Tutorial básico de PSPP: Indicaciones específicas para los
Anuncio

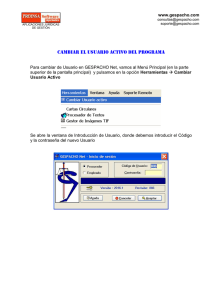
Tutorial básico de PSPP: • Vídeo 1: Describe la interfaz del programa, explicando en qué consiste la vista de datos y la vista de variables. • Vídeo 2: Muestra cómo crear una base de datos, comenzando por la definición del listado de variables. • Vídeo 3: Muestra cómo guardar la base de datos y cómo rellenar manualmente una secuencia consecutiva de casos o sujetos. • Nota: No se deben utilizar acentos ni caracteres especiales en el nombre de las bases de datos ni de las carpetas que las contienen, porque el sistema podría no interpretar correctamente la ubicación de esta información. Indicaciones específicas para los análisis estadísticos. En el siguiente apartado se explica brevemente cómo realizar con PSPP una serie de análisis básicos para cualquier investigación de Psicología de las organizaciones. En primer lugar, nos situaremos en la Vista de Datos para revisar nuestra base de datos: Desde aquí podemos observar todo el contenido de la base de datos, desplazándonos de arriba a abajo para ver a los distintos participantes (filas), y desplazándonos de un lado al otro para ver las distintas variables (columnas). 1. Menú de opciones. Pero lo más interesante son las opciones de análisis a las que podemos acceder desde el menú del programa PSPP. Desde el menú podemos guardar los cambios en la base de datos en que estamos trabajando (opción Archivo... Guardar), mostrar u ocultar las etiquetas de valor de las variables (opción Vista... Etiquetas de valor), calcular nuevas variables (opción Transformar... Calcular), o realizar complejos cálculos estadísticos desde el menú Analizar... En el siguiente ejemplo se ve cómo queda la base de datos al mostrar las etiquetas de valor desde la opción Vista... Etiquetas de valor. Las etiquetas de valor de las variables se pueden mostrar u ocultar según nos interese, o bien definir y modificar desde la Vista de Variables, en la casilla correspondiente. Hay que tener en cuenta que las variables pueden tener una etiqueta (que describe en detalle su contenido), y también etiquetas de valor asociadas a cada valor en concreto. 2. Estadísticos descriptivos. Antes de contrastar nuestras hipótesis conviene realizar análisis descriptivos de todas las variables de interés. Para este fin utilizaremos las opciones de análisis descriptivos que contiene el menú. Adicionalmente, este tipo de análisis nos servirá para describir las características demográficas de nuestra muestra. Por ejemplo, pinchando la opción Análisis... Estadística descriptiva... Frecuencias... se abre el siguiente cuadro de diálogo. Si seleccionamos la variable sexo y pulsamos después el botón “Aceptar”, podremos ver una tabla de frecuencias de dicha variable y consultar más estadísticos (cualquiera de los que figuran en la casilla de la derecha, siempre que tenga sentido realizar dicho cálculo). La opción Análisis... Estadística descriptiva... Descriptivos... muestra un cuadro de diálogo similar donde se pueden calcular los estadísticos habituales para variables de tipo cuantitativo: por ejemplo, media, desviación estándar, varianza, etc. Desde esta opción se puede calcular la media y desviación típica de la variable Edad. 3. Análisis de fiabilidad de las escalas. En la base de datos, las variables independientes vienen representadas por palabras en mayúsculas (FUSION, URGENCIA y EFICACIA), cada una de estas variables tiene asociada una etiqueta que describe su significado. Las tres variables independientes han sido previamente calculadas a partir de las respuestas de los participantes, y nos van a permitir diferenciar a los participantes que han obtenido una menor puntuación (1 = "baja") de aquellos que han obtenido una mayor puntuación (2 = "alta"). La base de datos también contiene una serie de enunciados que se corresponden con las variables dependientes del estudio: acción pacífica, acción violenta e interés por formar parte del FLT. Para medir dichas variables se han utilizado tres escalas que se dividen en 4 grupos de enunciados cada una, identificables por el número y contenido de su etiqueta. Una de las primeras tareas que debemos hacer es estudiar la fiabilidad y validez de estas escalas. Para simplificar, nos centraremos en la consistencia interna de las escalas (Alpha). Podemos calcular el valor de Alpha para cada escala desde la opción Analizar... Fiabilidad... En la casilla de la izquierda del cuadro de diálogo que se presenta, seleccionamos los cuatro enunciados de la escala que queremos analizar: A continuación pulsamos la flecha, desplazando los enunciados hasta la casilla de la derecha, y por último pulsamos el botón “Aceptar”: 4. Cálculo de nuevas variables. Para poder realizar los análisis necesitaremos crear antes algunas variables nuevas, en las cuales guardaremos el promedio de las distintas escalas. Dichos promedios serán las variables dependientes del resto de análisis estadísticos. Para calcular el promedio de una escala abrimos la opción Transformar... Calcular... A continuación rellenamos el cuadro de diálogo correspondiente. Por ejemplo, para calcular el promedio de la segunda escala de nuestra base de datos, le asignamos como nombre “VIOLENCIA” (rellenando la casilla superior izquierda) y calcularemos el promedio usando la fórmula MEAN (item1, item2, ..., itemN), que podemos localizar desplazándonos en el listado del área derecha (las funciones están ordenadas alfabéticamente). En el interior del paréntesis, hay que borrar el signo de interrogación que sale por defecto en MEAN (?) e ir pasando los diversos enunciados de la escala, separados por comas. El cuadro de diálogo quedaría así: Una vez que hayamos calculado la fiabilidad y el promedio de las escalas, podremos usar estos valores en diversos análisis. A continuación se especifican las fórmulas que deberán utilizarse para calcular las tres variables dependientes del estudio: • PACIFISMO = MEAN(escala11, escala12, escala13, escala14) • VIOLENCIA = MEAN(escala21, escala22, escala23, escala24) • PERTENENCIA = MEAN(escala31, escala32, escala33, escala34) 5. Prueba T de diferencias entre medias para dos muestras independientes. Una de las pruebas más sencillas que pueden utilizarse en el contraste de hipótesis es la prueba T, que permite detectar diferencias entre las medias de dos grupos distintos. En este apartado vamos a aplicar la prueba T para comprobar si existen diferencias en ecologismo pacifista al comparar a “bajos” vs. “altos” en fusión con la Naturaleza. En concreto, queremos saber si los participantes con nivel “alto” en fusión tienen mayor puntuación en ecologismo pacifista, que los participantes con nivel “bajo” en fusión. Para ello, en primer lugar abrimos la opción Analizar... Comparar Medias... Prueba T para Muestras Independientes, y rellenamos el cuadro de diálogo añadiendo FUSION a la lista “Definir Grupos” y PACIFISMO a la lista “Variable(s) de contraste”. A continuación, pulsamos el botón “Definir Grupos” y definimos los grupos que van a ser comparados, introduciendo los valores 1 [= “bajos”] y 2 [= “altos”]. Por último, pulsamos el botón “Continuar” en el cuadro de diálogo de Definir Grupos, y después el botón “Aceptar” en el cuadro de diálogo de la Prueba T. Una vez realizada la anterior operación, el Visor de Resultados mostrará la siguiente información separada en dos tablas: La tabla titulada Estadísticas de grupo muestra, entre otros datos, el valor de la media para cada grupo. En este caso la media de los “bajos” en fusión es 4,08 y la media de los “altos” en fusión es de 4,93. No obstante, sólo con estos datos aún no sabemos si existe una diferencia significativa entre ellas, o la diferencia aparente se debe al azar. La tabla titulada Prueba para muestras independientes es la que nos permitirá decidir si las diferencias encontradas entre grupos son o no significativas. Aunque se presenta bastante información, la forma de leer su contenido es sencilla. En primer lugar, hay que revisar el valor del estadístico F de la prueba de Levene de igualdad de varianzas, en este caso F = 0,20 (p = ,66). Como la probabilidad asociada es mayor que α = 0,05 mantenemos la hipótesis nula de la prueba de Levene y asumimos que la varianza de ambos grupos, “bajos” y “altos” en fusión, es similar. Esto únicamente nos sirve para decidir qué versión de la prueba T vamos a utilizar, la versión para varianzas iguales (línea superior) o la versión para varianzas diferentes (línea inferior). En este caso en particular debemos consultar los resultados de la línea superior (marcados en verde) y descartar los resultados de la línea inferior de la tabla (marcados en rojo). Es decir, el resultado de la prueba indica un valor de t = -4,50, con 113 grados de libertad, y una probabilidad asociada de p = ,00. Por tanto, rechazamos la hipótesis nula de la prueba T y concluimos que la diferencia entre la media para “bajos” en fusión (= 4,08) y para “altos” en fusión (= 4,93) resulta estadísticamente significativa (t113 = -4,50; p < ,01).