Presentación de PowerPoint - técnicas estadisticas en análisis de
Anuncio

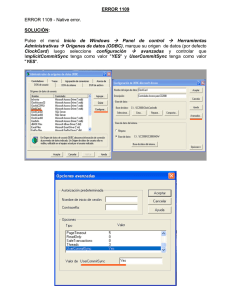
Sesión 013. “El árbol no me deja ver el bosque: Clasificación y Selección de Variables de Interés” 1480-Técnicas Estadísticas en Investigación de Mercados Grado en Estadística empresaria Curso 2012-13 – Segundo semestre Profesor: Xavier Barber i Vallés Departamento: Estadística, Matemáticas e Informática La naturaleza está viva… Deja que los datos te hablen… Índice • Definición de Árbol • Árboles frente a Logística – Ventajas y Desventajas • Diferentes tipos • Diferentes tipos de Modelos – Índice Gini – Selección de Recursiva: CART • En R: rpart() & ctree() Los “Tree Models” • Habitualmente llamados como: – Árboles de Decisión, – o simplemente Árboles • Son métodos para modelizar la predicción. • Un ejemplo clásico es “Considerar una regla para decidir que tarjeta de crédito ofrecer al cliente”: – – – – Interés inferior al 25% Meses de carencia de pago >1 Salario mensual superior a 3000€ Si ya dispone de alguna trarjeta similar El Algoritmo de búsqueda • Para crear un árbol usaremos un algoritmo basado en la información de los datos. • El algoritmo de búsqueda para la regla de decisión se basa en la variables predictoras para progresivamente dividir los “casos” en pequeños grupos “afines”. – Los grupos finales los llamamos “hojas”. Tree vs. Logistic 1. Ambos modelos necesitan información histórica, variables predictoras y una variable OBJETIVO (Target) binaria. 2. Ambos algoritmos usan información histórica para crear (estimar) el modelo que relaciona a los predictores con el Target. 3. Los modelos de regresión necesitan de una formula algebraica, mientras que los Árboles son una secuencia de reglas. Tree vs. Logistic 4. Uno y otro modelo, una vez generado, puede usar un nuevo caso para predecir el comportamiento de la variable Target. 5. El modelo de regresión calcula la probabilidad de que una variable target tome un valor “bueno” para ese caso. Se utilizarán estas probabilidades para dividir en dos grupos. 6. El modelo de Árbol puede saignar directamente un nuevo caso al grupo del Target. Ventajas y Desventajas • La interpretación del calibrado del árbol es muy sencilla, siendo muy útil su uso para audiencias no especializadas. • Es más flexible que la regresión logística en las asunciones para su ajuste, y se ve menos afectado por los valores perdidos. • Pero los modelos de regresión pueden detectar efectos más débiles con un número menor de datos Diferentes tipos de modelos Los algoritmos varian según su características, incluyendo el tipo de objetivo , manejando la complejidad de las ramas. Utilizaremos la librería de R, rpart (recursive partitioning) (Venables and Ripley 2002). Tambien se utilizarán las librerias party y party. Índice Gini Definimos PL y PR como las proporciones de el nodo original en la derecha y en la izquierda, cuyo resultado es: = PL n= PR nNo / N Sí / N Definimos la proporción de un tipo (1) dentro de los subnodos derecho e izquierdo como pL y pR, dados por = pL n= pR nX 1B / nNo X 1 A / nSi Definimo el Índice Gini como (medida de cambio impurea al resultado al particionar los datos) PL ( pL )(1 − pL ) + PR ( pR )(1 − pR ) Selección recursiva Y=Sí o Y=No X1=A y Y=Sí etc. etc. X1=B y Y= NO etc. Reglas de Parada • Todos los casos en un nodo tienes igual valor para los predictores • La “profundidad” del árbol sobrepasa el máximo establecido. • El tamaño del nodo es más pequeño que el mínimo establecido. • El corte de un nodo va a provocar un tamaño menor del establecido. • El nodo se convierte en “puro”. • … Y algunas relacionas con estás mismas Validación del resultado: Cross-Validation y Random Forest • Como en los métodos de regresión es muy importante validar el modelo: – Particionar la base de datos en dos y utilizar uan para Estimar y otra para Validar – Realizar una validación cruzada (ajustar tantos modelos como Datos, eliminando el dato i-ésimo en el modelo i-ésimo). – Utilizando Random Forest (próxima Sesión) MÁS ALGORITMOS, MÁS MEDIDAS DE EFICIENCIA CLASIFICANDO EN R Reseña Histórica. Análisis y decisión (www.analisisydecision.es) Formación para la óptima gestión de la información: …… Tanto el programa comercial CART como la función rpart() están basados en el libro Classification and Regression Trees. Como lector y revisor de alguno de sus primeros borradores, llegué a dominar la materia. CART comenzó como un enorme programa en Fortran que escribió Jerry Friedman y que sirvió para contrastar las ideas contenidas en el libro. Tuve el código durante un tiempo y realicé algunos cambios, pero me resultó demasiado frustrante el trabajar con él. Fortran no es el lenguaje adecuado para un algoritmo recursivo [...]. Salford Systems adquirió los derechos de dicho código e ignoro si alguna de las líneas origininales permanecen en él todavía. Mantuve muchas conversaciones con su principal programador (hace 15 o 20 años) sobre procedimientos para hacerlo más eficiente, esencialmente un problema interesante de indexación óptima. ….. Rpart se llama rpart porque los autores registraron comercialmente el término CART. Era la mejor alternativa que se me ocurrió entonces. Me parece curioso que una de las consecuencias de haber registrado "CART" es que ahora se utilice "particionamiento recursivo" mucho más a menudo que CART como nombre genérico para los métodos basados en árboles. rpart() libraryry(rpart) ### recuperamos los datos del CCS data(CCS, package="BCA") #### Seccionamos la muestra para evitar problemas de overfitting CCS$Sample <- create.samples(CCS, est = 0.34, val = 0.33, rand.seed = 1) tree1CCS<-rpart(MonthGive ~ Age20t29 + Age70pls + AveDonAmt + AveIncEA + DonPerYear + EngPrmLang + FinUnivP + LastDonAmt + Region + YearsGive, data=CCS[CCS$Sample=="Estimation",], method="class") print(tree1CCS) ################### El gráfico ############### par(mar = rep(0.1, 4)) plot(tree1CCS) text(tree1CCS, cex=0.8) rpart() > print(tree1CCS) n= 544 node), split, n, loss, yval, (yprob) * denotes terminal node 1) root 544 264 No (0.5147059 0.4852941) 2) AveDonAmt< 11.45833 166 28 No (0.8313253 0.1686747) * 3) AveDonAmt>=11.45833 378 142 Yes (0.3756614 0.6243386) 6) DonPerYear< 0.5227273 206 93 Yes (0.4514563 0.5485437) 12) DonPerYear>=0.08712121 192 93 Yes (0.4843750 0.5156250) 24) Age20t29< 0.110101 98 41 No (0.5816327 0.4183673) 48) EngPrmLang< 0.9751829 59 18 No (0.6949153 0.3050847) 96) AveDonAmt< 62.91667 48 11 No (0.7708333 0.2291667) * 97) AveDonAmt>=62.91667 11 4 Yes (0.3636364 0.6363636) * 49) EngPrmLang>=0.9751829 39 16 Yes (0.4102564 0.5897436) * 25) Age20t29>=0.110101 94 36 Yes (0.3829787 0.6170213) 50) LastDonAmt< 17.5 13 3 No (0.7692308 0.2307692) * 51) LastDonAmt>=17.5 81 26 Yes (0.3209877 0.6790123) 102) YearsGive< 2.5 15 5 No (0.6666667 0.3333333) * 103) YearsGive>=2.5 66 16 Yes (0.2424242 0.7575758) * 13) DonPerYear< 0.08712121 14 0 Yes (0.0000000 1.0000000) * 7) DonPerYear>=0.5227273 172 49 Yes (0.2848837 0.7151163) 14) AveIncEA>=54376.5 72 29 Yes (0.4027778 0.5972222) 28) AveIncEA< 69546 42 18 No (0.5714286 0.4285714) 56) LastDonAmt< 27.5 24 5 No (0.7916667 0.2083333) * 57) LastDonAmt>=27.5 18 5 Yes (0.2777778 0.7222222) * 29) AveIncEA>=69546 30 5 Yes (0.1666667 0.8333333) * 15) AveIncEA< 54376.5 100 20 Yes (0.2000000 0.8000000) * rpart() AveDonAmt< 11.46 | DonPerYear< 0.5227 No DonPerYear>=0.08712 AveIncEA>=5.438 Age20t29< 0.1101 AveIncEA< 6.955e+04 Yes Yes LastDonAmt< 27.5 Yes EngPrmLang< 0.9752 LastDonAmt< 17.5 AveDonAmt< 62.92 YearsGive< 2.5 Yes No Yes No No Yes No Yes rpart() > printcp(tree4CCS) Classification tree: rpart(formula = MonthGive ~ AveIncEA + DonPerYear + Log.AveDonAmt + NewRegion + Log.LastDonAmt, data = CCS[CCS$Sample == "Estimation", ], method = "class") Variables actually used in tree construction: [1] AveIncEA DonPerYear Log.AveDonAmt Log.LastDonAmt NewRegion Root node error: 264/544 = 0.48529 n= 544 1 2 3 4 CP nsplit rel error 0.356061 0 1.00000 0.020202 1 0.64394 0.017677 5 0.55682 0.010000 8 0.50379 xerror 1.00000 0.64773 0.64773 0.62879 xstd 0.044155 0.041016 0.041016 0.040681 • rel error= rel error(before) - (nsplit nsplit(before)) * CP(before); where (before) always denotes the entry in the row above. • xerror=The xerror column contains of estimates of cross-validated prediction error for different numbers of splits. • xstd= standard errors of those estimates party() & partykit() > tree1<-(MonthGive ~ Age20t29 + Age70pls + AveDonAmt + AveIncEA + + DonPerYear + EngPrmLang + FinUnivP + LastDonAmt + Region + YearsGive) > > tree1CCS<-ctree(tree1, data=CCS[CCS$Sample=="Estimation",]) > tree1CCS Conditional inference tree with 5 terminal nodes Response: MonthGive Inputs: Age20t29, Age70pls, AveDonAmt, AveIncEA, DonPerYear, EngPrmLang, FinUnivP, LastDonAmt, Region, YearsGive Number of observations: 544 1) AveDonAmt <= 11.25; criterion = 1, statistic = 40.318 2) AveDonAmt <= 5.25; criterion = 0.991, statistic = 11.024 3)* weights = 78 2) AveDonAmt > 5.25 4) YearsGive <= 1; criterion = 0.964, statistic = 8.446 5)* weights = 18 4) YearsGive > 1 6) DonPerYear <= 0.5714286; criterion = 0.989, statistic = 10.719 7)* weights = 59 6) DonPerYear > 0.5714286 8)* weights = 11 1) AveDonAmt > 11.25 9)* weights = 378 party() & partykit() 1 AveDonAmt p < 0.001 11.25 11.25 2 AveDonAmt p = 0.009 5.25 9 n = 378 y = (0.376, 0.62 5.25 3 n = 78 y = (0.936, 0.064) 4 YearsGive p = 0.036 1 1 6 DonPerYear p = 0.011 5 n = 18 y = (0.389, 0.611) 0.571 0.571 7 n = 59 y = (0.898, 0.102) 8 n = 11 y = (0.455, 0.545) partykit() 1 Log.AveDonAmt library(partykit) plot(as.party(tree4CCS), tp_args= list(id=FALSE)) < 2.52225 >= 2.52225 3 DonPerYear < 0.52273 >= 0.08712 >= 0.52273 4 11 DonPerYear AveIncEA < 0.08712 >= 54376.5 < 54376.5 5 12 NewRegion AveIncEA VanFraser 7 < 69546 >= 69546 13 Log.LastDonAmt Log.LastDonAmt No n = 30 1 0.8 0.6 0.4 0.2 0 Yes No n = 18 1 0.8 0.6 0.4 0.2 0 Yes n = 24 1 0.8 0.6 0.4 0.2 0 No No n = 14 1 0.8 0.6 0.4 0.2 0 Yes No n = 87 1 0.8 0.6 0.4 0.2 0 < 3.34604 >= 3.34604 Yes No n=7 1 0.8 0.6 0.4 0.2 0 Yes No n = 98 1 0.8 0.6 0.4 0.2 0 Yes No n = 166 1 0.8 0.6 0.4 0.2 0 Yes Yes No < 2.1719 >= 2.1719 Yes Other n = 100 1 0.8 0.6 0.4 0.2 0 Seguimos trabajando… Habrá que leer algo para terminar de entender esto. Lecturas recomendadas rpart() – An Introduction to Recursive Partitioning – User Written Split Functions library(party) ctree() – party with the mob – party: A Laboratory for Recursive Partytionin library(partykit) – partykit: A Toolkit for Recursive Partytioning – Resumen Y un buen resumen Un buen resumen lo vamos a encontrar en : http://www.statmethods.net/advstats/cart.html Y en HSUAR