2. MPs de memoria compartida centralizada
Anuncio

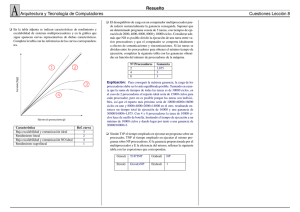
U NIDAD T EM ÁTICA 5: M ULTIPROCESADORES . 15. Arquitectura de los multiprocesadores. 16. Multiprocesadores de memoria compartida. 17. Multicomputadores. 15-1 T EMA 15: A RQUITECTURA DE LOS MULTIPROCESADORES . 1. Concepto de multiprocesador. 2. Multiprocesadores de memoria compartida centralizada. 3. Multicomputadores y COWs. 4. Multiprocesadores de memoria compartida distribuida. Bibliografı́a: S. Dasgupta, Computer Architecture: A Modern Synthesis, Volume 2: Advanced Topics, John Wiley & Sons, 1989 J.L. Hennessy & D. A. Patterson. Computer Architecture: A Quantitative Approach 2a y 3a ed., Morgan Kauffman Publishers, 1996 y 2002. Departamento de Informática de Sistemas y Computadores (DISCA) Facultad de Informática de Valencia 15-2 1 CONCEPTO DE MULTIPROCESADOR 1. Concepto de multiprocesador Multiprocesador 1. Dos o más procesadores de capacidades comparables. 2. Cooperando en la ejecución de una tarea. 3. Bajo el control de un único sistema operativo. Cada procesador posee su propia unidad de control → ejecuta su propio código sobre sus propios datos → puede ejecutar cualquier aplicación (no sólo programas vectoriales) ¿Qué se ejecuta en paralelo? Segmentos de un mismo programa → ↓ tiempo de ejecuci ón del programa de usuario. Programas independientes → ↑ productividad del sistema. 15-3 1 CONCEPTO DE MULTIPROCESADOR Granularidad del paralelismo Los procesos necesitan comunicarse y sincronizarse → sobrecarga que disminuye las prestaciones. Granularidad: Número medio de instrucciones ejecutadas entre dos operaciones de comunicación. Fino: Tarea repartida entre muchos procesadores. Menor tamaño de cada proceso. Mayor número de operaciones de comunicación. Grueso: Tarea repartida entre pocos procesadores. Mayor tamaño de cada proceso. Menor número de operaciones de comunicación. Clasificación de los multiprocesadores Criterio: Modelo de comunicación entre los procesos. Variables compartidas. Paso de mensajes. Criterio: Arquitectura de la memoria Memoria compartida. Memoria distribuida. Juntando ambos criterios: Multiprocesadores de memoria compartida centralizada: Variables compartidas + memoria compartida. Multiprocesadores de memoria compartida distribuida: Variables compartidas + memoria distribuida. Multicomputadores, Clusters de PCs: Paso de mensajes + memoria distribuida. 15-4 2 MPS DE MEMORIA COMPARTIDA CENTRALIZADA 2. MPs de memoria compartida centralizada P0 P1 AM0 AM1 .... Pn−1 AMn−1 RED DE INTERCONEXION M0 M1 .... Mm−1 Memoria central Compartida por todos los procesadores, y accesible desde cualquiera. → tambien llamados multiprocesadores simétricos: Symmetric (shared memory) Multiprocessors. Descompuesta en varios módulos, para permitir el acceso concurrente de varios procesadores. Cada procesador debe tener un espacio de direccionamiento suficientemente amplio como para poder direccionarla completamente. El tiempo de acceso a memoria es el mismo, independientemente del par procesador memoria que intervenga. → también llamadas arquitecturas UMA: Uniform Memory Access. 15-5 2 MPS DE MEMORIA COMPARTIDA CENTRALIZADA Red de interconexión Entre procesadores y memoria: • Cualquier procesador debe poder acceder a cualquier m ódulo de memoria. • El que un procesador acceda a un módulo de memoria no deberı́a impedir que otro procesador acceda un módulo de memoria distinto. Configuraciones: • Bus común • Múltiples buses. • Crossbar • Redes multietapa. ¿tiempo de acceso a memoria? Suma de: Tiempo de acceso del módulo. Retardo de la red de interconexión. Retardo debido a conflictos de acceso al módulo de memoria. Retardo debido a conflictos de acceso en la red de interconexi ón. → hay conflictos de acceso a los módulos de memoria y red de interconexión. → necesidad de circuitos de arbitraje en la red de interconexi ón y memoria. → Tiempo de acceso elevado. Problema tanto más grave cuantos más procesadores hayan. ¿Cómo reducir el tiempo de acceso a memoria? Antememorias locales a cada procesador. ⇒ Problema de la coherencia entre las antememorias. 15-6 2 MPS DE MEMORIA COMPARTIDA CENTRALIZADA Mecanismo de comunicación. Mediante variables compartidas, situadas en la memoria. Sincronización, a través de los mecanismos clásicos de exclusión mutua: • Cerrojos: LOCK, UNLOCK • Semáforos: ◦ P(S) if s>0 then s:= s-1 else Bloquear proceso y pasarlo a la cola. ◦ V(S) s := s+1 if Hay procesos en la cola then extraer de la cola. Las operaciones de sincronización deben ser indivisibles: instrucción TAS x (Test And Set x): 1. Leer (x) 2. Verificar la condición 3. Modificar y escribir (x) (en su caso) → El proceso que las ejecuta: 1. No debe perder el procesador. 2. No debe perder el módulo de memoria accedido → la operación de lecturamodificación-escritura debe ser atómica desde el punto de vista de la memoria. 15-7 3 MULTICOMPUTADORES Y CLUSTERS 3. Multicomputadores y Clusters P0 P1 AM0 AM1 M0 M1 .... Pn−1 AMn−1 .... Mm−1 RED DE INTERCONEXION Memoria Fı́sicamente distribuida entre los procesadores. Cada procesador accede a su módulo de memoria sin penalización. El espacio de direccionamiento de cada procesador debe ser suficiente s ólo para acceder la memoria local. El código a ejecutar debe estar copiado en todos los nodos. Red de interconexión Entre procesadores. • Los procesadores se comunican directamente con un subconjunto de los procesadores, • e indirectamente (circulando a través de la red) con el resto. Permiten la comunicación de los procesadores (procesos) por medio de mensajes. Hay conflictos de acceso a la red de interconexi ón, originando retardos extra y requiriendo árbitros. 15-8 3 MULTICOMPUTADORES Y CLUSTERS Prestaciones de la red de interconexión Latencia. Tiempo necesario para envı́ar un mensaje en la red. Productividad. Tráfico máximo que puede circular por la red. Parámetros de diseño de la red que afectan estos parámetros: Topologı́a. Mecanismo de conmutación. Algoritmo de encaminamiento. Mecanismo de comunicación. Mediante mensajes: send(proc,msg),receive(&msg). Sincronización, por medio de las propias primitivas de envı́o/recepción: • Envı́o y recepción bloqueantes. • Envı́o no bloqueante, recepción bloqueante. Las primitivas de comunicación tienen una sobrecarga asociada: llamada al sistema operativo, copia del mensaje de la memoria de usuario a la memoria del sistema, inyección en la red, etc. 15-9 3 MULTICOMPUTADORES Y CLUSTERS Clusters de PCs Idea original: Las estaciones de trabajo suelen estar ejecutando tareas interactivas durante un alto % de su tiempo. Es habitual disponer de una red local (de bajas prestaciones) interconectando las estaciones de trabajo. ⇒ Networks of workstations: Utilización de un grupo de estaciones de trabajo conectadas en red para ejecutar aplicaciones paralelas y distribuidas. RED DE INTERCONEXION (R.I.) Actualmente: Conjunto de PC’s “compactos” (sin teclado ni pantalla) ubicados en un mismo armario. Diferentes factores de forma. Ejemplos: 1U “blade” La red de interconexión es rápida. La principal sobrecarga suele estar en las librerı́as de comunicaciones. Constituyen una alternativa de bajo coste a los multicomputadores. 15-10 4 MPS DE MEMORIA COMPARTIDA DISTRIBUIDA 4. MPs de memoria compartida distribuida Multiprocesadores de memoria compartida centralizada. + Modelo de programación sencillo. - Pocas prestaciones si el número de procesadores es elevado. Multicomputador. + Potencia de cálculo crece con el número de procesadores. - Modelo de programación más incómodo. Solución: Multiprocesadores de memoria compartida distribuida o “Multiprocesadores escalables”: Multiprocesadores con modelo de programación de memoria compartida pero con memoria fı́sicamente distribuida. Caracterı́sticas Múltiples procesadores con su módulo de memoria local. Cada procesador es capaz de direccionar toda la memoria. Cada procesador accede a su módulo de memoria a la máxima velocidad. Cuando se referencia una posición de memoria no local, un mecanismo de conversión envı́a un mensaje al procesador correspondiente → el tiempo de acceso a las posiciones no locales es muy elevado. → Máquinas NUMA: Non Uniform Memory Access. Todas las posiciones de memoria no tienen el mismo tiempo de acceso → Problema de la coherencia entre las antememorias. → Máquinas NCC-NUMA Non Cache Coherent-Non Uniform Memory Access. No hay protocolo de coherencia. Se evita el problema por software. → Máquinas CC-NUMA Cache Coherent-Non Uniform Memory Access. Se emplea un protocolo para garantizar la coherencia entre las antememorias. 15-11