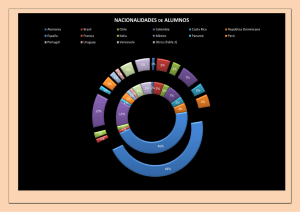
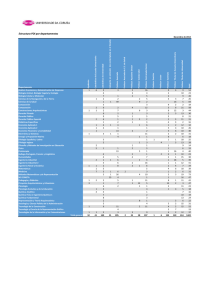
LOS MÉTODOS ESTADÍSTICOS
Anuncio

ANTONIO GARCÍA MEGÍA – DOCTOR EN FILOLOGÍA HISPÁNICA – ALMERÍA angarmegia@telelefonica.net LOS MÉTODOS ESTADÍSTICOS Y LA INVESTIGACIÓN LINGÜÍSTICA BREVE RECORRIDO HISTÓRICO Los recursos matemáticos de aplicación más generalizada a la investigación en cualquier campo de las ciencias, incluidas las sociales, son los que proceden de la Estadística y del Cálculo de Probabilidades. Cuando se habla coloquialmente de estadística, se suele pensar en una relación de datos numéricos presentada de forma ordenada y sistemática. Esta idea es la consecuencia del concepto popular que existe sobre el término por influencia del entorno. Diariamente se nos ofrecen informaciones sobre accidentes de tráfico, índices de crecimiento de población, turismo, tendencias políticas... Es al entrar en mundos más específicos de la Ciencias Sociales como la Medicina, Biología o Psicología, cuando se empieza a percibir la Estadística como un instrumento que da luz y produce valiosos resultados en estudios cuyos movimientos y relaciones, por su variabilidad intrínseca, no pueden ser abordados desde la perspectiva de las leyes deterministas. Cada manual sobre Ciencia Estadística incorpora una definición que varía en función del tipo de lector al que se dirige, pero todas coinciden en capacitar a la disciplina para registrar hechos y expresarlos matemáticamente, para investigar las relaciones que existen entre ellos aplicando principios emanados de la teoría de la probabilidad y para establecer, si es posible, el alcance de las leyes que regulan tales relaciones con la intención de realizar inferencias, ayudar a la toma de decisiones y, en su caso, formular predicciones. La Estadística mide y analiza los sucesos calificables de casuales para llegar a explicar los principios por los cuales se rigen. Los eventos en cuya descripción se utilizan medidas y conceptos estadísticos se denominan eventos estadísticos. Las leyes 1 ANTONIO GARCÍA MEGÍA – DOCTOR EN FILOLOGÍA HISPÁNICA – ALMERÍA angarmegia@telelefonica.net que expresan las relaciones exactas entre sucesos, propiedades o magnitudes parcial o totalmente estadísticas se llaman leyes estadísticas. Su grado de fiabilidad se incrementa en la medida que aumenta el número de elementos sobre los que operan. Desde los comienzos de la civilización han existido formas sencillas de estadística. Así se pueden calificar las representaciones gráficas y símbolos aparecidos en rocas y paredes de cuevas de la isla de Cerdeña, pertenecientes a la cultura Nuraga, que servían para llevar el control del ganado y la caza. De la antigüedad egipcia se conservan documentos acerca de movimientos poblacionales y censos, todo bajo la advocación de Safnkit, diosa de los libros y las cuentas. Hacia el año 3000 a. C. los babilonios usaban pequeñas tablillas de arcilla para recopilar datos tabulados sobre producción agrícola. China posee censos anteriores al 2000 a. C. En la Biblia se localizan varios recuentos de población, en el Libro de los Números y en el Libro de las Crónicas: “Locutusque est Dominus ad Moysen in deserto Sinai dicens: ‘Numera filios Levi per domos patrum suorum et familias omnem masculum ab uno mense et supra’.Numeravit eos Moyses, ut praeceperat Dominus, et inventi sunt filii Levi per nomina sua Gerson et Caath et Merari. Haec sunt nomina filiorum Gerson secundum familias suas: Lobni et Semei; filii Caath secundum familias suas: Amram et Isaar, Hebron et Oziel...”. [COLUNGA, A.1994:108]. Los griegos también realizan censos cuya información sirve para cobrar impuestos. A partir del Imperio Romano los gobiernos recopilan, de forma más o menos exhaustiva según época y talante, datos sobre población, superficie y renta de los territorios bajo su control. En 1662 aparece el primer estudio estadístico notable de población titulado Observations on the London Bills of Mortality. Un trabajo semejante sobre las defunciones contabilizadas en la ciudad de Breslau (Alemania), realizado en 1691, fue utilizado por el astrónomo inglés Edmund Halley como base para la primera tabla de mortalidad [A.H.E.P.E. 2002]. Los análisis estadísticos modernos se inician en el siglo XVII. Matemáticos como Pierre Fermat [FERMAT, P. 1894-1912] o Blaise Pascal [PASCAL. 1819], elaboran las primeras construcciones matemáticas probabilísticas a partir de aspectos relacionados con los juegos de azar que servirán de base para trabajos posteriores1. 1 Pueden encontrarse ediciones más modernas de estos autores. Véanse TANNERY, P. [1999] y TORRECILLAS, J. [1999], en relación a Fermat y MARTÍNEZ, R. [1999] sobre Pascal. 2 ANTONIO GARCÍA MEGÍA – DOCTOR EN FILOLOGÍA HISPÁNICA – ALMERÍA angarmegia@telelefonica.net El origen de la ciencia probabilística se fija en 1654 a partir de la correspondencia mantenida entre ambos [TURNBULL S. 1956:75-178] en resolución del llamado “problema de los puntos”. torno a la El Cálculo de Probabilidades y la Estadística se consolidan como disciplinas independientes entre la segunda mitad del siglo XVII y los primeros años del siglo XVIII. Es en este siglo cuando Godofredo Achenwall, profesor de Derecho Publico en la Universidad de Gottinga, utiliza por vez primera el término estadística como sustantivo etimológicamente derivado de status en su obra Geschichte der heutigen vornehmsten Europaeischen Staaten im Grundrisse [ACHENWALL, G.1749] y lo aplica al “conocimiento profundizado de la situación, o status, relativa y comparada de cada Estado”. La Estadística produce, pues, inventarios, que describen cuantitativamente las cosas notables de un estado, pero amplía rápidamente su esfera de estudio al campo de los seguros marítimos y de la ciencia. A lo largo del siglo XIX las compañías aseguradoras, que exigen un cálculo exacto de riesgos para ajustar el monto de sus pólizas, y la generalización del método científico, que precisa de un tratamiento más riguroso de sus datos para evitar la ambigüedad de las descripciones verbales y facilitar las comparaciones, estimulan la búsqueda de fórmulas capaces para trasladar cualquier clase de información a valores numéricos equivalentes. Desde 1738 la incorporan a sus trabajos de física hombres importantes como Bernoulli [BERNOULLI Society. 1987] o Maxwell [MAXWELL, J.C. 1998], que escribe en 1854: “E'ben noto che la conoscenza si basa sulle regole del corretto ragionamento. Tali regole sono, o dovrebbero essere, contenute nella Logica; ma quest' ultima tratta soltanto cose che sono certe, impossibili o completamente dubbie, nessuna delle quali (per fortuna) ci interessa. Perciò la vera logica di questo mondo è il calcolo delle probabilità, che tiene conto del concetto di probabilità che è, o dovrebbe essere, nella mente di ogni uomo ragionevole”. [CERASOLI, M. 1995:39-41]. Son ellos quienes van a constatar la existencia real de las leyes estadísticas y contribuirán de manera fundamental a su evolución. Posteriormente Boltzmann [COHEN, E. G. D. 1973] y Gibbs [GIBBS SYMPOSIUM. 1990] generalizan su empleo convenciendo a los escépticos de su utilidad en contextos experimentales. Bernoulli, por ejemplo, trabaja en la distribución que lleva su nombre y proporciona la primera solución al 3 ANTONIO GARCÍA MEGÍA – DOCTOR EN FILOLOGÍA HISPÁNICA – ALMERÍA angarmegia@telelefonica.net problema de estimar una cantidad desconocida a partir de un conjunto de mediciones de su valor que, por el error experimental, presentan variabilidad. Será pionero en la aplicación del cálculo infinitesimal al cálculo de probabilidades. Maxwell y Boltzmann desarrollan ecuaciones propias... A los estudios sobre la lengua llega más tarde y su introducción promueve avances considerables. Sugiere la posibilidad de establecer en el habla determinaciones cuantitativas y dota a los investigadores de un instrumento de análisis indispensable para fijar los rasgos característicos de ciertos fenómenos lingüísticos y sus relaciones. Permite demostrar que el lenguaje corriente responde en muchos aspectos a mecanismos que se ajustan a reglas fijas destinadas a conseguir la correcta transmisión de información. Esto resulta esencial para el desarrollo de la teoría de la información y los lenguajes computacionales. Weaver [WEAVER.1949] estableció que la palabra información en la teoría de la comunicación hace más referencia a lo que se puede decir que a lo que efectivamente se dice2, esto es, le interesa más la situación antes de la recepción del símbolo que el símbolo mismo. La información es una medida de la libertad de selección cuando se escoge un mensaje. Se pueden abordar, así, cuestiones de estilo, descubrir la longitud media y la frecuencia de ciertas palabras o establecer la probabilidad de que aparezca una sílaba en el seno de una lengua. Por ejemplo, en español, la información que sigue a la letra “q” es muy limitada puesto que hay una mínima libertad de elección en lo que viene después (casi siempre una “u”). El concepto de información se aplica no sólo a mensajes individuales, que sería más bien sentido, sino a la situación en tanto que un todo. Dice Zipf en 1949: “De todos los actos de la conducta humana, solo la corriente del habla parece constituir un continuo que, con una mínima distorsión, se puede aislar del contexto de la conducta y, al mismo tiempo, rotular y estudiar en forma estadística con un alto grado de exactitud”. [Zipf. 1949]. 2 Aquí se tratará más adelante, al tomar el tema de la entropía lingüística. 4 ANTONIO GARCÍA MEGÍA – DOCTOR EN FILOLOGÍA HISPÁNICA – ALMERÍA angarmegia@telelefonica.net El objeto predilecto de esta clase de estudio es la palabra3. Ya en el año 900 a. C., los estudiosos del Talmud contaban las palabras e ideas de la Tora [MILLER, G. A. 1979:107-108] para averiguar cuántas veces, y con qué frecuencia, aparecían formas inusuales. El respeto actual por ellas, consideradas como elementos obvios del lenguaje, no fue compartido por los antiguos. La escritura griega y la romana no las separaba en forma coherente. Fue alrededor del siglo X cuando los amanuenses, y con posterioridad los impresores, se esfuerzan por dar mayor legibilidad a su trabajo y dignifican las unidades verbales dejando un espacio entre una y otra. La frecuencia de palabras se asocia generalmente al nombre de Zipf4 por haber establecido una ley fundamental [ZIPF, G. K. 1949] que afirma que, en cualquier texto, el producto de la frecuencia de cada palabra por su rango es constante. George Kinsley Zipf (1902-1950), profesor de Filología en la Universidad de Harvard, supone que el ser humano trata siempre de minimizar el esfuerzo necesario para lograr sus objetivos, lo que, en circunstancias donde le es permitido escoger alternativas, le lleva a inclinarse por aquellos procesos que resultan en el menor consumo de energía. Esto significa la existencia del principio del menor esfuerzo [ZIPF, G. K. 1949] en la conducta humana y hace posible que, casi siempre, sus patrones de actuación puedan ser analizados de acuerdo con este principio. De igual modo que cuando busca la unión de dos puntos tiende hacia la línea recta, cuando escribe, cuando habla, tiende hacia la mayor economía de palabras. Basándose en estas observaciones Zipf formula su ley que relaciona frecuencia y rango. El procedimiento para cuantificar ambos conceptos [BRAUN, E. 1996] empieza por contar las veces que se repite cada palabra en un texto. Obtiene el indicador frecuencia dividiendo el resultado de cada recuento entre el total de palabras del texto. Se ordenan ahora todos los términos siguiendo el orden decreciente de las frecuencias resultantes. Se denomina rango de la palabra al lugar que ocupa cada término en ese listado. Si en un texto la palabra de más frecuencia es “de”, en la lista ocupará el primer lugar y, por tanto, tendrá rango uno. Si el artículo “el” tiene el segundo valor de frecuencia ocupará el segundo lugar en la lista y tendrá rango dos... Del estudio de diferentes textos en varios idiomas deduce la existencia de una 3 Es corriente distinguir entre palabras y unidades léxicas. Una unidad léxica es una entrada única en el diccionario, bajo la cual se agrupan varias palabras relacionadas. 4 Con anterioridad a Zipf ya se había trabajado con frecuencias e incluso rangos. LÓPEZ MATEO, V. [1998:31-38] hace una interesante reseña histórica sobre léxico-estadística que inicia en 1987 con Kärding y su búsqueda de las palabras más usuales del alemán. 5 ANTONIO GARCÍA MEGÍA – DOCTOR EN FILOLOGÍA HISPÁNICA – ALMERÍA angarmegia@telelefonica.net relación entre frecuencia y rango. Cuanto mayor es el rango menor es la frecuencia con la que aparece en el texto. Un rango alto se sitúa en la parte baja de la lista y eso significa menor frecuencia. Esta dependencia actúa en forma inversa porque disminuye a medida que el rango aumenta. Si f denota frecuencia y r rango, f depende de r como 1/r. Este resultado se llama ley de Zipf de rango-frecuencia5, más generalmente expresada del siguiente modo: rxf=C donde, r es el orden de la palabra en la lista (rango) f es la frecuencia C es la constante para el texto La tabla 1.2 - 1, tomada de Marcus, Nicolau y Staty [MARCUS. 1978:238] que supone un texto de 60 000 palabras, explica claramente la fórmula. Rango 10 Tabla 1.2 – 1 Frecuencia 2 653 Rango x frecuencia 26 530 100 265 26 530 1 000 26 26 530 10 000 2 26 530 29 000 1 26 530 Esta relación es la misma que se obtiene para otros fenómenos físicos y naturales y que recibe el nombre de ley de potencias 1/f. En este caso, hablando en términos matemáticos, potencia -1. De acuerdo con Zipf se puede predecir la frecuencia de una palabra partir de su rango usando la fórmula [GALICIA HARO, S. 2000:Cap.1.3] frecuencia = k x rango 5 También se conoce como “ley de Estoup-Zipf” ya que, al parecer había sido señalada por Estoup en 1916. Zipf se habría limitado a confirmarla [MARCUS, NICOLAU y STATI. 1978:237]. 6 ANTONIO GARCÍA MEGÍA – DOCTOR EN FILOLOGÍA HISPÁNICA – ALMERÍA angarmegia@telelefonica.net donde ky son constantes empíricamente determinadas. La ley de Zipf vincula la frecuencia de ocurrencia de una palabra y el número total de palabras conocidas o utilizadas; esto es, la amplitud de vocabulario. Cuanto menor es el vocabulario, mayor será la frecuencia de las palabras situadas en los primeros rangos. Este hecho va a ser tenido muy en cuenta en la elaboración del modelo metodológico alternativo para la determinación de los coeficientes de disponibilidad léxica que desarrolla esta Tesis. Otro ejemplo puede ilustrar el contenido de la teoría. Supóngase un buen escritor con un vocabulario activo cercano a las 100 000 palabras. Los términos que ocupen los primeros 10 lugares en la lista recogida de sus textos supondrán alrededor de 25% del total contabilizado, es decir, la frecuencia de estas 10 palabras es de 0.25. En contraste, en un texto periodístico de unas 10 000 palabras el porcentaje apenas crece al 30%. Esto se debe principalmente a que el escritor no podrá evitar el uso de palabras como “de”, “el”, “y”, “a”... que, generalmente, ocupan los primeros rangos en cualquier texto. La distribución de palabras, en varios lenguajes naturales, sigue la ley de Zipf [BAAYEN, H. 1992] siempre que el estudio se realice a partir de una muestra suficientemente amplia. Después de Zipf la lingüística moderna ha acumulado una enorme cantidad de material procedente de la observación y descripción de hechos, relaciones, leyes y comparaciones que ha desbordado la capacidad de tratamiento de los problemas por métodos tradicionales y ha elevado a objeto de culto, de forma a veces temeraria, la metodología basada en modelos estadísticos, que, supuestamente, proporcionan un amplio caudal de interpretaciones a cambio de no demasiada exigencia de conocimientos numéricos. Shannon [SHANNON. 1949; 1981] desde la teoría matemática de la comunicación, junto a la demanda de nuevos diccionarios más cercanos a la realidad y necesidades de una sociedad cada vez más global, contribuyen en gran manera a la difusión y conocimiento de experiencias, ensayos y formulaciones relacionadas con la estructura y enseñanza de las lenguas y la transmisión de datos. Los nombres de Simón de Laplace [LAPLACE. 1812; 1825], Bayes [BAYES. 1908], 7 ANTONIO GARCÍA MEGÍA – DOCTOR EN FILOLOGÍA HISPÁNICA – ALMERÍA angarmegia@telelefonica.net Markov [MARKOV. 1916] o Sharman [SHARMAN. 1989] entran de lleno en el ámbito lingüístico donde el auge del ordenador y la oferta de potentes programas informáticos, capaces de dar respuesta en segundos a complicados algoritmos matemáticos, colaboran a su desarrollo y favorecen la aparición de nuevas disciplinas. Despegan la lingüística estadística y la lingüística matemática, que, a su vez, sirven de apoyatura para la solución nuevos problemas relacionados, a modo de ejemplo, con la indización y localización en Internet. Ni que decir tiene que la mencionada “comodidad” es sólo aparente. Es grande el riesgo de incurrir en desviaciones de bulto por aplicar fórmulas cuyo fundamento teórico no es dominado por el investigador que las utiliza. Las consecuencias de estas actuaciones son construcciones artificiosas y estériles o, y ello es peor, engañosas. Aquí se entiende la estadística como un auxiliar útil para la lengua. La transformación de conceptos verbales en aspectos cuantitativos se debe hacer sólo en función de las necesidades metodológicas y con cuidado y respeto extremos para evitar interpretaciones abusivas que no se deriven de forma rigurosa y necesaria de los datos aducidos, o que se fuercen éstos para utilizarlos en algoritmos no aplicables al tipo al que corresponden. Así ocurre, por ejemplo, cuando se opera con datos ordinales o nominales como si de medidas de intervalo se tratasen, o se aplican estadísticos paramétricos sobre muestras y poblaciones no paramétricas. Debe tenerse en cuenta que: “La clase de medida que se obtiene es una función de las reglas bajo las cuales fueron asignados los números. Las operaciones y relaciones en la obtención de puntajes; las manipulaciones y operaciones deben ser las de la estructura numérica a la que la medición es isomórfica. [...] Las mediciones nominales y ordinales son las realizadas más comúnmente en las ciencias de la conducta. Los datos medidos por escalas nominales y ordinales deben analizarse por métodos no paramétricos. Los datos medidos con escalas de intervalo o de de proporción deben analizarse por métodos paramétricos si los supuestos del modelo estadístico paramétrico son sostenibles”. [SIEGEL. 1983:50] La Tabla 1.2 - 2, también tomada de Siegel [SIEGEL. 1983:51], define las relaciones que se admiten dentro de cada categoría y muestra en esquema las operaciones permitidas para cada rango de datos. 8 ANTONIO GARCÍA MEGÍA – DOCTOR EN FILOLOGÍA HISPÁNICA – ALMERÍA angarmegia@telelefonica.net De acuerdo con ella no es procedente, por ejemplo, calcular una media geométrica a partir de datos de intervalo. De igual manera determinar una media natural cuando se opera con medidas de proporción, que admiten la media geométrica, puede significar una perdida de información adicional valiosa para el proyecto en que se incardina la estimación. Escala Nominal Ordinal Intervalo Proporci ón Tabla 1.2 - 2 Relaciones definidas Estadísticos apropiados Equivalencia Moda Frecuencia Coeficiente de contingencia Equivalencia Mediana De mayor a menor Percentiles Spearman rs Kendall r Equivalencia Media De mayor a menor Desviación estándar Proporción conocida de un Correlación del intervalo a cualquier otro momento-producto de Pearson. Correlación del múltiple momento producto Equivalencia Media geométrica De mayor a menor Coeficiente de Proporción conocida de un variación intervalo a cualquier otro Proporción conocida de un valor de la escala a cualquier otro Pruebas apropiadas Pruebas estadísticas no paramétricas Pruebas estadísticas paramétricas y no paramétricas. Otra deficiencia de naturaleza más profunda puede emerger si las ecuaciones diseñadas no tienen su origen y fundamento en propiedades objetivamente extraídas de la organización lingüística misma. Se pueden aplicar formulaciones de carácter estrictamente teórico a partir de elementos empíricos, pero siempre que éstos se infieran matemáticamente de fenómenos de la lengua, sin forzar unas u otros en interés de la investigación. Los experimentos, a su vez, deben desarrollarse con arreglo a las condiciones 9 ANTONIO GARCÍA MEGÍA – DOCTOR EN FILOLOGÍA HISPÁNICA – ALMERÍA angarmegia@telelefonica.net impuestas por los algoritmos. Si no son significativos de esta manera, conviene delimitar con exactitud las diferencias que se observan para comprobar eventualmente por vía empírica la validez del cálculo en circunstancias más generales respecto de aquellas en que se estableció, homologando, si éste es el caso, las nuevas condiciones como una investigación teórica más. Tampoco se puede utilizar la forma matemática para dar imagen de cientificidad a las conclusiones derivadas de una determinada formulación universalmente validada y reconocida por la comunidad científica, cuando se han sustituido, en la totalidad o en parte, los factores y elementos constituyentes del cálculo, supuestamente asépticos y objetivos, por apreciaciones y mediciones subjetivas o no objetivadas. 10