Tema B.6: ÁRBOLES DE CLASIFICACIÓN
Anuncio

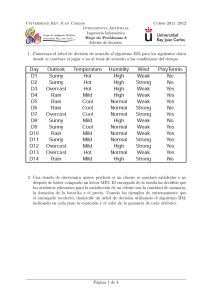
Introducción ID3 Mejoras C4.5 M5 Conclusiones Tema B.6: ÁRBOLES DE CLASIFICACIÓN Concha Bielza, Pedro Larrañaga Departamento de Inteligencia Artificial Facultad de Informática, Universidad Politécnica de Madrid Aprendizaje Automático Introducción ID3 Índice 1 Introducción 2 Algoritmo básico: ID3 3 Mejoras a ID3 4 C4.5 5 Variable clase continua 6 Conclusiones Mejoras C4.5 M5 Conclusiones Introducción ID3 Índice 1 Introducción 2 Algoritmo básico: ID3 3 Mejoras a ID3 4 C4.5 5 Variable clase continua 6 Conclusiones Mejoras C4.5 M5 Conclusiones Introducción ID3 Mejoras C4.5 M5 Conclusiones Introducción Árbol de decisión Muy utilizado y popular Aproxima funciones que toman valores discretos. La función aprendida se representa como un árbol Robusto a datos con ruido Aprende expresiones disyuntivas: los árboles aprendidos se pueden re-representar como reglas if-then (intuitivas) Numerosas aplicaciones: diagnósticos médicos, causa de fallo en equipos, evaluación de riesgos de créditos en la concesión de préstamos... Árbol de clasificación y de regresión Introducción ID3 Mejoras C4.5 M5 Conclusiones Introducción Representación como árboles Cada nodo (no terminal) especifica un test de algún atributo de la instancia Cada rama corresponde a un posible valor del atributo Cada nodo terminal indica la clase en la que se clasifica Instancias no vistas se clasifican recorriendo el árbol: pasándoles el test en cada nodo, por orden desde el nodo raı́z hasta algún nodo hoja, que da su clasificación Introducción ID3 Mejoras C4.5 M5 Conclusiones Introducción Ejemplo: PlayTennis Clasificar las mañanas de Sábado en si son o no adecuadas para jugar al tenis Instancia: Outlook=Sunny, Temperature=Hot, Humidity=High, Wind=Strong entra por el camino izdo. y se predice PlayTennis=No Introducción ID3 Mejoras C4.5 M5 Introducción Ejemplo: PlayTennis El árbol representa una disyunción de conjunciones de restricciones sobre los valores de los atributos de las instancias Un camino = una conjunción de tests de atributos Todo el árbol = disyunción de estas conjunciones Este árbol es: (Outlook=Sunny ∧ Humidity=Normal) ∨ (Outlook=Overcast) ∨ (Outlook=Rain ∧ Wind=Weak) Conclusiones Introducción ID3 Mejoras C4.5 M5 Introducción Generación de reglas R1: R2: R3: R4: R5: If (Outlook=Sunny) AND (Humidity=High) then PlayTennis=No If (Outlook=Sunny) AND (Humidity=Normal) then PlayTennis=Yes If (Outlook=Overcast) then PlayTennis=Yes If (Outlook=Rain) AND (Wind=Strong) then PlayTennis=No If (Outlook=Rain) AND (Wind=Weak) then PlayTennis=Yes Conclusiones Introducción ID3 Mejoras C4.5 M5 Conclusiones Introducción Tipos de problemas apropiados Instancias representadas como pares atributo-valor Función objetivo toma valores discretos (clasificación)... ...pero extensiones a valores continuos: árboles de regresión Robustez a errores, tanto en la variable respuesta como en los atributos Puede haber datos perdidos (missing) para algunas instancias en los valores de los atributos Dominios complejos donde no existe una clara separación lineal Introducción ID3 Mejoras C4.5 M5 Introducción Ejemplo Se divide el espacio en regiones etiquetadas con una sola clase y son hiperrectángulos (ojo!) Conclusiones Introducción ID3 Mejoras C4.5 M5 Introducción Tipos de árboles Árboles de clasificación: valores de salida discretos CLS, ID3, C4.5, ID4, ID5, C4.8, C5.0 Árboles de regresión: valores de salida continuos CART, M5, M5’ Conclusiones Introducción ID3 Índice 1 Introducción 2 Algoritmo básico: ID3 3 Mejoras a ID3 4 C4.5 5 Variable clase continua 6 Conclusiones Mejoras C4.5 M5 Conclusiones Introducción ID3 Mejoras C4.5 M5 Conclusiones Algoritmo básico: ID3 ID3=Iterative dicotomiser [Quinlan, 1986] Basado en el algoritmo CLS (Concept Learning Systems) [Hunt et al., 1966], que usaba sólo atributos binarios Estrategia de búsqueda voraz (greedy) por el espacio de posibles árboles de clasificación Construir el árbol de arriba a abajo, preguntando: ¿Qué atributo seleccionar como nodo raı́z? Se evalúa cada atributo para determinar cuán bien clasifica los ejemplos él solo Se selecciona el mejor como nodo, se abre el árbol para cada posible valor del atributo y los ejemplos se clasifican y colocan en los nodos apropiados Repetir todo el proceso usando los ejemplos asociados con el nodo en el que estemos (siempre hacia delante, buscando entre los atributos no usados) Parar cuando el árbol clasifica correctamente los ejemplos o cuando se han usado todos los atributos Etiquetar el nodo hoja con la clase de los ejemplos Introducción ID3 Mejoras C4.5 M5 Conclusiones Algoritmo básico: ID3 ID3 Paso clave: cómo seleccionar el atributo? Nos gustarı́a el más útil para clasificar ejemplos; el que los separa bien ID3 escoge la variable más efectiva usando la cantidad de información mutua (maximizarla) I(C, Xi ) = H(C) − H(C|Xi ) H(C) = − X c p(c) log2 p(c), (ganancia de información) H(C|X ) = − XX c p(x, c) log2 p(c|x) x Reducción esperada en entropı́a (incertidumbre), causada al particionar los ejemplos de acuerdo a este atributo Introducción ID3 Mejoras C4.5 M5 Algoritmo básico: ID3 Ejemplo ID3: PlayTennis Datos: Day 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Outlook Sunny Sunny Overcast Rain Rain Rain Overcast Sunny Sunny Rain Sunny Overcast Overcast Rain Temperature Hot Hot Hot Mild Cool Cool Cool Mild Cool Mild Mild Mild Hot Mild Humidity High High High High Normal Normal Normal High Normal Normal Normal High Normal High Wind Weak Strong Weak Weak Weak Strong Strong Weak Weak Weak Strong Strong Weak Strong PlayTennis No No Yes Yes Yes No Yes No Yes Yes Yes Yes Yes No Conclusiones Introducción ID3 Mejoras C4.5 M5 Conclusiones Algoritmo básico: ID3 Ejemplo ID3: PlayTennis Wind? 9 H(C) = − 14 log2 9 14 − 5 14 log2 5 14 = 0.940 H(C|Wind) = −p(Strong, Yes) log2 p(Yes|Strong) − p(Strong, No) log2 p(No|Strong) − p(Weak , Yes) log2 p(Yes|Weak) − p(Weak , No) log2 p(No|Weak) = 3 − 14 log2 3 6 − 3 14 log2 3 6 − 6 14 log2 6 8 − 2 14 log2 2 8 = 0.892 ⇒ I(C, Wind) = 0.940 − 0.892 = 0.048 Análogamente, I(C, Humidity) = 0.151 I(C, Outlook) = 0.246 ⇐ Escoger Outlook como nodo raı́z I(C, Temperature) = 0.029 Introducción ID3 Mejoras Algoritmo básico: ID3 Ejemplo ID3: PlayTennis C4.5 M5 Conclusiones Introducción ID3 Mejoras C4.5 M5 Conclusiones Algoritmo básico: ID3 Ejemplo ID3: PlayTennis Todos los ejemplos con Outlook=Overcast son positivos ⇒ Se convierte en nodo hoja El resto tienen entropı́a no cero y el árbol debe seguir Introducción ID3 Mejoras C4.5 M5 Conclusiones Algoritmo básico: ID3 Ejemplo ID3: PlayTennis Se repite el proceso para cada nodo descendiente no terminal, usando sólo los ejemplos asociados con el nodo Cualquier atributo aparece como mucho una vez en cada camino P.e., por la rama Sunny (con 5 instancias), buscamos el atributo siguiente: H(Csunny ) = − 35 log2 3 5 − 2 5 log2 2 5 = 0.97 I(Csunny , Temperature) = 0.97 − 0.4 = 0.57 I(Csunny , Humidity) = 1.94 I(Csunny , Wind) = 0.019 ⇒ ...Árbol final es el visto antes Introducción ID3 Mejoras C4.5 M5 Conclusiones Algoritmo básico: ID3 Observaciones generales Al ser voraz, puede que conduzca a una solución óptima local en vez de global Extensión de ID3 para añadir una forma de backtracking (post-poda) Por usar propiedades estadı́sticas de todos los ejemplos (ganancia de info), búsqueda menos sensible a errores en los datos Extensión de ID3 para manejar datos con ruido modificando su criterio de parada: crear hoja sin necesidad de esperar a que todas las etiquetas sean iguales (etiquetar con la mayorı́a) Complejidad crece linealmente con el número de instancias de entrenamiento y exponencialmente con el número de atributos Matemáticamente se demuestra que favorece la elección de variables con mayor número de valores Introducción ID3 Índice 1 Introducción 2 Algoritmo básico: ID3 3 Mejoras a ID3 4 C4.5 5 Variable clase continua 6 Conclusiones Mejoras C4.5 M5 Conclusiones Introducción ID3 Mejoras C4.5 M5 Conclusiones Mejoras a ID3 Cuestiones prácticas a tener en cuenta ¿Cúanto hacer crecer el árbol? ¿Es adecuada esta medida de selección de los atributos? ¿Cómo manejar atributos continuos? ¿Cómo manejar datos de entrenamiento con valores perdidos (desconocidos) en los atributos? ¿Cómo manejar atributos con costes diferentes? Introducción ID3 Mejoras C4.5 M5 Conclusiones Cúanto hacer crecer el árbol Problema de sobreajuste Problemas por hacer crecer el árbol hasta que clasifique correctamente todos los ejemplos de entrenamiento: Si hay ruido en los ejemplos, !podemos aprender el ruido! Si hay pocos ejemplos asociados a los nodos hoja, no son representativos de la verdadera función ⇒ ID3 produce árboles que sobreajustan los ejemplos de entrenamiento (y no funciona adecuadamente con nuevos ejemplos). El modelo no es capaz de generalizar Introducción ID3 Mejoras C4.5 M5 Conclusiones Sobreajuste Soluciones al sobreajuste Hay dos grupos de técnicas, que tratan de simplificar el árbol: Pre-poda: parar de aumentar el árbol antes de que alcance el punto en el que clasifica perfectamente los ejemplos de entrenamiento ⇒ Difı́cil estimar cuándo Post-poda: permitir que sobreajuste los datos, y después podarlo reemplazando subárboles por una hoja ⇒ La mejor en la práctica, aunque mayor coste comput. Introducción ID3 Mejoras C4.5 M5 Conclusiones Sobreajuste Pre-podas Aplicar un test estadı́stico para estimar si expandiendo un nodo particular es probable producir una mejora más allá del conjunto de entrenamiento (e.g. test χ2 como en Quinlan, 1986) Post-podas Comenzando desde abajo, examinar los subárboles de los nodos no terminales Podar un nodo significa eliminar su subárbol correspondiente con raı́z en ese nodo, convertir el nodo en nodo hoja y asignarle la clasificación más común de los ejemplos de entrenamiento asociados a ese nodo Se poda sólo si el árbol podado resultante mejora o iguala el rendimiento del árbol original sobre el conjunto de testeo Podar iterativamente, escogiendo siempre el nodo a podar que mejore más la precisión en el conjunto de testeo ... hasta que ya no convenga (precisión disminuye) Introducción ID3 Mejoras C4.5 M5 Conclusiones Otras medidas de selección de atributos Favorece elección de atributos con muchos valores Ejemplo extremo: “Fecha” en el problema de PlayTennis sale elegido como raı́z (predice perfectamente los ejemplos de entrenamiento y tendrı́amos un árbol muy ancho y de profundidad 1, con un nodo hoja por cada ejemplo) Su ganancia de info es la mayor (al tener tantas ramas le obliga a separar los ejemplos en subconjuntos muy pequeños) ...Pero serı́a muy malo en ejemplos no vistos Por ello hay otras medidas en vez de la ganancia de info: ⇒ p.e. ratio de ganancia I(C, Xi )/H(Xi ) , que penaliza los atributos con muchos valores y muchos uniformemente distribuidos Algunos estudios experimentales hablan de no demasiada influencia de estas medidas sobre el rendimiento y sı́ de las post-podas Introducción ID3 Mejoras C4.5 M5 Conclusiones Atributos con valores continuos Discretizarlos Por ejemplo, particionar el rango en 2 intervalos A < c y A ≥ c Buscar c que produzca la mayor ganancia de información Tal valor se demuestra que está siempre en donde el valor de la clase cambia (una vez ordenados los ejemplos por el atributo continuo A) ⇒ Ordenar los ejemplos de acuerdo al valor continuo de A, tomar 2 valores de A que van seguidos con distinto valor de C y promediarlos ⇒ Entre estos candidatos a ser c, escoger el que produzca mayor ganancia de info en este momento ⇒ Escogido el c, este nuevo atributo compite con los otros discretos para ver si es elegido ⇒ Si no es elegido, puede que salga luego otro valor de c distinto ⇒ Es decir, el atributo se crea dinámicamente Introducción ID3 Mejoras C4.5 M5 Conclusiones Atributos con valores continuos Discretizarlos Ejemplo: candidatos son c1 = (48 + 60)/2 = 54 y c2 = (80 + 90)/2 = 85: Temperature PlayTennis 40 No 48 No 60 Yes 72 Yes 80 Yes 90 No Otras alternativas: más de 2 intervalos o incluso usar combinaciones lineales de varias variables αA + βB > c... También si es discreta pero con muchos valores: agrupar los valores Introducción ID3 Mejoras C4.5 M5 Conclusiones Atributos con valores perdidos (missing) Imputarlos Eliminar instancias incompletas Estimar dichos valores –imputación–: Asignarles la moda: valor más común entre los ejemplos asociados al nodo donde estamos calculando I o entre los ejemplos del nodo que tienen la misma etiqueta que la instancia a imputar Asignar distribución de probabilidad de cada posible valor del atributo, estimada con las frecuencias observadas en el nodo (Si fueran e.g. 0.6/0.4, esas fracciones de la instancia son las que se distribuyen por el árbol y con las que se calcula la ganancia) Introducción ID3 Mejoras C4.5 M5 Conclusiones Atributos con diferentes costes Introducir el coste en la medida de selección de atributos Fiebre, Biopsia, Pulso, Análisis de sangre... todos con diferentes coste (monetario y de comfort para el paciente) Tratar de situar los de bajo coste arriba del árbol, acudiendo a los de alto coste sólo cuando sea necesario (para mejorar las clasificaciones) Ası́, por ejemplo: I(C, Xi ) coste(Xi ) Introducción ID3 Índice 1 Introducción 2 Algoritmo básico: ID3 3 Mejoras a ID3 4 C4.5 5 Variable clase continua 6 Conclusiones Mejoras C4.5 M5 Conclusiones Introducción ID3 Mejoras C4.5 M5 Conclusiones Algoritmo C4.5 [Quinlan, 1993] C4.5 Escoge atributos usando el ratio de ganancia (maximizarla) I(C, Xi )/H(Xi ) (ratio de ganancia) Incorporación de post-poda de reglas: generar las reglas (1 por camino) y eliminar precondiciones (antecedentes) siempre que mejore o iguale el error Convertir el árbol en un conjunto de reglas R Error = error de clasificación con R Para cada regla r de R: Nuevo-error = error al eliminar antecedente j de r Si Nuevo-error ≤ Error, entonces Nuevo-error = Error y eliminar de r este antecedente Si no hay más antecedentes en r , borrar r de R Ordenar las reglas por su error estimado (de menos a más) y considerarlas en esta secuencia cuando se clasifiquen instancias Introducción ID3 Mejoras C4.5 M5 Conclusiones Algoritmo C4.5 C4.5 Poda pesimista: C4.5 suele estimar el error e por resustitución, pero corrigiéndolo hacia una posición pesimista: da la aproximación e + 1.96 ∗ σ, con σ una estimación de la desviación tı́pica Por qué usar reglas en vez del árbol? La poda se hace distinguiendo los distintos contextos (caminos), pudiendo ser diferente en cada uno. Sin embargo, el subárbol se quita entero o no Fáciles de entender Última versión: C4.8, que es el C4.5 revisión 8, última versión pública de esta familia de algoritmos antes de la implementación comercial C5.0 ⇒ implementado en WEKA como J48 Introducción ID3 Índice 1 Introducción 2 Algoritmo básico: ID3 3 Mejoras a ID3 4 C4.5 5 Variable clase continua 6 Conclusiones Mejoras C4.5 M5 Conclusiones Introducción ID3 Mejoras C4.5 M5 Conclusiones Árboles de regresión y árboles de modelos Variable clase continua (predicción numérica) Generalizar estas ideas para dar funciones de regresión continuas Árbol de regresión: en las hojas está el valor de la clase que representa el valor medio de las instancias que llegan a esa hoja Es lo que utiliza el sistema CART [Breiman et al., 1984] Aproxima la función objetivo mediante una función constante a trozos Sirve para cualquier tipo de atributos Árbol de modelos de regresión: en las hojas hay un modelo de regresión lineal para predecir el valor de la clase de las instancias que llegan a esa hoja Algoritmo M5 [Quinlan, 1992] y M5’ [Wang y Witten, 1997] Todo tipo de atributos, especialmente continuos Árboles de regresión son un caso particular de árboles de modelos de regresión Introducción ID3 Mejoras C4.5 M5 Conclusiones Árboles de modelos de regresión Algoritmos M5 y M5’ M5 genera árboles de decisión similares a los de ID3 Escoge el atributo que minimiza la variación en los valores de la clase que resulta por cada rama Las hojas son modelos lineales M5’ introduce mejoras para: Tratar atributos discretos Tratar valores perdidos Reducir el tamaño del árbol Introducción ID3 Mejoras C4.5 Árboles de modelos de regresión Ejemplo 209 configuraciones diferentes de ordenadores: Salida (potencia de procesamiento) y atributos son continuos M5 Conclusiones Introducción ID3 Mejoras C4.5 Árboles de modelos de regresión Ejemplo Ecuación de regresión (a) y árbol de regresión (b) M5 Conclusiones Introducción ID3 Mejoras C4.5 Árboles de modelos de regresión Ejemplo Árbol de modelos de regresión: M5 Conclusiones Introducción ID3 Mejoras C4.5 M5 Conclusiones Árboles de modelos de regresión Fases de los algoritmos M5 y M5’ Construir el árbol Estimar el error Construir modelos lineales en cada nodo intermedio del árbol Simplificar los modelos lineales Podar nodos Suavizar (las predicciones) Introducción ID3 Mejoras C4.5 M5 Conclusiones Árboles de modelos de regresión Construcción del árbol con M5 Sea T el conjunto de ejemplos que llegan a un nodo La desviación tı́pica de los valores de la clase que llegan a un nodo se trata como medida del error en ese nodo Minimizar la variación en los valores de la clase que resultan por cada rama: Calcular la desviación tı́pica SD de C en T (≈ error en T ) Calcular la reducción esperada del error cuando se usa un atributo determinado P i| RSD = SD(T ) − i |T |T | SD(Ti ) donde Ti son los conjuntos que resultan al partir el nodo de acuerdo al atributo Escoger el atributo que maximiza dicha reducción –Que disminuya mucho la dispersión al bajar de nivel Introducción ID3 Mejoras C4.5 M5 Conclusiones Árboles de modelos de regresión Construcción del árbol con M5 Parar de hacer crecer el árbol cuando: Quedan pocos ejemplos (≤ 4) Hay poca variación de los valores de la clase (su SD es una pequeña fracción de la SD del conjunto total, p.e. un 5 %) Introducción ID3 Mejoras C4.5 M5 Conclusiones Árboles de modelos de regresión Error estimado, nodos intermedios Antes de podar, obtener un modelo lineal en todo nodo del árbol. Usar sólo los atributos que aún no se han tenido en cuenta en el nodo (los testados en el subárbol que cuelga de él) Estimar el error esperado en cada nodo para casos aún no vistos: Calcular la diferencia absoluta entre los valores reales y predichos (por el modelo del nodo) de los ejemplos de entrenamiento asociados al nodo Promediarlos. Supongamos que son n ejemplos n+v Como es estimación optimista, compensar multiplicando por n−v , donde o v es el n de atributos en el modelo del nodo Ésa es la estimación del error Simplificar el modelo, quitando atributos de uno en uno, siempre que la estimación del error (con el factor multiplicativo) disminuya Introducción ID3 Mejoras C4.5 M5 Conclusiones Árboles de modelos de regresión Podas Con un modelo en cada nodo interior, hacer poda desde las hojas siempre que el error estimado decrezca Para ello, se compara el error en el nodo con el del subárbol que cuelga de él. Éste se calcula como una ponderación de los errores en cada rama (pesos son los tamaños de los subconjuntos) Introducción ID3 Mejoras C4.5 M5 Conclusiones Árboles de modelos de regresión Suavizado de las predicciones Beneficioso un proceso de suavizado para compensar las grandes discontinuidades que ocurrirán entre modelos lineales adyacentes en las hojas del árbol podado Mejoran las predicciones Se realiza desde las hojas hasta la raı́z: 1 2 Predecir valor de la instancia como usualmente (hasta la hoja) Suavizar ese valor en cada nodo (hasta la raı́z) combinándolo con el valor que predice el nodo: Pasar la predicción p’ al nodo siguiente hacia arriba: p0 = np+kq n+k donde p es la predicción que le pasan desde abajo y q es el valor que predice el modelo del nodo, k es una constante (15, por defecto), n es el no de ejemplos en el nodo Introducción ID3 Mejoras C4.5 M5 Conclusiones Árboles de modelos de regresión Otras cuestiones Los atributos X discretos se tratan transformándolos primero en varias variables binarias: Antes de construir el árbol, hacer: Para cada valor de X , promediar sus correspondientes valores clase. Ordenar los valores de X de acuerdo a esto Si X toma k valores, reemplazar X por k − 1 var. binarias: la i-ésima vale 0 si el valor es uno de los primeros i en el orden y vale 1 e.o.c. Tratar valores perdidos en atributo X con una modificación en la fórmula del RSD (para seleccionar el atributo por el que particionar) y llevar las instancias con missing en X a la rama que diga el atributo más correlado con X (que actúa en su lugar) [Wang y Witten, 1997] Introducción ID3 Mejoras C4.5 M5 Conclusiones Árboles de modelos de regresión Ejemplo M5: 2 atributos continuos y 2 discretos Discretos son motor y screw (5 valores). Clase = tiempo elevación sistema de servo Orden de sus valores fue D, E, C, B, A para ambos Introducción ID3 Mejoras C4.5 M5 Árboles de modelos de regresión Usándolos para clasificación [Frank et al., 1998] Generar data sets de cada clase vs resto, del mismo tamaño que el original. Salidas fi aproximan la probabilidad. Escoger la más alta Conclusiones Introducción ID3 Mejoras C4.5 M5 Extensiones MARS: Multivariate Adaptive Regression Splines [Friedman, 1991] Generalización continua de CART Funciones base son un producto de funciones splines Una variable puede ser elegida varias veces Los test en los nodos pueden ser multivariantes (con combinaciones lineales de variables) Conclusiones Introducción ID3 Índice 1 Introducción 2 Algoritmo básico: ID3 3 Mejoras a ID3 4 C4.5 5 Variable clase continua 6 Conclusiones Mejoras C4.5 M5 Conclusiones Introducción ID3 Mejoras C4.5 Software Regresión logı́stica con WEKA Pestaña Classifier ⇒ Functions Logistic Árboles con WEKA Pestaña Classifier ⇒ Trees Id3 J48 M5P M5 Conclusiones Introducción ID3 Mejoras C4.5 M5 Conclusiones Conclusiones Árboles de decisión Algoritmo ID3 selecciona de forma voraz el siguiente mejor atributo a añadir al árbol Evitar sobreajuste es un aspecto importante para conseguir que el árbol generalice bien ⇒ Podas del árbol Gran variedad de extensiones del ID3: manejar atributos continuos, con valores missing, otras medidas de selección, introducir costes Clase continua: árboles de modelos de regresión (M5) con regresiones lineales en las hojas Introducción ID3 Mejoras C4.5 M5 Conclusiones Bibliografı́a Textos Alpaydin, E (2004) Introduction to Machine Learning, MIT Press [Cap. 9] Duda, R., Hart, P.E., Stork, D.G. (2001) Pattern Classification, Wiley [Cap. 8] Hernández-Orallo, J., Ramı́rez, M.J., Ferri, C. (2004) Introducción a la Minerı́a de Datos, Pearson Educación [Cap. 11] Mitchell, T. (1997) Machine Learning, McGraw-Hill [Cap. 3] Webb, A. (2002) Statistical Pattern Recognition Wiley [Cap. 7] Witten, I., Frank, E. (2005) Data Mining, Morgan Kaufmann, 2a ed. [Secciones 4.3, 6.1, 6.5, 10.4] Introducción ID3 Mejoras C4.5 M5 Conclusiones Bibliografı́a Artı́culos Quinlan, J.R. (1986) Induction of trees, Machine Learning, 1, 81-106. [ID3] Breiman, L., Friedman, J.H., Olshen, R.A., Stone, C.J. (1984) Classification and Regression Trees, Wadsworth. [CART] Quinlan, J.R. (1993) C4.5: Programs for Machine Learning, Morgan Kaufmann. [C4.5] Quinlan, J.R. (1992) Learning with continuous classes, Proc. of the 5th Australian Joint Conference on AI, 343-348. [M5] Wang, Y., Witten, I. (1997) Induction of model trees for predicting continuous classes, Proc. of the Poster Papers of the ECML, 128-137 [M5’] Frank, E., Wang, Y., Inglis, S., Holmes, G., Witten, I. (1998) Using model trees for classification, Machine Learning, 32, 63-76 Friedman, J.H. (1991) Multivariate adaptive regression splines, Annals of Statistics, 19, 1-141 [MARS] Introducción ID3 Mejoras C4.5 M5 Conclusiones Tema B.6: ÁRBOLES DE CLASIFICACIÓN Concha Bielza, Pedro Larrañaga Departamento de Inteligencia Artificial Facultad de Informática, Universidad Politécnica de Madrid Aprendizaje Automático