Bases de Datos Distribuidas
Anuncio

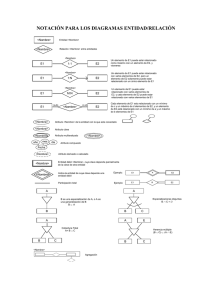
Bases de Datos Distribuidas Estructura de contenidos Mapa conceptual Introducción 1. Definición 2. Reglas Características 3. Diseño de Base de Datos Distribuidas 3.1 Consideraciones 3.2 Procedimiento 3.3 Fragmentación 3.3.1 Fragmentación Horizontal 3.3.2 Fragmentación Vertical 4. Replicación 4.1 Características 4.2 Objetos de replicación 4.3 Grupos de replicación 4.4 Los sitios de replicación 4.4.1 Un sitio maestro 4.4.2 Un sitio de instantáneas 4.5 Replicación de Instantáneas 4.5.1 Copias de sólo lectura 4.5.2 Instantáneas actualizables 4.5.3 Usos de la replicación de instantáneas. Glosario Bibliografía Control de Documento 2 3 4 4 6 6 7 9 10 11 12 12 12 13 13 13 14 14 14 15 15 16 17 18 1 FAVA - Formación en Ambientes Virtuales de Aprendizaje SENA - Servicio Nacional de Aprendizaje MAPA CONCEPTUAL Bases de Datos Distribuidas 2 FAVA - Formación en Ambientes Virtuales de Aprendizaje SENA - Servicio Nacional de Aprendizaje Bases de Datos Distribuidas Introducción La dinámica actual de las organizaciones las ha llevado a asumir la distribución como un factor de organización, bien sea por que se encuentran divididas en forma lógica a través de áreas o departamentos, o porque la división se asume de una forma física a partir de sucursales, plantas, laboratorios, etc. Siendo los datos factor determinante para la realización de los diferentes procesos, no es extraño que estos también se encuentren distribuidos a través de estas áreas. Lograr de una manera lógica y coherente la integración de la información producida por las diferentes divisiones organizacionales, requiere que las bases de datos manipuladas por estas áreas estén disponibles para los puntos o nodos de este sistema distribuido, de manera que puedan ser accedidas globalmente, pero de forma transparente para los usuarios quienes las procesarán localmente. Se requiere entonces de un robusto sistema que permita gestionar las actividades necesarias para garantizar entre otros aspectos, disponibilidad, seguridad, estrategias de almacenamiento y tráfico en la red de comunicación entre otros aspectos. Se presenta en este material de estudio, las principales de características de las Bases de Datos Distribuidas (BDD), así como los tipos de fragmentación que pueden implementarse para generar el almacenamiento distribuido y las réplicas como estrategia para aumentar la disponibilidad del servicio y optimización del manejo de concurrencia, asegurando un manejo eficiente de tráfico en la red. 3 FAVA - Formación en Ambientes Virtuales de Aprendizaje SENA - Servicio Nacional de Aprendizaje Bases de Datos Distribuidas 1. Definición Un Sistema de Base de Datos Distribuida es una colección de sitios, conectados por medio de una infraestructura de red, en el cual cada sitio es un sistema de base de datos completo y estos sitios tienen acuerdos para trabajar juntos, de tal manera que un usuario pueda acceder a los datos de un sitio como si estuviera accediendo a ellos de forma local.(Date, 2001) Las principales razones para utilizar un sistema de bases de datos distribuidas son: Compartir Datos: Proporcionar el acceso a los datos sin importar la ubicación facilita los medios para optimizar procesos que requieren de esta información. Autonomía: distribuidas. Posibilidad de realizar operaciones locales o Disponibilidad: Garantizar que los datos se encuentren disponibles aun cuando exista un fallo en algún nodo o sitio, de manera tal que se deben asumir estrategias de replicación sobre los datos. 2. Reglas Características Date en 2001, introdujo doce reglas que deben cumplir los Sistemas de Base de Datos Distribuidas, las cuales se resumen a continuación. Autonomía local: Aun cuando debe existir un administrador del sistema global, cada sitio o nodo debe disponer de administración local, lo cual determina un nivel de autonomía sobre la administración de los datos. Independencia de un sitio central: Todos los sitios deben ser tratados igual y realizar sus propios procesamientos con el fin de evitar que la caída del nodo central deje por fuera los demás nodos. Operación continua: Así como en un sistema centralizado, se debe garantizar que la inclusión de nuevos nodos o mantenimiento del sistema no impidan la disponibilidad del servicio. 4 FAVA - Formación en Ambientes Virtuales de Aprendizaje SENA - Servicio Nacional de Aprendizaje Bases de Datos Distribuidas Independencia de Localización: La estructura lógica del sistema, debe garantizar que se accede a los datos sin que sea necesario para los usuarios conocer su ubicación. Independencia de fragmentación: Algunos sistemas optimizan su despeño al utilizar la fragmentación, que implica que algunas de sus “tablas” o relaciones se encuentran divididas en diferentes ubicaciones de disco. El sistema distribuido utiliza principalmente las bases de datos relacionales por su facilidad para reconstruir operaciones de fragmentación, todo esto en forma transparente al usuario final. Independencia de réplica: Otra estrategia en los sistemas de Base de datos es la de generar “copias” de los datos almacenadas en sitios diferentes. Procesamiento Distribuido de Consultas: Se debe prestar especial atención a la optimización de consultas, teniendo en cuenta que su procesamiento se hace en diferentes nodos. Manejo Distribuido de Transacciones: Una transacción puede ocasionar el procesamiento en varios nodos y se requiere asegurar la atomicidad de la transacción, es decir “Todo o Nada”, para lo cual los diferentes agentes que controlan las transacciones locales deben estar sincronizados para ejecutar o retroceder las operaciones en forma simultanea en los diferentes nodos donde se requiera. Otro aspecto tienen que ver con el control de concurrencia, aquí el bloqueo de transacciones es la acción que principalmente se utiliza. Independencia respecto al equipo: Se debe validar que desde diferentes equipos se pueda ejecutar el DBMS. Independencia respecto al Sistema Operativo: También se debe garantizar que se pueden utilizar diversos Sistemas Operativos. Independencia respecto a la red: Debe garantizarse también que se pueden utilizar diferentes redes de comunicaciones. Independencia respecto al DBMS: Es recomendable que el SMBD que este en cada sitio manipule la misma interfaz sin que sean copias del mismo sistema. 5 FAVA - Formación en Ambientes Virtuales de Aprendizaje SENA - Servicio Nacional de Aprendizaje Bases de Datos Distribuidas 3. Diseño de Bases de Datos Distribuidas Un Sistema de Base de Datos Distribuida es una colección de sitios, conectados por medio de una infraestructura de red, en el cual cada sitio es un sistema de base de datos completo y estos sitios tienen acuerdos para trabajar juntos, de tal manera que un usuario pueda acceder a los datos de un sitio como si estuviera accediendo a ellos de forma local.(Date, 2001) 3.1. Consideraciones Para definir la estructura organizacional en una base de datos distribuida es necesario tener en cuenta los siguientes aspectos: • Necesidades sobre los datos compartidos • Tipo de acceso a los datos • Profundidad en la información Modo de acceso Dinámico Información parcial Estático Información total Datos Nivel de conocimiento Datos y programas Compartición 6 FAVA - Formación en Ambientes Virtuales de Aprendizaje SENA - Servicio Nacional de Aprendizaje Bases de Datos Distribuidas En primer lugar, se debe analizar si se requiere compartir aplicaciones o sólo datos, ya que los recursos requeridos serían diferentes. Si las aplicaciones y datos son independientes en cada nodo no se requiere de distribuir datos o programas, se podría pensar en replicación de datos sólo por aspectos de disponibilidad y seguridad. Para las situaciones en que se comparten datos únicamente las estrategias de replicación y fragmentación pueden utilizarse y en el caso que se compartan tanto datos como aplicaciones se debe proveer la comunicación entre aplicaciones para la obtención de datos remotos. El segundo factor corresponde al acceso de los usuarios, identificándose dos tipos: acceso estático y acceso dinámico: El acceso estático es aquel donde el usuario siempre solicita datos de la misma manera, controlado la mayoría de veces por las aplicaciones que ejecuta. El acceso dinámico corresponde a la posibilidad de estar ejecutando diferentes sentencias determinadas por los requerimientos del momento. El tercer factor es el nivel de conocimiento al que se tiene acceso, se requiere acceso parcial a los datos o el acceso es total, esto se consigue revisando las políticas de servicio y la estructuración de usuarios y roles del sistema. 3.2. Procedimiento Existen dos alternativas a seguir para el diseño de una BDD, la estrategia ascendente y la descendente. En la primera se parte de un numero de bases de datos y aplicaciones que requieren ser distribuidas para lo cual se debe generar un diseño global de administración y comunicación. Y la segunda donde se planifican desde lo global hasta llegar a cada uno de los nodos o sitios. Sin importar la estrategia adoptada es necesario realizar los siguientes procesos: Se inicia con el análisis de los requisitos que definirán el entorno del sistema basados en los procesos y datos requeridos por los usuarios de la base de datos, y por los parámetros de rendimiento, seguridad, disponibilidad y flexibilidad definidos para el sistema. Se procede a continuación a definir el diseño de las vistas y el diseño conceptual, que se desarrollan en forma paralela. El diseño de las vistas define las interfaces para los usuarios y en el diseño conceptual se 7 FAVA - Formación en Ambientes Virtuales de Aprendizaje SENA - Servicio Nacional de Aprendizaje Bases de Datos Distribuidas especifican las entidades, relaciones y aplicaciones tener acceso. a las que se debe El esquema conceptual global y la información respecto al acceso a los datos proveen la información para diseñar la distribución, donde se definirán los esquemas conceptuales locales a cada nodo o sitio. A nivel de distribución local es común utilizar la fragmentación para dividir las relaciones en otras menores que pueden ser alojadas en otros sitios. Este tema se afrontará en el siguiente numeral de este documento. En el diseño físico, se especifican los esquemas conceptuales locales sobre los dispositivos de almacenamiento físico disponibles para lo cual se revisan los esquemas conceptuales definidos y la información de acceso a los fragmentos. Como siempre un último proceso es el de la evaluación, en el cual se monitorea y ajusta el diseño con la revisión periódica de los requisitos, accesos y estadísticas de incidentes y uso. Análisis de requisitos Diseño conceptual Diseño de vistas Esquema conceptual global Esquemas externos Objetivos del sistema Información de acceso DISEÑO DE LA DISTRIBUCIÓN Esquemas conceptuales locales Diseño físico Esquema físico Monitorización y ajustes 8 FAVA - Formación en Ambientes Virtuales de Aprendizaje SENA - Servicio Nacional de Aprendizaje Bases de Datos Distribuidas 3.3. Fragmentación Una Base de Datos puede ser fragmentada para mejorar el rendimiento y simplificar su mantenimiento. Las consultas que tienen acceso a tablas que han sido divididas pueden ejecutarse con mayor rapidez al contar con menos datos a recorrer o al tener procesamiento simultáneo por varios procesadores; Por otra parte las tareas de copias de seguridad o reindexación pueden ejecutarse más rápido al contar con menos datos. Otra estrategia es la de particionar sin dividir las tablas, esto se consigue cuando se almacenan las tablas en unidades de disco independientes, lo cual hace que si se requiere utilizar estas tablas para una misma consulta, varias cabezas de lectura de disco accederán a los datos de manera simultánea, recorriendo más rápido los datos. Se recomienda retomar los conceptos de Raid, vistos anteriormente. Dir. PC1 Dir. PC2 Dir. PC3 Dir. PC4 ID 1 ID 1 ID 1 ID 1 ID 2 ID 2 ID 2 ID 2 ... ... ... ... ID n ID n ID n ID n Servidor D2 2 Usuario PC1 PC2 PC3 PC4 Dir. PC2 ID 1 Dir. PC1 ID 1 Dir. PC1 ID 1 Dir. PC1 ID 1 Dir. PC3 ID 2 Dir. PC3 ID 2 Dir. PC2 ID 2 Dir. PC2 ID 2 Dir. PC4 ... Dir. PC4 ... Dir. PC4 ... Dir. PC3 ... Dir. Server ID n Dir. Server IDn Dir. Server ID n Dir. Server ID n 9 FAVA - Formación en Ambientes Virtuales de Aprendizaje SENA - Servicio Nacional de Aprendizaje Bases de Datos Distribuidas La fragmentación también tiene inconvenientes, especialmente cuando una vista se alimenta de datos que han sido particionados, requiriendo de tareas de unión y combinación, así como la verificación de dependencias, que debería revisar en más de una ubicación. Existen dos tipos de fragmentación o división: horizontal y vertical, La división o fragmentación horizontal actúa sobre las filas, dividiendo la tabla en subtablas que contienen un subconjunto de las filas de la tabla inicial. La fragmentación vertical, se basa en las columnas de la tabla para efectuar la división. 3.3.1. Fragmentación Horizontal Llave Atributo 1 Atributo 2 Atributo 3 Llave Atributo 1 Atributo 2 Atributo 3 Atributo 4 Llave Atributo 1 Atributo 2 Atributo 3 Atributo 4 Llave Atributo 1 Atributo 2 Atributo 3 Atributo 4 Llave Atributo 1 Atributo 2 Atributo 3 Atributo 4 Atributo 4 Las particiones horizontales permiten dividir una tabla en varias tablas con el mismo número de columnas, pero con menor número de filas. El análisis de los datos será el que determine la forma en que se han de dividir los datos, con mucha frecuencia se utiliza el parámetro de tiempo o en su ausencia columnas de referencia como “sucursales”, “ciudades”, etc. De cualquier forma se requiere el menor número de ellas, ya que una gran cantidad de consultas e UNION para obtener el conjunto completo, puede afectar el rendimiento. 10 FAVA - Formación en Ambientes Virtuales de Aprendizaje SENA - Servicio Nacional de Aprendizaje Bases de Datos Distribuidas 3.3.2. Fragmentación Vertical Llave Atributo 1 Atributo 2 Llave Atributo 1 Llave Atributo 3 Atributo 3 Atributo 2 Dividir una tabla en varias utilizando el particionamiento vertical, hace que existan varias tablas con la misma cantidad de filas que la original, pero donde se varia el numero de columnas o atributos de la tabla. Este proceso puede ser realizado a partir de la normalización de datos que permitiría extraer columnas redundantes en otras tablas, accediendo a ellas a través de una llave relacional. Otra alternativa es la división de columnas en nuevas tablas, con la ayuda de una llave que relacione los registros particionados. Optimizan las consultas al recorrer menos datos, ya que no se tiene que recorrer el total de las columnas (especialmente si sólo se consultan algunas con mucha frecuencia), pero si se excede en el número de particiones se puede afectar el rendimiento. 11 FAVA - Formación en Ambientes Virtuales de Aprendizaje SENA - Servicio Nacional de Aprendizaje Bases de Datos Distribuidas 4. Replicación 4.1 Características Otra de las estrategias asociadas a las bases de datos es la de replicación, que consiste en copiar y mantener objetos de la base de datos en múltiples bases de datos. Se debe asegurar que los cambios que se aplican en un sitio se registran localmente antes de ser aplicados en los sitios remotos donde se comparten los mismos datos. Las siguientes son las principales características: Los nodos o sitios que conforman el sistema distribuido no comparten memoria, ni dispositivos de almacenamiento. Lo cual determina que físicamente se encuentran en lugares separados. Existen dos tipos de transacciones, las transacciones locales que son las que acceden a los datos que se encuentran en el lugar donde se inicio la transacción, y las transacciones globales que son las que acceden a datos que están ubicados en sitios diferentes al del inicio de la transacción. Se proporciona un acceso rápido y local a los datos y se protege la disponibilidad de las aplicaciones. 4.2 Objetos de replicación Se denomina objeto de replicación a las bases de datos existentes en varios servidores de un sistema de base de datos distribuida. La instalación de la replicación le permite “duplicar” las tablas y los objetos de apoyo, tales como vistas, disparadores de base de datos, paquetes, índices y sinónimos. Moscú Bogotá B Sídney Lectura y escritura C Datos replicados 12 FAVA - Formación en Ambientes Virtuales de Aprendizaje SENA - Servicio Nacional de Aprendizaje Bases de Datos Distribuidas 4.3. Grupos de replicación Para facilitar la adecuada gestión de los objetos de replicación se requiere la creación de “Grupos de Replicación”, allí se organizan los objetos de esquemas que sean necesarios para garantizar el correcto funcionamiento de una aplicación o servicio. Sin embargo es necesario aclarar que dentro de un grupo de replicación puede existir más de una base de datos, adicionalmente los objetos de una base de datos pueden pertenecer a varios grupos de replicación. Grupo de replicación Conexión Miembro Propuestas/Precios.xlm Proyectos/Espec.doc Proyectos Proyectos Propuestas Propuestas Carpetas replicadas 4.4 Los sitios de replicación Existen dos tipos de sitios básicos donde pueden existir los grupos de replicación, dependiendo de la estrategia de copia a utilizar. 4.4.1. Un sitio maestro En este caso se mantiene una copia completa de todos los objetos de un grupo de replicación. Todos los sitios principales en un entorno de replicación con múltiples maestros se comunican directamente entre sí para difundir los datos y los cambios de esquema en el grupo de replicación. 13 FAVA - Formación en Ambientes Virtuales de Aprendizaje SENA - Servicio Nacional de Aprendizaje Bases de Datos Distribuidas Se define un sitio maestro para cada grupo de replicación que se usa como punto de control y gestiona el grupo y los objetos accesados por el grupo. 4.4.2 Un sitio de instantáneas. En este caso sólo se tienen todos o un subconjunto de “instantáneas” del objeto del grupo de replicación. Sin embargo, éstos deben ser simples instantáneas con una correspondencia uno a uno a los objetos en el sitio principal. 4.5 Replicación de Instantáneas. Contiene una réplica parcial o total de una tabla maestra de destino desde un único punto en el tiempo. Una instantánea puede ser de sólo lectura o de escritura. 4.5.1 Copias de sólo lectura. En una configuración básica, pueden proporcionar acceso de sólo lectura a la tabla de datos que se origina a partir de un "maestro" o en el sitio principal. Las aplicaciones pueden consultar los datos de las réplicas de datos locales para evitar el acceso a la red independientemente de la disponibilidad. Sin embargo, las aplicaciones en todo el sistema deben acceder a los datos en el sitio principal cuando las actualizaciones son necesarias. Aplicaciones del cliente Actualización Remota Consulta Local Tabla Replicada Tabla Maestra Modificable Red Tabla de datos replicada 14 FAVA - Formación en Ambientes Virtuales de Aprendizaje SENA - Servicio Nacional de Aprendizaje Bases de Datos Distribuidas 4.5.2 Instantáneas actualizables. En una configuración más avanzada, puede crear una instantánea actualizable que permite a los usuarios insertar, actualizar y eliminar filas de la tabla maestra. Una instantánea actualizable también puede contener sólo un subconjunto del conjunto de la tabla maestra de destino. Las instantáneas actualizables se basan en tablas en un sitio principal que ha sido configurado para permitir la replicación con múltiples maestros. De hecho, las instantáneas actualizables deben ser parte de un grupo de instantáneas que se basa en un grupo maestro en un sitio maestro. 4.5.3 Usos de la replicación de instantáneas. La réplica de instantáneas es útil para varios tipos de aplicaciones. Descarga de la información: Las instantáneas de solo lectura son útiles como una forma de replicar bases de datos enteras o información de alta carga. Por ejemplo, cuando el rendimiento de sistemas de alto volumen de procesamiento de transacciones es crítico, puede ser ventajoso para mantener una base de datos duplicada y aislar las consultas exigentes de las aplicaciones. Distribución de la Información: A partir de una tabla maestra se tienen copias con las que se trabajan y estas réplicas son actualizadas una vez al día. Transporte de información: se pueden utilizar las réplicas de sólo lectura para mover datos de una base de datos de producción de procesamiento de transacciones a un almacén de datos. Entornos desconectados: Se utilizan las réplicas para facilitar procesos donde no se cuenta con conexión permanente, como en el caso de los vendedores “puerta a puerta”, donde cada vendedor debe visitar a los clientes regularmente con un ordenador portátil y pedidos en una base de datos personal mientras están desconectados de la red corporativa y del sistema de base de datos centralizada. A su regreso a la oficina, cada vendedor debe enviar todos los pedidos a una base de datos centralizada, de la empresa. 15 FAVA - Formación en Ambientes Virtuales de Aprendizaje SENA - Servicio Nacional de Aprendizaje GLOSARIO Bases de Datos Distribuidas Base de Datos Distribuida: Es una colección de sitios, conectados por medio de una infraestructura de red. Disponibilidad: Garantizar que los datos se encuentren disponibles aun cuando exista un fallo en algún nodo. Independencia: Todos los sitios deben ser tratados igual y realizar sus propios procesamientos. Replicación: Proceso de copiar y mantener objetos de BD en múltiples BD que componen un sistema de base de datos distribuida. 16 FAVA - Formación en Ambientes Virtuales de Aprendizaje SENA - Servicio Nacional de Aprendizaje RECURSOS BIBLIOGRÁFICOS Bases de Datos Distribuidas Wales, J., Sanger, L. (2001). Wikipedia La enciclopedia libre. Recuperado el 20 de julio de 2012 de http://es.wikipedia.org A. Silberschatz, H. F. Korth. Fundamentos de Bases de Datos, 4ta EdiciónCapítulo 19: Bases de datos distribuidas. Elmasri, R.,Navathe, S. Fundamentos de sistemas de Bases de Datos - 5ta Ed. Pearson Addison Wesley. C.J. Date. Introducción a los sistemas de bases de datos. 7ª Edición. Capitulo 20. Bases de datos distribuidas. Ed. Prentice Hall. 17 4 FAVA - Formación en Ambientes Virtuales de Aprendizaje SENA - Servicio Nacional de Aprendizaje Bases de Datos Distribuidas Control de documento Construcción Objeto de Aprendizaje Bases de Datos Distribuidas Desarrollador de contenido -Experto temático- Ana Yaqueline Chavarro Asesor pedagógico Rafael Neftalí Lizcano Reyes Producción Multimedia Eulises Orduz Amézquita Victor Hugo Tabares Carreño Programador Francisco José Lizcano Reyes Líder expertos temáticos Ana Yaqueline Chavarro Parra Líder línea de producción Santiago Lozada Garcés Atribución, no comercial, compartir igual Este material puede ser distribuido, copiado y exhibido por terceros si se muestran los créditos. No se puede obtener ningún beneficio comercial y las obras derivadas tienen que estar bajo los mismos téminos de licencia que el trabajo original. 18 FAVA - Formación en Ambientes Virtuales de Aprendizaje SENA - Servicio Nacional de Aprendizaje