CAPITULO 3 Análisis y Diseño de Bases de Datos
Anuncio

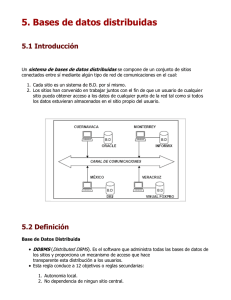
ESCUELA DE CIENCIAS BÁSICAS TECNOLOGÍA E INGENIERÍA Bases de Datos Distribuidas CAPITULO 3 Análisis y Diseño de Bases de Datos Distribuidas 3.1 El Análisis En el análisis para la construcción de una nueva base de datos distribuida se deben revisar el problema la distribución de carga y el manejo del costo de almacenamiento y la disponibilidad. Procesamiento Local: El procesamiento local en la distribución de los datos pretende maximizar el procesamiento que corresponde al principio simple de colocar los datos tan cerca como sea posible de las aplicaciones que los utilizan. Se puede realizar el análisis de la distribución de los datos para maximizar el procesamiento local agregando el número de referencias locales y remotas que le corresponden a cada fragmentación candidata y la localización del fragmento, que de esta forma se seleccione la mejor solución de ellas. Distribución de la Carga de Trabajo: La distribución de la carga de trabajo sobre los sitios, es una característica importante de los sistemas de cómputo distribuidos. Esta distribución de la carga se realiza para tomar ventaja de las diferentes características o utilidades de las computadoras de cada sitio, y maximizar el grado de ejecución de paralelismo de las aplicaciones. Sin embargo, la distribución de la carga de trabajo podría afectar negativamente el procesamiento local deseado. Costo de Almacenamiento Y disponibilidad: La distribución de la base de datos refleja el costo y disponibilidad del almacenamiento en diferentes sitios. Para esto, es posible tener sitios especializados en la red para el almacenamiento de datos. Sin embargo el costo de almacenamiento de datos no es tan relevante si éste se compara con el del CPU, I/O y costos de transmisión de las aplicaciones. 1 ESCUELA DE CIENCIAS BÁSICAS TECNOLOGÍA E INGENIERÍA Bases de Datos Distribuidas 3.2 El Diseño En el diseño para la construcción de una nueva base de datos distribuida se deben considerar las estrategias de diseño de bases de datos distribuidas referentes a los enfoques que se le otorgan a este tipo de procesos, como son el enfoque de arriba hacia abajo (Top-Down) como el diseño de abajo hacia arriba (BottomUp). Se ha propuesto que el diseño de una base de datos distribuida puede ser asistido e implantado a lo largo de tres dimensiones ortogonales. Estos tres niveles o dimensiones son: 1. Nivel de distribución 2. Comportamiento de los patrones de acceso. 3. Nivel de conocimiento en el comportamiento del patrón de acceso. En términos del nivel de distribución hay tres posibilidades. Primero: Que no haya distribución; cada aplicación y sus datos se ejecutan en un sitio y no hay comunicación con algún otro programa o acceso a algún archivo de datos de otro sitio. Esto caracterizaba a los primeros días de trabajo en red pero ya no es tan común en nuestros tiempos. Segundo: Distribución de datos; Todos los programas son replicados en todos los sitios pero no los archivos de datos, por consiguiente las peticiones de los usuarios son manejadas en el sitio donde fueron originados y solo los archivos de datos necesarios son movidos alrededor de la red. 2 ESCUELA DE CIENCIAS BÁSICAS TECNOLOGÍA E INGENIERÍA Bases de Datos Distribuidas Tercero: Datos más programas. Los archivos de datos y los programas pueden ser compartidos. En la primera dimensión se puede observar una distinción entre la distribución de datos y la distribución de datos más programas ilustrando las diferencias entre sistemas de computadora distribuidos homogéneos y heterogéneos. Indica correctamente que en un ambiente heterogéneo es más difícil e incluso imposible ejecutar un programa dado en diferente hardware bajo un diferente sistema operativo. A lo largo de la segunda dimensión del comportamiento de los patrones de acceso es posible identificar dos alternativas. Los patrones de acceso de peticiones de usuarios puede ser estático, es decir que no cambian en el tiempo, o dinámico. A lo largo de la tercera dimensión tenemos el nivel de conocimiento del comportamiento de los patrones de acceso. Podemos plantear la opción de que el desarrollador no conozca nada acerca de estos patrones pero sería difícil construir un DBMS que cubriera esta cuestión sin información previa por eso, y para que sea más fácil es necesario que el diseñador o desarrollador tenga la información completa. 3.3 Proceso de Diseño de Arriba Hacia Abajo (Top-Down) Este enfoque es más apropiado para aplicaciones nuevas y para sistemas homogéneos. Consiste en partir desde el análisis de requerimientos para definir el diseño conceptual y las vistas de usuario. A partir de ellas se define un esquema conceptual - global y los esquemas externos necesarios. Se prosigue con el diseño de la fragmentación de la base de datos, y de aquí se continúa con la localización de los fragmentos en los sitios, creando las imágenes físicas. Esta aproximación se completa ejecutando, en cada sitio, el diseño físico de los datos, que se localizan en éste. 3 ESCUELA DE CIENCIAS BÁSICAS TECNOLOGÍA E INGENIERÍA Bases de Datos Distribuidas 3.4 Proceso de Diseño de Abajo Hacia Arriba (Bottom-Up) Se utiliza particularmente a partir de bases de datos existentes, generando con esto bases de datos distribuidas. El diseño Bottom-Up de una base de datos distribuida requiere de la selección de un modelo de bases de datos común para describir el esquema global de la base de datos. Es posible que se utilicen diferentes SGBD. Después se hace la traducción de cada esquema local en el modelo de datos común y finalmente se hace la integración del esquema local en un esquema global común. 3.5 Fragmentación de Datos La fragmentación en una base de datos distribuida es encontrar un nivel de particionamiento adecuado en el rango que va desde tuplas o atributos hasta relaciones completas. 3.5.1 Fragmentación Horizontal Corresponde esencialmente al tratamiento que se le da a una tabla y el procedimiento consiste en dividirla en fragmentos menores; inmediatamente surgen dos alternativas lógicas para llevar a cabo el proceso: la división horizontal y la división vertical. La división o fragmentación horizontal trabaja sobre las tuplas, dividiendo la relación en sub relaciones que contienen un subconjunto de las tuplas que alberga la primera. 3.5.2 Fragmentación Vertical La fragmentación vertical, se basa en los atributos de la relación para efectuar la división. La fragmentación vertical es la subdivisión de atributos en grupos. Los fragmentos se obtienen proyectando la relación global sobre cada grupo. La fragmentación es correcta si cada atributo se procesa en al menos un atributo del fragmento. 4 ESCUELA DE CIENCIAS BÁSICAS TECNOLOGÍA E INGENIERÍA Bases de Datos Distribuidas 3.5.3 Fragmentación Híbrida Fundamentalmente, se habla de fragmentación mixta o híbrida cuando el proceso de partición hace uso de los dos tipos anteriores. La fragmentación mixta puede llevarse a cabo de tres formas diferentes: desarrollando primero la fragmentación vertical y, posteriormente, aplicando la partición horizontal sobre los fragmentos verticales (denominada partición VH), o aplicando primero una división horizontal para luego, sobre los fragmentos generados, desarrollar una fragmentación vertical (llamada partición HV), o bien, de forma directa considerando la semántica de las transacciones. 3.6 Transparencia El concepto de transparencia de un sistema de base de datos distribuida va ligado a la idea de que todo el sistema funcione de forma similar en todos los puntos de la red, independientemente de la posición del usuario. Los siguientes son los niveles de independencia al emitir el concepto de Transparencia: Independencia Lógica de Datos: Se refiere a la inmunidad de los sistemas de información de usuario a los cambios en la estructura lógica de la base de datos. Esto permite que un cambio en la definición de un esquema no debe afectar a las aplicaciones de usuario. Por ejemplo, el agregar un nuevo atributo a una relación, la creación de una nueva relación, el reordenamiento lógico de algunos atributos. Independencia Física de los Datos: La Independencia física de datos. se refiere al ocultamiento de los detalles sobre las estructuras de almacenamiento a las aplicaciones de usuario. Esto quiere decir que la descripción física de datos puede cambiar sin afectar a las aplicaciones de usuario. Por ejemplo, los datos pueden ser movidos de un disco a otro, o la organización de los datos puede cambiar. Transparencia al Nivel de Red: La transparencia al nivel de red se refiere a que los datos en un SGBDD se accesan sobre una red de computadoras, sin embargo, las aplicaciones del usuario final no deben notar su existencia. La transparencia al nivel de red conlleva a dos cosas: 5 ESCUELA DE CIENCIAS BÁSICAS TECNOLOGÍA E INGENIERÍA Bases de Datos Distribuidas 1. Transparencia sobre la localización de datos. El proceso se define como el comando que se usa para acceso a datos es independiente de la ubicación de los datos en la red y del lugar en donde la operación se lleve a cabo. 2. Transparencia sobre el esquema de nombramiento. El proceso se logra proporcionando un nombre único a cada objeto en el sistema distribuido. Así, no se debe mezclar la información de la localización con en el nombre de un objeto. Transparencia Sobre Replicación: La transparencia sobre replicación de datos se refiere a que si existen réplicas de objetos de la base de datos, su existencia debe ser controlada por el sistema, no por el usuario. Se debe tener en cuenta que cuando el usuario se encarga de manejar las réplicas en un sistema, el trabajo de éste es mínimo por lo que se puede obtener una eficiencia mayor. Sin embargo, el usuario puede olvidarse de mantener la consistencia de las réplicas teniendo así datos diferentes. Transparencia a Nivel de Fragmentación de Datos: La transparencia a nivel de fragmentación de datos permite que cuando los objetos de la bases de datos están fragmentados, el sistema tiene que manejar la conversión de consultas de usuario definidas sobre relaciones globales, a consultas definidas sobre fragmentos. Así también, será necesario mezclar las respuestas a consultas fragmentadas para obtener una sola respuesta a una consulta global. El acceso a una base de datos distribuida debe hacerse en forma transparente. La transparencia tiene como punto central la independencia de datos. transparencia se pueden organizar en capas como se muestra en la Figura. 6 Los diferentes niveles de ESCUELA DE CIENCIAS BÁSICAS TECNOLOGÍA E INGENIERÍA Bases de Datos Distribuidas En el primer nivel se soporta la transparencia de red. En el segundo nivel se permite la transparencia de replicación de datos. En el tercer nivel se permite la transparencia de la fragmentación. En el cuarto nivel se permite la transparencia de acceso. La responsabilidad sobre el manejo de transparencia debe estar compartida tanto por el sistema operativo, el sistema de manejo de bases de datos y el lenguaje de acceso a la base de datos distribuida. Entre estos tres 7 ESCUELA DE CIENCIAS BÁSICAS TECNOLOGÍA E INGENIERÍA Bases de Datos Distribuidas módulos se deben resolver los aspectos sobre el procesamiento distribuido de consultas y sobre el manejo de nombres de objetos distribuidos. 3.7 Replica de Datos Las réplicas en las bases de datos distribuidas consisten en un duplicado de las bases de datos del servidor en el disco duro de su computadora, es decir, en el servidor local. Estas bases de datos contienen aparte de los datos, un identificador que permitirá posteriormente actualizar sus contenidos, tanto en el servidor como en las bases de datos locales. Esto constituye una ayuda especialmente útil cuando se desea trabajar en un equipo de cómputo que en ocasiones no estará conectado a la red donde se encuentra el servidor en el que reside el servidor de datos. La réplica de una base de datos se realiza solamente una vez y posteriormente se procede a la "replicación" de los documentos cada vez que se considere necesario. Para poder trabajar desde distintos equipos en una base de datos distribuida es necesario crear una o varias réplicas de dicha BDD que después, deberán ser sincronizadas. Cada réplica es miembro de un conjunto de réplicas que se pueden sincronizar con otras réplicas del mismo grupo, es decir, los cambios realizados en una réplica se aplican a las otras réplicas y al diseño principal o base de datos original. 8