PRUEBAS DE HIPÓTESIS
Anuncio

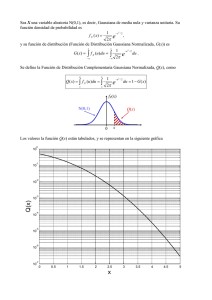
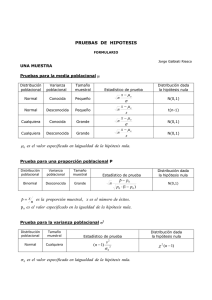
Teorema Central del Límite (1) • Definición. Cualquier cantidad calculada a partir de las observaciones de una muestra se llama estadístico. La distribución de los valores que puede tomar un estadístico respecto a todas las muestras de tamaño n que se podrían extraer se llama distribución muestral del estadístico. • Determinar cómo aumenta la representatividad de una muestra al aumentar su tamaño. • Se tiene una población de N observaciones a partir de la cual se extraen muestras, Xi, cada una con n observaciones. El promedio de todas las muestras sería: • ¿Cómo se distribuyen los valores de las medias muestrales? • Calcular el valor esperado y la varianza de . Usar las siguientes propiedades: • Ejercicio: Consideremos las observaciones 1, 3, 4, 5 y 12 y obténganse todas las muestras posibles de tamaño 2. Verificar si el valor medio de todas las medias muestrales es igual a la media de la población. Si no se conoce , se puede estimar a partir de la muestra, con lo cual: s = s/ Teorema Central del Límite (2) El TCL establece que, en el límite, cuando el tamaño de la muestra crece, la suma (o equivalentemente la media aritmética) de un conjunto de variables aleatorias tendrá una distribución Gaussiana, sin importar la distribución de la población de la cual provienen las observaciones. Nos permite usar estadísticos muestrales para hacer inferencias con respecto a los parámetros de la población sin tener información sobre la forma de la distribución de la población, excepto la que podamos obtener de la muestra. Si la distribución de X es Gaussiana: • Si la distribución de X es desconocida o no es Gaussiana: • Este teorema explica la importancia de la distribución Gaussiana ya que aparece de manera natural asociada a cualquier distribución si consideramos la distribución de la media muestral o de la suma de realizaciones independientes. En particular, si un error de medición se puede considerar como la suma de muchas pequeñas perturbaciones independientes, el TCL implica que la distribución de sus valores es aproximadamente Normal. • Si consideramos un número grande n de variables aleatorias independientes e idénticamente distribuidas, cada una con media µ y varianza finita σ2, entonces la variable Y = ∑nXn se distribuye aproximadamente como una Gaussiana con media µY = nµ y varianza σ2Y = nσ2. Zn = Xn – nμ σ √n Estimadores • Estimar un parámetro de un modelo probabilístico para la distribución de una variable X, consiste en obtener una aproximación de su valor con base en las observaciones. • Definición. Cualquier estadístico diseñado para aproximar el valor de un parámetro Ө del modelo, se llama estimador puntual del parámetro. • Un estimador es una variable aleatoria, e.d., su valor concreto depende de la muestra escogida. • Propiedades deseables de un estimador: Estimador insesgado Estimador consistente Estimación por intervalos. Nos permite obtener una medida del error que pensamos cometer al estimar un parámetro. Intervalo de confianza para la media µ de una distribución Normal con varianza conocida PRUEBAS DE HIPÓTESIS Una hipótesis estadística es una proposición acerca del valor de un parámetro en el modelo considerado. Pruebas Paramétricas y No Paramétricas Las pruebas paramétricas se llevan a cabo en situaciones en las que sabemos o asumimos que una distribución teórica particular es una representación apropiada para los datos y/o el estadístico de prueba. Las pruebas no-paramétricas se llevan a cabo sin la necesidad de hacer suposiciones acerca de la distribución paramétrica de los datos (si la hay). Las pruebas paramétricas consisten esencialmente en hacer inferencias respecto a los parámetros de alguna distribución particular, la cual podemos considerar que representa la naturaleza de los procesos físicos de interés subyacentes. Un estadístico es una cantidad calculada a partir de un conjunto de datos. Los estadísticos muestrales están sujetos a variaciones de muestreo, es decir, también son variables aleatorias y su valor cambia de una muestra a otra. Las variaciones de los estadísticos muestrales pueden describirse usando distribuciones de probabilidad denominadas distribuciones muestrales. El concepto de distribución muestral es fundamental en todas las pruebas estadísticas ya que proporciona un modelo probabilístico que describe las frecuencias relativas de los valores posibles del estadístico de prueba. Elementos de cualquier prueba de hipótesis 1) Identificar un estadístico de prueba (EP) apropiado, el cual será el objeto de la prueba. En las pruebas paramétricas el EP es con frecuencia un estimador muestral de algún parámetro de una distribución de probabilidad dada. 2) Definir una hipótesis nula (H0). Define un marco de referencia lógico específico contra el cual se juzga al EP observado. Con frecuencia H0 se formula de modo que esperamos rechazarla. 3) Definir una hipótesis alternativa (HA). Con frecuencia HA es simplemente “H0 no es verdadera”. 4) Obtener la distribución nula, que es la distribución muestral del EP si suponemos que HO es verdadera. Identificar la distribución nula es la parte crucial de la prueba de hipótesis. 5) Comparar el EP observado con la distribución nula. Si el EP cae en una región suficientemente improbable de la distribución nula, H0 es rechazada. Si el EP cae dentro del rango ordinario de valores descritos por la distribución nula, el EP es considerado como consistente con H0 y por consiguiente no se rechaza. La región suficientemente improbable de la distribución nula (región crítica o región de rechazo) está definida por el nivel de la prueba, α (nivel de significación o de significancia). El nivel de confianza de la prueba es igual a 1 – α. H0 es rechazada si la probabilidad de ocurrencia del EP (p) (de acuerdo con la distribución nula) es menor o igual que el nivel de significancia α. Dicho nivel se elige de forma arbitraria antes de realizar los cálculos. El nivel más comúnmente utilizado es el del 5% (α = 0.05), pero también se acostumbran niveles del 10% (α = 0.1) o 1% (α = 0.01). El valor p de una prueba es la probabilidad específica de que el valor observado del EP ocurrirá. Entonces, HO se rechaza si el valor p es <= α. Si rechazamos HO a un nivel de confianza dado, también la rechazaremos para cualquier nivel de confianza menor. -zα/2 zα/2 NOTA: El aceptar (es decir, no rechazar) H0 no significa necesariamente que ésta sea verdadera, sino solamente que no hay evidencia suficiente para rechazarla dada la información que se tiene. Tipos de errores • Error Tipo I – probabilidad de rechazar HO dado que de hecho es verdadera (α). • Error Tipo II – probabilidad de aceptar HO cuando de hecho es falsa (β). Aunque nos gustaría minimizar las probabilidades de ambos errores, esto no es posible. Podemos prescribir α pero generalmente no se puede prescribir β ya que HA se define de forma más general que H0 y no se conoce su distribución. Pruebas unilaterales y bilaterales • Una prueba estadística puede ser unilateral (de una cola, one-sided) o bilateral (de dos colas, two-sided). Esto depende de la naturaleza de la hipótesis que se va a probar. • Las pruebas unilaterales son apropiadas si hay una razón a priori para esperar que las violaciones de la H0 conducirán a valores del EP sobre un lado particular de la distribución nula. La HA se establece en términos de probar si el valor verdadero es mayor (o menor) que el valor de la HO. P (-zα < Z ) = P ( Z < zα ) = 1 - α -zα zα Las pruebas bilaterales son apropiadas cuando tanto valores muy grandes como muy pequeños del EP son desfavorables para la H 0. Tales pruebas pertenecen a casos en los que la HA es muy general, como “HA: H0 no es verdadera o HA: μ ≠ μ0”. La región de rechazo consiste de ambos extremos de la distribución nula. En este caso las dos porciones de la región de rechazo están delimitadas de manera que la suma de sus probabilidades bajo la distribución nula sea igual al nivel α. Si el EP es mayor o menor que el valor crítico ±z1-α/2 entonces se rechaza la hipótesis nula. P (-zα/2 < Z < zα/2 ) = 1 - α -zα/2 zα/2 Prueba de hipótesis para la media µ de una distribución Normal con varianza conocida • Hipótesis bilateral • Hipótesis unilateral Pruebas de hipótesis e intervalos de confianza • El intervalo de confianza alrededor de un estadístico muestral consiste de otros valores posibles del estadístico para los cuales la hipótesis nula no sería rechazada. • Se usan típicamente para construir barras de error alrededor de estadísticos muestrales en una gráfica. • Puede pensarse que los intervalos de confianza se construyen encontrando valores del Estadístico de Prueba que no caerían en la región de rechazo, es decir, es la operación inversa de la prueba de hipótesis.