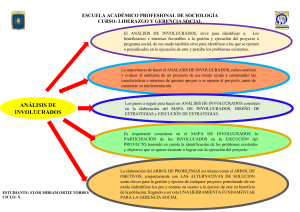
Temas Sele tos de Estru turas de Datos Jorge L. Ortega Arjona Departamento de Matem ati as Fa ultad de Cien ias, UNAM Febrero 2004 2 Indi e general 1. Arboles de B usqueda Re orrido y Mantenimiento 7 2. Ordenamiento Se uen ial Un Lmite Inferior de Velo idad 15 3. Alma enamiento por Hashing La Clave esta en la Dire ion 19 4. Compresi on de Texto Codi a ion Hu man 27 5. B usqueda de Cadenas El Algoritmo Boyer-Moore 33 6. Bases de Datos Rela ionales Consultas \Hagalo Usted Mismo" 39 3 4 Prefa io Los Temas Sele tos de Estru turas de Datos introdu en en forma simple y sen illa a algunos temas relevantes de Estru turas de Datos. No tiene la inten ion de substituir a los diversos libros y publi a iones formales en el area, ni ubrir por ompleto los ursos rela ionados, sino mas bien, su objetivo es exponer brevemente y guiar al estudiante a traves de los temas que por su relevan ia se onsideran esen iales para el ono imiento basi o de esta area, desde una perspe tiva del estudio de la Computa ion. Los temas prin ipales que se in luyen en estas notas son: Arboles de Busqueda, Ordenamiento Se uen ial, Alma enamiento por Hashing, Compresion de Texto, Busqueda de Cadenas y Bases de Datos Rela ionales. Estos temas se exponen ha iendo enfasis en los elementos que el estudiante (parti ularmente el estudiante de Computa ion) debe aprender en las asignaturas que se imparten omo parte de la Li en iatura en Cien ias de la Computa ion, Fa ultad de Cien ias, UNAM. Jorge L. Ortega Arjona Febrero 2004 5 6 Cap tulo 1 Arboles de B usqueda Re orrido y Mantenimiento Un arbol es una de las estru turas de datos mas utiles que se han onebido en programa ion de sistemas. Consiste en un onjunto de nodos organizados que alma enan algun tipo de dato. Ciertamente, existen mu hos algoritmos para la busqueda y manipula ion de los datos alma enados en arboles. Este aptulo des ribe omo se onstruyen los arboles, un algoritmo de busqueda de datos en el arbol, algunos esquemas de re orrer el arbol, y una te ni a de mantener (a~nadiendo o borrando) los datos del arbol. El uso de nodos y apuntadores es fundamental para la onstru ion de arboles de busqueda. Un nodo no es mas que una ole ion de lo alidades de memoria aso iadas en onjunto por un programa. Cada nodo tiene un nombre que, ya sea dire ta o indire tamente, se re ere a la dire ion de una de sus lo alidades de memoria. Esta ultima normalmente tiene un ontenido, que es el elemento a ser alma enado en el nodo. Ademas, in luye ero, uno o dos (y a ve es mas) apuntadores o ligas. Estos apuntadores no son mas que los nombres de otros nodos en el arbol. Los programas que usan arboles de busqueda tienen la op ion de pasar de un nodo a otro seguiendo tales apuntadores. Con eptualmente, un arbol de busqueda se representa por ajas y e has ( gura 1.1). Cada aja representa un nodo, y ada e ha representa un apuntador. Cada nodo en el diagrama onsiste de ampos (espa ios donde puede alma enarse un dato o apuntador), que en este aso, son un ampo de datos y dos ampos de apuntadores. 7 37 29 5 0 51 0 −80 17 0 0 0 0 42 6 0 0 9 0 0 Figura 1.1: Un arbol de busqueda on nueve nodos Un arbol puede dire tamente implementarse en memoria prin ipal mediante un programa a nivel ensamblador, o puede implementarse en forma de arreglo en un programa de alto nivel. La gura 1.2 ilustra ambas posibilidades para el arbol anterior. Elemento 101 102 103 104 −80 29 42 nil 105 106 107 37 5 17 102 nil nil nil 106 nil nil 101 1 2 2 1 2 37 3 4 3 5 4 29 4 11 4 nil nil 5 51 5 10 5 7 110 107 nil 6 109 51 1 derecha 3 108 110 izquierda 111 111 6 104 112 112 9 nil nil 6 7 6 7 8 42 8 9 9 6 8 7 9 8 9 nil 9 nil 10 −80 10 nil 10 nil 11 12 5 11 12 nil 11 12 13 13 17 13 nil 13 nil 14 14 Directamente en memoria 14 Como arreglo Figura 1.2: Dos formas de programar un arbol de busqueda 8 No resulta dif il trazar en ambos diagramas los datos y apuntadores de un nodo a otro; meramente, se ini ia en el nodo indi ado on la e ha en ambos asos. En el primer aso, los tres ampos se alma enan en una sola palabra en la dire ion de memoria 105. El ampo de datos ontiene el valor 37, y los ampos de apuntador indi an respe tivamente los nodos \hijos" izquierdo y dere ho de ese nodo. En este aso, el nodo hijo izquierdo se en uentra en la dire ion 102, y el nodo hijo dere ho en la dire ion 110. En la segunda representa ion, los ampos de datos y apuntadores se en uentran alma enados en tres arreglos separados llamados Elemento, izquierda y dere ha, respe tivamente. En este aso, los ampos son utilizados de la misma manera que en el aso anterior. Los ampos de apuntador que no apuntan a nada ontienen un valor \nil". Esto meramente signi a que se usa un smbolo distinguible de valores (dire iones) validos para los apuntadores. Los espa ios en ambas representa iones se muestran para ha er evidente que los arboles son onstruidos en formas que el programador no siempre puede ontrolar. Cuando los datos se alma enan en un arbol, fre uentemente es on el proposito de a eder a elementos parti ulares rapidamente. Por ejemplo, si los elementos que se alma enan tienen un orden en parti ular, omo puede ser < (menor que), enton es la busqueda por elementos puede ha erse en forma espe ialmente rapida si los nodos se ordenan de a uerdo a la siguiente regla: \En ada nodo, todos los elementos alma enados en su subarbol izquierdo tienen un valor menor que el elemento alma enado en ese nodo; y todos los elementos alma enados en el subarbol dere ho tienen un valor mayor que el elementos alma enado en ese nodo" ( gura 1.3) Un arbol de datos que satisfa e tal ondi ion se le ono e omo arbol de busqueda binario. La gura 1.4 muestra un ejemplo en el que puede verse que tan rapido puede ha erse una busqueda en arboles. En este aso, los elementos son nombres, y el ordenamiento simplemente es alfabeti o. Para bus ar en este arbol, se puede usar un algoritmo muy simple, que toma omo entrada el \nombre", y su salida es s o no dependiendo si tal nombre fue hallado en el arbol. Las nota iones item(node), left(node) y right(node) se re eren, respe tivamente, al elemento, al apuntador izquierdo y al apuntador dere ho de un nodo dado. El algoritmo omienza en el nodo mas alto del arbol: 9 X Todos los elementos aqui son <x Todos los elementos aqui son >x Figura 1.3: Un arbol de busqueda puede organizarse mediante un orden Knuth Cook Shannon Church Chomsky Hoare Dijkstra Codd Michie McCarthy Kleene Von Neumann Turing Minsky Wiener Figura 1.4: Utilizando nombres omo datos alma enados en un arbol 10 pro edure 1. found 2. node 3. SEARCH false top repeat a) item(node) = name print si; node nil; found b ) if item(node) > name then node right(node); ) if item(node) < name then node left(node); if then 4. until 5. if not then true; node = nil; found print no; El pro edimiento SEARCH des iende nodo a nodo: si el nombre que se bus a es \menor que" el nombre alma enado en tal nodo, el algoritmo toma la rama izquierda; si el nombre que se bus a es \mayor que" el nombre almaenado en el nodo a tual, el algoritmo toma la rama dere ha. Finalmente, si el nombre es en ontrado en un nodo, el algoritmo imprime s. El i lo termina tan pronto omo node = nil. Esto su ede no solo uando el nombre bus ado se en uentra, sino tambien uando el algoritmo trata de des ender a traves de un apuntador nulo, es de ir, ha llegado al fondo del arbol. Notese el uso de la variable logi a found, que a tua omo se~nal para la prueba, al nal del algoritmo. Esta variable se ini ializa on un valor de false, y solo ambia si la busqueda es exitosa. Es notorio que el numero de itera iones en el i lo prin ipal de SEARCH no es nun a mayor que el numero de niveles en el arbol. Ya que la antidad de trabajo he ho dentro del i lo se limita a un numero onstante de pasos, es posbile es ribir la omplejidad en el tiempo de busqueda limitado por O(l), donde l es el numero de niveles en el arbol. Sin embargo, en un arbol de busqueda binario on n nodos, y todos los nodos ex epto los mas profundos teniendo dos hijos, el numero de niveles l esta dado por: l = dlog2 ne 11 Esto permite es ribir la omplejidad en el tiempo de SEARCH omo O(log n) en el aso general, al menos uando el arbol se en uentra \lleno" en el sentido dado previamente. Este tiempo de busqueda es ex esivamente rapido. Si en lugar de 15 de los mas famosos personajes en omputa ion se olo an mil millones de nombres de quienes trabajan en omputa ion1 el tiempo de busqueda se in rementara apenas de 4 pasos a solo 30. Ahora bien, puede darse el aso de que se requiera listar todos los datos alma enados en un arbol de busqueda. Un algoritmo que produ e tal lista puede re orrer el arbol, es de ir, visitar ada nodo en alguno de varios ordenamientos, el mas omun de los uales es el orden de \primero profundidad" (depth- rst order) o preorden. Este modo de re orrido o visita se programa fa ilmente utilizando la re ursion. El algoritmo se mueve ha ia arriba y abajo dentro del arbol siguiendo los apuntadores. La regla sen illa que de ne su progreso requiere, por ejemplo, que ningun nodo a la dere ha de un nodo dado sea visitado hasta que todos los nodos a la izquierda hayan sido visitados. pro edure DEP T H (x) 1. usex left(x) 6= nil then DEP T H (left(x)) 2. if 3. if right(x) 6= nil DEP T H (right(x)) then program DEP T H (root) El paso \use x" signi a aqu imprimir x o pro esarlo de alguna manera. Si el pro edimiento no ha al anzado el fondo del arbol donde los apuntadores son nulos, enton es se llama a s mismo primero des endiendo por la izquierda del nodo a tual, y luego por la dere ha. Obviamente, la llamada a DEP T H on el nodo izquierdo omo argumento podra resultar inmediatamente en otra llamada igual, y as hasta llegar al fondo del arbol. De esta forma, el algoritmo onsiste en una sola llamada a DEP T H on argumento en el nodo raz (root) del arbol, lo que resulta en un barrido sistemati o de izquierda a dere ha atraves de todos los nodos del arbol. 1 Lo ual sera su iente para onsiderar a todos quienes trabajamos en omputa ion 12 En mu has apli a iones, los arboles de busqueda binarios no se en uentran jos de prin ipio a n, sino que pueden re er o empeque~ne erse omo ualquier ar hivo de datos. Para insertar un nuevo elemento en un arbol de busqueda ( gura 1.5), es tan solo ne esario modi ar levemente el algoritmo de busqueda: tan pronto omo la busqueda por el elemento falla, obtengase una dire ion nueva (no usada), y reempla ese el apuntador a nulo en ontrado on tal dire ion. En seguida se olo a el nuevo elemento en la dire ion, y se rean dos apuntadores nulos, para formar entre los tres los ampos de un nuevo nodo. 35 nil nil 35 42 nil 42 nil nil Figura 1.5: A~nadiendo un nodo Borrar un nodo resulta algo mas ompli ado. De nuevo, el algoritmo de busqueda puede ser utilizado para lo alizar un elemento, pero la dire ion del nodo que apunta ha ia el debe preservarse por el algoritmo de borrado. En la segunda parte de la gura 1.6 un algoritmo de borrado se muestra en opera ion. Inspe ionando la gura 1.6, es notorio que el nodo onteniendo el valor 42 se remueve del arbol onjuntamente on sus dos apuntadores. Conseuentemente, otros dos apuntadores (mar ados on un asteris o) deben ser re-arreglados. Esen ialmente, todo el subarbol dere ho dependiente del nodo onteniendo el valor 42 se mueve ha ia arriba un nivel, mientras que todo el subarbol izquierdo se ha deslizado ha ia abajo dos niveles hasta el primer nodo disponible en la posi ion mas a la izquierda del primer subarbol. La palabra \disponible" aqu se re ere a que el apuntador izquierdo del nodo es nulo y es posible olo ar el segundo subarbol ah. 13 58 58 * Borrar 42 47 35 30 nil 47 36 46 46 nil 54 54 35 nil nil * 30 Figura 1.6: Borrando un nodo 14 nil 36 nil nil Cap tulo 2 Ordenamiento Se uen ial Un Lmite Inferior de Velo idad Ordenar es una tarea omputa ional on enormes impli a iones en el omer io y la industria. Mu has de las omputadoras de uso omer ial e industrial pasan una fra ion signi ativa de su tiempo ordenando listas. De este modo, resulta muy pra ti o preguntarse: >Dada una lista de n el- ementos, ual es la mnima antidad de tiempo que puede llevarle a una omputadora ordenarla? Un algoritmo ono ido omo mez la-ordenamiento (merge-sort) puede lograr esta tarea en un tiempo O(n log n). Partiendo de esto, y onsiderando una n lo su ientemente grande, es posible proponer una onstante positiva tal que el numero de pasos que requiere este algoritmo para ordenar n elementos nun a es mayor que n log n. Esta antidad tiene tambien el orden de magnitud orre to para ser un lmite inferior de el numero de pasos requerido, al menos uando la pregunta anterior se reformula ade uadamente. Si la palabra \ordenarla" se restringe a signi ar que la omputadora solo ompara dos elementos de la lista de n elementos en un momento dado, enton es este lmite inferior no es dif il de demostrar. Sea la lista a ser ordenada representada omo: L = x1 ; x2 ; :::; x 15 n Considerese que la omputadora omienza omparando una x on una x , y ha e una de dos osas omo resultado de la ompara ion ( gura 2.1). i j L xi< xj xi> xj L0 L1 Figura 2.1: De ision ini ial de un algoritmo de ordenamiento Lo que se onsidera ha e la omputadora es alterar la lista L para onvertirla en L0 o L1 , dependiendo de la ompara ion. Por ejemplo, a partir de L la omputadora puede inter ambiar x y x para rear L0 , o dejar x y x en su posi ion original para rear L1 . De modo similar, la omputadora puede ontinuar trabajando sobre L0 o L1 , apli ando pre isamente la misma observa ion. Continuando on este pro eso, resulta un arbol uyos nodos mas bajos orresponden todos a una version ordenada de la lista ini ial. i j i j Por ejemplo si L tiene solo tres elementos, la gura 2.2 muestra omo el \arbol de de ision" podra ser. Para entender la signi an ia de los nodos terminales, es util imaginarse que ha e el algoritmo de ordenamiento on todas las n! posibles versiones de listas de un onjunto de n elementos. Dadas dos de tales listas, supongase que el algoritmo toma la misma rama para ambas listas en ada nivel del arbol, de tal modo que se llega al mismo nodo terminal en ada aso. Cada vez que el algoritmo de ordenamiento toma una de ision omo resultado de una ompara ion, se realiza una permuta ion de la version a tual de la lista de entrada L. Mas aun, se realiza esta permuta ion en ualquier lista que se tenga a tualmente. Por lo tanto, si dos versiones distintas de la lista de un mismo onjunto terminan en el mismo nodo terminal, enton es ambas listas han permutado de forma identi a. Pero esto signi a que a lo mas, una de esta listas ha sido ordenada orre tamente. La uni a on lusion que surge de todo esto es que si el algoritmo de ordenamiento se realiza orre tamente, el arbol de de ision orrespondiente debe tener al menos n! nodos terminales. 16 L xi< xj xi> xj L0 L1 L 01 L 00 L 000 L 001 L 010 L 10 L 11 L 011 Figura 2.2: Un arbol de de ision para una lista de tres elementos Ahora bien, un arbol binario on m nodos terminales debe tener una profundidad de al menos dlog me, y la profundidad (D) del arbol de de ision debe satisfa er que: D = dlog me = log n(n 1)(n n > log( ) 2 2 n n = log 2 2 = O(n log n) 2):::(n=2) n= Esto es tan solo otra forma de de ir que ualquier ompara ion para ordenamiento que tome una lista de n elementos omo entrada debe realizar al menos O(n log n) ompara iones en el peor de los asos. Cualquier algoritmo que se reali e substan ialmente mejor que esto, en total, debe ha er su de ision para ordenamiento en base a otro riterio, o debe ser apaz de ha er las ompara iones en paralelo. 17 18 Cap tulo 3 Alma enamiento por Hashing La Clave esta en la Dire ion Hay prin ipalmente tres te ni as de alma enar y re obrar registros en ar hivos grandes. La mas simple involu ra una busqueda se uen ial a traves de los n registros, y requiere O(n) pasos para re obrar un registro parti ular. Si los n registros estan espe ialmente ordenados o alma enados en un arbol, enton es un registro puede re obrarse en O(log n) pasos (vesae el aptulo 1). Finalmente, si ierta informa ion de ada registro se utiliza para generar una dire ion de memoria, enton es un registro puede re obrarse promedio en O(1) pasos. Esta ultima te ni a, que es el tema de este aptulo, se le ono e omo hashing. Considerese un registro \tpi o" en un ar hivo, onsistente de una llave y un dato, omo se muestra en el siguiente ejemplo: 3782-A:670-15 DURALL RADIAL, 87.50, STOCK 24 Aqu, la llave es 3782-A, y el dato onsiste de un tama~no y mar a de llanta seguido por su pre io por unidad y numero de elementos en alma enamiento. Respe to a alma enar, bus ar y re obrar registros de ar hivos, es su iente espe i ar omo manipular la llave; el dato se \a~nade" dada la programa ion apropiada. Transformar una llave (o hashing), en un sentido, es ortarla y usar solo parte de ella. La parte usada dire tamente genera una dire ion de memoria, 19 Llave TO IT IS AS AT IF OF AM BE DO AN GO SO ASCII 124117 111124 111123 101123 101124 111106 117106 101115 102105 104117 101116 107117 123117 Direccion 17 24 23 23 24 06 06 15 05 17 16 17 17 05 06 07 10 11 14 15 16 17 23 24 25 BE IF, OF AM AN TO, DO, GO AS, IS IT, AT Figura 3.1: Transforma ion de llaves en dgitos omo se muestra en la gura 3.1, la ual usa palabras de dos letras en ingles omo llaves. Los dos ultimos dgitos del odigo ASCII para ada llave k se utilizan omo dire ion h(k), en la ual ada palabra puede ser alma enada. De a uerdo on esto, en la parte dere ha de la gura 3.1 se muestra una por ion de memoria en forma esquemati a. Ademas de ada lo alidad de memoria, se muestra la llave que ha sido transformada a tal dire ion. Algunas lo alidades de memoria no tienen llaves, y otras tienen mas de una. Esto ultimo se ono e omo olision, y para ha er que el hashing trabaje orre tamente, las olisiones deben resolverse. Uno podra pensar que las olisiones son relativamente raras. Ciertamente, el gran numero de olisiones en el ejemplo previo se debe al he ho de que varias de las palabras de dos letras usadas omo llaves terminan en la misma letra. De he ho, omo lo apunta Knuth, las olisiones son asi la regla, aun on llaves distribuidas aleatoriamente, mu ho antes de que el espa io de memoria reservado para el alma enamiento sea totalmente utilizado. Knuth ilustra este punto on la famosa paradoja del umplea~nos: >Cual es la probabilidad de que al menos dos personas en una habita ion on 23 personas tengan el mismo umplea~nos? 20 La respuesta es mas que 0.5. Si se onsidera a los 365 posibles umplea~nos omo lo alidades de memoria, a los nombres de las 23 personas omo datos, y sus umplea~nos omo llaves, enton es este simple ejemplo muestra que tan posibles son las olisiones: la probabilidad de que al menos su eda una olision es mayor que 0.5 aun antes de que el 10 por iento de las lo alidades de memoria sean utilizadas. Existen prin ipalmente dos metodos para resolver las olisiones, llamados en adenamiento ( haining) y area de desbordamiento (open addresing). Sin embargo, antes de des ribirlos, se observa que puede lograrse mediante mantener las olisones a un mnimo. El medio de alma enamiento se onsidera omo un onjunto de dire iones enteras de 0 a M ; estas pueden ser ndi es de un arreglo o dire iones verdaderas de memoria, dependiendo del nivel del lenguaje usado. Una llave k es generalmente una adena alfanumeri a, pero siempre podemos onvertir k en su equivalente entero ASCII. Suponiendo que k es ya un entero, > omo generar una dire ion de memoria en un rango de 0 a M a n de minimizar la probabilidad de olisiones? Una forma es utilizar la opera ion modulo de M: h(k) = k mod M La uni a forma en que se puede ontrolar la fun ion h es sele ionando M ; no es una uestion de que tan grande o peque~na ha er M . Es solo ne esario que M sea el tipo orre to de numero. Se ha observado que si M es un numero primo, enton es h genera dire iones de memoria bien distribuidas, siempre y uando M no tenga la forma r + a, donde r es la raz del onjunto de ara teres (r = 128 para los ara teres ASCII), y a es un entero peque~no. Si se toma este onsejo para el ejemplo anterior, enton es es notorio que M = 23 esta iertamente muy lejos de la forma 128 . k k Con este mismo valor de M se obtienen muy diferentes resultados para las mismas 13 palabras de dos letras. Las dire iones de memoria en la gura 3.2 se expresan en nota ion de imal. Con la primera fun ion hash se sufran uatro olisiones ( ontando TO, DO y GO omo dos olisiones), pero on la nueva fun ion hash este numero baja a tan solo dos. 21 h = dos ultimos digitos 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 h = modulo 23 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 BE IF, OF AM AN TO, DO, GO AS, IS IF SO DO BE AM TO AN AS AT IS, OF IT GO Figura 3.2: Utilizando la fun ion modulo on primos genera una mejora Ademas del metodo de la division, hay otro metodo util el ual usa la multipli a ion. Se basa en la observa ion general de que si uno toma un numero irra ional x, y forma n de sus multiplos: x; 2x; 3x; :::; nx y tomando sus partes fra ionales hasta n: x1 ; x2 ; x3 ; :::; x n los numero resultantes son todos diferentes y dividen al intervalo unitario en n + 1 subintervalos. Cada uno de estos subintervalos tiene al menos uno de tres posibles longitudes, y si se a~nade un nuevo punto x +1 , este ae en un subintervalo del tipo mas grande. Su ede que si x se es oge a ser la \media aurea" ( on el valor aproximadamente de 0.61803399), enton es las tres longitudes sufren la menor varia ion, y todas estan mas er anas que las produ idas por ualquier otro numero irra ional. Estas observa iones sugieren una fun ion hash h produ ida de a uerdo al siguiente algoritmo. n 22 Sea g la razon aurea, tan er ana omo el tama~no de una palabra pueda aproximarla. 1. h kg 2. h parte fra ional de h 3. h hM 4. h parte entera de h Este al ulo forma el produ to k g, toma su parte fra ionaria, lo es ala a M y toma el entero mas er ano (menor que) el resultado. Apli ando este metodo al ejemplo de las llaves para palabras de dos letras, solo se obtiene una olision, lo ual es el mejor desempe~no que se pudiera esperar bajo las ir unstan ias a tuales. Ahora bien, habiendo dis utido algunos tipos de fun iones hash, se retoman las te ni as para manejo de olisiones. La primera involu ra la onstru ion de una adena de apuntadores desde ada dire ion en la ual o urra una olision, y la segunda se re ere a ambiarse a una nueva dire ion de memoria dentro de la tabla hash en la por ion de memoria dedi ada al alma enamiento de llaves. El en adenamiento se ilustra en la gura 3.3 para la fun ion hash del ejemplo. 15 16 17 AM AN TO DO 23 AS IS GO Figura 3.3: En adenamiento ( haining) Las llaves TO, DO y GO se aso ian todas on la dire ion 17, en ese orden. Las llaves AS e IS se aso ian on la dire ion 23. Si una por ion 23 de ada lo alidad de memoria en la tabla se reserva para un apuntador, enton es uando una llave omo DO se aso ia on la misma dire ion que TO, una nueva lo alidad se a~nade de un espa io de memoria auxiliar. La llave DO se olo a en esta lo alidad, y su dire ion se inserta en el espa io para apuntador aso iado on la primera palabra TO. Similarmente, uando despues llega GO a la misma dire ion, se le a~nade a la adena tras DO mediante un segundo apuntador. La otra te ni a para resolver olisiones, llamada area de desbordamiento, onsiste en insertar una llave k, y des ubrir que h(k) se en uentra ya o upada por otra llave; enton es, se \prueba" la tabla hash, examinando dire iones a una distan ia ja p(k) adelante de la dire ion que se onsidera a tualmente. Si h(k) esta o upada, se examina h(k) p(k), y si esta se en uentra o upada, se examina h(k) 2p(k), y as su esivamente. Si p(k) = 1, la te ni a lineal resulta en un largos \ra imos" ( lusters) onforme se llena la tabla. Al ha er p(k) = , donde es un entero \relativamente primo" (i.e. on po os divisores) respe to a M , hay una tenden ia menor a formarse ra imos. Quiza la mejor te ni a de todas es ombinar esta prueba se uen ial on una tabla hash ordenada: si las llaves k se han insertado en la tabla en orden de re iente de k, enton es el siguiente algoritmo inserta una nueva llave en la tabla, siempre y uando haya espa io para ella. 1. i h(k) 2. if ontenido(i) = 0 then 3. if ontenido(i) < k then 4. i 5. i goto ontenido(i) k; exit inter ambia valores de ontenido(i) y k p mod M 2 Es interesante notar que si esta polti a de inser ion se sigue desde el ini io de la onstru ion de la tabla, produ ira la misma tabla que se ha supuesto. Es de ir, este algoritmo tanto introdu e omo mantiene la misma tabla que se obtuvo al insertar primero la llave mas grande, despues la siguiente mas grande, y as su esivamente. Claramente, se ha e mas on una tabla hash que meramente ha er inser iones. Mas fre uentemente, se bus a en la tabla para ver si una llave se en uentra ah. O asionalmente, tambien se borran elementos de la tabla. 24 En la mayora de los asos, bus ar en una tabla hash es muy similar a insertar una nueva llave: se al ula el valor hash h(k), y se veri a la dire ion para ver si k se en uentra en la tabla. Dependiendo si se trata de en adenamiento o de area de desbordamiento, se sigue una adena de apuntadores o se prueba una se uen ia dentro de la tabla. Si m dire iones de las M dire iones en una tabla ontienen llaves , y las adenas de tal tabla ontienen ademas n llaves, enton es el numero de pasos requeridos para bus ar en una tabla on en adenamiento es n=m. Si la funion hash lleva a una distribu ion relativamente uniforme de llaves, enton es m es mayor que n, y el tiempo de busqueda es esen ialmente onstante (y peque~no). La razon m=M se ono e omo \fa tor de arga" (load fa tor) de una tabla hash. Bajo la te ni a de area de desbordamiento, una se uen ia de pruebas requiere de O M M m pasos para lo alizar una llave dentro de la tabla. Aun uando este resultado puede ser derivado teori amente, hasta ahora solo hay eviden ia empri a que el orden de una tabla hash requiere de M M log O m M m pasos para una busqueda exitosa. Este lmite de omplejidad promedio es, sin embargo, una onjetura. Notese que la omplejidad de una prueba lineal re e mu ho mas rapidamente que el orden supuesto de la omplejidad onforme m se aproxima a M . Resulta util omparar varias te ni as de alma enamiento y re upera ion para de idir ual es la mejor para una apli a ion dada. Por ejemplo, es posible omparar las tablas hash on los metodos de arboles binarios (vease el aptulo 1), y on luir que aun uando el tiempo de a eso es mu ho menor en las tablas hash, esto se debe a que generalmente se utiliza una tabla de tama~no jo M . Esta in exibilidad puede ser una desventaja si el ar hivo que se mantiene no tiene un lmite espe o de re imiento. Sin embargo, las tablas hash son mas fa iles de programar que algunos esquemas basados en arboles. 25 26 Cap tulo 4 Compresi on de Texto Codi a ion Hu man Las dos apli a iones mas importantes de las te ni as de odi a ion son la prote ion y ompresion. Cuando un mensaje es odi ado omo una adena de eros y unos, existen te ni as que, mediante la inser ion de algunos bits extra en la adena a trasmitir, permiten al re eptor del mensaje desubrir uales eros o unos (si los hay) son erroneos. Ademas, hay metodos de a ortamiento de la adena, de tal modo que no se requieren transmitir mu hos bits. Las dos grandes areas de apli a ion de la teora de odi a ion son tiempo y espa io. Las apli a iones de tiempo son aquellas de omuni a ion tradiional en que un mensaje se transmite ele troni amente a traves del tiempo, y la mayor preo upa ion es proteger el mensaje de errores. Las apli a iones de espa io involu ran la prote ion o ompresion de datos durante el alma enamiento en algun medio ele troni o, omo la memoria de una omputadora o los dis os magneti os. Si una gran antidad de texto debe alma enarse, o si el espa io de alma enamiento es importante, onviene omprimir el texto de alguna forma antes de alma enarlo. La odi a ion Hu man ha e esto mediante explotar la redundan ia en el texto fuente. En esen ia, la idea es muy simple. Supongase que se tiene una adena de texto que usa un alfabeto on smbolos s1 , s2 , ..., s , y que la probabilidad de que el i-esimo smbolo que apare e en un punto aleatoriamente sele ionado de la adena es p . Cada smbolo s se substituye por una adena binaria de n i i 27 longitud l , de tal modo que la longitud promedio que representa un smbolo esta dado por i L= X n pl i i =1 Suponiendo que p1 > p2 > ::: > p , se nota que L se minimiza solo si l1 < l2 ::: < l . Esta observa ion forma la base para una te ni a que sele iona las adenas binarias reales que odi an los varios smbolos. Supongase, por ejemplo, que los smbolos A, B , C , D, E , F y G apare en on las probabilidades 0.25, 0.21, 0.18, 0.14, 0.09, 0.07 y 0.06 respe tivamente. Notese que la suma de todas las probabilidades suma 1.0. i n n Un arbol de Hu man para estos smbolos y sus probabilidades es una representa ion visual onveniente de la sele ion, en la ual las adenas binarias representan los smbolos ( gura 4.1). Cada nodo del arbol esta etiquetado on la suma de las probabilidades asignadas a los nodos que tiene debajo. 0 1.0 1 0.57 0.43 0.32 0.25 0 0.21 1 0.22 0.14 0.13 0 C 1 0 B A 0.18 1 0 1 0 0.09 1 D E 0.07 0.06 F G Figura 4.1: Un arbol de Hu man Antes de des ribir omo se onstruye este arbol, notese que ada smbolo en el alfabeto fuente se en uentra en un nodo terminal del arbol, y que la adena binaria que lo odi a esta en la se uen ia de eros y unos que se 28 en uentran al re orrer el arbol desde la raz a un nodo en parti ular. La odi a ion Hu man para el sistema que se ha des rito es por lo tanto: A 00 B 10 C 010 D 011 E 111 F 1100 G 1101 La longitud promedio del odigo L es 2.67 bits, y este es un mnimo. El algoritmo que asigna estos odigos onstruye un arbol de Hu man expl ito de abajo ha ia arriba. Un arreglo llamado \subarboles" ontiene los ndi es de las ra es de todos los subarboles de los que se onstruye el arbol de Hu man. Ini ialmente, subarboles no ontiene mas que subarboles de un solo nodo, uno por ada uno de los n smbolos s del alfabeto que se odi a. Hay, por lo tanto, un arreglo orrespondiente de probabilidades \prob", que por ada nodo raz en ada subarbol en onstru ion, ontiene la probabilidad aso iada on ese nodo. Dos arreglos de apuntadores \ligaizquierda" y \ligadere ha" ontienen la estru tura del arbol de Hu man, y uando el algoritmo se termina, debe haber 2n 1 nodos, de los uales n son nodos y el resto apuntadores. i A la i-esima itera ion del algoritmo, los primeros n i+1 subarboles se reordenan, de tal modo que sus probabilidades aso iadas formen una se uen ia de re iente. Los dgitos binarios apropiados se a~naden a los nodos terminales de los ultimos dos subarboles en se uen ia reordenada, y estos se mez lan para formar un nuevo subarbol que se olo a en el arreglo subarboles. for i 1 to n 1 1. reordena subarboles desde 1 a n i+1 2. a~nade 0 a la terminal del subarbol n i 3. a~nade 1 a la terminal del subarbol n i+1 4. prob(n + i) prob(subarboles(n 5. ligadere ha(n + i) 6. ligaizquierda(n + i) i+1 n n i 29 i)) + prob(subarboles(n i + 1)) 7. subarboles(n i) n+i El pro eso que se indi a por el paso \a~nade 0 a la terminal del subarbol n i" simplemente quiere de ir re orrer el (n i)-esimo subarbol y a~nadir un 0 a ada palabra alma enada omo sus nodos terminales. No se ha e referen ia expl ita de estas palabras en el algoritmo, pero son fa ilmente manejadas uando el algoritmo se onvierte en un programa. El paso \ a~nade 1 a la terminal del subarbol n i + 1" tiene un signi ado similar. Despues de que los apuntadores se modi an para aso iarse on el nuevo nodo n + i (siendo los nodos anteriores 1; 2; :::; n; n + 1; :::; n + i 1), el algoritmo nalmente reemplaza las dos ultimas entradas en el arreglo subarboles por la raz del nuevo subarbol onstruido. Cuando i llega a ser n 1, hay un solo subarbol en todo el arreglo, y este es el arbol de Hu man. Los primeros pasos de la opera ion del algoritmo pueden ilustrarse por el ejemplo ya presentado. Ini ialmente hay n i + 1 = 7 subarboles que onsisten de un nodo ada uno. Esto se rearreglan en orden de re iente respe to a su probabilidad ( gura 4.2). 1 2 3 4 5 6 7 0.25 0.21 0.18 0.14 0.09 0.07 0.06 A B C D E F G Figura 4.2: Siete subarboles de un solo nodo Despues de que un 0 y un 1 se a~naden a las terminales de los subarboles 6 y 7, se rea un nuevo subarbol on ndi e n + i = 8. Este se liga a la dere ha on el subarbol 7 y a la izquierda on el subarbol 6. A la siguiente itera ion del algoritmo, los subarboles se rearreglan en orden de re iente de probabilidad ( gura 4.3). A la siguiente itera ion, un nuevo subarbol se forma de los dos anteriores, y el numero de subarboles se redu e a 5 ( gura 4.4). Despues de n = 7 itera iones, solo queda un subarbol, el ual es el arbol de Hu man. A ada paso, se asignan 0 o 1 omo dgitos del odigo a la liga izquierda y dere ha respe tivamente, en forma su esiva a los subarboles on probabilidades menores. Esto asegura que las palabras mas largas de la odi a ion tiendan a ser menos fre uentemente utilizadas. 30 8 1 2 3 4 0.25 0.21 0.18 0.14 A B C D 5 0.13 0.09 E 6 7 0.07 0.06 F G Figura 4.3: Subarboles despues de la primera itera ion 1 9 2 3 0.25 0.22 0.21 0.18 0.14 B C D A 8 4 5 0.13 0.09 E 6 7 0.07 0.06 F G Figura 4.4: Subarboles despues de la segunda itera ion 31 Para alma enar una pieza dada de texto utilizando la odi a ion Hu man, se rea una tabla en la ual se uenta el numero de ve es n que el i-esimo smbolo o urre. La probabilidad p de la pieza de texto es simplemente n =l, donde l es la longitud de la pieza de texto. Apli ar el algoritmo resulta en la asigna ion de un odigo a ada smbolo, as omo en la onstru ion del arbol de Hu man. El texto se re orre, y en una sola pasada, se onvierte en una larga adena binaria de odigos on atenados. En seguida, esta adena se divide en bloques de longitud m, que se re ere al tama~no de palabra de la omputadora parti ular para la que el algoritmo se implementa. Cada bloque, enton es, se onvierte en un solo entero, y se alma ena en la memoria de esta forma. El arbol de Hu man, por su parte, se alma ena en otro sitio de la memoria. i i i Para re uperar el texto que ha sido as alma enado, se invo a el proedimiento inverso, y el arbol de Hu man se utiliza en el ultimo paso del pro esamiento para los smbolos de la adena binaria. Cada smbolo orresponde a una sola sub- adena, determinada por una sola busqueda desde la raz hasta el nodo terminal pertinente del arbol. Para evitar onstruir un arbol ada vez que algun texto se alma ena, es posible onstruir un arbol mas general de una vez por todas, que re eje las probabilidades de ada smbolo en forma mas generi a. Por ejemplo, la ora ion promedio en Ingles (ignorando la puntua ion) ontiene los smbolos de A a Z y un espa io en blan o ( ) en una lo alidad aleatoria on las siguientes probabilidades A D G J M P S V Y 0.065 B 0.032 E 0.015 H 0.001 K 0.032 N 0.015 Q 0.056 T 0.008 W 0.017 Z 0.013 C 0.104 F 0.047 I 0.005 L 0.058 O 0.001 R 0.081 U 0.018 X 0.001 32 0.022 0.021 0.058 0.032 0.064 0.049 0.023 0.001 0.172 Cap tulo 5 B usqueda de Cadenas El Algoritmo Boyer-Moore Existen algunas sutilezas en lo que pare e ser el asunto sen illo de bus ar un patron parti ular dentro de una adena de ara teres, espe ialmente si desea ha erse rapidamente. Por lo tanto, la pregunta >Que tan rapido se puede bus ar un patron dado dentro de una adena de n ara teres? tiene una ierta di ultad pra ti a. Por ejemplo, omo todo minero sabe, hay mu has formas de bus ar ORO en LAS MINAS. Una antidad razonable de metodos di tan que se busque la adena en un orden de nido, por ejemplo, de izquierda a dere ha. Se intenta ha er oin idir el patron on la parte mas a la izquierda de la adena, y si la oin iden ia falla, se ontinua re orriendo la adena ha ia la dere ha hasta que se en uentra una oin iden ia o se a aba la adena. Realmente, pare e razonable omparar los primeros ara teres en el patron y la adena en tal orden: LAS MINAS ORO Ya que O y L no oin iden, no es ne esario en ontinuar las omparaiones, por lo que se re orre el patron en una unidad a la dere ha, y se intenta de nuevo: 33 LAS MINAS ORO De nuevo, los ara teres omparados, A y O, no oin iden. Re orriendo de esta forma, eventualmente la adena se a aba, y se on luye que no hay ORO en LAS MINAS. Varios editores de texto ha en busquedas de adenas de esta forma. Un algoritmo des ubierto por R.S. Boyer y J.S. Moore en 1977 mejoran este metodo mediante veri ar la oin iden ia de los ara teres de dere ha a izquierda en lugar de izquierda a dere ha. Si la se ion de la adena no oin ide on el patron, se puede re orrer el patron por toda su longitud. De este modo, se puede ir de: LAS MINAS ORO inmediatamente a: LAS MINAS ORO A primera vista, pare e ser un dramati o in remento en la e ien ia, espe ialmente si en el siguiente paso el patron puede saltar otros tres ara teres por la misma razon. Desafortunadamente, este in remento en la e ien ia es meramente ilusorio, ya que para veri ar si A no esta en ORO requiere tantas ompara iones omo el re orrer ORO ha ia adelante un espa io ada vez despues de una ompara ion de la primera O on ada uno de los tres ara teres en la adena. Sin embargo, si se onstruye una tabla (llamada tabla 1) la ual por ada letra del alfabeto ontiene su posi ion mas a la dere ha en el patron ORO, enton es solo es ne esario bus ar A en la tabla (lo que se puede ha er muy rapidamente) y notar que su entrada orrespondiente es nula (no existe A en ORO, lo que se simboliza por ;). Uno puede enton es re orrer el patron a la dere ha por tantos ara teres omo los haya en el. 34 Ademas de la te ni a de re orrer basado en tabla 1, el algoritmo BoyerMoore usa otra buena idea: supongase que en el pro eso de ha er oin idir los ara teres del patron on los ara teres de la adena, los primeros m ara teres (de dere ha a izquierda) se en uentra que oin iden: TRESTRISTESTIGRESTRAGABANTRIGO TRASTRA En tal aso, la por ion que on ide hasta ahora al nal del patron podra bien o urrir en ualquier otro lado del patron. Sera enton es inteligente re orrer el patron a la dere ha solo la distan ia entre las dos por iones: TRESTRISTESTIGRESTRAGABANTRIGO TRASTRA En el ejemplo anterior, el algoritmo Boyer-Moore podra des ubrir rapidamente que B no esta en TRASTRA, y omo resultado, re orrere el patron por otros siete ara teres. El algoritmo Boyer-Moore es orto y dire to. Ademas de tabla 1, utiliza otra tabla, tabla 2, que por ada por ion terminal del patron indi a su re urren ia mas a la dere ha y no terminal. Esta tabla puede a ederse tambien rapidamente. ST RING 1. i 2. largo while haya adena a ) j an ho b ) if j = 0 then imprime `Coin iden ia en' i + 1 ) if string(i) = pattern(j ) then 35 j j 1, i i 1, goto 2.b d) i i + max(table1(string(i)); table2(j )) donde an ho es la longitud del patron, largo es la longitud de la adena, i es la posi ion a tual en la adena de ara teres, j es la posi ion a tual en el patron, string(i) es el i-esimo ara ter en la adena, y pattern(j) es el j -esimo ara ter en el patron. Como ejemplo del algoritmo anterior en opera ion, supongase que el patron TRASTRA se ha olo ado en seguida de ...GRESTRA... en la adena. Comenzando en el paso 2. , se nota que i = 20 y j = 7. Ya que string(26) = pattern(7), ambos i y j se de rementan. Retornando al paso 2.b on i = 19 y j = 6 se en uentra otra oin iden ia, volviendo i = 18 y j = 5. Finalmente, una nueva on iden ia su ede, lo que deja i = 17 y j = 4. Sin embargo, los ara teres en las siguientes posi iones no oin iden, y la eje u ion pro ede on string(17) = E. Por otro lado, la entrada en tabla 1 apare e omo sigue: C 2 D 2 E 5 F 6 G 6 Por tanto, tabla1(E) = 5 signi a que el apuntador i debe re orrerse al menos 5 ara teres a la dere ha antes de que un nuevo intento de oin iden ia tenga ualquier esperanza de exito. Esto es equivalente a re orrer el patron uatro ara teres a la dere ha, en donde las T oin iden de nuevo. Sin embargo, tabla 2 se podra ver omo sigue: 1 11 2 10 3 9 4 5 5 4 5 1 De nuevo, el apuntador i debe re orrerse al menos 5 ara teres a la dere ha antes de que sea razonable re omenzar el pro eso de oin iden ia. Como su ede en este ejemplo, tabla1(E) = tabla2(4), lo que impli a que el apuntador i debe re orrerse 5 ara teres en ualquier aso. Sin embargo, 36 tratando otros patrones es posible notar mas laramente la utilidad que provee la independen ia de las dos tablas. El algoritmo Boyer-Moore ha sido exhaustivamente probado y rigurosamente analizado. El resultado de las pruebas muestra que en promedio, este algoritmo es \sublineal". Esto es, para en ontrar un patron en la i-esima posi ion de una adena requiere de menos de i + an ho pasos uando el algoritmo esta ade uadamente odi ado. En terminos del omportamiento en el peor aso, el algoritmo aun se eje uta en el orden de i + an ho. En uanto a la utilidad de tabla 1 y tabla 2, es interesante que on alfabetos grandes y patrones peque~nos, tabla 1 resulta mas util. Sin embargo, esta situa ion se ha e inversa para peque~nos alfabetos y grandes patrones. 37 38 Cap tulo 6 Bases de Datos Rela ionales Consultas \Hagalo Usted Mismo" En mu has apli a iones que involu ran el alma enamiento de informaion en ar hivos de omputadora, normalmente se dan algunas onsultas que un usuario del ar hivo desea ha er. Por ejemplo, el ar hivo podra ser un dire torio telefoni o. Para en ontrar el numero telefoni o de alguien, el usuario del sistema meramente es ribe el nombre de la persona en el te lado, y momentos mas tarde el orrespondiente numero telefoni o apare e en pantalla. La omputadora, usando el nombre omo lave o llave, ha bus ado a traves del ar hivo por el nombre, re obrado el numero telefoni o alma enado, y lo despliega en pantalla. Sin embargo, algunas formas de alma enar datos son mas omplejas que otras. Involu ran mu has lases de informa ion on rela iones espe iales entre ellas. Considerese, por ejemplo, los datos aso iados on una liga de futbol. Existen varias rela iones entre jugadores y equipos, entre jugadores y numeros telefoni os, entre equipos y entrenadores, et . (Figura 6.1). Para asos omo la liga de futbol, se utilizan bases de datos rela ionales, mediante las uales es posible produ ir informa ion que no esta alma enada en forma inmediatamente a esible. Puede haber, por ejemplo, una lista de jugadores, sus equipos, y hasta de sus numeros telefoni os, pero no haber una lista de numeros telefoni os de todos los jugadores de un equipo en parti ular 1 . 1 Lo ual sera de mu ha utilidad para avisarles si uno de sus juegos resulta an elado 39 Jugador Edad Numero telefonico Entrenador Equipo Figura 6.1: Rela iones de datos en una liga de futbol En una base de datos rela ional, es posible rear una \ onsulta" (query) que produz a tal lista (y mu ha mas informa ion). Para espe i ar los rangos de onsultas posibles en una base de datos rela ional, supongase que la informa ion de la liga de futbol se alama ena en tres tablas separadas: Tabla de Entrenadores Equipo Entrenador Tel efono Leones M. Cervantes 5535 6798 Demonios G. Gonzalez 5671 2033 ... ... ... Tabla de Jugadores Jugador A. Johns L. E heverra K. Or ... Edad 22 33 25 ... Tel efono 5432 6592 5574 6378 5522 1362 ... Equipo Leones Angeles Leones ... Tabla de En uentros Lo al Demonios Leones ... Visitante Angeles Tornados ... D a Hora Lugar 22 O tubre 12:00 hrs. Estadio \Julian Gar a" 12 Noviembre 16:00 hrs. Estadio Na ional ... ... ... 40 Cada tabla representa una rela ion que sera usada por la base de datos. Mas aun, ada rela ion es realmente un onjunto de tuplas; por ejemplo, la primera rela ion onsiste en tros de datos on la forma: Entrenadores:(equipo,entrenador,telefono) Las otras rela iones onsisten en tuplas de 4 y 5 elementos, respe tivamente: Jugadores:(jugador,edad,telefono,equipo) Juegos:(lo al,visitante,da,hora,lugar) Cada olumna en una tabla (rela ion) representa un atributo. Algunos atributos fun ionan omo llaves uando se bus a en las tablas. En las tres tablas anteriores, algunos atributos llave podran ser equipo, jugador, lo al y visitante. Hablando matemati amente, una rela ion es un onjunto de n-tuplas (x1 ; x2 ; :::; x ) donde ada elemento x se obtiene de un onjunto X , y ninguna tupla se repite. Las tablas en una base de datos rela ional satisfa en esta de ni ion. Como resultado, la teora matemati a se puede apli ar; en parti ular, una teora llamada algebra rela ional de ne opera iones sobre las tablas. n i i Dos opera iones del algebra rela ional son sele ion y proye ion. La opera ion de sele ion espe i a un sub onjunto de renglones en una tabla mediante una expresion booleana que involu ra atributos. La opera ion de proye ion espe i a un onjunto de olumnas en una tabla, mediante listar los atributos involu rados. Tambien elimina las dupli a iones que se tengan de los renglones resultantes. Para obtener una lista de telefonos de los Leones, estas dos opera iones son su ientes. La sele ion se denota por , y la proye ion por : jugadorytelef ono ( = equipo Leones (Jugadores)) Analizando de adentro ha ia afuera, la opera ion de sele ion espe i a todos los renglones de la tabla de jugadores en el ual el nombre del equipo es Leones. En seguida, de entre estos, la proye ion espe i a los atributos 41 \jugador" y \telefono", des artando todos los otros atributos de la tupla no espe i ados por . Por tanto, la siguiente lista apare e: A. Johns 5432 6592 K. Or 5522 1362 ... ... Otra rela ion importante es llamada la \union natural" (natural join), y se denota on el smbolo ./. Opera sobre dos tablas que tienen uno o mas atributos omunes. Para ada par de tuplas (una de la primera tabla y una de la segunda), produ e una nueva tupla si los atributos omunes tienen valores identi os para tal par. Supongase por ejemplo que se le pide a la base de datos rela ional la union de las tablas Entrenadores y Jugadores: Entrenadores ./ Jugadores Las dos tablas tienen a equipo omo un atributo omun. Un registro dentro de la nueva tabla (es de ir, una rela ion) que resulta de la opera ion de union podra ser: Leones, M. Cervantes, 5535 6798, A. Johns, 22, 5432 65 92 El atributo equipo, que tiene un valor omun de Leones para un renglon de Entrenadores y un renglon de Jugadores, resulta en un renglon nuevo en una nueva tabla. La opera ion union fun iona de forma ombinada on otras opera iones para produ ir onsultas de datos mas versatiles. Supongase que un usuario de la base de datos quisiera una lista telefoni a del equipo entrenado por M. Cervantes. La siguiente se uen ia de opera iones produ ira esa lista: jugadorytelef ono ( entrenador = M:C ervantes (Entrenadores ./ Jugadores)) Dada la tabla Entrenadorer ./ Jugadores, la sele ion de M. Cervantes omo entrenador produ ira tuplas de 6 elementos onteniendo el atributo entrenador on valor de M. Cervantes. Es laro, el valor de Leones sera redundante en este aso. Ya que se requieren solo los nombres y numeros telefoni os de los jugadores entrenados por M. Cervantes, la proye ion se realiza onsiderando solo estos datos. 42 Notese que la misma informa ion es re uperable en mu has formas diferentes de una base de datos rela ional. Ademas, no siempre se obtienen los datos a la misma velo idad. Por ejemplo, la opera ion union que se invo a en la onsulta anterior es inherentemente ine iente, ya que se apli a a dos tablas relativamente grandes. Una forma equivalente, pero mas e iente, sera la siguiente: jugadorytelef ono (Jugadores ./ ( entrenador = M:C ervantes (Entrenadores))) La sele ion on entrenador = M. Cervantes, uando se apli a a Entrenadores, produ e una sola tupla de tres elementos: Leones, M. Cervantes, 5535 6798 La union on Jugadores de esta tupla, enton es, espe i a todos los jugadores del equipo de Leones. Una proye ion nal elimina todos los valores de los atributos ex epto nombre y telefono de las tuplas resultantes. Este ejemplo ilustra una ara tersti a importante de la lase de lenguajes de onsulta de alto nivel que se usan en bases de datos rela ionales, y se basa en el algebra rela ional. Tales lenguajes, uando son ompletamente implementados, ha en posible a los usuarios optimizar sus onsultas. Y dado que hay mas de una manera de produ ir onsultas, tambien es posible sele ionar aquella que lo ha e mas rapidamente. >Como se implementan las bases de datos rela ionales? Ya que solo se mantienen tablas en la memoria de la omputadora, todas las opera iones rela ionales deben redu irse a opera iones sobre las tablas. El operador sele ion es fa ilmente implementado: simplemente revisa la tabla renglon por renglon, probando una expresion booleana que de ne los renglones a ser sele ionados a partir de los valores de los atributos de los propios renglones. La proye ion tambien es bastante simple de programar, mediante ordenar los renglones resultantes y eliminar los dupli ados. La opera ion union se puede eje utar mas rapidamente en tablas relativamente grandes si las tablas primero se ordenan a partir de los valores del atributo omun. Cuando las tablas se ordenan, pueden mez larse mediante el atributo omun, valor por valor. Hay mu has varia iones para el operador union. En lugar de igualdad, puede pedirse que los atributos omunes satisfagan otras formas de om43 para ion, omo por ejemplo, desigualdades. Por otro lado, existen otros operadores ademas de la sele ion, proye ion y union, disponibles para las onsultas. En la mayora de los sistemas de bases de datos rela ionales, las onsultas pueden formarse a partir de opera iones artesianas de produ to, union, interse ion, y substra ion de onjuntos. Hasta la de ada de los 1970s, se introdujeron tres formas de sistemas de bases de datos: jerarqui a, distribuida y rela ional. Ahora se re ono e que las bases de datos rela ionales son las que tienen la mas amplia variedad de apli a iones y utilidad. Conse uentemente, solo se men ionan aqu tal tipo de bases de datos. Los lenguajes en que las onsultas para bases de datos rela ionales se expresan se han desarrollado durante varias genera iones de lenguajes, que han ido so sti andose y re nandose. Las onsultas que se han ilustrado hasta ahora tienen una forma algebrai a y pro edural. Un lenguaje desarrollado para expresar parti ularmente onsultas, llamado SQL, ha sido dise~nado para ser usado en forma natural por el humano, y es no-pro edural. La onsulta basi a en SQL tiene la siguiente forma general: SELECT A1 ; A2 ; :::; A FROM R1 ; R2 ; :::R WHERE Expresion Booleana n m Tal onsulta impli a no solo la opera ion sele ion, sino tambien la proye ion, produ to artesiano, y union natural. Los argumentos A espe i an uales atributos son parte de la onsulta, y los argumentos R son rela iones. Los usuarios espe i an uales rela iones son requeridas para produ ir una respuesta a una onsulta. Ciertamente, la lista R1 ; :::; R de ne un produ to artesiano de todas las rela iones (tablas) existentes. La expresion booleana que apare e en la por ion \WHERE" de la onsulta in luye una variedad de operadores, omo por ejemplo, sele iones y uniones. i j m Ahora es posible mostrar omo algunas de las onsultas anteriores, expresadas usando algebra rela ional, pueden re-expresarse usando SQL. Para produ ir la lista de los jugadores de los Leones y sus numeros de telefono, es posible es ribir: SELECT jugador; telefono FROM Jugadores WHERE equipo = Leones 44 Para el ejemplo donde se involu ran una lista de jugadores y sus numeros telefoni os on el equipo entrenado por M. Cervantes, se podra obtener la onsulta de la siguiente forma: SELECT jugador; telefono FROM Jugadores; Entrenadores WHERE Entrenadores:entrenador = M:Cervantes and Entrenadores:equipo = Jugadores:equipo Para aquellos programadores que onsideran a SQL (o el algebra relaional) redu ido a estru turas relativamente simples, se ofre e el siguiente ejemplo on una onsulta anidada: SELECT jugador; telefono FROM Jugadores WHERE equipo In (SELECT equipo FROM Entrenadores WHERE entrenador = M:Cervantes ) A tualmente, SQL se ha onvertido en el lenguaje de onsultas estandar para los sistemas de bases de datos rela ionales de grandes omputadoras. 45 46 Bibliograf a [1℄ A.V. Aho, J.E. Hop roft, and J.D. Ullman. The Design and Analysis of Computer Algorithms. Addison-Wesley, 1974. [2℄ A.V. Aho, J.E. Hop roft, and J.D. Ullman. Data Stru tures and Algorithms. Addison-Wesley, 1983. [3℄ C.J. Date. An Introdu tion to Database Systems. Addison-Wesley, 1980. [4℄ D.E. Knuth. The Art of Computer Programming, vol. 1. AddisonWesley, 1967. [5℄ D.E. Knuth. The Art of Computer Programming, vol. 3. AddisonWesley, 1967. [6℄ R.W. Hamming. Coding and Information Theory. Prenti e-Hall, 1980. [7℄ T.A. Standish. Data Stru tures and Te hniques. Addison-Wesley, 1980. [8℄ J.D. Ullman. Prin iples of Database Systems. Computer S ien e Press, 1980. [9℄ N. Wirth. Algoritmos y Estru turas de Datos. Prenti e-Hall, 1987. 47