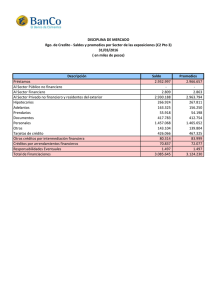
María Paula Estupiñan Martinez – 202212331 Taller de bases de datos documentales # threads Ramp-Up 50 100 200 500 1000 10 10 10 10 10 A 182 190 189 254 5985 App sin patrones T %E 5 0 9.9 0 19.7 0 48.7 0 39.1 6 Prueba de 50 threads: • Sin patrones: • Con patrones: Prueba de 100 threads: • Sin patrones: • Con patrones: Prueba de 200 threads: • Sin patrones: • Con patrones: App con patrones A T %E 180 5.0 0 183 9.9 0 184 19.7 0 194 49.1 0 4157 42.4 1.3 Prueba de 500 threads: • Sin patrones: • Con patrones: Prueba de 1000 threads: • Sin patrones: • Con patrones: En la evaluación de ambas aplicaciones, observamos que con un volumen bajo de datos, su desempeño es bastante similar. No obstante, al incrementar la carga a 100 hilos, se evidencia una superior eficiencia en la aplicación que implementa patrones de diseño. Esta eficiencia se manifiesta en su capacidad para procesar el mismo número de solicitudes en un tiempo significativamente menor y con un rendimiento más óptimo. Esta ventaja se atribuye principalmente al método de cálculo de promedios en la aplicación con patrones. En dicha aplicación, los promedios se actualizan automáticamente con cada nueva inserción en la lista de medidas, lo que optimiza el tiempo de respuesta durante las consultas subsiguientes. Esta característica se hace especialmente evidente durante la inserción de datos marcados como críticos (critical = true), donde aunque el tiempo de inserción es mayor, facilita un acceso más rápido durante las consultas de promedios. Por el contrario, la aplicación sin patrones realiza el cálculo de promedios en tiempo real cada vez que se solicita, lo que incrementa el tiempo de respuesta a medida que el volumen de datos crece. Además, en la versión sin patrones, todos los datos se almacenan en un único documento, requiriendo que el sistema evalúe cada registro para calcular el promedio. Esto contrasta con la estructura de la aplicación con patrones, donde los datos críticos se almacenan de manera separada, simplificando y acelerando la consulta de estos registros específicos. • ¿Qué diferencias identificaron en cuanto al punto de inflexión de la aplicación que usa una base de datos relacional y una base de datos documental? Al comparar los resultados, noté que las aplicaciones con bases de datos relacionales exhiben un punto de inflexión más alto para las peticiones GET que aquellas con bases de datos documentales. Sin embargo, la situación se invierte en el caso de las peticiones POST, donde las bases de datos documentales muestran un punto de inflexión más elevado. Esto se debe a que las consultas son generalmente más eficientes en los sistemas relacionales, ya que realizar operaciones de JOIN entre diversas tablas suele ser más rápido que ejecutar lookups en documentos de MongoDB. En cuanto a la inserción de datos, MongoDB resulta ser más ágil porque no realiza verificaciones de persistencia de datos ni maneja las dependencias de estas, lo que acelera el proceso de inserción. En cambio, las bases de datos relacionales efectúan revisiones exhaustivas para asegurar la integridad y la persistencia, lo que incrementa el tiempo necesario para completar las inserciones. Además, en términos del porcentaje de error, las aplicaciones que utilizan bases de datos documentales tienden a mantener un índice de errores por debajo del 5%, mientras que las que operan con sistemas relacionales frecuentemente registran tasas de error superiores al 10%.