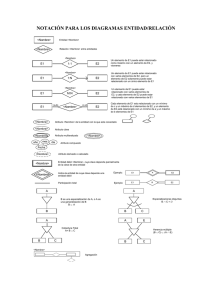
Explotación de un Data Warehouse.
Anuncio

Escuela Técnica Superior de Ingenieros Universidad de Sevilla Explotación de un Data Warehouse. Fundamentos y caso práctico para la gestión de proyectos. Autor: Ignacio Reinoso Rojas Tutor: María Teresa Ariza Gómez Proyecto Fin de Carrera Ingeniería de Telecomunicación Sevilla, Septiembre de 2014 Este Proyecto se realizó en el Departamento de Ingeniería Telemática 1 2 DEDICATORIA A mi familia y amigos “Any fool can make things bigger, more complex, and more violent. It takes a touch of genius-and a lot of courage-to move in the opposite direction.” Albert Einstein 3 4 Agradecimiento A mis padres, hermanos y abuelos, porque sin ellos no sería nada. En especial a mi tata, que me enseñó que la sonrisa es lo último que se pierde. A mi sobrino, porque me ha enseñado que algo diminuto puede ser enorme en tu corazón. A mis amigos, que siempre han estado ahí para lo bueno y lo malo. En especial a Guaje y a Dani, siempre ahí para unas buenas risas. 5 6 Resumen Vivimos en la sociedad de la información. Gracias a Internet y al desarrollo de los sistemas de información, se puede acceder a mucha más información, de más calidad y con mayor rapidez. Gestionar y aprender a competir con esta información es fundamental para la toma de decisiones, el crecimiento y la gestión de nuestra empresa. Se hace necesario y fundamental el uso de herramientas de Business Intelligence (BI) junto con conceptos altamente estandarizados, que permitan mejorar el proceso de soluciones de este tipo, todo ello de cara a mejorar la toma de decisiones, en definitiva, a mejorar la empresa. En este proyecto se pretende dar a conocer los fundamentos necesarios para realizar una solución de Business Intelligence. Además, llevaremos a cabo un estudio de un sistema de BI, eligiendo para ello el software MicroStrategy e ilustraremos en un caso práctico gran parte de sus funcionalidades para poder optimizar la gestión, es decir, la toma de decisiones. 7 8 Abstract We are currently living in the so-called Information Society. Due to the Internet and the Information Systems development, it's possible to access much more information, faster and reliably. Managing and learning how to exploit this information is crucial to take decisions to improve our company growth. Therefore, it's necessary to use Business Intelligence along with highly-standarized concepts allowing the improvement of the process of this kind of solutions, aiming to improve the company. The aim of the project is to give an overview for the foundations to implement a BI system. Besides, a MicroStrategy BI system analysis will be conducted illustrating in a practical case most of its management optimization functionalities, in other words, the decision-making process. 9 Índice general Agradecimiento................................................................................................................. 5 Resumen ........................................................................................................................... 7 Abstract ............................................................................................................................. 9 Índice general.................................................................................................................. 10 Índice de figuras ............................................................................................................. 13 Índice de tablas ............................................................................................................... 15 1 2 Introducción............................................................................................................. 16 1.1 Motivación ....................................................................................................... 16 1.2 Objetivos .......................................................................................................... 17 1.3 Estructura de la memoria ................................................................................. 17 Fundamentos............................................................................................................ 20 2.1 Business Intelligence........................................................................................ 21 2.1.1 ¿Qué es Business Intelligence?................................................................. 21 2.1.2 Componentes del Business Intelligence ................................................... 22 2.1.2.1 Esquema de una solución de Business Intelligence .......................... 22 2.1.2.2 Diseño conceptual ............................................................................. 23 2.1.2.3 Construcción/alimentación del Data Warehouse y/o los Datamarts . 24 2.1.2.4 Herramientas de explotación de la información ................................ 24 2.1.3 Selección de herramientas de Business Intelligence ................................ 25 2.1.4 Áreas funcionales y beneficios del Business Intelligence ........................ 26 2.1.5 Protagonistas del Business Intelligence .................................................... 27 2.2 Data Warehouse ............................................................................................... 28 2.2.1 Data Warehousing y Data Warehouse ...................................................... 28 2.2.2 Ventajas e inconvenientes de un Data Warehouse ................................... 30 2.2.3 Diferencias entre: Data Warehouse y base de datos transaccional ........... 32 2.2.4 Arquitectura de un Data Warehouse ......................................................... 33 2.2.4.1 Procesos ETL de un Data Warehouse ............................................... 34 2.2.4.2 Datamarts........................................................................................... 35 2.2.5 2.2.5.1 Diseño de un Data Warehouse.................................................................. 37 Diseño lógico ..................................................................................... 38 10 2.2.5.2 2.2.6 3 Explotación de un Data Warehouse: Herramientas OLAP ....................... 43 2.2.6.1 ¿Qué es OLAP? ................................................................................. 43 2.2.6.2 Diferencias entre procesamiento OLTP y OLAP .............................. 45 2.2.6.3 Cubos, Dimensiones, Medidas y Operaciones aplicables ................. 46 2.2.6.4 ROLAP, MOLAP y HOLAP............................................................. 50 Tecnologías.............................................................................................................. 56 3.1 Redmine ........................................................................................................... 56 3.1.1 ¿Qué es Redmine? .................................................................................... 56 3.1.2 Características ........................................................................................... 57 3.2 Kettle (Pentaho Data Integrator) ...................................................................... 57 3.2.1 ¿Qué es Kettle? ......................................................................................... 57 3.2.2 Características ........................................................................................... 58 3.3 Oracle Warehouse Builder ............................................................................... 58 3.3.1 ¿Qué es Oracle Warehouse Builder? ........................................................ 59 3.3.2 Características ........................................................................................... 59 3.4 Oracle Database ............................................................................................... 60 3.4.1 ¿Qué es Oracle Database? ........................................................................ 60 3.4.2 Características ........................................................................................... 61 3.4.3 Estructuras internas a la Base de Datos .................................................... 62 3.5 4 Diseño físico ...................................................................................... 43 MicroStrategy................................................................................................... 63 3.5.1 ¿Qué es MicroStrategy?............................................................................ 63 3.5.2 Conceptos importantes.............................................................................. 64 3.5.3 Elementos de MicroStrategy..................................................................... 67 3.5.4 Bases de datos necesarias para utilizar MicroStrategy ............................. 68 3.5.5 Origen de proyectos .................................................................................. 69 3.5.6 Informes .................................................................................................... 70 3.5.7 Documentos .............................................................................................. 71 3.5.8 Requisitos del sistema............................................................................... 71 3.5.9 Ejemplo de Cuadro de Mando realizado con MicroStrategy.................... 72 Caso práctico ........................................................................................................... 75 4.1 Análisis............................................................................................................. 75 4.1.1 Contexto.................................................................................................... 75 11 4.1.2 4.2 Diseño .............................................................................................................. 77 4.2.1 Parseo de la Fuente de Datos .................................................................... 78 4.2.2 Procesos de Extracción, Transformación y Carga .................................... 82 4.2.3 Explotación de la información .................................................................. 87 4.3 5 Escenario................................................................................................... 76 4.2.3.1 MicroStrategy: primeros pasos .......................................................... 87 4.2.3.2 Creación del proyecto ........................................................................ 93 Resultados ...................................................................................................... 100 4.3.1 Informe para controlar el exceso de trabajo ........................................... 100 4.3.2 Informe de la evolución del desempeño ................................................. 101 4.3.3 Informe de tareas completadas en fecha ................................................. 102 4.3.4 Informe de jerarquía en el equipo de trabajo .......................................... 103 Conclusiones y líneas futuras ................................................................................ 106 5.1 Conclusiones .................................................................................................. 106 5.2 Líneas futuras ................................................................................................. 107 Bibliografía ................................................................................................................... 109 Anexos .......................................................................................................................... 111 A.- Guía para la explotación de datos mediante MicroStrategy ................................... 111 12 Índice de figuras Fig. 1: Datos, Información y Conocimiento ..........................................................21 Fig. 2: Esquema de una solución BI ......................................................................23 Fig. 3: Cuadrante de Gartner: herramientas Business Intelligence ........................28 Fig. 4: Comparativa entre Base de Datos Operacional y DWs ..............................33 Fig. 5: Arquitectura Data Warehouse ....................................................................33 Fig. 6: Arquitectura Datamarts...............................................................................36 Fig. 7: Arquitectura Datamarts como complemento al Data Warehouse ..............37 Fig. 8: Arquitectura Datamarts como almacenamiento intermedio al DW ...........37 Fig. 9: Esquema Estrella ........................................................................................40 Fig. 10: Esquema Copo de Nieve ..........................................................................41 Fig. 11: Comparativa entre OLAP y OLTP ...........................................................45 Fig. 12: Estructura cubo multidimensional ............................................................46 Fig. 13: Ejemplo cubo multidimensional ...............................................................47 Fig. 14: Ejemplo de dos jerarquías ........................................................................49 Fig. 15: Redmine....................................................................................................56 Fig. 16: Pentaho Data Integrator (Kettle)...............................................................57 Fig. 17: Oracle Warehouse Builder........................................................................58 Fig. 18: Oracle Database ........................................................................................60 Fig. 19: MicroStrategy ...........................................................................................63 Fig. 20: Catálogo de productos de MicroStrategy .................................................64 Fig. 21: Objetos dentro de MicroStrategy..............................................................65 Fig. 22: Modelo básico para uso en MicroStrategy (Modelo en Estrella) .............66 Fig. 23: Arquitectura completa de MicroStrategy .................................................70 Fig. 24: Ejemplo Cuadro de Mando en MicroStrategy ..........................................73 Fig. 25: Diagrama general de los procesos del caso práctico ................................78 Fig. 26: Modelo de datos de la base de datos de Redmine ....................................79 Fig. 27: Transformaciones mediante Kettle (Redmine -> Oracle) ........................80 Fig. 28: Procesos ETL............................................................................................82 Fig. 29: Fases del flujo de datos dentro de la metodología de los procesos ETL ..85 Fig. 30: Traza de la ejecución de los procesos ETL ..............................................86 Fig. 31: Connectivity Configuration Wizard .........................................................88 Fig. 32: Connectivity Configuration Wizard validación de la conexión ...............89 Fig. 33: Configuration Wizard ...............................................................................89 Fig. 34: Tablas del repositorio ...............................................................................90 Fig. 35: Definiciones de MicroStrategy Intelligence Server .................................91 13 Fig. 36: Orígenes de Proyecto................................................................................92 Fig. 37: Asistente para la creación de proyectos....................................................94 Fig. 38: Elementos que forman el Sistema ............................................................95 Fig. 39: Seleccionar tablas mediante el Asistente para la creación de Proyectos ..96 Fig. 40: Selección de tablas desde el Catálogo de Warehouse ..............................97 Fig. 41: Creación del modelo lógico usando MicroStrategy Architect .................99 Fig. 42: Informe para controlar el exceso de trabajo ...........................................101 Fig. 43: Informe de la evolución del desempeño .................................................102 Fig. 44: Informe de tareas completadas en fecha.................................................103 Fig. 45: Informe de jerarquía en el equipo de trabajo ..........................................104 14 Índice de tablas Tabla 1: Ejemplo operaciones multidimensionales ...............................................49 Tabla 2: Ejemplo agregación (Roll) .......................................................................50 Tabla 3: Ejemplo disgregación (Drill) ...................................................................50 Tabla 4: Ejemplo pivotar (Pivot) ...........................................................................50 Tabla 5: Requisitos del Sistema .............................................................................72 Tabla 6: Tablas de Hechos y Dimensiones del Modelo en Estrella.......................81 15 Capítulo 1 1 Introducción 1.1 Motivación Vivimos en la sociedad de la información. Gracias a Internet y al desarrollo de los sistemas de información, se puede acceder a mucha más información, de más calidad y con mayor rapidez. Gestionar esta información en las empresas es, hoy en día, vital para poder sobrevivir en un mercado cambiante, dinámico y global. Aprender a competir con esta información es fundamental para la toma de decisiones, el crecimiento y la gestión de nuestra empresa. La disciplina denominada Inteligencia de Negocios (Business Intelligence) nos acerca a los sistemas de información que nos ayudan a la toma de decisiones en nuestra organización. Toda empresa dispone, no importa su tamaño, de sistemas de información más o menos sofisticados que son convenientes de analizar y optimizar. Para enfrentar estos retos, en los últimos años han surgido una serie de técnicas que facilitan el procesamiento avanzado de los datos. La idea clave es que los datos contienen más información oculta de la que se ve a simple vista. El verdadero valor de la información se revela cuando a partir de ella somos capaces de descubrir conocimiento. Este es el verdadero objetivo del Business Intelligence. Sin embargo, el desarrollo de una solución de Business Intelligence conlleva todas las dificultades de un proyecto de ingeniería: complejidad de la implementación, requisitos volátiles, desafíos tecnológicos, desarrollo colaborativo, dificultad para asegurar la calidad, etc. Además, el mercado cada vez exige presupuestos más ajustados y plazos de entrega más reducidos. Por todo esto, se hace necesario y fundamental el uso herramientas junto con conceptos altamente estandarizados, que permitan mejorar el proceso de soluciones de este tipo, todo ello de cara a mejorar la toma de decisiones, en definitiva, a mejorar la empresa. 16 1.2 Objetivos El objetivo de este proyecto es introducir los conceptos necesarios para afrontar una solución BI y además mostrar a modo de ejemplo algunas de las posibilidades que estas soluciones permiten. Se propone un marco tecnológico para una solución de Business Intelligence, contextualizado en el desarrollo de informes y análisis (reporting), mediante la herramienta MicroStrategy, con los cuales mejorar la toma de decisiones de cara a la gestión de un proyecto. Concretamente, los objetivos específicos son: Establecer unos fundamentos teóricos con los cuales poder abordar un proyecto de Business Intelligence. Desarrollar un caso práctico basado en los fundamentos previos. Desarrollo de informes que permitan mejorar la toma de decisiones en un proyecto. 1.3 Estructura de la memoria A continuación se presenta la estructura del proyecto: El capítulo 1 incluye una introducción a la motivación de este trabajo y el objetivo que persigue este proyecto en el área del Business Intelligence. En el capítulo 2 se ha realizado una introducción a los fundamentos necesarios para poder abordar un proyecto de Business Intelligence. Se introduce el concepto de Business Intelligence, viendo cada uno de los componentes que lo forman, áreas funcionales, beneficios y los actuales protagonistas. Además se analizan todos los aspectos de un Data Warehouse y se habla de las herramientas OLAP utilizadas para su explotación. En el capítulo 3 se describirán las principales tecnologías involucradas, haciendo especial hincapié en la herramienta MicroStrategy. En el capítulo 4 se aborda un caso práctico partiendo de la base de datos de una herramienta para la gestión de proyectos (Redmine). Se mencionará la conversión mediante procesos ETL de la base de datos MySQL (Redmine) a un Data Warehouse, sin entrar en detalles ya que esto se escapa de los objetivos de este proyecto. Se ahondará en la creación de indicadores, reporting, etc, mediante la herramienta MicroStrategy con el fin de mejorar la gestión de un proyecto. 17 Finalmente, el capítulo 5 concluye el proyecto con un resumen del trabajo realizado haciendo hincapié en las conclusiones y en las líneas futuras. Adicionalmente, hay un anexo que incluye guía de explotación de datos mediante MicroStrategy, en la cual se explica al usuario como poder realizar informes y explotar la información del Data Warehouse mediante esta herramienta. 18 19 Capítulo 2 2 Fundamentos “Knowledge has become the key economic resource and the dominant, if not the only, source of competitive advantage.” - Peter F. Drucker. En este sentido, y en los tiempos que nos ocupan, para una correcta gestión es necesario tener la posibilidad de analizar rápidamente los puntos críticos, establecer tendencias, así como poder determinar relaciones causa efecto ante el cambio en determinados parámetros externos o internos. Así, el establecimiento de los denominados sistemas de Business Intelligence y el uso del potencial actual de las herramientas TIC permiten un tratamiento cada vez más rápido, complejo e inmediato de los datos, de la información y, en definitiva, del conocimiento. Los antiguos sistemas de información para la Dirección, que convertían datos operacionales en indicadores de gestión (la mayor parte de las veces de naturaleza económico‐financiera), se han visto absorbidos y superados por un nuevo concepto del tratamiento de la información para la toma decisiones: Business Intelligence. En el esquema de una solución de Business Intelligence, un Data Warehouse viene determinado por su situación central como fuente de información para las herramientas de análisis. En este capítulo se realiza una introducción al concepto de Business Intelligence, viendo cada uno de los componentes que lo forman, áreas funcionales, beneficios y los actuales protagonistas en el mundo del Business Intelligence. Además se explicará con más detalle los conceptos de Data Warehousing y Data Warehouse, cómo se diseña éste último y en qué consiste su proceso de extracción, transformación y carga llamado ETL 20 2.1 Business Intelligence 2.1.1 ¿Qué es Business Intelligence? Business Intelligence (BI) es la habilidad para transformar los datos en información, y la información en conocimiento (Fig. 1), de forma que se pueda optimizar el proceso de toma de decisiones en los negocios. Fig. 1: Datos, Información y Conocimiento Desde un punto de vista más pragmático, y asociándolo directamente con las tecnologías de la información, podemos definir Business Intelligence como el conjunto de metodologías, aplicaciones y tecnologías que permiten reunir, depurar y transformar datos de los sistemas transaccionales e información desestructurada (interna y externa a la compañía) en información estructurada, para su explotación directa (reporting, análisis OLAP, etc.) o para su análisis y conversión en conocimiento, dando así soporte a la toma de decisiones sobre el negocio. La inteligencia de negocio actúa como un factor estratégico para una empresa u organización, generando una potencial ventaja competitiva, que no es otra que proporcionar información privilegiada para responder a los problemas de negocio: entrada a nuevos mercados, promociones u ofertas de productos, eliminación de islas de información, control financiero, optimización de costes, planificación de la producción, análisis de perfiles de clientes, rentabilidad de un producto concreto, etc. 21 2.1.2 Componentes del Business Intelligence Durante los siguientes puntos se van a estudiar los distintos componentes de una solución BI. Para comenzar, se observará cuál es el típico esquema de una solución de este tipo, pasando a continuación a ofrecer las definiciones y características de los distintos componentes que lo forman. 2.1.2.1 Esquema de una solución de Business Intelligence Una solución de Business Intelligence parte de los sistemas de origen de una organización (bases de datos, ERP, ficheros de texto, etc.), sobre los que suele ser necesario aplicar una transformación estructural para optimizar su proceso analítico. Para ello se realiza una fase de extracción, transformación y carga de datos. Esta etapa suele apoyarse en un almacén intermedio, llamado ODS, que actúa como pasarela entre los sistemas fuente y los sistemas destino (generalmente un Data Warehouse), y cuyo principal objetivo consiste en evitar la saturación de los servidores funcionales de la organización. La información resultante, ya unificada, depurada y consolidada, se almacena en un Data Warehouse corporativo, que puede servir como base para la construcción de distintos Datamarts departamentales. Un Datamart es una base de datos especializada, departamental, orientada a satisfacer las necesidades específicas de un grupo particular de usuarios. En otras palabras, un Datamart es un subconjunto del Data Warehouse corporativo con transformaciones específicas para el área a la que va dirigido. Estos Datamarts se caracterizan por poseer la estructura óptima para el análisis de los datos de esa área de la empresa, ya sea mediante bases de datos transaccionales (OLTP, OnLine Transaction Processing) o mediante bases de datos analíticas (OLAP, OnLine Analytical Processing). 22 Fig. 2: Esquema de una solución BI Los datos albergados en el Data Warehouse o en cada Datamart se explotan utilizando herramientas comerciales de análisis, reporting, etc. En estas herramientas se basa también la construcción de productos BI más completos, como los sistemas de soporte a la decisión (DSS), los sistemas de información ejecutiva (EIS) y los cuadros de mando (CMI) o Balanced Scorecard (BSC). 2.1.2.2 Diseño conceptual Para resolver el diseño de un modelo BI se deben contestar a tres preguntas básicas: cuál es la información requerida para gestionar y tomar decisiones; cuál debe ser el formato y composición de los datos a utilizar; de dónde proceden esos datos y cuál es la disponibilidad y periodicidad requerida. En otras palabras, el diseño conceptual tiene diferentes momentos en el desarrollo de una plataforma BI: en la fase de construcción del Data Warehouse y los Datamarts primarán los aspectos de estructuración de la información según potenciales criterios de explotación. En la fase de implantación de herramientas de soporte a la alta dirección se desarrolla el análisis de criterios directivos: misión, objetivos estratégicos, factores de seguimiento, indicadores clave de rendimiento o KPIs, 23 modelos de gestión, en definitiva, información para el qué, cómo, cuándo, dónde y para qué de sus necesidades de información. Estos momentos no son, necesariamente, correlativos, sino que cada una de las etapas del diseño condiciona y es condicionada por el resto. 2.1.2.3 Construcción/alimentación del Data Warehouse y/o los Datamarts Un Data Warehouse es una base de datos corporativa que replica los datos transaccionales una vez seleccionados, depurados y especialmente estructurados para actividades de query y reporting. La vocación del Data Warehouse es aislar los sistemas operacionales de las necesidades de información para la gestión, de forma que cambios en aquéllos no afecten a éstas y viceversa (únicamente cambiarán los mecanismos de alimentación, no la estructura, contenidos, etc.). No diseñar y estructurar convenientemente y desde un punto de vista corporativo el Data Warehouse y los Datamarts generará problemas que pueden condenar al fracaso cualquier esfuerzo posterior: información para la gestión obtenida directamente a los sistemas operacionales, florecimiento de Datamarts descoordinados en diferentes departamentos, etc. En definitiva, según la estructuración y organización de cada compañía, pueden originarse situaciones no deseadas y caracterizadas generalmente por la ineficiencia y la falta de calidad en la información resultante. 2.1.2.4 Herramientas de explotación de la información Es el área donde más avances se han producido en los últimos años. Sin embargo, la proliferación de soluciones mágicas y su aplicación coyuntural para solucionar aspectos puntuales ha llevado, en ocasiones, a una situación de desánimo en la organización respecto a los beneficios de una solución BI. Sin entrar a detallar las múltiples soluciones que ofrece el mercado, a continuación se identifican los modelos de funcionalidad o herramientas básicas (cada producto de mercado integra, combina, potencia, adapta y personaliza dichas funciones): Query & Reporting. Herramientas para la elaboración de informes y listados, tanto en detalle como sobre información agregada, a partir de la información de los Data Warehouses y Datamarts. Desarrollo a medida y/o herramientas para una explotación libre. 24 Cuadro de mando analítico (EIS tradicionales). Elaboración, a partir de Datamarts, de informes resumen e indicadores clave para la gestión (KPI) que permitan a los gestores de la empresa analizar los resultados de la misma de forma rápida y eficaz. En la práctica es una herramienta de query orientada a la obtención y presentación de indicadores para la dirección (frente a la obtención de informes y listados). Cuadro de mando integral o estratégico (Balanced Scorecard). Este modelo parte de que la estrategia de la empresa es el punto de referencia para todo proceso de gestión interno. Con él, los diferentes niveles de dirección y gestión de la organización disponen de una visión de la estrategia de la empresa traducida en un conjunto de objetivos, iniciativas de actuación e indicadores de evolución. Los objetivos estratégicos se asocian mediante relaciones causa‐efecto y se organizan en cuatro áreas o perspectivas: financiera, cliente, procesos y formación, y desarrollo. El cuadro de mando integral es una herramienta que permite alinear los objetivos de las diferentes áreas o unidades con la estrategia de la empresa y seguir su evolución. OLAP (on-line analytical processing). Herramientas que manejan cuestiones complejas de bases de datos relacionales, proporcionando un acceso multidimensional a los datos, capacidades intensivas de cálculo y técnicas de indexación especializadas. Permiten a los usuarios trocear sus datos, planteando queries sobre diferentes atributos o ejes. Utilizan un servidor intermedio para almacenar los datos multidimensionales precalculados, de forma que la explotación sea rápida. Minería de Datos (Data Mining). Son auténticas herramientas de extracción de conocimiento útil, a partir de la información contenida en las bases de datos de cualquier empresa. El objetivo que se persigue es descubrir patrones ocultos, tendencias y correlaciones, y presentar esta información de forma sencilla y accesible a los usuarios finales para solucionar, prever y simular problemas del negocio. El Data Mining incorpora la utilización de tecnologías basadas en redes neuronales, árboles de decisión, reglas de inducción, análisis de series temporales y visualización de datos. 2.1.3 Selección de herramientas de Business Intelligence La selección de una u otra herramienta estará en función de múltiples aspectos a considerar: 25 Qué información se necesita. Es importante no complicarse, sobre todo al principio, con indicadores y modelos complejos: indicadores selectivos, sencillos, admitidos por todos los usuarios, etc. son una buena fórmula en las primeras etapas del BI. Para qué se quiere la información. Bajo el concepto general “soporte a la toma de decisiones” se esconden múltiples necesidades particulares: contrastar que todo va bien, analizar diferentes aspectos de la evolución de la empresa, presentar información de forma más intuitiva, comparar información en diferentes periodos de tiempo, comparar resultados con previsiones, identificar comportamientos y evoluciones excepcionales, confirmar o descubrir tendencias e interrelaciones, necesidad de realizar análisis predictivos, etc., son todas ellas necesidades parciales dentro del concepto general. A quién va dirigida. Organización en general, gestión, dirección, dirección estratégica, etc. Aspectos meramente técnicos (tiempos de respuesta, integración, seguridad, etc.) y funcionales (navegación, entorno gráfico, etc.). 2.1.4 Áreas funcionales Intelligence y beneficios del Business Originariamente, los sistemas de información a la dirección aportaban básicamente información económico‐financiera. Con la extensión de las herramientas de Business Intelligence, este concepto abarca ahora todas las áreas funcionales de la empresa: recursos humanos, logística, calidad, comercial, marketing, etc. En la actualidad, estas visiones funcionales han sido superadas por el concepto de CPM (Corporate Performance Management), que aporta información integral de la empresa en todas sus áreas y a través de todos sus ciclos de gestión: planificación, operación y análisis de resultados. Entre los obstáculos tradicionales a la implantación BI se encuentra la dificultad para calcular su ROI (Return On Investment). La mayor parte de los beneficios producidos son intangibles, derivados de la mejora de la gestión de la compañía. En términos económicos, se evidencia una reducción de costes por incremento de la eficiencia de la infraestructura TIC y un incremento de la 26 productividad de los empleados, directamente derivado de la disponibilidad de información; estas magnitudes son difícilmente cuantificables, aunque diferentes fuentes las sitúan en torno al 5% y 10‐15%, respectivamente. Cualitativamente, los beneficios se derivan, obviamente, del incremento de la eficiencia en el proceso de toma de decisiones: mayor información, de mejor calidad, más fiable, compartida por toda la organización, menores tiempos de respuesta en su obtención, mejora de la comunicación en la empresa y creación de un lenguaje homogéneo. En el debe de las implantaciones BI hay que destacar la dificultad de integración con el resto de sistemas de la compañía y, sobre todo, la dificultad para conjugar las expectativas de los usuarios con las soluciones implementadas, por lo que los aspectos de definición conceptual y selección de plataforma, junto a la gestión del cambio en la implantación de los proyectos, adquieren una importancia relevante. La experiencia dice que los factores puramente organizativos originan más de la mitad de los fracasos de proyectos BI. Por todo ello, para el éxito de una estrategia BI podemos identificar los siguientes factores críticos: Importancia del diseño. Importancia de seleccionar y disponer de una plataforma tecnológica y de herramientas adecuadas. Alineación de los objetivos del departamento de sistemas de información y los usuarios. Importancia de consensuar con los usuarios. Importancia de contar con apoyo e impulso desde la dirección general. Importancia de contar con personal cualificado, tanto en las fases de diseño como de implantación. 2.1.5 Protagonistas del Business Intelligence A continuación se muestra un informe publicado por Gartner Inc. (Fig. 3) sobre las mejores plataformas de Business Intelligence. El estudio está organizado en tres categorías de funcionalidad: integración, suministro de información y análisis. 27 Fig. 3: Cuadrante de Gartner: herramientas Business Intelligence Los líderes son definidos como aquellos proveedores que pueden ofrecer grandes implementaciones empresariales y soportar una amplia estrategia de BI. Según el gráfico, estos líderes son SAP, Oracle, Microsoft, IBM, SAS, Information Builders y MicroStrategy. Además, se observa que no aparecen compañías habituales de dicho informe como Hyperion, Cognos o Business Objects, ya que todas ellas fueron adquiridas en los últimos años por parte de las compañías líderes. Concretamente, Hyperion fue adquirida por Oracle en 2007, Cognos fue adquirida por IBM en 2008 y finalmente Business Objects fue adquirida por SAP en 2008. El resto de competidores son soluciones de nicho, que ofrecen soluciones de visualización avanzada (típicamente para cuadros de mando y análisis OLAP). Estos "pequeños" proveedores tienen hueco debido a la complejidad, limitaciones y costes que tienen los grandes proveedores en este segmento del mercado BI. 2.2 Data Warehouse 2.2.1 Data Warehousing y Data Warehouse Para llevar a cabo BI, es necesario gestionar datos guardados en diversos formatos, fuentes y tipos, para luego depurarlos e integrarlos, además de almacenarlos en un solo destino o base de datos que permita su posterior análisis y 28 exploración. Por esto, es imperativo y de vital importancia contar con un proceso que satisfaga todas estas necesidades. Este proceso se denomina Data Warehousing. Data Warehousing es el proceso encargado de extraer, transformar, consolidar, integrar y centralizar los datos que la empresa genera en todos los ámbitos de su actividad diaria de negocios (compras, ventas, producción, etc.) y/o información externa relacionada. Permitiendo de esta manera el acceso y exploración de la información requerida, a través de una amplia gama de posibilidades de análisis multivariables, con el objetivo final de dar soporte al proceso de toma de decisiones estratégico y táctico. Data Warehousing posibilita la extracción de datos de sistemas operacionales y fuentes externas, permite la integración y homogeneización de los datos de toda la empresa, provee información que ha sido transformada y sumarizada, para que ayude en el proceso de toma de decisiones estratégicas y tácticas. Data Warehousing, convertirá entonces los datos operacionales de la empresa en una herramienta competitiva, debido a que pondrá a disposición de los usuarios indicados la información pertinente, correcta e integrada, en el momento que se necesita. Pero para que el Data Warehousing pueda cumplir con sus objetivos, es necesario que la información que se extrae, transforma y consolida, sea almacenada de manera centralizada en una base de datos con estructura multidimensional denominada Data Warehouse. Un Data Warehouse (DW) es un repositorio central o colección de datos, en el cual se encuentra integrada la información de la organización que se usa como soporte para el proceso de toma de decisiones gerenciales. El concepto de DW comenzó a surgir cuando las organizaciones tuvieron la necesidad de usar los datos que cargaban a través de sus sistemas operacionales para planeamiento y toma de decisiones. Para cumplir estos objetivos se necesitan efectuar consultas que sumarizan los datos, y que si se hacen sobre los sistemas operacionales reducen mucho el rendimiento de las transacciones que se están haciendo al mismo tiempo. Fue entonces cuando se decidió separar los datos usados para reportes y toma de decisiones de los sistemas operacionales y diseñar y construir DWs para almacenar estos datos. Las principales características que posee un DW se detallan a continuación: 29 Orientado al tema: orientado a la información relevante de la organización. En un DW la información se clasifica en base a los aspectos de interés para la empresa, es decir, se diseña para consultar eficientemente información relativa a las actividades básicas de la organización, como ventas, compras y producción, y no para soportar los procesos que se realizan en ella, como gestión de pedidos, facturación, etc. Integrado: integra datos recogidos de diferentes sistemas operacionales de la organización y/o fuentes externas. Esta integración se hace estableciendo una consistencia en las convenciones para nombrar los datos, en la definición de las claves, y en las medidas uniformes de los datos. Variable en el tiempo: los datos son relativos a un periodo de tiempo y deben ser incrementados periódicamente. La información almacenada representa fotografías correspondientes a ciertos periodos de tiempo. No volátil: la información no se modifica después de que se inserta, sólo se incrementa. El periodo cubierto por un DW varía de 2 a 10 años. 2.2.2 Ventajas e inconvenientes de un Data Warehouse La utilización de un DW por parte de una organización conlleva una serie de ventajas. Algunas de las ventajas más sobresalientes son las siguientes: Transforma datos orientados a las aplicaciones en información orientada a la toma de decisiones. Integra y consolida diferentes fuentes de datos (internas y/o externas) y departamentos empresariales, que anteriormente formaban islas, en una única plataforma sólida y centralizada. Provee la capacidad de analizar y explotar las diferentes áreas de trabajo y de realizar un análisis inmediato de las mismas. Permite reaccionar rápidamente a los cambios del mercado. Aumenta la competitividad en el mercado. Elimina la producción y el procesamiento de datos que no son utilizados ni necesarios, producto de aplicaciones mal diseñadas o ya no utilizadas. Mejora la entrega de información, es decir, información completa, correcta, consistente, oportuna y accesible. Información que los usuarios necesitan, en el momento adecuado y en el formato apropiado. Logra un impacto positivo sobre los procesos de toma de decisiones. Cuando los usuarios tienen acceso a una mejor calidad de 30 información, la empresa puede lograr por sí misma: aprovechar el enorme valor potencial de sus recursos de información y transformarlo en valor verdadero; eliminar los retardos de los procesos que resultan de información incorrecta, inconsistente y/o inexistente; integrar y optimizar procesos a través del uso compartido e integrado de las fuentes de información; permitir al usuario adquirir mayor confianza acerca de sus propias decisiones y de las del resto, y lograr así, un mayor entendimiento de los impactos ocasionados. Aumento de la eficiencia de los encargados de tomar decisiones. Los usuarios pueden acceder directamente a la información en línea, lo que contribuye a su capacidad para operar con mayor efectividad en las tareas rutinarias o no. Además, pueden tener a su disposición una gran cantidad de valiosa información multidimensional, presentada coherentemente como fuente única, confiable y disponible en sus estaciones de trabajo. Así mismo, los usuarios tienen la facilidad de contar con herramientas que les son familiares para manipular y evaluar la información obtenida en el DW, tales como: hojas de cálculo, procesadores de texto, software de análisis de datos, software de análisis estadístico, reportes, tableros, etc. Permite la toma de decisiones estratégicas y tácticas. No obstante, el uso de los almacenes de datos no está exento de desventajas, siendo las más comunes las siguientes: Requiere una gran inversión, debido a que su correcta construcción no es tarea sencilla y consume muchos recursos, además, su misma implementación implica desde la adquisición de herramientas de consulta y análisis, hasta la capacitación de los usuarios. Existe resistencia al cambio por parte de los usuarios, ya que la forma de consultar la información para elaborar informes o tomar decisiones varía. Los beneficios del almacén de datos son apreciados en el mediano y largo plazo. Este punto deriva del anterior, y básicamente se refiere a que no todos los usuarios confiarán en el DW en una primera instancia, pero sí lo harán una vez que comprueben su efectividad y ventajas. Además, su correcta utilización surge de la propia experiencia. Si se incluyen datos propios y confidenciales de clientes, proveedores, etc, el depósito de datos atentará contra la privacidad de los mismos, ya que cualquier usuario podrá tener acceso a ellos. 31 Infravaloración de los recursos necesarios para la captura, carga y almacenamiento de los datos. Infravaloración del esfuerzo necesario para su diseño y creación. Incremento continuo de los requerimientos del usuario. Subestimación de las capacidades que puede brindar la correcta utilización del DW y de las herramientas de BI en general. 2.2.3 Diferencias entre: Data Warehouse y base de datos transaccional La mayoría de los sistemas operacionales están dirigidos a la carga de datos, con cientos o miles de transacciones diarias y repetitivas, que además requieren un tiempo de respuesta muy corto por parte de los usuarios. Ejemplos de este tipo de operaciones lo son las reservas de vuelos, depósitos bancarios, y reservaciones de hotel. Las bases de datos operacionales deben estar diseñadas con el objetivo de hacer esta tarea lo más eficiente posible. Si se contraponen las características de una base de datos operacional y un DW, se puede deducir que se está ante conceptos totalmente distintos a pesar de actuar los dos como “contenedores” de información. En la siguiente tabla (Fig. 4) se pueden apreciar algunas de las diferencias existentes entre las dos: 32 Fig. 4: Comparativa entre Base de Datos Operacional y DWs 2.2.4 Arquitectura de un Data Warehouse En este punto y teniendo en cuenta que ya se han detallado las características generales del Data Warehousing, se definirán y describirán todos los componentes que intervienen en su arquitectura utilizando el siguiente gráfico: Fig. 5: Arquitectura Data Warehouse 33 Tal y como se puede apreciar, el ambiente está formado por diversos elementos que interactúan entre sí y que cumplen una función específica dentro del sistema. Concretamente, en una arquitectura Data Warehouse encontramos los siguientes componentes: Datos operacionales procedentes de las bases de datos transaccionales y de otras fuentes de datos que genera la empresa en su accionar diario. Sistema ETL que realiza las funciones de extracción de las fuentes de datos (transaccionales o externas), transformación (limpieza, consolidación, etc.) y la carga del almacén, realizando las siguientes acciones: o Extracción de los datos. o Filtrado de los datos: limpieza, consolidación, etc. Un ejemplo de limpieza de datos sería eliminar los datos con valores nulos o incorrectos. o Carga inicial del almacén: ordenación, agregaciones, etc. Refresco del almacén: operación periódica que propaga los cambios de las fuentes externas al almacén de datos. Repositorio propio de datos que contiene información relevante y metadatos. Interfaces y Gestores de Consulta que permiten acceder a los datos y sobre los que se conectan herramientas más sofisticadas (OLAP, minería de datos). Sistemas de Integridad y Seguridad que se encargan de un mantenimiento global, copias de seguridad, etc. 2.2.4.1 Procesos ETL de un Data Warehouse La migración de los datos desde las fuentes operacionales al DW requiere la necesidad de procesos para extraer, transformar y cargar los datos, actividad que se conoce como ETL. Extraer (Extract) La primera tarea del proceso ETL consiste en extraer los datos almacenados en los distintos sistemas de origen. En un número elevado de casos, en los proyectos de almacenamiento de datos se fusionan datos que provienen de distintos sistemas de origen. Cada sistema puede usar una organización distinta de los datos, o formatos diferentes. Dichas fuentes pueden ser bases de datos, ficheros planos, etc., sea cual sea su estructura. La tarea de extracción convierte todos 34 estos datos a un formato preparado para comenzar con el proceso de transformación. El requerimiento imprescindible a la hora de realizar la tarea de extracción es que la misma cause un impacto mínimo en los sistemas de origen. Si la cantidad de datos a extraer es muy elevada, el sistema se puede ralentizar, o incluso colapsarse, por lo que las grandes operaciones de extracción se suelen realizar en momentos donde el impacto sobre el sistema sea el mínimo posible. Transformar (Transform) En la tarea de transformación se aplican una serie de funciones sobre los datos extraídos al objeto de convertirlos en datos preparados para su carga. Algunas fuentes de datos tan solo requerirán mínimas transformaciones, mientras que otras necesitarán de un gran número de ellas. Entre las operaciones de transformación podemos encontrar las siguientes: Traducción y codificación de códigos. Obtención de valores calculados. Generación de nuevos campos. División de la información. Unión de datos de múltiples fuentes. Cargar (Load) Es la tarea mediante la cual los datos ya transformados en la fase anterior son cargados en el sistema de destino. Durante esta fase se interactúa directamente con las bases de datos de destino, por lo que se aplicarán todas las restricciones y disparadores que se hayan definido en la misma, contribuyendo este hecho a que se garantice la calidad de los datos durante el proceso íntegro. 2.2.4.2 Datamarts Las corporaciones de hoy se esfuerzan por conducir sus negocios hacia una base internacional. Vemos compañías que surgieron en Estados Unidos y se expandieron a Europa, Asia y África. La expansión del negocio crea la necesidad de acceder a datos corporativos que están ubicados en diferentes puntos geográficos. Por ejemplo, un ejecutivo de ventas de una compañía con origen en Brasil que está situado en Chile puede necesitar acceso a la base de datos de la empresa para identificar los clientes potenciales que residen en Chile. 35 Este problema se soluciona creando versiones más pequeñas del DW, los Datamarts. Estas versiones se crean usando algún criterio particular, como por ejemplo el lugar geográfico. En el ejemplo anterior los datos de los clientes que residen en Chile se deben almacenar en el Datamart de la sucursal en ese país. La existencia de los Datamarts crea nuevas formas de pensar cuando se diseñan los repositorios corporativos de datos. Algunas corporaciones reemplazan completamente el concepto de tener un DW central, por varios Datamarts más pequeños que se alimenten directamente de los sistemas operacionales. Fig. 6: Arquitectura Datamarts Otras compañías usan Datamarts para complementar sus DWs. Mueven datos desde el DW hacia varios Datamarts con el fin de permitir un análisis más eficiente. La separación de los datos se determina según criterios como departamentos, áreas geográficas, periodos de tiempo, etc. 36 Fig. 7: Arquitectura Datamarts como complemento al Data Warehouse Finalmente, algunas organizaciones usan sus Datamarts como el primer paso de almacenamiento de datos operacionales. Luego los datos de todos los Datamarts se replican en un DW corporativo central. Fig. 8: Arquitectura Datamarts como almacenamiento intermedio al DW 2.2.5 Diseño de un Data Warehouse Debido a las diferencias en el propósito y objetivos de las bases de datos operacionales con las bases orientadas a análisis se originaron técnicas de diseño diferentes para estas últimas. 37 Al igual que el resto de proyectos de desarrollo software, la construcción de un DW sigue una serie de fases: 1. Recogida y análisis de requisitos: Se trata de discernir las fuentes necesarias del sistema de información de la organización (OLTP) y analizar los requisitos de usuario para detectar las consultas de análisis necesarias, nivel de agregación, etc. En esta etapa se deben tener claro cuáles son los diferentes focos sobre los que se va a centrar el almacén de datos. 2. Diseño conceptual: Se modela el sistema haciendo uso de modelos tales como el Entidad‐Relación. 3. Diseño lógico: A partir de uno de los esquemas multidimensionales existentes, se realiza el modelado multidimensional de la base de datos. 4. Diseño físico: Se define el esquema a seguir en la organización física del DW y las herramientas OLAP (ROLAP, MOLAP u HOLAP) y se diseña el ETL. 5. Implementación: Se realiza la carga del almacén (ETL) y la preparación de las vistas de usuario (herramientas OLAP). Dado que ya conocemos las principales características de este tipo de base de datos, a continuación veremos cuáles son los requerimientos en cuanto al diseño lógico y físico de las mismas. 2.2.5.1 Diseño lógico Las premisas básicas en el diseño lógico son: La mayoría de los analistas de negocios van a querer ver datos totalizados. Estos datos en lo posible deben precalcularse y almacenarse de antemano para que esta recuperación sea rápida y eficiente. Es importante además discutir el nivel de granularidad y de detalle esperado por los analistas cuando hacen operaciones de Drill Down. El diseño debe estar dirigido por el acceso y por el uso, es decir, teniendo en cuenta qué tipo de reportes o resúmenes son los más frecuentes, y cuales los más urgentes. Un diseño normalizado no es bueno porque no resulta demasiado intuitivo para una persona de negocios, y podría volverse demasiado complejo. Todos los datos que se incluyan ya deben existir en las fuentes de datos operacionales, o ser derivables a partir de ellos. Las dos técnicas de diseño más populares y utilizadas son el esquema en estrella y el esquema en copo de nieve. Estas técnicas siguen un esquema multidimensional de datos, el cual han adoptado las herramientas de explotación. De esta forma se 38 ofrece al usuario una visión multidimensional de los datos que son objeto de análisis. Esquema Estrella (Star) Este esquema está formado por un elemento central que consiste en una tabla llamada Tabla de Hechos, que está conectada a varias Tablas de Dimensiones. Las tablas de hechos contienen los valores precalculados que surgen de totalizar valores operacionales atómicos según las distintas dimensiones, tales como clientes, productos o periodos de tiempo. Representan un evento crítico y cuantificable en el negocio, como ventas o costos. Su clave está compuesta por las claves primarias de las tablas de dimensión relacionadas (las foreign keys). Pueden existir varias tablas de hechos con información redundante, porque podrían contener distintos niveles de agregación de los mismos datos. Por ejemplo podría existir una tabla de hechos para las Ventas por Sucursal, Región y Fecha, otra para Ventas por Productos, Sucursal y Fecha, y otra tabla que almacene las Ventas por Cliente, Región y Fecha. En general las tablas de hechos tienen muchas filas y relativamente pocas columnas. Las tablas de dimensión representan las diferentes perspectivas desde donde se ven y analizan los hechos de la tabla de hechos. A diferencia de las anteriores, su clave primaria está formada por un solo atributo, y su característica principal es que están desnormalizadas. Esto significa que si la dimensión incluye una jerarquía, las columnas que la definen se almacenan en la misma tabla dando lugar a valores redundantes, lo cual es aceptable en este esquema. En general suelen tener muchas columnas pero pocas filas. Siempre que sea posible, es conveniente compartir las tablas de dimensión entre distintas tablas de hechos. Una de las dimensiones más comunes es la que representa el tiempo, con atributos que describen periodos para años, cuatrimestres, periodos fiscales, y periodos contables. Otras dimensiones comunes son las de clientes, productos, representantes de ventas, regiones y sucursales. En la siguiente figura (Fig. 9) vemos un ejemplo de esquema Estrella, donde la tabla de hechos es la tabla Ventas, y el resto son las tablas de dimensiones. 39 Fig. 9: Esquema Estrella El esquema estrella es el más usado porque maneja bien el rendimiento de consultas y reportes que incluyen años de datos históricos, y por su simplicidad en comparación con una base de datos normalizada. Esquema Copo de Nieve (Snowflake) Es una variante al esquema estrella en el cual las tablas de dimensión están normalizadas, es decir, pueden incluir claves que apuntan a otras tablas de dimensión. En la siguiente figura (Fig. 10) vemos un esquema similar al de figura anterior, donde la tabla de dimensión Cliente se expande en las tablas Sexo y FranjaEdad. Ahora la tabla Cliente contiene una columna clave idSexo que apunta a la tabla Sexo y además tiene una columna idEdad que apunta a la tabla de dimensión FranjaEdad. Algo parecido podría haberse realizado para la dimensión Tiempo, expandiendo esta en dimensiones Día, Mes, Anyo, por ejemplo. 40 Fig. 10: Esquema Copo de Nieve Las ventajas de esta normalización son la reducción del tamaño y redundancia en las tablas de dimensión, y un aumento de flexibilidad en la definición de dimensiones. Sin embargo, el incremento en la cantidad de tablas hace que se necesiten más operaciones SQL de unión de tablas (JOINs) para responder a las consultas, lo que empeora el rendimiento. Otra desventaja es el mantenimiento adicional que requieren las tablas adicionales. Una vez seleccionado el esquema multidimensional, para construir el almacén de datos seguiremos alguna de las metodologías de diseño de almacenes de datos existentes. Una de las metodologías más conocidas es la de Kimball, la cual está basada en el modelo relacional. Según esta metodología, los pasos a seguir en el diseño de un almacén de datos son los siguientes: 41 1. Elegir un proceso de la organización para modelar. Un proceso es una actividad de la organización soportada por un OLTP del cual se puede extraer información con el propósito de construir el almacén de datos. Es decir, es cada uno de los focos que hemos identificado en la etapa de análisis. Ejemplos de estos procesos podrían ser las ventas de productos, los pedidos de clientes o las compras a los proveedores. 2. Decidir el gránulo o nivel de detalle de representación. El gránulo es el nivel de detalle al que se desea almacenar información sobre la actividad a modelar (información diaria, semanal, mensual, etc.). Permite definir el nivel atómico de datos en el almacén de datos, determina el significado de las tuplas de la tabla de hechos y determina las dimensiones básicas del esquema. En un almacén de datos se almacena información a un nivel de detalle fino, no porque se vaya a interrogar el almacén a ese nivel sino porque ello permite clasificar y analizar la información desde muchos puntos de vista. Sin embargo es importante hacer un esfuerzo para no almacenar más detalle del necesario, o el consumo de espacio se disparará y pueden surgir problemas de rendimiento cuando se acceda a los datos. 3. Identificar las dimensiones que caracterizan el proceso. Se identifican las dimensiones que caracterizan la actividad al nivel de detalle que se ha elegido. De cada dimensión se debe decidir los atributos relevantes para el análisis de la actividad. Si entre los atributos de una dimensión existieran jerarquías naturales, éstas deben ser identificadas. En el caso de la dimensión tiempo, existe una jerarquía entre los atributos día‐mes‐año. 4. Decidir la información a almacenar sobre el proceso. Se decide la información que se desea almacenar en cada tupla de la tabla de hechos y que será objeto de análisis. 42 Dicha información podría ser el importe total de las ventas de un producto en el día o el número total de clientes distintos que han comprado el producto en el día. 2.2.5.2 Diseño físico Debido a que los DWs trabajan tanto con datos detallados como con datos resumidos, y frecuentemente almacenan algunos datos en forma redundante, el tamaño de estas bases de datos puede ser enorme. Las bases de datos que se acercan o exceden el terabyte son llamadas VLDBs (Very Large Databases). Diseñar una base de datos de este tipo es un gran desafío y la tarea de mantenerla es costosa. Entre las decisiones de implementación que se deben tomar se incluyen el tamaño del espacio libre, el tamaño del buffer, el tamaño del bloque, y si se usa o no una técnica de compactación de la base de datos. Todas estas cuestiones afectarán el rendimiento del DW. Los motores de base de datos están basados en reglas internas intrincadas, que deben entenderse y seguirse. Una situación común es que se deje el diseño de la base de datos a los programadores, quienes quizá no estén del todo familiarizados con el funcionamiento interno del motor, y como consecuencia creen un diseño pobre que no aproveche al máximo las características que brinda el producto. 2.2.6 Explotación de un Data Warehouse: Herramientas OLAP Las herramientas OLAP se usan para convertir los datos corporativos, almacenados en la base de datos orientada al análisis (DW), en conocimiento útil para la toma de decisiones. Mientras que el DW almacena la información a secas, es decir, tal y como ha sido obtenida de la base de datos operacional, los sistemas OLAP hacen agregaciones y sumarizaciones de estos datos, y los organizan en cubos o almacenamientos especiales para permitir una rápida recuperación ante una consulta. 2.2.6.1 ¿Qué es OLAP? OLAP se información define como el análisis multidimensional e interactivo de la de negocios a escala empresarial. El análisis multidimensional 43 consiste en combinar distintas áreas de la organización, y así ubicar ciertos tipos de información que revelen el comportamiento del negocio. ¿Por qué se dice que el análisis es interactivo? Los usuarios de la herramienta OLAP se mueven suavemente desde una perspectiva del negocio a otra, por ejemplo, pueden estar observando las ventas anuales por sucursal y pasar a ver las sucursales con más ganancias en los últimos tres meses, y además con la posibilidad de elegir entre diferentes niveles de detalle, como ventas por día, por semana o por cuatrimestre. Es esta exploración interactiva lo que distingue a OLAP de las herramientas simples de consulta y reportes. ¿Por qué es útil la multidimensionalidad? Es lo que permite a los analistas de negocios examinar sus indicadores clave o medidas, como ventas, costos, y ganancias, desde distintas perspectivas, como periodos de tiempo, productos y regiones. Estas perspectivas constituyen las dimensiones desde las que se explora la información. ¿Por qué a escala empresarial? OLAP es robusto y escalable, al punto de permitir satisfacer completamente las necesidades de análisis de información de la organización. Se trabaja con fuentes de datos corporativas, que contienen datos de toda la empresa, y se comparte y cruza la información existente en todas las áreas de la misma. Para proveer estas características, toda herramienta OLAP tiene tres principales componentes: Un modelo multidimensional de la información para el análisis interactivo: cubo multidimensional. Un motor OLAP que procesa las consultas multidimensionales sobre los datos: arquitectura ROLAP, MOLAP o HOLAP. Un mecanismo de almacenamiento para guardar los datos que se van a analizar: Data Warehouse. Los usuarios de OLAP se centran en los conceptos de negocios, trabajando intuitivamente con ellos, sin necesidad de conocer cuestiones técnicas tales como el formato físico de los datos, instrucciones de lenguajes como SQL, nombres de tablas o columnas en la base de datos, o la arquitectura OLAP subyacente. 44 2.2.6.2 Diferencias entre procesamiento OLTP y OLAP La compra, venta, producción, y distribución son ejemplos comunes de actividades de negocios del día a día. Estas actividades constituyen el llamado procesamiento operacional u OLTP (Online Transactional Processing), y las aplicaciones que soportan este procesamiento se diseñan con orientación a la carga de datos. El planeamiento de recursos, planeamiento financiero, alianzas estratégicas e iniciativas de mercado son ejemplos de actividades que generan y usan información basada en análisis y orientada a la toma de decisiones. Este tipo de actividades son soportadas por las aplicaciones de tipo OLAP. Si se contraponen las características de OLTP y OLAP podemos apreciar las siguientes diferencias: Fig. 11: Comparativa entre OLAP y OLTP Todas estas diferencias se reflejan en las características de las bases de datos subyacentes a ambos tipos de aplicaciones, y hacen que no sea posible la convivencia en una única base de datos de los entornos OLAP y OLTP. 45 2.2.6.3 Cubos, Dimensiones, Medidas y Operaciones aplicables Cubo multidimensional Un cubo es un subconjunto de datos de un almacén, que provee un mecanismo para buscar información con rapidez y en tiempos de respuesta uniforme independientemente de la cantidad de datos que lo formen o la complejidad del procedimiento de búsqueda. Estos cubos multidimensionales o cubos OLAP se generan a partir de los esquemas en estrella o copo de nieve diseñados en el DW y/o Datamarts. Las tablas relacionadas (tablas de hechos y de dimensiones) proporcionan la estructura de datos al cubo. Fig. 12: Estructura cubo multidimensional En un cubo, la información se representa por medio de matrices multidimensionales o cuadros de múltiples entradas, que nos permite realizar distintas combinaciones de sus elementos para visualizar los resultados desde distintas perspectivas y variando los niveles de detalle. Esta estructura es independiente del sistema transaccional de la organización, y facilita y agiliza la consulta de información histórica ofreciendo la posibilidad de navegar y analizar los datos. 46 En la siguiente figura (Fig. 13) vemos como ejemplo un cubo multidimensional que contiene información de ventas discriminadas por periodos de tiempo, productos y clientes. Fig. 13: Ejemplo cubo multidimensional Los ejes del cubo son las Dimensiones, y los valores que se presentan en la matriz, son las Medidas. Si comparamos estos elementos con los componentes del esquema multidimensional del DW, observamos que las dimensiones se corresponden con las diferentes tablas de dimensiones definidas en dicho esquema mientras que las medidas se corresponden con los tipos de valores precalculados contenidos en la tabla de hechos del esquema. Una instancia del modelo está determinada por un conjunto de datos para cada eje del cubo y un conjunto de datos para la matriz. Dimensiones Son objetos del negocio con los cuales se puede analizar la tendencia y el comportamiento del mismo. Las definiciones de las dimensiones se basan en políticas de la compañía o del mercado, e indican la manera en que la organización interpreta o clasifica su información para segmentar el análisis en sectores, facilitando la observación de los datos. Para determinar las dimensiones requeridas para analizar los datos podemos preguntarnos: ¿Cuándo? La respuesta a esta pregunta permite establecer la dimensión del tiempo y visualizar de manera comparativa el desempeño del negocio. 47 ¿Dónde? Esta pregunta nos ubica en un área física o imaginaria donde se están llevando a cabo los movimientos que se desean analizar. Estos lugares pueden ser zonas geográficas, divisiones internas de la organización, sucursales, etc. ¿Qué? Es el objeto del negocio, o el objeto de interés para determinada área de la compañía. Para estos casos se tienen los productos y/o servicios, la materia prima como elemento de interés para la división de abastecimientos, los vehículos para la sección de transportes, las maquinarias para el área de producción, etc. ¿Quién? En esta dimensión se plantea una estructura de los elementos que inciden directamente sobre el objeto de interés. En estos casos se hace referencia al área comercial o de ventas, o a los empleados de la organización si se está llevando a cabo un análisis a nivel del talento humano, etc. ¿Cuál? Habla de hacia dónde se enfoca el esfuerzo de la organización o una determinada área del negocio, para hacer llegar los productos o servicios. Una dimensión que surge de esta pregunta es la de clientes. Medidas Son características cualitativas o cuantitativas de los objetos que se desean analizar en las empresas. Las medidas cuantitativas están dadas por valores o cifras porcentuales. Por ejemplo, las ventas en dólares, cantidad de unidades en stock, cantidad de unidades de producto vendidas, horas trabajadas, el promedio de piezas producidas, el porcentaje de aceptación de un producto, el consumo de combustible de un vehículo, etc. Jerarquías de Dimensiones y Niveles Generalmente las dimensiones se estructuran en jerarquías, y en cada jerarquía existen uno o más niveles, los llamados Niveles de Agregación o simplemente Niveles. Toda dimensión tiene por lo menos una jerarquía con un único nivel. A continuación (Fig. 14) vemos un ejemplo de una dimensión Fecha y otra dimensión Geografía, ambas consisten en una única jerarquía, pero la primera de cuatro niveles de agregación y la última de tres niveles de agregación. 48 Fig. 14: Ejemplo de dos jerarquías Operaciones multidimensionales Una consulta a una herramienta OLAP consiste generalmente en la obtención de medidas sobre los hechos, parametrizadas por atributos de las dimensiones y restringidas por condiciones impuestas sobre las dimensiones. Así por ejemplo, podríamos tener una consulta que enunciará lo siguiente: “Importe total de las ventas durante el año 2013 de los productos del tipo Dispositivos Móviles, por trimestre y por marca”. Si leemos detenidamente la consulta podemos enlazar los distintos conceptos que aparecen en la definición de consulta con la enunciada en el párrafo anterior. Hecho: Ventas Medida: Importe Restricciones: Tipo de producto Dispositivos Móviles, Año 2013 Parámetros de la consulta: Trimestre y Marca Una vez realizada la consulta obtendríamos el siguiente resultado: Marca Samsung iPhone LG Trimestre T1 40.000 36.000 6.000 T2 48.000 44.000 14.000 T3 44.000 40.000 10.000 T4 48.000 44.000 14.000 Tabla 1: Ejemplo operaciones multidimensionales Además de la posibilidad de realizar consultas tan flexibles (que con menor o mayor complejidad se pueden realizar mediante selecciones, concatenaciones y agrupamientos tradicionales), lo realmente interesante de las herramientas OLAP son sus operadores de refinamiento o manipulación de consultas. Estos operadores facilitan la agregación (consolidación) y la disgregación (división) de los datos: 49 Agregación (Roll): permite eliminar un criterio de agrupación en el análisis, agregando los grupos actuales. Si hiciésemos la agregación de producto, el resultado sería el mostrado a continuación: Trimestre Marca Dispositivos Móviles T1 T2 T3 T4 82.000 106.000 94.000 106.000 Tabla 2: Ejemplo agregación (Roll) Marca Samsun g iPhone LG Disgregación (Drill): permite introducir un nuevo criterio de agrupación en el análisis, disgregando los grupos actuales. Si hiciésemos disgregación sobre el trimestre, obtendríamos el siguiente informe: E 10 k 12 k 2k F 10 k 12 k 2k M 20 k 12 k 2k A 12k M 12k 10k 10k 4k 4k Trimestre J J 24 12 k k 24 10 k k 6k 3k A 12k 10k 3k S 20 k 20 k 4k O 10k N 10k 12k 10k 4k 4k D 28k 22k 6k Tabla 3: Ejemplo disgregación (Drill) Si las operaciones de agregación y disgregación se hacen sobre atributos de una dimensión sobre los que se ha definido una jerarquía, estas operaciones reciben el nombre de Drill-Down y Roll-Up respectivamente. Sin embargo, si dichas operaciones se hacen sobre atributos de dimensiones independientes, las operaciones reciben el nombre de Drill-Across y Roll-Across. Pivotar (Pivot): reorienta las dimensiones del informe. Trimestre T1 T2 T3 T4 Marca iPhone 36.000 44.000 40.000 44.000 Samsung 40.000 48.000 44.000 48.00 LG 6.000 14.000 10.000 14.000 Tabla 4: Ejemplo pivotar (Pivot) 2.2.6.4 ROLAP, MOLAP y HOLAP Los cubos, las dimensiones y las jerarquías son la esencia de la navegación multidimensional del OLAP. Al describir y representar la información en esta forma, los usuarios pueden navegar intuitivamente en un conjunto complejo de datos. Sin embargo, el solo describir el modelo de datos en una forma más 50 intuitiva, hace muy poco para ayudar a entregar la información al usuario más rápidamente. Un principio clave del OLAP es que los usuarios deberían obtener tiempos de respuesta consistentes para cada vista de datos que requieran. Dado que la información se colecta en el nivel de detalle solamente, el resumen de la información es usualmente calculado por adelantado. Estos valores precalculados son la base de las ganancias de desempeño del OLAP. En los primeros días de la tecnología OLAP, la mayoría de las compañías asumía que la única solución para una aplicación OLAP era un modelo de almacenamiento no relacional. Después, otras compañías descubrieron que a través del uso de estructuras de base de datos (esquemas de estrella y de copo de nieve), índices y el almacenamiento de agregados, se podrían utilizar sistemas de administración de bases de datos relacionales (RDBMS) para el OLAP. Estos vendedores llamaron a esta tecnología OLAP relacional (ROLAP). Las primeras compañías adoptaron entonces el término OLAP multidimensional (MOLAP), estos conceptos, MOLAP y ROLAP, se explican con más detalle en los siguientes párrafos. Las implementaciones MOLAP normalmente se desempeñan mejor que la tecnología ROLAP, pero tienen problemas de escalabilidad. Por otro lado, las implementaciones ROLAP son más escalables y son frecuentemente atractivas a los clientes debido a que aprovechan las inversiones en tecnologías de bases de datos relacionales preexistentes. Sistemas MOLAP La arquitectura MOLAP usa unas bases de datos multidimensionales para proporcionar el análisis, su principal premisa es que el OLAP está mejor implantado almacenando los datos multidimensionalmente. Por el contrario, la arquitectura ROLAP cree que las capacidades OLAP están perfectamente implantadas sobre bases de datos relacionales. Un sistema MOLAP usa una base de datos propietaria multidimensional, en la que la información se almacena multidimensionalmente, para ser visualizada en varias dimensiones de análisis. El sistema MOLAP utiliza una arquitectura de dos niveles: la base de datos multidimensional y el motor analítico. La base de datos multidimensional es la encargada del manejo, acceso y obtención del dato. El nivel de aplicación es el responsable de la ejecución de los requerimientos OLAP. El nivel de presentación se integra con el de aplicación y proporciona un 51 interfaz a través del cual los usuarios finales visualizan los análisis OLAP. Una arquitectura cliente/servidor permite a varios usuarios acceder a la misma base de datos multidimensional. La información procedente de los sistemas operacionales, se carga en el sistema MOLAP, mediante una serie de rutinas por lotes. Una vez cargado el dato elemental en la Base de Datos multidimensional (MDDB), se realizan una serie de cálculos por lotes, para calcular los datos agregados, a través de las dimensiones de negocio, rellenando la estructura MDDB. Tras rellenar esta estructura, se generan unos índices y algoritmos de tablas hash para mejorar los tiempos de accesos a las consultas. Una vez que el proceso de compilación se ha acabado, la MDDB está lista para su uso. Los usuarios solicitan informes a través de la interfaz, y la lógica de aplicación de la MDDB obtiene el dato. La arquitectura MOLAP requiere unos cálculos intensivos de compilación. Lee de datos precompilados, y tiene capacidades limitadas de crear agregaciones dinámicamente o de hallar ratios que no se hayan precalculados y almacenados previamente. Algunos fabricantes son: Oracle’s Hyperion Essbase, Services, TM1, SAS OLAP, Cognos PowerCubes. Microsoft Analysis Sistemas ROLAP La arquitectura ROLAP, accede a los datos almacenados en un Data Warehouse para proporcionar los análisis OLAP. La premisa de los sistemas ROLAP es que las capacidades OLAP se soportan mejor contra las bases de datos relacionales. El sistema ROLAP utiliza una arquitectura de tres niveles. La base de datos relacional maneja los requerimientos de almacenamiento de datos, y el motor ROLAP proporciona la funcionalidad analítica. El nivel de base de datos usa bases de datos relacionales para el manejo, acceso y obtención del dato. El nivel de aplicación es el motor que ejecuta las consultas multidimensionales de los usuarios. El motor ROLAP se integra con niveles de presentación, a través de los cuáles los usuarios realizan los análisis OLAP. Después de que el modelo de datos para el Data Warehouse se ha definido, los datos se cargan desde el sistema operacional. Se ejecutan rutinas de bases de datos para agregar el dato, si así es requerido 52 por el modelo de datos. Se crean entonces los índices para optimizar los tiempos de acceso a las consultas. Los usuarios finales ejecutan sus análisis multidimensionales, a través del motor ROLAP, que transforma dinámicamente sus consultas a consultas SQL. Se ejecutan estas consultas SQL en las bases de datos relacionales, y sus resultados se relacionan mediante tablas cruzadas y conjuntos multidimensionales para devolver los resultados a los usuarios. La arquitectura ROLAP es capaz de usar datos precalculados si estos están disponibles, o de generar dinámicamente los resultados desde los datos elementales si es preciso. Esta arquitectura accede directamente a los datos del Data Warehouse, y soporta técnicas de optimización de accesos para acelerar las consultas. Estas optimizaciones son, entre otras, particionado de los datos a nivel de aplicación, soporte a la desnormalización y joins múltiples. Algunos fabricantes son: Oracle’s BI EE, SAP Netweaver BI, MicroStrategy, Cognos 8, BusinessObjects Web Intelligence. Sistemas HOLAP Un desarrollo un poco más reciente ha sido la solución OLAP híbrida (HOLAP), la cual combina las arquitecturas ROLAP y MOLAP para brindar una solución con las mejores características de ambas: desempeño superior y gran escalabilidad. Un tipo de HOLAP mantiene los registros de detalle (los volúmenes más grandes) en la base de datos relacional, mientras que mantiene las agregaciones en un almacén MOLAP separado. Algunos fabricantes son: Microsoft Analysis Services, SAS OLAP, Oracle’s Hyperion Essbase. Cada alternativa tiene sus ventajas y desventajas. Algunas de las ventajas más importantes de cada enfoque son: MOLAP Consultas rápidas debidas a la optimización del rendimiento de almacenamiento, la indexación multidimensional y la memoria caché. Ocupar menor tamaño en disco en comparación con los datos almacenados en base de datos relacional debido a técnicas de compresión. Automatización del procesamiento de los datos agregados de mayor nivel. Muy compacto para conjuntos de datos de pocas dimensiones. 53 El modelo de almacenamiento en vectores/matrices proporciona una indexación natural. Eficaz extracción de los datos lograda gracias a la pre‐estructuración de los datos agregados. ROLAP Soportan análisis OLAP contra grandes volúmenes de datos. Los sistemas pueden crecer hasta un gran número de dimensiones. Los tiempos de carga son mucho menores. Los datos se almacenan en una base de datos relacional que puede ser accedida por cualquier herramienta de generación de informes SQL. Es posible modelar datos con éxito que de otro modo no se ajustarían a un modelo dimensional estricto. Resumiendo, el sistema ROLAP es una arquitectura flexible y general, que crece para dar soporte a amplios requerimientos OLAP. MOLAP es una solución particular, adecuada para soluciones departamentales con unos volúmenes de información y número de dimensiones más modestos. 54 55 Capítulo 3 3 Tecnologías En este capítulo se presenta el marco tecnológico en el que ha sido desarrollada la solución Business Intelligence objeto de este proyecto y se analiza cada una de las tecnologías utilizadas. Dado que este proyecto se centra fundamentalmente en la parte de diseño de indicadores, informes (reporting) y cuadros de mando mediante la herramienta MicroStrategy, a continuación únicamente se van a analizar en profundidad las tecnologías utilizadas en esa parte del proceso de desarrollo. Tanto la aplicación origen de los datos del caso práctico (Redmine), como las tecnologías específicas utilizadas para obtener un Data Warehouse mediante procesos ETL (estudiados en el capítulo anterior), no se explicarán en profundidad. 3.1 Redmine Fig. 15: Redmine 3.1.1 ¿Qué es Redmine? Redmine es una aplicación web flexible para la gestión de proyectos que incluye un sistema de seguimiento de incidentes con seguimiento de errores. Otras herramientas que incluye son calendario de actividades, diagramas de Gantt para la representación visual de la línea del tiempo de los proyectos, wiki, foro, visor del repositorio de control de versiones, RSS, control de flujo de trabajo basado en roles, integración con correo electrónico, etcétera. 56 Está escrito usando el framework Ruby on Rails y es multiplataforma. Redmine es software libre y de código abierto, disponible bajo la Licencia Pública General de GNU v2 (GPL). 3.1.2 Características Algunas de las principales características de Redmine son las siguientes: Soporta múltiples proyectos. Roles flexibles basados en control de acceso. Sistema de seguimiento de errores flexible. Diagramas de Gantt y calendario. Administración de noticias, documentos y archivos. Fuentes web y notificaciones por correo electrónico. Foros y wikis para los proyectos. Seguimiento temporal. Campos personalizables. Integración SCM (Subversion, CVS, Git, Mercurial, Bazaar y Darcs) Soporte multilenguaje. Soporta diferentes bases de datos (MySQL, PostgreSQL y SQLite) 3.2 Kettle (Pentaho Data Integrator) Fig. 16: Pentaho Data Integrator (Kettle) 3.2.1 ¿Qué es Kettle? Muchas organizaciones tienen información disponible en aplicaciones y base de datos separados. Pentaho Data Integration (Kettle) abre, limpia e integra esta valiosa información y la pone en manos del usuario. Provee una consistencia, una sola versión de todos los recursos de información, que es uno de los más grandes 57 desafíos para las organizaciones TI hoy en día. Pentaho Data Integration permite una poderosa ETL (Extracción, Transformación y Carga). El uso de kettle permite evitar grandes cargas de trabajo manual frecuentemente difícil de mantener y de desplegar. 3.2.2 Características A parte de ser open source y sin costes de licencia, las características básicas de esta herramienta son: Entorno gráfico de desarrollo. Uso de tecnologías estándar: Java, XML, JavaScript. Fácil de instalar y configurar. Multiplataforma: windows, macintosh, linux. Basado en dos tipos de objetos: Transformaciones (colección de pasos en un proceso ETL) y trabajos (colección de transformaciones) Incluye cuatro herramientas: o Spoon: para diseñar transformaciones ETTL usando el entorno gráfico. o PAN: para ejecutar transformaciones diseñadas con spoon. o CHEF: para crear trabajos. o Kitchen: para ejecutar trabajos. 3.3 Oracle Warehouse Builder Fig. 17: Oracle Warehouse Builder 58 3.3.1 ¿Qué es Oracle Warehouse Builder? Oracle Warehouse Builder (OWB) es una completa solución de integración de datos, almacenamiento de datos, gestión de calidad de datos y gestión de metadatos diseñados para la base de datos Oracle. Oracle Warehouse Builder es una parte integral de Oracle Database 11g Release 2 (11.2) y se instala como parte de todas las instalaciones de bases de datos Oracle (a excepción de Oracle Database XE). Oracle Warehouse Builder también permite integración extensible de datos y ofrece un tratamiento de calidad de los datos. Oracle Warehouse Builder se puede ampliar para administrar metadatos específicos para cualquier aplicación, y se puede integrar con los nuevos tipos de fuentes de datos y de destino, y poner en práctica el apoyo a los nuevos mecanismos de acceso a datos y plataformas, hacer cumplir las buenas prácticas de las organizaciones, y fomentar la reutilización de los componentes. 3.3.2 Características Las principales características de Oracle Warehouse Builder son: El modelado de datos. Extracción, Transformación y Carga (procesos ETL) Perfilado y calidad de datos. Gestión de metadatos. Integración a nivel de negocios de datos de la aplicación ERP. Integración con herramientas Oracle de inteligencia de negocios para reporting. Linaje avanzado de datos y análisis de impactos. 59 3.4 Oracle Database Fig. 18: Oracle Database 3.4.1 ¿Qué es Oracle Database? Oracle es un sistema de gestión de base de datos relacional (o RDBMS por el acrónimo en inglés de Relational Data Base Management System), desarrollado por Oracle Corp. Se considera a Oracle como uno de los sistemas de bases de datos más completos. Sin tener en cuenta la versión Oracle Database 12c (diseñada para la nube), la última versión de Oracle es la versión 11g, liberada en el mes de julio de 2009, es un RDBMS portable ya que se puede instalar en los sistemas operativos más comunes en el mercado, la capacidad de datos es alta ya que soporta hasta 4 peta bytes de información. Cuenta con administración de usuarios así como la administración de roles, además soporta triggers y store procedure, cuenta con conectividad JDBC y ODBC, siempre y cuando se tengan los drivers adecuados para la misma. Es un DBMS seguro ya que cuenta con un proceso de sistema de respaldo y recuperación de información. Soporta Data Warehouse por lo que facilita el acceso a la información y da mayor versatilidad. La mayor parte de las empresas de telecomunicaciones en Latinoamérica utilizan Oracle, por lo que se puede decir que es un DBMS confiable, seguro para ser utilizado en una empresa y sobre todo permite reducir costos por su accesibilidad en el mercado. Oracle Database maneja todos tus datos, no solo objetos relacionales de datos que están sobre grandes empresas sino también datos no estructurados tales como: Hojas de Cálculo Documentos de Word Presentaciones de Power Point XML Tipos de datos multimedia como MP3, gráficos, vídeo, fotos, etc. 60 Los datos ni siquiera tienen que estar en la base de datos, Oracle Database 10g tiene servicios a través de los cuales se puede almacenar metadatos de tu información almacenados en los llamados Archivos de Sistema, quieres más pues también puedes a través del Servidor de bases de datos manejar y servir información donde quiera que esté alojada. 3.4.2 Características Oracle Database tiene como características básicas: Es una herramienta de administración gráfica que es mucho más intuitiva y cómoda de utilizar. Ayuda a analizar datos y efectuar recomendaciones concernientes a mejorar el rendimiento y la eficiencia en el manejo de aquellos datos que se encuentran almacenados. Apoya en el diseño y optimización de modelos de datos. Asistir a los desarrolladores con sus conocimientos de SQL y de construcción de procedimientos almacenados y triggers, entre otros. Apoya en la definición de estándares de diseño y nomenclatura de objetos. Documentar y mantener un registro periódico del mantenimiento, actualizaciones de hardware y software, cambios en las aplicaciones y, en general, todos aquellos eventos relacionados con cambios en el entorno de utilización de una base de datos. Además, las características principales de las bases de datos Oracle son: Índices: Un índice es una estructura creada para ayudar a recuperar datos de una manera más rápida y eficiente. Un índice se crea sobre una o varias columnas de una misma tabla. De esta manera, cuando se solicita recuperar datos de ella mediante alguna condición de búsqueda (cláusula where de la sentencia), ésta se puede acelerar si se dispone de algún índice sobre las columnas-objetivo. Clusters: Un cluster es un grupo de tablas almacenadas en conjunto físicamente como una sola tabla que comparten una columna en común. Si a menudo se necesita recuperar datos de dos o más tablas basado en un valor de la columna que tienen en común, entonces es más eficiente organizarlas como un cluster, ya que la información podrá ser recuperada en una menor cantidad de operaciones de lectura realizadas sobre el disco 61 Vistas: Una vista implementa una selección de varias columnas de una o diferentes tablas. Una vista no almacena datos; sólo los presenta en forma dinámica. Se utilizan para simplificar la visión del usuario sobre un conjunto de tablas, haciendo transparente para él la forma de obtención de los datos Secuencias: El generador de secuencias de Oracle se utiliza para generar números únicos y utilizarlos, por ejemplo, como claves de tablas. La principal ventaja es que libera al programador de obtener números secuenciales que no se repitan con los que pueda generar otro usuario en un instante determinado Procedimientos (procedures) y Funciones: Una función es un grupo de sentencias SQL, escritas generalmente en PL/SQL que implementan una serie de rutinas que devuelven un valor. Son casi idénticas a los procedimientos y sólo se diferencian en esa última condición. Disparadores (triggers): Un trigger es un procedimiento que se ejecuta en forma inmediata cuando ocurre un evento especial. Estos eventos sólo pueden ser la inserción, actualización o eliminación de datos de una tabla. 3.4.3 Estructuras internas a la Base de Datos Las estructuras internas son: Tablas: Es la unidad lógica básica de almacenamiento. Contiene filas y columnas (como una matriz) y se identifica por un nombre. Columnas: Las columnas también tienen un nombre y deben especificar un tipo de datos. Una tabla se guarda dentro de un tablespace (o varios, en el caso de las tablas particionadas). Usuarios: Es la indicación del nombre y el password de la cuenta (esquema) que se está creando. Esquemas: Es una colección de objetos lógicos, utilizados para organizar de manera más comprensible la información y conocidos como objetos del esquema. 62 3.5 MicroStrategy Fig. 19: MicroS trategy 3.5.1 ¿Qué es MicroStrategy? La plataforma MicroStrategy es una herramienta de pago (hay que adquirir licencias para su uso), desarrollada por uno de los proveedores punteros de software empresarial: MicroStrategy. MicroStrategy se fundó en 1989 y desde entonces ha construido una plataforma que cubre todas las necesidades BI empresariales, desde el clásico reporting hasta elaborados y vistosos Cuadros de Mando, pasando por el análisis OLAP. Se diferencia de los grandes proveedores en que su arquitectura es más clara y homogénea. Su plataforma es una plataforma BI integrada (y no un conglomerado de productos diversos). Esta plataforma incluye productos y funcionalidades para cubrir cualquier necesidad BI, que ellos dividen en los que denominan los "5 estilos de BI": Scorecards y dashboards Reporting Análisis OLAP Análisis avanzado y predictivo Alertas y notificaciones proactivas El catálogo de productos de la plataforma MicroStrategy se muestra en la siguiente figura: 63 Fig. 20: Catálogo de productos de MicroS trategy A partir del propio MicroStrategy Desktop es posible gestionarlo todo, desde el mapeo a las tablas, como la creación de cuadros de mando, informes, etc. 3.5.2 Conceptos importantes Los conceptos más MicroStrategy son: importantes para comprender el funcionamiento de ETL El ETL es el conjunto de procesos de extracción, transformación y carga de los datos que formaran el Warehouse que utilizará MicroStrategy. En el proceso de ETL se crea el catálogo de tablas con toda la información útil del negocio. 64 Objetos Todas las definiciones e información son almacenadas en elementos denominados objetos, los cuales son agrupados en tres grandes categorías: Objetos de esquema (Schema Objects), Son los elementos de más bajo nivel, reflejan la estructura física del Data Warehouse: Tablas, columnas, hechos, atributos, jerarquías, etc. Objetos de aplicación (Public Objects), Son elementos de más alto nivel, definidos en base a los objetos esquema y/o a otros objetos de aplicación: Informes, documentos, filtros, indicadores o métricas, etc. Objetos de configuración, Usuarios, Grupos y definición del Servidor. En la siguiente ilustración se pueden observar los objetos de cada una de estas categorías: Fig. 21: Objetos dentro de MicroS trategy Los diseñadores de proyectos crean los objetos de esquema que se pueden utilizar para crear objetos de aplicación. Los diseñadores de informes crean objetos de aplicación que se usan para crear informes y documentos y que, a su vez, se pueden utilizar para crear otros objetos de aplicación. Hechos 65 Los hechos son objetos de categoría esquema. A través de objetos de tipo “Hechos”, se indica a MicroStrategy cómo puede obtener los valores que se desean asociar a los atributos, es decir, se indicarán en qué tablas y columnas se encuentran. Su finalidad es ser el soporte de los indicadores. Métricas o Indicadores Las métricas son objetos de tipo aplicación, porque no acceden directamente a los datos del DW, sino lo hacen a través de los Hechos que se han definido previamente. Están conformadas por 4 elementos: Una fórmula, un nivel de agregación, una condición y una transformación. Sólo la fórmula es elemento obligatorio a definir, el cual podrá hacer referencia a uno o más hechos u a otras métricas. Toda métrica tiene asociada una función de agregación, por defecto es la Suma. Modelo El modelo es la manera que se relacionan las distintas tablas del catálogo de warehouse para poder ser explotadas. Los dos grandes grupos de tablas que existen en un modelo informacional son: Tablas de hechos: contiene los indicadores del negocio Tablas de dimensiones: recogen las características del negocio El modelo básico es un modelo en estrella (Fig. 22) formado por una tabla de hechos central, conectada con las tablas de dimensiones, como se representa en la siguiente figura: Fig. 22: Modelo básico para uso en MicroS trategy (Modelo en Estrella) 66 Proyecto Un proyecto es la intersección de un datawarehouse, un repositorio de metadata y una comunidad de usuarios. El proyecto: Determina el conjunto de tablas de warehouse que se usarán y, por lo tanto, el conjunto de datos disponibles para el análisis. Contiene todos los objetos de esquema utilizados para interpretar los datos de estas tablas (hechos, atributos, jerarquías, etc.). Contiene todos los objetos de informes utilizados para crear informes y analizar los datos (indicadores, filtros, informes, etc.) Define el esquema de seguridad en el que funcionará la comunidad de usuarios que tendrá acceso a estos objetos (filtros de seguridad, roles de seguridad, permisos, control de acceso, etc.). 3.5.3 Elementos de MicroStrategy Los elementos más importantes que forman la herramienta son los siguientes: MicroStrategy metadata La metadata de MicroStrategy contiene información en un datawarehouse y se almacena como objeto de MicroStrategy. Esta información facilita la transferencia de datos entre el datawarehouse y la plataforma MicroStrategy. Almacena definiciones de objetos e información sobre el datawarehouse, y asigna objetos de MicroStrategy al contenido y la estructura del datawarehouse. MicroStrategy Intelligence Server El MicroStrategy Intelligence Server es el motor de procesamiento y gestión de los trabajos de las aplicaciones de informes, análisis y monitorización. Utiliza una arquitectura orientada al servicio (SOA), y estandariza en una única plataforma todas las necesidades de análisis y reporting, a través de varios canales de acceso: Web browsers, Microsoft® Office, Desktop clients, y email. En este paso de la configuración se asocia al Intelligence Server el esquema de base de datos del 67 Metadata y se indican parámetros adicionales de configuración (como el puerto TCP). Existirá un único Intelligence Server en nuestro sistema. MicroStrategy Web and Web Universal Interfaz de usuario altamente interactivo para la ejecución de informes y análisis. MicroStrategy Desktop MicroStrategy Desktop es un entorno avanzado que proporciona una gama de funciones analíticas, diseñadas para facilitar y realizar la implantación de los informes en interfaces. Desktop controla los objetos de aplicación que interactúan con el escritorio, como informes, filtros e indicadores. Permite crear “objetos de aplicación” y “objetos de esquema”. Creados los informes, se podrán implantar a través de una serie de interfaces diferentes. MicroStrategy Web Esta herramienta dispone de funcionalidades similares a MicroStrategy Desktop, pero muy útil para implantar informes y objetos relacionados, en grandes grupos de usuarios a través de la Web. No se requerirá instalar un producto en cada ordenador. Sólo será necesario conocer la URL del sitio Web. 3.5.4 Bases de datos MicroStrategy necesarias para utilizar Para trabajar con MicroStrategy, es necesario tener disponibles varios esquemas de base de datos, cada uno con un cometido diferente: Datawarehouse: una o varias bases de datos de donde la herramienta leerá la información (según el modelo), para elaborar los informes, consultas, cuadros de mando, cubos, etc. Metadata: son las tablas internas de MicroStrategy donde se guarda toda la información del modelo de datos que se defina y de todos los objetos 68 que se construyan utilizando la herramienta (filtros, informes, indicadores, etc.). Historial: historial de las modificaciones que se realizarán con los objetos. Estadísticas: tablas para mantener y controlar la actividad del sistema. 3.5.5 Origen de proyectos Es un contenedor de proyectos que utiliza MicroStrategy Desktop para acceder al repositorio de la Metadata. Es la ubicación centralizada de los diferentes proyectos. Es un contenedor que luego permitirá definir dentro de él los proyectos existentes en la infraestructura de BI. Se pueden definir varios orígenes de proyecto (no necesariamente solo uno). Al crear un origen de proyectos, se le asocia un tipo de origen y se le indica el tipo de validación de usuarios que se va a realizar para él (usuario de Windows, de MicroStrategy, LDAP, de base de datos, etc.). Hay dos tipos: Server (o de tres capas) Indica que utilizará el Intelligence Server. Pensado para instalaciones en productivo. En este caso se pasará a través del Intelligence Server, y por tanto, se utiliza el origen de datos del Metadata que se definió anteriormente en él. Directo (o de dos capas) Permite conectarse directamente a la Metadata y al Datawarehouse. Están pensados para instalaciones de test, formación o prototipos. En este caso, no se pasa a través del Intelligence Server, sino que se accede directamente al Metadata cuando se crea un proyecto (por eso hay que indicar que origen de datos contiene el Metadata). En la siguiente figura (Fig. 23) se observa la arquitectura tanto utilizando el Servidor Intelligence Server como contando directamente al Metadata y al datawarehouse y el tipo de conexión que se realiza en cada caso: 69 Fig. 23: Arquitectura completa de MicroS trategy 3.5.6 Informes Un informe de MicroStrategy es un objeto de categoría “Aplicación”, que representa una petición de un conjunto de datos formateados procedentes del data warehouse. Antes de comenzar a crear informes se debe haber definido, por lo menos, un origen de proyecto, un proyecto con atributos, hechos y métricas. El editor de informes tiene cuatro vistas disponibles: Diseño, Cuadrícula, Gráfico y SQL. La vista de Diseño, describe la definición del informe. No muestra datos del datawarehouse, muestra objetos de MicroStrategy que utilizaremos para obtener un informe. La cuadrícula de informe contiene el diseño en los tres ejes: filas, columnas y páginas. Objetos de Informe: Muestra todos los objetos presentes en el informe. Explorador de Objetos: Se utiliza para navegar a través del proyecto y localizar objetos para definir los indicadores. Detalles del informe: Muestra la información sobre los indicadores, filtros y la descripción disponible. 70 Filtros de Informe: Se definen las condiciones para los resultados. Definición del Informe: Esta sección es la definición del informe en modo tabla. Incluye objetos como atributos e indicadores, así como su posición 3.5.7 Documentos Los documentos son un conjunto de uno o más informes formateados, obteniendo una salida compacta y amigable de cara a facilitar el análisis de la información. En un documento es posible incluir múltiples elementos, tener diferentes componentes relacionados entre sí o no, a los que además es posible dar dinamismo con el uso de controles, listas de selección, botones, pestañas o permitiendo la navegación y el uso de las funcionalidades de reporting. Los documentos son los objetos con los que se crearán los Cuadros de Mando. Los documentos se pueden ejecutar desde el entorno Office, embebidos dentro de la suite de Microsoft. La exportación de los documentos vía PDF, Excel, HTML o Flash puede ser una forma de generar contenido estático para enviar o para una intranet. 3.5.8 Requisitos del sistema MicroStrategy Intelligence Server debe instalarse por separado, en un servidor. MicroStrategy Web debe instalarse por separado, en un servidor Web. El resto de los productos puede instalarse en diversas combinaciones, según quién los vaya a usar y en qué máquinas. La siguiente tabla (Tabla 5) muestra las configuraciones de hardware recomendadas (y mínimas) para los productos de MicroStrategy: 71 Tabla 5: Requisitos del S istema Además de los requerimientos Hardware Listados, los componentes de MicroStrategy requieren los siguientes requisitos Software. Microsoft Windows 2003 SP2, Windows 2003 R2 SP2, Windows XP Professional Edition SP3 (on x86) or SP2 (on x64), Windows Vista Business Edition SP1, o Windows Vista Enterprise Edition SP1 (cualquier sistema operativo Windows en x86 or x64). Microsoft Internet Information Services (IIS) version 5.1, 6.0, or 7.0 Además, el servidor de metadata debe ejecutarse en una máquina con la siguiente configuración como mínimo: Procesador: Pentium a 400 MHz o superior compatible Memoria: 256 MB Almacenamiento: 200 MB 3.5.9 Ejemplo de Cuadro de Mando realizado con MicroStrategy A continuación (Fig. 24) se muestra un ejemplo de la realización de un Cuadro de Mando utilizando la herramienta MicroStrategy. 72 Fig. 24: Ejemplo Cuadro de Mando en MicroS trategy 73 74 Capítulo 4 4 Caso práctico El objetivo de este apartado es ver de manera práctica cómo mediante MicroStrategy podemos mejorar la gestión de un proyecto. Estudiaremos la problemática de un Equipo de Trabajo de una Empresa, que tiene una herramienta para gestionar proyectos pero no están aprovechando la información recopilada. Una vez descrita la problemática, veremos en orden lógico y de manera práctica cómo puede ayudar MicroStrategy a la gestión eficaz de la información en cada uno de los ámbitos del Equipo de Trabajo. 4.1 Análisis 4.1.1 Contexto Toda empresa tiene una problemática común en cuanto a gestión de la información. En el día a día, las empresas se enfrentan a preguntas constantes de sus clientes, proveedores e incluso de sus propios empleados. A lo largo del año, en una empresa se reciben gran cantidad de e-mails, se organizan multitud de reuniones y se realizan muchísimas llamadas de teléfono. Profundizando en la estructura de una empresa, llegamos a los denominados Equipos de Trabajo, los cuales se pueden ver envueltos en uno o más proyectos. En estos equipos, se maneja gran cantidad de información tanto interna, de cara a la gestión de los recursos/tareas del propio equipo, como externa, de cara al cliente que incluso puede ser la propia empresa. La gestión de toda esta información es un proceso fundamental para el éxito de un Equipo de Trabajo, y con ello de la organización. Como norma general, un equipo de trabajo debe gestionar múltiples proyectos y tareas en paralelo, relacionadas de forma directa con numerosos miembros del equipo de trabajo. Así, comprobaremos que una gestión inteligente de todo este flujo de información es crucial para el éxito de una organización. Por ello, en primer lugar debemos observar cómo recopilamos la información del equipo de trabajo día a día e identificar qué información resulta clave para nuestro 75 objetivo de optimización en la gestión. Una vez identificada esta información tenemos que recoger los datos oportunos y organizarlos de tal forma que podamos obtener dicha información cuando sea necesario. Una empresa sin un sistema de BI para la gestión implantado no tiene más remedio que recurrir a herramientas tradicionales para poder extraer información relevante de cara a la toma de decisiones de la empresa, esto es directamente aplicable a un equipo de trabajo o un proyecto. El volumen de información hace que ésta sea una pesada carga y llegado un momento toda esa información empieza a ser demasiado extensa y pesada para esos medios tradicionales. Corriendo el riesgo, como es habitual, de quedar dispersa e inutilizable con cierto orden y correlación. Nos damos cuenta que necesitamos de otras herramientas que nos ayuden a gestionar la información de manera más inteligente y fácil. MicroStrategy es una de esas herramientas que nos ayudan a transformar la información en conocimiento, aportando a las empresas reducción de costes, eficiencia en la gestión de tareas, satisfacción del cliente que acaba redundando en su fidelización y, en definitiva, mejor gestión del negocio. La implementación de MicroStrategy en una organización sin sistema de Business Intelligence, o dado nuestro caso, dentro de un equipo de trabajo, aporta tres elementos claves para la mejora de la gestión: Asignación eficiente del recurso humano. Control de las actividades y sus plazos temporales. Control y análisis de la relación con el cliente y, principalmente, con los propios miembros del equipo. A continuación, veremos en orden lógico y de manera práctica cómo puede ayudar MicroStrategy a la gestión de un equipo de trabajo. 4.1.2 Escenario Para el caso práctico consideramos la empresa ficticia BI Solutions. El grupo BI Solutions es una consultora tecnológica especializada en aportar soluciones de Business Intelligence a empresas de diferentes sectores. Dentro del grupo BI Solutions encontramos un equipo de trabajo encargado de implantar un sistema de Business Intelligence al Servicio de Salud de una comunidad autónoma, denominaremos a este equipo de trabajo como BI Servicio de Salud. El equipo BI Servicio de Salud cuenta con una plantilla de diez trabajadores divididos bajo la siguiente estructura jerárquica: 76 Un director de proyecto. Dos jefes de proyecto. Dos seniors. Tres analistas programadores. Dos analistas funcionales. Además, este equipo emplea una aplicación web, Redmine, para: asignación y seguimiento de tareas, definición de usuarios por roles, entre otras cosas. En esta herramienta confluye toda la información que rodea al equipo BI Servicio de Salud. El equipo BI Servicio de Salud decide aplicar los conocimientos y la metodología propia, empleada en sus implantaciones de BI a clientes, de cara a optimizar la gestión del equipo de trabajo. Para ello, deciden extraer todo el conocimiento posible a partir de la información recopilada en la aplicación web Redmine. Se definen los siguientes requisitos funcionales: Informes de tareas con retrasos en la fecha de finalización. Informes porcentuales de grado de finalización de tareas. Ranking de tareas con mayor carga laboral. Ranking de horas laborales de los miembros del equipo. 4.2 Diseño Como se comentó en el apartado anterior, el objetivo del equipo BI Servicio de Salud es aplicar los procesos de una solución de BI tomando como fuente de datos la información recopilada en la aplicación web Redmine. A continuación (Fig. 25) se presenta un diagrama general de los procesos que entran en juego y de las respectivas herramientas empleadas: 77 Fig. 25: Diagrama general de los procesos del caso práctico Tomando este flujograma como referencia, se puede dividir el diseño de la solución Business Intelligence en tres fases: Parseo de la Fuente de Datos (Redmine). Procesos de Extracción, Transformación y Carga (ETL). Explotación del Almacén de Datos (Data Warehouse) 4.2.1 Parseo de la Fuente de Datos Redmine es una aplicación web que concentra una gran cantidad de información. Toda esta información se vuelca en una base de datos, en este caso una base de datos MySQL. Dicha información es aprovechable por la aplicación ya que ofrece una gran diversidad de características y funciones, como ya se ha podido ver en el capítulo anterior. Dentro de este mar de información, se encuentran muchos datos relacionados con la gestión de proyectos y tareas, en todos sus aspectos, que pueden resultar de interés, pero estos no son fácilmente apreciables y se ven inmersos en las propias entrañas de la aplicación web. El objetivo de esta fase es filtrar, podar y concentrar la información origen del entorno de producción a un entorno dónde se pueda manejar dicha información de forma más sencilla, rápida y que además permita el uso de diversas herramientas BI. 78 A continuación (Fig. 26) se presenta el modelo de datos de la BD de Redmine: Fig. 26: Modelo de datos de la base de datos de Redmine Podemos apreciar la complejidad de este modelo de datos, esto afecta directamente a la complejidad de la solución de esta fase. En este punto se ha de tener especial cuidado, ya que una mala decisión de la información a extraer y del modelo de datos destino puede conllevar complicaciones y retrasos mayores en el futuro. Teniendo en cuenta los requisitos funcionales y el modelo de datos de Redmine, se diseña mediante la herramienta Kettle (Pentaho Data Integrator), un trabajo para poder extraer de la Fuente de Datos la información útil y llevarla a la base de datos Oracle, lugar donde se concentrará toda la información. En este punto es de interés explicar los dos principales esquemas que se usarán: DWRM_ETL: en este esquema se almacenará toda la información y metadatos relacionados con el proceso de Extracción, Transformación y Carga. 79 DW_REDMINE: en este esquema se almacenará el Data Warehouse, para su posterior explotación de la información mediante la herramienta MicroStrategy. Mediante Kettle nos podemos conectar fácilmente a la base de datos MySQL de Redmine y realizar transformaciones, en nuestro caso mapeos de datos, a las tablas que realmente se usarán como fuente de datos de los procesos ETL (localizadas en el esquema DWRM_ETL dentro de la base de datos Oracle). A continuación (Fig. 27) podemos ver el conjunto de transformaciones que forman parte del trabajo de parseo de datos de Redmine a Oracle. Fig. 27: Transformaciones mediante Kettle (Redmine -> Oracle) Tras ejecutar el trabajo, las tablas que se alimentan en la base de datos Oracle, y que pasarán a ser la Fuente de Datos para los procesos ETL, son: RM_CUSTOM_VALUES_EXT_PAR RM_CUSTOM_FIELDS_EXT_PAR RM_ENUMERATIONS_EXT_PAR RM_ISSUE_CATEGORIES_EXT_PAR RM_ISSUE_RELATIONS_EXT_PAR 80 RM_ISSUE_STATUSES_EXT_PAR RM_ISSUES_EXT_PAR RM_JOURNAL_DETAILS_EXT_PAR RM_JOURNALS_EXT_PAR RM_PROJECTS_EXT_PAR RM_TIME_ENTRIES_EXT_PAR RM_TRACKERS_EXT_PAR RM_USERS_EXT_PAR Los nombres de dichas tablas (excluyendo los prefijos RM y sufijos EXT_PAR), provienen de las correspondientes tablas origen del modelo de datos de Redmine. En este punto, teniendo en cuenta la información disponible y como paso previo a la definición de los procesos ETL, se define el modelo de datos objetivo, Data Warehouse, que se empleará como fuente de datos de la herramienta de explotación de información MicroStrategy. Teniendo en cuenta los conceptos explicados en el capítulo 2, se decide emplear un modelo en estrella (ideal por su simplicidad y velocidad para ser usado en análisis multidimensionales, además permite acceder tanto a datos agregados como en detalle.). A continuación en la Tabla 6 podemos ver las diferentes tablas de hechos y tablas de dimensiones que forman el modelo en estrella: Tablas de Dimensiones DWD_HORA DWD_RM_ACTIVIDADES DWD_RM_ESTPET DWD_RM_PETCAMVAL DWD_RM_PETICIONES DWD_RM_USUARIOS DWD_TIEMPO DWD_PROJECTS Tablas de Hechos DWH_RM_DEDIC DWH_RM_HISESTPET Descripción Definición de las horas Actividades que se realizan Estado de las peticiones Registro de los cambios de valores Peticiones (tareas) definidas Usuarios del equipo Definición del tiempo Proyectos Descripción Dedicación de los usuarios Histórico del estado de las peticiones Planificación de las peticiones DWH_RM_PLAPET Tabla 6: Tablas de Hechos y Dimensiones del Modelo en Estrella 81 4.2.2 Procesos de Extracción, Transformación y Carga El sistema de explotación de datos, MicroStrategy, requiere un origen o modelo de datos “preparado” para una explotación eficiente y de calidad, cuando indicamos “preparado” nos referimos a que debe ser un modelo de datos de tipo “estrella” o “copo de nieve”, de forma que, por lo general, no es buena idea apuntar nuestro sistema contra un origen de datos en producción, por varios motivos: Rendimiento: los entornos de producción normalmente están preparados para que las aplicaciones que sustentan tengan un rendimiento óptimo, no están preparados para una explotación masiva de información que es lo que pretendemos con nuestro sistema de BI. Modelado de datos: los entornos de producción no suelen tener preparados sus modelos de datos en “estrella” o “copo de nieve”, a menos que incluyan procesos específicos para ir informando dichos modelos (con la intención posterior de ser explotados). Por norma general, es buena idea separar de los entornos productivos la explotación de información, en esta separación es cuando entran en juego los sistemas ETL (Extract, Transformation and Load) (Fig. 28), cuya función no es más que preparar/actualizar modelos de datos (normalmente en “estrella” o “copo de nieve”) desde las fuentes origen de datos hacia otros contenedores (otras bases de datos, otros sistemas) para una posterior explotación por parte de sistemas de Business Intelligence. Fig. 28: Procesos ETL 82 Habitualmente, “ETL Source” son entornos de producción (aunque podrían ser otros, como sistemas replicados de otros entornos de producción, etc.) y “ETL Target” son bases de datos DW (Data Warehouse). En la fase de “Parseo de la Fuente de Datos” se han replicado los datos de interés desde el entorno de producción (fuente de datos origen) a un entorno controlado y habilitado para el procesado de la información (base de datos Oracle). Para obtener el Almacén de Datos (Data Warehouse) con la información útil, el equipo BI Servicio de Salud decide emplear la metodología interna desarrollada por BI Solutions. Dentro de esta metodología encontramos dos importantes agentes: Metadatos: encargados de controlar la ejecución de los procesos y albergar toda la información relevante de la estructura del Data Warehouse. Procesos: encargados de procesar la información (procesos ETL). Metadatos Uno de los componentes más importantes de la arquitectura de un almacén de datos son los metadatos. Se define comúnmente como "datos acerca de los datos", en el sentido de que se trata de datos que describen cuál es la estructura de los datos que se van a almacenar y cómo se relacionan. El metadato documenta, entre otras cosas, qué tablas existen en una base de datos, qué columnas posee cada una de las tablas y qué tipo de datos se pueden almacenar. Los datos son de interés para el usuario final, el metadato es de interés para los programas que tienen que manejar estos datos. Sin embargo, el rol que cumple el metadato en un entorno de almacén de datos es muy diferente al rol que cumple en los ambientes operacionales. En el ámbito de un Data Warehouse el metadato juega un papel fundamental, su función consiste en recoger todas las definiciones y el concepto de los datos en el almacén de datos, debe contener toda la información relativa a: Tablas Columnas de tablas Relaciones entre tablas Jerarquías y Dimensiones de datos Entidades y Relaciones 83 Además de lo comentado, también incluye toda la información relevante a la ejecución de los procesos ETL (definición de procesos y jerarquía de los procesos). Procesos Para mantener una ejecución de los procesos jerarquizada y con ello mantener los datos alineados, la ejecución de los mismos se ve soportada por la información definida en los metadatos. La metodología empleada por BI Servicio de Salud, define un mecanismo común en el flujo de información para los procesos de Extracción, Transformación y Carga. Dentro de este flujo participan cuatro grupos de tablas: PAR: fuente de datos origen (fruto de la fase de parseo). No se modifica durante los procesos de ETL. EXT: almacena el histórico de la información procesada. MOD: almacena las modificaciones detectadas en el correspondiente proceso. CAM: almacena los campos que se han visto modificados. En la Fig. 29 podemos ver las cuatro fases que conforman el flujo de datos dentro de los procesos ETL. Estas fases aplican tanto a la fase de Extracción, como a la de Transformación y a la de Carga. 84 Fig. 29: Fases del flujo de datos dentro de la metodología de los procesos ETL Fase 1 Se realiza una comparación entre las fuentes de datos (PAR) y lo almacenado en las tablas históricas (EXT). Se utilizan unos campos de arquitectura START_DATE y END_DATE para controlar la historificación. Fase 2 Las modificaciones de los registros se vuelcan en las tablas de modificaciones (MOD). Fase 3 Se almacenan en las tablas de cambios (CAM) únicamente los campos que han variado. Fase 4 Se actualiza la tabla histórica (EXT). El flujo de datos descrito se ve soportado principalmente por: Paquetes: mediante la herramienta OWB (Oracle Warehouse Builder) se realiza un tratado de la información de forma gráfica. Finalmente, este tratamiento de la información se convierte en paquetes PL/SQL de Oracle. 85 Funciones: se definen diferentes funciones en código PL/SQL utilizadas en determinadas partes de los procesos ETL (propias de la metodología definida por BI Solutions). A continuación (Fig. 30), podemos ver una parte de la traza de la ejecución de los procesos ETL: Fig. 30: Traza de la ejecución de los procesos ETL En esta figura podemos ver cómo están jerarquizados los procesos, y en función de los niveles y pesos definidos en los metadatos se van ejecutando secuencialmente. 86 4.2.3 Explotación de la información Llegados a este punto, ya disponemos de un Data Warehouse con toda la información de interés. Esto no basta para poder cumplir nuestro objetivo principal, optimizar la toma de decisiones y con ello mejorar la gestión de proyectos. Ahora será necesario realmente aprovechar esta información. En los siguientes puntos se procede a describir los pasos necesarios para poder crear un proyecto en MicroStrategy y los respectivos Objetos, necesarios ya que son indispensables para la creación de los gráficos, informes y documentos con MicroStrategy. Esta descripción se realiza a nivel general. Posteriormente, en el siguiente apartado de este capítulo se verán ejemplos de uso. 4.2.3.1 MicroStrategy: primeros pasos Antes de empezar a utilizar la herramienta MicroStrategy, es necesario realizar una serie de configuraciones del entorno de trabajo: configurar la conectividad y realizar una configuración básica de los esquemas utilizados por MicroStrategy. Para trabajar con MicroStrategy, tendremos que tener disponibles varios esquemas de base de datos, cada uno con un cometido diferente: Datawarehouse: una o varias bases de datos de donde la herramienta leerá la información (según el modelo que construyamos), para elaborar los informes, consultas, cuadros de mando, cubos, etc. Es la base de datos que hemos modelado, construido y llenado con los procesos ETL utilizando Oracle Warehouse Builder y código PL/SQL. Metadata: son las tablas internas de MicroStrategy donde se guarda toda la información del modelo de datos que definamos y de todos los objetos que construyamos utilizando la herramienta (filtros, informes, indicadores, etc.). Es el corazón del sistema de BI. Historial: historial de las modificaciones que realicemos con los objetos. Estadísticas: tablas para mantener y controlar la actividad del sistema. MicroStrategy nos permite trabajar de forma directa con los principales motores de base de datos (DB2, Informix, MySql, Oracle, PostreSQL, Sybase o SQL Server). Igualmente, a través de ODBC podremos acceder a otras muchas bases de datos. 87 Configuración de la base de datos En nuestro caso, utilizaremos ODBC (Open DataBase Connectivity), con el driver proporcionado por Oracle, y configuraremos los siguientes orígenes de datos (podemos utilizar el Connectivity Configuration Wizard (Fig. 31) proporcionado por MicroStrategy o el gestor de conexiones ODBC de Windows): DW_REDMINE: base de datos donde se ubicara el Data Warehouse (corresponde a la base de datos con esquema DW_REDMINE en Oracle). MD_REDMINE: base de datos donde se ubicara el Metadata de nuestro proyecto (corresponde a la base de datos con esquema DWRM_ETL en Oracle). HS_REDMINE: base de datos donde se ubicara el Historial. ST_REDMINE: base de datos donde estarán las estadísticas. Fig. 31: Connectivity Configuration Wizard 88 Fig. 32: Connectivity Configuration Wizard validación de la conexión Configuración inicial del Sistema Una vez definidos las conexiones ODBC e instalada correctamente la aplicación y su licencia, vamos a utilizar el asistente de configuración (Configuration Wizard) para dejar el sistema listo para empezar a trabajar con él. Fig. 33: Configuration Wizard 89 El Configuration Wizard (Fig. 33) tiene 3 tareas a realizar, que son las siguientes: Tablas de repositorio: en este paso creamos en las bases de datos los catálogos de tablas necesarios para los diferentes componentes (como hemos visto Metadatos, Estadísticas e Historial). El proceso se conecta a las bases de datos y crea en ellas todas las tablas necesarias para gestionar el metadato de MicroStrategy, llenando además el contenido de las tablas con los objetos predefinidos. Fig. 34: Tablas del repositorio Definiciones de MicroStrategy Intelligence Server: el MicroStrategy Intelligence Server es el motor de procesamiento y gestión de los trabajos de las aplicaciones de informes, análisis y monitorización. Utiliza una arquitectura orientada al servicio (SOA, Service Oriented Architecture), y estandariza en una única plataforma todas las necesidades de análisis y reporting, a través de varios canales de acceso: web browsers, Microsoft Office, Desktop clients y email. En este paso de la configuración le asociamos al Intelligence Server el esquema de base de datos del Metadata (que habremos dejado preparado en el paso anterior), e indicamos parámetros adicionales de configuración (como el puerto TCP o si queremos registrarlo como un servicio). Tendremos un único Intelligence Server en nuestro sistema. 90 Fig. 35: Definiciones de MicroS trategy Intelligence S erver Orígenes de Proyecto: un origen de proyecto es la ubicación centralizada de los diferentes proyectos. Es un contenedor que luego nos permitirá definir dentro de él los proyectos que tengamos en nuestra infraestructura de BI. Se pueden definir varios orígenes de proyecto (no necesariamente sólo uno). Al crear un origen de proyectos, le asociamos un tipo de origen y le indicamos el tipo de validación de usuario que se va a realizar para el (usuario de windows, usuario de MicroStrategy, usuario LDAP, usuario de base de datos, etc). En nuestro caso creamos el origen de proyecto REDMINE que va a incluir todos los elementos de nuestro proyecto. 91 Fig. 36: Orígenes de Proyecto Los tipos de origen de proyecto, según el siguientes: tipo de configuración, son los Directo o 2 niveles: pensado para instalaciones de test, formación o prototipos. En este caso, no pasamos a través del Intelligence Server, sino que accedemos directamente al Metadata cuando creemos un proyecto (por eso hay que indicar que origen de datos contiene el Metadata). MicroStrategy Intelligence Server o 3 niveles: pensado para instalaciones en productivo. En este caso pasamos a través del Intelligence Server, y por tanto, utilizamos el origen de datos del Metadata que definimos anteriormente en él. En un origen de proyectos podremos definir uno o varios proyectos utilizando el Project Builder o el MicroStrategy Desktop (y su asistente para la creación de proyectos). Hemos concluido con estos pasos la configuración básica de nuestro servidor de MicroStrategy 9. Ha sido relativamente sencillo dejar el sistema preparado para comenzar a trabajar con las herramientas de MicroStrategy. 92 4.2.3.2 Creación del proyecto El primer paso que se realiza para trabajar con la herramienta es crear un nuevo proyecto. Para la creación del proyecto, tenemos dos herramientas: Project Builder: es un asistente pensado para la creación de proyectos sencillos, demos y prototipos, por lo que tiene bastantes limitaciones. Para cualquier proyecto productivo, será conveniente utilizar la herramienta Desktop. En la entrada 8 del blog, construimos un prototipo de nuestro proyecto utilizando esta herramienta (se explica allí de forma detallada todos los pasos seguidos). Desktop – Asistente para la creación de proyectos: es la herramienta principal de desarrollo para trabajar con MicroStrategy. En la herramienta Desktop vemos los diferentes orígenes de proyecto que tenemos definidos en nuestro sistema, y seleccionaremos uno de ellos para crear en él el nuevo proyecto. A continuación lanzaremos el asistente, tal y como vemos en pantalla. Tiene una serie de pasos donde configuraremos los diferentes elementos que conformaran el modelo Dimensional del proyecto. Con la herramienta Architect se completa la configuración jerárquica de los atributos que forman las dimensiones. En este caso se ha empleado el Asistente para la creación de proyectos (Fig. 37). Para configurar la creación del proyecto se hace click en Esquema -> Crear Proyecto Nuevo. 93 Fig. 37: Asistente para la creación de proyectos Aparece un menú emergente donde se selecciona Crear Proyecto. En la nueva ventana se da nombre al proyecto, así como su descripción, idioma, y directorio donde se guardaran los objetos creados. Una vez finalizado, se hace click en Aceptar. Con la herramienta realizaremos una asociación entre las tablas de bases de datos del Data Warehouse (modelo físico), con los elementos lógicos de nuestro modelo (dimensiones y sus atributos; jerarquía entre los diferentes atributos que forman las dimensiones y finalmente, hechos e indicadores de negocio). Una vez configurado el servidor y creado el proyecto, vamos a proceder a implementar el modelo lógico de nuestro Data Warehouse dentro del esquema de metadatos de MicroStrategy. Esta tarea es fundamental para empezar a trabajar con nuestra herramienta de BI. Es el punto de partida para empezar a preparar los diferentes elementos que formarán nuestro sistema de Business Intelligence (informes, análisis, etc). 94 Fig. 38: Elementos que forman el S istema Del modelo lógico al metadata de MicroStrategy Las tareas que realizaremos en este paso será la definición de los atributos de las dimensiones, la relación entre ellos (organización jerárquica), así como de los indicadores de negocio relevantes en nuestro caso. Aquí estableceremos la relación entre estos elementos lógicos y sus equivalentes a nivel físico (tablas y campos de la base de datos). Existen dos conceptos importantes: Hechos / indicadores: son los valores de negocio por los que querremos analizar nuestra organización (importe ventas, margen, rentabilidad). En nuestro caso del equipo BI Servicio de Salud hablamos de dedicación, plazos, etc. Dimensiones: las perspectivas o diferentes ámbitos por los que querremos analizar estos indicadores de negocio (son las que dan sentido al análisis de los indicadores de negocio, pues sin dimensiones no son más que un valor más). Permiten contestar preguntas sobre los hechos y darles un contexto de análisis. En nuestro modelo, las dimensiones serán el tiempo (siempre suele haber una dimensión temporal), usuarios, peticiones, actividades y proyectos. 95 Para configurar esto dentro de MicroStrategy, realizaremos tres tareas principales: 1.- Selección de tablas del catálogo del Warehouse: de todas las tablas que tendremos en la base de datos del Data Warehouse, seleccionaremos con cuales de ellas vamos a trabajar. Las tablas seleccionadas y sus campos determinarán los elementos disponibles para el resto de pasos. 2.- Creación de hechos: de las tablas seleccionadas en el paso anterior, indicaremos que campos son los que corresponden a los hechos. Estos campos nos servirán de base para la creación de las métricas, que serán las que utilizaremos en los informes, documentos y análisis. Estas métricas, partiendo de las base de los hechos, podrán incluir operaciones, cálculos de uno o más campos, así como el uso de funciones complejas (MicroStrategy incluye un gran número de funciones para realizar cálculos complejos sobre los datos, incluyendo funciones estadísticas). Esto nos permitirá disponer de valores que se calculan y que realmente no están guardados en la base de datos. 3.- Creación de atributos: en este paso, de la misma manera, seleccionaremos los campos que corresponden a los atributos y realizaremos la configuración básica de ellos, como descripciones, ordenación, asignación de descripciones a códigos (lookups), así como la configuración de la estructura jerárquica de los diferentes componentes que forman una dimensión (a través de las relaciones padres e hijos). Fig. 39: S eleccionar tablas mediante el Asistente para la creación de Proyectos 96 Para realizar estas tareas, utilizaremos el Asistente para la creación de proyectos, que nos guiará de una forma ordenada, en todos los pasos a realizar para completar estas tareas. El asistente sólo se utiliza cuando se crea el proyecto y los procesos de mantenimiento posteriores de las tablas, atributos y hechos los realizaremos desde la herramienta de desarrollo MicroStrategy Architect o bien desde el Desktop. Veamos un poco más en profundidad cada uno de estos pasos: Selección de tablas del catálogo del Warehouse En este paso indicaremos la base de datos que corresponde al Data Warehouse, y del catálogo que indiquemos, nos aparecerán todas las tablas definidas en el nivel físico. De dichas tablas, seleccionaremos aquellas que sean relevantes para nuestro modelo (tal y como vemos en la siguiente figura). Fig. 40: S elección de tablas desde el Catálogo de Warehouse MicroStrategy nos permite trabajar con la misma tabla varias veces a través de los “alias” de tabla. Puede ser útil cuando la misma dimensión física se utiliza de forma lógica en varios lugares (y no es necesaria la existencia de una tabla física 97 para cada una de las dimensiones). Igualmente, también nos permite trabajar con vistas. El uso de vistas es de gran interés ya que en soluciones BI donde se necesita realizar algún cálculo complejo, hacer esto directamente desde MicroStrategy puede perjudicar el rendimiento. Por ello, se crean vistas (tablas lógicas) en las cuales directamente se realiza la operación compleja en base de datos y sólo se tienen que leer los resultados desde la aplicación de explotación de datos. Creación de Hechos De los campos de las tablas indicadas en el punto anterior, en este paso seleccionaremos cuáles de ellos son las que consideraremos Hechos. En principio, aunque se puede configurar, solo se toman para este cometido los campos que están definidos como numéricos. Creación de Atributos La creación de atributos es un poco más compleja y lleva asociados varios pasos. En primer lugar, de todos los campos de las tablas, seleccionaremos cuales son los que corresponden a nuestros atributos. En el caso de que un atributo lleve asociado un campo identificador y un campo descripción, solo seleccionaremos el campo identificador (pues después se establecerá la relación entre campos de código y campos de descripción o de lookup). A continuación, para cada uno de los atributos, indicaremos su campo de lookup. Cuando un campo no dispone de este (por ejemplo un campo “Código Postal”, que en sí mismo se describe), indicaremos “Utilizar ID como descripción”. Como último paso en la creación de los atributos, para cada uno de ellos indicaremos qué atributos son hijos de él (están después en la jerarquía de la dimensión) o cuales son padre (están arriba en el árbol). Este paso lo omitiremos, pues lo realizaremos a continuación con la herramienta gráfica Architect, que es mucho más ágil para realizar esta definición. Mantenimiento del modelo usando MicroStrategy Architect El Architect es, junto con el Desktop, la herramienta principal de desarrollo dentro de MicroStrategy. Utilizando esta última herramienta podríamos igualmente haber 98 realizado la definición de los hechos y atributos (el paso de selección de tablas habría que haberlo realizado igualmente como un paso previo). El Architect es una herramienta gráfica y con ella se realizan las tareas de mantenimiento dentro de MicroStrategy. En nuestro caso, dejamos sin definir las jerarquías de atributos y las hemos completado utilizando esta herramienta. Esto es tan sencillo como seleccionar el atributo padre y arrastrar hacia el atributo hijo para que se cree la relación. Posteriormente, seleccionamos en el conector para modificar la cardinalidad de la relación (1-1, 1-n o n-n). Fig. 41: Creación del modelo lógico usando MicroS trategy Architect En la figura, podemos ver cómo hemos definido la estructura jerárquica dentro de la dimensión Usuario. Además, desde aquí podemos crear nuevos atributos, nuevos hechos o modificar las propiedades de estos (en la parte de la derecha tenemos la tabla de propiedades). Seleccionando el elemento, en esa sección nos aparece toda la información de cómo está configurado. Llegados a este punto, ya tenemos definido el modelo lógico del proyecto en MicroStrategy. Con esto ya estamos en disposición de empezar a crear informes y analizar los datos. 99 Esta parte del proyecto es eminentemente práctica, para evitar volver engorroso este apartado reiterando información, se recomienda la lectura/seguimiento de la Guía para la explotación de datos mediante MicroStrategy. Esta guía se ha creado para abarcar los conceptos necesarios para el uso de la aplicación, y explica de forma práctica paso a paso mediante diversos ejemplos todas las funcionalidades de cara a la explotación de datos. La guía para la explotación de datos se encuentra en los anexos del proyecto (Anexo A.- Guía para la explotación de datos mediante MicroStrategy). 4.3 Resultados Este apartado busca reflejar los resultados obtenidos mostrando una serie de casos de uso, los cuales pueden aportar gran valor de cara a la gestión y toma de decisiones. Se hará mención a cinco informes que brindan información útil de forma clara y concisa: Informe Informe Informe Informe Informe para controlar el exceso de trabajo. de la evolución del desempeño. con la desviación en la finalización de tareas. de tareas completadas en fecha. de jerarquía en el equipo de trabajo. 4.3.1 Informe para controlar el exceso de trabajo Objetivo Con este informe se pretende poder visualizar fácilmente el número horas de trabajo, durante un periodo de tiempo, de los miembros del equipo. Decisiones a posteriori La idea es detectar si existe algún problema como: necesidad de mayor apoyo en sus tareas, problema de planificación o tareas no aptas para el miembro del equipo, entre otras; y tomar medidas para corregir esto. 100 En este caso se han utilizado los siguientes objetos del proyecto: Atributos o Atributo para poder visualizar el listado de miembros del equipo. Indicadores o Indicador con las horas excedidas, este indicador calcula la diferencia entre un valor fijo (horas laborales correspondientes a un mes) y otro indicador (suma de las horas dedicadas). o Indicador con las horas dedicadas por el correspondiente usuario. Filtros o Filtro temporal para filtrar por meses. Fig. 42: Informe para controlar el exceso de trabajo 4.3.2 Informe de la evolución del desempeño Objetivo Con este informe se pretende poder visualizar fácilmente la evolución temporal, en cuanto a número y prioridad de tareas asignadas, de los miembros del equipo de trabajo. Esto nos permitirá fácilmente hacer un seguimiento del desempeño de los integrantes del equipo de trabajo. 101 Decisiones a posteriori La idea es ver si el número de tareas asignadas (prioridad) evoluciona hacia “más tiempo, más tareas, más responsabilidad”, concepto clave y deseado en la evolución laboral de un miembro dentro de un equipo o empresa. En función de los resultados se podrá evaluar el desempeño de los miembros, y profundizar en los casos puntuales en los que no se vea reflejada la evolución deseada. En este caso se han utilizado los siguientes objetos del proyecto: Atributos o Atributo para poder visualizar el listado de miembros del equipo. o Atributo con la prioridad de las tareas Indicadores o Indicador con la suma de tareas asignadas. Filtros o Filtro temporal para filtrar por años. Fig. 43: Informe de la evolución del desempeño 4.3.3 Informe de tareas completadas en fecha Objetivo Con este informe se pretende poder visualizar fácilmente las tareas que han sido finalizadas en fecha (fecha finalización real menor a la fecha de finalización prevista). 102 Decisiones a posteriori La idea es poder valorar a los miembros del equipo de trabajo y además sirve de feedback de cara a la planificación del proyecto. En este caso se han utilizado los siguientes objetos del proyecto: Atributos o Atributo para poder visualizar el listado de miembros del equipo. o Atributo con la prioridad de las tareas Indicadores o Indicador con la suma de tareas asignadas. Filtros o Filtro temporal para filtrar por meses o Filtro de informe de los datos que cumplan la condición fecha finalización real < fecha finalización prevista. Fig. 44: Informe de tareas completadas en fecha 4.3.4 Informe de jerarquía en el equipo de trabajo Objetivo Con este informe se pretende poder visualizar fácilmente la jerarquía de los miembros pertenecientes al equipo de trabajo. 103 Decisiones a posteriori La idea es saber en cada momento la vinculación jerárquica entre los miembros del equipo, todo esto determinado por sus categorías (roles). De cara a la gestión o incluso yendo más allá, de cara a saber con quién tratar en determinados casos, esta información puede ser muy útil. Este informe es muy específico (ad hoc) y nos sirve para ilustrar lo personalizable que puede a llegar a ser el manejo de datos. En relación a las categorías de los miembro, partiendo de los datos que nos ofrece la fuente de datos (Redmine), sólo tenemos los roles de cada miembro sin ninguna relación entre estos. Se pretende hacer uso de vistas materializadas (comentadas brevemente en apartados anteriores) y con ello construir la información que no tenemos de forma directa. Se construyen tres vistas materializadas para incluir los tres niveles deseados: Nivel 1: rol jefe de proyecto. Nivel 2: rol senior. Nivel 3: roles analista programador y funcional. Una vez creadas las Vistas Materializadas (Materialized Views), se tendrán que vincular en nuestro modelo de MicroStrategy de forma lógica mediante la herramienta Architect. Esto nos permitirá en los informes navegar por los niveles. Fig. 45: Informe de jerarquía en el equipo de trabajo 104 105 Capítulo 5 5 Conclusiones y líneas futuras 5.1 Conclusiones Trabajando para la consultora tecnológica Everis, comencé a percatar la enorme importancia del manejo y uso de la información, en todos sus aspectos. Posteriormente, en mi actual trabajo, esta idea ha seguido creciendo dentro de mí. En el mundo empresarial, la toma de decisiones es una cuestión vital para el desarrollo de la empresa. Es por ello, que la información que va generando y almacenando día a día, sirve de indicador para poder obtener un conocimiento que permite a los dirigentes analizar y consensuar unas decisiones que ayudaran a la empresa a crecer y controlar sus activos y recursos. Todo esto es igualmente extrapolable para una parte vital y que conforma a las organizaciones: los equipos de trabajo. En este proyecto se ha intentado transmitir el conocimiento necesario para poder afrontar el desarrollo de una solución de Business Intelligence. En relación a la herramienta empleada para la explotación de información, uno de sus puntos fuertes que hemos observado en la herramienta es que todo está centralizado en las mismas aplicaciones, y desde ellas realizaremos todas las tareas de desarrollo, desde la configuración del sistema, creación del modelo, así como la creación de los componentes que utilizaran los usuarios. El producto parece ser compacto y consistente, esta es la primera impresión que transmite. Igualmente, MicroStrategy proporciona gran cantidad de documentación, ejemplos, video tutoriales, etc, para que sea más fácil empezar a trabajar con la herramienta y buscar información sobre los diferentes elementos que la conforman. Hasta se incluye en la instalación un curso Web de la herramienta con exámenes de evaluación. Resaltar que además de la parte más técnica que aprendí, la realización de este proyecto me ha aportado una visión empresarial y la importancia de una buena gestión para tener una relación más beneficiosa con los miembros de un equipo, lo que se traduce en éxito para la organización. 106 Teniendo en cuenta todo lo anteriormente comentado, la experiencia personal y todo lo transmitido en este proyecto, podemos concluir que la transformación de los datos en información, y de la información en conocimiento (facilitado por el uso de herramientas de BI como MicroStrategy) es completamente vital en el mundo actual tan competitivo, dónde los pequeños detalles son los que marcan enormes diferencia. 5.2 Líneas futuras Ha quedado fuera del alcance del proyecto algunos temas que se han tratado pero en los que no se ha profundizado. Se describen a continuación diferentes líneas de continuidad. Una primera vía de continuidad sería la integración del módulo de BI MicroStrategy Mobile para su uso desde Smartphones. Es un tema muy interesante y que hoy en día, cada vez más, se hace indispensable para cualquier organización. Otra vía de continuidad que no se ha tratado en el presente proyecto sería la configuración de perfiles para los diferentes usuarios de MicroStrategy. Dentro de un equipo de trabajo o dentro de cualquier empresa, hay diferentes roles predefinidos para aprovechar la información: analistas, desarrolladores, etc. Una tercera vía de continuidad sería hacer un estudio en profundidad de las diferentes metodologías para los procesos de Extracción, Transformación y Carga, con el fin de encontrar la más óptima, aunque cabe tener en cuenta que esto se rige por el volumen de datos, capacidades técnicas, presupuesto y tiempo. 107 108 Bibliografía Se ha consultado la siguiente bibliografía y páginas Web: 1.- Josep Lluís Cano. Business Intelligence: Competir con Información. 2.- Proyecto Gestión Conocimiento: http://www.pgconocimiento.com/Soluciones/que-es-bi.html 3.- Outsourceando (blog): http://outsourceando.blogspot.com.es/2013/03/business.intelligence.y.gestion.del. cambio.html 4.- DataPrix: http://www.dataprix.com/ 5.- Indira María Calderón Morales. Ensayo sobre la importancia en la gestión de proyectos. http://es.slideshare.net/yndyryta/ensayo-sobre-la-importancia-de-la-gestin-deproyectos 109 110 Anexos A.- Guía para la explotación de datos mediante MicroStrategy 111 INDICE OBJETO DEL DOCUMENTO ..........................................................................................118 ALCANCE DEL DOCUMENTO .......................................................................................119 GUÍA PARA LA EXPLOTACIÓN DE DATOS MEDIANTE MICROSTRATEGY..........120 CREACIÓN DE INFORMES............................................................................................ 121 1.1.1 Editor de Informes ............................................................................................. 121 1.1.2 Creación, guardado y visualización de informes................................................... 125 1.1.3 Manipulación de los datos del informe ................................................................ 134 1.1.3.1 Drilling.................................................................................................... 134 1.1.3.2 Paginación ............................................................................................... 136 1.1.3.3 Pivotar..................................................................................................... 137 1.1.3.4 Subtotales ................................................................................................ 139 1.1.3.5 Ordenación .............................................................................................. 140 1.1.4 Manipulación del estilo de un informe ................................................................ 141 1.1.4.1 Umbrales ................................................................................................. 141 1.1.4.2 Fijar encabezado de filas y columnas ......................................................... 143 1.1.4.3 Formato gráfico básico ............................................................................. 144 CREACIÓN DE FILTROS................................................................................................ 146 1.1.5 Tipos de Filtros de Informe ................................................................................ 147 1.1.5.1 Calificación de atributo ............................................................................ 147 1.1.5.2 Calificación de conjunto ........................................................................... 147 1.1.6 Operadores de conjunto...................................................................................... 148 1.1.7 Creación, guardado y utilización de filtros independientes .................................... 148 1.1.7.1 Editor de Filtros ....................................................................................... 148 1.1.7.2 Creación de filtros independientes simples ................................................. 152 1.1.7.3 Creación de filtros independientes con múltiples condiciones...................... 160 1.1.7.4 Utilización de filtros independientes .......................................................... 161 1.1.8 Creación de filtros dentro de un informe.............................................................. 163 CREACIÓN DE SELECCIÓN DINÁMICA....................................................................... 164 1.1.9 Tipos de Selecciones Dinámicas ......................................................................... 165 1.1.9.1 Selecciones dinámicas de definición de filtro ............................................. 165 1.1.9.2 Selecciones dinámicas de objeto................................................................ 165 1.1.9.3 Selecciones dinámicas de valor ................................................................. 165 1.1.10 Creación, guardado y utilización de selecciones dinámicas independientes ....... 166 1.1.10.1 Editor de Selecciones dinámicas................................................................ 166 1.1.10.2 Creación de Selecciones Dinámicas independientes .................................... 169 1.1.10.3 Utilización de selecciones dinámicas independientes .................................. 173 1.1.11 Creación de selecciones dinámicas dentro de un filtro ..................................... 178 1.1.12 Creación de selecciones dinámicas dentro de un informe ................................. 180 CREACIÓN DE GRUPO PERSONALIZADO................................................................... 181 1.1.13 Editor de grupo personalizado........................................................................ 182 1.1.14 Creación, guardado y utilización de grupos personalizados simples .................. 184 1.1.14.1 Creación de elementos de grupos personalizados con múltiples condiciones 190 1.1.14.2 Formato de Grupos Personalizados............................................................ 191 1.1.14.3 Utilización de Grupos Personalizados ........................................................ 192 CREACIÓN DE ANÁLISIS.............................................................................................. 193 1.1.15 Visual Insight ............................................................................................... 193 1.1.16 Tipos de visualización ................................................................................... 193 1.1.17 Creación de análisis de Visual Insight a partir de un informe ........................... 194 1.1.17.1 Editor de Análisis..................................................................................... 196 1.1.17.2 Creación de análisis de Visual Insight........................................................ 198 112 CREACIÓN DE DOCUMENTOS ..................................................................................... 201 1.1.18 Creación de documentos................................................................................ 201 REFERENCIAS .................................................................................................................203 113 LISTA DE FIGURAS Figura 1. Pantalla de Bienvenida. .......................................................................................... 120 Figura 2. Estructura de un informe......................................................................................... 121 Figura 3. Acceso Editor de informes. ..................................................................................... 122 Figura 4. Editores de informe. ............................................................................................... 122 Figura 5. Interfaz editor de informes. ..................................................................................... 122 Figura 6. Áreas del editor de informes.................................................................................... 123 Figura 7. Pestaña todos los objetos......................................................................................... 124 Figura 8. Explorador de carpetas. .......................................................................................... 125 Figura 9. Mover a columnas o eje de paginación. .................................................................... 126 Figura 10. Plantilla con atributo categoría. ............................................................................. 126 Figura 11. Selección de representaciones de un atributo. ......................................................... 127 Figura 12. Barra de herramientas modo diseño. ...................................................................... 127 Figura 13. Guardar informe. .................................................................................................. 128 Figura 14. Pestañas disponibles tras ejecutar informe. ............................................................. 129 Figura 15. Barra de herramientas pestaña inicio. ..................................................................... 129 Figura 16. Barra de herramientas pestaña herramientas ........................................................... 130 Figura 17. Barra de herramientas pestaña datos ...................................................................... 131 Figura 18. Barra de herramientas pestaña cuadrícula. .............................................................. 132 Figura 19. Barra de herramientas pestaña gráfico. ................................................................... 133 Figura 20. Barra de herramientas pestaña formato................................................................... 133 Figura 21. Realización drilling. ............................................................................................. 134 Figura 22. Drilling click derecho del ratón. ............................................................................ 135 Figura 23. Editor de navegación. ........................................................................................... 136 Figura 24. Informe paginado por categoría. ............................................................................ 136 Figura 25. Paginación. .......................................................................................................... 137 Figura 26. Eje de paginación. ................................................................................................ 137 Figura 27. Opciones del menú ‘Mover’. ................................................................................. 138 Figura 28. Objetos excluidos de la cuadrícula. ........................................................................ 139 Figura 29. Opciones de configuración ‘Subtotales’. ................................................................ 140 Figura 30. Informe con ‘Subtotales’. ...................................................................................... 140 Figura 31. Ordenación rápida. ............................................................................................... 141 Figura 32. Ventana de ordenación avanzada. .......................................................................... 141 Figura 33. Informe con umbrales. .......................................................................................... 142 Figura 34. Umbrales rápidos. ................................................................................................ 142 Figura 35. Editor de umbrales de visualización. ...................................................................... 143 Figura 36. Formato de umbral de visualización. ...................................................................... 143 Figura 37. Fijar encabezados filas y columnas desde ‘Herramientas’........................................ 144 Figura 38. Fijar encabezados y columnas desde ‘Cuadrícula’................................................... 144 Figura 39. Personalización de gráfico desde barra de herramientas........................................... 145 Figura 40. Formato de un gráfico. .......................................................................................... 145 Figura 41. Diagrama ejemplo de filtrado. ............................................................................... 146 Figura 42. Ejemplo de Operadores de Conjunto. ..................................................................... 148 Figura 43. Acceso editor de filtros. ........................................................................................ 149 Figura 44. Interfaz editor de filtros......................................................................................... 149 Figura 45. Áreas de editor de filtros. ...................................................................................... 150 Figura 46. Explorador de carpetas.......................................................................................... 151 Figura 47. Objeto añadido a la ventana de creación de filtros arrastrando. ................................ 151 Figura 48. Objeto añadido a la ventana de creación de filtros mediante click derecho. ............... 152 Figura 49. Calificar atributo. ................................................................................................. 153 Figura 50. Calificación de representación de atributo. ............................................................. 153 Figura 51. Aplicar filtro. ....................................................................................................... 154 Figura 52. Guardar filtro. ...................................................................................................... 154 114 Figura 53. Seleccionar filtro de selección de lista. ................................................................... 155 Figura 54. Búsqueda y adición a la lista de seleccionados. ....................................................... 156 Figura 55. Aplicar condiciones de filtro. ................................................................................ 156 Figura 56. Seleccionar atributo para comparación. .................................................................. 157 Figura 57. Selección de representación de atributo. ................................................................. 158 Figura 58. Ventana selección de atributo. ............................................................................... 158 Figura 59. Selección operador y valor de calificación. ............................................................. 159 Figura 60. Selección de indicador para comparación. .............................................................. 160 Figura 61. Selección de operador. .......................................................................................... 160 Figura 62. Selección de operador de conjunto. ........................................................................ 161 Figura 63. Panel filtro de informe. ......................................................................................... 162 Figura 64. Selección orden de evaluación. .............................................................................. 162 Figura 65. Configuración de filtro creado dentro de un informe. .............................................. 163 Figura 66. Acceso Editor de Selecciones Dinámicas. .............................................................. 166 Figura 67. Editores de Selecciones Dinámicas. ....................................................................... 166 Figura 68. Interfaz del editor de selección dinámica de calificación de atributo. ........................ 167 Figura 69. Áreas del editor de Selecciones Dinámicas. ............................................................ 167 Figura 70. Pestaña ‘Definición’. ............................................................................................ 168 Figura 71. Pestaña ‘General’. ................................................................................................ 168 Figura 72. Pestaña ‘Estilo’. ................................................................................................... 168 Figura 73. Pestaña ‘Calificación’. .......................................................................................... 169 Figura 74. Selección de atributo para la selección dinámica. .................................................... 170 Figura 75. Representaciones de atributo mostradas. ................................................................ 170 Figura 76. Nombre y descripción de la selección dinámica. ..................................................... 170 Figura 77. Limitaciones del número de respuestas. ................................................................. 171 Figura 78. Configuración del diseño y estilo de visualización. ................................................. 171 Figura 79. Configuración de cómo se muestran las calificaciones. ........................................... 172 Figura 80. Almacenamiento de la selección dinámica.............................................................. 172 Figura 81. Configuración de calificación en selección dinámica de calificación de indicador. .... 173 Figura 82. Adición de selección dinámica a un informe........................................................... 174 Figura 83. Ventana de selección de Selección Dinámica.......................................................... 174 Figura 84. Adición del atributo para calificar. ......................................................................... 175 Figura 85. Selección de la representación del atributo. ............................................................ 175 Figura 86. Selección de valor de atributo para comparación..................................................... 176 Figura 87. Ejecución del informe tras configurar la selección dinámica. ................................... 176 Figura 88. Resultados del informe tras uso de selección dinámica. ........................................... 177 Figura 89. Adición de nueva condición al filtro de selección dinámica. .................................... 177 Figura 90. Múltiples condiciones dentro de una selección dinámica. ........................................ 178 Figura 91. Resultados de informe con selección dinámica multicondicional.............................. 178 Figura 92. Creación de selección dinámica como parte de un filtro. ......................................... 179 Figura 93. Ventada de configuración de selección dinámica dentro de un filtro. ........................ 179 Figura 94. Ejemplo de Grupo personalizado ........................................................................... 181 Figura 95. Acceso al editor de grupos personalizados.............................................................. 182 Figura 96. Editor de grupos personalizados. ........................................................................... 182 Figura 97. Elementos de grupo personalizado. ........................................................................ 183 Figura 98. Editor de condición............................................................................................... 184 Figura 99. Explorador de objetos. .......................................................................................... 185 Figura 100. Selección de atributo. .......................................................................................... 185 Figura 101. Selección representación de atributo. ................................................................... 186 Figura 102. Selección de operador. ........................................................................................ 186 Figura 103. Nombre del elemento de grupo personalizado. ...................................................... 187 Figura 104. Guardado de Grupo Personalizado. ...................................................................... 187 Figura 105. Adición de elementos de grupo personalizado. ..................................................... 188 Figura 106. Lista de elementos de atributo disponibles. ........................................................... 188 Figura 107. Selección de atributo para el nivel de salida. ......................................................... 189 115 Figura 108. Filtrado según valor de indicador. ........................................................................ 190 Figura 109. Agregar nueva condición al elemento de grupo. .................................................... 190 Figura 110. Selección de operador de conjunto. ...................................................................... 191 Figura 111. Editor de formato de elementos de grupo personalizado. ....................................... 191 Figura 112. Áreas del Editor de Formato. ............................................................................... 192 Figura 113. Análisis de Visual Insight.................................................................................... 193 Figura 114. Directorios de informes. ...................................................................................... 195 Figura 115. Selección de informe para análisis. ...................................................................... 195 Figura 116. Selección de visualización. .................................................................................. 196 Figura 117. Editor de Análisis. .............................................................................................. 196 Figura 118. Áreas del Editor de Análisis. ............................................................................... 197 Figura 119. Barra de herramientas del Editor de Análisis. ....................................................... 197 Figura 120. Múltiples áreas de visualización. ......................................................................... 198 Figura 121. Creación y editado de análisis en Visual Insight. ................................................... 199 Figura 122. Adición de atributos e indicadores a la visualización. ............................................ 199 Figura 123. Modificación de filtros. ....................................................................................... 200 Figura 124. Selección de plantillas de tablero. ........................................................................ 202 Figura 125. Editor de documentos. ........................................................................................ 202 116 LISTA DE TABLAS Tabla 1. Filtros de Informe vs Filtros de Visualización............................................................ 146 Tabla 2. Tipos de visualización de Visual Insight.................................................................... 194 117 Objeto del documento El objeto del presente documento es la realización de un manual que sirva de guía a los usuarios para la utilización de la herramienta de Explotación de Datos MicroStrategy. Este documento está enfocado directamente a que el usuario pueda trabajar con la herramienta y pretende servir de guía paso a paso en las diferentes fases de la explotación de información: Creación de Informes, Filtros, Selecciones Dinámicas, Grupos Personalizados y de Documentos, ya que se comentan los conceptos clave para posteriormente, mediante ejemplos, explicar el uso. 118 Alcance del documento El alcance del manual de usuario cubre: Creación de informes. Creación de filtros, selecciones dinámicas y grupos personalizados. Análisis mediante Visual Insight. Generación de Tableros. 119 Guía para la explotación de datos mediante Microstrategy El presente manual servirá de apoyo y guía para los usuarios a la hora de enfrentarse a la realización de un análisis mediante la herramienta MicroStrategy. La funcionalidad cubierta en el presente manual estará alineada con los objetivos del presente proyecto. Dentro del correspondiente proyecto aparecerá la página de bienvenida de la aplicación (Figura 1). Desde está interfaz se tendrá acceso a las distintas funcionalidades: - Creación de informes - Crear selección dinámica - Crear grupo personalizado - Crear filtros - Crear documento Figura 1. Pantalla de Bienvenida. 120 CREACIÓN DE INFORMES Los informes son el centro de los análisis realizados dentro de un sistema de Business Intelligence. Permiten a los usuarios recopilar información del negocio mediante el análisis de los datos. Normalmente un informe está compuesto de una plantilla (template) más determinados criterios de filtrado (Figura 2). Figura 2. Estructura de un informe. La plantilla especifica que información del Data Warehouse se desea mostrar y cómo se visualizará dicha información. El filtro del informe especifica que condición deberán cumplir los datos para que éstos se incluyan en el informe. 1.1.1 Editor de Informes Para crear un informe se deberá acceder al editor disponible para tal efecto. Dentro de la página de bienvenida existe un acceso directo al editor de informes (Figura 3). 121 Figura 3. Acceso Editor de informes. Para acceder al editor de informes hacer click sobre el acceso directo. A continuación, aparecerán los distintos tipos de editores de informe. Se seleccionará la opción informe en blanco (Figura 4). Se recomienda la utilización de esta opción ya que es la que permite mayor grado de libertad a la hora de crear un informe. Figura 4. Editores de informe. A continuación aparecerá la interfaz de creación de informes (Figura 5). Figura 5. Interfaz editor de informes. 122 El editor de informes se utiliza tanto para crear informes como para poder modificar los informes existentes. Dentro de la interfaz se distinguen 3 áreas principales (Figura 6): - Área de exploración de objetos - Área de filtros - Área de plantilla de informe o layout. Figura 6. Áreas del editor de informes. A continuación se detallan las distintas áreas: - Explorador de objetos: Dentro del explorador de objetos habrá disponibles la pestaña de objetos de informe, todos los objetos, objetos MDX, notas e informes relacionados. Cada uno de estos componentes realizan las siguientes funciones: o Objetos del informe: Muestra al usuario un resumen de todos los objetos que se han incluido sobre la plantilla del informe, aunque estos objetos inicialmente no se hayan utilizado en la vista del informe. La consulta que genera el motor de MicroStrategy incluye todos los objetos que existen en esta ventada y no sólo los objetos que se hayan desplegado cuando se ejecuta el informe. Por tanto, es importante a la hora de elaborar un informe no tener gran cantidad de elementos en la ventana “Objetos del Informe” ya que penalizaría considerablemente el rendimiento. o Todos los Objetos: Se trata de una estructura en forma de árbol que permite acceder a los distintos elementos disponibles en la plataforma de explotación (Figura 7). 123 Figura 7. Pestaña todos los objetos. Los principales objetos que se utilizarán para la creación de los informes serán los atributos y los indicadores. Los indicadores serán las distintas medidas disponibles dentro del sistema de explotación (Ej.: Gasto de los pedidos, Importes, Demoras, etc…) mientras que los atributos serán las distintas variables que permiten categorizar los indicadores (Ej: Plataforma, Genérico de Centro, Año, etc…). Dentro del componente “Todos los objetos” están disponibles accesos directos a los indicadores y atributos de la plataforma de Explotación. Para acceder a los atributos e indicadores basta con realizar click sobre los accesos directos disponibles a tal efecto. Para facilitar la búsqueda de los distintos objetos se ha creado una carpeta por cada una de las entidades disponibles (Figura 8). Se puede navegar a través de las diferentes carpetas de la misma forma que se navega a través del explorador de carpetas de Windows. Existe también disponible un acceso directo a “Mis Objetos Personales”. Dentro de “Mis Objetos Personales” están disponibles los distintos objetos propios creados por cada uno de los usuarios del sistema. 124 Figura 8. Explorador de carpetas. 1.1.2 Creación, guardado y visualización de informes. Siempre que se crea un informe tal y como se comentó anteriormente, lo que se crea es una plantilla y un filtro de informe. En los casos en los que no se especifique ningún filtro la sección de filtros del informe seguirá existiendo y se creará en este caso un filtro vacío. Plantilla: Una plantilla especifica que información se recibe del Data Warehouse y como se visualiza esa información dentro del informe. Para definir la plantilla, se pueden utilizar dos métodos: - Arrastrar los objetos desde el visualizador de objetos hasta la plantilla de informe. Una línea amarilla indica que el objeto se puede soltar en esa posición. - Realizar click con el botón derecho del ratón y seleccionar “Agregar a cuadrícula”. Esta operación te agrega el objeto como fila del informe. Haciendo click derecho sobre el atributo y seleccionando la opción “Mover” es posible conmutar de filas a columnas y viceversa. El hecho de mover un atributos a columnas es conocido como pivotar o cross-tab. También existe la posibilidad de mover el atributo como eje de paginación. Esto te permite incluir dentro del informe un selector sobre ese atributo (Figura 9). 125 Figura 9. Mover a columnas o eje de paginación. Si se selecciona dentro del ‘Explorador de objetos’ la pestaña ‘Objetos de informe’ se visualizarán los distintos objetos disponibles en el informe (Figura 10). Figura 10. Plantilla con atributo categoría. Realizando click sobre cada uno de los atributos disponibles en los ‘Objetos de informe’ aparecerán las distintas representaciones del atributo en cuestión. Las representaciones son las diferentes formas de visualizar un mismo atributo. Ej.: Suponiendo que existe un atributo mes. Para el mismo atributo es posible tener diferentes representaciones. Se puede tener una representación para el mes en formato corto (Jul-2013), una en formato largo (Julio-2013), una representación para el ID (072013) y así sucesivamente. Realizar click con el botón derecho sobre el atributo, permite seleccionar la representación que se quiere visualizar cuando se ejecute el informe (Figura 11). 126 Figura 11. Selección de representaciones de un atributo. Filtro de Informe: Un filtro establece las condiciones que deben cumplir los datos para que sean incluidos en los resultados de un informe. Es posible crear objetos de tipo filtro de forma independiente mediante el editor de filtros o bien crearlos directamente en el informe (Ver Apartado 4.3). Si se crean como objetos independientes estos filtros podrán ser reutilizados por otros informes. Las opciones de guardado, ejecución del informe y cambiar la vista del informe (modo tabla, modo gráfico y modo tabla/gráfico) están disponibles en la barra de herramientas superior (Figura 12). Figura 12. Barra de herramientas modo diseño. A continuación se detallan cada una de las opciones disponibles en la barra de herramientas: - Ejecutar informe : Realizar click sobre el icono permite ejecutar el informe para poder visualizar los resultados. - Cancelar : A través de esta opción es posible cancelar la edición de un informe. - Guardar como : Con esta opción se puede almacenar el informe que se está visualizando en ese momento, con los cambios y parametros que tenga aplicado. Se deberá asignar un nombre al informe y guardarlo en “Mis informes (ver Figura 13). En el caso de que se quiera compartir el informe seleccionar guardar en “Informes Compartidos”. - Filtros de Informe - Modo cuadricula tabla. - Modo gráfico gráfico. - Modo gráfico/tabla tabla y gráfico. : Muestra los filtros que tiene aplicado el informe. : Esta opción permite visualizar la salida del informe en vista modo : Esta opción permite visualizar la salida del informe en vista modo : Esta opción permite visualizar la salida del informe en vista modo Nota: Cuando se selecciona la vista en modo gráfico o la vista en modo gráfico/tabla, se habilitan en la barra de herramientas los iconos que permiten al usuario seleccionar el tipo y subtipo de gráfico que se quiere visualizar. 127 Figura 13. Guardar informe. Cuando se ejecuta un informe se habilitan una serie de pestañas que permiten configurar el informe (ver Figura 14). Las pestañas disponibles son: - Inicio: Ofrece la posibilidad de guardar el informe, exportarlo, añadirlo al historial, imprimirlo, etc. - Herramientas: Permite ocultar o mostrar las distintas herramientas disponibles y configurar las propiedades del informe. - Datos: Permite configurar las distintas propiedades relacionadas con los datos del informe (ordenación, navegación, filtro de visualización, intercambiar filas y columnas, mostrar totales, etc.) - Cuadricula: Esta pestaña aparece cuando se selecciona el modo de vista tabla o tabla/gráfico. - Gráfico: Esta pestaña aparece cuando se selecciona el modo de vista gráfica o tabla/gráfico. - Formato: Permite establecer las propiedades de formato de la tabla y el gráfico. 128 Figura 14. Pestañas disponibles tras ejecutar informe. Cada una de las pestañas anteriores lleva asociada una barra de herramientas que permite acceder a las distintas opciones. A continuación se detallan cada una de las barras de herramientas: Pestaña Inicio: Figura 15. Barra de herramientas pestaña inicio. La pestaña inicio dispone de una barra de herramientas (ver Figura 15) con las siguientes opciones: - Guardar como : Con esta opción se puede almacenar el informe que se está visualizando en ese momento, con los cambios y parametros que tenga aplicado. Se deberá asignar un nombre al informe y guardarlo en ‘Mis informes’ (ver Figura 13). En el caso de que se quiera compartir el informe seleccionar guardar en ‘Informes Compartidos’. - Deshacer - Rehacer - Diseño - Cuadrícula - Gráfico - Cuadrícula y gráfico la vez. - Agregar a Historial : Suscribe el informe a la lista de historial. Si esta opción no está disponible, significa que el informe ya ha sido añadido. - Imprimir : Permite acceder a la ventana de impresión, donde se puede configurar la impresión del informe. : Permite deshacer modificaciones realizados en el informe. : Permite rehacer modificaciones deshechas en el informe. : Permite volver a la ventana principal de diseño. : Permite acceder al modo de visualización cuadrícula del informe. : Permite acceder al modo de visualización gráfico del informe. : Permite acceder al modo de visualización gráfico y cuadrícula a 129 - Planificar entrega a lista de historiales : Se accede a la ventana de ‘Suscripción de lista de historial’, esta permite configurar la entrega planificada de historiales. Se debe guardar el informe en cuestión previamente. - Exportar : Permite acceder a la ventana de exportación, donde se podrá configurar el formato del informe a exportar. - PDF - Modo de pantalla completa modo normal. : Permite acceder a la ventana de exportación en formato PDF. : Permite permutar entre el modo pantalla completa y el Pestaña Herramientas: Figura 16. Barra de herramientas pestaña herramientas La pestaña herramientas dispone de una barra de herramientas (ver Figura 16) con las siguientes opciones: - Nuevo : Permite acceder a la ventana de creación de nuevo informe. Crear documento : Permite convertir el informe en cuestión en un documento. Se pedirá guardar el informe, tras esto se podrá regresar al informe original o ejecutar el informe recién creado. - Guardar como : Con esta opción se puede almacenar el informe que se está visualizando en ese momento, con los cambios y parametros que tenga aplicado. Se deberá asignar un nombre al informe y guardarlo en ‘Mis informes’ (ver Figura 13). En el caso de que se quiera compartir el informe seleccionar guardar en ‘Informes Compartidos’. - Deshacer - Rehacer - Diseño - Cuadrícula - Gráfico - Cuadrícula y gráfico la vez. - Objetos de informe - Todos los objetos - Notas : Extiende/contrae la ventana ‘Notas’ en el lateral. Será necesario que se guarde el informe para poder acceder a esta funcionalidad, tras guardar el informe se deberá seleccionar la opción ‘ejecutar el informe recién creado’. - Informes relacionados lateral. - Eje de paginación : Extiende/contrae la ventana ‘Eje de paginación’ sobre la ventana de navegación del informe. - Filtro de visualización : Extiende/contrae la ventana ‘Filtro de visualización’ sobre la ventana de navegación del informe. Permite agregar/modificar/borrar condiciones de filtrado. : Permite deshacer modificaciones realizados en el informe. : Permite rehacer modificaciones deshechas en el informe. : Permite volver a la ventana principal de diseño. : Permite acceder al modo de visualización cuadrícula del informe. : Permite acceder al modo de visualización gráfico del informe. : Permite acceder al modo de visualización gráfico y cuadrícula a : Extiende/contrae la ventana ‘Objetos de informe’ en el lateral. : Extiende/contrae la ventana ‘Todos los objetos’ en el lateral. : Extiende/contrae la ventana ‘Informes relacionados’ en el 130 - Detalles del informe : Extiende/contrae la ventana ‘Detalles del informe’. Permite visualizar en detalle las características, en cuanto a filtrado, del informe en cuestión. - Mostrar botones para cambiar la situación de los objetos : Habilita/deshabilita los botones para poder modificar la situación de los objetos del informe. - Mostrar botones para ordenar : Habilita/deshabilita los botones que permiten modificar la ordenación de los datos de las columnas. - Opciones del informe : Abre la ventana ‘Opciones del informe’, donde podemos modificar la configuración del informe. Pestaña datos: Figura 17. Barra de herramientas pestaña datos La pestaña datos dispone de una barra de herramientas (ver Figura 17) con las siguientes opciones: - Guardar como : Con esta opción se puede almacenar el informe que se está visualizando en ese momento, con los cambios y parametros que tenga aplicado. Se deberá asignar un nombre al informe y guardarlo en ‘Mis informes’ (ver Figura 13). En el caso de que se quiera compartir el informe seleccionar guardar en ‘Informes Compartidos’. - Deshacer - Rehacer - Diseño - Cuadrícula - Gráfico - Cuadrícula y gráfico la vez. - Filtro de visualización : Extiende/contrae la ventana ‘Filtro de visualización’ sobre la ventana de navegación del informe. Permite agregar/modificar/borrar condiciones de filtrado. - Mostrar botones para ordenar : Habilita/deshabilita los botones que permiten modificar la ordenación de los datos de las columnas. - Navegación : Extiende/contrae las opciones para configurar la navegación. Actualizar : Actualiza el informe. - Intercambiar filas y columnas representación del informe. - Insertar nuevo indicador : Permite la inserción de un nuevo indicador al informe actual. En la ventana emergente se podrán realizar diferentes operaciones. - Cambiar de nombre/editar objetos del informe. - Editar representaciones de atributo : Permite seleccionar las representaciones de los atributos que se mostrarán en el informe. Cambiar los nombres de las representaciones de atributos : Permite mostrar/ocultar el nombre de las diferentes representaciones de atributos. - : Permite deshacer modificaciones realizados en el informe. : Permite rehacer modificaciones deshechas en el informe. : Permite volver a la ventana principal de diseño. : Permite acceder al modo de visualización cuadrícula del informe. : Permite acceder al modo de visualización gráfico del informe. Mostrar totales : Permite acceder al modo de visualización gráfico y cuadrícula a : Permite el intercambio entre filas y columnas en la : Permite acceder a la ventana de edición de objetos : Permite ocultar/mostrar el total de los indicadores. 131 - Modificar totales : Permite acceder al editor de subtotales, donde se podrán configurar y activar diferentes funciones de subtotales. - Umbrales rápidos : Permite seleccionar de una lista los diferentes estilos de umbrales. Se debe seleccionar previamente un indicador. - Cambiar umbrales : Permite activar/desactivar los umbrales configurados. Editor de umbrales visuales : Abre el editor de umbrales visuales. Pestaña Cuadrícula: Figura 18. Barra de herramientas pestaña cuadrícula. La pestaña cuadrícula dispone de una barra de herramientas (ver Figura 18) con las siguientes opciones: - Guardar como : Con esta opción se puede almacenar el informe que se está visualizando en ese momento, con los cambios y parametros que tenga aplicado. Se deberá asignar un nombre al informe y guardarlo en ‘Mis informes’ (ver Figura 13). En el caso de que se quiera compartir el informe seleccionar guardar en ‘Informes Compartidos’. - Deshacer - Rehacer - Diseño - Cuadrícula - Gráfico - Cuadrícula y gráfico la vez. - Selector de formato de informe estilo del informe. - Rangos - Mostrar indentado - Combinar encabezados de columnas : Activa/desactiva la combinación automática de los encabezados de columnas que estén repetidos. - Combinar encabezados de filas : Activa/desactiva la combinación automática de todos los encabezados de filas que contengan el mismo valor - Bloquear los encabezados de filas - Bloquear los encabezados de columnas - Ajustar al contenido automáticamente : Ajusta el informe al contenido del mismo. - Ajustar a la ventana automáticamente : Ajusta el informe a la ventana. : Permite deshacer modificaciones realizados en el informe. : Permite rehacer modificaciones deshechas en el informe. : Permite volver a la ventana principal de diseño. : Permite acceder al modo de visualización cuadrícula del informe. : Permite acceder al modo de visualización gráfico del informe. : Permite acceder al modo de visualización gráfico y cuadrícula a : Permite seleccionar de una lista de plantillas el : Activa/desactiva la diferenciación visual entre filas. : Permite extraer/contraer el modo indentado. : Permite fijar los encabezados de las filas. : Permite fijar los encabezados de las columnas. 132 Pestaña Gráfico: Figura 19. Barra de herramientas pestaña gráfico. La pestaña gráfico dispone de una barra de herramientas (ver Figura 19) con las siguientes opciones: - Guardar como : Con esta opción se puede almacenar el informe que se está visualizando en ese momento, con los cambios y parametros que tenga aplicado. Se deberá asignar un nombre al informe y guardarlo en ‘Mis informes’ (ver Figura 13). En el caso de que se quiera compartir el informe seleccionar guardar en ‘Informes Compartidos’. - Deshacer - Rehacer - Diseño - Cuadrícula - Gráfico - Cuadrícula y gráfico : Permite acceder al modo de visualización gráfico y cuadrícula a la vez. Estilos de gráfico : Permite seleccionar el estilo del gráfico. Subtipo de gráfico : Permite seleccionar el subtipo de gráfico. Leyenda : Permite visualizar la leyenda del gráfico. Valores de datos : Representa los valores de los datos. Series por fila : Representa las filas como eje Y (series). Series por columna : Representa las columnas como eje Y (series). Organización automática : Número de categorías : Limita el número de representaciones simultáneas en el eje X. Numero de series : Limita el número de representaciones simultáneas en el eje Y. Aplicar : Aplica los cambios efectuados en la representación del gráfico. - : Permite deshacer modificaciones realizados en el informe. : Permite rehacer modificaciones deshechas en el informe. : Permite volver a la ventana principal de diseño. : Permite acceder al modo de visualización cuadrícula del informe. : Permite acceder al modo de visualización gráfico del informe. Pestaña Formato: Figura 20. Barra de herramientas pestaña formato. La pestaña formato dispone de una barra de herramientas (ver Figura 20) con las siguientes opciones: - Guardar como : Con esta opción se puede almacenar el informe que se está visualizando en ese momento, con los cambios y parametros que tenga aplicado. Se deberá asignar un nombre al informe y guardarlo en ‘Mis informes’ (ver Figura 13). En el caso de que se quiera compartir el informe seleccionar guardar en ‘Informes Compartidos’. - Deshacer : Permite deshacer modificaciones realizados en el informe. 133 - Rehacer - Diseño - Cuadrícula - Gráfico - Cuadrícula y gráfico : Permite acceder al modo de visualización gráfico y cuadrícula a la vez. : Permite seleccionar el indicador al cual se modificará el formato. : Permite seleccionar la sección del indicador a la cual se dará formato. Estilo de moneda : Activa la representación del tipo de moneda. Estilo de porcentaje : Activa la representación del porcentaje. Estilo de coma : Activa el separador de unidades. Aumentar decimales : Aumenta el número de decimales en una unidad. Disminuir decimales : Disminuye el número de decimales en una unidad. Formato de cuadrícula avanzado : Abre la ventana de formato de cuadrícula avanzado. Formato de gráfico avanzado : Abre la ventana de formato de gráfico avanzado. - 1.1.3 : Permite rehacer modificaciones deshechas en el informe. : Permite volver a la ventana principal de diseño. : Permite acceder al modo de visualización cuadrícula del informe. : Permite acceder al modo de visualización gráfico del informe. Manipulación de los datos del informe En este apartado se cubrirán las distintas manipulaciones que permiten a los usuarios realizar cambios sobre la forma en la que se presentan los datos en el informe. Las principales manipulaciones de datos son las siguientes: - Drilling - Paginación - Pivotar - Subtotales - Ordenación 1.1.3.1 Drilling La opción de Drilling o navegación permite a los usuarios ver los datos en niveles diferentes a los que se muestran en el informe originalmente (ver Figura 21). Figura 21. Realización drilling. Se pueden realizar dos tipos de drilling: 134 - Drilling Down o navegación hacia abajo: Permite a los usuarios acceder a los datos que se encuentran en un nivel inferior de la jerarquía. Ej.: Suponiendo que se tiene un informe de ventas por año. Es posible realizar un drill down para analizar las ventas a nivel de mes. - Drilling Up o navegación hacia arriba: Es el caso opuesto al drill down. Permite a los usuarios visualizar los datos que se encuentran en un nivel superior en la jerarquía. Ej.: Suponiendo que se tiene un informe de ventas por mes. Es posible realizar un drill up para analizar las ventas a nivel de año. Por defecto, cuando se realiza un drilling sobre un informe, el informe original permanece abierto, y el informe que muestra los datos en el nuevo nivel se muestran en otra ventana. Métodos de Drilling: Se puede realizar un Drilling mediante los siguientes métodos: - Realizando click sobre el elemento del atributo en cuestión. Esta operación realiza un Drill Down hacia el siguiente nivel de la jerarquía. Cuando se posiciona el ratón sobre el elemento del atributo aparece un mensaje indicando hacia donde se navega. - Realizando click con el botón derecho del ratón sobre la cabecera del atributo o sobre algún valor del atributo en cuestión, y seleccionando la opción navegar. De esta forma, se permite seleccionar hacia qué nivel se quiere navegar (ver Figura 22). Figura 22. Drilling click derecho del ratón. - Otra forma de realizar Drilling es seleccionando el botón de navegación ( ) de la barra de herramientas. Mediante esta opción se habilita un editor que permite seleccionar hacia donde queremos navegar (permite elegir entre atributos de la misma jerarquía o diferente jerarquía), y si mantener el padre de la navegación (se trata del elemento desde el que hemos hecho drilling) (ver Figura 23). 135 Figura 23. Editor de navegación. 1.1.3.2 Paginación La paginación permite a los usuarios seleccionar y visualizar un subconjunto de los datos disponibles en el informe. Esta característica es muy útil cuando existen muchos datos y es necesario mover la barra de desplazamiento para visualizarlos. Al paginar se habilita un selector que permite seleccionar los distintos valores del atributo que se ha paginado (Ver Figura 24). Figura 24. Informe paginado por categoría. Para paginar realizar click con el botón derecho del ratón sobre la cabecera del atributo que se desea paginar y seleccionar la opción ‘Mover’. Dentro de ‘Mover’ seleccionar la opción ‘Hacia el eje de Paginación’ (Figura 25). 136 Figura 25. Paginación. Otra opción para paginar es arrastrar el atributo en cuestión hacia el eje de paginación. Cuando se posiciona el ratón sobre el eje de paginación aparecerá una línea amarilla indicando que es una zona válida para soltar el atributo (ver Figura 26). Figura 26. Eje de paginación. Nota: Es posible añadir varios atributos sobre el eje de paginación. 1.1.3.3 Pivotar Las opciones de pivotar los datos permiten al usuario reordenar las columnas y filas en un informe. De esta forma, es posible visualizar los datos desde diferentes perspectivas. Es posible realizar las siguientes acciones: - Mover objetos desde las filas a las columnas y viceversa. 137 - Cambiar el orden de los objetos tanto de las cabeceras de filas como las cabeceras de las columnas. Mover objetos desde las cabeceras de filas o cabeceras de columnas hacia el eje de paginación. Conmutar filas o columnas. A continuación se indican los diferentes métodos para pivotar los datos: - Arrastrar los objetos y moverlos alrededor de la plantilla del informe. Una marca amarilla indica que es una posición valida en la que poder soltar el objeto. - Realizar click con el botón derecho del ratón y apuntar a la opción “Mover”, y seleccionar una de las opciones disponibles del menú (ver Figura 27). Figura 27. Opciones del menú ‘Mover’. Existe la opción de eliminar un atributo o indicador de la cuadrícula. Esta opción no elimina el objeto del cuando de objetos disponibles en el informe sino que exclusivamente lo oculta en la visualización. Importante: No confundir eliminar de la cuadricula con la opción eliminar del informe. Si se elimina un objeto del informe ese objeto dejaría de estar disponible. Para eliminar un objeto de la cuadrícula realizar click con el botón derecho del ratón sobre la cabecera del objeto que se desea eliminar y seleccionar la opción “Quitar de la cuadrícula”. Los objetos que se han eliminado de la cuadrícula aparecerán dentro de la ventana objetos del informe marcados en negrita (ver Figura 28). 138 Figura 28. Objetos excluidos de la cuadrícula. 1.1.3.4 Subtotales Los subtotales reflejan agregaciones en los niveles de los atributos seleccionados, y pueden aplicarse de forma dinámica a cualquier informe. Hay varios tipos de subtotales disponibles como por ejemplo cuenta, mínimo, máximo, promedio, etc. Para añadir subtotales hay que hacer click en el icono de la barra de herramientas, que permite configurar las distintas opciones disponibles para los subtotales (ver Figura 29). 139 Figura 29. Opciones de configuración ‘Subtotales’. Para visualizar los subtotales que previamente se han configurado en el informe se debe seleccionar el icono disponible en la barra de herramientas (ver Figura 30). Figura 30. Informe con ‘Subtotales’. 1.1.3.5 Ordenación Los criterios de ordenación permiten a los usuarios especificar el orden, ascendente o descendente, en el cual se muestran los datos de una determinada fila o columna. Es posible ordenar basándose en cualquiera de los objetos disponibles en la plantilla. A continuación se detallan los distintos métodos de ordenación de los datos. - Ordenación de tipo rápida: Permite al usuario seleccionar una columna o fila, y ordenarla en sentido ascendente o descendente. Para realizar este tipo de ordenación realizar click con el botón derecho del ratón sobre la cabecera del objeto que se pretende ordenar, apuntar en la opción “Ordenar” y seleccionar ascendente o descendente (ver Figura 31). 140 Figura 31. Ordenación rápida. - Ordenación Avanzada: La ordenación avanzada permite a los usuarios configurar ordenaciones múltiples. Es posible seleccionar los atributos y métricas que se desean utilizar para la ordenación de los datos y el orden en el cual se quieren ordenar. Para realizar una ordenación avanzada pinchar en el icono herramientas (ver Figura 32). disponible en la barra de Figura 32. Ventana de ordenación avanzada. 1.1.4 Manipulación del estilo de un informe En este apartado se cubrirá la manipulación del estilo, permitiendo determinar el formato que tendrá el informe. Se puede modificar la apariencia de un informe de diversas formas. Se distinguen principalmente las siguientes manipulaciones de estilo: - Umbrales - Fijar encabezado de filas y columnas - Formato gráfico básico 1.1.4.1 Umbrales Un umbral, bajo el contexto de la manipulación de estilos, se puede definir como un valor de un indicador por el cual se condiciona el formato. El desarrollador de informes puede personalizar el 141 valor del umbral, para así representar con un formato específico los criterios de su elección (Figura 33). Figura 33. Informe con umbrales. Para poder aplicar umbrales a un informe determinado, en primer lugar se deberá ejecutar dicho informe. A continuación, se accederá a la pestaña ‘Datos’. En la barra de herramientas de datos, se dispone de 3 botones encargados de gestionar la umbralización: - Umbrales rápidos: Permite seleccionar estilos de umbralización ya definidos de una lista desplegable. Para abrir la lista desplegable y aplicar el umbral, será necesario haber seleccionado previamente un indicador haciendo click sobre este (Figura 34). - C ambiar umbrales: Permite activar/desactivar los umbrales configurados. Cuando se selecciona un umbral rápido o se modifica el estilo desde el editor de umbrales, esta casilla se activa automáticamente. - Editor de umbrales visuales: Al hacer click en el botón de ‘Editor de umbrales visuales’ se abrirá la ventana de edición de umbrales (Figura 35). Desde este editor se podrá seleccionar el indicador a umbralizar desde ‘Umbrales para:’. A continuación del campo ‘Propiedades’, se podrá hacer click y seleccionar el operador a utilizar para establecer el umbral. En la barra deslizante, se podrá desplazar el separador de bandas (umbral) creando diferentes tramos. Al hacer click en este separador se podrá especificar el valor del mismo. Además, haciendo click en los diferentes tramos, aparecerá una serie de opciones que permiten realizar diferentes acciones como: dar formato al tramo, borrar el formato, agregar un nuevo umbral o eliminar el umbral. Figura 34. Umbrales rápidos. 142 Figura 35. Editor de umbrales de visualización. Al hacer click en el botón ‘’ se abrirá la ventana de formato de umbral (Figura 36), con diferentes opciones configurables. Figura 36. Formato de umbral de visualización. 1.1.4.2 Fijar encabezado de filas y columnas MicroStrategy permite fijar los encabezados de filas y columnas en un informe, así mientras se están visualizando los resultados del informe, es posible desplazarse horizontal y verticalmente sin perder de vista los encabezados de las filas y columnas. Esta propiedad es particularmente ventajosa cuando se quiere ver información que devuelve más filas o columnas de las que pueden ser visualizadas a la vez. Para poder fijar los encabezados de filas o columnas, será necesario en primer lugar ejecutar el informe deseado. Una vez realizado esto, hay dos formas para poder fijar los encabezados: - Herramientas: Accedemos a la pestaña ‘Herramientas’. Posteriormente se tendrá que hacer click en el botón ‘Opciones del Informe’ de la barra de herramientas. Se abrirá una ventana emergente con diferentes opciones de formato, en la sección de ‘Encabezados’ habrá que marcar el campo ‘Bloquear’ de interés (Figura 37). 143 Figura 37. Fijar encabezados filas y columnas desde ‘Herramientas’. - Cuadrícula: Accedemos a la pestaña ‘Cuadrícula’. Desde la barra de herramientas de cuadrícula (Figura 38), existen dos botones que permitirán fijar/liberar los encabezados de filas ( ) y columnas ( ). Figura 38. Fijar encabezados y columnas desde ‘Cuadrícula’. 1.1.4.3 Formato gráfico básico Hay numerosas propiedades de gráfico que permiten personalizar el aspecto del informe modo gráfico. Para poder personalizar el gráfico de un informe, en primer lugar habrá que seleccionar el modo de visualización gráfico o cuadrícula/gráfico. En este modo de visualización, se podrá personalizar el correspondiente gráfico desde: 144 - Barra de herramientas de la pestaña ‘Gráfico’: Como se explicó con anterioridad en el apartado 4.2.1, en la pestaña ‘Gráfico’ existen diferentes botones que nos permiten configurar el informe (Figura 39). Figura 39. Personalización de gráfico desde barra de herramientas. - Opciones de formato de gráfico: Haciendo click derecho sobre el gráfico, se podrá seleccionar la opción ‘Formato’. Se abrirá una ventana con las diferentes opciones disponibles (Figura 40). Figura 40. Formato de un gráfico. 145 CREACIÓN DE FILTROS Un filtro de informe especifica las condiciones que los datos han de cumplir, para ser incluidos en los resultados del informe en cuestión. Otra forma de definir un filtro de informe, es resaltando su equivalencia a una clausula ‘WHERE’ de la sintaxis SQL. En el siguiente diagrama (Figura 41), se puede apreciar el filtrado de los datos según tres condiciones diferentes: Figura 41. Diagrama ejemplo de filtrado. Se pueden agrupar los filtros en dos categorías: - Filtros de informe: Permiten filtrar objetos aunque no formen parte de la plantilla del informe. El filtro de informe es creado como parte del informe, además es guardado junto a la definición del mismo. Se pueden crear tanto desde el editor de informe como desde el editor de filtros. - Filtros de visualización: Permiten filtrar objetos que existan en la ventana de Objetos de Informe (no se exige que estén o no incluidos en la plantilla). Los filtros de visualización no afectan al código SQL generado al crear el informe. Estos filtros se aplican después de que los datos son devueltos por el almacén de datos, por tanto, sólo un subgrupo de resultados aparece en la vista del informe. Se pueden crear desde la ventana de Filtros de Visualización. A continuación, podemos ver una tabla con las principales diferencias entre las dos categorías de filtros: Tipo de Filtro Filtros de informe Filtros de visualización SQL Generado Cada vez que se realiza un cambio (suele modificar la cláusula WHERE del código SQL) Ninguno Referencia Cualquier objeto, forme o no parte del informe Solo objetos en la ventana de Objetos de Informe Tabla 1. Filtros de Informe vs Filtros de Visualización 146 Aplicación Antes de la generación del código SQL enviado al data warehouse Después de que la información es devuelta por el data warehouse 1.1.5 Tipos de Filtros de Informe Como se ha comentado anteriormente, a través de los Filtros de Informe, o usualmente llamados simplemente filtros, es posible establecer las condiciones que deben cumplir los datos, para que así puedan ser incluidos en los resultados del informe. Estos filtros pueden crearse desde el editor de informes (ver apartado 4.3.3), siendo un filtro independiente que se podrá utilizar en diferentes informes, o dentro de un informe (ver apartado 4.3.4), formando parte del propio informe. Los principales tipos de Filtros de Informe que se pueden crear, son los siguientes: - Calificación de atributo: Permiten filtrar por una representación del atributo o por los elementos de una lista del atributo en cuestión. - Calificación de conjunto: Permiten crear un subconjunto de atributos, en función del valor de un indicador o de la relación que existe entre los atributos. 1.1.5.1 Calificación de atributo La calificación de atributo limita los datos relacionados con atributos en el informe. Dentro de este tipo de filtros, existen las siguientes calificaciones: - Calificación de representación de atributo: Filtra datos teniendo en cuenta la representación del atributo. Por ejemplo, filtrando los valores del atributo ‘apellido’ que comienzan por la letra ‘R’. - Calificación de lista de elementos de atributo: Filtra datos teniendo en cuenta los elementos de un atributo, es decir, una lista de valores. Por ejemplo, filtrando los valores del atributo ‘ciudad’ que pertenezcan a la lista de elementos ‘Sevilla’, ‘Málaga’ y ‘Cádiz’. - Calificación de atributo a atributo: Filtra datos comparando la representación de atributo de dos atributos. Por ejemplo, filtrando los clientes cuya ‘fecha de primer pedido’ sea igual a ‘fecha de último pedido’. 1.1.5.2 Calificación de conjunto La calificación de conjunto limita los datos según el valor, categoría o porcentaje de un indicador, al comparar los valores de dos indicadores o según las relaciones entre los atributos del informe. Dentro de este tipo de filtros, existen las siguientes calificaciones: - Calificación de conjunto de indicadores: Filtra datos relacionados con un conjunto de atributos específicos, en función de los indicadores asociados a tales atributos. Por ejemplo, filtrando datos de venta que estén por debajo de un valor de recuento de inventario especificados. - Calificación de indicador a indicador: Filtra datos comparando los valores de dos indicadores. Por ejemplo, filtrando los datos en los cuales ‘ingresos actuales’ sean mayores que ‘ingresos año pasado’. 147 1.1.6 Operadores de conjunto Cuando un filtro de informe tiene múltiples condiciones, estas son combinadas mediante operadores de conjunto. Los operadores de conjunto gobiernan las interacciones entre las diferentes condiciones de filtrado. Los operadores de conjunto son: - AND (Y) - OR (O) - OR NOT (O NO) - AND NOT (Y NO) Por defecto, el operador de conjunto insertado entre las condiciones de filtrado es AND. A continuación, se puede apreciar gráficamente la funcionalidad de cada operador (Figura 42). Hay que tener en cuenta, que estos ejemplos se realizan para unir dos condiciones de filtrado: año=2012 OPERADOR región=’noreste’ (en amarillo se aprecia el conjunto de resultados obtenido). Operador AND Operador OR Operador AND NOT Operador OR NOT Figura 42. Ejemplo de Operadores de Conjunto. 1.1.7 Creación, guardado y utilización de filtros independientes Como se ha comentado con anterioridad, existe la posibilidad de crear filtros independientes en un proyecto de MicroStrategy, los cuales pueden ser utilizados en diferentes informes. A continuación, se explicará cómo poder crear estos filtros y la utilización de los mismos. 1.1.7.1 Editor de Filtros Para crear un filtro en el proyecto, filtro independiente, el cual se podrá utilizar en diferentes informes, se debe acceder al editor disponible para tal efecto. El editor de filtros se utiliza para crear filtros de informe independientes, no siendo posible la edición de un filtro ya creado. De sde 148 esta interfaz es posible crear filtros tanto de tipología ‘calificaciones de atributos’, como de tipo ‘calificaciones de conjunto’. Dentro de la página de bienvenida existe un acceso directo al editor de filtros (Figura 43). Figura 43. Acceso editor de filtros. Para acceder al editor de filtros hay que hacer click sobre el acceso directo. A continuación, aparece la interfaz de creación de filtros (Figura 44). Figura 44. Interfaz editor de filtros. Dentro de la interfaz se distinguen 2 áreas principales (Figura 45): - Área de exploración de objetos. - Área de creación de filtros. 149 Figura 45. Áreas de editor de filtros. A continuación se detallan las distintas áreas: - Explorador de objetos: Dentro del explorador de objetos tenemos un árbol de directorios, desde donde podemos tener acceso a las diferentes carpetas las cuales conforman el proyecto. Los principales objetos que se utilizarán para la creación de filtros serán los atributos, los indicadores y además otros filtros. Como se ha explicado en el apartado 4.3.1, dependiendo del tipo de filtro en cuestión tendrá mayor o menor importancia cada uno de los elementos comentados con anterioridad. Dentro de la ventana de exploración de objetos, podemos acceder a los distintos objetos que conforman la plataforma de Explotación. Para acceder a los atributos e indicadores basta con realizar click sobre los accesos directos disponibles a tal efecto. Para facilitar la búsqueda de los distintos objetos, se ha creado una carpeta por cada una de las entidades disponibles. Se puede navegar a través de las diferentes carpetas de la misma forma que se navega a través del explorador de carpetas de Windows (modo lista) o mediante pestañas desplegables (modo árbol). Los principales filtros empleados en la plataforma de Explotación, se encuentran en la carpeta “Filtros compartidos”, dentro de la carpeta principal “Objetos públicos” (Figura 46). Existe también disponible un acceso directo a “Mis Objetos Personales”. Dentro de “Mis Objetos Personales” están disponibles los distintos objetos propios creados por cada uno de los usuarios del sistema. 150 Figura 46. Explorador de carpetas. - Área de creación de filtros: Dentro de la ventana de creación de filtros se realizará la definición de cada filtro. De forma general, en el editor de filtros existen dos formas para poder crear un filtro y que este aparezca de la ventana de creación de filtro: arrastrando el atributo, indicador o filtro a la ventana (Figura 47), o haciendo click derecho encima del objeto en cuestión (Figura 48). En el primer caso, al arrastrar el objeto se verá cómo se ilumina la ventana de creación de filtros de amarillo. Figura 47. Objeto añadido a la ventana de creación de filtros arrastrando. En el segundo caso antes mencionado, haciendo click derecho sobre el atributo, indicador o filtro, se abrirá un desplegable con las opciones disponibles. Estas opciones variarán dependiendo del tipo de objeto del que se trate, pero principalmente serán dos: ‘agregar al filtro’ o ‘agregar selección dinámica de…’. 151 Figura 48. Objeto añadido a la ventana de creación de filtros mediante click derecho. 1.1.7.2 Creación de filtros independientes simples En general, el proceso para crear un filtro independiente es: 1. Seleccionar el atributo o indicador de atributos base del filtrado (Figura 47 y Figura 48). 2. Seleccionar la operación de filtrado. 3. Seleccionar el atributo o indicador utilizado para definir la calificación. A continuación, se verá como crear cada uno de los tipos de filtros comentados en el apartado 3.1.5. Calificación de representación de atributo En primer lugar, se tendrá que seleccionar el atributo cuya representación se desee que filtre los datos del informe. Se añade a la ventana de filtros mediante alguno de los 2 métodos antes comentados (arrastrando o mediante click derecho). 152 Una vez que el atributo en cuestión se encuentra en la ventana de creación de filtros, se seleccionará ‘calificar’ (Figura 49). Figura 49. Calificar atributo. En el primer menú desplegable, se selecciona la representación según la cual se desea filtrar los datos. En el siguiente menú desplegable, se selecciona el operador que describe el modo en que se desea que los datos se filtren. En el último campo, se escribe el valor que se va a utilizar para calificar la representación del atributo, este es el valor con el que se compararán los datos del origen de datos (Figura 50). Figura 50. Calificación de representación de atributo. Hay que tener en cuenta, que en caso de seleccionar un operador que requiera más de un valor para calificar, estos se deberán introducir en el campo correspondiente separados por el símbolo ‘ ; ‘. 153 Tras configurar el filtro, se tendrá que hacer click en ‘Aplicar’ y posteriormente en ‘Guardar’ (Figura 51). Como paso final, se tendrá que seleccionar el directorio destino del filtro, el nombre del mismo y la descripción si se desea, desde la ventana emergente para tal fin (Figura 52). Figura 51. Aplicar filtro. Figura 52. Guardar filtro. Calificación de lista de elementos de atributo En primer lugar, se tendrá que seleccionar el atributo que queremos calificar mediante una lista de elementos, para así filtrar los datos del informe. Se añade a la ventana de filtros mediante alguno de los 2 métodos comentados (arrastrando o mediante click derecho). 154 Posteriormente, se tendrá que hacer click en ‘Seleccionar’. En la lista desplegable ‘En la lista’, se podrá seleccionar que el atributo esté en la lista o que no esté (Figura 53). Con esto se definirá para qué elementos de atributo el filtro debe incluir datos o no. Figura 53. Seleccionar filtro de selección de lista. El área ‘Disponible’ situada a la izquierda, muestra los elementos que pertenecen al atributo que se selecciona para este filtro. El área ‘seleccionados’ de la derecha, muestra los elementos que formarán parte del filtro, es decir, forman la lista de atributos que se utilizará para calificar. En caso de tener numerosos valores, es posible realizar una búsqueda de unos objetos concretos, para ello se utilizará la ventana ‘Buscar’. Es posible buscar objetos que: - Contengan un valor específico: Escribiendo directamente un valor, esto devolverá todos los objetos que contengan el valor buscado. - Contengan letras específicas: Escribiendo los caracteres separados por el símbolo de porcentaje (%). - Comiencen con letras específicas: Escribiendo las letras seguidas de un asterisco (*). - Finalicen con letras específicas: Escribiendo un asterisco (*), seguido de las letras. - Comiencen y terminen con letras específicas: Escribiendo las primeras letras seguidas de un asterisco (*) y posteriormente las letras finales. Para añadir campos a la lista ‘seleccionados’, en primer lugar se deben elegir los valores de interés haciendo click (es posible seleccionar más de un valor manteniendo pulsada la tecla CTRL y haciendo click), y posteriormente pulsando sobre la flecha derecha (Figura 54). La acción inversa, quitar elementos de la lista ‘seleccionados’, se realiza de la misma manera pero haciendo click izquierdo. 155 Figura 54. Búsqueda y adición a la lista de seleccionados. Tras configurar el filtro, se tendrá que hacer click en ‘Aplicar’ y posteriormente en ‘Guardar como’ (Figura 55). Como paso final, se tendrá que seleccionar el directorio destino del filtro, el nombre del mismo y la descripción si se desea, desde la ventana emergente para tal fin (Figura 52). Figura 55. Aplicar condiciones de filtro. Calificación de atributo a atributo Para la creación de un filtro de tipo ‘calificación de atributo a atributo’, se procede de igual manera que para la creación de un filtro tipo ‘calificación de representación de atributo’, con la salvedad que en lugar de utilizar un valor que se elige de forma manual para la comparación, se empleará otro atributo. 156 Una vez que el atributo base de la comparación se encuentra en la ventana de creación de filtros, se debe seleccionar el atributo con el cual se comparará, para ello se hará click en el botón ‘Seleccionar atributo’ (Figura 56). Figura 56. Seleccionar atributo para comparación. En la ventana emergente se ha de seleccionar el atributo con el cual queremos comparar el atributo base (Figura 58). En la nueva pestaña disponible, se podrá definir la representación del atributo seleccionado con anterioridad que se va a emplear para la comparación (Figura 57). 157 Figura 58. Ventana selección de atributo. Figura 57. Selección de representación de atributo. Finalmente, se debe aplicar y guardar el filtro creado. Calificación de conjunto de indicadores Para la creación de filtros de tipo ‘Calificación de conjunto de indicadores’, se debe proceder de forma similar a la creación de filtros de tipo ‘Calificación de representación de atributo’, con la diferencia de la definición de los mismos. 158 En este caso en primer lugar, se deberá seleccionar y añadir el indicador que se desea utilizar como base del filtro, a la ventana de creación de filtros. En tipo de filtros, se puede apreciar que sólo existen dos campos: campo operador y campo valor de calificación. (Figura 59) Figura 59. Selección operador y valor de calificación. Una vez que se han definido estos valores, se procederá a aplicar y guardar el filtro. Calificación de indicador a indicador La creación de filtros de tipo ‘calificación de indicador a indicador’ es análoga a la creación de filtros de tipo ‘calificación de atributo a atributo’. En primer lugar, se deberá seleccionar y añadir el indicador base del filtro. A continuación, se debe hacer click en el botón ‘Seleccionar indicador’ (Figura 60). Se abrirá una ventana de selección de objetos, donde se podrá seleccionar el indicador que se utilizará para comparar con el indicador base. Una vez seleccionado el indicador, se procederá a seleccionar la operación deseada, aplicar y guardar el filtro (Figura 61). 159 Figura 60. Selección de indicador para comparación. Figura 61. Selección de operador. 1.1.7.3 Creación de filtros independientes con múltiples condiciones Para la creación de filtros independientes con múltiples condiciones, se debe proceder de forma similar a como se ha comentado anteriormente. 160 En primer lugar, hay que ir añadiendo los filtros deseados a la ventana de creación de filtros. Es importante mencionar, que una vez que se define un filtro, es necesario que este se aplique previamente a la adición de otro filtro. Por defecto, el operador de conjunto será ‘Y’. Es posible elegir el tipo de operador de conjunto a utilizar para unir las diferentes condiciones del filtro, para ello se hace click en ‘Y’ (Figura 62), y se abrirá una lista desplegable con las diferentes opciones mencionadas en el apartado 4.3.2. Figura 62. Selección de operador de conjunto. Una vez que se han añadido los diferentes filtros que conformarán el filtro con múltiples condiciones, se debe guardar como se ha comentado con anterioridad. 1.1.7.4 Utilización de filtros independientes Para agregar a un informe un filtro independiente ya creado, en primer lugar se deber abrir el informe en cuestión para el cual se quiere añadir el/los filtros. Una vez que se tiene el informe abierto, en el menú ‘Inicio’ se debe seleccionar ‘Diseño’. En caso de no aparecer el panel ‘Filtro de informe’ sobre el informe, se debe mostrar haciendo click en el icono de la barra de herramientas (Figura 63). 161 Figura 63. Panel filtro de informe. En la parte izquierda, habrá que seleccionar la pestaña ‘Todos los objetos’, y se deberá seleccionar el filtro que se quiera añadir. Se puede añadir el filtro de dos formas diferentes: haciendo doble click sobre el filtro, o haciendo click derecho y seleccionando ‘Agregar al Filtro’. En el panel ‘Filtro de informe’ se pueden ver los filtros que se han añadido al informe. En caso de tener más de un filtro añadido, es posible configurar el operador de conjunto de forma similar a como se ha explicado en el apartado 4.3.3.3. Además, es posible elegir el orden en el cual se evalúan las diferentes calificaciones, haciendo click en el botón ‘Mover arriba’ o ‘Mover abajo’ junto a la calificación de filtro (Figura 64). Figura 64. Selección orden de evaluación. Finalmente, tras la adición y configuración de los diferentes filtros independientes deseados, se debe proceder a guardar el informe. 162 1.1.8 Creación de filtros dentro de un informe Es importante recordar, que los filtros creados dentro de un informe forman parte del propio informe, por tanto estos no podrán ser utilizados fuera del mismo. Para crear un filtro de informe dentro de un informe, en primer lugar se tendrá que abrir el informe, una vez que se tiene el informe abierto, se procederá a activar el panel de ‘Filtro de informe’ como se ha visto en el apartado 4.3.3.4. Una vez realizados los pasos anteriores, la creación de filtros es similar a la creación de filtros de informe desde el editor de informes. En el explorador de objetos de la izquierda, se podrá seleccionar el objeto en el cual se quiera basar el filtro. Se podrá añadir al panel de ‘Filtro de informe’ haciendo click derecho sobre el objeto y seleccionando ‘Agregar al Filtro’. Una vez realizado esto, la configuración del filtro es idéntica a como se ha visto en el apartado 4.3.3.2 (Figura 65Figura 64). Figura 65. Configuración de filtro creado dentro de un informe. Una vez creado el filtro dentro del informe, se debe aplicar y guardar el informe. 163 CREACIÓN DE SELECCIÓN DINÁMICA Una selección dinámica es una pregunta que el sistema presenta al usuario cuando se ejecuta un informe. La forma en que el usuario responda a la pregunta determina los datos que se mostrarán en el informe cuando se devuelva desde el origen de datos. Un diseñador de informes puede incluir una o varias selecciones dinámicas en cualquier informe. Las selecciones dinámicas son una herramienta eficaz para: - Permitir a cada usuario que ejecuta el informe solicitar conjuntos de datos individualizados del origen de datos cuando responde a las selecciones dinámicas y ejecuta el informe. De hecho, cada usuario crea un filtro para el informe. - Permitir al diseñador de informes crear en general un menor número de informes utilizando objetos más globales, en vez de tener que crear muchos informes más específicos individualizados para cada analista. - Permitir al diseñador de informes garantizar que los objetos del informe sean los últimos objetos disponibles del proyecto. Esto es posible utilizando un objeto de búsqueda en una selección dinámica. Cuando un usuario inicia una selección dinámica al ejecutar un informe, el objeto de búsqueda recupera los últimos objetos que se ajusten a los criterios de búsqueda definidos por el diseñador de informes. Por lo tanto, independientemente de cuándo se creó la selección dinámica, cada vez que un usuario ejecute el informe, seleccionará las respuestas de la selección dinámica en una lista de los objetos más actualizados disponibles en el proyecto, incluidos los objetos que puedan no haber existido cuando se creó la selección dinámica. - Permitir a los usuarios actualizar los objetos de sus informes guardados. Los usuarios pueden guardar un informe de selecciones dinámicas de manera que los objetos de la selección dinámica permanezcan conectados a los objetos originales del proyecto en los que se basaron originalmente cuando se creó la selección dinámica. Si se modifican o eliminan objetos del proyecto, el informe podrá reflejar esos cambios la próxima vez que se ejecute el informe con selecciones dinámicas. Las partes que conforman una selección dinámica controlan la forma en la que aparece y funciona una selección dinámica. Estos componentes incluyen lo siguiente: - Requisito de respuesta: Este componente le permite determinar si los usuarios deben responder a la selección dinámica o si la respuesta es opcional. Si se requiere una respuesta, el informe no se podrá ejecutar hasta que esta se proporcione. - Respuestas por defecto de selección dinámica: Este componente le permite incluir una respuesta preseleccionada para la selección dinámica, que el usuario podrá aceptar, sustituir por una respuesta distinta, o aceptar y agregar más respuestas. - Título y descripción: Este componente le permite proporcionar un nombre y una descripción útiles para la selección dinámica, lo que puede afectar en gran medida a que el usuario encuentre la selección dinámica sencilla o compleja. - Estilo: Este componente determina el aspecto de la selección dinámica y el diseño de cómo se seleccionan las respuestas a la selección dinámica. Existen tres categorías de selecciones dinámicas: selecciones dinámicas independientes, selecciones dinámicas como parte del informe, y selecciones dinámicas como parte de filtros: 164 - Selecciones dinámicas independientes: Una selección dinámica independiente es una selección dinámica creada como objeto independiente de MicroStrategy. Puede utilizarse en muchos informes distintos, así como en filtros, indicadores y otros objetos, y pueden utilizarla otros diseñadores de informes. Una selección dinámica independiente da mayor flexibilidad a los diseñadores de informes. - Selecciones dinámicas como parte de un informe: Las selecciones dinámicas también pueden crearse como parte intrínseca de un informe determinado al mismo tiempo que se crea el propio informe. Las selecciones dinámicas creadas como parte de un informe se guardan con la definición del informe. Por lo tanto, una selección dinámica creada como parte de un informe no puede utilizarse en cualquier otro informe. - Selecciones dinámicas como parte de un filtro: Las selecciones dinámicas también pueden crearse como parte intrínseca de un filtro al mismo tiempo que se crea el propio filtro. Las selecciones dinámicas creadas como parte de un filtro se guardan con la definición del filtro. Por lo tanto, una selección dinámica creada como parte de un filtro no puede utilizarse en cualquier otro filtro. 1.1.9 Tipos de Selecciones Dinámicas Existen distintos tipos de selecciones dinámicas, que se podrán utilizar en función del objeto sobre el que se quiere filtrar la información a petición del usuario. 1.1.9.1 Selecciones dinámicas de definición de filtro Este tipo de selección dinámica permite a los usuarios determinar cómo se filtran los datos del informe en función de los atributos de una jerarquía, listas de elementos de atributos o indicadores. Dentro de este tipo de selecciones dinámicas, existen las siguientes variantes: - Selección dinámica de calificación jerárquica: Permite a los usuarios elegir de entre todos los atributos de una jerarquía. - Selección dinámica de calificación de atributos: Permite a los usuarios calificar sobre un atributo. - Selección dinámica de lista de elementos de atributo: Permite a los usuarios elegir de una lista de elementos de atributo. - Selección dinámica de calificación de indicador: Permite a los usuarios calificar sobre un indicador. 1.1.9.2 Selecciones dinámicas de objeto Este tipo de selección dinámica permite a los usuarios seleccionar objetos para incluirlos en un informe, como atributos, indicadores o filtros. Los usuarios pueden utilizar esta selección dinámica para agregar más datos en un informe. 1.1.9.3 Selecciones dinámicas de valor Este tipo de selección dinámica permite que los usuarios seleccionen un valor único, como una fecha o una cadena de texto específica, y filtren los datos del informe en función de sus selecciones. Dentro de este tipo de selecciones dinámicas, existen las siguientes variantes: 165 - Solicitud de fecha y hora: Los usuarios introducen una fecha y hora específicas para las que desean ver los datos. Esta selección dinámica se utiliza en un filtro. - Selección dinámica numérica: Los usuarios escriben un número específico que se utilizará como parte de un filtro o de un indicador para buscar unos datos numéricos específicos. - Selección dinámica de texto: Los usuarios escriben una palabra o frase que se utilizará como parte de un filtro para buscar datos específicos que contengan ese texto. - Selección dinámica de decimal grande: Los usuarios pueden introducir hasta 38 dígitos para buscar datos numéricos con el tipo de datos de decimal grande asignado. 1.1.10 Creación, guardado y utilización de selecciones dinámicas independientes Como se ha comentado con anterioridad, existe la posibilidad de crear selecciones dinámicas independientes en un proyecto de MicroStrategy, las cuales pueden ser utilizadas en diferentes informes. A continuación, se explicará cómo poder crear estas selecciones dinámicas y su utilización. 1.1.10.1 Editor de Selecciones dinámicas Para crear una selección dinámica independiente se debe acceder al editor disponible para tal efecto. Dentro de la página de bienvenida existe un acceso directo al editor de selecciones dinámicas (Figura 66). Figura 66. Acceso Editor de Selecciones Dinámicas. Para acceder al editor de selecciones dinámicas hay que hacer click sobre el acceso directo. A continuación, aparecerán los distintos tipos de editores los cuales permiten crear los diferentes tipos de selecciones dinámicas independientes (Figura 67). 166 Figura 67. Editores de Selecciones Dinámicas. La elección del editor dependerá de la correspondiente selección dinámica que se quiera crear. Se seleccionará el editor de ‘Selección Dinámica de calificación de atributo’ como ejemplo. A continuación, aparecerá la interfaz de creación de selecciones dinámicas (Figura 68). Figura 68. Interfaz del editor de selección dinámica de calificación de atributo. El editor de los diferentes tipos de selecciones dinámicas es en general muy parecido. La elección de los diferentes editores de selecciones dinámicas repercutirá en las opciones disponibles. Dentro de la interfaz se distinguen 4 áreas principales, a las cuales se accede haciendo click en la pestaña correspondiente (Figura 69): - Definición - General - Estilo - Calificación Figura 69. Áreas del editor de Selecciones Dinámicas. A continuación distintas áreas: - se detallan las Definición: Dentro de la pestaña ‘Definición’ se realiza la caracterización de la selección dinámica deseada. Como se ha comentado con anterioridad, las opciones variarán según el tipo de selección que se emplee (Figura 70). Salvo en la ‘selección dinámica de calificaciones de jerarquías’ y en la ‘selección dinámica de un valor’, en el resto de selecciones se deberá definir el objetivo de la selección para poder acceder a las otras pestañas. 167 Figura 70. Pestaña ‘Definición’. - General: Dentro de la pestaña ‘General’ se podrán configurar aspectos generales de las selecciones dinámicas como el nombre y la descripción. Además, se pueden limitar el número de respuestas de selección dinámica, y obligar a que los usuarios respondan antes de ejecutar el informe (Figura 71). Figura 71. Pestaña ‘General’. - Estilo: Dentro de la pestaña ‘Estilo’ se podrá establecer el formato para la selección dinámica. Serán configurables características como la forma en que la selección dinámica va a aparecer ante el usuario, limitaciones del tamaño de los campos, ordenación de las opciones, y forma de navegar por los carpetas y realizar búsquedas (Figura 72). Figura 72. Pestaña ‘Estilo’. 168 - Calificación: Dentro de la pestaña ‘Calificación’ se podrá especificar cómo se muestran las calificaciones en la selección dinámica. Son configurables características como el tipo de expresión de calificación permitida, la condición por defecto que se muestra en la selección dinámica, el operador condición por defecto, y diversas limitaciones y permisos (Figura 73). Figura 73. Pestaña ‘Calificación’. 1.1.10.2 Creación de Selecciones Dinámicas independientes En general, el proceso para crear una selección dinámica independientes es siempre el mismo. : 1. Seleccionar el editor de Selección Dinámica correspondiente (Figura 66 y Figura 67). 2. Configurar las diferentes opciones de las pestañas comentadas con anterioridad. 3. Guardar la selección dinámica. A continuación, se verá cómo crear las principales selecciones dinámicas. Selección Dinámica de calificación de atributo En primer lugar, se tendrá que seleccionar el editor correspondiente. Se accederá a la interfaz del editor de selección dinámica de calificación de atributo. A continuación, se deberá configurar la pestaña ‘Definición’. Existen 3 opciones disponibles: elegir el atributo del que un usuario puede seleccionar los elementos, explore y seleccione el atributo; crear una lista predefinida de atributos en la que los usuarios puedan elegir opciones; y utilizar el resultado de un objeto de búsqueda creado previamente. Se seleccionará un atributo. Haciendo click en el botón seleccionar atributo, se abrirá un explorador de objetos desde el cual se podrá seleccionar el atributo en cuestión. (Figura 74). 169 Figura 74. Selección de atributo para la selección dinámica. En la pestaña inferior ‘Representaciones mostradas’, se podrán seleccionar las representaciones de atributo que se deben mostrar al usuario para la calificación del atributo seleccionado (Figura 75). Por defecto, estarán disponibles todas las representaciones del atributo. Figura 75. Representaciones de atributo mostradas. El siguiente paso será configurar las características generales. Para ello se hará click en la pestaña ‘General’. En los campos ‘Título’ e ‘Instrucciones’ se deberá introducir el nombre de la selección dinámica y la descripción respectivamente (Figura 76). 170 Figura 76. Nombre y descripción de la selección dinámica. En relación a las casillas inferiores: - Se necesita respuesta de selección dinámica: Sirve para solicitar a los usuarios que respondan a la selección dinámica antes de ejecutar el informe. - Número mínimo/máximo de calificaciones: Para establecer un número mínimo/máximo de respuesta de la selección dinámica. Para poder establecer estos números, tras activar la casilla correspondiente, se podrá introducir el valor en el campo disponible para tal fin (Figura 77). Se podrá establecer un número mínimo aunque no se haya especificado un número máximo, y viceversa. Figura 77. Limitaciones del número de respuestas. Tras configurar las opciones generales, es posible configurar las opciones de diseño y estilo de visualización. Una vez que se ha accedido a la pestaña ‘Estilo’, se podrán configurar las diferentes opciones. Las principales opciones son (Figura 78): - Estilo de visualización: Desplegable que permite seleccionar el estilo visual de la selección dinámica. Dependiendo del valor del mismo se activarán/desactivarán diferentes opciones de estilo. - Ancho/alto fijo del cuadro de texto: Se utiliza para garantizar que los campos de texto y las opciones de la selección dinámica tienen un tamaño fijo. - Orientación: Sirve para establecer el modo en el que las opciones de selección dinámica van a ordenarse. 171 Figura 78. Configuración del diseño y estilo de visualización. Como paso final, se deberá configurar la sección ‘Calificación’, para así especificar cómo se muestran las calificaciones en la selección dinámica. Las principales opciones configurables son las siguientes (Figura 79): - Tipo de expresión permitido: Desplegable que se utiliza para determinar el tipo de expresiones de calificación permitidas en la selección dinámica. - Tipo de expresión por defecto: Determina el tipo de expresión por defecto. - Operador condicional por defecto: Determina el tipo de operador condicional por defecto. - Permitir exploración de elementos en la calificación de atributo: Casilla que permite que los usuarios puedan explorar los elementos de la calificación de atributos. - Permitir modificación del operador lógico: Permite a los usuarios modificar las expresiones. Habrá dos opciones posibles: forzar que se utilice un único operador lógico entre todas las condiciones, y permitir al usuario configurar operadores lógicos independientes entre condiciones. Figura 79. Configuración de cómo se muestran las calificaciones. Finalmente, tras haber configurado la selección dinámica, se procederá al guardado de la misma. Para ello, se hará click en ‘Guardar como’, se abrirá un explorador de directorios donde se podrá seleccionar la carpeta de almacenamiento, además es posible especificar el nombre y la descripción de la selección dinámica (Figura 80). Figura 80. Almacenamiento de la selección dinámica. 172 Selección dinámica de calificación de indicador Para acceder al editor de creación de ‘Selección dinámica de calificación de indicador’, se deberá hacer click en su correspondiente acceso directo explicado con anterioridad (Figura 67). La creación de una selección dinámica de calificación de indicador es idéntica a la creación de una selección dinámica de calificaciones de atributos, salvo la sección ‘Calificación’ que varía levemente. Los pasos a seguir antes de acceder a la pestaña ‘Calificación’ son los mismos. Tras configurar las opciones de las secciones ‘Definición’, ‘General’ y ‘Estilo’, se deberá acceder a la pestaña ‘Calificación’. Las principales opciones disponibles para configurar cómo se muestran las calificaciones en la selección dinámica son (Figura 81): - Operador condicional por defecto y operador condicional por defecto entre condiciones: Determinan cual va a ser el operador condicional y operador condicional entre condiciones por defecto. - Permitir modificación del operador lógico: Permite a los usuarios modificar las expresiones. Habrá dos opciones posibles: forzar que se utilice un único operador lógico entre todas las condiciones, y permitir al usuario configurar operadores lógicos independientes entre condiciones. - Mostrar selector de nivel de salida: Permite que el usuario pueda especificar el nivel de salida de los indicadores. Figura 81. Configuración de calificación en selección dinámica de calificación de indicador. 1.1.10.3 Utilización de selecciones dinámicas independientes Para explicar este apartado de forma práctica, se hará uso de una selección dinámica de calificación de atributo, la cual filtrará según la plataforma deseada, además se obligará que el usuario tenga que responder a la selección dinámica antes de que se ejecute el informe. Para agregar a un informe una selección dinámica independiente ya creada, en primer lugar se debe abrir el informe en cuestión para el cual se quiere añadir dicha selección dinámica. Una vez que se tiene el informe abierto, en el menú ‘Inicio’ se debe seleccionar ‘Diseño’. Posteriormente se deberá navegar por el explorador de objetos de la izquierda, para así seleccionar la selección dinámica creada. Para añadirla al informe, se tendrá que hacer click derecho sobre la selección dinámica y elegir ‘Agregar al filtro’ (Figura 82). 173 Figura 82. Adición de selección dinámica a un informe. Una vez que se ha creado el informe, se tendrá que ejecutar para ver la funcionalidad de la selección dinámica. Se abrirá la ventana de selección (Figura 83). Figura 83. Ventana de selección de Selección Dinámica. Para agregar el atributo a la calificación se tendrá que seleccionar, hacer click en la flecha derecha (Figura 84), y así se podrá modificar la calificación. 174 Figura 84. Adición del atributo para calificar. En el campo ‘Seleccionadas’ es posible configurar las condiciones de calificación del filtrado. Los diferentes términos de la expresión de filtrado son, de izquierda a derecha, el atributo; el tipo de expresión; la representación del atributo a calificar; la operación; y finalmente el/los valores para comparar. Se puede especificar cada uno de los términos de la expresión haciendo click sobre ellos, y se abrirá un desplegable con las pertinentes opciones. Estas opciones de calificación vendrán limitadas según como se haya creado la selección dinámica. Además, dependiendo del tipo de expresión o del tipo de operador variarán las mismas. Por ejemplo, para filtrar el atributo ‘Plataforma’ utilizando la selección dinámica creada, siendo la calificación mediante su representación ‘DESC_LARGA’, y haciendo que esta tenga un valor concreto, se tendrá en primer lugar que seleccionar la representación correspondiente en la ventana ‘Seleccionadas’ (Figura 85) y elegir el operador correspondiente. Figura 85. Selección de la representación del atributo. A continuación, habrá que hacer click en el campo ‘valor’, y dentro del desplegable disponible aparecerán dos opciones: introducir el valor manualmente, o hacer click en ‘Explorar valores’ para así seleccionar los valores desde la lista de valores existentes. Al utilizar la última opción, se abrirá 175 una ventana que permitirá buscar el valor de atributo, como ya se ha explicado anteriormente (Figura 54), y seleccionar el mismo (Figura 86). Figura 86. Selección de valor de atributo para comparación. Finalmente, se tendrá que hacer click en el botón ‘Ejecutar informe’ (Figura 87), y así se ejecutara la selección dinámica filtrando los datos del informe. Figura 87. Ejecución del informe tras configurar la selección dinámica. Siendo el resultado final el siguiente (Figura 88): 176 Figura 88. Resultados del informe tras uso de selección dinámica. Además de la condición creada anteriormente, se pueden añadir múltiples condiciones haciendo click en el botón ‘Nueva condición’ (Figura 89 ). Figura 89. Adición de nueva condición al filtro de selección dinámica. La configuración de esta nueva condición es idéntica a la ya explicada. Se puede ver como aparecen dos nuevas opciones a la derecha, estas permiten definir el tipo de operador condicional a utilizar (Figura 90): - Todas las selecciones: Es el equivalente al operador condicional ‘Y’. Cualquier selección: Es el equivalente al operador condicional ‘O’. 177 Figura 90. Múltiples condiciones dentro de una selección dinámica. Tras configurar las nuevas condiciones de la selección dinámica y ejecutar el informe, se puede comprobar que los resultados son los esperados (Figura 91): Figura 91. Resultados de informe con selección dinámica multicondicional. 1.1.11 Creación de selecciones dinámicas dentro de un filtro Para crear una selección dinámica como parte de un filtro, se debe proceder como en la creación de filtros independientes vista en el apartado 4.3.3.2. Una vez que estamos en el editor de filtros, para añadir el atributo, indicador u objeto a la ventana de creación de filtros, se tendrá que hacer click derecho en este y seleccionar ‘Agregar a calificación dinámica de…’’ según el tipo de selección dinámica que se quiera crear (Figura 92). 178 Figura 92. Creación de selección dinámica como parte de un filtro. Para editar la selección dinámica, se tendrá que hacer click en el campo que se ha añadido a la ventana de creación de filtros (Figura 93). Se abrirá la misma venta de creación de selecciones dinámicas vista en el apartado 4.4.2.1. Figura 93. Ventada de configuración de selección dinámica dentro de un filtro. Finalmente, se tendrá que guardar el filtro independiente con la selección dinámica. Es de interés comentar, que al igual que con la creación de filtros independientes (apartado 3.1.7.3.), es posible crear filtros multicondicionales. Para ello se tratará la selección dinámica como una condición más, pudiendo añadirse más de una selección dinámica en la definición del mismo filtro. La utilización de filtros independientes con selecciones dinámicas es idéntica a la de filtros independientes normales. 179 1.1.12 Creación de selecciones dinámicas dentro de un informe Para crear una selección dinámica como parte de un informe, se debe proceder de la misma forma que se explicó en el apartado anterior, salvo que el objeto base de la selección dinámica será seleccionado desde el explorador de objetos del editor de informes, y no desde el explorador de objetos del editor de filtros. 180 CREACIÓN DE GRUPO PERSONALIZADO Un grupo personalizado es un objeto de informe hecho de una colección ordenada de componentes llamados elementos de grupo, cada uno de los cuales consta de un encabezado y una o más calificaciones que se deben cumplir para que los datos se incluyan en el elemento del grupo personalizado (Figura 94). Figura 94. Ejemplo de Grupo personalizado Desde el punto de vista del proceso de diseño de informes, los grupos personalizados son objetos que se pueden incluir en la plantilla. Cada elemento de grupo personalizado contiene su propio conjunto de calificaciones de filtrado o de rango. En un grupo personalizado se pueden definir los siguientes tipos de condiciones: - Calificación de atributos: limita los datos según el valor de una representación de atributo, ver datos sólo para elementos de atributo en una lista o comparar dos representaciones de atributos para filtrar datos. - Calificación de conjunto: limita los datos según el valor, categoría o porcentaje de un indicador o al comparar los valores de dos indicadores. - Acceso directo a un informe: limita los datos usando los resultados de un informe ya existente. - Acceso directo a un filtro: limita los datos usando un filtro ya existente. - Acceso directo a una selección dinámica: limita los datos usando las respuestas a una selección dinámica ya existente. 181 1.1.13 Editor de grupo personalizado Para crear un grupo personalizado se debe acceder al editor disponible para tal efecto. Dentro de la página de bienvenida existe un acceso directo al editor de grupos personalizados (Figura 95). Figura 95. Acceso al editor de grupos personalizados. Se abrirá la interfaz para la creación de grupos personalizados (Figura 96) Figura 96. Editor de grupos personalizados. 182 Dentro de la interfaz se encuentran principalmente 3 áreas (Figura 97): - Nombre del grupo personalizado. - Descripción del grupo personalizado. - Área de elementos de grupo personalizado. Figura 97. Elementos de grupo personalizado. A continuación se detalla el área principal: - Elementos de grupo personalizado: En esta área será donde se definan los distintos elementos que conformarán el grupo personalizado. Aquí se definirán las condiciones que se usarán para filtrar los datos al seleccionar un atributo, indicador, informe o filtro y, a continuación, especificar las correspondientes opciones. Para realizar esto, dentro de esta área se encuentra el ‘Editor de condición’, al cual se accede tras hacer click en ‘Nuevo elemento de grupo personalizado’ (Figura 98). Es posible la creación de grupos personalizados con múltiples condiciones, para ello hay que ir añadiendo más elementos al grupo personalizado, y ajustar el condicionado con los operadores de conjunto deseados. La creación de grupos personalizados, y la utilización del ‘Editor de condición’ se detallarán más adelante. 183 Figura 98. Editor de condición. 1.1.14 Creación, guardado y utilización de grupos personalizados simples De forma resumida, para la creación de un grupo personalizado se debe definir un elemento de grupo personalizado, y tantos elementos de grupo personalizado adicionales como se desee. Hay que tener en cuenta que cada uno de estos elementos, puede hacer uso de diversas calificaciones, así como contener múltiples condiciones de filtrado. A continuación se detallarán los distintos pasos para la creación de grupos personalizados. Una vez que se ha accedido al editor de grupo personalizado, se deberá hacer click en ‘Nuevo elemento de grupo personalizado’ para así abrir el ‘Editor de condición’ (Figura 98). Como se ha comentado anteriormente, se podrán añadir elementos de grupo adicionales a un mismo grupo personalizado, para ello habrá que hacer click en ‘Nuevo elemento de grupo personalizado’. Es importante mencionar, que incrementar el número de elementos de grupo personalizado provocará una mayor carga computacional, ya que aumentarán el número de consultas al Data Warehouse. En la ventana ‘Editor de condición’, al hacer click en ‘Explorador’ se abrirá el explorador de objetos que permite seleccionar el objeto base del nuevo elemento de grupo personalizado (Figura 99). Esta ventana emergente, el explorador de objetos, será el punto de referencia para la creación de los diferentes filtros que definirán nuestros elementos de grupo personalizado. Hay que tener en cuenta, que dependiendo del tipo de objeto que se seleccione habrá diferentes opciones de filtrado. A continuación, se hará una distinción según los tipos de filtrado más relevantes. 184 Figura 99. Explorador de objetos. Filtrar datos según el valor de una representación de atributo Desde el ‘explorador de objetos’, se selecciona el atributo que se usará para filtrar datos (Figura 100). Figura 100. Selección de atributo. A continuación, se selecciona la representación del atributo sobre la que se desea filtrar los datos (Figura 101). 185 Figura 101. Selección representación de atributo. El siguiente paso será seleccionar el operador que describe como se desean filtrar los datos (Figura 102). Hay que tener en cuenta, que este listado de operaciones posibles depende del tipo de objeto seleccionado y, en caso de ser un atributo, la representación del mismo. En función del operador que se haya seleccionado en el menú desplegable anterior, es posible que deban seleccionar valores adicionales, o ningún valor. Por ejemplo, el operador ‘Entre’ requiere dos valores, y el operador ‘Es nula’ no requiere ningún valor para la calificación. Figura 102. Selección de operador. Después de hacer click en ‘Aceptar’, se puede ver el elemento de grupo personalizado que se ha creado. A continuación, configuramos el nombre del elemento seleccionando ‘Elemento 1’ y escribiendo el nombre deseado (Figura 103). 186 Figura 103. Nombre del elemento de grupo personalizado. El paso final será guardar el grupo personalizado haciendo click en ‘Guardar’ y seleccionando el directorio deseado (Figura 104). Figura 104. Guardado de Grupo Personalizado. 187 Como se ha comentado, para añadir elementos de grupo adicionales a un Grupo Personalizado, se ha de hacer click en ‘Nuevo elemento de grupo personalizado’, y configurar el filtro (Figura 105). Figura 105. Adición de elementos de grupo personalizado. Filtrar datos para elementos de atributo en una lista especificada Partiendo de la ventana de selección de objetos (Figura 99) se añade un atributo, en la lista desplegable de representaciones de atributo a elegir, se selecciona ‘En la lista’ o ‘No está en la lista’. A continuación, habrá que hacer click en ‘Explorar elementos’ y se abrirá una ventana con la lista de elementos de atributo disponible (Figura 106). Figura 106. Lista de elementos de atributo disponibles. Dentro de la ventana de selección de elementos, en el campo habilitado para buscar elementos específicos, se podrá hacer uso de las técnicas de búsqueda vistas en el apartado 4.3.3.2 (Figura 54). 188 El resto de pasos a seguir son idénticos a los ya mencionados. Filtrar datos según el valor de un indicador Partiendo de la ventana de selección de objetos (Figura 99) se añade un indicador, se selecciona el operador que se utilizará. Para realizar la comparación, se puede introducir un valor, o seleccionar un indicador haciendo click en ‘Seleccionar indicador’. A continuación, se deberá seleccionar el atributo que se usará para el nivel de salida para la condición, haciendo click en ‘Seleccionar atributo’ (Figura 107). Figura 107. Selección de atributo para el nivel de salida. Se deberá aceptar la condición creada, podremos ver esta condición en la ventana principal del editor de Grupos Personalizados (Figura 108). Finalmente se ha de guardar el Grupo Personalizado. 189 Figura 108. Filtrado según valor de indicador. 1.1.14.1 Creación de elementos de grupos personalizados con múltiples condiciones Para crear elementos de grupos personalizados con múltiples condiciones, se ha de partir de una condición ya creada. Desde el ventana principal del editor de Grupos Personalizados, se ha de poner el ratón sobre la primera condición creada, se activará el botón ‘Agregar condición’ (Figura 109). Figura 109. Agregar nueva condición al elemento de grupo. Al hacer click en este botón, se nos abrirá el editor de condición ya mencionado en apartados anteriores. Se ha de crear la condición deseada y aceptar. Nuevamente, en la ventana principal del editor de Grupos Personalizados se pueden ver las condiciones creadas. 190 El operador de conjunto empleado por defecto es ‘Y’. Es posible cambiar este haciendo click en el operador de conjunto, se abrirá un desplegable con los posibles operadores de conjunto que se pueden utilizar (Figura 110). Figura 110. Selección de operador de conjunto. 1.1.14.2 Formato de Grupos Personalizados Es posible dar formato a la representación, dentro de un informe, de los elementos de grupos personalizados. Este formato se puede dar de forma independiente a cada elemento. Para abrir el editor de formato, se ha de hacer click en el botón ‘Formato’ disponible en la ventana principal del editor de grupos personalizados (Figura 111). Figura 111. Editor de formato de elementos de grupo personalizado. En el editor de formato, se pueden apreciar tres áreas principales (Figura 112): - Área de selección de elemento de grupo personalizado y su sección objetivo del formato: En esta área es posible seleccionar el elemento de grupo al que se dará formato (primera 191 lista desplegable), además es posible seleccionar la sección del grupo personalizado al que se desea dar formato (segunda lista desplegable). - Área de selección de tipo de formato: Aquí se podrá seleccionar el tipo de formato que se quiere configurar. Las opciones disponibles son ‘Fuente’, ‘Número’, ‘Alineación’, y ‘Color y líneas’. - Área de configuración del formato: En esta área se configurará el formato. Dependiendo del tipo de formato seleccionado las opciones variarán. Figura 112. Áreas del Editor de Formato. 1.1.14.3 Utilización de Grupos Personalizados Los Grupos Personalizados se utilizan dentro de un informe, de igual manera que los objetos de tipo atributo. Para añadirlos a un informe, basta con seleccionarlos dentro del explorador de objetos en la ventana de diseño, hacer doble click o botón derecho más ‘Agregar a informe’. 192 CREACIÓN DE ANÁLISIS Un análisis de exploración visual de datos es una visualización personalizada e interactiva que se puede usar para explorar los datos empresariales. Un análisis muestra los datos de un conjunto de datos subyacente en una interfaz simplificada diseñada para permitirle explorar los elementos de manera fácil y rápida (Figura 113). Figura 113. Análisis de Visual Insight Un análisis es semejante a un documento en que puede visualizar los datos en cuadrículas, gráficos y widgets interactivos que ha agregado al análisis. Sin embargo, el proceso de diseño y creación de un análisis es mejor, lo que permite crear esos objetos rápidamente desde un informe o cubo inteligente existentes. Los análisis permiten explorar los datos de varias maneras, como por ejemplo las siguientes: - Ordenar y pivotar los datos en un análisis para crear una vista personalizada. Agrupar los datos en un análisis para trabajar fácilmente con grandes conjuntos de datos. Filtrar los datos en un análisis mediante la selección de elementos de atributo o valores métricos. Mostrar los datos en un gráfico, como por ejemplo un gráfico de barras o uno circular, para comprender fácilmente las relaciones entre los datos. Mostrar los datos en una visualización, como por ejemplo un mapa de calor o una matriz gráfica. Alternar rápidamente entre diferentes representaciones visuales de los datos. 1.1.15 Visual Insight Visual Insight es la herramienta que permite la creación de análisis visuales desde el entorno web de MicroStrategy. Los datos que emplea para realizar el análisis pueden ser los datos de un informe o cubo inteligente. 1.1.16 Tipos de visualización Una visualización es una representación visual de los datos en un análisis de exploración visual de datos, como por ejemplo una cuadrícula o un gráfico. Se pueden agregar visualizaciones a un análisis para proporcionarle al usuario varias formas de mostrar e interactuar con los datos del conjunto de datos del análisis. 193 La siguiente tabla muestra las visualizaciones disponibles y sus correspondientes subtipos: Tipos de visualización Subtipos de visualización Cuadrícula N/D Mapa de calor Google Map Circular N/D N/D Circular Anillo Matriz de gráficos de barras Barra vertical - Estándar Barra vertical - Apilado Barra vertical - Agrupado Barra horizontal - Estándar Barra horizontal - Apilado Barra horizontal - Agrupado Matriz de gráficos de líneas Línea vertical - Estándar Línea vertical - Apilado Línea vertical - Absoluto Línea horizontal - Estándar Línea horizontal - Apilado Línea horizontal - Absoluto Matriz de gráficos de dispersión Dispersión y de burbujas con marcadores de Dispersión (indicadores en los ejes X-Y) círculo Cuadrícula de dispersión Matriz de gráficos de dispersión Burbuja y de burbujas con marcadores de Burbuja: (indicadores en los ejes X-Y) cuadrado Cuadrícula de burbujas Gráficos de barras verticales y Barra vertical horizontales Barra vertical: doble eje Barra horizontal Barra horizontal: doble eje Gráficos de líneas verticales y Línea vertical horizontales Línea vertical: doble eje Línea horizontal Línea horizontal: doble eje Gráficos de áreas verticales y Área vertical horizontales Área vertical: doble eje Área horizontal Área horizontal: doble eje Combinación de distintos Barra y área gráficos Barra y área: doble eje Tabla 2. Tipos de visualización de Visual Insight. 1.1.17 Creación de análisis de Visual Insight a partir de un informe Para crear análisis partiendo de un informe, se tendrá que acceder al editor de análisis de Visual Insight. Dentro de la página de bienvenida, hay dos directorios donde se almacenan los diversos informes (Figura 114). 194 Figura 114. Directorios de informes. Una vez que se ha accedido a alguno de los dos directorios disponibles, se tendrá que hacer click en el icono ‘convertir en análisis’ . Se abrirá una ventana que permitirá seleccionar el informe sobre el cual se quiere basar el análisis de Visual Insight (Figura 115). Figura 115. Selección de informe para análisis. 195 Al seleccionar el informe y hacer click en ‘aceptar’, se abrirá el ‘Editor de análisis’ con la ventana principal de selección de visualización (Figura 116). Figura 116. Selección de visualización. 1.1.17.1 Editor de Análisis Una vez que se ha elegido una visualización de partida, o se ha abierto un análisis ya creado, se abrirá la ventana principal del ‘Editor de Análisis’ (Figura 117). Figura 117. Editor de Análisis. Dentro de la interfaz del Editor de Análisis se distinguen principalmente seis áreas/paneles (Figura 118): - Área de visualización: Los datos que se agregaron al análisis de Visual Insight se muestran en el centro de la interfaz como una visualización interactiva. 196 - Panel de Objetos del conjunto de datos: Este panel está ubicado en el costado izquierdo de la interfaz y muestra una lista de todos los atributos e indicadores del conjunto de datos del análisis. Se pueden arrastrar y colocar objetos de informe del panel Objetos del conjunto de datos para agregarlos a la visualización, lo cual permite que los usuarios puedan filtrar a partir de un atributo, un indicador, etc. - Panel Zonas de descenso (Mi vista): Se pueden arrastrar y colocar atributos e indicadores en el panel Zonas de descenso para agregarlos a la visualización activa actualmente. - Panel de Filtros: Este panel está ubicado en la izquierda de la interfaz por defecto. Se pueden seleccionar distintas opciones de filtros en el panel Filtros para permitir que los usuarios filtren los datos que se muestran en un análisis. - Área de paginación: Se pueden arrastrar y colocar para agregar un atributo al área de paginación a fin de permitir que los usuarios agrupen y organicen los datos de un análisis a partir de un elemento de atributo seleccionado. - Panel Filtro local: Este panel está ubicado en la parte inferior de la interfaz y muestra los filtros locales del análisis. Cuando un usuario filtra los datos en una visualización usando elementos de distintos atributos, se crea por defecto un filtro local y se muestra en el panel Filtro local. Figura 118. Áreas del Editor de Análisis. La funcionalidad de la barra de herramientas del editor (Figura 119), principalmente es la de ocultar/mostrar las principales áreas/paneles que conforman el Editor de Análisis. Figura 119. Barra de herramientas del Editor de Análisis. El objetivo de los botones de la barra de herramientas, según su nombre, es intuitivo. A continuación se definen: 197 - Mostrar/Ocultar objetos del conjunto de datos ( ‘Objetos de conjunto de datos’. - Mostrar/Ocultar filtros ( - Mostrar/Ocultar zonas de descenso y propiedades ( de ’Zonas de descenso’. - Mostrar/Ocultar paginación ( ): Permite mostrar/ocultar el área de ‘Paginación’. - Mostrar/Ocultar filtro local ( ): Permite mostrar/ocultar el panel de ‘Filtro local’. - Guardar datos ( - Cambiar visualización ( actual. - Ficha ( ): Indica el área de visualización actual. En caso de tener más de un área de visualización en un análisis, se puede seleccionar el área de visualización deseado haciendo click sobre su correspondiente pestaña (Figura 120). Agregar visualización ( ): Permite agregar un nuevo área de visualización. Al hacer click sobre este icono se nos abrirá la ventana de selección de visualización. - ): Permite mostrar/ocultar el panel de ): Permite mostrar/ocultar el panel de ‘Filtros’. ): Permite mostrar/ocultar el panel ): Permite guardar los datos como un fichero CSV. ): Permite cambiar el modo de visualización Figura 120. Múltiples áreas de visualización. 1.1.17.2 Creación de análisis de Visual Insight Como se ha comentado anteriormente, se deberá seleccionar el informe que se tomará como base del análisis. Una vez que se ha seleccionado el informe en cuestión y una visualización, se abrirá el 'Editor de análisis’ (Figura 121). 198 Figura 121. Creación y editado de análisis en Visual Insight. Dentro del editor de Visual Insight, los datos de interés (atributos e indicadores) se podrán añadir a la visualización de dos formas posibles: arrastrando los campos hacia su correspondiente área o haciendo click en el botón y marcando el objeto en cuestión (Figura 122). Figura 122. Adición de atributos e indicadores a la visualización. Además es posible hacer un filtrado de las posibles representaciones de los atributos. Para ello desde el área de filtros, se deberá hacer click en la flecha para desplegar el listado de valores (Figura 123), y marcando/desmarcando se podrá seleccionar que valores se representarán. 199 Figura 123. Modificación de filtros. 200 CREACIÓN DE DOCUMENTOS Un documento de MicroStrategy contiene objetos que representan los datos procedentes de uno o varios informes, además de la información de posición y formato. Se utiliza para dar formato a datos de varios informes en un solo archivo con calidad de presentación. Al crear un documento, puede especificar los datos que se incluyen, controlar el diseño, el formato, el agrupamiento y los subtotales de datos y especificar la posición de los saltos de página. Además, puede insertar imágenes y dibujar bordes en el documento. La mayor parte de los datos de un documento procede de un conjunto de datos subyacente. Un conjunto de datos es un informe de MicroStrategy que define la información que Intelligence Server recupera del warehouse o la caché. Existen tres maneras para crear un documento en MicroStrategy: - Desde el principio: Se puede crear un documento desde el principio hasta el final, seleccionando los datos que se van a incluir y aplicando formato al documento. Los documentos utilizan conjuntos de datos, o informes de MicroStrategy, como origen de datos en los documentos. - A partir de una plantilla: Se puede usar otro documento como plantilla, que permite aplicar un patrón al nuevo documento basado en otro existente. En el nuevo documento se utilizan el mismo conjunto de datos, los controles, los formatos y el diseño del original. Es posible modificar dicho documento o agregar elementos a este. - A partir de un informe: Se puede comenzar a partir de un informe de MicroStrategy y utilizarlo como conjunto de datos principal del documento. El informe se agrega a un documento nuevo como objeto Cuadrícula/Gráfico en la sección Encabezado de detalles del documento. 1.1.18 Creación de documentos Las principales formas de crear un documento son dos: - Partiendo de un informe: Para ello, se tendrá que hacer click derecho sobre el informe deseado, y posteriormente habrá que seleccionar la opción ‘Crear documento’. Se abrirá la ventana de edición de documentos. - Accediendo a la ventana de creación de documentos: Para ello se seleccionará desde la ventana de bienvenida el acceso directo a ‘Crear documento’. Se podrá elegir entre plantillas de documento o plantillas de tablero. Esta última opción, ‘Plantillas de tablero’, es la opción de interés ya que permitirá crear tableros de mando (Figura 124). 201 Figura 124. Selección de plantillas de tablero. Una vez que se ha seleccionado la plantilla de tablero deseada, se abrirá el ‘Editor de documentos’. Desde aquí se podrá seleccionar los diferentes objetos, informes, imágenes, widgets, etc, que se quiera incluir en el tablero de mando. Para ello se deberá seleccionar ‘Agregar contenido’, y se abrirá una ventana desplegables con las distintas opciones (Figura 125). Figura 125. Editor de documentos. 202 Referencias Se desglosa a continuación el material de soporte, utilizado para la elaboración del presente documento: Manual MicroStrategy: Reporting Essentials Manual MicroStrategy: Advanced Reporting 203