RESILIENT PACKET RING
Anuncio

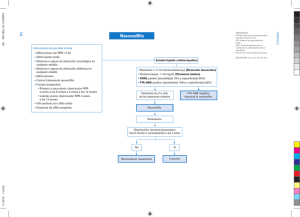
Trabajo de Prospección Resilient Packet Ring SISTEMAS DE TELECOMUNICACIÓN. RESILIENT PACKET RING ------------------------------------------------------------------------------------------- 0 Leticia Rueda Rojo Esther Moreno Estébanez Rocío Ocampo Godoy Trabajo de Prospección Resilient Packet Ring 1. Introducción 2. ¿Qué es RPR? a. Características b. Control de Acceso al Medio c. Prioridad de paquetes i. Ejemplo de Simulación d. Algoritmo “Fairness” i. Funciones de la FCU ii. Determinación del «Fair Rate» iii. Ejemplo de Simulación. Funcionamiento de los modos agresivo y conservador. e. Descubrimiento de la topología i. Formato de mensaje de descubrimiento de topología f. Resistencia a errores i. Inicialización ii. Suma de una nueva estación iii. Fallo iv. Protección v. Mecanismo «Steering» vi. Mecanismo Wrapping g. Compatibilidad con otros protocolos h. Formatos de trama 3. Comparación de rendimiento con otras arquitecturas a. Ventajas e inconvenientes de diferentes tecnologías i. SDH y SONET ii. Next Gen SDH iii. Ethernet iv. Ethernet sobre MPLS (EoMPLS) v. RPR IEEE 802.17 b. Comparativa 4. Prestaciones a. Robustez, capacidad b. Servicios soportados por RPR 5. Equipo necesario a. Ejemplo de empresa desarrolladora de equipos b. Interconexión de anillos. Dual RPR Interconnect. 6. Aplicaciones a. Redes MAN y WAN. Evolución. i. Nuevos Requerimientos en redes MAN y WAN ii. Evaluación de la Calidad de los Servicios en Redes E-MAN b. Servicios Ofrecidos sobre RPR i. Triple Play ii. Red de retorno inalámbrica (Wireless Backhaul) 7. Conclusión 1 Trabajo de Prospección Resilient Packet Ring 1. INTRODUCCIÓN El protocolo Resilient Packet Ring, (Anillo de recuperación de paquetes), normalizado como IEEE 802.17, nace como necesidad de una nueva forma de transporte de datos. Tradicionalmente los datos se han estado transportando sobre redes ATM y SDH, optimizadas para servicios TDM, no para una comunicación por paquetes. Hoy en día, la tendencia es llevar la conexión Ethernet desde la central del proveedor hasta el abonado, ya que todos los servicios que se están ofreciendo y se van a ofrecer a los usuarios finales están basados en el mundo IP. Además las redes Ethernet cada vez se van haciendo más grandes y se les va pidiendo mayor ancho de banda, rapidez y fiabilidad. RPR trata de responder con tecnología Ethernet a las carencias de SONET/SDH y a su obsolescencia en las redes en anillos de fibra óptica. 2. ¿QUÉ ES RPR? RPR o Resilient Packet Ring, es un protocolo de nivel 2 que proporciona un servicio de transmisión de paquetes no orientado a conexión entre elementos de un anillo. Ha sido inspirado en Ethernet, del que persigue sus ventajas sin renunciar a la calidad de servicio de la red SDH subyacente. La topología es de doble anillo, denominados interior y exterior, ambos contra-direccionales que transportan paquetes de datos y control. Ambos anillos llevan tráfico útil, utilizando técnicas de nivel 2 para la protección del tráfico en lugar de reservar ancho de banda para estos fines, por lo que incrementa el ancho de banda utilizable. RPR utiliza un algoritmo de descubrimiento de nodos que permite aprender automáticamente la topología de la red y almacena en cada nodo de red dos caminos (primario y secundario) al resto de nodos de la red. Los datos se enviarán por el camino óptimo y, sólo en caso de fallo de la red, se utilizará el camino secundario de modo automático en un tiempo no superior a 50 mseg. Otra característica importante es que los nodos destinatarios de los paquetes los retiran del anillo (salvo en multicast), por lo que los paquetes no circulan por todo el anillo, sino en el tramo comprendido entre emisor y receptor, dejando libres el resto de segmentos, lo que se conoce como “Reutilización espacial”. Todos los nodos en un anillo RPR comparten el ancho de banda disponible, sin necesidad de provisionar circuitos, negociando el acceso de forma 2 Trabajo de Prospección Resilient Packet Ring equitativa. A fin de garantizar diferentes calidades de servicio, RPR implanta cuatro clases de servicio con diferentes prioridades en cuanto a garantías de ancho de banda, retardo y “jitter” (Reservado, y clases A, B y C). En cuanto a la latencia, RPR tiene una arquitectura de “camino de paso o en tránsito” que permite a los paquetes cruzar rápidamente los nodos intermedios entre origen y destino, con lo que se consiguen valores muy bajos de latencia y “jitter”, siendo adecuado para voz y vídeo, alcanzando el objetivo de soportar múltiples servicios y aplicaciones. Adicionalmente implanta de forma excepcionalmente simple la funcionalidad de “multicast” y “broadcast”, ya que simplemente se dejan circular estos paquetes por el anillo sin necesidad de replicarlos. Con este protocolo se permite “sobre-suscripción” (multiplexación estadística), garantizando la transmisión de paquetes hasta el valor comprometido y, a partir de ahí, en función del estado de ocupación de la red. Por tanto, utilizando RPR se obtiene una gran eficiencia en el uso de ancho de banda, con una calidad de servicio próxima a la que proporcionan las redes de transporte SDH, permitiendo un acceso equitativo y diferenciado por clases de servicio al ancho de banda de la red, de muy fácil gestión y escalabilidad (hasta 64 nodos por anillo, ADMs), debido a la inteligencia de los nodos que automatiza gran parte de la operación. a. Características Dentro de sus principales características destacan las siguientes: ¾ Es una tecnología de transporte de nivel 2, complementaria a las que ya existen (SDH, ATM, Ethernet). ¾ Se implementa sobre fibra óptica. ¾ Soporta múltiples servicios y aplicaciones (datos, voz, vídeo). ¾ Basado en paquetes. ¾ Soporta tramas IP, MPLS o Ethernet (su principal objetivo). ¾ Topología de red sencilla: doble anillo, interior y exterior, ambos con tráfico útil. ¾ Descubrimiento automático de nodos y topología de red. Cada nodo de red almacena dos caminos (primario y secundario) al resto de nodos de la red. Conmutación automática a secundario en caso de fallo en menos de 50 ms. ¾ Comparte los anillos de fibra, y reutiliza espacio (ancho de banda). Los paquetes no circulan por todo el anillo, sino simplemente en el tramo comprendido entre emisor y receptor, lo que permite que circulen varios paquetes por el anillo simultáneamente. 3 Trabajo de Prospección Resilient Packet Ring ¾ Todos los nodos comparten el ancho de banda disponible, sin necesidad de provisionar circuitos, negociando el acceso de forma equitativa. ¾ Implanta de forma simple la funcionalidad de “multicast” y “broadcast”, ya que los paquetes pueden circular por el anillo sin necesidad de replicarlos. ¾ Implanta cuatro clases de servicio con diferentes prioridades en cuanto a garantías de ancho de banda, retardo y “jitter” (Reservado y clases A, B y C). ¾ Arquitectura de “camino de paso o en tránsito” que permite a los paquetes cruzar rápidamente los nodos intermedios. Valores muy bajos de latencia y “jitter”. ¾ Permite “sobre-suscripción” (multiplexación estadística), garantizando un valor comprometido, y a partir de ahí en función del estado de ocupación de la red. ¾ Reduce los costes de operación y de construcción de red (Capex y Opex): ¾ Reduce la complejidad de la red. ¾ Reduce los tiempos de dar servicio. ¾ Escalable. ¾ Eficiencia en la utilización de fibra. ¾ Protección de anillos, resistente a fallos. ¾ Usa técnicas de nivel 2 para protección de tráfico. No reserva ancho de banda para este fin. ¾ Múltiples niveles de calidad de servicio. b. Control de acceso al medio Las estaciones en el anillo de RPR utilizan un protocolo de control de acceso al medio (MAC) que controla el acceso de las estaciones al medio de comunicación del anillo. Se definen varias interfaces de la capa física (subcapas de la reconciliación) para Ethernet (llamada PacketPHYs) y SONET/SDH. La entidad MAC también implementa puntos de acceso a los que los clientes se pueden conectar para enviar y recibir tramas de información de estatus. 4 Trabajo de Prospección Resilient Packet Ring c. Prioridad de paquetes RPR proporciona prioridad de paquetes mediante tres niveles/clases de servicios. El objetivo de este esquema de transporte es dar a la clase A baja latencia y bajo jitter, a la clase B latencia y jitter predecibles, y a la C un mejor esfuerzo (Best Effort). RPR no descarta tramas para solucionar la congestión. Las tramas de la clase A se pueden dividir en A0 y A1 y las tramas de clase B se dividen a su vez en B-CIR (commmited information rate) y B-EIR (Excess information rate). Las clases C y B-EIR son denominadas «FE» (fairness elegible), debido a que este tipo de tráfico es controlado por el algoritmo «fairness». Para garantizar los servicios de las clases A0, A1 y B-CIR, se asigna ancho de banda. El ancho de banda asignado a la clase A0 se denomina «reservado» y solamente puede ser utilizado por la estación que lo tiene asignado. El ancho de banda preasignado a A1 o B-CIR se denomina «reclamable». El ancho de banda reservado que no se utiliza se desperdicia, pero el tráfico reclamable no utilizado puede ser reutilizado por el tráfico FE. Cuando una estación quiere reservar ancho de banda A0 envía una reserva mediante broadcast al resto de las estaciones. Una vez recibida la misma información del resto de estaciones, cada estación hace el cálculo de ancho de banda no reservado disponible, que puede ser utilizado por el resto de clases de tráfico. Cada estación del anillo RPR tiene un formateador de tráfico por cada A0, A1 y BCIR, ya preconfigurados, y también uno para FE. Hay otro formateador para todo el tráfico diferente a A0, llamado «downstream shaper». El downstream shaper asegura que el ancho de banda utilizado por el tráfico no reservado no exceda el ancho de banda no reservado. Los otros formateadores se encargan de limitar la inserción de tráfico del resto de clases de tráfico. 5 Trabajo de Prospección Resilient Packet Ring Una cola es suficiente para realizar el «buffereing » de tramas en tránsito de cada estación. La cola puede estar definida como una cola con prioridades, donde las tramas con prioridades más altas son desencoladas antes que las de prioridades más bajas. Opcionalmente RPR considera la utilización de dos colas, una principal PTQ (primary transit queue) y otra secundaria STQ (secondary transit queue). Las tramas de clase A son encoladas en la cola PTQ, mientras que las tramas de clases B y C son encoladas en STQ. El envío desde la cola PTQ tiene prioridad sobre STQ y sobre la mayor parte de tipos de inserción de tráfico. Conexión a un único anillo mostrando el buffer de inserción y la cola de tránsito. i. Ejemplo de simulación La figura muestra un ejemplo ejecutado donde se mide la latencia de las tramas enviadas entre dos estaciones dadas en un anillo RPR. Las estaciones del anillo tienen dos colas de tránsito. El anillo es sobrecargado con tráfico aleatorio de fondo, de clase C. La latencia se mide desde que el paquete está listo para entrar en el anillo(es decir, está el primero en la cola), hasta que llega al receptor. Observar cómo el tráfico de clase A mantiene su retardo bajo incluso cuando el anillo está congestionado. Notar también cómo el tráfico de clase B todavía tiene un jitter bajo en alta carga, mientras que el tráfico de clase C experimenta algunos retardos muy altos. Latencia de una trama desde la estación 1 a la 7 en un anillo sobrecargado de 16 estaciones. La propagación y la latencia mínima de trama son 180 microsegundos. 6 Trabajo de Prospección Resilient Packet Ring d. Algoritmo Fairness En el método de acceso básico de “inserción al buffer”, una estación puede enviar una trama solamente si la cola en tránsito está vacía. Por lo tanto es muy fácil que una estación de flujo de bajada (downstream) sea privada por las estaciones de flujo de subida (upstream). En RPR, la solución a este problema es que las estaciones se comporten de acuerdo al algoritmo Fairness. El objetivo del algoritmo Fairness, es distribuir el ancho de banda recuperable, sin asignar y no utilizado de manera equitativa en las estaciones y usar este ancho de banda para enviar tráfico de clase B-EIR y clase C, por ejemplo el trafico fairness eligible (FE). Al definir la distribución equitativa del ancho de banda, RPR hace cumplir el principio de que cuando la demanda de ancho de banda en un enlace es mayor que la oferta, el ancho de banda disponible se debe distribuir equitativamente entre las estaciones emisoras contendientes. Se asigna un peso a cada estación, a fin de que la distribución equitativa no sea igual entre estaciones de diferente peso. Cuando el ancho de banda de un enlace de transmisión de una estación está agotado, se dice que el enlace y la estación están congestionados, es entonces cuando el algoritmo Fairness comienza a funcionar. Se considera que una estación está congestionada cuando (con una o dos colas) el tráfico total transmitido supera ciertos límites. Para estaciones con una sola cola, se dice que está congestionada cuando las tramas insertadas en ella tienen que esperar mucho para salir de la cola. Cuando existe cola principal y secundaria, se dice que hay congestión cuando la segunda cola (STQ) se llena. Esto implica que todas las tramas que lleguen a la cola STQ, tardarán bastante en salir. Como solución a la congestión, cada entidad MAC 802.17 tiene una «Fairness Control Unit» con las siguientes características: • Respuesta rápida. • Alta utilización de ancho de banda. • Escalabilidad. 7 Trabajo de Prospección Resilient Packet Ring • Reclamación de ancho de banda. • «Source-based weighted fairness». • Soporte de «Single and multichoke de clientes». • Estabilidad. La FCU proporciona a los clientes la velocidad a la que pueden transmitir tráfico FE. Las estaciones del anillo negocian la velocidad basándose en la cantidad total de ancho de banda no reservado disponible en el anillo. i. Funciones de la FCU Para comunicar el estado de la entidad MAC, la FCU genera y recibe mensajes de control fairness. La FCU genera mensajes para advertir de la utilización de ancho de banda de cada estación. La FCU también recibe mensajes fairness con los que determina: • Estado de congestión del anillo. • Ancho de banda permitido para cada estación. Con la información de ancho de banda, la FCU también configura los formateadores de transmisión para cumplir con las limitaciones de ancho de banda. ii. Determinación del «Fair Rate» Las estaciones utilizarán algunas variables para calcular dinámicamente la cantidad de ancho de banda que tienen permitido consumir «Fair Rate»: ReceivedFairRate: Ancho de banda recibido de las estaciones anteriores. LocalFairRate: Ancho de banda que la estación está consumiendo actualmente. FullLineRate: La máxima velocidad del anillo. 8 Trabajo de Prospección Resilient Packet Ring ForwardRate: Ancho de banda utilizado por estaciones siguientes en el anillo. Básicamente, el fair rate de una estación se calcula utilizando el ReceivedFairRate de las estaciones vecinas y comparando con sus LocalFair-Rate. Cuando el LocalFairRate excede el ReceivedFairRate, un nodo asume que está utilizando demasiado ancho de banda y reduce su LocalFairRate. Durante periodos de congestión, un nodo recibe valores de ReceivedFairRate más bajos. Cuando la congestión cesa, el ReceivedFairRate crece hacia FullLine-Rate. Cada nodo genera mensajes de control fairness indicando sus requerimientos de ancho de banda y teniendo en cuenta el estado de congestión del anillo. iii. Ejemplo de simulación. Algoritmo fairness. Funcionamiento de los modos agresivo y conservador. La figura muestra el funcionamiento de los modos agresivo y conservador del algoritmo de equidad (fairness), respecivamente, en un escenario dado. Ambos escenarios son simulados para un anillo de 16 estaciones de 50 km de longitud, enlaces de 1 Gbps de los que cada estación usa el 1% para tráfico A0. Todas las estaciones tienen dos colas, y las estaciones 1, 2 y 3 están enviando a la estación 4. El tráfico comienza en el instante 1.0 s, e inicialmente sólo envía la estación 3. En el instante 1.1 s, la estación 1 empieza a enviar. Ambos flujos son de clase C, y ambos métodos de equidad comparten rápidamente el ancho de banda del enlace congestionado (desde la estación 3 a la 4) de forma igualitaria. En el instante 1.2 s, la estación 2 empieza a enviar un flujo de 200 Mbps (también de clase C y hacia la estación 4). Vemos que el método agresivo se adapta a la nueva distribución equitativa de ancho de banda muy rápidamente, aunque después de algunas oscilaciones altas. El método conservativo, que espera un FRTT (fairness round trip time) entre cada ajuste de tasa, tarda más tiempo en ajustarse a la nueva carga. 9 Trabajo de Prospección Resilient Packet Ring Tráfico dinámico manejado por los algoritmos de equidad conservativo y agresivo (nº bps recibidos por la estación 4). En el instante 1.5 s, para el tráfico desde la estación 1. En ambos métodos, vemos que algo de tráfico desde la estación 2 que ha sido encolado, ahora está siendo liberado, y por tanto hay una cantidad añadida de paquetes recibidos desde la estación 2 en la 4. El método agresivo sufre algunas oscilaciones adicionales, pero aún así se ajusta rápidamente al nuevo patrón de tráfico. El método conservativo se ajusta con menos oscilaciones, pero más despacio. e. Descubrimiento de la topología La entidad 802.17 tiene un mecanismo de descubrimiento de topología. Los mensajes de topología son enviados desde cada estación a las demás estaciones en el anillo. Cada estación construye un mapa de topología, conteniendo información sobre localización, capacidades y estado de los nodos en el anillo. Los mensajes son generados periódicamente y tras la detección de cambio de estado. i. Formato de mensaje de descubrimiento de topología. El mensaje de descubrimiento de topología contiene información sobre la estación que lo envía. Las capacidades de las estaciones son Jumbo y Wrap. Hay también capacidades contenidas en los campos TypeLengthValue (TLV) del mensaje «extended topology message». La trama TLV ofrece un formato de trama flexible, en el que entrega información de las capacidades de la estación. f. Resistencia a errores. Operación. i. Inicialización El mapa de topología contiene información sobre la estación local. La estación escucha los mensajes Broadcast de otras estaciones. Cada estación envía a las demás su información de topología periódicamente, o cuando detecta un cambio en la misma. ii. Suma de una nueva estación. 10 Trabajo de Prospección Resilient Packet Ring Una nueva estación se inicializa a sí misma después de unirse a un anillo y envía a todas las estaciones su mensaje de topología. Después de detectar un cambio, los otros nodos del anillo envían sus mensajes de topología. Para detectar estaciones contiguas, el nodo actúa recibiendo los mensajes que han viajado por la red un sólo salto. iii. Fallo. Cuando una estación se quita o falla la fibra, las estaciones adyacentes al fallo graban su estado en sus mapas de topologías. Estados de fallo RPR (en orden decreciente de severidad): 1. Forced Switch: un operador inicia el comando para forzar un evento de protección en una interface. 2. Signal Fail: evento de protección ocasionado por fallo en la señal o por fallo en un mensaje «RPR Keepalive». 3. Signal degrade: evento de protección ocasionado por excesivo BER. 4. Manual Switch: igual que Torced Switch, pero de menor prioridad. 5. Wait to Restore: temporizador de retardo configurable para restaurar un enlace después de que un fallo se solucione. 11 Trabajo de Prospección iv. Resilient Packet Ring Protección. El protocolo 802.17 MAC protege el tráfico seleccionado contra fallos de fibra y estación en menos de 50 ms. El mecanismo de protección también soporta la adición y extracción de estaciones en el anillo. Las estaciones intercambian mensajes para comunicar el estado de «salud» del anillo. También se intercambian mensajes «Keepalive» entre las estaciones para comunicar el funcionamiento normal de la estación. Todas las estaciones dentro de un mismo anillo deben utilizar el mismo mecanismo de protección. Características de protección: — Protección en menos de 50 ms tanto para tráfico unicast como multicast. — Soporta tanto mecanismo «Steering» como «Wrapping». — Soporta adición y extracción dinámica de estaciones en el anillo. — Cada estación funciona independientemente, sin un nodo Master. — Escalable a mayor número de estaciones. v. Mecanismo «Steering» El mecanismo de protección por defecto es el Steering. Cuando se produce un evento de protección, se comunica a todas las estaciones la situación del mismo. Las estaciones transmisoras eligen el sentido en el que tienen que enviar la información para evitar el fallo, hasta que reciben la notificación de que este ha sido solucionado. Los paquetes que llegan al punto de fallo son extraídos del anillo. Los paquetes multicast son enviados en Broadcast por los dos lados del anillo, y el TTL se pone con el número correcto de estaciones antes del fallo. vi. Mecanismo Wrapping Un mecanismo opcional es el Wrapping. Ante un evento de protección, la estación adyacente al fallo vuelve el tráfico hacia el lado opuesto para evitar el punto de quiebra. Jerarquía de Protección: El mecanismo de protección tiene la posibilidad de manejar varios fallos simultáneamente. El más severo tiene prioridad sobre los demás. Por ejemplo, un fallo de degradación de señal tendrá menor severidad, y por tanto no tendrá preferencia sobre un fallo de señal en el anillo. 12 Trabajo de Prospección Resilient Packet Ring g. Compatibilidad con otros protocolos RPR es un complemento a las tecnologías SDH, ATM Y ETHERNET que aprovecha lo mejor de todas ellas y, a la vez, las redes ya existentes. Optimiza las redes públicas para transportar datos, e interconecta eficientemente las redes LAN con las redes SDH actuales. Al ser una tecnología de capa 2 (nivel de enlace), su funcionamiento es independiente de las capas superiores e inferiores. Esto significa que es compatible con cualquier tecnología a nivel físico, como por ejemplo SONET o Ethernet PHYs, aplicando los siguientes protocolos físicos de transporte: GigabitEthernet, 10GbEth, SDH, WDM, DWDM, etc. Esto simplifica mucho las redes, ya que hasta ahora en la mayor parte de los casos coexistían las ATM, SDH, TDM, IP y Frame Relay, todas ellas superpuestas. En cuanto al tipo de tráfico que puede ser transportado en RPR en sus capas superiores figuran: IP, MPLS y tramas Ethernet, siendo éstas, su principal objetivo. Así pues, al transportar estos tipos de tráfico, es capaz de soportar múltiples servicios y aplicaciones en las capas superiores, como vídeo, VoIP, IPx, etc. ya que todos los servicios que se están ofreciendo y se van a ofrecer a los usuarios finales están basados en IP. h. Formatos de trama Existen cuatro formatos diferentes de tramas definidos en el estándar RPR: «Data», «Fairness», «Control» e «Idle». Data: Las tramas Data tienen 2 formatos, el básico y el extendido. El formato de trama extendido aplicaciones de bridging transparente permitiendo el fácil procesamiento de egreso y encapsulación de ingreso de otras tramas de control de acceso al medio (MAC). Usando el formato de trama extendido, permite también a los anillos RPR eliminar paquetes bridge duplicados y fuera de orden. El siguiente es un ejemplo de una trama de datos básico. Fairness: La trama fairness de 16 bytes principalmente provee el “faireRate” advertido y la fuente de las tramas fairness. La información es usada en el algoritmo fairness RPR. Control: Una trama de control es similar a una trama de datos, pero son distinguidas por el valor del campo “ft” y su campo controlType especifica el tipo de información 13 Trabajo de Prospección Resilient Packet Ring contenida. Hay diferentes tipos de tramas de control RPR, por ejemplo, información de topología y protección y OAM (Operación, Administración y Mantenimiento). Iddle: Son utilizadas para compensar los errores entre estaciones vecinas. 3. COMPARACIÓN DE RENDIMIENTO CON OTRAS ARQUITECTURAS Las actuales soluciones de transporte SDH, ATM y Ethernet tienen ciertas limitaciones a la hora de afrontar el crecimiento de las redes metropolitanas. Las principales carencias de SONET/SDH son su elevado coste, la ineficiencia para el tráfico de paquetes de la asignación en modo circuito de ancho de banda estático. Igualmente ineficiente es el ancho de banda reservado para protección de los circuitos establecidos, y el provisionamiento del servicio es lento. Estas carencias empujan hacia la sustitución de los anillos SDH. Pero el estándar Ethernet no satisface los requisitos de SDH porque el árbol de expansión no soporta las topologías de anillos múltiples requeridas y no tiene la rapidez requerida por el estándar de protección de SDH (reconfiguración en 50 mseg.). Asimismo es necesaria una separación de cliente/servicio en capa dos que sea escalable. RPR tiene como objetivo ser alternativa a SDH mediante tecnología Ethernet resolviendo dichas limitaciones. Como resumen, en la tabla siguiente se detallan los pros y contras de estas tres tecnologías junto con el nuevo estándar RPR. 14 Trabajo de Prospección Resilient Packet Ring . a. Ventajas e inconvenientes de diferentes tecnologías i. SDH y SONET Ventajas: - Asegura un alto grado de protección: tiempos de restauración de servicio inferiores a 50 ms - Garantiza la calidad de servicio, mediante establecimiento de circuitos. - supervisión de calidad, operación y mantenimiento completos basados en TDM Inconvenientes: - Restringido a topología en anillo. - El coste de los equipos es mucho mayor que para redes Ethernet. - Requiere elevados anchos de banda. - Altamente ineficiente para el transporte de datos. Al haber sido diseñadas inicialmente para tráfico de voz TDM, estas redes no están optimizadas para tráfico LAN, ya que el ancho de banda empleado es fijo Y de granuladidad gruesa, por lo que no se adapta a los requerimientos de las aplicaciones. - Se pueden aprovechar los mecanismos de multiplexación estadística montando ATM sobre SDH/SONET, pero se trata de una solución de coste económico elevado. - Deja sin utilizar el 50% del ancho de banda, ya que una de las fibras debe estar libre para entrar en servicio cuando se produzca el fallo y suministrar el respaldo correspondiente. 15 Trabajo de Prospección ii. Resilient Packet Ring Next Gen SDH Surge de la necesidad de transportar tráfico IP y Ethernet sobre SDH de una forma más óptima. Consiste en la adición de los siguientes protocolos al SDH clásico: GPF, VCAT, LCAS y Ethernet sobre LAPS. ¾ Generic framing procedure (GFP): definido en el ITU-T Rec. G.7041. Este protocolo encapsula cualquier tipo de servicio de enlace de datos, incluidos Ethernet, DVB (Digital Video Broadcasting), RPR y SAN (Storage Area Networks). GFP, comparado con otros procedimientos de entramado como POS (Packet over SDH/SONET) o X86, tiene un overhead bajo que requiere menos análisis de procesamiento. Además, soporta multiplexación de tributarios. ¾ Concatenación Virtual (VCAT): definido en el ITU-T Rec. G.7041. Permite la agrupación de múltiples VCs. Ajusta la capacidad a las necesidades de tráfico, y no exige disponibilidad de recursos contiguos. Además, es transparente a los equipos intermedios antiguos y se comporta mejor frente a cortes. ¾ Link capacity adjustment scheme (LCAS): definido en el ITU-T Rec. G.7042. Adapta SDH (orientado a circuitos) a tráfico orientado a paquetes. Permite la modificación dinámica del ancho de banda, añadiendo o suprimiendo VCs de una concatenación virtual en función de las necesidades de la aplicación que soporta. En caso de fallo parcial de enlaces SDH utilizados, permite reducir el ancho de banda sin perder totalmente la conexión. Se puede usar VCAT sin LCAS, pero no LCAS sin VCAT. ¾ Ethernet sobre LAPS: definido en el ITU_T X.86. Éste es un protocolo de la familia HDLC, que incluye monitoreo del funcionamiento, detección de errores remota y control de flujo. Sin embargo, usa técnicas de concatenación de ancho de banda contiguo, que no se corresponden a la naturaleza explosiva de Ethernet. iii. Ethernet Ventajas: ¾ Ubicuidad: Es la tecnología predominante en las redes de empresa y una de las interfaces más comunes en los PCs, debido en gran parte a la disponibilidad de estándares mundialmente aceptados y demostrada interoperabilidad entre los elementos de todos los suministradores. ¾ Disponibilidad de grandes anchos de banda: 1Gbps, 10 Gbps, con alcances de hasta 5km. 16 Trabajo de Prospección Resilient Packet Ring ¾ Precios reducidos.: Si comparamos con los precios de otros elementos de transporte y conmutación equivalentes en cuanto a capacidad (SDH, ATM), el coste de los elementos Ethernet resulta ser entre la décima y la quinta parte. ¾ Facilidad de operación y provisión del servicio, debido en parte a la autoconfiguración y asignación flexible de ancho de banda. ¾ Permite topologías en anillo, en estrella, en bus y malladas. Problemas de Ethernet: • Garantía de calidad de servicio extremo a extremo. La solución más extendida es sobredimensionar el sistema para que no se congestione. El IEEE 802.1q107 asigna tres bits para indicar la prioridad de las tramas, pero no existen mecanismos establecidos de control de admisión. • Mecanismos de protección contra fallos, aplicables sobre todo al segmento metropolitano. o Mecanismos de recuperación de nivel 2 en redes Ethernet nativas: Spanning Tree Protocol (STP) tradicional. Tiempo de recuperación muy lento, del orden de 30 segs., o incluso más. El enlace de reserva permanece inactivo. IEEE 802.1w: Rapid Spanning Tree Protocol (RSTP). Permite recuperar la topología de red en tiempos en torno a 1 seg. No permite balanceo de carga y requiere un sobredimensionado excesivo. IEEE 802.3ad (Link Aggregation). Ofrece tiempos de recuperación en torno a decenas de milisegundos, pero sólo protege de caídas de enlace, y no de caídas de nodo. Dadas las carencias de estos mecanismos, es habitual utilizar por encima mecanismos de tolerancia a fallos de nivel 3. o Mecanismos de recuperación de nivel 3 en redes Ethernet basados en protocolos de enrutamiento y backup de puertas de enlace. Se basan en la utilización de protocolos y algoritmos de enrutamiento con soporte de balanceo de carga a través de múltiples enlaces y con convergencia rápida ante los cambios. Protocolo OSPF: utilizado en entornos con múltiples fabricantes. Tiempos de convergencia que pueden oscilar entre 2 y 4 segundos. 17 Trabajo de Prospección Resilient Packet Ring • Protocolo EIGRP: utilizado en entornos Cisco puros. Puede llegar incluso a converger en sólo 1 segundo Evidentemente, estos tiempos están fuera del rango deseado, pero si utilizamos varias rutas simultáneas con balanceo de carga, conseguimos el objetivo, siempre y cuando partamos de una situación de operación normal con dos o más rutas activas. Si deseamos redundancia, es necesario duplicar los routers y emplear métodos de tolerancia a fallos de la puerta de enlace o gateway por defecto de cara a los equipos. En este caso, se utiliza el estándar VRRP (Virtual Router Redundancy Protocol) u otro método propietario similar como HSRP de Cisco. Pocas prestaciones de supervisión de la calidad de servicio, operación y mantenimiento. • Problemas de escalabilidad de algunos recursos. El indentificador de red virtual de las tramas Ethernet está limitado a 12 bits, por lo que el máximo número de redes virtuales es de 4096. Esto en un entorno público, y particularmente si se utiliza este mecanismo para separar usuarios individuales, supone un severo límite al tamaño de un área metropolitana. iv. Ethernet sobre MPLS (EoMPLS) En cuanto a los mecanismos de protección, MPLS se distingue por: - Recuperación garantizada en tiempos inferiores a 50 ms. mediante Fast-reroute. - Calidad de servicio garantizada durante la transición. - Distribución óptima del tráfico después de la caída, con redistribución homogénea de la carga. - Posibilidad de definir servicios con diferentes esquemas o calidad de protección. v. RPR IEEE 802.17 Ventajas: RPR cuenta con multitud de ventajas, las cuales serán expuestas en el siguiente apartado de prestaciones. Inconvenientes: ¾ Si se produce una caída, todo el tráfico se traslada al otro anillo, lo que implica riesgos de congestión y de deterioro del servicio. ¾ A pesar de sus mecanismos de QoS, no se puede hablar de niveles de servicio garantizados. ¾ Restringido a topología en anillo, lo que limita mucho su aplicabilidad, haciendo inadecuada su aplicación en redes campus (malladas), dado el bajo rendimiento (longitud de camino y rápida saturación de la red) que presentan las topologías en anillo. 18 Trabajo de Prospección Resilient Packet Ring b. Comparativa La solución SDH/SONET, consigue tiempos de restauración de servicio inferiores a 50 ms, pero además de tratarse de una solución cara, desaprovecha el 50% del ancho de banda, que queda a la espera de ser utilizado en caso de fallo. Las limitaciones de los mecanismos Ethernet de nivel 2, se centran en dos puntos: en el caso de topología en anillo, el camino de reserva sigue sin utilizarse, y los tiempos de recuperación ante fallos no bajan de 0,5 segundos en el mejor de los casos. Los mecanismos de recuperación de nivel 3, constituyen la solución más utilizada actualmente en la red de acceso con topologías de doble anillo en cobre y fibra, en gran parte por su coste moderado, pero resulta poco compacta (hacen falta varios conmutadores y al menos dos routers por LAN, uno para cada anillo) y su efectividad desaparece cuando disponemos de un único anillo activo, ya que en este caso los tiempos de convergencia impactan directamente sobre el funcionamiento de las aplicaciones de tiempo real, provocando bloqueos del sistema. Por lo tanto, podemos decir que Ethernet supera a SDH/SONET en el uso más eficiente del ancho de banda para tráfico de datos, sin embargo, el protocolo no fue originalmente diseñado para ser usado en topologías en anillo o con tráfico de tiempo real. Los mecanismos de recuperación de Ethernet durante un corte de fibra son mucho más lentos (del orden de segundos), y no son apropiados para protección a nivel de camino, que asegura la restauración del servicio según clases. Así mismo, tampoco es muy eficiente en el reparto equitativo del ancho de banda de los anillos. Por otra parte, como RPR tiene problemas de escalabilidad y los costes están muy lejos de las soluciones IP/Ethernet tradicionales, no es probable que se consume el despliegue total de la tecnología. Con respecto a EoMPLS, un factor diferenciador frente a Ethernet es su capacidad para monitorizar el rendimiento, verificando la conectividad y la calidad de las conexiones, tanto en el plano de control, como en el plano de datos, mientras que en Ethernet nativa sólo es posible verificar el estado de los equipos y la conectividad en el plano de control. En cuanto a la escalabilidad, EoMPLS permite establecer conexiones siempre por el camino mejor, optimizando el dimensionado de la red y garantizando una mayor escalabilidad. Mientras que en Ethernet nativa, las topologías o caminos calculados por el algoritmo Spanning Tree no son el óptimo, sino tan sólo uno de los caminos posibles, por lo que se requiere un sobredimensionado mucho mayor, que incrementan la inversión en equipos y medios de transmisión (canales SDH o PDH, fibra oscura, etc.). Por lo tanto, las redes EoMPLS permiten transportar diferentes tipos de tráfico, facilitando la convergencia de servicios sobre la red, y evitando la creación y mantenimiento de redes separadas (red de tiempo real, red multiservicio, etc.). El mayor problema de estas redes es su complejidad de configuración y gestión, el alto coste económico, y carencias importantes de seguridad, que deben ser subsanadas mediante mecanismos complejos de cifrado, autenticación y autorización. 19 Trabajo de Prospección Resilient Packet Ring Comparación de las tecnologías para el futuro: GigabitEthernet, Next Gen SDH y RPR sobre ambas. GbE RPR sobre GbE RPR sobre NextGen SDH Next-Gen SDH Retardo de recuperación 1s 50 ms 50 ms 50 ms Retardo de transporte El mayor El más pequeño El más pequeño Medio Disponibilidad 99.9% 99.999% 99.999% 99.999% IP sobre GbE IP sobre RPR sobre GbE IP sobre RPR sobre Next-Gen SDH IP sobre NextGen SDH Eficiencia del ancho de banda 93 89 87 88 Eficiencia de la tasa de la línea. 74 71 87 88 Protección Actualización Costes de desarrollo GbE RPR sobre GbE RPR sobre NextGen SDH Next-Gen SDH En estrella: excelente pero cara. En anillo: no muy buena, pero barata. Fácil y barata. Muy buena y no demasiado cara Muy buena y a precio normal. Muy buena y a precio normal. Fácil y no demasiado cara. Más difícil y más cara. Difícil y cara. No demasiado caro Sobre SDH tipo 1: el más caro SDH tipo 2: no demasiado caro SDH tipo 1: caro SDH tipo 2: no demasiado caro Barato 4. PRESTACIONES RPR RPR proporciona las siguientes prestaciones: a) Optimizado para anillos de una circunferencia máxima de 2000 Km (objetivo de diseño, no restricción física). 20 Trabajo de Prospección Resilient Packet Ring b) Soporta hasta 255 estaciones por anillo (station attachments). c) Compatible con múltiples protocolos físicos de transporte (GigabitEthernet, 10GbEth, SDH, WDM, DWDM, fibra oscura). d) Direccionamiento: soporta transferencias de datos unicast, multicast y broadcast simple. e) Servicios: Soporta múltiples calidades de servicio (QoS). El tráfico introducido por los clientes es regulado por protocolos de control de flujo por calidad de servicio. 1) Clase A: el ancho de banda asignado/garantizado tiene jitter bajo e independiente de la circunferencia del anillo y retardo bajo extremo a extremo. Esta clase tiene preferencia sobre las demás. 2) Clase B: el ancho de banda asignado/garantizado tiene jitter y retardo extremo a extremo limitados y dependientes de la circunferencia del anillo. Permite transmisiones de anchos de banda con tasa de información excesiva (EIR) (con propiedades de clase C). Los servicios de clase B tienen preferencia sobre los de clase C. 3) Clase C: servicios de mejor esfuerzo. El ancho de banda no está garantizado y ni el jitter ni el retardo están limitados. f) Eficiencia. Las estrategias de diseño incrementan el ancho de banda efectivo más allá que el de un anillo broadcast. 1) Transmisiones concurrentes, una en cada sentido. 2) Reasignación de ancho de banda en segmentos no solapados. 3) Reclamación de ancho de banda no usado por parte de servicios oportunistas. 4) Reutilización del ancho de banda espacial 5) Reutilización temporal del ancho de banda g) Equidad (fairness). Asegura particionado apropiado del tráfico oportunista. Los nodos del anillo comparten el ancho de banda disponible, sin provisionar circuitos, negociando el acceso de forma equitativa. 1) Por peso. 2) Simple. 3) Detallado. h) Plug-and-play. El descubrimiento automático de la topología y el anuncio de la capacidad de cada estación permite a los sistemas convertirse en operacionales sin intervención manual. i) Robustez. 21 Trabajo de Prospección Resilient Packet Ring 1) Respondedor. El tiempo de restauración del servicio es menor que 50 ms después de un fallo de estación o de enlace. 2) Sin pérdidas. Las especificaciones de encolamiento y de forma evitan la pérdida de tramas en operación normal. 3) Tolerante. La arquitectura de control totalmente distribuida elimina los puntos de fallo únicos. 4) OAM. Servicio de soporte de operación, administración y mantenimiento. 5. EQUIPOS Aunque el estándar es reciente, los miembros de «Resilient Packet Ring Alliance», y algunos otros fabricantes de equipos que no pertenecen a esta alianza ni al grupo de trabajo IEEE802.17ae, han ido sacando al mercado plataformas basadas en el mismo. Éste es un ejemplo de red que ilustra cómo se despliega RPR y los tipos de equipos utilizados para el despliegue. 22 Trabajo de Prospección Resilient Packet Ring xPON y VDSL son los próximos mecanismos de distribución para servicios triple play. Esto coloca a RPR en equipo OLT (Optical Line Terminal) para PONs y en DSLAM para VDSL. Por supuesto, muchos vendedores de equipos producen una única plataforma para ambos, lo que típicamente se conoce como MSPP (Multiservice Provisioning Platform). Además, hay un Terminal de Oficina Central (COT) que debe conectar las redes metropolitanas con la red troncal o con la red regional. Este terminal también debe soportar RPR. Los tipos de equipos en esta categoría van desde “edge routers” (unen redes) a “core switches” (unen dispositivos en la misma red). a. Ejemplo de empresa desarrolladora de equipos Una de las empresas que lleva a cabo la investigación de equipos RPR es Cisco Systems, durante mucho tiempo líder en la industria de la tecnología RPR y muy involucrado en el grupo de trabajo de IEEE 802.17, centrado en esta Norma. De hecho, la primera gran propuesta técnica para el protocolo RPR fue sometida por Cisco®, basado en su tecnología dinámica del transporte del paquete (DPT). Cisco ha estado implementando arquitecturas RPR con DPT en las redes del proveedor de servicios durante más de cinco años. Cisco ONS 15454 MSPP and ML-Series Cards 23 Trabajo de Prospección Resilient Packet Ring Usando su software líder en la industria, Cisco IOS ®, la familia Cisco ONS ahora soporta RPR. Con Cisco ML-Series tarjetas Ethernet, los proveedores de servicios pueden ofrecer una solución RPR que ofrece a los clientes una amplia gama de beneficios, incluyendo: • Mejora de la utilización del ancho de banda SONET / SDH, en comparación con el tradicional Protocolo Spanning Tree (árbol de extensión) en topologías en anillo . • Un mecanismo de recuperación SONET/SDH con una convergencia de menos de 50 ms para fibra rota, restauración, fallas de nodos, e inserción de nodos. • La capacidad para llevar a cabo la ubicuidad de garantía de QoS en todo el tráfico de datos-de tránsito, pérdida y agregación. La completa solución RPR de Cisco permite a los proveedores de servicios aprovechar las ventajas competitivas de esta innovadora tecnología de hoy y pueden ayudar a garantizar la cuota de mercado y maximizar los beneficios en el futuro. Aunque el proyecto 802.17 se utilizó como referencia para la aplicación Cisco ML-Series RPR, el actual ML protocolo RPR no cumple con todas las cláusulas de IEEE 802.17. b. Interconexión de anillos. Dual RPR Interconnect El estándar IEEE 802.17 se centra en la conmutación de paquetes dentro de un anillo RPR, pero no se ocupa de la comunicación entre los anillos. En virtud de la norma 802.17, el tráfico anillo a anillo deberá salir de un dominio RPR y entrar en otro utilizando los puertos estándar User-Network Interface (UNI). Para gestionar estas interconexiones UNI, los administradores deben utilizar protocolos de control en el centro de la red que se utilizan normalmente sólo en los puntos finales de la red. Para proporcionar interconexión RPR 802.17 con interfaces redundantes Ethernet, los administradores deben utilizar protocolos de enrutamiento de clientes para servicios IP e introducir Spanning Tree con el fin de evitar bucles. La tecnología RPR multicapa de Cisco ofrece una alternativa que permite a los proveedores interconectar dominios RPR sin utilizar protocolos de control tradicionales del Nivel 2 o alterar los esquemas de enrutamiento de clientes. El RPR de interconexión Dual (DRPRI) proporciona soporte para pares redundantes de conexiones Ethernet back-to-back entre las distintas redes de RPR. 24 Trabajo de Prospección Resilient Packet Ring DRPRI interconnection Con DRPRI, la recuperación entre anillos de transición se produce en menos de 100 ms. Los casos de protocolos de enrutamiento de clientes y Spanning Tree no se tocan, independientemente de los saltos. DRPRI es lo suficientemente flexible como para dar cabida a una variedad de equipos de red, sistemas de enrutamiento y topologías. De hecho, los nodos de conexión redundante no necesitan ser adyacentes o incluso estar cerca unos de otros. Por tanto, podemos concluir que el puente-optimizado multicapa RPR de Cisco, permite a los proveedores entregar transporte de paquetes eficientes sobre la arquitectura de sus redes tradicionales SONET / SDH . El Multicapa RPR de Cisco soporta las características más importantes de RPR, incluyendo el transporte en anillo bidireccional, la reutilización espacial para ahorrar ancho de banda y la rápida recuperación de enlace. Habrá que estar atentos, ya que esta empresa seguirá dando muestras de su compromiso proporcionando nuevas soluciones RPR basadas en el estándar IEEE 802.17. Estas nuevas soluciones serán compatibles con el actual protocolo multicapa RPR de Cisco, que permite a los proveedores de servicios que tomen 25 Trabajo de Prospección Resilient Packet Ring medidas rápidamente para prestar servicios de valor añadido para satisfacer la demanda de los clientes y, al mismo tiempo, proteger sus inversiones en los próximos años. 6. APLICACIONES a. Redes MAN y WAN . Evolución. Tradicionalmente los datos se han estado transportando sobre redes ATM y SDH. Hoy en día, la tendencia es llevar la conexión Ethernet desde la central del proveedor hasta el abonado, ya que todos los servicios que se están ofreciendo y se van a ofrecer a los usuarios finales están basados en el mundo IP. Además las redes Ethernet cada vez se van haciendo más grandes y se les va pidiendo mayor ancho de banda, rapidez y fiabilidad. i. Nuevos Requerimientos en Redes MAN y WAN Al haber entre el abonado y el proveedor de servicios una comunicación de paquetes, pero sobre una red optimizada para servicios TDM, nos encontramos con un problema. Es necesario evolucionar las redes MAN y WAN. Por lo tanto, ¿qué se le va a pedir a esta nueva manera de transporte? Se le pide que combine los beneficios de la tecnología SDH con los de la Ethernet; — Compartir el ancho de banda de manera dinámica. — Eliminar la ingeniería de circuitos. — Gestión sencilla y simplificada. — Reutilización espacial. — Protección eficiente. — Transporte de video y voz. — Cumplir con compromisos de calidad de servicio. — Protección en anillo en menos de 50 ms. La tecnología Ethernet ha evolucionado muy rápidamente en los últimos años, con la aparición en el año 1998 del estándar IEEE 802.3z, mas conocido por Gigabit Ethernet y en el 2002 con el estándar de 10GigabitEthernet ó 802.3ae. La evolución de la tecnología Ethernet ha provocado que sea la tecnología dominante en las Redes de Área Local (LAN). Lo cuál hace que se establezca cada día mas firme en el ámbito empresarial, con aproximadamente 95 % del tráfico en todas las empresas, con un estimado de 200 millones de puertos Ethernet en Redes Metropolitanas o Redes Troncales (Backbones) de interconexión de LAN. Tres factores son los fundamentales en el rendimiento de una red Ethernet: el tamaño de la trama, el número de estaciones en la red y el tiempo de propagación entre estaciones. Las LAN con tecnología Ethernet no garantizan la mayoría de los parámetros necesarios para la obtención de Calidad en el Servicio tales como: disponibilidad, pérdida de tramas, reordenamiento de tramas, duplicación de tramas, retardo de tránsito y tiempo de vida de la trama. Por lo tanto, Ethernet no fue diseñada pensando en la calidad de los servicios. La solución más extendida ha sido la fuerza bruta, es decir, sobredimensionar el sistema para que no se 26 Trabajo de Prospección Resilient Packet Ring congestione. Aquí es donde entra MPLS (Multiprotocol Label Switch), el cual es una tecnología de conmutación de paquetes que se encuentra entre los niveles 2 y 3 del modelo OSI, lo que posibilita mejorar la funcionalidad de capa 2 en Ethernet sin sacrificar sus prestaciones. Luego entonces MPLS es estratégicamente importante debido a que ofrece una clasificación y conducción rápida de paquetes y que dispone de un mecanismo de túnel eficiente. EoMPLS (Ethernet over MPLS) ofrece servicios de determinación de rutas en grandes redes, proporciona calidad de los servicios, establece grupos de usuarios privados, ancho de banda reservado, mecanismos de seguridad e ingeniería de tráfico. Ambas arquitecturas se complementan perfectamente: el encapsulado MPLS y la conmutación Ethernet en la red metropolitana, ofreciendo conectividad punto a punto y el soporte para un servicio de LAN privada virtual (VPLS). Por último, el factor de una rápida recuperación es vital en redes de área Metropolitana, para lo cual se integra una tercera tecnología en el intento de converger a las redes Ethernet al área Metropolitana, esta tecnología se concibe bajo el grupo de estandarización IEEE 802.17 (Resilient Packet Ring), un mecanismo que nos asegura una confiabilidad en el transporte de tramas Ethernet mediante restauraciones rápidas de fallos en los enlaces, gracias a su doble anillo y equidad en el reenvío de tramas sobre el núcleo de la red metropolitana. ii. Evaluación de la Calidad de los Servicios en Redes E-MAN Una de las características distintivas de las redes MAN de hoy es su alta tolerancia a fallos. No es una casualidad que la topología que predomina en este tipo de redes sea la de anillos dobles. Los anillos de por sí son particularmente interesantes porque representan la conectividad física más baja posible entre un conjunto de nodos, al mismo tiempo que garantiza dos conexiones diferentes entre cualquier par de nodos. Además, en caso de fallo de un cable o de un nodo, el tráfico correspondiente puede ser automáticamente re-conducido por otra dirección alrededor del anillo. Esta forma de protección alcanzó su máximo desarrollo con las técnicas SDH/SONET que son capaces de restablecer el tráfico en 50 ms después de un fallo. En las E-MAN estas técnicas de protección no sirven ya que con las mismas se protege la carga útil a nivel de contenedor. Esto es perfecto si el tráfico entre nodos se organiza en contenedores TDM. Pero, en el caso de las E-MAN, la totalidad del tráfico está en forma de paquetes y no hay circuitos entre nodos. En consecuencia es necesario organizar la protección a nivel de paquete. Ethernet siempre se ha basado en el STP (Spanning Tree Protocol) para restablecer los fallos en los enlaces. Un árbol de descubrimiento define una topología sin bucles sobre la red, y se define así un camino único, que un paquete seguirá por la red. Cuando sucede un fallo de un enlace o de un nodo, el árbol de descubrimiento se recalcula. Aunque se hace automáticamente mediante STP (STP IEEE 802.1d), pueden pasar hasta 50 segundos antes que la red se reconfigure. El IEEE ha considerado dos opciones para mejorar esto: la primera optimiza el protocolo STP, mientras que la segunda introduce una nueva capa MAC específica para arquitecturas metropolitanas en anillo, Anillo de recuperación de paquetes (RPR; Resilient PacketRing). Podemos obtener una descripción de parámetros de la calidad de los servicios de cada una de las tecnologías involucradas en la red e-man. En la siguiente tabla se considera que tres tecnologías son esenciales para la convergencia en la red e-man: Paquete de Anillo Optimizado (RPR), Gigabit Ethernet y Conmutación de Etiquetas Multiprotocolo (MPLS). Cada una de 27 Trabajo de Prospección Resilient Packet Ring estas tecnologías presenta diversos parámetros de calidad de los servicios y desempeño que las caracterizan. Se describen también los tipos de pruebas que se proponen ejecutar en cada una de las tecnologías. b. Servicios Ofrecidos sobre RPR i. Triple Play RPR se puede utilizar de muchas formas para distribuir diferentes servicios. El último “rumor” acerca de servicios "triple play" es que ofrece servicios RPR como una pareja perfecta para el servicio de agregación de tráfico en zonas metropolitanas. Triple Play incluye servicios de voz, vídeo y datos, aunque existen algunos matices para cada uno de ellos. Proporciona servicios de voz en tiempo real de tráfico de voz, por ejemplo, una llamada telefónica, grabaciones, distribución streaming de música... Tradicionalmente, los servicios de vídeo incluyen distribución streaming de video, por ejemplo, vídeo bajo demanda. Este último servicio también pueden incluir Teleconferencias , servicio en tiempo real. Estas diferencias en los servicios requieren diferentes niveles de QoS de los mecanismos de transporte en la red. 28 Trabajo de Prospección Resilient Packet Ring RPR funciona bien para ofrecer todos estas aplicaciones debido a los diferentes tipos de clase de servicios definidos en IEEE 802.17: clases A, B y C, descritos anteriormente en el apartado de prestaciones. Dado este conjunto de servicios, está claro que los servicios de voz o video en tiempo real usarán la Clase A para mantener la latencia más baja posible y garantizar el ancho de banda. La distribución streaming de video y voz usaría la clase B. Y finalmente, los servicios de datos usarían la clase C. Este esquema proporciona el uso más eficiente del ancho de banda disponible en la red. Aunque, algunos proveedores de servicios podrían proporcionar servicios de datos de clase B para aquellos clientes dispuestos a pagar más. RPR puede soportar múltiples tasas: 1G, 2.5G, y 10G, que son las tasas estándar. Esto permite escalabilidad en la tecnología para acomodarla al crecimiento de la red. El transporte de 1G usa como capa física Gigabit Ethernet, el de 2.5G usa SONET OC48 y el de 10G usa SONET OC-192 o 10GE. A continuación se adjuntan tres diagramas de red de servicios que habilita RPR combinando las ventajas de SDH y Ethernet. 29 Trabajo de Prospección Resilient Packet Ring ii. Red de retorno inalámbrica (Wireless Backhaul) Otra interesante aplicación de RPR es el transporte sobre redes de retorno inalámbricas. Las clases de servicio de RPR funcionan bien para garantizar la baja latencia requerida para los servicios de voz en tiempo real. La figura 2 muestra una posible red basada en la arquitectura de red de UMTS y en RPR. 30 Trabajo de Prospección Resilient Packet Ring RPR puede eliminar gran parte de la complejidad en los interfaces Iu’x’ debido a que incorpora la QoS de los servicios de transporte en el nivel 2 en vez de dentro de los PCVs ATM, que son ineficientes en ancho de banda. Un escenario común de aplicación es MPLS sobre RPR. Usando LSP estático, MPLS puede proporcionar la dirección secundaria para puertos que son transportados sobre RPR. Sobre todo, estas aplicaciones muestran que RPR tiene un amplio espacio de mercado y puede tener un papel clave en servicios de futuro. Otra cosa a destacar el la falta de tecnología RPR disponible para habilitar el despliegue del estándar. Las FPGAs son un dispositivo ideal para soportar RPR si se puede conseguir una implementación eficiente que no haga los costes de la tecnología prohibitivos. 7. CONCLUSION A lo largo de este trabajo se ha discutido y explicado la arquitectura RPR. Hemos visto como RPR ha tomado características de protocolos anteriores basados en anillo y los ha combinado en una arquitectura coherente y novedosa. Las piezas importantes que se han cubierto en este trabajo incluyen el esquema de prioridad basado en clases, el diseño de estación, la equidad (fairness) y la resistencia (resilience). Se ha descrito cómo los métodos agresivos fairness actúan muy rápidamente para tratar de adaptarse a un cambio en la carga de tráfico. RPR es una nueva tecnología de la capa MAC que puede abarcarse en redes MANs y WAN. RPR también puede realizar conmutación en la red troncal, dejando que un anillo RPR implemente enlaces virtuales punto a punto entre los routers conectados a las estaciones del anillo. Además, puede diferenciar tráfico; por tanto, cuando se usa para implementar enlaces IP, puede ayudar a los routers que utilizan este protocolo a implementar la QoS que requiere la comunicación en una red que transporta tráfico multimedia. 31