bioestadística i
Anuncio

BIOESTADÍSTICA I
1. DEFINICIONES
1.1 ESTADÍSTICA.
Es una disciplina, que hace parte de la matemática aplicada, que provee métodos y
procedimientos para colectar, clasificar, resumir y analizar información (datos) proveniente
de una población.
1.2 BIOESTADÍSTICA.
Es la disciplina que se encarga de generar y aplicar métodos estadísticos a información o
datos provenientes de las áreas biológicas.
1.3 VARIABLE.
Es una característica que interesa evaluar ya sea en un individuo o en un objeto, y que,
como su nombre lo dice, varía o cambia de un individuo a otro. Si todos los individuos
observados son homogéneos para la característica en cuestión, ya no se habla de una
variable, sino de una constante. Otra definición más corta: variable es lo que está siendo
observado o medido.
Las variables pueden ser clasificadas de diferentes maneras:
1.3.1 Cualitativas y Cuantitativas. Las variables cualitativas o atributos no se pueden
medir numéricamente (por ejemplo: nacionalidad, color de la piel, sexo). Las variables
cuantitativas tienen valor numérico (edad, precio de un producto, ingresos anuales).
Ejemplos:
Cuantitativas
• Peso
• Diámetro
• Altura
• Número de plantas
Cualitativas
• Variedad o especie
• Raza
• Color
• Tipo de suelo
1.3.2 Discretas y continuas. Esta es otra forma de clasificar las variables. Una variable
es discreta si entre dos valores contiguos no existe ningún otro valor posible, es decir,
hay “saltos” entre los valores que toma la variable; mientras que en una variable continua,
entre cualquier para de valores observables siempre hay infinitos valores posibles de ser
observados. A veces se toma como regla de clasificación que las variables discretas no
pueden tomar valores que involucren cifras decimales, pero esto no siempre se cumple,
veamos un ejemplo:
Si en un examen definimos una variable como la relación de respuestas correctas
respecto al total de preguntas formuladas, los valores posibles siempre serán
fraccionarios: 1/5, 2/5, ...etcétera y a pesar de esto, la variable sería discreta.
2
Otras definiciones: Una variable es discreta si sólo puede tomar valores en un conjunto
finito; es continua, si puede tomar cualquier valor de un intervalo determinado. Debido a
las unidades en que algunas variables son expresadas, éstas pueden parecer discretas,
por ejemplo, el tiempo expresado en segundos, el peso expresado en gramos. En estos
casos, las limitaciones están dadas por el instrumento de medida. Sin embargo,
conceptualmente tales variables siguen siendo continuas, pues sin importar que contemos
con el instrumento para su medición o no, entre 4 g y 5 g hay infinitos pesos.
Discretas
• Número de huevos
• Sexo
• Número de plantas
Continuas
• Peso
• Altura
• Tiempo
1.3.3 Escalas de medición. Esta forma de clasificar las variables hace referencia a la
cantidad de información que contenga cada una de ellas y a la forma en que se mida.
1.3.3.1 Nominal. Es la escala de medición más débil, los valores de la variable
simplemente indican diferentes categorías y no existe un orden entre ellas. Ejemplo:
Color, sexo, especie, raza, nombre, materia. Una forma de evaluar si una variable es
nominal, es identificar si al representarla gráficamente se pierde información al colocar en
diferentes posiciones cada una de las categorías. Si las categorías pueden presentarse
indiferentemente en cualquier posición, se trata de una variable medida en escala
nominal.
1.3.3.2 Ordinal. En este tipo de escala se halla un poco más de información que en la
anterior. Existe un orden o jerarquía entre los objetos del grupo, de tal forma que se sabe
cuál es el primero, el segundo,... con relación a una característica particular. No puede
afirmarse, sin embargo, que la diferencia o distancia entre las categorías sea la misma.
Ejemplo: Nivel de producción (Alto, medio o bajo), orden de llegada en una carrera
(primero, segundo, tercero), evaluación nutricional, calificación (excelente, bueno, regular,
malo).
1.3.3.3 Interválica. En esta escala existen categorías ordenadas y las distancias o
intervalos entre éstas son iguales, por eso se puede afirmar que la diferencia entre 5 y 6
es la misma que entre 10 y 11, es decir, una unidad. Una característica de esta escala es
que el cero no es verdadero, es arbitrario, pues no indica ausencia de la característica
medida, por lo tanto, aunque se pueden realizar comparaciones de diferencia (restas), las
comparaciones de razón (divisiones) no son posibles. Ejemplos: Cociente intelectual y, la
más famosa de todas, la temperatura, donde el valor de 0 °C no indica ausencia de
temperatura; una ilustración de porque las razones no son posibles se tiene al comparar
las temperaturas 20 °C y 40 °C ; aunque numéricamente 40 es el doble de 20, en el caso
de la temperatura no se puede afirmar que a 40 °C es el doble de calor que a 20 °C.
1.3.3.4 Razón o Proporción. Es la escala que tiene más información. Además de existir
un orden entre los niveles de la escala, estos tienen igual distancia entre sí y el cero sí es
real (indica ausencia). Por lo tanto, las comparaciones de razón (divisiones) sí son
posibles. Ejemplos: Peso, altura, número de hojas de una planta, etcétera.
3
1.4 POBLACIÓN.
Es cualquier conjunto de individuos o elementos que tienen una o más características
comunes. Las características comunes no son sólo físicas, pueden ser espaciales o
temporales. Ejemplos: estudiantes matriculados en el primer semestre del 2004
(característica temporal) ; estudiantes del núcleo de minas (característica espacial).
La estadística matemática define una población como el conjunto de todos los valores que
puede tomar una variable, en este caso se hablaría de población de pesos, etcétera, lo
que pasa es que desde el punto de vista del investigador, se define como el conjunto de
individuos poseedores de la característica.
1.5 MUESTRA.
Es cualquier subconjunto de elementos seleccionado de una población, lo ideal es que
sea un subconjunto representativo de toda la población, o sea que refleje las
características esenciales de la misma, de manera que se puedan realizar
generalizaciones sobre la población.
Las razones para trabajar con muestras son: ahorro de tiempo, ahorro de dinero,
facilidades operativas y conservación de la población (si la variable que se quiere medir
implica destrucción de la unidad experimental, como en análisis bromatológicos, de
composición, etcétera).
1.6 PARÁMETRO.
Es una medida que caracteriza a una población, por lo cual se necesitaría tener acceso a
todos los elementos de la población para su cálculo. Se representa por medio de letras
griegas.
1.7 ESTADÍSTICO.
Es cualquier medida de resumen calculada a partir de los datos de la muestra. Sirve
como estimador del respectivo parámetro poblacional. Se representa por medio de letras
latinas.
1.8 ESTADÍSTICA DESCRIPTIVA.
Es la rama de la estadística que se dedica a la presentación, organización y resumen de
los datos, usando tablas, gráficos y “medidas de resumen” que son aquéllas que
representan las características esenciales de los datos en términos fáciles de interpretar.
1.9 ESTADÍSTICA INFERENCIAL.
Esta es la parte de la estadística que permite generalizar los resultados obtenidos a partir
de los datos de una muestra, a un número más grande de individuos. En otras palabras,
hacer inferencia estadística es sacar conclusiones válidas acerca de una población de
elementos o medidas, con base en información contenida en una muestra de dicha
población. Se hace a través de dos actividades relacionadas: estimación y prueba de
hipótesis.
4
Tarea: Plantear 10 variables que tengan que ver con su carrera y clasificarlas con las tres
formas vistas.
2. ESTADÍSTICA DESCRIPTIVA.
Como se mencionó anteriormente, la estadística descriptiva se basa en el uso de tres
herramientas básicas: medidas de resumen, tablas y gráficos.
2.1 MEDIDAS DE RESUMEN
Las medidas de resumen, como su nombre lo dice, sirven para resumir la información
contenida en un grupo de datos y se dividen en: medidas de tendencia central, medidas
de dispersión, medidas de forma y medidas de posición.
2.1.1 Medidas de Tendencia Central. Una medida de tendencia central es aquel valor
hacia el cual converge la mayoría de los datos, viene a ser una especie de representante
del conjunto de datos, existen varias medidas de tendencia central.
2.1.1.1 Media. Es la más famosa de las medidas de tendencia central y se define como el
promedio aritmético de todos los datos. Podemos definir la media muestral (estadístico) y
la media poblacional (parámetro).
n
___
X =
∑x
i =1
i
; Así, es un estadístico.
n
N
µ=
∑x
i =1
N
i
; Así, es el parámetro.
Tarea: Calcule la media para el siguiente conjunto de datos:
Repita con el siguiente conjunto de datos:
Compare los dos valores obtenidos y concluya.
{3, 5, 6, 8, 9}
{3, 5, 6, 8, 20}
2.1.1.2 Mediana: Es el valor central de un conjunto de datos ordenados, se dice también
que es aquel valor que divide el conjunto de datos exactamente por la mitad. Para el
siguiente conjunto de datos:
{2, 4, 5, 6, 8}
la mediana es 5
¿ Y para el siguiente conjunto de datos?
2, 4, 5, 6, 20
la mediana es 5
¿Qué se puede concluir a partir de estos resultados?
5
Si se tiene un conjunto de datos par : {2, 4, 5, 6} ¿qué hacemos? La solución es calcular
la media de los dos valores centrales. Existen dos fórmulas que facilitan el cálculo de la
mediana cuando se tienen muchos datos, pero para ver las fórmulas, primero debemos
definir que es un “Estadístico de Orden”.
2.1.1.3 Estadístico de Orden. Se define el estadístico de orden i-ésimo como el valor
que toma la observación i-ésima, después de ordenar todos los datos, así:
X(1) es el estadístico de orden 1 y correspondería al menor valor de todos.
X(2) es el estadístico de orden 2 y correspondería al segundo menor valor.
.
.
.
X(n) es el estadístico de orden n y correspondería al mayor valor.
Al calcular la mediana de un conjunto de datos siempre se estará en una de dos
situaciones: el conjunto de datos es impar o el conjunto de datos es par.
Si el conjunto es impar, Me =
X(
n +1
2
)
X(
n +1
2
) ; es decir, el estadístico de orden
(n+1)/2
X(
n
Si el conjunto es par, Me =
2
) + X ((n 2 )+1)
X(
2
n
2
) + X ((n 2 )+1)
2
; es decir, la media
aritmética de los dos estadísticos de orden que aparecen en el numerador.
Nota: “n” es el número de datos evaluados.
2.1.1.4 Moda. El significado estadístico de la palabra moda es similar al que le damos en
nuestra sociedad, ¿qué es moda? Lo que más se usa, entonces la moda es simplemente
el valor que más se repite, ejemplo: en el siguiente conjunto de datos la moda sería 5:
{2, 5, 5, 5, 6, 7, 8}
En el conjunto de datos: : {3, 5, 6, 3, 4, 3, 5, 8, 5}, ¿cuál es la moda?
Se puede apreciar que hay dos modas: 3 y 5. (el conjunto es bimodal)
Un último conjunto de datos: {2, 4, 6, 8, 9, 3, 5}, ¿cuál es la moda?
Aquí vemos que no hay moda, a partir de estos tres ejemplos se puede observar que la
moda puede no existir, ser única o pueden existir múltiples modas (datos multimodales).
Cuando exista, siempre corresponderá con algunos de los valores observados en el
conjunto de datos.
2.1.1.5 Media ponderada. Es una media donde todas las observaciones no tienen el
mismo “peso” o importancia, un ejemplo clásico es la nota definitiva de una asignatura,
supongamos el caso de un estudiante en un curso cualquiera con las siguientes notas:
6
Evaluación
Parcial 1
Parcial 2
Parcial 3
Taller
Porcentaje (Pi)
30%
20%
30%
20%
Nota (Xi)
4.2
2.1
3.2
3.7
Para calcular la nota definitiva no podríamos simplemente calcular la media aritmética
de las cuatro notas, pues le estaríamos dando el mismo “peso” a cada una de las
notas, por lo tanto calculamos la media ponderada, que permite darle “pesos”
diferentes a los valores observados.
n
__
X
p
=
∑P *X
i
i =1
= 3.38
n
∑P
i =1
i
i
2.1.1.6 Recorrido Medio. Esta medida de tendencia central se utiliza muy poco, una
aplicación práctica se da cuando se quiere calcular la temperatura media de un día
cualquiera, simplemente consiste en calcular la media aritmética de los valores mayor
y menor.
Tarea: Analizar para cada una de las escalas de medición cuáles medidas de tendencia
central es posible aplicar y cuáles no.
Antes de continuar con la siguiente medida de resumen, veamos lo siguiente: se tienen
dos explotaciones A y B de cualquier producto agrícola:
Explotación
A
B
Producción Promedio
4 t/ha
4 t/ha
A simple vista podríamos decir que los conjuntos de datos que dieron origen a estas dos
medias son iguales, pero si ahora vemos los conjuntos originales, la situación es muy
diferente:
Explotación
A
B
Producción Promedio Datos
4 t/ha
4, 4, 4
4 t/ha
0, 4, 8
Estos dos conjuntos de datos ponen en evidencia que la medida de tendencia central por
sí sola no es suficiente para describir un conjunto de datos, de ahí la importancia de
utilizar otra medida de resumen que me refleje la situación del ejercicio anterior.
7
2.1.2 Medidas de Dispersión. Las medidas de dispersión indican qué tan cerca o qué
tan lejos están los datos de la medida de tendencia central, en otras palabras, indican que
tan homogéneos o heterogéneos son los datos.
2.1.2.1 Varianza. Es la más conocida de las medidas de dispersión y su análisis es la
base de todos los métodos de estadística inferencial. Podemos definir la varianza
muestral (estadístico) y la varianza poblacional (parámetro).
___
⎛
⎞
−
X⎟
⎜
∑
x
i
⎠
⎝
S 2 = i =1
n −1
n
⎞
⎛
⎜ xi − µ ⎟
∑
⎠
i =1 ⎝
=
N
N
σ2
2
; Así, es un estadístico.
2
; Así, es el parámetro.
Existe una fórmula operacional que hace mucho más fácil el cálculo de la varianza, que
surge de desarrollar y luego simplificar el numerador de la expresión anterior:
⎛ n
⎞
⎜ ∑ xi ⎟
n
2
xi − ⎝ i =1 n ⎠
∑
S 2 = i =1
n −1
2
Supongamos valores de producción de mango en t/ha: 3, 5, 6, 8, 9
Donde la varianza es: 5.7 (t/ha)2, (verificar el cálculo) ahora..... ¿qué es una (t/ha)2 ? pues
este es el problema de la varianza, está dada en unidades al cuadrado, lo cual hace que
no tenga una interpretación fácil, entonces.... ¿qué hacemos? ¡Pues saquemos raíz
cuadrada!
2.1.2.2 Desviación estándar. Simplemente es la raíz cuadrada de la varianza y por lo
tanto está dada en las unidades de medida originales y por eso es más utilizada.
Podemos definir la desviación estándar muestral (estadístico) y la desviación estándar
poblacional (parámetro).
S = Raíz cuadrada de: S2; Así, es un estadístico.
σ = Raíz cuadrada de: σ2; Así, es el parámetro.
En el ejemplo anterior la desviación estándar sería: S = 2.387 t/ha, valor que está dado en
las unidades de medida originales y por lo tanto es fácil de entender.
Ejercicio: Se tienen los siguientes conjuntos de datos, ¿en cuál de ellos hay mayor
dispersión?
Media
DE
A
10 t/ha
2.5 t/ha
B
4 t/ha
2 t/ha
8
Se podría pensar que el conjunto A tiene una mayor dispersión que el B, pero debe
recordarse la definición de medida de dispersión: es un valor que me indica qué tan lejos
o cerca se encuentran los datos respecto a la medida de tendencia central, de tal manera
que si se desea saber cuál de los dos conjuntos tiene una mayor dispersión, el análisis no
puede basarse exclusivamente en la D. E., debe tener en cuenta también la media. Para
hacer esta comparación se podría hacer uso de la siguiente medida de dispersión.
2.1.2.3 Coeficiente de Variación (CV). Esta es una medida de dispersión muy utilizada
porque es adimensional (no tiene unidades de medida) y por lo tanto es muy útil para
comparar la dispersión de dos conjuntos de datos, ya sea que éstos tengan o no, la
misma unidad de medida; expresa la desviación estándar como un porcentaje de la
media.
CV =
S
_____
*100
X
2.1.2.4 Desviación Mediana. Es una medida de dispersión donde la medida de
tendencia central de referencia es la Mediana y se calcula así:
n
∑ x − Me
D. Mediana =
i =1
i
n
Básicamente es para variables ordinales; en general, cuando se calcule la mediana como
medida de tendencia central, lo correcto entonces será calcular la desviación mediana.
2.1.2.5 Recorrido o Rango. Es una medida poco utilizada porque provee de muy poca
información, se calcula como la diferencia entre los dos valores extremos del conjunto de
datos, por lo tanto simplemente indica la distancia que hay entre el valor menor y el valor
mayor.
R: (Valor mayor – Valor menor) ≡ (X(n) – X(1)).
Tarea: Analizar para cada una de las escalas de medición cuáles medidas de dispersión
es correcto aplicar y cuáles no
Ejercicio: Qué se puede decir de la producción de mango en estas dos fincas?
A
9.475
4.26807
Media:
S
B
9.475
4.26807
Aparentemente son dos conjuntos de datos iguales, pero si vemos los datos originales
vamos a encontrar lo siguiente:
A:
B:0.85,
5,
6.3, 6.9, 7.4, 9.2, 10,
12.9,
6.05,
11.55, 12.05, 12.65, 13.95
8.95, 9.75,
18.1
9
Con estos dos conjuntos se hace evidente que una medida de tendencia central junto con
una medida de dispersión, tampoco son suficientes para describir de manera completa un
conjunto de datos, hace falta algo más, veamos la siguiente medida de resumen.
2.1.3 Medidas de Forma. Una medida de forma simplemente refleja cual es la forma de
los datos al hacer un gráfico de dispersión con ellos.
2.1.3.1 Coeficiente de Asimetría (a). Indica si un conjunto de datos es simétrico o no
respecto a la media, se calcula de la siguiente manera:
__ 3 ⎤
⎡ n ⎛
⎞
⎢ ∑ ⎜⎜ xi − x ⎟⎟ ⎥
⎡
⎤ ⎢ i =1 ⎝
n
⎠ ⎥
a =⎢
⎥
3
⎢
⎥
⎣ (n − 1)(n − 2 )⎦ ⎢
S
⎥
⎢⎣
⎥⎦
Donde S es la desviación estándar. Básicamente se puede hablar de tres situaciones (no
son las únicas):
•
Distribución Simétrica: a = 0:
Cuando hay simetría perfecta, la media, la mediana y la moda toman el mismo
valor.
•
Sesgo a la derecha: a > 0:
Cuando hay sesgo a la derecha, la moda < la mediana < la media.
•
Sesgo a la izquierda: a < 0:
10
Cuando hay sesgo a la izquierda, la media < la mediana < la moda.
Evaluemos los dos conjuntos de datos anteriores:
aA = [ 8 / 7*6 ]*[ (5-9.475)3 + (6.3-9.475)3 +...... +(18.1-9.475)3 / 4.2683]
aA = 1.3089 = Asimetría positiva o sesgo a la derecha.
aB = [8 / 7*6 ]*[(0.85-9.475)3+ (6.05-9.475)3 +....+(13.95-9.475)3 /4.2683]
aB = - 1.3089 = Asimetría negativa o sesgo a la izquierda.
Tarea: Verificar los anteriores resultados.
Ejercicio: ¿Qué se puede decir de la producción de mango en estas dos fincas?
A
7
3.6228
0
Media:
S
a
B
7
3.6228
0
Aparentemente son dos conjuntos de datos iguales, pero si vemos los datos originales
vamos a encontrar lo siguiente:
A: 0.5,
B:
1.5,
4,
6, 6.5, 7, 7.5, 8,
10,
3.5,
4,
8,
6,
7,
13.5
10, 10.5, 12.5
Con estos dos conjuntos se hace evidente que una medida de tendencia central junto con
una medida de dispersión y la medida de asimetría, tampoco son suficientes para
describir de manera completa un conjunto de datos, hace falta algo más.
2.1.3.2 Coeficiente de Curtosis o Curtosis (K). Evalúa como es la concentración de los
datos alrededor de la media y de las colas.
__ 4 ⎤
⎡ n ⎛
⎞
⎢ ∑ ⎜⎜ xi − x ⎟⎟ ⎥
2
⎡
⎤ ⎢ i =1 ⎝
n(n + 1)
⎠ ⎥ ⎡ 3(n − 1) ⎤
K= ⎢
−
⎥⎢
4
⎥ ⎢ (n − 2 )(n − 3) ⎥
⎣ (n − 1)(n − 2 )(n − 3) ⎦ ⎢
⎦
S
⎥ ⎣
⎢⎣
⎥⎦
Situaciones posibles:
Distribución Mesocúrtica: K = 0.
11
Distribución Leptocúrtica: K > 0
Distribución Platicúrtica: K < 0
Evaluemos los dos conjuntos de datos anteriores:
KA: 1.235 : Leptocúrtica
KB: -1.004: Platicúrtica
Tarea : Verificar los dos valores de curtosis anteriores.
2.1.4 Medidas de Posición. Son medidas que permiten estimar en qué punto de la
distribución de los datos se encuentra un determinado valor.
2.1.4.1 Cuantiles. Son la expresión más general de medidas de posición y
comprenden a todas las otras; el valor que tome el cuantil “X” es el valor que deja por
debajo de sí al “X” % de los datos. Para el calculo de los cuantiles vamos a recurrir
nuevamente a los estadísticos de orden.
Primero se debe calcular el valor n*X (Siendo n el número de datos y “X” el cuantil
deseado), a partir del valor hallado se hace lo siguiente:
si (nx/100) no es entero, entonces el Cuantil X = X ( [| nx/100 |] + 1 ) ;.
Recordar, [| |] quiere decir menor entero contenido en, lo que traduce: redondee por
debajo.
Si (nx/100) es entero, entonces el Cuantil X = {X (nx/100) + X[(nx/100) + 1] }/ 2;.
Importante:
12
Cuantil “0”
Cuantil “100”
= X (1) = El valor Mínimo
= X (n) = El valor Máximo
2.1.4.2 Cuartiles. Son valores que dividen el conjunto de datos en cuatro partes.
•
Q1: Primer cuartil: Es el valor por debajo del cual se encuentra el 25% de
los datos.
•
Q2: Segundo cuartil: Es el valor por debajo del cual se encuentra el 50% de
los datos.
•
Q3: Tercer cuartil: Es el valor por debajo del cual se encuentra el 75% de
los datos.
2.1.4.3 Deciles. Son valores que dividen el conjunto de datos en diez partes.
•
•
D1: Decil uno: Es el valor por debajo del cual está el 10% de los datos.
D2: Decil dos: Es el valor por debajo del cual está el 20% de los datos.
2.1.4.4 Percentiles. Son los valores que dividen la información en centésimas, o sea
en 100 partes. Son los mismos cuantiles.
P1: Percentil uno: Es el valor por debajo del cual está el 1% de los datos.
P2: Percentil dos: Es el valor por debajo del cual está el 2% de los datos.
Tarea: Hallar equivalencias entre las diferentes medidas de posición, ejemplo:
Mediana = Q2 = D5 = P50
Tarea: Calcular todas las anteriores medidas de resumen para describir dos conjuntos de
datos que ustedes mismos pueden inventar.
2.2 TABLAS.
2.2.1 Tablas de frecuencias (Tablas de distribución de frecuencias). La distribución
de frecuencia es la representación estructurada, en forma de tabla, de toda la información
que se ha recogido sobre la variable estudiada.
Veamos un ejemplo:
Medimos la altura de los niños de una clase y obtenemos los siguientes resultados (cm):
13
Estudiante
Estudiante 1
Estudiante 2
Estudiante 3
Estudiante 4
Estudiante 5
Estudiante 6
Estudiante 7
Estudiante 8
Estudiante 9
Estudiante 10
Estatura
1,25
1,28
1,27
1,21
1,22
1,29
1,30
1,24
1,27
1,29
Estudiante
Estudiante 11
Estudiante 12
Estudiante 13
Estudiante 14
Estudiante 15
Estudiante 16
Estudiante 17
Estudiante 18
Estudiante 19
Estudiante 20
Estatura
1,23
1,26
1,30
1,21
1,28
1,30
1,22
1,25
1,20
1,28
Estudiante
Estudiante 21
Estudiante 22
Estudiante 23
Estudiante 24
Estudiante 25
Estudiante 26
Estudiante 27
Estudiante 28
Estudiante 29
Estudiante 30
Estatura
1,21
1,29
1,26
1,22
1,28
1,27
1,26
1,23
1,22
1,21
Si presentamos esta información estructurada obtendríamos la siguiente tabla de frecuencias:
Variable
(Valor)
Frecuencias absolutas
Simple
Acumulada
Frecuencias relativas
Simple
Acumulada
1,20
1
1
3,3%
3,3%
1,21
1,22
4
4
5
9
13,3%
13,3%
16,6%
30,0%
1,23
2
11
6,6%
36,6%
1,24
1,25
1,26
1,27
1,28
1,29
1,30
1
2
3
3
4
3
3
12
14
17
20
24
27
30
3,3%
6,6%
10,0%
10,0%
13,3%
10,0%
10,0%
40,0%
46,6%
56,6%
66,6%
80,0%
90,0%
100,0%
Si los valores que toma la variable son muy diversos y cada uno de ellos se repite muy pocas
veces, entonces conviene agruparlos por intervalos, ya que de otra manera obtendríamos una tabla
de frecuencia muy extensa de muy poco valor para fines de síntesis.
2.2.1.1 Distribuciones de frecuencia agrupada. Supongamos que medimos la
estatura de los habitantes de un edificio y obtenemos los siguientes resultados (cm):
Habitante
Habitante 1
Habitante 2
Habitante 3
Habitante 4
Habitante 5
Habitante 6
Habitante 7
Habitante 8
Estatura
1,15
1,48
1,57
1,71
1,92
1,39
1,40
1,64
Habitante
Habitante 11
Habitante 12
Habitante 13
Habitante 14
Habitante 15
Habitante 16
Habitante 17
Habitante 18
Estatura
1,53
1,16
1,60
1,81
1,98
1,20
1,42
1,45
Habitante
Habitante 21
Habitante 22
Habitante 23
Habitante 24
Habitante 25
Habitante 26
Habitante 27
Habitante 28
Estatura
1,21
1,59
1,86
1,52
1,48
1,37
1,16
1,73
14
Habitante 9
Habitante 10
1,77
1,49
Habitante 19
Habitante 20
1,20
1,98
Habitante 29
Habitante 30
1,62
1,01
Si presentáramos esta información en una tabla de frecuencia obtendríamos una tabla de 30 líneas
(una para cada valor), cada uno de ellos con una frecuencia absoluta de 1 y con una frecuencia
relativa del 3,3%. Esta tabla nos aportaría escasa información
En lugar de ello, preferimos agrupar los datos por intervalos, con lo que la información queda más
resumida (se pierde, por tanto, algo de información), pero es más manejable e ilustrativa:
Tabla de distribución de frecuencias para la variable aleatoria estatura de los estudiantes.
Estatura
Cm
Frecuencias absolutas
Simple
Acumulada
Frecuencias relativas
Simple
Acumulada
1,01 - 1,10
1
1
3,3%
3,3%
1,11 - 1,20
1,21 - 1,30
3
3
4
7
10,0%
10,0%
13,3%
23,3%
1,31 - 1,40
2
9
6,6%
30,0%
1,41 - 1,50
1,51 - 1,60
1,61 - 1,70
1,71 - 1,80
1,81 - 1,90
1,91 - 2,00
6
4
3
3
2
3
15
19
22
25
27
30
20,0%
13,3%
10,0%
10,0%
6,6%
10,0%
50,0%
63,3%
73,3%
83,3%
90,0%
100,0%
El número de intervalos en los que se agrupa la información es una decisión que debe
tomar el analista: la regla es que mientras más intervalos se utilicen menos información se
pierde, pero puede que menos representativa e informativa sea la tabla.
Se encuentran varias propuestas para esto; una es la formula de Sturges:
K = 1 + 3.32 * log(n) , pero también se usan (Scott) K = 2n o K =
3
n[rango]
2 * (Q3 − Q1 )
3
(Freedman, and Diaconis,1981).
Se recomienda que sean menos de 20 y más de cuatro intervalos.
El procedimiento para crear una tabulación de frecuencias tiene las siguientes
operaciones:
•
•
Determine el número de intervalos a construir (K).
Calcule el rango (r = máximo - mínimo).
•
Calcule el ancho inicial del intervalo: Ai =
•
Establezca una amplitud de clase (ancho del intervalo) aumentando Ai al menos en
un 2% ( A ≈ (1.02) * A i ). Esta no es una regla que se tenga que cumplir al pie de
la letra, el asunto es que se pueda ampliar “razonablemente” el rango.
r
K
15
•
Determine el rango ampliado: ra = A * K
•
Calcule 2d = ra − r
•
Reste d al valor mínimo de la muestra (mínimo reducido).
El primer intervalo se construye o va desde el mínimo reducido (límite inferior) a la suma
del mínimo reducido y la amplitud de clase (A).
El segundo intervalo tiene como límite inferior el límite superior del primer intervalo; el
límite superior se construye con sumar la amplitud de clase al límite inferior. De esta
forma se repite el proceso hasta completarse todos los intervalos.
La tabla se completa al contabilizar, para cada intervalo, las respectivas frecuencias
absolutas y el resto de los componentes de la tabla (columnas).
En una tabla de frecuencias, los percentiles (y cualquier cuantil) se calculan
usando la siguiente expresión:
i*n
− ∑ fk
100
Pi = L i +
*C
fj
Pi :
Li:
∑fk:
fj:
C:
Es el i-ésimo percentil.
Límite inferior de la clase o intervalo de interés, esto es, la clase que supera
o iguala la proporción buscada por el percentil.
Es la suma de las frecuencias anteriores a la clase de interés.
La frecuencia absoluta de la clase de interés.
Amplitud de clase o longitud del intervalo
Tarea: calcule a la tabla de frecuencias anterior la mediana, el percentil diez, el cuartil uno
y el percentil 95.
2.2.2 Tablas de contingencia. En muchas ocasiones para el investigador será de
interés recolectar, de manera simultánea, en una muestra más de una cualidad o variable.
Por ejemplo, se midió en una empacadora de carnes la cantidad (concentración) de
preservativos que se requieren para que las proteínas no inicien su proceso de
desnaturalización. Para esto se evaluaron los efectos de tres tipos (marcas comerciales)
de preservantes en cuatro dosis, sobre la carne de burro, de caballo, de cerdo y de res.
Como se puede apreciar, estos resultados serán mejor evaluados si se presentan
resumidos en una tabla de doble entrada como la que se muestra a continuación.
Tabla de contingencia. Días para el inicio de la desnaturalización de la carne de caballo
Concentración (mg/k)
5
12
18
20
Marca
Rocinante
19
25
27
17
Imperial
17
28
30
24
Resplandor
12
20
22
25
Nótese que será necesaria la construcción de una tabla similar para cada tipo de carne o
construir una tabla más elaborada que muestre toda la información.
16
2.3 GRÁFICOS.
Los gráficos son el principal instrumento de análisis exploratorio de las características de
una variable y se construyen de varios tipos, según el propósito y/o el nivel deseado para
el análisis y según el tipo de variable que se grafique.
2.3.1 Diagrama de dispersión. La representación en un gráfico los pares de valores de
dos variables suministra información a cerca de posibles relaciones entre las ellas, con
una simple inspección a la nube de puntos.
Ejemplo: Se tiene la siguiente información acerca de número de nemátodos en una muestra de suelo
y el contenido de materia orgánica en la misma muestra
Nematodos
Materia
Nemátodos
Orgánica
7
4.2
6.7
12
9.8
11
15
12.5
13
23
15.7
24
4
5.8
4
Dibuje el diagrama de dispersión entre las dos variables.
Materia
Orgánica
4
11
12.5
15.9
6.8
2.3.2 Diagrama de barras. Se usa para variables de tipo categórico. Se realiza
graficando las frecuencias absolutas o las frecuencias relativas de la variable (eje Y)
contra los valores observados (eje X). Se distingue del histograma por la separación de
las barras, que no existe en el histograma.
2.3.3 Diagrama de sectores. Las frecuencias relativas de las categorías que se
encuentran en la variable son graficadas usando el círculo como representación de la
totalidad de la muestra, cada categoría se le asigna un sector (segmento de arco) que es
proporcional a esta frecuencia. De esta forma, una categoría que tenga una frecuencia
relativa de 50% le corresponde el arco descrito por un ángulo de 180º
17
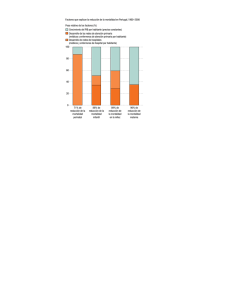
¿Qué porcentaje de las ventas corresponde a los helados de manzana (apple)?
2.3.4
Diagrama de cajas.
Se construyen usando la mediana y los cuartiles. La caja tiene un par de líneas que se prolongan
a 1,5 veces el rango intercuartílico (1.5*{Q3 – Q1}). La caja la constituyen tres líneas, la primera
está a la altura del cuartil uno (Q1), la segunda es la mediana y la tercera el cuartil tres (Q3).
Diagrama de cajas y bigotes para la variable aleatoria X.
2.3.5
Histograma de frecuencias
Se construye graficando las frecuencias absolutas o las frecuencias relativas de la variable (eje Y)
contra las categorías o clases en las que se dividió la misma (eje X). Se distingue del diagrama de
barras por que la separación de las barras es cero.
18
Los pasos para construir el histograma son:
1. Defina los intervalos o clases de igual longitud.
2. Cuente el número de observaciones que caen en cada clase o intervalo. Esto es llamado la
frecuencia.
3. Calcule la frecuencia relativa, hi =
observacio nes _ en _ el _ int ervalo
número _ de _ datos
4. Grafique los rectángulos cuyas alturas son proporcionales a las frecuencias relativas.
Realizar histogramas de esta manera tiene las siguientes ventajas
•
•
•
•
Es útil para apreciar la forma de la distribución de los datos, si se escoge adecuadamente el
número de clases y su amplitud.
Se puede presentar como un gráfico definitivo en un reporte.
Se puede utilizar para comparar dos o más muestras o poblaciones.
Se puede refinar para crear gráficos más especializados, por ejemplo la pirámide poblacional.
Desventajas
•
•
Las observaciones individuales se pierden.
La selección del número de clases y su amplitud que adecuadamente representan la
distribución puede ser complicado. Un histograma con muy pocas clases agrupa demasiadas
observaciones y uno con muchas deja muy pocas en cada clase. Ninguno de los dos
extremos es adecuado.
Debido a que nuestros ojos responden al área de las barras, es importante mantener la anchura de
las barras iguales. Si estamos enfrentados a un problema donde los intervalos tienen diferente
amplitud, por ejemplo cuando obtenemos datos agrupados desde la fuente, la siguiente fórmula se
usa
Altura del rectángulo = Frecuencia Relativa / Amplitud del Intervalo
19
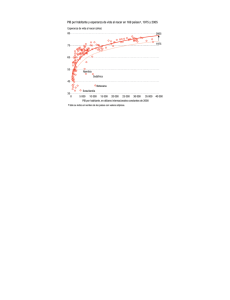
2.3.6 Ojiva. Se realiza graficando las frecuencias acumuladas de la variable en estudio (eje Y)
contra los valores de la variable (punto medio del intervalo de clase {xi} en el eje X).
Tarea: usando las frecuencias acumuladas de la tabla de distribución de frecuencias de los
estudiantes grafique la ojiva correspondiente.