Análisis estadístico de datos muestrales
Anuncio

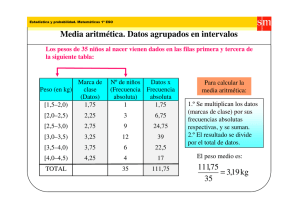
Análisis estadístico de datos muestrales M. en A. Víctor D. Pinilla Morán Facultad de Ingeniería, UNAM Resumen Representación de los datos de una muestra: tablas de frecuencias, frecuencias relativas y frecuencias relativas acumuladas. Representación gráfica de dichas tablas: Histogramas y polígonos de frecuencias. Analogías de estos polígonos con las funciones de probabilidad según el concepto frecuentista de la probabilidad: distribuciones empíricas de probabilidad. Medidas de tendencia central, de dispersión de la muestra, de sesgo y aplanamiento de la muestra, cuando los datos de ella están o no agrupados. Analogía de estas medidas con las correspondientes a la función de probabilidad de la variable aleatoria discreta. 1.1 La población y la muestra. Relación entre la probabilidad y la estadística. Clasificaciones de la estadística. De esta definición pueden percibirse dos grandes áreas de acción de la Estadística, la Descriptiva y la Inferencial. Estadística: En el lenguaje común es conocida como un conjunto de datos. Se refiere a un conjunto de métodos para manejar la obtención, presentación y el análisis de observaciones numéricas. Sus fines son: Describir al conjunto de datos obtenidos y tomar decisiones, o bien, realizar generalizaciones acerca de las características de todas las posibles observaciones bajo consideración. Estadística Descriptiva. Se refiere a aquella parte del estudio que incluye la obtención, organización, presentación y descripción de la información numérica. Probabilidad y Estadística Noviembre 2009 Estadística Inferencial. Es una técnica de la cual se obtienen generalizaciones o se toman decisiones con base a información parcial o incompleta obtenida mediante técnicas descriptivas. M.A. Víctor Damián Pinilla Morán. 1 Es necesario determinar que todas las ciencias sin importar la disciplina tienen como denominador común al método científico, por ende, la Estadística al ser una herramienta necesaria ara el método científico, forma parte también de todas las ciencias. Desde el punto de vista de la naturaleza de la información manipulada, la Estadística puede clasificarse como Paramétrica y No Paramétrica. Estadística Paramétrica. Son todas aquellas técnicas y herramientas estadísticas que utilizan variables cuantitativas, es decir, medibles. Estadística No Paramétrica. Son todas aquellas técnicas y herramientas estadísticas que utilizan variables cualitativas. Desde el punto de vista del número de variables sobre las cuales se basa el análisis matemático respectivo, siendo la estadística univariable la que utiliza una sola variable, mientras que la estadística multivariable analiza dos o más variables. Población. Conjunto de todas las posibles observaciones. Sinónimo de Conjunto Universal se le define como la totalidad de todas las posibles mediciones observables, bajo consideración en una situación dada por determinado problema, circunstancias diferentes implican situaciones diferentes. Probabilidad y Estadística Noviembre 2009 Las Poblaciones se clasifican en función a su cardinalidad. Población Finita. Es aquella que incluye un número limitado de medidas y observaciones. Población Infinita. Es aquella que por incluir un gran número de medidas y observaciones no es posible determinar la cantidad de éstas. En lo general, las características medibles de una población son denominadas Parámetros. Muestra. Conjunto de observaciones o medidas tomadas a partir de una población dada, es decir, es un subconjunto de la población. Desde luego, la cardinalidad de la muestra depende de la cardinalidad de la población. Las muestras deben ser representativas para evitar un sesgo u error. Estadísticos Muestrales1. En lo general, son las características medibles de una muestra El muestreo es la técnica seguida para obtener o extraer una muestra. Su ventaja radica en que nos permite conocer, con un grado de aproximación aceptable, a partir de sus características, las características propias de la población de la cual proviene. Esto resulta En la literatura suelen denominarse por igual estadísticos o estadísticas a las características de las muestras. 1 M.A. Víctor Damián Pinilla Morán. 2 invaluable, tomando en cuenta que en la mayoría de los casos, las características de las muestras son desconocidas. El sesgo es la diferencia que existe entre los datos obtenidos a través de una muestra y los datos reales (normalmente desconocidos) pertenecientes a la población. Puede interpretarse como un error absoluto entre un valor real y uno aproximado. Cuando se denomina como sesgado a determinado resultado se pretende establecer que su valor es diferente al real. Las técnicas de muestreo pueden clasificarse de la siguiente forma: Muestreo Estratificado. Esta técnica implica dividir a la población en clases o grupos denominados Estratos. Se supone que las unidades que componen al estrato, son relativamente homogéneas, con respecto a las características que vayan a estudiarse. A menudo se toma una razón de muestreo igual para todos los estratos generalmente en proporción; a una muestra seleccionada así, se le llama Muestra Estratificada Proporcional. (Se estudia sólo el estrato) Cuando la proporción de rastreo está directamente relacionada con la homogeneidad es decir entre más homogéneo sea el estrato menor será su proporción incluida en la muestra. A una muestra obtenida de esta forma se le denomina: Muestra estratificada Desproporcionada. (De una población normal se toma una muestra proporcional) Muestreo por Conglomerados. Este procedimiento implica la selección de grupos (conglomerados) a partir de la población, las diferencias entre conglomerados son generalmente pequeñas, aunque internamente sus unidades son heterogéneas. Cada conglomerado es una miniatura de la población. Muestreo Probabilístico. Es aquel en donde en la elección de una muestra interviene el azar. Muestreo No Probabilístico. Es aquel en donde en la selección de una muestra no interviene el azar. Muestreo sistemático. Se selecciona una muestra tomada cada k-ésima unidad de la población a la vez, una vez que las unidades de la población están arregladas de alguna forma. k, es la razón del muestreo. (En el metro, preguntar a cada 5 personas que pasan.) Muestreo Aleatorio Simple. Cada uno de los componentes de la muestra tienen la misma probabilidad de ser elegido. Puede ser: Con Reemplazo logra un número infinito de las muestras, lo que asegura la independencia estadística entre ellas. Sin Reemplazo logra un número finito de las muestras las cuales son estadísticamente dependientes. Probabilidad y Estadística Noviembre 2009 M.A. Víctor Damián Pinilla Morán. 3 Representación de los datos de una muestra. La Estadística Descriptiva se encarga de la obtención, organización, representación y descripción de los datos. general se coincide que no sean tan pocos que no resulte apropiada la agrupación de datos ni tantos que la haga poco práctica. En general, se recomienda que el número de intervalos no sea ni menor de cinco ni mayor a quince. La obtención de los datos se logra a través de las técnicas de muestreo, conforme al diseño del experimento seleccionado. Por otra parte, ciertos autores han establecido algunas reglas matemáticas para determinar el número de intervalos. Dos de ellas son: 1.2 Estadística descriptiva. Como se podrá observar más adelante, existen expresiones que permiten trabajar con la totalidad de los datos de la muestra; al arreglo que utiliza la totalidad de los datos se le conoce como datos no agrupados. Antes de la evolución tecnológica o bien, cuando los recursos de cómputo son limitados, trabajar con un número alto de datos resulta complicado. Por tal motivo, se conformó un arreglo de datos basado en intervalos conocido como tabla de frecuencias. Cuando se utiliza la tabla de frecuencias se dice que se trabaja con datos agrupados. Ahora bien, con el avance en los recursos de cómputo resulta ahora de lo más sencillo trabajar con datos no agrupados, lo que evita errores numéricos y los propios ocasionados por el agrupamiento de los datos en las tablas de frecuencia. No obstante, las tablas de frecuencias son necesarias para construir las representaciones gráficas de las muestras. Intervalos de clase. Se refiere a los intervalos en los cuales serán agrupados los n datos obtenidos en el muestreo. Una tabla de frecuencias se compone de un número finito de intervalos continuos, todos del mismo ancho. El número de intervalos es variable y su elección depende de la experiencia de quién construye la tabla. No existe consenso por parte de los autores para determinar el número óptimo de intervalos, pero en lo Probabilidad y Estadística Noviembre 2009 Ley de Sturges: # intervalos = 1 + 3.322 Log (n) # intervalos = n En ambos casos, n es el número total de datos. Lo que resulta importante, más que determinar el número de intervalos, es que estos cumplan con una serie de características: 1. Todos los intervalos deben tener el mismo ancho. 2. Un dato sólo puede pertenecer a un solo intervalo. 3. No debe haber intervalos vacíos. Ilustremos lo anterior con un ejemplo. Ejemplo. Los siguientes datos corresponden a 80 mediciones de la longitud de un travesaño parte de un chasis. Sus dimensiones son en centímetros. 50.1 50.6 50.7 51.1 52.0 50.8 51.4 49.9 51.8 51.3 50.6 49.1 51.4 51.8 51.3 51.5 51.0 50.9 50.3 51.2 51.1 51.8 51.9 50.3 51.1 51.1 51.7 50.2 50.5 51.6 50.8 51.0 50.4 51.5 50.8 51.2 50.1 51.5 51.7 51.9 52.2 50.8 51.7 51.7 49.4 50.3 52.1 51.0 51.7 51.9 51.9 51.8 51.0 50.3 50.3 51.3 51.0 50.2 50.4 51.6 51.2 51.1 49.5 49.9 51.1 51.7 52.8 49.6 49.6 53.1 52.0 49.7 52.0 49.7 51.2 51.8 51.1 51.3 51.2 51.8 M.A. Víctor Damián Pinilla Morán. 4 El primer paso para construir los intervalos de clase consiste en ordenar los datos de menor a mayor, sin eliminar ninguno de ellos. 49.1 49.4 49.5 49.6 49.6 49.7 49.7 49.9 49.9 50.1 50.1 50.2 50.2 50.3 50.3 50.3 50.3 50.3 50.4 50.4 50.5 50.6 50.6 50.7 50.8 50.8 50.8 50.8 50.9 51.0 51.0 51.0 51.0 51.0 51.1 51.1 51.1 51.1 51.1 51.1 51.1 51.2 51.2 51.2 51.2 51.2 51.3 51.3 51.3 51.3 51.4 51.4 51.5 51.5 51.5 51.6 51.6 51.7 51.7 51.7 51.7 51.7 51.7 51.8 51.8 51.8 51.8 51.8 51.8 51.9 51.9 51.9 51.9 52.0 52.0 52.0 52.1 52.2 52.8 53.1 Rango. Es la diferencia entre el dato mayor y el menor. Rango = 53.1 – 49.1 = 4.0 Número de intervalos. Es atribución del diseñador del experimento definir el número de intervalos con la recomendación de que no sean ni menos de cinco ni más de quince. No obstante, es posible utilizar como guía las siguientes expresiones: # intervalos = 1 + 3.322 Log (80) = 7.32 # intervalos = n = 80 = 8.94 Se conviene en establecer ocho intervalos Ancho del intervalo. Se define como: menor. Para motivos de nuestro ejemplo, comenzaremos en el dato menor. Clase 1 2 3 4 5 6 7 8 4.0 8 Uno de estos recursos consiste en aprovechar la uniformidad de los datos producto del diseño del experimento. En nuestro caso, el muestreo arrojó datos uniformes en el sentido de que todos ellos son compuestos por dos cifras enteras y una cifra decimal. Se puede proceder de dos formas: 1. Iniciar los intervalos un poco antes que el dato menor, por ejemplo en 49.05. Al establecer un límite de intervalos con una cifra decimal más, se minimiza la probabilidad de que algún dato coincida con alguna frontera. Sin embargo, el dato mayor quedará excluido del último intervalo, por lo que se deberá aumentar el ancho del intervalo. = 0.5 Todos los intervalos medirán 0.5 cm de ancho. Ahora bien, el primer intervalo puede comenzar justo en el dato más pequeño, aunque esto no es regla general; si al diseñador le conviene, puede empezar con un límite inferior menor al dato 2 Probabilidad y Estadística Noviembre 2009 49.6 50.1 50.6 51.1 51.6 52.1 52.6 53.1 A este respecto, algunos autores en apego fiel a la definición de intervalos expresan a los intervalos de clase en forma de intervalos abiertos por un extremo y cerrados por el otro (el extremo cerrado o abierto es decisión del diseñador)2. Sin embargo, por usos y costumbres y pensando en las representaciones gráficas de los datos, se utilizan algunos recursos para evitar esta eventualidad. Para nuestro ejemplo: = 49.1 49.6 50.1 50.6 51.1 51.6 52.1 52.6 Puede observarse que tanto el dato menor como el mayor son incluidos en algún intervalo; sin embargo, se produce un conflicto ya que algunos datos coinciden con las fronteras compartidas de los intervalos, lo cual no satisface la segunda característica de los intervalos de clase. W : Ancho del Intervalo Rango W= # intervalos W Intervalos de Clase Límite Límite Inferior Superior Se les denomina Límites Reales de Clase. M.A. Víctor Damián Pinilla Morán. 5 2. Aumentar el ancho de intervalo en una cifra decimal más que la que contienen los datos, por ejemplo, 0.55. Debe tomarse en cuenta que en determinado momento, la suma de los anchos de intervalo pueden hacer coincidir un dato. Resulta más conveniente utilizar 0.51 Clase 1 2 3 4 5 6 7 8 Intervalos de Clase Límite Límite Inferior Superior 49.10 49.61 50.12 50.63 51.14 51.65 52.16 52.67 49.61 50.12 50.63 51.14 51.65 52.16 52.67 53.18 Marcas de clase. Son los puntos intermedios de cada intervalo de clase. Clase 1 2 3 4 5 6 7 8 Ti = Lsup − Linf Intervalos de Clase Límite Límite Inferior Superior 49.10 49.61 49.61 50.12 50.12 50.63 50.63 51.14 51.14 51.65 51.65 52.16 52.16 52.67 52.67 53.18 50.1 50.2 50.2 50.3 50.3 50.3 50.3 50.3 50.4 50.4 50.5 50.6 50.6 50.7 50.8 50.8 50.8 50.8 50.9 51.0 51.0 51.0 51.0 51.0 51.1 51.1 51.1 51.1 51.1 51.1 51.1 51.2 51.2 51.2 51.2 51.2 51.3 51.3 51.3 51.3 51.4 51.4 51.5 51.5 51.5 51.6 51.6 51.7 51.7 51.7 51.7 51.7 51.7 51.8 51.8 51.8 51.8 51.8 51.8 51.9 51.9 51.9 51.9 52.0 52.0 52.0 52.1 52.2 52.8 53.1 Naturalmente, la suma de todas las frecuencias debe coincidir con el número total de datos (n). Este último arreglo garantiza el cumplimiento de las tres características de los intervalos de clase. Ti : Marca de Clase 49.1 49.4 49.5 49.6 49.6 49.7 49.7 49.9 49.9 50.1 2 Frecuencia Relativa. Se refiere a la frecuencia de cada una de las clases dividida entre el número total de datos (n). De aquí se deriva la interpretación frecuentista de la probabilidad. F 'i : Frecuencia relativa de la i-ésima clase F F 'i = i n Comprobando el axioma de la probabilidad para variables aleatorias discretas: P( x) = 1 , la Marcas de Clase 49.36 49.87 50.38 50.89 51.40 51.91 52.42 52.93 ∑ ∀X suma de todas las frecuencias relativas debe ser la unidad. Frecuencia Acumulada. Son los datos acumulados desde el primer dato hasta la i-ésima clase. Faci : Frecuencia Acumulada de la i-ésima clase. Frecuencia. Es el número de datos que pertenece a cada intervalo de clase. Fi : Frecuencia de la i-ésima clase Probabilidad y Estadística Noviembre 2009 Este concepto coincide con el particular de Función de Distribución o Función de Probabilidad Acumulada. Debe destacarse que la Frecuencia Acumulada de la última clase debe coincidir con el número total de datos (n). M.A. Víctor Damián Pinilla Morán. 6 Frecuencia Acumulada Relativa. En la frecuencia acumulada de la clase i-ésima entre el numero total de datos (n). F ' aci : Frecuencia Acumulada Relativa F ' aci = Faci n El polígono de frecuencias es una línea quebrada que une los puntos de intersección de la abscisa que corresponde a la marca de clase con la ordenada que puede ser la frecuencia o la frecuencia relativa. El polígono se cierra con el eje horizontal al iniciarlo en el límite inferior del primer intervalo de clase y concluirlo en el límite superior del última intervalo de clase. De la misma forma, se comprueba que P( x) = 1 ya que la frecuencia relativa de la ∑ ∀X última clase, debe ser la unidad. La tabla completa queda de la siguiente forma: Clase 1 2 3 4 5 6 7 8 Σ Intervalos de Clase Límite Límite Inferior Superior 49.10 49.61 49.61 50.12 50.12 50.63 50.63 51.14 51.14 51.65 51.65 52.16 52.16 52.67 52.67 53.18 Marcas de Clase 49.36 49.87 50.38 50.89 51.40 51.91 52.42 52.93 Esta tabla se conoce como Distribución de Frecuencias. Representación gráfica de la distribución de frecuencias. Una forma muy rápida y efectiva de interpretar la información contenida en una distribución de frecuencias consiste en graficar sus elementos. Básicamente existen representaciones: tres tipos El Histograma en una gráfica de barras o columnas que se construye en un sistema coordenado en cuyo eje horizontal o de abscisas se detallan los intervalos de clase y en el eje vertical o de ordenadas se ubican las frecuencias o las frecuencias relativas. Frecuencia Frecuencia Relativa 5 6 12 18 16 20 2 1 80 0.06 0.08 0.15 0.23 0.20 0.25 0.03 0.01 1.00 Frecuencia Frecuencia Acumulada Acumulada Relativa 5 0.06 11 0.14 23 0.29 41 0.51 57 0.71 77 0.96 79 0.99 80 1.00 Cuando un polígono se dibuja sobre un histograma de la misma distribución, la línea quebrada une los centros de las bases superiores de los rectángulos del histograma. Las ojivas de frecuencias son líneas quebradas que se trazan por los puntos de intersección de las coordenadas que corresponden a las marcas de clase y sus respectivas frecuencias acumuladas o frecuencias acumuladas relativas. de Histograma Representaciones Gráficas Polígono de frecuencias Ojiva de frecuencias Probabilidad y Estadística Noviembre 2009 M.A. Víctor Damián Pinilla Morán. 7 20 18 20 16 12 15 10 5 6 2 5 1 0 49 . 1 0 49. 61 50. 12 50. 63 5 1. 14 5 1. 65 52. 16 52. 67 5 3. 18 Histograma 20 20 18 16 15 12 10 5 5 6 2 0 49.36 49.87 50.38 50.89 51.40 51.91 52.42 1 52.93 Polígono de frecuencias 100 80 60 77 79 80 51.91 52.42 52.93 57 41 40 23 20 5 0 49.36 11 49.87 50.38 50.89 51.40 Ojiva de frecuencias Probabilidad y Estadística Noviembre 2009 M.A. Víctor Damián Pinilla Morán. 8 Medidas descriptivas. Estos índices permiten caracterizar a las distribuciones de frecuencias para poder hacer una interpretación acertada de la misma. representar de la mejor forma a los datos de los cuales proviene. Esta representación puede lograrse de varias formas. Media Aritmética En lo general, todas estas medidas pueden ser calculadas para datos no agrupados y para datos agrupados. Cuando se datos agrupados se trata, se utiliza la información contenida en la distribución de frecuencias lo que realmente implica una simplificación, ya que se considera que todos los datos que se ubican en un mismo intervalo de clase (frecuencia) son iguales y se ubican sobre la marca de clase respectiva. Naturalmente, esta simplificación origina un error en los cálculos, mismo que no se considera significativo y que puede reducirse utilizando intervalos de confianza angostos. Medidas de Tendencia Central. Son aquellas medidas que nos proporcionan un dato que, con ciertos matices, puede considerarse representante de los n datos obtenidos del muestreo. Media. Tradicionalmente se considera a la media como un promedio aritmético de n datos. En realidad es más que esto. La media pretende Probabilidad y Estadística Noviembre 2009 n X = Para datos no agrupados: ∑X i =1 i n donde n es el número total de datos. Para datos agrupados: k X= ∑F T i i =1 n i k = ∑ F 'i Ti i =1 Donde: Fi es la frecuencia de la i-ésima clase Ti es la marca de clase de la i-ésima clase F 'i es la frecuencia relativa de la i-ésima clase k representa el total de clases de la distribución M.A. Víctor Damián Pinilla Morán. 9 Como dato representante de una muestra, la media aritmética presenta el problema de los datos ubicados en los extremos de la muestra, los más pequeños y los más grandes, que en la generalidad suelen ser pocos, sesgan o inducen un error en el resultado. La media aritmética nunca debe utilizarse por sí sola para hacer alguna conclusión sobre la muestra, resulta conveniente acompañarla de alguna medida de dispersión como se verá más adelante. Media Ponderada. A diferencia del promedio aritmético, el promedio ponderado toma en cuenta la existencia de los elementos además de su valor a promediar. Es decir, al tomar en cuenta el número de elementos repetidos minimiza la posibilidad de uno o dos datos extremos modifiquen dramáticamente el resultado. La media ponderada corresponde directamente al valor esperado o esperanza matemática estudiado en Probabilidad. Para calcular la media ponderada de n datos (datos no agrupados) es necesario contar todos ellos para establecer cuantos de ellos se repiten. En la práctica, esto implica ordenarlos, motivo por el cual no se acostumbra su cálculo en esta modalidad. Por otra parte, como puede observarse, la media ponderada para datos agrupados coincide con la media aritmética para datos agrupados, si consideramos un punto de vista frecuentista de la probabilidad, ya que la frecuencia de la clase i-ésima dividida entre el número total de datos es la probabilidad de que un dato pertenezca a la clase respectiva, mientras que la marca de clase representa el valor específico del dato. k X= ∑F T i i =1 i n k = ∑ F 'i Ti i =1 Media geométrica. En la práctica suele obtenerse a través de logaritmos. Log (G ) = 1 [Log ( X 1 ) + Log ( X 2 ) + Log ( X 3 ) + ... + Log ( X n )] n Media armónica. La media armónica de una serie de números es el recíproco de la media aritmética de los recíprocos de los números. X= 1 n 1 1 ∑ n i =1 X i = n n 1 ∑n i =1 en la práctica se utiliza: n 1 = X 1 ∑X i =1 i n Mediana. Es el dato que divide exactamente a la mitad a la muestra. n impar n par Se muestran los dos posibles casos de la mediana con datos no agrupados, en el primer caso la muestra está compuesta por un número non de observaciones. La mediana es el dato que se encuentra exactamente a la mitad de la muestra ordenada. (de menor a mayor por ejemplo); esto se puede entender considerando una balanza que contiene los datos; para que esté equilibrada debe existir el mismo número de datos de cada lado, por lo que la mediana será la que quede situada en el centro de la balanza. X = n X 1 ⋅ X 2 ⋅ X 3 ⋅ ... ⋅ X n Probabilidad y Estadística Noviembre 2009 M.A. Víctor Damián Pinilla Morán. 10 El segundo caso cuando la muestra está compuesta por un número par de observaciones. En este caso, la mediana es el promedio de los dos valores centrales. Para su cálculo como dato no agrupado es necesario ordenar los datos en forma descendente o ascendente y atender la siguiente regla, de acuerdo a la naturaleza del número total de datos n: Si n es impar: med = X n +1 2 Xn +Xn Si n es par: med = 2 2 +1 2 Como puede observarse, cuando el número de elementos es par no hay un valor que se encuentre exactamente a la mitad de la muestra; en este caso se pueden promediar los dos valores más cercanos a la mitad. Para nuestro caso, n es par e igual a 80. De tal forma: X 80 + X 80 med = 2 2 2 +1 = X 40 + X 41 51.1 + 51.1 = = 51.1 2 2 Para su cálculo como dato agrupado, la mediana se obtiene determinando cual es la clase que incluye a la mediana, la cual se distingue porque tiene una frecuencia acumulada relativa mayor o igual a 0.5 (50% de los datos). Para obtener una expresión que permita su cálculo, a partir de la ojiva de frecuencias acumuladas relativas se puede aproximar su mediana trazando una línea horizontal a partir de la ordenada 0.5 (o 50%) hasta cortar la gráfica y en dicho punto localizar el correspondiente en el eje de las abscisas. Fac w n n 2 Fk F’ack-1 Linfk Probabilidad y Estadística Noviembre 2009 Med Lsupk M.A. Víctor Damián Pinilla Morán. 11 A partir de una interpolación lineal, se utiliza la ecuación de la recta: y = y0 + m( x − x0 ) de acuerdo con la anterior figura: y = 0.5 y = F ' ack −1 x = med x 0 = Liminf m= f 'k w donde: k : Clase donde se ubica a la mediana F ' ack : Frecuencia acumulada relativa de la clase anterior a la en que se encuentra la mediana f 'k : frecuencia de la clase donde se ubica la median w : ancho del intervalo Liminf : Límite inferior de la clase donde se ubica la mediana. Sustituyendo los valores: 0.5 = F ' ac k −1 + f 'k (me − Lminf ) w para nuestro ejemplo, la clase mediana (o la que incluye a la mediana) es la clase 4, ya que su frecuencia acumulada relativa es de 0.51. De tal forma: ⎛ 80 ⎞ ⎜ − 23 ⎟ ⎟(0.51) = 51.11 med = 50.63 + ⎜ 2 ⎜ 18 ⎟ ⎜ ⎟ ⎝ ⎠ Moda. Es el elemento de la muestra que más se repite. Una muestra puede tener una o más modas. Cuando todos los elementos de la muestra son diferentes, no tiene sentido hablar de ella. Para datos no agrupados, la moda se determina por inspección, mientras que para datos agrupados se puede aproximar con la marca de clase del intervalo de la clase modal, que es la que tenga la mayor frecuencia. En algunos casos se puede mejorar la aproximación considerando que la moda es la abscisa del máximo de una curva hipotética que pasa por las marcas de clase, como se observa: R D1 E S P D2 T despejando: med = Liminf F w (0.5 − F ' ac k −1 ) + f 'k Q No obstante, por motivos generalistas, resulta mejor expresar a la mediana en función de frecuencias absolutas en lugar de relativas: X Linf med = Liminf Lsup ⎛n ⎞ ⎜ − Fac k −1 ⎟ ⎟w +⎜ 2 ⎜ ⎟ Fk ⎜ ⎟ ⎝ ⎠ Probabilidad y Estadística Noviembre 2009 mod M.A. Víctor Damián Pinilla Morán. 12 Medidas de dispersión. Estas medidas reflejan la separación o alejamiento de los elementos de una muestra. Estas medidas deben acompañar a las medidas de tendencia central, particularmente a la media, para evitar los efectos que los datos extremos tienen sobre ellas. De acuerdo con lo anterior, se puede considerar que la moda debe pertenecer al intervalo de clase con máxima frecuencia, pero proporcionalmente más cercano al intervalo adyacente que le siga en frecuencia, de esta manera se puede plantear la proporción (triángulos semejantes): EP PF = RQ ST ⎯ ⎯→ La medida de dispersión más sencilla es el Rango, amplitud o recorrido, que como ya se mencionó es la diferencia entre el dato mayor y del menor. Mod − Linf Lsup − Mod = D1 D2 (Mod − Linf )D2 = (Lsup − Mod )D1 Varianza. Tal y como la define la probabilidad, la varianza de una variable aleatoria es el segundo momento de la misma con respecto a la media. Asimismo, se interpreta de la misma forma, como un promedio de las distancias de cada dato hacia la media. Mod (D1 − D2 ) = Linf D2 + Lsup D1 Si: w = Lsup − Linf ⎯ ⎯→ Lsup = Linf + w sustituyendo Momentos Mod (D1 − D2 ) = Linf D2 + (Linf + w)D1 mk = L (D + D2 ) + wD1 Mod = inf 1 D1 + D2 Mod = Linf para mk = agrupados: para datos 1 k Fi (Ti − X ) ∑ n i =1 agrupados: r 3 Para datos no agrupados la varianza se define como: donde: ∑ (X 2 −X) n Linf : Límite inferior de la clase modal w : ancho del intervalo D1 :diferencia de las frecuencias de la σ = 2 clase modal y la premodal D2 : diferencia de las frecuencias de la clase modal y la postmodal i =1 i n Esta fórmula puede expresarse de una forma más sencilla a partir del desarrollo del binomio al cuadrado: para nuestro ejemplo, la clase modal es la número 6. Dado lo anterior: ∑ (X 2 n σ = 2 ⎛ 4 ⎞ mod = 51.65 + ⎜ ⎟(0.51) = 51.7 ⎝ 4 + 18 ⎠ σ = 2 A partir de la inspección de la muestra, el dato que más se repite es 51.1 con siete repeticiones. no 1 ∑ (X i − X ) n i =1 Momentos ⎛ D1 ⎞ ⎟⎟ w + ⎜⎜ ⎝ D1 + D2 ⎠ datos k n i =1 i −X) = n n n i =1 i =1 ∑ (X n i =1 ∑ X i2 − 2 X ∑ X i + n X n 2 i − 2X i X + X 2 ) n n 2 1 n = ∑ X i2 − 2 X n i =1 ∑X i =1 3 En este caso r representa el total de clases, haciendo una distinción con k, que es el orden del momento. Probabilidad y Estadística Noviembre 2009 M.A. Víctor Damián Pinilla Morán. 13 n i +X 2 n ya que X = ∑X i =1 i sustituyendo n σ2 = 1 2 2 X i2 − 2 X − X ∑ n Desviación media. Ciertos autores opinan que para obtener el promedio de las distancias de cada dato con respecto a la media debe obtenerse el valor absoluto de la distancia entre ambos puntos y después obtenerse su promedio. De tal forma, la desviación media (para datos no agrupados) se define como: n σ2 = n 1 2 X i2 − X ∑ n i =1 Para datos agrupados: Desviación Media = ∑X i =1 Utilizando esta última expresión, para nuestro ejemplo la varianza es de: σ 2 = 0.6564 Por otra parte, utilizando la fórmula para datos no agrupados: σ 2 = 0.6308 Desviación estándar. Es fácil de percibir, a partir de un análisis dimensional, que la varianza posee las unidades de la variable muestreada elevada al cuadrado. Esta situación no permite una rápida visualización o interpretación de la dispersión de los datos. En virtud de lo anterior, la desviación estándar es la raíz cuadrada de la varianza: σ = σ2 La desviación estándar también es conocida como desviación típica o error estándar. Probabilidad y Estadística Noviembre 2009 −X n Asimismo, algunos autores utilizan como referencia a la mediana en lugar de la media. n r 1 r 2 2 σ 2 = ∑ Fi (Ti − X ) = ∑ F ' i (Ti − X ) n i =1 i =1 i Desviación Media = ∑X i =1 − med i n Es necesario comentar que debido a las complejidades que implica el manejo del valor absoluto, estos conceptos no son muy socorridos. Asimetría. Esta medida, también llamada sesgo, tiene como finalidad mostrar hacia qué lado de le media se ubican más datos. Corresponde al tercer momento con respecto a la media determinar esta situación. No obstante, en situación similar a lo que ocurre con la varianza, el tercer momento posee las unidades de la variable muestreada elevada al cubo. Con el fin de volver adimensional al tercer momento, se define al coeficiente de asimetría de la siguiente forma: α3 = ( m3 m2 = m3 ) (σ ) 3 3 2 2 Este coeficiente tiene como referencia al valor cero. Si: α 3 = 0 La distribución es simétrica, es decir, existe la misma cantidad de datos a ambos lados de la media. M.A. Víctor Damián Pinilla Morán. 14 Esto implica que debe cumplirse la siguiente relación: X = med = mod Si: α 3 < 0 La distribución es asimétrica negativa, es decir, existen más datos a derecha de la media. Datos no agrupados: α 3 = − 0.28 Datos agrupados: α 3 = − 0.2382 Implica que se trata de una curva asimétrica negativa. Comprobando lo anterior: X = 51.0571 med = 51.1117 mod = 51.7423 Esto implica que debe cumplirse la siguiente relación: mod = med = X mod < med < X Si: α 3 > 0 La distribución es asimétrica positiva, es decir, existen más datos a izquierda de la media. Esto implica que debe cumplirse la siguiente relación: X > med > mod α3 = 0 Apuntamiento. Corresponde al cuarto momento con respecto a la media identificar a una medida que auxiliar directamente a las medidas de dispersión. El apuntamiento o curtosis4 detalla lo puntiagudo o aplastado de una distribución. Una distribución puntiaguda implica que los datos están más cercanos a la media lo que a su vez arroja una varianza pequeña. En caso contrario, una distribución aplastada implica que los datos se alejan de la media, lo que implica una varianza grande. El cuarto momento con respecto a la media posee las unidades de la variable muestreada elevadas a la cuarta potencia. Para mejorar una posible interpretación, se define al coeficiente de apuntamiento o coeficiente de curtosis: α3 > 0 α3 < 0 α4 = m4 (m2 ) 2 = m4 (σ ) 2 2 El valor de referencia de este coeficiente es tres. Algunos autores, para homologar el uso de este coeficiente con el de simetría, disminuyen en tres unidades el valor obtenido y así logran que el valor de referencia sea cero. α4 = m4 (m2 ) 2 −3= m4 (σ ) 2 2 −3 Para nuestro ejemplo: 4 Probabilidad y Estadística Noviembre 2009 Kurtosis en Inglés M.A. Víctor Damián Pinilla Morán. 15 El lector deberá estar atento a esta situación, ya que la gran mayoría de los programas de computadoras realizan su comparación contra el cero. La interpretación es la siguiente: Si α 4 = 0 (o tres), se trata de una distribución mesocúrtica. Si α 4 > 0 (o tres), se trata de una distribución Leptocúrtica (o puntiaguda). Si α 4 < 0 (o tres), se trata de una distribución Platicúrtica (o aplastada). Fractiles. Si una serie de datos que se colocan en orden de magnitud, el valor medio (o la media aritmética de los dos valores medios) que divide al conjunto de datos en dos partes iguales es la mediana. Por extensión, de esta idea se puede pensar en aquellos valores que dividen a los datos en cuatro partes iguales. Estos valores se llaman primero, segundo y tercer cuartíl, respectivamente; el segundo cuartíl corresponde a la mediana de la distribución. Análogamente, los valores que dividen a la distribución en diez partes iguales se denominan deciles, mientras que aquellos que lo hacen en cien partes iguales se llaman percentiles. El quinto decíl y el quincuagésimo percentil corresponden a la mediana. Para nuestro ejemplo: α = − 0.1121 4 Para datos no agrupados: Para datos agrupados: α = − 0.4986 El cálculo de los fractiles es bajo el mismo procedimiento utilizado para la mediana. 4 ⎛ n ⋅ fracción − Fac k −1 ⎞ ⎟⎟ w Fractil = Liminf + ⎜⎜ Fk ⎝ ⎠ donde: Probabilidad y Estadística Noviembre 2009 M.A. Víctor Damián Pinilla Morán. 16 Liminf : n: fracción : Fack −1 : Fk : w: Límite inferior de la clase en que se ubica el fractil buscado. Total de datos de la distribución. Porcentaje de la muestra buscado. Frecuencia acumulada de la clase anterior a aquella en que se ubica el fractil buscado. Frecuencia de la clase en la cual se ubica el fractil buscado. Ancho del intervalo. Asimismo, si se restan el tercer y primer cuartíl estaremos acotando el 50% de la distribución, pero centrada en torno a la mediana. A esta distancia se le conoce como distancia intercuartílica. Análogamente, a la diferencia entre el noveno y el primer decíl se le conoce como distancia interdecílica y acta al 80% de la población centrada en torno a la mediana. Para el ejemplo desarrollado, los cálculos son los siguientes: Primer cuartíl (ubicado en la tercera clase) El procedimiento es análogo al utilizado para calcular la mediana. Con auxilio de la frecuencia acumulada relativa debe ubicarse la clase en la cual se ubica el fractil buscado. Por ejemplo, si de desea calcular el primer cuartíl debe ubicarse la clase que incluye a la frecuencia acumulada relativa al 0.25 o 25%; para el tercer cuartíl corresponde al 0.75 o 75% de la distribución; para noveno decíl ocurre a .90 o 90%. La fracción corresponde a la parte de la distribución en la que se desea dividir, por ejemplo, para la mediana o mitad de la distribución la fracción fue primer cuartíl será 1 4 1 o 0.5, para el 2 o 0.25 y Una forma de interpretar la información que nos entregan los fractiles consiste en ubicar los límites que comprenden las fronteras mismas que son los fractiles. Por ejemplo, la mediana nos ubica a la frontera que divide en dos partes iguales a la muestra. Pero además implica que la primer parte de la muestra inicia en el límite inferior de la primera clase y concluye en la mediana, así como que la segunda parte inicia en la mediana y concluye en el límite superior del último intervalo de clase. Noviembre 2009 Tercer cuartíl (ubicado en la sexta clase) ⎡ (80)(.75) − 57 ⎤ Q3 = 51.65 + ⎢ ⎥⎦ (0.51) = 51.7265 20 ⎣ Distancia intercuartílica: 51.7265 – 50.5025 = 1.224 Primer decíl (ubicado en la segunda clase) así consecutivamente. Probabilidad y Estadística ⎡ (80 )(.25) − 11⎤ Q1 = 50.12 + ⎢ ⎥⎦ (0.51) = 50.5025 12 ⎣ ⎡ (80(0.1) − 5) ⎤ D1 = 49.61 + ⎢ ⎥⎦ (0.51) = 49.8650 6 ⎣ Noveno decíl (ubicado en la sexta clase) ⎡ (80 )(0.9 ) − 57 ⎤ D9 = 51.56 + ⎢ ⎥⎦ (0.51) = 52.0325 20 ⎣ Distancia interdecílica: 52.0325 – 49.8650 = 2.1675 M.A. Víctor Damián Pinilla Morán. 17 Como conclusión de este capítulo, se muestra una tabla resumen con las medidas descriptivas del ejemplo que se ha desarrollado a lo largo del mismo. Datos no agrupados n Rango Sturges n 80 4.0 7.32 8.94 51.0625 media= mediana= moda= Varianza= 0.6308 Desv. Est.= 0.7943 Asimetría= -0.2800 Apuntamiento= -0.1121 Primer cuartil= 50.4750 Tercer cuartil= 51.7000 Primer decil= 49.9000 Noveno decil= 51.9 Datos Agrupados media= mediana= moda= Varianza= Desv. Est.= Asimetría= Apuntamiento= Primer cuartil= Tercer cuartil= Primer decil= Noveno decil= 51.0571 51.1117 51.7427 0.6564 0.8102 -0.2382 -0.4986 50.5025 51.7265 49.8650 52.0325 Bibliografía Taro Yamane, Estadística, Editorial Harla, México 1999. Spiegel, Estadística Serie Schaum, Edit. Mc. Graw Hill, México 1999. Frontana et al, Apuntes de Probabilidad y Estadística, Facultad de Ingeniería, México 1985 Berk & Carey, Análisis de datos con Microsoft Excel, Edit. Thompson Learning, México 2001 Canavos, Probabilidad y Estadística, Mc. Graw Hill, México 1994. Captura y Edición: M.A. María Torres Hernández. Probabilidad y Estadística Noviembre 2009 M.A. Víctor Damián Pinilla Morán. 18