa que la encuesta tuvo una predicción dentro de su margen de error. Un índice positivo significa que la encuesta tuvo una predicción fuera de su margen de error. De las 12 encuestas, 5 estuvieron dentro de sus márgenes de error. De las 7 encuestas restantes, Imaginacción tuvo el error-no-forzado más bajo (0,7%), y ICSO-UDP tuvo el error-no-forzado más alto (5,2%). Error-No-Forzado Relativo El tercer paso es estimar el Error-No-Forzado Relativo. Esta es la diferencia entre el error-no-forzado de cada encuesta y el promedio de error-no-forzado de todas las encuestas. Esto permite estimar la capacidad predictiva de cada encuesta en base a la capacidad predictiva promedio de todas las encuestas. El siguiente cuadro muestra el error-no-forzado relativo. Las columnas ‘Margen de Error’ y ‘Error-No-Forzado’ son lo mismo que arriba. La columna ‘Error-No-Forzado Relativo’ es la diferencia entre ‘Error-No-Forzado’ y el promedio de ‘Error-No-Forzado’. El índice de mayor interés es ‘Error-No-Forzado Relativo’, que muestra el error que tiene una encuesta, en comparación con todas las encuestas. Un índice negativo significa que la encuesta tuvo un error-no-forzado menor que el promedio de todas las encuestas. Un índice positivo significa que la encuesta tuvo error-no-forzado mayor que el promedio de todas las encuestas. Por ejemplo, La Tercera tuvo un error-no- forzado de 1,4% menos que el resto de las encuestas. Asimismo, Giro País/Subjetiva tuvo un error-no-forzado de 0,03% más que el resto de las encuestas. Personalmente, tengo algunas aprensiones metodológicas con las características particulares de algunas de las encuestadoras que figuran en la parte superior del ranking. Principalmente con los tamaños de las muestras y los métodos de recopilación de datos. Sin embargo, el ranking esta construido en base a la capacidad predictiva de las encuestas, y no a sus características metodológicas. Para efectos de un ranking, las encuestas que tienden a introducir un error-no-forzado relativo menor simplemente deben tender a figurar en la parte alta de la tabla. Un argumento en contra de este punto es que no todas las encuestas son predictivas. Dado que algunas encuestas se hacen con meses de anticipación a la elección (e.g., ICSO-UDP), las encuestadoras pueden argumentar que su encuesta es solo una foto del momento. La respuesta es simple. Cuando una encuestadora decide preguntar sobre “la elección del próximo domingo”, esta haciendo una predicción. Además, si cada año electoral la encuestadora hace la misma pregunta con la misma distancia de tiempo a la elección, podremos fácilmente anticipar su error real si no cambia su metodología.