ESTADÍSTICA
GRADO INGENIERÍA MECÁNICA
Celeste Pizarro Romero
Departamento de Matemática Aplicada. ESCET. URJC
Curso 2018/19
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
TEMA 1
DESCRIPCIÓN DE DATOS
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Introducción
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Buscando patrones en los datos
▶ Una forma razonable de buscar hipótesis que permitan
explicar algún fenómeno de la naturaleza es recolectar datos y
buscar en ellos patrones de comportamiento.
▶ Pero cuando nos limitamos a observar un listado de datos,
suele resultar difícil identificar ningún patrón. Por ejemplo, la
lista siguiente recoge el número de huevos de todos los nidos
de ñandú encontrados en el Parque Nacional de Talampaya
(Argentina):
0
2
1
2
1
1
3
6
4
5
0
0
0
3
1
1
0
5
5
5
1
6
4
4
1
0
0
1
1
2
1
3
5
5
0
1
0
2
2
3
2
2
2
1
0
0
1
0
1
1
0
1
1
3
2
2
1
0
2
3
3
1
2
4
0
3
1
3
2
1
0
1
1
5
2
3
2
6
4
5
2
0
1
2
0
1
3
2
2
0
4
0
2
1
2
4
3
1
3
0
5
5
2
4
1
4
3
1
3
0
.
3
1
2
1
3
1
1
1
3
4
.
.
.
.
.
2
1
2
2
0
6
2
4
4
2
. . . .
. . . .
2
2
4
1
4
1
3
1
3
0
. . . .
. . . .
1
3
1
2
1
0
0
2
1
5
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Estadística descriptiva
▶ El listado anterior contiene toda la información que nos
interesa sobre el número de huevos de ñandú en Talampaya,
pero el simple examen de los datos uno detrás de otro no es
suficiente para identificar las características más relevantes del
conjunto.
▶ Este ejemplo ilustra el hecho de que, para poder indentificar
patrones de comportamiento, es preciso ordenar y resumir las
observaciones.
▶ La estadística descriptiva es la exploración de conjuntos
de datos mediante técnicas gráficas y numéricas con el fin
extraer la información más relevante.
▶ En este tema analizaremos métodos para describir conjuntos
de observaciones a fin de poder descubrir sus carácterísticas
principales.
▶ El análisis es diferente dependiendo de que la variable sea
cualitativa o cuantitativa, y en este último caso dependiendo
de que sea discreta o continua.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Esquema
▶ Descripción de variables categóricas o cualitativa
▶ Descripción de variables cuantitativas:
Distribución de frecuencias en variables discretas
Distribución de frecuencias en variables continuas
▶ Resumen numérico de los datos: (Estadísticos descriptivos)
▶
▶
Medidas de centralización
Medidas de posición
▶ Medidas de dispersión
▶
▶
▶
Otros aspectos a tener en cuenta
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Descripción de variables categóricas
o cualitativas
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Modalidades de una variable cualitativa
▶ Recordemos que las
variables categóricas o cualitativas
son aquellas cuyos posibles valores o modalidades son
atributos o categorías, es decir, no son números.
▶ Consideremos una población de n individuos u objetos, y una
variable estadística categórica C con k valores, clases o
modalidades,
c1 , ...., ck
▶ Estas modalidades deben de estar bien definidas; esto supone
que han de ser exhaustivas y excluyentes, es decir, todas las
unidades experimentales deben pertenecer a una categoria y
sólo a una de ellas.
exhaustivas: que todo el mundo se tiene que ver reflejado, representado
excluyentes: ningun sujeto puede estar en 2 categorías diferentes
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Frecuencias absolutas y relativas
▶ Podemos considerar las siguientes magnitudes:
La frecuencia absoluta de la modalidad ci , que denotaremos
por ni , es el número total de observaciones en esta modalidad.
▶ La frecuencia relativa de la clase c , que denotaremos por f ,
i
i
es el cociente entre la frecuencia absoluta de dicha clase y el
número total de observaciones, es decir,
▶
fi =
ni nº total de personas cn ojos verdes ej 2
.
n población total ej 30
fi es la proporción (o tanto por uno) de observaciones que
están en la clase ci . Multiplicado por 100 representa el
porcentaje o tanto por ciento ( %) de la población que
pertenece a esa clase.
Las frecuencias relativas permiten comparar conjuntos de
datos con distinto numero de observaciones.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Distribución de frecuencias
▶ La distribución de frecuencias es la descripción del conjunto
de clases con sus correspondientes frecuencias.
▶ Para presentar de forma ordenada la distribución de
frecuencias se utilizan tablas de frecuencias, cuya estructura
general es la siguiente:
Modalidades
negro c1
.
azul ..
Frec. Absolutas
n1
..
.
Frec. Relativas
f1 = nn1
..
.
cj
..
.
nj 2
..
.
fj = nj
..
.
ck
nk
fk = nnk
Total:
n
1
n
2/20
▶ La distribución de frecuencias también puede visualizarse
mediante gráficos.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: tabla de frecuencias
La siguiente tabla de frecuencias resume el tipo de residuos al
que corresponden los lotes almacenados en un vertedero en
2008:
Modalidad
Agropecuarios
Forestales
Industriales
Mineros
Municipales
Radiactivos
Sanitarios
Total
F. absoluta (ni ) F. relativa (fi )
6 lotes
6 hay
0.2000 6/30
de agropec
4
0.1333 4/30
5
0.1667
9
0.3000
3
0.1000
1
0.0333
2
0.0667
30 total
1
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Propiedades de las frecuencias
▶ Las frecuencias, tanto absolutas como relativas, son números
no negativos, es decir,
no es lo mismo que positivo, no negativo incluye al 0.
ni ≥ 0, fi ≥ 0, para i = 1, ...k.
▶ Puesto que las modalidades son exhaustivas y excluyentes, la
suma de las frecuencias absolutas de todas las
modalidades es el número total de observaciones, esto es,
k
∑
nj = n1 + n2 + . . . + nk = n.
j=1
▶ La suma de las frecuencias relativas de todas las
modalidades es 1, o sea,
k
∑
j=1
fj = f1 + . . . fk =
n1
nk
n1 + . . . + nk
n
+ ... +
=
= = 1.
n
n
n
n
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Representaciones gráficas para var cualitativas
▶ Habitualmente resulta más inmediato visualizar la distribución
de frecuencias de una variable representándolos gráficamente.
▶ Los gráficos más utilizados para representar la distribución de
las variables cualitativas son:
Diagramas de barras
Diagramas de sectores (forma de quesito)
▶ Pictogramas dibujos representativos
▶ Cartogramas mapas
▶
▶
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Diagramas de barras
▶ Los diagramas de barras permiten visualizar de manera
sencilla la distribución de frecuencias de una variable
categórica.
▶ Para ello se representan
▶
▶
en el eje de abscisas (eje X) las modalidades
en el de ordenadas (eje Y) las frecuencias (absolutas o
relativas). si se ponen 2 poblaciones diferentes siempre se ponen relativas
salvo que ambos tengan los mismos datos
▶ El aspecto del gráfico es el mismo si se usan frecuencias
absolutas o frecuencias relativas. Sólo cambia la escala.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: diagrama de barras
▶ Para los datos sobre el tipo de residuos, los diagramas de
barras de frecuencias absolutas y relativas son,
respectivamente,
Diagrama de barras (frecuencias relativas)
0.20
0.15
frecuencias relativas
0
0.00
0.05
0.10
6
4
2
frecuencias absolutas
8
0.25
10
0.30
Diagrama de barras (frecuencias absolutas)
Agro
Fores
Indus
Miner
Muni
Radia
Sani
Agro
Fores
Indus
RESIDUOS
Miner
Muni
Radia
Sani
RESIDUOS
▶ Observamos que los dos gráficos sólo difieren en la escala.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Diagramas de barras comparativos
▶ Los diagramas de barras permiten también comparar la
distribución de frecuencias en varias poblaciones.
▶ Ejemplo: La siguiente tabla de frecuencias resume el tipo de
residuos al que corresponden a lotes almacenados en el
vertedero durante los años 2000 y 2008:
Modalidad
2000: ni 2000: fi 2008: ni 2008: fi
Agropecuarios
4
0.1250
6
0.2000
Forestales
4
0.1250
4
0.1333
Industriales
6
0.1875
5
0.1667
Mineros
8
0.2500
9
0.3000
Municipales
4
0.1250
3
0.1000
Radiactivos
2
0.0625
1
0.0333
Sanitarios
2
0.0625
4
0.0667
Total
32
1
30
1
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: diagrama de barras comparativo
▶ El siguiente gráfico representa los datos de la tabla anterior:
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
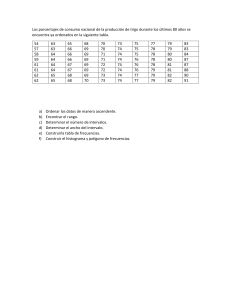
Diagramas de barras 3D
▶ En ocasiones los diagramas de barras aparecen representados
en tres dimensiones, como en el siguiente ejemplo sobre
consumo de drogas:
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Diagramas de sectores (tartas)
▶ Los diagramas de sectores (piecharts) constituyen otra
herramienta gráfica para visualizar la distribución de
frecuencias de una variable categórica.
▶ Para construirlo:
Se divide un círculo en sectores proporcionales a las frecuencias
(absolutas o relativas) de cada clase.
▶ El arco de cada porción, a , se calcula usando una regla de tres:
i
▶
n −→ 3600 ,
360 · ni nº de datos
ni −→ ai =
n nº total
▶
Los habitual, no obstante, es que para construirlo se utilice
algún paquete estadístico, como por ejemplo R.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: diagrama de sectores
▶ El diagrama de sectores correspondiente a los datos sobre el
tipo de residuos es
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Opciones gráficas de los diagramas de sectores
▶ Los diagramas de sectores pueden hacerse más vistosos
dibujándolos en tres dimensiones y/o separando sus sectores
para resaltar algunas características.
▶ Ejemplos:
hay que poner siempre el porcentaje
▶ Los diagramas tridimensionales son más espectaculares, pero
menos claros. Esto es algo que ocurre con los gráficos en
general, no sólo con los de sectores.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Inconvenientes de los diagramas de sectores
pero no son muy buenos para
dar información
▶ Los diagramas de sectores son bastante populares. Por
ejemplo, es muy habitual que los resultados electorales se
ilustren con este tipo de gráficos.
▶ Sin embargo, estos diagramas de tarta presentan muchas
limitaciones:
No permiten identificar el número total de observaciones.
Cuando las frecuencias de las modalidades son similares, es
difícil identificar las diferencias entre ellas en los diagramas de
sectores, ya que el ojo humano no evalua con los angulos con
la misma facilidad que las alturas.
▶ Cuando la variable tiene más de 5 o 6 clases, el diagrama
resultante es difícil de interpretar.
▶
▶
▶ Por todo ello es más informativo (y casi siempre preferible)
utilizar diagramas de barras.
▶ Los diagramas de sectores no deben utilizarse nunca para
representar variables numéricas.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: inconvenientes diagramas sectores
▶ El siguiente diagrama de sectores representa los resultados de
unas elecciones:
Resultado electoral
Democratas
Otros
Republicanos
▶ En este gráfico es difícil identificar cuál ha sido el partido
ganador.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo (continuación)
▶ El diagrama de barras siguiente representa los mismos datos:
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
Resultado electoral
Democratas
Otros
Republicanos
▶ En este gráfico sí permite conocer la clasificación electoral.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Inconvenientes diagramas sectores (continuación)
▶ Antes de emplear uno de estos gráficos es muy importante
cerciorarse de que lo que se va a representar es un todo a
repartir entre varias modalidades. De lo contrario se
pueden cometer errores como el de la cadena Fox, que en
noviembre de 2009 publicó el siguiente gráfico:
está mal
porque no
suma el 100%
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Inconvenientes diagramas sectores (continuación)
▶ El diagrama anterior pretendía ilustrar el resultado de la
siguiente encuesta electoral:
opinión
opinión
Candidat@
favorable desfavorable NS/NC
Sara Palin
70 %
21 %
9%
Mike Huckabee
63 %
15 %
22 %
Mitt Romney
60 %
16 %
24 %
▶ Sin embargo, lo que que transmitió, fue que un total del
193 % del electorado (????) apoyaba a estos tres candidatos
republicanos.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Inconvenientes diagramas sectores (continuación)
▶ Lo adecuado habría sido utlizar un diagrama de barras:
0
10
20
30
40
50
60
70
GOP Candidates
Huckabee
Palin
Romney
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Pictogramas
▶ Los pictogramas expresan con dibujos alusivos al tema de
estudio las frecuencias de las modalidades de la variable.
▶ El escalamiento de los dibujos debe ser proporcional a la
frecuencia que representa.
▶ Este tipo de gráficos se utilizan frecuentemente en los medios
de comunicación.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: pictogramas
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: pictogramas
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Cartogramas
▶ En la prensa gráfica aparecen a menudo cartogramas, que
representan los datos datos sobre una base geográfica,
normalmente un mapa.
▶ La densidad de datos en cada zona se indica mediante
sombreados, rayados, colores, etc.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: cartogramas
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
La moda
categoría se puede acompañar con el valor , es decir, el n1 de veces que aparece
▶ Por su naturaleza, las variables cualitativas no permiten un
análisis numérico.
▶ Como resumen descriptivo de una variable categórica puede
usarse la moda o clase modal, que es el dato o clase con
mayor frecuencia.
▶ La moda es el dato más representativo por ser el más
frecuente.
▶ La moda no es siempre única, ya que puede existir más de una
clase con la máxima frecuencia.
▶ Ejemplo: Para los datos sobre los residuos almacenados en el
vertedero en el año 2008 la moda es residuos mineros.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Descripción de variables cuantitativas
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Variables cuantitativas
▶ El caracter numérico de las variables cuantitativas permite un
tratamiento estadístico más elaborado.
▶ Con ellas pueden realizarse operaciones matemáticas que
permiten una descripción más precisa y completa.
▶ El tratamiento es diferente según la variable sea continua o
discreta. Recordemos que:
Las variables discretas son aquellas cuyos posibles valores
son una cantidad numerable, y no admiten un valor
intermedio entre dos cualquiera de sus valores (por ejemplo el
número de huevos de un nido).
▶ Las variables continuas pueden tomar cualquiera de los
valores de un intervalo real (admiten cualquier cantidad de
cifras decimales), y por consiguiente el cardinal de su dominio
es una cantidad no numerable (por ejemplo el peso o la
longitud de un lobo ibérico).
▶
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Distribución de frecuencias para variables discretas
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Distribución de frecuencias para variables discretas
▶ Para las variables discretas, las clases en las que se agrupan
los datos vienen definidas y separadas de forma natural por los
valores que toma la variable, x1 , . . . , xk .
▶ Por ello la noción de distribución de frecuencias es semejante
al de las variables categóricas.
▶ Sin embargo, a diferencia de lo que ocurre con los datos
cualitativos, las clases vienen ordenadas de forma natural de
menor a mayor.
▶ Esto permite introducir la idea de distribuciones
acumuladas.
▶ La frecuencia absoluta de cada valor xi , que denotaremos
por ni , es el numero de observaciones que toman dicho valor.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: descripción de una variable discreta
variable discreta: suelen ser numero enteros
▶ La lista siguiente recoge el número de huevos de todos los
nidos de ñandú encontrados en el Parque Nacional de
Talampaya: ej es discreta xk no m puedo encontrar 1,7 huevos
0 0 1 1 2 0 3 0 2 4 5 3 2 2 1
2 0 6 3 2 1 1 1 0 0 5 1 1 2 3
1 0 4 5 2 1 2 1 1 2 2 2 2 4 1
2 3 4 5 1 3 4 5 2 1 4 1 2 1 2
1 1 1 0 0 2 0 2 0 2 1 3 0 4 1
1 1 0 1 0 2 3 3 1 4 4 1 6 1 0
3 0 0 0 1 1 1 2 3 3 3 1 2 3 0
6 5 1 2 0 0 3 6 2 1 1 1 4 1 2
4 5 1 2 1 2 2 4 2 3 3 3 4 3 1
5 5 2 3 1 3 1 5 0 0 0 4 2 0 5
▶ La población y la variable de interés son, respectivamente, ’nidos de
nandúes que viven en Talampaya’ y X = ’número de huevos’.
▶ Este listado de datos contiene toda la información que nos interesa.
Pero si nos limitamos a observar estos números, resultará difícil
obtener una idea de las características de los datos.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo (continuación)
▶ El dominio (o rango, o recorrido) de X es {0, 1, 2, 3, 4, 5, 6}.
Contando cuantas veces aparece cada uno de los valores del
dominio, se obtienen las frecuencias absolutas de cada
modalidad.
▶ La distribución de X puede resumirse en una tabla de
frecuencias:
xi
ni
Fi
0
26 26/150
1
42
moda 1
2
32
lo más común es
3
21
encontrar un nido de 1
4
14
huevo, 42 veces de un
total de 150
5
11
6
4
Total 150
1
▶ La tabla permite observar, por ejemplo, que lo más frecuente
es encontrar nidos con 1 único huevo.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Frecuencias relativas para variables discretas
▶ La frecuencia relativa del valor xi , que denotaremos por fi , es
el cociente entre la frecuencia absoluta de dicho valor y el
número total de observaciones, es decir,
fi =
ni
.
n
▶ La frecuencia relativa fi indica la proporción (o tanto por uno)
de observaciones que toman el valor xi . Al multiplicar fi por
100 obtenemos el porcentaje o tanto por ciento ( %) de la
población con valor xi .
▶ Las frecuencias relativas permiten comparar las frecuencias en
conjuntos de datos con distinto numero de observaciones.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: frecuencias relativas en variables discretas
▶ Para los datos sobre el número de huevos de los nidos de
Talampaya, el total de observaciones es n = 150. Dividiendo
las frecuencias absolutas por esta cantidad se obtienen las
frecuencias relativas de cada valor de X:
xi
0
1
2
3
4
5
6
Total
ni
26
42
32
21
14
11
4
150
fi
0.173
0.280
0.213
0.140
0.093
0.073
0.027
1
▶ Se observa, por ejemplo, que el 28 % de los nidos tienen 1 sólo
huevo.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Frecuencias acumuladas para variables discretas
es acumulada porque existe el orden
▶ La frecuencia absoluta acumulada, que denotaremos por
Ni , es el numero de elementos de la población con valor
menor o igual a xi :
Ni =
i
∑
nj
j=1
= n1 + n2 + . . . + ni
= Ni−1 + ni .
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: frecuencias acumuladas para v discretas
▶ Siguiendo con el caso del número de huevos de ñandú por
nido, las frecuencias absolutas acumuladas son:
xi
ni fi
Ni
0
26 0.173
26
hay 68 huevos que tienen
1
42 0.280
68 26+42
hasta 1 nido
2
32 0.213 100
3
21 0.140 121
4
14 0.093 135
5
11 0.073 146
6
4 0.027 150
Total 150 1
▶ Esto nos indica, por ejemplo, que hay un total de 121 nidos
con 3 huevos de ñandú o menos.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Frecuencias relativas acumuladas para v discretas
▶ La frecuencia relativa acumulada, Fi , es el tanto por uno de
los elementos de la población que toman un valor de la
variable menor o igual que xi :
Ni
Fi =
n
=
n1 + n2 + . . . + ni
n
= f1 + f2 + . . . + fi
=
i
∑
fj
j=1
▶ Las frecuencias relativas acumuladas se calculan dividiendo las
frecuencias relativas absolutas entre el número total de datos,
o bien sumando las frecuencias relativas de todos los valores
menores o iguales a cada xi .
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: frecuencias relativas acumuladas
▶ Para el caso del número de huevos de ñandú por nido en
Talampaya, la tabla de frecuencias completa es
xi
ni fi
Ni Fi porcentaje
0
26 0.173
26 0.173
1
42 0.280
68 0.453
2
32 0.213 100 0.667
80,7% tiene hasta 3
3
21 0.140 121 0.807 elhuevos
4
14 0.093 135 0.900
5
11 0.073 146 0.973
6
4 0.027 150 1
Total 150 1
▶ Se observa, por ejemplo, que el 66.7 % de los nidos de ñandú
tienen 2 huevos o menos.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Distribución de frecuencias en variables discretas
▶ En general, la distribución de frecuencias
de una variable
discreta está formada por el conjunto de clases y sus
frecuencias correspondientes.
▶ Se puede presentar de forma ordenada en una tabla
estadística:
Valor
F. Abs.
x1
..
.
n1
..
.
xj
..
.
nj
..
.
xk
nk
Total
n
F. Rel.
n1
f1 =
n
..
.
nj
fj =
n
..
.
nk
fk =
n
1
F. Abs. Acum.
Nj = n1 + . . . + nj
..
.
F. Rel. Acum
N1
F1 =
= f1
n
..
.
Nj
Fj =
= fj
n
..
.
Nk = n
Fk = 1
N1 = n1
..
.
▶ Observación: Las frecuencias acumuladas (tanto absolutas como
relativas) sólo se calculan sobre variables cuantitativas. No tiene
sentido hacerlo para las variables categóricas.. . . . . . . . . . . . . . . .
.
.
.
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
Propiedades de las frecuencias
▶ Las frecuencias son cantidades no negativas, es decir, verifican
ni ≥ 0, fi ≥ 0, Ni ≥ 0, Fi ≥ 0, para i = 1, . . . , k.
▶ La suma de todas las frecuencias absolutas es n:
k
∑
nj = n1 + n2 + . . . + nk = n.
j=1
▶ La suma de las frecuencias relativas de todos los valores es 1:
k
∑
j=1
fj = f1 + . . . fk =
n1
nk
n1 + . . . + nk
n
+ ... +
=
= = 1.
n
n
n
n
▶ Las frecuencias acumuladas (absolutas o relativas) son no
decrecientes, esto es, satisfacen
Ni ≤ Ni+1 y Fi ≤ Fi+1 , para i = 1, . . . , k − 1.
▶ La frecuencia absoluta acumulada de la última clase es Nk = n.
▶ La frecuencia relativa acumulada de la última clase es Fk = 1.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Representación gráfica de variables discretas
▶ La distribución de frecuencias de una variable discreta puede
representarse mediante diagramas de barras, que transmiten
una una idea visual inmediata sobre las principales
características de los datos.
▶ Ejemplo:
0.25
0.20
0.15
frecuencias relativas
0.00
0.05
0.10
30
20
10
0
frecuencias absolutas
40
0.30
50
0.35
La representación gráfica del número de huevos de
ñandú de los nidos de Talampaya es la siguiente:
0
1
2
3
4
5
6
0
1
2
numero de huevos
3
4
5
6
numero de huevos
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Distribución de frecuencias para variables continuas
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Distribución de frecuencias para variables continuas
▶ El análisis de las variables cuantitativas continuas es más
complejo que el de las discretas.
▶ Las categorías ya no vienen dadas de forma natural por la
variable, sino que tienen que elegirse.
▶ El primer paso es dividir el dominio de la variable en clases o
intervalos que no se solapen y cubran todo el rango.
▶ Al punto central de cada uno de estos intervalos lo
llamaremos marca de clase, y lo denotaremos por ci .
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Distribución de frecuencias para variables continuas
▶ Una vez hecha esta división en clases se definen las mismas
frecuencias que para las variables discretas.
▶ En el caso continuo, la forma de la tabla estadística de
frecuencias es la siguiente:
Clase
[l0 , l1 ]
..
.
(lj−1 , lj ]
.
..
(lk−1 , lk ]
Total
M clase
c1
..
.
cj
.
..
ck
F Abs
n1
..
.
nj
.
..
nk
n
F Rel
f1 = n1 /n
..
.
fj = nj /n
.
..
fk = nk /n
1
F Abs Ac
N1 = n1
..
.
Nj = Nj−1 + nj
.
..
Nk = n
.
.
.
.
.
.
. . . .
. . . .
F Rel Ac
F1 = f1
..
.
Fj = Nj /n
.
..
Fk = 1
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: distribución de variables continuas
frec abs
frec rel
▶ La siguiente tabla resume los pesos registrados para los
ejemplares de lobo ibérico de un zoológico:
Intervalo
ci
ni
fi
Ni
[40, 45]
42,5 3 0,1428
3
(45, 50] 47,5 2 0,0952
5
(50, 55] 52,5 7 0,3333 12
(55, 60] 57,5 3 0,1428 15
(60, 65] 62,5 6 0,2857 21
Total
21
1
marca de clase
(representante)
Fi
0,1428
0,2381
0,5714
0,7143
1
no podemos calcular la media exacta
porque no sabemos el peso exacto
de cada uno
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Representación gráfica de variables continuas
▶ Para visualizar gráficamente la distribución de variables
continuas se utilizan histogramas, que representan las
frecuencias mediante áreas.
▶ Un histograma se construye a partir de la tabla estadística,
mediante rectángulos cuyas bases equivalen a los intervalos. El
área de cada rectángulo es proporcional a la frecuencia
(absoluta o relativa) de la clase.
▶ A diferencia del diagrama de barras, los rectángulos verticales
se representan contiguos para reflejar la idea de que la variable
es continua. Esto incluye la posibilidad de que el histograma
tenga clases vacias (es decir, con altura 0).
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: histograma
▶ El siguiente histograma representa los pesos de los lobos
Histograma
4
2
0
frecuencia absoluta
6
8
ibéricos de la tabla anterior:
40
45
50
55
60
65
peso lobo ibérico
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Elección del número de clases o intervalos
▶ En algunas ocasiones la información sobre una variable
continua se proporciona ya resumida en una tabla de
frecuencias con clases o intervalos fijados por quién recogió los
datos.
▶ Pero lo más habitual es que se disponga de la lista completa
de observaciones de la variable continua. En tales casos, para
realizar un análisis estadístico deben agruparse estos valores en
intervalos. Para ello hay que elegir el numero de intervalos (k).
▶ El número de intervalos debe ser tal que refleje la información
más relevante sobre la variable.
▶
▶
Si se toman muy pocas clases, se pierde precisión.
Si se toman demasiadas clases, se pierde visión sobre las
características de la variable.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: elección del número de clases
▶ Los siguientes histogramas, que representan las notas de
estadística de los alumnos de un curso, ilustran esta idea:
Notas de Estadistica
Notas de Estadistica
Notas de Estadistica
40
80
20
Frequency
40
Frequency
20
10
50
100
Frequency
200
150
100
0
2
4
6
notas
8
10
0
2
4
6
notas
8
10
0
0
0
50
0
Frequency
60
30
250
150
300
350
Notas de Estadistica
0
2
4
6
8
10
0
2
4
notas
6
8
10
notas
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: elección del no de clases (continuación)
▶ En el primero de los histogramas se ha divido el rango de las
notas (que va de 0 a 10) en cinco intervalos:
200
150
0
50
100
Frequency
250
300
350
Notas de Estadistica
0
2
4
6
8
10
notas
▶ Obviamente 5 clases no son suficientes, ya que ni siquiera
permite saber cuántos alumnos han aprobado y cuántos han
suspendido.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: elección del no de clases (continuación)
▶ El segundo histograma, con 10 clases, refleja perfectamente la
distribución de las notas:
100
Frequency
[4, 5) [5, 6)
esta forma sería
la correcta ya que
las personas que
tienen un 5 irían
con las personas
aprobadas
50
la persona que
ha sacado un 5
iría con los
suspensos por
lo que no es
correcto
0
( 4, 5] (5, 6]
150
Notas de Estadistica
0
2
4
6
8
10
notas
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: elección del no de clases (continuación)
▶ El tercer gráfico, con 20 intervalos, es más confuso que el
anterior.
40
0
20
Frequency
60
80
Notas de Estadistica
0
2
4
6
8
10
notas
▶ No obstante este gráfico puede resultar útil, por ejemplo, para
un profesor que quiera decidir a partir de qué nota poner
sobresalientes.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: elección del no de clases (continuación)
▶ El último de los histogramas, tiene 50 clases.
20
0
10
Frequency
30
40
Notas de Estadistica
0
2
4
6
8
10
notas
▶ En este gráfico se observan muchos picos poco relevantes que
no permiten apreciar lo más importante de la distribución de
las notas.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Elección del número de clases (continuación)
▶ Es recomendable ayudarse de histogramas para elegir un
número de clases que resulte apropiado.
▶ Aunque la información gráfica es mucho más fiable a la hora
de fijar el número de intervalos, existen distintas reglas
empíricas para elegir el número de intervalos.
▶ Una de las más utilizadas es la regla de Sturges, que consiste
en elegir el número de clases, k, de la forma siguiente:
√
si n no es muy grande,
n
k≃
1 + 3,3 log(n) si n es muy grande.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Elección del número de clases (continuación)
▶ Según la regla de Sturges, por ejemplo,
si el numero de observaciones
es n = 100, agruparemos las
√
observaciones en k = 100 = 10 intervalos.
▶ Sin embargo, si tenemos n = 1000000, resultará casi imposible
√
trabajar con k = 1000000 = 1000 intervalos, por lo que es
más razonable elegir k = 1 + 3,3 log(1000000) ≃ 21 clases.
▶
▶ La regla de Sturges es la que está implementada por defecto
para determinar el número de clases en la mayor parte de los
paquetes estadísticos, incluyendo R-commander.
▶ No obstante, en muchas ocasiones, como en la del ejemplo de
las notas de Estadística, hay elecciones mucho más
adecuadas, que pueden determinarse utilizando el sentido
común y ayudándose de representaciones gráficas.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
En las comparaciones, la escala es importante
▶ Estos dos histogramas paracen a simple vista bastante
Histograma
10
Histograma
6
4
frecuencia absoluta
4
0
0
2
2
frecuencia absoluta
6
8
8
diferentes:
40
45
50
55
60
65
35
40
45
peso lobo ibérico
50
55
60
65
70
peso lobo ibérico
▶ Sin embargo, ambos representan el mismo conjunto de datos:
los pesos de los lobos ibéricos del zoo. Además ambos
histogramas tienen 5 intervalos. Tienen distinto aspecto
porque las escalas son diferentes.
▶ Para poder comparar varios gráficos, deben tener la misma
escala.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Patrones de distribución más comunes
▶ La forma del histograma refleja muchas propiedades de la
variable estadística a la que se refiere: simetría, número de
modas, apuntamiento, etc.
▶ Los patrones más frecuentes de histogramas son
Unimodal simétrico (por ejemplo peso o altura)
Bimodal simétrico (por ejemplo peso en poblaciones mixtas, o
pesos medidos en kilos y en libras)
▶ Unimodal asimétrico a la derecha (por ejemplo ingresos o
gastos)
▶ Unimodal asimétrico a la izquierda (por ejemplo esperanza de
vida por países)
▶
▶
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Gráficos: patrones de distribución
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Gráfico: distribución unimodal simétrica
Distribución unimodal simétrica
2000
es simestrica
1000
500
0
Frequency
1500
moda
30
40
50
60
x
.
70
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Gráfico: distribución bimodal simétrica
Distribución bimodal simétrica
2000
1500
1000
500
0
Frequency
2500
3000
3500
hay simetria pero también hay 2 modas
30
40
50
60
70
80
90
100
ej peso entre escarabajos machos y hembras
x
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Gráfico: distribución asimétrica hacia la derecha
Distribución asimétrica a la derecha
es simetrica hacia la derecha
1000 1500 2000 2500 3000 3500
Frequency
Ejemplo
sueldos de una gran empresa
0
500
frecuencia= nº personas
0
5
sueldo anual 10
15
x
.
20
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Gráfico: distribución asimétrica hacia la izquierda
1500
1000
500
0
Frequency
2000
2500
Distribución asimétrica a la izquierda
50
55
60
65
70
x
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Diagramas de puntos
▶ Cuando se tienen pocos datos de una variable continua, puede
ser útil representarlos mediante un simple diagrama de puntos.
▶ Supongamos por ejemplo que las longitudes de las pirañas de
un banco de peces son 8, 17, 3, 10 y 12 cm. Estos datos
pueden representarse mediante el siguiente diagrama de
puntos:
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Otros gráficos para variables cuantitativas
▶ Los datos cuantitativos también pueden representarse
mediante otros diagramas, como pictogramas o cartogramas.
▶ Las posibilidades de representación gráfica dependen del tipo
de variable que se esté analizando.
▶ Uno de los objetivos es que los gráficos faciliten la
interpretación de los datos.
▶ En las siguientes páginas aparecen ejemplos de pictogramas y
cartogramas para variables numéricas.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: pictogramas
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: pictogramas
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: cartogramas
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: cartogramas
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Variables discretas que se asemejan a continuas
▶ Cuando la variable que se está analizando es discreta pero
tiene un rango muy amplio (es decir, toma muchos valores
distintos) es conveniente agrupar los datos del mismo modo
que para las variables continuas.
▶ Un ejemplo de esta situación es la edad de una población
heterogénea expresada en años.
▶ En tales casos, el histograma es un gráfico más adecuado para
representar la variable que el diagrama de barras.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Resumen numérico de los datos
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Resumen numérico de conjuntos de observaciones
▶ Si los datos son cuantitativos, es conveniente complementar la
información visual proporcionada por el análisis gráfico con
algunas medidas numéricas que proporcionen una idea sobre el
centro de los datos, la concentración de éstos y otros rasgos
de la distribución.
▶ Estas medidas numéricas que se calculan a partir de los datos
y resumen parte de su comportamiento, reciben el nombre de
estadísticos.
▶ Vamos a analizar estadísticos que resumen numéricamente las
siguientes características de una distribución:
la tendencia central de los datos (medidas de centralización),
los datos que ocupan ciertas posiciones (medidas de posición),
▶ la variabilidad con respecto al centro (medidas de dispersión).
▶
▶
▶ La utilización de estos estadísticos permite formarse una idea
bastante fidedigna del comportamiento de un conjunto de
grande de datos a partir de unas pocas medidas que
concentran mucha información.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Medidas de centralización
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Medidas de centralización
▶ La descripción más elemental de un conjunto de datos
consiste en especificar su centro.
▶ El concepto de centro se puede definir de diferentes formas.
▶ Vamos a analizar los siguientes estadísticos de centralización:
Media
Mediana
▶ Moda
▶ Media recortada
▶
▶
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Media
▶ La idea de media aritmética o promedio formaliza el
concepto intuitivo de punto de equilibrio o centro de
gravedad de los datos.
▶ Dado un conjunto de observaciones, x1 , . . . . . . , xn , su media,
que denotaremos por x, es la suma de todos los datos dividida
por el número total de datos.
▶ La definición formal de media es
1∑
xi
n
n
x=
i=1
es decir
x=
x1 + · · · + xn
n
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Número medio de huevos en Talampaya
▶ Para calcular la media del número de huevos en Talampaya
0
2
1
2
1
1
3
6
4
5
0
0
0
3
1
1
0
5
5
5
1
6
4
4
1
0
0
1
1
2
1
3
5
5
0
1
0
2
2
3
2
2
2
1
0
0
1
0
1
1
0
1
1
3
2
2
1
0
2
3
3
1
2
4
0
3
1
3
2
1
0
1
1
5
2
3
2
6
4
5
2
0
1
2
0
1
3
2
2
0
4
0
2
1
2
4
3
1
3
0
5
5
2
4
1
4
3
1
3
0
3
1
2
1
3
1
1
1
3
4
2
1
2
2
0
6
2
4
4
2
2
2
4
1
4
1
3
1
3
0
1
3
1
2
1
0
0
2
1
5
0 + 0 + 1 + 1 + 2 + 0 + 3 + 0 + 2 + 4 + 5 + ...... + 4 + 2 + 0 + 5
150
▶ ¿Hay una forma menos tediosa de calcularla?
x̄ =
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Media de una variable discreta
▶ Cuando los datos son discretos y las observaciones se repiten,
podemos disponerlos en una tabla de frecuencias,
X ni fi
x1 n1 f1
.
.
.
.
.
.
.
.
.
xk nk fk
y usar la fórmula
1∑
x1 n1 + · · · + xk nk
xi ni =
,
n
n
k
x=
i=1
o bien la fórmula equivalente,
x=
k
∑
xi fi = x1 f1 + · · · + xk fk .
i=1
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: media de una variable discreta
▶ Para el ejemplo de los nidos de Talampaya,
xi
0
1
2
3
4
5
6
Total
ni
26
42
32
21
14
11
4
150
fi
0.173
0.280
0.213
0.140
0.093
0.073
0.027
1
Ni
26
68
100
121
135
146
150
Fi
0.173
0.453
0.667
0.807
0.900
0.973
1
el número medio de huevos de ñandú por nido es
x=
0 × 26 + 1 × 42 + 2 × 32 + .... + 6 × 4
= 2,027.
150
que también puede calcularse como
x = 0 × 0,173 + 1 × 0,280 + 2 × 0,213 + .... + 6 × 0,027 = 2,027.
▶ Por tanto, en promedio, los nidos tienen 2.027 huevos. Obsérvese que éste no
es uno de los valores posibles de la variable.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Media de una variable continua
▶ Si los datos son continuos y no disponemos de sus valores
originales, sino sólo de una tabla de frecuencias por intervalos
del tipo
Intervalos ci ni
[lo , l1 ]
c1 n1
.
.
.
.
.
.
.
.
.
[lk−1 , lk]
ck nk
podemos usar la fórmula aproximada
1∑
c1 n1 + · · · + ck nk
ci ni =
,
n
n
k
x≃
i=1
o bien la fórmula equivalente,
x≃
k
∑
ci fi = c1 f1 + · · · + ck fk .
i=1
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Media de una variable continua (continuación)
▶ La fórmula aproximada
c1 n1 + · · · + ck nk
1∑
ci ni =
,
x≃
n
n
k
i=1
sustituye cada dato (desconocido) por la marca de clase (o
punto central) del intervalo al que pertenece.
▶ La media obtenida usando esta fórmula es una aproximación
que, en general, no coincide con la verdadera media de los
datos, aunque será un número cercano al promedio si los
intervalos no son excesivamente amplios.
▶ Al aumentar la amplitud de las clases se pierde precisión.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: media de una variable continua
▶ Vamos a calcular la media aproximada de los pesos de los
lobos ibéricos (medidos en kilos) resumidos en la tabla
siguiente;
Intervalo
ci
ni
fi
Ni
Fi
[40, 45]
42,5 3 0,1428
3 0,1428
(45, 50]
47,5 2 0,0952
5 0,2381
(50, 55]
52,5 7 0,3333 12 0,5714
(55, 60]
57,5 3 0,1428 15 0,7143
(60, 65]
62,5 6 0,2857 21
1
Total
21
1
▶ Puesto que los datos están agrupados, usaremos las marcas de clase
(ci ) para calcular una aproximación a la media:
1∑
42,5 × 3 + 47,5 × 2 + . . . . . . + 62,5 × 6
ci ni =
= 54,1667 kg
n
20
k
x≃
i=1
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Linealidad de la media
▶ Si a todas las observaciones de una variable se les suma una misma
cantidad, la media de los nuevos datos es la media de las
observaciones originales más esa cantidad, es decir,
x + b = x + b.
Ejemplo: El sueldo medio de los trabajadores de cierta reserva
natural es de 1655 euros por mes. Si el gobierno decide aumentar en
44 euros el salario de todos sus empleados, ¿cuál será el sueldo
medio de los trabajadores a partir de ese momento? (Solución: 1699
euros)
▶ Si se multiplican todas las observaciones por una misma cantidad, la
media de los nuevos datos queda multiplicada por la misma
cantidad, esto es
ax = a x.
Ejemplo: En una muestra de 20 plantas, el peso medio ha resultado
ser 2.3 kilos. ¿Cuál será la media de los pesos medidos en gramos de
estas mismas plantas? (Solución: 2300 gramos)
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Linealidad de la media (continuación)
▶ Juntando las dos propiedades anteriores, deducimos que, si Y
es una transformación lineal de X, esto es, si
Y = a + bX,
entonces la media de Y es
y = a + bx.
Es decir, la media es un operador lineal.
▶ Ejemplo: En cierta localidad, la temperatura media durante
el mes de agosto ha sido de 14 o C. ¿Cuál será la temperatura
media en la localidad durante el mismo periodo si ésta se
mide en o F?
Solución: 57.2 o F.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Inconvenientes de la media
▶ La media es muy sensible a la presencia de valores atípicos
(tambien llamados outliers).
Puesto que todas las observaciones intervienen en su cálculo,
cuando hay alguna observación extrema la media se desplace
en esa dirección.
Se dice por ello que la media no es robusta.
Esta falta robustez provoca paradojas como esta: por muy
extraño que pueda parecer, la gran mayoría de las personas
tiene un número de piernas superior a la media...
▶ En las distribuciones muy asimétricas, no es recomendable
usar la media como medida central.
▶ Para variables discretas el valor de la media puede no
pertenecer al conjunto de valores posibles de la variable.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Mediana
▶ La mediana es una medida de centralización que divide en dos
mitades (dos grupos con la misma cantidad de elementos) el
conjunto de datos ordenados de menor a mayor.
▶ Es decir, la mediana es un punto que deja el 50 % de las
observaciones por debajo de él y el otros 50 % por
encima de sí:
si en estadística salen () quiere decir
que los datos ya están ordenados
▶ Si queremos saber, por ejemplo, si una jirafa está entre las
más altas o entre las más bajas, debemos comparar su altura
con la mediana, y no con la media.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Muestra ordenada
▶ Para calcular la mediana, en primer lugar hay que ordenar los
datos de menor a mayor.
▶ Dado un conjunto de datos, x1 , x2 · · · , xn , suele utilizarse la
notación
x(1) , x(2) , · · · , x(n) ,
para designar las mismas observaciones ordenadas de mayor
menor.
▶ Es decir, x(1) es el dato más pequeño, x(2) es el siguiente, y
así hasta x(n) que es la observación máxima.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Cálculo de la mediana
▶ Observemos que
▶
Cuando el número de observaciones es una cantidad impar,
uno de los datos está exactamente en el centro: la observación
que ocupa la posición (n + 1)/2. Este número central es la
mediana.
Ejemplo: Para los datos
6, 12, 14, 20, 45
▶
la mediana es 14.
Cuando la cantidad de datos es par, hay dos observaciones
centrales: las observaciones que están en las posiciones n/2 y
n/2 + 1. En este caso se toma como mediana el promedio o
semi-suma de las dos observaciones centrales.
Ejemplo: Para los datos
6, 12, 14, 20, 45, 61
la mediana es el promedio de 14 y 20, es decir, 17.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Definición de la mediana
▶ La mediana de un conjunto de datos, x1 , x2 , . . . , xn , se define
como
Medx =
x n+1 ,
( 2 )
si n es impar
x n + x( n +1)
2
(2)
,
2
si n es par
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: mediana de datos discretos
▶ Retomemos los datos sobre número de huevos de ñandú en los
% que deja x debajo
nidos de Talampaya:
el dato
xi
ni
fi
Ni
Fi
0
26 0.173 26 0.173
1
42 0.280 68 0.453
es el primer dato que
2
32 0.213 100 0.667
deja x debajo al 50%
x lo k es la mediana
3
21 0.140 121 0.807
4
14 0.093 135 0.900
5
11 0.073 146 0.973
6
4
0.027 150
1
Total 150
1
▶ Observamos que la mediana de estos datos es 2 huevos,
ya que 2 es el primer valor con una frecuencia relativa
acumulada mayor o igual que 0,5.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Mediana de datos agrupados
▶ Cuando no se dispone del conjunto de las observaciones, sino
sólo de una tabla estadística con datos agrupados en clases,
no se puede determinar la mediana con exactitud.
▶ En estos casos, lo que sí puede asegurarse es que la mediana
está en el primero de los intervalos con una frecuencia relativa
acumulada igual o mayor que 0.5. Existen fórmulas
aproximadas, basadas en interpolación, para calcular la
mediana en estos casos.
Ejemplo: La mediana de pesos de los lobos ibéricos está en
el intervalo (50, 55], que es el primero que verifica Fi ≥ 0,5:
Intervalo
[40, 45]
(45, 50]
(50, 55]
(55, 60]
(60 ,65]
ci
42,5
47,5
52,5
57,5
62,5
ni
3
2
7
3
6
21
fi
0,1428
0,0952
0,3333
0,1428
0,2857
1
Ni
3
5
12
15
21
.
Fi
0,1428
0,2381
0,5714
0,7143
1
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Propiedades de la mediana
▶ Las observaciones atípicas tienen un efecto mucho menor en la
mediana que en la media, ya que la mediana no depende de los
valores que toma la variable, sino del orden de las mismas. Se dice
por ello que la mediana es una medida de centralización robusta.
Ejemplo: vamos a comparar las medias y medianas de los conjuntos
de datos:
X ∼ 2, 5, 7, 8, 13
Y ∼ 2, 5, 77, 8, 13
La muestra Y puede ser el resultado de un simple error al teclear los
datos de X. Las medias de X e Y son muy diferentes: x = 7, y = 21;
sin embargo sus medianas apenas difieren: Medx = 7, Medy = 8.
▶ Cuando la distribución es asimétrica, la mediana es más apropiada
como medida de posición central que la media.
▶ Las propiedades matemáticas de la mediana son más complicadas
que las de la media, y por eso en inferencia estadística es más
frecuente utilizar la media.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Comparación de media y mediana
▶ Es preferible resumir el centro de una distribución usando
tanto la media como la mediana.
▶ La comparación entre ellas, además, aporta información sobre
la forma de la distribución, ya que en general:
Si la distribución es simétrica alrededor del centro, x ≃ Medx
Si la distribución es asimétrica a la derecha, x >> Medx
▶ Si la distribución es asimétrica a la izquierda, x << Med
x
▶
▶
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Media-mediana: distribución simétrica
▶ Cuando la distribución es bastante simétrica, media y mediana
toman valores muy próximos entre sí:
▶ Si la distribución fuese perfectamente simétrica, la media y la
mediana coincidirían exactamente.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Media-mediana: asimetría a la derecha
▶ Si la distribución es asimétrica hacia la derecha, hay una
pequeña proporción de datos que son mucho mayores que la
mayoría.
▶ Estos datos tiran de la media hacia arriba, provocando que
ésta sea considerablemente mayor que el valor que la mediana:
COLA A LA DERECHA
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Media-mediana: asimetría a la izquierda
▶ Las distribuciones asimétricas hacia la izquierda tienen una
pequeña proporción de datos mucho menores que la mayoría
que tiran hacia abajo de la media.
▶ Por ello, en estos casos la media es bastante menor la
mediana:
COLA A LA IZQUIERDA
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Moda
▶ La moda es el valor de la variable que se repite con mayor
frecuencia. Es una medida de centralización muy fácil de
calcular.
▶ La moda no es siempre única, ya que puede existir más de un
valor con la máxima frecuencia.
▶ La moda es una medida informativa tanto en variables
categóricas como para en cuantitativas discretas.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: moda de una variable discreta
▶ Para los datos sobre número de huevos de ñandú por nido, la
moda es 1 huevo:
xi
0
1
2
3
4
5
6
Total
ni
26
42
32
21
14
11
4
150
fi
0.173
0.280
0.213
0.140
0.093
0.073
0.027
1
Ni
26
68
100
121
135
146
150
Fi
0.173
0.453
0.667
0.807
0.900
0.973
1
▶ Habíamos visto que el centro de gravedad (la media) es 2.027
huevos, y la mediana (el valor central) es 2. La moda aporta
información complementaria: lo más frecuente en
Talampaya en encontrar nidos de ñandú con 1 huevo.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Clase modal de una variable continua
▶ En el caso de las variables continuas la moda no aporta
ninguna información, ya que lo habitual es que no existan
datos repetidos (y todos los valores sean modas) o que si se
repiten sea debido al redondeo (en cuyo caso la moda no es
relevante).
▶ Para variables continuas lo que sí tiene interés es el intervalo o
clase modal, es decir, el intervalo de frecuencia más alta.
▶ Ejemplo: para los pesos de los lobos ibéricos, la clase modal
es (50,55]:
Intervalo
ci
ni
fi
Ni
Fi
[40, 45]
42,5 3 0,1428
3 0,1428
(45, 50] 47,5 2 0,0952
5 0,2381
(50, 55] 52,5 7 0,3333 12 0,5714
(55, 60] 57,5 3 0,1428 15 0,7143
(60 ,65] 62,5 6 0,2857 21
1
Total
21
1
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Media recortada
no entra
▶ Una forma de mejorar la falta de robustez de la media
consiste en moderar el efecto de los datos atípicos en el
cálculo de la media.
▶ La media recortada al α por ciento es la media de los datos
que quedan después de eliminar el α por ciento de las
observaciones más grandes y el α por ciento de las más
pequeñas.
▶ Por ejemplo, la media recortada al 10 % en un conjunto de 50
datos vendrá dada por
1 ∑
x(i)
40
45
i=6
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: media recortada
▶ Consideremos de nuevo los datos sobre el número de huevos
de ñandú de los nidos del Parque Nacional Talampaya:
xi
ni
fi
Ni
Fi
0
26 0.173 26 0.173
1
42 0.280 68 0.453
2
32 0.213 100 0.667
3
21 0.140 121 0.807
4
14 0.093 135 0.900
5
11 0.073 146 0.973
6
4
0.027 150
1
Total 150
1
▶ La media recortada al al 20 % para estos datos es
1 ∑
x(i) = 1,8 huevos.
90
120
i=31
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Medidas de posición
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Percentiles
te posiciona dentro de la población
▶ La media, mediana y moda son medidas de la posición central
de los datos, pero hay otras posiciones que pueden ser de
interés al analizar la distribución. De manera genérica a tales
observaciones se les da el nombre de cuantiles.
▶ Los percentiles
dividen en conjunto de observaciones en 100
partes del mismo tamaño.
▶ El percentil de orden k, que denotaremos por Pk , es la
observación que deja por debajo de sí el k % de los datos.
▶ Por ejemplo, si la altura de una jirafa está en el percentil 80,
significa que el 80 % de las jirafas miden menos que ella. O lo
que es lo mismo, que el 20 % son más altas que ella.
▶ Para calcular Pk se toma la primera observación con una
frecuencia relativa acumulada mayor o igual que k/100.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: percentiles
▶ Para la distribución del número de huevos en Talampaya,
xi
ni
0
26
1
42
2
32
3
21
4
14
5
11
6
4
Total 150
se tiene, por ejemplo, que
fi
0.173
0.280
0.213
0.140
0.093
0.073
0.027
1
Ni
26
68
100
121
135
146
150
Fi
0.173
0.453
0.667
0.807
0.900
0.973
1
P10 = 0,
P20 = 1,
P90 = 4,
P99 = 6.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Algunas utilidades de los percentiles
▶ Normalmente las personas que tienen hijos suelen estar
familiarizas con los percentiles, ya que los pediatras les indican
los percentiles de la altura, el peso u otras magnitudes del
niño.
Por ejemplo, si la altura de un niño está en el percentil 69, sus
padres saben que el 69 % de los niños de su edad miden
menos que él.
La OMS publica tablas de referencia para cada segmento de
edad. Las referencias son distintas para niños y niñas.
▶ También se usan los percentiles para medir los resultados de
los tests de inteligencia. Si una persona está en el percentil 85
significa que sólo el 15 % de la población le supera en esa
habilidad.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Cuartiles
%miN
25%
Q1
Q2
50%
Q3
MAX
75%
▶ Los cuartiles son los percentiles de orden 25, 50 y 75:
El primer cuartil, que denotaremos por Q1 , es la observación
que deja por debajo de sí el 25 % de los datos (Q1 = P25 ).
▶ El segundo cuartil, que denotaremos por Q , es la
2
observación que deja por debajo de sí el 50 % de los datos, es
decir, la mediana (Q1 = P50 = Med).
▶ El tercer cuartil, que denotaremos por Q , es la observación
3
que deja por debajo de sí el 75 % de los datos (Q3 = P75 ).
▶
▶ Q1 , Q2 y Q3 dividen el conjunto de datos ordenados en 4
subconjuntos con la misma cantidad de observaciones.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Cuartiles (continuación)
▶ Por ejemplo, los cuartiles del conjunto de datos
114, 125, 114, 124, 142, 152, 133, 113, 127, 135, 122, 127, 185, 134, 147.
son Q1 = 122, Q2 = 130, y Q3 = 142, como se aprecia en el
siquiente esquema:
▶ ¿Qué información proporcionan los cuartiles? Supongamos por
ejemplo se está analizando la longitud de las hojas de una planta, y
que sus cuartiles son Q1 = 10 cm, Q2 = 13 cm, y Q3 = 30 cm.
Con esto sabemos por ejemplo que una hoja de 8 cm está entre el
25 % de las más pequeñas. Una de 15 cm está entre la mitad más
grande pero por lo menos un 25 % de las hojas son mayores que
ella. Una hoja de 22 cm está entre el 25 % de las más grandes.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: cuartiles
▶ Para la distribución del número de huevos en Talampaya,
xi
0
1
2
3
4
5
6
Total
ni
26
42
32
21
14
11
4
150
fi
0.173
0.280
0.213
0.140
0.093
0.073
0.027
1
Ni
26
68
100
121
135
146
150
Fi
0.173
0.453
0.667
0.807
0.900
0.973
1
se tiene que
Q1 = 1,
Q2 = 2,
Q3 = 3.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Medidas de dispersión
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
¿Por qué es importante medir la dispersión?
▶ Una vez localizado el centro de los datos es importante analizar si
las observaciones están muy concentradas alrededor de ese centro o
si por el contrario están alejadas de él.
▶ Imaginemos por ejemplo dos bancos de pirañas, A y B. Las
longitudes de las pirañas del banco A son 11, 7, 10, 13 y 9 cm, y las
del banco B, 8, 17, 3, 10 y 12 cm. Aunque en ambos bancos tanto
la media como la mediana son 10 cm, las pirañas del banco A tienen
longitudes mucho más concentradas en torno a 10 que las del banco
B:
Por ello, la longitud central de 10 cm es mucho más representativa
del conjunto de pirañas del banco A que de las del banco B.
▶ Este ejemplo sugiere que es conveniente contar con estadísticos que
midan cómo de cercanos o de alejados están los datos.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Estadísticos de dispersión
▶ Las medidas de dispersión proporcionan información sobre del
grado de separación de las observaciones alrededor su
centro.
▶ Analizaremos las siguientes medidas de dispersión:
Amplitud o rango.AMPLITUD: RECORRIDO DEL MIN AL MAX
Varianza y desviación típica.
▶ Cuasi-varianza y cuasi desviación típica.
▶ Recorrido intercuartílico.
▶ Coeficiente de variación.
▶
▶
▶ Las medidas de dispersión son siempre no negativas. Cuando
los datos no presentan ninguna variabilidad (es decir, cuando
son todos iguales) toman el valor 0, y cuanto más separadas
estén las observaciones, mayor será su valor.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Amplitud, recorrido o rango
▶ La forma más elemental de evaluar la dispersión de un
conjunto de observaciones consiste en calcular la amplitud de
su dominio, es decir la diferencia entre el mayor y el
menor de los datos.
▶ Dado un conjunto de datos, x1 , · · · , xn , definimos su
amplitud, o recorrido o rango como
Ax = máximo(x1 , x2 , . . . , xn )−mínimo(x1 , x2 , . . . , xn ) = x(n) −x(1)
▶ Ejemplo: Para los datos sobre el número de huevos de los
nidos de Talampaya el rango o amplitud es
A = x(150) − x(1) = 6 − 0 = 6 huevos.
▶ El rango tiene la ventaja de que es fácil de calcular y sus
unidades son las mismas que las de las observaciones
originales.
▶ Su principal inconveniente es su enorme falta de robustez.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Varianza y desviación típica
▶ Una manera natural de medir la dispersión alrededor del
centro consiste en promediar las distancias de cada una de
las observaciones a la media.
▶ Como tales distancias, no podemos tomar las diferencias entre
las observaciones y la media (xi − x), ya que estas son unas
positivas y otras negativas, y al hacer la media se compensan
entre sí.
▶ Para evitar este problema, lo que se hace es tomar los
cuadrados de estas diferencias. De este modo los signos no
se compensan unos con otros.
▶ Formalmente, dado un conjunto de datos, x1 , · · · , xn ,
definimos su varianza, s2x , como la media de los cuadrados de
las diferencias entre las observaciones y su media, es decir,
1∑
(xi − x)2
n
n
s2x =
i=1
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Varianza y desviación típica (continuación)
▶ Una fórmula equivalente para la varianza es la siguiente
1
s2x =
n
n
∑
x2i − x2
i=1
▶ Es decir, la varianza es la media de los cuadrados de las
observaciones menos el cuadrado de su media. Con esta
segunda fórmula resulta más sencillo realizar los cálculos.
▶ Las unidades de la varianza son el cuadrado de las
unidades de las observaciones. Por ejemplo, si las
observaciones se miden en metros, la varianza vendrá dada en
metros2 .
▶ Para obtener una medida de dispersión con las mismas
unidades que las observaciones basta con tomar la raíz
cuadrada de la varianza. La desviación típica es la raíz
cuadrada positiva de la varianza, es decir
√
sx = + s2x
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: varianza y desviación típica
▶ Consideremos las edades 1, 4, 5, 5, 7 y 8 años.
▶ Para hallar la varianza de estas observaciones, el primer paso es
calcular su media:
x=
1+4+5+5+7+8
= 5 años.
6
▶ Podemos calcular la varianza como
1∑
(1 − 5)2 + (4 − 5)2 + . . . + (8 − 5)2
2
(xi − x) =
= 5 años2 ,
n
6
n
s2x =
i=1
o bien mediante la fórmula equivalente
1∑ 2 2
12 + 42 + 52 + 52 + 72 + 82 2
xi −x =
−5 = 30−25 = 5 años2 ,
n
6
n
s2x =
i=1
▶ Por tanto, la desviación típica es sx =
√
s2x =
.
√
.
.
.
.
MEDIA AL
CUADRADO
5 = 2,236 años.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: varianza y desviación típica
▶ Consideremos una vez más el número de huevos de los 150
nidos.
▶ Para estos datos se tiene que
1 ∑
x=
xi = 2,027,
150
n
i=1
1 ∑ 2
xi = 6,68,
150
n
i=1
▶ Luego
s2x = 6,68 − 2,0272 = 2,57 huevos2 ,
sx =
√
2,5794 = 1,6 huevos.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Propiedades de la varianza y la desviación típica
min 29 22/09
X -- > S
dt=
x
S'x = 5x
▶ La varianza y la desviación típica son siempre números no negativos,
es decir,
s2x ≥ 0,
sx ≥ 0.
▶ La varianza sólamente toma el valor 0 en los casos en los que todas
las observaciones son iguales. Lo mismo le ocurre a la desviación
típica.
▶ Si Y es una transformación lineal de X, esto es, si
Y = aX + b,
entonces la varianza y la desviación de Y son
s2y = s2ax+b = a2 s2x ,
sy = sax+b = |a| sx .
▶ La varianza y la desviación típica no son medidas robustas, ya que
se ven muy infuenciadas por las observaciones atípicas.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Aplicación de x̄ y sx : tipificación de variables
▶ Cuando se quieren comparar observaciones de una variable que
pertenecen a dos poblaciones distintas, puede ocurrir que la
media y la varianza de dichas poblaciones sean muy diferentes.
▶ En estos casos, comparar las observaciones directamente
puede llevar a conclusiones erróneas.
▶ Por ejemplo, si se quiere comparar el nivel de colesterol de
una persona con el de glucosa, no tiene mucho sentido hacerlo
directamente, ya que los niveles de colesterol son, como
conjunto, bastante mayores que los de glucosa.
▶ Para solventar este problema, se pueden transformar los datos
de cada una de las poblaciones para llevarlos a una escala
donde sean comparables.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Tipificación de variables (continuación)
▶ Tipificar o estandarizar las observaciones de una variable
consiste en aplicarles una transformación lineal de tal manera
que el conjunto de datos transformados tenga media 0 y
varianza 1.
▶ Dada una variable X y un conjunto de observaciones,
x1 , x2 , . . . , xn , los datos tipificados se construyen restando a
cada observación la media y dividiendo esta diferencia por la
desviación típica, es decir,
z1 =
x1 − x
x2 − x
xn − x
, z2 =
, . . . , zn =
.
sx
sx
sx
▶ Los nuevos datos, z1 , z2 , . . . , zn , reciben el nombre de datos
tipificados, y expresan el número de desviaciones típicas
que cada observación dista de la media. Esto permite
comparar la posición relativa de datos procedentes de
diferentes distribuciones.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: tipificación de variables
▶ Un individuo que acaba de hacerse unos análisis de sangre tiene un
nivel de glucosa de 125 mg/dl y un nivel de colesterol de 247 mg/dl.
Para las personas de su edad, el nivel medio de glucosa es 80 mg/dl,
con una desviación típica de 30 mg/dl, mientras que el nivel medio
de colesterol es de 190 mg/dl con una varianza de 3249(mg/dl)2 .
¿Cuál de los dos niveles resulta más preocupante en este individuo?
Solución: El valor tipificado del nivel de glucosa del individuo es
zg =
125 − g
125 − 80
=
= 1,5.
sg
30
nos preocupa el que
más se aleje de la
media en este caso la
glucosa
Esto indica que su nivel de glucosa está 1.5 desviaciones típicas por
encima de la media de su grupo de edad.
Por otra parte, el valor tipificado de su de colesterol en sangre es
zc =
247 − 190
247 − c
247 − 190
=
= √
= 1,
sc
57
3249
luego está 1 desviación por encima de la media de su grupo.
Puesto que zg > zc , concluimos que problema de azucar de este
individuo es más severo que el de colesterol. . . . . . . . . . . . . . . .
.
.
.
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Cuasi-varianza y cuasi desviación típica
▶ La cuasi-varianza es una medida de dispersión estrechamente
relacionada con la varianza. Su definición es
1 ∑
(xi − x)2 .
n−1
n
S2x =
i=1
▶ Observamos que la única diferencia con la varianza es que la
suma de cuadrados de las desviaciones a la media se divide
por n − 1 en lugar de por n.
▶ El interés de la cuasi-varianza radica en que, cuando se quiere
estimar la varianza de una variable en una población a partir
de las observaciones de una muestra pequeña, la
cuasi-varianza presenta ciertas propiedades que la hacen más
adecuada que la varianza. Cuando n es grande la diferencia
entre s2x y S2x es prácticamente imperceptible.
√
▶ La raíz cuadrada de la cuasi-varianza, Sx = + S2
x , recibe el
nombre de cuasi-desviación típica.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Rango intercuartílico
▶ El rango intercuartílico, o recorrido intercuartílico, es la
diferencia entre el tercer y el primer cuartil, esto es,
RIx = Q3 − Q1 .
25%
el 50 %
75%
R1
▶ Este valor indica la distancia que separa a las dos
observaciones que limitan la mitad central de los datos.
▶ El rango intercuartílico es una medida de dispersión
robusta,
ya que en su cálculo no intervienen las observaciones más
extremas.
▶ Ejemplo: Para los datos sobre el número de huevos en
Talampaya teniamos que Q1 = 1 y Q3 = 3; por tanto su
rango intercuartílico es RI = 3 − 1 = 2 huevos.
▶ A partir del rango intercuartílico de un conjunto de datos de
puede construir un diagrama de caja para representarlos
gráficamente.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Diagramas de caja
▶ El diagrama de caja (box-plot) es un gráfico basado en los
cuartiles. Contiene información sobre la simetría de la
distribución y además nos permitirá formalizar la idea de dato
atípico.
▶ Para construir el diagrama de caja, se construye un rectángulo
(o caja) cuyos lados verticales pasan por el primer y tercer
cuartil, con una línea vertical a la altura de la mediana.
▶ La caja contiene la mitad central de los datos, y cada una de
las otras dos cuartas partes queda a uno de los lados de la
caja.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Diagramas de caja (continuación)
▶ A continuación se traza una barrera vertical imaginaria a la
izquierda de Q1 a distancia 1.5×RI,
Q1 − 1,5 × RI
barrera inferior:
y otra barrera imaginaria a la derecha de Q3 también a
distancia 1.5×RI,
Q3 + 1,5 × RI
barrera superior:
▶ Después se traza un bigote desde cada lado de la caja al dato
más extremo que esté dentro de las barreras.
▶ Las observaciones que quedan fuera de las barreras pueden
considerarse datos atípicos, y se dibujan como puntos
aislados.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: diagrama de caja
▶ Vamos a construir un diagrama de caja para los datos
114, 125, 114, 124, 142, 152, 133, 113, 127, 135, 122, 127, 185, 134, 147
▶ Los cuartiles de esta muestras son Q1 = 122, Q2 = 130, PRIMER DATO
QUE ME
ENCUENTRO
X DEBAJO
Q3 = 142, ya que
PRIMER
DATO
MAYOR
(PATITA
INFERIOR)▶
172
Por tanto el rango intercuartílico es RI = 142 − 122 = 20
MIN 49 Y FTO
PUNTO
MEDIO DE
LOS 3
VALORES
CENTRALES
127+133/2
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: diagrama de caja (continuación)
▶ Multiplicándo el rango intercuartílico por 1.5,
1,5 × RI = 1,5 × 20 = 30,
determinamos que las barreras del diagrama son
barrera inferior:
Q1 −1,5×RI = 122−30 = 92
barrera superior:
Q3 +1,5×RI = 142+30 = 172
▶ Puesto que no hay ningún dato inferior a 92, el bigote de la
izquierda va hasta 113, que es la observación más pequeña.
▶ Sí hay un dato superior a 172: el 185, que se dibujará fuera de
la caja como un punto aislado. El bigote de la derecha llegará
hasta 152, que es la mayor de las observaciones que no
exceden la barrera.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: diagrama de caja (continuación)
▶ Con todo esto se obtiene el siguiente diagrama de caja:
Diagrama de caja
100
120
140
160
180
.
.
.
.
.
.
200
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: diagrama de caja (continuación)
▶ El diagrama de caja también puede representarse
verticalmente:
dato atípico
160
180
200
Diagrama de caja
140
primer dato menor
Q3
50% DE
LOS DATOS
120
Q2 o mediana
Q1
100
EL PRIMER DATO MAYOR DE LA FRONTERA
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Utilidad de los diagramas de caja
▶ Los diagramas de caja son muy utiles para explorar los datos,
ya que proporcionan información visual sobre cómo se
distribuyen los datos, sobre su simetría y sobre sus posibles
datos atípicos.
▶ Además, son una herramienta muy útil para comparar
conjuntos de datos, como puede apreciarse en el siguiente
ejemplo.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: utilidad de los diagramas de caja
▶ Un equipo de ambientólogos ha desarrollado un sofisticado
programa informático para predecir los niveles de
calentamiento del planeta en el futuro en función de diversos
factores.
Con el fin de evaluar el tiempo de compilación de dicho
programa, lo han puesto a correr en todos todos los
ordenadores de su laboratorio, tanto en los fijos como en los
portátiles.
El gráfico de la transparencia siguiente representa los tiempos
de compilación resultantes medidos en horas.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo (continuación)
portatiles
fijos
75%
20
40
60
80
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo (continuación)
▶ Mirando estos diagramas, podemos responder a cuestiones
como las siguientes:
1. El ordenador que menos tarda en compilar el programa, ¿es un
fijo o un portatil? portátil, por los datos que hay atípicos
2. ¿Cuál es la proporción de ordenadores portátiles que complilan
el programa en menos de 60 segundos? el 25%
3. ¿Qué proporción de ordenadores fijos tardan en compilar el
programa entre 15 y 80 segundos?
4. ¿Qué proporción de portátiles tardan en compilar un tiempo
inferior al del más lento de los ordenadores fijos?
5. El tiempo medio de compilación de los ordenadores portátiles,
¿es menor que 80 segundos, exactamente 80, o mayor que 80?
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo (continuación)
▶ A partir de los diagramas de caja, es fácil dar las siguientes
respuestas:
1. El gráfico muestra que el tiempo mínimo de compilación
(inferior a 20 horas) corresponde a un ordenador portatil.
2. En el diagrama de caja se puede apreciar que 60 horas es el
primer cuartil del tiempo de compilación para el grupo de
ordenadores portátiles (Q1 = 60).
En consecuencia, la proporción de portátiles de esta empresa
que compilan el programa en menos de 60 horas es 0.25.
3. En el diagrama de caja podemos ver que todos los ordenadores
fijos tardan más de 15 horas en compilar el programa, y que 80
horas es el tercer cuartil del tiempo de compilación para los
ordenadores fijos (Q3 = 80).
Luego la proporción de ordenadores fijos tardan en compilar el
programa entre 15 y 80 horas es 0.75.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo (continuación)
4. El más lento de los ordenadores fijos tarda 90 horas en
complilar el programa. Por otra parte 90 minutos es el tercer
cuartil para los tiempo de compilación de los portátiles.
Por consiguiente la proporción de portátiles tardan en compilar
un tiempo inferior al del más lento de los ordenadores fijos es
0.75.
5. La mediana de los tiempos de compilación es 80 horas. El
diagrama de caja evidencia que la distribución de los tiempos
es muy asimétrica a la izquierda, y que hay dos datos atípicos
a la izquierda.
En consecuencia el tiempo medio de compilación de los
ordenadores portátiles será sensiblemente inferior a 80 horas.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Otras utilidades de los box-plots
▶ Los diagramas de caja también resultan útiles para analizar la
evolución de una variable a lo largo del tiempo. Por ejemplo,
el gráfico siguiente permite comparar la concentración de
oxígeno disuelto en el agua de un río a lo largo de los 12
meses de un año:
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Coeficiente de variación
▶ ¿Qué tiene más variabilidad: la altura de las jirafas o la de los
ping�inos?
▶ Las medidas de dispersión que hemos visto hasta ahora dependen de
las unidades en las que se mida la variable y de su magnitud.
▶ Pero, evidentemente, no es lo mismo una desviación típica de 30 cm
en las alturas de las jirafas que en las de los ping�inos.
▶ Para poder comparar la dispersión de variables que están medidas
en unidades diferentes, o que toman valores de magnitudes muy
distintas, es preciso contar con una medida de variabilidad que no
dependa de las unidades ni del tamaño de los datos.
▶ Las unidades de la media y de la desviación típica son las mismas
que las de los datos. Una manera natural de construir una medida
de variabilidad que no dependa de las unidades ni de la magnitud de
los datos es calcular el cociente
CVx =
sx
,
|x|
sirve para comparar 2 grupos
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Observaciones sobre el coeficiente de variación
▶ El cociente
CVx =
sx
,
|x|
recibe el nombre de coeficiente de variación y puede
interpretarse como la proporción o tanto por uno de
variabilidad.
▶ El coeficiente de variación es invariante ante cambios de
escala: si multiplicamos los datos por una constante a,
entonces
|a|sx
sx
sax
=
=
= CVx
CVax =
|ax|
|a||x|
|x|
▶ El coeficiente de variación sirve para comparar las
variabilidades de dos conjuntos de datos con unidades o
magnitudes diferentes, mientras que si deseamos comparar
dos elementos pertenecientes cada uno a uno de esos
conjuntos, debemos usar los valores tipificados.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Ejemplo: coeficiente de variación
▶ Un médico desea determinar si la variabilidad de los niveles de
glucosa en sangre de los individuos de cierto grupo de edad es
mayor o menor que la de los niveles colesterol. La distribución
del nivel de glucosa en ese grupo de edad tiene una media de
80 mg/dl y una desviación típica de 30 mg/dl, mientras que el
nivel medio de colesterol es de 190 mg/dl con una varianza de
3249(mg/dl)2 .
Los coeficientes de variación son:
sg
30
CVg =
=
= 0,375
g
80
√
sc
3249
57
CVc =
=
=
= 0,3
c
190
190
Por tanto, en este grupo de edad, los niveles de glucosa
presentan mayor dispersión que los de colesterol, o lo que es lo
mismo, los niveles de colesterol están más concentrados que
los de glucosa.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Otros aspectos a tener en cuenta al describir datos
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Datos atípicos
▶ Los datos atípicos requieren una atención especial. Es
importante identificarlos y decidir cómo tratarlos, ya que
pueden tener una fuerte infuencia en las conclusiones del
análisis.
▶ En algunos casos el outlier aparece como consecuencia de un
acontecimiento extraordinario. En este caso, el ese dato
atípico no es representativo y puede ser eliminado del análisis.
▶ Otras veces la observación atípica es simplemente
consecuencia de un error en la recogida o la transcipción de
los datos. Debe evitarse que este tipo de outliers influyan en el
análisis.
▶ También hay observaciones anómalas para las que no parece
haber explicación. Estos datos pueden aportar información
relevante sobre el comportamiento de la variable, y conviene
tratar de averiguar su por qué.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Datos ausentes
▶ Es frecuente encontrarse con que los valores de la variable son
desconocidos para algunas de las unidades experimentales.
▶ Por ejemplo, podría ocurrir que algunos de los nidos de
Talampaya fuesen inaccesibles y no se pudiese registrar el
número de huevos que tienen.
▶ Evidentemente, la validez de un estudio se ve afectada por la
reducción del número total de casos.
▶ Puede ocurrir, por ejemplo, que los nidos inaccesibles sean
precisamente los que tienen más huevos, porque los ñandúes
que han decidido anidar en lugares más difíciles sean los que
tienen más huevos que proteger.
▶ El tratamiento de los posibles datos perdidos es también parte
importante de un análisis descriptivo.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Datos temporales
▶ Cuando se quiere tener en cuenta el orden de los datos, el
análisis descriptivo requiere herramientas específicas.
▶ Por ejemplo, representar observaciones temporales mediante
un histograma o un diagrama de barras tiene muy poca
utilidad. Deben representarse en un diagrama de serie
temporal, como el siguiente:
170
160
150
140
130
Ejemplares
180
190
Avistamientos de ballenas
2002
2003
2004
2005
2006
2007
2008
2009
año
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Datos temporales (continuación)
▶ La elección de la escala influye mucho en la percepción que
transmite un gráfico temporal. Por ejemplo, los dos gráficos
siguientes representan los mismos datos sobre avistamientos de
ballenas:
Avistamientos de ballenas
200
100
150
Ejemplares
170
160
150
0
130
50
140
Ejemplares
180
250
190
300
Avistamientos de ballenas
2002
2003
2004
2005
2006
2007
2008
2009
2002
2003
2004
año
2005
2006
2007
2008
2009
año
▶ Los estadísticos de centralización, posición o dispersión son poco
informativos para datos temporales. Por ejemplo, el número de
medio de ballenas avistadas por año no es un buen resumen de su
.
. . . . . . . . . . . . . .
.
evolución.
.
.
.
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
¿Cómo enfrentarse a un conjunto de datos?
▶ Finalmente, hay que tener en cuenta que
Para extraer la máxima información de un conjunto de datos
deben combinarse las técnicas gráficas y numéricas.
▶ Es muy importante tener en mente la variable que se está
midiendo y el objetivo que se persigue.
▶ En el análisis de datos no existen recetas universales validas
para todas las muestras y poblaciones: cada conjunto de
observaciones es un mundo diferente con sus propias
particularidades. Por ello hay que dejar que los datos ”hablen”.
▶
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.
Bibliografía
▶ Grima, P. (2010) La certeza absoluta y otras ficciones. Los
secretos de la estadística. RBA
Capítulo 1.
▶ Ross, S.M. (2007) Introducción a la Estadística. Reverte
Capítulos 2 y 3.
▶ Méndez Iglesias, M. Introducción a la estadística para
ornitólogos que odian el Ardeola:
http://www.escet.urjc.es/biodiversos/espa/personal/marcos/cpp/Estadis.pdf
▶ Peña, D. (2001) Fundamentos de Estadística. Alianza Editorial
Capítulo 2.
.
.
.
.
.
.
. . . .
. . . .
. . . .
. . . .
. . . .
. . . .
.
.
.
.
.
.
.
.
.
.