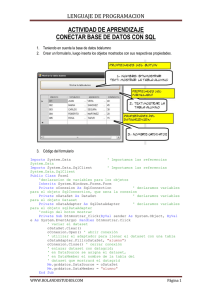
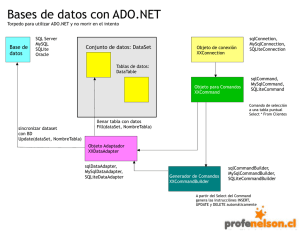
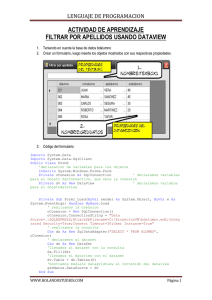
Tutoriales Básicos - Datasets Escrito por Javier Esta entrada la voy a dedicar a los datasets. Veremos los diferentes tipos que existen, los parámetros longitud de registro, formato de registro y bloque de registros. También cómo crear los datasets mediante paneles y cómo editarlos. En una futura entrada de tutoriales básicos, veremos cómo crearlos todos mediante JCL. En zOS, la información se guarda en datasets, también llamados librerías. Esta información puede ser: configuración del sistema, JCLs, programas, paneles, etc. Como hay distintos tipos de información, también tendremos distintos tipos de datasets. Los dataset, internamente, contienen registros y bloques de registros. Un registro es la información que procesará un programa y el bloque de registros, es la información que se transfiere en cada operación de entrada/salida. Por ejemplo, tenemos un dataset en un disco, cada operación de entrada/salida que se haga contra ese disco para tener información del dataset, se mandará por bloques de registros. Después, el programa que reciba ese bloque de registros, procesará cada registro con la información. Los bloques de registros permiten reducir las operaciones de entrada/salida a las unidades. Los tipos de registros pueden ser: Fijo (F). Todos los registros tienen la misma longitud. Por ejemplo, un registro fijo de 80, guardará 80 posiciones de datos aunque solo haya 1 posición escrita. En este caso, el bloque de registro manda un registro por cada operación de entrada/salida. El tamaño del bloque de registro es igual al tamaño del registro. Este formato casi no se usa. Variable (V). La longitud del registro es variable según su contenido. En este caso, el bloque de registro manda un registro por cada operación de entrada/salida. El tamaño del bloque de registro es igual al tamaño del registro. Este formato casi no se usa. Fijo bloqueado (FB). Todos los registros tienen la misma longitud y su información se manda en bloques de registros que contienen varios registros. El tamaño del bloque de registro es superior al tamaño de cada registro. Este tipo de registro se usa habitualmente. Variable bloqueado (VB). La longitud del registro es variable según su contenido. Su información se manda en bloques de registros que contienen varios registros. El tamaño del bloque de registros es superior al tamaño de cada registro. Undefined (U). No tiene una estructura predefinida. Esta opción se usa para las librerías que contienen módulos compilados (programas). Cuando creemos dataset, veremos cómo definir el tipo de registro, la longitud del registro y el tamaño del bloque. Una vez hemos visto los tipos de registro que puede tener internamente un dataset, vamos a ver los tipos de dataset que existen: Secuencial (PS – Physical Sequence). Los registros van de forma secuencial. Los nuevos registros, se añaden al final y su lectura se hace de forma secuencial. Por ejemplo, para leer la línea 10, hay que leer las nueve anteriores. Para hacernos una idea, podríamos decir que “es como un fichero TXT de Windows”. En la imagen vemos un dataset secuencial. Particionado (PDS – Partitioned Dataset). Los dataset particionados están divididos en ficheros secuenciales llamados miembros. Se pueden añadir o borrar miembros sin afectar a otros miembros. Cuando un miembro es borrado, el espacio que deja no se puede reutilizar. Para poder disponer de ese espacio, habría que comprimir la librería. Como esto algunas veces es peligroso porque los datos se pueden corromper, otra forma es crear una librería de mayor tamaño y copiar ahí los miembros. Estos dataset particionados no pueden contener otros dataset particionados, sólo ficheros secuenciales. Particionado extendido (PDSE – Partitioned Dataset Extended). Es muy similar a un dataset particionado normal, pero este tipo tiene ciertas ventajas: permite reutilizar el espacio que deja un miembro borrado sin tener que comprimir la librería, permite 123 extensiones de espacio, frente a 16 extensiones de un particionado normal, etc. Este tipo de librerías NO se pueden usar como librerías de procedimientos (PROCLIB) ni para librerías que intervengan en el IPL (arranque/parada del sistema). En la siguiente imagen vemos un dataset particionado. VSAM. Aunque hay varios tipos, nos centraremos en el tipo KSDS (keysequenced dataset). Se caracterizan por tener dos partes: una parte con los datos y otra parte con un índice o clave que hace referencia a esos datos para poder acceder a ellos. La clave va en secuencia, es única y no puede ser alterada. Este tipo de ficheros se suelen crear/copiar/borrar mediante JCL con la utilidad IDCAMS. Lo veremos en futuras entradas. En la siguiente imagen vemos que el dataset “NVAS.ADCD.EMSALLT” es de tipo VSAM y tiene dos dataset más llamados “.INDEX”, con las claves, y “.DATA”, con los datos. GDG. GDG o fichero generacional. Imaginemos que tenemos un proceso que nos genera datos diarios en un dataset y sólo queremos guardar 20 días de datos. Para evitar tener que hacer un mantenimiento manual de esos dataset, usaremos un fichero GDG. Para crear este tipo de dataset se define una base, mediante JCL con la utilidad IDCAMS, en la que indicaremos el número máximo de versiones que deben existir. También se especifican otros parámetros que veremos en otra entrada dedicada a GDGs y cómo trabajar con ellos. En la siguiente imagen vemos un ejemplo de GDG. La base del GDG suele venir identificada con “??????” en el campo “Volume”. Además, si intentamos ver sus datos con una “S”, aparecerá el mensaje “GDG base”. También aparecen tres generaciones: “G0001V00”, “G0002V00” y “G0003V00”. Estas generaciones son las que tendrán los datos que deseemos. Ya hemos hecho un pequeño resumen sobre los tipos de dataset. Ahora veremos cómo crear: un dataset secuencial, uno particionado PDS con tipo de registro FB y con tipo de registro U (undefined), uno particionado PDSE y un miembro de un dataset particionado, mediante paneles. También se pueden crear por JCL, pero lo veremos cuando hablemos de JCL. Dataset secuencial. Desde el menú principal de ISPF, entramos a la opción 3 – Utilitities. Ahora entraremos en la opción 2 – Data Set. En el panel que saldrá elegiremos la opción A – Allocate new data set. Tendremos que poner un nombre de fichero, para elegirlo hay seguir ciertas reglas: El nombre está dividido en calificadores separados por puntos. El tamaño máximo del nombre es de 44 caracteres, incluyendo los puntos. El número máximo de calificadores es 22, pero nunca he visto un dataset así. Cada calificador puede tener 8 caracteres como máximo. El calificador debe empezar por una letra o carácter (@, #). No puede empezar por número. Al primer calificador del nombre se le llama High-level Qualifier (HLQ). Esto es útil saberlo si se trabaja con manuales de IBM, ya que suelen hacer referencia a ello. Yo he elegido el nombre “IBMUSER.DSPS”. En este caso, el nombre tiene 12 caracteres, dos calificadores y el HLQ es “IBMUSER”. Vamos a explicar las diferentes opciones que nos encontramos en el siguiente panel: Management class, Storage class, Data class. Esto son clases gestionadas por una herramienta llamada DFSMS o SMS. Sirve para asignar ciertos atributos a un dataset según la clase que le demos. En mi caso, lo dejo en blanco porque no tengo configurado DFSMS. Volume serial. Podemos indicarle uno o que coja uno por defecto. Cuando un sistema es manejado por el SMS, aunque pongamos un disco, después se almacenará donde crea oportuno. Space units. La unidad de espacio. Dependiendo del fichero, se suele usar Tracks (TRKS) o cilindros (CYLS). Un cilindro equivale a 15 tracks. Primary quantity. Cantidad primaria de espacio. Si hemos elegido la unidad “CYLS”, en este caso, le estamos dando 1 cilindro de espacio primario. Secondary quantity. Cuando un dataset llena su espacio primario, puede extenderse el espacio que pongamos en este parámetro para intentar almacenar más datos. Si indicamos 0 en este espacio, el fichero no tendrá extensiones. Este tipo de ficheros, pueden tener hasta 16 extensiones. Si sobrepasa eso, dará el error B37. Directory blocks. Este parámetro indica si el fichero será secuencial o particionado. Como en este caso es secuencial, lo dejaremos a 0. Record format. Lo que explicamos al principio de la entrada. En este caso usaremos fijo bloqueado (FB). Record length. Le pondremos una longitud de registro. En este caso le vamos a poner 111. Block size. Este es el tamaño del bloque de registros. Lo dejaremos en blanco para que el sistema asigne el valor óptimo. Dataset name type. En este caso, al ser un fichero secuencial, lo dejamos en blanco. Una vez rellenados los datos, pulsaremos Intro (control). Saldrá un mensaje indicando “Data set allocated”. Si ahora vamos a la opción 3.4 de ISPF y buscamos el fichero, podremos editarlo. Pulsaremos intro. Podremos editarlo y salvarlo. Dataset particionado PDS. Volvemos a la opción 3.2 de ISPF para crear un dataset particionado. Pondremos la opción “A – Allocate” y elegiremos un nombre teniendo en cuenta las reglas que mencionamos en el caso anterior. Vamos a ver las diferencias que hay en las opciones comparándolo con el caso anterior: Directory blocks. Sirve para indicar el número de miembros que podrá almacenar la librería. Cada bloque de directorios puede almacenar 6 miembros. Por lo tanto, 10 bloques de directorios podrán almacenar 60 miembros. Record length. En caso de librerías particionadas que contendrán JCLs, y otros tipos de código, hay que poner 80. Data set name type. En este caso, como es una librería particionada, pondremos PDS. Si queremos crear un miembro en este dataset, lo haremos de la siguiente forma (también hay otras formas posibles). Entraremos en la opción 2 – Edit. Pondremos el nombre de la librería y el nombre del miembro entre paréntesis. El nombre del miembro puede tener 8 caracteres como máximo. Lo editaremos y salvaremos. Dataset particionado extendido PDSE. En caso de querer tener una librería particionada extendida (PDSE), solo deberemos cambiar lo siguiente: Data set name type. Deberemos poner LIBRARY. El resto de parámetros es igual que una librería PDS. Dataset particionado con tipo de registro “U – Undefined”. Como hemos dicho anteriormente, este tipo de dataset particionado se utiliza para guardar programas ya compilados. Tiene las siguientes diferencias con un particionado normal: Record format. Dejará de ser FB y será U. Record length. No hay que poner nada. Block size. Si en casos anteriores no lo indicábamos, aquí es obligatorio ponerlo. La cantidad óptima es 32760. Ahora vamos a la opción 3.4 de ISPF y buscamos las librerías que hemos creado. Pulsaremos F11 dos veces para ver los datos del tipo de registro, longitud de registro y el tamaño de bloque de registros que le ha asignado el sistema. Vemos que, aunque tres de esos dataset son particionados, su tamaño de bloque de registros óptimo es distinto, al tener diferentes características. Por último, dejo una imagen de cómo es una librería particionada con tipo de registro “U – Undefined”, para que se pueda ver la diferencia frente a un dataset particionado normal. Hasta aquí hemos hecho un pequeño resumen de los tipos de datasets y hemos visto cómo crear algunos de ellos. El resto lo dejaremos para cuando hablemos de JCL. En la próxima entrada de tutoriales básicos intentaré explicar cómo usar el editor de ISPF y algunas de sus opciones para poder manipular los datos que contienen los ficheros. Visto: 3931