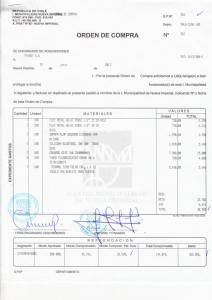
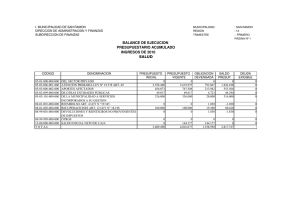
“Aplicación de técnicas de minería de datos para la detección de
Anuncio

Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Universidad Nacional de Misiones Facultad de Ciencias Exactas Químicas y Naturales Tesis de grado Licenciatura en Sistemas de Información “Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones” Autor: ASC Facundo José Yatchesen Tutor: Dr. Horacio Daniel Kuna (UNaM) Co-tutor: Dr. Ramón García Martínez (UNLa) Co-tutora: CPN María Eugenia Safrán (UNaM) Año 2015 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones “Hay tres caminos que llevan a la sabiduría: la imitación, el mas sencillo; la reflexión, el más noble; y la experiencia, el más amargo” Confucio II Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Resumen La minería de datos (MDD) se constituye como una alternativa altamente viable para la detección de fraude tributario, permitiendo minimizar el coste de recursos asociados, principalmente en las etapas iniciales del proceso, acotando el espectro de casos que requieren un estudio de mayor profundidad. Sin embargo las municipalidades de pequeño y mediano tamaño tienen particularidades en cuanto a la disponibilidad de cantidad, calidad y fuente de datos , como así también en lo referente a los recursos para afrontar la utilización de esta alternativa. En este trabajo se plantean una serie de consideraciones formuladas a partir del estudio de un caso particular de detección de fraude mediante la aplicación de técnicas de MDD, sobre un municipio de mediano tamaño de la provincia de Misiones, República Argentina. Palabras clave: minería de datos, CRISP-DM, fraude tributario, clustering, contribuyentes, municipalidad III Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Abstract Data mining (MDD) is established as a highly feasible to detect tax fraud alternative , allowing to minimize the cost associated resources, mainly in the initial stages of the project quoting the spectrum of cases that require further study. However municipalities small and medium size have particularities concerning the availability of quantity, quality and source of data , as well as regarding the resources to address the use of this alternative. This paper raises a number of considerations made from the study of a particular case of fraud detection by applying MDD techniques on a medium sized town in the province of Misiones, Argentina. Keywords: data mining, CRISP-DM, tax fraud, clustering, taxpayers, municipality IV Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Agradecimientos A mi familia por el apoyo en todos estos años y en especial a Melanie por ser mi compañera de camino en todo momento. A la sede de Apóstoles de la Facultad de Ciencias Exactas, Químicas y Naturales, Universidad Nacional de Misiones, por haberme permitido formarme como profesional y en particular al Dr. Horacio Daniel Kuna por su orientación, paciencia y confianza. A todos los colegas con los que he tenido el privilegio de trabajar a lo largo de estos años. VI Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Indice Capitulo 1: Introducción.....................................................................................................................13 1.1 Introducción.............................................................................................................................14 Capitulo 2: Estado del arte.................................................................................................................17 2.1 Minería de datos.......................................................................................................................18 2.2 Clasificación de técnicas de MDD ..........................................................................................22 2.3 Metodología de implementación de MDD .............................................................................24 2.4 Minería de datos y detección de fraude...................................................................................26 2.5 Técnicas de MDD aplicadas a la detección de fraude financiero............................................28 2.6 Construcción del conjunto de datos para la detección de fraude financiero aplicando técnicas de MDD.........................................................................................................................................30 Capitulo 3: Planteamiento del problema............................................................................................33 3.1 Planteamiento del problema.....................................................................................................34 3.2 Objetivos generales..................................................................................................................34 3.3 Objetivos específicos...............................................................................................................34 Capitulo 4: Solución propuesta..........................................................................................................37 4.1 Fase I: Comprensión del negocio.............................................................................................38 4.2 Fase II: Comprensión de los Datos..........................................................................................47 4.3 Fase III: Preparación de los Datos...........................................................................................52 4.4 Fase IV: Modelado...................................................................................................................58 4.5 Fase V: Evaluación..................................................................................................................64 4.6 Fase VI: Implementación.........................................................................................................81 Capitulo 5: Conclusiones y futuras lineas de investigación...............................................................83 5.1 Conclusión...............................................................................................................................84 5.2 Futuras lineas de investigación................................................................................................85 Apéndices / Anexos............................................................................................................................87 Anexo 1: Tabla de atributos para el conjunto de datos..................................................................88 Anexo 2: Función de categorización de importes..........................................................................90 Anexo 3: Procedimiento de transformación de datos hacia el conjunto de datos..........................91 Bibliografía.......................................................................................................................................103 VIII Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Indice de figuras Figura 1: Diagrama de base de datos sistema de comercio................................................................42 Figura 2: Diagrama de base de datos sistema de inmuebles...............................................................44 Figura 3: Diagrama de base de datos sistema de patentes..................................................................45 Figura 4: Diagrama de base de datos sistema de padrón....................................................................46 Figura 5: Diseño tabla inm_pagos......................................................................................................48 Figura 6: Diseño tabla inm_datoscontribuyente.................................................................................49 Figura 7: Diseño tabla inm_intimaciones...........................................................................................49 Figura 8: Diseño tabla pat_pagos.......................................................................................................50 Figura 9: Diseño tabla pat_propietarios.............................................................................................50 Figura 10: Diseño tabla ccio_pagos...................................................................................................50 Figura 11: Diseño tabla ccio_pagos_detalle.......................................................................................51 Figura 12: Diseño tabla pco_entidad_personas..................................................................................51 Figura 13: Diseño tabla ccio_intimaciones_rec_deudas....................................................................52 Figura 14: Esquema de implementación del proyecto........................................................................54 Figura 15: Resultado exploración inicial - Tasa de inmueble.............................................................57 Figura 16: Resultado exploración inicial - Tasa de patente................................................................58 Figura 17: Resultado exploración inicial - Tasa de comercio.............................................................58 Figura 18: Diagrama modelo de MDD, RapidMiner v5.2.................................................................61 Figura 19: Modelo de optimización, principal...................................................................................62 Figura 20: Modelo de optimización, sub proceso bucle de parámetros.............................................62 Figura 21: Configuración de parámetros y medidas de performance disponibles.............................63 Figura 22: Resultado del proceso de optimización del parámetro k...................................................64 Figura 23: Resultado ejecución 1 - Vista texto distribución de clusters.............................................66 Figura 24: Resultado ejecución 1 - Gráfico de centroides de clusters................................................67 Figura 25: Resultado ejecución 1 - Tabla de centroides.....................................................................68 Figura 26: Resultado ejecución 1 - Vista detallada cluster_3.............................................................70 Figura 27: Indice Davies Bouldies para sub conjunto cluster_4........................................................71 Figura 28: Indice de distancia promedio dentro del cluster_4............................................................72 Figura 29: Resultado ejecución 2 - Vista texto distribución de clusters.............................................72 Figura 30: Resultado ejecución 2 - Vista gráfica de centroides de clusters.......................................74 Figura 31: Resultado ejecución 2 - Vista tabla centroides de clusters................................................75 IX Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Figura 32: Resultado ejecución 2 - Árbol de decisión.......................................................................76 Figura 33: Indice de distancia promedio dentro del cluster_1............................................................78 Figura 34: Resultado ejecución 3 - Vista texto distribución de clusters.............................................78 Figura 35: Resultado ejecución 3 - Vista tabla centroides de clusters................................................79 Figura 36: Resultado ejecución 3 - Vista gráfica de centroides de clusters.......................................80 Figura 37: Resultado ejecución 3 - Árbol de decisión.......................................................................81 X Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Indice de tablas Tabla 1: Rango de categorías para los importes abonados.................................................................55 XI Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Facundo José Yatchesen 12 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Capitulo 1 Introducción Facundo José Yatchesen 13 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones 1.1 Introducción Hoy en día los seres humanos nos encontramos rodeados por una inmensa cantidad de datos, a tal punto de abrumarnos. Este hecho no es más que el resultado de la evolución de los gigantes mainframes de los años sesenta, restringidos a uso exclusivamente corporativos, en lo que hoy se ha transformado en computadoras omnipresentes, vinculadas a cada una de nuestras actividades diarias, y sin las cuales gran parte de estas actividades no podrían ser llevadas a cabo, a tal punto que cada una de nuestras acciones se representa en un registro de una base de datos, desde las enfermedades que nos afectan, los detalles de nuestras llamadas telefónicas, estadísticas gubernamentales, los hábitos de compra en el supermercado, la elección de amigos en redes sociales, conducta financiera hasta imágenes de cuerpos astronómicos. Hoy en día, como resultado de la evolución de los dispositivos informáticos, léase dispositivos móviles, bases de datos, disponibilidad y velocidad de conexión a internet, redes sociales, cada una de nuestras decisiones, al interactuar con estos elementos, es almacenada en algún registro de alguna base de datos. Si bien la capacidad de generación de datos ha sido ampliamente expandida, la capacidad de entenderlos no. Esta abundancia de datos ha sido ocasionalmente denominada datos ricos pero información pobre, que se traduce en la toma de decisiones basadas no en la información que se dispone, sino más bien en la experiencia e intuición de los responsables de las decisiones. En algunos casos los expertos en las áreas se encargan de actualizar manualmente bases de conocimiento que sirvan de base para la toma de decisiones, sin embargo, este es un proceso engorroso, costoso tanto monetariamente como en tiempo, además del hecho de que puede estar sujeto a sesgo por parte del experto. Otro inconveniente se relaciona al esfuerzo sobre humano que supone la comprensión de tal volumen de datos sin las herramientas de análisis apropiadas, y que deriva también en la falta de utilización de conocimiento potencialmente útil. Existen puntos críticos relacionados a la detección de fraude mediante la aplicación de técnicas de minería de datos: por un lado la falta de datos confiables y reales sobre los cuales se puedan trabajar, ya que las organizaciones que son víctimas de fraude informático tienden a ocultar cualquier tipo de evidencia que ponga de manifiesto sus debilidades y llegara a afectar su accionar; por otro lado la falta de investigación intensiva de métodos y técnicas de minería de datos orientados a la detección de fraude informático. Actualmente no se disponen de estudios en los que Facundo José Yatchesen 14 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones se plantee la detección de fraude en administraciones municipales, sin embargo, existen trabajos en los que se analizan los diferentes enfoques, técnicas innovadoras, desde los puntos críticos que deberán tenerse en cuenta para su aplicación a la detección de fraude informático. Así en [1] se plantea una serie de indicadores para medir la eficiencia de técnicas y métodos de minería de datos aplicados a la detección de fraude informático, como así también conceptos relacionados, para luego hacer una comparación de los métodos y técnicas disponibles de acuerdo al enfoque de cada uno de ellos. En [2] se realiza un intensivo análisis de las técnicas y métodos para la detección de anomalías desde las diferentes áreas de conocimiento, incluyendo áreas relacionadas a la minería de datos. En el Capitulo 2 se desarrolla el estado del arte, introduciendo conceptos y trabajos realizados en el ámbito de la MDD y la detección de fraude, principalmente financiero. Dentro del Capitulo 3 se lleva adelante el planteo del problema y las consideraciones pertinentes. El Capitulo 4 presenta la solución propuesta utilizando la metodología CRISP-DM. Finalmente en el Capitulo 5 se plantean las conclusiones de la tesis como así también las futuras lineas de investigación. Facundo José Yatchesen 15 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Facundo José Yatchesen 16 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Capitulo 2 Estado del arte Facundo José Yatchesen 17 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones 2.1 Minería de datos La industria de la tecnología de la información ha evolucionado de manera asombrosa en las ultimas décadas, empezando con la introducción y difusión masiva de las computadoras personales en la década del 80, hasta la actualidad con la explosión del uso de servicios relacionados a Internet (cloud computing, teléfonos inteligentes, Voice Over IP, Software as a Service, entre otros). Hoy en día los sistemas de información modernos, son capaces de generar volúmenes siderales de datos, registrando los conceptos mas diversos, desde las mas triviales como el acceso a un sitio web, el acceso a un edificio, imágenes de cámaras de seguridad, pasando por movimientos bancarios, transacciones con tarjetas de crédito e inclusive documento y patentes generados en centros de investigación, laboratorios, o centros de observación del espacio. La gestión de estos datos ha acompañado esta evolución desde dos grandes ramas, por un lado las colecciones de datos, la creación y mantenimiento de estos datos, y por otro lado el análisis y la comprensión de los mismos. La evolución del hardware, sumada al desarrollo de software de control, trajo aparejada un sin fin de mejoras en lo relacionado al almacenamiento y gestión de los datos, pasando de archivos planos simples y de pequeño tamaño a complejos sistemas de gestión de base de datos, con un gran volumen de información sobre ellos, con una gran heterogeneidad en el formato, origen y medios de almacenamiento. Si bien la gestión eficiente de un alto volumen de información es competitivamente ventajosa para todas las organizaciones, lo que resulta aún mas importante se relaciona con la capacidad de transformar este marcado volumen de información en conocimiento potencialmente útil para la toma de decisiones, disminuyendo la probabilidad de cometer errores en el proceso decisorio aprovechando el gran activo que representa la información para la organización. El problema que se plantea es que al contar con un alto volumen de información a procesar, la capacidad humana se ve rebalsada, dando lugar a lo que se conoce como muchos datos pero poco conocimiento [3], por lo que es necesaria la utilización de herramientas que permitan automatizar este procesamiento y obtener así, en periodos de tiempo razonables, conocimiento utilizable para la toma de decisiones, bajo esta necesidad, surge lo que se conoce como inteligencia de negocios. Dentro de la inteligencia de negocios se enmarca a la explotación de información [4], que consiste en el proceso por el cual se transforma la información presente en las bases de datos en conocimiento aplicable a la toma de decisiones; un termino similar a explotación de información Facundo José Yatchesen 18 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones para representar la misma idea se plantea con Knowledge Discovery in Databases (KDD). La explotación de información es un proceso que puede ser llevado a cabo manualmente a través del análisis de expertos en el área de estudio, el principal inconveniente en que este análisis resulta altamente costoso en términos monetarios, lento en términos de tiempo y altamente subjetivo dada la alta influencia del factor humano [5], estos motivos provocan que el análisis manual sea inpráctico, surgiendo la necesidad de utilizar herramientas que aporten eficiencia al proceso. La minería de datos (MDD) constituye una de las etapas centrales del proceso de explotación de información o KDD, en la cual se tiene como objetivo la obtención de patrones en base a los datos disponibles; usualmente se utiliza el concepto de MDD como sinónimo del termino explotación de información, dada la importancia que ésta aporta al proceso. La MDD es el análisis de conjuntos de datos, generalmente de gran tamaño, para encontrar relaciones insospechadas y para sumarizar los datos en nuevas maneras de modo que sean útiles y comprensibles para el propietario de los datos; los resultados de este análisis dependen de la técnica y del objetivo que se persigue, pueden convertirse en modelos o patrones, representados por ecuaciones lineales, reglas, clusters, gráficos, árboles de decisión, patrones recurrentes en series de tiempo, entre otros [6]. Otra definición de MDD la plantea como la extracción de información interesante, no trivial, implícita, previamente desconocida, y potencialmente útil de grandes bases de datos [5]; otro autor la define como el proceso de encontrar patrones, previamente desconocidos, en los datos, a través de procesos automáticos o semi automáticos, teniendo como objetivo que estos resultados sean potencialmente útiles para la obtención de algún tipo de ventaja, por lo general económica [7]. Para lograr este objetivo la MDD utiliza técnicas de diferentes disciplinas, como por ejemplo, estadística, matemática, computación gráfica, visualización de datos, inteligencia artificial, economía, computación de alta prestación, sistemas expertos, reconocimiento de patrones, bases de datos, ingeniería de software [5], entre otras. Cabe aclarar que la obtención de patrones puede realizarse utilizando técnicas provenientes de la estadística, el inconveniente que se plantea es que al contar con un volumen alto de información esta técnicas sufren una disminución de su eficiencia; otro punto a tener en cuenta es que el uso de la estadística implica la adecuación del conjunto de datos analizado a un modelo matemático previamente planteado del cual se obtienen las características, mientras que con la MDD lo que se busca es la obtención de un modelo conformado por patrones que caractericen al Facundo José Yatchesen 19 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones conjunto de datos analizado [8]. Otra diferencia que se plantea entre la estadística y la MDD, es el hecho de que en la MDD los datos son observacionales, es decir, son resultado de procesos ajenos al de MDD en si, en otras palabras, fueron generados como requerimiento de otro proceso, como por ejemplo la registración de las cobros de un determinado impuesto, mientras que en la estadística los datos obtenidos son experimentales, es decir, se obtienen o conforman específicamente para el análisis estadístico a través de cuestionarios, encuestas, etcetera. Los objetivos que se pueden alcanzar a través de la ejecución de un proceso de MDD, pueden definirse en dos grandes grupos, dependiendo ello del/de los algoritmos utilizados, por un lado la predicción de valores, en la que se pretendes obtener valores para atributos a futuro teniendo en cuenta el histórico de los datos y por otro la obtención de patrones que caractericen a la información [9]. Teniendo en cuenta el objetivo de la MDD, las herramientas disponibles y los recursos que son utilizados como materia prima para el proceso, es posible identificar a los siguientes elementos de un sistema [3]: • Bases de datos, datawarehouse u otros repositorios de información: esta constituido por todas las fuentes de información sobre las cuales se pretende aplicar algoritmos a fin de obtener patrones; incluye bases de datos, hojas de calculo, datawarehouse, archivos de diferentes formatos. En algunos casos es necesaria la aplicación de técnicas de limpieza e integración de datos para que estos sean utilizables. • Servidor de bases de datos o datawarehouse: es el responsable de obtener los datos desde las diferentes fuentes y, opcionalmente, transformarlo en datos utilizables por los algoritmos seleccionados. • Base de conocimiento: esta conformado por una serie de lineamientos que permiten medir la calidad de los patrones obtenidos como resultado de la aplicación de los algoritmos, puede incluir aseveraciones de expertos en el dominio de estudio, rangos para valores, mínimos y máximos. • Motor de minería de datos: consiste en una serie de módulos funcionales en los que se implementan algoritmos de clusterizacion, descubrimiento de reglas, descubrimiento de reglas de pertenencia a grupos, ponderación de atributos, ponderación de reglas de pertenencia a Facundo José Yatchesen 20 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones grupos entre otros. • Modulo de evaluación de patrones: consiste en la utilización de la base de conocimiento para el filtrado de patrones potencialmente útiles. Para mejorar el rendimiento del sistema es recomendable que el modulo de evaluación se encuentre integrado al motor de minería para minimizar la cantidad de patrones irrelevantes obtenidos de la aplicación de los algoritmos. • Interfaz gráfica: se encarga de la comunicación entre el usuario y el sistema de minería de datos, debe permitir el monitoreo del rendimiento y el ajuste de los parámetros necesarios a fin de hacer mas eficiente el sistema. Es posible generalizar las etapas que conlleva el proceso de MDD, de la siguiente manera [3]: 1. Integración de datos: en primera instancia los datos, materia prima del proceso, pueden provenir de distintas fuentes, las cuales deberán ser integradas en un formato común para su posterior procesamiento. Cabe destacar la importancia que cobra la utilización de técnicas que permitan la limpieza de los datos con ruido o inconsistentes, para de esta manera aumentar la eficiencia del procesamiento de los mismos. Otra de las tareas relacionadas a la integración de datos tiene que ver con la selección de los mismos, es decir, la selección de aquellos atributos que aportan información o que son potencialmente útiles para la obtención de patrones, esta tarea puede ser llevada a cabo si se cuenta con el conocimiento de un experto en el área de estudio, o puede ser resultado de la aplicación de los propios algoritmos de MDD. 2. Transformación de datos: debido a que los algoritmos de MDD poseen requisitos en cuanto a las características de los atributos que pueden procesar, en necesaria la transformación de los datos integrados, para que puedan constituirse en entradas para los algoritmos a utilizar. 3. Minería de datos: constituye la etapa central del proceso, en la cual mediante la aplicación de los diferentes algoritmos es posible la obtención de patrones en la información. La utilización de los algoritmos dependerá directamente del/de los objetivo/s del proceso. Una vez obtenidos los resultados de los algoritmos es importante contar con la asistencia de un experto en el área de estudio, que aporte medidas de monitoreo de la calidad de los resultados, tanto como criterio de parada del proceso o como herramienta para eliminar Facundo José Yatchesen 21 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones patrones triviales para aumentar la eficiencia del algoritmo. 4. Presentación de resultados: tiene por objetivo la presentación de los resultados finales obtenidos del proceso de MDD, se utilizan principalmente técnicas relacionadas a la visualización de información y conocimiento, las mismas varían dependiendo del publico al que va dirigida. Si bien las etapas del proceso de MDD son definidas de manera secuencial, la naturaleza del procesamiento lo hace iterativo, ya que presentar los datos al experto en el área de estudio (aunque implique una presentación preliminar), puede resultar en una necesidad de ajuste de los datos integrados, y esto acarrear un re procesamiento de todas las etapas, siempre teniendo como objetivo el aumento de la eficiencia del proceso y de la calidad de los patrones obtenidos. 2.2 Clasificación de técnicas de MDD Existen diferentes modelos aplicables dentro de procesos de MDD, en general resulta conveniente caracterizarlos según los objetivos perseguidos por los responsables de llevarlos adelante, este hecho no elimina la posibilidad de fusionar estos modelos heterogéneos para lograr un objetivo mas complejo. En el nivel de mayor abstracción las técnicas de MDD pueden enmarcarse en dos grandes grupos, por un lado las técnicas descriptivas, las cuales buscan, como su nombre lo indica, expresar las características del conjunto de datos a través de un modelo, el cual sumariza las características de los datos analizados; y por el otro lado las técnicas predictivas, las cuales tienen por objetivo, teniendo como base los datos disponibles, predecir el valor o el comportamiento que tendrá un conjunto de datos teniendo en cuenta un rango de valores para ciertos atributos. La principal diferencia que se plantea entre las técnicas descriptivas y las predictivas, esta en que en las primeras el análisis no se encuentra enfocado en un atributo o variable en particular, mientras que en las segundas si, convirtiéndose ésta en el centro del análisis. Esta caracterización de alto nivel, resulta superficial y poco practica, por lo que es recomendable disminuir el nivel de abstracción utilizando taxonomías que tengan en cuenta el objetivo de estas, facilitando la elección de las mismas al momento de aplicarlas al análisis, una de las que resulta interesante es la propuesta en [6], la cual lo plantea de la siguiente manera: Facundo José Yatchesen 22 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones 1. Análisis de datos exploratorio: consiste básicamente en técnicas que permiten explorar el conjunto de datos disponible sin tener bases y/o ideas solidas o especificas sobre qué es lo que se esta buscando. Estas técnicas son principalmente interactivas y visuales, las cuales permiten proyectar los puntos del conjunto de datos en el espacio, para espacios hasta 3 o 4 variables existen técnicas simples y efectivas de visualización, pero a medida que la cantidad de variables aumenta, resulta compleja su visualización he aquí en donde cobran importancia las técnicas de proyección. El representar un set de datos de gran tamaño puede resultar engorroso, e inclusive complicar la visualización y comprensión de los mismos, por este motivo existen casos en los que resulta necesaria la sumarización o acotación del conjunto de datos, surgiendo el riesgo de perder detalles importantes. Dentro de estas técnicas podemos mencionar a los gráficos coxcomb, DOE scatter, autocorrelación, caja, estrella, Weibull, Youden, entre otros. 2. Modelos descriptivos: en estas técnicas el objetivo es describir a todos los datos analizados, para lograrlo se utilizan técnicas relacionadas a la estimación de la probabilidad de atributos, segmentación del conjunto de datos en unidades mas pequeñas que poseen características similares, análisis de la relación entre los atributos del conjunto de datos. Cabe aclarar que el análisis de los resultados obtenidos mediante estas técnicas debe ser realizado por expertos en el área de estudio, ya que a partir de esta monitorización puede ser necesario un ajuste de los parámetros de las técnicas utilizadas, sobre todo teniendo en cuenta que para ciertos algoritmos no existen modelos y/o técnicas formales que permitan definir de manera única el mejor valor para todos los casos aplicables. Dentro de estas técnicas podemos mencionar: k-means, redes SOM, k-medoids, DBSCAN, Suport Vector Clustering estimación de densidad no paramétrica, entre otros. 3. Modelos predictivos, clasificación y regresión: la meta en estos casos es, mediante el análisis y modelado a partir de los datos disponibles, permitir la predicción de los valores de ciertos atributos. En la clasificación la variable a predecir es categórica, mientras que en la regresión la variable es cuantitativa. Dentro de este grupo podemos mencionar: arboles de decisión, redes bayesianas, redes neuronales, regresión logística, entre las mas populares. 4. Descubrimiento de patrones y reglas: las tareas mencionadas en los tres puntos anteriores se refieren a la construcción de modelos, en este grupo, en cambio, el objetivo es el Facundo José Yatchesen 23 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones descubrimiento de patrones o reglas que definan el comportamiento de los datos, como así también la relación que existe entre los datos en si. Una tarea la cual en la actualidad posee un incipiente desarrollo y se encuentra enmarcada en este grupo de técnicas, se relaciona con la detección de transacciones fraudulentas, la cual ha sido ampliamente estudiada en el campo de la estadística, planteando un gran numero de desafíos, principalmente en cuanto a la diferenciación entre aquellas transacciones fraudulentas y las verdaderas; esta tarea en general es delegada a expertos en el área de estudio, aunque esta pericia por parte del experto resulta prácticamente nula al analizar un gran volumen de datos. 5. Recuperación por contenido: en esta categoría se enmarcan aquellas técnicas, las cuales parten de un patrón de información conocido y se buscan réplicas de ese comportamiento y/o modelo en un gran volumen de datos. Este grupo posee dos grandes divisiones, por un lado la búsqueda de patrones sobre texto y por el otro, sobre imágenes. En el primer sub grupo, mediante la obtención de palabras claves, se buscan textos que posean ocurrencias de estas palabras claves o combinaciones de las mismas. En el segundo sub grupo, lo que se persigue es, partiendo de una imagen o un patrón especifico, la obtención de imágenes que contengan este patrón, tomando como base un gran volumen de imágenes, teniendo en cuenta, como en todos los casos, criterios de similitud. Un punto a tener en cuenta es que si bien los objetivos de estas técnicas son claramente diferentes, existen tareas que son comunes a todos ellos, como por ejemplo, las medidas de adecuación del modelo a los datos, o de distancia entre el modelo y la instancia. Sumado a esto se debe contemplar la posibilidad de aplicar sistemáticamente varias de estas técnicas para la resolución de un problema en particular, por ejemplo, se puede en primer lugar clusterizar un set de datos, y después indagar respecto a las reglas que hicieron que las instancias pertenezcan a cada uno de los grupos descubiertos. 2.3 Metodología de implementación de MDD El proceso de MDD esta constituido por una serie de tareas relacionadas lógicamente [10], las cuales son ejecutadas sobre un conjunto de información ya existente en la organización, y que tiene por objetivo añadir un nuevo conjunto de información de mayor valor que el conjunto inicial Facundo José Yatchesen 24 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones [11] [12]. En el ámbito de la ingeniería de software, la utilización de modelos y metodologías se basa en el seguimiento de proyectos de tecnología de la información para dotarlos de una alta cuota de predictibilidad y calidad mediante la incorporación de puntos de control en las diferentes fases que forman parte del proceso productivo, no limitándose unicamente a los productos de cada una de estas fases, sino también a los procesos asociados a los mismos [13]. Teniendo en cuenta este proceso ingenieril relacionado al proceso de de MDD, surge la importancia en la utilización de metodologías que doten de mayor calidad al proceso y en consecuencia al producto obtenido de este proceso de calidad. En el desarrollo de software existe una gran cantidad de modelos y metodologías que tienen por objetivo el aporte de calidad al producto a través de la mejora de los procesos, dentro de las mismas podemos mencionar CMMI [14], COMPETISOFT [15] y MoProSoft [16]; la mejora que aportan estos modelos es ampliamente conocida en el ámbito de desarrollo de software, el inconveniente que se plantea es que los procesos de MDD tienen características particulares que lo diferencian de los desarrollos de productos software, teniendo en cuenta este punto surge la necesidad de utilizar metodologías y/o modelos específicamente destinados a procesos de MDD. Actualmente existen tres metodologías disponibles y reconocidas en el ámbito académico e industrial, en primer lugar P3TQ [17], SEMMA y CRISP-DM [18]; se plantea que estas metodologías tienen una falencia en lo relacionado a las tareas de gestión del proyecto [13], esta puede deberse a la corta evolución que han sufrido las mismas dada la novedad de los proyectos relacionados a MDD. Estas metodologías para procesos de MDD constituyen una implementación del proceso de KDD descripto por [5], teniendo en cuenta este concepto, a primera vista podría decirse que la metodología CRISP-DM presenta un grado mayor de completud, ya que incorpora a las etapas propias del proceso de MDD, las tareas pre y post proceso, en las que se trabajan las tareas relacionadas a la comprensión del negocio y despliegue; cabe aclarar que si se realiza un análisis mas profundo se puede observar que en SEMMA se puede integrar el desarrollo de la comprensión del dominio de aplicación, el conocimiento previo relevante y los objetivos del usuario final en la etapa Muestreo de SEMMA, debido a que los datos no pueden someterse a un muestreo a menos que exista un conocimiento real de los aspectos presentados [19]. Si bien no existen estadísticas formales que fundamenten la amplia utilización de la metodología CRISP-DM para procesos de MDD, es una de las mas utilizadas, ya que, como se menciona anteriormente posee una alta cuota de aportes obtenidos de la practica en la implementación de proyectos de MDD, esto Facundo José Yatchesen 25 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones puede verse reflejado en una encuesta llevada a cabo en un sitio de Estados Unidos, en el que sobre un total de 150 expertos en el área de MDD, se les consultó sobre la metodología que utilizan para llevar adelante proyectos de este tipo, en la misma se ha observado que un 42% opto por CRISPDM, seguido con un 19% por metodologías propias [20]. 2.4 Minería de datos y detección de fraude El termino fraude hace referencia al abuso de los beneficios de una organización sin derivar directamente en consecuencias legales para los autores, lo cual puede convertirse en un problema critico si ocurre de manera recurrente o los mecanismos de prevención no son lo suficientemente blindados ante fallos. Generalmente, el mayor esfuerzo se enfoca en brindar herramientas para el monitoreo y chequeo de procesos, los cuales de realizarse de manera manual implica un inmenso esfuerzo y estarían sujeto a numerosas subjetividades. Se debe tener en cuenta que es absolutamente imposible tener la certeza respecto a la intención o legitimidad detrás de una aplicación o transacción, lo que se busca en realidad, es acotar el espacio de aplicaciones y/o transacciones que puedan ser fraudulentas teniendo en cuenta la evidencia obtenida mediante la aplicación de algoritmos [1]. Cabe destacar que el aporte de la MDD a la detección de fraude no se limita únicamente el hecho de detectar casos potencialmente fraudulentos, minimizando el espectro del conjunto de datos, sino que también permite la obtención de patrones que describan las características de los casos detectados, lo cual puede, con la colaboración de expertos en el área de estudio, a acotar y/o detectar de manera mas eficiente aquellos potenciales casos fraudulentos [21]. Existe una estrecha relación entre el fraude y la detección de anomalías, ya que puede considerarse que aquellos casos que representan operaciones fraudulentas presentan ciertas diferencias (aunque estas se minimicen a medida que los infractores evolucionan sus técnicas) con los operaciones normales. La detección de anomalías se refiere al problema de encontrar patrones en los datos, los cuales se alejan del comportamiento normal o esperado del dominio estudiado; Facundo José Yatchesen 26 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones existen variaciones en cuanto al nombre que toman estas instancias representadas por los patrones como anomalías, outliers, observaciones discordantes, excepciones, aberraciones, sorpresas, peculiaridades, contaminantes, entre otras [2]. La detección de anomalías no es un tema novel de investigación, sino que se cuentan con registros de fines del siglo XIX [22], lo que ha evolucionado y sobre en lo que actualmente se centran las investigaciones son las técnicas aplicables para su detección, como por ejemplo la utilización de MDD. El punto de unión entre la MDD y la detección de fraude contable o financiero, es la introducción de la MDD como una herramienta analítica avanzada que puede asistir al auditor en la toma de decisiones al momento de detectar casos de fraude y tiene el potencial para resolver la tan mencionada contradicción entre los efectos y la eficiencia de la detección de fraude [23]. A simple vista se puede plantear que la detección de anomalías es simplemente aislar aquellas instancias que no presentan las mismas características que la mayoría de las instancias analizadas, sin embargo, esta tarea presenta una serie de desafíos que definen su complejidad [2]: • Definir la región “normal” de tal manera que represente a todos y cada uno de los comportamientos normales resulta sumamente difícil, esto sumado al hecho de que la diferencia entre el comportamiento normal y el anómalo puede ser insignificante, contribuye al hecho de poder identificar a las instancias normales como anómalas o vice versa. • Cuando las anomalías son resultado de acciones maliciosas pre meditadas, los infractores suelen adaptarse y/o evolucionar las técnicas utilizadas para cometer la irregularidad, de forma de emular de manera casi perfecta a las instancias normales. • La naturaleza de los dominios de estudio es evolutiva, es decir, que a medida que va pasando el tiempo van tomando características distintas, esto representa un desafío importante, ya que el identificar los comportamientos normales en el presente, puede no representar las características en el futuro. Otro punto relacionado a la naturaleza del dominio se relaciona con la escala con la cual se miden, un valor numérico puede ser insignificante en un dominio pero totalmente drástico en otro, he aquí la importancia en la selección de la técnica y los parámetros disponibles para la misma. • La no disponibilidad de datos etiquetados, como conjuntos para entrenamiento validación de modelos, contra los cuales pueda validarse la eficiencia de los procesos aplicados representa otro inconveniente a solucionar. • Existe un inconveniente relacionado al ruido en los datos analizados, ya que los mismos Facundo José Yatchesen 27 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones tienen a ser similares a las anomalías que se planea detectar, por lo que agrega cierta complejidad a la tarea de limpieza de datos dado que la distinción entre datos anómalos y con ruido resulta compleja. El fraude en impuestos o evasión fiscal, se ha transformado en una preocupación crítica para los administradores de organización relacionadas a la administración pública, y con mayor intensidad en los países en vías de desarrollo [24]. La principal motivación de esta preocupación es que los ingresos de estas organizaciones provienen del cobro de impuestos sobre bienes y actividades, y si bien, en general, no son la única fuente de ingreso de la misma, representa un alto porcentaje, por lo que el hecho de sufrir operaciones fraudulentas en su contra afecta directamente a la forma en la que estas distribuyen sus recursos. Es posible divisar dos tipos distintos de utilización fraudulenta de documentos, por un lado la material, que consiste principalmente en la adulteración de formularios, firmas, sellos, certificados y demás documentos relacionados; y por el otro lado la ideológica, en la que la confección de estos documentos se hace en el marco de la legalidad, pero teniendo en cuenta datos ficticios, inventados de manera arbitraria a fin de obtener algún tipo de beneficio. Actualmente el volumen de información producido por las organizaciones, de las cuales no se encuentran excluidas aquellas publicas, es extremadamente alto, y los costos asociados a las operaciones fraudulentas son también extremadamente altos, no solo desde el punto de vista monetario sino también desde el punto de vista social de la organización para con el medio, lo que conlleva a que los técnicas utilizadas para su análisis deban ser altamente eficientes, que faciliten la comprensión de los datos y de los procesos que representan [25]. Las organizaciones publicas han ido incorporando paulatinamente procedimientos que les permitieron detectar casos fraudulentos, en primera instancia a través de la selección casi al azar de casos, los cuales eran sometidos a un análisis mas intensivo, pasando a la utilización de herramientas estadísticas de análisis, las cuales a su vez luego derivaron en sistemas expertos y modelos de riesgos, incorporándose recientemente las técnicas de MDD e inteligencia artificial, dada la creciente necesidad de dotar de mayor eficiencia y confiabilidad al proceso de detección de fraude [26]. 2.5 Técnicas de MDD aplicadas a la detección de fraude financiero Facundo José Yatchesen 28 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones El espectro de técnicas de minería de datos es bastante amplio, por lo que enumerarlo sería una tarea tediosa, por tal motivo, resulta conveniente acotar el estudio a las técnicas mas relevantes para la detección de fraude en organizaciones administradoras de impuestos. En [26] se hace un relevamiento de las técnicas de MDD usadas por organizaciones administradoras de impuestos para la detección de fraude; entre ellas se mencionan: redes neuronales, arboles de decisión, regresión logística, Mapas Auto Organizados (Self Organized Maps o SOM), K-Means, Support Vector Machines (SVM), redes bayesianas, técnicas de visualización de datos, K-Nearest neighbour, reglas de asociación, reglas difusas, cadenas de Markov, series de tiempo, regresión y simulación. Es importante destacar la notable mejora que proporciona la utilización de tecnicas de mineria de datos en forma combinada, para de esta manera potenciar las ventajas de las mismas y minimizar los efectos negativos [27]. Teniendo en cuenta los obstáculos que son necesarios traspasar para la detección de fraude se analizan las siguientes técnicas en profundidad: • Mapas Auto Organizados (Self-Organizing Maps o SOM [28]) constituye un método de red neuronal con aprendizaje no supervisado, que produce como resultado un gráfico de similitud de los datos de entrada. Consiste en un conjunto finito de modelos, que aproxima el conjunto de datos de entrada inicial, y los modelos son asociados con nodos (neuronas) que son organizadas en un grilla regular de dos dimensiones. Los modelos son producidos por un proceso de aprendizaje automático que ordena las instancias sobre una grilla de dos dimensiones teniendo en cuenta su similaridad, este algoritmos es un proceso de regresión recursivo [29]. Una ventaja que propone SOM es que no es necesario indicar el conjunto de grupos inicial, lo que minimiza el error aportado por procesos heurísticos en la definición inicial de grupos. • Neural Gas: se trata de un modelo de red neuronal que busca principalmente minimizar el error por distorsión basándose en reglas de adaptación suaves [30]. En lugar de utilizar la distancia |v – wi| o la del arreglo de wi's dentro de un enrejado externo, utiliza un ranking de vecindario de los vectores de referencia w i, para el vector dado v. Esta técnica se asemeja a las redes SOM, en el hecho de que no solo el vector de código ganador es adaptado; la diferencia radica en que los vectores de código no son forzados a estar en una grilla, y la adaptación de aquellos vectores de código cercanos al ganador se hace teniendo en cuenta un ranking de Facundo José Yatchesen 29 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones distancia, así cada vez que se presenta el patrón x todo los vectores de código v j, son ranqueados de acuerdo a su distancia a x, el mas cercano obtiene el rango mas bajo [31]. • Arboles de decisión: un árbol de decisión es un método de aprendizaje supervisado no paramétrico construido a partir se un set de entrenamiento que consiste en una serie de objetos, cada uno de estos objetos es descripto por un conjunto de atributos y una etiqueta de clase, estos atributos a su vez pueden ser ordenables o no ordenables, el método busca formar todos los pares posibles y combinación de categorías, agrupando aquellas que se comportan de manera similar con respecto a una variable en un grupo y manteníendolas separadas de aquellas que se comportan de forma distinta [32]. • Redes bayesianas [33]: estas redes son gráficos acíclicos que permiten una representación eficiente y efectiva de la distribución de probabilidad conjunta sobre un conjunto de variables aleatorias. Cada vértice en el gráfico representa una variable aleatoria y las lineas representan relaciones directas entre las variables, mas precisamente, la red codifica las siguientes sentencias de independencia condicional: cada variable es independiente de sus no descendientes en el gráfico dado el estado de sus padres. Estas independencias son luego explotadas pare reducir el numero de parámetros necesarios para caracterizar a una distribución de probabilidad, a para procesar eficientemente probabilidades posteriores dada la evidencia. Los parámetros probabilísticos con codificados en un conjunto de tablas, una para cada variable, en la forma de distribuciones condicionales locales de una variable dados sus padres. Usando las sentencias de independencia codificadas en la red, la distribución conjunta es unívocamente determinada por estas distribuciones condicionales locales [34]. • K-means: consiste en un método de particionado de datos en un conjunto de grupos (clusters), los cuales se agrupan teniendo en cuenta un centroide, alrededor del cual se agrupan las instancias, buscando minimizar al máximo las diferencias de las instancias dentro de un grupo o la función de error cuadrático. El proceso se inicia asignando por medio de alguna heurística los centroides de forma aleatoria, luego, teniendo en cuenta la segmentación resultante de la etapa anterior calcula nuevamente los centroides para luego re evaluar las instancias del cluster, el proceso se repite iterativamente hasta converger, lo cual ocurre cuando no se producen cambios de cluster por parte de las instancias. Se debe tener en cuenta que el algoritmo no asegura la obtención de un óptimo global, ya que la calidad de la solución depende Facundo José Yatchesen 30 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones directamente de los conjuntos de grupos iniciales, es por este motivo que para la utilización de esta técnica es recomendable varias ejecuciones variando la composición de los conjuntos iniciales [8]. 2.6 Construcción del conjunto de datos para la detección de fraude financiero aplicando técnicas de MDD Una de las partes fundamentales del proceso de MDD es la construcción y/o selección de los atributos que formaran parte del conjunto de datos, sobre el cual las técnicas de MDD seleccionadas del proceso de modelado serán aplicadas. En los casos posibles, la mejor fuente utilizable para la creación del conjunto de datos es el datawarehouse de la organización, ya que en este reside toda la información de las operaciones de la misma y ocasionalmente información externa, la cual puede ser utilizada dentro del proceso de MDD. Sin embargo, en muchas ocasiones no se cuenta con un datawarehouse sobre el cual se pueda trabajar, en estas ocasiones resulta necesario hacer una extracción, transformación y limpieza de los datos (ETL). Al momento de definir la estructura de datos que servirá como entrada a los procesos de MDD, se debe tener en cuenta o priorizar la utilización de atributos relativos por sobre los absolutos[21], en otras palabras, es conveniente la incorporación de atributos que resulten del calculo de diferencias y/o promedios, para de esta manera obtener valores de atributos que engloben la mayor parte de la instancia analizada. Otro punto crucial a tener en cuenta al momento de construir el conjunto de datos es el de contar con un amplio conocimiento del área de estudio, o al menos, contar con la asistencia de un experto en el área, el cual puede aportar información importante que fortifique el conjunto de datos incorporando variables que pueden ser pasadas por alto, principalmente aquellas relacionadas al comportamiento de infractores. Como ejemplo de estas variables es posible mencionar a aquellas que se relacionan a los periodo de fechas en los que los infractores consideran que es mas probable que no sean detectados, años de antigüedad de productos y su valor de mercado, etapa del año[27], categoría de socio, actividad, consumo[35], datos del proveedor, datos del cliente, encabezado y detalle del reclamo[36], consumos históricos del cliente, consumo actual, fecha de incidencia, tipo de operación[37], por citar algunos ejemplos. Facundo José Yatchesen 31 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Una de las limitaciones en cuanto a la utilización de técnicas de MDD relacionada al conjunto de datos tiene que ver con la disponibilidad o no de datos etiquetados, es decir, si lo que se desea construir es por ejemplo un clasificador, necesitaremos contar con datos etiquetados, lo cual implica que hayan sido previamente analizados y etiquetados para una u otra clase, el inconveniente que acarrea esta operación es que si la misma es llevada adelante por un ser humano posee un factor de subjetividad, que puede sesgar el resultado del proceso de MDD. Existe una serie de desafíos relacionados a la construcción de un conjunto de datos para la aplicación de técnicas de MDD, los cuales deben ser tratados y minimizados en la medida de lo posible, en [38] se hace una interesante reseña de los mismos: • Heterogeneidad y diversidad: generalmente los conjuntos de datos son formados mediante la integración de diferentes fuentes, de distintas organizaciones e inclusive de distintos departamentos de la misma organización. El principal inconveniente es que al momento de integrar, es posible que se pierdan datos, producto de la unión de varios atributos estadísticos en uno solo, derivando en interpretaciones parcial o completamente erróneas. • Calidad de datos: el hecho de integrar datos de diferentes fuentes puede enriquecer el contenido del conjunto de datos pero con una calidad pobre. Existen varios motivos que pueden acentuar este problema, por un lado diferencias de criterio y estándares en cuanto a la identificación de tuplas o entidades, modelos de datos con un mal diseño, documentación pobre o inexistente, datos faltantes o diferencias de interpretación para valores similares. • Escala: para que los procesos de MDD sean eficientes el volumen de datos debe ser alto, pero lo suficientemente resumido para que el procesamiento de los mismos sea aceptable, de esta manera uno de los trabajos es construir un sub conjunto que resuma el gran volumen de datos disponible en una partición, pero que mantenga en la mayor medida posible las características del conjunto original. • Nuevos paradigmas de datos: es conocido el hecho de que el volumen de datos crece de manera exponencial, pero a esto debe sumarse la heterogeneidad con la que estos datos son almacenados (bases de datos, audio, video, imágenes, logs de equipos como servidores, routers, relojes biométricos, sensores, documentos en una infinidad de formatos), constituyendo un enorme desafío integrar estos datos en un conjunto manejable. Facundo José Yatchesen 32 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Capitulo 3 Planteamiento del problema Facundo José Yatchesen 33 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones 3.1 Planteamiento del problema ¿Es posible la aplicación de técnicas de minería de datos para la detección de fraude tributario en la Municipalidad de la ciudad de Apóstoles? ¿Cuáles son los algoritmos y técnicas de minería de datos más eficientes para la detección de fraude tributario en la administración municipal? 3.2 Objetivos generales Desarrollar un análisis de las técnicas de minería de datos para determinar cuáles son aquellas que mejor se ajustan a la detección de fraude tributario en administraciones municipales, utilizando las fuentes de datos de la Municipalidad de Apóstoles. Implementar las técnicas resultantes del análisis de las técnicas a la obtención de conocimiento aplicable a la detección de fraude tributario en la Municipalidad de la ciudad de Apóstoles, presentación de los resultados obtenidos. 3.3 Objetivos específicos Documentar todo el proceso de investigación de acuerdo a la normativa de la cátedra Trabajo Final, de la carrera de Licenciatura en Sistemas de Información, Facultad de Ciencias Exactas, Químicas y Naturales, Universidad Nacional de Misiones. Fundamentar teóricamente la aplicación de minería de datos a la detección de fraude tributario en administraciones municipales Evitar la alteración de los datos en esta etapa, a fin de evitar costos adicionales relacionadas a entrada de datos Fomentar la utilización de herramientas de software libre en todas las etapas del proyecto Analizar y evaluar las distintas técnicas descriptivas y predictivas Analizar y evaluar algoritmos Evaluar las metodologías para la implementación de proyectos de minería de datos Analizar y comparar las herramientas para minería de datos Facundo José Yatchesen 34 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Analizar los datos y definición de la base de datos mineable para el caso de la Municipalidad de Apóstoles Analizar de calidad de datos de la Municipalidad de Apóstoles Implementar minería de datos en la Municipalidad de Apóstoles Analizar e interpretar los resultados obtenidos Facundo José Yatchesen 35 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Facundo José Yatchesen 36 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Capitulo 4 Solución propuesta Facundo José Yatchesen 37 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Para la implementación de las solución se ha considerado la importancia de la utilización de metodologías para procesos de MDD, por este motivo, y teniendo en cuenta los avances tanto a nivel académico como industrial, se ha optado por utilizar CRISP-DM, por ello, este capitulo se estructura de acuerdo a las fases de la misma. 4.1 Fase I: Comprensión del negocio Objetivos de la organización Las municipalidades en la provincia de Misiones, rigen su funcionamiento a través del uso de presupuestos, los cuales deben ser aprobados por el Honorable Concejo Deliberante (HCD) del propio municipio, al menos tres meses (90 días) antes del inicio del ejercicio económico al cual esta dirigido, estos inician el 01 de Enero y finalizan el 31 de Diciembre. Las unidades funcionales del presupuesto son las partidas presupuestarias, estas representan conceptos que utiliza el municipio para llevar adelante sus actividades, dentro del presupuesto se sigue un esquema de partida doble, en donde se planifican tanto los gastos como los ingresos que tendrá el municipio dentro del ejercicio económico; este presupuesto tiene por objetivo planificar, para su aprobación por parte del HCD, los ingresos de fondos que tendrá el municipio y como ejecutara esos fondos en las diferentes obligaciones del mismo. De acuerdo al presupuesto de recursos elaborado por el Poder Ejecutivo de la Municipalidad de Apóstoles, y posteriormente aprobado por el HCD de Apóstoles, para el ejercicio 2013 se contó con un presupuesto, al 31 de Diciembre de 2013 de $ 74.118.122,69, mientras que para el ejercicio 2014, al día 31 de Diciembre de 2014, contaba con un presupuesto de $ 103.482.893,88 lo que representa un incremento del orden del 39% inter anual. Dentro de los ingresos que posee el municipio, alrededor del 29% de los mismos corresponden a gravámenes que se efectúan sobre: actividades comerciales, industriales y de servicios que son llevadas adelante dentro del municipio, bienes radicados dentro del municipio y servicios brindados por el municipio hacia los habitantes del mismo, estos son denominados ingresos de jurisdicción municipal. El resto de los ingresos (71% del presupuesto) proviene de ingresos nacionales y Facundo José Yatchesen 38 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones provinciales, los cuales ingresan al municipio como participación de impuestos nacionales y provinciales, subsidios, fondos especiales, aportes no reintegrables, prestamos, entre los conceptos mas importantes. Los ingresos de jurisdicción municipal a su vez, se subdividen en 4 grandes grupos: comercio e industrias, patentes de rodados, tasa de inmueble y otra tasas. Del total de ingresos de jurisdicción municipal, el 53% corresponde a ingresos relacionados a comercio e industrias, 19% corresponde a todas las tasas relacionadas a patentes de rodados, el 12% a tasa de inmueble, dentro de la que se incluyen impuestos a obras publicas, tasa de inmueble y alumbrado publico, el porcentaje restante corresponde a tasas generales, que engloban conceptos variados. En los casos de los ingresos provenientes de los rubros de comercio e industrias y patentes, la tasa de recaudación es aceptable, superando el 60% del presupuestado, y en lo referente a tasas varias se calculan sobre la recaudación de años anteriores, por lo que el porcentaje de recaudación obtenido es variable teniendo en cuenta temporadas, conceptos incluidos, indices de precios, entre otras variables. Uno de los principales inconvenientes se da en la tasa de inmueble, en la cual la recaudación no supera el 20% del presupuestado, esto de debe en gran medida a la propia naturaleza del impuesto, en donde no se hacen controles respecto a los estados de deuda de cada unidad inmobiliaria, principalmente por la cantidad (actualmente el municipio cuenta con 10.000 unidades inmobiliarias) y el alto costo de recursos que implica su control. En el caso de los impuestos relacionados a comercio, industrias y patentes, son necesarios para operar (en el caso de los comercios e industrias), siendo controlados tanto por el municipio como por organizaciones externas (AFIP, DGR, SENASA, Gendarmería Nacional, Policía, entre otros). Los ingresos de jurisdicción propia resultan una fuente muy importante de financiamiento para la Municipalidad, ya que tiene disponibilidad completa sobre los mismos, de aquí surge la imperiosa necesidad de aumentar la eficiencia en el cobro de los mismos, mejorando las tasas de recaudación con la menos cantidad de recursos posibles. Si bien la elaboración del presupuesto para su aprobación por parte del H.C.D. Rige los ingresos estimados para el ejercicio económico, estos son calculados en base a los antecedentes recaudatorios de las tasas, sin considerar el estado de deuda de los contribuyentes, como tampoco la previsión de recursos basados en las mejoras implementadas en los diferentes ámbitos, como por Facundo José Yatchesen 39 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones ejemplo: instalación de carteles publicitarios, asfaltado, alumbrado público, cordones-cuneta, re valuación de vehículos, proyección de ventas, entre otros conceptos. A raíz de este inconveniente se comenzaron a hacer cálculos sobre los estados de deuda de los contribuyentes, principalmente sobre el impuesto inmobiliario, agrupados por barrios, dando porcentajes de cumplimiento por debajo del 10% en algunos casos. Evaluación de la situación Los sistemas de información de la Municipalidad de Apóstoles se encuentran desarrollados en varias plataformas, la mayoría fueron desarrollados en Visual Basic 6, una pequeña parte Visual Studio .NET, otra pequeña parte con Power Builder, todos ellos utilizando como motor de base de datos SQL Server 2000 y dependiendo el sistema, en bases de datos separadas. El caso particular se da con el impuesto a la patente automotor, en la cual hasta Octubre del año 2012 se trabajo con un sistema desarrollado por la Municipalidad de Apóstoles, cuando se migro a la utilización de un aplicativo provisto por el gobierno provincial; un caso similar se dio con las licencias de conductores, sistema que fue centralizado por el gobierno provincial. La Municipalidad de Apóstoles cuenta con un departamento de sistemas, constituido por 5 profesionales del área de sistemas, tres de los cuales se encargan del desarrollo y mantenimiento de los sistemas de gestión para las diferentes áreas, uno de ellos se encarga del soporte técnico de hardware y redes de todas las dependencias y el quinto integrante se encarga del mantenimiento del sitio web, imagen institucional en las redes sociales y tareas relacionadas al diseño gráfico. Dentro de este equipo no existe personal dedicado a tareas relacionadas a inteligencia de negocios (tableros de comando, cubos OLAP o minería de datos), por lo que no se cuentan con antecedentes de implementación de procesos de este tipo dentro de la organización como tampoco información que pueda ser útil para el presente proyecto. Actualmente no se dispone de un sistema unificado de datos de contribuyentes, sino que la información esta replicada en los distintos sistemas, de acuerdo a la información necesaria en cada uno de ellos, por lo que obtener la información de estados de deuda por concepto, inscripciones y perfiles en cada uno de los impuestos y pagos, resulta complicado, dada la heterogeneidad de los datos. Otro concepto a tener en cuenta, es que en el sistema de cobro de tasa de inmueble, se hicieron al menos dos migraciones de datos de sistemas desarrollados bajo MS-DOS, y nunca se Facundo José Yatchesen 40 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones tomó la decisión política de llevar adelante un proceso de limpieza de datos, esto sumado al hecho de que la información que llega a la municipalidad tiene cierto atraso, lo que obstaculiza aun mas la calidad de los datos. Con las herramientas actuales es posible llevar adelante un proceso de ingeniería inversa para obtener el modelo de datos, el cual será detallado en secciones posteriores, aunque no se dispone de un diccionario de datos para las bases de datos, por lo que es necesario recurrir al personal responsable del desarrollo y mantenimiento de los sistemas de información para aclarar los conceptos representados en el modelo de datos. Hay dos características importantes en cuanto al diseño de base de datos que se deben considerar al momento de analizar los datos: la primera tiene que ver con la forma en la que se liquidan los impuestos o los conceptos a pagar, esta operación se realiza en el momento en que el se hará efectivo el cobro, complicando obtener el estado de deuda de los contribuyentes y aumentando el riesgo de errores, ya que al momento de efectuar la liquidación pueden alterarse “provisoriamente” valores y porcentajes de tasas; la segunda tiene que ver con la falta de unificación de contribuyentes, ya que en cada sistema (con cada tipo de impuesto) se posee un padrón para ese impuesto, con un bajo nivel de normalización y sin restricciones como por ejemplo en numero de CUIT o DNI, lo que provocan datos duplicados, y por ende un caída severa en la calidad de los datos. • Sistema de Tasa de comercio El sistema de tasa de comercio tiene por objetivo el cobro de un porcentaje de las ventas realizadas por un comercio o industria radicado dentro del municipio de Apóstoles, este importe se calcula sobre el monto consignado en una declaración jurada mensual que lleva adelante el propio comercio y es calculado al momento en el que el contribuyente hace la presentación de la misma. A través de este sistema se emite la habilitación de comercio, la cual debe ser ubicada en un lugar visible a los clientes de los comercios e industrias, para obtenerla se debe cumplir con una serie de requisitos como ser planos, habilitación por parte de los bomberos, contrato de alquiler en caso de ser necesario, toda esta información es registrada dentro del sistema. Este sistema es el único que se encuentra integrado con el sistema de padrón, se encuentra desarrollado en Microsoft VB6, utiliza como motor de base de datos a Microsoft SQL Server 2000 y Crystal Reports 9 como motor de reportes. El modelo de datos es el siguiente: Facundo José Yatchesen 41 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Figura 1: Diagrama de base de datos sistema de comercio Facundo José Yatchesen 42 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones • Sistema de Tasa de Inmueble El sistema en cuestión se encarga de gestionar toda la información relacionada a los inmuebles (información catastral, propietarios, impuestos, servicios, categorias), los montos a abonar son establecidos cada año a través de una Ordenanza Municipal aprobada por el H.C.D., y se calcula sobre la cantidad de metros de frente de la propiedad, sin considerar la/s construcciones sobre el mismo, excepto un adicional que se cobra en el caso de que se trate de una construcción multifamiliar. Para obtener el importe a ser abonado por el contribuyente se efectúa la liquidación al momento de concretar el pago o al momento de emitir el recibo del monto a pagar y el cual se distribuye a los contribuyentes. Uno de los inconvenientes se plantea con el historial de los inmuebles, con sus respectivas subdivisiones, e historial de titulares, en donde al momento en el que se hace la venta de un inmueble, se borra el anterior y es registrado como uno nuevo sin tener en cuenta el historial, o en el caso de que se realice una subdivisión surgen dos nuevos inmuebles sin ningún tipo de relación con el original. El modelo de datos es el siguiente: Facundo José Yatchesen 43 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Figura 2: Diagrama de base de datos sistema de inmuebles • Sistema de Patentes A partir del mes de Enero del año 2013 la provincia de Misiones centralizó la información para el cobro de la tasa de patente de vehículos en un sistema de información propiedad de la misma, dejando obsoletos los desarrollos de los municipios, sin embargo, teniendo en cuenta la información presente en el sistema de patentes de la Municipalidad de Apóstoles a la fecha de cambio de sistema, se optó por utilizar esta información. El impuesto en cuestión consiste en el cobro de un impuesto en base al valor del vehiculo en cuestión, valor que es alterado de acuerdo a la fecha en que se pague, obteniendo descuentos por pago total al inicio del año, o recargos por pagos de cuotas vencidas. El modelo es el siguiente: Facundo José Yatchesen 44 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Figura 3: Diagrama de base de datos sistema de patentes Facundo José Yatchesen 45 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones • Sistema de Padrón El sistema de padrón surge con la intención de unificar los datos de los contribuyentes, para de esta manera unificar los datos y conectarlos con todos los sistemas utilizados por la Municipalidad de Apóstoles, actualmente se encuentra relacionado con el Sistema de Tasa de Comercio, y carnet de sanidad, aunque estaba integrado con el sistema de licencias de conductor, el cual fue centralizado por la provincia quedando este obsoleto. El modelo utilizado es el siguiente: Facundo José sistema Yatchesende padrón Figura 4: Diagrama de base de datos 46 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Determinación de los objetivos de MDD El objetivo del proyecto será la obtención indicios que evidencien posibles conductas fraudulentas tanto por parte de los contribuyentes como por el personal interno a la organización a través del uso de técnicas y algoritmos de MDD, tomando como base a los datos de pagos correspondientes a las tasa de inmueble, comercios y patentes. Plan de proyecto Teniendo en cuenta los recursos con los que se cuenta y el alcance del presente proyecto, el mismo se llevará adelante por un único profesional, quien contará con el asesoramiento de profesionales con amplia experiencia en proyectos de estas características, que se encargará de ejecutar las tareas detalladas a continuación: 1. Analizar preliminarmente los datos 2. Seleccionar herramientas de software para el proceso 3. Implementar procesos de captura de datos 4. Implementar modelos de minería de datos 5. Ejecutar pruebas sobre los sets de datos 6. Documentar pruebas y resultados 7. Formular recomendaciones basadas en los resultados obtenidos 4.2 Fase II: Comprensión de los Datos Recolección inicial de datos 1. Sistema inmuebles Los datos que se planea utilizar de la tasa de inmuebles se encuentran en dos tablas relacionales, una con los datos del pago propiamente dicho, el cual puede verse en la Figura Facundo José Yatchesen 47 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones 5 y la segunda con los datos del contribuyente responsable del mismo Figura 6. Contiene los pagos de la tasa desde al año 1995 al año 2015; un dato peculiar es que cada una de los conceptos que se cobran dentro de la tasa esta discriminado en columnas, por lo que el importe total del pago debe ser calculado, esto rompe el esquema de normalización y puede provocar ciertos inconvenientes ya que si quisiera agregarse un concepto, sería necesaria una modificación del diseño de la base de datos, junto a las aplicaciones y reportes asociados. Figura 5: Diseño tabla inm_pagos Los datos del contribuyente al que se encuentra asociado el inmueble se encuentran en una segunda tabla, la cual es utilizada en forma exclusiva por el sistema de tasa de inmueble. Como puede observarse a simple vista, la relación de NxM entre las unidades de inmueble y los contribuyentes no se encuentra modelada, por lo que es necesario repetir los datos del contribuyente tantas veces como unidades de inmueble posea el contribuyente, esto presenta dos inconvenientes, por un lado el aumento en la posibilidad de que el operador de la aplicación cometa un error al realizar la carga de los datos duplicados, y por el otro la imposibilidad de implementar restricciones de unicidad a nivel base de datos que mejoren la calidad de los datos. Facundo José Yatchesen 48 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Figura 6: Diseño tabla inm_datoscontribuyente Se considero importante incorporar información relacionada a las intimaciones que se hayan hecho al inmueble, consignando información del periodo reclamado al contribuyente, en busca de patrones que indiquen variaciones en la conducta de los mismos. Esta información se encuentra en una tabla adicional visible en la Figura 7, en la que solo se consigna el periodo intimado, no así la evolución del reclamo, es decir, si pago, si el dato era incorrecto y el inmueble fue transferido, o si se encuentra en etapa judicial, completa el esquema la fecha en la que se hizo la intimación, y observaciones en formato texto relacionadas a la intimación. Figura 7: Diseño tabla inm_intimaciones 2. Sistema patentes Facundo José Yatchesen 49 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Para el cobro de la tasa de patentes el esquema utilizado es similar al planteado para el caso de inmuebles (una única tabla para los pagos, sin incorporar encabezado-detalle como se ve en la Figura 8), se trata de una tabla exclusiva para los contribuyentes de patente Figura 9, y al no tener la relación NxM implementada en el modelo, se dan las mismas falencias. Para la tasa de patentes no se dispone de un sistema que registre las intimaciones hechas a cada una de las patentes y/o propietarios, sino que el único registro son los comprobantes impresos. Figura 8: Diseño tabla pat_pagos Figura 9: Diseño tabla pat_propietarios 3. Sistema comercios Para el cobro de la tasa de comercio se utiliza un modelo de datos con mayor normalización, ya que el pago del mismo se encuentra con un encabezado Figura 10 y detalle Figura 11, lo que junto a la utilización del sistema de padrón de contribuyentes mejora notablemente la calidad de los datos. Facundo José Yatchesen 50 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Figura 10: Diseño tabla ccio_pagos Figura 11: Diseño tabla ccio_pagos_detalle Como se aclaró en el punto anterior, el sub sistema de tasa de comercio es el único que utiliza el padrón general Figura 12 para relacionar los datos de los contribuyentes con los de los comercios, sin embargo puede detectarse una importante falla relacionada con la exigibilidad a nivel base de datos de dos campos elementales como el DNI y/o CUIT; es decir, que si bien conceptualmente no deberían presentarse datos duplicados, y la carga no se repite, en la practica, pueden no cargarse estos datos, complicando las tareas de control. Figura 12: Diseño tabla pco_entidad_personas Facundo José Yatchesen 51 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Para el sub sistema de tasa de comercio, se dispone de una tabla que almacena las intimaciones y/o reclamos de deudas hechos hacia el comercio Figura 13. Figura 13: Diseño tabla ccio_intimaciones_rec_deudas Existe una consideración particular al analizar el impuesto a la tasa de comercio, se trata de un impuesto que se calcula sobre el importe de la declaración jurada presentada por el comercio ante la municipalidad, y la tasa de comercio propiamente dicha se calcula sobre este importe, pero, no existen controles a nivel aplicación que indiquen si todos los comercios hicieron la presentación, por lo que si el contribuyente no hizo la correspondiente presentación, al emitir un estado de deuda, la misma se encuentra regular, es decir, el contribuyente no posee deudas con el municipio. 4.3 Fase III: Preparación de los Datos Recolección y descripción de datos El primer esquema planteado consiste en utilizar los campos de numero de contribuyente dentro del impuesto, si el contribuyente fue intimado en alguna oportunidad, el tipo de empresa, el impuesto al que corresponde, la cantidad de pagos dentro de cada uno de los días de la semana, el día, mes y año de inscripción del contribuyente, junto a la cantidad de pagos y la sumatoria del importe de los mismos agrupados por año, desde el año 1989 hasta el año 2013. Si bien cada uno de los impuestos analizados tiene características particulares, las cuales no son compatibles con los demás, el objetivo del proyecto es analizar los pagos de los diferentes impuestos como un solo concepto, es por ello que se eligieron aquellos que son comunes a todos los analizados. No se ha detectado la existencia de un diccionario de datos de las bases de datos utilizadas Facundo José Yatchesen 52 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones en el presente proyecto, por lo fue necesario un intenso proceso de análisis, el cual fue complementado por la información aportada por el departamento de sistemas de la organización. • Planteamiento conceptual Teniendo en cuenta que se dispone información de varios impuestos que abonan los contribuyentes y del hecho de que hay casos en los cuales la tasa de recaudación es alta, mientras que en otros resulta extremadamente baja, se decidió crear un set de datos que unifique todos los impuestos, con los conceptos similares y de esta manera buscar patrones que relacionen las conductas de los contribuyentes en los diferentes impuestos. • Plataforma técnica Debido a la complejidad del esquema seleccionado para generar el set de datos, junto a la gran cantidad de operaciones de preparación de los mismos, se ha decidido implementarlas en el motor de bases de datos nativo de la organización para la cual se desarrolla el presente proyecto (Microsoft SQL Server 2000). Una vez finalizada la etapa de ETL se procedió a la utilización de RapidMiner V5.2 para la implementación de los algoritmos de MDD. En la Figura 14 puede verse el esquema de la plataforma técnica planteada, tanto las bases de datos como el proceso de transformación de los mismos residirán en el servidor de base de datos Microsoft SQL Server 2000, los cuales alimentarán al proceso de MDD implementado en RapidMiner v5.2 desde donde se obtendrán los reportes para ser analizados por los expertos en el dominio a fin de formular un informe con el conocimiento obtenido para su posterior implementación. Cabe aclarar que entre los puntos de transformación de datos, el proceso de MDD y los expertos en el dominio hay una doble cardinalidad en las conexiones, esto se plantea de esta manera debido a que al momento de implementar los algoritmos de MDD en ocasiones resulta necesario ajustar campos y tipos de datos en la etapa de transformación, lo mismo ocurre al obtener las evaluaciones de los expertos en el dominio, cuando en ocasiones los resultados se tornan complejos de interpretar, es necesario ajustar los algoritmos utilizados y su configuración y esto en ocasiones puede traer aparejado ajustes sobre la etapa de transformación de datos. Facundo José Yatchesen 53 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Figura 14: Esquema de implementación del proyecto • Criterios de éxito La determinación de criterios de éxitos numéricos resulta compleja por dos motivos, el primero se relaciona con el hecho de que a priori, no se conocen el o los tipos de patrones que resultan sospechosos, tampoco se conoce si se trata de conductas generalizadas o de un grupo en particular, el segundo motivo se relaciona con la cantidad de tuplas que efectivamente corresponden a contribuyentes activos, por lo que los porcentajes asignables como criterios de éxito resultan difusos, por este motivo es beneficioso plantear el criterio de éxito en función del conocimiento obtenido [42]. El éxito del presente proyecto estará dado por la obtención de patrones de comportamiento de contribuyentes desconocidos hasta el momento, que puedan permitir tomar medidas preventivas y/o correctivas por parte de la dirección de la municipalidad. • Conceptos seleccionados Luego de una serie de pruebas preliminares cuyo objetivo era definir la estructura del set de datos, los mejores resultados se obtuvieron analizando la conducta de cada contribuyente a través de todos los impuestos, para cada uno de los años comprendidos entre el periodo 2000-2010. Los importes pagados fueron extraídos de las correspondientes tablas para cada Facundo José Yatchesen 54 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones uno de los impuestos, relacionándolos con la unidad contributiva correspondiente y a partir de allí con el contribuyente; si bien el dato identificador (Clave Única de Identificación de Personas, CUIP o documento) no fueron utilizados en el proceso de MDD propiamente dicho, si fueron incluidos en el set de datos para, en primer lugar, llevar adelante las relaciones y limpieza de datos y en segundo lugar para facilitar el análisis especifico una vez obtenidos los resultados de los procesos de MDD. Debido al hecho de que se trata de una sumarización de unidades impositivas teniendo en cuenta el numero de CUIP/documento, se considero importante mantener la información de la cantidad de unidades involucradas, así se incorporaron tres columnas que indican la cantidad de unidades impositivas para el contribuyente. Se agrego una serie de campos que indican la cantidad de años reclamados a través de intimaciones y/o reclamación de deudas al contribuyente, discriminado por año en que se hizo la misma y concepto involucrado. Como se indico en el punto anterior, el objetivo es comparar los aportes de los contribuyentes para cada impuesto seleccionado, subdivido para cada uno de los años comprendidos entre el año 2000 – 2010, lo que provoca una sumatoria de los importes de todo el año, que, sumado a la heterogeneidad de los importes para cada uno de los conceptos, sesgaba notablemente los resultados, por este motivo se decidió segmentar los importes, teniendo en cuenta las categorías dentro de cada una de las tasas analizadas, los valores medios, modas y frecuencias, la cual es implementada en el set de datos mediante una función programada sobre el motor de base de datos. En la Tabla 1 se muestran los limites inferiores y superiores para cada una de las categorías utilizadas en la función de segmentación. Código devuelto Limite inferior (>=) Limite superior (<) 0 - 0 1 0 50 2 50 100 3 100 200 4 200 500 5 500 800 6 800 1500 Facundo José Yatchesen 55 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones 7 1500 3000 8 3000 6000 9 6000 12000 10 12000 24000 11 24000 48000 12 48000 96000 13 96000 - Tabla 1: Rango de categorías para los importes abonados • Consideraciones adicionales Tal como se mencionó, uno de los principales inconvenientes esta relacionado a la calidad de los datos, ya que al no tener restricciones en cuanto a datos obligatorios, muchos datos se encuentran en blanco, lo que hace imposible compararlos con otras filas, dada la enorme cantidad de filas con este inconveniente se opto por eliminar estas filas para no alterar los resultados de aquellas que si poseen información utilizable, y para no incluir interferencia en los resultados. • Esquema de ejecución El esquema seleccionado para llevar adelante la captura de datos y su posterior análisis consiste en hacer la lectura, limpieza y transformación de los datos a través de un procedimiento almacenado en el servidor de base de datos, el cual utiliza tablas temporales, las cuales luego son accedidas desde la herramienta RapidMiner v5.2, que hace la lectura del set de datos y aplica los procesos seleccionados. • Exploración inicial de los datos Con el objetivo de tener una aproximación inicial de los datos, se han formulado una serie de consultas en SQL para cada tasa, obteniendo medidas relacionadas a limites, cantidad de filas, valores perdidos, tipos de datos. En primer lugar se analizaron los registros correspondientes a la tasa de inmueble Figura 15, podemos observar que se dispone de 11744 filas, que representan cada uno de los inmuebles registrados, vale recordar el hecho de que no se cuenta con un campo que indique si el inmueble se encuentra activo o fue dado de baja, por lo que el estado activo puede definirse como aquellos que posean movimientos Facundo José Yatchesen 56 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones de pagos recientes, aunque esto permitiría que aquellos contribuyentes que nunca abonaron su obligación de tasa de inmueble sean tomados como inactivos. El otro punto destacado es que el rango de números de documento va desde el numero 0 al 999999999, lo que deja en evidencia las limitaciones de los datos utilizados, ya que valores tan bajos indican un claro error en la carga de la información. En cuanto a los rangos obtenidos en la sumatoria para la tasa de inmueble para todos los años vemos que se mantienen relativamente dentro de rangos similares, excepto para el año 2001, donde se observa un pico en la recaudación de alguno de los contribuyentes, esto puede explicarse por moratorias o regularización de deudas antiguas. Dada la estructura seleccionada para formar el set de datos, y al tratarse se datos ya procesados, no se observan valores perdidos. Indagando en los números de documento de los contribuyentes, se ha detectado que del total de las 11744 filas, 1576 corresponden a “contribuyentes” con documento 0, esto representa mas del 10% del set de datos, por lo que se ha optado por no considerar estas filas. Cabe aclarar un punto relacionada a la gran cantidad de contribuyentes cuyo importes pagos son cero (0), es decir, que nunca abonaron una tasa dentro del municipio; si bien esto puede considerarse como materia de análisis para el proceso de MDD, se ha optado por quitar a aquellos contribuyentes que no hayan abonado tasas en el periodo 2000-2010 debido a que esto se debe, en parte a las características propias del sistema de tasa inmueble. Facundo José Yatchesen 57 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Figura Figura 15: 16: Resultado Resultado exploración exploración inicial inicial -- Tasa Tasa de de inmueble patente En cuanto a los datos de patente Figura 16, se dan las mismas características que para la tasa de inmuebles, valores de documento que inician en cero, y terminan en valores superiores a los correctos. Para esta tasa la cantidad de contribuyentes con valor para el documento (dni) 0 es de 1360, a pesar de que se dispone de un numero de CUIT en la tabla del propietario, la cantidad de filas perdidas sigue siendo alta. Para el caso de la información proveniente del sub sistema de comercios Figura 17, se detectaron unicamente dos casos en los que el documento tenia un valor nulo, por lo que fueron eliminados del set de datos. En cuanto al rango de los valores para el atributo documento, sigue manteniendo similares características a la las tasas anteriores. Lo que puede observarse es una amplia diferencia en cuanto a los valores extremos para los atributos que representan la sumatoria de lo abonado por los contribuyentes. Figura 17: Resultado exploración inicial - Tasa de comercio 4.4 Fase IV: Modelado Facundo José Yatchesen 58 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Para la aplicación de técnicas de minería de datos se ha optado por utilizar Rapid Miner 5.2, que es una herramienta desarrollada en Java, y ademas de la cantidad de procesos ya incluidos, permite añadir plugins como por ejemplo WEKA, lo que suma todos los algoritmos de esta herramienta; dado el lenguaje sobre el que se encuentra desarrollada, Java, permite tener independencia en cuanto a la plataforma necesaria para aplicar los procesos. Durante la etapa de pruebas del modelo se intento hacer una prueba utilizando la herramienta TANAGRA v1.4, se hizo la transformación del set de datos a formato .TXT a fin de ser reconocido por la herramienta y aplicar los procesos, sin embargo, la lectura del mismo fue extremadamente lenta, no pudiendo completar la lectura del set de datos, por este motivo se decidió descartar el uso de la mencionada herramienta. En la etapa preliminar de pruebas se optó por analizar cada uno de los pagos realizados ante la organización, tratándolos en forma de fila, e incluyendo información relacionada a esa instancia de pago unicamente, sin embargo, este primer enfoque no aporto resultados significativos, por lo que fue necesario re diseñar el set de datos, pasando a considerar el agrupamiento del historial de pago de cada uno de los contribuyentes, para cada uno de los impuestos analizados (tasa de inmueble, patentes, comercios) en el rango comprendido entre el 01/01/2000 al 31/12/2010. El esquema para el set de datos consiste en analizar cada uno de los contribuyentes registrados en alguno de los impuestos seleccionados para el análisis, junto a una serie de 33 columnas, subdivididas en tres grupos: inmueble, comercio y patente; dentro de cada una de estas columnas se totalizan los importes abonados por el contribuyente en el impuesto indicado entre los años 2000 y 2010; se considero importante agregar tres columnas dentro de las cuales se consignando la cantidad de unidades que posee el contribuyente para cada impuesto; se incorporo ademas la cantidad de intimaciones que recibió el contribuyente para cada uno de los impuestos, y la cantidad de años que le fueron reclamados. En la etapa de pruebas-evaluación se ha detectado que el análisis se veía seriamente afectado por los importes, esto de debe a que hay un amplio abanico de valores posibles (-100.000 a 700.000), por lo que fue necesario segmentar los importes para de esta manera obtener mejores resultados. En el Anexo 1 pueden verse los nombres, tipos de datos y significado de cada uno de los atributos del conjunto de datos definitivo diseñado para la aplicación de algoritmos y técnicas de MDD. Se ha desarrollado un proceso en RapidMiner v5.2, el cual se encarga de la lectura del Facundo José Yatchesen 59 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones conjunto de datos previamente transformado, la aplicación de técnicas y algoritmos de MDD propiamente dichos y la presentación de resultados; el esquema se refleja en la Figura 18 y se explica en detalle a continuación: 1. Lectura DB: el operador se encarga de hacer la lectura a la base de datos y cargar el resultado a memoria, para su posterior utilización por parte de la herramienta. 2. Filtro: brinda flexibilidad a la hora de trabajar con las diferentes ejecuciones de las pruebas, permitiendo quitar o agregar campos del set de datos original sin afectar ni la estructura del conjunto de datos, ni los métodos de lectura. 3. K-Means k=6: se trata de una implementación del algoritmo k-means, el cual agrega al conjunto de datos un atributo adicional que indica el cluster dentro del que fue caracterizado. Para este conjunto en particular, para la medición de la distancia entre clusters, se ha seleccionado la distancia Numérica-Euclidea, ya que los atributos de los campos del conjunto de datos han sido normalizados en la etapa de preparación de los datos. El principal parámetro se relaciona con la cantidad de clusters en los que al algoritmo debe dividir al conjunto de datos (parámetro k), para obtener este valor se ha desarrollado un proceso particular que se encarga de arrojar los valores óptimos para el parámetro, este proceso será explicado detalladamente en el próximo párrafo. La ventaja de este algoritmo radica en su simplicidad y efectividad en un amplio espectro de dominios en las tareas relacionadas al particionado del conjunto de datos. 4. Mult. 1: multiplica de acuerdo a la cantidad necesaria las entradas al proceso, en este caso son tres las multiplicaciones, la primera esta dirigida al operador de asignación de rol, para su posterior uso en los árboles de decisión, la segunda al resultado del proceso, lo que permite el análisis pormenorizado de las filas obtenidas luego de la aplicación del algoritmo k-means y la tercera al operador de escritura en la base de datos. 5. Escribir DB: dado que el conjunto de datos original, y las tablas utilizados para construirlo se encuentran en una base de datos relacional, resulta practico contar con los resultados del algoritmo k-means en una tabla relacional también, para de esta manera simplificar el análisis y el trabajo sobre los resultados. 6. Est. Rol: los algoritmos que implementan arboles de decisión requieren de un atributo de Facundo José Yatchesen 60 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones tipo etiqueta (label en inglés) en base al cual se analizan las características y se obtienen las reglas. Como el conjunto de datos generado no tiene un atributo de este tipo, siendo el mismo necesario para la obtención de reglas de pertenencia a los clusters obtenidos a partir de la ejecución del método k-means, se utilizo el atributo generado por el operador del punto 3. 7. Mult. 2: similar función al operador del punto 4, aunque en este caso en particular se duplico la salida del operador 6 para asignarlo a los operadores de arboles de decisión. 8. C4.5: implementa un árbol de decisión, utilizando un algoritmo similar a C4.5, a fin de obtener reglas que expliquen la pertenencia de cada contribuyente a cada uno de los clusters obtenidos. En [39], [40], [41] se presentan las ventajas de la utilización de este algoritmo en la detección de datos anómalos en base de datos. 9. Tabla de decisión: constituye un algoritmo de la extensión WEKA para RapidMiner v5.2, y el objetivo es obtener reglas que expliquen las segmentación por parte de los algoritmos de clusterización. Facundo José Yatchesen 61 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Figura 18: Diagrama modelo de MDD, RapidMiner v5.2 Dado que para la clusterización se utiliza el algoritmo K-Means, el principal parámetro de este está dado por el valor de K, el cual indica la cantidad de clusters que se buscan obtener como resultado de la aplicación del algoritmo, teniendo en cuenta que para la definición del valor óptimo para este parámetro no existen reglas formales, sino que surge del análisis empírico de los resultados, se optó por desarrollar un proceso dentro de la herramienta de MDD Figura 19 y Figura 20, que se encargue de aplicar iterativamente y de forma automática diferentes valores a este parámetro, y partir de los resultados obtener indices que permitan seleccionar el valor óptimo. Los indices a utilizar fueron Davies Bouldin y la distancia interna dentro del cluster. Facundo José Yatchesen 62 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Figura 19: Modelo de optimización, principal Figura 20: Modelo de optimización, sub proceso bucle de parámetros En la Figura 21 puede observarse la lista de posibles valores que puede tomar el parámetro k, para el algoritmo k-means, juntos a las medidas de performance seleccionadas y disponibles. Facundo José Yatchesen 63 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Figura 21: Configuración de parámetros y medidas de performance disponibles En la Figura 22 puede observarse el resultado de la ejecución del proceso descripto para la obtención del valor optimo para el parámetro k, a ser utilizado en el algoritmo k-means. Para este conjunto de datos en particular, la herramienta no ha arrojado resultados del indice Davies Bouldies a raíz de las características intrínsecas del mismo, sin embargo, se ha considerado, aunque no exclusivamente, como medida de calidad de clusterización a la distancia media dentro del cluster. La no exclusividad se refiere a que si consideramos este indicador unicamente el valor optimo vendría dado por k=2, sin embargo, esto resulta complejo de interpretar a los expertos en el dominio, por lo que se ha optado por hacer ejecuciones consecutivas variando dentro de lo considerado aceptable de este indicador (k=4 y k=6), obteniendo los mejores resultados con k=6, basando el éxito en los los casos detectados y la claridad para interpretar las características de los mismos por parte de los expertos en el dominio. Facundo José Yatchesen 64 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Figura 22: Resultado del proceso de optimización del parámetro k 4.5 Fase V: Evaluación Para la etapa de evaluación se ha contado con el aporte realizado por dos C.P.N. (contadores públicos nacionales), una de ellas se ha desempeñado en el cargo de secretaria de hacienda de la municipalidad de Apóstoles y la segunda ocupa este cargo actualmente; se ha contado también con el aporte del responsable del sector de recaudaciones de la misma organización. Se debe tener presente que las conductas detectadas representan indicios que pueden evidenciar conductas fraudulentas, a fin de avanzar sobre estos contribuyentes y verificar que se trate efectivamente de un caso de fraude, es necesario llevar adelante una minusciosa investigación. Para ello se puede avanzar, solicitando información complementaria dentro de la misma municipalidad, al contribuyente como así también a organismos externos relacionados. Una métrica a considerar fue el tiempo que le demandaba al proceso de MDD completar la ejecución, a pesar de que esto se ve influenciado directamente por el hardware disponible el tiempo requerido por la dirección de la municipalidad fue que no supere los 30 minutos. Para llevar adelante la prueba se dispuso de un equipo con un microprocesador Intel i7 QM 2630 de 8 nucleos, Facundo José Yatchesen 65 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones 8GB de RAM DDR3, placa de video ATI Radeon 6770M, disco rígido SATA de 750GB a 7200 RPM, ejecutado bajo Microsoft Windows 7 Home Premium 64 bits. De acuerdo al esquema de ejecución, la primera etapa consiste en ejecutar el procedimiento almacenado en el motor de base de datos, lo que demanda, para la configuración disponible, no más de 4 minutos, considerando que este procedimiento almacenado se ejecuta una única vez al principio del proceso, se genera el set de datos y luego es manipulado por la herramienta exclusiva para MDD; para la ejecución del proceso de MDD el mayor tiempo requerido no supero los 3 minutos, el cual fue disminuyendo a medida que el tamaño del conjunto de datos fue siendo acotado. Los resultados y sugerencias planteadas por los expertos fueron introducidas progresivamente en el modelo para obtener los resultados que se discuten a continuación: 1. En la etapa preliminar al análisis de los datos ha podido observarse el primer inconveniente relacionado a la calidad de los mismos, se trata de que la información de los contribuyentes para cada uno de los impuestos se encuentra replicada en los subconjuntos de datos propios de cada uno de ellos, sin existir nexo alguno entre los mismos y eliminando cualquier posibilidad de rastrear esta relación si datos vitales como por ejemplo el CUIP se encuentran mal cargados. Otro inconveniente, aunque relacionado específicamente al impuesto Tasa de Inmueble, tiene que ver con que no es posible detectar cuales inmuebles se encuentran activos y cuales fueron subdivididos, dados de baja o eliminados. 2. Avanzando en la etapa de análisis de los datos, y en particular en valores extremos al momento de ejecutar procesos de MDD, es posible detectar una gran cantidad de contribuyentes (diferentes personas o sociedades) con números identificatorios de CUIP con comodines como por ejemplo 0, 999999999, -1, 99999998, inclusive se detectaron casos en los que el mismo nombre de contribuyente aparece con varios números de CUIT distintos. Esto presenta dos hipótesis posibles, por un lado una falla de los procedimientos por parte de la organización al no exigir toda la documentación pertinente para una registración completa del contribuyente, junto a una falencia del sistema de información; la segunda tiene que ver con una posible maniobra interna, en la que de forma arbitraria se cargan datos incorrectos para evitar intimaciones, bloqueos por infracciones o bloqueos para operar en, por ejemplo licitaciones publicas o privadas. Facundo José Yatchesen 66 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Debatiendo este punto con los expertos en el dominio, manifiestan que es una situación regular en organizaciones en donde los procedimientos no se encuentran formalmente definidos, o existe una falencia en los responsables de controlar que toda la información sea correcta y completa. Este punto tiene un impacto negativo en los resultados de los mecanismos de regularización de la situación contributiva de los contribuyentes para las diferentes tasas de la municipalidad, ya que impide que por ejemplo, al momento de emitir un carnet de conductor, iniciar una actividad comercial, registrar un nuevo rodado o inscribir un inmueble y se controle que todas las unidades contributivas del mismo se encuentren libres de deuda (actividades comerciales, inmuebles y patentes), resulta imposible al no contar con un dato elemental como el CUIP y/o numero de documento. 3. En la Figura 23 puede verse el resultado en forma de texto de la primera ejecución del proceso de MDD, aplicado sobre el total del conjunto de datos (8191 filas), siendo posible detectar de un total de 6 clusters, los cuales se encuentra distribuidos irregularmente en cuanto a cantidades. Facundo José Yatchesen 67 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Facundo José Yatchesen 68 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Figura 23: Resultado ejecución 1 - Vista texto distribución de clusters En esta primera etapa no se obtiene conocimiento utilizable que nos permita formular hipótesis respecto a cuales son clusters sospechosos, por ello es necesario profundizar la interpretación, por lo que se optó por un análisis gráfico del resultado, visible en la Figura 24, teniendo en cuenta los centroides de cada uno de los clusters. En la figura indicada puede observarse en primer lugar, un extremo claramente marcado en el centroide para el cluster_3 en el atributo cantidad de inmuebles, junto a una abrupta caída en él cuando se produce el cambio de tasa de comercio a inmueble en el cluster_4. Cabe aclarar la importancia que toma el orden de los campos de acuerdo a lo que representan, ya que como nos encontramos trabajando con series, al estructurarlo de esta manera las variaciones quedan evidenciadas de una forma clara tanto para el ingeniero en conocimiento como para al experto en el dominio. Otra consideración es que si se observa la base del gráfico indicado, podemos ver que en la mayoría de los atributos, la linea base aparece por encima del 0, lo cual resulta contradictorio si consideramos que se encuentran filas en los que los contribuyentes no han hecho aportes al municipio, esto es explicado por la segmentación que hemos elegido para los importes, en donde el valor 0 se utiliza para designar a los valores por debajo del 0. Facundo José Yatchesen 69 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Figura 24: Resultado ejecución 1 - Gráfico de centroides de clusters Si bien el análisis gráfico permite generar diversas hipótesis de los clusters que contienen casos que pueden considerarse sospechosos, es necesario analizar medidas numéricas para respaldar las mismas, lo que puede observarse en la Figura 25, ratificando que efectivamente los cluster_3 y cluster_4 poseen diferencias marcadas en atributos del mismo grupo, entiendo por grupo a cada tipo de impuesto, mientras que los casos restantes mantienen las diferencias dentro de valores mas razonables; puede verse también el extremo para el campo “cantidadinmueble”. Facundo José Yatchesen 70 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Figura 25: Resultado ejecución 1 - Tabla de centroides En el modelo de MDD se plantea la utilización de arboles de decisión para obtener reglas que describan las características cada uno de los clusters, para esta primera ejecución el arbol de decisión y la tabla de reglas obtenidas es ilegible, ya que su tamaño resulta demasiado extenso, por lo que se optó por llevar adelante una segunda ejecución del proceso pero solamente sobre el cluster de 113 filas, ya que en el cluster de 8 filas se observa una clara influencia del atributo “cantidadinmuebles”. Teniendo en cuenta este dato, la cantidad Facundo José Yatchesen 71 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones de filas y la dificultad para obtener reglas se procedió al análisis detallado de los casos, haciendo uso de la información disponible en los sistemas de información involucrados. Las filas del cluster de 8 filas analizado puede verse en la Figura 26, a primera vista se trata de contribuyentes que tienen una gran cantidad de inmuebles a su nombre, y en cinco de ellos se detecta que tienen un alto poder contributivo en este impuesto pero prácticamente nulo en patentes y comercios, por ejemplo (ids 704, 1946, 2047, 2199, 3577), lo cual resulta al menos extraño, ya que disponen en todos los casos de alrededor de 40 inmuebles y no poseen vehículos registrados a su nombre, ni tampoco realizan alguna actividad comercial. Los expertos coincidieron en indicar que esta información resulta importante, ya que actualmente en la provincia de Misiones, tiene lugar una forma de fraude consistente en registrar vehículos en las localidades cercanas de la provincia de Corrientes, ya que el monto a pagar en concepto de patente en esa dependencia es significativamente menor, y, dado que en estos municipios la documentación exigida para el registro no es estricta puede llevarse a cabo, a pesar de tener domicilio real en la provincia de Misiones. Otro punto a considerar es que de los 8, tres coinciden con contribuyentes con numero de CUIP duplicados (99999999), dentro de los que se incluyen grandes contribuyentes, el propio municipio y organismos oficiales; el segundo contribuyente se trata de un “DESCONOCIDO”. Los restantes constituyen contribuyentes cuyo aporte al municipio se encuentra balanceado entre los impuestos analizados, pero incluidos en este cluster por la gran cantidad de inmuebles a su nombre, lo que es explicable a través de lo que se conoce como loteo, es decir, la subdivisión de un inmueble de gran superficie en unidades mas pequeñas. Desde el punto de vista de los expertos, esto representa un hallazgo importante, ya que estos indicadores no son comunes en los reportes gerenciales utilizados actualmente, además, sientan las bases para formular procedimientos internos que de alguna manera controlen y/o prevengan potenciales conductas fraudulentas tanto por parte del personal interno como de los propios contribuyentes. Otra cuestión que surge es que estas conductas pueden ser respaldadas de forma completamente legal y transparente, por ejemplo porque el contribuyente se encuentra dentro de una sociedad y utiliza los vehículos de la misma, posee los mismos a nombre de su cónyuge, su ingreso viene dado por la venta de inmuebles, realiza servicios en el exterior, o inclusive puede encontrarse en relación de dependencia, lo Facundo José Yatchesen 72 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones que sí queda claro es que representan indicios de potenciales conductas sospechosas y es necesario profundizar las tareas de auditoría y control. Un caso particular que destacaron los expertos trata de un contribuyente antiguo, que poseía un lote agrícola hace mas 50 años, que con la expansión de la ciudad y la desaparición de sus herederos, fue tomado por varios contribuyentes y transformándose en una gran cantidad de lotes, de los cuales nunca se hizo una actualización de los datos en el municipio, ni tampoco pagaron alguna vez las tasas municipales correspondientes. De este punto se desprenden dos cuestiones, la primera tiene que ver con la investigación más profunda por parte del departamento de fiscalización teniendo en cuenta la cantidad de inmuebles, ya que para este caso de contribuyente el algoritmo no detectó el caso, y la segunda tiene que ver con la necesidad de re plantearse la estructura de datos para obtener la liquidación de cada una de las tasas y no depender del pago o no del contribuyente, dado que actualmente no es posible determinar si se trata de un contribuyente que no paga su obligación o corresponde a un inmueble inactivo. Facundo José Yatchesen 73 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Facundo José Yatchesen 74 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Figura 26: Resultado ejecución 1 - Vista detallada cluster_3 4. Como se mencionó en el punto anterior, se planteo una segunda ejecución, utilizando unicamente los datos correspondientes al cluster_4 resultante de la primera ejecución, ya que si bien se trata de un cluster cuyos centroides se encontraban alejados de los demás obtenidos, ha resultado complejo obtener las características de este sub conjunto de datos. Reutilizando el proceso de MDD desarrollado, al cambiar el conjunto de datos, es necesario volver a obtener valores óptimos para k, para ello se reutilizo también proceso de optimización. En la Figura 31 en la cual puede observarse el indice Davies Bouldin del proceso de optimización del valor k para el algoritmo k-means, el cual de acuerdo a su formulación a medida que es menor la calidad de la clusterización es mejor, para este caso particular los valores óptimos se encuentran en 16 y 20, sin embargo, al contar con un conjunto de datos tan pequeño, la cantidad de clusters complica la evaluación de los resultados, por este motivo, la alternativa viene dada por buscar el equilibrio entre la cantidad de clusters y la complejidad para interpretar los resultados; considerando este punto Facundo José Yatchesen 75 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones y la indice de distancia promedio interna del cluster se ha optado por utilizar un valor de k=7. Facundo José Yatchesen 76 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Figura 27: Indice Davies Bouldies para sub conjunto cluster_4 Figura 28: Indice de distancia promedio dentro del cluster_4 Una vez que se dispuso de valores optimizados se procedió a ejecutar el proceso de MDD, el resultado puede verse en la Figura 29 puede verse el resumen de la cantidad de filas dentro Facundo José Yatchesen 77 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones de casa uno de los clusters, la distribución en cuanto a cantidad resulta bastante equitativa, y al contar con tan poca cantidad de filas resulta un tanto complejo inferir hipótesis. Figura 29: Resultado ejecución 2 - Vista texto distribución de clusters Avanzando en el análisis utilizando la vista gráfica Figura 30, puede observarse una conducta similar a la detectada en la primera ejecución, aunque sobre la tasa de comercio, los importes recaudados van aumentando progresivamente y cuando se produce el cambio de impuesto hacia inmueble se produce una caída importante, esta conducta puede verse en los clusters clusters_4, cluster_5 y cluster_6. Para el caso del cluster_5 en particular, se observa que en los primeros atributos de la serie la gráfica inicia en 1 (importe mínimo de aporte al municipio), para luego aumentar a los valores máximos para el subconjunto de atributos. Para los casos del cluster_4 y cluster_6 lo llamativo es que esta compuesto por contribuyentes con alto poder contributivo para la tasa de comercio, pero un valor mínimo para patentes e inmueble, e inclusive para este ultimo valores muy cercanos a cero, considerando que esto representa a los centroides del cluster. Observando el cluster_5 puede verse un comportamiento similar, pero con una particularidad, la contribución en concepto de tasa de patente resulta prácticamente nula, acentuándose en el atributo que indica la cantidad de patentes registradas a nombre del contribuyente. En el cluster_0 si bien la curva resulta homogénea, hay un cambio brusco para el atributo inmueble2007, lo cual resulta intrigante teniendo en cuenta la capacidad contributiva de los Facundo José Yatchesen 78 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones contribuyentes y que la curva no contrarresta la marcada disminución en el atributo inmediatamente anterior. Para los clusters restantes (cluster_1, cluster_2, cluster_3) lo que puede observarse es que si bien se observan variaciones en la curva de los importes aportados por el contribuyente al municipio, la gráfica resulta homogénea, sin variaciones bruscas. Al momento de interpretar y debatir los resultados con los expertos en el dominio, les resulto mas práctico la vista gráfica de los centroides, ya que con la misma esto es posible obtener una idea de cual es la situación, la cual puede ser respaldada por las medidas numéricas que aportan las vistas de tabla. Por ejemplo, para el caso Figura 30 un punto que fue detectado por los expertos fue la linealidad de la curva para el impuesto de patentes, considerando que los valores de los rodados van evolucionando a lo largo del tiempo, esto en parte puede ser explicado por el hecho de que el atributo principal en el árbol de decisión viene dado por el atributo “patente2000”, esto no quita que sea necesario un análisis mas profundo de las categorías, importes para los vehículos registrados en el municipio. Figura 30: Resultado ejecución 2 - Vista gráfica de centroides de clusters Si bien el análisis utilizando gráficos resulta práctico es necesario evaluar si las inferencias Facundo José Yatchesen 79 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones llevadas adelante en el punto anterior efectivamente tienen un asidero numérico, para esto se ha analizado la tabla de centroides presentada en la Figura 31, en donde puede verse que por ejemplo, para el cluster_5 el centroide para los atributos del subconjunto de patentes es “1”, lo que significa de acuerdo a la segmentación, una contribución nula; otra observación que puede hacerse es que para el caso del subconjunto de tasa de patentes se mantiene fijo a lo largo de la serie. Figura 31: Resultado ejecución 2 - Vista tabla centroides de clusters Facundo José Yatchesen 80 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones En esta segunda ejecución el árbol de decisión obtenido resulto mas legible que el obtenido en la primera, el mismo puede verse en la Figura 32, en donde el algoritmo detecta como atributo de mayor influencia para la pertenencia al cluster al atributo “patente2000”. Si se observa con mayor detalle podemos ver que en la mayor parte del árbol se utilizan los campos de inicio de las series de los subconjuntos de impuesto, e inclusive podemos observar en una de las hojas el atributo “inmueble2007” en donde se producía un marcado corte para el cluster_0. Otro punto destacado es que en una de las hojas figura el atributo intermedio “comercio2004”, lo que coincide con la tendencia marcada para el cluster_5, en donde el aporte del contribuyente era prácticamente nulo, y de pronto inicia una tendencia ascendente. Figura 32: Resultado ejecución 2 - Árbol de decisión Un punto interesante planteado por los expertos al verse las diferencias entre los aportes de las diferentes tasas es una falencia relacionada con la “confianza” que debe tener el municipio para con los contribuyentes, ya que por ejemplo para el caso de la tasa de comercio, el importe a abonar depende del monto de la declaración jurada, sobre un formulario completado y presentado por el contribuyente, sin solicitar comprobantes que respalden esta información (lease AFIP o DGR Misiones), o para el caso de los inmuebles, Facundo José Yatchesen 81 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones depende de que el contribuyente presente la documentación que acredita el cambio de titularidad de un inmueble o un documento que respalde la ocupación del mismo. En el caso de la segunda ejecución el planteo de los expertos en el dominio es amplio en cuanto a la explicación, las mismas cubren un amplio abanico de opciones, las cuales no se relacionan con el objetivo de esta tesis, lo que sí resulta importante, es que, a pesar de la calidad y cantidad de los datos, de haberlo hecho en un período acotado, ha sido posible a través del uso de las técnicas y algoritmos de MDD obtener patrones de conducta de contribuyentes que resultan sospechosos. El análisis en profundidad de los mismos permitirá formular políticas y procedimientos para aplicarlas a la gestión de la municipalidad en aras de mejorar la gestión eficiente de los recursos disponibles. 5. Luego del análisis de los puntos anteriores, uno de los expertos plantea el caso de patentes, es decir, casos en los que los contribuyentes tienen un alto aporte en cuanto a importe en concepto de tasa de patentes pero su contribución para las tasas de inmueble y comercio resultan prácticamente nulas, advirtiendo que si bien esto puede ser fácilmente explicable por el hecho de que corresponde a un trabajador en relación de dependencia que aun no adquirió su propio inmueble, sin embargo, se decidió hacer un análisis de los casos haciendo una tercer ejecución. El punto de partida estuvo dado en la tabla de centroides de la primera ejecución, para los atributos que representan a la tasa de patentes, en la Figura 25 se puede observar que el mayor valores para los centroides se presenta en el cluster_1, por lo que se aislaron las filas de este cluster para profundizar el análisis. El primer punto tiene que ver con obtener los valores óptimos para el parámetro k del algoritmo k-means, en la Figura 33 podemos ver los resultados obtenidos, teniendo en cuenta el tamaño del cluster en cuanto a cantidad de filas, el valor óptimo para k se encuentra entre 4 y 10. Si consideramos el indice de distancia promedio dentro del cluster, no pudiéndose obtener para este conjunto valores correspondientes al indice Davies Bouldin, aunque después de haber hecho una serie de pruebas para los valores indicados, los resultados más claros se obtuvieron con k = 4, por lo que finalmente este fue el valor seleccionado. Facundo José Yatchesen 82 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Figura 33: Indice de distancia promedio dentro del cluster_1 Habiendo obtenido el valor óptimo, se procedió a la ejecución del proceso de MDD, el resultado de la distribución puede verse en la Figura 34, donde en principio la distribución es bastante equitativa, excepto para el caso del cluster_2, si se observa la Figura 35, se puede ver que la mayor diferencia para el valor de los centroides del sub conjunto de la tasa de patentes se da justamente en el cluster_2, notándose una amplia diferencia numérica respecto para el atributo “cantidapatentes”. Evaluando esta situación con los expertos, se ha determinado que resulta llamativo el hecho de que posean una gran cantidad de patentes, por lo que resulta evidente que la actividad comercial que realizan se relaciona a vehículos, aunque el impacto en la contribución relacionada a las actividades comerciales es nula. Figura 34: Resultado ejecución 3 - Vista texto distribución de clusters Facundo José Yatchesen 83 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Figura 35: Resultado ejecución 3 - Vista tabla centroides de clusters Dada la reducida cantidad de filas en cluster en el cual se plantea la mayor distancia, se decidió analizar en detalle cada uno de los casos corroborando la información las bases de datos, de donde surge, a través del aporte del responsable de la secretaría de hacienda, que se trata de contribuyentes que se dedican al transporte de cargas, pero curiosamente su actividad comercial no se encuentra registrada dentro del municipio como tal. Otra arista que surge del análisis de estos casos, es que, al momento de analizarlos, el experto plantea Facundo José Yatchesen 84 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones como se encuadra un contribuyente en particular, el cual es conocido por residir en otra provincia y tributar la tasa de patentes en el municipio de Apóstoles, mayor aún fue la sorpresa al detectar que para ese contribuyente, el CUIP figuraba en 0. En la Figura 36 puede verse reflejado lo planteado en base al análisis de la tabla de centroides de la Figura 35; en este punto los expertos en dominio resaltaron la tendencia que se da en el sub conjunto de la tasa de patente, en donde los centroides mantienen una linealidad notable, lo cual, según ellos, puede deberse a políticas de ajuste de los importes de los vehículos, aunque sugieren que esto sea analizado con mayor profundidad por el departamento de fiscalización. Figura 36: Resultado ejecución 3 - Vista gráfica de centroides de clusters Pasando al resultado del algoritmo del árbol de decisión de la Figura 37 se mantiene la tendencia de los atributos que poseen mayor injerencia en la clasificación por parte del algoritmo de clusterización, sumando los efectos sobre este subconjunto de los datos en particular. Facundo José Yatchesen 85 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Figura 37: Resultado ejecución 3 - Árbol de decisión 4.6 Fase VI: Implementación Se detalla a continuación lo que consistirá en la implementación del presente proyecto de MDD, teniendo en cuenta los hallazgos de la Fase V. • Los expertos en el dominio coinciden en que la clave para aprovechar el conocimiento obtenido, principalmente en el punto 3, 4 y 5, reside en avanzar profundamente desde el departamento de fiscalización en investigaciones minuciosas de los casos detectados, cruzando la información en los distintos sistemas de información de la propia municipalidad, formular pedidos de informes a organismos externos junto a solicitudes de información a los propios contribuyentes en busca de explicaciones de sus respectivas situaciones tributarias. • Teniendo en cuenta el punto 1 y 2, se detecta la necesidad de implementar, en primer lugar y como medida inmediata, una mayor cantidad de controles, en especial en los referente a datos vitales como el numero de documento o CUIP, y en segundo lugar, plantearse como meta futura en el corto o mediano plazo, la re ingeniería de los sistemas de información relacionados a la recaudación de impuestos por parte de la municipalidad, enfocándose en la unificación del padrón de contribuyentes, la pre liquidación de la deuda y la mayor cantidad de controles. Facundo José Yatchesen 86 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones • Desde el punto 1 al 5 los expertos remarcan la necesidad de ajustar los procedimientos internos, minimizando la injerencia tanto del personal interno a la municipalidad como del contribuyente, solicitando mayor documentación que respalde las operaciones relacionadas al registro y cobro de unidades contributivas, lo cual a su vez debe ir acompañado de un control de todo el circuito por parte del departamento de fiscalización. • Una variación del punto anterior consiste en formular procedimientos de intercambio de información con organismos recaudatorios tanto provinciales como nacionales, como así también con organismos reguladores tales como D.N.R.P.A. (Dirección Nacional de Registro de la Propiedad Automotor) o R.P.I.M. (Registro de la Propiedad Inmueble de Misiones), esto permitiría agilizar el proceso administrativo municipal de carga de datos. • A raíz del punto 3, 4 y 5, surge el requerimiento por parte de los expertos de desarrollar reportes gerenciales que contengan indicadores tales como cantidad de inmuebles, patentes y comercios, para de esta manera derivar la tarea de controlar casos que resulten sospechosos, pero no hayan sido detectados por los algoritmos, al departamento de fiscalización. • Como consecuencia de los hallazgos del punto 3, 4 y 5, se han detectado actividades comerciales y/o particulares que si bien se encuentran reguladas en cuanto a los impuestos que deben abonar, se escudan en el débil control por parte de la municipalidad como cuestiones particulares de dichas actividades para evadir el pago de los mismos. El conocimiento obtenido permitió a la dirección de la municipalidad formular la reglamentación correspondiente que le permita el cobro de estos recursos ociosos. Facundo José Yatchesen 87 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Capitulo 5 Conclusiones y futuras lineas de investigación Facundo José Yatchesen 88 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones 5.1 Conclusión El objetivo central de esta tesis fue analizar la viabilidad de la aplicación de técnicas y algoritmos de MDD para la detección de fraude tributario en municipalidades de pequeño y mediano tamaño, tomando como caso de estudio a la Municipalidad de Apóstoles, provincia de Misiones, planteando un caso práctico para procesos de explotación de información, extensible a municipalidades de similares características. Si bien actualmente la MDD constituye una herramienta fundamental para la explotación del conocimiento obtenible de los datos registrados en los sistemas de información de las organizaciones, con comprobada eficiencia en un amplio espectro de dominios, tales como financiero, medico, educativo, industrial, agronómico, comercial, genética, recursos humanos, una de las principales limitantes en cuanto a la calidad del conocimiento obtenible se relaciona justamente con la cantidad y calidad de los datos disponible, este punto es crítico en municipalidades de pequeño y mediano tamaño, en donde los recursos disponibles no siempre permiten el planteo integral de sistemas de información, sino que los requerimientos van solucionándose contra demanda, enfocándose en la solución operativa y, en la mayoría de los casos, dejando a un lado los mecanismos para el aprovechamiento de la información generada. Mediante la utilización de algoritmos y técnicas de MDD ha sido posible formular patrones de comportamiento de los contribuyentes basándose en la información histórica de los mismos, y que a priori, no eran conocidos, inclusive por expertos del dominio estudiado haciendo los siguientes aportes: • Acotar notablemente la cantidad de contribuyentes sospechosos, reducción a un 3% del total aproximadamente, en los cuales es necesario una auditoría más profunda por parte del departamento de fiscalización y legal a fin de tomar las medidas correspondientes. • La introducción de indicadores que permitan prevenir y/o minimizar las conductas fraudulentas por parte de los contribuyentes. • La formalización de procesos administrativos relacionados a los impuestos, como así también el control en cuanto al correcto funcionamiento de los mismos. • La detección de actividades económicas que no tributan ante la municipalidad, y pueden Facundo José Yatchesen 89 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones representar un importante aporte de recursos para la misma. En base a la calidad del conocimiento obtenido del proyecto de MDD llevado adelante en esta tesis, la ventaja competitiva aportada ha sido ampliamente valorada tanto por los expertos en el dominio como por parte de la dirección de la municipalidad. De esto se desprenden dos cuestiones, la primera la importancia del trabajo en conjunto con equipos multidisciplinarios, principalmente en la etapa de comprensión de los datos y evaluación de resultados, y por otro lado, el amplio espectro de beneficios que aportan este tipo de proyectos, mediante la utilización de los propios datos generados por los sistemas de información de la municipalidad, la expertise de los recursos humanos en el dominio, coordinado con un equipo técnico capacitado en proyectos de MDD y en la utilización de metodologías relacionadas, aun teniendo una cantidad y calidad limitada en cuanto a los datos disponibles. Considerando el conocimiento obtenido, los problemas técnicos superados, la legislación tributaria actual, las implementaciones técnicas y algoritmos utilizados, es viable plantear el presente caso como un modelo de proyecto extensible a otras municipalidades de similares características. 5.2 Futuras lineas de investigación En primer lugar se plantea continuar evolucionando en los procesos de MDD, aplicando diferentes tipos de técnicas y algoritmos sin limitarse a la clusterización y formulación de reglas y/o arboles de decisión, sin embargo para que los resultados de esta evolución sean significativos es necesaria la mejora de la calidad de los datos, principalmente en lo relacionado a las características de los contribuyentes, sumando la mayor cantidad de datos posibles. Otra posible evolución se relaciona a la posibilidad de fomentar mecanismos de intercambio de información entre el municipio y organismos oficiales relacionados a cada una de las tasas descriptas, tales como Dirección Nacional de Registro de Propiedad Automotor (D.N.R.P.A), Administración Federal de Ingresos Públicos (A.F.I.P.), Registro de Propiedad Inmueble de la provincia de Misiones, Dirección General de Rentas Misiones(D.G.R.), Administración Nacional de Seguridad Social (ANSES) para de esta manera obtener, por un lado información fidedigna instantánea o al menos lo mas actualizada posible y por el otro lado minimizar la posibilidad de que Facundo José Yatchesen 90 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones operadores internos cometan errores voluntarios o involuntarios en la carga de información. Facundo José Yatchesen 91 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Facundo José Yatchesen 92 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Apéndices / Anexos Facundo José Yatchesen 93 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Anexo 1: Tabla de atributos para el conjunto de datos Tabla 1: dm_integrado Campo Tipo de dato Descripcion documento bigint CUIP/documento del contribuyente tipoempresa integer Tipo de contribuyente Sumatoria de pagos realizados en concepto de tasa de comercio2000 money comercio, año 2000 Sumatoria de pagos realizados en concepto de tasa de comercio2001 money comercio, año 2001 Sumatoria de pagos realizados en concepto de tasa de comercio2002 money comercio, año 2002 Sumatoria de pagos realizados en concepto de tasa de comercio2003 money comercio, año 2003 Sumatoria de pagos realizados en concepto de tasa de comercio2004 money comercio, año 2004 Sumatoria de pagos realizados en concepto de tasa de comercio2005 money comercio, año 2005 Sumatoria de pagos realizados en concepto de tasa de comercio2006 money comercio, año 2006 Sumatoria de pagos realizados en concepto de tasa de comercio2007 money comercio, año 2007 Sumatoria de pagos realizados en concepto de tasa de comercio2008 money comercio, año 2008 Sumatoria de pagos realizados en concepto de tasa de comercio2009 money comercio, año 2009 Sumatoria de pagos realizados en concepto de tasa de comercio2010 money comercio, año 2010 Cantidad de años reclamados en el año 2000 en concepto de intcomercio2000 integer comercios Cantidad de años reclamados en el año 2001 en concepto de intcomercio2001 integer comercios Cantidad de años reclamados en el año 2002 en concepto de intcomercio2002 integer comercios Cantidad de años reclamados en el año 2003 en concepto de intcomercio2003 integer comercios Cantidad de años reclamados en el año 2004 en concepto de intcomercio2004 integer comercios Cantidad de años reclamados en el año 2005 en concepto de intcomercio2005 integer comercios Cantidad de años reclamados en el año 2006 en concepto de intcomercio2006 integer comercios Cantidad de años reclamados en el año 2007 en concepto de intcomercio2007 integer comercios Cantidad de años reclamados en el año 2008 en concepto de intcomercio2008 integer comercios Cantidad de años reclamados en el año 2009 en concepto de intcomercio2009 integer comercios intcomercio2010 integer Cantidad de años reclamados en el año 2010 en concepto de Facundo José Yatchesen 94 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones inmueble2000 money inmueble2001 money inmueble2002 money inmueble2003 money inmueble2004 money inmueble2005 money inmueble2006 money inmueble2007 money inmueble2008 money inmueble2009 money inmueble2010 money intinmueble2000 integer intinmueble2001 integer intinmueble2002 integer intinmueble2003 integer intinmueble2004 integer intinmueble2005 integer intinmueble2006 integer intinmueble2007 integer intinmueble2008 integer intinmueble2009 integer intinmueble2010 integer patente2000 money patente2001 patente2002 money money comercios Sumatoria de pagos realizados en concepto de tasa de inmueble, año 2000 Sumatoria de pagos realizados en concepto de tasa de inmueble, año 2001 Sumatoria de pagos realizados en concepto de tasa de inmueble, año 2002 Sumatoria de pagos realizados en concepto de tasa de inmueble, año 2003 Sumatoria de pagos realizados en concepto de tasa de inmueble, año 2004 Sumatoria de pagos realizados en concepto de tasa de inmueble, año 2005 Sumatoria de pagos realizados en concepto de tasa de inmueble, año 2006 Sumatoria de pagos realizados en concepto de tasa de inmueble, año 2007 Sumatoria de pagos realizados en concepto de tasa de inmueble, año 2008 Sumatoria de pagos realizados en concepto de tasa de inmueble, año 2009 Sumatoria de pagos realizados en concepto de tasa de inmueble, año 2010 Cantidad de años reclamados en el año 2000 en concepto de inmuebles Cantidad de años reclamados en el año 2001 en concepto de inmuebles Cantidad de años reclamados en el año 2002 en concepto de inmuebles Cantidad de años reclamados en el año 2003 en concepto de inmuebles Cantidad de años reclamados en el año 2004 en concepto de inmuebles Cantidad de años reclamados en el año 2005 en concepto de inmuebles Cantidad de años reclamados en el año 2006 en concepto de inmuebles Cantidad de años reclamados en el año 2007 en concepto de inmuebles Cantidad de años reclamados en el año 2008 en concepto de inmuebles Cantidad de años reclamados en el año 2009 en concepto de inmuebles Cantidad de años reclamados en el año 2010 en concepto de inmuebles Sumatoria de pagos realizados en concepto de tasa de patente, año 2000 Sumatoria de pagos realizados en concepto de tasa de patente, año 2001 Sumatoria de pagos realizados en concepto de tasa de Facundo José Yatchesen 95 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones patente2003 money patente2004 money patente2005 money patente2006 money patente2007 money patente2008 money patente2009 money patente2010 money intpatente2000 integer intpatente2001 integer intpatente2002 integer intpatente2003 integer intpatente2004 integer intpatente2005 integer intpatente2006 integer intpatente2007 integer intpatente2008 integer intpatente2009 integer intpatente2010 cantidadcomercios cantidadinmuebles cantidad patentes integer integer integer integer patente, año 2002 Sumatoria de pagos realizados en concepto de tasa de patente, año 2003 Sumatoria de pagos realizados en concepto de tasa de patente, año 2004 Sumatoria de pagos realizados en concepto de tasa de patente, año 2005 Sumatoria de pagos realizados en concepto de tasa de patente, año 2006 Sumatoria de pagos realizados en concepto de tasa de patente, año 2007 Sumatoria de pagos realizados en concepto de tasa de patente, año 2008 Sumatoria de pagos realizados en concepto de tasa de patente, año 2009 Sumatoria de pagos realizados en concepto de tasa de patente, año 2010 Cantidad de años reclamados en el año 2000 en concepto de patentes Cantidad de años reclamados en el año 2001 en concepto de patentes Cantidad de años reclamados en el año 2002 en concepto de patentes Cantidad de años reclamados en el año 2003 en concepto de patentes Cantidad de años reclamados en el año 2004 en concepto de patentes Cantidad de años reclamados en el año 2005 en concepto de patentes Cantidad de años reclamados en el año 2006 en concepto de patentes Cantidad de años reclamados en el año 2007 en concepto de patentes Cantidad de años reclamados en el año 2008 en concepto de patentes Cantidad de años reclamados en el año 2009 en concepto de patentes Cantidad de años reclamados en el año 2010 en concepto de patentes Cantidad de comercios para el documento indicado Cantidad de inmuebles para el documento indicado Cantidad de patentes para el documento indicado Anexo 2: Función de categorización de importes CREATE FUNCTION fx_municipal_categoria (@importe money) RETURNS money AS Facundo José Yatchesen 96 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones BEGIN --devuelve el la categoria dado el import declare @respuesta integer if (@importe) < 0 set @respuesta = 0 if ((@importe) >= 0 and (@importe) < 50) set @respuesta = 1 if ((@importe) >= 50 and (@importe) < 100) set @respuesta = 2 if ((@importe) >= 100 and (@importe) < 200) set @respuesta = 3 if ((@importe) >= 200 and (@importe) < 500) set @respuesta = 4 if ((@importe) >= 500 and (@importe) < 800) set @respuesta = 5 if ((@importe) >= 800 and (@importe) < 1500) set @respuesta = 6 if ((@importe) >= 1500 and (@importe) < 3000) set @respuesta = 7 if ((@importe) >= 3000 and (@importe) < 6000) set @respuesta = 8 if ((@importe) >= 6000 and (@importe) < 12000) set @respuesta = 9 if ((@importe) >= 12000 and (@importe) < 24000) set @respuesta = 10 if ((@importe) >= 24000 and (@importe) < 48000) set @respuesta = 11 if ((@importe) >= 48000 and (@importe) < 96000) set @respuesta = 12 if ((@importe) >= 96000) set @respuesta = 13 return @respuesta END Anexo 3: Procedimiento de transformación de datos hacia el conjunto de datos CREATE PROCEDURE DM_Insertar_Datos AS DECLARE @cantidad AS INT DECLARE @documento AS BIGINT DECLARE @var1 AS BIGINT DECLARE @var2 AS BIGINT DECLARE @var3 AS BIGINT DECLARE @var4 AS BIGINT Facundo José Yatchesen 97 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones DECLARE @var5 AS BIGINT DECLARE @var6 AS BIGINT DECLARE @var7 AS BIGINT DECLARE @var8 AS BIGINT DECLARE @var9 AS BIGINT DECLARE @var10 AS BIGINT DECLARE @var0 AS BIGINT DECLARE @auxiliar AS INT --Con este SP Inserto todo los datos en la table --Primero vacio la tabla DELETE FROM dm_integrado --Primero inserto los datos de inmuebles INSERT INTO dm_integrado (documento, comercio2000, intcomercio2000, comercio2001, intcomercio2001, comercio2002, intcomercio2002, comercio2003, intcomercio2003, comercio2004, intcomercio2004, comercio2005, intcomercio2005, comercio2006, intcomercio2006, comercio2007, intcomercio2007, comercio2008, intcomercio2008, comercio2009, intcomercio2009, comercio2010, intcomercio2010 ) (SELECT (SELECT CASE WHEN (documento < 3) THEN convert(integer, substring(cuit, 4, 8)) ELSE documento END from Pco_Entidad_Personas WHERE Pco_Entidad_Personas.id_entidad = Ccio_comercios.id_entidad) AS documento, (SELECT (ISNULL(SUM(Ccio_Pagos_Detalle.importe), 0)) FROM Ccio_Pagos INNER JOIN Ccio_Pagos_Detalle ON Ccio_Pagos.id_pagos = Ccio_Pagos_Detalle.id_pagos WHERE Ccio_Pagos_Detalle.id_comercio = Ccio_comercios.id_comercio AND year(fecha) = 2000) AS importe2000, (SELECT count(*) FROM Ccio_intimaciones_rec_deudas WHERE Ccio_intimaciones_rec_deudas.id_comercio = Ccio_comercios.id_comercio AND year(fecha) = 2000) AS intimado2000, (SELECT(ISNULL(SUM(Ccio_Pagos_Detalle.importe), 0)) FROM Ccio_Pagos INNER JOIN Ccio_Pagos_Detalle ON Ccio_Pagos.id_pagos = Ccio_Pagos_Detalle.id_pagos WHERE Ccio_Pagos_Detalle.id_comercio = Ccio_comercios.id_comercio AND year(fecha) = 2001) AS importe2001, (SELECT count(*) FROM Ccio_intimaciones_rec_deudas WHERE Ccio_intimaciones_rec_deudas.id_comercio = Ccio_comercios.id_comercio AND year(fecha) = 2001) AS intimado2001, (SELECT(ISNULL(SUM(Ccio_Pagos_Detalle.importe), 0)) FROM Ccio_Pagos INNER JOIN Ccio_Pagos_Detalle ON Ccio_Pagos.id_pagos = Ccio_Pagos_Detalle.id_pagos WHERE Ccio_Pagos_Detalle.id_comercio = Ccio_comercios.id_comercio AND year(fecha) = 2002) AS importe2002, (SELECT count(*) FROM Ccio_intimaciones_rec_deudas WHERE Ccio_intimaciones_rec_deudas.id_comercio = Ccio_comercios.id_comercio AND year(fecha) = 2002) AS intimado2002, (SELECT (ISNULL(SUM(Ccio_Pagos_Detalle.importe), 0)) FROM Ccio_Pagos INNER JOIN Ccio_Pagos_Detalle ON Ccio_Pagos.id_pagos = Ccio_Pagos_Detalle.id_pagos WHERE Facundo José Yatchesen 98 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Ccio_Pagos_Detalle.id_comercio = Ccio_comercios.id_comercio AND year(fecha) = 2003) AS importe2003, (SELECT count(*) FROM Ccio_intimaciones_rec_deudas WHERE Ccio_intimaciones_rec_deudas.id_comercio = Ccio_comercios.id_comercio AND year(fecha) = 2003) AS intimado2003, (SELECT (ISNULL(SUM(Ccio_Pagos_Detalle.importe), 0)) FROM Ccio_Pagos INNER JOIN Ccio_Pagos_Detalle ON Ccio_Pagos.id_pagos = Ccio_Pagos_Detalle.id_pagos WHERE Ccio_Pagos_Detalle.id_comercio = Ccio_comercios.id_comercio AND year(fecha) = 2004) AS importe2004, (SELECT count(*) FROM Ccio_intimaciones_rec_deudas WHERE Ccio_intimaciones_rec_deudas.id_comercio = Ccio_comercios.id_comercio AND year(fecha) = 2004) AS intimado2004, (SELECT (ISNULL(SUM(Ccio_Pagos_Detalle.importe), 0)) FROM Ccio_Pagos INNER JOIN Ccio_Pagos_Detalle ON Ccio_Pagos.id_pagos = Ccio_Pagos_Detalle.id_pagos WHERE Ccio_Pagos_Detalle.id_comercio = Ccio_comercios.id_comercio AND year(fecha) = 2005) AS importe2005, (SELECT count(*) FROM Ccio_intimaciones_rec_deudas WHERE Ccio_intimaciones_rec_deudas.id_comercio = Ccio_comercios.id_comercio AND year(fecha) = 2005) AS intimado2005, (SELECT (ISNULL(SUM(Ccio_Pagos_Detalle.importe), 0)) FROM Ccio_Pagos INNER JOIN Ccio_Pagos_Detalle ON Ccio_Pagos.id_pagos = Ccio_Pagos_Detalle.id_pagos WHERE Ccio_Pagos_Detalle.id_comercio = Ccio_comercios.id_comercio AND year(fecha) = 2006) AS importe2006, (SELECT count(*) FROM Ccio_intimaciones_rec_deudas WHERE Ccio_intimaciones_rec_deudas.id_comercio = Ccio_comercios.id_comercio AND year(fecha) = 2006) AS intimado2006, (SELECT(ISNULL(SUM(Ccio_Pagos_Detalle.importe), 0)) FROM Ccio_Pagos INNER JOIN Ccio_Pagos_Detalle ON Ccio_Pagos.id_pagos = Ccio_Pagos_Detalle.id_pagos WHERE Ccio_Pagos_Detalle.id_comercio = Ccio_comercios.id_comercio AND year(fecha) = 2007) AS importe2007, (SELECT count(*) FROM Ccio_intimaciones_rec_deudas WHERE Ccio_intimaciones_rec_deudas.id_comercio = Ccio_comercios.id_comercio AND year(fecha) = 2007) AS intimado2007, (SELECT(ISNULL(SUM(Ccio_Pagos_Detalle.importe), 0)) FROM Ccio_Pagos INNER JOIN Ccio_Pagos_Detalle ON Ccio_Pagos.id_pagos = Ccio_Pagos_Detalle.id_pagos WHERE Ccio_Pagos_Detalle.id_comercio = Ccio_comercios.id_comercio AND year(fecha) = 2008) AS importe2008, (SELECT count(*) FROM Ccio_intimaciones_rec_deudas WHERE Ccio_intimaciones_rec_deudas.id_comercio = Ccio_comercios.id_comercio AND year(fecha) = 2008) AS intimado2008, (SELECT (ISNULL(SUM(Ccio_Pagos_Detalle.importe), 0)) FROM Ccio_Pagos INNER JOIN Ccio_Pagos_Detalle ON Ccio_Pagos.id_pagos = Ccio_Pagos_Detalle.id_pagos WHERE Ccio_Pagos_Detalle.id_comercio = Ccio_comercios.id_comercio AND year(fecha) = 2009) AS importe2009, (SELECT count(*) FROM Ccio_intimaciones_rec_deudas WHERE Ccio_intimaciones_rec_deudas.id_comercio = Ccio_comercios.id_comercio AND year(fecha) = Facundo José Yatchesen 99 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones 2009) AS intimado2009, (SELECT(ISNULL(SUM(Ccio_Pagos_Detalle.importe), 0)) FROM Ccio_Pagos INNER JOIN Ccio_Pagos_Detalle ON Ccio_Pagos.id_pagos = Ccio_Pagos_Detalle.id_pagos WHERE Ccio_Pagos_Detalle.id_comercio = Ccio_comercios.id_comercio AND year(fecha) = 2010) AS importe2010, (SELECT count(*) FROM Ccio_intimaciones_rec_deudas WHERE Ccio_intimaciones_rec_deudas.id_comercio = Ccio_comercios.id_comercio AND year(fecha) = 2010) AS intimado2010 FROM Ccio_comercios WHERE (ccio_comercios.n_habilitacion NOT LIKE '%E/T%' AND ccio_comercios.n_habilitacion NOT LIKE '%A%' AND ccio_comercios.n_habilitacion NOT LIKE '%a%' AND ccio_comercios.n_habilitacion NOT LIKE '%B%') AND Ccio_comercios.fecha_habilitacion <= '31/12/2010') DELETE FROM dm_integrado WHERE documento = 0 ---Actualizo la cantidad de unidades para el documento para comercios DECLARE CURSORITO CURSOR FOR SELECT documento, COUNT(*) AS cantidad FROM dm_integrado GROUP BY documento ORDER BY cantidad DESC OPEN CURSORITO ---Avanzamos un registro y cargamos en las variables los valores encontrados en el primer registro FETCH NEXT FROM CURSORITO INTO @documento, @cantidad WHILE @@fetch_status = 0 BEGIN UPDATE dm_integrado SET cantidadcomercios = @cantidad WHERE documento = @documento FETCH NEXT FROM CURSORITO INTO @documento, @cantidad END ---cerramos el cursor CLOSE CURSORITO DEALLOCATE CURSORITO ---Vacio la tabla temporal DELETE FROM dm_integrado2 ---Guardo en la tabla temporal los que son con mas de un comercio Facundo José Yatchesen 100 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones INSERT INTO dm_integrado2 (documento, cantidadcomercios, comercio2000, intcomercio2000, comercio2001, intcomercio2001, comercio2002, intcomercio2002, comercio2003, intcomercio2003, comercio2004, intcomercio2004, comercio2005, intcomercio2005, comercio2006, intcomercio2006, comercio2007, intcomercio2007, comercio2008, intcomercio2008, comercio2009, intcomercio2009, comercio2010, intcomercio2010 ) (SELECT documento, cantidadcomercios, SUM(comercio2000), SUM(intcomercio2000), SUM(comercio2001), SUM(intcomercio2001), SUM(comercio2002), SUM(intcomercio2002), SUM(comercio2003), SUM(intcomercio2003) , SUM(comercio2004), SUM(intcomercio2004), SUM(comercio2005), SUM(intcomercio2005), SUM(comercio2006), SUM(intcomercio2006), SUM(comercio2007), SUM(intcomercio2007), SUM(comercio2008), SUM(intcomercio2008) , SUM(comercio2009), SUM(intcomercio2009), SUM(comercio2010), SUM(intcomercio2010) FROM dm_integrado GROUP BY documento, tipoempresa, anioinscomercio, cantidadcomercios) ---Vacio la tabla original DELETE FROM dm_integrado ---Cargo todo en la tabla felpa INSERT INTO dm_integrado (documento, cantidadcomercios, comercio2000, intcomercio2000, comercio2001, intcomercio2001, comercio2002, intcomercio2002, comercio2003, intcomercio2003, comercio2004, intcomercio2004, comercio2005, intcomercio2005, comercio2006, intcomercio2006, comercio2007, intcomercio2007, comercio2008, intcomercio2008, comercio2009, intcomercio2009, comercio2010, intcomercio2010 ) (SELECT documento, cantidadcomercios, SUM(comercio2000), SUM(intcomercio2000), SUM(comercio2001), SUM(intcomercio2001), SUM(comercio2002), SUM(intcomercio2002), SUM(comercio2003), SUM(intcomercio2003) , SUM(comercio2004), SUM(intcomercio2004), SUM(comercio2005), SUM(intcomercio2005), SUM(comercio2006), SUM(intcomercio2006), SUM(comercio2007), SUM(intcomercio2007), SUM(comercio2008), SUM(intcomercio2008) , SUM(comercio2009), SUM(intcomercio2009), SUM(comercio2010), SUM(intcomercio2010) FROM dm_integrado2 GROUP BY documento, tipoempresa, anioinscomercio, cantidadcomercios) ---Borro el loquito que esta con documento null DELETE FROM dm_integrado WHERE documento IS NULL ---Cargo lo de inmuebles DELETE FROM dm_integrado2 INSERT dm_integrado2 (tipoempresa, documento, comercio2000, comercio2001, comercio2002, comercio2003, comercio2004, comercio2005, comercio2006, comercio2007, comercio2008, comercio2009, comercio2010 ) ( SELECT Inm_DatosContribuyente.NContribuyente, documento, (SELECT isnull((SUM(tasa) + sum(alumbrado) + sum(catastro) + sum(recargos) + sum(obraspublicas)), 0) FROM Inm_Pagos WHERE year(fecha) = 2000 and Facundo José Yatchesen 101 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Inm_Pagos.NContribuyente = Inm_DatosContribuyente.NContribuyente), (SELECT isnull((SUM(tasa) + sum(alumbrado) + sum(catastro) + sum(recargos) + sum(obraspublicas)), 0) FROM Inm_Pagos WHERE year(fecha) = 2001 and Inm_Pagos.NContribuyente = Inm_DatosContribuyente.NContribuyente), (SELECT isnull((SUM(tasa) + sum(alumbrado) + sum(catastro) + sum(recargos) + sum(obraspublicas)), 0) FROM Inm_Pagos WHERE year(fecha) = 2002 and Inm_Pagos.NContribuyente = Inm_DatosContribuyente.NContribuyente), (SELECT isnull((SUM(tasa) + sum(alumbrado) + sum(catastro) + sum(recargos) + sum(obraspublicas)), 0) FROM Inm_Pagos WHERE year(fecha) = 2003 and Inm_Pagos.NContribuyente = Inm_DatosContribuyente.NContribuyente), (SELECT isnull((SUM(tasa) + sum(alumbrado) + sum(catastro) + sum(recargos) + sum(obraspublicas)), 0) FROM Inm_Pagos WHERE year(fecha) = 2004 and Inm_Pagos.NContribuyente = Inm_DatosContribuyente.NContribuyente), (SELECT isnull((SUM(tasa) + sum(alumbrado) + sum(catastro) + sum(recargos) + sum(obraspublicas)), 0) FROM Inm_Pagos WHERE year(fecha) = 2005 and Inm_Pagos.NContribuyente = Inm_DatosContribuyente.NContribuyente), (SELECT isnull((SUM(tasa) + sum(alumbrado) + sum(catastro) + sum(recargos) + sum(obraspublicas)), 0) FROM Inm_Pagos WHERE year(fecha) = 2006 and Inm_Pagos.NContribuyente = Inm_DatosContribuyente.NContribuyente), (SELECT isnull((SUM(tasa) + sum(alumbrado) + sum(catastro) + sum(recargos) + sum(obraspublicas)), 0) FROM Inm_Pagos WHERE year(fecha) = 2007 and Inm_Pagos.NContribuyente = Inm_DatosContribuyente.NContribuyente), (SELECT isnull((SUM(tasa) + sum(alumbrado) + sum(catastro) + sum(recargos) + sum(obraspublicas)), 0) FROM Inm_Pagos WHERE year(fecha) = 2008 and Inm_Pagos.NContribuyente = Inm_DatosContribuyente.NContribuyente), (SELECT isnull((SUM(tasa) + sum(alumbrado) + sum(catastro) + sum(recargos) + sum(obraspublicas)), 0) FROM Inm_Pagos WHERE year(fecha) = 2009 and Inm_Pagos.NContribuyente = Inm_DatosContribuyente.NContribuyente), (SELECT isnull((SUM(tasa) + sum(alumbrado) + sum(catastro) + sum(recargos) + sum(obraspublicas)), 0) FROM Inm_Pagos WHERE year(fecha) = 2010 and Inm_Pagos.NContribuyente = Inm_DatosContribuyente.NContribuyente) FROM Inm_DatosContribuyente WHERE documento != 0 ) ---Actualizo la cantidad de unidades para el documento para comercios DECLARE CURSORITO2 CURSOR FOR SELECT documento, COUNT(*) AS cantidad, sum(comercio2000), sum(comercio2001), sum(comercio2002), sum(comercio2003), sum(comercio2004), sum(comercio2005), sum(comercio2006), sum(comercio2007), sum(comercio2008), sum(comercio2009), sum(comercio2010) FROM dm_integrado2 GROUP BY documento OPEN CURSORITO2 ---Avanzamos un registro y cargamos en las variables los valores encontrados en el primer registro FETCH NEXT FROM CURSORITO2 INTO @documento, @cantidad, @var0, @var1, @var2, @var3, @var4, @var5, @var6, @var7, @var8, @var9, @var10 Facundo José Yatchesen 102 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones WHILE @@fetch_status = 0 BEGIN SET @auxiliar = 0 SET @auxiliar = (SELECT COUNT(*) FROM dm_integrado WHERE documento = @documento) IF @auxiliar = 0 INSERT INTO dm_integrado (documento, cantidadinmuebles, inmueble2000, inmueble2001, inmueble2002, inmueble2003, inmueble2004, inmueble2005, inmueble2006, inmueble2007, inmueble2008, inmueble2009, inmueble2010 ) VALUES ( @documento, @cantidad, @var0, @var1, @var2, @var3, @var4, @var5, @var6, @var7, @var8, @var9, @var10) ELSE UPDATE dm_integrado SET cantidadinmuebles = @cantidad , inmueble2000 =@var0 , inmueble2001 =@var1, inmueble2002 =@var2, inmueble2003 =@var3, inmueble2004 =@var4, inmueble2005 =@var5 , inmueble2006 =@var6, inmueble2007 =@var7, inmueble2008 =@var8, inmueble2009 =@var9, inmueble2010 =@var10 WHERE documento = @documento FETCH NEXT FROM CURSORITO2 INTO @documento, @cantidad, @var0, @var1, @var2, @var3, @var4, @var5, @var6, @var7, @var8, @var9, @var10 END ---cerramos el cursor CLOSE CURSORITO2 DEALLOCATE CURSORITO2 ---Cargo lo de patentes DELETE FROM dm_integrado2 INSERT dm_integrado2 (tipoempresa, documento, comercio2000, comercio2001, comercio2002, comercio2003, comercio2004, comercio2005, comercio2006, comercio2007, comercio2008, comercio2009, comercio2010 ) (SELECT id_patente, dni, (SELECT isnull(SUM(IMPOT), 0) FROM pat_pagos WHERE YEAR(fechap) = 2000 AND pat_pagos.id_patente = pat_propietarios.id_patente), (SELECT isnull(SUM(IMPOT), 0) FROM pat_pagos WHERE YEAR(fechap) = 2001 AND pat_pagos.id_patente = pat_propietarios.id_patente), (SELECT isnull(SUM(IMPOT), 0) FROM pat_pagos WHERE YEAR(fechap) = 2002 AND pat_pagos.id_patente = pat_propietarios.id_patente), (SELECT isnull(SUM(IMPOT), 0) FROM pat_pagos WHERE YEAR(fechap) = 2003 AND pat_pagos.id_patente = pat_propietarios.id_patente), (SELECT isnull(SUM(IMPOT), 0) FROM pat_pagos WHERE YEAR(fechap) = 2004 AND pat_pagos.id_patente = pat_propietarios.id_patente), Facundo José Yatchesen 103 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones (SELECT isnull(SUM(IMPOT), 0) FROM pat_pagos WHERE YEAR(fechap) = 2005 AND pat_pagos.id_patente = pat_propietarios.id_patente), (SELECT isnull(SUM(IMPOT), 0) FROM pat_pagos WHERE YEAR(fechap) = 2006 AND pat_pagos.id_patente = pat_propietarios.id_patente), (SELECT isnull(SUM(IMPOT), 0) FROM pat_pagos WHERE YEAR(fechap) = 2007 AND pat_pagos.id_patente = pat_propietarios.id_patente), (SELECT isnull(SUM(IMPOT), 0) FROM pat_pagos WHERE YEAR(fechap) = 2008 AND pat_pagos.id_patente = pat_propietarios.id_patente), (SELECT isnull(SUM(IMPOT), 0) FROM pat_pagos WHERE YEAR(fechap) = 2009 AND pat_pagos.id_patente = pat_propietarios.id_patente), (SELECT isnull(SUM(IMPOT), 0) FROM pat_pagos WHERE YEAR(fechap) = 2010 AND pat_pagos.id_patente = pat_propietarios.id_patente) FROM pat_propietarios WHERE dni != 0 GROUP BY id_patente, dni) ---Actualizo la cantidad de unidades para el documento para comercios DECLARE CURSORITO3 CURSOR FOR SELECT documento, COUNT(*) AS cantidad, sum(comercio2000), sum(comercio2001), sum(comercio2002), sum(comercio2003), sum(comercio2004), sum(comercio2005), sum(comercio2006), sum(comercio2007), sum(comercio2008), sum(comercio2009), sum(comercio2010) FROM dm_integrado2 GROUP BY documento OPEN CURSORITO3 ---Avanzamos un registro y cargamos en las variables los valores encontrados en el primer registro FETCH NEXT FROM CURSORITO3 INTO @documento, @cantidad, @var0, @var1, @var2, @var3, @var4, @var5, @var6, @var7, @var8, @var9, @var10 WHILE @@fetch_status = 0 BEGIN SET @auxiliar = 0 SET @auxiliar = (SELECT COUNT(*) FROM dm_integrado WHERE documento = @documento) IF @auxiliar = 0 INSERT INTO dm_integrado (documento, cantidadpatentes, patente2000, patente2001, patente2002, patente2003, patente2004, patente2005, patente2006, patente2007, patente2008, patente2009, patente2010 ) VALUES ( @documento, @cantidad, @var0, @var1, @var2, @var3, @var4, @var5, @var6, @var7, @var8, @var9, @var10) ELSE UPDATE dm_integrado SET cantidadpatentes = @cantidad , patente2000 =@var0 , patente2001 =@var1, patente2002 =@var2, patente2003 =@var3, patente2004 =@var4, patente2005 =@var5 , patente2006 =@var6, patente2007 =@var7, patente2008 =@var8, Facundo José Yatchesen 104 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones patente2009 =@var9, patente2010 =@var10 WHERE documento = @documento FETCH NEXT FROM CURSORITO3 INTO @documento, @cantidad, @var0, @var1, @var2, @var3, @var4, @var5, @var6, @var7, @var8, @var9, @var10 END ---cerramos el cursor CLOSE CURSORITO3 DEALLOCATE CURSORITO3 ---Borro todos los que nunca pagaron algo DELETE FROM dm_integrado WHERE (comercio2000 + comercio2001 + comercio2002 + comercio2003 + comercio2004 + comercio2005 + comercio2006 + comercio2007 + comercio2008 + comercio2009 + comercio2010 + inmueble2000 + inmueble2001 + inmueble2002 + inmueble2003 + inmueble2004 + inmueble2005 + inmueble2006 + inmueble2007 + inmueble2008 + inmueble2009 + inmueble2010 + patente2000 + patente2001 + patente2002 + patente2003 + patente2004 + patente2005 + patente2006 + patente2007 + patente2008 + patente2009 + patente2010) = 0 ---Vacio la tabla temporal para cargar las intimaciones DELETE FROM dm_integrado2 ---Inserto las intimaciones de comercio INSERT INTO dm_integrado2 (documento, tipoempresa, anioinscomercio, cantidadcomercios) (SELECT Ccio_comercios.id_comercio, CASE WHEN (documento < 3) THEN convert(integer, substring(cuit, 4, 8)) ELSE documento END, year(fecha) - año_desde as cantidad, year(fecha) FROM Ccio_intimaciones_rec_deudas INNER JOIN Ccio_comercios ON Ccio_intimaciones_rec_deudas.id_comercio = Ccio_comercios.id_comercio INNER JOIN Pco_Entidad_Personas ON Ccio_comercios.id_entidad = Pco_Entidad_Personas.Id_Entidad WHERE YEAR(fecha) >= 2000 AND YEAR(fecha) <= 2010) ---Borro todo los documentos = 0 DELETE FROM dm_integrado2 WHERE documento = 0 ---Borro todo los cantidades con valores superiores DELETE FROM dm_integrado2 WHERE anioinscomercio < 0 OR anioinscomercio > 100 ---Actualizo de acuerdo al tipo y anio DECLARE CURSORITO4 CURSOR FOR SELECT tipoempresa, SUM(anioinscomercio), cantidadcomercios FROM dm_integrado2 GROUP BY tipoempresa, cantidadcomercios OPEN CURSORITO4 ---Avanzamos un registro y cargamos en las variables los valores encontrados en el primer registro Facundo José Yatchesen 105 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones FETCH NEXT FROM CURSORITO4 INTO @documento, @cantidad, @var0 WHILE @@fetch_status = 0 BEGIN IF @var0 = 2000 UPDATE dm_integrado SET intcomercio2000 = @cantidad WHERE documento = @documento IF @var0 = 2001 UPDATE dm_integrado SET intcomercio2001 = @cantidad WHERE documento = @documento IF @var0 = 2002 UPDATE dm_integrado SET intcomercio2002 = @cantidad WHERE documento = @documento IF @var0 = 2003 UPDATE dm_integrado SET intcomercio2003 = @cantidad WHERE documento = @documento IF @var0 = 2004 UPDATE dm_integrado SET intcomercio2004 = @cantidad WHERE documento = @documento IF @var0 = 2005 UPDATE dm_integrado SET intcomercio2005 = @cantidad WHERE documento = @documento IF @var0 = 2006 UPDATE dm_integrado SET intcomercio2006 = @cantidad WHERE documento = @documento IF @var0 = 2007 UPDATE dm_integrado SET intcomercio2007 = @cantidad WHERE documento = @documento IF @var0 = 2008 UPDATE dm_integrado SET intcomercio2008 = @cantidad WHERE documento = @documento IF @var0 = 2009 UPDATE dm_integrado SET intcomercio2009 = @cantidad WHERE documento = @documento IF @var0 = 2010 UPDATE dm_integrado SET intcomercio2010 = @cantidad WHERE documento = @documento FETCH NEXT FROM CURSORITO4 INTO @documento, @cantidad, @var0 END ---cerramos el cursor CLOSE CURSORITO4 DEALLOCATE CURSORITO4 Facundo José Yatchesen 106 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones ---Vacio la tabla temporal para cargar las intimaciones DELETE FROM dm_integrado2 ---Inserto las intimaciones de inmuebles INSERT INTO dm_integrado2 (documento, tipoempresa, anioinscomercio, cantidadcomercios) (SELECT n_contribuyente, documento, YEAR(fecha) - desde_año as cantidad, YEAR(fecha) FROM Inm_Intimaciones INNER JOIN inm_datoscontribuyente ON Inm_Intimaciones.n_contribuyente = inm_datoscontribuyente.ncontribuyente WHERE YEAR(fecha) >= 2000 AND YEAR(fecha) <= 2010) ---Borro todo los documentos = 0 DELETE FROM dm_integrado2 WHERE documento = 0 ---Borro todo los cantidades con valores superiores DELETE FROM dm_integrado2 WHERE anioinscomercio < 0 OR anioinscomercio > 100 ---Actualizo de acuerdo al tipo y anio DECLARE CURSORITO5 CURSOR FOR SELECT tipoempresa, SUM(anioinscomercio), cantidadcomercios FROM dm_integrado2 GROUP BY tipoempresa, cantidadcomercios OPEN CURSORITO5 ---Avanzamos un registro y cargamos en las variables los valores encontrados en el primer registro FETCH NEXT FROM CURSORITO5 INTO @documento, @cantidad, @var0 WHILE @@fetch_status = 0 BEGIN IF @var0 = 2000 UPDATE dm_integrado SET intinmueble2000 = @cantidad WHERE documento = @documento IF @var0 = 2001 UPDATE dm_integrado SET intinmueble2001 = @cantidad WHERE documento = @documento IF @var0 = 2002 UPDATE dm_integrado SET intinmueble2002 = @cantidad WHERE documento = @documento IF @var0 = 2003 UPDATE dm_integrado SET intinmueble2003 = @cantidad WHERE documento = @documento IF @var0 = 2004 UPDATE dm_integrado SET intinmueble2004 = @cantidad WHERE documento = @documento IF @var0 = 2005 UPDATE dm_integrado SET intinmueble2005 = @cantidad WHERE documento = @documento Facundo José Yatchesen 107 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones IF @var0 = 2006 UPDATE dm_integrado SET intinmueble2006 = @cantidad WHERE documento = @documento IF @var0 = 2007 UPDATE dm_integrado SET intinmueble2007 = @cantidad WHERE documento = @documento IF @var0 = 2008 UPDATE dm_integrado SET intinmueble2008 = @cantidad WHERE documento = @documento IF @var0 = 2009 UPDATE dm_integrado SET intinmueble2009 = @cantidad WHERE documento = @documento IF @var0 = 2010 UPDATE dm_integrado SET intinmueble2010 = @cantidad WHERE documento = @documento FETCH NEXT FROM CURSORITO5 INTO @documento, @cantidad, @var0 END ---cerramos el cursor CLOSE CURSORITO5 DEALLOCATE CURSORITO5 ---Actualizo de acuerdo al tipo y anio SET @cantidad = 1 DECLARE CURSORITO6 CURSOR FOR SELECT documento FROM dm_integrado OPEN CURSORITO6 ---Avanzamos un registro y cargamos en las variables los valores encontrados en el primer registro FETCH NEXT FROM CURSORITO6 INTO @documento WHILE @@fetch_status = 0 BEGIN UPDATE dm_integrado SET tipoempresa = @cantidad WHERE documento = @documento SET @cantidad = @cantidad + 1 FETCH NEXT FROM CURSORITO6 INTO @documento END Facundo José Yatchesen 108 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones ---cerramos el cursor CLOSE CURSORITO6 DEALLOCATE CURSORITO6 GO Facundo José Yatchesen 109 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Bibliografía Facundo José Yatchesen 110 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones [1] C. Phua, V. Lee, K. Smith, y R. Gayler, «A Comprehensive Survey of Data Mining-based Fraud Detection Research», arXiv:1009.6119, sep. 2010. [2] V. Chandola, A. Banerjee, y V. Kumar, «Anomaly detection: A survey», ACM Comput. Surv., vol. 41, no. 3, pp. 15:1–15:58, jul. 2009. [3] J. Han y M. Kamber, Data Mining: Concepts and Techniques. Morgan Kaufmann, 2005. [4] F. B. Clyde W. Holsapple, Handbook on Decision Support Systems 2: Variations. Springer, 2008. [5] U. Fayyad, G. Piatetsky-Shapiro, y P. Smyth, «From data mining to knowledge discovery in databases», AI magazine, vol. 17, no. 3, p. 37, 1996. [6] D. J. Hand, H. Mannila, y P. Smyth, Principles of Data Mining. A Bradford Book, 2001. [7] S. Chakrabarti, Data Mining: Know it all. Morgan Kaufmann, 2008. [8] Perversi Ignacio, Fernandez Enrique, y Garcia-Martinez Ramon, «APLICACIÓN DE MINERÍA DE DATOS PARA LA EXPLORACIÓN Y DETECCIÓN DE PATRONES DELICTIVOS EN ARGENTINA», Instituto Tecnologico de Buenos Aires, 2007. [9] Dunja Mladenic, Nada Lavra, Marko Bohanec, Steve Moyle, Data Mining and Decision Support: Integration and Collaboration. Springer. [10] B. Curtis, M. I. Kellner, y J. Over, «Process modeling», Commun. ACM, vol. 35, no. 9, pp. 75–90, sep. 1992. [11] S. Kanungo, «Using Process Theory to Analyze Direct and Indirect Value-Drivers of Information Systems», in Proceedings of the 38th Annual Hawaii International Conference on System Sciences, 2005. HICSS ’05, 2005, p. 231c. [12] J. E. Ferreira, O. K. Takai, y C. Pu, «Integration of business processes with autonomous information systems: a case study in government services», in Seventh IEEE International Conference on E-Commerce Technology, 2005. CEC 2005, 2005, pp. 471 – 474. [13] R. García-Martínez, P. Britos, P. Pesado, y R. Bertone, «Towards an Information Mining Engineering», Software Engineering, Methods, Modeling and Teaching, pp. 83–99, 2011. [14] C. P. Team, «CMMI for Development, version 1.2», 2006. [15] H. Oktaba, F. Garcia, M. Piattini, F. Ruiz, F. J. Pino, y C. Alquicira, «Software Process Improvement: The Competisoft Project», Computer, vol. 40, no. 10, pp. 21 –28, oct. 2007. Facundo José Yatchesen 111 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones [16] Hanna Oktaba, «Modelo de Procesos para la Industria de Software MoProSoft. Version 1.3». ago-2005. [17] D. Pyle, Business Modeling and Data Mining. Morgan Kaufmann, 2003. [18] Pete Chapman, CRISP-DM 1.0: Step-by-step Data Mining Guide. SPSS, 2000. [19] A. I. R. L. Azevedo, «KDD, SEMMA and CRISP-DM: a parallel overview», 2008. [20] «What main methodology are you using for data mining? [150 votes total]». ago-2007. [21] R.-S. Wu, C. S. Ou, H. Lin, S.-I. Chang, y D. C. Yen, «Using data mining technique to enhance tax evasion detection performance», Expert Systems with Applications, vol. 39, no. 10, pp. 8769–8777, ago. 2012. [22] F. Y. Edgeworth, «XLI. On discordant observations», Philosophical Magazine Series 5, vol. 23, no. 143, pp. 364–375, 1887. [23] S. Wang, «A Comprehensive Survey of Data Mining-Based Accounting-Fraud Detection Research», in 2010 International Conference on Intelligent Computation Technology and Automation (ICICTA), 2010, vol. 1, pp. 50 –53. [24] H. R. Davia, P. C. Coggins, J. C. Wideman, y J. T. Kastantin, Accountant’s Guide to Fraud Detection and Control, 2.a ed. Wiley, 2000. [25] G. J. Myatt, Making Sense of Data: A Practical Guide to Exploratory Data Analysis and Data Mining, 1.a ed. Wiley-Interscience, 2006. [26] P. C. González y J. D. Velásquez, «Characterization and detection of taxpayers with false invoices using data mining techniques», Expert Systems with Applications. [27] C. Phua, D. Alahakoon, y V. Lee, «Minority report in fraud detection: classification of skewed data», SIGKDD Explor. Newsl., vol. 6, no. 1, pp. 50–59, jun. 2004. [28] T. Kohonen, Self-Organizing Maps. Springer, 2001. [29] T. Kohonen, S. Kaski, K. Lagus, J. Salojarvi, J. Honkela, V. Paatero, y A. Saarela, «Self organization of a massive document collection», IEEE Transactions on Neural Networks, vol. 11, no. 3, pp. 574 –585, may 2000. [30] T. M. Martinetz, S. G. Berkovich, y K. J. Schulten, «`Neural-gas’ network for vector quantization and its application to time-series prediction», IEEE Transactions on Neural Facundo José Yatchesen 112 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones Networks, vol. 4, no. 4, pp. 558 –569, jul. 1993. [31] M. F. F. C. F. Masullia y S. Rovettaa, «A survey of kernel and spectral methods for clustering». [32] S. K. Murthy, «Automatic construction of decision trees from data: A multi-disciplinary survey», Data mining and knowledge discovery, vol. 2, no. 4, pp. 345–389, 1998. [33] J. Pearl, Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference, 1.a ed. Morgan Kaufmann, 1988. [34] N. Friedman, D. Geiger, y M. Goldszmidt, «Bayesian network classifiers», Machine learning, vol. 29, no. 2, pp. 131–163, 1997. [35] J. E. Cabral, J. O. P. Pinto, E. M. Martins, y A. M. A. Pinto, «Fraud detection in high voltage electricity consumers using data mining», in Transmission and Distribution Conference and Exposition, 2008. T #x00026;D. IEEE/PES, 2008, pp. 1 –5. [36] R. Ghani y M. Kumar, «Interactive learning for efficiently detecting errors in insurance claims», in Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining, New York, NY, USA, 2011, pp. 325–333. [37] P. Britos, H. Grosser, D. Rodríguez, y R. Garcia-Martinez, «Detecting Unusual Changes of Users Consumption», Artificial Intelligence in Theory and Practice II, pp. 297–306, 2008. [38] T. Dasu y T. Johnson, Exploratory Data Mining and Data Cleaning, 1.a ed. Wiley- Interscience, 2003. [39] N. Abe, B. Zadrozny, & J. Langford, «Outlier detection by active learning». Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2006, 504-509. [40] G. H. John, «Robust Decision Trees: Removing Outliers from Databases». KDD, 1995 174- 179. [41] Z. H. Zhou, & Y. Jiang, «Medical diagnosis with C4.5 rule preceded by artificial neural network ensemble». Information Technology in Biomedicine, IEEE Transactions on, 7(1), 2003, 37-42. [42] P. Gutierrez Rüegg, P. Britos, R. García-Martínez, «CARACTERIZACIÓN DE LA POBLACIÓN CARCELARIA EN ARGENTINA MEDIANTE LA APLICACIÓN DE MINERÍA Facundo José Yatchesen 113 Aplicación de técnicas de minería de datos para la detección de fraude tributario, caso de estudio Municipalidad de Apóstoles, provincia de Misiones DE DATOS PARA LA PREVENCIÓN DE HECHOS DELICTIVOS». Tesis de grado, 2008. Facundo José Yatchesen 114