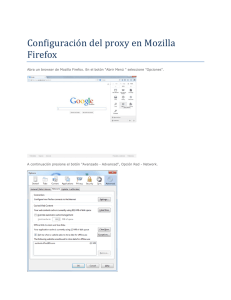
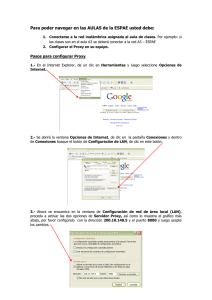
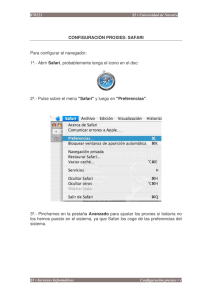
TP1 HTTP - Facultad de Ingeniería
Anuncio

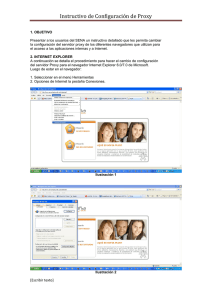
FACULTAD DE INGENIERÍA UNIVERSIDAD DE BUENOS AIRES 66.48 – Seminario de Redes de Computadora Trabajo Práctico N°1 HTTP Hyper Text Transfer Protocol Integrantes: - Santiago Boeri (79529) - Hernán Castagnola (79555) - Christian Picot (80297) - Tomás Shulman (84050) Profesores: - Marcelo Utard - Pablo Ronco - Javier Bozzuto Introducción: En este trabajo práctico examinaremos como es el protocolo primario usado para la transferencia de paginas web desde un servidor hacia un navegador web. Actualmente la transferencia de páginas web ocupa el 75% del tráfico de Internet. Arquitectura Conceptualmente la Web consiste en un gran set de documentos llamados páginas web que son accesibles desde internet. Cada pagina web es clasificada como un documento hypermedia. El prefijo media se usa para indicar que un documento puede contener además de texto gráficos, imágenes, etc. El prefijo hyper se refiere a que un documento puede contener links que nos refieran hacia otro documento. Un navegador web consiste en un programa aplicativo que un usuario invoca para acceder y ver una pagina web. El navegador, entonces se convierte en un cliente que contacta a un servidor web para adquirir una copia de la pagina especificada. Una pagina que contenga una mezcla de texto y otros ítems se representa usando Hypertext Markup Language (HTML). Un documento html es un archivo que contenga texto y comandos. Estos comandos, llamados tags, dan una guía de cómo deben estar ubicados los elementos de la pagina resultante. Uniform Resource Locators Cada página web tiene asignado un único nombre que la identifica. El nombre es llamado URL. Este empieza con el protocolo de transferencia. Siendo http el protocolo de transferencia la URL tendría la siguiente forma: http:// hostname (FQDN o IP) [:port] / path [; parámetros] [?query] donde los corchetes denotan ítems opcionales. El :port es necesario solo cuando el puerto usado no es el well know port 80, path es una cadena que identifica un documento particular en el servidor, ;parámetros son cadenas que especifican parámetros adicionales dados por el cliente, ?query es una cadena opcional cuando el navegador manda una pregunta. La forma de la URL anterior se la conoce como absoluta. Cuando el servidor ya ha sido determinado y la comunicación con el ya esta establecida el hostname se omite en la URL y esa forma se la conoce como URL relativa. Hypertext Transfer Protocol El protocolo usado para la comunicación entre un navegador y un servidor web o entre maquinas intermedias y servidores web se lo conoce como Hypertext Transfer Protocol (http). http tiene las siguientes características: • Nivel de aplicación: http opera en el nivel de aplicación. Utiliza TCP para asumir confiabilidad y conexión, pero no provee confiabilidad o retransmisión por si mismo. • • • • • • Pedido/Respuesta: una vez que la sesión se ha establecido un lado pide una http donde el otro lado responde Stateless: el servidor no lleva un historial de un pedido anterior o una sesión anterior. Transferencia bidireccional: http permite la transferencia desde un navegador a un servidor. Capacidad de negociación. http permite a los navegadores y servidores negociar detalles tales como el set de caracteres usados durante la transferencia. Cache: para mejorar el tiempo se respuesta un navegador guarda una copia de la pagina que recibe. Si un usurario pide una pagina, http permite al navegador interrogar al servidor si la pagina cambio desde que hecho una copia. Soporte de intermediarios: http permite que una maquina en el medio del camino entre el navegador y el web server actué como proxy server que guarde paginas web y responda a los navegadores consultando primero a su cache. HTTP GET Request En el caso mas simple, un navegador contacta a una servidor web directamente para obtener una pagina. El navegador extrae el hostname de la URL, usa DNS para mapear el nombre en una dirección IP y usa la dirección IP para establecer una conexión TCP al servidor. Una vez que la conexión esta establecida el navegador y el web server usan HTTP para comunicarse; el navegador manda un pedido para recibir una pagina determinada y el servidor responde con una copie de la pagina. El navegador manda un comando HTTP GET como pedido de una pagina web al servidor. El pedido consiste en una línea de texto que empieza con GET seguida de la URL por ejemplo GET http://www.fi.uba.ar/materias GET es un método de solicitud pero existen diversos tipos de solicitudes como OPTIONS, HEAD, POST, PUT, PATCH, COPY, MOVE, DELETE, LINK, UNLNK, TRACE, WRAPPED y otras extensiones que se puedan definir sin modificar el protocolo aunque ni se puede suponer que el receptor los reconozca. EJEMPLOS DE PEDIDOS MENSAJES DE RESPUESTA Un mensaje de respuesta completo consta de una línea de estado seguida por una o mas cabeceras (headers) generales, de respuesta y de entidad seguidas por un cuerpo (opcional) de entidad. Un mensaje de respuesta completo comienza con una Status-Line que tiene el siguiente formato: Status-Line= HTTP-Version SP Status-Code SP Reason-Phrase CRLF El valor de HTTP- Versión es el numero de versión HTTP utilizado por el emisor. Status-Code es un entero de 3 digitos que indica la respuesta a una solicitud recibida y Reason-Phrase proporciona una breve explicación del codigo recibido. En la siguiente tabla se organizan los códigos en diferentes categorías EJEMPLOS DE RESPUESTAS Escenario 1 HTTP 1.0 Vs. HTTP 1.1 En este escenario, vamos a exponer las principales diferencias que existen entre la versión anterior del protocolo HTTP (versión 1.0) y la actual (versión 1.1). Destacamos algunos puntos claves, que luego intentaremos confirmar mediante las experiencias realizadas. HTTP V 1.0 Utiliza TCP para realizar las conexiones a través del puerto 80. Las conexiones NO son persistentes, es decir cuando se finaliza la transmisión de un elemento, esta se cierra. No especifica un nombre de host, por lo cual no es compatible con multihomed hosts. Sin soporte para Proxys jerárquicos. HTTP V 1.1 Utiliza TCP para realizar las conexiones a través del puerto 80. Las conexiones son persistentes, y una conexión tcp solo es finalizada cuando se lo requiera explícitamente. Agrega al header un campo denominado host, en el cual se debe especificar donde reside el recurso a obtener. Esto brinda compatibilidad con multi-homed hosts. Agrega soporte para Proxys jerárquicos. Mejoras: En cuanto a las mejoras implementadas, podemos comentar lo siguiente: Conexiones persistentes Favorece a la disminución de tráfico dentro de la red, ya que para cada página se podría mantener una única conexión tcp y descargar todos sus elementos en ella. Esto evitaría tener que abrir una conexión para cada elemento de la página con la consecuente sobrecarga de header innecesario. Adicionalmente se estaría optimizando el uso de tcp dado que el mismo favorece las conexiones más duraderas para maximizar el aprovechamiento del ancho de banda. En el caso de establecer muchas conexiones por pequeño intervalo de tiempo hace que la misma trabaje casi siempre dentro de la zona de “slow-start. Al uso de conexiones persistentes también se adiciona el pipeling de solicitudes al servidor, de manera que no se espera la respuesta del mismo para un elemento para mandar el siguiente requerimiento. Soporte para multi-homed hosts En la versión anterior del protocolo si un equipo montaba más de una pagina web bajo la misma ip, era imposible para un cliente indicar a cual de ellas iba destinado el mensaje, dado que el destino era una dirección ip. De esa manera al introducir en la versión actual del protocolo un campo dentro del encabezado denominado host, se puede discriminar dentro de una misma dirección IP múltiples sitios web. Esta mejora es fundamental dado que las direcciones ip son escasas y la posibilidad de asociar mas de un sitio a una misma ip es una posibilidad de ahorro importante, evitando tener para cada sitio web una ip distinta como así lo requería HTTP 1.0. Soporte para Proxys jerárquicos El soporte que presentaba anteriormente para cache, era simple y escaso. Se basaba en utilizar los campos expires, pragma, If-Modified-Since y LastModified, sin embargo la especificación completa para cache y proxies es definida explícitamente recién para la versión actual del protocolo. Esta mejora optimiza mas el tráfico dejando a los proxies administrar los recursos obtenidos previamente del servidor. Maqueta del escenario 1: Se utilizó un servidor Apache en Linux para el HTTP 1.1 y un servidor basado en Java en Windows/Linux para el HTTP 1.0. Se utilizó Firefox como cliente web. Se capturaron los datos en el cliente utilizando Wireshark. Capturas Realizamos el pedido de una página web bajo distintas configuraciones Cliente HTTP 1.1 – Servidor HTTP 1.0 Cliente HTTP 1.0 – Servidor HTTP 1.0 Cliente HTTP 1.0 – Servidor HTTP 1.1 Cliente HTTP 1.1 – Servidor HTTP 1.1 Cliente HTTP 1.1 – Servidor HTTP 1.1 con los objetos almacenados en el navegador Cliente HTTP 1.1 – Servidor HTTP 1.1 pedido de un recurso no disponible 1) En el primer punto se consulto la página de prueba utilizando un cliente 1.1 y un servidor 1.0, con lo cual comprobamos que para cada elemento que se pedía se generaba una nueva conexión, que finalizaba cuando ese elemento llegaba a destino al cliente. El pedido se generaba con la versión 1.1 por el cliente, pero el servidor contestaba con 1.0 y es por eso que además aparece el campo host, aunque el servidor web no lo toma en cuenta. Cliente HTTP 1.1 – Servidor HTTP 1.0 2) En este punto se consulto la página de prueba utilizando un cliente 1.0 y un servidor 1.0, con lo cual comprobamos que para cada elemento que se pedía se generaba una nueva conexión, tal como lo pudimos comprobar en el primer caso. Aquí el mensaje de petición es armado desde el cliente con el formato de 1.0, por lo que no aparece el campo de host. De la misma manera que en punto anterior también se cierra la conexión una vez terminada la respuesta por parte del servidor, y es por eso que el siguiente elemento se peticiona abriendo otra conexión tcp desde otro numero de puerto. CLIENTE HTTP 1.0 – SERVIDOR HTTP 1.0 3) En este punto se consulto la página de prueba utilizando un cliente 1.0 y un servidor 1.1, con lo cual comprobamos que para cada elemento que se pedía se generaba una nueva conexión, tal como lo pudimos comprobar en el primer y segundo caso. Aquí el mensaje de petición es armado desde el cliente con el formato de 1.0, por lo que no aparece el campo de host. De la misma manera que en punto anterior también se cierra la conexión una vez terminada la respuesta por parte del servidor, y eso por eso que el siguiente elemento se peticiona abriendo otra conexión tcp desde otro numero de puerto. Este ejemplo presenta el mismo resultado práctico que el anterior. CLIENTE HTTP 1.0 – SERVIDOR HTTP 1.1 4) En este punto se consulto la página de prueba utilizando un cliente 1.1 y un servidor 1.1, con lo cual debería utilizarse una única conexión para establecer todas las peticiones para esa pagina, dado que tanto el cliente como el servidor son compatibles con la versión 1.1. Adicionalmente vemos que existe la presencia del campo connection: Keep alive, lo que le indica al servidor que la conexión no debe cerrarse. Sin embargo podemos observar que en este caso también se cierra la conexión una vez descargado el recurso. Esto tiene dos posibles explicaciones: O bien el servidor contesto con un valor en el campo connection: close, con lo cual se inicia el cierre de la sesión TCP; o simplemente el timout configurado bajo el campo keepAlive se venció, por lo que el resultado es el cierre de la conexión. CLIENTE HTTP 1.1 – SERVIDOR HTTP 1.1 5) En este punto se consulto la página de prueba una vez más, utilizando un cliente 1.1 y un servidor 1.1. Como esta ya se había cargado, con la información del mensaje utilizado por el cliente, el servidor resuelve que el contenido que le solicitan no ha sido modificado, por lo que responde con un mensaje del tipo 304 (Not modified). Esta respuesta hace que el cliente se dé cuenta de que la página no cambio, con lo que no se transfiere ningún elemento desde el servidor al cliente. Junto con la respuesta del servidor se incluye la orden de cerrar la conexión, dado que no tiene sentido mantenerla abierta. CLIENTE HTTP 1.1 – SERVIDOR HTTP 1.1 – EL CONTENIDO YA ESTA EN EL CACHE DEL NAVEGADOR 6) En este punto se consulto un recurso de la página de prueba una vez más, utilizando un cliente 1.1 y un servidor 1.1. Se trata de obtener del servidor un recurso inexistente, por lo que el mismo contesta con un mensaje 404 (No encontrado) y una petición de cierre de la conexión. CLIENTE HTTP 1.1 – SERVIDOR HTTP 1.1 – EL RECURSO NO ESTA DISPONIBLE Luego de analizadas las distintas situaciones presentadas y analizando las capturas, podemos ver las limitaciones de la versión anterior del protocolo, y como fueron resueltas en esta ultima versión. Además vimos que en el caso del punto 4, esperamos que se utilice una única conexión para mantener todo el dialogo entre el servidor y el cliente y sin embargo esto no ocurrió, y el comportamiento fue similar al de la versión 1.0. Una explicación para esto es que si bien esta nueva versión soporta el fenómeno de conexiones persistentes, nada dice que no puede actuar con una adecuada configuración de las opciones que brinda como su antecesor. Escenario 2: HTTP Proxy Un Proxy es una aplicación que escucha requerimientos de un cliente para un determinado servicio y los reenvía hacia un servidor remoto. Un HTTP Proxy realiza esta tarea pero para el protocolo HTTP. Los objetivos de utilizar un Proxy pueden ser diversos, pero principalmente se utilizan en organizaciones/instituciones para proveer un acceso a sitios de Internet seguro y en cumplimiento de las políticas adecuadas de uso de la red corporativa. Existen diferentes tipos de Proxy HTTP: Cache Proxy Este tipo de servidor se utiliza para almacenar una copia del recurso HTTP en un cache local, con el fin de evitar que ese mismo recurso sea descargado de la Internet nuevamente por otro cliente, si el contenido original del servidor web no cambió. Esto no solo economiza el uso de ancho de banda de Internet si no que proporciona más velocidad de respuesta en la navegación, ya que el contenido se obtiene de recursos de la red local. Filtering Proxy Este tipo de servidor se utiliza con el fin de limitar el acceso a recursos de Internet que no cumplen con políticas de uso adecuado. Puede incluir filtros por expresiones regulares, sitios prohibidos o sitios marcados en una base de datos como no apropiados. Generalmente, ante un pedido que no cumple con las políticas, el servidor Proxy devuelve una página por defecto indicando que el recurso no estará disponible. Intercepting Proxy Este método intercepta las peticiones HTTP en una red sin el conocimiento del usuario y las redirige al servidor Proxy. El usuario no configura en su navegador la dirección del Proxy. También se lo denomina Proxy Transparente. El servidor Proxy, de no ser transparente, se debe configurar explícitamente en el navegador web, y generalmente tiene asociado el puerto TCP 8080 o TCP 3128. Estos tipos de Proxy no son exclusivos, si no que pueden ser complementarios unos de otros. Generalmente en corporaciones/instituciones hay un servidor Proxy por defecto que todos los clientes deben configurar para poder acceder a Internet, que combina un Cache Proxy con un Filtering Proxy. En escenarios donde la configuración de cada equipo resulta difícil, generalmente se implementa también un Intercepting Proxy. Proxies Jerárquicos Estas configuraciones se realizan en organizaciones que poseen una estructura con sub-organizaciones. En este caso, el Proxy Server de una suborganización, si no dispone de un recurso en su cache, consulta al Proxy de la organización antes que salir directamente a Internet. Esto es conveniente ya que de esta forma se puede evitar el uso de un enlace WAN, que es generalmente más costoso. Esta opción surge a partir de HTTP1.1. Describiremos a continuación unas capturas que se realizaron a un Cache Proxy de acuerdo a la siguiente maqueta: Se utilizo el Servidor Proxy Squid y el mismo diagrama del escenario anterior. Primer Pedido Captura CLIENTE PROXY (Desde el cliente) En esta captura se puede observar como el cliente inicia la conexión al puerto TCP 3128 desde un puerto efímero para realizar los pedidos HTTP. Se muestra también que en el GET se utiliza el FQDN completo además del recurso específico, ya que el pedido no se hace directamente al servidor web si no que se realiza a través del servidor Proxy. También se puede observar que el navegador solicita que la conexión con el Proxy se mantenga. (ProxyConnection: Keep-Alive) Captura PROXY SERVIDOR (Desde el servidor) En esta captura podemos observar que el servidor Proxy solicita el recurso como si fuese un simple cliente HTTP. Próximos pedidos del mismo recurso por parte del cliente (u otros clientes que utilicen el mismo Proxy.). TIPO DE PEDIDO F5 (Actualizar) Ctrl+F5 (Pragma: no-cache) Respuesta Pide al Proxy el recurso, y de Fuerza la descarga acuerdo a la configuración de nuevamente desde el la validez de los datos de su servidor web. cache interno, lo sirve desde el cache o lo recupera del servidor web nuevamente. Captura de Proxy jerárquico Conclusiones Escenario 2: Pudimos ver el funcionamiento básico de un cache-proxy, desde el lado del cliente y desde el lado del servidor, la necesidad de cada header y la ventaja de tener un Proxy, sin embargo, no pudimos verificar realmente que un Proxy almacena la información, y en caso de un pedido de otro cliente, la provee de su cache en vez de utilizar el enlace a Internet nuevamente. Escenario 3: HTTPS HTTPS es un protocolo de transferencia de recursos web de manera segura a través de la unión de los protocolos HTTP y SSL (Secure Socket Layers). Mediante este último protocolo se genera un canal encriptado para dicha aplicación usando el puerto de transporte TCP 443. Es usado principalmente para: Transacciones comerciales Operaciones bancarias Transmisión de datos de manera privada Administración remota Webmail Estos servicios requieren un marco de seguridad en la comunicación ya que implican movimientos de información crítica. El objetivo de este canal encriptado es lograr: 1. Privacidad: Garantizar que la información sólo pueda ser leída por los miembros de la conversación. 2. Autenticación: Evitar que se falsifiquen los mensajes por algún impostor (ataques man in the middle). El servidor siempre debe autenticarse mediante un despliegue de infraestructura de claves públicas (PKI). 3. Integridad de los datos: Que la información llegue completa y sin corrupción en sus datos. De no ser así que sea posible detectarlo por cualquiera de las partes. Cierta integridad ya es proporcionada por la capa transporte mediante TCP. SSL SSL es un servicio de propósito general que yace sobre TCP y da servicio de encriptamiento a la capa de aplicación. Podría ser ubicado en el nivel 6 de la arquitectura OSI (como los protocolos MIME, ASN.1), ya que cumple funciones de presentación al encriptar datos. A su vez también cumple con funciones del nivel 5 de la misma arquitectura ya que permite establecer sesiones, pausarlas y retomarla en otro momento además de aprovechar en una misma sesión el establecimiento de varias conexiones. El uso de SSL no está restringido únicamente a HTTP (443). Otros protocolos también utilizan sus ventajas: FTPS (well known ports TCP 989, 990), TELNETS (992), IMAPS (993) y POP3S (995). La arquitectura de SSL especifica los siguientes protocolos: Aplicación Protocolo SSL Record (Autenticación) Este protocolo es el encargado de transportar en su Payload datos aplicativos o datos de control (handshake, alertas, cambio de algoritmo de cifrado). El tratamiento de los datos es realizado de acuerdo al siguiente esquema: ≤ 214 Bytes Opcional 2da. llave compartida (confidencialidad) MAC (Message Auth. Code) 1era. llave compartida (integridad) •Content type •Version mayor de SSL •Version menor de SSL •Longitud del fragmento (comprimido) Los paquetes de datos son fragmentados en tamaños de hasta 16KB, se los comprime (opcional), se les concatena una M.A.C. (message authentication code: un hash cifrado de los datos que se usa como firma para autenticar cualquiera de los dos remitentes), se encripta el conjunto mediante una llave compartida y se le agrega un header indicando: tipo de contenido (20: cipher change; 21: alert; 22: handshake; 23: aplicación), versiones de SSL soportadas y longitud del fragmento. Protocolo SSL Handshake (Privacidad) Este protocolo es el primero en utilizarse para generar una sesión SSL. Permite a las partes autenticarse mutuamente (el cliente por lo general no es obligado a hacerlo), negociar algoritmos de cifrado y de generación de MAC y llaves de sesión para cifrar el intercambio de mensajes en forma bidireccional (server – cliente y viceversa). La idea consiste en utilizar un primer diálogo mediante cifrado asimétrico (usando la clave pública para dirigir mensajes al servidor) para generar una clave compartida de sesión. Una vez generada, el dialogo va encriptado en ambos sentidos mediante dicha clave (simétrica). xxxxxx Ksesión Cliente Server Kpública Ksesión Kprivada xxxxxx Data Cliente Ksesión Server Data Ksesión El intercambio protocolar del SSL Handshake se divide a grandes rasgos en dos fases: La fase Hello es usada para ponerse de acuerdo sobre el conjunto de algoritmos para lograr la privacidad y la autenticación mutua una vez establecida una sesión segura. Client Hello, cliente envía: ♦ Algoritmos de cifrado y funciones de hash soportadas ♦ Numero aleatorio (time stamp de 32 bits + 28B de nros aleatorios) que servirá junto a otro número aleatorio dado por el servidor para generar la clave de sesión favoreciendo el No Replay ♦ Versión SSL ♦ Session ID (0 = nueva sesión) Server Hello, Certificate, Server Hello done; el servidor envía ♦ Certificado digital de identidad (clave pública) X.509 (cadena de certificadoras) ♦ Elige el algoritmo de cifrado y la función de hash que cree más seguro de la lista que provee el cliente ♦ Session ID (elegida por cliente) La fase de intercambio de claves en que se genera la clave de sesión y se comienza a hablar en cifrado Client Key Exchange, Change Cipher_spec el cliente informa: ♦ La verificación del certificado ♦ La clave de sesión encriptada con la llave pública del servidor ♦ Los próximos datos serán encriptados con dicha clave compartida Server Change Cipher_spec el server informa: ♦ Los próximos datos serán encriptados con dicha clave compartida Protocolo SSL Change Cipher_spec (hablar en cifrado) Sirve para avisar que los datos siguientes serán transmitidos de manera encriptada. Protocolo SSL Alert Define un sistema de alertas entre los E.S. Especifica dos tipos de alertas: a) Fatales: SSL termina inmediatamente la conexión. (ej: MAC incorrecta, handshake failure, Certificadora desconocida) b) Advertencias: Avisa anomalías que puedan surgir pero que no afectan la seguridad. (ej.: close notify) Se describe a continuación tres capturas de HTTPS realizadas entre un cliente y varios servidores que soportan dicho protocolo de acuerdo a la siguiente maqueta: Captura al servidor webmail de fi.uba.ar Host iniciando conexión a https://webmail.fi.uba.ar En esta captura es apreciable que una vez establecida la conexión al puerto TCP 443 de webmail.fi.uba.ar, el cliente comienza el Handshaking de SSL tal como se esperaba de acuerdo a lo investigado y comentado en los párrafos anteriores. Después de haber finalizado dicho protocolo y haber comenzado a hablar en cifrado, el cliente repentinamente inicia la finalización de la conexión de capa de TCP al puerto 443. A su vez el servidor envía un mensaje de alerta. Paradójicamente, a esta altura del diálogo, es imposible detectar que tipo de mensaje de alerta fue mandado ya que está encriptado, sin embargo en el web browser apareció el siguiente cartel de advertencia: Este mensaje indica que hay un problema con el certificado de clave publica del servidor y requiere de la autorización del usuario para continuar. Lo más probable es que en el browser cliente no se haya registrado la Autoridad Emisora del certificado de clave del Servidor como una Entidad de confianza y por eso se prefiere dar por terminada la sesión para que el usuario se dé por aludido de dicha falencia y sea él quien se responsabilice de seguir adelante. Captura al servidor webmail de hotmail.com Host iniciando conexión a https://login.live.com Una vez más se comprueba el uso del HandShaking para establecer los parámetros de conexión segura. En esta captura hay dos cosas interesantes para destacar: la ausencia de alertas por parte de ambos E.S. y el time stamp que usa el cliente para establecer una segunda sesión en el servidor. La ausencia de alertas probablemente se deba a que el web browser reconoce a la Autoridad Emisora del Certificado de clave pública del Servidor como confiable. Dicha Autoridad no es más ni menos que VeriSign, un referente en todo lo que respecta a Certificaciones en Internet. Además dicho certificado consta de una cadena de tres certificaciones para darle aún mayor autenticidad. En segundo lugar es interesante destacar que el time stamp (que se utiliza para crear una clave compartida de sesión) generado en el Cliente no tiene ninguna correlación con la fecha actual favoreciendo de esta manera el No Replay. Captura de Host iniciando sesión de MSN Host iniciando conexión al servidor MSN Nuevamente en esta captura hecha en base a la iniciación de una conexión al MSN Messenger se puede apreciar la difusión que tiene el protocolo HTTPS y que no sólo se restringe a navegadores web. En esta ocasión el Cliente, como en las anteriores veces, realiza el HandShaking e intercambia cierta información sensible mediante cifrado. Probablemente lo que se intercambia es la clave de la cuenta hotmail. Es interesante destacar que de ser así es lo único que se transmite vía HTTPS, el resto de la información: usuario, lista de contactos y mismo mensajes son transmitidos en limpio. Conclusiones Escenario 3: Se logró demostrar el funcionamiento de HTTP montado en SSL. Fue apreciable el uso del protocolo de SSL HandShaking para establecer comunicaciones encriptadas para pasar datos “sensibles”. Fue posible documentar el uso del sistema de alarmas ante imprevistos como el desconocimiento por parte del Web Browser de la confiabilidad del certificado de clave pública del servidor. Se destacó una técnica para favorecer el No Replay a partir de la generación de un time stamp descorrelacionado con la fecha actual más 28 Bytes aleatorios. Y se pudo observar que HTTPS es de uso general y que no está únicamente restringido a web-browsers.