: Introducción y Aplicación")
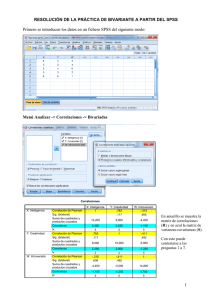
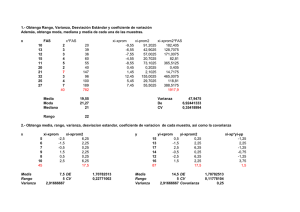
ANÁLISIS DE COVARIANZA (ANCOVA) INTRODUCCIÓN Ronald Fisher en 1932 desarrolló una técnica conocida como Análisis de Covarianza, que combina el Análisis de Regresión con el Análisis de Varianza. Covarianza significa variación simultánea de dos variables que se asume están influyendo sobre la variable respuesta. En este caso se tiene la variable independiente tratamientos y otra variable que no es efecto de tratamientos pero que influye en la variable de respuesta, llamada a menudo: covariable • El Análisis de Covarianza consiste básicamente en elegir una o más variables adicionales o covariables que estén relacionadas con la variable de respuesta, evitando que los promedios de tratamientos se confundan con los de las covariables, incrementando de esa manera la precisión del experimento. Por ejemplo: número de plantas por unidad experimental, pesos iniciales en animales, grado de infestación de garrapatas, días de lactancia o edad, etc.; pueden ser covariables que influyan en el resultado final y cuyo efecto de regresión sobre la variable respuesta el investigador desea eliminar, ajustando las medias de tratamientos a una media común de X. En este análisis se asume que la variable dependiente Y está asociada en forma lineal con la variable independiente X, existiendo homogeneidad de pendientes. SUPOSICIONES BÁSICAS DEL ANÁLISIS DE COVARIANZA • Como es de esperarse, las suposiciones que se hacen cuando se efectúa un análisis decovarianza son similares a las requeridas para la regresión lineal y el análisis de varianza. De esta manera, se encuentran las suposiciones usuales de independencia, normalidad, homocedasticidad, X fijas, etc. Para ser más exactos, se presenta a continuación los modelos estadísticosmatemáticos asociados con algunos de los diseños más comunes cuando se realiza un análisis de covarianza. EJEMPLO DE APLICACIÓN • Un grupo de estudiantes del curso de Investigación Agrícola de la Escuela Nacional Central de Agricultura evaluó en 1990 el efecto del tiempo de cosecha sobre el rendimiento de grano de maíz. Se utilizaron 4 tratamientos y 3 repeticiones, con el diseño bloques completos al azar. Los tratamientos fueron: 30, 40, 50 y 60 días después de la polinización. El número de plantas planificado por parcela útil fue de 52, pero al cosechar se obtuvieron diferentes números de plantas por unidad experimental. Los resultados se presentan en el cuadro siguiente: Cuadro No. 1