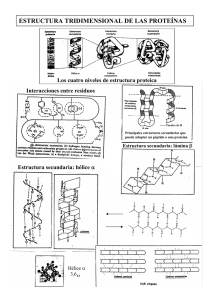
Identificación y caracterización estructural del gen ARGONAUTA1
Anuncio

UNIVERSIDAD VERACRUZANA FACULTAD DE QUÍMICA FARMACÉUTICA BIOLÓGICA Identificación y caracterización estructural del gen ARGONAUTA1 de Marchantia polymorpha Tesis Que para acreditar la Experiencia Recepcional de la Licenciatura de Química Farmacéutica Biológica Presenta Adolfo Aguilar Cruz Director Dr. Mario Alberto Arteaga Vázquez Co-Director Dr. Ángel Rafael Trigos Landa Xalapa de Enríquez, Ver Enero, 2015 I II Laboratorio de Epigenética y Biología del Desarrollo Este trabajo se realizó en el laboratorio de Epigenética y Biología del Desarrollo, del Instituto de Biotecnología y Ecología Aplicada (INBIOTECA) de la Universidad Veracruzana. Bajo la dirección del Dr. Mario Alberto Arteaga Vázquez y III la Co-Dirección del Dr. Ángel Rafael Trigos Landa. ÍNDICE Índice de figuras ............................................................................................................ VII Índice de tablas. ............................................................................................................. IX Listado de abreviaturas ................................................................................................... X RESUMEN..................................................................................................................... XII I. INTRODUCCIÓN .......................................................................................................... 1 II. ANTECEDENTES ....................................................................................................... 3 2.1. Marchantia polymorpha, un modelo emergente para estudios de biología molecular en las plantas. ................................................................................................................. 3 2.2. Descubrimiento del silenciamiento de genes mediado por RNA. ............................. 7 2.3. RNAs pequeños en las plantas. ............................................................................... 8 2.3.1. Diversidad de RNAs pequeños en las plantas ................................................... 8 2.4. Silenciamiento génico mediado por miRNAs en las plantas ..................................... 9 2.4.1. ¿Qué son los miRNAs? ...................................................................................... 9 2.4.2. Biogénesis de los miRNAs en las plantas. ....................................................... 10 2.4.3. Mecanismo del silenciamiento génico mediado por miRNAs en las plantas. ... 12 2.5. La familia de proteínas ARGONAUTA. ................................................................... 14 2.5.1. Características estructurales de las proteínas ARGONAUTA. ......................... 16 2.5.2. Mecanismo de reconocimiento y escisión del blanco por las proteínas ARGONAUTA............................................................................................................. 18 2.6. El clado de la familia de proteínas ARGONAUTA en Arabidopsis. ........................ 21 2.6.1. Especialización de las proteínas AGO de Arabidopsis por clases específicas de RNAs pequeños. ........................................................................................................ 22 2.7. La proteína ARGONAUTA1 de Arabidopsis es efectora del silenciamiento génico mediado por microRNAs................................................................................................ 24 III. PLANTEAMIENTO DEL PROBLEMA....................................................................... 28 IV. HIPÓTESIS .............................................................................................................. 29 V. OBJETIVOS .............................................................................................................. 29 Objetivo general ............................................................................................................ 29 Objetivos particulares .................................................................................................... 29 VI. MATERIAL Y MÉTODOS ......................................................................................... 31 6.1. Búsqueda e identificación del gen ARGONAUTA1 de M. polymorpha................ 31 IV 6.2. Material vegetal y condiciones de crecimiento. ................................................... 31 6.3. Colecta de tejido de M. polymorpha para obtener el perfil de expresión del gen MpAGO1. ................................................................................................................... 32 6.4. Diseño de iniciadores para la amplificación de la secuencia codificante (CDS) y una región del extremo 3’UTR de MpAGO1 .............................................................. 32 6.5. Aislamiento de RNA total de M. polymorpha. ...................................................... 32 6.6. Transcripción reversa acoplada a la reacción en cadena de la polimerasa (RTPCR). ......................................................................................................................... 33 6.6.1. Trascripción Reversa (RT). ........................................................................... 33 6.6.2. Reacción en cadena de la polimerasa (PCR). .............................................. 34 6.7. Reacción de ligación. .......................................................................................... 34 6.8. Transformación de células electrocompetentes. ................................................. 35 6.9. Escrutinio de clonas. ........................................................................................... 35 6.10. RT-PCR para el perfil de expresión de MpAGO1. ............................................. 36 6.11. Análisis de la relación filogenética de MpAGO1 y las proteínas AGO1 de las plantas terrestres........................................................................................................ 36 6.12. Determinación de los dominios estructurales de la proteína MpAGO1. ............ 37 VII. RESULTADOS ........................................................................................................ 38 7.1. Identificación del gen ARGONAUTA1 de M. polymorpha. ................................. 38 7.2. Oligonucleótidos empleados para la amplificación de la secuencia codificante y una región del extremo 3’UTR de MpAGO1. ............................................................. 38 7.3. Aislamiento de RNA total de M. polymorpha. ...................................................... 39 7.4. Amplificación de la secuencia codificante de MpAGO1 (CDSMpAGO1) por RTPCR............................................................................................................................ 39 7.4. Clonación del CDS de MpAGO1. ........................................................................ 40 7.5. Caracterización de las clonas recombinantes ..................................................... 42 7.6. Perfil de expresión de MpAGO1 en diferentes tejidos. ........................................ 49 7.7. Estructura del gen MpAGO1 ............................................................................... 50 7.8. Análisis filogenético de MpAGO1 y sus homólogos en las plantas terrestres. .... 52 7.9. Análisis de los dominios estructurales de la proteína MpAGO1 y sus homólogos en las plantas terrestres. ............................................................................................ 54 7.10. Conservación de la arquitectura de los dominios estructurales entre MpAGO1 y sus homólogos en las plantas terrestres. ................................................................... 55 V 7.11. Modelo de la estructura tridimensional de MpAGO1. ........................................ 57 VIII. DISCUSIÓN ........................................................................................................... 64 IX. CONCLUSIONES .................................................................................................... 66 XI. ANEXOS .................................................................................................................. 78 Anexo 1. Concentración de las muestra de RNA de M. polymorpha.......................... 78 Anexo 2. Purificación de productos de PCR usando el QIAquick PCR Purification Kit (QIAGEN). .................................................................................................................. 79 Anexo 3. Características y mapa del vector pGEM ®-T Easy (Promega). ................. 80 Anexo 4. Preparación de células electrocompetentes................................................ 81 Anexo 5. Preparación de placas con medio LB/Agar/Ampicilina/IPTG/X-gal. ............ 82 Anexo 6. Protocolo de ligación usando el vector pGEM ®-T Easy (Promega). .......... 83 Anexo 7. Selección de clonas recombinantes (escrutinio azul/blanco). ..................... 84 Anexo 8. Aislamiento de DNA plasmídico por el método de lisis alcalina. ................. 85 Anexo 9. Purificación de plásmidos usando el QIAprep Spin Miniprep Kit. ................ 86 Anexo 10. Especies a las que pertenece cada una de las secuencias de aminoácidos empleadas en los análisis bioinformáticos. ................................................................ 87 VI Índice de figuras Figura 1. Marchantia polymorpha……………………………………………...…………...….4 Figura 2. Estructuras reproductivas de M. polymorpha……………………………………..5 Figura 3. Eventos principales en la biogénesis de los miRNAs en las plantas...……….13 Figura 4. Mecanismo del silenciamiento de genes mediado por miRNA en las plantas.14 Figura 5. Estructura general de las proteínas ARGONAUTA…………………………....16 Figura 6. Esquema del reclutamiento y catálisis de AGO…………………………………18 Figura 7. Participación del dominio N en el desenrollamiento del dúplex de RNA pequeño y en la escisión del RNA mensajero………………………………………………20 Figura 8. Árbol filogenético de las proteínas AGO de Arabidopsis……………………….21 Figura 9. Niveles de regulación de la expresión génica y proteínas AGO asociadas a cada uno………………………………………………………………………………………...23 Figura 10. Fenotipos de las muntantes hyl1, hen1 y ago1 de Arabidopsis……………..25 Figura 11. FLAG-AGO1 rescata el fenotipo silvestre de la mutante ago1-36 de Arabidopsis……………………………………………………………………………………...26 Figura 12. La proteína AGO1 inicia la ruta de biogénesis de ta-siRNAs………………...27 Figura 13. Análisis electroforético del RNA total extraído de tejido de M. polymorpha..39 Figura 14. Análisis electroforético de los productos de amplificación del CDS de MpAGO1………………………………………………………………………………………...40 Figura 15. Esquema de la clonación del CDS de MpAGO1……………………………….41 Figura 16. Mapas de la construcción pGEM-CDSMpAGO1………………………………42 Figura 17. Mapa de restricción de la construcción pGEM-CDSMpAGO1……………….43 Figura 18. DNA plasmídico extraído de las colonias transformantes…………………….44 Figura 19. Plásmidos digeridos con la enzima EcoRI……………………………………...45 Figura 20. Caracterización de la construcción pGEM-CDSMpAGO1…………………….45 Figura 21. Productos de PCR de los oligonucleótidos para secuenciación del CDSMpAGO1…………………………………………………………………………………..48 VII Figura 22. Perfil de expresión de MpAGO1 en diferentes tejidos………………………..49 Figura 23. Estructura genómica de MpAGO1……………………………………………….50 Figura 24. Alineamiento de la región correspondiente al dominio PIWI, el cual actúa como centro catalítico en la proteína AGO1………………………………………………...51 Figura 25. Análisis filogenético de MpAGO1 y sus homólogos en diversas especies de plantas terrestres……………………………………………………………………………….53 Figura 26. Dominios estructurales de MpAGO1…………………………………………….55 Figura 27. Organización y conservación de los dominios estructurales de MpAGO1 y sus homólogos en las plantas terrestres…………………………………………………….56 Figura 28. Representación esquemática de los dominios de MpAGO1, AtAGO1, AtAGO4, HsAGO2 y SpAGO1………………………………………………………………..57 Figura 29. Esquema y estructura proteica de MpAGO1…………………………………...59 Figura 30. Acercamiento a los residuos catalíticos en la estructura proteica de MpAGO1……………………………………………………………………………………......60 Figura 31. Estructuras de MpAGO1 y AtAGO1……………………………………………..61 Fugura 32. Superimposición de las estructuras de MpAGO1 y AtAGO1………………..62 Figura 33. Superimposición de los residuos catalíticos de MpAGO1 y AtAGO1……….63 Figura 34. Mapa del vector pGEM ®-T Easy…..……………………………………………80 Figura 35. Esquema del procedimiento del escrutinio azul-blanco……………………….84 VIII Índice de tablas. Tabla 1. Características de los oligonucleótidos para la amplificación del CDS del gen MpAGO1 y la región 3’UTR…………………………………………………………………...38 Tabla 2. Concentración de los plásmidos extraídos………………………………………..46 Tabla 3. Secuencia de los oligonucleótidos empleados para la secuenciación del CDSMpAGO1…………………………………………………………………………………..47 Tabla 4. Resumen de las características del gen MpAGO1 y su proteína………………58 Tabla 5. Concentración de las muestra de RNA de M. polymorpha……………………..78 Tabla 6. . Componentes de la reacción de ligación con pGEM ®-T Easy……………….83 IX Listado de abreviaturas a.a: Aminoácidos AG: Gen AGAMOUS AG: Proteína AGAMOUS AGO: Proteína Argonauta ago1-26: Mutante 26 del gen AGO1 ago1-27: Mutante 27 del gen AGO1 ago1-3: Mutante 3 del gen AGO1 AMP1: Gen ALTERED MERISTEM PROGRAM1 AMP1: Proteína ALTERED MERISTEM PROGRAM1 AP1: Gen APETALA1 AP1: Proteína APETALA1 ARF: Factor de transcripción de respuesta a auxinas AtAGO1: Gen Argonauta1 de A. thaliana AtAGO1: Proteína Argonauta 1 de A. thaliana cDNA: DNA complementario CDS: Secuencia del DNA codificante CHS: Gen Chalcona sintasa CHS: Proteína Chalcona sintasa CLF: Gen CURLYLEAF CLF: Proteína CURLYLEAF DCL: Dicer-Like DCL1: Gen Dicer-Like1 DCL1: Proteína Dicer-Like1 DNA: Ácido Desoxirribonucleico DUF1785: Dominio de función desconocida 1785 FLAG-AGO1: Proteína AGO1 fusionada con el octapéptido FLAG hc-siRNA: Ácidos nucleicos interferentes pequeños provenientes de regiones heterocromáticas HEN1: Gen HUA ENHANCER1 HEN1: Proteína HUA ENHANCER1 hen1-4: Mutante 4 del gen HEN1 HESO: HEN1 SUPPRESSOR1 hpRNA: Ácidos ribonucleicos provenientes de estructura de tallo y asa HST: Gen HASTY HST: Proteína HASTY HYL1: Gen HYPONASTIC LEAVES 1 HYL1: Proteína HYPONASTIC LEAVES 1 hyl1-2: Mutante 2 del gen HYL1 IPTG: isopropil-β-D-1tiogalactopiranósido Kb: 1000 pares de bases kDa: kiloDalton LFY: Gen LEAFY LFY: Proteína LEAFY MID: Middle domain miRNAs: microRNAs MpAGO1: Gen Argonauta1 de M. polymorpha MpAGO1: Proteína Argonauta1 de M. polymorpha ng: nanogramos nt: nucleótidos ON: Toda la noche (del inglés, overnight) PAZ: PIWI/Argonaute/Zwill pb: pares de bases PHV: Gen PHAVOLUTA PHV: Proteína PHAVOLUTA PIWI: P-element induced wimpy testis Pol II: RNA polimerasa II PTGS: Silenciamiento Génico Posttranscripcional RDR: RNA polimerasa dependiente de RNA RISC: Complejo de Silenciamiento Inducido por RNA X RNA: Ácido Ribonucleico RNAm: Ácido Ribonucleico mensajero rpm: Revoluciones por minuto SDN1: Small RNA Degrading Nuclease1 sdRNA: RNA de doble cadena SE: SERRATE siRNA: Ácidos ribonucleicos interferentes pequeños sRNA: RNA pequeño TAS1: precursor del ta-siRNA 1 TAS2: precursor del ta-siRNA 2 ta-siRNA: RNA pequeño interferente que actúa en trans (del inglés transacting siRNA) TF: Factores de transcripción TGH: TOUGH X-gal: 5-bromo-4-cloro-3-indolil-β-Dgalactopiranósido XI RESUMEN Las proteínas ARGONAUTA (AGO) juegan un papel importante en la regulación de la expresión de genes dirigida por RNAs pequeños no codificantes y se encuentran conservadas en todos los dominios de la vida (arqueobacterias, bacterias y eucariotas). Los microRNAs (miRNAs) son moléculas de RNAs pequeños de 20 a 21 nucleótidos (nt) presentes en los eucariotas que regulan postranscripcionalmente la expresión genética mediante la degradación o la atenuación traduccional de los RNA mensajeros que muestran complementariedad con el miRNA. La función de los miRNAs es esencial en las plantas, y prácticamente todos los programas de desarrollo, las respuestas fisiológicas y las respuestas ambientales (bióticas y abióticas) se encuentran influenciados por al menos un miRNA. Los miRNAs ejercen su función a través de la formación de un complejo ribonucleoprotéico con la proteína ARGONAUTA1 (AGO1). Marchantia polymorpha es una hepática, de la familia de las briófitas que es descendiente directo de las primeras plantas que colonizaron los ambientes terrestres. Para tratar de entender la evolución de la maquinaria de regulación mediada por miRNAs, en el presente trabajo nos dimos a la tarea de identificar el gen homólogo a AGO1 en M. polymorpha (MpAGO1). Nuestros resultados muestran que el gen MpAGO1 tiene una longitud de 12.3 kilobases (kb) y se encuentra constituido por 22 intrones y 22 exones. La secuencia codificante (CDS) tiene una longitud de 3,330 pares de bases (pb), codifica una proteína de 1,109 aminoácidos con un peso molecular de 93.7 kDa y un punto isoeléctrico de 9.6. El gen MpAGO1 se expresa de manera constitutiva en tejido vegetativo y reproductivo. Mediante análisis de genómica comparativa y análisis in silico de la estructura tridimensional de la proteína MpAGO1 encontramos que tanto los dominios característicos PAZ y PIWI como la triada de residuos catalíticos Asp-Asp-His (DDH) presente en el dominio PIWI se encuentran conservados, lo que sugiere fuertemente que MpAGO1 codifica una proteína con capacidad de escisión. Nuestros resultados muestran que a pesar de la gran diversificación funcional de las proteínas AGO en las plantas terrestres, existen genes que se mantienen ultraconservados desde el linaje de las plantas más basales hasta las angiospermas, como es el caso del gen MpAGO1 XII I. INTRODUCCIÓN Las proteínas ARGONAUTA (AGO) desempeñan una función esencial en la regulación transcripcional y postranscripcional de la expresión genética mediada por RNAs pequeños no codificantes (small RNAs o sRNAs, por sus siglas en inglés) (Meister, 2013). Estas proteínas se encuentran evolutivamente conservadas a través de todos los dominios de la vida (Schirle y MacRae, 2012a; Swarts et al., 2014). Los miembros de la familia AGO se definen por la presencia de dos dominios principales característicos: el dominio PAZ y el dominio PIWI (Cerutti et al., 2000). El miembro fundador de la familia AGO fue identificado en la planta modelo Arabidopsis thaliana (Arabidopsis) (Bohmert et al., 1998). El número de loci de la familia AGO varia en los organismos, el nematodo Caenorhabditis elegans posee 27 miembros (Yigit et al., 2006), los humanos poseen 4 (Carmell et al., 2002) y Drosophila melanogaster dos (Hutvanger y Simard, 2008). El genoma de Arabidopsis posee 10 proteínas AGO (Morel et al., 2002) que se pueden clasificar en 3 diferentes grupos o clados con base en el tipo de sRNA que reclutan y el tipo de regulación (transcripcional o postranscripcional) en la que participan (Mallory y Vaucheret, 2010; Wei et al., 2012). La unión de un AGO con un sRNA específico, forma el núcleo del complejo riboprotéico denominado RNA Induced Silencing Complex (RISC, por sus siglas en inglés) (Mi et al., 2008). El complejo RISC emplea la secuencia del sRNA como una guía para identificar a sus blancos, que pueden ser otros RNAs no codificantes, RNAs mensajeros (RNAm) o DNA (Hannon, 2002). La proteína ARGONAUTA1 (AGO1) recluta a un grupo particular de sRNAs denominados microRNAs (miRNAs) (Vaucheret et al., 2004; Baumberger y Baulcombe, 2005). Los miRNAs son sRNAs de 20 a 21 nt de longitud que se generan a partir de un transcrito primario (pri-miRNA) poliadenilado que no es traducido y que tiene la capacidad de adquirir una estructura secundaria tipo tallo-asa o pasador que por la actividad de una RNasa tipo III denominada DICER-LIKE1 (DCL1) libera un precursor (pre-miRNA) de menor tamaño. El pre-miRNA es procesado también por DCL1 para liberar un dúplex que contiene al miRNA maduro y a un sRNA complementario 1 denominado miRNA* (miRNA estrella). El miRNA maduro que es reclutado por AGO1 reconoce a su blanco con base en la complementariedad de secuencia entre el RNAm y el miRNA (Jones-Rhoades et al., 2006; Mallory y Vaucheret, 2006; Rogers y Chen, 2013). Por lo general, si el apareamiento entre el miRNA y su blanco no es completo, entonces se induce la atenuación traduccional (Valencia-Sánchez et al., 2006). En cambio, si el apareamiento es perfecto, se induce la degradación del RNAm blanco (Jones-Rhoades et al., 2006; Voinnet, 2009). En las plantas, prácticamente todos los programas de desarrollo, procesos fisiológicos y respuestas al ambiente requieren de la actividad de al menos un miRNA. Marchantia polymorpha es una hepática, de la familia de las briófitas y evidencia filogenética, paleontológica y molecular indica que es descendiente directo de las primeras plantas que colonizaron los ambientes terrestres (Graham et al., 2004, Qiu et al., 2006; Bowman et al., 2007). La posición evolutiva privilegiada, entre otras características, hacen de M. polymorpha un modelo atractivo para estudiar procesos moleculares, celulares y evolutivos. Por lo anterior, y para tratar de entender la evolución del gen ARGONAUTA1 en las plantas terrestres, el objetivo central de este trabajo es identificar y caracterizar la estructura del gen ARGONAUTA1 de M. polymorpha (MpAGO1). 2 II. ANTECEDENTES 2.1. Marchantia polymorpha, un modelo emergente para estudios de biología molecular en las plantas. El origen y la diversificación temprana de las plantas terrestres a partir de un ancestro acuático marca un intervalo de innovación sin precedentes en la historia de la vida de las plantas y es uno de los eventos más críticos de la evolución para la vida en nuestro planeta (Ishizaki et al., 2013). Las briofitas (incluyendo hepáticas, musgos y antoceros) se caracterizan por poseer un ciclo de vida con una fase haploide dominante (Shaw et al., 2011), y particularmente las hepáticas son consideradas como el grupo más basal (Kubota et al., 2013). Análisis filogenéticos y moleculares apoyan fuertemente la relación de parentesco entre las hepáticas con las demás plantas terrestres (Qiu et al., 2006), por lo tanto las hepáticas son consideradas como un linaje clave para entender las bases genéticas que permitieron a las plantas verdes evolucionar desde un ancestro acuático hasta colonizar el ambiente terrestre (Ishizaki et al., 2013). M. polymorpha (Figura 1) es la especie mejor caracterizada de las hepáticas, y evidencia paleontológica así como filogenética sugieren que pertenece al linaje de plantas terrestres más basales y que es descendiente directo de las primeras plantas que colonizaron los ambientes terrestres (Graham et al., 2004, Qiu et al., 2006; Bowman et al., 2007). A diferencia de las angiospermas donde el esporofito diploide es la fase dominante, el gametofito de M. polymorpha se desarrolla hasta formar un talo de vida libre (Bell y Hemsley, 2000; Goffinet y Shaw, 2009). M. polymorpha habita en ambientes húmedos como las orillas de los ríos, arroyuelos y estanques y sobre las piedras, donde forma una especie de tapete verde de talos que crecen uno sobre otro (Ortega, 1948). M. polymorpha es una especie dioica, con plantas hembras que portan un cromosoma X y plantas macho con un cromosoma Y, además de 8 autosomas (Okada et al., 2000); mientras los talos de ambas son morfológicamente idénticos 3 (Figura 1), sus estructuras reproductivas son sexualmente dimórficas (Figura 2) (Bell y Hemsley, 2000; Goffinet y Shaw, 2009). Figura 1. Marchantia polymorpha. Talos maduros de M. polymorpha con cenceptáculos y gemas. Mendoza-Mejía, 2014. M. polymorpha es una hepática taloide cuyos talos crecen unos sobre otros formando una especie de alfombra verde, sus talos se bifurcan en dos lóbulos y tienen una superficie ventral y dorsal; en la superficie ventral se encuentran los rizoides que son estructuras unicelulares, mientras que en la superficie dorsal posee cámaras de intercambio gaseosos con poros epidermales y tejido subepidermal que forma filamentos fotosintéticos. En la superficie dorsal también se desarrollan unas estructuras con forma de copa llamadas conceptáculos que contiene a las gemas, las cuales tienen forma de disco aplanado y a partir de una sola gema se puede generar un organismo completo (Ortega, 1948; Bell y Hemsley, 2000; Goffinet y Shaw, 2009). Los talos de M. polymorpha son unisexuales, sus estructuras reproductivas se encuentran sobre un pedicelo que se levanta unos cuantos centímetros de la superficie dorsal, en el extremo de este se encuentra un disco lobulado cuando se trata de un órgano reproductor masculino o anteridióforo, y una sombrilla estrellada cuando se trata de un órgano reproductor femenino o arquegonióforo (Figura 2) (Ortega, 1948). 4 Figura 2. Estructuras reproductivas de M. polymorpha. A) Anteridióforo, estructura masculina; B) Arquegonióforo, estructura femenina. Arteaga-Vázquez, 2013 Una de las características que hace de M. polymorpha un modelo ideal es su rápido crecimiento y fácil propagación sexual y asexual (Bell y Hemsley, 2000). M. polymorpha se reproduce de manera asexual mediante gemas o propágulos que se producen a partir de una sola célula en el interior de los conceptáculos; cada gema da origen a un individuo idéntico a su progenitor, este es un ejemplo de clonación natural y de esta manera se pude propagar sencillamente una población de plantas isogénicas (Ishizaki et al., 2008). Otra forma de reproducción asexual es mediante cortes en los talos y regeneración natural de un organismo completo (Kubota et al., 2013). M. polymorpha también se reproduce de manera sexual, en los anteridióforos se producen los anterozoides o gametos masculinos, mientras que las plantas hembras producen los gametos femeninos en los arquegonióforos; en la naturaleza la fertilización se lleva a cabo con ayuda de las gotas de lluvia que transportan el esperma hasta el arquegonióforo y en el laboratorio se pueden hacer cruzas colocando una gota de agua sobre el anteridióforo y transportarla después al arquegonióforo (Tanurdzic y Banks, 2004). Al igual que en Arabidopsis, en M. polymorpha también se puede realizar transformación genética mediada por Agrobacterium tumefaciens, usando talos inmaduros desarrollados a partir de esporas (Ishisaki et al., 2008; Sugano et al., 2014) o 5 mediante talos regenerados (Kubota et al., 2013). También se pude hacer transformación por biobalística mediante el bombardeo de partículas sobre talos maduros e inmaduros (Takenaka et al., 2000; Chiyoda et al., 2008), y dado que durante su ciclo de vida la fase dominante es la haploide, el escrutinio y aislamiento de plantas mutantes es mucho más fácil que en las plantas diploides (Takenaka et al., 2000), siendo esto una ventaja para hacer análisis de genética funcional. En M. polymorpha también se puede hacer reemplazo o inactivación de genes por recombinación homóloga (Ishizaki et al., 2013), la cual es una herramienta muy útil para análisis de genética reversa. Además de las herramientas anteriores, se encuentra disponible la secuencia completa del genoma mitocondrial (Oda et al., 1992) y la secuencia completa del cromosoma Y de M. polymorpha (Yamato et al., 2007), al igual que varios transcriptomas disponibles (Sharma et al., 2013; Sharma et al., 2014). El genoma nuclear de aproximadamente 280 MB está siendo secuenciado por el U.S. Department of Energy Joint Genome Institute (DOE JGI) (http://www.jgi.doe.gov/sequencing/why/99191.html). El genoma de M. polymorpha es más simple que el genoma de la gran mayoría de las plantas terrestres, por ejemplo, en Arabidopsis se han identificado 600 genes de receptor- like kinasas (RLKs) distribuidos en 52 familias, mientras que en M. polymorpha se identificaron 29 genes RLK distribuidos en 26 familias (Sasaki et al., 2007). De la misma manera M. polymorpha posee 3 genes que codifican a los factores de transcripción de respuesta a auxinas (ARF), mientras que en Arabidopsis existen 23 ortólogos de los mismos (Flores-Sandoval, 2013). Recientemente se reportó la identificación de una copia única del gen que codifica a las oleosinas en M. polymorpha, de los cuales existen 10 en Arabidopsis (Fang et al., 2014). De igual modo, hemos identificado cuatro genes que codifican a las proteínas Argonauta en M. polymorpha mientras que en plantas superiores como Arabidopsis, maíz y arroz existen 10, 18 y 19, respectivamente (Morel et al., 2002; Kappor et al., 2008; Qian et al., 2011). La relativa simplicidad genética y las características antes mencionadas hacen de M. polymorpha un modelo único para el estudio de procesos moleculares y celulares, estudios evolutivos, biología del desarrollo y genómica funcional. 6 2.2. Descubrimiento del silenciamiento de genes mediado por RNA. En 1990 el grupo de investigación de Richard Jorgensen fue el primero en reportar este fenómeno; ellos introdujeron el gen quimérico de la enzima chalcona sintasa (CHS) en plantas de petunia, con el objetivo de sobre-expresarlo y determinar si esta enzima era limitante en la biosíntesis de antocianinas, dado que estas son las responsables del color violeta de las petunias; inesperadamente obtuvieron petunias completamente blancas y petunias violetas con patrones blancos. Los niveles del RNAm del gen endógeno, así como del transgén, en los pétalos de las petunias transgénicas eran 50 veces más bajos que los de las petunias silvestres. Con base en estos resultados, postularon la hipótesis de que la introducción del gen quimérico de chalcona sintasa bloqueaba la ruta de biosíntesis de antocianinas al cosuprimir la expresión del gen endógeno y del gen introducido. A este fenómeno lo llamaron cosupresión (Napoli et al., 1990). En 1992, Romano y Macino reportaron un fenómeno similar al transformar Neurospora crassa con porciones de los genes carotenogénicos albino-1 y albino-3 los cuales causaban la inactivación transcripcional de los mismos genes y obtenían una variedad de fenotipos mutantes que iban del color blanco al amarillo, considerando a este fenómeno como “quelling” (Romano y Macino, 1992). En los animales, el primer reporte del empleo de moléculas de RNA antisentido para inhibir específicamente la expresión de un gen fue hecho por Fire y colaboradores en 1991, al emplear esta estrategia en el gusano C. elegans para inhibir la expresión de los genes unc-22 y unc-54. Esta misma estrategia fue empleada por Guo y Kemphues en 1995 para hacer fenocopias y confirmar la identificación del gen par-1, inyectaron moléculas de RNA antisentido homólogas a par-1 en las gónadas de C. elegans y observaron el fenotipo característico de la pérdida de función en par-1, a diferencia de Fire y cols. ellos emplearon RNA sentido sintetizado in vitro como control, ya que suponían que este no se hibridaría con el RNAm de par-1 y sorprendentemente observaron el mismo fenotipo causado por el RNA antisentido. Durante la época en que se llevaron a cabo estos experimentos existía el dogma de que la inactivación de la 7 expresión de genes por RNA antisentido era debida a la hibridación con el RNAm endógeno, lo cual causaba la degradación del mensajero por acción de ribonucleasas (Sen y Blau, 2006). Dado que en los experimentos de Gou y Kemphues tanto el RNA antisentido como el sentido produjeron la degradación del RNAm homólogo, Fire y Mello decidieron investigar si este fenómeno se debía a la formación de RNA de doble cadena (dsRNA), argumentando que en el RNA sentido inyectado había contaminación por moléculas antisentido y viceversa. Para probar esta hipótesis purificaron moléculas individuales de RNA sentido y antisentido, y las compararon con la actividad de la mezcla de ambas en la cual se formaba dsRNA, como blanco eligieron el gen unc-22 de C. elegans cuyo fenotipo de pérdida de función genera espasmos en los gusanos. En sus resultados observaron que ninguna de las moléculas de RNA individual provocaba tal fenotipo, pero la mezcla de ambos generaba el fenotipo esperado, de esta manera concluyeron que este fenómeno de silenciamiento de genes era debido a un dsRNA, al cual llamaron RNA de inferencia (RNAi) (Fire et al., 1998). El RNAi resultó ser de naturaleza sistémica (Voinnet y Baulcombe, 1997) y transmitido a la progenie (Grishok et al., 2000), por lo tanto debería haber un intermediario para tal fenómeno, este intermediario fue encontrado como una molécula de RNA antisentido de 25 nucleótidos (nt) de longitud que derivada del dsRNA (Hamilton y Baulcombe, 1999). Más tarde se demostró que el dsRNA es procesado a pequeños dúplex de 21 a 23 nt de longitud de los cuales se deriva el RNA antisentido que se enlaza al RNAm homólogo y provoca su degradación (Zamore et al., 2000; Elbashir et al., 2001). 2.3. RNAs pequeños en las plantas. 2.3.1. Diversidad de RNAs pequeños en las plantas Los sRNAs de las plantas poseen una longitud de 19 a 30 nt y pueden ser clasificados en varios grupos tomando en cuenta su biogénesis y función (Bartel 2004; Kim 2005; Brodersen y Voinnet, 2006; Vaucheret, 2006). En una clasificación primaria estos se pueden catalogar en dos grupos principales: el primer grupo corresponde a 8 aquellos sRNAs cuyo precursor es un RNA de cadena sencilla que por su complementariedad intramolecular forma una estructura secundaria de tallo-asa o “hairpin” y son catalogados como hpRNAs. En el segundo grupo se encuentran los sRNAs provenientes de RNAs que forman un precursor largo de doble cadena con perfecta complementariedad; estos son catalogados como small interferring RNAs o siRNAs (por sus siglas en inglés) (Fei et al., 2013; Axtell, 2013). El primer grupo de sRNAs se subdivide a su vez en miRNAs — de los cuales se hablará con más detalle en apartados posteriores — y otros hpRNAs; por su parte los siRNAs, a su vez, también son divididos en tres categorías: siRNAs heterocromáticos (hc-siRNAs), siRNAs secundarios y siRNAs naturales antisentido (NAT-siRNAs). Algunas de las categorías secundarias pueden subdividirse en categorías terciaras: los miRNAs pueden ser específicos de la especie o miRNAs largos; los siRNAs secundarios pueden ser “transacting” o “pahsed”, mientras que los NAT-siRNAs pueden ser clasificados de acuerdo a que actúen en trans o en cis (Axtell, 2013). 2.4. Silenciamiento génico mediado por miRNAs en las plantas 2.4.1. ¿Qué son los miRNAs? Los miRNAs son RNAs pequeños que tiene una longitud de 21 a 22 nucleótidos (Mallory y Vaucheret, 2010) provenientes de un RNA precursor de cadena sencilla cuya secuencia posee complementariedad intramolecular (Axtell, 2013); regulan la expresión de genes codificantes a nivel pos-transcripcional en eucariotas (Bartel, 2004) reprimiendo la expresión de sus RNAm blanco por complementariedad de secuencia a través de un mecanismo de atenuación traduccional o por la degradación del RNAm (Voinnet, 2009). En las plantas, los miRNAs controlan la expresión de genes que codifican factores de transcripción, proteínas de respuesta a estrés y otras proteínas que impactan el desarrollo, crecimiento y fisiología de las plantas (Rogers y Chen, 2013). Los miRNAs participan en la regulación de la expresión de genes a nivel postranscripcional uniéndose de manera casi perfectamente complementaria a su RNAm blanco por el extremo 3’UTR o a los exones codificantes, provocando así la 9 degradación del RNAm o la atenuación de su traducción (Farazi et al., 2008; Fujiwara y Yada, 2013 ). En las plantas, algunas familias de miRNAs se encuentran evolutivamente conservados desde las briofitas hasta las angiospermas (Reinhart et al., 2002; Axtell y Bartel, 2005, Montes et al., 2014, Lara-Mondragón y Arteaga-Vázquez, resultados sin publicar), y aunque la mayoría de sus precursores muestran gran variabilidad (Cuperus et al., 2011), sus secuencias maduras muestran complementariedad extensa de secuencia a su RNAm blanco y se encuentran conservadas (Axtell y Bartel, 2005). 2.4.2. Biogénesis de los miRNAs en las plantas. Los miRNAs provienen de loci genéticos definidos — los genes MIR — estos se encuentran en regiones intergénicas del genoma y la mayoría posee su propia unidad transcripcional (Reinhart et al., 2002; Jones-Rhoades et al., 2006; Griffiths-Jones et al., 2008). En los promotores de los loci generadores de miRNAs se han logrado identificar cajas TATA y diversos elementos reguladores en cis, lo que implica que la regulación de la transcripción de los genes MIR puede ocurrir por factores que actúan en trans, como los factores de transcripción (TF) (Rogers y Chen, 2013) (Figura 3). La transcripción de los genes MIR es activada por el complejo Mediator el cual recluta a la enzima RNA polimerasa II (Pol II) (Kim et al., 2011), Pol II genera un miRNA primario (pri-miRNA) con estructura secundaria de tallo y asa que es estabilizado por la adición de un grupo 7-metilguanosina en el extremo 5’ (5-cap) y una cola de poliadenina en el extremo 3’ (Rogers y Chen, 2013) (Figura 3). La longitud de los pri-miRNAs es heterogénea y puede tener desde 70 a cientos de nt (Axtell et al., 2011). Los primiRNAs poseen una o más horquillas en su estructura y el miRNA se encuentra en el tallo (Meister, 2013), la presencia de horquillas es crucial para el procesamiento del primiRNA ya que si éstas se eliminan por completo el pri-miRNA no puede ser procesado (Mateos et al., 2010; Werner et al., 2010). En las plantas, el pri-miRNA es procesado en un intermediario denominado premiRNA o precursor del miRNA que también posee una estructura de tallo y asa. El procesamiento del pri-miRNA al pre-miRNA y del pre-miRNA al miRNA maduro son 10 catalizados por DICER LIKE 1 (DCL1), una RNasa tipo III que es capaz de procesar RNA de doble cadena (Park et al., 2002; Reinhart et al., 2002), esta enzima procesa al pri-miRNA dejando una secuencia de entre 15 y 14 nt del tallo próximos a la secuencia madura del miRNA (Mateos et al., 2010; Werner et al., 2010). DCL1 actúa en conjunto con las proteínas TOUGH (TGH) (Ren et al., 2012), SERRATE (SE) una proteína con “dedos de zinc” (Lobbes et al., 2006; Machida et al., 2011) y una proteína de enlace a dsRNA HYPONASTIC LEAVES1 (HYL1/DRB1) (Han et al., 2004). Las tres proteínas se unen al RNA de forma secuencial: SE enlaza al pri-miRNA, TGH se une al RNA de una sola hebra y HYL1 enlaza al dsRNA (Rogers y Chen, 2013) (Figura 3) estas proteínas permiten que DCL1 corte al pri-miRNA con precisión. El pre-miRNA con estructura de tallo y asa es adicionalmente procesado por DCL1 en conjunto con las enzimas HYL1 y SE. La enzima DCL1 corta la horquilla del tallo dejando un dúplex de miRNA/miRNA* con una longitud de alrededor de 21 nucleótidos y dejando 2 nucleótidos que sobresalen del extremo 3’ de cada hebra del dúplex (Rogers y Chen, 2013) (Figura 3). Este dúplex miRNA/miRNA* es ahora conocido como miRNA maduro y es estabilizado por la metiltransferasa HUA ENHANCER 1 (HEN1) dependiente de S-adenosilmetionina, así los nucleótidos del extremo 3’ de ambas cadenas del dúplex son metilados en el grupo 2’OH de la ribosa para prevenir su uridilación y la subsecuente degradación (Li et al., 2005; Yu et al; 2005; Yang et al., 2006). Después de la metilación, el dúplex de miRNA es exportado del núcleo al citoplasma por la proteína HASTY (HST) (Park et al., 2005). Posteriormente, ambas hebras del miRNA dúplex son separadas, y una de ellas es incorporada en un complejo efector donde se enlaza directamente a un miembro de la familia de proteínas AGO (Peters y Meister, 2007); en la ruta de silenciamiento por miRNAs la proteína de la familia AGO asociada al complejo RISC es AGO1 (Vaucheret et al., 2004; Baumberger y Baulcombe, 2005). El complejo de silenciamiento RISC contiene un sRNA que guía la escisión-secuencia específica de RNAs blancos complementarios (Peters y Meister, 2007). Un determinante importante para la selección de la hebra que se incorpora al RISC se encuentra en la misma estructura del dúplex, la hebra con el extremo 5’ apareado menos estable es reclutada 11 preferencialmente por una proteína AGO específica; estas diferencias termodinámicas entre los extremos del sRNA son conocidas como la regla de la asimetría (Tolia y Joshua-Tor, 2007; Meister, 2013). Otro determinante para la selección del sRNA que será reclutado por una proteína AGO es la identidad del nucleótido terminal 5’ (Mi et al., 2008; Montgomery et al., 2008; Takeda et al., 2008) por ejemplo la proteína AGO1 de Arabidopsis preferencialmente recluta miRNAs que tienen uracilo en el extremo 5’ (Mi et al., 2008). Después de que los miRNAs llevan a cabo su función, estos no se quedan acumulados, sino que son degradados por una nucleasa que degrada sRNAs, conocida como SDN1 (Small RNA Degrading Nuclease1, por sus siglas en inglés); ésta posee actividad exoribonucleasa 3’-5’ dirigida a sRNAs de cadena sencilla, y es capaz de degradar substratos 2’-O-metilados pero es inhibida por la 3´oligouridilación (Ramachandran y Chen, 2008). La enzima HEN1 SUPPRESSOR1 (HESO1) es una nucleotidiltransferasa que agrega colas de oligouridilato a los miRNAs no metilados (Zhao et al., 2012), HESO1 y SDN1 actúan juntas en la degradación de miRNAs metilados (Rogers y Chen, 2013). 2.4.3. Mecanismo del silenciamiento génico mediado por miRNAs en las plantas. Los miRNAs pueden dirigir al RISC para regular la expresión de genes mediante dos mecanismos postranscripcionales: la escisión del RNAm o la atenuación de la traducción. Una vez que el miRNA ha sido incorporado en el RISC, el miRNA especificará la escisión si el RNAm tiene suficiente complementariedad al miRNA, o reprimirá la traducción si el RNAm no tiene suficiente complementariedad al miRNA para ser escindido (Figura 4) (Bartel, 2004). Los miRNAs de las plantas guían la escisión del RNAm blanco en el enlace fosfodiéster opuesto a los nucleótidos 10 y 11 del miRNA (Bartel, 2004; Jones-Rhoades et al., 2006; Chen, 2009): la escisión es llevada a cabo por la actividad endonucleasa del dominio PIWI de AGO1 (Baumberger y Baulcombe, 2005). 12 Figura.3. Eventos principales en la biogénesis de los miRNAs en las plantas. Tomado y modificado de Rogers y Chen, 2013. 13 Existe evidencia de que los miRNAs de las plantas también atenúan la traducción de sus RNAm blanco (Chen, 2004; Arteaga-Vázquez et al., 2006; Brodersen et al., 2008; McCue et al., 2012) y recientemente se identificó una proteína involucrada en la atenuación traduccional. ALTERED MERISTEM PROGRAM1 (AMP1), codifica una proteína integral de membrana que se asocia con el retículo endoplásmico, con la proteína AGO1 que ha reclutado a un miRNA efector y una proteína periférica de membrana del retículo endoplásmico (Figura 4). La medición de la síntesis de proteínas demostró que los miRNAs de plantas inhiben la traducción del RNAm blanco de una manera dependiente de AMP1 y que AMP1 no impacta en la síntesis de proteínas en general. También se demostró que su locación subcelular es justamente en el retículo endoplásmico (Li et al., 2013). Figura 4. Mecanismo del silenciamiento de genes mediado por miRNA en las plantas. Los miRNAs en las plantas regulan la expresión de genes por la escición de su RNAm blanco o por la atenuación de la traducción del mismo. Tomada y modificada de Rogers y Chen, 2013. 14 2.5. La familia de proteínas ARGONAUTA. El nombre de las proteínas ARGONAUTA se deriva del fenotipo observado en una mutante nula del gen AGO1 de Arabidopsis (ago-1-1) la cual muestra un fenotipo pleiotrópico con hojas tubulares emulando la forma de un calamar del género Argonauta (Bohmert et al., 1998). Con base en su similitud de secuencia, la familia de proteínas ARGONAUTA puede clasificarse filogenéticamente en tres subfamilias: la subfamilia AGO cuyos miembros son homólogas de las AGOs de Arabidopsis, la subfamilia PIWIlike similares a Piwi (P-element induced wimpy testis) en D. melanogaster, y la subfamilia WAGO en la cual se agrupan las proteínas Argonauta de C. elegans (Yigit et al., 2006; Tolia y Joshua-Tor, 2007; Farazi et al., 2008; Hutvanger y Simard, 2008; Vaucheret, 2008; Czech y Hannon, 2011; Meister, 2013). Las proteínas ARGONAUTA son una pieza clave en todos los procesos de silenciamiento génico mediado por sRNAs y en conjunto con la molécula de sRNA forman el núcleo del complejo RISC, el sRNA guía a la proteína AGO hacia su RNAm blanco mediante el apareamiento de bases y la proteína AGO ejerce la acción de silenciamiento (Figura 4) (Poulsen et al., 2013). Estas proteínas se encuentran conservadas, y los miembros de esta familia están presentes en todos los eucariotas, con la excepción de Saccharomyces cerevisiae, la cual ha perdido la maquinaria de los RNAs pequeños (Meister, 2013). En los procariotas también se ha reportado la presencia de AGOs que forman parte de un mecanismo de defensa a nivel de DNA (Makarova et al., 2009; Olovnikov et al., 2013; Swarts et al., 2014). El número y la diversidad de las proteínas AGO varía entre los organismos (Hutvagner y Simard, 2008); una sola proteína AGO existe en levadura Schizosccharomyces pombe, dos proteínas AGO y tres PIWI en D. melanogaster, 4 proteínas AGO y 4 PIWI en humanos, en Arabidopsis, en arroz y en maíz existen 10, 18 y 19 AGOs respectivamente (Vaucheret, 2008; Qian et al., 2011). Estudios bioquímicos de las proteínas AGO indican que la función original de esta familia de proteínas era similar a la de la familia de endonucleasas tipo RNasa H, la cual usa DNA como molde para enlazar moléculas de RNA (Yuan et al., 2005), así que durante la evolución, las proteínas AGO se especializaron en usar RNA de una sola 15 hebra como molde en lugar de DNA para dirigirse contra sus RNAs blanco (Hutvagner y Simard, 2008). 2.5.1. Características estructurales de las proteínas ARGONAUTA. Las proteínas ARGONAUTA tienen ciertas propiedades que les permiten llevar a cabo su función en la regulación de la expresión de genes; deben reclutar sRNAs que mediante el apareamiento de bases les permitan encontrar a su blanco, la mayoría posee actividad de endonucleasa, y también funcionan como módulos para la unión de otros cofactores que participan en los procesos del silenciamiento de genes (Poulsen et al., 2013). Estas propiedades son conferidas por la presencia de cuatro dominios característicos de esta familia de proteínas: un dominio N terminal, un dominio Piwi/Argonaute/Zwille (PAZ), un domino MID (Middle domain) y un dominio PIWI (Song et al., 2004; Yuan et al., 2005; Wang et al., 2008; Nakanishi et al., 2012; Schirle y MacRae, 2012b) (Figura 5). Figura 5. Estructura general de las proteínas ARGONAUTA. A) Esquema de los dominios que conforman a la proteína PfAGO. B) Modelo de la estructura cristalina de la proteina PfAGO. C) Modelo esquemático de una proteína Argonauta activa; el miRNA se muestra en amarillo, el mRNA blanco en rojo y el sitio catalítico esta representado por las tijeras, en acercamiento al dominio PIWI se muestra la triada catalítica DDH. Tomados y modificados de Song et al., 2004. 16 Los dominios característicos de las proteínas ARGONAUTA son esenciales para el reconocimiento y reclutamiento de la cadena guía del sRNA y para la acción de RISC como el complejo efector del silenciamiento por sRNAs. El par de nucleótidos que sobresalen del extremo 3’ del miRNA y que son generados por el procesamiento de DCL1 son acomodados dentro de una cavidad de residuos aromáticos e hidrofóbicos formada por el plegamiento del dominio PAZ (Ma et al., 2004; Yuan et al., 2005). Por su parte, el dominio MID también forma una cavidad rica en residuos de aminoácidos básicos y altamente conservados que permite el anclaje del sRNA a la proteína AGO a través del grupo fosfato del extremo 5’ (Yuan et al., 2005; Boland et al., 2010). El dominio PIWI se pliega de forma similar a una RNasa H (Song et al., 2004) y tanto estudios bioquímicos como estructurales han revelado que este dominio posee actividad de endonucleasa y es el encargado de llevar a cabo la escisión del RNAm blanco (Parker et al., 2004; Song et al., 2004; Baumberger y Baulcombe, 2005; Yuan et al., 2005; Wang et al., 2008). Este dominio posee una triada de residuos catalíticos conservados (Asp-Asp-Asp o Asp-Asp-His) que dirigen la escisión del RNAm (Mallory y Vaucheret, 2010; Meister, 2013) en el enlace fosfodiéster entre los nucleótidos 10 y 11 de la cadena guía (Yuan et al., 2005; Wang et al., 2008; Wang et al., 2009). Sin embargo, el hecho de que en una proteína AGO se encuentre conservada dicha triada catalítica no es el determinante esencial para que la proteína tenga actividad de endonucleasa (Faehnle et al., 2013; Hauptmann et al., 2013). El dominio N-terminal puede subdividirse en tres estructuras: bobina N-terminal, dominio N y dominio de función desconocida 1785 (DUF1785) (Poulsen et al., 2013); este dominio es el menos estudiado, sin embargo un estudio estructural de una proteína AGO de Thermus thermophilus reveló que este dominio bloquea la propagación del apareamiento entre la cadena guía y su blanco después del nucleótido 16 (Wang et al., 2009). En un estudio más reciente en HsAGO2 se demostró que el dominio N está involucrado en la formación del RISC maduro, específicamente en la escisión y desenrollamiento de la cadena pasajera (siRNA* o miRNA*) (Kwak y Tomari, 2012), este dominio también es importante para la actividad catalítica de las proteínas AGO (Faehnle et al., 2013; Hauptmann et al., 2013). 17 2.5.2. Mecanismo de reconocimiento y escisión del blanco por las proteínas ARGONAUTA. De acuerdo con los resultados obtenidos de la estructura cristalina de la proteína AGO de Aquifex aeolicus Yuan et al. (2005) proponen que las AGOs pasan por distintas conformaciones durante la catálisis, las cuales permiten el enlace de la cadena guía, el reconocimiento del blanco, la propagación del dúplex, escisión y liberación del producto (Figura 6). Figura 6. Esquema del reclutamiento y catálisis de AGO. El cilco abarca el reclutamiento de la cadena guía, el reconocimiento del blanco, formación y propagación del dúplex, escsión del RNAm y liberación de los productos de escisión. Tomada y modificada de Yuan et al., 2005. 18 Primero, la proteína AGO recluta a la cadena guía anclándola a los dominios PAZ y MID por los extremos 3’ y 5’ respectivamente (I); el siguiente paso es la nucleación o reconocimiento del blanco mediante la región semilla de la cadena guía, específicamente de los nucleótidos 2 a 8 (II); inmediatamente después de la nucleación sigue la propagación del dúplex hacia el extremo 3’ y la formación del dúplex completo podría requerir la rotación de PAZ alejándolo del dominio N y provocando la liberación del extremo 3’ de la cavidad de enlace en PAZ (III). Cuando se ha formado el dúplex completo el residuo catalítico de la RNasa H en PIWI rompe el enlace fosfodiéster del RNAm entre los nucleótidos 10 y 11 contados a partir del extremo 5’ de la cadena guía, finalmente los productos de escisión son liberados (IV). El extremo 3’ de la cadena guía se ancla de nuevo en PAZ dejando al complejo AGO-sRNA listo para el reconocimiento de otro blanco (Figura 6) (Yuan et al., 2005). El modelo anterior que propone un mecanismo para la catálisis de AGO parte de un complejo AGO-sRNA preestablecido y no toma en cuenta el mecanismo previo del desenrollamiento del dúplex del sRNA para la selección de la cadena guía y descartar la cadena pasajera, Kwak y Tomari (2012) proponen un modelo para el desenrollamiento del dúplex tomando en cuenta los resultados obtenidos de estudios bioquímicos en mutantes dañadas en el dominio N de HsAGO2; suponen que la proteína AGO vacía adopta una estructura conformacional abierta que es dependiente de la acción de la chaperona HSC70-HSP90 y de la hidrólisis de ATP que obliga al dominio N a girar hacia una posición más alejada creando así un espacio para acomodar al dúplex del sRNA, cuando este se ha incorporado la proteína AGO regresa a su conformación cerrada y el dominio N gira hacia el extremo 3’ del dúplex, rompe el enlace de varios pares de bases iniciando el desenrollamiento del dúplex de manera independiente de PIWI. Otro posible mecanismo es que posicione al dúplex en los residuos catalíticos de la RNasa H de PIWI para la subsecuente escisión de la cadena pasajera. Finalmente, la cadena guía se ancla al dominio PAZ mediante el extremo 3’ (Figura 7a) y llegamos al inicio del modelo anterior (Figura 6). También es probable que el dominio N participe en el mecanismo de escisión del RNAm, ya que después de que ha iniciado el proceso de propagación del dúplex, el dominio N bloquea la extensión del apareamiento de la cadena guía y su blanco después del nucleótido 16 (Wang et al., 19 2009) y al igual que en el proceso del desenrollamiento del dúplex del sRNA, el dominio N contribuiría a posicionar al fosfato escindible del RNAm blanco para la endonucleosis llevada a cabo por PIWI (Figura 7b). Recientemente, dos grupos de investigación demostraron que el dominio N de HsAGO2 al parecer tiene un papel fundamental en la actividad catalítica de las proteínas AGOs, ya que el intercambio del dominio N de HsAGO2 en HsAGO3 es suficiente para activarla y también el intercambio de ambos dominios, N y PIWI de HsAGO2 en HsAGO1, le confiere actividad de endonucleasa a esta última (Faehnle et al., 2013; Hauptmann et al., 2013). Figura 7. Participación del dominio N en el desenrollamiento del dúplex de RNA pequeño y en la escisión del RNA mensajero. A) El dominio N inicia el desenrollamiento del dúplex al romper los enlaces de algunos pares de bases y posiciona al dúplex en los dominios catalíticos de PIWI para la degradación de la cadena pasajera. B) La propagación del dúplex sRNA/RNAm es detenida hasta el nucleótido 16 por el dominio N y posiciona a este en los residuos catalíticos para la degradación del RNAm. Tomada y adecuada de Kwak y Tomari, 2012. 20 2.6. El clado de la familia de proteínas ARGONAUTA en Arabidopsis. En el genoma de Arabidopsis existen 10 genes que codifican a las proteínas ARGONAUTA (Morel et al., 2002), todas pertenecientes a la subfamilia AGO. Una comparación filogenética las coloca en tres clados principales (Figura 8), el primer clado incluye a AGO1, AGO5 y AGO10; el segundo clado está conformado por AGO2, AGO3 y AGO7; y un tercer clado que incluye AGO4, AGO6, AGO8 y AGO9 (Zheng et al., 2007; Vaucheret, 2008). Esta clasificación de las proteínas AGOs de Arabidopsis solo obedece a su similitud en la secuencia de aminoácidos, y no quiere decir que tengan funciones similares, de hecho las proteínas AGO de Arabidopsis tienen preferencia por ciertas clases y tamaños determinados de sRNAs. Figura 8. Árbol filogenético de las proteínas AGO de Arabidopsis. Tomado de Vaucheret, 2008. 21 2.6.1. Especialización de las proteínas AGO de Arabidopsis por clases específicas de RNAs pequeños. En Arabidopsis existen tres clases principales de sRNAs, la clase más abundante corresponde a los siRNAs que actúan en cis y que para su transcripción dependen de las RNAs polimerasas Pol IV y Pol V mientras que para su procesamiento requieren DCL3. Los miRNAs conforman la segunda clase y estos dependen de la acción de Pol II y DCL1 (Vaucheret, 2006; Poulsen et al., 2013). La tercera clase corresponde a los ta-siRNAs que para su biogénesis requiere la maquinaria de los miRNAs y de las proteínas RNA-DEPENDENT RNA POLYMERASE 6 (RDR6), SUPPRESSOR OF GENE SILENSING 3 (SGS3) y DCL4 (Fei et al., 2013). Diferentes poblaciones de estas clases de sRNAs interaccionan y se asocian de manera distinta con las proteínas AGOs de Arabidopsis (Mi et al., 2008; Montgomery et al., 2008; Takeda et al., 2008). La proteína AGO1 se asocia principalmente con miRNAs de 21 y 22 nt de longitud que en su extremos 5’ tienen uracilo (U), mientras que AGO2 recluta preferencialmente ta-siRNAs de 21 nt cuyo extremo 5’ inicia con adenina (A). AGO4 muestra una preferencia similar por adenosina en 5’ aunque recluta mayoritariamente siRNAs de 24 nt de longitud. Por otro lado AGO5 preferencialmente recluta siRNAs de 24 nt con citosina (C) en 5’, aunque también muestra cierta tendencia por siRNA de 21 y 22 nt (Mi et al., 2008). Las proteínas AGO6, AGO8 y AGO9 tienen un comportamiento similar a AGO4 al reclutar siRNAs de 24 nt con adenina (A) en 5’ (Vaucheret, 2008; Mallory y Vaucheret, 2010). A diferencia de las anteriores, AGO7 parece no seguir la tendencia de reclutar sRNAs de acuerdo a la identidad del extremo 5’, ya que AGO7 sólo se asocia con miR390 restando importancia al nucleótido que se encuentre en el 5’ (Montgomery et al., 2008). Como resultado de la interacción de las proteínas AGOs de Arabidopsis con determinados sRNAs, estas participan en la regulación de la expresión de genes a diferentes niveles (Figura 9); AGO4, AGO6 y AGO9 regulan la expresión de genes a nivel transcripcional; AGO1 y AGO7 son efectoras del silenciamiento génico a nivel postranscripcional; mientras que AGO10 interfiere con la traducción de los blancos de su sRNA asociado (Mallory y Vaucheret, 2010). Además de actuar a diferentes 22 niveles, las proteínas AGO también muestran diversificación funcional, por ejemplo en Arabidopsis AGO1 participa en la formación del meristemo y afecta la expresión de los factores de transcripción LEAFY (LFY), APETALA1 (AP1) y AGAMOUS (AG) los cuales determinan la identidad del meristemo, la transición floral y la polaridad de los órganos; AGO1 también regula el silenciamiento post-transcripcional de CURLYLEAF (CLF) que codifica un grupo de proteínas Polycomb que mantiene la represión de los genes AG y APETALA3 (AP3) en hojas vegetativas y el desarrollo del polen (Kidner y Martienssen, 2005). AGO7 está involucrada en la transición del estado juvenil al adulto durante el desarrollo vegetativo (Hunter et al., 2003). Por su parte AGO4 participa en la metilación del DNA dirigido por RNA y en el silenciamiento de elementos transponibles (Qi et al., 2006; Matzke y Mosher., 2014). Figura 9. Niveles de regulación de la expresión génica y proteínas AGO asociadas a cada uno. Tomada y modificada de Contreras-Cubas, 2012. 23 2.7. La proteína ARGONAUTA1 de Arabidopsis es efectora del silenciamiento génico mediado por microRNAs. En las plantas los miRNAs se generan a partir de precursores de RNA de cadena sencilla que adoptan una estructura secundaria de tallo y asa que es procesada en múltiples pasos por la proteína DCL1 hasta generar el miRNA dúplex que será reclutado por una proteína de la familia AGO a la cual dirige hacia su blanco (Figura 4). En Arabidopsis, la proteína AGO1 recluta al miRNA y es la efectora del silenciamiento de genes por esta vía (Vaucheret et al., 2004; Baumberger y Baulcombe, 2005) incluso la expresión del gen AGO1 de Arabidopsis es regulada por la ruta de los miRNAs (miR168) (Vaucheret et al., 2004; Vaucheret et al., 2006; Vaucheret, 2009). El descubrimiento de la participación de AGO1 en la vía del silenciamiento de genes mediado por miRNAs se realizó a partir de análisis de plantas mutantes ago1 que mostraban fenotipos con anormalidades en el desarrollo y en el PTGS (Fagard et al., 2000; Morel et al., 2002; Vaucheret et al., 2004). Vaucheret y colaboradores (2004) observaron que las mutantes hipomórficas ago1 de Arabidopsis tienen fenotipos similares a las mutantes dcl1, hen1 y hyl1 (Figura 10) en las cuales los niveles basales de miRNAs se encuentran disminuidos con respecto a la planta silvestre y en contraste los niveles de RNAm que son blanco de miRNAs se encuentran en aumento y además hay una disminución de sus productos de escisión (Kasschau et al., 2003; Vazquez et al., 2004), lo anterior los llevó a suponer que AGO1 podría tener un papel importante en la ruta de los miRNAs. Para comprobar su hipótesis midieron los niveles de RNAm de diez genes que son blancos de miRNAs de 10 familias distintas y encontraron que los niveles basales de estos RNAm estaban elevados en la mutante nula ago1-3, mientras que en las mutantes hipomórficas ago1-26 y ago1-27 el incremento en los niveles de los mismos RNAm eran ligeramente más elevados que los de la planta silvestre. También midieron los niveles de los mismos RNAm en las mutantes hen1-4 y hyl1-2 encontrando que los niveles de RNAm se encontraban elevados de forma similar a las mutantes hipomórficas ago1-26 y ago1-27. También evaluaron los niveles de miRNA en las 24 mutantes ago1-27, ago1-26 y ago1-3, encontrando que en las mutantes hipomórficas los niveles fueron similares a los de la planta silvestre y sólo en la mutante nula no había acumulación de miRNA, de acuerdo a estos resultados ellos propusieron que AGO1 podría participar en la vía de los miRNAs después de que DCL1, HEN1 y HYL1 ejercen su acción y que la actividad de una proteína AGO1 completamente funcional es esencial para la acumulación de miRNAs (Vaucheret et al., 2004). Figura 10. Fenotipos de las muntantes hyl1, hen1 y ago1 de Arabidopsis. Los fenotipos de estas mutantes muestran características similares. A) Rosetas, B) Flores. Tomada de Vaucheret et al., 2004. El trabajo fundamental que señaló a la proteína AGO1 como efectora del silenciamiento de genes por miRNAs fue el de Baumberger y Baulcombe (2005) al constatar que AGO1 se asocia con miRNAs así como con otras clases de sRNAs y que además posee actividad endonucleasa la cual le permite escindir los RNAm que son blancos de miRNAs. Para llegar a esta conclusión hicieron una construcción del cDNA de AGO1 acoplado al octapéptido FLAG (FLAG-AGO1) para la subsecuente inmunoprecipitación de la proteína y análisis de sus sRNAs asociados. La construcción FLAG-AGO1 la introdujeron en la mutante ago1-36 de Arabidopsis restaurando completamente el fenotipo silvestre (Figura 11). La fusión protéica FLAG-AGO1 se asocia con miRNAs tanto de 21 nt (miR160, 167 y 319) como de 24 nt (miR163) así como con ta-siRNAs (ta-siRNA255) y con siRNAs de transgenes; FLAG-AGO1 escinde in vitro al RNAm de PHAVOLUTA (PHV) el cual es blanco de miR165 (Baumberger y Baulcombe, 2005). 25 Figura 11. FLAG-AGO1 rescata el fenotipo silvestre de la mutante ago1-36 de Arabidopsis. Toamda de Baumberger y Baulcombe, 2005. Mediante un análisis de genómica comparativa Baumberger y Baulcombe (2005) determinaron que AGO1 posee la triada DDH de residuos catalíticos conservados en el dominio PIWI, al igual que la proteína HsAGO2 (Tolia y Joshua-Tor, 2007), así que realizaron mutaciones en el primer residuo de aspartato y en el residuo de histidina suprimiendo por completo la actividad endonucleasa de AGO1. Todos los hallazgos anteriores apuntan a que AGO1 participa en la vía de los miRNAs como efectora del silenciamiento de genes y que además es una “slicer” que recluta miRNAs y corta al RNAm. La proteína AGO1 también está involucrada en la biogénesis de ta-siRNAs — los cuales participan en PTGS — derivados de los genes TAS1 y TAS2, en asociación con miR173, ya que este complejo (AGO1/miR173) activa la ruta de biogénesis al escindir a los transcritos primarios de TAS1 y TAS2 (Figura 12) (Montgomery et al., 2008). 26 Figura 12. La proteína AGO1 inicia la ruta de biogénesis de ta-siRNAs. Tomada de Montgomery et al., 2008 27 III. PLANTEAMIENTO DEL PROBLEMA De manera general, la regulación de la expresión de genes se puede llevar a cabo a distintos niveles: a nivel transcripcional, post-transcripcional, traduccional y posttraduccional. En uno de los mecanismos de regulación a nivel post-transcripcional intervienen sRNAs de 21 a 22 nucleótidos conocidos como miRNAs, los cuales provocan la atenuación de la traducción o degradación de RNAm del gen blanco. Uno de los elementos clave de este proceso es una proteína de la familia ARGONAUTA, particularmente la proteína ARGONAUTA1 (AGO1) que es la efectora del silenciamiento de genes a nivel postranscripcional mediado por miRNAs. La proteína AGO1 y por ende el silenciamiento de genes por la vía de los miRNAs son importantes para el desarrollo de las plantas, ya que juegan un papel relevante en su desarrollo, en la diferenciación de órganos, en el cambio de fase, en la transducción de señales y en la respuesta ante estímulos ambientales. La familia de proteínas ARGONAUTA se encuentra conservada en todos los dominios de la vida e incluso el genoma de un mismo organismo codifica más de una proteína AGO. Actualmente se conoce el número de proteínas de esta familia que existen en animales como C. elegans, D. melanogaster y en plantas superiores como en Arabidopsis, arroz o maíz, e incluso ya se sabe la función de alguna de estas proteínas en cada una de estas especies. Sin embargo la presencia de genes que codifiquen a las proteínas de la familia AGO en el linaje más basal de las plantas terrestres no ha sido reportada previamente, así que en el presente trabajo se pretende identificar y caracterizar la estructura del gen ARGONAUTA1 que codifica a la proteína AGO1 de M. polymorpha ya que esta es la planta terrestre más ancestral y descendiente directo de las primeras plantas que colonizaron los ambientes terrestres. 28 IV. HIPÓTESIS El gen ARGONAUTA1, cuya función es esencial para el adecuado desarrollo de Arabidopsis thaliana, se encuentra conservado en el genoma de la planta ancestral Marchantia polymorpha. V. OBJETIVOS Objetivo general Identificar y caracterizar estructuralmente, el gen ARGONAUTA1 de Marchantia polymorpha. Objetivos particulares Realizar un análisis computacional para tratar de identificar un transcrito similar a ARGONAUTA1 (AGO1) de A. thaliana, en el transcriptoma y el genoma de M. polymorpha. Diseñar oligonucleótidos para amplificar el gen AGO1 de M. polymorpha (MpAGO1). Obtener por transcripción reversa el cDNA del gen MpAGO1 y amplificarlo por PCR (ensayos tipo RT-PCR). Clonar el cDNA de MpAGO1 en un plásmido bacteriano. Secuenciar el gen MpAGO1. Obtener el perfil de expresión del gen MpAGO1 en tejidos vegetativos y reproductivos de M. polymorpha. Generar un modelo de la estructura genómica del gen MpAGO1. 29 Determinar los dominios estructurales de la proteína MpAGO1. Realizar un análisis de genómica comparativa entre el gen MpAGO1 y los genes similares a AGO1 en los genomas de las plantas terrestres, mejor anotados y disponibles en bases de datos públicas. 30 VI. MATERIAL Y MÉTODOS 6.1. Búsqueda e identificación del gen ARGONAUTA1 de M. polymorpha. La búsqueda del gen MpAGO1 se realizó empleando el algoritmo tblastn (sin modificación de parámetros) (versión blast 2.2.4), usando la secuencia de aminoácidos del dominio PIWI de la proteína AGO1 de Arabidopsis (AthAGO1) como secuencia query para compararla contra el transcriptoma de M. polymorpha. Los transcritos con mayor porcentaje de identidad con PIWI de AthAGO1 fueron leídos en sus 6 marcos abiertos de lectura (de sus siglas ORF, del inglés Open Reading Frame) empleando la herramienta ORF Finder del NCBI (http://www.ncbi.nlm.nih.gov/gorf/gorf.html) con el fin de encontrar el sitio de inicio y final de la traducción. Estos transcritos fueron mapeados contra el genoma de M. polymorpha (datos confidenciales sin publicar) empleando el algoritmo megablast (versión blast 2.2.4) para encontrar la estructura genómica de exones, intrones, regiones 5’UTR y 3’UTR. 6.2. Material vegetal y condiciones de crecimiento. Las plantas de M. polymorpha, tanto macho y hembra, son mantenidas asexualmente propagadas por crecimiento de gemas. Las plantas son cultivadas usando el medio B5 de Gamborg a concentración media suplementado con agar al 1.3% (w/v). El pH es ajustado a 5.7 con KOH antes de la esterilización. Las plantas son crecidas bajo 50-60 µmol de fotones m-2s-1 continuos con luz blanca fluorescente a 22°C en una cámara de crecimiento. Para la inducción de las estructuras reproductivas las plantas se retiraron de las cámaras después de 3 semanas de crecimiento, y se colocaron en estantes con lámparas que emiten luz blanca fluorescente y que se encuentran en un cuarto a 22°C emulando las condiciones de la cámara y adicionalmente se expusieron a la luz roja lejana (FR) usando FR-LEDs (MILIF18, Sanyo Electric Biomedical, Osaka Japan; peak emission at 734 nm, a half-bandwidth in 13 nm, 15 µmol photons m-2s-1). 31 6.3. Colecta de tejido de M. polymorpha para obtener el perfil de expresión del gen MpAGO1. Para obtener el perfil de expresión del gen MpAGO1 se colectaron muestras de los siguientes tejidos: gemas, talos de 7 y 14 días, anteridióforos y arquegonióforos; inmediatamente se congelaron con nitrógeno líquido y se almacenaron a -80°C hasta su procesamiento. 6.4. Diseño de iniciadores para la amplificación de la secuencia codificante (CDS) y una región del extremo 3’UTR de MpAGO1 A partir de la secuencia de AGO00546 a la que nosotros denominamos MpAGO1, se diseñaron oligonucleótidos sentido y antisentido para amplificar mediante PCR el CDS completo y una región del extremo 3’UTR de MpAGO1. Los oligonucleótidos fueron diseñados empleando el software SnapGene (ver 2.5) y Primer3 (ver 4.0.0) con una Tm de 60°C para todos. En la Tabla 1 se muestran las características de cada uno de estos oligonucleótidos. 6.5. Aislamiento de RNA total de M. polymorpha. La extracción de RNA Total se realizó con el reactivo TRIzol (Invitrogen Life Technologies) a partir de 300 mg de una mezcla de tejidos de M. polymorpha, genotipo Tak-1, que contenía estructuras reproductivas (anteridióforos), conceptáculos con gemas y talos maduros. La extracción se hizo empleando ocho muestras con el contenido anterior. El tejido fue criogenizado con nitrógeno líquido y triturado en un mortero hasta conseguir un polvo fino, este fue colectado en un tubo de 1.5 mL, se le agregó 1 mL de TRIzol, fue homogeneizado con vortex y centrifugado a 12,000 rpm durante 10 minutos a 4°C. El sobrenadante fue transferido a un tubo nuevo al que se adicionaron 200 µL de cloroformo (Sigma-Aldrich) para después agitarlo vigorosamente e incubarlo 5 minutos a temperatura ambiente. Posteriormente, fue centrifugado a 12,000 rpm durante 15 minutos a 4°C. Se recuperaron 500 µL de sobrenadante en un 32 tubo nuevo y el RNA fue precipitado con 1 volumen de isopropanol (J.T. Baker) incubándolo a temperatura ambiente por 10 minutos, posteriormente fue centrifugado a 12,000 rpm durante 10 minutos a 4°C. El sobrenadante fue removido y la pastilla fue lavada con etanol al 75% con vortex, después fue centrifugada por 5 minutos a 120000 rpm a 4°C. Finalmente se eliminó el alcohol y la pastilla de RNA fue resuspendida en 30 µL de agua libre de nucleasas. La concentración y calidad del RNA total fue determinada mediante espectrofotometría usando el espectrofotómetro NanoDrop 2000 (Thermo Scientific). Para determinar la integridad del RNA se hizo un gel de agarosa al 2% en TBE 1X teñido con bromuro de etidio (10mg/ µL), se hicieron los cálculos para tener una concentración total de 200 ng de RNA en cada pozo con el fin de igualar las cargas, las muestras fueron incubadas a 65°C durante 5 minutos con el buffer de carga e incubadas en hielo antes de realizar la electroforesis. 6.6. Transcripción reversa acoplada a la reacción en cadena de la polimerasa (RT-PCR). 6.6.1. Trascripción Reversa (RT). Antes de llevar a cabo la RT, el RNA extraído anteriormente se incubó con DNasaI (Invitrogen Life Technologies): en un tubo de 200 µL se añadieron 2 µL de RNA (1ug), 1 µL de buffer (10x DNaseI Reaction Buffer), 1 µL de DNasaI (1 U/ µL) y 6 µL de agua libre de nucleasas para un volumen final de 10 µL. La reacción se incubó durante 15 minutos a temperatura ambiente, para inactivar la enzima se agregó al tubo 1 µL de EDTA 25 mM y se incubo 10 minutos a 65°C. Este RNA tratado con DNasa se utilizó para la síntesis del DNA complementario (cDNA): a un tubo de 200 µL se agregaron 5 µL de RNA, 1 µL del oligo dT y 6 µL de agua para tener un volumen final de 12 µL, la reacción fue incubada durante 5 minutos a 65°C en un termociclador (Eppendorf Mastercycler gradient), se colocó en hielo 2 minutos y al mismo tubo de reacción se añadió lo siguiente: 4 µL de buffer 5X, 2 µL de dNTP’s 100 µM, 1 µL de la enzima Revert Aid H Minus (Thermo Scientific) y 1µL de la enzima Ribolock RNasa (Thermo Scientific), para un volumen final de 10 µL, la reacción se mezcló por pipeteo y se 33 incubó en un termociclador a 42°C durante 60 minutos y una temperatura final de 72°C por 5 minutos. 6.6.2. Reacción en cadena de la polimerasa (PCR). El cDNA sintetizado se utilizó para amplificar el CDS completo del gen MpAGO1, que tiene un tamaño de 3,330 pb. Para llevar a cabo la reacción se utilizó como molde el cDNA sintetizado. A un tubo de 500 µL se añadió lo siguiente: 4 µL de buffer 5X HF, 0.4 µL de dNTPs 10 mM, 1 µL del iniciador sentido a 10 pM/ µL (MAV84F), 1 µL del iniciador antisentido a 10 pM/ µL (MAV84R), 0.2 µL de la enzima Phusion High-Fidelity DNA Polymerase (New England BioLabs), 12.4 µL de agua libre de nucleasas y 1 µL de cDNA. Se prepararon 6 tubos con 20 µL cada uno de la mezcla de reacción anterior. Las reacciones se incubaron en un termociclador (Bio-Rad) con el siguiente programa: 1 ciclo de 98°C durante 3 minutos, 35 ciclos de 98°C por 1minuto, 58°C por 30 segundos y 72°c por 2 minutos, 1 ciclo de 72°C por 5 minutos y se mantuvieron a una temperatura final de 4°C. Los productos de PCR fueron analizados en un gel de agarosa 0.8% en buffer TBE 1X teñido con bromuro de etidio 10mg/ µL. Dado que la enzima utilizada deja extremos romos y el producto de PCR fue utilizado para ligarlo a un vector linearizado que en sus extremos tiene colas de timina (T), al producto de PCR se le agregaron las colas de poli-A en el extremo 3’ mediante la reacción de Taq Fill-in; para esto los productos fueron colectados en un mismo tubo y se purificaron usando el QIAqucik PCR Purification Kit (QIAGEN) (ver Anexo 2), en un tubo de 200 µL se agregaron 25 µL del producto purificado y 25 µL de GoTaq Green Master Mix 2X (Promega), la reacción fue incubada en un termociclador durante a 72°C por 20 minutos. Después de agregar las colas de poli-A en 3’ el producto fue purificado. 6.7. Reacción de ligación. La reacción de ligación al vector pGEM-T (Figura 34) (Promega) (ver Anexo 3) para clonar el CDS de MpAGO1 se hizo con la enzima T4 DNA ligasa siguiendo las instrucciones del fabricante (ver Anexo 4). Para hacer la ligación se empleó una 34 relación molar vector:inserto 1:3, y las cantidades fueron calculadas empleando la siguiente fórmula: 6.8. Transformación de células electrocompetentes. Para la transformación se usaron bacterias Escherichia coli de la cepa DH5α preparadas en el laboratorio (ver anexo 5). Previo a la transformación la reacción de ligación se dializó con una membrana con poros de 0.025 µm. Se descongelaron 50 µL de células electrocompetentes y en el mismo tubo se agregaron 3 µL de la ligación previamente dializada. Esta mezcla se incubó 2 minutos en hielo y se transfirió a una cubeta de electroporación estéril y fría, la cubeta se colocó en el electrodo del electroporador (BioRad Micropulser) y se le aplicó un pulso de 1.8 kV durante 5.8 milisegundos inmediatamente después del pulso, a la solución de bacterias se le añadió 1 mL de medio SOC y se incubó durante 90 minutos a 37°C con agitación, transcurrido el lapso de incubación las bacterias se sembraron en placas con medio de cultivo LB/Agar/Ampicilina/IPTG/X-gal (ver en Anexo 6 la preparación). Las placas se incubaron a 37°C por 16 horas. 6.9. Escrutinio de clonas. Las colonias obtenidas se analizaron por el método de escrutinio azul-blanco (ver Anexo 7), de las clonas se extrajo DNA plasmídico por el método de lisis alcalina (ver anexo 8). Para hacer el análisis de las clonas positivas se hicieron digestiones con diferentes enzimas de restricción. Las clonas que resultaron positivas se propagaron y los plásmidos fueron extraídos utilizando el QIAprep Spin Miniprep Kit (QIAGEN) (ver Anexo 9) y enviadas a secuenciar a la unidad de Servicios Genómicos del LANGEBIO Irapuato. 35 6.10. RT-PCR para el perfil de expresión de MpAGO1. La extracción de RNA total para cada muestra de tejido se realizó siguiendo el mismo método del apartado 6.5 y la reacción de transcripción reversa se llevó a cabo con el protocolo del apartado 6.6.1 usando 1 µg de RNA por cada muestra. Para obtener el perfil de expresión, se amplificó un segmento del extremo 3’UTR de MpAGO1; como iniciador sentido se empleó el oligonucleótido MAV2F y como iniciador antisentido se empleó el oligonucleótido MAV2R. La reacción de PCR se realizó en un volumen total de 12 µL conteniendo lo siguiente: 6 µL de GoTaq Green Master Mix (Promega), 1 µL de iniciador sentido, 1 µL de iniciador antisentido, 1 µL de cDNA y 3 µL de agua libre de nucleasas. Las reacciones se incubaron en un termociclador (Eppendorf Mastercycler gradient) bajo las siguientes condiciones: 95°C 5 min; 35 ciclos de 95°C 30 segundos, 55°C 30 segundos y 72°C 30 segundos; 72°C 10 minutos y se mantuvieron a una temperatura final de 4°C. Los productos se analizaron en un gel de agarosa al 0.8% teñido con bromuro de etidio. 6.11. Análisis de la relación filogenética de MpAGO1 y las proteínas AGO1 de las plantas terrestres. Para hacer el análisis filogenético de la proteína AGO1 de las plantas terrestres primero se descargaron todas las secuencias de aminoácidos de la familia de proteínas AGO de las plantas disponibles en la base de datos especializada ChromDB (www.chromdb.org), que suman un total de 327 secuencias correspondientes a 38 diferentes especies de plantas que incluyen clorófitas, musgos, licófitas, gimnospermas y angiospermas. A estas secuencias se les sumó la secuencia de aminoácidos de MpAGO1 y fueron alineadas usando CLUSTALW y dado que MpAGO1 tiene un porcentaje de identidad del 71.09 % con AtAGO1, se eligieron las secuencias que tuvieran un porcentaje de identidad ≥ 70% con AtAGO1. De estas secuencias, se eligieron aquellas que contaran con dominios PAZ y PIWI y aquellas que solo contaran con uno de los dos dominios fueron descartadas. Al final, se tuvieron 24 secuencias en 36 total las cuales fueron alineadas nuevamente con el software CLUSTALW2 (Larkin et al., 2007), y la reconstrucción filogenética de la proteína AGO1 de las plantas terrestres se hizo empleado la paquetería de Phylip (PHYLogeny Inference Package) versión 3.69 (Felsenstein, 2009). Se hicieron 2000 réplicas de bootstrap con el programa Seqboot, después se hizo el cálculo de distancias usando una matriz por bloques (PMB) en el programa Protdist, con las matrices de distancias generadas se hizo la construcción de árboles filogenéticos empleando el modelo Neighbor-joining y como grupo externo se utilizó la secuencia de AGO1 de D. melanogaster. Para la elección del mejor árbol se usó el programa Consense siguiendo el criterio de la mayoría. Finalmente la visualización y edición del árbol filogenético se hizo con el programa FigTree versión 1.4.0 (Rambaut, 2012). 6.12. Determinación de los dominios estructurales de la proteína MpAGO1. La identificación de los dominios estructurales se realizó empleado la secuencia de aminoácidos de la proteína MpAGO1 y haciendo uso de la base de datos Conserved Domains Database (CCD) del NCBI, la cual es específica para diferentes proteínas: PAZ (Cd02846) de la superfamilia (Cl00301), PIWI (Cd04657) (Marchler-Bauer et al., 2005). El modelo tridimensional de la proteína MpAGO1 fue construido empleando el servidor PHYRE2 (Kelley y Sternberg, 2009), el cual nos proporciona la estructura tridimensional en formato PDB, este resultado fue cargado en el software YASARA (Krieger et al., 2002) para dibujar y editar la estructura tridimensional y asignar los dominios estructurales N-terminal, PAZ, MID y PIWI de la proteína MpAGO1. 37 VII. RESULTADOS 7.1. Identificación del gen ARGONAUTA1 de M. polymorpha. El primer paso de esta investigación fue la identificación de transcritos similares al gen AtAGO1 en el transcriptoma de M. polymorpha. Encontramos 5 transcritos con altos porcentajes de similitud a AtAGO1 y estos fueron mapeados en el genoma de M. polymorpha para identificar su estructura genómica completa. Mediante análisis filogenéticos se determinó que solo uno de estos transcritos era el ortólogo de AtAGO1 y se le denominó inicialmente AGO00546 con base en el número de registro del transcrito en el transcriptoma de M. polymorpha. 7.2. Oligonucleótidos empleados para la amplificación de la secuencia codificante y una región del extremo 3’UTR de MpAGO1. Todos los oligonucleótidos fueron diseñados con una Tm de 60°C, en la Tabla 1 se detallan las características de cada uno de estos. Tabla 1. Características de los oligonucleótidos para la amplificación del CDS del gen MpAGO1 y la región 3’UTR Iniciador Secuencia Tm Número °C de bases MAV84F ATGCCGAGACGGCGGA 60 16 MAV84R TCAACAATAAAACATTACCTTTTTTACATTTTCCTTCAACG 60 41 MAV2F TGTTCCCCCAGCCTATTATG 60 20 MAV2R CTCGGTAGAGGGAGGAAACC 60 20 38 7.3. Aislamiento de RNA total de M. polymorpha. En la Figura 13 se muestra el resultado de la electroforesis en gel de agarosa del RNA total extraído de varias muestras de una mezcla de tejidos de M. polymorpha, en dicha imagen se pude apreciar que no hay señales aparentes de degradación y que el RNA se encuentra íntegro y que por lo tanto puede ser empleado para la amplificación del CDS de MpAGO1. La concentración de cada muestra y los datos de la pureza del RNA se muestran en el Anexo1. Figura 13. Análisis electroforético del RNA total extraído de tejido de M. polymorpha. Gel de agarosa al 2% TBE1X. Teñido con Bromuro de Etidio 7.4. Amplificación de la secuencia codificante de MpAGO1 (CDSMpAGO1) por RT-PCR. Se utilizó una muestra del RNA extraído para sintetizar el cDNA el cual se usó como molde para la amplificación del CDS de MpAGO1 mediante PCR con la enzima de alta fidelidad Phusion (New England Biolabs). Las mezclas de reacción se especifican en los Materiales y Métodos. Las temperaturas y los tiempos para cada una de las etapas de PCR se especifican también en el mismo apartado y los amplicones se muestran en la Figura 14. El CDS de MpAGO1 posee una longitud de 3,330 pb y el 39 análisis electroforético confirma que se obtuvieron los fragmentos con el tamaño esperado. Figura 14. Análisis electroforético de los productos de amplificación del CDS de MpAGO1. Gel de agarosa al 0.8% en TBE1X teñido con bromuro de etidio que muestra los productos de PCR obtenidos del CDS de MpAGO1 (3,330 pb). 7.4. Clonación del CDS de MpAGO1. Al producto de PCR del CDSMpAGO1 se le agregó la cola de poli-A y después de subsecuentes purificaciones y la cuantificación del mismo, este fue ligado al vector pGEM®-T Easy. La reacción de ligación se realizó con una relación 3:1 inserto:vector y finalmente la reacción se hizo con 25 ng de vector y 83 ng de inserto, en la Figura 15 se 40 muestra un esquema de la clonación. Las proporciones fueron calculadas de la siguiente forma: Figura 15. Esquema de la clonación del CDS de MpAGO1. A) CDS del gen MpAGO1 obtenido por PCR, B) CDS con colas de poli-A en 3’. C) Vector p-GEM linearizado. D) Construcción pGEM-CDSMpAGO1. 41 7.5. Caracterización de las clonas recombinantes Antes de iniciar con la caracterización de las clonas se generaron dos mapas de la construcción pGEM-CDSMpAGO1 con el software SnapGene®, cada uno con el CDS de MpAGO1 en diferente orientación y en ellos se muestran los sitios de corte de las diferentes enzimas que fueron utilizadas para su caracterización, y una enzima adicional que nos indica la orientación del inserto (Figura 16). Ambas construcciones tiene un tamaño de 6347 pb. Figura 16. Mapas de la construcción pGEM-CDSMpAGO1. A) CDS en posición 3’-5’ con respecto al promotor T7, B) CDS en posición 5’-3’ con respecto al promotor T7. Con el mismo software se generó un mapa de restricción in silico de ambas construcciones (Figura 17) para emplearlo como referencia al hacer las restricciones de los plásmidos. En este mapa de restricción se incluyen las enzimas EcoRI, PvuII, HindIII y para determinar la orientación del insertó se utilizó la enzima SacI, ya que ésta es una de las enzimas que genera un patrón diferencial de fragmentos para las construcciones de la Figura 16. 42 Figura 17. Mapa de restricción de la construcción pGEM-CDSMpAGO1. Ambas construcción generan fragmentos del mismo tamaño cuando son digeridos con EcoRI, PvuII y HindIII, sin embargo cuando son digeridos con SacI si hay un patrón de restricción diferente. Estos mapas fueron validados experimentalmente y para ello se extrajeron plásmidos de las clonas obtenidas mediante el método de lisis alcalina y se analizaron por electroforesis en gel de agarosa (Figura 18). Los plásmidos no fueron cuantificados debido a que el método de extracción utilizado los deja con impurezas 43 Figura 18. DNA plasmídico extraído de las colonias transformantes. Se analizaron los plásmidos extraídos de 10 colonias cuyo color era de diferentes tonalidades de azul. Gel de agarosa al 0.8% teñido con bromuro de etidio. Todos los plásmidos extraídos fueron digeridos con la enzima EcoRI para verificar que tuvieran el inserto y catalogar a las clonas como positivas o negativas. Los plásmidos digeridos fueron analizados en un gel de agarosa y como se puede apreciar en la Figura 19 todas las clonas son positivas, ya que muestran el patrón esperado: tres bandas una en 2997 pb, otra en 2368 pb y uno más de 982 pb. Dos de las clonas positivas fueron resembradas en medio líquido y se extrajeron plásmidos empleando el QIAqucik PCR Purification Kit (QIAGEN), de esta manera se obtuvieron plásmidos libres de impurezas y pudieron ser cuantificados, en la Tabla 2 se muestra la concentración de los plásmidos. Estos plásmidos se caracterizaron por el patrón de restricción de las 4 enzimas antes mencionadas y además se determinó la orientación del inserto (Figura 20). 44 Figura 19. Plásmidos digeridos con la enzima EcoRI. Las restricciones muestran el patrón de bandas esperado y estan enumerados en la misma secuencia en la que aparecen en la restricción in silico (Figura 17). Todas las clonas tienen el inserto. Figura 20. Caracterización de la construcción pGEM-CDSMpAGO1. Análisis electroforético en gel de agarosa al 0.8% TBE1X teñido con Bromuro de Etidio, de las restricciones de la construcción pGEM-CDSMpAGO1. El plásmido fue digerido con 4 enzimas diferentes, EcoRI, PvuII, HindIII y SacI, obteniendo un patrón de restricción igual al generado in silico (Figura 17), la enzima SacI indica la orientación del plásmido, para la construcción con el CDS en la orientacion 5’-3’ genera dos fragmentos de 5018 y 1329 pbn, mientras que para la construcción en la orientación 3’-5’, genera fragmentos de 4250 y 2097 pb. El resto de las enzimas usadas genran un patrón similar para ambas construcciones. 45 Tabla 2. Concentración de los plásmidos extraídos. Los plásmidos fueron extraídos de las transformantes con la construcción pGEM-CDSMpAGO1. Muestra Concentración Unidades A260 A280 260/280 260/230 Factor AGO1-1 466.5 ng/µL 9.33 4.968 1.88 2.19 50 AGO1-2 479.9 ng/µL 9.598 5.13 1.87 2.26 50 Después de haber caracterizado los plásmidos por restricción con diferentes enzimas, estos fueron enviados a secuenciar a la Unidad de Servicios Genómicos del LANGEBIO CINVESTAV-Campus Guanajuato (http://langebio.cinvestav.mx/labsergen/). Para la secuenciación se diseñaron 7 pares de oligonucleótidos que amplifican segmentos del CDS de MpAGO1, cuya secuencia de sobrelapara una con otra y fuera sencillo ensamblar la secuencia completa del CDS. En la Tabla 3 se muestran las características de los oligonucleótidos y en la Figura 21 los amplicones obtenidos con cada par de iniciadores. 46 Tabla 3. Secuencia de los oligonucleótidos empleados para la secuenciación del CDSMpAGO1 Iniciador Secuencia Tm Longitud °C pb AGO1-seq-F1 ATGCCGAGACGGCGGA 58 16 AGO1-seq-R1 TAGTTGGGTAGGGGCCATTGTAG 58 23 AGO1-seq-F2 ACAATTAGGACGCGCACCAG 58 20 AGO1-seq-R2 CCTTGAAGAAACTGGCCTAGGTGATG 58 26 AGO1-seq-F3 AAGATGGCAGCAGCACTCCT 58 20 AGO1-seq-R3 GGTTTCGAATGGTGTACTGATACGTCTC 58 28 AGO1-seq-F4 CAGCCGACCCAAGAGTTGTCC 58 21 AGO1-seq-R4 CACAGGTTCTTGGTTGAAATGCATTCC 58 27 AGO1-seq-F5 TTGTATGGAGCTCGCTCAGATGTG 58 24 AGO1-seq-R5 TGCCGATGTGCCTGTGC 58 17 AGO1-seq-F6 TGGTCGCTTCCCAAGATTGGC 58 21 AGO1-seq-R6 AGACAGATCGTGTGCACCGC 58 20 AGO1-seq-F7 GGCCGATGAACTTCAGTCTT 58 20 AGO1-seq-R7 CATTTTCCTTCAACGGTGGT 58 20 47 Figura 21. Productos de PCR de los oligonucleótidos para secuenciación del CDSMpAGO1. Los productos de PCR fueron analizados en un gel de agarosa al 2% TBE 1X teñido con Bromuro de Etidio y como se puede apreciar estos tienen el tamaño esperado. 48 7.6. Perfil de expresión de MpAGO1 en diferentes tejidos. Se analizó el perfil de expresión de MpAGO1 en tejido vegetativo (gemas, talos de 7 y 14 días) y reproductivo (anteridióforos y arquegonióforos). Pata tal fin se amplificó un segmento de extremo 3’UTR de MpAGO1 con un tamaño de 450 pb, como control se amplifico el CDS del Factor de Elongación 1 de M. polymorpha (MpEF1 CDS), cuya expresión es constitutiva, demostrando que el gen MpAGO1 se expresa prácticamente a los mismos niveles tanto en tejido vegetativo como en tejido reproductivo (Figura 22). Figura 22. Perfil de expresión de MpAGO1 en diferentes tejidos. El gen MpAGO1 se expresa de manera constitutiva en tejido vegetativo y en tejido reproductivo. 49 7.7. Estructura del gen MpAGO1 Con la secuencia obtenida del CDS de MpAGO1 validamos la información genómica y transcriptómica. Con esta secuencia se generó la estructura del gen MpAGO1, la cual en total tiene una longitud de 13.2 kb que consta de 22 exones, 22 intrones, un extremo 5’UTR de 332 pb, un extremo 3’UTR de 450 pb, una secuencia codificante de 3.3 Kb y codifica a una proteína de 1109 aminoácidos (Figura 23). Figura 23. Estructura genómica de MpAGO1. Los exones se muestran en color gris, los espacios en color azul corresponden a los intrones, las regiones 5’y 3’’ UTR en rosa y verde respectivamente. También se señalan los exones que comprenden los dominios PAZ y PIWI. El esquema de la estructura de MpAGO1 fue generada con el programa DOG (Domain Graph, versión 1.0) (Ren et al., 2009). Utilizando la secuencia traducida de aminoácidos del gen MpAGO1 se hizo un alineamiento en ClustalX con las secuencias en aminoácidos de los genes similares a AGO1 en los genomas de las plantas terrestres mejor anotados y disponibles en las bases de datos públicas, y los resultados arrojados por este alineamiento indican que el gen MpAGO1 se encuentra muy bien conservado desde las briofitas hasta las angiospermas como se puede apreciar en la Figura 24 en la cual solo se muestra la región correspondiente al dominio PIWI, también se resaltan las posiciones de la triada catalítica DDH y estos residuos se encuentran igualmente conservados en todas las 50 proteínas similares a MpAGO1. En el Anexo 10 se indican los nombres de las especies a las que pertenecen las secuencias empleadas en el alineamiento. 51 Figura 24. Alineamiento de la región correspondiente al dominio PIWI, el cual actúa como centro catalítico en la proteína AGO1. Las posiciones de los residuos catalíticos Asp, Asp, His (DDH) son señalados por las flechas en color negro. En rojo se remarca MpAGO1 y en azul AtAGO1 7.8. Análisis filogenético de MpAGO1 y sus homólogos en las plantas terrestres. Se generó un árbol filogenético de distancias tipo Neighbor-Joinnig empleando matriz por bloques con 2000 réplicas de bootstrap, todo esto se hizo empleando algunos de los programas de la paquetería de Phylip versión 3.69. Como grupo externo o raíz se usó la secuencia en aminoácidos de la proteína AGO1 de D. melanogaster. El árbol filogenético generado ubica a MpAGO1 en el clado más basal de las plantas terrestres (Figura 25), el clado de las briófitas, y en ese mismo clado también se encuentra la proteína AGO1 del musgo Physcomitrella patens, esto sugiere que MpAGO1 surgió temprano en la evolución y mucho antes de que divergieran el resto de las plantas terrestres y que posiblemente al función del gen AGO1 se encuentra conservada desde las briofitas hasta las angiospermas. 52 Figura 25. Análisis filogenético de MpAGO1 y sus homólogos en diversas especies de plantas terrestres. 53 7.9. Análisis de los dominios estructurales de la proteína MpAGO1 y sus homólogos en las plantas terrestres. La búsqueda de los dominios estructurales de la proteína MpAGO1 se hizo en la base de datos de Dominios Conservados (CDD) del Centro Nacional de Información para la Biotecnología (NCBI) y se encontró que la secuencia de MpAGO1 presenta tres dominios: un dominio DUF185 (Pfam08699) del cual hasta el momento no se conoce su función (DUF, Domain Unknown Function), y también es conocido como Linker-1, un dominio PAZ (Cd02846) el cual interactúa con el extremo 3’ del RNA pequeño, y un dominio PIWI (Cd004657) cuya función en la mayoría de las proteínas AGO tiene actividad catalítica. El dominio MID no fue identificado por la base de datos en la secuencia de aminoácidos, sin embargo después de hacer un alineamiento de la secuencia que comprende el dominio MID en Arabidopsis con la secuencia del dominio PIWI de MpAGO1 se encontró que el dominio MID abarca una región dentro de la secuencia completa que la base de datos reportó como dominio PIWI, mientras que el dominio N-terminal se tomó como la secuencia de aminoácidos que abarca desde el Ala235 hasta el inicio del domino DUF185, ya que al hacer el alineamiento con las proteínas similares a MpAGO1 la región que abarca los aminoácidos 1 a 234 quedan fuera del alineamiento, del mismo modo cuando se generó el modelo tridimensional de la proteína MpAGO1, el software generó la estructura a partir de Ala235. La región entre el final del dominio PAZ y el inicio del dominio MID fue asignada como el Linker-2, región que ha sido reportada en todos los modelos de proteínas AGO generados a partir de cristalografía de rayos X. También se buscó la posición de los residuos catalíticos en el dominio PIWI de MpAGO1 y se encontró que estos se encuentran perfectamente conservados ya que la triada Asp-Asp-His (DDH) está presente en esta proteína, en las posiciones 817, 903 y 1043 respectivamente. En la Figura 26 se muestra la distribución de estos dominios estructurales en MpAGO1. 54 Figura 26. Dominios estructurales de MpAGO1. Los rectángulos coloreados muestran la identidad de los dominios estructurales. Las letras D y H sobre el dominio PIWI representan la triada catalítica. Debajo de cada letra se indica la posición de los residuo en el CDS de MpAGO1 7.10. Conservación de la arquitectura de los dominios estructurales entre MpAGO1 y sus homólogos en las plantas terrestres. Para evaluar que tan conservada se encuentra la arquitectura de los dominios estructurales de entre MpAGO1 y las proteínas similares en las plantas terrestres, se identificaron los dominios estructurales de todas las secuencias de aminoácidos empleadas para el análisis filogenético y se compararon con los dominios de MpAGO1 (Figura 27). Los dominios comparados fueron PAZ, MID y PIWI, y se compararon a nivel de longitud de secuencia. Encontramos que prácticamente estos dominios se encuentran conservados desde las briófitas hasta las angiospermas, además también se encuentran conservados los residuos catalíticos DDH. 55 Figura 27. Organización y conservación de los dominios estructurales de MpAGO1 y sus homólogos en las plantas terrestres. Los dominios se encuentran conservados desde las birófitas hasta la angiospermas. Los residuos catalíticos que participan en la esción del RNA pequeños también se encuentran conservados. Dado que el alineamiento de MpAGO1 con sus homólogos reveló que la triada de residuos catalíticos se encuentra perfectamente conservada, se decidió hacer una alineamiento más de MpAGO1 con las proteínas de la familia AGO que ya se ha probado experimentalmente su actividad catalítica, así que se hizo un alineamiento de MpAGO1 con las proteínas AGO1 y AGO4 de Arabidopsis, AGO2 de H. sapiens y la única proteína AGO de S. pombe. Observamos que los residuos catalíticos e incluso la región alrededor de los mismos también se mantiene conservada (Figura 28), sugiriendo que MpAGO1 podría también podría tener actividad catalítica. 56 Figura 28. Representación esquemática de los dominios de MpAGO1, AtAGO1, AtAGO4, HsAGO2 y SpAGO1. Acercamiento a los residuos catalíticos conservados DDH y secuencias flanqueantes. El grado de similitud se indica en la parte superior del alineamiento: un asterisco indica identidad de toda la secuencia, dos puntos indican sustitución conservativa, un punto indica sustitución semi-conservativa. 7.11. Modelo de la estructura tridimensional de MpAGO1. Los resultados anteriores indican que la secuencia de aminoácidos de MpAGO1 se encuentra ultraconservada tanto en la organización de los dominios estructurales como en la presencia de la tríada de residuos catalíticos. Para evaluar la conservación a nivel de la estructura tridimensional se generó un modelo in silico de la estructura proteica de MpAGO1 (Figura 29) usando el servidor Phyre2, el cual construye el modelo tridimensional de la proteína a partir de las estructuras de proteínas determinadas experimentalmente y que son depositadas en las bases de datos Clasificación Estructural de las Proteínas (SCOP) (http://scop.mrc-lmb.cam.ac.uk/scop/)y en el Banco de Datos de Proteínas (PDB) (http://www.rcsb.org/pdb/home/home.do) ; la estructura de MpAGO1 fue construida por el servidor Phyre2 a partir de las estructuras de la proteínas AGO eucariotas HsAGO2 y Argonauta de K. polysporus, y de las Argonautas procariotas T. thermophilus y P. furiosus, las cuales ya fueron determinadas 57 estructuralmente. La edición y asignación de los dominios se hizo con el software YASARA (http://www.yasara.org/). La proteína MpAGO1 tiene un peso molecular de 93.719 kDa y un punto isoeléctrico de 9.6, estos valores fueron calculados con el software YASARA y la herramienta Compute pI/MW del servidor ExPASy (http://web.expasy.org/compute_pi/) En la Tabla 4 se resumen las características del gen MpAGO1 y la proteína MpAGO1. Tabla 4. Resumen de las características del gen MpAGO1 y su proteína. Nombre Nombre del Longitud Longitud del gen transcrito del gen del CDS Longitud Peso Punto (pb) (pb) (a.a) molecular isoeléctrico Proteína Tipo (kDa) MpAGO1 AGO00546 12315 3330 1109 93.719 9.6 AGO1 En la Figura 30 se muestra la ubicación de los residuos catalíticos Asp-Asp-His en el sitio activo de la proteína MpAGO1. 58 Figura 29. Esquema y estructura proteica de MpAGO1. El dominio N es mostrado en color azul, el dominio PAZ en rojo, el dominio Mid en verde y el dominio PIWI en magenta. En un círculo se señala la ubicación del sitio activo. En el esquema de la organización de los dominios se indican los límites de cada uno, así como la posición de los residuos catalíticos. 59 Figura 30. Acercamiento a los residuos catalíticos en la estructura proteica de MpAGO1. En la proteína AtAGO1 estos residuos son escenciales para que lleve a cabo la actividad de escición del dúplex sRNA:RNAm. 60 De la misma forma en que se construyó el modelo de MpAGO1, también se generó la estructura proteica de AGO1 de Arabidopsis, ya que a pesar de ser la proteína AGO1 mejor estudiada hasta el momento no hay un modelo de la proteína completa, solo existe el modelo del dominio Mid; de esta manera se pudieron comparar ambas estructuras y analizar qué tan conservada se encuentra MpAGO1. En la Figura 31 se muestran las estructuras de ambas proteínas por separado y ambas tienen prácticamente la misma estructura. Usando el software YASARA se hizo una superimposición ambas estructuras (Figura 32) comprobando que la conservación de MpAGO1 no solo es a nivel de la secuencia de aminoácidos, sino también a nivel de la estructura protéica, también se hizo una acercamiento a la superimposición de los residuos catalíticos de ambas estructuras (Figura 33), y se encontró que estos se encuentran en posiciones muy similares en la conformación de la proteína, y ya que estos residuos son lo que le aportan la actividad catalítica a AtAGO1, se podría inferir que MpAGO1 también tiene actividad catalítica. Figura 31. Estructuras de MpAGO1 y AtAGO1. La asignación de los dominios para AtAGO1 es la misma que en MpAGO1 (Figura 29). 61 Figura 32. Superimposición de las estructuras de MpAGO1 y AtAGO1. 62 Figura 33. Superimposición de los residuos catalíticos de MpAGO1 y AtAGO1. Los residuos de MpAGO1 se encuentran en la misma región del dominio PIWI y en una posición similar a los de AtAGO1. MpAGO1: Asp817, Asp903, His1043; AtAGO1: Asp760, Asp846, His986. 63 VIII. DISCUSIÓN En las plantas, el silenciamiento de genes a nivel post-transcripcional dirigido por miRNAs regula diferentes procesos fisiológicos importantes para su adecuado desarrollo (Rogers y Chen., 2013). En Arabidopsis el silenciamiento de genes por miRNAs es efectuado por la proteína AGO1 (Vaucheret et al., 2004; Baumberger y Baulcombe, 2005). En este trabajo se identificó, clonó y secuenció el CDS completo del gen AGO1 de la planta ancestral M. polymorpha y mediante análisis de genómica comparativa se determinó que la secuencia completa de este gen consta de 12.3 Kb distribuida en 22 exones y 22 intrones y codifica una proteína de 1109 aminoácidos, proporciones similares a las del gen AGO1 de Arabidopsis (Bohmert et al., 1998) y a los genes AGO1 de otras plantas superiores (Kapoor et al., 2008; Qian et al., 2011; TianIong et al., 2011; Meng et al., 2013; Shao et al., 2013), además a nivel de la secuencia de aminoácidos se encuentra ultraconservada desde las briofitas hasta las angiospermas. En general, las proteínas de la familia AGO son de naturaleza básica (Carmell et al., 2002), al igual MpAGO1 pues la predicción de su punto isoeléctrico arrojó un valor de ~9.6 con un peso molecular de 93.7 kDa, y estos valores son similares a los que se obtuvieron in silico para varios miembros de la familia AGO en las plantas (Mirzaei et al., 2014); y aunque hasta ahora no se ha reportado la estructura cristalina de proteínas AGO de plantas, en 2005 Baumberger y Baulcombe reportaron que el peso de la proteína inmunoprecipitada FLAG-AGO1 de Arabidopsis era de 116kDa, el cual no es muy distante al inferido en este trabajo para MpAGO1. Las dominios PAZ y PIWI son característicos de las proteínas Argonautas (Cerutti et al., 2000) y son importantes durante el proceso de silenciamiento efectuado por estas proteínas. En esta familia de proteínas el dominio PAZ interactúa con el extremo 3’ del sRNA y lo ancla a la proteína AGO, mientras que el dominio PIWI que se pliega de forma similar a una RNasa H , lleva a cabo la escisión del dúplex sRNA/RNAm y es el que le aporta la actividad catalítica a la mayoría de las proteínas de esta familia (Mallory y Vaucheret., 2010); mediante un análisis bioinformático se determinó que estos dominios se encuentran conservados entre las proteínas AGO1 de M. polymorpha y Arabidopsis e incluso entre las proteínas similares a AGO1 en las plantas terrestres. La 64 elucidación de la estructura cristalina de proteínas AGO procariotas y eucariotas reporta la implicación de una triada de residuos catalíticos en la actividad de endonucleasa del dominio PIWI (Song et al., 2004; Yuan et al., 2005; Nakanishi et al., 2012; Faehnle et al., 2013). El dominio PIWI de las proteínas Argonautas de Arabidopsis contienen esta triada de residuos catalíticos (Asp-Asp-His [DDH]) conservada, y mutaciones en estos residuos indican que son necesarios para su actividad de endonucleasa (Baumberger y Baulcombe, 2005; Qi et al., 2006; Ji et al., 2011; Zhu et al., 2011). Esta triada de residuos catalíticos fue detectada en MpAGO1 y mediante análisis de genómica comparativa se encontró que estos se encuentran conservados en todas las proteínas similares de las plantas terrestres desde las briofitas hasta las angiospermas. El modelo de la estructura tridimensional de MpAGO1 reveló qué estos residuos se encuentra espacialmente muy cerca uno de otro en el sitio activo del dominio PIWI, y la superimposición con AGO1 de Arabidopsis demostró que se encuentran en la misma posición en el sitio activo. En Arabidopsis, el gen AGO1 se expresa constitutivamente en tejido vegetativo y reproductivo (Kapoor et al., 2008; Mallory y Vaucheret., 2010), las contrapartes de AGO1 en arroz (OsAGO1a y OsAGO1b) tienen un patrón de expresión similar en tejido vegetativo y reproductivo, con un ligero incremento en tejido meristemático (Kappor et al., 2008). En trigo, TaAGO1b se expresa de manera ubicua en tejido reproductivo y vegetativo (Meng et al., 2013). Nuestros resultados muestran que MpAGO1 se expresa constitutivamente en tejido reproductivo y vegetativo. Los resultados antes mencionados sugieren fuertemente que MpAGO1 tiene una función similar a AGO1 de Arabidopsis con un papel regulatorio importante en la ruta de silenciamiento de genes mediado por miRNAs. Actualmente, estamos empleando diversas estrategias de genómica funcional para determinar la función del gen AGO1 de M. polymorpha. 65 IX. CONCLUSIONES Clonamos y secuenciamos el CDS completo del gen MpAGO1 y determinamos sus características estructurales a nivel de la secuencia de nucleótidos y de la secuencia de aminoácidos. El gen MpAGO1 muestra una expresión constitutiva en tejido vegetativo y reproductivo, tiene una longitud de 12.3 kb y se encuentra constituido por 22 exones y 22 intrones. La secuencia codificante de MpAGO1 tiene una longitud de 3,330 pb. La proteína MpAGO1 está formada por 1,109 aminoácidos, tiene un peso molecular calculado de 93.719 kDa y un punto isoeléctrico de 9.6. La proteína MpAGO1 tiene los dominios característicos PAZ y PIWI de las proteínas AGO y también conserva los residuos catalíticos Asp-Asp-His (DDH). En conjunto estas características sugieren fuertemente que el gen MpAGO1 codifica una proteína AGO1 funcional. Nuestros resultados muestran que en el genoma de la planta ancestral M. polymorpha existen genes de la familia ARGONAUTA y que a pesar de la gran diversificación y subfuncionalización que ha experimentado la familia AGO en las plantas terrestres, existen genes ultraconservados evolutivamente como MpAGO1 cuya estructura proteica se ha conservado desde las primeras plantas que colonizaron los ambientes terrestres hasta las angiospermas. 66 X. BIBLIOGRAFÍA. Arteaga-Vázquez M, Caballero-Pérez J, Vielle-Calzada JP. A family of microRNAs present in plants and animals. Plant Cell. 2006. 18(12):3355-3369. Arteaga-Vázquez M. Estructuras reproductivas de M. polymorpha. México. 2013. Axtell MJ, Bartel DP. Antiquity of microRNAs and their targets in land plants. Plant Cell. 2005. 17: 1658-1673. Axtell MJ, Westholm OJ, Lai Ce. Vive la différence: biogenesis and evolution of microRNAs in plants and animals. Genome Biology. 2011. 12: 221. Axtell MJ. Classification and comparison of small RNAs from plants. Annu Rev Plant Biol. 2013. 64: 137-159. Bartel DP. MicroRNAs: genomics, biogenesis, mechanism, and function. Cell. 2004. 116(2): 281-297. Baumberger N, Baulcombe CD. Arabidopsis ARGONAUTE1 is an RNA slicer that selectively recruits microRNAs and short interfering RNAs. Proc Natl Acad Sci USA. 2005. 102(33): 11928-11933. Bell PR, Hemsley AR. Green plants: their origin and diversity. 2 da Ed. Cambridge. Cambridge University Press; 2000. Bohmert K, Camus I, Bellini C, Bocuhez D, Caboche M, Benning C. AGO1 defines a novel locus of Arabidopsis controlling leaf development. EMBO Journal. 1998. 17(1): 170-180. Boland A, Tritschler F, Heimstädt S, Izaurralde E, Weichenrieder O. Crystal structure and ligand binding of the MID domain of a eukaryotic Argonaute protein. EMBO Rep. 2010. 11(7): 522-527. Bowman JL, Floyd SK, Sakakibara K. Green genes-comparative genomics of the green branch of life. Cell. 2007. 129(2): 229-234. Brodersen P, Sakvarelidze-Achard L, Bruun-Rasmussen M, Dunoyer P, Yamamoto YY, Sieburth L, Voinnet O. Widespread translational inhibition by plant miRNAs and siRNAs. Science. 2008. 320 (5880): 1185-1190. Brodersen P, Voinnet O. The diversity of RNA silencing pathways in plants.Trends Genet. 2006. 22(5):268-280. Carmell MA, Xuan Z, Zhang MQ, Hannon GJ. The Argonaute family: tentacles that reach into RNAi, developmental control, stem cell maintenance, and tumorigenesis. Genes Dev. 2002. 16(21). 2733-2742. 67 Cerutti L, Mian N, Bateman A. Domains in gene silencing and cell differentiation proteins: the novel PAZ domain and redefinition of the Piwi domain. Trends Biochem Sci. 2000. 25(10): 481-482. Chen X. A microRNA as a translational repressor of APETALA2 in Arabidopsis flower development. Science. 2004. 303(5666):2022-2025. Chen X. Small RNAs and their roles in plant development. Annu. Rev. Cell. Dev. Biol. 2009. 35:21-44. Chiyoda S, Ishizaki K, Kataoka H, Yamato KT, Kohchi T. Direct transformation of the liverwort Marchantia polymorpha L. by particle bombardment using immature thalli developing from spores. Plant Cell Rep. 2008. 27(9): 1467-1473. Contreras-Cubas, C. Regulación de RNA mensajeros mediada por AGO1 y microRNAs en frijol (Phaseolus vulgaris). Tesis Doctoral Inédita. 2012. Universidad Nacional Autónoma de México. Cuperus JT, Fahlgren N, Carrington JC. Evolution and functional diversification of MIRNA genes. Plant Cell. 2011. 23(2): 431-442. Czech B, Hannon GJ. Small RNA sorting: matchmaking for Argonautes. Nat. Rev. Genet. 2011. 12(1): 19-31. Elbashir SM, Lendeckel W, Tuschl T. RNA interference is mediated by 21-ans 22nucleotide RNAs. Genes Dev. 2001. 15: 188-200. Faehnle CR, Elkayam E, Haase AD, Hannon GJ, Joshua-Tor L. The making of a slicer: activation of human Argonaute-1. Cell Rep. 2013. 3(6): 1901-1909. Fagard M, Boutet S, Morel JB, Bellini C, Vaucheret H. AGO1, QDE-2, and RDE-1 are related proteins required for post-transcriptional gene silencing in plants, quelling in fungi, and RNA interference in animals. Proc Natl Acad Sci U S A. 2000. 97(21): 11650-11654. Fang Y, Zhu RL, Mishler BD. Evolution of oleosin in land plants. PLoS One. 2014. 8;9(8):e103806. Farazi TA, Juranek SA, Tuschl T. The growing catalog of small RNAs and their association with distinct Argonaute/Piwi family members. Development. 2008. 135(7): 1201-1214. Fei Q, Xia R, Meyers BC. Phased, secondary, small interfering RNAs in posttranscriptional regulatory networks. Plant Cell. 2013. 25(7): 2400-2415. Felsenstein J. PHYLIP (Phylogeny Inference Package) version 3.69. 2009. Seattle: Department of Genetics, University of Washington. 68 Fire A, Albertson D, Harrison SW, Moerman DG. Production of antisense RNA leads to effective and specific inhibition of gene expression in C. elegans muscle. Development. 1991. 113 (2): 503-514. Fire A, Xu S, Montgomery MK, Kostas SA, Driver SE, Mello CC. Potent and specific genetic interference by double-stranded RNA in Caenorhabditis elegans. Nature. 1998. 391 (6669): 806-811. Flores-Sandoval, E. The role of auxin response in patterning the thallus of the liverwort Marchantia polymorpha. Tesis Doctoral Inédita. 2013. Monash University. Fujiwara T, Yada T. miRNA-target prediction based on transcripcional regulation. BMC Genomic. 2013. 14. 1-10. Goffinet B, Shaw AJ. Bryophyte biology. 2da Ed. Cambridge. Cambridge University Press; 2009. Graham LE, Wilcox LW, Cook ME, Gensel PG. Resistant tissues of modern marchantioid liverworts resemble enigmatic Early Paleozoic microfossils. Proc Natl Acad Sci U S A. 2004. 101(30):11025-11029. Griffiths-Jones S, Saini HK, van Dongen S, Enright AJ. miRBase: tools for microRNA genomics. Nucleic Acids Res. 2008. 36: D154-D158. Grishok A, Tabara H, Mello CC. Genetic requirements for inheritance of RNAi in C. elegans. Science. 2000. 287: 2494-2497. Guo S, Kemphues JK. par-1, a gene required for establishing polarity in C. elegans embryos, ecodnes a putative Ser/Thr kinase that is asymmetrically distributed. Cell. 1995. 81(4): 611-620. Hamilton AJ, Baulcombe DC. A species of small antisense RNA in posttranscriptional gene silencing in plants. Science. 1999. 286 (5441): 950-952. Han MH, Goud S, Song L, Fedoroff N. The Arabidopsis double-stranded RNA-binding protein HYL1 plays a role in microRNA mediated gene regulation. Proc. Natl. Acad. Sci. 2004. 101: 1093-1098. Hannon GJ. RNA interfernce. Nature. 2002. 418(6894). 224-251. Hauptmann J, Dueck A, Harlander S, Pfaff J, Merkl R, Meister G. Turning catalytically inactive human Argonaute proteins into active slicer enzymes. Nat Struct Mol Biol. 2013. 20(7): 814-817. Hunter C, Sun H, Poethig RS. The Arabidopsis heterochronic gene ZIPPY is an ARGONAUTE family member. Curr. Biol. 13(19): 1734-1739. Hutvanger G, Simard MJ. Argonaute proteins: key players in RNA silencing. Nat. Rev. Mol. Cell. Biol. 2008. 9(1): 22-32. 69 Ishizaki K, Chiyoda S, Yamato KT, Kohchi T. Agrobacterium-mediated transformation of the haploid liverwort Marchantia polymorpha L., an emerging model for plant biology. Plant Cell Physiol. 2008. 49(7):1084-1091. Ishizaki K, Johzuka-Hisatomi Y, Ishida S, Iida S, Kohchi T. Homologous recombinationmediated gene targeting in the liverwort Marchantia polymorpha L. Sci. Rep. 2013. 3. 1532. JGI Marchantia Genome http://www.jgi.doe.gov/sequencing/why/99191.html. sequencing effort: Ji L, Liu X, Yan J, Wang W, Yumul RE, Kim YJ, Dinh TT, Liu J, Cui X, Zheng B, Agarwal M, Liu C, Cao X, Tang G, Chen X. ARGONAUTE10 and ARGONAUTE1 regulate the termination of floral stem cells through two microRNAs in Arabidopsis. PLoS Genet. 2011. 7(3):e1001358. Jones-Rhoades MW, Bartel DP, Bartel B. MicroRNAs and their regulatory roles in plants. Annu. Rev. Plant. Biol. 2006. 57: 19-53. Kapoor M, Arora R, Lama T, Nijhawan A, Khurana JP, Tyagi AK, Kapoor S. Genomewide identification, organization and phylogenetic analysis of Dicer-like, Argonaute and RNA-dependent RNA Polymerase gene families and their expression analysis during reproductive development and stress in rice. BMC Genomics. 2008. 9:451. Kasschau KD, Xie Z, Allen E, Llave C, Chapman EJ, Krizan KA, Carrington JC. P1/HCPro, a viral suppressor of RNA silencing, interferes with Arabidopsis development and miRNA unction. Dev Cell. 2003. 4(2).205-217. Kelley LA, Sternberg MJ. Protein structure prediction on the Web: a case study using the Phyre server. Nat Protoc. 2009. 4(3):363-71. Kidner CA, Martienssen RA. The role of ARGONAUTE1 (AGO1) in meristem formation and identity. Dev. Biol. 2005. 280(2): 504-517. Kim VN. Small RNAs: Classification, biogenesis, and function. Mol. Cells. 2005. 19 (1):1–15 Kim YJ, Zheng B, Yu Y, Won SY, Mo B, Chen X. The role of Mediator in small and long noncoding RNA production in Arabidopsis thaliana. EMBO J. 2011. 30: 814-822. Krieger E, Koraimann G, Vriend G. Increasing the precision of comparative models with YASARA NOVA — a self-parameterizing force field. Proteins. 2002. 47(3):393-402. Kubota A, Ishizaki K, Hosaka M, Kohchi T. Efficient Agrobacterium-mediated transformation of the liverwort Marchantia polymorpha using regenerating thalli. Biosci Biotechnol Biochem. 2013. 77(1): 167-172. Kwak PB, Tomari Y. The N domain of Argonaute drives duplex unwinding during RISC assembly. Nat Struct Mol Biol. 2012. 19(2): 145-151. 70 Lara-Mondragón C, Arteaga-Vázquez M. Resultados no publicados. Larkin MA, Blackshields G, Brown NP, Chenna R, McGettigan PA, McWilliam H, Valentin F, Wallace IM, Wilm A, Lopez R, Thompson JD, Gibson TJ and Higgins DG. Clustal W and Clustal X version 2.0. Bioinformatics. 2007. 23(21): 2947-2948. Li J, Yang Z, Yu B, Liu J, Chen X. Methylation protects miRNAs and siRNAs from a 3'end uridylation activity in Arabidopsis. Curr. Biol. 2005. 15(16): 1501-1507. Li S, Liu L, Zhuang X, Yu Y, Liu X, Cui X, Ji L, Pan Z, Cao X, Mo B, Zhang F, Raikhel N, Jiang L, Chen X. MicroRNAs inhibit the translation of target mRNAs on the endoplasmic reticulum in Arabidopsis. Cell. 2013. 153(3). 562-574. Lobbes D, Rallapalli G, Schmidt DD, Martin C, Clarke J. SERRATE: A new player on the plant microRNA scene. EMBO Rep. 2006. 7: 1052-1058. Ma JB, Ye K, Patel DJ. Structural basis for overhang-specific small interfering RNA recognition by the PAZ domain. Nature. 2004. 429(6989): 318-322. Machida S, Chen HY, Yuan YA. Molecular insights into miRNA processing by Arabidopsis thaliana SERRATE. Nucleic Acids Res. 2011. 39: 7828-7836. Makarova KS, Wolf YI, van der Oost J, Koonin EV. Prokaryotic homologs of Argonaute proteins are predicted to function as key components of a novel system of defense against mobile genetic elements. Biol Direct. 2009. 4:29. Mallory AC, Vaucheret H. Form, function, and regulation of ARGONAUTE proteins. Plant Cell. 2010. 22: 3879-3889. Mallory AC, Vaucheret H. Functions of microRNAs and related small RNAs in plants. Nat Genet. 2006. S31-S36. Marchler-Bauer A, Anderson JB, Cherukuri PF, DeWeese-Scott C, Geer LY, Gwadz M, He S, Hurwitz DI, Jackson JD, Ke Z, Lanczycki CJ, Liebert CA, Liu C, Lu F, Marchler GH, Mullokandov M, Shoemaker BA, Simonyan V, Song JS, Thiessen PA, Yamashita RA, Yin JJ, Zhang D, Bryant SH. CDD: a Conserved Domain Database for protein classification. Nucleic Acids Res. 2005. 1(33):D192-D196. Mateos JL, Bologna NG, Chorostecki U, Palantnik JF. Identification of microRNA processing determinants by random mutagenesis of Arabidopsis MIR172a precursor. Curr Biol. 2010. 20: 49-54. Matzke MA, Mosher RA. RNA-directed DNA methylation: an epigenetic pathway of increasing complexity. Nat Rev Genet. 2014. 15(6): 394-408. McCue AD, Nuthikattu S, Reeder SH, Slotkin RK. Gene expression and stress response mediated by the epigenetic regulation of a transposable element small RNA. PLoS Genet. 2012. 8(2). e1002474. 71 Meister G. Argonaute proteins: functional insights and emerging roles. Nat. Rev. Genet. 2013. 14(7): 447-459. Mendoza-Mejía A. Marchantia polymorpha. México. 2014. Meng F, Jia H, Ling N, Xue Y, Liu H, Wang K, Yin J, Li Y. Cloning and characterization of two Argonaute genes in wheat (Triticum aestivum L.). BMC Plant Biol. 2013. 13:18. Mi S, Cai T, Hu Y, Chen Y, Hodges E, Ni F, Wu L, Li S, Zhou H, Long C, Chen S, Hannon JG, Qi Y. Sorting of small RNAs into Arabidopsis Argonaute complexes is directed by the 5’ terminal nucleotide. Cell. 2008. 133: 116-127. Mirzaei K, Bahramnejad B, Shamsifard MH, Zamani W. In silico identification, phylogenetic and bioinformatic analysis of argonaute genes in plants. Int J Genomics. 2014. 2014:967461. Montes RA, de Fátima Rosas-Cárdenas, De Paoli E, Accerbi M, Rymarquis LA, Mahalingam G, Marsch-Martínez N, Meyers BC, Green PJ, de Folter S. Sample sequencing of vascular plants demonstrates widespread conservation and divergence of microRNAs. Nat Commun. 2014. 5:3722. Montgomery TA, Howell MD, Cuperus JT, Li D, Hansen JE, Alexander AL, Chapman EJ, Fahlgren N, Allen E, Carrington JC. Specificity of ARGONAUTE7-miR390 interaction and dual functionality in TAS3 trans-acting siRNA formation. Cell. 2008. 133(1): 128141. Morel JB, Godon C, Mourrain P, Béclin C, Boutet S, Feuerbach F, Proux F, Vaucheret H. Fertile hypomorphic ARGONAUTE (ago1) mutants impaired in post-transcriptional gene silencing and virus resistance. Plant Cell. 2002. 14(3): 629-639. Nakanishi K, Weinberg DE, Bartel DP, Patel DJ. Structure of yeast Argonaute with guide RNA. Nature. 2012. 486(7403): 368-374. Napoli C, Lemieux C, Jorgensen R. Introduction of a chimeric chalcone synthase gene into petunia results in reversible co-suppression of homologous genes in trans. Plant Cell. 1990. 2: 279-289. Oda K, Yamato K, Ohta E, Nakamura Y, Takemura M, Nozato N, Akashi K, Kanegae T, Ogura Y, Kohchi T, Oyama K. Gene organization deduced from the complete sequence of liverwort Marchantia polymorpha mitochondrial DNA. A primitive form of plant mitochondrial genome. J Mol Biol. 1992. 223(1):1-7. Okada S, Fujisawa M, Sone T, Nakayama S, Nishiyama R, Takenaka M, Yamaoka S, Sakaida M, Kono K, Takahama M, Yamato KT, Fukuzawa H, Brennicke A, Ohyama K. Construction of male and female PAC genomic libraries suitable for identification of Y-chromosome-specific clones from the liverwort, Marchantia polymorpha. Plant J. 2000. 24(3):421-428. 72 Olovnikov I, Chan K, Sachidanandam R, Newman DK, Aravin AA. Bacterial argonaute samples the transcriptoma to identify foreign DNA. Mol Cell. 2013. 51(5): 594-605. Ortega RC. Estudio sistemático, morfológico, estructural y biológico de Marchantia polymorpha L. Tesis de Licenciatura. México DF. Universidad Nacional Autónoma de México, Facultad de Ciencias, Departamento de Biología. 1948. Park MY, Wu G, Gonzalez-Sulser A, Vaucheret H, Poethig RS. Nuclear processing and export of microRNAs in Arabidopsis. Proc. Natl. Acad. Sci. 2005. 102: 3691-3696. Park W, Li J, Song R, Messing J, Chen X. CARPEL FACTORY, a Dicer homolog, and HEN1, a novel protein, act in microRNA metabolism in Arabidopsis thaliana. Curr. Biol. 2002. 12: 1484-1495. Parker JS, Roe SM, Barford D. Crystal structure of a PIWI protein suggests mechanisms for siRNA recognition and slicer activity. EMBO J. 2004. 23(24): 4727-4737. Peters L, Meister G. Argonaute proteins: Mediator of RNA silencing. Mol Cell. 2007. 26(5): 611-623. Poulsen C, Vaucheret H, Brodersen P. Lessons on RNA silencing mechanisms in plants from eukaryotic argonaute structures. Plant Cell. 2013. 25(1): 22-37. Qi Y, He X, Wang XJ, Kohany O, Jurka J, Hannon GJ. Distinct catalytic and noncatalytic roles of ARGONAUTE4 in RNA-directed DNA methylation. Nature. 2006. 443(7114): 1008-1012. Qian Y, Cheng Y, Cheng X, Jiang H, Zhu S, Cheng B. Identification and characterization of Dicer-like, Argonaute and RNA-dependent RNA polymerase gene families in maize. Plant Cell Rep. 2011. 30(7): 1347-1363. Qiu YL, Li L, Wang B, Chen Z, Knoop V, Groth-Malonek M, Dombrovska O, Lee J, Kent L, Rest J, Estabrook GF, Hendry TA, Taylor DW, Testa CM, Ambros M, CrandallStotler B, Duff RJ, Stech M, Frey W, Quandt D, Davis CC. The deepest divergences in land plants inferred from phylogenomic evidence. Proc Natl Acad Sci U S A. 2006. 103(42): 15511-15516. Ramachandran V, Chen X. Degradation of microRNAs by a family of exoribonucleases in Arabidopsis. Science. 2008. 321(5895): 1490-1492. Rambaut A. Figtree v 1.4.0. 2012. http://tree.bio.ed.ac.uk/software/figtree/ Reinhart BJ, Weinsten EG, Rhoades MW, Bartel B, Bartel DP. MicroRNAs in plants. Genes Dev. 2002. 16. 1616-1626. Ren G, Xie M Dou Y, Zhang S, Zhang C, Yu B. Regulation of miRNA abundance by RNA binding protein TOUGH in Arabidopsis. Proc. Natl. Acad. Sci. 2012. 109: 12817-12821. 73 Ren J, Wen L, Gao X, Jin C, Xue Y, Yao X. DOG 1.0: illustrator of protein domain structures. Cell Res. 2009. 19(2):271-273. Rogers K, Chen X. Biogenesis, turnover, and mode of action of plant microRNAs. Plant Cell. 2013. 25: 2383-2393 Romano N, Macino G. Quelling: transient inactivation of gene expression in Neurospora crassa by transformation with homologous sequences. Mol. Microbiol. 1992. 6: 3343-3353. Sasaki G, Katoh K, Hirose N, Suga H, Kuma K, Miyata T, Su ZH. Multiple receptor-like kinase cDNAs from liverwort Marchantia polymorpha and two charophycean green algae, Closterium ehrenbergii and Nitella axillaris: Extensive gene duplications and gene shufflings in the early evolution of streptophytes. Gene. 2007. 401(1-2):135-44. Schirle NT, MacRae IJ. Structure and mechanism of Argonaute proteins. En Guo F, Tamanoi F, (eds). The Enzymes. Eukaryotic RNases and their Partners in RNA Degradation and Biogenesis, Part B, Vol. 32. 1ra Ed. Londres: Academic Press/ Elsevier; 2012a. P. 83-100 Schirle NT, MacRae IJ. The crystal structure of human Argonaute2. Science. 2012b. 336(6084): 1037-1040. Sen GL, Blau HM. A brief history of RNAi: the silence of the genes. FASEB J. 2006. 20(9): 1293-1299. Shao F, Lu S. Genome-wide identification, molecular cloning, expression profiling and posttranscriptional regulation analysis of the Argonaute gene family in Salvia miltiorrhiza, an emerging model medicinal plant. BMC Genomics. 2013. 14:512. Sharma N, Bhalla PL, Singh MB. Transcriptome-wide profiling and expression analysis of transcription factor families in a liverwort, Marchantia polymorpha. BMC Genomics. 2013. 14:915. Sharma N, Jung CH, Bhalla PL, Singh MB. RNA sequencing analysis of the gametophyte transcriptome from the liverwort, Marchantia polymorpha. PLoS One. 2014. 19;9(5):e97497. Shaw AJ, Szövényi P, Shaw B. Bryophyte diversity and evolution: windows into the early evolution of land plants. Am J Bot. 2011. 98(3): 352-369. Song JJ, Smith SK, Hannon GJ, Joshua-Tor L. Crystal structure of Argonaute and its implications for RISC slicer activity. Science. 2004. 305(5689): 1434-1437. Sugano SS , Shirakawa M, Takagi J, Matsuda Y, Shimada T, Hara-Nishimura I, Kohchi T. CRISPR/Cas9-mediated targeted mutagenesis in the liverwort Marchantia polymorpha L. 2014. Plant Cell Physiol. 55(3):475-478. 74 Swarts DC, Jore MM, Westra ER, Zhu Y, Janssen JH, Snijders AP, Wang Y, Patel DJ, Berenguer J, Brouns SJ, van der Oost J. DNA-guided DNA interference by a prokaryotic Argonaute. Nature. 2014. 507(7491): 258-261. Swarts DC, Makarova K, Wang Y, Nakanishi K, Ketting RF, Koonin EV, Patel DJ, van der Oost J. The evolutionary journey of Argonaute proteins. Nat Struct Mol Biol. 2014. 21(9):743-753. Takeda A, Iwasaki S, Watanabe T, Utsumi M, Watanabe Y. The mechanism selecting the guide strand from small RNA duplex is different among Argonaute proteins. Plant Cell Physiol. 2008. 49(4): 493-500. Takenaka M, Yamaoka S, Hanajiri T, Shimizu-Ueda Y, Yamato KT, Fukuzawa H, Ohyama K. Direct transformation and plant regeneration of the haploid liverwort Marchantia polymorpha L. Transgenic Res. 2000. 9(3):179-185. Tanurdzic M, Banks JA. Sex-determining mechanisms in land plants. Plant Cell. 2004. 16 Suppl, S61-71. Tian-long L, Jin-cai L, Jun-tao G, Wen-jing L, Cheng-jin G, Rui-juan L, Kai X. Cloning and molecular characterization of TaAGO1, a member of argonaute gene family in wheat (Triticum aestivum L.). African Journal of Biotechnology. 2011. 10(62): 1340713417. Tolia NH, Joshia-Tor L. Slicer and the argonautes. Nat Chem Biol. 2007. 3(1): 36-43. Valencia-Sanchez MA, Liu J, Hannon GJ, Parker R. Control of translation and mRNA degradation by miRNAs and siRNAs. Genes Dev. 2006. 20(5): 515-524. Vaucheret H, Mallory AC, Bartel DP. AGO1 homeostasis entails coexpression of MIR168 and AGO1 and preferential stabilization of miR168 by AGO1. Mol Cell. 2006. 22(1): 129-136. Vaucheret H, Vazquez F, Crété P, Bartel PD. The action of ARGONAUTE1 in the miRNA pathway and its regulation by the miRNA pathway are crucial for plant development. Genes Dev. 2004. 18 (10):1187-1197. Vaucheret H. AGO1 homeostasis involves differential production of 21-nt and 22-nt miR168 species by MIR168a and MIR168b. PLoS One. 2009. 4(7): e6442 Vaucheret H. Plant ARGONAUTES. Trends. Plant. Sci. 2008. 13(7): 350-358. Vaucheret H. Post-transcriptional small RNA pathways in plants: mechanisms and regulations. Genes Dev. 2006. 20(7). 759-771. Vazquez F, Gasciolli V, Crété P, Vaucheret H. The nuclear dsRNA binding protein HYL1 is required for microRNA accumulation and plant development, but not posttranscriptional transgene silencing. Curr Biol. 2004. 14(4): 346-351. 75 Voinnet O, Baulcombe CD. Systematic signaling in gene silencing. Nature. 1997. 389: 593. Voinnet O. Origin, biogenesis, and activity of plant microRNAs. Cell. 2009. 136(4): 669687. Wang Y, Juranek S, Li H, Sheng G, Tuschl T, Patel DJ. Structure of an argonaute silencing complex with a seed-containing guide DNA and target RNA duplex. Nature. 2008. 456(7224): 921-926. Wang Y, Juranek S, Li H, Sheng G, Wardle GS, Tuschl T, Patel DJ. Nucleation, propagation and cleavage of target RNAs in Ago silencing complexes. Nature. 2009. 461(7265): 754-761. Wei KF, Wu LJ, Chen J, Chen YF, Xie DX. Structural evolution and functional diversification analyses of argonaute protein. J Cell Biochem. 2012. 113(8):25762585. Werner S, Wollmann H. Schneeberger K, Weigel D. Structure determinants for accurate processing of miR172a in Arabidopsis thaliana . Curr. Biol. 2010. 20: 42-48. Yamato KT, Ishizaki K, Fujisawa M, Okada S, Nakayama S, Fujishita M, Bando H, Yodoya K, Hayashi K, Bando T, Hasumi A, Nishio T, Sakata R, Yamamoto M, Yamaki A, Kajikawa M, Yamano T, Nishide T, Choi SH, Shimizu-Ueda Y, Hanajiri T, Sakaida M, Kono K, Takenaka M, Yamaoka S, Kuriyama C, Kohzu Y, Nishida H, Brennicke A, Shin-i T, Kohara Y, Kohchi T, Fukuzawa H, Ohyama K. Gene organization of the liverwort Y chromosome reveals distinct sex chromosome evolution in a haploid system. Proc Natl Acad Sci U S A. 2007. 104(15):6472-6477. Yang Z, Ebright YW, Yu B, Chen X. HEN1 recognizes 21-24 nt small RNA duplexes and deposits a methyl group onto the 2' OH of the 3' terminal nucleotide. Nucleic. Acids. Res. 2006. 34(2): 667-675. Yigit E, Batista PJ, Bei Y, Pang KM, Chen CC, Tolia NH, Joshua-Tor L, Mitani S, Simard MJ, Mello CC. Analysis of the C. elegans Argonaute family reveals that distinct Argonautes act sequentially during RNAi. Cell. 2006. 127(4): 747-757. Yu B, Yang Z, Li J, Minakhina S, Yang M, Padgett RW, Steward R, Chen X. Methylation as a crucial step in plant microRNA biogenesis. Science. 2005. 307(5711): 932-935. Yuan YR, Pei Y, Ma JB, Kuryavyi V, Zhadina M, Meister G, Chen HY, Dauter Z, Tuschl T, Patel DJ. Crystal structure of A. aeolicus argonaute, a site-specific DNA-guided endoribonuclease, provides insights into RISC-mediated mRNA cleavage. Mol Cell. 2005. 19(3): 405-419. Zamore PD, Tuschl T, Sharp PA, Bartel DP. RNAi: double-strand RNA directs the ATPdependent cleavage of mRNA at 21 to 23 nucleotides intervals. Cell. 2000. 101. 2533. 76 Zhao Y, Yu Y, Zhai J, Ramachandran V, Dinh TT, Meyers BC, Mo B, Chen X. The Arabidopsis nucleotidyl transferase HESO1 uridylates unmethylated small RNAs to trigger their degradation. Curr. Biol. 2012. 22: 689-694. Zheng X, Zhu J, Kapoor A, Zhu JK. Role of Arabidopsis AGO6 in siRNA accumulation, DNA methylation and transcriptional gene silencing. EMBO J. 2007. 26(6): 16911701. Zhu, H., Hu, F., Wang, R., Zhou, X., Sze, S.H., Liou, L.W., Barefoot, A., Dickman, M., and Zhang, X. Arabidopsis Argonaute10 specifically sequesters miR166/165 to regulate shoot apical meristem development. Cell. 2011. 145(2): 242–256. 77 XI. ANEXOS Anexo 1. Concentración de las muestra de RNA de M. polymorpha. Tabla 5. Concentración de las muestra de RNA de M. polymorpha. Muestra Concentración Unidad A260 A280 260/280 260/230 1 125.7 ng/µL 3.142 1.727 1.82 0.26 2 35.3 ng/µL 0.882 0.516 1.71 0.08 3 354.1 ng/µL 8.851 4.762 1.86 0.9 4 607.4 ng/µL 15.186 8.988 1.69 0.27 5 1014.2 ng/µL 25.356 13.164 1.93 0.42 6 871 ng/µL 21.776 11.33 1.92 0.39 7 698 ng/µL 17.45 9.389 1.86 0.35 8 909.5 ng/µL 22.7736 11.697 1.94 0.47 78 Anexo 2. Purificación de productos de PCR usando el QIAquick PCR Purification Kit (QIAGEN). 1. Agregar 5 volumenes de buffer PB a 1 volumen de reacción de PCR y mezclar. Si el color de la mezcla es naranja o violeta, agregar 10 µL de acetato de sodio 3M, pH 5.0, y mezclar. El color de la mezcla debe ser amarillo. 2. Colocar una columna QIAquick en un tubo colector de 2 mL. 3. Poner la muestra en la columna y centrifugar a 13000 rpm durante 1 minuto y desechar el líquido residual del tubo colector. Colocar de nuevo la columna en el tubo. 4. Para lavar, agregar 750 µL de buffer PE a la columna y centrifugar a 13000 rpm durante 1 minuto, desechar el líquido residual y regresar la columna al tubo. 5. Centrifugar la columna una vez más en el tubo colector a 13000 rpm por 1 minuto para eliminar el buffer de lavado residual. 6. Colocar la columna en un tubo limpio de 1.5 m. 7. Para eluir el DNA, agregar 30 µL de buffer EB (Tris-Cl 10 mM, pH 8.5) o agua libre de nucleasas pH 7.0. Dejar la columna reposar 1 minutos y centrifugar a 13000 rpm durante 1 minuto. 8. Si el producto de PCR se va a cuantificar usar 1-2 µL. Si se va a analizar en un gel de agarosa agregar 1 volumen de buffer de cargar por cada 5 volumenes del DNA purificado. 79 Anexo 3. Características y mapa del vector pGEM ®-T Easy (Promega). El vector pGEM ®-T Easy (Promega) es un vector linearizado en el que ambos extremos 3’ contiene timidinas terminales las cuales permiten la fácil inserción y ligación de productos de PCR, además de que previene la recircularización del mismo. El sitio múltiple de clonación está flanqueado por varios sitios de restricción (EcoRI, NotI) que permiten la liberación del inserto con una sola digestión del vector. Éste vector también contiene el gen lacZ que permite hacer la selección de colonias recombinantes mediante el escrutinio blanco/azul, además posee el gen de la β-lactamasa, el cual codifica a la enzima del mismo nombre y aporta la resistencia a los antibióticos βlactámicos como la ampicilina a las bacterias transformadas con este vector, este también es un método de selección positiva, ya que en un medio de cultivo adicionado con ampicilina solo van a crecer aquellas bacterias que fueron transformadas. Las bacterias transformadas con este vector producen un elevado número de copias del mismo ya que cuenta con el origen de replicación de pUC. Figura 34. Mapa del vector pGEM ®-T Easy. Solo se muestran las enzimas que flanquean el sitio múltiple de clonación. 80 Anexo 4. Preparación de células electrocompetentes. 1. Inocular una sola colonia de E. coli de la cepa DH5α en 2.5 mL de medio LB e incubar ON con agitación a 37°C. 2. Inocular 250 mL de medio LB con el cultivo anterior y dejar crecer hasta alcanzar una densidad óptica DO de 0.5-0.6 (2-4 horas). 3. Incubar 10 a 15 minutos en hielo. 4. Transferir a tubos de 50 mL (~40 mL x 6 tubos) para rotor de ángulo fijo. Centrifugar 10 minutos a 6000 rpm. 5. Eliminar el sobrenadante y resuspender las pastillas de bacterias en 1.25 mL de agua estéril helada. 6. Añadir el mismo volumen de agua estéril del que se partió (40 mL en cada tubo). 7. Centrifugar 10 min a 6000 rpm, remover el sobrenadante y resuspender en 200 µL de agua estéril helada. 8. Añadir el mismo volumen de agua estéril del que se partió (40 mL en cada tubo). 9. Centrifugar 10 min a 6000 rpm, remover el sobrenadante y resuspender en 200 µL de agua estéril helada. 10. Añadir la mitad del volumen de LB inicial de agua helada (20 mL en cada tubo). 11. Centrifugar 10 minutos a 6000 rpm, remover el sobrenadante y resuspender en 5 mL de glicerol muy frío al 10%, juntando todas las pastillas en una sola (resuspender primero la pastilla del tubo 1, luego pasar este al tubo 2 y resuspender, así hasta el último tubo). 12. Centrifugar 10 min a 6000 rpm y remover el sobrenadante. 13. Añadir 0.75 mL de glicerol al 10% y resuspender. 14. Hacer alícuotas de 40 µL. Poner en nitrógeno líquido. Almacenar a -70°C hasta por 3 meses. 81 Anexo 5. Preparación LB/Agar/Ampicilina/IPTG/X-gal. de placas con medio 1. Para prepara 1L de medio LB/agar colocar en un frasco 25g de medio LB (Triptona 10g/L; NaCl 10g/L; Extracto de levadura 5g/L) y 7.2g de agar, aforar a 1L con agua destilada y esterilizar en autoclave. 2. Cuando el medio de cultivo esté a una temperatura de 50-40°C agregar 1µL de ampicilina 100 µg/mL por cada mL de medio. 3. Colocar 25 mL de LB/agar/ ampicilina en una caja Petri. 4. Dejar solidificar el medio a temperatura ambiente con las tapas abiertas dentro de una campana de flujo laminar o en un ambiente estéril. 5. Agregar sobre el medio de cultivo sólido 100 µL de IPTG 0.1M y esparcir de manera homogénea por toda la caja con una espátula Drigalski previamente flameada. 6. Agregar 20 µL de X-gal 20 mg/mL sobre el medio sólido y esparcir de forma homogénea con una espátula Drigalski. 82 Anexo 6. Protocolo de ligación usando el vector pGEM ®-T Easy (Promega). 1. Descongelar el vector y centrifugar brevemente para colectar el contenido en el fondo del tubo. 2. Preparar las reacciones como se indica en la Tabla 6. 3. Mezclar la reacción por pipeteo e incubarla 1 hora a temperatura ambiente, después incubarla toda la noche a 4°C. Tabla 6. Componentes de la reacción de ligación con pGEM ®-T Easy. *Depende de la relación molar producto de PCR: Vector Componente Cantidad 2X Rapid Ligation Buffer, T4 DNA ligasa 5 µL pGEM ®-T Easy (25ng) 0.5 µL Producto de PCR X*µL T4 DNA ligasa (3 unidades/µL) 1 µL Agua libre de nucleasas cbp 10 µL 83 Anexo 7. Selección de clonas recombinantes (escrutinio azul/blanco). Esta técnica de escrutinio se utiliza para identificar y seleccionar de forma rápida a las bacterias recombinantes. El plásmido utilizado para la clonación contiene el gen lacZ, y siempre y cuando su ORF no sea interrumpido por un inserto de DNA va a producir la enzima β-galactosidasa. En conjunto con un inductor de la expresión de esta enzima (IPTG), la β-galactosidasa convierte al X-gal en un compuesto azul insoluble, de esta forma las bacterias con un gen lacZ funcional serán distinguidas por su color azul. Cuando un inserto se ha introducido en el sitio múltiple de clonación en el gen lacZ, el ORF se interrumpe y por lo tanto ya no se sintetizará la β-galactosidasa, así que las colonias de las bacterias recombinantes serán de color blanco. De acuerdo a este principio serán seleccionadas las clonas de bacterias, y solo se analizarán las colonias blancas. Antes de empezar el análisis de las clonas, se tomará cada una de las colonias blancas y se inocularan en 3 mL de medio LB líquido, después serán incubadas a 37°C con agitación durante 12 horas. Figura 35. Esquema del procedimiento del escrutinio azul-blanco. Las colonias son azules cuando el inserto interrume al gen lacZ. Adaptado de SIGMA-ALDRICH Copyright © 2014. 84 Anexo 8. Aislamiento de DNA plasmídico por el método de lisis alcalina. 1. En 3 mL de medio de cultivo adicionado con el antibiótico adecuado inocular una sola colonia bacteriana. Incubar toda la noche a 37°C con agitación, el cultivo debe llegar a la fase estacionaria. 2. A un tubo de microcentrifuga agregar 1.5 mL del cultivo de toda la noche y centrifugar a 13000 rpm durante 2 minutos o hasta formar una pastilla de bacterias visible. Decantar el sobrenadante en un contenedor con desinfectante. 3. Resuspender la pastilla en 100 µL de Solución de Resuspensión I (50mM Tris pH 8.0 con HCl, 10mM EDTA, 100ug/mL RNasa A) 4. Agregar 200 µL de Solución de lisis II (200mM NaOH, 1%SDS), mezclar por inversión y dejar reposar a temperatura ambiente por 5 minutos. La solución de bacterias se tornará transparente. 5. Agregar 150 µL de Solución de neutralización III (3.0M Acetato de potasio, pH5.5), mezclar por inversión. Se formará un precipitado blanco insoluble. Dejar reposar en hielo por 5 minutos. 6. Centrifugar a 13000 rpm durante 15 minutos. 7. Transferir el sobrenadante a un tubo nuevo ~ 400 µL (Si el sobrenadante aún tiene restos del precipitado blanco, centrifugar los tubos nuevamente). El sobrenadante tiene el DNA plasmídico. 8. Agregar 1 volumen (400 µL) de etanol frío. Mezclar por inversión. 9. Dejar reposar a -20°C por 1 hora o 30 minutos a -80°C. 10. Centrifugar a 13000 rpm durante 30 minutos. Se obtendrá una pastilla lo suficientemente visible. 11. Decantar el sobrenadante con cuidado de no desechar la pastilla. Lavar la pastilla con 700 µL de etanol al 75%, mezclar y centrifugar a 13000rpm durante 5 minutos. 12. Decantar el sobrenadante. Dejar secar el tubo abierto a la temperatura ambiente, sin que se seque la pastilla por completo. 13. Resuspender la pastilla con 25 µL de agua libre de nucleasas o con buffer TE (10mM Tris pH 8.0 con HCl, 1mM EDTA). 85 14. Analizar los plásmidos extraídos por electroforesis en gel de agarosa. Anexo 9. Purificación de plásmidos usando el QIAprep Spin Miniprep Kit. 1. Verter 1.5 mL del cultivo líquido bacteriano de toda la noche en un tubo de 1.5 mL y centrifugar a 13000 rpm durante 2 minutos. 2. Resuspender la pastilla de bacterias en 250 µL de buffer P1 . 3. Agregar 250 µL del buffer P2 y mezclar por inversión 4 a 6 veces, no use vortex, si es necesario seguir mezclando el tubo por inversión hasta que la solución se torne viscosa y clara. No permitir que la reacción de lisis ocurra por más de 5 minutos. 4. Agregar 350 µL de buffer N3 y mezclar inmediatamente por inversión 4 a 6 veces. En la solución se formará un precipitado blanco insoluble. 5. Centrifugar por 10 minutos a 13000 rpm. 6. Mientras transcurre el tiempo de centrifugación lavar la columna QIAprep ensamblada en el tubo colector agregando 500 µL del buffer PB y centrifugar por 1 minuto a 13000 rpm. 7. Retirar el sobrenadante con una pipeta y colocarlo en la columna ensamblada en el tubo colector. 8. Centrifugar la columna por 1 minuto a 13000 rpm. Desechar el líquido residual y colocar de nuevo la columna en el tubo colector. 9. Lavar la columna agregando 750 µL del buffer PE y centrifugar por 1 minutos a 13000 rpm. Desechar el líquido residual y volver a colocar la columna en el mismo tubo colector. 10. Volver a centrifugar la columna para eliminar el buffer de lavado residual. 11. Colocar la columna en un tubo limpio de 1.5 mL. Para eluir el DNA agregar 30 µL de buffer EB ( Tris-Cl 10mM, pH 8.5) o agua libre de nucleasas directamente en el centro de la columna. Dejar reposar por 1 minuto y centrifugar a 13000 rpm por 1 minuto. 12. Si se va a cuantificar el DNA plasmídico usar 1-2 µL. 86 Anexo 10. Especies a las que pertenece cada una de las secuencias de aminoácidos empleadas en los análisis bioinformáticos. AGO00546 | Marchantia polymorpha | protein sequence |Argonaute gen family AGO3402 | Chlamydomonas reinhardtii | protein sequence | Argonaute gene family AGO1 | Arabidopsis thaliana | protein sequence | Argonaute gene family AGO117 | Zea mays | protein sequence | Argonaute gene family AGO708 | Oryza sativa ssp. japonica | protein sequence | Argonaute gene family AGO1213 | Glycine max | protein sequence | Argonaute gene family AGO915 | Populus trichocarpa | protein sequence | Argonaute gene family AGO1607 | Selaginella moellendorffii | protein sequence | Argonaute gene family AGO16702 | Citrus clementina | protein sequence | Argonaute gene family AGO28103 | Eutrema halophilum | protein sequence | Argonaute gene family AGO20909 | Ricinus communis | protein sequence | Argonaute gene family AGO4506 | Mimulus guttatus | protein sequence | Argonaute gene family AGO25802 | Setaria italica | protein sequence | Argonaute gene family AGO25701 | Aquilegia coerulea | protein sequence | Argonaute gene family AGO6905 | Vitis vinifera | protein sequence | Argonaute gene family AGO28405 | Capsella rubella | protein sequence | Argonaute gene family AGO8506 | Manihot esculenta | protein sequence | Argonaute gene family AGO1503 | Physcomitrella patens | protein sequence | Argonaute gene family AGO7003 | Malus x domestica | protein sequence | Argonaute gene family AGO5305 | Linum usitatissimum | protein sequence | Argonaute gene family AGO2605 | Sorghum bicolor | protein sequence | Argonaute gene family AGO5801 | Prunus persica | protein sequence | Argonaute gene family AGO21206 | Arabidopsis lyrata | protein sequence | Argonaute gene family AGO401 | Drosophila melanogaster | protein sequence | Argonaute gene family 87