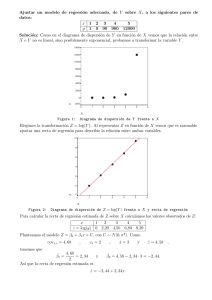
por otra parte solo hace variar el número de ellos, más no su
Anuncio

Diego Rojas por otra parte solo hace variar el número de ellos, más no su localización. Como se observa el procedimiento con un span más grande representa perdida de precisión en la localización además de ignorar, o simplificar particularidades locales. Por esto se escoge un span del 5 % de las observaciones que es conveniente para los fines de esta investigación y consistente con el análisis exploratorio. Figura 9: Candidatos a centros de empleo varias distancias y span Fuente: INEC (2010). Censo Nacional Económico. El procedimiento en la segunda parte del método se aplicó solo para los candidatos obtenidos con el span de 0.05; tanto para las distancias de 1.000 y 2.000 metros. Lo que se hace es utilizar un proceso de regresión stepwise, es decir que descarta variables del modelo original de manera que se corre el modelo cada vez que una variable es descartada en función de un criterio de significancia. El modelo de regresión utilizado, como ya se mencionó en los fundamentos metodológicos, es de tipo semiparamétrico utilizando una expansión de Fourier para poder representar la relación entre la distancia al CBD y la densidad del empleo; usa la parte paramétrica para estimar la relación entre la densidad y la distancia a cada uno de los candidatos a centro de empleo identificados en la primera parte. Este proceso permite identificar aquellas localidades que además de tener una densidad de empleo alta, en términos estadı́sticamente significativos, ejercen también influencia en la densidad de empleo bien de toda el área de estudio o bien del área próxima a este. 24 78 Analítika, Revista de análisis estadístico, (2015), Vol. 9