Redalyc.Reconocimiento de caracteres manuscritos usando la
Anuncio

Científica
ISSN: 1665-0654
revista@maya.esimez.ipn.mx
Instituto Politécnico Nacional
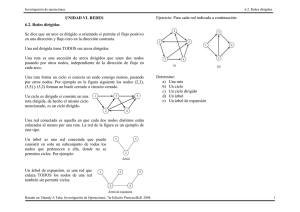
México
Toscano Medina, Karina; Nakano Miyatake, Mariko; Sánchez Pérez, Gabriel; Pérez Meana, Héctor M.;
Yasuhara, Makoto
Reconocimiento de caracteres manuscritos usando la función spline natural
Científica, vol. 9, núm. 3, 2005, pp. 143-154
Instituto Politécnico Nacional
Distrito Federal, México
Disponible en: http://www.redalyc.org/articulo.oa?id=61490306
Cómo citar el artículo
Número completo
Más información del artículo
Página de la revista en redalyc.org
Sistema de Información Científica
Red de Revistas Científicas de América Latina, el Caribe, España y Portugal
Proyecto académico sin fines de lucro, desarrollado bajo la iniciativa de acceso abierto
Científica Vol. 9 Núm. 3 pp.143-154
© 2005 ESIME-IPN. ISSN 1665-0654. Impreso en México
Reconocimiento de caracteres manuscritos
usando la función spline natural
Karina Toscano-Medina1
Mariko Nakano-Miyatake1
Gabriel Sánchez-Pérez1
Héctor M. Pérez-Meana1
Makoto Yasuhara2
trazos, se determina a cual caracter pertenece los punto
significativos del caracter de entrada. La taza de recono
cimiento global del sistema propuesto es aproximadament
de 96.0%.
Sección de Estudios de Posgrado e Investigación (SEPI),
Escuela Superior de Ingeniería Mecánica y Eléctrica (ESIME),
Unidad Culhuacán, Instituto Politécnico Nacional.
Av. Santa Ana 1000, Col. San Francisco Culhuacán,
CP 04430, Del. Coyoacan, México, DF.
MÉXICO
2
University of Electro-Communications.
Chofugaoka 1-5-1, Tokyo, Japan.
JAPÓN
During last two decade, numerous handwriting characte
recognition systems have been proposed. Many of them
presented their limitation when the handwriting character i
cursive type and it has some deformation. However this typ
of cursive characters is easily recognized by the human being
In this paper we research its human ability and apply it t
the dynamic handwriting character recognition. In th
proposed system, significant knots of each character ar
extracted using natural Spline function named SLALOM an
their position is optimized Steepest Descent Method. Usin
optimal knots of the training set, character’s models ar
constructed. The optimal knots of an unknown inpu
character are compared with each model of all characters
and it is classified to one group of character with maximum
similitude score. The recognition stage consists in two-steps
classification using global feature and classification usin
local feature. The global recognition rate after two-step
recognition stage in the proposed system is approximatel
96.0%.
1
email:
hmpm@prodigy.net.mx
Recibido el 7 de junio de 2004; aceptado el 18 de febrero de 2005.
1. Resumen
Durante las últimas dos décadas se han propuesto una gran
cantidad de sistemas para el reconocimiento de caracteres
manuscritos. Sin embargo aún existen varias limitaciones
relativas a su funcionamiento y porcentaje de reconocimiento,
sobre todo cuando los caracteres manuscritos son de tipo
cursivo. Para reducir este problema, en este artículo se propone
un nuevo algoritmo de reconocimiento dinámico de caracteres
manuscritos de tipo cursivo. En el algoritmo propuesto, los
puntos significativos para cada caracter se estiman usando
una función spline natural llamada Slalom. Posteriormente,
partiendo de los puntos significativos se construye un modelo
para cada caracter. En la etapa de reconocimiento, los puntos
significativos de un caracter de entrada desconocido se
comparan con los modelos de cada uno de los caracteres
existentes para identificar el caracter de entrada. La etapa de
reconocimiento consiste de dos niveles de clasificación. En
la primera etapa se agrupan las letras parecidas, mientras que
en la segunda etapa, usando las características locales de los
2. Abstract (Handwriting Character Recognition System
using Natural Spline Function)
Palabras clave: reconocimiento de caracteres manuscritos
reconocimiento en línea, función spline natural, método d
Slalom, método de búsqueda gradiente, longitud mínima d
descripción.
3. Introducción
El reconocimiento convencional de caracteres manuscrito
está basado en la extracción de características a partir de l
forma particular del caracter bajo análisis, tales como: l
inclinación de las líneas, la posición relativa de cada línea, e
ancho de las diferentes partes de la línea, etc. [1]. Este métod
de reconocimiento se puede usar para reconocer caractere
manuscritos en letra de molde (no cursivo) de una maner
eficiente. Sin embargo, para el reconocimiento de caractere
cursivos, éste no es eficiente.
Científica
Una razón por la cual los seres humanos pueden leer y entender
los caracteres cursivos (muy aerodinámicos o deformados) es
porque tenemos la habilidad de trazar mentalmente, varias veces
la letra en el orden en que fue escrita. Cuando una persona
escribe un caracter, generalmente realiza los siguientes 4 pasos:
1) Tener en mente el símbolo que se va a escribir.
2) El orden de los movimientos del caracter a escribir.
3) La realización del trazo.
4) La imagen del caracter.
El proceso de generación del caracter se realiza del paso 1 al
4, mientras el proceso de reconocimiento puede ser realizado
en orden inverso al de la generación, esto es del 4 al 1. Sin
embargo la realización de este proceso inverso es sumamente
difícil.
Los sistemas de reconocimiento se dividen en dos categorías:
sistemas en línea y sistemas fuera de línea [1]. En los sistemas en
línea se requiere de la presencia física de la persona que realiza el
trazo de un caracter; de aquí que se utilicen características como
la inclinación del bolígrafo, la velocidad del trazo, la secuencia de
direcciones tomadas por el trazo, los momentos gráficos, entre
otras[1]. Los procesos de reconocimiento de caracteres
manuscritos en línea equivalen a realización de los procesos
inversos del 3 a 1, mientras los procesos de reconocimiento fuera
de línea equivalen a los procesos inversos completos de 4 a 1.
Por lo tanto se puede decir que el reconocimiento en línea es una
parte del proceso inverso completo del reconocimiento fuera de
línea de caracteres manuscritos.
Hasta la fecha se han propuestos varios sistemas para realizar
el reconocimiento de caracteres manuscritos en línea, por
ejemplo, Manke y Bodenhausen [2] realizaron una investigación
proponiendo una solución conexionista para el problema del
reconocimiento de la escritura cursiva y del caracter aislado.
Ellos proponen a la MS-TDNN (red neuronal de retraso en
tiempo con estados múltiples) el cual integra a la red TDNN
(red neuronal de retraso en tiempo) con un procedimiento de
alineación no lineal en tiempo, para encontrar los movimientos
y los límites tanto de los caracteres aislados como de las
palabras; para posteriormente llevar a cabo el reconocimiento.
Las palabras manuscritas se pueden representar como una
secuencia de tiempo, la velocidad y la presión variante en
cada coordenada. El problema principal de reconocer palabras
continuas es que los caracteres o los límites del movimiento
no son conocidos y se debe encontrar una alineación de
tiempo óptima. El reconocedor conexionista, integra el
reconocimiento y la segmentación dentro de una sola
arquitectura de red MS-TDNN, que fue propuesta
originalmente para las tareas del reconocimiento del habla
continuo.
Nakatani et al. [3] propusieron un sistema de reconocimient
en línea para caracteres manuscritos en hiragana usando u
modelo de AR complejo. El sistema fue evaluado por do
escritores, quienes evaluaron el funcionamiento del sistem
cambiando los valores de los parámetros usados en el model
de AR. El funcionamiento de reconocimiento al que se lleg
después de adecuar los valores de los parámetros del sistem
fue de aproximadamente 98 %.
Plamondon y Maarse [4] propusieron el estudio de la escritur
desde el programa motor del cerebro que es donde se piens
lo que se quiere escribir, después se transmite esta informació
a los nervios, posteriormente los movimientos del músculo s
activan, para finalmente trazar la trayectoria en una tablet
digitalizadora. De esta manera, se lleva a cabo la escritura, si
embargo los autores querían determinar que característica
variable debe ser controlada para llevar a cabo el proceso d
forma inversa, desde la trayectoria de la escritura en la tablet
digitalizadora hasta el programa motor del cerebro. Los autore
haciendo pruebas, llegaron a la conclusión de que usando l
teoría de la transformada de Laplace y los modelos lineale
hasta de segundo orden usando la velocidad como variabl
de control es posible realizar el proceso inverso.
Mezghani et al. [5] propusieron un sistema de reconocimient
de caracteres arábigos usando redes neuronales de Kohonen
Aquí de la información dinámica de las letras arábigas, s
extrajeron los coeficientes de Fourier elípticos. Los autore
evaluaron el sistema usando 18 letras arábigas, trazando 1
escritores cada letra 24 veces construyendo así 7400 trazo
Los resultados de reconocimiento varían demasiad
dependiendo de la letra (desde un 40% hasta un 2% de error
debido a la similitud existentes entre las diferentes letras. E
reconocimiento global para solo un escritor es de aproxima
damente 88%.
Sin et al. [6] propusieron un sistema combinado de modelo
ocultos de markov (HMM) y programación dinámica para e
reconocimiento de caracteres tipo cursivo. El sistema realiza
tanto la segmentación de cada caracter dentro de la palabr
como el reconocimiento del caracter segmentado usando e
mismo HMM. El funcionamiento del sistema para caractere
(alfabeto inglés) escritos dentro de una región establecida e
de aproximadamente 91%.
Este artículo se enfoca en la realización de los proceso
inversos de escritura mencionados anteriormente desde e
paso (3) al paso (1). Aquí la realización del paso (3) al paso (2
está basada en una aproximación por medio de la funció
spline natural, mediante la cual es posible obtener el orden de
movimiento requerido para realizar el trazo del caracter a part
de los datos capturados en tableta digitalizadora, mientra
Científica
que la realización del paso (2) al paso (1) se lleva a cabo
mediante la creación de modelos y cálculo de similitud entre
los modelos y los datos obtenidos del caracter a analizar.
donde α es un factor en el intervalo [0,1] que determina e
peso o importancia de las condiciones anteriorment
mencionadas.
Este artículo está organizado de la siguiente manera: en la sección
1 se describió la metodología para atacar el problema del
reconocimiento de caracteres cursivos y los principales trabajos
reportados en la literatura. En la sección 2, se explica brevemente
el método de Slalom que juega un papel importante en el sistema
propuesto, el sistema propuesto se describe detalladamente en
la sección 3. En la sección 4, los resultados obtenidos por
simulación computacional son mostrados y finalmente las
conclusiones de este artículo se proporcionan en la sección 5.
El valor de la primera derivada de la función g(t) correspondient
al i+1-ésimo nodo en manera discreta, lo podemos escribir :
gi' +1 =
gi +1 − gi gi +1 − gi
=
ti +1 − ti
∆
donde: ∆ es el intervalo entre el i-ésimo nodo y el i+1-ésim
nodo, y de manera similar el valor de la segunda derivada par
el i+1-ésimo nodo está dada por:
4. Desarrollo
4.1 Método de Slalom
gi''+1 =
El método de Slalom fue desarrollado como un método de
cuantificación inversa para señales o imágenes [7]. Usando
este método, partir de los datos muestreados f1, f2, ..., fM en
tiempo t1, t2, ..., tM (t1 < t2 < ... < tM ) se puede obtener una
función suave y continua g(ti). Por lo tanto el método de
Slalom se puede considerar como un método para generar
una función spline natural. El método de Slalom obtiene una
función g(ti) que cumple las dos condiciones siguientes:
1. La diferencia entre g(ti) y fi debe ser menor que un valor
aceptable δ.
2. La función g(ti) debe ser una función suave y continua.
Sin embargo estas dos condiciones no se pueden satisfacer
fácilmente de manera simultánea ya que, para que la función
g(ti) sea suave, la diferencia entre valores de g(ti) y fi no se
puede mantener en cero. El grado de suavización de la función
g(t) se determina por medio de la función J[g] dada en
ecuación (1).
(4
gi' +1 − gi'
(5
ti +1 − ti
Suponiendo que los intervalos de los dos nodos consecutivo
son iguales, la ecuación (5) se puede escribir como:
gi' +1 =
gi +1 − gi
∆
gi' =
gi − gi −1
∆
Sustituyendo la ecuación (6) en (5), obtenemos:
g’’i + 1 = 1/∆
(gi+ 1 − gi)−(gi − gi−1)
∆
= (gi+ 1 − 2gi + gi−1)
∆2
[{
}/ ]
/
(6
(7
Suponiendo que ∆ es igual a 1, se obtiene:
g’’i + 1 = gi+ 1 - 2gi + gi-1
(8
El primer término de la ecuación (3) en forma discreta, e
d2
J [g] =m( 2 g(t))2 dt
dx
(1)
para i = 1, 2, …, M
(2)
donde δ es un valor aceptable de error. Así para satisfacer
las dos condiciones de manera simultanea, se define una
función J’[g] como: [8,9],
2
M
d2
2
J ' [ g ] = ∫ 2 g ( t ) dt + α ∑ ( g ( t i ) − f i ) dx
dx
i
=1
2
i
ción (8) como
Cuando la ecuación (1) se minimiza, la función aproxima a una
función más suave. La primera condición se puede escribir
como se indica en la ecuación (2)
|g(t) - fi| < δ
Σ(g ’’(t)) , por lo cual ésta se puede rescribir usando la ecua
(3)
N−1
J’[g] = Σ (gi+ 1 − 2gi + gi−1)2 + α
j=2
M
Σ (gji − fi)2
i=1
(9
donde N (>M) es el número de nodos para estimar la funció
g(t) y M es el número de muestras, gi es el valor de la i-ésim
muestra de la función Spline g y gji es el valor del ji-ésim
nodo. El problema de minimizar J’[g] se puede resolver usand
la condición de que la derivada parcial de J’[g] con respecto
gk, sea igual a cero.
o sea:
MJ’
= 0,
Mgk
k = 1, ..., N
(10
Científica
Así el primer término de la ecuación (9) queda de la siguiente
manera:
N−1
A=
Σ (g
j−1
− 2gj + gj+1)2
j=2
= (g1 − 2g2 + g3)2 + (g2 − 2g3 + g4)2 + (g3 − 2g4 + g5)2 + ...
... + (gN−3 − 2gN−2 + gN−1)2 + (gN−2 − 2gN−1 + gN)2
(11)
Las derivadas parciales de la ecuación (11) se determinan de
la siguiente manera:
4.2 Sistema propuesto
...
∂J '
= 2( g N − 4 − 4 g N − 3 + 6 g N − 2 − 4 g N −1 + g N )
∂g N − 2
+ 2αδ N − 2, Ω ( g N − 2 − f N − 2 ) = 0
∂J '
= 2(−2 g N − 3 + 5 g N − 2 − 4 g N −1 + g N )
∂g N −1
+ 2αδ N −1, Ω ( g N −1 − f N −1 ) = 0
∂J '
= 2( g N − 2 − 2 g N −1 + g N )
∂g N
(12)
+ 2αδ N , Ω ( g N − f N ) = 0
Para obtener el valor de gk, k = 1, 2, …, N, hay que resolver el
siguiente sistema lineal:
αδ1,Ω (f1 − g1)
αδ2,Ω (f2 − g2)
αδ3,Ω (f3 − g3)
...
αδN-2,Ω (fN-2 − gN-2)
αδN-1,Ω (fN-1 − gN-1)
αδN,Ω (fN − gN)
j0Ω
j0 Ω
La figura 1 muestra una forma esquemática del sistem
propuesto, el cual realiza el reconocimiento de caractere
manuscritos a partir de su trazo u orden de su articulación
Aquí el trazo se captura por medio de una tableta digitalizadora
generando posteriormente los datos de dichos caracteres. Esto
datos generados se emplean para encontrar las característica
propias de cada caracter manuscrito, por medio de u
preprocesamiento que consiste de filtraje y normalización qu
permita posteriormente realizar la extracción de característica
en la que se estiman los nodos significativos usando el métod
de Slalom. Finalmente el reconocimiento se realiza por medi
de la construcción de los modelos de caracteres. Con este fi
las características extraídas del caracter de entrada se emplea
para construir un modelo el cual se compara con los modelo
de todos los caracteres existentes, calculándose el grado d
similitud entre éstos para identificar así al caracter de entrada
Cada etapa del sistema propuesto se mencionará detalladamente
4.2.1 Adquisición de datos
donde Ω es el espacio de muestreo y δj, Ω se puede representar
como:
{01
M
Σ (gji − fi)
i=1
∂J '
= 2( g1 − 4 g 2 + 6 g3 − 4 g 4 + g5 ) + 2αδ 3, Ω ( g3 − f3 ) = 0
∂g3
δj,Ω =
(15
g(n) es la función g en tiempo n de adaptación.
∂J '
= 2(−2 g1 + 5 g 2 − 4 g3 + g 4 ) + 2αδ 2, Ω ( g 2 − f 2 ) = 0
∂g 2
g1
g2
g3
...
=
gN-2
gN-1
gN
g(n) = g(n − 1) − λ [MS/ Mg(n − 1)]
donde S =
∂J '
= 2( g1 − 2 g 2 + g3 ) + 2αδ1, Ω ( g1 − f1 ) = 0
∂g1
1 −2 1
−2 5 −4 1
1 −4 6 −4 1
...
1 −4 6 −4 1
1 −4 5 −2
1 −2 1
El segundo término de la ecuación (9) se resuelve usand
método de búsqueda de gradiente. En el sistema propuesto
se consideró que la condición de ser una función suave
diferencia entre g y f mínima tenga el mismo peso, por lo tant
el valor a es igual a 1. La ecuación (15) muestra la solución d
la ecuación (10) en el segundo término de la ecuación (9).
(14)
δj,Ω = 0, cuando el nodo j-ésimo no corresponde a un tiempo de
muestreo y δj,Ω = 1, cuando el nodo j-ésimo es un tiempo de
muestreo. Para resolver la ecuación (13), no se puede usar el
método tridiagonal, debido a la forma de la matriz, por lo que
se usa el método de eliminación gaussiana.
Los datos de la escritura se obtienen por medio de la tablet
digitalizadora y la pluma o lápiz ergonómico Intuos2 d
Wacom, con la cual los escritores trazan los caracteres sobr
la tableta digitalizadora conociendo así el orden d
articulación de cada caracter. La tableta arroja la imagen d
lo que se escribe en el monitor, así como también los dato
de acuerdo al orden de articulación como se escribe u
caracter. La figura 2 muestra los datos adquiridos de la letr
'h' y sus señales en los ejes x, y.
4.2.2 Construcción de base de datos
Se construye una base de datos de caracteres manuscrito
con la tableta digitalizadora. Se tomó en cuenta a 26 letras
caracteres del alfabeto inglés realizado 100 veces cada caracte
con 3 escritores, por lo que, la base de datos cuenta con 7 80
Científica
Adquisición de datos por medio de la tableta digitalizadora y
construcción de base de datos
Preprocesamientos (Normalización en tamaño, posición y tiempo)
Extracción de características (nodos óptimos)
usando el método de Slalom
Construcción de modelos de caracteres
Reconocimiento de caracteres manuscritos
usando el modelo del caracter
Fig. 1. Sistema propuesto.
datos. De aquí se toman 4 680 datos para la creación del
modelo de cada caracter, lo que equivale a 60 veces cada
caracter y 3120 datos para la prueba, que son 40 veces cada
caracter. La figura 3 muestra algunos de los caracteres (a,n,m,o)
que forman parte de la base de datos.
4.2.3 Preprocesamiento
Los datos capturados varían en tamaño, posición y la
velocidad de escritura. Estas variaciones afectan a una
extracción de características adecuada. Además de las
variaciones geométricas mencionadas, generalmente los datos
capturados contienen componentes de alta frecuencia
introducidos por una vibración pequeña de la mano a la hora
de la escritura. Como preprocesamientos, se realizan el filtraje
y la normalización en posición, tamaño y tiempo.
(a)(a)
Fig. 3. Ejemplos de letras que forman en bases de datos.
4.2.4 Filtraje
Para eliminar los componentes de alta frecuencia producido
por la vibración de la mano, se aplica un filtro pasa baja a l
señal de trazo en eje-x y en eje-y. En este artículo se utilizó u
filtro Butterworth con orden 5. La figura 4 muestra el traz
original y el trazo filtrado.
4.2.5 Normalización
Después de que realiza un filtraje pasa bajas, la letra filtrad
se normaliza en posición, en tamaño y en tiempo. La norma
lización en posición y en tamaño se realiza aplicando la trans
formada Affine, mientras que la normalización en tiempo s
(b)
(a)
Fig. 2. Los datos capturados partir del trazo de la letra 'h',
(a) trazo realizado, (b) señales en eje-x y en eje-y.
Fig. 4. (a) Trazos original de la letra 'e' y (b) el trazo
filtrado de (a).
(b)
Científica
(a)
(b)
Fig. 5. (a) Trazo original, (b) trazo después del filtrado y
normalización.
realiza usando interpolación y decimación. La figura 5 muestra el trazo original y el trazo filtrado y normalizado tanto en
tamaño como en posición y en tiempo.
(a)
4.2.6 Extracción de características
El proceso de extracción de características consiste en la
obtención de nodos óptimos a partir de las señales tanto del ejex como del eje-y de los trazos realizados. El proceso de obtención
de nodos óptimos se realiza usando el método de Slalom. El
esquema del proceso de extracción de características se muestra
en la figura 6.
4.2.7 Inicialización de nodos óptimos
(b)
A las señales del trazo tanto en el eje-x como en el eje-y se les
aplica la segunda derivada debido a que el punto en el que
Inicialización de nodos óptimos
Obtención de nodos óptimos
usando el primer término de Slalom
Ajuste de posición de nodos óptimos
usando el segundo término de Slalom
NO
Criterio de
terminación
MDL
SÍ
Nodos óptimos
Fig. 6. Los procesos de extracción de características.
Fig. 7. (a) señales correspondientes a la letra 'm' después
del preprocesamiento y (b) segunda derivada filtrada por
un filtro pasa bajas correspondientes a las señales (a).
cambia la velocidad de la escritura tiene una relación con e
orden de la articulación por el cerebro. Sin embargo los cambio
pequeños de velocidad pueden ser ruido producido por l
vibración de las manos. Para evitar esto las señales derivada
(en el eje-x y en el eje-y) se filtran usando filtros pasa bajas
La figura 7 muestra las señales preprocesadas de la letra 'm'
la segunda derivada de las señales después de ser filtradas
respectivamente. Las señales derivadas se dividen en vario
segmentos por cruce por ceros, debido a que el valor cero e
segunda derivada significa que el cambio de velocidad e
cero. En cada segmento, los datos con valor absoluto máxim
se consideran como los nodos iniciales. La figura 8 muestr
los nodos iniciales de la letra 'm' y la letra 'e'. Estos nodo
iniciales no son nodos óptimos, ya que los errores entre la
señales reconstruidas usando estos nodos y señales originale
Científica
(a)
(b)
Fig. 5. (a) Trazo original, (b) trazo después del filtrado y
normalización.
realiza usando interpolación y decimación. La figura 5 muestra el trazo original y el trazo filtrado y normalizado tanto en
tamaño como en posición y en tiempo.
(a)
4.2.6 Extracción de características
El proceso de extracción de características consiste en la
obtención de nodos óptimos a partir de las señales tanto del ejex como del eje-y de los trazos realizados. El proceso de obtención
de nodos óptimos se realiza usando el método de Slalom. El
esquema del proceso de extracción de características se muestra
en la figura 6.
4.2.7 Inicialización de nodos óptimos
(b)
A las señales del trazo tanto en el eje-x como en el eje-y se les
aplica la segunda derivada debido a que el punto en el que
Inicialización de nodos óptimos
Obtención de nodos óptimos
usando el primer término de Slalom
Ajuste de posición de nodos óptimos
usando el segundo término de Slalom
NO
Criterio de
terminación
MDL
SÍ
Nodos óptimos
Fig. 6. Los procesos de extracción de características.
Fig. 7. (a) señales correspondientes a la letra 'm' después
del preprocesamiento y (b) segunda derivada filtrada por
un filtro pasa bajas correspondientes a las señales (a).
cambia la velocidad de la escritura tiene una relación con e
orden de la articulación por el cerebro. Sin embargo los cambio
pequeños de velocidad pueden ser ruido producido por l
vibración de las manos. Para evitar esto las señales derivada
(en el eje-x y en el eje-y) se filtran usando filtros pasa bajas
La figura 7 muestra las señales preprocesadas de la letra 'm'
la segunda derivada de las señales después de ser filtradas
respectivamente. Las señales derivadas se dividen en vario
segmentos por cruce por ceros, debido a que el valor cero e
segunda derivada significa que el cambio de velocidad e
cero. En cada segmento, los datos con valor absoluto máxim
se consideran como los nodos iniciales. La figura 8 muestr
los nodos iniciales de la letra 'm' y la letra 'e'. Estos nodo
iniciales no son nodos óptimos, ya que los errores entre la
señales reconstruidas usando estos nodos y señales originale
Científica
(a)
(a)
(b)
Fig. 8. (a) nodos iniciales de la letra 'm' y (b) nodos iniciales
de la letra 'e'.
(b)
Fig. 9. Señales originales (línea '-') y señales reconstruidas
(línea '-.') a partir de los nodos obtenidos ('*') por el método
de Slalom. (a) letra 'm' y (b) letra 'e'.
son muy grandes. Para reducir este error se toman los nodos
iniciales como de la ecuación (9), y se obtiene una función
suave y continua usando el método de Slalom.
búsqueda del gradiente para incluir el segundo término de l
ecuación (9), se pueden obtener los nodos óptimos qu
minimizan la ecuación (9).
4.2.8 Obtención de nodos óptimos
4.2.9 Ajuste de nodos óptimos
Aplicando las ecuaciones (13) y (14), obtenemos los nodos
intermedios que genera una función suave y continúa. La
figura 9 muestra los nodos obtenidos por el primer término del
método de Slalom junto con la señal reconstruida.
El ajuste del número y posición de los nodos óptimos se efec
túa usando el método de búsqueda del gradiente descenden
te. La figura 10 muestra los resultados de la eliminación d
nodos redundantes y la figura 11 muestra los resultados de
ajuste obtenido por el método de búsqueda del gradiente
Estas operaciones del método de Slalom (obtención de nodo
eliminación de redundancia y ajuste de posición por el méto
do de búsqueda de gradiente) se iteran mientras el criteri
MDL (Minimum Descripción Length) disminuye o llega e
Como podemos observar en la figura 9, los puntos obtenidos
resultan redundantes, ya que varios nodos representan casi
la misma posición. Además existe diferencia entre la señal
original y la señal reconstruida (caso de la letra 'm' en el eje y).
Eliminando los nodos redundantes y aplicando el método de
número de nodos a 2 n .
Científica
(a)
(a)
(b)
(b)
Fig. 10. Señales originales (línea '-') y señales reconstruidas
(línea '-.') a partir de los nodos reducidos '*', (a) letra 'm' y (b)
letra 'e'.
Fig. 11. Nodos ajustados por el método de búsqueda de
gradiente. Señales originales (línea '-') y señales
reconstruidas (línea '-.') a partir de los nodos '*'. (a) letra 'm'
y (b) letra 'e'.
4.2.10 El criterio MDL
EL método de longitud de descripción mínima conocido como
MDL (Minimum Description Length) fue propuesto por
Rissanen en 1978 [10], éste es un criterio para obtener el mínimo número de parámetros para construir un modelo que tenga
una capacidad de generalización suficientemente buena. El
método MDL está basado en el criterio de entropía máxima de
Akaike [11,12], y se define en la ecuación (16).
MDL =
n f (t ) − g (t ) 2
n
(
i
i ) p
log e ∑
+ log e n
2
n
i =1
2
(16)
donde n es el número de datos capturados, f(ti) es i-esimo
dato de entrada, g(ti) es i-esimo es el dato estimado usando el
método de Slalom y el método de búsqueda de gradiente, p es
número de parámetros, que equivale al número de nodos óp
timos. Además el número máximo de parámetros esta limitad
por 2(n)1/2, o sea
p≤2 n
(17
Cuando el valor de MDL con el número de nodos obtenido
ya no disminuye, la iteración de los procesos de extracción d
características se termina y entonces los nodos obtenidos e
eje-x y eje-y se consideran nodos óptimos. La figura 12 mues
tra los nodos óptimos (en eje-x y eje-y), el trazo original y e
trazo construido a partir de los nodos óptimos.
4.2.11 Construcción de modelos de caracteres
Para construir el modelo de cada caracter se utilizan 60 trazo
de cada uno de ellos por cada escritor, el modelo se genera co
Científica
(a)
(b)
Fig. 12. Trazos originales y trazos construidos a partir de
nodos óptimos. '*' indica nodos óptimos en eje-x y ' ' indica
nodos óptimos en eje-y.
(a)
los nodos óptimos, es decir, se suma el número de apariciones
de cada nodo óptimo, tomando en cuenta el valor del nodo, es
decir si el valor del nodo es positivo se incrementa y si el valor
del nodo es negativo se decrementa, obteniendo así una gráfica del porcentaje de aparición de los nodos óptimos para cada
eje. Seguidamente se le aplica un filtro pasa-bajas obteniendo
una gráfica a la cual llamaremos modelo del caracter. Las figuras
13 y 14 muestran modelos de las letras 'm','e', 'b' y 'v'.
4.2.12 Reconocimiento de caracteres
Una vez obtenidos los modelos (eje-x y eje-y) de los caracteres
usando 40 trazos para caracter, se introduce un caracter no
conocido para su reconocimiento, realizándose todas las operaciones mencionadas desde la normalización hasta obtener
los nodos óptimos y sus valores correspondientes, es decir
obtenemos la información del signo para comparar con los
modelos de todos los caracteres. Si el signo es igual se suma y
si es diferente se resta, se calcula el grado de similitud entre la
información del caracter no conocido y el modelo de cada letra
donde el grado de similitud mayor determinará a que caracter
corresponde el caracter no conocido. Las figuras 15 y 16 muestran las comparaciones entre las características del caracter de
entrada y de los modelos de caracter 'f' y del caracter 'm', respectivamente. Aquí las líneas sólidas significan que la posición
de nodos óptimos de ambas letras (de modelo y de entrada)
coincide, mientras las líneas punteadas significan que la posición de nodos óptimos de ambas letras no coincide. La suma de
la longitud de líneas sólida aumenta el grado de similitud entre
ambas letras, mientras la longitud de líneas punteada desminuye
el grado de similitud de ambas letras. Por lo tanto el grado de
similitud entre el caracter de entrada y el modelo de un caracter
se calcula como ecuación (18).
ns
nd
Gs = ∑ Lsi − ∑ Ldi
i =1
i =1
(18)
donde Lsi es la longitud i-ésima de la línea sólida y Ldi es la
longitud i-ésima de la línea punteada mientras que ns y nd son el
(b)
Fig. 13. Modelos de letras. (a) modelo de letra 'm', (b)
modelo de letra 'e', en ambos ejes.
numero de líneas sólidas y punteadas, respectivamente. La ecua
ción (18) aplica al modelo de eje-x y eje-y, el grado de similitud G
es la suma de ambos ejes.
Debido a que en alfabeto inglés existen algunas letras mu
parecidas por su trazo, tales como {'y', 'g', 'z'} y {'a', 'u', 'v'},
{'h', 'n'}, estas letras no son fáciles de discriminar usando la
características globales y deben de ser discriminadas por su
características locales. Por lo tanto, en el proceso de recono
cimiento se realizan dos etapas de clasificación. La figura 1
muestra el esquema de reconocimiento.
4.3 Resultados obtenidos
En esta sección, se muestran los resultados de la evaluació
del sistema propuesto usando 120 trazos para cada caracte
realizados por tres escritores diferentes. La figura 18 muestr
el resultado de reconocimiento en la primera etapa de clasif
Científica
(a)
Fig. 15. Comparación entre el modelo del caracter 'f' y las
características del caracter de entrada. El grado de similitud
calculado es -0.0746.
En la misma forma, se construyen las reglas para discrimina
los caracteres parecidos de cada grupo. El funcionamient
global de reconocimiento después de las dos etapas de clas
ficación aumenta hasta un 96%. La tabla 1 muestra el desem
peño de la segunda etapa de clasificación respecto a la prime
ra etapa para las letras parecidas.
(b)
Para analizar si el funcionamiento del sistema propuesto e
favorable o no, se requiere realizar una comparación con lo
sistemas reportados en la literatura. Sin embargo una compa
ración justa es bastante complicada, debido a que el tamaño
Fig. 14. Modelos de caracteres. (a) Modelo del caracter'b',
(b) modelo del caracter 'v', en ambos ejes.
cación. El reconocimiento global de la primera etapa de clasificación es 93.5% [13].
A partir de la matriz de confusión obtenida en la primera etapa
de clasificación, se determinaron los siguientes tres conjuntos de letras con mayor frecuencias de confusión entre ellas:
{'a', 'u','v'}, {'h', 'n'} y {'g', 'y', 'z'}. Por lo tanto en la primera
etapa de clasificación se clasifican 18 letras y 3 grupos que
consisten de dos o tres letras cada uno, como se muesra en la
figura 17.
La segunda etapa de clasificación se basa en las características locales de cada caracter, por ejemplo para los caracteres
'h' y 'n', los nodos óptimos de inicios de los trazos son características importantes para distinguirlos. La figura 19 muestra
un ejemplo de los trazos de 'n' y 'h', tanto en el eje x como en el
y. Aquí se puede observar claramente que las partes iniciales
de las señales en el eje-y de ambas letras discriminan a estas
dos letras.
Fig. 16. Comparación entre el modelo del caracter 'm' y las
características del caracter de entrada. El grado de similitud
calculado es 0.1941.
(a)
(b)
(c)
(d)
Fig. 17. Etapas de reconocimiento
el contenido (tipo de letras, tipo de alfabeto) de la base de
datos utilizado para cada sistema son diferentes. A partir de
un análisis realizado sobre los sistemas reportados en la literatura [1-6], podemos observar que el funcionamiento de los
sistemas están dentro un rango de 85% a 98% de reconocimiento. Considerando esta cifra, el sistema propuesto tiene
un funcionamiento mejor o al menos equivalente que otros
propuestos en la literatura.
5. Conclusiones
Este artículo propone un nuevo método para el reconocimiento de caracteres manuscritos para letra de tipo cursivo. El
sistema propuesto emplea el método de Slalom para la detección de los nodos óptimos que representan los puntos significativos para realizar los trazos de las letras. Estos nodos
óptimos se consideran como características de cada caracter,
los cuales permiten la construcción de los modelos de cada
caracter. El método de extracción de características en el sistema propuesto esta basado en una consideración relativa a la
capacidad humana para trazar las letras a partir de sus versiones escritas.
En el proceso de reconocimiento, existen dos etapas de clasificación, debido a que el grado de similitud global no se puede
Fig. 18. Resultados de reconocimiento en la primera etapa
de clasificación.
Fig. 19. Diferencia local de las señales de caracteres
parecidos.
discriminar entre letras cursivas parecidas, tales como {'a', 'v
'u'} y {'h' y 'n'}. Estas letras únicamente se pueden distingu
usando características locales. Así en la primera etapa de clas
ficación, las letras se clasifican usando el grado de similitud e
18 letras y 3 grupos de letras parecidas, y posteriormente en l
segunda etapa de clasificación se clasifican las 8 letras conte
nidas en los 3 grupos usando sus características locales.
Los resultados obtenidos por simulación computacional mues
tran un 93.5% de reconocimiento después de primera etapa d
clasificación y una taza de reconocimiento global de 96.0%
después de aplicar las dos etapas de clasificación. Este resu
tado es bastante aceptable considerando que los caractere
Tabla 1. Reconocimiento en segunda etapa de clasificación
Caracter
1a clasificación
2a clasificación
‘a’
80%
96.6%
‘u’
91%
96.6%
‘v’
100%
100%
‘g’
80%
100%
‘y’
100%
100%
‘z’
94%
100%
‘n’
95%
100%
‘h’
80%
93.3%
manuscritos son cursivos y por lo mismo tienen cierto grado
de deformación. Así la tasa de reconocimiento del sistema
propuesto es muy similar a las tazas de reconocimiento más
altas reportadas a la fecha. Las tasas de reconocimiento reportado en la literatura esta en el rango de 85% a 98% para
caracteres manuscritos de diferentes idiomas.
[5]
[6]
Agradecimientos
Los autores agradecen al Consejo Nacional de Ciencia y Tecnología de México y al Programa JUSST del Gobierno del Japón por el apoyo económico proporcionado para la realización de esta investigación.
[7]
[8]
6. Referencias
[1]
R. Plamondon, S. N. Srihari, "On-Line and Off-Line
Handwriting Recognition: A Comprehensive Survey",
IEEE Trans. on Pattern Analysis and Machine
Intelligence, vol. 22, no. 1, 2000, pp. 63-84.
[2] S. Manke y U. Bodenhausen, "A Connectionist Recognizer
for On-line Cursive Handwriting Recognition", Proc. Int
Conf. Acoustic, Speech and Signal Processing, ICASSP
'94, vol. 2, 1994, pp.633-636.
[3] Y. Nakatani, D. Sasaki, Y. Iiguni y H. Maeda, "Online
Recognition of Handwritten Hiragana Characters Based
Upon a Complex Autoregressive Model", IEEE Trans.
on Pattern Analysis and Machine Intelligence, vol. 21,
no.1, 1999, pp. 73-76.
[4] R. Plamondon y F. J. Maarse, "An Evaluation of Motor
Models of Handwriting", IEEE Trans. System, Man, and
Cybernetics, vol.19, no. 5, 1989, pp. 1060-1072.
[9]
[10]
[11]
[12]
[13]
N. Mezghani, A. Mitiche y M. Cheriet, "On-lin
Recognition of Handwritten Arabic Characters using
Kohonen Neural Network", Proc. of the 8th In
Workshop on Frontiers in Handwriting Recognition
2002.
B. Sin, J. Ha, S. Oh y J. Kim "Network-Based Approac
to Online Cursive Script Recognition", IEEE Trans
System, Man, and Cybernetics, vol. 29, no. 2, 1999, pp
321-328.
Y. Isomichi, "Inverse-Quantization Method for Digita
Signals and Images", IEICE Transaction. vol. J64-A
no. 4, pp. 285-292, 1981.
T. Huang y M. Yasuhara, "A Total Stroke SLALOM
Method for Searching for the Optimal Drawing Order o
Off-line Handwriting", Proc. IEEE Int. Conf. on System
Man and Cybernetics, vol. 3, 1995, pp. 2789-2794.
Y. Qiao y M. Yasuhara, "Recovering Dynamic Informatio
from Static Handwritten Image", Proc. of the Int. Worksho
on Frontiers in Handwriting Recognition, 2004.
J. Rissanen, "Modeling by Shortest Data Description"
Automatica, vol. 14, pp. 465-471, 1978.
H. Akaike, "A new Look at the Statistical Mode
Identification", IEEE Trans. on Automatic Control, Vo
AC-19, No. 6, 1974.
H. Akaike, On Entropy Maximization Principle, P.R
Krishnaiah, Ed. Applications of Statistics, North
Holland, 1977.
K. Toscano-Medina, M. Nakano, H. Pérez-Meana y M
Yasuhara, "On-Line Handwritten Cursive Characte
Recognition System", aceptado en The 9th World Mult
Conference on Systemics, Cybernetics and Informatic
2005.
ESIME Zacatenco
La Coordinación del Piso de Pruebas
para Transformadores de los
Laboratorios Pesados II de Ingeniería Eléctrica
cuenta con pruebas acreditadas
que se encuentran al servicio de la industria nacional.
Tel. 5729 6000, ext. 54750
correo electrónico:
piso_pruebas@hotmail.com