el análisis de conglomerados en los estudios de mercado
Anuncio

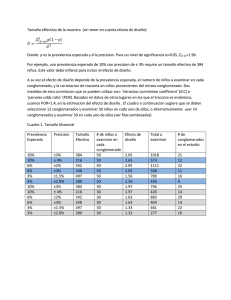
EL ANÁLISIS DE CONGLOMERADOS EN LOS ESTUDIOS DE MERCADO Beatriz Meneses A. de Sesma * I. INTRODUCCIÓN En los estudios de mercado intervienen muchas variables que son importantes para el cliente, sin embargo, en los que no se puede considerar todas, se hace un estudio univariado o bivariado. Cuando se tiene un caso multivariado en el cual se desea estudiar un conjunto de relaciones interdependientes y no se hace distinción entre variables dependientes e independientes, se podría realizar análisis factorial o análisis de conglomerados. La diferencia entre ambos estudios es que en el análisis de conglomerados el objetivo principal es reducir el número de objetos y reunirlos en un número de grupos mucho menor que la totalidad de los objetos o casos iniciales y que sean similares internamente y diferentes entre grupos. En cambio, en el análisis factorial el propósito es reducir el número de variables. El análisis de conglomerados lo constituye un conjunto de técnicas mediante las cuales se clasifican objetos o casos en grupos relativamente homogéneos llamados conglomerados o clusters; en este ensayo se usará indistintamente cualquiera de los dos nombres. El nombre en inglés de este tipo de análisis es cluster analysis y a los grupos que se forman se les llama clusters, este término fue usado por primera vez por Tyron en 19391. Este análisis tiene un gran número de aplicaciones en muchos campos del conocimiento, pues en cierta forma puede contestar a la pregunta que se hacen los investigadores sobre cómo organizar los datos observados en grupos para desarrollar alguna taxonomía. Las aplicaciones que tiene este análisis en investigaciones de mercados, son principalmente dos : 1. La segmentación de mercados, cuando los consumidores se agrupan en base a su semejanza de acuerdo las preferencias respecto a las variables seleccionadas o al beneficio que buscan al adquirir un producto 2. Comportamiento del consumidor, cuando se quiere identificar grupos de compradores homogéneos El propósito de este artículo es dar a conocer un poco del análisis de conglomerados, para lograr lo anterior, en la segunda parte se describirán los pasos que se siguen al realizar un análisis de conglomerados, en la tercera parte se mencionará cómo se clasifican los procedimientos de conglomerados y en la cuarta parte se hará una ilustración con un ejemplo. II. ETAPAS EN UN ANÁLISIS DE CONGLOMERADOS En los estudios de mercado en los que se necesite identificar segmentos o agrupar a los consumidores en grupos homogéneos, se recomienda seguir el siguiente procedimiento: 1. Formular el problema. En esta etapa, el investigador puede realizar entrevistas informales para identificar y seleccionar las variables en las que basará la agrupación, ya que si se incluyen variables irrelevantes, pueden distorsionar el problema. 2. Seleccionar una medida de similitud. Se necesita una forma de medir la diferencia o semejanza entre observaciones u objetos, la forma en que generalmente se hace es en términos de la distancia entre cada par de casos; cuando la distancia es menor se considera que los casos son más parecidos entre sí. Existen * 1 Investigadora del I.I.E.S.C.A. Statsoft on line: http://www.statsoft.com.textbook/stclauan.html El FODA: una técnica para el análisis de problemas en el contexto de la planeación en las organizaciones diversas maneras de calcular la distancia, las que se aplican con mayor frecuencia son: la distancia euclidiana que es la raíz cuadrada de la suma de las diferencias al cuadrado entre los valores de dos casos para cada variable; la distancia euclidiana al cuadrado, para esto sería el valor como se explicó anteriormente, antes de calcular la raíz cuadrada; la distancia de Manhattan o de calles urbanas entre dos casos es la suma de los valores absolutos de la diferencia entre observaciones para cada variable; la distancia de Chebychev entre dos objetos es el valor absoluto de la diferencia máxima entre los valores para cualquier variable2. Cuando las variables se miden en unidades muy diferentes, antes de agrupar los casos, se recomienda estandarizar los datos para eliminar la influencia de la unidad de medición. 3. Seleccionar un procedimiento de agrupamiento. Para este paso hay diversos métodos, de los que se tratará en la siguiente sección. 4. Decidir el número de conglomerados a conservar. Una vez que ya se ha hecho un clasificación, se decidirá con cuántos conglomerados se trabajará o en cuántos segmentos se dividirá el mercado, algunas veces esto es una decisión administrativa. 5. Interpretar y elaborar un perfil de los conglomerados. En esta etapa se procederá a determinar las características de cada conglomerado que se conservará y posteriormente la estrategia de mercadotecnia pertinente a cada conglomerado. III. CLASIFICACIÓN DE LOS PROCEDIMIENTOS DE CONGLOMERADOS Los procedimientos de conglomerados se dividen en jerárquicos y no jerárquicos de acuerdo al procedimiento de agrupación3. Los conglomerados jerárquicos se caracterizan porque dicha jerarquía se hace en forma de árbol. Los procedimientos jerárquicos pueden ser por aglomeración o por división. Siguiendo el método de conglomerados por aglomeración, la formación de los conglomerados, se puede hacer de diferentes maneras; en la investigación de mercados se aplican tres métodos que son: el de enlace, el que utiliza la varianza y el de centroides. El método de enlace puede ser simple, completo y enlace promedio. El de enlace simple se basa en la distancia mínima entre casos o sea la regla del vecino más próximo o cercano, en este método, los primeros dos objetos que se agrupan serán aquéllos que tengan la distancia menor entre sí, luego que la distancia más corta se identifica, la siguiente puede ser entre un tercer objeto que se agrupe con los dos primeros o entre un tercero y cuarto objeto y así se forme un nuevo conglomerado. La diferencia entre formar los conglomerados por aglomeración o por división consiste en que el conglomerado por aglomeración empieza con tantos clusters como casos tenga el estudio, a partir de ellos, los conglomerados se empiezan a formar al agrupar los individuos que se asemejan más y así sucesivamente se van haciendo grupos cada vez más grandes y el número de clusters va disminuyendo hasta que se abarca a todas las observaciones en un solo conglomerado. Por otra parte, en el conglomerado por división se empieza con un solo cluster y se va haciendo la división hasta que cada observación es un grupo independiente4. Los procedimientos no jerárquicos se conocen como agrupación de k medias ( k means clustering). Estos métodos se dividen en tres que son: umbral secuencial, umbral paralelo y división para la optimización. IV. EJEMPLO En este ensayo se aplicará el método de clasificación jerárquica por aglomeración de enlace simple y para medir la distancia se calculará la distancia euclidiana al cuadrado, para esto se considerará un ejemplo hipotético con cuatro observaciones y cuatro variables. 2 Naresh K. Malhotra. Investigación de mercados. (México: Prentice Hall Hispanoamericana, 1997), p.676 Ibíd., p.677 4 Seymour Sudman and Edward Blair. Marketing Research. (Singapore: McGraw-Hill International, 1998), p. 559 3 Suponga que se desea segmentar a los clientes de un supermercado en base a la actitud que tienen cuando salen de compras. De acuerdo a una investigación previa, se identificaron cuatro variables de actitud y se pidió a los cuatro entrevistados que expresaran su grado de acuerdo con cuatro afirmaciones en una escala de siete puntos en la cual 1 significa en desacuerdo y 7 significa de acuerdo. Las afirmaciones podrían ser las siguientes: V1 Salir de compras es divertido V2 Combino la salida de compras con la comida fuera de casa V3 Puedo ahorrar mucho dinero si comparo precios V4 Prefiero salir de compras con mi familia Si los resultados para cada una de las afirmaciones se considera que son las variables, se tienen cuatro, las cuales se representarán con V1, V2, V3 y V4; por otra parte, las respuestas de cada uno de los entrevistados constituyen los cuatro casos, que se representarán con C1, C2, C3 y C4. Los valores de las variables para los cuatro casos, se presentan en el Cuadro 1. Cuadro 1. Resultados de la encuesta a los clientes del supermercado Variable V1 V2 V3 V4 C1 1 2 2 1 C2 5 7 7 5 C3 2 2 1 1 C4 7 5 7 5 Caso Fuente: datos hipotéticos Si se sigue el procedimiento que se explicó en la segunda sección, lo primero sería formular el problema, en este caso el problema que se desea resolver es segmentar el mercado en base a los resultados obtenidos en la encuesta, para lo cual se puede aplicar el análisis de conglomerados. El segundo paso, sería seleccionar una medida de similitud, es decir, cómo medir la distancia entre los casos de estudio, para este ejemplo, se seleccionará la distancia euclidiana al cuadrado, la cual se obtiene con la suma de las diferencias al cuadrado entre los valores de dos observaciones para cada variable, para el caso que se resuelve, se tiene lo siguiente: D12 = (1 – 5)2 + (2 – 7)2 + (2 – 7)2 + (1 – 5)2 = 82 D13 = (1 – 2)2 + (2 – 2)2 + (2 – 1)2 + (1 – 1)2 = 2 D14 = (1 – 7)2 + (2 – 5)2 + (2 – 7)2 + (1 – 5)2 = 86 D23 = (5 – 2)2 + (7 – 2)2 + (7 – 1)2 + (5 – 1)2 = 86 D24 = (5 – 7)2 + (7 – 5)2 + (7 – 7)2 + (5 – 5)2 = 8 D34 = (2 – 7)2 + (2 – 5)2 + (1 – 7)2 + (1 – 5)2 = 86 Los subíndices nos indican entre cuáles casos se calcula la distancia. El siguiente paso sería seleccionar un procedimiento de agrupamiento, el procedimiento que se ha seleccionado para resolver este problema es un método jerárquico por aglomeración usando enlace simple; por lo tanto partimos de cuatro clusters y en cada cluster tenemos cada uno de los casos y para proceder a reducir a tres el número de clusters, se buscarán los casos que tengan la distancia menor. De las distancias calculadas se observa que la menor diferencia se encuentra entre los elementos uno y tres y le sigue la diferencia entre los elementos dos y cuatro; por lo tanto, las primeras observaciones agrupadas serían la uno y la tres, quedando tres clusters, El FODA: una técnica para el análisis de problemas en el contexto de la planeación en las organizaciones el siguiente paso, sería agrupar los casos dos y cuatro, con lo que quedarían dos clusters y finalmente se agruparían en un solo conglomerado los dos conglomerados formados anteriormente. Los elementos en cada cluster en cada una de estas etapas, quedarían como se muestra en el Cuadro 2. Cuadro 2. Número de conglomerados por etapa y elementos en cada conglomerado Número de Conglomerados Casos en cada conglomerado 4 1, 2, 3, 4 3 13, 2, 4 2 13, 24 1 1324 Cuando ya se tienen los conglomerados, el siguiente paso consiste en decidir cuántos conglomerados conservar, en este ejemplo, si se conservaran tres segmentos, en el primero quedarían los casos uno y tres en el segundo el dos y en el tercero el cuatro, sin embargo, se observa que entre los casos dos y cuatro la diferencia no es muy grande, entonces podría ser que se conservaran solamente dos conglomerados, que corresponden a dos segmentos, el primero quedaría con los casos uno y tres y el segundo con el dos y el cuatro. Finalmente se procedería a hacer un perfil de cada uno de estos segmentos del mercado, para diseñar una estrategia de mercadotecnia para cada uno de ellos. Si se quisiera representar en un plano cartesiano cada caso, para tratar de analizar cuáles serían los más semejantes y cuáles se podrían agrupar en un cluster, como lo presentan Seymour y Blair5, solamente podríamos tomar dos variables, se haría esta representación considerando las variables uno y dos en el Diagrama 1. 5 Op. cit., p.560 Revista Ciencia Administrativa 1997 | Editorial | Artículos | Reportes de Investigación | Regresar al Menú Principal | Regresar al Servidor | Diagrama 1. DIAGRAMA DE PUNTOS VAR1 vs. VAR2 7.5 6.5 VAR2 5.5 4.5 3.5 2.5 1.5 0 1 2 3 4 5 6 7 8 VAR1 En el diagrama que se obtiene se observa que el C1(1,2) y C3(2,2) son los más próximos y con ellos dos se podría formar un cluster, si se quisiera formar otro cluster, entonces en segundo lugar se agruparían C2(5,7) y C4(7,5), con esto se tendrían dos clusters. Para representar cómo se van agrupando los casos en conglomerados, considerando todas las variables, se puede elaborar un diagrama de árbol, también conocido como dendrograma, en él se colocan las observaciones en el eje vertical de acuerdo a la forma en que se agruparon y en el eje horizontal se mide la distancia de enlace. Para elaborar este diagrama se necesita conocer la distancia entre los elementos que se van uniendo al formar cada cluster. Si se utiliza la distancia euclidiana al cuadrado, ya tenemos la medida entre: D13 = 2 D24 = 8 Hace falta calcular la distancia entre estos dos clusters, si seguimos el método de agrupación de enlace simple, debemos identificar cuál es la menor distancia o el vecino más cercano entre los dos clusters anteriores, para esto debemos comparar las distancias entre los casos uno y tres que forman el primer cluster y con los casos dos y cuatro que forman el segundo cluster y escoger la menor; como ya se calcularon antes las distancias entre todos los casos, podemos ver que los vecinos más cercanos son el uno y el dos, pues entre ellos la distancia es 82, mientras que entre los demás (D14, , D23 y D34 ) la distancia es 86. De lo anterior concluimos que la distancia entre los dos clusters es 82, con esta información ya se puede elaborar el diagrama de árbol, que quedaría como se presenta en el Diagrama 2. En este diagrama puede apreciarse cómo se agrupan los elementos C_1 y C_3 , también los elementos C_2 y C_4, entre los cuales su distancia es mayor que entre los dos primeros y finalmente, la mayor distancia se presenta entre estos dos clusters formados. Aunque el ejemplo desarrollado en este ensayo tiene solamente cuatro casos y cuatro variables, lo mismo se podría hacer para un estudio de mercado en el que interesara agrupar casos para identificar segmentos y aplicando el software de estadística correspondiente a análisis cluster o de conglomerados se puede llevar a cabo el análisis para un número mayor de casos y variables; los resultados del mismo y el diagrama de árbol se obtienen automáticamente. Diagrama 2. El FODA: una técnica para el análisis de problemas en el contexto de la planeación en las organizaciones Diagrama de árbol para cuatro casos Enlace sencillo Distancia euclidiana al cuadrado C1 C3 C2 C4 0 10 20 30 40 50 60 70 80 90 Distancia de enlace V. CONCLUSIÓN Después de explicar un procedimiento para formar conglomerados a partir de una serie de datos y también el diagrama en el que se pueden identificar los conglomerados que en un estudio de mercado representa los posibles segmentos a considerar, podemos observar que esta representación gráfica resulta clara para interpretar y nos arroja información de mucha utilidad cuando se quieren identificar diferencias o similitudes entre los clientes o clientes potenciales de una empresa. Además de tener aplicación este procedimiento en la segmentación del mercado, lo podríamos aplicar a otras situaciones en las cuales nos interesa identificar semejanzas o diferencias entre preferencias, identificar oportunidades para nuevos productos, identificar nuevos nichos en el mercado, etc. Además del método que se describió, podemos darnos cuenta de que hay otras formas de realizar este análisis y combinando estos y la experiencia podríamos seleccionar el que mejor resuelva el problema de interés.