TEMA 1 TCP/IP: LOS PROTOCOLOS DE LA RED INTERNET 1
Anuncio

Redes
TEMA 1 TCP/IP: LOS PROTOCOLOS DE LA RED INTERNET
Tema 1
TCP/IP: Los protocolos de la red
Internet
1. Estructura de protocolos en
Internet
2. Redes de acceso a Internet
3. El IP
4. El ARP
5. El ICMP
6. Protocolos de nivel de
transporte
7. El UDP
8. El TCP
1. ESTRUCTURA DE PROTOCOLOS EN INTERNET
El modelo de red Internet consta sólo de 4 partes o niveles: Todo lo que
hay por debajo del IP, el IP, el TCP y lo que hay por encima del TCP:
Modelo de red
Nivel de red: Está formado por una red LAN y constituye todo lo que hay por
debajo del IP es decir, el nivel de red física o simplemente nivel de red.
Nivel IP: O nivel Internet, confiere unidad a todos los miembros de la red e
independientemente de que la conexión sea por ADSL o RDSI, permite que
todos los equipos se puedan interconectar.
Nivel TCP: O nivel de transporte, confiere fiabilidad a la red, lleva a cabo un
control de flujo y errores y solo se implementa por los equipos conectados a la
red y no por redireccionadores o routers.
Nivel de aplicación: Engloba todo lo que hay por encima del TCP y
corresponde a las aplicaciones que utilizan Internet: correo electrónico, www,
ftp…
En cada uno de los niveles de red expuestos anteriormente encontramos
protocolos distintos que podemos observar en la siguiente figura:
El protocolo TCP, va sobre otro protocolo, el IP, y éste último a su vez, va
sobre Ethernet. Todo este encapsulamiento funciona con estructuras
fundamentales que genéricamente se conocen como PDU (protocol data units) pero
en cada nivel tienen nombres diferentes para designar una misma función. En el
nivel más bajo, en Ethernet, se denominan tramas, al ascender en IP se denominan
paquetes y en TCP se denominan segmentos. La consecuencia de todos estos
niveles es que cuando el nivel superior quiere transmitir cierta información, se
provoca una cascada de PDU que va descendiendo hasta el nivel inferior. Así para
transmitir 1 byte de información, éste se encapsula en un segmento TCP con 20
bytes agregados de cabecera. Al bajar al nivel IP se encapsula en un paquete con
otros 20 bytes de cabecera, y finalmente, en el nivel de red se encapsula con otros
2 · Redes
8 bytes de cabecera. Como resultado para transmitir 1 byte de información,
debemos acabar enviando una cadena de 49 bytes.
2. REDES DE ACCESO A INTERNET
Los tres modelos de acceso que vamos a estudiar son el acceso telefónico
(más utilizado en hogares), el acceso ADSL (empresas y hogares) y el acceso
Ethernet.
2.1. El acceso telefónico
El PPP es el protocolo de acceso telefónico, y tiene una trama como la que
se ve en la siguiente figura:
8 bits
8 bits
8 bits
16 bits
Flag
Dirección
Control
Tipo
LCP
Prto. Red
Paquete NCP
Max 200-250
bytes
Datos
Datos LCP
Datagrama IP
Datos NCP
16 bits
8 bits
CRC
Flag
Los campos flag, dirección y control están fijados en valores determinados. El
campo Tipo define la multiplexación de diferentes protocolos que pueden ser:
LCP: Test de enlace y gestión del mismo.
Protocolos de red: Encapsulan paquetes de nivel superior, como puede ser IP.
NCP: Permite que uno de los terminales asigne la dirección de Internet al otro
(redireccionador, máscara…).
La pirámide PDU que vimos en el punto anterior provoca muchas ineficacias en
el transporte, ineficacias que se dejan notar especialmente en protocolos como
Telnet (en tiempo real) y para evitar este problema se utiliza la compresión de
cabeceras de Van Jacobson que mejora considerablemente este problema
eliminando campos inútiles en la mayoría de las conexiones.
La MTU es la longitud máxima de transmisión que, en principio, no tienen
ningún límite y las podríamos hacer tan largas como la probabilidad de error nos
permite (es decir, muy larga), pero el confort de conexión sí se resentirá; se ha
lelgado al acuerdo que el usuario debe recibir una reacción a sus acciones en una
décima de segundo como máximo, dado que retrasos superiores provocan
cansancio y dan la sensación de poca velocidad en la máquina. Si estamos
utilizando un protocolo como Telnet a la par que otro como FTP o web que tienen
paquetes más largos, y los nuestros en tiempo real (telnet) deben esperar en la
cola de espera a los demás, ralentizamos exageradamente a transmisión, por ello
se establece un límite máximo del tamaño del paquete que puede ser enviado con
cualquier protocolo, y en conexiones PPP la MTU está entre 250 y 500 bytes.
2.2. Acceso ADSL
El ADSL ofrece más ventajas que la línea telefónica convencional, dado que
deja libre la línea para llamadas mientras se está conectado a Internet; para ello se
realiza una división del espectro de frecuencias que se puede recibir por el par de
hilos telefónicos, hasta 4 kHz (la voz que puede alcanzar el oído humano) y a partir
de aquí el espectro de codificación del ADSL, y se pueden alcanzar velocidades de
hasta 1,92 Mbps de entrada y 15,36 Mbps de salida; aunque es difícil alcanzar este
límite máximo y las operadores solo ofrecen hasta 8 Mbps en la mejor conexión
ADSL.
Redes · 3
2.3. Acceso LAN: El protocolo Ethernet
La simplicidad de este protocolo y no sus prestaciones, ha hecho que sea el
más utilizado en redes de área local, desde que DEC, Intel y Xerox establecieron un
estándar. Hay que saber que en las redes de área local lo que una estación
transmite es recibido por todas las demás, pero una estación en concreto sabe
cuando una trama va destinada a ella porque lee todas las que le llegan y
comprueba la dirección de destino, lógicamente rechaza todas las que no vengan a
ella (aunque se puede configurar toda tarjeta en modo promiscuo, “escuchando”
todas las informaciones que pasen por ella, aunque no sea su dirección de destino).
64 bits
Preámbulo
48 bits
@destino
48 bits
2origen
16 bits
Tipo
Entre 46 y 1500 bytes
Datos
32 bits
CRC
Los campos que forman la trama Ethernet son:
Preámbulo: Formado por 64 bits, alternativamente 0 y 1 y los dos últimos son
11. Obviaremos su presencia en el resto del temario pues solo indica el inicio
de la trama.
Dirección de origen: Lleva la dirección física o dirección MAC del transmisor de
la trama. Sobre papel, las direcciones LAN se escriben en hexadecimal,
separando los bytes con dos puntos y escribiendo primero el byte menos
significativo, por ejemplo: 08:00:00:10:97:00.
Dirección de destino: Dirección MAC de destino.
Tipo: Indica el tipo de contenido del campo de datos que lleva la trama.
Datos: La longitud debe ser múltiplo de 8 bits, es decir Ethernet transmite la
información en bytes; la longitud máxima, es decir, su MTU es de 1500 bytes; y
además el campo de datos debe tener como mínimo 46 bytes de longitud.
CRC: Es el código de redundancia cíclica para la detección de errores y abarca
toda la trama a excepción del preámbulo.
3. EL IP
IP y TCP son un par de protocolos bien compenetrados. El IP es un
protocolo de interconexión de red orientado a datagrama por lo que no es capaz de
recuperar tramas perdidas ni de garantizar que las tramas se entregarán en el
orden correcto ni que el ritmo de recepción sea el adecuado para que el
destinatario pueda procesar convenientemente los datos. El IP es del tipo “best
effort” o con la mejor intención; para subsanar estas deficiencias del IP tenemos al
TCP.
Las Direcciones IP
Estas direcciones son únicas para cada máquina, aunque para ser más
precisos, cada dirección es única para cada una de las interfaces de red IP de cada
máquina, así si una máquina dispone de más de una interfaz de red, necesitará una
dirección IP para cada una. Las direcciones IP tienen una longitud de 32 bits, y se
suelen escribir los 4 bytes que lo componen en decimal separados por puntos, por
ejemplo 147.83.153.100.
Para conseguir que no haya ninguna dirección repetida, Internetp dispone
de una organización denominada InterNIC que se dedica a esta tarea.
La máscara de red se utiliza para poder gestionar un conjunto de
direcciones internamente. La máscara de red nos permite esta flexibilidad, a través
de 32 bits de máscara podemos saber si el destino de un paquete se encuentra
dentro de la misma red de área local que el origen o si por el contrario, se
encuentra en una LAN remota y por tanto debe delegar su transmisión a algún
equipo de su misma LAN. Todas las estaciones de una misma red de área local
deben utilizar el mismo identificador de red y es preciso que todas las estaciones
posean la misma máscara. Así, si tenemos dos estaciones 147.83.153.100 y
4 · Redes
147.83.153.200 podemos deducir que están interconectadas directamente, si la
máscara de su red es 255.255.255.0. Una notación alternativa es proporcionar el
número de bits 1 de la máscara, así pues 255.255.255.0 es una máscara de 24 bits
y 255.255.255.128 es de 15 bits; y se notaría así: 147.83.153.100/24
Existen direcciones de propósito especial como son:
Direcciones de red: Se expresan con la dirección que tendría cualquier
estación suya y con los bits del identificador de estación a 0. Poe ejemplo la red
en que se encuentra la estación 147.83.153.100/24 es la 147.83.153.0/24.
Dirección 127.0.0.1: Loopback es una dirección no válida para los paquetes
IP y lo utiliza el software de red para transmitir paquetes a la misma máquina
local.
Dirección 255.255.255.255 (broadcast): Solo es válida como dirección de
destino de un paquete y sirve para enviar paquetes a todas las estaciones
localizadas dentro de la misma LAN que la máquina de origen.
El formato del paquete IP
Versión
Longitud
de
cabecera
4 bits
4 bits
Tipo de
servicio
Longitud
total del
paquete
Identificación
del paquete
Indicadores
Posición de
este
fragmento
Tiempo
de vida
TTL
Protocolo
Checksum
@origen
@destino
Opciones
16 bits
16 bits
3 bits
13 bits
8 bits
8 bits
16 bits
32 bits
32 bits
<=40 bits
Versión: Para la versión actual IPv4 siempre vale cuatro (0100).
Longitud de la cabecera: El número de bytes de la cabecera siempre debe ser
múltilplo de 4, asimismo la longitud de la cabecera está limitada a 60 bytes
puesto que 15 es el máximo que se puede expresar con 4 dígitos binarios.
Tipo de servicio: Contiene a su vez varios subcampos aunque raramente se
implementa.
Longitud total del paquete: Como este campo es de 16 bits, un paquete IP no
puede tener más de 65.535 bytes.
Identificación del paquete: Identificador distinto para cada paquete
Indicadores y posición de este fragmento: Permiten gestionar la fragmentación
de paquetes. Se divide en DF, + y un bit añadido. Recordemos que existe la
MTU de la interfaz de red que restringe el tamaño máximo del paquete según
el protocolo utilizado que se puede enviar. Si mandamos un paquete a una red
con MTU inferior al tamaño de ese paquete, debemos fragmentarlo y los
nuevos fragmentos tienen características comunes: tienen el mismo
identificador de paquete en las cabeceras IP, indican en el campo Posición de
este fragmento (lo veremos después) el primer byte de datos del fragmento
dentro del paquete original. El bit + del campo indicadores es 1 en todos los
fragmentos a excepción del último, por lo que se le suele denominar a este
campo “hay más?”. El resto de los campos de la cabecera se copia
íntegramente excepto claro está el indicador de longitud del paquete y el
checksum que debe calcularse de nuevo. Como el direccionador de Internet
hace el trabajo mínimo, el responsable de recomponer todos los fragmentos es
únicamente la estación de destino. Cuando le llega un paquete fragmentado
reserva memoria suficiente (65536 bytes) para tratarlo y pone un temporizador
en marcha dado que no sabe la longitud completa de lo que ha de llegar. Si
pasado el tiempo no llegan todos los fragmentos se descarta todo lo recibido y
el nivel TCP (el IP no es capaz) es el responsable de pedir una retransmisión
nueva cuando sea posible.
Tiempo de vida o TTL: Indica el número máximo de direccionadores que
pueden cruzar el paquete. Y sirve para evitar que un paquete pueda quedar
dando vueltas indefinidamente dentro de la red en caso de que haya algún
problema al entregarlo. Cada direccionador disminuye el campo en 1 y cuando
Redes · 5
llega a 1 el siguiente direccionador lo elimina y envia al originario del mensaje
un error.
Protocolo: Identifica el tipo de protocolo que transporta el paquete.
Checksum: Realiza el control de errores en la cabecera para evitar posibles
errores en su contenido. Aunque a decir verdad tampoco es demasiado fiable,
es decir, el algoritmo es fácil y rápido de calcular (suma aritmética de los bytes
de la cabecera agrupados de dos en dos), pero por ello mismo poco fiable.
Dirección de origen IP: el que envía el paquete.
Dirección de destino IP: El destinatario del mismo.
Opciones: Hay varios servicios que se pueden implementar aquí, aunque
generalmente no se utilizan
Direccionamiento y direccionadores
Los direccionadores deben interconectar dos o más subredes IP y
encargarse de direccional el tráfico destinado a estaciones remotas. Cada
direccionador no decide la ruta entera de un paquete de datos, sino solo el trozo de
ruta en que participa y debemos saber que entre origen y destino de un paquete
tenemos un número variable de saltos y por tanto de direccionadores. Esto plantea
varios problemas: Cuando se salta entre varias redes, hay que averiguar la
correspondencia entre direcciones IP y MAC, aunque el paquete no tenga la
dirección MAC el mapeado IP-MAC realizado por el protocolo ARP es capaz de
solventar este problema; además también el direccionador debe decidir en cada
momento cual es el siguiente direccionador a utilizar.
Para esto se utilizan las tablas de direccionamiento que disponen de
información limitada, pero suficiente en cada salto, para permitir la conexión de
todas las subredes que componen Internet. Todo equipo conectado a una red IP
necesita una tabla de direccionamiento. Vamos a distinguir a continuación dos
tablas de direccionamiento, para una estación con una única interfaz o con más de
una:
1
2
3
4
5
Tabla de direccionamiento de la estación con una única interfaz
Dirección
Máscara
Direccionador
Interfaz
147.83.153.103
255.255.255.255
127.0.0.1
Loopback
127.0.0.0
255.0.0.0
127.0.0.1
Loopback
147.83.153.0
255.255.255.0
147.83.153.103
Ether0
255.255.255.255 255.255.255.255
147.83.153.103
Ether0
0.0.0.0
0.0.0.0
147.83.153.5
Ether0
En la tabla anterior tenemos la tabla de direccionamiento de una estación
conectada a una lan con dirección 147.83.153.103/24 con una única tarjeta
ethernet.
La primera y segunda entradas permiten transmitir paquetes IP a las
direcciones 147.83.153.103 y a todas las direcciones que empiecen por 127. En
ambos casos se envían a la interfaz visual del propio ordenador local, y ninguno
de los paquetes que se direccione con alguna de estas dos reglas saldrá a la
red.
La tercera entrada serña adoptada por todos los paquetes destinados a la red
local.
La cuarta entrada nos indican que los broadcasts IP se restringirán a la red
local, por tanto tiene una importancia relativa.
La quinta entrada permite a la estación comunicarse con estaciones remotas.
Notemos que la máscara no tiene ningún bit en 1 y será la ruta por defecto. El
direccionador establecido queda identificado en la tabla por 147.83.153.5.
6 · Redes
Toda la información anterior se calcula a partir de la dirección local (en el
ejemplo anterior 147.83.153.103), la máscara de la LAN (255.255.255.0) y la
dirección del direccionador (147.83.153.5).
En un direccionador, las tablas de direccionamiento lógicamente tienen más
entradas que las de una estación, aunque el funcionamiento es el mismo.
4. EL ARP
Es el encargado de llevar a cabo la resolución automática del mapeado entre
direcciones MAC. Es decir, cuando efectuamos la transmisión de un paquete entre
dos direcciones LAN, indicamos únicamente la IP, entonces el sistema identifica
esta dirección IP, busca en la caché ARP la dirección MAC a la que corresponde
dicha IP y envía el paquete.
Obviamente no todas las direcciones se encuentran en la caché ARP,
primero porque no mandamos constantemente paquetes a todas las IP-MAC
posibles, pero además las direcciones que se encuentran en la caché caducan en
un espacio de tiempo breve, entre uno o varios minutos.
Cuando se desconoce la MAC de destino y no se encuentra en la caché
ARP, se envía una petición ARP que transporta la dirección IP que se quiere
conocer (con una trama broadcast FF: FF: FF: FF: FF: FF; todas las estaciones de la
LAN procesan la trama pero solo la poseedora de la IP pedida contesta; entonces
se produce la respuesta ARP comunicando la dirección MAC directamente a quien
la ha pedido. Los formatos de estas peticiones y respuestas son irrelevantes.
5. EL ICMP
El Internet Control Message Protocol se puede definir como un protocolo o
como una herramienta que utiliza el protocolo IP para notificar errores.
Los mensajes ICMP viajan dentro de paquetes IP
(no como los ARP) y existen 13 tipos de mensajes ICMP
como petición de eco, respuesta de eco, redireccionamiento,
petición de hora, el tiempo de vida ha expirado, etc…
El programa ping permite descubrir si una
estación se encuentra activa o no, simplemente efectuando
ping <dirección IP de destino>. La instrucción
Ping envía un menaje ICMP de tipo 8 (petición de eco) con
el destino indicado; el receptor debe responder con un eco
(ICMP tipo 0) lo cual indica que la estación remota está
activa).
Ping
ping 66.194.152.210
Haciendo ping a 66.194.152.210 con 32 bytes de datos:
Respuesta
Respuesta
Respuesta
Respuesta
desde
desde
desde
desde
66.194.152.210:
66.194.152.210:
66.194.152.210:
66.194.152.210:
bytes=32
bytes=32
bytes=32
bytes=32
tiempo=2800ms
tiempo=3146ms
tiempo=3221ms
tiempo=2564ms
Estadísticas de ping para 66.194.152.210:
Paquetes: enviados = 4, recibidos = 4, perdidos = 0
(0% perdidos),
Tiempos aproximados de ida y vuelta en milisegundos:
Mínimo = 2564ms, Máximo = 3221ms, Media = 2932ms
El programa traceroute permite encontrar las rutas entre un origen y un
destino, utiliza un mecanismo bastante ingenioso: Recordemos que cuando un
direccionador recibe un paquete aparte de las funciones que deba llevar a cabo,
reduce en una unidad el valor del campo TTL (tiempo de vida) y en caso de que el
resultado sea 0 el paquete debe eliminarse, pero además se envía una notificación
de la misma al originador del paquete. Pues bien, el programa traceroute
simplemente debe enviar paquetes al destino con TTL secuencialmente
ascendentes, es decir, comienza con TTL=1 que será rechazado por el primer
redireccionador, el TTL=2 superará este primero pero será rechazado por el
segundo, etc. hasta llegar a su fin.
TTL=47
TTL=47
TTL=47
TTL=47
Redes · 7
tracert 66.194.152.210
Traza a la dirección 66-194-152-210.gen.twtelecom.net [66.194.152.210]
sobre un máximo de 30 saltos:
1 <1 ms <1 ms <1 ms 129.Red-213-97-197.pooles.rima-tde.net [213.97.197.129]
2 1533 ms 1636 ms 1821 ms 129.Red-213-97-197.pooles.rima-tde.net [213.97.197.129]
3 2036 ms 2231 ms 2154 ms 19.Red-80-58-11.pooles.rima-tde.net [80.58.11.19]
4 2093 ms 2172 ms 1970 ms 37.Red-80-58-76.pooles.rima-tde.net [80.58.76.37]
5 2188 ms 1696 ms 1401 ms 17.Red-80-58-72.pooles.rima-tde.net [80.58.72.17]
6 2186 ms 2215 ms 1988 ms 242.Red-80-58-73.pooles.rima-tde.net [80.58.73.242]
7 2031 ms 1677 ms 1969 ms 114.Red-80-58-72.pooles.rima-tde.net [80.58.72.114]
8 1689 ms 1787 ms 1512 ms GE4-1-0-0-grtmadde1.red.telefonica-wholesale.net [213.140.50.149]
9 1294 ms 1590 ms 1364 ms So5-1-0-0-grtmadpe1.red.telefonica-wholesale.net [213.140.36.113]
10 1797 ms 1851 ms 1701 ms So7-0-0-0-grtparix1.red.telefonica-wholesale.net [213.140.36.146]
11 2309 ms 1844 ms 2446 ms P14-0-grtwaseq1.red.telefonica-wholesale.net [213.140.37.190]
12 2303 ms 2074 ms 2166 ms timewarner-2-1-grtwaseq1.red.telefonica-wholesale.net [213.140.39.246]
13 2020 ms 1507 ms 1655 ms 66.192.255.228
14 1423 ms 1269 ms 1534 ms core-02-so-0-0-0-0.atln.twtelecom.net [66.192.255.23]
15 1506 ms 1229 ms 1335 ms 66.192.243.15
16
*
1492 ms 1588 ms dist-01-ge-2-3-0-0.mtld.twtelecom.net [66.192.243.129]
17 1891 ms 1805 ms 1562 ms hagg-01-ge-0-3-0-0.mtld.twtelecom.net [66.192.243.146]
18 1558 ms 2216 ms 1923 ms 66.162.30.58 19 1260 ms 1195 ms 1422 ms 66-194-152-210.gen.twtelecom.net
[66.194.152.210]
Traza completa.
6. PROTOCOLOS DEL NIVEL DE TRANSPORTE
Modelo de red
El objetivo principal del nivel de transporte es actuar de interfaz entre
los niveles orientados a la aplicación y los niveles orientados a la red de
jerarquía de protocolos. El nivel de transporte oculta a los niveles altos del
sistema el tipo de tecnología al que está conectado el Terminal. Por encima
del TCP e IP tenemos el puerto, y por debajo la dirección IP.
Las aplicaciones que podemos encontrar son muy variadas y necesitan
un protocolo de nivel de aplicación como puede ser FTP, http, SMTP, SNMP,
etc. Por tanto, cuando se establece la comunicación no sólo es esencial
conocer la IP del Terminal o servidor de destino, sino también el puerto que
identifica la aplicación de destino. Así se utilizan puertos como:
7 para el servidor de eco.
20 y 21 para el FTP de datos y control y POP3
80 para http (Internet).
Las comunicaciones se realizan en forma cliente/servidor. El cliente, como
hemos dicho antes, necesita conocer no solo la dirección IP de la máquina
servidora para poder comunicar con ella, sino también el puerto de aplicación con
que desea comunicarse con el cliente: ftp, http, correo electrónico…
Jerarquía de protocolos TCP/IP
7. EL UDP
El UDP es un protocolo no orientado a
la conexión, de manera que no proporciona
ningún tipo de control de errores, como vemos
en la figura lateral, por debajo utiliza el IP para
su transmisión.
Recordemos
que
hablamos
de
datagramas, y, en este caso también
recordemos que no garantiza la fiabilidad, pues
el UDP utiliza el protocolo best-effort, es decir,
hace lo posible por transferir los datagramas,
pero no garantiza su entrega. Se compone la
cabecera del paquete de:
8 · Redes
Puertos de origen y destino, cada uno con 16 bits.
Campo Longitud: otros 16 bits.
Checksum: otros 16 bits, aunque el cálculo del checksum al igual que en el
protocolo IP no es demasiado fiable.
El UDP es útil para entregar información en modo multicast o broadcast a un
grupo de usuarios o todos los usuarios de la red sin esperar respuesta de ellos. En
principio la ventaja que representa el UDP sobre el IP que en principio también
podría hacer todo esto es que el UDP ofrece un servicio de multiplexación a las
aplicaciones que el IP no ofrece.
8. EL TCP
El TCP a diferencia del UDP proporciona fiabilidad a la aplicación, es decir,
garantiza la entrega de toda la información en el mismo orden en que ha sido
transmitida por la aplicación de origen, sus principales características son:
Transmisión libre de error: La información se transmite “casi libre” de errores,
puesto que siempre puede haber algún error que se quede oculto.
Garantía de entrega de la información y de la secuencia de la transmisión.
Eliminación de duplicados: Si se reciben copias a causa del mal funcionamiento
de la red, el TCP las eliminará.
El TCP utiliza el concepto buffered transfer es decir, cuando se transfiere la
información el TCP divide el flujo en trozos del tamaño que más le convenga,
esperando si hay poca información a llenar un buffer completo para ser enviado o
mandar la información sin que la memoria intermedia esté completamente llena.
El formato del segmento TCP es como sigue:
Puerto
de origen
Puerto
de
destino
Número de
secuencia
Número
ACK
Longitud
de la
cabecera
Reservado
Control
Ventana
Checksum
Urgent
Pointer
Opciones
TCP
16 bits
16 bits
32 bits
32 bits
4 bits
4 bits
6 bits
16 bits
16 bits
16 bits
32 bits
Los campos puerto de origen y destino identifican la aplicación en el Terminal
de origen y destino respectivamente.
Número de secuencia identifica el primer byte del campo de datos, pues en el
TCP no se numeran segmentos, sino bytes.
El número ACK menos uno indica el último byte reconocido.
La longitud de cabecera indica eso mismo, puede ser de 20 bytes, pero si se
utiliza el campo opciones, puede llegar a 60 bytes.
El campo reservado lo está y se suelen utilizar ceros.
El campo control está formado por 6 indicadores independientes: URG
(urgente), ACK (si esta a 1 el campo número ACK tiene sentido), PSH (dice al
receptor si está a 1 que envíe todos los datos aunque la memoria intermedia no
esté completamente llena), RST (reset de la conexión), SYN (inicio y
resincronización de la conexión) y FIN (fin de la transmisión).
El campo ventana indica cuantos bytes componen la ventana de transmisión,
en los protocolos de enlace el tamaño de la ventana era constante, pero ahora
un extremo TCP advierte al otro extremo de la cantidad de datos que está
dispuesto a recibir en cada momento.
El campo checksum, como siempre detecta errores.
Urgent Pointer tiene sentido cuando URG está a 1 e indica que los datos que
envía el origen son urgentes e identifica el último byte del campo de datos que
también lo es.
Opciones TCP permite añadir campos a la cabecera para marcar el tiempo en
que se transmitió el segmento, aumentar el tamaño de la ventana, indicar el
tamaño máximo del segmento MSS. Cuanto mayor sea el tamaño MSS (tamaño
Redes · 9
máximo del segmento) más datos enviaremos y más amortizaremos las
cabeceras que enviemos, pero claro dependemos de la MTU local. Podemos
antes de empezar la conexión preguntar cuánto vale la MTU local y ajustar ese
mismo valor para la MSS o fragmentar el MSS en caso de que la MTU sea
menor.
Establecimiento y cierre de la conexión
Para establecer una conexión se utiliza el protocolo 3way
handshake, en el que hacen falta 3 segmentos TCP para iniciar
la conexión. Veamos como se desarrolla la secuencia de
comandos:
Segmento de petición de la conexión: El cliente TCP envía
este segmento para iniciar la conexión, se conoce como
segmento SYN porque tiene activado el bit SYN en el ampo
control de la cabecera, el número de secuencia es elegido al
azar.
Segmento de confirmación de la conexión: El servidor TCP
responde con un segmento SYN que indica el número de
secuencia inicial que utilizará y el ACK del segmento SYN es
igual al ISN del cliente más uno.
Segmento de reconocimiento de la conexión: Se reconoce
la conexión conteniendo el ISN del servidor más 1; y a partir de
aquí ya se inicia la conexión.
Establecimiento y cierre de la conexión
15:56:54.796091 argos.1023 > helios.login: S 3541904332:
3541904332 (0) win 31744 <mss 1460>
15:56:54.796091 helios.login > argos.1023: S 548133143:
548133143(0) ack 3541904333 win 8760 <mss 1460>
15:56:54.796091 argos.1023 > helios.login: . ack 548133144
<mss 1460>
En este ejemplo vemos como argos intenta conectarsea Helios eligiendo ISn 35..32,
luego responde Helios devolviéndole ese número más 1 como ACK y diciendo que
espera recibir mandar segmentos con tamaño 1460 (igual que argos). Finalmente
Argos responde con ack del helios más uno.
Esta conexión abierta se dice que es activa por parte del que envía el
primer segmento, en este caso argos y pasiva del que la recibe. Para el cierre de la
conexión normalmente se considera cierre activo el del cliente y pasivo el del
servidor.
Cuando se cierra la conexión el cliente envía un segmento TCP del tipo FIN
con el número de secuencia correspondiente; el servidor envía una confirmación de
cierre por medio de un ACK con el número de secuencia recibido más uno. El
servidor envía un segmento TCP de tipo FIN con el número de secuencia
correspondiente al cliente y este responde automáticamente con el número más
uno.
15:57:01.616091
15:57:01.616091
15:57:01.616091
15:57:01.616091
helios.login > argos.1023: F 1417:1417 (0) ack 41 win 8760
argos.1023> helios.login: .ack 1418 win 31744
argos.1023> helios.login: F 41:41 (0) ack 58031744
helios.login > argos.1023: .ack 42 win 8760
Los estados por los que puede pasar una conexión tanto al abrirse, como al
cerrarse, pueden observarse en la figura adjunta de la página siguiente.
Transferencia de la información
El TCP envía datos manteniendo un temporizador, cuando éste salta, el TCP
empieza a transmitir.
Cuando el TCP recibe un segmento de datos, envía un reconocimiento.
10 · Redes
Si un segmento enviado es incorrecto (se sabe por el campo checksum) el TCP
descarta ese segmento y envía un segmento con el mismo numero de ACK que
reconoció correctamente la última vez. El transmisor verá un ACK duplicado e
interpretará que no le han reconocido la información.
Si los datos llegan desordenados (reconozcamos que por debajo tenemos el IP
que no reconoce la información, únicamente la transporta), el TCP los reordena
y los pasa correctamente a la aplicación, si algunos aparecen repetidos, los
descarta.
Como el TCP posee una memoria limitada, se realiza un control de flujo
mediante el campo ventana que estudiaremos posteriormente.
Estados por los que puede pasar una conexión
Hay dos tipos de información que se
puede enviar: la transmisión de datos
interactivos y la transmisión de un gran
volumen de datos; Ambos, para aprovechar
los recursos de la red, se tratan de forma
distinta. En el caso de datos interactivos:
Reconocimientos retrasados: Es habitual
que el TCP no envía en este caso los
reconocimientos ACK inmediatamente
tras recibir los datos, sino que espera un
tiempo a que haya datos que
retransmitir en sentido contrario. Por
ejemplo en la aplicación Telnet es
habitual que retransmitamos muy pocos
datos, por ejemplo para pedir el
contenido de todo un directorio; en este
caso el TCP utiliza un temporizador de
hasta 200 ms por si hay datos que
transmitir antes de enviar el ACK.
Algoritmo de Nagle: Cuando tenemos
muy pocos datos que enviar, por
ejemplo solo 1 byte, recordemos que le añadimos entre el TCP y el IP 40 bytes
de cabecera, y esto es poco práctico. El algoritmo de Nagle se utiliza para que
se puedan enviar segmentos pequeños sin que se haya reconocido; eso sí solo
se puede enviar uno a la red y esperar a que sea recibido para poder mandar el
siguiente. Esto es útil cuando el segmento debe atravesar WAN, pero si es una
LAN no es necesario; e incluso se debe desinhibir para determinadas funciones
como es el movimiento del ratón que genera segmentos de pocos bytes pero
que deben mandarse inmediatamente.
Para los grandes volúmenes de datos el tratamiento es diferente, se basa
en la ventana deslizante donde la ventana de transmisión no es fija sino
variable. La idea es que cada extremo TCP regula la cantidad de datos que el otro
extremo puede transmitir, con esta finalidad cada extremo notifica al extremo
opuesto cada vez que envía un segmento, la ventana que puede aceptar en ese
momento y el par TCP se actualiza con esa información. Hemos de recordar que un
reconocimiento reconoce posiciones de bytes en el flujo de datos sin tener en
cuenta el segmento al que pertenecen.
En la imagen lateral vemos una ventana de 7 bytes en total; se han
reconocido hasta el byte 999 con lo cual se podría transmitir sin esperar
confirmación hasta el 1006; solo se ha transmitido hasta el 1003, si esto es
reconocido la ventana se deslizaría desde el 1004 hasta el 1010. La ventana puede
variar: puede deslizarse a la derecha a medida que se van enviando y reconociendo
datos, puede cerrarse si el límite izquierdo alcanza el derecho (se cerraría el envío
de datos), puede comprimirse cuando el límite derecho se mueve hacia la izquierda
o puede disminuir si el límite izquierdo se desliza hacia la derecha (esto es menos
Redes · 11
problemático porque a pesar de que se pueden enviar menos datos en el próximo
envío, todos los enviados han sido correctamente reconocidos).
Ejemplo de ventana deslizante
Temporizadores
Los segmentos de datos, pero también los de
reconocimiento se pueden perder durante la
transmisión, por ello se hace necesario utilizar un
temporizador de retransmisiones o RTO. Pero la
cuestión estriba en qué tiempo hay que darle a este
temporizador para considerarlo correcto. Si le damos
el RTT que es el tiempo de ida y vuelta, es decir,
desde que se envía un segmento hasta que ser recibe
el ACK, puede ocurrir digo en este caso RTO=RTT que
el siguiente envío por cualquier causa se retrase un
milisegundo y ya salte el error. Para evitar estos
problemas existen varios tipos de algoritmos que lo calculan:
Algoritmo de retransmisión adaptativo: Se calcula el RTT a partir del RTT medio
y del valor del último RTT; el problema de este cálculo es que no considera las
posibles fluctuaciones.
Algoritmo de Jacobson: Se sirve tanto de la media estimada del RTT como de la
desviación estándar estimada; mejora, en parte, el cálculo del algoritmo
anterior.
Algoritmo de Karn: Hay que tener en cuenta que uno de los parámetros para
calcular los algoritmos anteriores se basa en la medida del tiempo de ida y
vuelta RTT, por tanto si el ACK que llega no es el esperado en la retransmisión
se producen cálculos incorrectos. Karn considera hacer cálculos sólo cuando el
segmento no sea reconocido, duplicando entonces el valor del temporizador.
Algoritmo slow start: Cuando el transmisor emite el mayor número de
segmentos que le está permitido, pero en su viaje, estos segmentos tienen que
atravesar equipos intermedios que se pueden congestionar por muchas
razones, es normal que estos equipos descarten datagramas IP enteros; estos
datagramas le vuelven al origen por la congestión intermedia y la congestión
así aumenta. Este algoritmo permite que el transmisor incremente el número
de segmentos que es preciso transmitir exponencialmente cada vez que recibe
un reconocimiento. Comienza enviando un solo segmento y abriéndose una
ventana de congestión que se inicializa con el valor MSS máximo y cada vez
que se recibe un ACK de reconocimiento, se incrementa en un segmento.
Algoritmo congestion avoidance: Este algoritmo reduce la ventana de
congestión a la mitad cada vez que se pierde un segmento y reduce la
congestión en la red.
Temporizador keepalive: Cuando una conexión TCp no dispone de datos para
emitir, no se envía ningún tipo de información entre el cliente y el servidor pero
la conexión puede estar abierta horas o días enteros si la aplicación no se
cierra. Normalmente, si no hay actividad durante dos horas, el servidor envía
uno o varios segmentos de prueba al cliente y si no hay respuesta, cierra la
conexión; si hay respuesta se vuelve a poner el temporizador a cero.
12 · Redes
TEMA 2 PROGRAMACIÓN DE SOCKETS
1. QUÉ SON LOS SOCKETS
Un socket es un punto de acceso a los servicios de comunicación en el
ámbito de transporte. Para ello, cada socket tiene asociada una dirección diferente
que lo identifica y así se puede establecer una comunicación con él, dentro del
ámbito de la misma máquina como en ámbito mundial.
Los sockets comenzaron con el inicio de la red Arpanet y, por ello, suelen
estar muy unidos al sistema operativo Unix. Por ello algunas llamadas a sockets van
directas al kérnel del sistema y otras están integradas en el lenguaje C.
Actualmente otros lenguajes de programación como Java hacen uso de los sockets.
Como está muy unido al mundo Unix, se sigue su filosofía general de tratar los
sockets como dispositivos y los mecanismos de entrada y salida como ficheros.
Direcciones de Sockets
Es fundamental como hemos dicho anteriormente conocer la dirección de
un socket para poder establecer comunicación con él. Existen dos tipos de nombres
(direcciones) que se le pueden dar a un socket:
El espacio de nombres de ficheros: Se utiliza para sockets que deben
comunicar un proceso con otro del mismo sistema. En este caso el socket
constituye un nombre de fichero y en este sentido, es similar al mecanismo de
comunicación mediante pipes que vimos en sistemas operativos 1, aunque las
pipes solo podían leer por un lado y escribir por otro y, en los sockets, la
comunicación es bidireccional.
El espacio de nombres de Internet: En este caso el nombre se compone del
protocolo concreto que debe utilizarse, de la dirección del nodo de ned
(dirección Internet de la máquina correspondiente por medio de los números
de 32 bits utilizados en el protocolo IP; recordemos que una máquina puede
disponer de múltiples direcciones de Internet, pero cada dirección solo debe
corresponder a una máquina) y también se compone del número de puerto,
dicho número puede ser un valor comprendido entre 1 y 65535, aunque
veremos que hay en el punto siguiente algunas restricciones.
Socket servidor y socket cliente
El socket que inicia la comunicación, en realidad hace una petición por lo
que es el socket cliente, mientras que el que sirve la petición es el socket
servidor. La dirección de este socket servidor es muy importante y debe estar muy
bien determinada, dado que los socket clientes las necesitarán para poder
establkecer la conexión. Hemos dicho que existen 65535 puertos distintos, pero los
1024 primeros suelen estar reservados para servicios estándar como ftp, telnet,
smtp,… con lo que generalmente el socket servidor toma una dirección entre 1024
y 65535.
El número de puerto del socket cliente suele ser irrelevante, tal es así
que se suele dejar al sistema que seleccione uno automáticamente, puesto que
esta dirección solo la tiene que conocer el servidor para saber donde enviar la
petición.
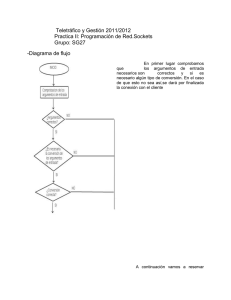
Estilos de comunicación
Existen dos estilos de comunicación o tipos de socket que son:
Estilo secuencia de bytes: Los datos son transmitidos de extremo a extremo
como una corriente o flujo ordenado de bytes. Se denomina orientado a
conexión puesto que cuando se hace utilizando el espacio de nombres de
Tema 2
Programación de sockets
1. Qué son los sockets
2. Sockets con lenguaje C
3. Sockets con lenguaje Java
Redes · 13
Comunicación entre sockets
Internet, se corresponde con el protocolo TCP. Este estilo garantiza
la llegada de todos los datos, sin pérdidas, desordenaciones ni
repeticiones.
Estilo datagrama: Cada vez que el emisor escribe datos, se
transmite un paquete individual o datagrama con dichos datos y
cada vez que el destinatario quiere leer estos últimos, recibe como
máximo un datagrama. Como todos los datagramas tienen la
dirección del socket al que van dirigidos, son independientes, y se
pueden perder por el camino, desordenar, etc. Es un estilo no
orientado a conexión que no garantiza la llegada de todos los datos,
ni su orden, ni su unicidad. La ventaja es que requiere muchos
menos recursos que la secuencia de bytes y se utilizan cuando no es
indispensable la fiabilidad total en la recepción de datos.
La comunicación entre sockets se establece como vemos en
la figura lateral dividiendo las operaciones que deben realizar los
sockets clientes y los servidores
2. SOCKETS CON LENGUAJE C
Vamos a estudiar a continuación las operaciones comunes a
servidores y clientes, luego las propias de los servidores y por último
las propias de los clientes.
2.1. Operaciones comunes a servidores y clientes
Crear un Socket
El prototipo de la llamada básica para crear un socket está declarado en el fichero
cabecera <sys/socket.h> y es
Int socket (int espacio, int estilo, int protocolo)
El primer parámetro, espacio, especifica el espacio de nombres o familia de
protocolos correspondiente al socket y puede ser:
PF_FILE: Espacio de nombres de ficheros.
PF_UNIX: Versiones antiguas de PF_FILE.
PF_INET: Protocolos de Internet
El parámetro estilo indica el estilo de comunicación y puede ser:
SOCK_STREAM: Secuencia de bytes.
SOCK_DGRAM: Datagrama.
SOCK_RAW: Acceso directo a un nivel más superior pero parecido al datagrama
SOCK_SEQPACKET: Datagramas transferidos de manera fiable.
Estos dos parámetros, el espacio y el estilo, limitan el valor del tercer
parámetro protocolo, tal es así que si se deja a 0 puede ser porque para un estilo y
espacio de nombres determinado solo exista un tipo de protocolo o porque así se
deja por defecto el más utilizado establecidos ya los dos primeros.
El valor retornado por el socke es -1 si se ha producido un error y no se ha
podido producir el socket o un número que estará asociado a un descriptor de
fichero.
Hay llamadas que permiten crear dos sockets de un plumazo y ya conectados:
Int socketpair (int espacio, int estilo, int protocolo, int vs[2])
En este caso, los 3 primeros parámetros actúan igual que anteriormente y
el último es la dirección de un vector de enteros que disponga de al menos dos
14 · Redes
elementos. Si la llamada tiene éxito retorna 0 y llena los dos primeros elementos
del vector con los descriptores de los sockets creados. Estos sockets creados deben
pertenecer necesariamente al mismo sistema y al mismo proceso, por lo que quizá
inicialmente no parezca de mucha utilidad, pero si lo es en el caso de
comunicaciones entre un proceso padre y uno hijo.
Asignar dirección a un socket
El fichero cabecera <sys/socket.h> proporciona la definición del tipo sockaddr:
Struct sockaddr
{
Short int sa_family;
Char sa_data […];
};
El tipo sockaddr como vemos contiene los campos sa_family y sa_data. El
primero de ellos indica el espacio de nombres o familia de protocolos y puede ser el
formato de direcciones del espacio de nombres de ficheros (F_FILE y AF_UNIX) o el
formato de direcciones del espacio de nombres de Internet (AF_INET y
AF_UNSPEC). El campo sa_data por su parte, es un contenedor genérico de la
dirección que se quiere representar.
Si utilizamos el espacio de nombres de ficheros debemos especificar los
parámetros sun_family (formato de la dirección) y sun_path (nombre del socket); si
utilizamos el espacio de nombres Internet especificaremos sin:family (formato de
dirección), sin_addr (dirección internet del servidor) y sin_port (puerto al que
conectarse).
Dicho todo esto la llamada para asignar una dirección a un socket
posee el prototipo siguiente:
Int bind (int descr, const struct sockaddr *adr, size_t long_adr)
El parámetro descr es el descriptor del socket, adr es un puntero a la
estructura que representa la dirección que debe asignarse y long_adr cuantos bytes
ocupa esta estructura por si su longitud es variable.
El valor retornado por la llamada bind es 0 si se ha podido asignar
correctamente, -1 si se ha producido algún error, de entre los que destacan que el
primer parámetro no es un descriptor o no es un descriptor válido, no se puede
asignar la dirección especificada desde este sistema, la dirección especificada ya
está asignada a otro socket, etc.
Enviar datos
Para enviar datos podemos utilizar tres llamadas diferentes:
La llamada write envía datos a un socket que sea orientado a conexión o si es no
orientado, que tenga definida una dirección de destino por defecto.
Ssize_t write (int dexcr, const void *datos, size_t longitud);
Descr es un descriptor que puede ser un dispositivo, una pipe, un socket, un
fichero… datos es la dirección de la memoria donde se encuentran los datos que
queremos escribir y longitud indica cuantos bytes queremos escribir.
La llamada send es específica de los socket:
Int send (int descr, const void *datos, size_t longitud, int flags)
Se diferencia de write en el último parámetro, flags, que permite especificar
ciertas opciones de transmisión como son envío de datos urgentes (admitido por el
protocolo TCP) u otras.
Redes · 15
La última llamada que queda es sendto:
Int sendto (int descr, const void *datos, size_t longitud, int flags, const
struct sockaddr *adr, size_t long_adr)
Se diferencia del primer send en que los dos parámetros adicionales
permiten especificar a qué socket deben enviarse los datos por medio de un
puntero a su dirección (adr) y el número de bytes que ésta última ocupa
(long_adr). Si el socket correspondiente es no orientado a conexión esta llamada
envía el socket indicado por los parámetros adr y long:adr un datagrama con los
datos especificados.
En muchos sistemas estas 3 llamadas anteriores retornan cuando los datos
se han copiado en el buffer de transmisión del socket, si el buffer está lleno,
tendrán que esperar hasta que haya suficiente espacio disponible, por lo cual, un
retorno sin error no implica necesariamente una recepción correcta en el socket
remoto.
Recibir datos
De forma análoga a enviar datos, al recibir contamos con 3 llamadas
complementarias:
La llamada read:
Ssize_t read (int descr, void *datos, size_t longitud);
Descr es el descriptor del socket, datos es un puntero a la zona de memoria
en que deben dejarse los datos leídos y longitud es el número de bytes máximo
que queremos leer. Se retorna el valor de bytes leídos, que puede ser menor al
este último parámetro si de momento no hay más disponibles.
La llamada recv es específica de los socket para leer datos, y análogamente a
send, se conforma de:
Int recv (int descr, void *datos, size_t longitud, int flags);
Se diferencia igual que antes en el parámetro adicional flag, que puede servir para
indicar el envío de datos urgentes. Cuando UNIX recibe esta llamada, normalmente
la descarta, pero se puede capturar y definir procesos propios para conferir
prioridad a los datos urgentes sobre los que no lo son.
La llamada recvform lee datos e indica de dónde han venido, opera como sendto y
se conforma de:
Int recvform (int descr, void *datos, size_t longitud, int flags, struct
sockaddr *adr, size_t *long_adr);
La diferencia entre recv y recvform es que la última llena la estructura apuntada
por el parámetro adr con la dirección del socket del que se han recibido los datos
(salvo que este parámetro constituya un puntero nulo).
Esperar disponibilidad de datos
La llamada select en Unix permite esperar hasta que se puedan leer o escribir
datos en algún descriptor de una lsita determinada. Esta llamada también es
aplicable a los sockets y es muy útil cuando un proceso debe recibir datos pro
diferentes canales. El prototipo de la llamada select es:
Int select (int n_descr, fd_set *d_lect, fd_set *d_escr, fd_set *d_excep,
struct timeval *tiempo)
16 · Redes
El tipo fd_set sirve para representar conjuntos de descriptors, struct timeval sirve
para representar un intervalo de tiempo definido en segundos y/o microsegundos.
La llamada select retorna en una de las 4 siguientes condiciones:
Se puede llevar a cabo una lectura sin bloque, o porque hay datos preparados
para ser leidos en alguno de los descriptores especificados en d_lect o porque
hemos llegado al final de los datos.
Se pueden escribir datos inmediatamente en alguno de los descriptores de la
lista especificada en d_escr.
Hay una situación excepcional en alguno de los descriptores de la lista que se
halla en d_excep.
Ha transcurrido el tiempo especificado en el parámetro tiempo.
Cerrar un socket
Se utiliza para ello la llamada close:
Int close (int descr);
Sirve para cerrar un descriptor cuando ya no se va a trabajar más en el
mismo y así liberar los recursos que el sistema tiene ocupados en él. En general si
se cierra un socket que utiliza un protocolo de transmisión fiable y todavía quedan
datos pendientes de enviar, la llamada close no retorna hasta que no se han
acabado de enviar todos los datos.
Existe una llamada más específica que es shutdown que permite dar por
finalizada la comunicación en cualquiera de los dos canales del intercambio de
datos bidireccional.
2.2. Operaciones propias de los servidores
Preparar un socket para recibir conexiones
Con la cláusula:
Int listen (int descr, unsigned int n_petic);
Se crea una cola en la que se iran guardando las peticiones de conexión que
lleguen destinadas a la dirección del socket; como es natural primero los clientes
deben saber la dirección del socket servidor, para poder conectar al mismo, y eso
se asigna previamente con la llamada bin.
Aceptar una petición de conexión
Un socket servidor al que se le haya aplicado la llamada listen, debe utilizar la
llamada accept para establecer las conexiones con los clientes que lo soliciten:
Int accept (int descr, struct sockaddr *adr, size_t *long_adr);
Esta llamada extrae la primera petición de conexión de la cola asociada al
socket indicado por el primer parámetro descr, crea un nuevo socket que tendrá la
misma dirección que el original y estará conectado al originador de la petición. El
valor int retornado es el descriptor del nuevo socket creado, que deberá utilizarse
en el intercambio de datos con el cliente.
Si en el momento de invocar la llamada accept no hay ninguna petición de
conexión a la cola, dicha llamada actúa de la misma manera que read; se bloquea y
se queda esperando hasta que llegue una, salvo que el socket trabaje en modo no
bloqueante.
El servidor inetd
Muchos servidores UNIX se encargan de dar servicio a distintos tipos de
conexiones: FTP, www, pop… En lugar de crear un proceso por cada conexión
Redes · 17
pedida, lo que se hace es crear un único proceso llamado inetd (Internet daemon)
que se encarga de escuchar simultáneamente todos los puertos por los que pueden
llegar peticiones, y cada vez que llega una, arranca un proceso hijo que
proporciona el servicio correspondiente. Al proceso inetd se le pasan los puertos
que debe escuchar por medio de un fichero de configuración denominado
inetd.conf que tiene lo siguientes campos:
Servicio estilo protocolo espera usuario programa argumentos.
2.3. Operaciones propias de los clientes
Conectar un socket
La llamada connect sirve para que un cliente inicie de manera activa una conexión
de la manera siguiente:
Int connetc (int descr, const struct sockaddr *adr, size_t long_adr);
2.4. Operaciones auxiliaries
Obtener direcciones de socket
Hay dos llamadas al sistema que permiten conocer la dirección de un socket local y
el socket remoto al que está conectado.:
Getsockname: int getsockname (int descr, struct sockaddr *adr, size_t
El parámetro adr contiene la dirección del socket correspondiente
al parámetro descr y el parámetro long_adr es un inicio debe contener el
número máximo de bytes de la estructura que deben llenarse.
Getpeername: int getpeername (int descr, struct sockaddr *adr, size_t
*long_adr); éste permite conocer la dirección del socket remoto.
*long_adr);
Convertir direcciones de Internet
Permiten trabajar con la representación de las direcciones IP en la notación textual
de los bytes en decimal separados por puntos (tipo 66.193.215.28) y encontramos
dos llamadas diferentes:
Int inet_aton (const char *text, struct in_addr *adr);
Char *inet_ntoa (struct in_addr adr);
Consultar bases de datos de nombres
Habitualmente lod dos protocolos de nombres más importantes y con los que más
se trabajan son con las direcciones IP y con los números de puerto. Según el
sistema los datos se pueden obtener de un fichero de texto (Unix), por medio de
un servicio de información distribuida local (NIS) o global (DNS de Internet).
Para el servicio NIS obtendremos los nombres con la cláusula gethostbyname
(recibe como parámetro el nombre del servidor, lo busca en la base de datos
correspondiente y si lo encuentra, llena una variable con información sobre el
servidor). También se puede aplicar gethostbyaddr, que realiza una búsqueda
inversa: dada la dirección especificada por los parámetros, retorna la información
del servidor que tiene esta dirección o retorna NULL si no la puede encontrar.
La función getservbyname y getservbyport buscan información sobre el servicio por
el nombre y por el puerto, respectivamente.
18 · Redes
3. SOCKETS CON LENGUAJE JAVA
En lenguaje Java se esconden todos los detalles de implementación que
hemos visto en C y proporcional al programador esencialmente lo que se necesita.
El mecanismo principal es la clase socket que implementa todas las funcionalidades
de los sockets. El constructor de la clase es el equivalente a la función socket de la
librería C, crea el socket, mientras el resto de funciones lo constituyen métodos de
la clase.
Constructor:
Socket (InetAddress adr, int port)
Socket (InetAddress adr, int port, InetAddress adr_local, int port_local)
Socket (string maquina, int port)
Según la manera de especificar el servidor al que se quiere conectar condiciona
cual de los constructors se ejecuta:
La primera consiste en pasar por parámetro la Dirección IP y el puerto en que
se quiere realizar la conexión.
La segunda consiste en suministrarle además de lo anterior, la dirección y el
puerto locales que van a utilizarse.
La última consiste en especificar la máquina remota con el nombre y no con la
dirección IP.
La clase ServerSocket se utiliza en el extremo del servidor, y se encarga de
crear el socket, vincularlo a una dirección y crear la cola en que se almacenarán las
peticiones de conexión no atendidas todavía.
Constructor:
ServerSocket (int port)
ServerSocket (int port, int n_petic)
ServerSocket (int port, int n_petic, inetAddress adr)
En el primer caso se sumistra solo el Puerto en que debe vincularse el
socket, en el Segundo el puerto y el tamaño de la cola y en el tercero además de
estos dos, la dirección IP de la interfaz a la que se quiere vincular el socket.
Una vez creado el objeto de la clase ServerSocket, el método accept se
encarga de esperar conexiones de clientes po medio del socket, cuando se haya
efectuado la conexión ya podrá empezar el intercambio de información
Para la comunicación con datagramas disponemos de las clases
DatagramSocket y DatagramPacket: la primera para los objetos socket UDP y la
segunda para los paquetes que deben enviarse.
Redes · 19
TEMA 3 APLICACIONES INTERNET
Tema 3
Aplicaciones Internet
1. El modelo cliente/servidor
2. Servicio de nombres Internet
3. Servicios básicos de Internet
4. Transferencia de ficheros
5. Correo electrónico Intertet
6. Servicio de noticias: NNTP
7. Servicio de hipermedia: WWW
8. Acceso al servicio de directorio
9. Protocolos Internet
en tiempo real
10. Seguridad en las
comunicaciones
1. EL MODELO CLIENTE/SERVIDOR
Las redes de computadores han hecho aparecer un nuevo modelo en el
mundo de la programación: la programación distribuida, con la que se pretende
aprovechar la potencia y recursos de varios ordenadores interconectados. La
cooperación de los diferentes ordenadores se realiza mediante un protocolo común,
del que existen varios tipos, pero sin duda el que más éxito ha tenido es el modelo
cliente/servidor. En este modelo el servidor ofrece un servicio y el cliente realiza
una petición al servidor y espera un resultado de la misma.
Este sencillo sistema puede “complicarse” mucho más incluyendo múltiples
clientes o múltiples servidores, que a su vez entre ellos, se comunican por el
modelo cliente/servidor. Un servidor por tanto, puede ser a su vez cliente de otro
servicio simultáneamente.
El diseño de una aplicación distribuida que siga el modelo cliente/servidor incluye
dos elementos: la especificación de los servicios que el servidor ofrece y la
especificación del protocolo de acceso a esos servicios.
2. SERVICIO DE NOMBRES INTERNET
La red Internet permite el acceso a una ingente cantidad de ordenadores y
de recursos que se pueden referenciar mediante un nombre. Todos estos nombres
están lógicamente ordenados de forma jerárquica, formando un sistema de
dominios.
Para obtener un servicio determinado (por ejemplo una página web) se
consultaba el nombre en una base de datos centralizada y se obtenía la respuesta,
pero la rápida expansión de la red hicieron inviable este método y se pasó al
sistema de nombres de dominio. El sistema de nombres de dominio (DNS)
proporciona un espacio de nombres para referenciar recursos, el nombre de
dominio correspondiente a un nodo se define como la secuencia formada por las
etiquetas existentes en el camino entre este nodo y la raíz, así para llegar a
campus.uoc.edu; el primer nodo es edu (TLD o dominio de nivel superior), de ahí
se pasa a uoc y dentro de este al subdominio campus.
Los dominios de nivel superior inicialmente era com, edu, gov, mil y org y
agrupaban diferentes tipos de organizaciones (comercial, educativa, gubernativa,
militar y ONG), pero actualmente hay nuevos dominios: net, biz, info, museum,
name, pro… y cada país además tiene el suyo propio constituido por dos
caracteres: España (es), Alemania (de), Francia (fr)…
Modelo de DNS
Tenemos dos partes en el modelo bien diferenciadas:
Servidores: Reciben las consultas y envían las respuestas correspondientes;
tanto desde la base de datos local como accediendo a otros servidores cuando
no se haya la respuesta prontamente.
Revolvedores: Son clientes del servicio, es un programa o librería que recibe
peticiones de las aplicaciones de usuario, las traduce a consultas DNS y extrae
de la respuesta, la información solicitada.
Para que este modelo sea efectivo, se han agrupado por zonas los sistemas de
nombres de dominio, de manera que cada zona es gobernada por un administrador
que además tiene permisos para delegar parte del trabajo o a su vez dividirlo en
subzonas. El administrador o sus delegados pueden añadir o quitar nodos en la
zona y toda esta información se debe almacenar en la base de datos local de un
servidor, del que se dice que tiene autoridad sobre esa zona. Cuando se envían
20 · Redes
consultas a este servidor, se dice que responde con autoridad. Si le llega una
consulta de otra zona puede responder de dos formas:
Modo no recursivo: La respuesta solo incluye una referencia a otro servidor que
puede proporcionar más información. Este modo es obligatorio en todos los
servidores con autoridad.
Modo recursivo: El servidor busca la información que no tiene en otros
servidores y sirve la respuesta, pero no referencias al servidor que le dio la
respuesta correcta. Hecho esto el servidor añade la respuesta a su caché por si
recibe la misma consulta de nuevo; pero si sirve la respuesta de nuevo, añade
un comentario que es sin autoridad, pues el dato correcto puede haber
cambiado en ese breve lapso de tiempo. Este método de funcionamiento es
opcional en los servidores pero en la práctica es la forma habitual de
funcionamiento.
Configuración de un servicio DNS en un ordenador
Bases de datos DNS
La información asociada a un nodo consta de un conjunto de registros de recurso,
que en total forman la base de datos DNS. Cada registro consta de los campos
siguientes:
Nombre: Nombre de dominio del nodo al que está asociado el registro.
Tipo: Indica que tipo de información contiene el registro. Los valores que se
pueden encontrar en este campo pueden ser la dirección de un ordenador (A),
el nombre canónico de un alias (CNAME), información sobre el tipo de
ordenador (HINFO), nombre de un servidor de correo (MX),
Configuración de un servicio DNS en un ordenador
nombre de un servidor DNS con autoridad para esa zona
(NS)…
Clase: Indica la familia de protocolos utilizados en el espacio
de nombres.
Tiempo de vida (TTL): El tiempo máximo que un servidor o
revolvedor pueden guardar el registro en su caché.
Datos del recurso (RDATA): Depende del tipo de registro,
puede ser una dirección IP, un conjunto de caracteres…
Protocolo
Para acceder al DNS se puede utilizar tanto el protocolo UDP
como el TCP. El primero se suele utilizar en las consultas de los
clientes por su simplicidad y los pocos recursos que requiere; el
segundo se utiliza cuando conviene asegurar una transmisión
fiable.
La estructura de un mensaje DNS es como sigue:
ID: Número de 16 bits que asigna quién realiza la consulta y
Redes · 21
que luego se copiará en la respuesta.
QR (Quero/response): es un bit que indica si el mensaje es una consulta (0) o
una respuesta (1).
OPCODE: Código de operación de 4 bits que indica si es una consulta directa,
inversa, petición de status…
AA: Indica si el mensaje es una respuesta con autoridad.
TC (Truncation): Avisa si el mensaje ha sido truncado porque no cabe en el
datagrama.
RD: Indica si el cliente solicita respuesta en modo recursivo.
RA: Indica si el servidor soporta las respuestas en modo recursivo.
RCODE: Código de posibles errores.
En la sección de la pregunta, se puede disponer de una o más entradas (una
o más preguntas) cada una contará con el nombre del dominio del que el
cliente desea obtener información, el tipo de registro de recurso que se quiere
obtener como respuesta y la clase de registros deseados.
En la sección de la respuesta encontramos las respuestas a todo lo
preguntado en el apartado anterior
En autoridad se pueden contener registros que referencien un servidor con
autoridad si la respuesta ha sido en modo no recursivo.
En la mayoría de ordenadores conectados a Internet ya se cuentan con alguna
implementación de un cliente DNS para poder acceder a otros ordenadores
conociendo los nombres de los mismos. En UNIX sin ir más lejos se cuenta además
con la utilidad denominada nslookup que sirve para efectuar todo tipo de
consultas directamente a un servidor DNS.
3. SERVICIOS BÁSICOS DE INTERNET
Vamos a estudiar dos servicios básicos que ofrece Internet, que son el
protocolo telnet y el protocolo rlogin.
El protocolo telnet es un Terminal virtual, un dispositivo imaginario para
el que se definen unas funciones de control canónicas, de manera que se puede
establecer una correspondencia entre ellas y las de cada tipo de Terminal real.
Antes era muy utilizado en los famosos teletipos, que era un Terminal
generalmente unido a una impresora o, más directamente, una impresora con
teclado.
El protocolo telnet se basa en el protocolo de transporte TCP, y se sigue
normalmente el modelo cliente/servidor, así el usuario establece una conexión con
el sistema proveedor, que está esperando peticiones de conexión en un puerto
determinado (aunque puede ser cualquier puerto, si la sesión de trabajo va a ser
interactiva, se utiliza el 23). En las sesiones interactivas, además se usa el concepto
de Terminal virtual de red (NVT) con una funcionalidad muy básica pero soportada
por todos los ordenadores. Normalmente una vez iniciada la sesión básica, se ve
seguida por un proceso de negociación para soportar funcionalidades más
avanzadas (esto es lo habitual) y consiste en intercambiar códigos que indican las
opciones del protocolo que cada parte desea o está dispuesta a utilizar. Cuando se
llega a un acuerdo, en ocasiones se necesita todavía una subnegociación para
determinar valores de parámetros.
El protocolo Telnet se utiliza en UNIX a través del comando telnet.
El protocolo rlogin se utiliza cuando se desea establecer una sesión de
trabajo interactiva desde un sistema UNIX con otro sistema UNIX. En este tipo de
protocolo cada Terminal conoce y soporta perfectamente al otro con lo que no hay
procesos de negociación y también se informan mutuamente de sus respectivas
identidades con lo que se automatiza el proceso de autenticación. EN UNIX se
utiliza con el comando rlogin.
Existen otros servicios denominados triviales como echo, discard, chargen,
daytime y time, pero que no interesa tampoco conocerlos en profundidad.
22 · Redes
4. TRANSFERENCIA DE FICHEROS
Una de las primeras aplicaciones desarrolladas entre
ordenadores conectados fue el FTP o File transfer protocol, es
decir, el protocolo de transferencia de ficheros, que se basa en el
modelo cliente/servidor y permite la transferencia de ficheros
entre el cliente y el servidor de forma bidireccional y entre dos
servidores por mediación del cliente. El protocolo habitual de
funcionamiento podemos observarlo en la imagen lateral; además
como hemos dicho antes existe una variación del modelo general
para el caso de que el cliente controle una transferencia entre dos
servidores sin que los archivos deban copiarse primariamente al
cliente, sino que pasan del servidor activo, al pasivo directamente.
Modelo funcional del protocolo FTP
El FTP está basado en conexiones TCP, y el puerto
oficial asignado para su funcionamiento es el 21. Los comandos
FTP constituyen los mensajes que envía el cliente al servidor, que
responde con otros comandos. Las respuestas se generan en
orden cronológico estricto, pues en general el servidor Ejemplo de comunicación FTP
efectúa sus operaciones de forma secuencial, es decir, no STATUS:>
Getting listing "public_html"...
Resolving host name ftp.sinpuntocom.com...
empieza una nueva operación hasta que no ha terminado STATUS:>
Host name ftp.sinpuntocom.com resolved: ip =
la anterior. Comandos FTP encontramos muchos: nombre STATUS:>
66.194.152.210.
de usuario (USER), directorio actual (PWD), puerto STATUS:>
Connecting to ftp server
(PORT), listar (LIST), etc, no pueden tener más de 4 ftp.sinpuntocom.com:21 (ip = 66.194.152.210)...
STATUS:>
Socket connected. Waiting for welcome
caracteres, y las respuestas FTP son una numeración de 3 message...
220---------- Welcome to Pure-FTPd [privsep]
dígitos, seguidos de un texto descriptivo a ese error o
[TLS] ---------respuesta enviados.
220-You are user number 1 of 50 allowed.
Habitualmente cuando se inicia la conexión, lo
primero que hace el cliente FTP es enviar el nombre de
usuario (USR), el FTP servidor pide entonces la contraseña
(PASS) a veces se pide un nombre de cuenta, y a
continuación se establecen verificaciones de la estructura
de fichero y del modo de transmisión.
En
la
actualidad
existen
muchísimas
implementaciones de FTP, incluso a través de www; sin
embargo durante mucho tiempo el más utilizado fue la
utilidad ftp del sistema operativo UNIX.
El TFTP (Trivial File Transfer Protocol) es una
variación del FTP, mucho más sencilla de utilizar, que
admite muy pocos comandos (solamente leer y escribir
ficheros) y que se suele utilizar sobre todo para transferir
ficheros a un ordenador por ejemplo para cargar un
sistema operativo a través de red. Esta operación sencilla
no se podría llevar a cabo con el FTP habitual pues
requiere la carga del sistema UDP y una serie de
protocolos que requieren la existencia de sistema
operativo. Este sistema funciona enviando un datagrama
por parte del cliente, al que responde el servidor, y así
alternativamente el datagrama siguiente responde al
anterior y se sabe que la comunicación se va realizando
correctamente.
En Unix este sistema TFTP está implementado a
través de la utilidad tftpd, y como no existe ningún tipo de
identificación de usuario, en principio los clientes pueden
acceder a cualquier fichero con permiso de acceso público;
por ello se suele restringir el acceso a un directorio
(tftpboot) o directamente se inhabilita el servicio.
inactivity.
STATUS:>
COMMAND:>
COMMAND:>
sinpunto
220-Local time is now 15:34. Server port: 21.
220 You will be disconnected after 5 minutes of
Connected. Authenticating...
USER sinpunto
331 User sinpunto OK. Password required
PASS *****
230-User sinpunto has group access to:
230 OK. Current restricted directory is /
Login successful.
PWD
257 "/" is your current location
STATUS:>
Home directory: /
COMMAND:>
FEAT
211-Extensions supported:
EPRT
IDLE
MDTM
SIZE
REST STREAM
MLST
type*;size*;sizd*;modify*;UNIX.mode*;UNIX.uid*;UNIX.gid*;unique*;
MLSD
ESTP
PASV
EPSV
SPSV
ESTA
PROT
211 End.
STATUS:>
This site supports features.
STATUS:>
This site supports SIZE.
STATUS:>
This site can resume broken downloads.
COMMAND:>
REST 0
350 Restarting at 0
COMMAND:>
CWD /public_html
250 OK. Current directory is /public_html
STATUS:>
PWD skipped. Current dir: "/public_html".
COMMAND:>
PASV
227 Entering Passive Mode
(66,194,152,210,195,139)
COMMAND:>
LIST
STATUS:>
Connecting ftp data socket
66.194.152.210:50059...
STATUS:>
COMMAND:>
Redes · 23
5. CORREO ELECTRÓNICO INTERNET
El correo electrónico es la operación distribuida que permite enviar
mensajes electrónicos por medio de sistemas informáticos. Para llevar a cabo esta
funcionalidad se definieron 3 protocolos que pasamos a estudiar: el SMTP, el POP3
y el IMAP, aunque antes debemos ver el formato de los mensajes de correo.
Formato de los mensajes de correo
Un correo electrónico tiene dos grandes campos: la cabecera y el cuerpo del
mensaje. Éste último no reviste gran interés puesto que contiene el mensaje en sí.
La cabecera, a su vez cuenta con varios campos:
Originador: La identidad y la dirección del buzón del remitente.
Destinatario.
Destinatario de copia (CC).
Destinatario de copia oculta (BCC).
Destinatario de respuesta: especialmente útil si se necesita recibir la respuesta
al mensaje en un correo diferente al de origen.
Asunto (Subject).
Data: Hora y fecha, que lo genera automáticamente el primer sistema de
correo que recibe el mensaje.
Sistema remitente
Camino de retorno hacia el originador
Información de sistemas intermedios: Información de cada uno de los sistemas
informáticos por los que pasa un mensaje. Hay que saber que un mensaje de
correo electrónico no parte de un ordenador, va a una “oficina postal” y de ahí
lo recoge el destinatario. En absoluto: un mensaje viaja por muchas oficinas
postales, si cuando llega a una oficina, ésta no tiene en su lista de usuarios el
destinatario, lo envía a otra más cercana, y así hasta que llega a la oficina del
destinatario donde será recogido por éste. Funciona igual que el correo postal y
aunque es un funcionamiento sencillo, asegura que aunque se caigan las líneas
no se pierda el correo, puesto que en cada momento alguna oficina es
responsable de ese mensaje.
Palabras clave
Comentarios
Identificación del mecanismo de cifrado.
El SMTP
O Simple Mail Transfer Protocol, proporciona la funcionalidad necesaria
para conseguir la transferencia fiable y eficiente de mensajes de correo entre
ordenadores que actúan como una oficina de correos. El modelo SMTP (que utiliza
el puerto 25) funciona como se observa en la figura inferior. Hay que aclarar que
los sistemas que actúan como oficina, deben tener un receptor SMTP para recibir
correos y un emisor para “desprenderse” de los que no son suyos.
Modelo SMTP
Las direcciones
de correo utilizan como
“apellido” el nombre de
dominio, por ejemplo
uoc, y previo el nombre
de usuario seguido de
arroba.
EL POP3
O Post Office Protocol version 3, es una funcionalidad añadida al SMTP. En sistemas
pequeños no es práctico soportar el SMTP, porque ello implicaría tener el sistema
constantemente conectado y dispuesto a recibir mensajes en cualquier momento.
Lo que se hace es que las anteriores “oficinas de correo”, almacenan los mensajes
de los buzones de usuario y con un servidor POP3 los facilitan al usuario cuando
24 · Redes
éstos se conectan para conocer los Modelo POP3
mensajes nuevos que le han
llegado a su buzón. Como vemos,
seguimos manteniendo el modelo
cliente/servidor, y la imagen de la
página anterior para SMTP, ahora
la vemos completada con el
servidor y el cliente POP3 (éste
último es el usuario) en su acceso
al correo. El POP3 utiliza el puerto
110 del ordenador.
La utilización del POP3 se inicia con
la identificación del usuario, el
envío de la contraseña y después
se puede optar por ver la lista de
mensajes (solo el encabezado),
bajarlos todos, bajar los seleccionados, borrar, etc. Una vez que, por ejemplo y es
lo que usualmente suelen hacer los gestores de correo, hemos bajado todo el
correo, automáticamente pasamos al estado de actualización, donde se borran
todos los mensajes marcados (aquellos que nos hemos bajado a nuestro ordenador
correctamente) y después se liberan todos los recursos y se cierra la conexión TCP.
El IMAP
O Internet Messages Access Protocol permite al cliente acceder a los
mensajes de correo electrónico de un servidor y manipularlos. Como mejora
respecto al POP3 proporciona una estructura jerárquica del buzón en forma de
carpetas, así como facilidades de suscripción, lo que da lugar a nuevos comandos
que permiten gestionar todos estos elementos. Por ejemplo, cuando con Outlook
nos “bajamos los mensajes”, esto se hace de forma automática: identificación,
contraseña, bajada de mensajes, y liberación de recursos; no podemos pararnos en
cualquiera de esas partes, ni estudiar los buzones de correo. En cambio con IMAP
una vez que se ha establecido la conexión somos nosotros los que llevamos la voz
cantante y decidimos qué hacer con nuestros mensajes y cuando hacerlo.
Formato MIME de los mensajes de correo
El modelo de mensaje de correo que estudiábamos en la página anterior es
insuficiente para las capacidades de comunicación y multimedia que están
surgiendo hoy día. Por tanto de la norma RFC822 se pasó al formato MIME
(Multipurpose Internet Mail Extensions), que recoge, como su nombre indica,
extensiones de multipropósito. Se crearon nuevos campos de cabecera sobre todo
para información de texto adjunta, imágenes, audio, vídeo y aplicaciones.
6. SERVICIO DE NOTICIAS: NNTP
El servicio de noticias permite el envío de mensajes, como el servicio de
correo, pero sin un destinatario o destinatarios específicos, sino que cualquier
usuario que pueda acceder al servicio puede leerlos; viene a ser como un tablón de
anuncios. En principio este servicio se conocía como Usenet por el nombre de la
red que lo originó.
El servicio de noticias es completamente descentralizado. Los artículos no
están en un único servidor sino que se alojan en uno o más servidores, los cuales
se encargarán de reenviarlo a los más próximos, que a su vez lo reenviarán al
resto. No se puede asegurar que un determinado artículo llegue a todos los
servidores e incluso a uno específico, pero este modelo funciona mucho mejor que
el modelo con un único servidor centralizado.
Los artículos así publicados tienen un encabezado como el de correo con un
remitente, fecha y hora, subjetc, mensaje y como destinatario el grupo o grupo de
noticias donde se publicará.
Redes · 25
7. SERVICIO HIPERMEDIA: WWW
El http es la base del servicio www; sus orígenes fueron los trabajos de un
grupo de investigadores del Centro Europeo de Investigación Nuclear, que lo
utilizaban para acceder de manera sencilla y cómoda a la información distribuida en
diferentes sedes del centro; cuando el conjunto de sistemas se extendió a otras
organizaciones y países de todo el mundo nacío la World Wide web.
El http sigue el método general de peticiones y respuestas entre un cliente
y un servidor. En la versión 1.0 el cliente establece una conexión con el servidor, le
envía un mensaje http con la petición ya continuación el servidor envía la respuesta
y cierra la conexión. En la versión 1.1 cambia a conexión persistente con diferentes
peticiones y respuestas en una misma conexión.
Para optimizar el tráfico de la red es habitual que los clientes http guarden
una copia de las respuestas que reciben en los servidores, este almacén se conoce
como memoria caché y su dimensión máxima y su política de almacenamiento es
controlada por el usuario. También es habitual que un cliente no se conecte
directamente a un servidor, sino a un Proxy, el cual establece la conexión con el
servidor o, incluso, con otro proxie. Estos proxies guardan también en caché las
respuestas recibidas a las peticiones para poder dar un servicio más rápido a otros
usuarios. Es decir si una petición de un cliente ya está en la caché de un proxie, no
la pedirá de nuevo al servidor de origen. El problema estriba en la actualización de
estas memorias caché, pues la informació que puede recibir el cliente puede ser
obsoleta o desfasada. El uso del proxie además sirve como un cortafuegos que aísla
una red local del resto de las redes y como memoria caché compartida en esta red
local.
8. ACCESO AL SERVICIO DE DIRECTORIO
El servicio de directorio X.500 permite el almacenamiento de todo tipo de
información de manera distribuida. El X.500 define la estructura de la información,
así como los protocolos necesarios para acceder a la misma.
El servicio de directorios no está ideado como una base de datos de
propósito general, sino como un mecanismo de almacenamiento de información
distribuida y se basa en que las peticiones de información son más frecuentes que
las actualizaciones y que para acceder a la información se utilizan nombres con
estructura jerárquica y no la dirección en que se encuentra la información. Así un
objeto tiene dos nombres, el nombre relativo de directorio (diferencia un objeto
de sus hermanos dentro del directorio, se forma a partir de los atributos de una
entrada que tiene valores distintivos, así que éstos deben ser persistentes y tener
pocas probabilidades de quedar obsoletos), y el nombre de directorio (permite
diferenciar un objeto del resto de objetos del directorio). Así exponemos un
ejemplo de ambos casos:
Nombre relativo: {CN=Ramón Martí}
Nombre relativo: {O=UOC, L=Barcelona}
Nombre de directorio: {C=ES; O=IRIS; OU=UOC; L=Barcelona; CN=Ramón Martí}
9. PROTOCOLOS INTERNET EN TIEMPO REAL
Hay una serie de aplicaciones como la transmisión de audio y vídeo en
tiempo real en la que es preciso que los datos se vayan presentando al destinatario
a medida que van llegando. En este sentido se encuentran varios protocolos
implementados:
RTP: Es un estándar que proporciona servicios de entrega punto a punto para
datos con características de tiempo real como audio y vídeo. Se hacen
necesarios dos puertos entre el cliente y el servidor: uno para el RTP y otro
para el RTCP. El RTP es el protocolo de transporte en tiempo real y es capaz de
26 · Redes
hacer reconstrucciones temporales, detectar pérdidas e identificar el contenido
y la seguridad. El RTCP, por su parte, proporciona soporta para conferencias en
tiempo real de grupos de cualquier tamaño.
RSTP: EL protocolo de flujo de tiempo real proporciona el control del flujo de
datos multimedia. Se considera más un entorno de trabajo que un protocolo.
Con este protocolo los datos se fragmentan en múltiples paquetes del tamaño
apropiado al ancho de banda disponible entre cliente y servidor. Cuando el
cliente ha recibido suficientes paquetes, es capaz de reproducir el primero,
mientras descomprime el segundo y recibe un tercero; así el usuario cliente
puede empezar a reproducir los datos casi inmediatamente, sin necesidad de
esperar a recibirlos todos.
RSVP: El protocolo de reserva de recursos está orientado a la calidad del
servicio (retraso, jitter, ancho de banda y pérdida de datos).
10. SEGURIDAD EN LAS COMUNICACIONES
Las principales amenazas que podemos tener en nuestras comunicaciones
informáticas pueden ser por acciones hostiles: Interrupción de mensajes por
terceros, intercepción de los mismos, modificación o impostura (hacerse pasar por
otro usuario) o por acciones que no incluyan otro usuario como son el repudio (un
usuario niega haber mandado un mensaje a otro) o la negación de recepción (en
este caso el que recibe el mensaje niega haberlo hecho).
las
Los servicios de seguridad por tanto, intentarán proteger a los usuarios de
siguientes amenazas, implementando:
Confidencialidad
Integridad
Autenticación
No rechazo.
Las técnicas criptográficas son los sistemas que sirven para codificar y
decodificar mensajes que pueden ayudarnos en aumentar la seguridad del sistema.
Hay dos técnicas principales de criptografía: la simétrica y la asimétrica.
La criptografía simétrica consiste en que se utiliza la misma clave para cifrar
y descifrar un mensaje. Es fácil y rápido, pero los dos usuarios A y B deben ponerse
previamente de acuerdo en las claves a usar, dado que no las pueden enviar por el
mismo canal de comunicación.
En cambio, la criptografía asimétrica se basa en dos claves, pública y
privada. Dada una de estas claves (la privada) es sencillo obtener la otra (la
pública) pero a la inversa es imposible. Esto nos da dos modalidades de uso de la
criptografía asimétrica:
Si se cifra el mensaje con la clave pública y se utiliza la privada para descifrarlo,
el remitente del mensaje puede estar seguro que solo el destinatario con la
clave privada adecuada podrá leerlo.
Si se utiliza la clave privada para cifrar el mensaje y la pública para descifrarlo,
prácticamente cualquiera podrá leer el mensaje, pero se tendrá la certeza de
quien ha sido el remitente, esto es la base de la firma digital.
Texto elaborado a partir de:
Redes
Jordi Íñigo Griera, Enric Peig Olivé, José M. Barceló Ordinas,
Xavier Perramon Tornil, Ramon Martí Escalé
Junio 2004