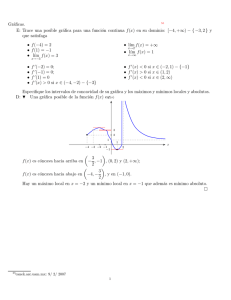
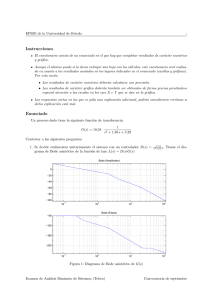
")
ASIGNATURA: COMPLEMENTOS DE ESTADISTICA Titulación: Máster en Ingeniería Industrial Práctica 1: Análisis de la varianza de un factor 1. Introducción El menú Estadı́sticos → Medias → ANOVA de un factor... permite llevar a cabo de manera automática todos los cálculos relacionados con el análisis de la varianza de un solo factor, ası́ como la comprobación de las hipótesis del modelo. Para ilustrar los comandos necesarios, resolveremos paso a paso el ejemplo siguiente: Ejemplo 1 Una compañı́a algodonera, interesada en maximizar el rendimiento de la semilla de algodón, desea comprobar si dicho rendimiento depende del tipo de fertilizante utilizado para tratar la planta. A su disposición tiene 5 tipos de fertilizantes. Para comparar su eficacia fumiga, con cada uno de los fertilizantes, un cierto número de parcelas de terreno de la misma calidad y de igual superficie. Al recoger la cosecha se mide el rendimiento de la semilla (peso por unidad de superficie), obteniéndose las siguientes observaciones: Fertilizante 1 2 3 4 5 51 56 48 47 43 Rendimiento 49 50 49 51 60 56 56 57 50 53 44 45 48 49 44 43 46 47 45 50 46 La variable respuesta (Y ) que nos interesa corresponde con el rendimiento de la semilla y el factor es el tipo de fertilizante aplicado. La observación yij hace referencia al rendimiento medido en la j-ésima parcela en la que se aplicó el fertilizante i, para i = 1, . . . , 5 y j = 1, . . . , ni . Para la formulación del modelo de análisis de la varianza se parte de la hipótesis que las variables aleatorias Yij son independientes con distribución N(µi , σ 2 ). Importamos los datos del archivo fertilizante.txt. En la primera variable están los datos observados para el rendimiento y en la segunda el tipo de fertilizante utilizado (de 1 a 5). Para cada variable se tendrán 26 datos. Lo primero que debemos hacer es asegurarnos que el factor está definido como tal y no como variable numérica (podemos comprobar que esto es ası́ seleecionando el menú Estadı́sticos → Medias 1 → ANOVA de un factor... y viendo si la opción está o no activa). Recordemos que para convertir una variable numérica en factor debemos seleccionar Datos → Modificar variables del conjunto de datos activo → Convertir variable numérica en factor..., eligiendo como variable a modificar el fertilizante y usando números para los niveles del factor. El paso preliminar al análisis numérico de los datos será una inspección visual de gráficos. Para visualizar los datos utilizamos un diagrama de puntos y una gráfica de medias, que se pueden seleccionar en el menú Gráficas. Como variable explicativa elegimos el fertilizante y como variable explicada el rendimiento. Pulsamos “Aceptar” y obtenemos los gráfico que se muestran en las Figuras 1a y 1b 54 52 44 46 45 48 50 mean of Rendimiento 50 Rendimiento 55 56 58 60 Plot of Means 1 2 3 4 5 1 2 3 4 5 Fertilizante (a) Diagrama de puntos. Observaciones frente a nivel del factor (b) Gráfica de las medias. Figura 1. Gráficas para inspección visual de los datos En el primer gráfico podemos ver cómo se distribuyen los datos para cada nivel del factor y se puede apreciar si la distribución en cada nivel se puede considerar normal o si la dispersión de los datos es homogénea entre niveles. El gráfico de las medias nos da una información similar, uniendo las medias en cada nivel del factor y proporcionando intervalos de confianza para tener una idea, de nuevo, de la dispersiı́on de los datos. A continuación pasaremos a hacer el análisis numérico de los datos. Vamos al menú que aparece en la Figura 2 y aparece la ventana de la Figura 3. Seleccionamos la variable fertilizante en “Grupos” y el rendimiento como “Variable explicada”. Los resultados en forma de tabla ANOVA aparecen en la ventana de R Commander (Figura 4). En la tabla ANOVA se muestran las sumas de cuadrados, grados de libertad y medias cuadráticas para el factor y los residuos, ası́ como el estadśtico F (en este caso F = 23.565) y el p-valor asociado al test de hipótesis. Encontramos un p-valor muy pequeño (p = 1.649e−07), con lo que podemos rechazar la hipótesis nula y afirmar con mucha confianza que el tipo de fertilizante influye en el rendimiento. De 2 Figura 2. Figura 3. Figura 4. esta información podemos obtener también la estimación de la varianza del modelo (que sabemos que es la media cuadrática residual, con un valor de 4.667 en este caso). 3 2. 2.1. Comprobación de las hipótesis del modelo Diagnósticos gráficos Una vez obtenidos los resultados del análisis de la varianza, conviene comprobar si se cumplen las hipótesis de normalidad y homocedasticidad de los residuos. Para ello haremos uso de la gráficas básicas de diagnóstico proporcionadas por R Commander. Seleccionamos Modelos → Gráficas → Gráficas básicas de diagnóstico. Aparecerán los gráficos mostrados en la Figura 5 aov(Rendimiento ~ Fertilizante) Normal Q−Q 15 48 50 52 54 2 1 −2 −1 0 1 2 Scale−Location Residuals vs Leverage 3 Theoretical Quantiles 0.5 48 50 52 54 0.5 2 14 1 1.0 20 0 15 −2 −1 Standardized residuals 1.5 0 56 14 46 20 15 Fitted values 0.0 Standardized residuals 46 −1 2 0 −2 −4 Residuals 8 14 −2 4 14 Standardized residuals 3 6 Residuals vs Fitted 56 20 Cook’s distance 0.00 Fitted values 0.05 0.10 0.15 15 0.20 0.25 Leverage Figura 5. Nos interesan las dos gráficas de la parte superior. En la de la izquierda podemos observar los residuos frente a las medias (o valores ajustados). Como no se observa ningún patrón seguido por los datos, podemos decir que no hay problemas de homocedasticidad. En el gráfico de la derecha aparece un gráfico cuantil-cuantil (Q-Q plot) de los residuos, en el que se observa una tendencia lineal, que nos lleva a poder decir que también se está cumpliendo la hipótesis de normalidad. 4 2.2. Diagnósticos numéricos Además del uso de gráficas, conviene realizar diagnósticos numéricos para la comprobación de las hipótesis del modelo. R Commander lleva incorporados dos test de igualdad de varianzas (hipótesis de homocedasticidad) que podemos aplicar: El test de Levene y el test de Bartlett. El test de Levene es menos sensible a la falta de normalidad que el de Bartlett. Sin embargo, si estamos seguros de que los datos provienen de una distribución normal, entonces el test de Bartlett es el mejor. Encontramos ambos tests en el siguiente menú: Estadı́sticos → Varianzas → Test de Bartlett / Test de Levene.... De nuevo seleccionamos la variable fertilizante en “Grupos” y el rendimiento como “Variable explicada”. En ambos casos el p-valor obtenido debe ser superior al α para poder aceptar la igualdad de varianzas. En este caso obtenemos los resultados mostrados en la Figura 6. En ambos casos los p-valores (0.0883 y 0.1533) son superiores a α = 0.05 con lo que podemos aceptar la igualdad de varianzas, es decir, que hay homocedasticidad. Figura 6. Para el chequeo numérico de la hipótesis de normalidad debemos utilizar los residuos. Éstos han sido calculados directamente por R al realizar el análisis numérico y se encuentran en la memoria, pero no están visibles. Podemos aplicar un test de normalidad de Shapiro-Wilks y/o de Kolmogorov-Smirnov a los residuos escribiendo los siguientes comandos en la ventana de R Commander (hay que tener en cuenta el nombre del modelo ANOVA generado en nuestro caso particular, que aparece en azul en la parte superior derecha de la ventana de R Commander). shapiro.test(AnovaModel.1$res) ks.test(AnovaModel.1$res,‘‘pnorm’’,mean(AnovaModel.1$res),sd(AnovaModel.1$res)) Tras escribir esas lı́neas, colocar el cursor del ratón sobre cada una de ellas y pulsar “Ejecutar”. Se obtiene, para los test de Shapiro-Wilks y de Kolmogorov-Smirnov, unos p-valores de 0.65 y de 0.8793 5 respectivamente (Figura 7). Al tratarse de p-valores altos, no podemos rechazar la hipótesis de que los residuos siguen una distribución normal. Figura 7. Para comprobar la hipótesis de independencia, que deberı́a cumplirse si el diseño del experimento es adecuado, realizamos un test de Durbin-Watson (asumiendo que las medidas están tomadas en orden cronológico idéntico al orden de presentación de los datos), siguiendo la siguiente ruta: Modelos → Diagnósticos numéricos → Test de Durbin-Watson para autocorrelación.... En la ventana que aparece elegimos como hipótesis alternativa la bilateral (segunda opción) y tras pulsar aceptar observamos el p-valor que aparece en la ventana de resultados de R Commander. En nuestro caso es p = 0.3449, con lo que podemos aceptar la hipótesis de independencia de los residuos. 3. Comparaciones múltiples Como se ha confirmado la existencia de diferencias significativas entre los tipos de fertilizante, será conveniente hacer comparaciones por pares de las medias para cada tipo de fertilizante para determinar cuáles son los tipos de fertilizante estadı́sticamente diferentes o en cuánto oscilan esas diferencias. Para ello volvemos a realizar los pasos para el análisis de la varianza en Estadı́sticos → Medias → ANOVA de un factor..., activando esta vez la casilla “Comparaciones dos a dos de las medias”, que aparece en la ventana donde hay que seleccionar el factor y la variable respuesta (Figura 8). El método usado por R Commander para las comparaciones múltiples es el de Tukey. Al aceptar, aparece un gráfico de intervalos de confianza para la diferencia de medias 2 a 2 (Figura 9). Si ese intervalo corta a la lı́nea punteada vertical que pasa por el cero, significará que esos dos niveles del factor corresponden al mismo grupo, y viceversa. Con este gráfico es sencillo hacer una clasificación de los grupos. Aún as, en caso de tener muchos pares de medias, podemos ahorrarnos el trabajo de interpretar el gráfico mirando la información que ha aparecido en la ventana inferior de R Commander (Figura 10) 6 Figura 8. 95% family−wise confidence level ( 2−1 ( 3−1 ) ( 5−1 ) ( 3−2 ) ( 4−2 5−2 ) ( 4−1 ) ( ) ( 4−3 ) ( 5−3 ) ( 5−4 −15 ) −10 ) −5 0 5 10 Linear Function Figura 9. Esta última pantalla de información nos proporciona los valores lı́mites de los intervalos de confianza calculados (ası́ como las diferencias de medias muestrales), y nos da una clasificación, aunque no ordenada, de los grupos. Según la clasificación obtenida en este ejemplo el resultado serı́a: 7 Figura 10. Fertilizante 2 1 3 4 5 Media 57 50 48 47 45 Grupo A B B B C C C Con esta clasificación se observa que el fertilizante 2 es superior a los demás mientras que el 5 es el peor de todos. 8 4. Problemas propuestos 1. En 1879 el fı́sico A. A. Michelson realizó en cinco ensayos 100 determinaciones de la velocidad de la luz en el aire. El fichero luz.txt contiene esos datos en km/s, después de haberles restado 299000. a) Proponer un modelo estadı́stico para investigar si existen diferencias entre los distintos ensayos. b) Realizar la validación del modelo anterior. c) ¿Qué se puede decir sobre la homogeneidad de las mediciones entre los distintos grupos? d) Repetir el análisis con los datos de los cuatro últimos ensayos. Basándose en estos cuatro ensayos, ¿qué valor se estimarı́a para la velocidad de la luz en el aire? 2. Se quiere estudiar el nivel de bilirrubina en la sangre. Para ello se analiza cada semana la sangre de tres hombres jóvenes, midiendo la concentración de bilirrubina. Se ha realizado un test con anterioridad para asegurarse que la concentración de una semana no influye significativamente sobre la concentración de la semana siguiente. Los datos se encuentran en el fichero bilirrubi.txt. a) Proponer un modelo estadı́stico para estudiar si hay diferencias entre los niveles de bilirrubina de los tres individuos. b) Realizar una gráfica normal de las concentraciones de bilirrubina. ¿Parece aceptable la hipótesis de normalidad de las variables? c) Definir una nueva variable que sea igual al logaritmo de la concentración de bilirrubina y realizar de nuevo una gráfica normal para la variable transformada. ¿Qué ocurre ahora? d) Realizar un análisis de la varianza para el logaritmo de las concentraciones de los tres individuos, con comparaciones múltiples si fuese necesario. 3. El fenómeno de El Niño se refiere a corrientes oceánicas inusualmente calientes en el Pacı́fico que aparecen alrededor de Navidad y pueden durar varios meses. Efectos catastróficos como huracanes y tempestades se han relacionado con El Niño. Una hipótesis que fue emitida es que una fase caliente de El Niño tiende a disminuir el número de huracanes mientras que éste tiende a aumentar en una fase frı́a. Desde el National Hurricane Center se ha obtenido el número de huracanes y tempestades desde 1950 hasta 1995, ası́ como el tipo de corrientes de El Niño (calientes, frı́as o neutras). Después de haber importado los datos del fichero elnino.txt (Fuente: Exploring Statistics (1996) L. Kitchen, Duxbury press, p. 813 ), contestar a las siguientes preguntas: a) Construir diagramas de cajas para el número de tempestades asociadas con cada una de las tres fases de El Niño. ¿Qué conclusiones se pueden extraer? b) ¿Parecen razonables las hipótesis del modelo para el análisis de varianza para estos datos? Realizar el test F para el número de tempestades. c) ¿Cuál es la correlación entre el número de tempestades y el número de huracanes? d) Realizar el test F para el número de huracanes. ¿Son los resultados coherentes con los dos apartados anteriores? 9