Data collection for developing the Employment National Survey
Anuncio

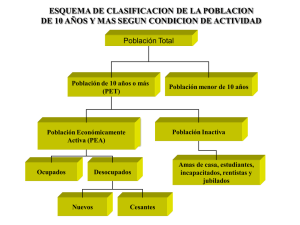
documentos de trabajo RECOPILACIÓN DE INFORMACIÓN ACERCA DE LA CONSTRUCCIÓN DE PRODUCTO ENE Junio 2007 Nº4 RECOPILACIÓN DE INFORMACIÓN ACERCA DE LA CONSTRUCCIÓN DE PRODUCTO ENE Departamento de Investigación y Desarrollo Instituto Nacional de Estadísticas de Chile RECOPILACIÓN DE INFORMACIÓN ACERCA DE LA CONSTRUCCIÓN DE PRODUCTO ENE Departamento de Investigación y Desarrollo Coordinadora Departamento I+D Claudia Matus Correa Jefe Área Análisis de Estadísticas Sociales Miguel Guerrero Herrera Analista Jaime Vargas Barraza 2 RECOPILACIÓN DE INFORMACIÓN ACERCA DE LA CONSTRUCCIÓN DE PRODUCTO ENE Introducción Dando cumplimiento a las actividades propuestas para el trimestre Abril – Junio de 2007, en cuanto a la Recopilación de Información Acerca de la Construcción de Encuestas de Empleo, en este documento se presentan un estudio de comparación de metodologías de trabajo, en diversos países que llevan a cabo encuestas de empleo. La idea es presentar las distintas visiones y resultados obtenidos por países pertenecientes a la Unión Europea y contrastar esto con lo hecho por países de América, incluyendo a Chile. Puntualmente los países en estudio son: Unión Europea: Bélgica, Dinamarca, Alemania, Grecia, España, Francia, Irlanda, Italia, Luxemburgo, Los Países Bajos, Austria, Portugal, Finlandia, Suecia y El Reino Unido. América: Estados Unidos, Argentina, Perú, Colombia y Chile Dentro de los puntos analizados se encuentran: i) ii) iii) iv) v) Diseño muestral, Metodología de levantamiento de los datos, Métodos de cálculo de factores de expansión, Inclusión o no de la no respuesta como parte del factor de expansión, Esquemas de rotación de la muestra. En el ámbito del cálculo de factores de expansión se presentan ejemplos de metodologías utilizadas tanto a nivel europeo como a nivel americano y en los esquemas de rotación de la muestra se presentan los distintos enfoques con que se enfrenta el problema de la carga de los entrevistados, en el sentido del agotamiento que produce en los entrevistados las constantes visitas o contactos por parte del equipo de encuestadores. Además para el caso de las encuestas a nivel europeo, se presenta de forma breve las principales legislaciones que regulan la construcción de las encuestas de empleo de los Países Miembros de la Unión Europea. Por último, con el afán de dar una mirada más general a la construcción de las encuestas, se han construidos tablas resumen sobre la metodología y tratamiento de los datos para las distintas encuestas de empleo. La información contenida en dichas tablas corresponde a: i) ii) iii) Cobertura, Frecuencia y Tasa de Respuesta Tamaño y Diseño Muestral Estratificación, Esquema de Rotación y Ponderación 3 RECOPILACIÓN DE INFORMACIÓN ACERCA DE LA CONSTRUCCIÓN DE PRODUCTO ENE Unión Europea Base Usada para la Muestra: Los registros de población y el último censo de población o lista de direcciones usadas en ese Censo son las dos principales fuentes para el marco muestral. Otras fuentes incluyen listas de direcciones desde, por ejemplo, las Autoridades Postales o bases de datos del servicio público. Los países Nórdicos tales como Bélgica e Italia usan los registros de población como su única base, mientras que Alemania y Los Países Bajos complementan esta información con el Censo o Datos Postales. Etapas de Muestreo y Unidades de Muestreo Primarias (UMP) Dinamarca, Luxemburgo, Austria, Finlandia, Suecia y El Reino Unido, usan un diseño muestral de una etapa. Alemania, usa un diseño muestral bietápico. Todos los otros países usan un diseño bietápicos o trietapicos, usualmente seleccionando distritos administrativos o áreas de enumeración censal en la primera etapa (Irlanda es un caso especial y usa un diseño de conglomerados bietápico). Unidades de Muestreo Últimas Tres tipos de unidades de muestreo últimas son empleadas: 1) Hogares, 2) Viviendas ó Direcciones, y 3) Personas. Alemania, Irlanda y Portugal muestrean clusters de unidades de viviendas. En las muestras de viviendas o direcciones, usualmente todas las personas y de ese modo, todas las unidades de hogares residentes dentro de la vivienda/dirección son entrevistadas (Alemania, España, Francia, Austria, Portugal y El Reino Unido). La excepción es Los Países Bajos donde una etapa de muestreo final es implementada, es decir, submuestras de hogares desde direcciones de correo de multi-hogares. Cuando las personas constituyen las unidades de muestreo primarias, la selección de personas constituye la muestra final (los países nórdicos). Estratificación Todos los países estratifican el marco muestral antes del muestreo. Región, Regiones NUTS II, NUTS III, NUTS IV o áreas definidas nacionalmente, es la variable de estratificación más común (todos menos Dinamarca y El Reino Unido). La Urbanización es también una variable de estratificación popular (Grecia, Francia, España e Irlanda). Otras variables de estratificación incluyen registros de estados de empleo o desempleo de los individuos (Dinamarca y Suecia) e información auxiliar sobre las características (tamaño, tipo) de las unidades de muestreo primarias (España, Francia e Italia). Descripción del Esquema de Rotación Todos los países usan un diseño de panel de rotación para las muestras. Los paneles (o rondas) van de dos a ocho paneles. Los diseños de paneles con cuatro o cinco paneles son el más común. Cada panel es entrevistado sucesivamente sin interrupción, o el panel puede 4 RECOPILACIÓN DE INFORMACIÓN ACERCA DE LA CONSTRUCCIÓN DE PRODUCTO ENE salir uno o más trimestres antes de ser entrevistado otra vez. Dependiendo del énfasis nacional, el número de rondas y patrones de salidas conducen a diferentes resultados de sobrelapos entre dos trimestres sucesivos o en el mismo trimestre en dos años sucesivos. Breve Descripción de método de Cálculo de Factores de Ponderación El Consejo de Regulación (EC) No 577/98 sobre las Encuestas de Fuerza Laboral (LFS) de la Unión Europea impone que los factores de ponderación deberían ser tomados en cuenta “en particular la probabilidad de selección y datos externos relacionados con la distribución de la población que está siendo encuestada, por sexo, edad (grupos etáreos de cinco años) y región (nivel de NUTS II), donde tales datos externos cumplen con ser lo suficientemente confiables para los Estados Miembros afectados” (Articulo 3(5)). Los métodos de cálculo de las ponderaciones difieren mucho entre países. Dos métodos principales son usados, dependiendo del detalle de la información externa y de si la información externa permite o no hacer cruces de tabulados: 1) inverso de la probabilidad de selección ajustada a posteriori por la distribución de la población por sexo, grupo etareo, y otras fuentes externas (administrativas), y 2) Diferentes variaciones del método de Ranking-Ratio, incluyendo calibración generalizada. La mayoría de los países realizan ajustes para la no respuesta, directamente en el proceso de ponderación o en un paso preliminar antes de ajustar las ponderaciones a fuentes externas. Ejemplo de Cálculo de Factores de Ponderación La ponderación de los datos muestrales sirven dos fines: El primero es compensar por la no respuesta entre diferentes subgrupos de la población y segundo es ajustar la distribución de ciertas características en la muestra de los valores poblacionales. Estos valores se toman desde proyecciones de la población, que están en los países basadas más o menos directamente en los Datos Censales. En Austria este proceso inicia calculando una ponderación básica para cada registro. Esta ponderación básica para cada persona depende del estrato y del dominio, al cual la persona pertenece. Así cada ponderación de persona puede ser a través del número de individuos que la persona representa en el subgrupo (post-estratificación). Un paso más adelante, el ajuste a la distribución de la población toma lugar. Esta calibración es hecha por medio de un proceso iterativo. En el paso 1 las ponderaciones son ajustadas de modo que el grueso de la distribución de la variable Estado Federal por edad y sexo sea igual a la proyección de la población. En el paso 2 esto es continuado para la variable Estado Federal por nacionalidad. En el paso 3 se calcula el valor medio de todas las personas que viven en una vivienda, ya que es deseable tener los mismos pesos en una vivienda. A causa de la posibilidad que por estos cálculos los ajustes en pasos 1 o 2 son arruinados, el paso 4 chequea, si la distribución en cualquier celda corresponde suficientemente a la estructura de la población. En al caso de no estar entre algunos rangos predefinidos, otras iteraciones son necesarias. De todas formas el procedimiento para después de 100 iteraciones. Para la LFS finlandesa en un comienzo se hace el cálculo de los pesos para cada persona de acuerdo a la post-estratificación para las variables sexo, edad y región. Luego, los pesos 5 RECOPILACIÓN DE INFORMACIÓN ACERCA DE LA CONSTRUCCIÓN DE PRODUCTO ENE calibrados son calculados de acuerdo a sexo, edad, región, semana de referencia (en el caso de una encuesta continua la tasa de respuesta varía semanalmente, de modo que ella debería ser balanceada sobre el nivel mensual) y basado en el registro del estado de búsqueda de trabajo tomado de un registro mantenido por el Ministerio de Trabajo. Para el procedimiento de Calibración una función de distancia lineal es usada, disponible en el programa CLAN En el microcenso Alemán en el paso de compensación de la no respuesta diferentes tipos de supuestos de compensación son formados por medio de la combinación de las siguientes características: tamaño del hogar, nacionalidad, para alemanes: lugar de residencia, para hogares de una persona: sexo y edad. Para cada hogar de estos tipos en un nivel regional con a lo menos 100.000 habitantes la no respuesta es compensada. En el paso de calibración del procedimiento ponderación la nacionalidad en combinación con el sexo es utilizada como variable auxiliar. El ajuste es desarrollado dentro de cada estrato regional con a lo menos 500.000 habitantes. Multiplicando el peso relativo al hogar del paso 1 por el peso relacionado a la persona resultado del paso 2 en el respectivo peso de la persona. Además del peso de la persona, para los datos de hogares un peso para los hogares es calculado como el valor medio de todos los pesos de las personas de un hogar (ver, Gruber, 1996). En Los Países Bajos el Procedimiento de ponderación para la LFS neerlandesa comienza con pesos de inclusión que se derivan las personas que responden, que toma en cuenta el sobremuestreo de direcciones, que ocurre en el registro de la Oficina de Empleo, el submuestreo de direcciones con sólo personas de 65 años y más, el mes de entrevistas y las diferencias en las tasas de respuesta entre regiones geográficas (ver, Hilbink et al., 2001). Estos pesos de inclusión son los pesos de partida para un estimador de regresión que usa varias combinaciones de las variables auxiliares, área, edad, sexo, estado civil y origen étnico. El método de Lemaitre and Dufour (1987) se aplica para obtener pesos iguales para miembros del mismo hogar. Finalmente para las LFS de El Reino Unido, la etapa 1 del proceso de ponderación corrige para la no respuesta a nivel de área local. El ajuste de la categoría en la etapa 2 Métodos de Levantamiento de los Datos Existen tres formas de levantamiento de datos para las LFS de la Unión Europea, visitas personales, entrevistas telefónicas y formas de papel enviadas por correo. Muchos de los estados miembros mezclan los dos primeros de modo que en la primera ronda es siempre por medio de visitas personales mientras que en rondas subsecuentes son mediante teléfono si es que esto es posible. Alemania levanta datos en una mezcla de cuestionarios por correo y entrevistas personales. Dinamarca recoge los datos con entrevistas telefónicas pero las personas que no pueden ser localizadas por teléfono reciben un cuestionario por correo. Bélgica utiliza éstos tres modos en la segunda (y última) entrevista. Luxemburgo, Suecia y Finlandia cuentan únicamente de encuestas telefónicas. Grecia, Irlanda y Portugal sólo realizan entrevistas personales. Cuatro países utilizan cuestionarios computarizados, España, Italia, Los Países Bajos y El Reino Unido; en todos ellos se realiza una primera entrevista personal y las posteriores rondas se realizan vía telefónica. En al caso de Francia, 6 RECOPILACIÓN DE INFORMACIÓN ACERCA DE LA CONSTRUCCIÓN DE PRODUCTO ENE sea realiza un entrevista personal en la primera ronda y encuestas telefónicas en las rondas siguientes, en todos los casos utiliza cuestionarios de papel. Por último, Austria, realiza en su primera ronda una entrevista con lápiz y papel, y en las rondas siguientes realiza la encuesta vía telefónica en cuestionarios computarizados. Principales Regulaciones de las LFS de la Unión Europea La LFS de la Unión Europea (UE) es gobernada por varias regulaciones del Consejo, Parlamento Europeo y la Comisión. Council Regulation (EC) No 577/98 es la principal regulación de la LFS de la UE, desde el 9 de Marzo de 1998, y trata sobre la organización de una encuesta muestral de fuerza laboral en la Comunidad. Entrega recomendaciones sobre frecuencia de la encuesta, representatividad, características y conducción de la muestra; además de la transmisión de los resultados, reportes y procedimientos. Regulation (EC) No 1991/2002 del Parlamento Europeo y del Consejo del 8 de Octubre de 2002 sobre la organización de una encuesta muestral de fuerza laboral en la Comunidad. Esta regulación pone un límite de tiempo sobre la adopción de la LFS continua. Otra de las regulaciones que establece parámetros sobre la implementación de la LFS a nivel nacional para poder suministrar datos a Eurostat y formar la LFS de la EU es Commission Regulation (EC) No 1897/2000 del 7 de Septiembre de 2000. Esta regulación contiene los 12 principios para la construcción del cuestionario nacional. 7 RECOPILACIÓN DE INFORMACIÓN ACERCA DE LA CONSTRUCCIÓN DE PRODUCTO ENE Comparación de Encuesta de Empleo en América USA, Colombia, Perú, Argentina y Chile Tamaño y Diseño de la Muestra La fuente del marco muestral está basado en la información del último censo de población y vivienda de cada país y de su respectivo material cartográfico. La unidad final de muestreo es el hogar (USA) o bien la vivienda (Chile, Perú, Argentina), a excepción de Colombia cuya unidad final de muestreo son los segmentos, los cuales corresponden en promedio a grupos de 10 viviendas cada uno. La edad base para considerar a un individuo en situación de empleo difiere para cada uno de los países analizados. En el caso de USA, Chile y Perú, las edades son 16, 15 y 14 años respectivamente. Por su parte, Colombia, establece distintas edades dependiendo si se es de zona urbana o rural (12 y 10 años respectivamente). En el caso de Argentina no se especifica en sus documentos metodológicos, la edad mínima para ser considerado individuo en situación de empleo. Los esquemas de rotación que se plantean en estas encuestas son de dos tipos: 1) con salida temporal (USA, Argentina), y, 2) Con permanencia continua hasta su salida definitiva (Chile). El esquema de rotación utilizado por USA es mensual, estableciendo una permanencia de 4 meses consecutivos, una posterior salida temporal durante 8 meses y un una reincorporación por un período de 4 meses, para luego salir definitivamente de la muestra. De forma similar Argentina establece un esquema de rotación de 2 – (2) – 2, es decir, que la vivienda es encuestada durante 2 trimestres, y la misma cantidad de períodos se deja sin encuestar, para luego entrevistarla durante otros 2 trimestre. Luego de esto la vivienda sale de la muestra. En el documento metodológico de la encuesta de empleo Argentina se plantea que: “Se optó por este esquema 2-(2)-2, teniendo en cuenta: La experiencia previa, sobre la tasa de no respuesta cuando se trabaja con períodos largos de permanencia en el panel. La necesidad de contar con un solapamiento mínimo entre períodos consecutivos. La necesidad de contar con un solapamiento mínimo entre iguales períodos de años consecutivos”. Además plantea que: “El solapamiento de las muestras entre dos períodos consecutivos (o sea el porcentaje de muestra en común) juega en sentido contrario para los primeros dos aspectos: si un esquema tiene un alto porcentaje de solapamiento entre un período y el siguiente, medirá bien los cambios pero disminuirá su precisión para una agregación a lo largo de varios períodos. Por el contrario, un bajo solapamiento mejora la precisión cuando se agrega muestra, pero disminuye la precisión de la estimación del cambio entre períodos sucesivos”. Por su parte, nuestra encuesta de empleo establece un sistema de rotación de 6-, es decir, que cada vivienda es visitada en seis ocasiones, con una diferencia entre cada entrevista, de tres meses. Luego de transcurrido ese período la vivienda sale definitivamente de la muestra. En el caso de Perú y Colombia, no aparece establecido ningún esquema de rotación en sus documentos metodológicos. En cuanto al método de levantamiento de la información, este se realiza por medio de entrevista personal (en la primera y quinta entrevista) y vía telefónica las restantes 8 RECOPILACIÓN DE INFORMACIÓN ACERCA DE LA CONSTRUCCIÓN DE PRODUCTO ENE ocasiones, en el caso de USA. El resto de los países analizados, realizan sus encuestas a través de entrevistas personales. Sustitución, No Respuesta e Imputación A nivel de estos cinco países americanos, no se realiza sustitución de las unidades finales de muestreo que no responden y sólo Perú y USA realizan ajustes en sus estimaciones para considerar el efecto de la no respuesta. Tanto Chile como Colombia, no llevan a cabo dicho ajuste. En el caso de Argentina no se encontraba disponible esa información. Por último la imputación por no respuestas de ítems se realiza sólo en USA y no hay información sobre Argentina que señale si se realiza esta imputación o no. Factores de Ponderación, el caso de USA, Perú y Chile En el caso de Chile, en la Encuesta Nacional de Empleo el factor de ponderación o expansión utilizado es: ( 2) hi F Mh M hi' PhSE = ⋅ ⋅ SE nh ⋅ M hi mhi Pˆh el cual está formado por dos partes: (1) hi F Mh M hi' = ⋅ nh ⋅ M hi mhi que depende sólo del diseño muestral y que puede ser interpretado como el inverso de la probabilidad de inclusión en la muestra, para una persona perteneciente al estrato h y a la sección i. La otra parte del factor de expansión corresponde a un ajuste que considera la proyección de la población del estrato correspondiente. Un estimador similar es utilizado en la Encuesta de Empleo de Perú. Para que las estimaciones derivadas de la Encuesta Permanente de Empleo sean representativas de la población, es necesario multiplicar los datos de cada hogar muestral contenido en los archivos por el peso o factor de expansión calculado según el diseño muestral. Todo este proceso es resumido al obtener la probabilidad de selección de cada vivienda, lo cual es determinado de la siguiente manera: 1. ETAPA I. Se seleccionan un conjunto de conglomerados, su probabilidad de selección esta dada por: Nº Conglomerados Seleccionados en la Provincia * Nº Viviendas Ocupadas del i-ésimo Conglomerado P1 = -----------------------------------------------------------------------------------------------------------------------------Nº Viviendas Ocupadas en la Provincia 9 RECOPILACIÓN DE INFORMACIÓN ACERCA DE LA CONSTRUCCIÓN DE PRODUCTO ENE 2. ETAPA II. Selección de submuestras (grupo de viviendas) en cada conglomerado seleccionado, la probabilidad de selección es: Nº Submuestras Seleccionadas en el Conglomerado * Nº Viviendas Ocupadas en la j-ésima Submuestra P2 = -----------------------------------------------------------------------------------------------------------------------------Nº Viviendas Ocupadas en el Conglomerado La probabilidad de selección final es la multiplicación de P1 y P2 (P= P1 * P2). El inverso a la probabilidad de selección final nos da el factor de expansión básico: Wi = 1 / P Wi = Factor de expansión básico para las viviendas seleccionadas dentro de la i–ésima UPM muestral (conglomerado). También, es importante ajustar los factores de expansión teniendo en cuenta la magnitud de la no respuesta en cada UPM (conglomerado) muestral. El factor final de expansión (W´i ) para cada registro tiene dos componentes: el factor de expansión básico (Wi) y el factor de ajuste por la no respuesta. Dado que los factores de expansión son calculados al nivel de cada UPM (conglomerado) seleccionada, es importante ajustar los factores de expansión a este nivel. En este caso el factor final de expansión (W´i) para las viviendas seleccionadas dentro de la i–ésima UPM seleccionada se puede expresar como: W´i = ( Wi ) * (mi / m´i) Donde: mi = Total de viviendas seleccionadas dentro de la i – ésima UPM seleccionada, es decir, el número de entrevistas más el número de no entrevistas. m´i = Total de viviendas entrevistadas dentro de la i–ésima UPM seleccionada. La no entrevista, se refiere a unidades de muestreo válidas, es decir, que no pudieron ser entrevistadas a causa de rechazos y/o ausencia de informantes. Por otro lado, las no entrevistas no incluyen unidades de muestreo no válidas seleccionadas como viviendas desocupadas, abandonadas, transitorias, destruidas, etc. Es decir, donde se sabe concretamente, por las causas que los motivaron, que no existe hogar, es decir, reflejan problemas de marco. En la LFS de USA el procedimiento de estimación involucra la ponderación de los datos de cada persona en la muestra por el inverso de la probabilidad de que la persona esté en la muestra. A través de una serie de pasos de estimación, las probabilidades de selección son ajustadas por la no respuesta y subcobertura de la muestra; los datos de meses previos son incorporados en las estimaciones a través del procedimiento de estimación compuesto. 10 RECOPILACIÓN DE INFORMACIÓN ACERCA DE LA CONSTRUCCIÓN DE PRODUCTO ENE 1. Ajuste para la no respuesta. Las ponderaciones para todos los hogares entrevistados son ajustados para tener en cuenta la muestra de hogares ocupados para los cuales la información no fue obtenida debido a la ausencia de los ocupantes, caminos inaccesibles, rechazos, o incapacidad de los encuestados por otras razones. Este ajuste por no respuesta es hecho separadamente de los cluster similares de áreas muestrales que son usualmente, pero no necesariamente, contenidos en los Estados. La similaridad de las áreas muestrales se basan en estatus y tamaño del Área Estadística Metropolitana (MSA). Dentro de cada Cluster, existe un post desglose por residencia. Cada cluster MSA es dividido en “ciudad central” y “resto de la MSA”. Cada cluster no MSA es dividido en categorías de residencia “Urbano” y “Rural”. La proporción de la encuesta no entrevistada varía de 7% a 8%, dependiendo del tiempo, época de vacaciones y así sucesivamente. 2. Estimaciones de Razón: La distribución de la población seleccionada para la muestra se diferencia, por azar, del total de la población en las características tales como edad, raza, sexo, origen étnico, y estado de la residencia. Ya que estas características son muy correlacionadas con la participación en la fuerza laboral y otras mediciones principales hechas a partir de la muestra, las estimaciones de la encuesta pueden ser sustancialmente mejoradas cuando ponderamos apropiadamente por la distribución conocida de esas características poblacionales. Esto es realizado a través de un ajuste de razón de dos etapas, como sigue: a. Estimación de Razón, Primera Etapa: El propósito del ajuste de razón de primera etapa es reducir la contribución a la varianza de la selección de muestras de Unidades de muestreo primarias más que seleccionando una muestra de hogares desde cada unidad de muestra primaria en la Nación. Este ajuste es hecho para las ponderaciones de la Current Population Survey (CPS) en dos celdas de raza: Negro y no negro, y dos celdas de edad: 0 a 15 años y 16 años y más; esto sólo aplicado a datos desde las UMP que no son auto-representativas y para aquellos estados que tienen un número sustancial de viviendas negras. El procedimiento corrige las diferencias que existieron en cada celda de Estado al momento del censo 2000 entre 1) la distribución de la de la población por raza en la muestra de unidades de muestreo primario y 2) la distribución de la raza para todas las UMP. (Ambos, 1 y 2, de las UMP auto-representadas). b. Estimación de Razón, Segunda Etapa: Este procedimiento reduce sustancialmente la variabilidad de las estimaciones y corrige, en cierto modo, para las subcoberturas de la CPS. Las ponderaciones de la muestra de la CPS son ajustadas para asegurar que las estimaciones de la población, basadas en la muestra, coincidan con las variables poblacionales independientes de control. Iniciando el 2003, la ponderación de dos etapas tiene nuevos pasos de cobertura “0A” y “0B” que son seguidos por un proceso ------- iterativo. California y Nueva York son divididos en áreas subestados, y 53 Estados/áreas son usadas en el Paso 0B y el paso 1 (los Angeles-Long Beach 11 RECOPILACIÓN DE INFORMACIÓN ACERCA DE LA CONSTRUCCIÓN DE PRODUCTO ENE área metropolitana; resto de California; Ciudad de Nueva York; resto de Nueva York; los otros 48 Estados; y el Distrito de Columbia). El paso 0A de cobertura nacional no iterado es adicionado en primer lugar para mejorar la eficiencia del ajuste para subpoblaciones que son propensas a subcoberturas. El paso 0A también provee algún control para la raza Asiática que podría no ser incluida en los pasos de iteración. El paso 0B de cobertura de Estados no iterados es diseñado para ajustar por diferencia de coberturas, para raza/género/edad, entre los Estados. La raza es limitada a negro y no negro, y no existe componente de origen étnico en el paso. Los tres pasos iterados ajustan las ponderaciones de la muestra a los siguientes grupos control: i. ii. iii. Paso Estado – 6 géneros x celdas de edad definidas para 53 estados/áreas Paso Origen étnico – 26 hispanos y 26 no hispanos, celdas de género x edad. Paso Raza – 34 sólo blancos, 26 sólo negros, y 26 Sólo asiáticos y el resto, celdas de genero x edad. Los controles para la población independiente son preparados mediante proyecciones a largo plazo de la población residente enumerada igual que el 1 de Abril de 2000. Las proyecciones son derivadas mediante la actualización de los datos del censo demográfico con información de una gran cantidad de otras fuentes de datos que informan nacimientos, muertes e inmigración neta. Restando el número de personal de Fuerzas Armadas y personas institucionalizadas residentes se reduce la población residente a la población no institucional civil. 3. Procedimiento de Ponderación Compuesto: El último paso en la preparación de mayoría de las estimaciones de la CPS hace uso de un procedimiento de estimación compuesto. Estimaciones compuestas son creadas como un promedio ponderado de dos factores: (1) La estimación de razón de dos etapas basado en los datos de la muestra completa del mes actual; y, (2) La estimación compuesta para el mes anterior, ajustado por una estimación del cambio de un mes a otro basado en los seis grupos de rotación común a ambos meses. Un término de ajuste de sesgo es añadido al promedio ponderado para reducir la varianza y considerar parcialmente para el sesgo asociado a estimaciones de las muestra del mes. Este sesgo en la muestra del mes es expuesto mediante estimaciones de desempleo de personas en su primer y quinto mes en la CPS que son generalmente más altos que las estimaciones obtenidas para los otros meses. Estas estimaciones compuestas luego son usadas como controles en el procedimiento de ponderación compuesto. Tanto empleados como desempleados son controlados en cada celda definida, y los no incluidos en la fuerza laboral son controlados como resto. El procedimiento iterativo es similar al usado para la ponderación de segunda etapa: 12 RECOPILACIÓN DE INFORMACIÓN ACERCA DE LA CONSTRUCCIÓN DE PRODUCTO ENE a) Paso Estado – una sola celda para CPS 16+ es usada para los 53 Estados/áreas. b) Paso Origen Étnico – 10 hispanos y 10 no hispanos, celdas de genero x edad. c) Paso Raza – 22 solo blanco, 14 solo negro, y 10 solo asiáticos y el resto, celdas de genero x edad. La estimación compuesta da como resultado una reducción en el error muestral más allá del que se espera a través de la estimación de razón de dos etapas. Para algunos ítems, la reducción es sustancial. Los aumentos resultantes en confiabilidad son datos históricos, generalmente por los 5 años más recientes, se hacen solamente al principio de cada año civil. Comentarios En el transcurso de la recopilación de los documentos y datos que dieron origen a este informe, se detectó una gran falencia en lo que respecta a las encuestas americanas, y en general a encuestas de países no pertenecientes a la Unión Europea. Dado que Eurostat intenta armonizar el formato y la información proveniente de las encuestas de fuerza laboral de sus países miembros y dado que apunta a lograr estadísticas de mejor calidad, entendiendo por calidad, la definición establecida por Eurostat en su documento metodológico “Definition of Quality in Statistics”, la información metodológica de la construcción, tanto de la LFS de la Unión Europea como de las LFS’s nacionales de cada uno de los Estados Miembros, es de muy fácil acceso y ésta se encuentra bastante detallada. El problema se presenta cuando nos alejamos del ámbito de la LFS de la Unión Europea. Particularmente en el caso de las encuestas americanas, es difícil encontrar documentos metodológicos de alto nivel de elaboración a disposición del público en general (mas precisamente en formato HTML o bien algún documento electrónico, en los sitios web de los distintos INE) y con información detallada y relevante. La metodología de USA es la más completa, en referencia a los países americanos estudiados. Otro detalle que pude apreciar con respecto a los países analizados, es uno de los pocos que no tiene registros para la Tasa de Respuesta (y de No Respuesta), aunque en la próximas versiones de la ENE esta información vendrá codificada en la base de datos y se podrá determinar. Además actualmente, el departamento de Investigación y Desarrollo está desarrollando un estudio, con respecto al impacto de la inclusión de la no respuesta, como parte del factor de expansión de la muestra, en las estadísticas de empleo. Esta política de incluir un ajuste para la no respuesta dentro del factor de expansión, como aquí se ha planteado, la utilizan varios países, entre ellos USA, Bélgica, Alemania, Portugal y Reino Unido, entre otros. Además dentro de este estudio hubiese resultado muy interesante poder analizar la forma de cálculo de los estimadores y la precisión de los mismo, en los distintos países de las regiones analizadas, pero esto no se pudo realizar debido a que dicha información no está disponible para el público en general, por lo menos no el las paginas web de los sitios visitados. Para terminar se presentan los cuadros resumen de las encuestas de empleo analizadas, con la información que se pudo obtener a través de sus respectivos documentos metodológicos. 13 RECOPILACIÓN DE INFORMACIÓN ACERCA DE LA CONSTRUCCIÓN DE PRODUCTO ENE Cuadros Resumen sobre las Encuestas de Fuerza Laboral de los Estados Miembros de la Unión Europea, Datos 2004 Cobertura, Frecuencia y Tasa de Respuesta de los Estados Miembros de la Unión Europea Labour Force Survey 2004 Participación Población entrevistada Población en Viviendas para situación de Institucionales empleo Frecuencia de los Resultados Tasa de Respuesta BE Obligatoria 15+ (2da ronda 15-64) No Trimestral 76,0% DK Voluntaria 15 - 74 Muestreo Trimestral 64,8% DE Obligatoria. Algunas Preguntas en la LFS son Voluntarias 15+ Muestreo Anual 96 - 97% EL NA 15+ No Trimestral 90,4% ES Obligatoria 16+ No Trimestral 91,0% FR Obligatoria 15+ Por medio del Hogar Trimestral 81,9% IE Voluntaria 15+ No Trimestral NA IT Obligatoria 15+ No Trimestral 89,5% LU Voluntaria 15 - 74 No Anual 33,4% NL Voluntaria 15+ No Trimestral 64,0% AT Obligatoria 15+ No Trimestral 80,2% PT Obligatoria 15+ No Trimestral 89,3% FI Voluntaria 15 - 74 Muestreo Mensual 84,1% SE Voluntaria 15 - 74 Muestreo Mensual 83,5% UK Voluntaria 16+ Por medio del Hogar (estudiantes) Trimestral 73,6% 14 RECOPILACIÓN DE INFORMACIÓN ACERCA DE LA CONSTRUCCIÓN DE PRODUCTO ENE Tamaño y Diseño Muestral de los Estados Miembros de La Unión Europea Labour Force Survey 2004 Tamaño Muestral Programado (Promedio Trimestral 2004) Personas Hogares 15 - 74 Bases del Marco Muestral Unidad de Muestreo Primaria Unidad de Muestreo Final Fracción de Muestreo Total por Trimestre BE Registro de Población Secciones Estadísticas Hogares 0,3% 11.300 22.400 DK Registro de Población Central / Registro de Desempleo -- Personas 0,4% -- 10.800 DE Censo 1987 / Registro de Población / Registro de Viviendas Nuevas -- Conglomerados de Viviendas (Distritos Muestrales) 0,5% 149.900 248.100 EL Censo 2001 Bloque Hogares 0,9% 32.000 62.200 ES Censo 2001, Actualizado con los Registros de Población Áreas Geográficas Viviendas 0,5% 61.300 134.300 FR Censo 1999 Conglomerados Geográficos (aires) Viviendas 0,2% 37.300 63.000 IE Censo 2002 Bloques Censales (75 viviendas) Conglomerados de Viviendas (15 Viviendas) 3,3% 30.400 64.100 IT Registros Municipales Municipalidades Hogares 0,3% 67.900 134.400 LU Registro de Población Central -- Hogares 2,6% 1.900 4.000 NL Direcciones Postales y Registro de Población Municipalidades --> Direcciones de Correo Hogares 0,7% 43.200 87.300 -- Viviendas 0,6% 19.100 36.500 -- Viviendas 0,6% 18.000 38.300 -- Personas 0,9% -- 36.400 -- Personas 1,0% -- 49.200 -- Direcciones / Números de Teléfonos en Norte de Escocia 0,1% 54.000 91.000 AT PT FI Registros de Población Central Censo 2001 / Base Referenciada de Información Geográfica (BGRI) Registro de Población Central Registro de Población Central Direcciones Postales / Números telefónicos (Norte UK Escocia) / Unidades de Hogares (Norte de Irlanda) SE 15 RECOPILACIÓN DE INFORMACIÓN ACERCA DE LA CONSTRUCCIÓN DE PRODUCTO ENE Estratificación, Esquema de Rotación y Ponderación de los Países Miembros de la Unión Europea Labour Force Survey 2004 Variables Usadas para la Estratificación Esquema de Rotación Variables de Ponderación BE Región 2- Sexo, Grupo Etareo, Provincia DK Desempleados Registrados 2 - (2) - 1 Sexo, Edad, Ingreso, Sector de Actividad, Educación Profesional, Registro de Desempleo DE Región 4 - (Anual) Sexo, Región, Nacionalidad EL Región (NUTS-3) * Urbanización 6- Sexo, Edad, Región (NUTS-2) ES Tamaño de la Población en la Municipalidad 6- Sexo, Edad, Región, Nacionalidad FR Región Francesa (NUTS-2) y Tipo de Unidad Urbana 6- Tamaño de Entidad Urbana, Tamaño y Tipo de Casas, Número de Nuevas Viviendas, Grupo Etareo, Sexo, Regiones, Ronda de Encuesta IE Región, Urbanización 5- Sexo, Grupo Etareo, Región 2 - (2) - 2 Sexo, Grupo Etareo, Región 2* - Clase de Tamaño de Hogar * Grupo Etareo, Sexo*Grupo Etareo*Ciudadanía IT LU Categorías de Tamaños de Municipalidades dentro de las Regiones (NUTS-3) Cantones, Clases de Tamaño de Hogares (1, 2, 3, 4+) NL Región (Corop), Regiones de Oficinas de Empleo 5- Sexo, Grupo Etareo, Región, Grupo Étnico, Estado Civil AT Estados Federados 5- Sexo, Grupo Etareo, Región, Nacionalidad PT Regiones (NUTS-3) 6- Sexo, Grupo Etareo, Región FI Región 3 - (1) - 2 Sexo, Grupo Etareo, Región, Semana de Referencia, Estado de Busqueda de Trabajo SE Sexo, Condado, Nacionalidad, Estado de Empleo 8- Sexo, Grupo Etareo, Sector de Actividad Desempleo Registrado. UK Mediante el Marco 5- Sexo, Grupo Etareo, Región 16 RECOPILACIÓN DE INFORMACIÓN ACERCA DE LA CONSTRUCCIÓN DE PRODUCTO ENE Cobertura, Frecuencia y Tasa de Respuesta Encuestas de Empleo Americanas Participación Población entrevistada para situación de empleo Población en Viviendas Institucionales Frecuencia de los Resultados Tasa de Respuesta USA Voluntaria 16+ No Mensual 93,0% Colombia -- 10+ zona rural 12+ zona urbana No Mensual, Bimestral, Trimestral, Semestral y Anual -- Perú Argentina Chile --Obligatoria 14+ ? 15+ No No No Trimestral Trimestral Mensual 95,7% -? Tamaño y Diseño Muestral Encuestas de Empleo Americanas Unidad de Muestreo Primaria Bases del Marco Muestral USA Colombia Perú Argentina Chile Encuesta de Población Actual Último Censo de Población Censo de Población y Vivienda de 2005 Precenso 2001 y Censo 2002 Fracción de Muestreo Total por Trimestre Tamaño Muestral Programado (Promedio Trimestral 2004) Personas Hogares 15 - 74 Áreas Geográficas -- Hogares 0,05% 60.000 110.000 Segmentos -- 37.500 ? -- Viviendas -- 11.960 ? Viivendas -- 25.000 ? Viviendas -- 34.511 ? Áreas Geográficas Secciones -- Unidad de Muestreo Final Estratificación, Esquema de Rotación y Ponderación Encuestas de Empleo Americanas USA Colombia Perú Argentina Chile Variables Usadas para la Estratificación Esquema de Rotación Variables de Ponderación Desempleo, Proporción de Casas con Tres o más Personas, Número de Personas Empleadas en Diversas Industrias y Promedio Mensual de Ingresos para Diferentes Industrias 4m - (8m) - 4m Edad, Género, Origen étnico, Raza ----- ? ? 2 - (2) - 2 6+ ----- 17 RECOPILACIÓN DE INFORMACIÓN ACERCA DE LA CONSTRUCCIÓN DE PRODUCTO ENE Bibliografía 1. Eurostat. (2006). Labour force survey in the EU, Candidate and EFTA countries: Main characteristics of the national survey 2004. http://epp.eurostat.ec.europa.eu/ cache/ITY_OFFPUB/KS-BF-06-001/EN/KS-BF-06-001-EN.PDF. 2. Eurostat. (2006). European Union Labour Force Survey:Quality Report 2004. http://epp.eurostat.ec.europa.eu/pls/portal/docs/PAGE/PGP_DS_QUALITY/PGE_DS _QUALITY_01/LABOUR%20FORCE%20SURVEY%20QUALITY%20REPORT% 202004%20KS-CC-06-007-EN.PDF. 3. Eurostat. (2004). Labour force survey in the acceding countries: Methods and definitions – 2002. http://epp.eurostat.ec.europa.eu/cache/ITY_OFFPUB/KS-BF-04001/EN/KS-BF-04-001-EN.PDF. 4. Eurostat. (2003). The European Union labour force survey: Methods and definitions – 2001. http://epp.eurostat.ec.europa.eu/cache/ITY_OFFPUB/KS-BF-03-002/EN/KSBF-03-002-EN.PDF. 5. Perú, INEI. (2007). Ficha Técnica Encuesta permanente de empleo, Trimestre Móvil: Febrero – Marzo – Abril 2007. INEI, Encuestas y Registros: http://www.inei.gob.pe/. 6. Colombia, DANE. (2007). Ficha Metodológica: Encuesta Continua de Hogares. http://www.dane.gov.co/files/investigaciones/fichas/empleo/ficha_ech.pdf. 7. USA, Bureau of Labor Statitics. (2007). Labor force data derived from the Current Population Survey. BLS Handbook of Methods, Capitulo1. http://www.bls.gov/opub/ hom/homch1_itc.htm. 8. Argentina, INDEC. La nueva encuesta permanente de hogares de Argentina 2003. http://www.indec.mecon.ar/nuevaweb/cuadros/4/Metodologia_EPH Continua.pdf. 9. Reino Unido. (2007). Eurostat and derived variables. Labour force survey user guide, Vol. 9, de http://www.statistics.gov.uk/statbase/Product.asp?vlnk=1537. 10. Quatember, A. (2002). A comparison of the five Labour Force Surveys of the DACSEIS Project from a sampling theory point of view. DACSEIS research paper series, No 3, de http://w210.ub.uni-tuebingen.de/dbt/volltexte/2002/547/ pdf/DRPS3.pdf 11. Bour, J y Susmel, N. (Junio de 2007). Las Estadísticas Laborales. Fundación de Investigaciones Económicas Latinoamericanas. Documento de Trabajo Nº 52. http://www.fiel.org/publicaciones/Documentos/doc52.pdf. 12. OIT. LABORSTA Internet. Población económicamente active, empleo, desempleo y horas de trabajo (encuestas de hogares). Fuentes y Métodos: Estadísticas del Trabajo, Vol. 3. http://laborsta.ilo.org/. 18