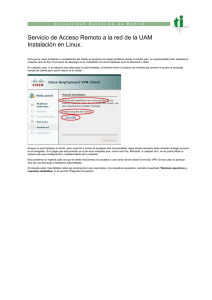
005.74-G934s-Capitulo II
Anuncio

16 CAPITULO II Marco Teórico En la actualidad el desarrollo de sistemas informáticos se encuentra muy ligado a la capacidad de las instituciones de implementar soluciones factibles en todos los aspectos sean estas de carácter técnico, operativo y económico. Siempre las empresas o instituciones ven el beneficio que se puede tener al implementar soluciones informáticas para solventar sus problemas o necesidades, es por ello que generalmente se busca utilizar tecnologías que proporcionen beneficios a las instituciones y que ofrezcan ser escalables con gran facilidad. En las aplicaciones desarrolladas a nivel institucional existe la necesidad de contar con la infraestructura física necesaria para sacarle el mayor provecho al software desarrollado, en la cual la implementación de una red solventa muchos de los problemas que pueden surgir si no estuviesen interconectadas las terminales que sirven como punto de acceso al sistema. El desarrollo con tecnologías del lado del servidor ofrece a los usuarios acceder al sistema mediante los navegadores Web que acostumbran utilizar. Las herramientas utilizadas en el desarrollo de sistemas pueden ser variadas, sean estas de pago o gratuitas, sin embargo, lenguajes de programación y herramientas gratuitas, proporcionan bondades que ni los mismos productos de pago ofrecen, es por ello que el uso de herramientas gratuitas va en aumento, considerando que los costos disminuyen con el uso de estos. La utilización de un lenguaje orientado a objetos permite que el desarrollo de sistemas se realice de una forma mas práctica, permitiendo que a largo plazo el mantenimiento de este tipo de aplicaciones sea menos complicado, facilitando la reutilización de código. Esto junto a la utilización de una arquitectura que permita integrarse con los recursos con que se cuenta y que 17 satisfaga los requerimientos de los usuarios lleva a pensar que el desarrollo de sistemas utilizando una arquitectura multi-nivel como es la utilizada en aplicaciones Web, es una solución con beneficio a corto, mediano y largo plazo. 2.1 ENTORNO DE PROGRAMACIÓN WEB. Hoy en día las redes informáticas dan respuesta a múltiples necesidades de las organizaciones. Entre Internet, red de redes de alcance mundial, y la más simple de las redes domésticas, existe todo un amplio abanico de posibilidades de implementación, entre las que se encuentran las intranets. Una intranet podría llegar a considerarse como un espacio propio y particular de la compañía u organización. Nacieron como simples herramientas de distribución de la información para llegar a convertirse en pocos años en herramientas de gestión de la información. La creación de una intranet va más allá de instalar físicamente una red de área local, o el simple hecho de informatizar algunos procesos. No se debería confundir una intranet con una simple herramienta de gestión que integra a los distintos departamentos y sus equipos. La intranet se configura como una red propia de una organización (o incluso más de una red) que permite acceder a información de la compañía utilizando los protocolos de comunicación propios de la tecnología de Internet, en concreto el protocolo TCP/IP (Transmission Control Protocol/Internet Protocol) y http (Hypertext Transfer Protocol). Sólo el personal de la organización (empresas, centros educativos,...) podrán acceder a la información que se considere como exclusiva de la intranet, evitando el uso de la intranet al público en general. Así, los usuarios de las intranets son, por su propia definición, usuarios de la misma organización o 18 relacionados con ella. El hecho de que las intranets utilicen la interfaz propia de Internet reduce el tiempo de aprendizaje de sus usuarios, y simplifica la instalación de aplicaciones. Permiten la automatización de ciertas tareas y una reducción de costes por el hecho de manejar información de forma digital, evitando el uso de soportes en formato papel. 2.1.1 IMPLEMENTACIÓN Y DISEÑO DE UNA INTRANET. Un buen diseño de una intranet ya desde una primera fase de implementación puede hacer ahorrar muchos costes a la empresa. La intranet debe adaptarse a la empresa: así, es clave un buen diseño estratégico de la misma, para que no resulte ineficaz y sea convenientemente amortizada por los usuarios a los que va dirigida. Bien planificada, la intranet puede resultar una muy buena herramienta para la empresa. Además, las redes internas son evidentemente dinámicas, y por lo tanto deberán ser ajustables a las nuevas necesidades que vayan surgiendo dentro de la organización. Aspectos como por ejemplo elevar el nivel de satisfacción de los usuarios de una organización (directivos, empleados,...), ya que se están utilizando herramientas de trabajo en equipo que potencian el grado de integración en la organización, pueden ser un buen motivo, entre otros, para llegar a tomar la decisión de implementar una intranet. Es de destacar que para sacarle el máximo provecho a una intranet, es necesario contar dentro de la organización con aplicativos que sean funcionales para la red, actualmente existe una tendencia a que las aplicaciones a nivel interno sean desarrolladas en entornos Web. 2.1.2 APLICACIONES WEB. Las aplicaciones Web generan dinámicamente una serie de páginas en un formato estándar, soportado por navegadores Web comunes como HTML 19 (HyperText Markup Language) o XHTML. Se utilizan lenguajes interpretados del lado del cliente, tales como JavaScript, para añadir elementos dinámicos a la interfaz de usuario. Generalmente cada página Web individual es enviada al cliente como un documento estático, pero la secuencia de páginas provee de una experiencia interactiva. Para tener esta idea más clara debemos hacer énfasis en el concepto de una aplicación Web y este se define así: “Un sistema informático que los usuarios utilizan accediendo a un servidor Web a través de Internet o de una Intranet”. Ahora bien las interfaces Web tienen ciertas limitantes en la funcionalidad del cliente. Métodos comunes en las aplicaciones de escritorio como dibujar en la pantalla o arrastrar-y-soltar no están soportadas por las tecnologías Web estándar. Los desarrolladores Web comúnmente utilizan lenguajes interpretados del lado del cliente para añadir más funcionalidad, especialmente para crear una experiencia interactiva que no requiera recargar la página cada vez. Recientemente se han desarrollado tecnologías para coordinar estos lenguajes con tecnologías del lado del servidor. Otra aproximación es utilizar los programas Java applets o Macromedia Flash para producir parte o toda la interfaz de usuario. Como casi todos los browsers incluyen soporte para estas tecnologías, usualmente por medio de plug-in, aplicaciones basadas en Java o Flash pueden ser implementadas con aproximadamente la misma facilidad. Como hacen caso omiso de las configuraciones de los browsers estas tecnologías permiten más control sobre la interfaz, aunque incompatibilidad entre implementaciones de Flash o Java puedan traer nuevas complicaciones. Por las similitudes con una arquitectura cliente-servidor, con un cliente un poco especializado, hay disputas sobre si llamar a estos sistemas aplicaciones Web; un término alternativo es “aplicación enriquecida de Internet”. 20 Una ventaja significativa en la construcción de aplicaciones Web que soporten las características de los browsers estándar es que deberían funcionar igual independientemente de la versión del sistema operativo instalado en el cliente. En vez de crear clientes para Windows, Mac OS X, GNU/Linux, y otros sistemas operativos, la aplicación es escrita una vez y es mostrada casi en todos lados. Sin embargo, aplicaciones inconsistentes de HTML, CSS y otras especificaciones de browsers pueden causar problemas en el desarrollo y soporte de aplicaciones Web. Por mencionar otras ventajas de las aplicaciones Web se tiene que: • Son más fáciles de actualizar. • Proporcionan acceso inmediato a la aplicación. • Requieren menos memoria. • Menor cantidad de errores y fallas. • Permiten múltiples usuarios al mismo tiempo. Para el caso de las aplicaciones Web la interacción con el usuario se realiza mediante formularios. Un formulario se puede definir como un diálogo que forma parte de una página Web. Este diálogo está construido por un conjunto de elementos como: • Campos de texto de una o varias líneas. • Checkboxes (opciones no excluyentes). • Radio buttons (opciones múltiples excluyentes). • Pull-down menus. • Botones. Para la validación de formularios y el manejo de los datos que puedan contener, existen numerosos lenguajes de programación utilizados para el desarrollo de aplicaciones Web, entre los que destacan: • Java, con sus tecnologías Java Servlets y JavaServer Pages (JSP). • PHP. 21 • ASP/ASP.NET, que no es un lenguaje de programación sino una arquitectura de desarrollo web en la que se puede usar por debajo distintos lenguajes (por ejemplo VB.NET o C# para ASP.NET, o VBScript/JScript para ASP). • Perl. • Ruby. • Python. En cuanto a las herramientas de software a utilizar, hoy en día están adquiriendo especial relevancia las herramientas de código libre. Las ventajas de utilizar servidores con código abierto como Apache son indudables y junto a Java se están convirtiendo en programas muy utilizados en estos entornos, por sus presentaciones y rendimientos equiparables o superiores a las de productos comerciales, y lo mejor de todo es que se reducen los costos de licenciamiento ya que no requieren pago por la utilización de estos. 2.2 TECNOLOGIA OPEN SOURCE. Open Source, podría traducirse como 'código fuente abierto': un programa que ofrece al usuario la posibilidad de entrar en sus líneas de código para poder estudiarlo o modificarlo. Pero no sólo hace referencia al libre acceso al código fuente. Las condiciones de distribución de un programa Open Source deben cumplir una serie de criterios. La intención de la 'Definición de Open Source' es establecer que esos criterios contengan la esencia de lo que los programadores quieren que signifique: que aseguren que los programas distribuidos con 'licencia Open Source' estarán disponibles para su continua revisión y mejora para que alcancen niveles de fiabilidad que no pueda conseguir ningún programa comercial 'cerrado'. A la idea esencial del Open Source, ofrecer programas con acceso al código fuente, van unidas una serie de conceptos: 22 • FLEXIBILIDAD. Si el código fuente está disponible, los desarrolladores pueden modificar los programas a su antojo. Además, se produce un flujo constante de ideas que mejora la calidad de los programas. • FIABILIDAD Y SEGURIDAD. Con varios programadores a la vez escrutando el mismo trabajo, los errores se detectan y corrigen antes, por lo que el producto resultante es más fiable y eficaz que el comercial. • RAPIDEZ DE DESARROLLO. Las actualizaciones y ajustes se realizan a través de una comunicación constante vía Internet. • RELACIÓN CON EL USUARIO. El programador se acerca mucho más a las necesidades reales de los clientes, y puede crear un producto específico para él. Su contraparte el Software libre, es el software que, una vez obtenido, puede ser usado, copiado y redistribuido libremente. El software libre suele estar disponible gratuitamente, pero no hay que asociar software libre a software gratuito, o a precio del coste de la distribución a través de otros medios; sin embargo no es obligatorio que sea así y, aunque conserve su carácter de libre, puede ser vendido comercialmente. Aunque en la práctica el software Open Source y el software libre comparten las mismas licencias, la FSF (Free Software Foundation) opina que el movimiento Open Source es filosóficamente diferente del movimiento del software libre. Esto debido a que existe confusión entre ambos, ya que se puede decir que de forma general todo software Open Source puede ser distribuido libremente y se puede modificar, sin embargo, no se pude decir lo mismo del Software libre ya que este se puede distribuir pero no se pude acceder al código fuente para modificarlo. En la actualidad existe un sin número de software que es de gran utilidad para los desarrolladores de sistemas que pueden ser de tipo Open 23 Source o Software libre, las cuales son de mucha ayuda a la hora de elaborar las aplicaciones. Estas herramientas abarcan los distintos campos de la informática tales como son: SGBD, Servidores WEB, Lenguajes de programación, IDEs, Sistemas Operativos, Software de aplicación, entre otros. 2.2.1 SISTEMAS DE GESTIÓN DE BASES DE DATOS. Los Sistemas de gestión de base de datos son un tipo de software muy específico, dedicados a servir de interfaz entre la base de datos, el usuario y las aplicaciones que la utilizan. Se compone de un lenguaje de definición de datos, de un lenguaje de manipulación de datos y de un lenguaje de consulta. De forma sencilla, un sistema de gestión de bases de datos se puede definir como una colección de datos interrelacionados y un conjunto de programas para acceder a esos datos. Existen dos grandes modelos de sistemas de gestión de bases de datos: • Sistemas de Gestión de Bases de Datos Relacionales (SGBDR) Las bases de datos que generan se construyen con información muy estructurada (datos) acerca de una organización o empresa determinada. Cuando un usuario realiza una consulta en una base de datos relacional, el sistema presenta como resultado la respuesta exacta a lo que se busca. A este tipo de bases de datos se les denomina bases de datos relacionales, y a los sistemas que las gestionan, Sistemas de Gestión de Bases de Datos Relacionales (SGBDR). Ejemplos de bases de datos relacionales son las bases de datos de cuentas y clientes de un banco o las bases de datos de productos creadas por los centros comerciales o las librerías para llevar un control de sus ventas. Entre los sistemas de gestión de bases de datos relacionales tenemos: MySQL, Oracle, Access, Dbase, Informix, entre otros. 24 • Sistemas de Gestión de Bases de Datos Documentales (SGBDD) o Sistemas de Recuperación de Información (SRI) Las bases de datos que generan se construyen con información no estructurada tipo texto (documentos) sobre uno o varios temas. Cuando un usuario realiza una consulta en una base de datos documental, el sistema presenta como resultado, no una respuesta exacta, sino documentos útiles para satisfacer la pregunta del usuario. A este tipo de bases de datos se les denomina bases de datos documentales, y a los sistemas que las gestionan, Sistemas de Gestión de Bases de Datos Documentales (SGBDD) o Sistemas de Recuperación de Información (SRI). Ejemplos de bases de datos documentales son las bases de datos bibliográficas, bases de datos de prensa, bases de datos de informes de una empresa. Ejemplos de sistemas de gestión de bases de datos documentales son Knosys, Inmagic, ISIS, BRS, entre otros. MÓDULOS DE UN SISTEMA DE GESTIÓN DE BASE DE DATOS. La gestión de los datos supone tanto la definición de estructuras para el almacenamiento de la información como la provisión de mecanismos para la gestión de la información que se almacena. Un sistema de base de datos se divide en módulos que tratan cada una de las responsabilidades del sistema general, entre los que podemos destacar: 1. Modelo de datos. 2. Lenguaje de definición de datos. 3. Lenguaje de manipulación de los datos. 25 1. Modelo de datos. La descripción de la estructura de una base de datos es el modelo de datos, una colección de herramientas conceptuales para describir datos, relación de datos, semánticas de datos y restricciones de datos. Modelo: instrumento que se aplica a una parcela del mundo real (un universo del discurso) para obtener una estructura de datos a la que se denomina esquema. Modelo de datos: conjunto de conceptos, reglas y convenciones que permiten describir los datos del universo del discurso. Definir cuál es el universo del discurso es el primer paso en la concepción de una base de datos. Los modelos de datos tienen su objetivo específico entre los que destacan: Formalización: el modelo de datos permite definir formalmente las estructuras permitidas y las restricciones para representar los datos de un sistema de información. Diseño: el modelo es uno de los elementos básicos (junto con los lenguajes, la documentación, etc.) para el desarrollo de una metodología de diseño de bases de datos. De lo que se trata es de representar el universo del discurso. Todo universo de un discurso tiene propiedades de dos tipos: • Estáticas: que no se modifican en el tiempo (las estructuras). • Dinámicas: que varían con el transcurso del tiempo (los datos o valores que se almacenan en las estructuras). Los sistemas de bases de datos disponen de unos lenguajes: conjunto de instrucciones que de acuerdo a una sintaxis ayudan a realizar las distintas funciones que ha de cumplir un SGBD. 26 Si atendemos al tipo de función distinguimos: lenguajes de definición y lenguajes de manipulación. Si atendemos al tipo de usuarios: lenguajes orientados a informáticos y lenguajes orientados a usuarios finales. El usuario final no necesita normalmente tanta potencia, por ello se le da un lenguaje de manipulación con sintaxis sencilla, a veces por medio de menús. La estructura y sintaxis de todos esos tipos de lenguajes dependen de cada SGBD, pero en los SGBD relacionales, SQL es un estándar muy extendido. 2. El lenguaje de definición de datos (DDL). Se almacena en un diccionario o directorio de datos. Un directorio o diccionario de datos es un archivo que contiene metadatos, es decir, "datos sobre datos". Es un conjunto de instrucciones que operan de acuerdo a una sintaxis y que permiten al administrador de la base definir los datos con facilidad y precisión, especificando sus distintas estructuras. • Lenguaje de definición de la estructura lógica: permite asignar nombre a los campos, a los registros, estableciendo sus longitudes y características, así como sus relaciones, restricciones, etc. • Lenguaje para la definición de la estructura interna. • Lenguaje de definición de estructuras externas: El SGBD debe poner a disposición de los usuarios medios que les permitan recuperar o actualizar los datos contenidos en la base, de acuerdo con la visión lógica o estructura externa (vista) que precise cada aplicación. 3. El lenguaje de manipulación de datos (DML). Sirve para recuperar datos, insertarlos, suprimirlos o modificarlos. Son un conjunto de instrucciones que operan de acuerdo a una sintaxis y que permiten a los usuarios la posibilidad de referirse a determinados conjuntos de datos que 27 cumplan ciertas condiciones (criterio de selección), como que un atributo tenga un determinado valor, o que un conjunto de atributos y valores satisfagan cierta expresión lógica. Además del criterio de selección, es preciso indicar la estructura externa que se desea actualizar o recuperar. Un ejemplo práctico y muy utilizado es el gestor de bases de datos MySQL, que es un sistema de gestión de bases de datos relacional, licenciado bajo la GPL de la GNU. Su diseño multihilo le permite soportar una gran carga de forma muy eficiente. MySQL fue creada por la empresa sueca MySQL AB, que mantiene el copyright del código fuente del servidor SQL, así como también de la marca. Aunque MySQL es software libre, MySQL AB distribuye una versión comercial de MySQL, que no se diferencia de la versión libre más que en el soporte técnico que se ofrece, y la posibilidad de integrar este gestor en un software propietario, ya que de no ser así, se vulneraría la licencia GPL. Con miles de implementaciones a escala mundial y clientes de la talla de Facebook, Google, Nokia, Baidu o China Mobile, con más de 100 millones de copias de MySQL descargadas y distribuidas, y diariamente se producen otras 50.000 descargas adicionales, MySQL probablemente es el gestor más usado en el mundo del software libre, debido a su gran rapidez y facilidad de uso. Esta gran aceptación es debida, en parte, a que existen infinidad de librerías y otras herramientas que permiten su uso a través de gran cantidad de lenguajes de programación, además de su fácil instalación y configuración. Características de MySQL. Las principales características de este gestor de bases de datos son las siguientes: • Aprovecha la potencia de sistemas multiprocesador, gracias a su implementación multihilo. 28 • Soporta gran cantidad de tipos de datos para las columnas. • Dispone de API's en gran cantidad de lenguajes (C, C++, Java, PHP, etc). • Gran portabilidad entre sistemas. • Soporta hasta 32 índices por tabla. • Gestión de usuarios y passwords, manteniendo un muy buen nivel de seguridad en los datos. 2.2.2 LENGUAJES DE PROGRAMACIÓN. Consiste en un conjunto de reglas sintácticas y semánticas que definen su estructura y el significado de sus elementos, respectivamente. Un lenguaje de programación permite a un programador especificar de manera precisa: sobre qué datos una computadora debe operar, cómo deben ser estos almacenados y transmitidos y qué acciones debe tomar bajo una variada gama de circunstancias. Clasificación de los lenguajes de programación. Los lenguajes de programación se determinan según el nivel de abstracción, según la forma de ejecución y según el paradigma de programación que poseen cada uno de ellos y esos pueden ser: Según el nivel de abstracción: • Lenguajes de bajo nivel. Los lenguajes de bajo nivel son lenguajes de programación que se acercan al funcionamiento de una computadora. El lenguaje de más bajo nivel es, por excelencia, el código máquina. A éste le sigue el lenguaje ensamblador, ya que al programar en ensamblador se trabajan con los registros de memoria de la computadora de forma directa. 29 • Lenguajes de medio nivel. Hay lenguajes de programación que son considerados por algunos expertos como lenguajes de medio nivel (como es el caso del lenguaje C) al tener ciertas características que los acercan a los lenguajes de bajo nivel pero teniendo, al mismo tiempo, ciertas cualidades que lo hacen un lenguaje más cercano al humano y, por tanto, de alto nivel. • Lenguajes de alto nivel. Los lenguajes de alto nivel son normalmente fáciles de aprender porque están formados por elementos de lenguajes naturales, como el inglés. En BASIC, el lenguaje de alto nivel más conocido, los comandos como "IF CONTADOR = 10 THEN STOP" pueden utilizarse para pedir a la computadora que pare si CONTADOR es igual a 10. Por desgracia para muchas personas esta forma de trabajar es un poco frustrante, dado que a pesar de que las computadoras parecen comprender un lenguaje natural, lo hacen en realidad de una forma rígida y sistemática. Según la forma de ejecución: • Lenguajes compilados. Naturalmente, un programa que se escribe en un lenguaje de alto nivel también tiene que traducirse a un código que pueda utilizar la máquina. Los programas traductores que pueden realizar esta operación se llaman compiladores. Éstos, como los programas ensambladores avanzados, pueden generar muchas líneas de código de máquina por cada proposición del programa fuente. Se requiere una corrida de compilación antes de procesar los datos de un problema. Los compiladores son aquellos cuya función es traducir un programa escrito en un determinado lenguaje a un idioma que la computadora entienda (lenguaje máquina con código binario). 30 Al usar un lenguaje compilado (como lo son los lenguajes del popular Visual Studio de Microsoft), el programa desarrollado nunca se ejecuta mientras haya errores, sino hasta que luego de haber compilado el programa, ya no aparecen errores en el código. • Lenguajes interpretados. Se puede también utilizar una alternativa diferente de los compiladores para traducir lenguajes de alto nivel. En vez de traducir el programa fuente y grabar en forma permanente el código objeto que se produce durante la corrida de compilación para utilizarlo en una corrida de producción futura, el programador sólo carga el programa fuente en la computadora junto con los datos que se van a procesar. A continuación, un programa intérprete, almacenado en el sistema operativo del disco, o incluido de manera permanente dentro de la máquina, convierte cada proposición del programa fuente en lenguaje de máquina conforme vaya siendo necesario durante el proceso de los datos. No se graba el código objeto para utilizarlo posteriormente. La siguiente vez que se utilice una instrucción, se le debe interpretar otra vez y traducir a lenguaje máquina. Por ejemplo, durante el procesamiento repetitivo de los pasos de un ciclo, cada instrucción del ciclo tendrá que volver a ser interpretado cada vez que se ejecute el ciclo, lo cual hace que el programa sea más lento en tiempo de ejecución (porque se va revisando el código en tiempo de ejecución) pero más rápido en tiempo de diseño (porque no se tiene que estar compilando a cada momento el código completo). El intérprete elimina la necesidad de realizar una corrida de compilación después de cada modificación del programa cuando se quiere agregar funciones o corregir errores; pero es obvio que un programa objeto compilado con antelación deberá ejecutarse con mucha mayor rapidez que uno que se debe interpretar a cada paso durante una corrida de producción. 31 Según el paradigma de programación. • Imperativo: describe la programación como una secuencia instrucciones o comandos que cambian el estado de un programa. El código máquina en general está basado en el paradigma imperativo. Su contrario es el paradigma declarativo. En este paradigma se incluye el paradigma procedimental (procedural) entre otros. • Declarativo: No se basa en el cómo se hace algo (cómo se logra un objetivo paso a paso), sino que describe (declara) cómo es algo. En otras palabras, se enfoca en describir las propiedades de la solución buscada, dejando indeterminado el algoritmo (conjunto de instrucciones) usado para encontrar esa solución. Es más complicado de implementar que el paradigma imperativo, tiene desventajas en la eficiencia, pero ventajas en la solución de determinados problemas. • Estructurado: la programación se divide en bloques (procedimientos y funciones) que pueden o no comunicarse entre sí. Además la programación se controla con secuencia, selección e iteración. Permite reutilizar código programado y otorga una mejor compresión de la programación. Es contrario al paradigma inestructurado, de poco uso, que no tiene ninguna estructura, es simplemente un “bloque”, como por ejemplo, los archivos batch (.bat). • Funcional: este paradigma concibe a la computación como la evaluación de funciones matemáticas y evita declarar y cambiar datos. En otras palabras, hace hincapié en la aplicación de las funciones y composición entre ellas, más que en los cambios de estados y la ejecución secuencial de comandos (como lo hace el paradigma procedimental). Permite resolver ciertos problemas de forma elegante y los lenguajes puramente funcionales evitan los efectos secundarios comunes en otro tipo de programaciones. 32 • Lógico: se basa en la definición de reglas lógicas para luego, a través de un motor de inferencias lógicas, responder preguntas planteadas al sistema y así resolver los problemas, por ejemplo Prolog. • Orientados a Objetos: En la Programación Orientada a Objetos (POO u OOP según siglas en inglés) se definen los programas en términos de "clases de objetos", objetos que son entidades que combinan estado (es decir, datos) comportamiento (esto es, procedimientos o métodos) e identidad (propiedad del objeto que lo diferencia del resto). La programación orientada a objetos expresa un programa como un conjunto de estos objetos, que colaboran entre ellos para realizar tareas. Esto permite hacer los programas módulos más fáciles de escribir, mantener y reutilizar. Un ejemplo de lenguaje orientado a objetos que tiene una gran aceptación a nivel mundial por sus diversas características es JAVA que en cualquier entorno en el que se utilice, ya sean grandes empresas, aplicaciones domésticas, educacionales, siempre se ve como uno de los lenguajes más potentes del mercado. Java. La tecnología Java se creó como una herramienta de programación en una pequeña operación secreta y anónima denominada "The Green Project" en Sun Microsystems en el año 1991. El equipo secreto ("Green Team"), compuesto por trece personas y dirigido por James Gosling, se encerró en una oficina desconocida de Sand Hill Road en Menlo Park, interrumpió todas las comunicaciones regulares con Sun y trabajó sin descanso durante 18 meses. Intentaban anticiparse y prepararse para el futuro de la informática. Su conclusión inicial fue que al menos en parte se tendería hacia la convergencia de los dispositivos digitales y los ordenadores. 33 El resultado fue un lenguaje de programación que no dependía de los dispositivos denominado "Oak". Para demostrar cómo podía contribuir este nuevo lenguaje al futuro de los dispositivos digitales, el equipo desarrolló un controlador de dispositivos de mano para uso doméstico destinado al sector de la televisión digital por cable. Por desgracia, la idea resultó ser demasiado avanzada para el momento y el sector de la televisión digital por cable no estaba listo para el gran avance que la tecnología Java les ofrecía. Poco tiempo después Internet estaba listo para la tecnología Java y, justo a tiempo para su presentación en público en 1995, el equipo pudo anunciar que el navegador Netscape Navigator incorporaría la tecnología Java. Java ha atraído a cerca de 4 millones de desarrolladores de software, se utiliza en los principales sectores de la industria de todo el mundo y está presente en un gran número de dispositivos, ordenadores y redes de cualquier tecnología de programación. La versatilidad y eficiencia, la portabilidad de su plataforma y la seguridad que aporta, la han convertido a Java en la tecnología ideal para su aplicación a redes, de manera que hoy en día, más de 2.500 millones de dispositivos utilizan la tecnología Java, por ejemplo: • Más de 700 millones de ordenadores. • 708 millones de teléfonos móviles y otros dispositivos de mano. • 1000 millones de tarjetas inteligentes. • Sintonizadores, impresoras, Web cams, juegos, sistemas de navegación para automóviles, terminales de lotería, dispositivos médicos, cajeros de pago, etc. Hoy en día, se puede encontrar la tecnología Java en redes y dispositivos que comprenden desde Internet y superordenadores científicos hasta portátiles y teléfonos móviles; desde simuladores de mercado en Wall 34 Street hasta juegos de uso doméstico y tarjetas de crédito: Java está en todas partes. La tecnología Java, una tecnología madura, extremadamente eficaz y sorprendentemente versátil, se ha convertido en un recurso inestimable ya que permite a los desarrolladores: • Desarrollar software en una plataforma y ejecutarlo en prácticamente cualquier otra plataforma. • Crear programas para que funcionen en un navegador Web y en servicios Web. • Desarrollar aplicaciones para servidores como foros en línea, tiendas, encuestas, procesamiento de formularios HTML, etc. • Combinar aplicaciones o servicios basados en la tecnología Java para crear servicios o aplicaciones totalmente personalizados. • Desarrollar potentes y eficientes aplicaciones para teléfonos móviles, procesadores remotos, productos de consumo de bajo coste y prácticamente cualquier dispositivo digital. La Máquina Virtual Java es el núcleo del lenguaje de programación Java. De hecho, es imposible ejecutar un programa Java sin ejecutar alguna implantación de la JVM. En la JVM se encuentra el motor que en realidad ejecuta el programa Java y es la clave de muchas de las características principales de Java, como la portabilidad, la eficiencia y la seguridad. Siempre que se corre un programa Java, las instrucciones que lo componen no son ejecutadas directamente por el hardware sobre el que subyace, sino que son pasadas a un elemento de software intermedio, que es el encargado de que las instrucciones sean ejecutadas por el hardware. Es decir, el código Java no se ejecuta directamente sobre un procesador físico, sino sobre un procesador virtual Java. 35 En la figura 2.1 puede observarse la capa de software que implementa la máquina virtual Java. Esta capa de software oculta los detalles inherentes a la plataforma, a las aplicaciones Java que se ejecuten sobre ella. Debido a que la plataforma Java fue diseñada pensando en que se implementaría sobre una amplia gama de sistemas operativos y de procesadores, se incluyeron dos capas de software para aumentar su portabilidad. La primera dependiente de la plataforma es llamada adaptador, mientras que la segunda, que es independiente de la plataforma, se le llama interfaz de portabilidad. De esta manera, la única parte que se tiene que escribir para una plataforma nueva, es el adaptador. El sistema operativo proporciona los servicios de manejo de ventanas, red, sistema de archivos, etcétera. CAPA DE SOFTWARE QUE IMPLEMENTA LA MÁQUINA VIRTUAL JAVA. Applets y Aplicaciones API Java Base Extensión Estándar al API Java Clases Java de Clases Java Base Extensión Estándar Maquina Virtual Java Interfaz de portabilidad Adaptador Adaptador JavaOS SO (Windows, Linux, Navegador OS2, etc.) SO (Unix, etc.) Hardware Hardware Hardware Figura 2.1 2.2.3 SERVIDOR WEB. Es un programa que implementa el protocolo HTTP (hypertext transfer protocol). Este protocolo está diseñado para transferir lo que llamamos hipertextos, páginas Web o páginas HTML (hypertext markup language): textos 36 complejos con enlaces, figuras, formularios, botones y objetos incrustados como animaciones o reproductores de música. Sin embargo, el hecho de que HTTP y HTML estén íntimamente ligados no debe dar lugar a confundir ambos términos. HTML es un formato de archivo y HTTP es un protocolo. Cabe destacar el hecho de que la palabra servidor identifica tanto al programa como a la máquina en la que dicho programa se ejecuta. Existe, por tanto, cierta ambigüedad en el término, aunque no será difícil diferenciar a cuál de los dos referirse en cada caso. Un servidor Web se encarga de mantenerse a la espera de peticiones HTTP llevada a cabo por un cliente HTTP que llamado navegador. El navegador realiza una petición al servidor y éste le responde con el contenido que el cliente solicita. Servidor Web Apache. Apache es un servidor Web de código abierto. Su desarrollo comenzó en febrero de 1995, por Rob McCool, en una tentativa de mejorar el servidor existente en el NCSA. La primera versión apareció en enero de 1996, el Apache 1.0. Hacia el 2000, el servidor Web Apache era el más extendido en el mundo. El nombre «Apache» es un acrónimo de «a patchy server» -un servidor de remiendos-, es decir un servidor construido con código preexistente y piezas y parches de código. Es la auténtica «kill app» del software libre en el ámbito de los servidores y el ejemplo de software libre de mayor éxito, por delante incluso del kernel Linux. Desde hace años, más del 60% de los servidores web de Internet emplean Apache. 37 Características del Servidor Apache. • Nuevos módulos Apache API.: se utiliza un nuevo conjunto de interfaces de aplicación (APIs). • Filtrado: Los módulos pueden actuar como filtros de contenido. • Soporte para IPv6: Se tiene soporte para la nueva generación de las direcciones IP. • Directivas simplificadas: Se han eliminado una serie de directivas complicadas y otras se han simplificado. • Respuestas a errores en diversos idiomas: Cuando usa documentos Server Side Include (SSI), las páginas de errores personalizables se pueden entregar en diversos idiomas • Soporte a múltiples protocolos. Para que una aplicación Web desarrollada con Java sea funcional, es necesario disponer de un contenedor de servlets para que se puedan interpretar y ejecutar las aplicaciones del lado del servidor, ya que es el motor que permite la funcionalidad de este tipo de aplicaciones. Uno de los más utilizados es Tomcat. Tomcat: es un contenedor de Servlets con un entorno JSP. Un contenedor de Servlets es un shell de ejecución que maneja e invoca servlets por cuenta del usuario. Podemos dividir los contenedores de Servlets en: 1. Contenedores de Servlets Stand-alone (Independientes) Estos son una parte integral del servidor web. Este es el caso cuando usando un servidor web basado en Java, por ejemplo, el contenedor de servlets es parte de JavaWebServer (actualmente sustituido por iPlanet). Este el modo por defecto usado por Tomcat. 38 2. Contenedores de Servlets dentro-de-Proceso. El contenedor Servlet es una combinación de un plugin para el servidor web y una implementación de contenedor Java. El plugin del servidor web abre una JVM (Máquina Virtual Java) dentro del espacio de direcciones del servidor web y permite que el contenedor Java se ejecute en él. Si una cierta petición debería ejecutar un servlet, el plugin toma el control sobre la petición y lo pasa al contenedor Java (usando JNI). Un contenedor de este tipo es adecuado para servidores multi-thread de un sólo proceso y proporciona un buen rendimiento pero está limitado en escalabilidad 3. Contenedores de Servlets fuera-de-proceso. El contenedor Servlet es una combinación de un plugin para el servidor web y una implementación de contenedor Java que se ejecuta en una JVM fuera del servidor web. El plugin del servidor web y el JVM del contenedor Java se comunican usando algún mecanismo IPC (normalmente sockets TCP/IP). Si una cierta petición debería ejecutar un servlet, el plugin toma el control sobre la petición y lo pasa al contenedor Java (usando IPCs). El tiempo de respuesta en este tipo de contenedores no es tan bueno como el anterior, pero obtiene mejores rendimientos en otras cosas (escalabilidad, estabilidad, etc.). Tomcat puede utilizarse como un contenedor solitario (principalmente para desarrollo y depuración) o como plugin para un servidor web existente (actualmente se soportan los servidores Apache, IIS y Netscape). Esto significa que siempre que despleguemos Tomcat tendremos que decidir cómo usarlo. 2.2.4 ENTORNOS INTEGRADOS DE DESARROLLO (IDE). El entorno de desarrollo integrado o en inglés Integrated Development Environment, es un programa compuesto por un conjunto de herramientas para un programador. Un IDE es un entorno de programación que ha sido 39 empaquetado como un programa de aplicación, es decir, consiste en un editor de código, un compilador, un depurador y un constructor de interfaz gráfica GUI y otras herramientas de utilidad para el programador. Los IDEs pueden ser aplicaciones por si solas o pueden ser parte de aplicaciones existentes. El leguaje Visual Basic por ejemplo puede ser usado dentro de las aplicaciones de Microsoft Office, lo que hace posible escribir sentencias Visual Basic en forma de macros para Word. Los IDEs proveen un marco de trabajo amigable para la mayoría de los lenguajes de programación tales como C++, JAVA, C#, Visual Basic, Object Pascal, Velneo y otros. En algunos lenguajes, un IDE puede funcionar como un sistema en tiempo de ejecución, en donde se permite utilizar el lenguaje de programación en forma interactiva, sin necesidad de trabajo orientado a archivos de texto, como es el caso de Smalltalk u Objective-C. Es posible que un mismo IDE pueda funcionar con varios lenguajes de programación. Este es el caso de Eclipse, que mediante plugins se le puede añadir soporte de lenguajes adicionales. Componentes de un IDE. • Un editor de texto. • Un compilador. • Un intérprete. • Herramientas de automatización. • Un depurador. • Posibilidad de ofrecer un sistema de control de versiones. • Factibilidad para ayudar en la construcción de interfaces gráficas de usuarios. 40 La historia de la programación ha evolucionado paralelamente a la de los editores de texto. Cuando los programas se almacenaban en tarjetas perforadas, la tarea de traducción del pseudo-código al lenguaje de “huecos y no-huecos” que la máquina entendía consumía la mayor parte del tiempo de producción. Los lenguajes, compiladores y entornos han cambiado muchísimo desde entonces. Lo cierto es que cuando hay que desenmarañar el código de un programa para llevar a buen puerto un proyecto, es importante que las herramientas que utilizamos no nos impongan límites artificiales y nos permitan automatizar tareas repetitivas, por lo que nos conviene conocer las alternativas con las que contamos. Hoy día existen técnicas pensadas para perfeccionar la programación como disciplina y típicamente integradas en los IDEs. Algunos editores señalan o colorean la sintaxis del lenguaje de programación, indexan el código automáticamente, completan los paréntesis y los corchetes y permiten compilar desde el mismo editor. Pero eso es todo. No escriben código, no están integrados con el compilador ni cuentan con un servidor de aplicaciones. Tampoco cuentan con herramientas gráficas de desarrollo. Los IDEs suministrarán todo esto y además te facilitarán la depuración el código, el control de versiones y la gestión de los archivos que vienen a componer un proyecto software. Existe diversidad de opiniones en cuanto a si es mejor emplear un “editor inteligente” o un entorno de desarrollo con docenas de herramientas. Algunas personas prefieren los editores, ya que piensan que cuesta mucho aprender a manejar un IDE, que generan código poco eficiente o que les fuerza e emplear un determinado estilo de programación. Otras prefieren los IDEs a la programación “de verde sobre negro” y comparan el no querer usarlos con la situación de programadores de “ensamblador” que rechazan emplear lenguajes de más alto nivel. Ambos grupos tienen parte de razón. Para elegir la alternativa que mejor nos convenga para cada proyecto, lenguaje o circunstancia particular, lo mejor es informarse adecuadamente. 41 Los IDEs son entornos, pues constituyen un lugar que envuelve al programador como un taller envuelve a un artesano. Son integrados o integradores, pues incorporan una serie de herramientas y utilidades de programación en un mismo espacio, y están creados para el desarrollo pues ayudan a construir software y ellos mismos son una forma de software más desarrollada y compleja que un compilador convencional. La construcción de un programa siempre va a consistir en la escritura de un listado de código que debe ser correcto, mantenible y modificable. Gracias a los IDEs podremos reutilizar, desde un repositorio, componentes software ya desarrollados y emplear funciones de auto-completado de código. Por ejemplo, cuando se escriben los primeros caracteres de una función definida en otra parte de nuestro programa, se nos sugerirán los argumentos que podremos emplear, evitándonos buscar la función y ahorrándonos errores y tecleo al construir un programa. Un IDE nos permitirá además emplear gran cantidad de opciones del compilador de forma integrada, desde el mismo entorno, con lo que se evitan cambios de contexto. Se facilita asimismo la documentabilidad de un proyecto software, muy importante a la hora de ampliar, modificar y mantener un programa. El estilo de Programación Orientada a Objetos es uno de los que más se beneficia del empleo de un IDE, gracias a las paletas de atributos de objeto que suelen incluir casi todos los IDEs, potenciando además características clave como la encapsulación y la herencia. La Programación Visual tal y como hoy existe no habría podido llegar a lo que es sin las herramientas gráficas que suministran los IDEs modernos. Todas estas ventajas, aplicadas a gran escala sobre un equipo de programadores formados a lo largo de una serie de proyectos software, incrementan el rendimiento y la productividad en modo apreciable. 42 Entre los grandes actores del mercado de los IDEs, hemos de mencionar a Borland, empresa que con sus entornos JBuilder, C++Builder y Delphi Builder ha ido perfeccionando la tecnología de los IDEs mediante su comercialización. Borland no deja de ser una casa de software privativo, razón por la cual existen una serie de iniciativas más abiertas a las que la comunidad Open Source suele ser más adepta, entre las cuales podemos destacar VIDE para Java y la comunidad Eclipse.org. Pero entre las mejores opciones para desarrollo en Java se encuentra Eclipse que ofrece una serie de ventajas sobre otros IDEs para la plataforma Java. Eclipse. Eclipse comenzó como un proyecto de IBM Canadá. Fue desarrollado por OTI (Object Technology International) como reemplazo de VisualAge también desarrollado por OTI. En Noviembre del 2001, se formó un consorcio para el desarrollo futuro de Eclipse como código abierto. En 2003, la fundación independiente de IBM fue creada. Arquitectura. La base para Eclipse es la Plataforma de cliente enriquecido (del Inglés Rich Client Platform RCP). Los siguientes componentes constituyen la plataforma de cliente enriquecido: 1. Plataforma principal - inicio de Eclipse, ejecución de plugins. 2. OSGi - una plataforma para bundling estándar. 3. El Standard Widget Toolkit (SWT) - Un widget toolkit portable. 4. JFace - manejo de archivos, manejo de texto, editores de texto. 5. El Workbench de Eclipse - vistas, editores, perspectivas, asistentes. Los widgets de Eclipse están implementados por una herramienta de widget para Java llamada SWT, a diferencia de la mayoría de las aplicaciones Java, que usan las opciones estándar Abstract Window Toolkit (AWT) o Swing. La 43 interfaz de usuario de Eclipse también tiene una capa GUI intermedia llamada JFace, la cual simplifica la construcción de aplicaciones basada en SWT. El entorno integrado de desarrollo (IDE) de Eclipse emplea módulos (en inglés plugin) para proporcionar toda su funcionalidad al frente de la plataforma de cliente rico, a diferencia de otros entornos monolíticos donde las funcionalidades están todas incluidas, las necesite el usuario o no. Este mecanismo de módulos es una plataforma ligera para componentes de software. Adicionalmente a permitirle a Eclipse extenderse usando otros lenguajes de programación como son C/C++ y Phyton, permite a Eclipse trabajar con lenguajes para procesado de texto como LaTeX, aplicaciones en red como Telnet y Sistemas de gestión de base de datos. La arquitectura plugin permite escribir cualquier extensión deseada en el ambiente, como seria Gestión de la configuración. Se provee soporte para Java y CVS en el SDK de Eclipse. Y no tiene porque ser usado únicamente para soportar otros lenguajes de programación. La definición que da el proyecto Eclipse acerca de su software es: “una especie de herramienta universal, un IDE abierto y extensible para todo y nada en particular”. En cuanto a las aplicaciones clientes, eclipse provee al programador con frameworks muy ricos para el desarrollo de aplicaciones gráficas, definición y manipulación de modelos de software, aplicaciones web, etc. Por ejemplo, GEF (Graphic Editing Framework - Framework para la edición gráfica) es un plugin de eclipse para el desarrollo de editores visuales que pueden ir desde procesadores de texto wysiwyg hasta editores de diagramas UML, interfaces gráficas para el usuario (GUI), etc. Dado que los editores realizados con GEF “viven” dentro de eclipse, además de poder ser usados conjuntamente con otros plugins, hacen uso de su interfaz gráfica personalizable y profesional. 44 El SDK de Eclipse incluye las herramientas de desarrollo de Java, ofreciendo un IDE con un compilador de Java interno y un modelo completo de los archivos fuente de Java. Esto permite técnicas avanzadas de refactorización y análisis de código. El IDE también hace uso de un espacio de trabajo, en este caso un grupo de metadata en un espacio para archivos plano, permitiendo modificaciones externas a los archivos en tanto se refresque el espacio de trabajo correspondiente. 2.2.5 FRAMEWORKS. Un framework es una estructura de soporte definida en la cual otro proyecto de software puede ser organizado y desarrollado. Típicamente, un framework puede incluir soporte de programas, bibliotecas y un lenguaje de scripting entre otros softwares para ayudar a desarrollar y unir los diferentes componentes de un proyecto. Es un conjunto de clases creadas para apoyar la escritura de código en un contexto de terminado. Un framework de persistencia es, por lo tanto, una librería de clases que facilita la tarea del programador al permitirle guardar objetos en bases de datos relacionales de manera lógica y eficiente, de otra manera tocaría hacerlo manualmente, y este es, potencialmente, un proceso tedioso, repetitivo y propenso a errores. Los frameworks son diseñados con el intento de facilitar el desarrollo de software, permitiendo a los diseñadores y programadores pasar más tiempo identificando requerimientos de software que tratando con los tediosos detalles de bajo nivel de proveer un sistema funcional. Un framework de persistencia de gran aceptación en el ambiente es Hibernate, ya que ofrece facilidad en su uso, funcionando perfectamente con JAVA y por sobretodo es una herramienta Open Source. 45 Los frameworks se clasifican en función de la forma en que se instancian en: • Frameworks de caja blanca: Para su instanciación, el desarrollador con reutilización necesita conocer su estructura interna. Al utilizarlos, el mecanismo predominante es la herencia, mediante la que se hacen concretas las propiedades abstractas de las clases del framework. • Frameworks de caja negra: Para su instanciación no es preciso conocer la forma en que están construidos. El desarrollador con reutilización personaliza los puntos calientes mediante la instanciación con parámetros actuales y la composición. Los frameworks también se clasifican en función del tipo de problema a que van dirigidos en: • Frameworks de aplicación: Encapsulan una capa de funcionalidad horizontal que se puede aplicar en la construcción de una gran variedad de programas. Los frameworks que implementan las interfaces graficas de usuario representan su paradigma. • Frameworks de soporte: Proporcionan servicios básicos a nivel de sistema. • Frameworks de dominio: Aplicables a un dominio de aplicación o línea de producto, implementan una capa de funcionalidad vertical. Estos frameworks deberán ser los más numerosos, y su evolución deberá también ser la mas rápida, pues deben adaptarse a las áreas de negocio para las que están diseñados. Hibernate: Hibernate es una herramienta de Mapeo objeto-relacional para la plataforma Java (y disponible también para .Net) que facilita el mapeo de atributos entre una base de datos relacional tradicional y el modelo de objetos de una aplicación, mediante archivos declarativos (XML) que permiten establecer estas relaciones. 46 Hibernate es software libre, distribuido bajo los términos de la LGPL (Licencia Pública General Menor de GNU). Hibernate fue una iniciativa de un grupo de desarrolladores dispersos alrededor del mundo conducidos por Gavin King. Tiempo después, J Boss Inc. (empresa comprada por Red Hat) contrató a los principales desarrolladores de Hibernate y trabajó con ellos en brindar soporte al proyecto. La rama actual de desarrollo de Hibernate es la 3.x, la cual incorpora nuevas características, como una nueva arquitectura, filtros definidos por el usuario, y opcionalmente el uso de anotaciones para definir la correspondencia en lugar (o conjuntamente con) los archivos XML. Hibernate 3 también guarda cercanía con la especificación EJB 3.0 (aunque apareciera antes de la publicación de dicha especificación por la Java Community Process) y actúa como la espina dorsal de la implementación de EJB 3.0 en JBoss. Hibernate se adapta al proceso de desarrollo de software, sin importar si se parte de una base de datos en blanco o de una ya existente. La característica principal de Hibernate es el mapeo de clases en Java a tablas de una base de datos (y de tipos de datos de Java hacia tipos de datos de SQL), ofreciendo también consulta de datos y facilidades de recuperación. Hibernate genera las sentencias SQL y libera al desarrollador del manejo manual de los datos que resultan de la ejecución de dichas sentencias, manteniendo la portabilidad entre todas las bases de datos con un ligero incremento en el tiempo de ejecución. Hibernate para Java puede ser utilizado en aplicaciones Java independientes o bajo aplicaciones Java EE haciendo uso de servlets o EJB beans de sesión. La implementación de las herramientas mencionadas lleva a pensar que es necesario tener claro como hacer encajar los requerimientos y concretizarlos 47 en un producto final que refleje el cumplimiento de estos, para ello se cuentan como se mencionó anteriormente con lenguajes de programación para el Web que son orientados a objetos, pero para utilizarlos de la mejor forma es necesario tener claros ciertos conceptos básicos del modelado orientado a objetos. 2.3 MODELADO ORIENTADO A OBJETOS (MOO). En el contexto del desarrollo de sistemas de software con orientación a objetos, el MOO es la construcción de modelos de un sistema por medio de la identificación y especificación de un conjunto de objetos relacionados, que se comportan y colaboran entre sí de acuerdo a los requerimientos establecidos para el sistema de objetos. La definición anterior ya sugiere la distinción, dentro del proceso de MOO, de tres dimensiones o perspectivas relativamente ortogonales para describir un sistema de objetos: • Dimensión estructural de los objetos: Se centra en las propiedades estáticas o pasivas de los sistemas. Está relacionada con la estructura estática del sistema de objetos. • Dimensión dinámica del comportamiento: Se centra en las propiedades activas y describe el comportamiento individual y la colaboración entre los objetos que constituyen el sistema. • Dimensión funcional de los requerimientos: Son consideradas las propiedades relativas a la función de transformación del sistema de objetos, es decir, los procesos de conversión de entradas en salidas. El Modelado y Diseño Orientado a Objetos se funda en pensar acerca de problemas a resolver empleando modelos que se han organizado tomando como base conceptos del mundo real. 48 La programación del modelo orientado a objetos se basa en ciertos conceptos básicos descritos a continuación: • Objetos. Un objeto es una agrupación de código, compuesta de propiedades y métodos, que pueden ser manipulados como una entidad independiente. Las propiedades definen los datos o información del objeto, permitiendo consultar o modificar su estado; mientras que los métodos son las rutinas que definen su comportamiento. Un objeto es una pieza que se ocupa de desempeñar un trabajo concreto dentro de una estructura organizativa de nivel superior, formada por múltiples objetos, cada uno de los cuales ejerce la tarea particular para la que ha sido diseñado. Todo objeto del mundo real tiene 2 componentes: características y comportamiento. Por ejemplo, los automóviles tienen características (marca, modelo, color, velocidad máxima, etc.) y comportamiento (frenar, acelerar, retroceder, llenar combustible, cambiar llantas, etc.). Los Objetos de Software, al igual que los objetos del mundo real, también tienen características y comportamientos. Un objeto de software mantiene sus características en una o más "variables", e implementa su comportamiento con "métodos". Un método es una función o subrutina asociada a un objeto. • Clases. Una clase no es otra cosa que el conjunto de especificaciones o normas que definen cómo va a ser creado un objeto de un tipo determinado; algo parecido a un manual de instrucciones conteniendo las indicaciones para crear el objeto. 49 Los términos objeto y clase son utilizados en POO (Programación Orientada a Objetos), con gran confusión y en contextos muy similares, por lo que para intentar aclarar en lo posible ambos conceptos, diremos que una clase constituye la representación abstracta de algo, mientras que un objeto constituye la representación concreta de lo que una clase define. La clase determina el conjunto de puntos clave que ha de cumplir un objeto para ser considerado perteneciente a dicha clase o categoría, ya que no es obligatorio que dos objetos creados a partir de la misma clase sean exactamente iguales, basta con que cumplan las especificaciones clave de la clase. Exponiendo ahora las anteriores definiciones mediante un ejemplo preciso: un molde para crear figuras de cerámica y las figuras obtenidas a partir del molde. En este caso, el molde representaría la clase Figura, y cada una de las figuras creadas a partir del molde, sería un objeto Figura. Cada objeto Figura tendrá una serie de propiedades comunes: tamaño y peso iguales; y otras propiedades particulares: un color distinto para cada figura. Aunque objetos distintos de una misma clase pueden tener ciertas propiedades diferentes, deben tener el mismo comportamiento o métodos. Para explicar mejor esta circunstancia, tomemos el ejemplo de la clase Coche; podemos crear dos coches con diferentes características (color, tamaño, potencia, etc.), pero cuando aplicamos sobre ellos los métodos Arrancar, Acelerar o Frenar, ambos se comportan o responden de la misma manera. Ahora bien el proceso por el cual se obtiene un objeto a partir de las especificaciones de una clase se conoce como instanciación de objetos. Por ejemplo cuando se fabrican celulares, los fabricantes aprovechan el hecho de que los celulares comparten esas características comunes y construyen modelos o plantillas comunes, para que a partir de esas se puedan crear 50 muchos equipos celulares del mismo modelo. A ese modelo o plantilla le llamamos clase, y a los equipos que sacamos a partir de ella la llamamos objetos. Figura 2.2 2.3.1 CARACTERÍSTICAS BÁSICAS DE UN SISTEMA ORIENTADO A OBJETOS. Para que un lenguaje o sistema sea considerado orientado a objetos, debe cumplir las características de los siguientes apartados. Abstracción. La abstracción es aquella característica que nos permite identificar un objeto a través de sus aspectos conceptuales. Las propiedades de los objetos de una misma clase, pueden hacerlos tan distintos que sea difícil reconocer que pertenecen a una clase idéntica. No obstante, nosotros reconocemos a qué clase pertenecen, identificando además, si se trata de la misma clase para ambos. Ello es posible gracias a la abstracción. 51 Tomando como ejemplo dos objetos coche, uno deportivo y otro familiar; su aspecto exterior es muy diferente, sin embargo, cuando pensamos en cualquiera de ellos, sabemos que ambos pertenecen a la clase Coche, porque realizamos una abstracción o identificación mental de los elementos comunes que ambos tienen (ruedas, volante, motor, puertas, etc.). Del mismo modo que se hace al identificar objetos reales, la abstracción nos ayuda a la hora de desarrollar una aplicación, permitiéndonos identificar los objetos que van a formar parte de nuestro programa, sin necesidad de disponer aún de su implementación; nos basta con reconocer los aspectos conceptuales que cada objeto debe resolver. Por ejemplo, cuando se aborda el desarrollo de un programa de gestión orientado a objetos, realizamos una abstracción de los objetos que necesitaríamos para resolver los procesos del programa: un objeto Empleado, para gestionar al personal de la empresa; un objeto Factura, para gestionar las ventas realizadas de productos; un objeto Usuario, para verificar las personas que utilizan la aplicación, etc. Encapsulación. La encapsulación establece la separación entre el interfaz del objeto y su implementación, aportándonos dos ventajas fundamentales. Por una parte proporciona seguridad al código de la clase, evitando accesos y modificaciones no deseadas; una clase bien encapsulada no debe permitir la modificación directa de una variable, ni ejecutar métodos que sean de uso interno para la clase. Por otro lado la encapsulación simplifica la utilización de los objetos, ya que un programador que use un objeto, si este está bien diseñado y su código correctamente escrito, no necesitará conocer los detalles de su implementación, se limitará a utilizarlo. 52 Tomando un ejemplo real, cuando nosotros utilizamos un objeto Coche, al presionar el acelerador, no necesitamos conocer la mecánica interna que hace moverse al coche, sabemos que el método Acelerar del coche es lo que tenemos que utilizar para desplazarnos, y simplemente lo usamos. Pasando a un ejemplo en programación, si estamos creando un programa de gestión y nos proporcionan un objeto Cliente que tiene el método Alta, y sirve para añadir nuevos clientes a la base de datos, no precisamos conocer el código que contiene dicho método, simplemente lo ejecutamos y damos de alta a los clientes en nuestra aplicación. Polimorfismo. El polimorfismo determina que el mismo nombre de método, realizará diferentes acciones según el objeto sobre el que sea aplicado. Al igual que sucedía en la encapsulación, el programador que haga uso del objeto, no necesita conocer los detalles de implementación de los métodos, se limita a utilizarlos. Pasando a un ejemplo real, tomamos dos objetos: Pelota y VasoCristal; si ejecutamos sobre ambos el método Tirar, el resultado en ambos casos será muy diferente; mientras que el objeto Pelota rebotará al llegar al suelo, el objeto VasoCristal se romperá. En un ejemplo aplicado a la programación, supongamos que disponemos de los objetos Ventana y Fichero; si ejecutamos sobre ambos el método Abrir, el resultado en Ventana será la visualización de una ventana en el monitor del usuario; mientras que en el objeto Fichero, se tomará un fichero en el equipo del usuario y se dejará listo para realizar sobre él operaciones de lectura o escritura. 53 Herencia. Se trata de la característica más importante de la POO, y establece que partiendo de una clase a la que denominamos clase base, padre o superclase, creamos una nueva clase denominada clase derivada, hija, o subclase. En esta clase derivada dispondremos de todo el código de la clase base, más el nuevo código propio de la clase hija, que escribamos para extender sus funcionalidades. A su vez podemos tomar una clase derivada, creando una nueva subclase a partir de ella. Existen dos tipos de herencia: simple y múltiple. La herencia simple es aquella en la que creamos una clase derivada a partir de una sola clase base, mientras que la herencia múltiple nos permite crear una clase derivada a partir de varias clases base. Como ejemplo real de herencia, podemos usar la clase Coche como clase base; en ella reconocemos una serie de propiedades como Motor, Ruedas, Volante, etc., y unos métodos como Arrancar, Acelerar, Frenar, etc. Como clase derivada creamos CocheDeportivo, en la cuál, además de todas las características mencionadas para la clase Coche, encontramos propiedades y comportamiento específicos como ABS, Turbo, etc. Un ejemplo basado en programación consistiría en disponer de la ya conocida clase Empleado. Esta clase se ocupa, como ya sabemos, de las operaciones de alta de empleados, pago de nóminas, etc.; pero en un momento dado, surge la necesidad de realizar pagos a empleados que no trabajan en la central de la empresa, ya que se trata de comerciales que pasan la mayor parte del tiempo desplazándose. Para realizar dichos pagos usaremos Internet, necesitando el número de tarjeta de crédito y la dirección e-mail del empleado. Resolveremos esta situación creando la clase derivada Caber Empleado, que hereda de la clase Empleado, en la que sólo tendríamos que añadir las nuevas propiedades y métodos para las transacciones electrónicas, puesto que las operaciones tradicionales ya las tendríamos disponibles por el mero hecho de haber heredado de Empleado. 54 2.4 ARQUITECTURA DE APLICACIONES WEB. En los primeros tiempos de la computación cliente-servidor, cada aplicación tenía su propio programa cliente y su interfaz de usuario, estos tenían que ser instalados separadamente en cada estación de trabajo de los usuarios. Una mejora al servidor, como parte de la aplicación, requería típicamente una mejora de los clientes instalados en cada una de las estaciones de trabajo, añadiendo un costo de soporte técnico y disminuyendo la eficiencia del personal. Los sistemas típicos cliente/servidor pertenecen a la categoría de las aplicaciones de dos niveles. Requiere una interfaz de usuario que se instala y corre en una PC o estación de trabajo; y que envía solicitudes a un servidor para ejecutar operaciones complejas. Por ejemplo, una estación de trabajo utilizada como cliente puede correr una aplicación de interfaz de usuario que interroga a un servidor central de bases de datos. En este tipo de aplicaciones el peso del cálculo recae en el cliente, mientras que el servidor hace la parte menos pesada, y eso que los clientes suelen ser máquinas menos potentes que los servidores. Al hablar del desarrollo de aplicaciones Web resulta adecuado presentarlas dentro de las aplicaciones multinivel. La arquitectura de las aplicaciones Web suelen presentar un esquema de tres niveles (ver figura 2.3). El primer nivel consiste en la capa de presentación que incluye no sólo el navegador, sino también el servidor Web que es el responsable de dar a los datos un formato adecuado. El segundo nivel está referido habitualmente a algún tipo de programa o script. Finalmente, el tercer nivel proporciona al segundo los datos necesarios para su ejecución. Una aplicación Web típica recogerá datos del usuario (primer nivel), los enviará al servidor, que ejecutará un programa (segundo y tercer nivel) y cuyo 55 resultado será formateado y presentado al usuario en el navegador (primer nivel otra vez). ESQUEMA DE TRES NIVELES PARA APLICACIONES WEB. Figura. 2.3 Ventajas de la Arquitectura Cliente/Servidor: • El desarrollo de aplicaciones en un ambiente de dos capas es mucho más rápido que en ambientes anteriores, pero no es necesariamente más rápido que con el nuevo ambiente de tres capas. • Las herramientas para el desarrollo con dos capas son robustas y evaluadas. Las técnicas de prototipo se emplean fácilmente. • Las soluciones de dos capas trabajan bien en ambientes no dinámicos estables, pero no se ejecutan bien en organizaciones rápidamente cambiantes. Desventajas: • Los ambientes de dos capas requieren control excesivo de las versiones y demandan esfuerzo de distribución de la aplicación cuando se les hacen cambios. Esto se debe al hecho de que la mayoría de la aplicación lógica existe en la estación de trabajo del cliente. 56 • La seguridad del sistema en un diseño de dos capas es compleja y a menudo requiere administración de las bases de datos; esto es debido al número de dispositivos con acceso directo al ambiente de esas bases de datos. • Las herramientas del cliente y de la base de datos, utilizadas en diseños de dos capas, constantemente están cambiando. La dependencia a largo plazo de cualquier herramienta, puede complicar el escalamiento futuro o las implementaciones. Ventajas de la Arquitectura Web: • Las llamadas de la interfaz del usuario en la estación de trabajo, al servidor de capa intermedia, son más flexibles que en el diseño de dos capas, ya que la estación sólo necesita transferir parámetros a la capa intermedia. • Con la arquitectura de tres capas, la interfaz del cliente no es requerida para comprender o comunicarse con el receptor de los datos. Por lo tanto, esa estructura de los datos puede ser modificada sin cambiar la interfaz del usuario en la PC. • El código de la capa intermedia puede ser reutilizado por múltiples aplicaciones si está diseñado en formato modular. Esto puede reducir los esfuerzos de desarrollo y mantenimiento, así como los costos de migración. • La separación de roles en tres capas, hace más fácil reemplazar o modificar una capa sin afectar a los módulos restantes. • Separando la aplicación de la base de datos, hace más fácil utilizar nuevas tecnologías de agrupamiento y balance de cargas. • Separando la interfaz del usuario de la aplicación, libera de gran procesamiento a la estación de trabajo y permite que las actualizaciones de la aplicación sean centralizadas en el servidor de aplicaciones. 57 Desventajas: • Los ambientes de tres capas pueden incrementar el tráfico en la red y requerir más balance de carga y tolerancia a las fallas. • Los exploradores actuales no son todos iguales. La estandarización entre diferentes proveedores ha sido lenta en desarrollarse. Muchas organizaciones son forzadas a escoger uno en lugar de otro, mientras que cada uno ofrece sus propias y distintas ventajas. La arquitectura MVC y Model 2. La arquitectura Model-View-Controller (MVC) surgió como patrón arquitectónico para el desarrollo de interfaces gráficos de usuario en entornos Smalltalk. Su concepto se basaba en separar el modelo de datos de la aplicación de su representación de cara al usuario y de la interacción de éste con la aplicación, mediante la división de la aplicación en tres partes fundamentales: • El modelo, que contiene la lógica de negocio de la aplicación. • La vista, que muestra al usuario la información que éste necesita. • El controlador, que recibe e interpreta la interacción del usuario, actuando sobre modelo y vista de manera adecuada para provocar cambios de estado en la representación interna de los datos, así como en su visualización. Sun Microsystems, creadora de la plataforma Java, acuñó el término Model 2 para referirse al modelo arquitectural recomendado para las aplicaciones Web desarrolladas sobre J2EE. La mencionada arquitectura consiste en el desarrollo de una aplicación según el patrón Model-View-Controller, pero especificando que el controlador debe estar formado por un único servlet, que centralice el control de todas las peticiones al sistema, y que basándose en la URL de la petición HTTP y en el estado actual del sistema, derive la gestión y control de la petición a una 58 determinada acción de entre las registradas en la capa controlador. Esta centralización del controlador en un único punto de acceso se conoce como patrón front controller. Las ventajas que este patrón ofrece provienen de la capacidad de gestionar en un único punto la aplicación de filtros a las peticiones, las comprobaciones de seguridad, la realización de logs, etc. La aplicación del patrón MVC ha demostrado ser muy apropiada para las aplicaciones Web y especialmente adaptarse bien a las tecnologías proporcionadas por la plataforma J2EE, de manera que: • El modelo, conteniendo lógica de negocio, sería modelado por un conjunto de clases Java, existiendo dos claras alternativas de implementación, utilizando objetos java tradicionales llamados POJOs (Plain Old Java Objects) o bien utilizando EJB (Enterprise JavaBeans) en sistemas con unas mayores necesidades de concurrencia o distribución. • La vista proporcionará una serie de páginas web dinámicamente al cliente, siendo para él simples páginas HTML. Existen múltiples frameworks que generan estas páginas web a partir de distintos formatos, siendo el más extendido el de páginas JSP (JavaServer Pages), que mediante un conjunto de tags XML proporcionan un interfaz sencillo y adecuado a clases Java y objetos proporcionados por el servidor de aplicaciones. Esto permite que sean sencillas de desarrollar por personas con conocimientos de HTML. Entre estos tags tienen mención especial la librería estándar JSTL (JavaServer Pages Standard Tag Library) que proporciona una gran funcionalidad y versatilidad. • El controlador en la plataforma J2EE se desarrolla mediante servlets, que hacen de intermediarios entre la vista y el modelo, más versátiles que los JSP para esta función al estar escritos como clases Java normales, evitando 59 mezclar código visual (HTML, XML...) con código Java. Para facilitar la implementación de estos servlets también existe una serie de frameworks que proporcionan soporte a los desarrolladores, entre los que cabe destacar Struts, que con una amplia comunidad de usuarios se ha convertido en el estándar de facto en este rol. Con todo lo anterior, el funcionamiento de una aplicación Web J2EE que utilice el patrón arquitectural MVC se puede descomponer en una serie de pasos: 1. El usuario realiza una acción en su navegador, que llega al servidor mediante una petición HTTP y es recibida por un servlet (controlador). Esa petición es interpretada y se transforma en la ejecución de código java que delegará al modelo la ejecución de una acción de éste. 2. El modelo recibe las peticiones del controlador, a través de un interfaz o fachada que encapsulará y ocultará la complejidad del modelo al controlador. El resultado de esa petición será devuelto al controlador. 3. El controlador recibe del modelo el resultado, y en función de éste, selecciona la vista que será mostrada al usuario, y le proporcionará los datos recibidos del modelo y otros datos necesarios para su transformación a HTML. Una vez hecho esto el control pasa a la vista para la realización de esa transformación. 4. En la vista se realiza la transformación tras recibir los datos del controlador, elaborando la respuesta HTML adecuada para que el usuario la visualice. 60 Esta arquitectura de aplicaciones otorga varias ventajas clave al desarrollo de aplicaciones Web, destacando: • Al separar de manera clara la lógica de negocio (modelo) de la vista permite la reusabilidad del modelo, de modo que la misma implementación de la lógica de negocio que maneja una aplicación pueda ser usado en otras aplicaciones, sean éstas Web o no. • Permite una sencilla división de roles, dejando que sean diseñadores gráficos sin conocimientos de programación o desarrollo de aplicaciones los que se encarguen de la realización de la capa vista, sin necesidad de mezclar código Java entre el código visual que desarrollen (tan sólo utilizando algunos tags, no muy diferentes de los usados en el código HTML). 2.5 MÉTODO DEL CICLO DE VIDA DE LOS SISTEMAS. Un ciclo de vida para un proyecto se compone de fases sucesivas compuestas por tareas planificables. Según el modelo de ciclo de vida, la sucesión de fases puede ampliarse con bucles de realimentación, de manera que lo que conceptualmente se considera una misma fase se pueda ejecutar más de una vez a lo largo de un proyecto, recibiendo en cada pasada de ejecución aportaciones de los resultados intermedios que se van produciendo. El modelo en espiral para la ingeniería del software ha sido desarrollado para cubrir las mejores características tanto del ciclo de vida clásico, como de la creación de prototipos, añadiendo al mismo tiempo un nuevo elemento: el análisis de riesgo, que falta en esos paradigmas. El modelo, representado mediante la espiral de la Figura 2.4 define cuatro actividades principales, representadas por los cuatro cuadrantes de la figura: 61 Figura 2.4 1. Planeación y análisis: determinación de objetivos, alternativas y restricciones. 2. Diseño: análisis de alternativas e identificación/resolución de riesgos. 3. Implementación: desarrollo del producto de “siguiente nivel” 4. Evaluación: valoración de los resultados de la implementación. Un aspecto intrigante del modelo en espiral se hace evidente cuando consideramos la dimensión radial representada en la Figura 2.4 Con cada iteración alrededor de la espiral (comenzando en el centro y siguiendo hacia el exterior), se construyen sucesivas versiones del software, cada vez más completas. Durante la primera vuelta alrededor de la espiral se definen los objetivos, las alternativas y las restricciones, y se analizan e identifican los riesgos. Si el diseño indica que hay una incertidumbre en los requisitos, se puede usar la creación de prototipos en el cuadrante de ingeniería para dar asistencia tanto al encargado del desarrollo como al cliente. Se pueden usar simulaciones y otros modelos para definir más el problema y refinar los requisitos. 62 El cliente evalúa el trabajo de implementación (cuadrante de evaluación) y sugiere modificaciones. En base a los comentarios del cliente se produce la siguiente fase de planificación y de análisis de riesgo. En cada bucle alrededor de la espiral, la culminación del análisis de riesgo resulta en una decisión de “seguir o no seguir”. Si los riesgos son demasiado grandes, se puede dar por terminado el proyecto. Sin embargo, en la mayoría de los casos, se sigue avanzando alrededor del camino de la espiral, y ese camino lleva a los desarrolladores hacia fuera, hacia un modelo más completo del sistema, y al final, al propio sistema operacional. Cada vuelta alrededor de la espiral requiere ingeniería (cuadrante inferior derecho), que se puede llevar a cabo mediante el enfoque del ciclo de vida clásico o de la creación de prototipos. Debe tenerse en cuenta que el número de actividades de desarrollo que ocurren en el cuadrante inferior derecho aumenta al alejarse del centro de la espiral. El paradigma del modelo en espiral para la ingeniería del software es actualmente el enfoque más realista para el desarrollo de software y de sistemas a gran escala. Utiliza un enfoque “evolutivo” para la ingeniería del software, permitiendo al desarrollador y al cliente entender y reaccionar a los riesgos en reducción del riesgo, pero lo que es más importante, permite a quien lo desarrolla aplicar el enfoque de creación de prototipos en cualquier etapa de la evolución del producto. Mantiene el enfoque sistemático correspondiente a los pasos sugeridos por el ciclo de vida clásico, pero incorporándola dentro de un marco de trabajo interactivo que refleja de forma más realista el mundo real. El modelo en espiral demanda una consideración directa de riesgos técnicos en todas las etapas del proyecto y, si se aplica adecuadamente, debe reducir los riesgos antes de que se conviertan en problemáticos. 63 Al igual que otros paradigmas, el modelo en espiral no es la panacea. Puede ser difícil convencer a grandes clientes (particularmente en situaciones bajo contrato) de que el enfoque evolutivo es controlable. Requiere una considerable habilidad para la valoración del riesgo, y cuenta con esta habilidad para el éxito. Si no se descubre un riesgo importante, indudablemente surgirán problemas. Por último, el modelo en sí mismo es relativamente nuevo y no se ha usado tanto como el ciclo de vida o la creación de prototipos. Pasarán unos cuantos años antes de que se pueda determinar con absoluta certeza la eficacia de este importante nuevo paradigma. Planeación y análisis. • Investigación preliminar. Recibe este nombre la investigación que obtiene su información de la actividad intencional realizada por el investigador y que se encuentra dirigida a modificar la realidad con el propósito de crear el fenómeno mismo que se indaga, y así poder observarlo. Es donde se recopilara la información que hace referencia a la institución que se le desarrollará el software y la necesidad que ésta tiene del mismo. • Determinación de requerimientos. El analista conversa con varias personas para reunir detalles relacionados con los procesos de la empresa. Se emplean cuestionarios para obtener información cuando no es posible entrevistar en forma personal a los miembros de la organización. Las investigaciones detalladas requieren el estudio de manuales y reportes, observaciones condiciones reales con el de comprender el proceso en su totalidad. Diseño. El diseño es el primer paso en la fase de desarrollo de cualquier producto o sistema de ingeniería. El objetivo del diseñador es producir un modelo o 64 representación de una entidad que se construirá posteriormente. El proceso combina iterativamente la intuición y los criterios basados en la experiencia, un conjunto principios para guiar la evolución del modelo, y un conjunto de criterios que permiten juzgar la calidad. Para poder desarrollar el sistema es necesario ocupar distintas herramientas de desarrollo tales como leguajes de programación, gestores de base de datos y herramientas de modelado. • Diseño lógico. Los analistas de sistemas comienza el proceso de diseño identificando los reportes y demás salidas que debe producir el sistema. Los diseñadores hacen un bosquejo del formato que esperan que aparezca cuando el sistema este terminado. Los diseñadores son los responsables de dar a los programadores las especificaciones de software completas y claras. La etapa de diseño lógico proporcionará los detalles que establecen la forma en la que el sistema cumplirá con los requerimientos identificados durante la fase de análisis • Diseño físico. Hasta esta etapa del diseño lo que se ha hecho es modelar los requerimientos de la aplicación por medio de sus especificaciones funcionales hasta encontrar distintos aspectos de cómo trabaja la aplicación por fuera. Ahora es necesario considerar como la aplicación trabaja por dentro, o más precisamente como las tecnologías y arquitecturas que se han elegido van a impactar en el diseño. Implementación y evaluación. La implantación es el proceso de verificar e instalar nuevo equipo entrenar a los usuarios, instalar la aplicación y construir todos los archivos de datos necesarios para utilizarla. Las organizaciones cambian con el paso del tiempo, por lo tanto debe darse mantenimiento a las aplicaciones; realizar 65 cambios y modificaciones en el software, archivos o procedimientos para satisfacer las nuevas necesidades de los usuarios. La implantación es un proceso en constante evolución. La evaluación de un sistema se lleva a cabo para identificar puntos débiles y fuertes. La evaluación ocurre a lo largo de cualquiera de las siguientes dimensiones: evaluación operacional, impacto organizacional, opinión de los administradores y desempeño del desarrollo. 2.6 CONCEPTUALIZACIONES SOBRE METODOLOGÍA DE LA INVESTIGACIÓN. Es necesario tener claro una definición de metodología para poderla aplicar correctamente. Para el caso, metodología se define como un proceso que, mediante la aplicación del método científico, trata de obtener información relevante y fidedigna, para entender, verificar, corregir o aplicar el conocimiento. Formulación del problema. Formular un problema es caracterizarlo, definirlo, enmarcarlo teóricamente, sugerir propuestas de solución para ser demostradas, establecer unas fuentes de información y unos métodos para recoger y procesar dicha información. La caracterización o definición del problema nos conduce otorgarle un título, en el cual de la manera más clara y denotativa indiquemos los elementos que le son esenciales. Fase exploratoria: Ninguna investigación parte de cero, de ahí que, cuando se comienzan un proyecto, deba consultarse informarse sobre lo ya investigado sobre el tema y realizar un primer contacto con el problema a estudiar. Existe una tarea de búsqueda de referencias, consulta bibliográfica y acercamiento preliminar a la realidad objeto de estudio. Esto es lo que suele denominarse fase exploratoria, cuyo propósito es de permitir al investigador familiarizarse e interiorizarse con 66 parte de los conocimientos existentes dentro del campo ámbito que es objeto de investigación. • Fuentes primarias. Una fuente primaria es aquella que provee un testimonio o evidencia directa sobre el tema de investigación. Las fuentes primarias son escritas durante el tiempo que se está estudiando o por la persona directamente envuelta en el evento. La naturaleza y valor de la fuente no puede ser determinado sin referencia al tema o pregunta que se está tratando de contestar. Las fuentes primarias ofrecen un punto de vista desde adentro del evento en particular o periodo de tiempo que se está estudiando. • Fuentes secundarias. Estas fuentes se ocuparán para interpretar y analizar las fuentes primarias. Las fuentes secundarias están distanciadas de las fuentes primarias. Los tipos de fuentes secundarias que se utilizarán serán las documentales, incluyendo libros, tesis, monografías y material en medios electrónicos. Diseño de la investigación. • Población. Constituye la totalidad de un grupo de elementos u objetos que se quiere investigar, es el conjunto de todos los casos que concuerdan con lo que se pretende investigar. • Delimitación de la población. Se delimita como población sujeta a estudio a todas aquellas personas que tengan interacción con el sistema, y que sean beneficiados con la implementación del mismo. 67 • Muestra. La muestra es un subconjunto de la población o una parte representativa, y puede ser de diferentes tipos dependiendo de la forma que seleccione a la población, tales como: muestra probabilística, muestra aleatoria simple, muestra estratificada, muestra por cuotas o proporcionales, muestra no probabilística, muestra intencionada. Técnicas e instrumentos de investigación. • Técnica documental. Este tipo de investigación es la que se realiza, como su nombre lo indica, apoyándose en fuentes de carácter documental, esto es, en documentos de cualquier especie. Esta técnica permite la recopilación de información para la elaboración del marco teórico del trabajo de investigación. • Técnica de Observación. Es el procedimiento empírico por excelencia, el más antiguo; consiste básicamente en utilizar los sentidos para observar los hechos, realidades sociales y a las personas en su contexto cotidiano. Para que dicha observación tenga validez es necesario que sea intencionada e ilustrada. Para poder aplicar la técnica, se tendrá que observar detenidamente los distintos procesos manuales que se realizan actualmente y tomar notas detalladas de los aspectos más relevantes de cada uno, la experiencia que posee cada integrante del grupo de investigación será de gran importancia para poder captar los más mínimos detalles. • Entrevista. La entrevista consiste en una conversación entre dos o más personas, sobre un tema determinado de acuerdo a ciertos esquemas o pautas determinadas. 68 Se utiliza este método de investigación para tener un mayor acercamiento con los potenciales usuarios del sistema y de esta forma recopilar los datos necesarios para poder desarrollar el sistema. La entrevista generalmente es aplicada de forma individual a la persona de interés y puede ser de forma dirigida. • Cuestionario. Es un proceso estructurado de recopilación de información a través de la complementación de una serie de preguntas. Con el cuestionario a diferencia de la entrevista se puede abarcar un mayor número de sujetos de estudios y de esta forma poder conseguir un mayor número de opiniones sobre lo que esperan del sistema y las necesidades que este tiene que solventar.