Estadística rama de las matemáticas que se ocupa de reunir
Anuncio

Estadística
rama de las matemáticas que se ocupa de reunir, organizar y analizar datos numéricos y que ayuda a resolver problemas como el diseño de experimentos y la
toma de decisiones.
Muestreo
en estadística, proceso por el cual se seleccionan los individuos que formarán una muestra.
Para que se puedan obtener conclusiones fiables para la población a partir de la muestra, es importante tanto su tamaño como el modo en que han sido
seleccionados los individuos que la componen.
El tamaño de la muestra depende de la precisión que se quiera conseguir en la estimación que se realice a partir de ella. Para su determinación se requieren
técnicas estadísticas superiores, pero resulta sorprendente cómo, con muestras notablemente pequeñas, se pueden conseguir resultados suficientemente
precisos. Por ejemplo, con muestras de unos pocos miles de personas se pueden estimar con muchísima precisión los resultados de unas votaciones en las
que participarán decenas de millones de votantes.
Para seleccionar los individuos de la muestra es fundamental proceder aleatoriamente, es decir, decidir al azar qué individuos de entre toda la población
forman parte de la muestra.
Si se procede como si de un sorteo se tratara, eligiendo directamente de la población sin ningún otro condicionante, el muestreo se llama aleatorio simple o
irrestrictamente aleatorio.
Cuando la población se puede subdividir en clases (estratos) con características especiales, se puede muestrear de modo que el número de individuos de
cada estrato en la muestra mantenga la proporción que existía en la población. Una vez fijado el número que corresponde a cada estrato, los individuos se
designan aleatoriamente. Este tipo de muestreo se denomina aleatorio estratificado con asignación proporcional.
Las inferencias realizadas mediante muestras seleccionadas aleatoriamente están sujetas a errores, llamados errores de muestreo, que están controlados. Si
la muestra está mal elegida —no es significativa— se producen errores sistemáticos no controlados.
Variable
cada una de las letras que se utilizan en álgebra en expresiones algebraicas, polinomios y ecuaciones, para designar números desconocidos. Véase
Indeterminada.
También se llaman variables a las letras (x, y…) que se relacionan mediante las funciones.
Variable discreta
Los distintos valores que puede tomar un carácter cuantitativo configuran una variable estadística. La variable estatura, en cierta población estadística, toma
valores en el intervalo 147-205; y la variable número de hermanos toma los valores 0, 1, 2, 3, 4, 5, 6, 7 y 8. Una variable estadística como esta última es
discreta, ya que sólo admite valores aislados. Una variable estadística es continua si admite todos los valores de un intervalo, como ocurre con la estatura.
Variable continua
Un carácter puede ser cuantitativo si es medible numéricamente o cualitativo si no admite medición numérica. El número de hermanos y la estatura son
caracteres cuantitativos mientras que el sexo y el estado civil son caracteres cualitativos.
Los distintos valores que puede tomar un carácter cuantitativo configuran una variable estadística. La variable estatura, en cierta población estadística, toma
valores en el intervalo 147-205; y la variable número de hermanos toma los valores 0, 1, 2, 3, 4, 5, 6, 7 y 8. Una variable estadística como esta última es
discreta, ya que sólo admite valores aislados. Una variable estadística es continua si admite todos los valores de un intervalo, como ocurre con la estatura.
Muestra de población
selección de un conjunto de individuos representativos de la totalidad del universo objeto de estudio, reunidos como una representación válida y de interés
para la investigación de su comportamiento. Los criterios que se utilizan para la selección de muestras pretenden garantizar que el conjunto seleccionado
represente con la máxima fidelidad a la totalidad de la que se ha extraído, así como hacer posible la medición de su grado de probabilidad.
La muestra tiene que estar protegida contra el riesgo de resultar sesgada, manipulada u orientada durante el proceso de selección, con la finalidad de
proporcionar una base válida a la que se pueda aplicar la teoría de la distribución estadística.
Se distinguen varios tipos de muestras: la muestra simple, en la que cada individuo del universo considerado tiene las mismas probabilidades de resultar
elegido; la muestra estratificada, si la selección se realiza sobre grupos o estratos diferentes; y, finalmente, la muestra por agrupamientos, que se basa en los
segmentos o asociaciones organizadas dentro del universo considerado.
ESTADÍSTICA DESCRIPTIVA
La estadística descriptiva analiza, estudia y describe a la totalidad de individuos de una población. Su finalidad es obtener información, analizarla, elaborarla y
simplificarla lo necesario para que pueda ser interpretada cómoda y rápidamente y, por tanto, pueda utilizarse eficazmente para el fin que se desee. El proceso
que sigue la estadística descriptiva para el estudio de una cierta población consta de los siguientes pasos:
Selección de caracteres dignos de ser estudiados.
Mediante encuesta o medición, obtención del valor de cada individuo en los caracteres seleccionados.
Elaboración de tablas de frecuencias, mediante la adecuada clasificación de los individuos dentro de cada carácter.
Representación gráfica de los resultados (elaboración de gráficas estadísticas).
Obtención de parámetros estadísticos, números que sintetizan los aspectos más relevantes de una distribución estadística.
ESTADÍSTICA INFERENCIAL
La estadística descriptiva trabaja con todos los individuos de la población. La estadística inferencial, sin embargo, trabaja con muestras, subconjuntos
formados por algunos individuos de la población. A partir del estudio de la muestra se pretende inferir aspectos relevantes de toda la población. Cómo se
selecciona la muestra, cómo se realiza la inferencia, y qué grado de confianza se puede tener en ella son aspectos fundamentales de la estadística inferencial,
para cuyo estudio se requiere un alto nivel de conocimientos de estadística, probabilidad y matemáticas.
Estudio Estadístico
La materia prima de la estadística consiste en conjuntos de números obtenidos al contar o medir elementos. Al recopilar datos estadísticos se ha de tener
especial cuidado para garantizar que la información sea completa y correcta.
El primer problema para los estadísticos reside en determinar qué información y en que cantidad se ha de reunir. En realidad, la dificultad al compilar un censo
está en obtener el número de habitantes de forma completa y exacta; de la misma manera que un físico que quiere contar el número de colisiones por segundo
entre las moléculas de un gas debe empezar determinando con precisión la naturaleza de los objetos a contar. Los estadísticos se enfrentan a un complejo
problema cuando, por ejemplo, toman una muestra para un sondeo de opinión o una encuesta electoral. El seleccionar una muestra capaz de representar con
exactitud las preferencias del total de la población no es tarea fácil.
Para establecer una ley física, biológica o social, el estadístico debe comenzar con un conjunto de datos y modificarlo basándose en la experiencia. Por
ejemplo, en los primeros estudios sobre crecimiento de la población, los cambios en el número de habitantes se predecían calculando la diferencia entre el
número de nacimientos y el de fallecimientos en un determinado lapso. Los expertos en estudios de población comprobaron que l a tasa de crecimiento
depende sólo del número de nacimientos, sin que el número de defunciones tenga importancia. Por tanto, el futuro crecimiento de la población se empezó a
calcular basándose en el número anual de nacimientos por cada 1.000 habitantes. Sin embargo, pronto se dieron cuenta que las predicciones obtenidas
utilizando este método no daban resultados correctos. Los estadísticos comprobaron que hay otros factores que limitan el crecimiento de la población. Dado
que el número de posibles nacimientos depende del número de mujeres, y no del total de la población, y dado que las mujeres sólo tienen hijos durante parte
de su vida, el dato más importante que se ha de utilizar para predecir la población es el número de niños nacidos vivos por cada 1.000 mujeres en edad de
procrear. El valor obtenido utilizando este dato mejora al combinarlo con el dato del porcentaje de mujeres sin descendencia. Por tanto, la diferencia entre
nacimientos y fallecimientos sólo es útil para indicar el crecimiento de población en un determinado periodo de tiempo del pasado, el número de nacimientos
por cada 1.000 habitantes sólo expresa la tasa de crecimiento en el mismo periodo, y sólo el número de nacimientos por cada 1.000 mujeres en edad de
procrear sirve para predecir el número de habitantes en el futuro.
Media
número calculado mediante ciertas operaciones a partir de los elementos de un conjunto de números, x1, x2,…,xn, y que sirve para representar a éste. Hay
distintos tipos de medias: media aritmética, media geométrica y media armónica.
La media aritmética es el resultado de sumar todos los elementos del conjunto y dividir por el número de ellos:
La media geométrica es el resultado de multiplicar todos los elementos y extraer la raíz n-ésima del producto:
La media armónica es el inverso de la media aritmética de los inversos de los números que intervienen:
Por ejemplo, para el conjunto de valores 4, 6, 9:
En estadística, la media es una medida de centralización. Se llama media de una distribución estadística a la media aritmética de los valores de los distintos
individuos que la componen.
Mediana
en estadística, una de las medidas de centralización. Colocando todos los valores en orden creciente, la mediana es aquél que ocupa la posición central.
En geometría, cada uno de los tres segmentos rectilíneos que unen un vértice de un triángulo con el punto medio del lado opuesto.
Moda (matemáticas)
en estadística, el valor que aparece con más frecuencia en un conjunto dado de números. Es una de las medidas de centralización. En el conjunto
{3,4,5,6,6,7,7,7,10,13} la moda es 7. Si son dos los números que se repiten con la misma frecuencia, el conjunto tiene dos modas. Otros conjuntos no tienen
moda.
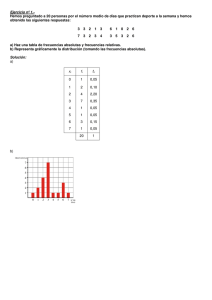
Distribución de Frecuencias:
tabla de datos, referentes a una variable en cuestión, en la que se exponen varias categorías de la misma, junto con sus frecuencias o número de veces que
se repite en la muestra (puede expresarse también en porcentaje). La tabla puede tener diferentes formatos y es llamada tabla de frecuencias. Cuando se
comparan la frecuencia de dos variables, se compone una tabla de contingencia, en la cual una variable ocupa las filas y la otra las columnas.
Ejemplo de una tabla de frecuencias simple de la variable COMA, en sus categorías: Ausente y Presente. (SPSS).
Gráfico de barra
gráfico de pastel
Si se unen los puntos medios de la base superior de los rectángulos se obtiene el polígono de frecuencias.
Los histogramas
se utilizan para representar tablas de frecuencias con datos agrupados en intervalos. Si los intervalos son todos iguales, cada uno de ellos es la base de un
rectángulo cuya altura es proporcional a la frecuencia correspondiente. El histograma
Medidas de dispersión
parámetros estadísticos que miden cómo de diseminados se encuentran los datos de una distribución. Los más utilizados se refieren al grado de lejanía de los
datos respecto a la media y son la desviación media, la varianza, la desviación típica y el coeficiente de variación.
La desviación media, D.m., es un promedio de los valores absolutos de las desviaciones, |xi - ÷|, de cada elemento, xi, de la distribución respecto a su media,
÷:
Por ejemplo, en la distribución 4, 6, 6, 7, 9, 11, 13, cuya media es 8, la desviación media es:
La varianza, V, es el promedio de los cuadrados de las desviaciones, (xi - ÷)2, de cada elemento, xi, respecto a la media, ÷:
La fórmula anterior es equivalente a esta otra:
que resulta más cómoda de aplicar, sobre todo cuando la media, ÷, no es un número entero.
En la distribución 4, 6, 6, 7, 9, 11, 13, de media 8, la varianza es:
Aplicando la segunda fórmula se obtiene, obviamente, el mismo resultado:
La desviación típica o desviación estándar
es la raíz cuadrada de la varianza:
La razón de ser de este parámetro es conseguir que la medida de dispersión se exprese en las mismas unidades que los datos a los que se refiere. Por
ejemplo, en una distribución de estaturas en la que los datos están dados en centímetros (cm), la media viene dada en centímetros, pero la varianza en
centímetros cuadrados (cm2). Para evitar este inconveniente se calcula su raíz cuadrada, obteniéndose así la desviación típica en centímetros.
El par de parámetros formado por la media y la desviación típica (÷, ó) aporta una información suficientemente buena sobre la forma de la distribución.
El coeficiente de variación, C.V., es el cociente entre la desviación típica y la media de la distribución:
Este parámetro sirve para relativizar el valor de la desviación típica y así poder comparar la dispersión de dos poblaciones estadísticas con gamas de valores
muy discretas. Por ejemplo, si en una compañía mexicana los salarios de los empleados tienen una media ÷1 = 7.000 pesos y una desviación típica ó1 = 500
pesos y en otra empresa española la media de los salarios es ÷2 = 200.000 pesetas y la desviación típica ó2 = 40.000 pesetas, para comparar la dispersión de
salarios se recurre al coeficiente de variación:
C.V.1 = 500/7.000 = 0,07
C.V.2 = 40.000/200.000 = 0,2
Se aprecia así que en la primera compañía los salarios tienen menor dispersión que en la segunda.
Otras medidas de dispersión son el recorrido y el recorrido intercuartílico.
El recorrido es la diferencia entre los valores mayor y menor de la distribución. Indica, pues, la longitud del tramo en el que se hallan los datos. También se
llama rango.
El recorrido intercuartílico es la diferencia, Q3 - Q1 , entre el cuartil superior, Q3, y el cuartil inferior, Q1. El par de parámetros formado por la mediana, Me, y el
recorrido intercuartílico, Q3 - Q1, proporciona una buena información sobre la forma de la distribución.
Medidas de centralización
parámetros estadísticos que marcan, bajo distintos criterios, los valores en torno a los cuales se disponen los datos de una distribución. También se llaman
medidas de tendencia central, pues entorno a ellas se disponen los elementos de las distribuciones. Las más importantes son la media, la mediana y la moda.
La media aritmética, promedio o, simplemente, media, de los valores x1, x2,…, xn, se designa por ÷ y se obtiene así:
Por ejemplo, si las edades de 7 niños son 4, 6, 6, 7, 9, 11 y 13, la media es:
La mediana, Me, es un número que supera a la mitad de los valores de la distribución y es superada por la otra mitad.
Si el número de términos de la distribución es impar, la mediana es el valor del individuo que ocupa el lugar central cuando los datos están ordenados de
menor a mayor. Por ejemplo, en la distribución de edades 4, 6, 6, 7, 9, 11, 13, la mediana es Me = 7, pues hay tres datos menores que 7 y tres mayores que 7.
Si el número de términos de la distribución es par, la mediana es el valor medio de los datos centrales. Así, en la distribución 4, 6, 6, 7, 8, 9, 11, 13, los valores
7 y 8 son los centrales. La mediana es Me = 7,5.
La moda, Mo, de una distribución estadística es el valor que más se repite. Una distribución puede tener más de una moda o no tener ninguna. En la
distribución 4, 6, 6, 7, 9, 11, 13, la moda es Mo = 6.
Gráfico Lineal de Perfil
en el siglo XIX, el matemático alemán Johann Benedict Listing demostró que un gráfico lineal con 2n vértices impares se puede dibujar utilizando n trazos
continuos, si cada uno de ellos comienza y termina en un vértice impar.
Frecuencias Matemáticas
Frecuencia (matemáticas), en estadística, el número de veces que ocurre un cierto suceso. También se denomina frecuencia absoluta, en contraposición con
la frecuencia relativa, que consiste en la proporción de veces que ocurre dicho suceso con relación al número de veces que podría haber ocurrido.
Por ejemplo, si una experiencia aleatoria se repite 80 veces y un cierto suceso, S, ocurre 36 veces, decimos que su frecuencia ha sido 36, y su frecuencia
relativa 36/80 = 0,45:
f(S) = 36 fr(S) =36/80 = 0,45
La frecuencia relativa también se expresa, en ocasiones, en tantos por ciento (45%).
FRECUENCIAS ACUMULADAS
En una tabla de frecuencias, cuando la variable es cuantitativa y, por tanto, los distintos valores de la tabla aparecen ordenados de menor a mayor, se llama
frecuencia acumulada de un valor de la variable a la suma de su frecuencia con las frecuencias de los valores anteriores. Por ejemplo, si al lanzar un dado 100
veces se obtienen los siguientes resultados:
f(1) = 16 f(2) = 13 f(3) = 21
f(4) = 19 f(5) = 14 f(6) = 17
las frecuencias acumuladas son:
fa(1) = 16 fa(2) = 16 + 13 = 29
fa(3) = 29 + 21 = 50 fa(4) = 50 + 19 = 69
fa(5) = 69 + 14 = 83 fa(6) = 83 + 17 = 100
Estos resultados se aprecian mejor en una tabla:
Las frecuencias relativas acumuladas son las frecuencias acumuladas divididas por el número total de individuos.
Diagramas de Tallo y Hojas
Una técnica de recuento y ordenación de datos la constituye los diagramas de Tallos y Hojas.
Supongamos la siguiente distribución de frecuencias
36 25 37 24 39 20 36 45 31 31
39 24 29 23 41 40 33 24 34 40
que representan la edad de un colectivo de N = 20 personas y que vamos a representar mediante un diagrama de Tallos y Hojas.
Comenzamos seleccionando los tallos que en nuestro caso son las cifras de decenas, es decir 3, 2, 4, que reordenadas son 2, 3 y 4.
A continuación efectuamos un recuento y vamos «añadiendo» cada hoja a su tallo
Por último reordenamos las hojas y hemos terminado el diagrama
Diagrama de Cajas y Bigotes
Teniendo en cuenta que con las representaciones anteriores los datos están ordenados, podemos aprovechar estas disposiciones para representar los
diagramas de Cajas y Bigotes (boxplots o box and whiskers).
Estos diagramas se basan en los siguientes parámetros de la distribución: valor mínimo, los cuartiles Q 1, Q 2 y Q 3 y el valor máximo.
Para la primera distribución
Su diagrama de Cajas y Bigotes es
Intervalo de clase
En la tabla adjunta se muestra cómo se han repartido 1.200 calificaciones entre 0 y 10, en 10 intervalos iguales —columna (a). Las marcas de clase (centros
de los intervalos) están en la columna (b), las frecuencias en la (c), las frecuencias relativas en la (d), las frecuencias acumuladas en la (e) y las frecuencias
acumuladas relativas en la columna (f).
(a)
(b)
(c)
(d)
(e)
(f)
INTERVALO
MARCA DE CLASE
FRECUENCIA
FRECUENCIA
RELATIVA
FRECUENCIA
ACUMULADA
FRECUENCIA ACUMULADA
RELATIVA
0-1
0,5
20
0,017
20
0,017
1-2
1,5
15
0,012
35
0,029
2-3
2,5
18
0,015
53
0,044
3-4
3,5
25
0,021
78
0,065
4-5
4,5
44
0,037
122
0,102
5-6
5,5
88
0,073
210
0,175
6-7
6,5
222
0,185
432
0,360
7-8
7,5
335
0,279
767
0,639
8-9
8,5
218
0,182
985
0,821
9-10
9,5
215
0,179
1.200
1,000
1.200 CALIFICACIONES DISTRIBUIDAS EN 10 INTERVALOS
Rango y amplitud
El número de clases y la amplitud de los intervalos los fija el investigador de acuerdo con el conocimiento que posea de la población, la necesidad de hacer
comparación con otras investigaciones y la presentación de la información. Sin embargo, se recomienda que la información no sea demasiado compacta, lo
cual le restaría precisión, ni demasiado dispersa, ya que no se tendría claridad.
La amplitud debe ser igual para todos los intervalos y, en lo posible, no se debe trabajar con clases abiertas.