C02 descriptiva
Anuncio

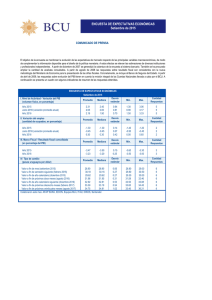
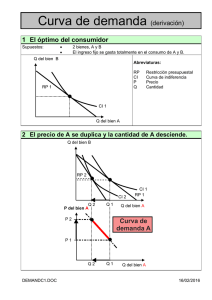
Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky 18 3. MEDIDAS RESUMEN: Numéricas y Gráficas. 3.1 Introducción Ejemplo. “Admítelo una salchicha no es una zanahoria”. Así decía la revista ”El Consumidor” en un comentario sobre la baja calidad nutricional de las salchichas. Hay tres tipos de salchichas: i. carne vacuna, ii. mezcla (carne porcina, vacuna y de pollo) iii. pollo. ¿Existe alguna diferencia sistemática entre estos tres tipos de salchichas, en estas dos variables? Calorías y sodio en salchichas por tipo Vacuno Mezcla Calorías Sodio Calorías Sodio 186 495 173 458 181 477 191 506 176 425 182 473 149 322 190 545 184 482 172 496 190 587 147 360 158 370 146 387 139 322 139 386 175 479 175 507 148 375 136 393 152 330 179 405 111 300 153 372 141 386 107 344 153 401 195 511 190 645 135 405 157 440 140 428 131 317 138 339 149 319 135 296 132 253 Pollo Calorías 129 132 102 106 94 102 87 99 170 113 135 142 86 143 152 146 144 Sodio 430 375 396 383 387 542 359 357 528 513 426 513 358 581 588 522 545 Nos interesa resumir las características más importantes del conjunto de datos en una pequeña cantidad de números que sean fácilmente interpretables. La distribución de la cantidad de sodio en las salchichas de pollo muestra dos grupos distintivos. Este tipo de distribuciones no estará bien representada por las medidas resumen. Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky 19 Los resúmenes pueden ser muy útiles pero no son los detalles. Generalmente los detalles agregan poco, pero es importante estar preparados para las ocasiones en que sí agregan mucho. 3.2 Centro y dispersión. Los conjuntos de datos provenientes de una población homogénea poseen, en general, dos propiedades importantes: un valor central y la dispersión alrededor de ese valor. Vemos esta idea en los siguientes histogramas hipotéticos: Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky 20 Veremos medidas de la posición del centro, la dispersión y otras medidas de posición. 3.3 Media y varianza muestrales Las medidas resumen clásicas utilizan solamente operaciones aritméticas simples (+, *, raíz cuadrada) para resumir un conjunto de datos de n observaciones, x1, x2, . . . , xn . La media muestral x , como medida de la posición del centro de los datos, x + x= 1 + xn n , la varianza muestral, 1 n 2 s = ∑ ( xi − x ) n − 1 i =1 2 ó el desvió estándar 1 n s = DS = ( xi − x ) 2 ∑ n − 1 i =1 como medida de variabilidad o dispersión. El desvío estándar es la medida clásica de variabilidad. Observación: el desvío estándar (DS) tiene las mismas unidades que las observaciones. Desviación respecto de la media xi − x desviación i-ésima respecto de la media. Los datos menores que la media tienen un desvío negativo. Los datos mayores que la media tienen un desvío positivo. Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky 21 Si • todas las diferencias son pequeñas en valor absoluto: • las observaciones • algún xi están cerca de x ∴ los datos presentan poca variabilidad, xi − x es grande en valor absoluto se tiene mayor variabilidad. Es fácil ver que ∑ ( xi − x ) = 0. La varianza muestral mide la desviación cuadrática de los datos respecto de su media Es más fácil realizar cálculos con desvíos cuadráticos, | xi − x |. (xi − x ) 2 , que con desvíos absolutos, 3.3 Media y varianza poblacionales, para poblaciones finitas Si datos son poblacionales tendremos: • como medida de posición, la media poblacional μ que se calcula como N ∑ xi 1 μ = i =N • como medida de dispersión, la varianza poblacional σ2 σ2 1 = N N ∑ ( xi − μ ) 2 i =1 ó la raíz cuadrada de σ2, σ , que llamaremos desvío estándar. . Población ocupada, República Argentina, Octubre de 1994. Síntesis 3, INDEC, 1995 Aglomerado Urbano Pobl. Ocup. Aglomerado Urbano Pobl. Ocup. Gran Buenos Aires 4300500 Gran Tucumán y Tafí Viejo 197809 Gran Córdoba 440558 Neuquén 66506 Gran Mendoza 294768 Paraná 66604 Gran Rosario 401203 Santa Rosa - Toay 32286 La cantidad media de ocupados por aglomerado urbano (n=8) es 725029 y su desvío estándar es 1359044. Si excluimos Gran Buenos Aires (n=7) tendremos media = 214248 y desvío estándar = 155692. Una sola observación ha modificado fuertemente los resultados. Las medidas resumen deberían ser resistentes (varíen poco en presencia de un cambio arbitrario de una pequeña parte del lote). Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky 22 Un único dato aberrante puede producir un importante efecto adverso tanto en la media muestral como la varianza muestral 3.4 Medidas resistentes a datos extremos o aberrantes. Las medidas resistentes utilizan los datos ordenados. Ordenamos los datos, x1, x2, . . . , xn , en orden ascendente y obtenemos la muestra ordenada: x(1) ≤ x(2) ≤ . . . ≤ x(n) ; Podemos contar desde el más pequeño hacia el más grande, rango ascendente, ó desde el más grande hacia el más pequeño, rango descendente. Definición: La profundidad de un dato en la muestra es el menor de los rangos ascendente y descendente. 3.4.1 Mediana Definición: La mediana, M es el valor que deja la misma cantidad de los datos ordenados de cada lado. La mediana es una medida resistente de posición del centro de los datos. La profundidad de la mediana es pM = n +1 . 2 La mediana se calcula como el valor central si n es impar y promedio de los dos valores centrales si n es par Ejemplo (continuación): La mediana es el dato con profundidad PROF. # hojas TALLO HOJAS 1 1 628 : 5 1 0 629 : 4 3 630 : 358 7 3 631 : 033 9 2 632 : 77 18 9 633 : 001446669 23 5 634 : 01335 10 635 : 0000113668 26 7 636 : 0013689 19 2 637 : 88 17 6 638 : 334668 11 5 639 : 22223 6 0 640 : 6 1 641 : 2 5 3 642 : 147 59 + 1 = 30 . M = 63.53. 2 La media, 63.589, es cercana a la mediana. Este hecho es coherente con la simetría que presentan los datos alrededor de la mediana. Una profundidad identifica dos valores de los datos, uno por debajo y otro por encima de la mediana. Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky 2 2 0 2 23 643 : 644 : 02 Comparación de media y mediana para distintos tipos de distribuciones mediante histogramas suavizados. Asimétrica a izquierda Simétrica Asimétrica a derecha 3.4.2 Media podada Ordene los datos, descarte las 100α% de las observaciones menores y el 100α% de las observaciones mayores; calcule el promedio de los datos restantes. Se recomienda tomar α entre 0.1 y 0.2: xα = x [ n α ]+1 + + x n −[nα ] n − 2[n α ] , 3.4.4 Otras medidas de posición A la mediana y los extremos les agregamos otro par de valores resumen, los cuartiles, que dejan un cuarto y tres cuartos de las observaciones a cada lado. p ro fu n d id ad d el cu artil = 59 + 1 = 15 4 Por lo tanto: Cuartil inferior=63.36 Cuartil superior=63.84 En el ejemplo, la profundidad del cuartil es 3.4.5 Otras medidas de dispersión de los datos. • distancia intercuartil (dQ) , o rango intercuartil, dQ = Cuartil superior - Cuartil inferior n +1 4 Estadística (Q) FCEN-UBA • Dra. Diana M. Kelmansky 24 rango, la diferencia entre los valores extremos, también refleja la dispersión pero valores sueltos afectan tanto el rango que su resistencia es despreciable. • MAD: Desvio absoluto respecto de la Mediana: Es una versión resistente del desvío estándar basada en la mediana. MAD = mediana ( xi − M ) ¿Cómo calculamos la MAD? • Ordenamos los datos de menor a mayor. • Calculamos la mediana, valor en la posición (n+1)/2. • Calculamos los desvíos absolutos de cada dato respecto de la mediana (la distancia de cada dato a la mediana, sin signo). • Ordenamos los desvíos absolutos de menor a mayor. • Calculamos la mediana de los desvíos. Observación: Si deseamos comparar la distancia intercuartil y la MAD con el desvío estándar es conveniente dividirlas por constantes adecuadas. En ese caso se compara el DS con MAD 0.675 dQ 1.35 Ejemplo: continuamos con los puntos de fusión de ceras naturales DESCRIPTIVE STATISTICS CERA 63.589 0.3472 62.850 63.360 63.840 64.420 0.2300 MEAN SD MINIMUM 1ST QUARTI 3RD QUARTI MAXIMUM MAD dQ = Cuartil superior - Cuartil inferior = 63.84 - 63.36 = 0.48 MAD 0.675 = 0.23 / 0.675 = 0. 341 Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky 25 dQ 1.35 = 0.48 / 1.35 = 0.356 SD = 0.3472 Las correcciones han acercado las estimaciones de la variabilidad de la MAD y la distancia intercuartil al valor obtenido para el desvío estándar. Veremos más adelante qué características deben presentar los datos para que las tres medidas de dispersión sean similares, como ocurre en el ejemplo. 3.4.6 Más medidas de posición: Percentiles La mediana de un conjunto de datos ordenados es el valor que los divide en dos partes iguales, tiene profundidad (n+1)*0.5. Es el percentil del 50% (100*0.5%). El cuartil inferior, que deja a su izquierda al 25% de los datos y se encuentra en la posición (n+1)*0.25, es el percentil del 25% (100*0.25%). El cuartil superior, tiene la posición (n+1)*0.75. Así, el valor que deja un 95% de los datos por debajo y un 5% por encima es el percentil del 95%. Gráfico de un percentil en un histograma suavizado. El percentil del 100*α%, Pα, de un conjunto de datos ordenados, es el valor que deja un 100*α% de los datos por debajo y un 100*(1-α)% por encima se encuentra en la posición (n+1)* α. Cuando este valor no es entero se interpola. Percentiles de la altura (cm) de mujeres y varones de 18 años (Crecimiento y Desarrollo. Sociedad Arg. de Pediatría. 1986) Percentil 3% 10% 25% 50% 75% 90% 97% Varón 1.60 1.64 1.68 1.72 1.77 1.81 1.85 Mujer 1.49 1.53 1.56 1.60 1.64 1.68 1.72 Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky En distribuciones perfectamente simétricas los percentiles del 100*α% y del 100*(1-α)% equidistan de la mediana. La distribución de las alturas de mujeres y varones es aproximadamente simétrica, pero la de los pesos no lo es. 26 Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky 27 4. Box Plots o Gráficos Caja El boxplot es la representación gráfica de la mediana, los cuartiles, y el máximo y mínimo siempre que no haya valores atípicos (outliers). En este caso el máximo y el mínimo se reemplazan por los valores adyacentes superior e inferior respectivamente y los valores atípicos se grafican por separado. Se trata de los valores externos que pueden clasificarse como moderados o severos. Permite extraer los siguientes aspectos del lote: Posición del centro - Dispersión - Asimetría - Longitud de la cola Puntos que yacen fuera del conjunto. 4.1 Identificación de valores atípicos. Utilizamos una medida de dispersión que sea insensible a los valores atípicos, la distancia intercuartil y definimos puntos de corte para detectar outliers: Valla Interna Inferior = Q I - 1.5 d Q Valla Interna Superior = Q S + 1.5 d Q Valla Externa Inferior = Q I - 3 d Q Valla Externa Superior = Q S + 3 d Q VALOR ADYACENTE ⎧valor más cercano, mayor o igual, . INFERIOR (VAI) = ⎨ ⎩a la valla interna inferior VALOR ADYACENTE ⎧valor más cercano, menor o igual, SUPERIOR (VAS) = ⎨ ⎩ a la valla interna superior. Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky Si no hay valores atípicos: VAI = mínimo 28 VAI = máximo 4.2 Construcción del Box Plot Construiremos un boxplot para las 15 concentraciones de CO2 (miligramos/M2*minuto ) siguientes: 9.21 51.52 10.6 55.71 13.65 58.1 14.17 206.43 16.95 207.08 28.27 497.15 38.36 1837.81 medidas en diferentes puntos de un depósito de residuos patológicos El boxplot se construye dibujando: i) una caja cuyos extremos son los cuartiles (QI =14.17) y (QS=206.43) y con una barra vertical en la mediana (M= 41.28), ii) una línea de cada extremo de la caja hasta el corresp. valor adyacente (VAI = VAS = ), iii) los valores que caen fuera de las vallas internas pero dentro de las externas son outliers moderados, iv) los valores que caen fuera de las vallas externas son outliers severos. OJO! no confundir la valla con el valor adyacente! Cálculos parciales La mediana (M= 41.28) se encuentra en la posición (15+1)/2 = 8 El cuartil inferior (QI =14.17) en la posición (15+1)/4 = 4 El cuartil superior (QS=206.43) en la posición (15+1)*3/4 = 12 distrancia intercuartil (dQ) = QS - QI = 206.43 - 14.17 = 192.26 1.5* dQ = 1.5 * 192.26 = 288.39 3* dQ = 3 * 192.26 = 576.78 QI - 1.5* dQ= -274.22 QI - 3* dQ= -562.61 QS + 1.5* dQ= 494.82 QS + 3* dQ= 783.21 41.28 Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky 29 Resistencia del Boxplot Un gráfico similar podría construirse en base a la media y el desvío muestrales. Tal gráfico carecería de resistencia. ¿Porqué es esto importante? 4.3 Comparación de lotes Boxplots del contenido calórico de tres tipos de salchichas Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky 30 Diagramas-tallo hoja de los datos de calorías en diferentes clases de salchichas. Vacuno Mezcla Pollo Tallo Hojas Tallo Hojas Tallo Hojas 8 8 8 67 9 9 9 49 10 10 7 10 226 11 1 11 11 3 12 12 12 9 13 1259 13 5689 13 25 14 1899 14 067 14 2346 15 2378 15 33 15 2 16 16 16 17 56 17 2359 17 0 18 146 18 2 19 00 19 015 De los Box-Plots: Las salchichas de pollo, como grupo, contienen menos calorías que las de carne o las de mezcla: la mediana del contenido calórico de las de pollo está por debajo del cuartil inferior de las otras distribuciones. Todos los tipos muestran una gran dispersión entre marcas; las salchichas de pollo no garantizan una comida de bajas calorías. De los diagramas Tallo-Hoja: Para los datos de “mezcla” vemos que se distinguen claramente dos grupos de marcas, la distribución tiene dos picos y un outlier en la cola inferior. Los cuartiles, Ci=139.50 y Cs=179.75, están aproximadamente en el centro de cada uno de los grupos, de manera que gran parte de la distancia intercuartil (dc ) está dada por la distancia entre los grupos. Por esta razón el 1.5* dc que se utiliza para graficar el box-plot no distinguió al outlier. Aunque en el diagrama correspondiente a las salchichas de pollo no se observan dos grupos separados, como en “vacuno” y “mezcla”, pueden verse claramente dos picos. Retomemos el ejemplo de la cantidad de sodio en las salchichas de pollo, cuyo diagrama tallo hoja tenemos a continuación 3 | 666889 4 | 033 4| 5 | 11234 5 | 589 Esta distribución bimodal también sugiere la presencia de dos grupos en los datos. Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky 31 Los valores ordenados de la cantidad de sodio en salchichas de pollo son: 357 358 359 375 383 387 396 426 430 513 522 528 542 581 588 La media (449,66) se encuentra en una zona donde no hay datos y la mediana (426) cerca del borde de uno de los dos grupos. El intervalo ( x − s , x + s ) no es una buena representación de los datos y el gráfico caja tampoco. Ni la media ni la mediana ni el boxplot dan una buena información sobre este tipo de datos porque no está presente en ellos un centro claro. 4.4 Ejemplos con Valores atípicos Ejemplo 1: En 1985 los científicos británicos anunciaron un agujero en la capa de ozono de la atmósfera terrestre sobre el polo sur. El reporte de los británicos fue descartado al comienzo pues estaba basado en instrumentos terrestres enfocados hacia arriba. Observaciones más completas, obtenidas por instrumentos satelitales mirando hacia abajo, no habían mostrado nada inusual. Luego, un análisis más exhaustivo de las mediciones satelitales, reveló que las lecturas de Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky 32 ozono en el polo sur eran tan bajas que el programa de computadora que las analizaba las había suprimido automáticamente como outliers en forma equivocada. Se reanalizaron las lecturas desde 1979. Éstas mostraron un agujero de tamaño creciente en la capa de ozono que no tenía explicación. Ejemplo 2: Mediciones obtenidas por Newcomb entre Julio y Septiembre de 1882. 28 22 36 26 26 28 26 24 32 30 27 24 33 21 36 32 31 25 24 25 28 36 27 32 34 30 25 26 26 25 -44 23 21 30 33 29 27 29 28 22 26 27 16 31 29 36 32 28 40 19 37 23 32 29 -2 24 25 27 24 16 29 20 28 27 39 23 ¿qué variable ha sido medida? • Newcomb midió cuánto tardó la luz en llegar, desde su laboratorio sobre el río Potomac a la base del monumento a Washington y volver, una distancia total de 7400 metros. • es necesario tener la descripción del instrumento • juzgar si la variable medida es la adecuada (conocimiento experto) • sobre el campo particular en estudio. Por ejemplo Newcomb construyó aparatos nuevos y complicados para medir el tiempo en que pasaba la luz. Nosotros aceptamos el juicio de los físicos sobre que este instrumento es adecuado para su propósito y más preciso que instrumentos anteriores. Codificación: La primera medición del tiempo de paso de la luz era 0.000024828 segundos. Corremos al punto decimal nueve lugares a la derecha, obteniendo 24828 y luego registramos únicamente el desvío respecto de 24800. Luego 28 es la versión corta de 0.000024828 y -2 se corresponde con 0.000024798. Variación Los aparatos cambian levemente con la temperatura, la densidad de la atmósfera cambia día a día y así siguiendo. Incluso los mejores experimentos producen resultados variables. Esta es la razón porque Newcomb tomó muchas mediciones en vez de una. En general, el promedio de varias observaciones es menos variable que el de una única observación. Poniéndonos en lugar de Newcomb, estamos tentados de calcular el promedio de los tiempos de pasaje de la luz, convertir este tiempo en una estimación nueva y mejor de la velocidad de la luz y correr, para hacernos una reputación, a publicar el resultado. !!PELIGRO!! Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky 33 Histograma de las 66 mediciones de Simon Newcomb Un dato atípico en la brillantez vista por un satélite de vigilancia puede representar el lanzamiento de un misil. Un dato atípico de las mediciones de actividad eléctrica en un detector utilizado en física de altas energías puede ser evidencia de una nueva partícula elemental. En tales casos la distribución general simplemente provee un patrón de referencia sobre el cual sobresalen los eventos extraordinarios. Cuando los datos atípicos son inesperados e indeseados se debería hallar una causa clara para cada outlier, como la falla del equipo durante el experimento o un error en la transcripción de los datos, en esos casos, se puede corregir o eliminar el dato. Cuando no se encuentra ninguna causa es muy difícil tomar una decisión. Newcomb finalmente eliminó el peor outlier (-44) pero retuvo el otro. La media de todas las 66 observaciones es 26.21; la media de las 65 observaciones retenidas es 27.29. El gran efecto del único valor -44 sobre la media es la razón para eliminarlo. Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky 34 Este gráfico sugiere levemente que la variabilidad (dispersión vertical) es decreciente con el tiempo. Quizás, a medida que ganó experiencia, Newcomb se volvió más experto en el uso de su equipo. Los efectos de aprendizaje como el que muestran los datos de Newcomb son muy frecuentes y deben ser tenidos en consideración. Si dejamos las primeras 20 observaciones de Newcomb para el aprendizaje, la media de las 46 restantes resulta 28.15. Las mejores mediciones modernas sugieren que el “verdadero valor” para el tiempo de paso de la luz del experimento de Newcomb es 33.02. Eliminar los outliers ó fijar un período de aprendizaje, acercan los resultados al verdadero valor. Pero si es posible, siempre, hay que hallar la razón de un outlier. RESUMEN • Una medida resistente no se ve afectada por cambios en los valores numéricos de una pequeña proporción de la cantidad total de observaciones, sin importar cuánto cambien estos valores. • El centro de una distribución es medido por la media, la media α podada ó la mediana. La media es el promedio aritmético de todos los datos. La media α podada es el promedio aritmético de los datos excluidos el 100*α% de los valores mayores y el 100*α% de los valores menores. La mediana es el punto medio de los datos ordenados. • La distancia intercuartil provee una medida resistente de la dispersión o variabilidad de la distribución. Los cinco números resumen, dados por la mediana, los cuartiles, el máximo y el mínimo proveen una descripción rápida de la forma global de una distribución. • Los Boxplots, basados en los cinco números resumen, son útiles para comparar varias distribuciones. Las vallas internas y externas son útiles para identificar potenciales valores atípicos (outliers). Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky 35 • La varianza muestral s2 y especialmente su raíz cuadrada, el desvío estándar DS, son medidas muy usuales, pero no resistentes, de la dispersión de los datos alrededor de la media. 5. Curvas de densidad ¿Existe alguna manera de describir una distribución completa mediante una única expresión? • un diagrama tallo-hoja no es práctico pues se trata de demasiados datos • un histograma elimina los detalles y depende de la elección de las clases • la mediana y los percentiles registran algunos aspectos específicos de los datos. Si queremos tener una descripción de la forma global de la distribución, omitiendo valores atípicos y otras desviaciones del patrón general, la respuesta es sí. Histograma del puntaje de vocabulario y la aproximación por una curva gaussiana. Aproximamos al histograma por una curva suave que muestre la forma de la distribución sin las irregularidades del histograma. En este ejemplo se trata de la curva gaussiana que describiremos en las próximas secciones. Observe que la escala de frecuencias relativas (Frecuencias/ 947; 0.05 0.11 0.16 0.21 0.26) coincide en este caso con la escala de densidad porque la longitud de los intervalos de clase del histograma es 1. 5.1 Superposición de una curva normal a un histograma a mano Estadística (Q) FCEN-UBA • grafique una curva simétrica de altura = Dra. Diana M. Kelmansky 1 DS 2π 36 y puntos de inflexión en x ± DS . • la escala en el eje vertical es la frecuencia relativa, siempre que la longitud de la base de los rectángulos de clase sea 1. En cualquier otro caso, en el eje vertical se grafica (la frecuencia relativa de cada clase) / (longitud de la clase) de manera que el área de un rectángulo = (longitud de la base)*(altura del rectángulo)= frecuencia relativa Verifiquemos este procedimiento para la superposición que muestra la figura sabiendo que la media del puntaje es 6.9156, el desvío es 1.6305, la longitud del intervalo de clase es 1 y 1 DS 2π = 0.2447 5.2 Propiedades de una curva de densidad Como la frecuencia relativa de todas las observaciones es 1, requerimos que el área total bajo la curva sea 1. El área bajo la curva y sobre un intervalo, correspondiente a cualquier rango de valores de la variable, es la proporción de observaciones que caen en ese rango. La curva describe la forma de la distribución y el área bajo la curva = frecuencia relativa. Es llamada curva de densidad de la distribución. El eje vertical mide la frecuencia relativa/(longitud del intervalo de clase). Una curva de densidad con la forma apropiada suele ser una descripción adecuada del patrón global de una distribución. Los datos atípicos, que son desviaciones del patrón global, no están descriptos por la curva. Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky 37 Media y mediana en una curva de densidad simétrica Media y mediana en una curva de densidad asimétrica a derecha Las medidas de posición y dispersión también se aplican al caso de curvas de densidad. El p-ésimo percentil, xp , en una curva de densidad es el punto que deja a su izquierda un p % del área bajo la curva y el (100 - p) % restante, a la derecha. p % del área (100 - p) % del área xp En particular la mediana es el punto de áreas iguales, es decir, el punto que deja áreas iguales de cada lado. Si pensamos a las observaciones como pesos en una vara delgada la media es el punto en que la vara quedaría equilibrada al poner un fiel justo debajo de él. Esta interpretación se extiende a la curva de densidad. Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky 38 . La media es un punto de equilibrio de una curva de densidad. Las curvas de densidad simétricas son perfectamente simétricas a pesar que los datos reales rara vez mostrarán simetría perfecta. Debemos distinguir los parámetros poblacionales , la media = μ y el desvío = σ , de una curva de densidad de los números x y DS calculados a partir de las observaciones. 5.3 Distribuciones Normales o Gaussianas. Todas las distribuciones gaussianas tienen la misma forma. Vemos dos curvas normales con μ= 1 y μ=5 y σ=1. Dos curvas normales con diferente σ. Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky 39 Podemos localizar σ a ojo en una curva normal. A medida que nos movemos en ambas direcciones desde el centro μ de la curva, ésta aumenta su pendiente hasta un punto (punto de inflexión) en que la pendiente empieza a disminuir Los dos puntos en los cuales ocurre este cambio de curvatura están localizados a una distancia σ a cada lado del centro μ. Recuerde que μ y σ sólos no determinan la forma de una distribución en general. Éstas son propiedades de las distribuciones gaussianas. Existen otras distribuciones no gaussianas con forma de campana. Las curvas de densidad normal están descriptas por la siguiente ecuación x−μ 2 − ( ) 1 y= e σ (2) σ 2π Observación: la ecuación (2) de la curva queda completamente especificada cuando se conocen los valores de μ y σ. Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky 40 Las distribuciones normales proveen buenos modelos para • puntajes de pruebas tomadas en poblaciones grandes (pruebas habilidades escolares y muchas pruebas psicológicas), • mediciones cuidadosamente replicadas y de la misma calidad (datos de Newcomb tabla 2.1 sin outliers), • características de una población biológicamente homogénea (longitudes de las cucarachas, rendimiento de la soja y pérdida de humedad en carne de pollo envasada). Las distribuciones de las siguientes variables, en cambio, son generalmente asimétricas: • variables económicas (ingreso personal, ventas en firmas comerciales), • tiempos de sobrevida (de pacientes de cáncer luego de realizado un tratamiento), • tiempo de vida (de componentes mecánicos o electrónicas). A pesar que la experiencia puede sugerir si un modelo gaussiano es o no factible en un caso particular, es muy riesgoso suponer la normalidad de los datos sin inspeccionarlos. Observaciones • El desvío estándar no significa nada si los datos no son Normales o aproximadamente Normales • La media no describe el centro si los datos no son simétricos • La mediana y la distancia intercuartil pueden fallar si los datos forman grupos • El significado de las medidas resumen está atado a la forma de la distribución de los datos. 5.4 Propiedades de la distribución Normal o gaussiana Sabemos que una transformación lineal no modifica la forma global de una distribución. a) Cualquier variable, X*, obtenida de una variable X que se distribuye de acuerdo con la curva Normal con media μ y desvío σ (X ~ N(μ,σ2) ) mediante una transformación lineal, sigue siendo teniendo distribución Normal (es decir gaussiana). b) Si los valores, x, de la variable X se transforman por la variable transformada, X*, x* = a + b x con b > 0 tendrá media a + bμ y desvío bσ . c) Si una variable X tiene distribución normal con media μ y desvío σ entonces la variable estandarizada Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky Z= 41 X −μ σ tiene una distribución normal con media 0 y desvío 1 (N(0,1)). Esta es llamada distribución normal estándar. Cuando la distribución de los valores de una variable es aproximadamente normal, las observaciones son frecuentemente estandarizadas restándole la media y dividiéndolas por el desvío. La estandarización de una observación indica a cuantos desvíos se encuentra de la media y para qué lado. Ejemplo. Las alturas de las mujeres jóvenes argentinas están distribuídas (aprox.) normalmente con μ = 160 cm σ = 4 cm. La altura estandarizada Z= altura - 160 4 sigue una distribución normal estándar. Una mujer que mide 170 cm tiene una altura estandarizada Z= 170 - 160 = 2.5 4 es decir 2.5 desvíos estándar por encima de la media. Análogamente una mujer que mide 155 cm tiene una altura estandarizada Z= 155 - 160 = −125 . 4 es decir 1.25 desvíos estándar por debajo de la media. ¿Qué proporción de mujeres miden menos de 155 cm? Esta frecuencia relativa es el área bajo la curva N(160, 42) a la izquierda del punto 155. Como la altura estandarizada es -1.25, esta área es la misma que el área bajo la curva normal estándar por debajo de -1.25. Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky 42 El área bajo la curva y sobre el punto 155 es cero, por lo tanto la frecuencia relativa de los valores de la variable que son estrictamente menores que él (X < 155) es igual a la frecuencia relativa de los valores de la variable que son menores ó iguales que él (X ≤ 155). Esto no es verdad en conjunto de datos reales, que pueden contener la altura 155 cm. 5.5 Función de distribución acumulada. Si Z es una variable cuya función de densidad está dada por la curva normal estándar, el área bajo dicha curva para valores menores o iguales que z • es la frecuencia relativa de los valores de Z que son menores o iguales que z • se representa por φ(z) • se denomina Función de Distribución Acumulada de la variable Z • se calcula mediante la siguiente integral, que está tabulada para diferentes valores de z y también es calculada por los programas estadísticos usuales, Φ( z ) = z x2 − e 2 1 ∫ 2π − ∞ Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky 43 5.6 Gráfico de probabilidad normal. Gráfico cuantil-cuantil. Un histograma o un diagrama tallo-hoja pueden revelar aspectos no normales en los datos como los outliers (Histograma de los datos de Newcomb ) o mostrar una pronunciada asimetría (ejemplo de gastos, tallo-hoja) Una medida más sensible para determinar si el modelo normal es adecuado para un conjunto de datos está provista por un gráfico cuantil-cuantil. Cuantil es la denominación alternativa a percentil cuando hablamos de proporciones en vez de porcentajes. La idea general de un gráfico cuantil-cuantil es comparar dos distribuciones graficando sus cuantiles (ó sus percentiles) uno versus el otro. Si las distribuciones son aproximadamente iguales sus cuantiles serán aproximadamente iguales. El gráfico cuantil-cuantil estará cerca de la recta y = x. Si nó, las desviaciones de esta recta mostrarán cómo difieren las distribuciones. también Estamos interesados en una aplicación de esta idea general: la comparación de la distribución observada de la variable, con la distribución normal. La idea de un gráfico cuantil-normal para un conjunto de observaciones es considerar a cada observación como el cuantil de la distribución observada y graficarlo contra el cuantil de la distribución normal estándar. La menor de 20 observaciones, es el cuantil 0.05 de los datos, porque 1/20 ó 0.05 de las observaciones son menores o iguales que ella. Graficamos cada observación contra el valor de la normal que deja la misma proporción de la distribución por debajo. Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky 44 Gráfico cuantil-normal para los datos del tiempo de paso de la luz de Newcomb. La mayoría de los puntos están cerca de una recta, indicando que un modelo gaussiano ajustaría bien. Los dos valores atípicos se desvían de la recta y muestra cómo responde el gráfico a colas pesadas a izquierda ó a outliers bajos. En una distribución asimétrica a izquierda las observaciones menores yacen notoriamente por debajo de la recta trazada por cuerpo principal de las observaciones mayores. El gráfico correspondiente a los datos del contenido calórico en salchichas de mezcla de carnes, muestra claramente dos grupos (clusters) y el outlier bajo. Es visible la asimetría a derecha del grupo de los valores más bajos por la curvatura de dichos puntos. Al trazar una recta por los primeros 4 puntos del grupo los otros cuatro quedan por encima de dicha recta. El diagrama tallo-hoja muestra muy claramente la distribución de este pequeño conjunto de datos, que es definitivamente no gaussiano. Comparar el diagrama tallo-hoja con el gráfico cuantil normal nos permite ver claramente como es el comportamiento de un gráfico cuantilnormal. Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky 45 Gráfico cuantil-normal para los datos del gasto de los clientes en un almacén. La marcada asimetría a derecha de esta distribución se destaca al trazar una recta por los puntos que se encuentran más abajo, que corresponden a las observaciones menores. Las observaciones mayores están sistemáticamente por encima de esta recta, indicando asimetría a derecha. No se observan outliers individuales. Gráfico cuantil-normal para los datos del tiempo de paso de la luz de Newcomb con los outliers Estadística (Q) FCEN-UBA Dra. Diana M. Kelmansky 46 omitidos. Las únicas desviaciones importantes de la normalidad son los numerosos grupitos horizontales de datos. Estos representan observaciones con el mismo valor, debidas a la limitación en la precisión y no traen problemas al adoptar el modelo normal Los datos reales, casi siempre, mostrarán algún apartamiento del modelo gaussiano teórico. Es importante al examinar un gráfico cuantil-normal buscar formas que muestren un claro apartamiento de la normalidad. RESUMEN Una curva de densidad frecuentemente permite describir en forma compacta el patrón general de una distribución. El área por debajo de una curva de densidad es una frecuencia relativa. El área total es 1. La media μ (punto de equilibrio), la mediana (punto de áreas iguales) y otros percentiles pueden ser localizados bajo una curva normal. El desvío estándar σ no puede localizarse a ojo en la mayoría de las curvas de densidad. La media y la mediana coinciden para curvas de densidad simétricas, pero la media de una curva asimétrica a derecha está localizada más lejos hacia la cola larga que la mediana. Las distribuciones normales, ó gaussianas, están representadas por curvas simétricas con forma de campana. La media μ y el desvío estándar σ especifican completamente la distribución N(μ,σ2). La media es el centro de simetría y σ es la distancia desde μ hasta los puntos de inflexión de la curva. Todas las curvas normales coinciden cuando las mediciones están realizadas en unidades de σ alrededor de la media. Estas son llamadas mediciones estandarizadas. Si X tiene distribución N(μ,σ2) luego la variable estandarizada Z = (X-μ)/σ tiene distribución normal estándar N(0,1). Las frecuencias relativas de cualquier distribución normal pueden calcularse a partir de la distribución N(0,1).