OpenMP - Universidad Tecnológica Nacional
Anuncio

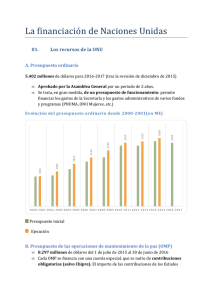
Procesamiento Paralelo
Introducción a OpenMP
Javier Iparraguirre
Universidad Tecnológica Nacional, Facultad Regional Bahı́a Blanca
11 de Abril 461, Bahı́a Blanca, Argentina
jiparraguirre@frbb.utn.edu.ar
http://www.frbb.utn.edu.ar/hpc/
22 de abril de 2016
Hilos
¿Qué es un hilo (thread)?
• Se define como una entidad con su propio contador de
programa, su datos y código
• Para el programador es un procedimiento que corre en
forma independiente del programa principal
• Estos procedimientos pueden ser más de uno y son
ejecutados y simultáneamente por el sistema operativos
(programa multi-threaded)
Un proceso en el sistema operativo
Procesos y threads
• Un proceso requiere bastante información adicional
• Algunos de los datos más relevante son ID proceso,
ambiente, directorio de trabajo, stack, heap, señales
• Los threads están asociados al proceso y ven los recursos
• Los threads duplican solo lo necesario para poder correr
de forma independiente
• Pueden compartir recursos
• Los threads mueren si el proceso padre muere
• Son más livianos que un proceso
Un proceso con threads
UMA y NUMA
El modelo de programación: UMA y NUMA
OpenMP
¿Qué es OpenMP?
• Una API para realizar explı́citamente paralelismo
multi-threaded de memoria compartida
• Tiene tres componentes: directivas al compilador, rutinas
en tiempo de ejecución y variables de entorno
• Es un estándar y es portable
Caracterı́sticas de OpenMP
1
Paralelismo de memoria compartida basado en threads
2
Explı́cito
3
Modelo fork-join
4
Basado en directivas al compilador
5
Soporta paralelismo dentro del paralelismo
6
Threads dinámicos
Ejemplo ejecución
Hola OpenMP!
# i n c l u d e <s t d i o . h>
# i n c l u d e <omp . h>
i n t main ( )
{
i n t nthreads , t i d ;
/∗ Se produce un f o r k de v a r i o s threads , t i d es una v a r i a b l e p r i v a d a para cada uno ∗/
#pragma omp p a r a l l e l p r i v a t e ( t i d )
{
/∗ Obtenemos e l i d de cada t h r e a d ∗/
t i d = omp get thread num ( ) ;
p r i n t f ( ” Hola mundo desde e l t h r e a d = %d\n ” , t i d ) ;
/∗ Solo e l t h r e a d maestro hace e s t o ∗/
i f ( t i d == 0 )
{
n t h r e a d s = omp get num threads ( ) ;
p r i n t f ( ” Numero t o t a l de t h r e a d s = %d\n ” , n t h r e a d s ) ;
}
} /∗ Todos l o s t h r e a d s se unen a l maestro y t e r m i n a n ∗/
return 0;
}
Salida
Hola mundo desde e l t h r e a d = 0
Hola mundo desde e l t h r e a d = 1
Numero t o t a l de t h r e a d s = 2
Compilando
Como compilar
• -openmp para el caso de Intel
• -fopenmp para el caso de GNU C/C++
Directivas
Estructura de las directivas
Son cuatro campos principales:
1
#pragma omp requerido para todas las directivas
OpenMP en C++
2
nombre de la directiva hay varias directivas posibles
3
[argumentos] opcional, pueden estar en cualquier orden y
se pueden repetir si es necesario
4
nueva linea requerido, precede al bloque de código
alcanzado por la directiva
Ejemplo
#pragma omp parallel default(shared) private(beta,pi)
Reglas generales
• Es sensitivo a las mayúsculas/minúsculas
• Las directivas siguen el estándar del compilador C/C++
• Solo un nombre de directiva puede ser especificada en
cada delcaración
• Cada directiva se aplica solo la instrucción que la sigue
(puede ser un bloque)
• Si la lı́nea de la instrucción es muy larga, se puede
continuar con el caracter \
Directiva parallel
#pragma omp p a r a l l e l [ c l a u s e . . . ]
newline
i f ( scalar expression )
private ( l i s t )
shared ( l i s t )
d e f a u l t ( shared | none )
firstprivate ( list )
reduction ( operator : l i s t )
copyin ( l i s t )
num threads ( i n t e g e r −expr )
{ structured block }
Ejemplo
# i n c l u d e <s t d i o . h>
# i n c l u d e <omp . h>
i n t main ( )
{
i n t nthreads , t i d ;
/∗ Se produce un f o r k de v a r i o s threads , t i d es una v a r i a b l e p r i v a d a para cada uno ∗/
#pragma omp p a r a l l e l p r i v a t e ( t i d )
{
/∗ Obtenemos e l i d de cada t h r e a d ∗/
t i d = omp get thread num ( ) ;
p r i n t f ( ” Hola mundo desde e l t h r e a d = %d\n ” , t i d ) ;
/∗ Solo e l t h r e a d maestro hace e s t o ∗/
i f ( t i d == 0 )
{
n t h r e a d s = omp get num threads ( ) ;
p r i n t f ( ” Numero t o t a l de t h r e a d s = %d\n ” , n t h r e a d s ) ;
}
} /∗ Todos l o s t h r e a d s se unen a l maestro y t e r m i n a n ∗/
return 0;
}
Comentarios
• La directiva parallel crea un grupo de threads que se une
al principal
• Se duplica el código para cada thread
• Hay una barrera de sincronización al final de bloque
Cantidad de threads
La cantidad de threads se determina siguiendo este criterio:
1
Se evalúa la condición IF
2
El valor del parámetro NUM THREADS
3
Uso de la función omp set num threads()
4
Seteo de la variable de ambiente OMP NUM THREADS
5
Por defecto se usa la cantidad de threads que soporta el
CPU
Compartiendo trabajo
• Estas directivas comparten el trabajo del bloque de código
alcanzado
• No hay creación de nuevos threads
• Hay tres casos DO/FOR, SECTIONS, SINGLE
DO/FOR
Directiva DO/FOR
#pragma omp f o r [ c l a u s e . . . ]
newline
schedule ( t y p e [ , chunk ] )
ordered
private ( l i s t )
firstprivate ( list )
lastprivate ( l i s t )
shared ( l i s t )
reduction ( operator : l i s t )
collapse (n)
nowait
for loop
Ejemplo DO/FOR
# i n c l u d e <omp . h>
# d e f i n e CHUNKSIZE 100
#define N
1000
i n t main ( )
{
i n t i , chunk ;
f l o a t a [ N] , b [N] , c [N ] ;
/∗ Some i n i t i a l i z a t i o n s ∗/
f o r ( i =0; i < N; i ++)
a[ i ] = b[ i ] = i ∗ 1.0;
chunk = CHUNKSIZE ;
#pragma omp p a r a l l e l shared ( a , b , c , chunk ) p r i v a t e ( i )
{
#pragma omp f o r schedule ( dynamic , chunk ) n o w a i t
f o r ( i =0; i < N; i ++)
c[ i ] = a[ i ] + b[ i ];
} /∗ end o f p a r a l l e l s e c t i o n ∗/
return 0;
}
SECTIONS
Directiva SECTIONS
#pragma omp s e c t i o n s [ c l a u s e . . . ]
newline
private ( l i s t )
firstprivate ( list )
lastprivate ( l i s t )
reduction ( operator : l i s t )
nowait
{
#pragma omp s e c t i o n
newline
structured block
#pragma omp s e c t i o n
structured block
}
newline
Ejemplo SECTIONS
# i n c l u d e <omp . h>
# d e f i n e N 1000
i n t main ( )
{
int i ;
f l o a t a [ N] , b [N] , c [N] , d [N ] ;
/∗ Some i n i t i a l i z a t i o n s ∗/
f o r ( i =0; i < N; i ++) {
a[ i ] = i ∗ 1.5;
b [ i ] = i + 22.35;
}
#pragma omp p a r a l l e l shared ( a , b , c , d ) p r i v a t e ( i )
{
#pragma omp s e c t i o n s n o w a i t
{
#pragma omp s e c t i o n
f o r ( i =0; i < N; i ++)
c[ i ] = a[ i ] + b[ i ];
#pragma omp s e c t i o n
f o r ( i =0; i < N; i ++)
d[ i ] = a[ i ] ∗ b[ i ];
} /∗ end o f s e c t i o n s ∗/
} /∗ end o f p a r a l l e l s e c t i o n ∗/
return 0;
}
SINGLE
Directiva CRITICAL para sincronización
#pragma omp c r i t i c a l [ name ]
structured block
newline
Ejemplo CRITICAL
# i n c l u d e <omp . h>
i n t main ( )
{
int x;
x= 0 ;
#pragma omp p a r a l l e l shared ( x )
{
#pragma omp c r i t i c a l
x = x + 1;
} /∗ end o f p a r a l l e l s e c t i o n ∗/
return 0;
}
Directiva BARRIER
#pragma omp b a r r i e r
newline
Resumen directivas
¡Muchas gracias!
¿Preguntas?
jiparraguirre@frbb.utn.edu.ar
Referencias
• G. Ananth, G. Anshul, K. George, and K. Vipin.
Introduction to parallel computing, 2003.
• OpenMP Tutorial @LLNL
https://computing.llnl.gov/tutorials/openMP/
• Sitio oficial OpenMP http://openmp.org/
• Wikipedia http://en.wikipedia.org/wiki/OpenMP