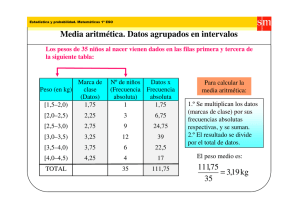
estadística para educación superior segunda edición
Anuncio

ESTADÍSTICA PARA EDUCACIÓN SUPERIOR SEGUNDA EDICIÓN Mary Nieves Cruz Zuluaga Institución Universitaria Esumer Todos los derechos reservados. Se prohíbe la reproducción total o parcial de esta obra, sea cual fuere el medio, sin permiso del editor. Las opiniones expresadas en esta publicación son responsabilidad directa de sus autores y no necesariamente representan los puntos de vista de la Institución Universitaria Esumer. La correspondencia en relación con esta publicación debe dirigirse a la Oficina de Comunicaciones de la Institución Universitaria Esumer, Calle 76 80-26, Carretera al Mar, Medellín, Colombia, o a la dirección electrónica comunicaciones@esumer.edu.co © Institución Universitaria Esumer ISBN 978-958-8599-15-1 Coordinación Editorial Comité Editorial Esumer Diseño de Portada Mónica Vasco Revisión y Evaluación Dirección de Investigación y Extensión Esumer Corrección de Estilo Juliana Marcela Vélez Díaz Diseño y Diagramación Sergio Andrés Calderón Ossa Institución Universitaria Esumer Calle 76 80-26, Carretera al Mar Teléfono: (57) (4) 403 81 30 www.esumer.edu.co Medellín, Colombia Publicado y hecho en Colombia Published in Colombia CONTENIDO Sobre la autora Agradecimiento Presentación PARTE I 1. La estadística: Conceptos básicos 1.1 Definición de estadística. 1.2 Importancia de la estadística. 1.2.1 Importancia dentro del proceso de investigación científica. 1. La investigación. 2. Esquema general por el cual surge un proceso de investigación. 3. Metodología de la investigación científica. 4. La ciencia. 5. Planteamiento del problema. 6. Objetivo. 7. Justificación. 8. Marco de referencia. 9. Marco metodológico. 10. Hipótesis. 1.2.2 Importancia en todas las áreas del saber humano. 1.3 Clasificación básica de la estadística. 1.3.1 Estadística descriptiva. 1.3.2 Estadística inferencial. Estadística para educación superior 1.4 Investigación estadística. 1.5 Población. 1.6 Muestra. 1.7 Unidad o elemento de investigación. 1.8 Variables. 1.8.1 Variables cualitativas. 1.8.2 Variables cuantitativas. 1.9 Base de datos. 2. Organización y procesamiento de la información 2.1 Tablas de frecuencia. 2.1.1 Para una variable cualitativa. 1. Frecuencia absoluta. 2. Porcentajes. 2.1.2 Para una variable cuantitativa sin agrupar por intervalos. 1. Frecuencia relativa. 2. Frecuencia absoluta acumulada. 3. Frecuencia relativa acumulada. 2.1.3 Para una variable cuantitativa agrupada por intervalos. 1. Marca de clase. 2. Amplitud de los intervalos. 3. Conformación de los intervalos. 4. Conteo de las frecuencias absolutas. 2.1.4 Para dos o más variables. 1. Tablas de clasificación cruzada para dos variables. 2. Tablas de clasificación cruzada para tres o más variables. 2.2 Gráficos estadísticos. 2.2.1 Representación visual. Estadística para educación superior 2.2.2 Descripción de los gráficos estadísticos más utilizados. 1. Gráfico circular. 2. Gráfico de barras. 3. Histograma. 4. Polígono. 5. Ojiva. 6. Diagrama de dispersión. 7. Gráfica lineal para series de tiempo. 3. Medidas de tendencia central 3.1 La media. 3.1.1 Propiedades de la media. 3.2 La mediana. 3.2.1 La mediana para datos desagrupados. 3.2.2 La mediana para datos agrupados. 3.3 La moda. 4. Medidas de variabilidad 4.1 La varianza. 4.1.1 Propiedades de la varianza. 4.2 La desviación típica o estándar. 4.3 Coeficiente de variación. 4.4 El rango recorrido. 4.5 Recorrido intercuartílico. 5. Medidas de posición (los cuantiles) Estadística para educación superior 5.1 Cuartiles. 5.1.1 Cuartiles para datos sin agrupar. 5.1.2 Cuartiles para datos agrupados. 5.2 Deciles. 5.2.1 Deciles para datos sin agrupar. 5.2.1 Deciles para datos agrupados. 5.3 Percentiles. 6. Medidas de asimetría y apuntamiento 6.1 Coeficiente de asimetría. 6.1.1 Distribución simétrica. 6.1.2 Distribución asimétrica. 6.2 Coeficiente de apuntamiento. 7. Ejercicios de aplicación resueltos 7.1 Precio de venta de bienes raíces. 7.2 Base de datos: Compañías por sector económico, ubicación geográfica y vinculación de aprendices. 8. Ejercicios de aplicación propuestos 8.1 Ingresos quincenales. 8.2 Volumen de exportación mensual de empresas distribuidoras de artículos de cuero. 8.3 Gastos quincenales de las personas de un sector de la ciudad. 8.4 Millas recorridas por galón de gasolina. 8.5 Asistencia promedio de los empleados del departamento de producción. 8.6 Salario de los obreros según el turno diurno o nocturno. Estadística para educación superior 8.7 Volumen de ventas semestral de establecimientos comerciales. 8.8 Ingreso semanal de los empleados ejecutivos de una corporación financiera. 8.9 Volumen de importación de papelerías especializadas. 8.10 Análisis estadístico de la sumatoria de las desviaciones respecto a la media. 8.11 Análisis estadístico sobre el grado de alejamiento de los datos alrededor de la media. 8.12 Justificación estadística con frecuencias absolutas y relativas (caso específico). 8.13 Explicación matemático-estadística del cálculo de la varianza. 8.14 Cálculo del a media y la varianza utilizando una expresión algebraica que representa la relación entre dos variables (caso específico). 8.15 Consumidores de latas de cerveza. 8.16 Ingreso quincenal de un grupo de empleados. 8.17 Percepción sobre el clima laboral. 8.18 Tiempo de permanencia del aroma de ambientadores adquiridos por un grupo de amas de casa. 8.19 Análisis estadístico: Marca de clase y mediana. 8.20 Nivel de exportación mensual de las empresas confeccionistas de vestidos ejecutivos. 8.21 Justificación estadística con frecuencia absoluta y relativa (caso específico). 8.22 Análisis estadístico: mediana, segundo cuartil, quinto decil, y percentil. 8.23 Unidades vendidas de computadores. 8.24 Auditoría de despacho y facturación de mercancía. 8.25 Investigación requerida por la unidad académica de una universidad, sobre el perfil del estudiante. 8.26 Justificación estadística de proposiciones según el valor de verdad asignado. 8.27 Identificación del elemento o unidad de investigación, variable y clasificación. 8.28 Presupuesto anual en bienestar institucional de establecimientos educativos. 8.29 Preferencias por candidatos electorales. Estadística para educación superior 8.30 Análisis estadístico del comportamiento asimétrico de las ventas en una cadena de supermercados. 8.31 Tiempo empleado en efectuar transacciones financieras. 8.32 Trabajo social y análisis del gasto en alimentación. 8.33 Cadena de minimercados y el volumen de ventas. 8.34 Producción mensual en textiles. 8.35 Gasto en publicidad de almacenes distribuidores de maletines en cuero. 8.36 Número de empleados por secciones en una compañía e ingreso promedio. 8.37 Nivel de capacitación semanal en corporaciones de ahorro y vivienda. 8.38 Urbanización de tres torres destinada para el arriendo de apartamentos. 8.39 Volumen de importación anual de materia prima. 8.40 Consumidores potenciales de una bebida alimenticia. PARTE II 9. Probabilidades 9.1 Conceptos básicos. 9.2 Enfoques básicos de las probabilidades. 9.3 Cálculo del valor de una probabilidad. 9.4 Axiomas básicos de probabilidad. 9.5 Probabilidad simple y conjunta, y su relación. 9.6 Probabilidad condicional. 9.7 Reglas de la adición y la multiplicación dentro del cálculo de probabilidades. 9.8 Teorema de Bayes. 9.9 Ejercicios resueltos. 9.9.1 Comercio y ventas: Enfoque frecuentista de probabilidades. 9.9.2 Producción-maquinaria 9.9.3 Análisis de características del personal por sexo y partido político. Estadística para educación superior 9.9.4 Administración y planeación. 9.9.5 Desempeño laboral y atención al cliente: Empresa de servicios. 9.10 Ejercicios propuestos. 9.10.1 Distribución porcentual de las familias de un barrio, según la tenencia de vivienda y carro propios. 9.10.2 Estudiantes de grado once con deseos de ingresar a la universidad. 9.10.3 Propietarios de acciones y bonos en una corporación financiera. 9.10.4 Medición de la eficacia de un procedimiento aduanero para detectar sustancias alucinógenas. 9.10.5 Almacenes distribuidores de electrodomésticos. 9.10.6 Población adulta clasificada según lectores de prensa y votantes en elecciones. 9.10.7 Transporte de mercancía: Embarque de cajas con juguetes y ropa para bebé. 9.10.8 Solicitudes de afiliación a una organización para estudiantes universitarios. 9.10.9 Comerciantes y distribuidores de amplificadores de sonido, botiquines y cosméticos. 9.10.10 Firma manufacturera y calidad del as piezas suministradas por los proveedores. 9.10.11 Estudiantes de educación superior con teléfono celular, beeper y fijo inalámbrico. 9.10.12 Control de calidad en una empresa manufacturera. 9.10.13 Amas de casa consumidoras de detergentes para el aseo del hogar. 9.10.14 Distribución de vuelos en una aerolínea. 9.10.15 Estudiantes universitarios con becas y vinculación laboral de medio tiempo. 9.10.16 Evaluación de un producto por parte de los consumidores, y grado de aceptación del mismo en el mercado. 9.10.17 Producción de muebles modulares y control de calidad en el ensamblaje. 9.10.18 Producción y comercialización de maletines escolares. 9.10.19 Mercadeo y lanzamiento de un nuevo producto. 9.10.20 Perfil de clientes de un reconocido restaurante. Estadística para educación superior 9.10.21 Secretaría de Desarrollo Comunitario y proyecto para jóvenes. 9.10.22 Distribución y comercialización de teléfonos. PARTE III 10. Distribuciones de probabilidad 10.1 Asociación de probabilidad con conceptos de estadística descriptiva. 10.2 Función de densidad de probabilidad. 10.3 Función de distribución acumulativa de probabilidad. 10.4 Parámetros en las distribuciones de probabilidad. 10.5 Cálculo de probabilidades. 10.6 Distribuciones de probabilidad discretas. 10.6.1 Distribución binomial. 10.6.2 Distribución Poisson. 10.6.3 Distribución hipergeométrica. 10.7 Distribuciones de probabilidad continuas. 10.7.1 Distribución normal. 10.7.2 Distribución exponencial. 10.7.3 Distribución uniforme continua. 10.7.4 Distribución Chi-cuadrada. 10.7.5 Distribución T-student. 10.8 Ejercicios resueltos. 10.8.1 Producción de empaques (unidades defectuosas). 10.8.2 Venta de seguros de vida. 10.8.3 Pago de facturas por parte de los usuarios de una compañía de teléfonos celulares. 10.8.4 Importación de chapas para puertas de seguridad e inspección de calidad. 10.8.5 Volumen de exportación mensual de una compañía de electrodomésticos. Estadística para educación superior 10.8.6 Vida útil de las pilas de una cierta marca. 10.8.7 Llegada de clientes a un banco. 10.8.8 Producción de circuitos electrónicos y su vida útil. 10.9 Ejercicios de aplicación propuestos. 10.9.1 Unidades defectuosas en un proceso de manufactura. 10.9.2 Campaña de mercadeo para un club nacional de automovilistas. 10.9.3 Pago de compras con tarjeta de crédito en un almacén. 10.9.4 Control de calidad en cajas de bombillas. 10.9.5 Asistencia tarde al trabajo por parte de empleados. 10.9.6 Preferencias por determinado candidato a la presidencia. 10.9.7 Hogares con televisión por cable. 10.9.8 Tiempo de llegada de estudiantes a una biblioteca. 10.9.9 Número de estudiantes que llegan a una biblioteca. 10.9.10 Tiempo de llegada de clientes a la caja registradora. 10.9.11 Número de clientes que llegan a la caja registradora. 10.9.12 Tiempo y número de clientes que llegan a una compañía de teléfonos celulares. 10.9.13 Proceso de selección y contratación de personal en una entidad financiera. 10.9.14 Firma de asesores en comercio internacional para nuevos proyectos. 10.9.15 Cálculo de áreas bajo la curva de la distribución normal estandarizada. 10.9.16 Ventas anuales a crédito. 10.9.17 Gasto semanal en loncheras para niños. 10.9.18 Estatura de los alumnos de un colegio. 10.9.19 Peso promedio de las frutas de un cargamento a transportar. 10.9.20 Duración de las baterías de una cierta marca. 10.9.21 Salario medio mensual. 10.9.22 Notas en un examen de legislación. 10.9.23 Peso de un grupo de deportistas. 10.9.24. Gasto semanal en transporte por parte de un grupo de empleados. 10.9.25 Publicación sobre los salarios mensuales de contadores. Estadística para educación superior 10.9.26 Fabricación de neumáticos y su vida útil. 10.9.27 Comisión mensual obtenida por un grupo de vendedores. 10.9.28 Vida útil de circuitos electrónicos. 10.9.29 Producción de arandelas: unidades aceptables y defectuosas. 10.9.30 Costo de trascripción e impresión de trabajo de tesis. 10.9.31 Puntaje en proceso de admisión para laborar en una empresa. 10.9.32 Tiempo de servicio en una compañía de reparación de fotocopiadoras. 10.9.33 Tiempo de espera en un restaurante. 10.9.34 Tiempo de servicio en una agencia de viajes. 10.9.35 Control de calidad en producción de bombillas eléctricas. 10.9.36 Vida útil de transistores importados por una firma nacional. 10.9.37 Transporte de mercancía en camiones hacia una bodega. 10.9.38 Servicio de taxis en un aeropuerto local. 10.9.39 Inducción y entrenamiento a un nuevo empleado. 10.9.40 Tiempo de llegada de clientes para pago de servicios públicos. 10.9.41 Contenido de cerveza envasada por botella. 10.9.42 Empaque de leche en polvo en una compañía de procesamiento de lácteos. PARTE IV 11. Muestreo básico 11.1 Tamaño de muestra. 11.2 Relación entre el tamaño poblacional y el muestral. 11.3 Relación entre nivel de confianza, margen de error y error de estimación. 11.4 Total de muestras posibles a extraer de una población. 11.5 Clases de muestreo. 11.5.1 Muestreo aleatorio simple. 1. Muestreo aleatorio simple con reposición. Estadística para educación superior 2. Muestreo aleatorio simple sin reposición. 11.5.2 Muestreo estratificado. 11.5.3 Muestreo por conglomerados. 11.5.4 Muestreo sistemático (muestreo tipificado). 11.6 Cálculo de estimativos poblacionales. 11.6.1 Estimación puntual. 11.6.2 Estimación por intervalos. 11.6.3 Estimación puntual y por intervalos para la proporción poblacional. 11.7 Ejercicios de aplicación resueltos. 11.7.1 Tamaño de muestra para una población de padres de familia. 11.7.2 Estimativo puntual y por intervalo de confianza para la media del ingreso poblacional. 11.7.3 Estimación puntual y por intervalo de confianza para la proporción del uso de transporte escolar. 11.7.4 Tamaño de muestra para un nivel de confianza del 95% y diferentes errores de estimación. 11.7.5 Tamaño de muestra para adelantar un proyecto a cargo de la secretaría de planeación de un municipio. 11.8 Ejercicios de aplicación propuestos. 11.8.1 Proyecto de capacitación académica para dirigentes gubernamentales. 11.8.2 Estimación puntual e intervalo de confianza para la proporción de dirigentes profesionales. 11.8.3 Plan de mercadeo y ayuda solidaria por parte de una empresa procesadora de leche: Tamaño de muestra de familias. 11.8.4 Estimativo del promedio de litros de leche a donar semanalmente por familia. 11.8.5 Tamaño de muestra de ejecutivos en diferentes empresas multinacionales. 11.8.6 Estimativo de la proporción poblacional de ejecutivos que viajan. 11.8.7 Intervalo de confianza para la proporción poblacional de ejecutivos que viajan. 11.8.8 Estimativo del gasto total por concepto de viajes y estadía. Estadística para educación superior 11.8.9 Tamaño de muestra para una población de empresas de una región determinada. 11.8.10 Tamaño de muestra para una población universitaria. 11.8.11 Tamaño de muestra de televidentes para mercadear un producto. 12. Pruebas de hipótesis 12.1 Prueba de hipótesis para la media. 12.2 Prueba de hipótesis para la proporción. 12.3 Prueba Chi-cuadrado para la bondad de ajuste. 12.4 Ejercicios de aplicación resueltos. 12.4.1 Proceso de producción: Prueba de bondad de ajuste. 12.4.2 Prueba de hipótesis para el promedio de exportación semestral. 12.4.3 Prueba de hipótesis para la proporción poblacional de cajas de CD-ROM en un proceso de producción. 12.5 Ejercicios de aplicación propuestos. 12.5.1 Número de empleados con trabajo pendiente para el día siguiente: Prueba de bondad de ajuste. 12.5.2 Prueba de hipótesis para la proporción de población potencial que rechaza un nuevo producto. 12.5.3 Prueba de hipótesis para el contenido promedio de latas de atún. 12.5.4 Prueba de hipótesis para el tiempo promedio de duración de velones especiales. PARTE V 13. Análisis de regresión y correlación 13.1 Conceptos básicos. 13.2 Ajuste lineal. Estadística para educación superior 13.2.1 Estimación de los parámetros. 13.2.2 Cálculo del pronóstico. 13.3 Error residual. 13.4 Coeficiente de correlación. 13.5 Medidas de variación en la regresión. 13.5.1 Variación total (VT). 13.5.2 Variación no explicada (VNE). 13.5.3 Variación explicada (VE). 13.5.4 Propiedades de las medidas de variación en la regresión. 13.6 Coeficiente de determinación (D). 13.7 Ajuste parabólico. 13.8 Ajuste exponencial. 13.9 Análisis de regresión en una serie de tiempo. 13.10 Ejercicios de aplicación resueltos. 13.10.1 Ajuste de regresión entre el precio y la demanda de un producto. 13.10.2 Comportamiento de la captación de una cooperativa a través del tiempo: Enfoque de regresión y correlación. 13.11 Ejercicios de aplicación propuestos. 13.11.1 Análisis de regresión entre el precio de entrada a una sala de videos y el número de estudiantes que entran. 13.11.2 Análisis de regresión entre la utilidad y el gasto en publicidad. 13.11.3 Análisis de regresión entre el nivel de ahorro y el ingreso. 13.11.4 Análisis de regresión: Utilidad a través del tiempo en una compañía distribuidora de computadores. 13.11.5 Análisis de regresión: Ventas versus espacio asignado. 13.11.6 Análisis de regresión: Pasivo pensional a través del tiempo. 13.11.7 Análisis de regresión: Presupuesto ejecutado de egresos a través del tiempo. 13.11.8 Análisis de regresión: Crecimiento de la población a través del tiempo. 13.11.9 Análisis de regresión: Utilidad semestral. Estadística para educación superior Sobre la autora Mary Nieves Cruz Zuluaga Egresada de la Facultad de Estadística e Informática de la Universidad de Medellín; Especialista en Gerencia de Proyectos de la Institución Universitaria ESUMER. Ha sido docente en el área de estadística en la Universidad de Medellín y en la Universidad Católica de Oriente, y actualmente es docente-investigadora de tiempo completo en la Institución Universitaria Esumer. Estadística para educación superior Agradecimiento A ti que no te veo, pero siempre estás presente, a ti que te debo la vida y todo lo que soy, a ti que pensaste en mí desde antes de yo nacer, a ti que iluminas mi camino y llenas mi vida de esperanza, a ti que me ayudas a soportar y a superar las diferentes dificultades que se presentan en mi camino. Gracias infinitas por todo lo que me ofreces, por ayudarme a perdonar, a superar los obstáculos y por las personas nobles que has puesto en las diferentes etapas de mi vida. Con amor, Mary Nieves Cruz Zuluaga Estadística para educación superior Presentación Este libro es el producto de muchos años de experiencia dedicados al estudio, la investigación y la docencia en el área de estadística. Contiene los aspectos fundamentales que todo profesional debe conocer para procesar estadísticamente información concerniente a diversas aplicaciones económico-administrativas. En el libro se maneja un lenguaje técnico, sencillo y de fácil comprensión, gracias a la metodología clara y didáctica que permite visualizar explicaciones paso a paso en cada una de las diferentes etapas de la solución de problemas o situaciones aplicadas al comercio nacional e internacional, mercadeo, ventas, logística, administración y procesos de producción, entre otras. El texto se encuentra distribuido en cinco partes, cada una de ellas contiene la explicación de la temática específica respectiva. En muchos casos se dan a conocer diferentes formas de obtener los cálculos y de analizar los resultados; se cuenta con una serie de ejemplos de aplicación resueltos y adicionalmente, con ejercicios de aplicación propuestos. En la Parte I se encuentra la estadística descriptiva, organización y procesamiento de la información, medidas de tendencia central, de variabilidad, de posición, de asimetría y apuntamiento; en la Parte II se visualizan diferentes aspectos de probabilidades; en la Parte III, distribuciones de probabilidad discretas y continuas; en la Parte IV, teoría de muestreo y pruebas de hipótesis; en la Parte V, el análisis de regresión y correlación. Estadística para educación superior PARTE I 1. La estadística: Conceptos básicos 1.1 Definición de estadística. La estadística es una ciencia que trata de la recopilación, organización, presentación, análisis e interpretación de información, con el fin de realizar una toma de decisión efectiva. 1.2 Importancia de la estadística. 1.2.1 Importancia dentro del proceso de investigación científica. 1. La investigación. Investigar es un verbo que denota una acción o movimiento, ¿a qué acción o movimiento hace referencia?, la respuesta no es simple, porque su acción conjuga simultáneamente diferentes verbos como descubrir, consultar, analizar, modelar, observar, plantear, comprobar, crear, comparar; sin olvidar que también es una acción muy importante dentro de todas las áreas del saber humano, trátese del ámbito académico, laboral, social, económico, biológico, entre otros. Es por ello que se habla de diferentes niveles de investigación y dentro de cada uno de éstos, del proceso de investigación. Desde la niñez, todo ser humano investiga aún sin ser consciente de ello, el infante observa y descubre nuevas sensaciones; con la experiencia de observar y descubrir por medios propios se llega al conocimiento de algo nuevo, al menos para dicho ser humano. En todas las etapas de la vida, de algún modo se investiga; durante el proceso de culturización y educación se recurre a la investigación como elemento fundamental para la construcción de conocimiento. Estadística para educación superior La organización del sistema educativo es diferente entre países. En Colombia se cuenta con diferentes niveles, denominados de forma genérica: primaria, secundaria, técnico, tecnológico, profesional, especialista, magíster, doctorado. El proceso de investigación dentro de cada uno de estos niveles educativos es diferente, así como el grado de profundidad de la temática a tratar. Todas las ramas o áreas del saber humano, como lo son el área jurídica, biológica, social, económica, contable, comercial, mercadeo, entre otras, cuentan con procesos de investigación propios de la misma, no obstante, existen unos lineamientos generales a seguir dentro de toda investigación científica. 2. Esquema general por el cual surge un proceso de investigación. En el momento inicial se parte de una necesidad sentida o de un problema detectado. El objetivo inmediato es satisfacer la necesidad o solucionar el problema, lo cual puede hacerse a través de un proceso de investigación (ver figura 1). Figura 1. Esquema general del surgimiento de un proceso de investigación MOMENTO INICIAL se parte de Problema Necesidad satisfacer resolver OJETIVO a través de LA INVESTIGACIÓN Estadística para educación superior La necesidad también puede hacer referencia al simple deseo de conocer a profundidad algún suceso. En muchas ocasiones existe una familia de problemas, siendo éste el caso, el investigador ha de estudiarlos en detalle hasta identificar el problema generatriz de los demás. Si se efectúa una investigación para solucionar un problema que no es el generatriz o principal se pierde el tiempo, el dinero y todo el trabajo invertido en el proyecto, porque los resultados no contribuirán efectivamente a mejorar la situación inicial. Surge una pregunta fundamental: ¿Cómo alcanzar el objetivo?, ¿cómo hacer las cosas para poder solucionar el problema?, el cómo hacerlo hace referencia al método, y la explicación de este método es precisamente lo que se denomina metodología de la investigación, lo que implica procedimientos teóricos basados en análisis lógicos previamente comprobados por la ciencia, y procedimientos empíricos basados en experiencia y opinión subjetiva. La metodología de la investigación científica excluye las opiniones subjetivas del investigador, eliminando todo rasgo de sentimiento afectivo frente al objeto (problema) que se estudia. 3. Metodología de la investigación científica. Es la explicación de cómo aplicar el método científico a una investigación; son los pasos y estrategias que utiliza el método científico, el cual construye conocimiento basándose en el análisis lógico del pensamiento intelectual y empleando leyes generales y particulares reconocidas previamente por la ciencia. La ejecución ordenada de la serie de pasos desemboca en la conformación de un proceso, caracterizado por ser sistémico, objetivo y racional. Cada una de las ciencias utiliza una terminología propia (términos y conceptos), así como procesos de investigación particulares al interior de la misma. Estadística para educación superior 4. La ciencia. Término empleado con gran frecuencia en el ámbito cultural y académico. Es difícil definirla, se trata de un sustantivo abstracto, no se puede tocar, es intangible, es un sustantivo común muy importante dentro de la evolución en el mundo real, se convierte en sustantivo propio cuando se habla de una ciencia en particular. Expresiones como la casa, la universidad, la empresa, el carro, el libro, etc., todos estos son sustantivos comunes que identifican algo, de igual manera se identifica la ciencia, al afirmar que la ciencia es una empresa. Esta empresa tiene unos empleados o trabajadores que se llaman investigadores, los cuales trabajan con diferentes insumos: Intelecto, pensamiento intelectual, la observación, la experimentación, el conocimiento adquirido en el proceso de culturización del investigador, leyes generales y particulares previamente reconocidas y comprobadas, la realidad inicial de un suceso o evento. Estos insumos se procesan mezclándolos entre sí, en el departamento de investigación. El producto final es un producto no terminado. Este producto se llama conocimiento de la realidad. Este producto tiene una presentación o empaque y llega al consumidor final (personas) de diversas formas como: Descripción, explicación, formulación, predicción. Estadística para educación superior Este producto se cataloga como no terminado, porque en el momento en que se demuestre lo contrario, se modifica o mejora el producto. En todo proceso de investigación se recolecta información, motivo por el cual la estadística es una herramienta de vital importancia dentro del estudio a realizar, porque permite organizar, resumir y analizar la información, logrando la descripción, contrastación de hipótesis y en muchas oportunidades, el planteamiento de pronósticos. 5. Planteamiento del problema. Para comprender el concepto que se transmite con este título, se hace indispensable concebir con gran claridad lo que es un problema y la acción de plantear. Problema. Situación o evento considerado perjudicial o con un grado de positivismo bajo, que de no solucionarse, genera consecuencias negativas. En ocasiones se requiere tomar decisiones, pero el desconocimiento de aspectos directamente relacionados con la situación impide la toma de decisiones acertadas; en este caso específico, la investigación parte de una necesidad o falencia sobre algo. El problema ocurre en algún lugar, tiempo, espacio, y afecta a alguien o algo de la vida real. Ese algo de la vida real que se ve afectado por el problema se denomina objeto de estudio, por tal motivo, el objeto de estudio es aquella parte de la realidad que ha de ser investigada. Plantear. Es una acción (verbo) que describe o formula, a través de una frase, lo que está aconteciendo. Esta acción es intelectual y requiere de un proceso mental, en el cual se asocia el conocimiento del problema con la capacidad de redacción y transcripción del mismo. Se requiere por lo tanto, conocer a profundidad el problema y transmitir con claridad el conocimiento que se tiene de éste. Sólo en esta medida quedará un problema bien formulado. Estadística para educación superior Relacionando los conceptos de problema y de plantear, se deduce lo que es el planteamiento de un problema: formular la situación problémica con un lenguaje sencillo y claro, en el que fácilmente se pueda detectar cuál es la falencia, necesidad o inconveniente respecto al objeto de estudio. Para el planteamiento de un problema es fundamental conocerlo a profundidad, si no se conoce a profundidad, se recomienda elaborar preliminarmente un diagnóstico de la situación, identificando las causas del problema, además las consecuencias actuales y futuras en caso de no ser solucionado (ver figura 2). Figura 2. Problema visualizado a través del tiempo FUTURO Conocer: PRESENTE Conocer: Posibles consecuencias futuras Situación actual PASADO Conocer: Causas presentes Consecuencias presentes Antecedentes Causas generadas en el pasado Diagnosticar es examinar la situación actual (presente), a partir del pasado (antecedentes) y mirar hacia el futuro. Las causas pueden estar en el presente o en el pasado, o en ambos; las consecuencias pueden estar en el presente o en el futuro, o en ambos. Estadística para educación superior 6. Objetivo. Enunciado con el que se expresa la solución al problema de investigación. Dentro de la Investigación existe un objetivo general y varios objetivos específicos. Objetivo general. Es una frase de carácter enunciativo, a través de la cual se plantea la solución del problema. Precisamente, lo que se va a hacer durante la investigación es solucionar el problema, de ahí el lazo de unión tan fuerte entre el problema y el objetivo general. Objetivos específicos. Son frases también de carácter enunciativo, a través de las cuales se plantean las diferentes acciones que encaminan al investigador para alcanzar el objetivo general. Todos los objetivos específicos, sin excepción alguna, deben apuntar al logro del objetivo general; de aquí surge también un lazo de unión fuerte entre el objetivo general y los objetivos específicos. El planteamiento de los objetivos también puede ser visualizado como un árbol, donde el tallo está representado por el objetivo general y las ramificaciones constituyen los objetivos específicos. Los objetivos se plantean utilizando verbos en infinitivo —aquellos terminados en ar, er, ir—, pero teniendo cuidado de que el verbo utilizado pueda lograrse o realizarse durante la investigación. La investigación sólo tiene sentido cuando se alcanza el objetivo general, porque es precisamente éste, el que plantea la solución del problema. Algunos verbos en infinitivo que son utilizados con gran frecuencia dentro del planteamiento de objetivos son los siguientes: conocer, describir, analizar, identificar, estudiar, elaborar, entre otros. Estadística para educación superior 7. Justificación. Describe la importancia de efectuar la investigación. La justificación es el respaldo del motivo considerado pertinente para la investigación; cobija todas las razones que se consideran de importancia y por las cuales se efectúa la investigación. Responde a las preguntas: ¿Para qué se hace la Investigación?, ¿por qué es importante efectuar la Investigación? El diagnóstico realizado es una base o guía para elaborar la justificación, porque dentro de éste se analizan las consecuencias de no solucionar el problema, es decir, las consecuencias de no realizar la investigación cuyo objetivo es precisamente solucionar el problema. La importancia de la Investigación radica precisamente en el hecho de tomar decisiones acertadas al solucionar un problema, de tal forma que las consecuencias negativas se minimicen o se eliminen totalmente dentro del evento o situación estudiada. 8. Marco de referencia. Se conoce también bajo el término de marco referencial. En el lenguaje cotidiano, marco es un objeto o bien tangible que encierra o delimita un área o superficie (ver figura 3). Figura 3. Ilustración del marco de referencia REFERENCIA MARCO En la figura 3 se visualiza la referencia dentro de un marco; el marco está limitando a la referencia. La referencia se utiliza para identificar, es un código establecido, por ejemplo, los artículos de un supermercado tienen su referencia. La referencia Indica y establece; mientras Estadística para educación superior que el marco limita y encierra. En una investigación, estos dos conceptos no son tangibles, no se puede tocar ni observar como si mirara un paisaje (referencia) en un cuadro (marco). En una investigación generalmente se hace referencia a la teoría, al tiempo y al espacio; por tal motivo, el marco referencial está conformado por el marco teórico, el marco espacial y marco temporal. Marco teórico. Una investigación se apoya en teorías y conceptos científicos ya establecidos. Durante el proceso de culturización del investigador, éste aprende, asimila e interioriza diversas teorías y conceptos científicos previamente comprobados por otras personas o científicos; una investigación, en cuanto a teoría se refiere, no parte de la nada o de cero, se soporta en teorías existentes y conocimiento previamente construido. Gracias a la teoría ya existente, el investigador actual fundamenta el proceso de conocimiento. Visualizando estos conceptos gráficamente se tiene la figura 4: Figura 4. Ilustración del marco teórico TEORÍA CIENTÍFICA MARCO La teoría y el conocimiento científico se encuentran al interior de un marco que los delimita, es este el motivo por el cual se habla de marco teórico. Es imposible que un investigador avance en su proyecto si no tiene el conocimiento sobre la teoría científica directamente asociada con la temática que se estudia. Cuando un investigador descubre cosas totalmente nuevas y formula leyes que antes no existían, complementando de este modo a las anteriores teorías, contribuye a la ampliación del marco teórico para futuras investigaciones. Estadística para educación superior Marco espacial. Está constituido por un área física, una zona geográfica determinada, una institución, una empresa, entre otros. Es la delimitación del lugar físico dentro del cual se lleva a cabo la investigación. La representación gráfica está en la figura 5. Figura 5. Ilustración del marco espacial ESPACIO MARCO Marco temporal. Es la delimitación del tiempo durante el cual se lleva a cabo la investigación. Intervalo o período de tiempo expresado en días, meses, semestres, años. Gráficamente: Figura 6. Ilustración del marco temporal TIEMPO MARCO 9. Marco metodológico. Se delimita o especifica claramente la metodología que se emplea durante la investigación. Gráficamente: Estadística para educación superior Figura 7. Ilustración del marco metodológico METODOLOGÍA MARCO Para especificar la metodología o sistematización del proceso dentro del método científico, es indispensable tomar la decisión sobre el tipo de estudio que ha de ejecutarse, así como el grado de profundidad del mismo. En todas las áreas o ramas del saber humano (biología, administración, comercio, demografía, mercadeo, geología, política, economía, química, física, etc.), existe la posibilidad de efectuar diferentes tipos de estudio como el exploratorio, descriptivo, histórico, experimental, explicativo, estudio de casos, entre otros. Se puede incluso conjugar simultáneamente diferentes tipos de estudio, además, variar el grado de profundidad de los mismos. Cada tipo de estudio presenta su metodología particular, sin embargo, tienen algo en común y es precisamente, la recolección de la información, procesamiento y análisis de la misma. No obstante, la técnica de recolección de información su procesamiento y su análisis pueden cambiar, dependiendo del tipo de estudio por el cual se haya optado; pero lo que no puede permitirse es de la falencia de información, por eso, sin excepción, en todo tipo de estudio se recolecta información. La información puede ser recolectada de diversas formas, tales como encuestas, lecturas, Internet, archivos, observación, experimentación, entre otras. Es aquí donde juega un papel importante la estadística, como herramienta fundamental para la recolección de información, procesamiento, análisis, pruebas de hipótesis, relación entre variables, pronósticos, probabilidades, modelamiento de eventos, entre otras actividades. Estadística para educación superior 10. Hipótesis. Es una proposición (frase) que describe un mensaje claro y sencillo, el cual ha de ser verificado durante la investigación para comprobar si es verdadero o falso. Igualmente, durante el proceso investigativo se puede efectuar comparación entre hipótesis contrastando una con otra, o con otras. Cada metodología en particular, dependiendo del tipo de investigación, tiene su forma operacional propia de efectuar pruebas de hipótesis, que validen, acepten o rechacen la misma. Este proceso de validación sigue los lineamientos del marco teórico asociado con el tipo de investigación elegido. El investigador parte de una realidad, supone resultados sobre lo que estudia, hace conjeturas que posiblemente pueden acontecer en el futuro, pero que de algún modo no son confiables totalmente, hasta no efectuar la prueba de validez de la hipótesis. Las hipótesis están relacionadas con los objetivos de la investigación, porque constituyen un recurso o medio de lograr los mismos; es por ello que la hipótesis tiene un lazo de unión directo con el problema, porque ésta es planteada suponiendo una respuesta o alternativa de solución al problema de la investigación. Hipótesis alternativa. Las hipótesis que se plantean como alternativa de solución posible al problema se consideran hipótesis alternativas o de trabajo, de ahí su nombre de hipótesis alternativa. Hipótesis nula. Es aquella hipótesis que se plantea totalmente opuesta o contraria a la hipótesis alternativa o de trabajo. La hipótesis nula se plantea cuando se hace necesario contrastar ésta con la realidad que supone el investigador (hipótesis alternativa o de trabajo). Estadística para educación superior 1.2.2 Importancia en todas las áreas del saber humano. Radica en sus grandes aplicaciones en las diferentes actividades que implican manejo de información. En todas las áreas del saber humano se maneja información de alguna índole, de ahí que la estadística es una herramienta vital para ayudar en el procesamiento, organización, análisis y presentación de resultados. Herramienta de vital importancia en la toma de decisiones. Los métodos estadísticos se utilizan a diario, tanto en el sector público como en el privado. Indispensable su aplicación en el manejo y análisis de información económicoadministrativa: estudios econométricos, análisis financieros, análisis de portafolio de inversiones, ventas, procesos de producción, investigaciones de mercado, políticas económicas y administrativas, elaboración de presupuestos de inversión, campañas electorales, control de calidad, análisis demográfico, entre otras. 1.3 Clasificación básica de la estadística. La estadística se clasifica o divide en dos grandes ramas: la estadística descriptiva y la estadística inferencial. El hecho de que exista esta división no implica que la inferencial esté disociada de la descriptiva, por el contrario, la descriptiva es la base, sin la cual sería imposible profundizar en conceptos inferenciales (ver figura 8). Estadística para educación superior Figura 8. Clasificación de la estadística ESTADÍSTICA Descriptiva Inferencial Observa y analiza el Realiza un trabajo conjunto comportamiento de con la estadística una serie de datos, descriptiva, probabilidades, para describirlo de muestreo para efectuar manera global. pronósticos e inferencias. 1.3.1 Estadística descriptiva. Describe un conjunto de datos a través de la organización de los mismos y el cálculo de medidas representativas; medidas que al ser interpretadas, hablan o describen al conjunto de datos. 1.3.2 Estadística inferencial. Tiene sus bases en la estadística descriptiva. Infiere o pronostica para la población, tomando como base la muestra. Emplea técnicas probabilísticas, análisis de muestreo, intervalos de confianza, pruebas de hipótesis. 1.4 Investigación estadística. La estadística puede ser aplicada en todas las ramas del saber humano: investigaciones de mercado, económicas, educativas, empresariales, biológicas, sicológicas, entre otras. Estadística para educación superior Cuando se desea investigar, se parte de un problema, necesidad, o simplemente del deseo por conocer lo que sucede bajo determinada situación. El problema necesita ser resuelto y la necesidad hay que satisfacerla; por eso es importante plantear un objetivo general y unos objetivos específicos que marquen las pautas para solucionar el problema o satisfacer la necesidad. Hay que tener definida la población y la muestra; si la investigación es a través del censo, se trabaja con todos los elementos de la población; pero si la investigación se hace con una parte representativa de la población, hablamos de muestreo. El elemento o unidad de investigación es precisamente sobre quién deseamos hacer las respectivas mediciones; y las mediciones constituyen las variables. Todo lo que necesitamos medir, consultar o averiguar en cada uno de los elementos o unidades de investigación, constituyen las variables. En ocasiones se necesita consultar (medir) características, en otras ocasiones, valores numéricos (cantidades). Por eso se habla de variables cualitativas y cuantitativas. Se necesita recolectar la información suministrada por cada unidad o elemento de investigación y que es alusiva a cada una de las variables. La recolección se efectúa con alguna de las técnicas de recolección de información (encuestas, entrevistas, vía telefónica, vía e-mail, anuarios estadísticos, archivos, bases de datos, entre otras). Toda la información que se recolecta se organiza, se procesa estadísticamente, se analiza, se concluye, y es en este momento cuando se alcanzan las metas u objetivos de la investigación. Estadística para educación superior 1.5 Población. La población, en el campo de la estadística, no se entiende únicamente como el total de personas de una zona geográfica determinada; la población también puede estar constituida por el total de establecimientos, total de objetos, total de plantas, total de animales, entre otros. Es indispensable delimitar muy bien la población, cada investigación, cada problema en particular por solucionar, tiene su respectiva población. Cuando la investigación se lleva a cabo consultándole a todos los elementos de la población, se habla de censo. 1.6 Muestra. Es una parte representativa de la población. Hablar de representatividad no es seleccionar las mejores unidades o elementos a criterio del investigador, nunca deberá entenderse en este sentido. La representatividad está asociada con el concepto de selección aleatoria de unidades. ¿Cuántas unidades debe tener la muestra? (tamaño de la muestra) y ¿cuáles unidades deben entrar a formar parte de esta muestra?, son dos problemas o interrogantes que se resuelven a través de las técnicas de muestreo o lo que se denomina simplemente teoría de muestreo. La representatividad de la muestra se alcanza con procesos aleatorios (muestreo aleatorio simple), esto significa que cada unidad o elemento de la población tiene igual posibilidad de ser seleccionada para entrar a formar parte de la muestra. Estadística para educación superior Dependiendo del caso particular de la investigación, para el cálculo del tamaño de muestra, se empleará la técnica de muestreo que más se ajuste al caso (muestreo aleatorio simple, muestreo estratificado, muestreo por conglomerados, entre otros). 1.7 Unidad o elemento de investigación. Una unidad está representada por uno y sólo un elemento de la población (en caso de trabajar con censo), o por un elemento de la muestra (en caso de trabajar con muestreo). 1.8 Variables. Una variable es todo aquello que se desea medir, consultar o averiguar, sobre cada unidad o elemento de investigación. 1.8.1 Variables cualitativas. Cuando lo que se desea medir, consultar, se refiere a una cualidad, atributo o característica; generalmente está expresado en palabras o códigos que no son precisamente valores numéricos sobre los cuales sea lógico efectuar operaciones aritméticas. Por ejemplo: el estado civil, color de ojos, preferencia musical, estrato socioeconómico, entre otras. 1.8.2 Variables cuantitativas. Cuando lo que se desea medir, consultar, se refiere a un valor numérico sobre el cual sea lógico efectuar operaciones aritméticas. Las variables cuantitativas se encuentran a su vez, clasificadas en dos grandes grupos: cuantitativas discretas y cuantitativas continuas. Estadística para educación superior Variables cuantitativas discretas. Son aquellas que sólo admiten valores enteros, por ejemplo: número de hermanos, número de personas a cargo, número de cargos ocupados, número de llegadas tarde al mes, volumen de ventas (en número de unidades). Variables cuantitativas continuas. Son aquellas que admiten valores fraccionarios. Si los datos originales no están expresados con cifras decimales, no significa que se trate necesariamente de una variable cuantitativa discreta, porque lo importante es el significado de la variable, lo que representa, para poder clasificarla en continúa o discreta. Por ejemplo: volumen de ventas (en dinero), ingresos, gastos, arriendo. 1.9 Base de datos. Está constituida por toda la información que se recolectó. Cada fila representa a cada unidad o elemento de investigación, y cada columna representa a cada variable, aunque también pueden existir columnas que representen datos de identificación. Esta base de datos también es conocida con el nombre de sábana de datos. Figura 9. Representación gráfica de una base de datos Elemento o unidad de investigación Elemento 1 Elemento 2 Elemento 3 … Variable 1 Variable 2 Variable 3 … Estadística para educación superior 2. Organización y procesamiento de la información La base de datos por sí sola no permite concluir acerca del total de datos, no permite tomar decisiones, por tal motivo se necesita procesar la información recolectada, iniciando por la organización de los datos a través de tablas de frecuencia, tanto univariadas (una sola variable) como bivariadas o multivariadas (dos o más variables), la elaboración de gráficos respectivos, el cálculo de medidas representativas que sean de utilidad para concluir respecto a la información recolectada, y el análisis e interpretación de todos los resultados obtenidos. 2.1 Tablas de frecuencia. Las tablas de frecuencia se pueden elaborar para variables cualitativas y cuantitativas (discretas y continuas). Se puede hacer alusión a frecuencia absoluta, relativa, absoluta acumulada y relativa acumulada. Cada una de las cuales tiene sus características e interpretaciones particulares. A medida que se explica el diseño de las tablas de frecuencia se menciona las propiedades y características de las diferentes clases de frecuencias. 2.1.1 Para una variable cualitativa. Para una variable cualitativa, la frecuencia hace referencia al número de veces que se repite determinada característica o atributo. El diseño de la tabla puede elaborarse de la siguiente manera (figura 10): Estadística para educación superior Figura 10. Diseño de tabla de frecuencia para una variable cualitativa Característica Número de elementos Porcentaje Atributo 1 f1 P1% Atributo 2 f2 P2% Atributo 3 f3 P3% … … … Atributo m fm Pm % Totales N 100% Cada uno de los atributos de la variable constituye cada una de las categorías de la variable, en este caso se cuenta con m categorías, cada una con su respectiva frecuencia absoluta. Las categorías son mutuamente excluyentes porque un elemento o unidad de investigación no puede pertenecer simultáneamente a varias categorías. 1. Frecuencia absoluta (fi). Las frecuencias absolutas las identificamos con fi —se puede visualizar en la segunda columna de la figura 10—. Las características de las frecuencias absolutas (fi) son: 1. Las frecuencias absolutas siempre son valores enteros y positivos. Se encuentran entre 0 y n. Siendo n el total de elementos o unidades de investigación, así: 0 ≤ fi ≤ n 2. La sumatoria de las frecuencias absolutas e igual a n: ∑ Fórmula (1) Estadística para educación superior 2. Porcentajes. Es la representación porcentual o en términos relativos de cada una de las respectivas frecuencias absolutas. Se calcula de la siguiente manera: Fórmula (2) La sumatoria de los Pi es igual al 100% de la información. 2.1.2 Para una variable cuantitativa sin agrupar por intervalos. Para una variable cuantitativa sin agrupar en intervalos, la frecuencia hace alusión al número de veces que se repite determinado valor de la variable. En este caso existirá una frecuencia respectiva para cada valor diferente que tome la variable (ver figura 11). Figura 11. Diseño de tabla de frecuencia para una variable cuantitativa sin agrupar por intervalos Xi fi hi Fi Hi X1 f1 h1 F1 H1 X2 f2 h2 F2 H2 X3 f3 h3 F3 H3 X4 f4 h4 F4 H4 … … … … … Xm fm hm Fm Hm Total N 1 - - Esta tabla (figura 11) contiene m renglones (filas). Cada uno de los valores de Xi representa cada una de las categorías que asume la variable, donde: Xi = cada uno de los diferentes valores que tiene la variable. Estadística para educación superior m = número de valores diferentes que asume la variable. fi = frecuencia absoluta; es el número de veces que se repite el valor Xi dentro de la serie de datos original. hi = frecuencia relativa. Fi = frecuencia absoluta acumulada. Hi = frecuencia relativa acumulada. 1. Frecuencia relativa (hi). Es la relación entre la frecuencia absoluta, fi, y el total de datos n; es el grado de representatividad de la fi frente al total, n; es el peso o ponderación de la fi dentro del total, n. Es la representación porcentual (aún sin multiplicar por 100) de cada una de las respectivas frecuencias absolutas. Las hi se calculan así: Fórmula (3) Características de las frecuencias relativas (hi): 1. Las frecuencias relativas siempre son valores fraccionarios positivos. 2. Las frecuencias relativas siempre se encuentran entre 0 y 1, así: 0 ≤ hi ≤ 1 3. La sumatoria de las frecuencias relativas siempre es igual a 1, así: ∑ 2. Frecuencia absoluta acumulada (Fi). Consiste en ir acumulando las frecuencias absolutas (fi), así: Fórmula (4) Estadística para educación superior F1 = f 1 F2 = f1 + f2 F3 = f1 + f2 + f3 F4 = f1 + f2 + f3 + f4 Fm = f1 + f2 + f3 +… + fm También, se tiene que: F2 = F1 + f 2 F3 = F2 + f 3 F4 = F3 + f 4 Fm = Fm-1 + fm Características de las frecuencias absolutas acumuladas (Fi): 1. El primer valor de las Fi siempre es igual al primer valor de las fi, así: F1 = f1. 2. El último valor de las Fi siempre es igual a n, así: Fm = n. 3. Las Fi siempre son valores enteros entre 0 y n. 3. Frecuencia relativa acumulada (Hi). Es ir acumulando las frecuencias relativas (hi), así: H1 = h1 H2 = h1 + h2 H3 = h1 + h2 + h3 H4 = h1 + h2 + h3 + h4 Hm = h1 + h2 + h3 +… + hm Estadística para educación superior También, se tiene que: H2 = H1 + h2 H3 = H2 + h3 H4 = H3 + h4 Hm = Hm-1 + hm Características de las frecuencias relativas acumuladas (Hi): 1. El primer valor de las Hi siempre es igual al primer valor de las hi, así: H1 = h1. 2. El último valor de las Hi siempre es igual a 1, así: Hm = 1. 3. Las Hi siempre son valores fraccionarios entre 0 y 1. 2.1.3 Para una variable cuantitativa agrupada por intervalos. Para una variable cuantitativa agrupada (organizada por intervalos), la frecuencia se refiere al número de valores dentro de la serie de datos que se encuentran incluidos en el intervalo respectivo. En este caso existirán tantas frecuencias como intervalos posea la tabla que se elabore (figura 12). Figura 12. Diseño de tabla de frecuencia para una variable cuantitativa agrupada por intervalos No. Intervalos Xi fi hi Fi Hi 1 Li - LS X1 f1 h1 F1 H1 2 Li - LS X2 f2 h2 F2 H2 3 Li - LS X3 f3 h3 F3 H3 4 Li - LS X4 f4 h4 F4 H4 … … … … … … … m Li - LS Xm fm hm Fm Hm Total - - n 1 - - Estadística para educación superior Esta tabla (figura 12) contiene m renglones que coinciden con el número de intervalos. Los intervalos representan cada una de las diferentes categorías que asume la variable. Aquí, un elemento o unidad de investigación no puede pertenecer simultáneamente a varias categorías. En la tabla: m = número de intervalos o número de marcas de clase. Xi = marca de clase del intervalo i-ésimo. fi = frecuencia absoluta del intervalo i-ésimo. Es el número de valores dentro de la serie de datos original que se encuentran incluidos en el intervalo i-ésimo. hi = frecuencia relativa. Fi = frecuencia absoluta acumulada. Acumulación de las fi hasta el intervalo i-ésimo. Hi = frecuencia relativa acumulada. Acumulación de las hi hasta el intervalo i-ésimo. 1. Marca de clase (Xi). Es el punto medio del intervalo. Para su cálculo se suma el límite inferior del intervalo más el límite superior del mismo intervalo, y luego se divide entre 2. Luego de tener calculada la primera marca de clase, las siguientes pueden ser calculadas siguiendo esta misma metodología o teniendo presente la amplitud que tienen los intervalos (C) y la anterior marca de clase, así: Fórmula (5) En esta fórmula se trabaja con el límite inferior (Li) y el límite superior (Ls) del respectivo intervalo i-ésimo. Si se desea calcular la primera marca de clase (X1) nos ubicamos en el intervalo i=1 (primer intervalo). Para las siguientes marcas de clase, se puede emplear la fórmula 5, o utilizar la fórmula 6: Fórmula (6) Estadística para educación superior Por ejemplo: X2 = X1 + C X3 = X2 + C X4 = X3 + C 2. Amplitud de los intervalos (C). La amplitud de los intervalos es un número constante C, el cual puede ser entero o decimal. 3. Conformación de los intervalos. Los intervalos se conforman teniendo presente el rango o recorrido de toda la serie de datos, el número de intervalos deseado, m y la amplitud constante, C de los intervalos, tal como se explica a continuación. Estadística para educación superior Cuadro 1. Procedimiento para la conformación de intervalos Paso 1: Identificar, dentro de la serie de datos original, el valor mayor y el valor menor: Xmáx = Valor máximo o mayor Xmín = Valor mínimo o menor Paso 2: Calcular el rango, R: R = Xmáx – Xmín Paso 3: Calcular el número de intervalos (m). El número de intervalos puede ser calculado utilizando la siguiente fórmula, o también a criterio subjetivo del investigador, en otras palabras, el investigador puede definir el número de intervalos con los cuales desea trabajar: m = 1 + 3,3 log (n) Paso 4: Calcular o definir la amplitud que van a tener los intervalos (C): 𝑅 = 𝑚 Se puede trabajar con el valor que dé, o con una aproximación siempre por encima del resultado, sin importar la regla de aproximación de decimales (nunca aproximar por debajo). Paso 5: Calcular el nuevo rango (R*): R* = C ⋅ m Paso 6: Comparar el nuevo rango (R*) con el rango inicial R: siempre se debe cumplir la condición de que el nuevo rango sea mayor o igual al rango inicial (nunca menor): R* ≥ R. En caso de no cumplirse esta condición, modificar los valores de C y de m, o de uno sólo (el que se desee). Lo más conveniente es que R* sea igual a R o tienda a ser igual al R, esto es, que el incremento del rango no sea muy alto (un valor pequeño). Paso 7: Calcular el incremento del Rango (ΔR): ΔR = R* – R Repartir el incremento del rango en dos partes iguales (dividir el Δ R sobre dos), de la siguiente manera: Xmín – (ΔR/2) = Li del primer intervalo Xmáx (ΔR/2) = Ls del último intervalo Paso 8: Conformar los intervalos: Primer intervalo: Al límite inferir del primer intervalo, sumarle el valor de la amplitud C, para obtener el límite superior de ese intervalo. Segundo intervalo: Asignar como límite inferior del segundo intervalo, el límite superior del primero, y luego, sumar de nuevo el valor de C, para obtener el límite superior del segundo intervalo. Continuar de la misma manera hasta llegar al último intervalo (el m-ésimo intervalo). Estadística para educación superior 4. Conteo de las frecuencias absolutas (fi). Para el conteo de cada una de las frecuencias absolutas correspondientes para cada intervalo, se debe primero tomar la decisión sobre cuál de los dos límites quedará abierto y cuál cerrado. Hay que recordar que límite abierto significa que no se incluye el valor respectivo, y límite cerrado significa que sí se incluye el valor respectivo; este detalle es muy importante para no alterar las frecuencias, y por consiguiente, el total de datos que arroja la sumatoria de las frecuencias absolutas. Si se cierra el límite superior y se deja abierto el límite inferior, el único intervalo que quedará cerrado en sus dos extremos es el primero; por el contrario, si se cierra el límite inferior y se deja abierto el superior, el único intervalo que quedará cerrado en sus dos extremos es el último. 2.1.4 Para dos o más variables. Las tablas de frecuencia para dos o más variables reciben el nombre de tablas bivariadas o multivariadas. La metodología para su elaboración es a través de cruce de variables. Cruzar variables es analizar simultáneamente las variables; si se trata del cruce de dos variables, es analizar simultáneamente las dos variables respectivas; si se trata de tres variables, es analizar simultáneamente las tres variables respectivas; y así sucesivamente. El análisis de clasificación cruzada se elabora a través del diseño de cuadros o tablas de doble entrada. 1. Tablas de clasificación cruzada para dos variables. Se conoce también con el nombre de tabla de doble entrada. En la parte superior se ubica una variable y en la parte izquierda la otra, cada una con sus respectivas categorías. Las frecuencias absolutas ubicadas en cada uno de los cruces reciben el nombre de frecuencia absoluta conjunta y los totales de las mismas por columna o por fila, se identifican como Estadística para educación superior frecuencias absolutas marginales. La sumatoria de los totales por fila y de los totales por columna siempre debe sumar lo mismo (ver figura 13). Figura 13. Diseño de tabla de clasificación cruzada bivariada Variable 2 Variable 1 Categoría 1 Categoría 2 Categoría 3 … Categoría n Total Categoría 1 Categoría 2 … Categoría m Total Para analizar porcentajes en una tabla de doble entrada se tienen tres opciones o posibilidades: Porcentajes con base en cada uno de los totales por fila. Porcentajes con base en cada uno de los totales por columna. Porcentaje con base en el gran total, es decir, el total ubicado en la esquina inferior derecha de la tabla. Para las interpretaciones de los porcentajes se debe tener en cuanta cuál de las alternativas anteriores fue la elegida para elaborar los respectivos cálculos. 2. Tablas de clasificación cruzada para tres o más variables. Para tres variables. Se tienen dos alternativas de diseño: una es ubicar dos variables en la parte superior y una en la parte izquierda; la otra alternativa es ubicar dos variables en la parte izquierda y una variable en la parte superior. La elección de cuáles van en un lado y cuales en otro, depende de las necesidades de cada caso particular dentro de la investigación. Un diseño puede ser como el que se muestra a continuación (ver figura 14); existen otros diseños, Estadística para educación superior los cuales dependen de las características de cómo se desee organizar la información recolectada. Figura 14. Diseño de tabla de clasificación cruzada trivariada Variable 3 Cat.1(V1) Cat.2(V1) Cat.j(V1) Total Cat.1(V2) Cat.2(V2) … Cat.j(V2) Cat.1(V2) Cat.2(V2) … Cat.j(V2) … Cat.1(V2) Cat.2(V2) … Cat.j(V2) Cat.1(V3) Cat.2(V3) Cat.3(V3) … Cat.k(V3) Total Las frecuencias absolutas que se ubican en cada una de las posiciones de cruce se denominan frecuencias absolutas conjuntas y las ubicadas en cada una de las casillas de totales (por fila y columna) se denominan frecuencias absolutas marginales. Los porcentajes se calculan con base en los totales por filas, columnas o el gran total; la interpretación y análisis del porcentaje respectivo depende del total que se haya tomado como base para el cálculo. El gran total se ubica en la esquina inferior derecha de la tabla y debe ser igual, tanto por filas como por columnas. Para más de tres variables. El diseño depende de las necesidades particulares que se tengan al efectuar el cruce. Si se tienen cuatro variables para cruzar: Ubicar dos en la parte superior de la tabla y dos en la parte izquierda. Ubicar tres en la parte superior y una en la izquierda. Ubicar una en la parte superior y tres en la parte izquierda. Si se tienen cinco variables para cruzar: Estadística para educación superior Ubicar dos en la parte superior y tres en la izquierda. Ubicar tres en la parte superior y dos en la izquierda. Ubicar una variable en un lado y cuatro en el otro. Para el cálculo y análisis de los porcentajes se debe tener en cuenta cuál de todos los totales o subtotales se toma como base. 2.2 Gráficos estadísticos. Los gráficos son una manera de complementar la información que se encuentra organizada en una tabla, para asimilar de manera visual el comportamiento de la variable. Los gráficos más utilizados son: Gráfico de pastel o circular. Diagrama de barras. Histograma. Polígono. Ojiva. Gráfico lineal (para series de tiempo). Diagrama de dispersión y función de ajuste. Estadística para educación superior 2.2.1 Representación visual. Figura 15. Ejemplo de gráfico circular o de pastel Medios publicitarios por los cuales se da a conocer Esumer entre los bachilleres Valla publicitaria 3,1% Visita de Esumer 12,5% Volante 3,1% Televisión 28,1% NR 14,1% Prensa 14,1% Radio 25,0% Estadística para educación superior Figura 16. Ejemplos de diagrama de barras Concepto de los bachilleres encuestados, sobre Esumer 45% 42,6% 44,1% 40% 35% 30% 25% 20% 10,8% 15% 10% 2,5% 5% 0,0% 0% Excelente Bueno Regular Malo Ninguno Grado de conocimiento que tienen los empresarios, de los programas de Esumer 70% 65,0% 60% 50% 40,0% 40% 30% 20,0% 20,0% 20% 10% 0% ME AF CI ASI Estadística para educación superior Figura 17. Ejemplos de diagramas de barras bivariados Nivel de dominio del Inglés, de los estudiantes de pregrado, según habilidades Avanzado 60% 53,2% 51,4% 50% 49,5% 49,5% 39,6% 40% 30% Intermedio Básico 38,7% 32,4% 31,5% 25,2% 20,7% 14,4% 20% 12,6% 10% 0% Escuchar Hablar Leer Escribir Áreas en las que el empresario considera que Esumer podria ofrecerle servicios de posgrado, consultoría y extensión Extensión Consultoria/Asesoría Ccio. Internacional Posgrado Pregrado 8,3% 2,8% 8,3% Mercadeo 5,6% 19,4% 8,3% 2,8% 2,8% Sistemas 2,8% 5,6% 13,9% Financiera 5,6% Administrativa 5,6% 0% 5% 8,3% 8,3% 8,3% 10% 15% 20% 25% Estadística para educación superior Figura 18. Ejemplo de diagrama de dispersión y función de ajuste Ventas (millones de $) 80 70 60 50 40 30 20 10 0 1986 1987 1988 1989 1990 1991 1992 1993 1994 2.2.2 Descripción de los gráficos estadísticos más utilizados. 1. Gráfico circular. La circunferencia se divide en sectores que representan los diferentes porcentajes, los 360 grados de la circunferencia representan el 100% de los datos. Se utiliza cuando las categorías de la variable son mutuamente excluyentes. 2. Gráfico de barras. Cada barra representa una categoría de la variable y su altura está asociada con la frecuencia absoluta o relativa de la respectiva categoría. Este gráfico puede ser utilizado para variable cuantitativa discreta y para variable cualitativa con categorías mutuamente excluyentes, y también en categorías no mutuamente excluyentes. Estadística para educación superior 3. Histograma. Se parece al gráfico de barras, con la diferencia de que no hay espacio entre barra y barra, las barras son consecutivas debido a que el histograma se utiliza para visualizar el comportamiento de una variable cuantitativa continua, organizada por intervalos. Generalmente en el eje X (eje horizontal) se ubican los intervalos y en el eje Y (eje vertical) se ubican las frecuencias absolutas o relativas. La altura de cada barra del histograma representa la frecuencia absoluta o relativa del intervalo respectivo. 4. Polígono. Se toma como base para su elaboración, el histograma de frecuencias, se unen con una línea los puntos medios de las alturas de cada una de las barras, esta gráfica lineal resultante es llamada Polígono. En otras palabras, se está trabajando con las marcas de clase y las frecuencias absolutas de cada intervalo. 5. Ojiva. Se toman como base las marcas de clase de cada intervalo y las frecuencias absolutas acumuladas, se unen mediante una línea, arrojando como resultado un gráfico lineal ascendente por tratarse de frecuencias absolutas acumuladas. 6. Diagrama de dispersión. Llamada también nube de puntos. Es utilizado para estudiar la relación existente entre variables, cada punto representa una coordenada en el plano cartesiano (X, Y) referente al dato real u original. Sobre el diagrama de dispersión se grafica la función de ajuste que representa a la serie de datos originales. En determinados casos, una de las variables es el tiempo. Estadística para educación superior 7. Gráfica lineal para series de tiempo. Es usada para analizar el comportamiento de una variable a través del tiempo, o lo que es lo mismo, para analizar dos variables conjuntamente siendo una de ellas el tiempo. En el eje X (eje horizontal) se ubica el tiempo, en el eje Y (eje vertical) se ubica la otra variable, se señalan puntos de cruce para cada unidad de tiempo con su respectivo valor de la variable y luego se unen los puntos con una línea, la cual va mostrando el movimiento ascendente o descendente a través del tiempo que puede presentar la variable analizada. Estadística para educación superior 3. Medidas de tendencia central 3.1 La media. Es la medida de tendencia central más importante y utilizada. Tiene en cuenta cada uno de los valores de la serie de datos, se ve afectada por valores altos y bajos, así como también por las respectivas frecuencias. Se identifica con ̅ , M(X) o también con la letra µ. 1. Media aritmética simple. ̅ ̅ ̅ ∑ ∑ ∑ Para datos desagrupados Fórmula (7) Para datos agrupados Fórmula (8) Para datos desagrupados y ponderados Fórmula (9) 2. Media aritmética ponderada. Es utilizada cuando los diferentes valores de la variable tienen diferente peso o ponderación, la ponderación está representada por los porcentajes de representatividad que tiene cada valor de la variable. ̅ ∑ En esta fórmula, los hi: los respectivos pesos o ponderaciones. Fórmula (10) Estadística para educación superior 3.1.1 Propiedades de la media. 1. La sumatoria de las desviaciones respecto a la media siempre es igual a cero. La expresión estadística ( ̅) se conoce con el nombre de desviación respecto a la media. La desviación respecto a la media puede ser positiva o negativa dependiendo si el valor de Xi se encuentra por encima o por debajo de la media, e incluso puede ser igual a cero si el valor de Xi coincide con el de la media. ̅) ∑( ̅) ∑( Para datos sin agrupar Fórmula (11) Para datos agrupados Fórmula (12) 2. La media aritmética de una constante es igual a la constante misma. ( ) o̅ Fórmula (13) 3. La media aritmética de una constante por una variable es igual a la constante por la media de la variable. ( ) ( ) ó ̅̅̅̅̅̅̅̅ ̅ Fórmula (14) 4. La media total: Cuando tenemos una población dividida en subgrupos y para cada uno de los subgrupos conocemos su respectiva media y el total de datos, siendo el objetivo calcular la media total, es decir, la media para todo el grupo o media poblacional, se calcula a través de la aplicación de la siguiente fórmula (media de medias): Estadística para educación superior ̅̅̅ ∑ ̅̅̅̅̅ ∑ Fórmula (15) Donde: ̅̅̅ media total o general ̅ media de cada subgrupo i total de datos del subgrupo i 3.2 La mediana. Es el valor que ocupa la posición central en una serie de datos, lo que significa que el 50% de los datos se encuentran por encima de la mediana o son valores superiores a la mediana y el otro 50% se encuentran por debajo de la mediana o son valores inferiores a la mediana. Se identifica con el símbolo Me. El cálculo de la mediana implica tener preliminarmente los datos organizados en orden ascendente, y se halla de manera diferente en caso de tener los datos desagrupados o agrupados. 3.2.1 La mediana para datos desagrupados. Para n impar: ordenar los datos de menor a mayor. Me es el valor de la variable que ocupa la posición ( ) Para n par: ordenar los datos de menor a mayor. Me es el promedio de los valores de la variable que ocupan las posiciones ( ) y [( ) ] Estadística para educación superior 3.2.2 La mediana para datos agrupados. Para variable continua: cuando los datos están agrupados en una tabla de frecuencia, los valores ya se encuentran organizados de menor a mayor. Cuadro 2. Pasos a seguir para determinar la mediana para datos agrupados, para variable continua Paso 1: Calcular ( ) 2 Paso 2: Buscar este resultado en la columna de las Fi (frecuencias absolutas acumuladas). Paso 3: Efectuar las indicaciones que se presentan a continuación, en caso de encontrar o no este valor. En caso de encontrarlo En caso de no encontrarlo - Señalar el valor de ( ) en la columna de las - Señalar el inmediatamente menor a ( ) en 2 Fi - Ir al renglón siguiente y señalar Li 𝑒 = 𝑖 2 la columna de las Fi e inmediatamente identificarlo con el nombre de Fi-1 - Ir al renglón siguiente y señalar la correspondiente frecuencia absoluta fi y el respectivo límite inferior del intervalo Li - Aplicar la siguiente fórmula: 𝑒 = 𝑖 + 2 𝐹𝑖 𝑖 Para variable discreta: a continuación se presenta el procedimiento: 1 Estadística para educación superior Cuadro 3. Pasos a seguir determinar la mediana para datos agrupados, para variable discreta Paso 1: Calcular ( ) 2 Paso 2: Buscar este resultado en la columna de las Fi (frecuencias absolutas acumuladas). Paso 3: Efectuar las indicaciones que se presentan a continuación, en caso de encontrar o no el valor respectivo. En caso de encontrarlo En caso de no encontrarlo - Señalar el valor de ( ) en la columna de las - Señalar el inmediatamente menor a ( ) en 2 2 Fi la columna de las Fi - Señalar el valor de la variable ubicada en - Ir al renglón siguiente y señalar el ese mismo renglón e identificarla como Xi-1, correspondiente valor de la variable e y el valor de la variable ubicada en el identificarlo como Xi renglón siguiente e identificarla como Xi - Aplicar la siguiente fórmula: - Aplicar la siguiente fórmula: 𝑒 = 𝑖 + 𝑖 1 𝑖 𝑒 = 2 3.3 La moda. Es el valor de la variable que se repite con mayor frecuencia. Se identifica con Md. Fórmula (16) Siendo Xi un valor particular de la variable, en caso de estar analizando una tabla para variable discreta, o un valor particular de una marca de clase, en caso de estar trabajando con una tabla para variable continua. Estadística para educación superior 4. Medidas de variabilidad Son utilizadas para analizar cómo varían, oscilan, van cambiando o se van distribuyendo los valores de la variable. 4.1 La varianza. Se identifica con Var(X), V(X), o simplemente σ2. Es un cálculo estadístico preliminar para poder hallar la desviación típica o estándar, en otras palabras, la varianza y la desviación típica o estándar van de la mano. La varianza se define como el promedio de las desviaciones cuadráticas respecto a su misma media. Toma como referencia para el análisis de la variabilidad, el promedio o media de la variable. ( ) ( ) ∑( ∑( ̅) ̅) Varianza para datos desagrupados Fórmula (17) Varianza para datos agrupados Fórmula (18) Nota. En las anteriores fórmulas para la varianza, n representa el total de datos que se están analizando, sin hacer diferencia entre población y muestra. Cuando el estudio implica hacer diferencia en cuanto a la población y a la muestra, hay que tener presente que N representa tamaño poblacional y n, tamaño muestral. Al estar trabajando con muestreo, la varianza cambia por el nombre de cuasivarianza o varianza muestral, la cuasivarianza está dada por: ( ) ∑( ̅) Fórmula (19) Estadística para educación superior Cuando se refiere a la cuasivarianza, se deja de identificar con σ2 y pasa a reconocerse con el símbolo de S2. 4.1.1 Propiedades de la varianza. 1. La varianza siempre es un valor positivo. Var(X) ≥ 0 2. La varianza de una constante K es igual a cero. Var(K) = 0 3. La varianza de una variable más o menos una constante es igual a la varianza de la variable. Var(X ± K) = Var(X) 4. La varianza de una constante por una variable es igual a la constante al cuadrado por la varianza de la variable. Var(KX) = K2 Var(X) 4.2 La desviación típica o estándar. Se identifica con σX o σ. Mide el promedio de variabilidad de los datos tomando como referencia la media de la variable, es decir, analiza el grado de alejamiento o de dispersión de los datos alrededor de la media. La desviación típica o estándar es la raíz cuadrada de la varianza. √ ( ) Fórmula (20) Estadística para educación superior 4.3 Coeficiente de variación. Se identifica con CV. Permite comparar la variabilidad de dos o más distribuciones expresadas en unidades de medidas diferentes, con el fin de determinar cuál de ellas tiene una mayor o menor variabilidad relativa. Se expresa en términos porcentuales. CV= desviación típica / media aritmética ̅ ̅ Fórmula (21) 4.4 El rango recorrido. Se identifica con la letra R. Es la diferencia entre el valor máximo y el mínimo de la serie de datos alusiva a la variable. 𝑅 Fórmula (22) Simplemente muestra el recorrido de la variable, es decir el espacio en unidades dentro del cual se encuentran los datos, pero no toma en cuenta como están distribuidos los datos entre el valor máximo y el valor mínimo. No debe utilizarse como medida de dispersión cuando se tienen observaciones extremas. Esta medida no permite saber nada acerca de los valores intermedios de la variable y tampoco tiene en cuenta aquellos valores con mayor peso, ponderación o importancia según la frecuencia. Estadística para educación superior 4.5 Recorrido intercuartílico1. Se identifica con RI. El recorrido intercuartílico, evita el problema de las observaciones extremas, sin embargo no tiene en cuenta el 25% inicial de la serie de datos ni el 25% final de la misma. Es indispensable tener la serie de datos organizada de menor a mayor (orden ascendente), por tal motivo, al hacer referencia al 25% inicial, no es otra cosa más que el 25% de los valores inferiores, y el 25% final, el 25% de los valores superiores. El recorrido intercuartílico considera la extensión en el 50% medio de los datos, esta extensión o recorrido está dada por la diferencia entre el cuartil de orden tres y el cuartil de orden uno (ver figura 19). Figura 19. Recorrido intercuartílico Q1 Q2 Q3 50% medio de los datos 𝑅 Fórmula (23) El recorrido intercuartílico tiene la ventaja de no verse afectado por valores extremos, sin embargo es desventajoso porque sólo mide la extensión en el 50% del centro de los datos y por ello, no dice nada de la extensión de los datos totales, además, tampoco analiza cómo se encuentran distribuidos los datos dentro de éste 50% central (entre Q1 y Q3). 1 cuartiles. Para comprender con mayor precisión esta medida se recomienda leer el tema de Medidas de posición, específicamente, los Estadística para educación superior 5. Medidas de posición (los cuantiles) Los cuantiles son medidas de posición no central, se emplean para resumir o describir un conjunto de datos tomando como base algunas posiciones específicas, teniendo preliminarmente la serie de datos organizada en forma ascendente. 5.1 Cuartiles. Los cuartiles dividen la serie de datos en cuatro partes iguales. Se calculan tres cuartiles: Q1, Q2 y Q3 (ver figura 20). Figura 20. Los cuartiles Q1 Q2 Q3 Q1 E l 25% de los datos son valores menores a Q1 , y el 75% de los datos son valores mayores a Q 1 Q2 E l 25% de los datos son valores menores a Q2, y el otro 50% de los datos son valores mayores a Q 2 . El Q 2 coincide con la mediana (Me) Q3 E l 75% de los datos son valores menores a Q3, y el otro 25% de los datos son valores mayores a Q 3 5.1.1 Cuartiles para datos sin agrupar. Cuando los datos no están organizados en una tabla de frecuencia, el procedimiento a seguir es el que se describe en el siguiente cuadro: Estadística para educación superior Cuadro 4. Procedimiento para el cálculo de cuartiles con datos sin agrupar Paso 1: Organizar los datos de forma ascendente Paso 2: Calcular la posición r ( +1 4 ) Nota: Si el valor resultante del punto de posición es un entero, se selecciona la observación numérica particular correspondiente al punto de posición. Si el punto de posición resultante está en la mitad de dos puntos de posición, se selecciona la media de sus valores. Si el punto de posición resultante no es un entero ni un valor a la mitad de dos puntos, se utiliza la regla de aproximación empírica de redondeo al punto de posición del entero más cercano. Paso 3: El cuartil de orden r esta dado por el valor de la variable que ocupa esta posición. ( Fórmula (24) ) 5.1.2 Cuartiles para datos agrupados. Cuando los datos están agrupados en una tabla de frecuencias, el procedimiento a seguir es el siguiente: Cuadro 5. Procedimiento para el cálculo cuartiles con datos agrupados Paso 1: Calcular × 4 Paso 2: Buscar este resultado en la columna de las frecuencias absolutas acumuladas y continuar con la misma metodología explicada para el cálculo de la mediana. 𝐹 Fórmula (25) 5.2 Deciles. Los deciles dividen la serie de datos en diez partes iguales. Se calculan nueve deciles: D1, D2, D3, D4, D5, D6, D7, D8, D9. El significado de cada decil es similar al análisis realizado para los Estadística para educación superior cuartiles, pero teniendo presente que se trata de una serie de datos dividida en 10 partes iguales. El decil de orden cinco, D5, coincide con el valor de la mediana. D1: Significa que el 10% de los datos son inferiores a D1, y el otro 90% son valores superiores a D1. D4: Significa que el 40% de los datos son inferiores o están por debajo de D4, y el otro 60% están por encima o son valores superiores a D4. 5.2.1 Deciles para datos sin agrupar. Cuando los datos no están organizados en una tabla de frecuencia, el procedimiento a seguir es el siguiente: Cuadro 6. Procedimiento para el cálculo de deciles con datos sin agrupar Paso 1: Organizar los datos de forma ascendente Paso 2: Calcular la posición r ( +1 10 ) Paso 3: El decil de orden r esta dado por el valor de la variable que ocupa esta posición. ( ) Fórmula (26) 5.2.1 Deciles para datos agrupados. Cuando los datos están agrupados en una tabla de frecuencias, el procedimiento a seguir es el que se indica a continuación: Estadística para educación superior Cuadro 7. Procedimiento para el cálculo de deciles con datos agrupados Paso 1: Calcular × 10 Paso 2: Buscar este resultado en la columna de las frecuencias absolutas acumuladas y continuar con la misma metodología explicada para el cálculo de la mediana. 𝐹 Fórmula (27) 5.3 Percentiles. Los percentiles dividen la serie de datos en 100 partes iguales. Se calculan 99 percentiles: P1, P2, P3,…, P56, P57,…, P98, P99. Para calcular los percentiles se sigue la misma metodología utilizada para los cuartiles y los deciles, simplemente que ya no se divide sobre 4 ó 10, sino sobre 100 al calcular ( ). Para su análisis también se emplea la misma metodología utilizada en cuartiles y deciles, pero teniendo presente que la serie de datos está dividida en 100 partes iguales. Estadística para educación superior 6. Medidas de asimetría y apuntamiento Son medidas utilizadas para analizar la forma como se distribuye la serie de datos. Se estudia conjuntamente con la gráfica adquirida en el polígono de frecuencias. 6.1 Coeficiente de asimetría. El coeficiente de asimetría es un cálculo estadístico que permite definir si una serie de datos es simétrica o asimétrica. 𝑚 Fórmula (28) Donde: m3 = momento de orden tres respecto a la media, o tercer momento respecto a la media. σ = desviación típica o estándar. Éstos son hallados de la siguiente manera: 𝑚 ( ) ∑( ̅) √ ( ) ∑( ̅) Fórmula (29) Fórmula (30) 𝑚 Fórmula (31) La varianza es el mismo momento de orden dos respecto a la media. El coeficiente de asimetría puede ser expresado utilizando el momento de orden dos y tres respecto a la media, así: Estadística para educación superior 𝑚 √𝑚 Fórmula (32) Para definir la simetría se compara el resultado obtenido del cálculo As con el número cero, así: As = 0 Distribución simétrica. As > 0 Distribución asimétrica positiva As < 0 Distribución Asimétrica negativa. 6.1.1 Distribución simétrica. En una serie de datos con distribución simétrica, los datos se encuentran concentrados alrededor de la media de manera proporcional, tanto por encima como por debajo de la media. Como es sabido, la media es una medida de tendencia central, algunos datos se encuentran por encima o son mayores que la media y otros datos se encuentran por debajo o son valores inferiores a la media e incluso, puede ocurrir que muchos de ellos coincidan con el valor de la media. Cuando esta distribución se presenta de manera simétrica, tomando como punto de referencia a la media, se concluye que la variable analizada se distribuye simétricamente. Gráficamente, se puede detectar la simetría a través del polígono de frecuencias, cuando éste presenta forma de campana (ver figura 21). Estadística para educación superior Figura 21. Representación gráfica de la simetría Distribución simétrica ̅ Con la tabla de frecuencias, sin necesidad de efectuar el polígono, también se puede detectar si la variable presenta distribución simétrica, esto se hace observando la columna de las frecuencias absolutas (o también las relativas), si éstas comienzan a crecer hasta llegar a un valor a partir del cual comienzan a decrecer de manera simétrica, es decir, el crecimiento y decrecimiento de las frecuencias se presenta con características particulares, siendo la primera frecuencia igual a la última, la segunda frecuencia igual a la penúltima y así sucesivamente. En una distribución simétrica, las tres medidas de tendencia central son iguales; la media, la mediana y la moda coinciden en su valor. 6.1.2 Distribución asimétrica. La asimetría se presenta cuando la serie de datos de la variable no se distribuye simétricamente respecto a la media. La asimetría puede ser positiva o negativa. Asimetría positiva. La serie de datos presenta una mayor concentración de los datos hacia la izquierda y una menor concentración a la derecha, bajo esta circunstancia, la serie de datos presenta un sesgo o caída que se extiende hacia la derecha. Las tres medidas de tendencia central son desiguales (ver figura 22). Estadística para educación superior Figura 22. Representación gráfica de la asimetría positiva Distribución asimétrica positiva ̅ Asimetría negativa. La serie de datos presenta una mayor concentración de los datos hacia la derecha y una menor concentración a la izquierda, bajo esta circunstancia, la serie de datos presenta un sesgo hacia la izquierda. Las tres medidas de tendencia central son desiguales (ver figura 23). Figura 23. Representación gráfica de la asimetría negativa Distribución asimétrica negativa ̅ Estadística para educación superior 6.2 Coeficiente de apuntamiento. Es un cálculo estadístico para analizar la altura de la distribución. La altura depende de las frecuencias altas o bajas que se presenten en la serie de datos, lo cual puede visualizarse claramente con el gráfico del polígono de frecuencias. Para calcular el coeficiente de apuntamiento se efectúan las siguientes operaciones: 𝑚 Fórmula (33) Donde: m4 = momento de orden cuatro respecto a la media, o cuarto momento respecto a la media. σ = desviación típica o estándar. 𝑚 ∑( ̅) Fórmula (34) Expresando el coeficiente de apuntamiento en términos de los momentos de orden dos y cuatro respecto a la media, se tiene: 𝑚 ( √𝑚 ) 𝑚 𝑚 Fórmula (35) El coeficiente de apuntamiento se compara con el valor de 3 para analizar si es apuntada, achatada o normal (ver figura 24), así: Ap = 3 Distribución con altura normal. Ap > 3 Distribución apuntada. Estadística para educación superior Ap < 3 Distribución achatada. Figura 24. Representación gráfica de la altura de la distribución con coeficiente de apuntamiento Apuntada Normal Achatada En una distribución apuntada existe una concentración alta (frecuencias altas) alrededor del valor de X donde se visualiza el punto de máximo en el polígono; por el contrario, en una distribución achatada, los datos se encuentran muy dispersos y no están concentrados alrededor de un valor específico. Se recomienda analizar conjuntamente asimetría y apuntamiento, para obtener mayor claridad sobre la forma de la distribución de la variable; así por ejemplo, en caso de tratarse de una distribución simétrica apuntada, se puede concluir que los datos se encuentran demasiado concentrados alrededor de la media debido a que las frecuencias más altas donde se refleja el apuntamiento en el polígono corresponden a intervalos alrededor de la media. Estadística para educación superior 7. Ejercicios de aplicación resueltos 7.1 Ejemplo: Precio de venta de bienes raíces. Los siguientes datos representan el precio (en millones de pesos) de 62 casas unifamiliares de cierta zona de la ciudad: Vivienda unifamiliar Precio de venta (en millones de pesos) 75 71 74 79 86 80 85 81 83 86 89 93 87 89 94 88 87 88 89 90 91 93 95 100 96 102 100 97 100 102 97 102 95 96 102 95 102 95 99 98 105 103 110 105 107 103 107 110 109 104 110 108 111 114 118 113 116 114 116 120 125 122 Se pide: a) Organizar los datos en una tabla de frecuencias. b) Elaborar el polígono de frecuencias. c) Calcular la media, la mediana y la moda. d) Calcular la desviación típica o estándar. e) Calcular el coeficiente de asimetría y de apuntamiento. f) Calcular el rango intercuartílico. g) Calcular el tercer cuartil, el decil de orden dos y el percentil 70. Analizar e interpretar los resultados obtenidos. Estadística para educación superior Solución a) Elaboración de la tabla de frecuencias. Se aplican los pasos descritos para la conformación de los intervalos: 1. 2. 𝑅 𝑅 3. Número de intervalos 𝑚 (opinión subjetiva). 𝑚 log( ) 𝑚 Puede calcularse con la fórmula o a criterio del investigador log 𝑚 4. Amplitud de cada intervalo 𝑅 𝑚 Se aproxima a número entero en caso de desear trabajar con una amplitud entera. Nota. Los pasos 3 y 4 pueden efectuarse con opinión subjetiva del investigador, dependiendo de cómo se desee que queden conformados los intervalos, lo único que siempre hay que tener presente es que el nuevo rango sea igual o mayor al rango inicial; cuando sea mayor se recomienda que no se aleje demasiado del valor del rango inicial. 5. Nuevo rango 𝑅 𝑅 𝑚 𝑅 Se puede trabajar con estos valores de C y m porque el nuevo rango cumple la condición de 𝑅 ≥𝑅 6. Incremento del rango 𝑅 𝑅 𝑅 𝑅 𝑅 7. Repartir el incremento en dos partes iguales. 𝑅 Xmín y hacia la derecha del Xmáx. . Se corre hacia la izquierda del El valor de 70 constituye el límite inferior del primer intervalo. El valor de 126 constituye el límite superior del último intervalo. Estadística para educación superior Para el conteo de las frecuencias absolutas límite queda abierto y cuál cerrado. es indispensable aclarar en los intervalos, cuál Para los intervalos en la tabla de frecuencias que se presenta, se tienen las siguientes observaciones, con el objeto de facilitar el conteo de las frecuencias absolutas: Primer intervalo: Límite inferior cerrado, límite superior cerrado. Segundo intervalo: Límite inferior abierto, límite superior cerrado. Tercer intervalo: Límite inferior abierto, límite superior cerrado. Intervalo n-ésimo: en este caso, séptimo intervalo, límite inferior abierto, límite superior cerrado. Siguiendo esta metodología de dejar abierto el límite inferior y cerrado el superior, el único intervalo que queda cerrado en sus dos extremos es el primero. Esto es muy importante porque si existe un valor en la serie de datos recolectada, que quede precisamente en uno de los límites, al hacer el conteo de frecuencias absolutas se puede tener claridad dentro de cuál intervalo es incluido dicho valor. Intervalos 70-78 78-86 86-94 94-102 102-110 110-118 118-126 Total Xi 74 82 90 98 106 114 122 ─ fi 3 7 12 18 12 7 3 62 hi 0,0484 0,1129 0,1935 0,2903 0,1935 0,1129 0,0484 1,0000 Fi 3 10 22 40 52 59 62 ─ Hi 0,0484 0,1613 0,3548 0,6452 0,8387 0,9516 1,0000 ─ Algunas interpretaciones o análisis de los cálculos estadísticos efectuados en la tabla de frecuencias son: Estadística para educación superior f3 = 12 Existen 12 casas unifamiliares con un precio entre 86 y 94 millones (sin incluir el 86), expresado de otra forma, entre 86,000001 y 94 millones. El valor 86,000001 (en millones de pesos) significa $ 86.000.001 (pesos). h5 = 0,1935 = El 19,35% de las casas unifamiliares están avaluadas entre 102,000001 y 110 millones de pesos. F3 = 22 Existen 22 casas avaluadas a un precio inferior o igual a 94 millones, es decir, entre 70 y 94 millones de pesos (por debajo de 94 millones). H5 = 0,8387 El 83,87% de las casas se encuentran avaluadas a un precio inferior o igual a 110 millones, es decir, entre 70 y 110 millones de pesos (por debajo de 110 millones). ∑ La sumatoria de las frecuencias absolutas es igual al total de datos recolectados, en este caso, n = 62 ∑ La sumatoria de las frecuencias relativas es igual a 1, equivalente al 100% de los datos. F7 = 62 El último valor de la columna de las frecuencias absolutas acumuladas es igual al total de datos. H7 = 1 El último valor de la columna de las frecuencias relativas acumuladas es igual a 1. b) Polígono de frecuencias. Polígono de frecuencias 20 Número de casas 15 10 5 0 70 78 86 94 102 110 Precio (millones de pesos) 118 126 Estadística para educación superior c) Media, mediana y moda. Intervalos Xi fi X1 x fi Fi 70-78 74 3 222 3 78-86 82 7 574 10 86-94 90 12 1080 22 94-102 98 18 1764 40 102-110 106 12 1272 52 110-118 114 7 798 59 118-126 122 3 366 62 ─ 62 6.076 ─ Total La media: ̅ ̅ ∑ ̅ Interpretación: El valor promedio de las casas unifamiliares es de 98 millones, es decir, el precio promedio es de $ 98.000.000 La mediana: Se calcula Se busca este valor en la columna de las frecuencias absolutas acumuladas: en este caso particular no se encuentra este valor. Como no se encuentra el valor, se señala el inmediatamente menor a 31, en este caso es 22, que corresponde a la tercera frecuencia absoluta acumulada, se le asigna el nombre de 𝐹 Se pasa al renglón siguiente, en éste señalamos el valor de la frecuencia absoluta y del límite inferior, se tiene por lo tanto que: Se sustituyen los valores en la fórmula para la mediana: 𝐹 ( ) ( ) Estadística para educación superior Interpretación: El 50% de las casas tienen un valor inferior a 98 millones, y el otro 50%, un precio por encima de 98 millones. La moda: Se visualiza en la columna de las frecuencias absolutas el valor más alto, en este caso corresponde a , por lo tanto, la moda es el valor de la marca de clase X4 asociada con esta frecuencia absoluta: Interpretación: El precio más frecuente para las casas unifamiliares es de aproximadamente 98 millones de pesos. Se presenta con mayor frecuencia que el precio asignado a las casas unifamiliares se encuentra cercano a 98 millones (cercano por debajo y por encima). Nota: La media, la mediana y la moda arrojaron un mismo valor, lo que indica que la variable precio tiene un comportamiento simétrico (se distribuye simétricamente) ̅ d) Desviación típica o estándar: Para calcular la desviación típica o estándar se hace indispensable conocer el valor de la √ varianza porque ( ) también puede ser expresada √ . Para hallar la varianza se necesita calcular la sumatoria de las desviaciones cuadráticas respecto a la media, para luego promediarla. Intervalos Xi fi X1 x fi 70-78 74 3 222 (X i - X )2 f i 1.728 78-86 82 7 574 1.792 86-94 90 12 1.080 768 94-102 98 18 1.764 0 102-110 106 12 1.272 768 110-118 114 7 798 1.792 118-126 122 3 366 1.728 ─ 62 6.076 8.576 Total ( ) ( ) ∑ ( ̅) Estadística para educación superior √ Interpretación: En promedio, los precios de las casas se encuentran alejados o dispersos alrededor de la media ($98 millones) en 11,76 millones. El polígono donde se visualiza el comportamiento de esta variable es simétrico, la variable precio presenta una distribución normal, la media, la mediana y la moda están ubicadas en todo el centro de la serie de datos; los sesgos del polígono caen a lado y lado del punto medio, se acercan al eje X donde se alejan de la media más o menos a 3 desviaciones estándares (3σ), esto se escribe µ 3σ, donde µ es el valor de la media. Gráficamente se tiene: Casas (frecuencia) Casas unifamiliares Distribución del precio (millones de pesos) 50,96 62,72 74,48 86,24 98 109,76 121,52 133,28 µ - 3σ µ - 2σ µ- σ µ µ+ σ µ + 2σ µ + 3σ 145,04 Precio Estadística para educación superior e) Coeficiente de asimetría y apuntamiento: As, Ap. 3 (X i - X )3 f i -41.472 (X i - X )4 f i 995.328 82 7 -28.672 458.752 90 12 -6.144 49.152 94-102 98 18 0 0 102-110 106 12 6.144 49.152 110-118 114 7 28.672 458.752 118-126 122 3 41.472 995.328 ─ 62 0 3.006.464 Intervalos Xi fi 70-78 74 78-86 86-94 Total Es necesario calcular los momentos de orden tres y cuatro respecto a la media, m3 y m4, para esto se elaboran dos columnas nuevas, una que permita calcular la sumatoria de las desviaciones cúbicas respecto a la media y otra para calcular la sumatoria de las desviaciones a la potencia cuatro respecto a la media. 𝑚 ̅) ∑( 𝑚 ( 𝑚 ) ̅) ∑( 𝑚 ( ) Interpretación: El valor del coeficiente de asimetría se compara con cero; como As = 0 se tiene que el precio presenta una distribución simétrica. El valor del coeficiente de apuntamiento se compara con tres; como Ap < 3 se tiene que el precio presenta una distribución achatada, el grado de achatamiento no es muy alto porque 2,53 no está demasiado alejado de 3. f) Rango intercuartil (RI) 𝑅 Se necesita calcular el primer cuartil y el tercero. Estadística para educación superior Cálculo de Q1 ( )( Efectuar ) Buscar este valor en la columna de las frecuencias absolutas acumuladas, como no se encuentra, se señala el inmediatamente menor, en este caso corresponde a la segunda frecuencia absoluta acumulada, se le asigna el nombre de 𝐹 Se pasa al renglón siguiente para seleccionar los valores correspondientes a la frecuencia absoluta y al límite inferior, en este caso corresponde y . Se sustituyen estos valores en la fórmula correspondiente para el cálculo de cuartiles: 𝐹 ( ) Cálculo de Q3 ( )( ) 𝐹 ( ) Cálculo de RI 𝑅 Interpretación: El 50% central de los precios de las casas unifamiliares se encuentra entre $89,67 y $106,33 millones, el rango (distancia o recorrido) entre estos límites es de $16,66 millones. g) Cuartil de orden tres, segundo decil y percentil 70: Cuartil de orden tres: Q3 ( )( 𝐹 ) 𝐹 ( ) Estadística para educación superior Interpretación de El 75% de los precios de las casa unifamiliares se encuentran por debajo de $106,33 millones y el otro 25% son precios superiores a $106,33 millones. Segundo decil o decil de orden dos: D2 ( ) 𝐹 𝐹 ( ) Interpretación de El 20% de los precios de las casas unifamiliares se encuentran por debajo de $87,6 millones y el otro 80% son precios superiores o por encima de $87,6 millones. Percentil 70: P70 ( 𝐹 ) 𝐹 ( ) Interpretación de El 30% de los precios de las casas unifamiliares están por debajo de $104,27 millones y el otro 70% son precios superiores a $104,27 millones. 7.2 Base de datos: Compañías por sector económico, ubicación geográfica y vinculación de aprendices. La siguiente base de datos hace referencia a un grupo de compañías ubicadas dentro de un departamento determinado del país. Se especifica para cada compañía, el sector económico al que pertenece, la zona de ubicación y la vinculación actual de aprendices dentro de su planta de personal. Estadística para educación superior Compañía 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 Sector F C A C F F C A I I F C A A C F F F F I I A I I F Zona S N O S S S O R N O N S S N O O S R R R S R O O O Vinculación S S N N S S S N S S S S S S N N S S S N S S N S N Compañía 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 Sector I F F F I C C C F F F F F F C C A F F C C F A F F Zona S S S S S S R N R R R S N S R N O S O O O N N O S Vinculación N S S S S N S N S S S S S N S N S S S N S S S S S Convenciones de la tabla Sector económico: Agrícola = A Comercial = C Industrial = I Financiero = F Ubicación geográfica: Zona norte = N Occidente = O Zona sur = S Oriente = R Vinculación de aprendices: Sí vinculan = S No vinculan = N Nota: Los códigos de la base de datos tambien pueden ser números o palabras. En este caso se usaron letras. Se pide: a) Cuál es la unidad o elemento de investigación. b) Cuáles son las variables de esta investigación con sus respectivas categorías. c) Elaborar tres tablas de frecuencia univariadas para: sector económico, ubicación geográfica y vinculación de aprendices. Calcular porcentajes e interpretar algunos datos. Elaborar gráficos. Estadística para educación superior d) Elaborar una tabla de frecuencias (bivariada) de doble entrada para la zona y el sector económico. Cuáles son los diferentes porcentajes que se pueden calcular. Analizar e interpretar algunos resultados. Elaborar gráfico. e) Elaborar una tabla de frecuencias (bivariada) de doble entrada para el sector económico y la vinculación de aprendices. Cuáles son los diferentes porcentajes que es posible calcular. Analizar e interpretar algunos resultados. Elaborar gráfico. f) Elaborar una tabla de frecuencias (trivariada) de tres entradas para el sector económico, zona y vinculación de aprendices. Cuáles son los diferentes porcentajes que se pueden calcular. Analizar e interpretar algunos resultados. Elaborar gráfico. Solución a) Unidad o elemento de investigación. Cada una de las compañías. b) Variables. V1: Sector económico. Categorías de la variable V1: agrícola, industrial, comercial, financiero. V2: Ubicación geográfica. Categorías de la variable V2: norte, sur, occidente, oriente. V3: Vinculación de aprendices. Categorías de la variable V3: sí, no. Estadística para educación superior c) Tablas de frecuencia univariadas. Sector económico Sector Número de Compañías Agrícola 7 14,0% Comercial 12 24,0% Financiero 23 46,0% Industrial Total 8 16,0% 50 100,0% 14% 16% Porcentaje 24% 46% Agrícola Comercial Financiero Industrial Interpretación: El 24% de las compañías pertenecen al sector comercial; el 46% al sector financiero; el 14% al sector agrícola; y el 16% de pertenecen al sector industrial. Ubicación geográfica Zona Número de Compañías Norte Porcentaje 9 18% Occidente 13 26% Oriente 10 20% Sur 18 36% Total 50 100,0% 20 18 16 14 12 10 8 6 4 2 0 36% 26% 20% 18% Norte Occidente Oriente Sur Interpretación: El 18% de las compañías se encuentran ubicadas en la zona norte; el 26% en la zona occidental; el 20% en la zona oriental; y el 36% están ubicadas en la zona sur. Vinculación de aprendices Vinculación Número de Compañías 28% Porcentaje No 14 28,0% Sí 36 72,0% Total 50 100,0% 72% No Sí Interpretación: El 28% de las compañías no vinculan aprendices, mientras que el 72% sí vinculan aprendices en su planta de personal. Estadística para educación superior d) Tabla de frecuencia: Cruce entre la zona y el sector económico. Sector económico Zona Norte Occidente Oriente Total Sur Agrícola 2 2 2 1 7 Comercial 3 4 2 3 12 Financiero 3 4 5 11 23 Industrial 1 3 1 3 8 Total 9 13 10 18 50 Distribución por sector económico y zona 12 10 8 6 4 2 0 Norte Agrícola Occidente Comercial Oriente Financiero Sur Industrial Se pueden calcular porcentajes por filas, por columnas o con base en el gran total: Tabla con porcentajes por filas: Sector económico Zona Norte Occidente Oriente Sur Total Agrícola 28,6% 28,6% 28,6% 14,3% 100,0% Comercial 25,0% 33,3% 16,7% 25,0% 100,0% Financiero 13,0% 17,4% 21,7% 47,8% 100,0% Industrial 12,5% 37,5% 12,5% 37,5% 100,0% Algunas interpretaciones: Fila 1, columna 2: El 28,6% de las empresas del sector agrícola están ubicadas en la zona occidental. Fila 3, columna 4: El 47,8% de las empresas del sector financiero están ubicadas en la zona sur. Fila 4, columna 1: El 12,5% de las empresas del sector industrial están ubicadas en la zona norte. Estadística para educación superior Tabla con porcentajes por columna: Zona Sector económico Norte Occidente Oriente Sur Agrícola 22,2% 15,4% 20,0% 5,6% Comercial 33,3% 30,8% 20,0% 16,7% Financiero 33,3% 30,8% 50,0% 61,1% Industrial Total 11,1% 23,1% 10,0% 16,7% 100,0% 100,0% 100,0% 100,0% Algunas interpretaciones: Fila 2, columna 1: El 33,3% de las compañías ubicadas en la zona norte se dedican a la actividad económica comercial. Fila 3, columna 3: El 50% de las compañías de la zona oriental pertenecen al sector financiero. Fila 4, columna 2: El 23,1% de las empresas ubicadas en la zona occidental pertenecen al sector industrial. Tabla de porcentajes con base en el gran total: Sector económico Zona Norte Occidente Oriente Sur Total Agrícola 4,0% 4,0% 4,0% 2,0% 14,0% Comercial 6,0% 8,0% 4,0% 6,0% 24,0% Financiero 6,0% 8,0% 10,0% 22,0% 46,0% Industrial 2,0% 6,0% 2,0% 6,0% 16,0% 18,0% 26,0% 20,0% 36,0% 100,0% Total Algunas interpretaciones: Fila 3, columna 4: El 22% de las compañías están ubicadas en la zona sur y pertenecen al sector financiero. Fila 2, columna 1: El 6% de las compañías pertenecen al sector comercial y están ubicadas en la zona norte. Fila 4, columna 3: El 2% de las compañías están ubicadas en la zona oriental y se dedican a la actividad industrial. Estadística para educación superior e) Tabla de frecuencia: Cruce entre el sector económico y vinculación de aprendices. Sector Vinculación aprendices económico No Sí Agrícola 2 Comercial Financiero Industrial Total Total 5 7 6 6 12 3 20 23 3 5 8 14 36 50 Distribución por sector económico y vinculación de aprendices 20 15 10 5 0 Agrícola Comercial No Financiero Industrial Sí De igual manera que en el anterior cruce, se pueden calcular porcentajes por filas, columnas o con base en el gran total. Tabla con porcentajes por filas: Sector Vinculación aprendices económico No Sí Total Agrícola 28,6% 71,4% 100,0% Comercial 50,0% 50,0% 100,0% Financiero 13,0% 87,0% 100,0% Industrial 37,5% 62,5% 100,0% Algunas interpretaciones: Fila 1, columna 2: El 71,4% de las empresas del sector agrícola sí vinculan aprendices en su planta de personal. Fila3, columna 1: El 13% de las empresas del sector financiero no vinculan aprendices. Fila 4, columna 2: El 62,5% de las empresas del sector industrial sí vinculan aprendices. Estadística para educación superior Tabla con porcentajes por columnas: Sector Vinculación aprendices económico No Sí Agrícola 14,3% 13,9% Comercial 42,9% 16,7% Financiero 21,4% 55,6% Industrial Total 21,4% 13,9% 100,0% 100,0% Algunas interpretaciones: Fila 2, columna 1: El 42,9% de las empresas que no vinculan aprendices pertenecen al sector comercial. Fila 4, columna 2: El 13,9% de las empresas que sí vinculan aprendices se dedican a la actividad económica industrial. Fila 3, columna 1: El 21,4% de las compañías que no vinculan aprendices pertenecen al sector financiero. Tabla de porcentajes con base en el gran total: Sector Vinculación aprendices económico No Sí Agrícola Total 4,0% 10,0% 14,0% Comercial 12,0% 12,0% 24,0% Financiero 6,0% 40,0% 46,0% 6,0% 10,0% 16,0% 28,0% 72,0% 100,0% Industrial Total Algunas interpretaciones: Fila 2, columna 1: El 12% de las empresas son del sector económico comercial y no vinculan aprendices en su planta de personal. Fila 3, columna 2: El 40% de las empresas pertenecen al sector financiero y sí vinculan aprendices en su planta de personal. Fila 4, columna 1: El 6% de las empresas pertenecen al sector industrial y no vinculan aprendices dentro de su planta de personal. Estadística para educación superior f) Tabla de frecuencia: Cruce entre el sector económico, la zona y la vinculación de aprendices. Sector económico Agrícola Comercial Financiero Industrial Vinculación aprendices Total sector Total sector y zona No Sí 0 2 2 1 1 2 7 1 1 2 0 1 1 2 1 3 2 2 4 12 0 2 2 2 1 3 0 3 3 2 2 4 23 0 5 5 1 10 11 0 1 1 1 2 3 8 1 0 1 1 2 3 14 36 50 ─ Zona Norte Occidente Oriente Sur Norte Occidente Oriente Sur Norte Occidente Oriente Sur Norte Occidente Oriente Sur Total Distribución por sector económico, zona y vinculación de aprendices 12 10 8 6 4 2 Financiero Sur Oriente Occidente Norte Sur Sí Oriente No Comercial Occidente Norte Oriente Occidente Norte Sur Agrícola Sur Oriente Occidente Norte 0 Industrial Algunas interpretaciones: Fila 5, columna 1: El 66,7% de las empresas comerciales ubicadas en la zona norte no vinculan aprendices dentro de su planta de personal. Fila 12, columna 2: El 90,9% de las empresas del sector financiero ubicadas en la zona sur no vinculan aprendices dentro de su planta de personal. Fila 16, columna 1: El 33,3% de las empresas del sector industrial ubicadas en la zona sur no vinculan aprendices dentro de su planta de personal. Estadística para educación superior Tabla con porcentajes por columna: Sector económico Agrícola Comercial Financiero Industrial Total Zona Norte Occidente Oriente Sur Norte Occidente Oriente Sur Norte Occidente Oriente Sur Norte Occidente Oriente Sur Vinculación aprendices No Sí 0,0% 5,6% 7,1% 2,8% 7,1% 2,8% 0,0% 2,8% 14,3% 2,8% 14,3% 5,6% 0,0% 5,6% 14,3% 2,8% 0,0% 8,3% 14,3% 5,6% 0,0% 13,9% 7,1% 27,8% 0,0% 2,8% 7,1% 5,6% 7,1% 0,0% 7,1% 5,6% 100,0% 100,0% Alguna interpretaciones: Fila 5, columna 1: El 14,3% de las empresas que no vinculan aprendices pertenecen al sector industrial y están ubicadas en la zona norte. Fila 11, columna 2: El 13,9% de las empresas que sí vinculan aprendices dentro de su planta de personal pertenecen al sector financiero y se ubican en la zona oriental. Fila 1, columna 2: El 5,6% de las empresas que sí vinculan aprendices se dedican a la actividad económica agrícola y están ubicadas en la zona norte. Estadística para educación superior Tabla de porcentaje con base en el gran total: Sector económico Agrícola Comercial Financiero Industrial Zona Norte Occidente Oriente Sur Norte Occidente Oriente Sur Norte Occidente Oriente Sur Norte Occidente Oriente Sur Total Vinculación aprendices Total sector Total sector Gran total y zona No Sí 0,0% 4,0% 4,0% 2,0% 2,0% 4,0% 14,0% 2,0% 2,0% 4,0% 0,0% 2,0% 2,0% 4,0% 2,0% 6,0% 4,0% 4,0% 8,0% 24,0% 0,0% 4,0% 4,0% 4,0% 2,0% 6,0% 100,0% 0,0% 6,0% 6,0% 4,0% 4,0% 8,0% 46,0% 0,0% 10,0% 10,0% 2,0% 20,0% 22,0% 0,0% 2,0% 2,0% 2,0% 4,0% 6,0% 16,0% 2,0% 0,0% 2,0% 2,0% 4,0% 6,0% 28,0% 72,0% 100,0% ─ ─ Alguna interpretaciones: Fila 3, columna 1: El 2% de las compañías pertenecen al sector agrícola, están ubicadas en la zona oriental y no vinculan aprendices. Fila 12, columna 2: El 20% de las empresas pertenecen al sector financiero, están ubicadas en la zona sur y sí vinculan aprendices en su planta de personal. Fila 16, columna 2: El 4% de las compañías pertenecen al sector industrial, están ubicadas en la zona sur y sí vinculan aprendices en su planta de personal. Estadística para educación superior Tabla de porcentaje con base en los subtotales por filas: Vinculación aprendices Sector económico Agrícola Comercial Financiero Industrial Zona Norte Occidente Oriente Sur Norte Occidente Oriente Sur Norte Occidente Oriente Sur Norte Occidente Oriente Sur No 0,0% 14,3% 14,3% 0,0% 16,7% 16,7% 0,0% 16,7% 0,0% 8,7% 0,0% 4,3% 0,0% 12,5% 12,5% 12,5% Sí 28,6% 14,3% 14,3% 14,3% 8,3% 16,7% 16,7% 8,3% 13,0% 8,7% 21,7% 43,5% 12,5% 25,0% 0,0% 25,0% Total sector y zona 28,6% 28,6% 28,6% 14,3% 25,0% 33,3% 16,7% 25,0% 13,0% 17,4% 21,7% 47,8% 12,5% 37,5% 12,5% 37,5% G ra n t o t a l ( c o n ba s e e n c a da secto r e c o nó m ic o ) 100,0% 100,0% 100,0% 100,0% Algunas interpretaciones: Fila 1, columna 2: El 28,6% de las compañías del sector agrícola están ubicadas en la zona norte y sí vinculan aprendices en su planta de personal. Fila 12, columna 1: El 4,3% de las empresas del sector financiero están ubicadas en la zona sur y no vinculan aprendices en su planta de personal. Fila 14, columna 1: El 12,5% de las empresas del sector industrial están ubicadas en la zona occidental y no vinculan aprendices. Estadística para educación superior 8. Ejercicios de aplicación propuestos 8.1 Ingresos quincenales. Los siguientes datos representan los ingresos quincenales de 50 personas en miles de pesos. 251 369 258 247 458 365 286 269 457 369 325 422 436 505 509 436 307 365 402 358 225 307 369 324 258 407 309 568 456 228 480 297 325 502 406 325 279 357 368 405 501 501 326 498 568 255 305 421 269 227 Se pide: a) Agrupar los datos en una tabla de frecuencias. b) Construir un polígono de frecuencias absolutas. c) Calcular la media, la mediana y la moda. d) Calcular la varianza y la desviación típica o estándar e) Calcular el coeficiente de asimetría. f) Calcular el coeficiente de apuntamiento. g) Calcular el segundo cuartil, el decil de orden seis y el percentil 83. Nota: Interpretar cada uno de los resultados obtenidos. 8.2 Volumen de exportación mensual de empresas distribuidoras de artículos de cuero. Los siguientes datos representan el volumen de exportación mensual (en millones de pesos) de un grupo de empresas dedicadas a la distribución de artículos de cuero: Estadística para educación superior Volumen de Número de exportación empresas 150 - 200 4 200 - 250 12 250 - 300 25 300 - 350 20 350 - 400 10 400 - 450 3 Se pide: a) Graficar el histograma de frecuencias. b) Calcular la media, la mediana y la moda. c) Calcular la desviación típica o estándar. d) Calcular el coeficiente de asimetría y el de apuntamiento. e) Calcular el rango intercuartil. f) Calcular el cuartil de orden tres, el decil 4 y el percentil 38. Nota: Interpretar cada uno de los resultados. 8.3 Gastos quincenales de las personas de un sector de la ciudad. En la siguiente tabla se observa la distribución de frecuencias de los gastos quincenales (en miles de pesos) de un grupo de personas de un sector determinado de la ciudad: Gastos 300 - 400 400 - 500 500 - 600 600 - 700 700 - 800 800 - 900 Número de personas 8 15 27 14 9 3 Se pide: a) Graficar el histograma y el polígono de frecuencias. Estadística para educación superior b) Calcular la media, la mediana y la moda. c) Calcular la desviación típica o estándar. d) Calcular el coeficiente de asimetría y el de apuntamiento. e) Calcular el cuartil uno, el decil 7 y el percentil 65. Nota: Interpretar cada uno de los resultados. 8.4 Millas recorridas por galón de gasolina. Una muestra aleatoria de automóviles del mismo tipo nos señala cuántas millas recorren por galón de gasolina: 25 29 28 31 35 33 27 26 29 31 33 27 26 30 33 35 25 27 29 32 27 30 33 35 26 25 29 32 34 25 28 31 35 26 28 25 33 30 35 29 29 27 25 35 33 26 31 30 34 27 28 32 27 30 31 29 28 32 29 28 Se pide: a) Construir una tabla de frecuencias con cinco intervalos. b) Elaborar un polígono de frecuencias. c) Calcular la media, la mediana y la moda. d) Calcular la desviación típica o estándar. e) Calcular el coeficiente de asimetría. f) Calcular el coeficiente de apuntamiento. g) Calcular el decil 7 y el percentil 64. Nota: Interpretar cada uno de los resultados obtenidos. Estadística para educación superior 8.5 Asistencia promedio de los empleados del departamento de producción. En una fábrica, el departamento de producción está dividido en tres secciones. Se sabe que en la sección A, con 100 empleados, la asistencia promedio es de 240 días al año. En la sección B, con 80 empleados, la asistencia promedio es de 216 días al año. Si la asistencia media en todo el departamento es de 226,5 días al año, ¿cuántos empleados hay en la sección C, donde la asistencia promedio es de 200 días al año? 8.6 Salario de los obreros según el turno diurno o nocturno. De un grupo de 200 obreros que laboran en una fábrica, 120 de ellos trabajan de día y 80 trabajan de noche. Se sabe que el salario medio de los 200 trabajadores es de $ 360.000. Los del turno de día reciben en valor medio, un 25% menos que los trabajadores de la noche. ¿Cuál es el salario medio de cada grupo? 8.7 Volumen de ventas semestral de establecimientos comerciales. El volumen de ventas semestral en millones de pesos de 50 establecimientos comerciales se muestra a continuación: 42 56 39 48 54 62 45 45 51 56 37 42 56 61 56 50 42 60 61 46 51 46 54 62 50 37 56 52 63 58 62 48 55 60 54 38 61 50 58 57 65 53 56 57 53 40 65 55 50 46 Se pide: a) Construir una tabla de frecuencias con siete intervalos y una amplitud de 4. Estadística para educación superior b) Elaborar un polígono de frecuencias. c) Calcular la media, la mediana y la moda. d) Calcular la desviación típica o estándar. e) Calcular el coeficiente de asimetría. f) Calcular el coeficiente de apuntamiento. g) Calcular el rango intercuartil. h) Calcular el cuartil de orden uno, el decil de orden cinco y el percentil 23. Nota: Interpretar cada uno de los resultados obtenidos. 8.8 Ingreso semanal de los empleados ejecutivos de una corporación financiera. El departamento de personal de una empresa del sector financiero desea analizar el comportamiento del ingreso semanal en miles de pesos de un grupo de 31 empleados de nivel ejecutivo. La información recolectada se muestra a continuación: 460 478 493 510 510 538 541 545 546 547 550 555 558 558 561 526 567 570 573 580 580 580 599 610 625 648 648 649 650 670 680 ─ Se pide: a) Organizar la información en una tabla de frecuencias con cinco intervalos. b) Graficar el polígono y la ojiva. c) Calcular la media, la mediana y la moda. d) Calcular la varianza y la desviación típica o estándar. e) Calcular coeficiente de asimetría y apuntamiento. f) Calcular el rango intercuartil. Estadística para educación superior g) Calcular el cuartil 3, el decil 9 y el percentil de orden 47. Nota: Analizar e interpretar los resultados obtenidos 8.9 Volumen de importación de papelerías especializadas. Un grupo de papelerías especializadas en el país importa lapiceros de marcas prestigiosas, el nivel de importación bimestral en millones de pesos, se presenta a continuación: Importación (millones de pesos) 3-5 5-7 7-9 9 - 11 11 - 13 13 - 15 Número de papelerías 7 12 18 15 9 5 Se pide: a) Calcular las frecuencias relativas, absolutas acumuladas y relativas acumuladas. b) Graficar el histograma, el polígono de frecuencias y la ojiva. c) Calcular la media, la mediana y la moda. d) Calcular la varianza y la desviación típica o estándar. e) Calcular el rango intercuartil. f) El 30% de las papelerías importan bimestralmente menos de un valor determinado (en millones de pesos), ¿cuál es ese nivel de importación y cuántas son las papelerías? g) Calcular el percentil de orden 85. Nota: Analizar e interpretar los resultados obtenidos. Estadística para educación superior 8.10 Análisis estadístico de la sumatoria de las desviaciones respecto a la media. Elegir dos tablas de frecuencias de alguno de los ejemplos anteriores y desarrollar los cálculos necesarios para demostrar que la sumatoria de las desviaciones respecto a la media es igual a cero (propiedad de la media). 8.11 Análisis estadístico sobre el grado de alejamiento de los datos alrededor de la media. Explique por qué para calcular el grado de alejamiento de los datos alrededor de la media, se toma el promedio de las desviaciones cuadráticas respecto a la media y no solamente las desviaciones respecto a la media. 8.12 Justificación estadística con frecuencias absolutas y relativas (caso específico). Según sus conocimientos sobre frecuencia absoluta, absoluta acumulada, relativa y relativa acumulada, justifique estadísticamente si es verdadero o falso el siguiente caso particular: 𝑚 8.13 Explicación matemático-estadística del cálculo de la varianza. Analizar y explicar por qué la varianza de una constante por una variable es igual a la constante al cuadrado por la varianza de la variable. Estadística para educación superior ( ) ( ) 8.14 Cálculo del a media y la varianza utilizando una expresión algebraica que representa la relación entre dos variables (caso específico). La siguiente expresión algebraica representa la relación entre el precio de un artículo y la cantidad de unidades que está dispuesto a ofrecer el comerciante a dicho precio, siendo X la cantidad y Y, el precio. La función lineal de oferta está dada por: ( ) Calcular la media y la varianza de X, si se sabe que la media y la desviación típica de Y son 4 y 0,3 respectivamente. 8.15 Consumidores de latas de cerveza. La siguiente tabla señala la cantidad de latas (con un contenido individual de 8 oz.) de cervezas ingeridas al mes por un grupo de 37 consumidores: Latas de cerveza 15 00 - 27 27 - 00 00 - 39 39 - 00 Total Se pide: Xi fi hi 18 0,135 Fi Hi 5 9 30 26 7 37 0,189 Estadística para educación superior a) Completar los espacios en blanco y señalar claramente los cálculos estadísticos empleados para encontrar los valores respectivos. b) Analizar e interpretar h3 y H3. c) ¿Qué significa f5? d) Graficar el polígono de frecuencias. e) Calcular la media, la mediana y la moda. f) Calcular la desviación típica o estándar. g) Calcular el coeficiente de asimetría y el de apuntamiento. h) Calcular el rango o recorrido. i) Calcular el recorrido intercuartílico. j) Calcular el decil 7 y el percentil 58. Nota: Analizar e interpretar los resultados obtenidos. 8.16 Ingreso quincenal de un grupo de empleados. La distribución de frecuencias del ingreso quincenal (en miles de pesos) de un grupo de empleados de una compañía se presenta a continuación: Ingreso quincenal (miles de pesos) 200 - 300 300 -400 400 - 500 500 - 600 600 - 700 700 - 800 800 - 900 Número de emleados 7 12 15 20 13 10 9 Se pide: a) Calcular las frecuencias relativas e interpretar h2 y h4. b) Graficar el histograma y el polígono. Estadística para educación superior c) Calcular la media, la mediana y la moda. d) Calcular la desviación típica o estándar. e) Calcular el coeficiente de asimetría y el de apuntamiento. f) Calcular el cuartil de orden tres, el decil 6 y el percentil 45. g) Calcular el rango o recorrido. h) Calcular el recorrido intercuartílico. Nota: Analizar e interpretar los resultados obtenidos. 8.17 Percepción sobre el clima laboral. La percepción que tienen un grupo de empleados sobre el clima laboral que reina dentro de la empresa donde están vinculados es la siguiente: Clima laboral Excelente Bueno Regular Malo Número de empleados 12 25 5 2 Se pide: a) ¿Cuál es la variable y cómo se clasifica? b) ¿Cuáles son las categorías de la variable, a qué clasificación pertenecen y por qué? c) ¿Cuál es la unidad o elemento de investigación? d) Calcular las frecuencias relativas y analizarlas. e) Elaborar el gráfico de pastel o circular. f) Elaborar el gráfico de barras. g) Hallar la moda e interpretarla. Estadística para educación superior 8.18 Tiempo de permanencia del aroma de ambientadores adquiridos por un grupo de amas de casa. Una empresa dedicada a la producción de ambientadores con atomizador realiza una investigación entre las amas de casa del barrio El Porvenir de una ciudad. Se seleccionan aleatoriamente 50 de ellas para analizar el tiempo de permanencia del aroma después de esparcirlo en el ambiente del hogar. Se pide: a) Definir la población (tamaño de la población). b) ¿Cuál es el tamaño de la muestra? c) ¿Cuál es la variable? d) ¿Cómo se clasifica esta variable? 8.19 Análisis estadístico: Marca de clase y mediana. ¿Cuál es la diferencia y cuál la similitud, entre marca de clase y mediana? 8.20 Nivel de exportación mensual de las empresas confeccionistas de vestidos ejecutivos. El nivel de exportación mensual (en millones de pesos) de un grupo de empresas confeccionistas de vestidos ejecutivos para dama y caballero, es el siguiente: Estadística para educación superior Exportación mensual (millones de pesos) Número de empresas 7- 9 9 - 11 11 - 13 13 - 15 15 - 17 17 - 19 19 - 21 21 - 23 3 8 15 32 12 7 5 2 Se pide: a) ¿Cuál es el volumen de exportación promedio mensual? b) ¿Cuál es el promedio del grado de alejamiento de los volúmenes de exportación mensual alrededor de dicho promedio? c) ¿De cuántas medias se está hablando en el numeral anterior? Explicar a qué hace referencia cada una de ellas y cómo se calculan. d) Graficar el polígono de frecuencias. e) Calcular el coeficiente de asimetría e interpretarlo. f) Calcular el percentil 74 y analizarlo. 8.21 Justificación estadística con frecuencia absoluta y relativa (caso específico). De acuerdo a los conocimientos sobre frecuencia absoluta, absoluta acumulada, relativa y relativa acumulada; justificar estadísticamente si es verdadero o falso el siguiente caso particular: 𝐹 Estadística para educación superior 8.22 Análisis estadístico: mediana, segundo cuartil, quinto decil, y percentil. Explicar si existe alguna relación entre mediana, segundo cuartil, quinto decil y percentil de orden 50. 8.23 Unidades vendidas de computadores. Las unidades vendidas de computadores en el semestre anterior, por un consorcio conformado por 76 agencias distribuidoras en el país, se muestra a continuación: Número de computadores 30 - 50 50 - 70 70 - 90 90 - 110 110 - 130 130 - 150 Total Número de agencias 7 13 18 15 18 5 76 Se pide: a) Graficar el histograma. b) Calcular la moda. c) En promedio, ¿cuántos computadores vendió el consorcio en el semestre? d) Calcular las frecuencias relativas. e) Calcular el decil de orden ocho. f) Calcular la desviación típica o estándar. Nota: Analizar e interpretar los resultados obtenidos. 8.24 Auditoría de despacho y facturación de mercancía. El gerente de ventas de un gran almacén de materiales para la construcción y remodelación desea efectuar auditoria sobre el proceso de despacho de mercancía y Estadística para educación superior facturación. Un estudio previo sobre el cálculo del tamaño de muestra indica que para llevar a buen término esta auditoría, se debe seleccionar una muestra aleatoria de 70 registros de solicitud y despacho de mercancía. Para cada registro se analiza: Forma de solicitud: personal, teléfono, fax, correo electrónico. Tiempo transcurrido desde recibida la solicitud hasta que es despachada (en horas). Elaboración de la factura: cálculos correctos y sin enmendaduras, cálculos incorrectos y con enmendaduras. Valor o monto de la factura (en miles de pesos). Forma de pago de la mercancía. El almacén sólo vende bajo las siguientes alternativas de pago: de contado, a la semana, a los quince días y al mes. Existencia del sello en la factura: si posee sello o si no plasmaron el sello. Firma de recibido: posee firma de la persona que recibe la mercancía o no hay firma que respalde la conformidad de quien recibe la mercancía. Registro de devoluciones: en caso de que la mercancía o parte de ella presente baja calidad. Si presenta registro o no lo presenta. Registro Número de facutra Forma de solicitud 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 231 521 41 123 587 415 635 412 852 741 963 952 523 654 742 623 418 795 862 743 2 1 2 3 1 1 1 4 3 2 2 4 2 1 4 4 1 4 4 2 Tiempo de despacho (horas) 5 2 1 0,5 1,5 1 1,5 2 0,5 7 2 6 1 2 2 6,5 2 5,5 1 1 Elaboración factura 1 1 1 2 2 2 1 1 1 1 1 1 2 2 1 2 1 2 1 2 Monto (miles de pesos) 250 268 752 824 365 1500 100 156 85 236 421 328 687 547 753 700 5 1230 50 98 Forma de pago Existencia de sello Firma de recibido Registro devolución 2 3 1 1 2 3 2 3 1 3 2 2 3 1 4 3 2 4 1 3 1 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1 2 1 2 1 2 1 1 1 1 1 1 1 1 1 1 1 1 2 1 2 2 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 Estadística para educación superior Registro Número de facutra Forma de solicitud 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 569 857 413 956 875 627 813 928 56 742 85 96 415 582 224 436 478 15 136 547 14 196 54 76 32 547 65 45 48 459 721 146 237 932 568 258 416 438 259 379 534 58 79 54 41 485 52 67 698 520 2 4 1 1 1 2 2 2 1 1 3 1 4 1 3 1 2 1 1 1 1 1 1 2 2 3 1 4 1 4 4 3 2 2 3 2 2 2 2 1 1 1 1 1 1 3 1 1 1 1 Tiempo de despacho (horas) 2,5 2 2 3 2 1,5 4 3,5 5 8 1 2 4,5 2 4 1,5 1,5 7 4 3,5 3 3 4 2 2 5 4 3 6 2 5 6 2,5 6 4 4 7 4 8 6 5 4,5 7 4 4 5 8 1 4 7 Elaboración factura 2 1 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 1 2 1 2 2 2 1 1 1 1 1 2 1 2 1 1 2 2 1 1 1 1 1 1 1 2 1 1 Monto (miles de pesos) 125 478 524 687 54 62 78 2125 524 569 789 623 15 524 500 639 1500 956 456 547 236 125 412 258 951 544 200 10 215 236 379 365 458 741 1600 125 456 478 456 1700 512 415 400 287 5 100 542 420 854 350 Forma de pago Existencia de sello Firma de recibido Registro devolución 2 2 3 3 1 1 1 4 3 2 4 3 1 3 2 1 1 4 2 2 3 3 2 1 3 3 2 1 3 3 2 3 1 1 1 1 2 2 4 4 3 3 1 1 1 1 3 3 3 1 1 1 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 2 1 2 1 2 2 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1 2 2 2 1 1 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 1 1 2 2 2 2 2 2 2 1 Estadística para educación superior Columna 1 = Columna 2 = Columna 3 = Personal= Teléfono = Fax = e-mail = Columna 4 = Columna 5 = Sin errores = Con errores = Columna 6 = Columna 7 = Contado = A la semana = A los 15 días = Al mes = Columna 8 = Sí = No = Columna 9 = Sí = No = Columna 10 = Sí = No = Convenciones Conteo de registros Número de factura Forma de solicitud del pedido 1 2 3 4 Tiempo de despacho (en horas) Elaboración de factura 1 2 Valor o monto de la factura (en miles de pesos) Forma de pago 1 2 3 4 Existencia de sello 1 2 Firma de recibido 1 2 Registro de devolución 1 2 En esta base de datos, los códigos que identifican a cada categoría de la variable son números, pero igualmente si el investigador opta por utilizar letras o palabras, puede hacerlo. Se pide: a) Definir la unidad o elemento de investigación. b) Hacer un listado de las variables que se trabajan en esta investigación. c) Clasificar cada variable y especificar sus categorías respectivas. d) Elaborar la tabla de frecuencia para cada variable con su respectivo gráfico y analizar las frecuencias relativas. e) Efectuar tabla de clasificación cruzada bivariada (con frecuencias absolutas) entre registro de devolución y el monto de la factura; elaborar gráfico. Calcular tres tablas con porcentajes: por filas, por columnas y con base en el gran total; interpretar los resultados obtenidos en cada tabla. f) Efectuar tabla de clasificación cruzada bivariada (con frecuencias absolutas) entre el valor o monto de la factura y la forma de pago; elaborar gráfico. Calcular tres tablas con Estadística para educación superior porcentajes: por filas, por columnas, con base en el gran total; interpretar los resultados obtenidos en cada tabla. g) Efectuar tabla de clasificación cruzada bivariada (con frecuencias absolutas) entre el monto de la factura y el tiempo de despacho; elaborar gráfico. Calcular tres tablas con porcentajes: por filas, por columnas y con base en el gran total; interpretar los resultados obtenidos. h) Elaborar tabla de clasificación cruzada trivariada (con frecuencias absolutas) entre forma de solicitud, monto de la factura y forma de pago; efectuar gráfico. Calcular tablas con porcentajes: por filas, por columnas, con base en subtotales y con base en el gran total; interpretar los resultados obtenidos. 8.25 Investigación requerida por la unidad académica de una universidad, sobre el perfil del estudiante. La dirección académica de una universidad reconocida en la ciudad, requiere efectuar una investigación sobre el perfil del estudiante de pregrado. La investigación es de carácter urgente, lo que imposibilita recolectar la información necesaria sobre toda la población actual de estudiantes; se opta por aplicar muestreo. El cálculo del tamaño de muestra arroja un total de 125 estudiantes. La información recolectada a través de una encuesta aparece registrada en la siguiente base de datos: Número de registro 1 2 3 4 5 6 7 8 9 10 Unidad académica 2 3 4 2 2 1 1 1 3 2 Semestre Género Trabajo 3 2 2 5 1 6 7 2 7 7 2 2 2 1 1 1 1 1 2 2 2 2 2 2 1 2 2 2 2 2 Tipo de matrícula 1 1 2 2 1 2 1 2 2 2 Estrato 3 5 4 6 4 3 3 4 4 4 Estadística para educación superior Número de registro 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 Unidad académica 3 4 1 1 4 2 3 1 4 3 2 4 1 3 3 2 4 1 1 1 2 2 2 4 1 4 4 4 1 1 4 4 4 4 4 1 3 3 4 1 4 4 2 2 4 3 4 2 3 2 3 2 2 3 1 4 4 3 1 4 Semestre Género Trabajo 2 8 5 1 3 8 2 4 9 6 1 2 10 3 1 2 9 10 9 1 2 5 10 2 1 10 2 6 3 1 10 2 10 1 10 3 9 9 1 10 3 8 1 5 2 4 10 1 6 3 2 1 10 10 9 10 1 1 10 7 2 1 2 1 1 2 2 2 2 2 1 1 2 1 1 1 2 2 1 1 1 1 1 2 2 2 2 1 2 1 2 2 1 1 1 1 2 2 2 2 1 2 1 1 2 2 2 1 1 2 1 2 2 2 1 2 1 2 2 2 2 1 1 2 2 1 2 2 1 2 2 2 1 1 1 2 2 2 1 2 2 2 1 2 2 1 2 2 2 2 1 2 1 2 2 2 2 1 2 1 2 1 2 2 2 2 1 2 2 2 2 2 1 1 1 2 2 2 2 1 Tipo de matrícula 2 2 1 2 2 1 2 2 1 2 2 2 2 1 2 2 2 2 2 1 1 2 1 2 2 2 2 2 1 1 2 1 2 1 2 2 2 2 2 1 2 1 1 1 2 1 1 2 2 2 2 2 1 1 1 2 2 2 2 2 Estrato 4 3 5 4 3 4 4 4 4 4 4 6 4 4 4 4 3 4 4 4 4 4 3 3 4 3 5 4 6 4 4 4 4 6 4 4 4 3 3 4 4 4 4 4 4 6 4 4 4 4 4 6 3 5 6 4 3 4 4 4 Estadística para educación superior Número de registro 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 Unidad académica 4 3 3 4 3 1 1 4 3 3 3 1 1 1 1 4 4 2 2 1 4 4 3 2 4 4 1 1 4 4 3 4 3 4 3 1 1 1 4 2 2 4 1 4 4 3 1 1 1 1 4 4 2 2 1 Semestre Género Trabajo 2 10 1 5 2 2 4 10 1 1 8 2 4 10 1 1 9 3 3 10 8 1 10 3 10 10 1 1 8 10 5 6 3 10 1 10 1 9 4 9 10 1 9 3 10 7 1 4 7 1 3 7 4 1 3 2 2 1 2 1 2 1 1 1 1 2 2 2 1 2 1 1 1 2 2 2 2 2 1 1 2 1 2 1 1 1 1 2 2 1 2 1 1 2 2 2 2 2 2 1 2 1 1 2 1 2 1 1 2 2 2 1 2 2 2 2 2 1 2 2 1 2 2 2 2 2 1 2 2 1 2 2 2 2 1 1 2 2 2 2 2 2 1 1 2 2 2 1 2 2 1 2 2 2 2 2 2 1 1 2 2 2 2 2 1 Tipo de matrícula 1 1 2 2 2 2 1 2 1 2 2 2 2 2 2 1 1 1 1 2 2 2 2 2 2 2 2 1 2 2 2 1 2 2 1 2 2 1 2 2 2 2 2 1 2 2 2 2 2 2 2 2 1 1 1 Estrato 5 4 4 6 4 4 3 3 4 3 4 4 4 4 4 5 6 3 3 5 3 4 4 4 3 3 4 4 6 3 6 4 4 4 5 4 3 3 3 6 4 4 6 4 4 4 4 3 4 4 4 4 4 5 3 Estadística para educación superior Columna 1 = Comunicación = Sicología = Economía = Contaduría = Columna 2 = Columna 3 = Masculino = Femenino = Columna 4 = Sí = No = Columna 5 = Tiempo parcial = Tiempo completo = Columna 6 = Convenciones Unidad académica a la que pertenece el estudiante. 1 2 3 4 Semestre que cursa el estudiante (de 1 a 10) Género del estudiante 1 2 Trabajo remunerado actual 1 2 Tipo de matrícula del estudiante 1 2 Estrato socioeconómico del estudiante (de 1 a 6) Se pide: a) ¿Cuál es la unidad o elemento de investigación? b) Identificar las variables, clasificarlas y especificar las categorías que posee cada una de ellas. c) Elaborar una tabla de frecuencia para cada variable, con el gráfico respectivo. Analizar las frecuencias relativas y especificarlas dentro de la tabla en términos porcentuales. d) Efectuar una tabla de clasificación cruzada (bivariada) con frecuencias absolutas para la unidad académica y el género. Elaborar el gráfico respectivo. Calcular tres tablas de frecuencia con porcentajes: por filas, por columnas y con base en el gran total. Analizar e interpretar los resultados obtenidos en estas tablas. e) Efectuar una tabla de clasificación cruzada (bivariada) con frecuencias absolutas para el semestre que cursa y trabajo actual. Elaborar el gráfico respectivo. Calcular tres tablas de frecuencias con porcentajes: por filas, por columnas y con base en el gran total. Analizar e interpretar los resultados obtenidos en cada una de estas tablas. f) Efectuar una tabla de clasificación cruzada (trivariada) con frecuencias absolutas para la unidad académica, género y trabajo actual. Efectuar varias tablas con porcentajes: por filas, por columnas, con base en el gran total, con base en subtotales. Analizar e interpretar los resultados obtenidos. Estadística para educación superior g) Efectuar varias tablas de clasificación cruzada (cuatrivariada) con frecuencias absolutas para unidad académica, género, estrato y tipo de matrícula. Diseñar el gráfico correspondiente para cada tabla de frecuencia. Con base en cada una de las tablas anteriores elaborar otras tablas de frecuencia donde se visualicen porcentajes: por filas, por columnas, con base en el gran total, con base en subtotales por filas, con base en subtotales por columna. Analizar e interpretar cada uno de los resultados obtenidos. 8.26 Justificación estadística de proposiciones según el valor de verdad asignado. Para cada uno de los enunciados siguientes especificar si es una proposición falsa o verdadera, además justificar estadísticamente el valor de verdad asignado. a) El momento de orden uno respecto a la media es igual a 1. b) Cuando los datos de la variable son muy heterogéneos la varianza arroja un valor negativo. c) La estadística sólo se puede aplicar en aquellos casos en que se tengan datos numéricos. d) La varianza es lo mismo que el momento de orden tres respecto a la media. e) Una serie de datos numéricos puede llegar a tener varias medias. f) Una serie de datos numéricos puede llegar a tener varias modas. g) Una serie de datos cualitativa sólo tiene una media. h) En una serie de datos cualitativa es imposible calcular la moda. i) Siempre la desviación respecto a la media es un valor positivo. j) Los momentos respecto a la media son promedios. k) El cuartil de orden dos nada tiene que ver con la mediana. l) El cuartil de orden dos es lo mismo que la varianza. m) El segundo cuartil es lo mismo que el percentil 50. n) El segundo cuartil es lo mismo que el quinto decil. o) La varianza es un promedio. p) La mediana es una medida de dispersión. Estadística para educación superior q) El momento de orden dos respecto a la media es una medida de dispersión. r) La desviación típica o estándar es negativa cuando los datos son decrecientes. 8.27 Identificación del elemento o unidad de investigación, variable y clasificación. Para cada uno de los siguientes enunciados, especificar si puede ser considerada alguna variable, en caso afirmativo, indicar cuál sería el nombre, clasificarla en cualitativa o cuantitativa, además, definir cuál es el elemento o unidad de investigación. a) El peso en gramos de cada uno de los 200 pollos adquiridos en un restaurante para su posterior preparación y venta. b) Los números telefónicos de un grupo de empleados de una compañía. c) El número de páginas de un libro. d) El número de libros en finanzas existentes en cada una de las bibliotecas de las universidades del departamento. 8.28 Presupuesto anual en bienestar institucional de establecimientos educativos. Los siguientes datos representan el gasto presupuestal anual (en millones de pesos) en la dependencia de Bienestar Institucional de 48 establecimientos educativos de secundaria de carácter privado. Gasto presupuestal Número de establecimientos 15 - 20 3 20 - 25 9 25 - 30 14 30 - 35 10 35 - 40 8 40 - 45 4 Estadística para educación superior Se pide: a) Calcular las frecuencias relativas y analizarlas. b) Elaborar el polígono de frecuencias. c) Calcular la media, la mediana y la moda. d) Calcular la desviación típica o estándar. e) Calcular el rango. f) Calcular el rango intercuartílico. g) Calcular el decil de orden siete. h) Calcular el coeficiente de asimetría. Nota: Analizar e interpretar los resultados obtenidos. 8.29 Preferencias por candidatos electorales. Los siguientes datos muestran las preferencias de un grupo de ciudadanos por cada uno de los candidatos electorales. Candidato Número de votos Anadidato AA 120 Anadidato BB 570 Anadidato CC 400 Anadidato DD 58 Se pide: a) ¿Cuál es la unidad o elemento de investigación? b) Definir la variable, clasificarla e indicar las categorías que posee. c) Elaborar un gráfico de pastel o circular. d) Calcular las frecuencias relativas e interpretarlas. e) Calcular la moda e interpretarla. f) Elaborar un gráfico de barras. Estadística para educación superior 8.30 Análisis estadístico del comportamiento asimétrico de las ventas en una cadena de supermercados. Si al director del departamento de ventas de una cadena de supermercados le informan que las ventas presentan un comportamiento asimétrico negativo, deberá tomar medidas correctivas. En caso afirmativo o negativo, justificar estadísticamente su respuesta. 8.31 Tiempo empleado en efectuar transacciones financieras. Los clientes que llegan a una entidad bancaria para llevar a cabo una transacción financiera tardan determinado tiempo (en minutos), se recolecta la información de un grupo de ellos de manera aleatoria, para analizar la distribución de frecuencias del tiempo, la información recolectada es la siguiente: 32 18 15 32 41 15 30 14 19 16 24 28 28 16 23 18 24 34 20 36 30 20 14 21 42 51 25 42 18 21 38 42 35 54 59 15 62 56 35 26 34 15 42 56 28 Se pide: a) Organizar el tiempo en una tabla de frecuencias con seis intervalos y una amplitud de 8. b) Graficar el histograma. c) Calcular la media, la mediana y la moda. d) Calcular la desviación típica o estándar. e) Calcular el rango intercuartil. f) Calcular el coeficiente de asimetría y el de apuntamiento. g) Calcular el decil de orden ocho y el percentil 67. Estadística para educación superior Nota: Analizar e interpretar los resultados obtenidos. 8.32 Trabajo social y análisis del gasto en alimentación. Una corporación dedicada al trabajo social desea analizar la distribución y el comportamiento del gasto destinado para la alimentación semanal (en miles de pesos) efectuado por un grupo de personas cabeza de hogar de una zona determinada de la ciudad, para tal fin, recolecta la siguiente información: 96 95 148 107 112 135 106 89 120 93 113 156 125 127 132 139 118 103 88 96 139 155 117 111 134 136 113 117 108 142 155 120 125 119 125 124 127 94 94 103 112 104 97 143 138 112 91 98 129 135 129 131 118 109 Se pide: a) Organizar el gasto en una tabla de frecuencia. b) Graficar el polígono. c) Calcular media, mediana y moda. d) Calcular desviación típica o estándar. e) Calcular el rango. f) Calcular el rango intercuartil. g) Calcular el decil 4 y el percentil 72. h) Calcular coeficiente de asimetría y de apuntamiento. i) ¿Cuál es el intervalo donde se encuentra el 50% de los gastos inferiores? j) ¿Cuál es el intervalo donde se encuentra el 25% de los gastos más altos? Nota: Analizar e interpretar los resultados obtenidos. Estadística para educación superior 8.33 Cadena de minimercados y el volumen de ventas. Una cadena de minimercados tiene ocho agencias de venta en la zona norte, siete en el occidente, 12 en el oriente y 20 en el sur. El volumen de venta promedio de toda la cadena es de $91,9 millones anuales. Se sabe que en el occidente el volumen de venta promedio fue de $38 millones, y en el oriente $96 millones. Calcular el volumen de ventas promedio para el norte y el sur, si además se sabe que el volumen de ventas promedio del sur es dos veces y medio el del norte. 8.34 Producción mensual en textiles. La producción diaria en metros de tela en una textilera, durante el último mes, se registra a continuación: Producción de Número de días tela (en metros) 500 - 600 1 600 - 700 3 700 - 800 6 800 - 900 10 900 - 1000 6 1000 - 1100 3 1100 - 1200 Total 1 30 Se pide: a) Calcular las frecuencias relativas, absolutas acumuladas y relativas acumuladas. b) Graficar el histograma y el polígono. c) Calcular la media, la mediana y la moda. ¿Qué relación existe entre estos valores?, ¿qué se puede concluir de la distribución de frecuencias de la producción de tela en metros? d) Calcular la varianza y la desviación típica o estándar. e) Calcular el coeficiente de asimetría y el de apuntamiento. Estadística para educación superior f) Calcular el decil de orden ocho y el percentil 39. g) Calcular el intervalo central del 68,3% y el del 95,5%. Nota: Analizar e interpretar los resultados obtenidos. 8.35 Gasto en publicidad de almacenes distribuidores de maletines en cuero. Los siguientes datos hacen referencia al gasto anual en publicidad (en miles de pesos) de un grupo de almacenes distribuidores de maletines y correas en cuero: Gasto en publicidad (miles de pesos) 400 - 900 Número de almacenes 15 900 - 1400 9 1400 - 1900 12 1900 - 2400 15 2400 - 2900 8 2900 - 3400 4 Se pide: a) Calcular frecuencias relativas, absolutas acumuladas y relativas acumuladas. b) Elaborar el histograma de frecuencias. c) Calcular la media, la mediana y la moda. d) Calcular la desviación típica o estándar. e) Calcular el rango. f) Calcular el rango intercuartil. g) Calcular el decil inferior y el decil superior. h) ¿Cuál es el intervalo central donde se encuentra el 80% de los gastos en publicidad? Nota: Analizar e interpretar los resultados obtenidos. Estadística para educación superior 8.36 Número de empleados por secciones en una compañía e ingreso promedio. Una compañía está dividida en tres secciones: La sección 1 cuenta con 80 empleados. La sección 2 cuenta con 130 empleados, que ganan en promedio, un 15% menos que los de la sección 1. La sección 3 cuenta con 100 empleados, que ganan en promedio, un 15% más que la sección 2. Se sabe que el salario promedio de toda la compañía es de $ 750.000. ¿Cuál es el ingreso promedio de cada sección? 8.37 Nivel de capacitación semanal en corporaciones de ahorro y vivienda. La captación semanal (en millones de pesos) a nivel nacional, de las agencias de una corporación de ahorro y vivienda, presenta la siguiente distribución de frecuencias: Nivel de captación 5-8 Número de agencias 2 8 - 11 7 11 - 14 12 14 - 17 18 17 - 20 21 20 - 23 16 Se pide: a) Calcular las frecuencias relativas e interpretarlas. b) Elaborar el polígono de frecuencias. c) Calcular la media, la mediana y la moda. d) Calcular la desviación típica o estándar. e) Calcular el coeficiente de asimetría y el de apuntamiento. f) Calcular el decil de orden siete y el percentil 43. Estadística para educación superior Nota: Analizar e interpretar los resultados obtenidos. 8.38 Urbanización de tres torres destinada para el arriendo de apartamentos. Una urbanización posee tres torres: la A, la B y la C. Sus apartamentos están destinados todos para el arriendo (ninguno de los habitantes es propietario). El arriendo promedio de todos los apartamentos de la urbanización es de $367.000. La torre A cuenta con 18 apartamentos, y el promedio de arriendo es de $360.000. La torre C posee 12 apartamentos y tiene un arriendo promedio de $450.000. Calcular el número de apartamentos de la torre B, si se sabe que el arrendamiento promedio de esta torre es de $280.000. 8.39 Volumen de importación anual de materia prima. La distribución de frecuencias para el volumen de importación anual (en millones de pesos) de materia prima necesaria para la fabricación de un producto nacional, por parte de una reconocida empresa con diferentes sucursales dentro del territorio, se visualiza a continuación: Importación anual (millones de pesos) 200 - 250 3 250 - 300 8 300 - 350 15 350 - 400 23 400 - 450 15 450 - 500 8 500 - 550 3 Total Se pide: Número de sucursales 75 Estadística para educación superior a) Calcular las frecuencias relativas e interpretarlas. b) Graficar el polígono de frecuencias. c) Calcular la media, la mediana y la moda. d) ¿Qué se puede concluir con relación a la forma de la distribución y comportamiento de la variable importación, con base en el resultado de las tres medidas de tendencia central? e) Calcular la desviación típica o estándar. f) Calcular el intervalo central para el volumen de importación, dentro del cual se encuentra el 68,3% de las sucursales. g) Calcular el intervalo central para el volumen de importación, dentro del cual se encuentra el 95,5% de las sucursales. h) Calcular el coeficiente de asimetría y el de apuntamiento. i) Calcular el percentil de orden 83. j) Calcular los deciles de orden tres y de orden siete. k) Calcular el intervalo central para el volumen de importación, dentro del cual se encuentra el 40% de las sucursales. 8.40 Consumidores potenciales de una bebida alimenticia. Los siguientes datos hacen referencia a la distribución de personas dentro de la muestra para una población potencial de consumidores de una bebida alimenticia, según su edad y género: Estadística para educación superior Número de Consume registro la bebida 9 2 10 1 11 1 12 1 13 2 14 2 15 1 16 2 17 1 18 1 19 2 20 1 21 2 22 2 23 1 24 1 25 1 26 1 27 2 28 1 29 1 30 2 31 1 32 2 33 2 34 2 35 1 36 1 37 1 38 2 39 2 40 1 Número de Consume registro la bebida 41 2 42 1 43 1 44 1 45 1 46 1 47 1 48 2 49 2 50 2 51 1 52 1 53 2 54 1 Edad Género 1 4 3 4 5 6 4 7 1 4 7 4 7 5 3 4 3 1 6 3 5 7 4 6 6 5 7 4 7 6 6 4 1 1 1 2 1 2 2 2 2 1 2 1 2 1 1 1 1 2 2 2 2 1 2 2 2 2 1 1 1 2 1 2 Edad Género 7 4 7 3 3 4 4 7 4 3 6 7 3 4 1 1 2 1 1 1 2 1 1 1 1 2 2 1 Estadística para educación superior Columna 1 = Columna 2 = Sí = No = Columna 3 = De 6 a 10 años = De 11 a 14 años = De 15 a 18 años = De 19 a 22 años = De 23 a 26 años = De 27 a 30 años = De 31 a 34 años = Clolumna 4 = Masculino = Femenino = Convenciones Número de registro de la persona Consume la bebida 1 2 Edad de la persona 1 2 3 4 5 6 7 Clasificación según género 1 2 Los códigos utilizados para identificar las categorías de cada variable son números, pero igualmente, si el investigador opta por utilizar letras o palabras, puede hacerlo. Se pide: a) Calcular tres tablas de frecuencia (cruzadas) porcentuales: por filas, por columnas y con base en el gran total. b) Elaborar el gráfico respectivo para cada una de las tablas anteriores. c) Calcular una tabla de frecuencia para la edad. d) Utilizando la tabla de frecuencia para la edad, calcular la edad promedio de los consumidores. e) ¿Cuál es la edad a partir de la cual se encuentra el 20% de los consumidores mayores? ¿Cuál decil será útil para hallar esta edad?, ¿se podrá también calcular utilizando los percentiles? f) ¿Cuál género (masculino o femenino) es el que más consume esta bebida y cuál es el porcentaje de representatividad? g) g) Elaborar una grafica de pastel para visualizar la distribución del género (masculino o femenino) de los consumidores de esta bebida. Estadística para educación superior PARTE II 9. Probabilidades 9.1 Conceptos básicos. La probabilidad. Es una medida estadística que se emplea para expresar el grado de certeza de la ocurrencia de un evento o suceso. Experimento. Cualquier proceso que genere una serie de datos; en cada realización presenta un resultado. Espacio muestral. Conjunto de todos los resultados posibles del experimento. Se denota por Ω. Punto muestral. Es cada uno de los elementos del espacio muestral. Suceso o evento. Subconjunto del espacio muestral. Se denota con las letras mayúsculas del alfabeto A, B, C,... Es cualquier conjunto de posibles resultados del experimento aleatorio. El suceso imposible se denota por el conjunto vacío, φ, y el suceso posible se denota por el conjunto de todos los posibles resultados, Ω. Sucesos o eventos contrarios. Son aquellos sucesos (conjuntos) que no tienen elementos comunes, y además, la unión de ellos conforma el conjunto de todos los posibles resultados Ω. Los eventos φ y Ω son eventos contrarios. El suceso contrario del evento A se denota con alguno de los tres símbolos siguientes: A', A*, Ac; y así sucesivamente, para cualquier evento identificado con otra letra del alfabeto. Estadística para educación superior Los sucesos B y B' son eventos contrarios. En los eventos contrarios se cumple que la intersección entre ellos arroja el conjunto vacío, φ, y la unión da como resultado el conjunto Ω. Gráficamente, se tiene: Figura 25. Sucesos o eventos contrarios Ω A A' Sucesos o eventos incompatibles. Son aquellos eventos que sin ser necesariamente contrarios, no presentan elementos en común, es decir, son eventos que no se pueden presentar simultáneamente, también conocidos como mutuamente excluyentes o exhaustivos. Gráficamente: Figura 26. Sucesos o eventos incompatibles Ω A B No siempre ocurre que A ⋃ B = Ω porque pueden existir elementos pertenecientes a Ω y que se encuentren por fuera de A o de B. Estadística para educación superior Número de elementos de un evento. La nomenclatura utilizada para identificar el número de elementos del evento A es n(A), para el evento B es n(B), y así sucesivamente. Unión de eventos. Se da como se explica en la figuras a continuación: Figura 27. Unión de eventos incompatibles Ω A Eventos incompatibles: B n(A ⋃ B) = n(A) + n(B) Se lee: número de elementos de A unión B es igual al número de elementos de A más del número de elementos de B Figura 28. Unión de eventos compatibles Ω A B Eventos compatibles: n(A ⋃ B) = n(A) + n(B) - n(A ∩ B) Se lee: número de elementos de A unión B es igual al número de elementos de A más el número de elementos de B, menos el número de elementos de A intersección B Estadística para educación superior Figura 29. Unión de tres eventos compatibles Ω A Unión de tres eventos compatibles: B n(A⋃B⋃C) = n(A) + n(B) + n(C) xxxxxxxxxxx- n(A∩B ) - n(A⋂C) - n(B⋂C) xxxxxxxxxx+ n(A⋂B⋂C) Se lee: número de elementos de A unión B unión C es igual a número de elementos de A, más número de elementos de B, más número de elementos de C, menos número de elementos de A intersección B, menos número de elementos de A intersección C, menos número de elementos de B intersección C, más número de elementos de A intersección B intersección C C Intersección de eventos. Se presenta cuando los eventos son compatibles, pudiéndose presentar simultáneamente. Figura 30. Intersección de eventos: A y B Ω A B Número de elementos de A y B: Los eventos A y B se presentan simultáneamente; son eventos compatibles. n(A ∩ B ) Figura 31. Intersección de eventos: A, B y C Ω B A Número de elementos de A, B y C: Número de elementos de los tres eventos, simultáneamente. n(A ∩ B ⋂ C ) C Estadística para educación superior Figura 32. Otras intersecciones entre A, B y C Ω A B Ω A B C Ω C Número de elementos de B y C: Número de elementos de sólo B y C: n(B ⋂ C) n(A ' ⋂ B ⋂ C) A B Ω A B C C Número de elementos de sólo A: Número de elementos de A, y no elementos de B o C Número de elementos de C: n ( C) n(A ⋂ B' ⋂ C') Complemento de la unión de eventos. Son todos aquellos elementos que pertenecen al conjunto Ω pero que no están incluidos dentro de la unión; es lo que le falta a la unión para ser igual a Ω. Estadística para educación superior Figura 33. Complemento de la unión de eventos Ω A B Complemento de la unión de eventos: En este caso, no hay elementos de A ni de B ni de C. n(A'⋂B'⋂C') = n(A⋃B⋃C)' C Figura 34. Leyes de Morgan Ω Ω A B n(A ⋃ B)' = n(A' ⋂ B') A B n(A ⋂ B)' = n(A' ⋃ B') 9.2 Enfoques básicos de las probabilidades. Existen tres formas básicas de visualizar o analizar las probabilidades, éstas son: Enfoque frecuentista. Se basa en las frecuencias relativas para su análisis. Recordar: Es la proporción de veces que ocurre un suceso o evento, siendo fi el número de veces que se repite el suceso, y n, el total de casos posibles. Estadística para educación superior Enfoque clásico. Es la relación o proporción entre el número de casos favorables para el evento A y el total de casos posibles, donde: n(A) = número de casos favorables para el evento A n(Ω) = número total de casos posibles. P(A) = probabilidad de que ocurra el evento A ( ) ( ) ( ) Fórmula (36) Enfoque subjetivo. Es el que se basa en la experiencia o conocimiento que tenga el investigador (persona) sobre el evento o suceso. 9.3 Cálculo del valor de una probabilidad. Para calcular el valor de una probabilidad bajo el enfoque clásico es indispensable calcular el número de elementos de cada evento en particular, n(A), n(B), n(C),... y el número total de casos posibles, n(Ω). Por ejemplo: Si se tienen dos eventos A y B, la probabilidad de que ocurran A y B, es decir, la probabilidad de que ocurran simultáneamente A y B, se calcula así: ( ⋂ ) ( ⋂ ) ( ) Con ayuda de la teoría de conjuntos, se visualiza de la siguiente manera: Fórmula (37) Estadística para educación superior Figura 35. Probabilidad de (A ⋂ B) Ω A B Si se tienen tres eventos A, B y C, la probabilidad de que ocurran A y B se representa: Figura 36. Probabilidad de (A ⋂ B) cuando existen A, B y C Ω A B C P( A y B ) = P( A ⋂ B ) ( ⋂ ) ( ⋂ )= ( ) Si se tienen tres eventos A, B y C, la probabilidad de que ocurran sólo A y B está representada por: Estadística para educación superior Figura 37. Probabilidad de (A ⋂ B ⋂ C') Ω A B C P(sólo A y B ) = P(A ⋂ B ⋂ C') ( ⋂ ⋂ ′) = ( ⋂ ⋂ ′) ( ) Si se tienen tres eventos A, B y C, la probabilidad de que ocurra A o B está dada gráficamente por: Figura 38. Probabilidad de (A U B), con A, B y C Ω A B C P(A o B) = P(A ⋃ B) ( ⋃ )= ( ⋃ ) ( ) Si se tienen tres eventos A, B y C, la probabilidad de que ocurra C es: Estadística para educación superior Figura 39. Probabilidad de (C), con A, B y C Ω A B C ( )= ( ) ( ) Si se tienen tres eventos A, B y C, la probabilidad de que ocurra sólo C es: Figura 40. Probabilidad de (A' ⋂ B' ⋂ C) Ω A B C P(sólo C) = P(A' ⋂ B' ⋂ C) ( ′⋂ ′⋂ ) ( ′⋂ ′⋂ ) = ( ) Si se tienen tres eventos A, B y C, la probabilidad de que se presenten simultáneamente los tres eventos es: Estadística para educación superior Figura 41. Probabilidad de (A ⋂ B ⋂ C) Ω A B C P(A y B y C) = P(A ⋂ B ⋂ C) ( ⋂ ⋂ )= ( ⋂ ⋂ ) ( ) Si se tienen tres eventos A, B y C, la probabilidad de que no se presente ninguno de los tres eventos es: Figura 42. Probabilidad de (A' ⋂ B' ⋂ C') Ω A B C P(ninguno) = P(A' ⋂ B' ⋂ C') = P(A' ⋂ B' ⋂ C') ( ′⋂ ′⋂ ′) ( ′⋂ ′⋂ ′) = ( ) Si se tienen tres eventos A, B y C, la probabilidad de que se presente A o B o C es: Estadística para educación superior Figura 43. Probabilidad de (A U B U C) Ω A B C P(A o B o C) = P(A ⋃ B ⋃ C) ( ⋃ ⋃ ) ( ⋃ ⋃ )= ( ) 9.4 Axiomas básicos de probabilidad. La probabilidad siempre es un valor positivo: P(A) ≥ 0 La probabilidad del suceso posible o seguro Ω, es 1: P(Ω) = 1 La probabilidad del suceso imposible φ, es igual a cero: P(φ) = 0 La probabilidad de un evento siempre es un valor entre cero y uno: 0 ≤ P(A) ≤ 1 La probabilidad de que ocurra el evento A o B es P(A U B) = P(A) + P(B), para eventos incompatibles; y P(A U B) = P(A) + P(B) - P(A ⋂ B), para eventos incompatibles. La probabilidad de la unión de eventos contrarios, A o A', es igual a la probabilidad del evento seguro: P(A U A') = P(Ω) P(A U A') = 1 P(A) + P(A') = 1 Estadística para educación superior P(A) = 1 - P(A') 9.5 Probabilidad simple y conjunta, y su relación. Probabilidad simple. Se conoce también como probabilidad marginal. Hace referencia a la probabilidad de ocurrencia de un solo evento descrito por una sola característica: P(A). Probabilidad conjunta. Hace referencia a la probabilidad de ocurrencia de dos o más eventos (características) simultáneamente: P(A ⋂ B). Relación entre probabilidad marginal y conjunta. La probabilidad marginal puede ser expresada como la sumatoria de probabilidades conjuntas. Las probabilidades marginales y conjuntas se ubican en una tabla de doble entrada, e incluso también es recomendable elaborar una tabla preliminar con el número de elementos incluidos en cada uno de los eventos conjuntos y marginales, que sirva de base para el cálculo de las respectivas probabilidades. Figura 44. Diseño de tabla para probabilidades marginales y conjuntas Eventos A1 A2 A3 … Aj Total B1 P(A1 ⋂ B1) P(A2 ⋂ B1) P(A3 ⋂ B1) … … P(B1) B2 P(A1 ⋂ B2) P(A2 ⋂ B2) P(A3 ⋂ B2) … … P(B2) B3 P(A1 ⋂ B3) P(A2 ⋂ B3) P(A3 ⋂ B3) … … P(B3) … … … … … … … Bi … … … … P(Aj ⋂ Bj) P(Bi) P(A1) P(A2) P(A3) … P(Aj) P(Ω) = 1 Total En la tabla se visualizan probabilidades marginales y conjuntas, así: Probabilidades marginales: P(A1), P(A2), P(A3), …, P(Aj) Estadística para educación superior P(B1), P(B2), P(B3), …, P(Bj) Probabilidades conjuntas: P(A1 ⋂ B1), P(A1 ⋂ B2), P(A1 ⋂ B3), …, P(A1 ⋂ Bi) P(A2 ⋂ B1), P(A2 ⋂ B2), P(A2 ⋂ B3), …, P(A2 ⋂ Bi), P(Aj ⋂ Bi) Nota: La intersección de eventos es conmutativa, es lo mismo escribir P(Aj ⋂ Bi) que P(Bi ⋂ Aj) La probabilidad marginal es la sumatoria de probabilidades conjuntas: ( ) ∑ ( ⋂ ) ( ) ∑ ( ⋂ ) Y así sucesivamente para P(A3), …, P(Aj). ( ) ∑ ( ⋂ ) ( ) ∑ ( ⋂ ) Y así sucesivamente para P(B3), …, P(Bi). 9.6 Probabilidad condicional. Es utilizada cuando se calcula la probabilidad de un evento A particular, teniendo información previa en cuanto a la ocurrencia de otro evento B. La probabilidad del evento A está condicionada o influenciada por la ocurrencia del evento B. Se escribe P(A/B), y se lee: probabilidad de A dado que se conoce B, o simplemente, probabilidad de A dado B. ( ) ( ⋂ ) ( ) Fórmula (38) Estadística para educación superior Siendo P(B) > 0 Nota: Cuando los eventos son independientes, la P(A/B) = P(A) y la P(B/A) = P(B). En estos casos se dice que la probabilidad de ocurrencia del evento A no está relacionada con la probabilidad de ocurrencia del evento B. 9.7 Reglas de la adición y la multiplicación dentro del cálculo de probabilidades. Regla de la adición. Es utilizada para calcular la probabilidad de que ocurra el evento A o el evento B, denominada también regla de la unión. Se escribe P(A ⋃ B). Su cálculo se desarrolla de la siguiente manera, dependiendo si se trata de eventos incompatibles (mutuamente excluyentes) o de eventos compatibles (no mutuamente excluyentes): P(A ⋃ B) = P(A) + P(B) Para eventos incompatibles. P(A ⋃ B) = P(A) + P(B) - P(A ⋂ B) Para eventos compatibles. Regla de la multiplicación. Es utilizada para calcular la probabilidad de que ocurra el evento A y el evento B. Se escribe P(A ⋂ B). Para su cálculo es necesario identificar si se trata de eventos dependientes o independientes. P(A ⋂ B) = P(A/B)P(B) Para eventos dependientes. P(A ⋂ B) = P(B/A)P(A) Para eventos independientes. 9.8 Teorema de Bayes. Es una técnica estadística para calcular el valor de una probabilidad cuando intervienen en el análisis, probabilidades condicionales y también un conjunto de eventos mutuamente excluyentes. Estadística para educación superior ( ) ( ) ( ∑ ( ) ( ) ) Fórmula (39) Los eventos Ai son eventos mutuamente excluyentes o incompatibles (no pueden ocurrir simultáneamente), sin embargo, cada Ai es compatible con B. La sumatoria de la probabilidad de ocurrencia de cada evento Ai es igual a 1, debido a que se trata de eventos mutuamente excluyentes: ∑ ( ) 9.9 Ejercicios resueltos. 9.9.1 Comercio y ventas: Enfoque frecuentista de probabilidades. De un grupo de 108 comerciantes: 53 venden amplificadores de sonido 46 venden botiquines para baños 78 venden cosméticos 23 venden amplificadores y botiquines 35, amplificadores y cosméticos 15 venden los tres productos anteriores 7 no venden ninguno de los tres productos anteriores. Si se selecciona aleatoriamente un comerciante, cuál es la probabilidad de: a) Que venda únicamente amplificadores. b) Que venda únicamente botiquines y cosméticos. c) Que venda amplificadores o botiquines o cosméticos. d) Que venda los tres productos simultáneamente. e) Que venda sólo cosméticos. f) Que venda cosméticos. Estadística para educación superior Elaborar el diagrama de Venn, escribir el procedimiento de los cálculos con nomenclatura estadística, efectuar operaciones e interpretar el resultado. Solución Los eventos de interés son: A = Vender amplificadores de sonido B = Vender botiquines para baños C = Vender cosméticos La información suministrada en el enunciado es la siguiente: n(Ω) = 108 n(A) = 53 n(B) = 46 n(C) = 78 n(A ⋂ B) = 23 n(B ⋂ C) = ? n(A ⋂ C) = 35 n(A ⋂ B ⋂ C) = 15 n(A' ⋂ B' ⋂ C') = 7 Para elaborar el diagrama de Venn es indispensable tener pleno conocimiento del total de elementos en cada uno de los eventos y en cada una de las partes del diagrama con su respectiva identificación. Después de conocer todos los datos, se comienza a llenar desde la parte más interna hacia la más externa, es decir, desde la intersección de los tres eventos, y luego los espacios donde se ubican las intersecciones de a dos eventos. Como el n(Ω) = n(A ⋃ B ⋃ C) + n(A ⋃ B ⋃ C)', se puede calcular el número de elementos de la unión de los tres eventos n(A ⋃ B ⋃ C). ( ⋃ ⋃ ) ( ) ( ⋃ ⋃ )′ ( ⋃ ⋃ ) ( ) ( ′⋃ ′⋃ ′) Estadística para educación superior ( ⋃ ⋃ ) ( ⋃ ⋃ ) Se aplica la fórmula para la unión de tres eventos, y de ésta, se despeja el valor de n(B ⋂ C) =?, posteriormente se procede a llenar el diagrama de Venn. ( ⋃ ⋃ ) ( ) ( ) ( ) ( ⋂ ) ( ⋂ ) ( ⋂ ) ( ⋂ ) ( ⋂ ⋂ ) ( ⋂ ) ( ⋂ ) ( ⋂ ) Diagrama de Venn Ω A B 10 5 8 15 20 7 18 25 C a) ( ⋂ ′⋂ ′) ( ) La probabilidad de que venda únicamente amplificadores es de 0,0925. El grado de certeza de que venda únicamente amplificadores es del 9,25%. b) ( ′⋂ ⋂ ) ( ) La probabilidad de que venda únicamente botiquines y cosméticos es de 0,1667. El grado de certeza de que sólo venda botiquines y cosméticos es del 16,67%. c) ( ⋃ ⋃ ) ( ) La probabilidad de que venda amplificadores o botiquines o cosméticos es de 0,9352. El grado de certeza de que venda amplificadores o botiquines o cosméticos es del 93,52%. ( ⋂ ′⋂ ′) ( ⋂ ⋂ ′) ( ⋃ ⋃ ) Estadística para educación superior d) ( ⋂ ⋂ ) ( ) La probabilidad de que venda amplificadores y botiquines y cosméticos es de 0,1389. El grado de certeza de que venda los tres productos simultáneamente es del 13,89%. e) ( ′⋂ ′⋂ ) ( ) La probabilidad de que únicamente venda cosméticos es de 0,2315. El grado de certeza de que venda sólo cosméticos es del 23,15%. f) ( ) ( ) La probabilidad de que venda cosméticos es de 0,7222. El grado de certeza de que venda cosméticos es del 72,22%. ( ⋂ ⋂ ) ( ) ( ′⋂ ′⋂ ) ( ) 9.9.2 Producción-maquinaria Una máquina está construida con cuatro componentes independientes, la máquina trabaja si cada uno de los componentes trabaja bien. Se sabe que la probabilidad de que cada componente funcione bien es de 0,98. ¿Cuál es la probabilidad de que la máquina trabaje bien? Solución Evento Ai = El componente i funciona bien. ( ) con i = 1, 2, 3, 4. ( ⋂ ⋂ ⋂ ) ( ⋂ ⋂ ⋂ ) ∏ ( ) ( ) ( ) ( ) ( ) La probabilidad de que la máquina funcione bien es de 0,92. El grado de certeza de que la máquina funcione bien es del 92%. Estadística para educación superior 9.9.3 Análisis de características del personal por sexo y partido político. De un grupo de empleados de una compañía determinada, el 60% son mujeres y el 40%, hombres. Se sabe que el 4% de los hombres no pertenecen a ningún partido político, y el 2% de las mujeres tampoco pertenecen a ningún partido político. Si se selecciona aleatoriamente un empleado y no pertenece a ningún partido político: a) ¿Cuál es la probabilidad de que el empleado sea mujer? b) ¿Cuál es la probabilidad de que el empleado sea hombre? Solución Se definen los eventos: H = Ser hombre M = Ser mujer N = No pertenecer a ningún partido político S = Pertenecer a algún partido político Probabilidades dadas a conocer en el enunciado: Probabilidades marginales: P(H)= 0,40 Probabilidad de ser hombre P(M)= 0,60 Probabilidad de ser mujer Probabilidades conjuntas: P(H ⋂ N) = 0,04 Probabilidad de ser hombre y no pertenecer a ningún partido político. P(M ⋂ N) = 0,01 Probabilidad de ser mujer y no pertenecer a ningún partido político. Estadística para educación superior Se elabora un cuadro de doble entrada para organizar la información suministrada: Partido político No (N) Género Hombre Mujer Total 0,04 0,01 ? Sí (S) ? ? ? Total 0,40 0,6 1 Se calculan las probabilidades desconocidas en la tabla: ( ( ( ( ⋂ ) ⋂ ) ) ) La tabla completa, con las respectivas probabilidades conjuntas y marginales, queda así: Probabilidades conjuntas Partido político Género Hombre Mujer Total No (N) 0,04 0,01 0,05 Sí (S) 0,36 0,59 0,95 Total 0,40 0,6 1,00 Probabilidades marginales a) P(M / N) = ? Probabilidad de que el empleado sea mujer dado que no pertenece a ningún partido político. ( ⋂ ) ( ) ( ) Si se selecciona un empleado al azar, el grado de certeza que sea mujer dado que no pertenece a ningún partido político es del 20%. b) P(H / N) = ? Probabilidad de que el empleado sea hombre dado que no pertenece a ningún Estadística para educación superior partido político. ( ⋂ ) ( ) ( ) Si se selecciona un empleado al azar, el grado de certeza que sea hombre dado que no pertenece a ningún partido político es del 80%. 9.9.4 Administración y planeación. El Departamento de Tránsito y Transporte de un municipio determinado planea reforzar el respeto a los límites de velocidad mediante la utilización de un sistema de radar, ubicándolos en cuatro sitios diferentes de la ciudad. Los sistemas L1, L2, L3 y L4 son puestos a funcionar el 40%, 30%, 20% y 30% del tiempo, respectivamente. La probabilidad de que una persona lleve exceso de velocidad dado que fue detectada por cada uno de los radares respectivamente es de 0,2, 0,1, 0,5 y 0,2. ¿Cuál es la probabilidad de que el tercer radar haya detectado a una persona dado que llevaba exceso de velocidad? Solución Se tienen los siguientes sucesos o eventos: B = Que lleve exceso de velocidad. L1 = Que sea detectado por el radar 1. L2 = Que sea detectado por el radar 2. L3 = Que sea detectado por el radar 3. L4 = Que sea detectado por el radar 4. Estadística para educación superior La información suministrada es la siguiente: P(L1) = 0,40 Probabilidad de que sea detectado por el radar 1. Probabilidad de que el radar 1 esté funcionando. P(L2) = 0,30 Probabilidad de que sea detectado por el radar 2. Probabilidad de que el radar 2 esté funcionando. P(L3) = 0,20 Probabilidad de que sea detectado por el radar 3. Probabilidad de que el radar 3 esté funcionando. P(L4) = 0,30 Probabilidad de que sea detectado por el radar 4. Probabilidad de que el radar 4 esté funcionando. P(B / L1) = 0,20 Probabilidad de que lleve exceso de velocidad dado que es detectado por el radar 1. P(B / L2) = 0,10 Probabilidad de que lleve exceso de velocidad dado que es detectado por el radar 2. P(B / L3) = 0,50 Probabilidad de que lleve exceso de velocidad dado que es detectado por el radar 3. P(B / L4) = 0,20 Probabilidad de que lleve exceso de velocidad dado que es detectado por el radar 4. P(L3 / B) =? Probabilidad de que sea detectado por el radar 3 dado que llevaba exceso de velocidad. ( ) ( ) ( ) ( ∑ ) ( ( ) ( ( ) ( ) ) ) ( ) ( ) Interpretación: La probabilidad de que un conductor sea detectado por el radar 3 dado que llevaba exceso de velocidad es de 0,37. El grado de certeza de que un conductor sea detectado por el radar 3 dado que lleve exceso de velocidad es del 37%. Estadística para educación superior 9.9.5 Desempeño laboral y atención al cliente: Empresa de servicios. En el departamento de historia clínica de un hospital, tres empleados tienen la tarea de procesar semanalmente los registros de los pacientes. El primer empleado procesa el 45% de los registros. El segundo empleado procesa el 30% de los registros. El tercer empleado procesa el 25 % de los registros. El primer empleado tiene una tasa de error en su trabajo del 3%. El segundo empleado tiene una tasa de error en su trabajo del 5%. El tercer empleado tiene una tasa de error en su trabajo del 2%. Si se selecciona un registro al azar entre los que se procesan durante la semana y se encuentra que tiene errores: a) ¿Cuál es la probabilidad de que el registro haya sido procesado por el primer empleado? b) ¿Cuál es la probabilidad de que el registro haya sido procesado por el segundo empleado? c) ¿Cuál es la probabilidad de que el registro haya sido procesado por el tercer empleado? Solución Se identifican inicialmente los datos suministrados en el problema, asociándolo con los respectivos eventos: P(E1) = 0,45 Probabilidad de que el empleado 1 procese el registro. P(E2) = 0,30 Probabilidad de que el empleado 2 procese el registro. P(E3) = 0,25 Probabilidad de que el empleado 3 procese el registro. Evento B = Que el registro presente error. P(B / E1) = 0,03 Probabilidad de que un registro presente error dado que fue procesado por el empleado 1. P(B / E2) = 0,05 Probabilidad de que un registro presente error dado que fue procesado por el empleado 2. Estadística para educación superior P(B / E3) = 0,02 Probabilidad de que un registro presente error dado que fue procesado por el empleado 3. El problema plantea: a) P(E1 / B) = ? Probabilidad de que el primer empleado procese el registro dado que el registro presenta error. b) P(E2 / B) = ? Probabilidad de que el segundo empleado procese el registro dado que el registro presenta error. c) P(E3 / B) = ? Probabilidad de que el tercer empleado procese el registro dado que el registro presenta error. Se aplica la fórmula definida en el teorema de Bayes: a) ( ) ( ) ( ) ( ∑ ( ) ( ( ) ) ) ( ) ( ) Interpretación: Si se selecciona un registro al azar, el grado de certeza de que lo haya procesado el primer empleado dado que presentó error, es del 40,29%. b) Al aplicar la fórmula se obtiene: ( ) Interpretación: Si se selecciona un registro al azar, el grado de certeza de que lo haya procesado el segundo empleado dado que presentó error, es del 44,77%. c) Al aplicar la fórmula se obtiene: ( ) Interpretación: Si se selecciona un registro al azar, el grado de certeza de que lo haya procesado el tercer empleado dado que presentó error, es del 14,92%. Estadística para educación superior 9.10 Ejercicios propuestos. 9.10.1 Distribución porcentual de las familias de un barrio, según la tenencia de vivienda y carro propios. El 18% de las familias de un barrio tienen carro propio, el 20% tienen vivienda propia y el 12% tienen vivienda y carro propio. Calcular: a) Probabilidad de que posea sólo carro. b) Probabilidad de que posea carro y vivienda. c) Probabilidad de que posea vivienda. d) Probabilidad de que posea sólo vivienda. e) Probabilidad de que no posea ni carro ni vivienda. 9.10.2 Estudiantes de grado once con deseos de ingresar a la universidad. De un grupo de 172 estudiantes de undécimo de determinado colegio: 110 se presentaron a Esumer, 70 a la Universidad Central, 12 no se presentaron a ninguna de las dos instituciones de educación anteriores. Al seleccionar aleatoriamente un estudiante, determine: a) La probabilidad de que se haya presentado a Esumer. b) La probabilidad de que se haya presentado sólo a Esumer. c) La probabilidad de que se haya presentado a Esumer y a la Universidad Central. d) La probabilidad de que no se haya presentado a ninguna de las dos instituciones de educación anteriores. Estadística para educación superior 9.10.3 Propietarios de acciones y bonos en una corporación financiera. Una corporación del sector financiero está pensando en utilizar una lista de propietarios de acciones y bonos para mercadear un nuevo servicio a través de publicaciones enviadas por correo a los inversionistas. El 40% de los inversionistas financieros tienen sólo acciones. El 10% de los inversionistas financieros tienen sólo bonos. El 20% de los inversionistas poseen ambos. El 30% no tienen bonos ni acciones (poseen otro documento financiero). a) ¿Cuál es la probabilidad de que un inversionista tenga sólo acciones? b) ¿Cuál es la probabilidad de que un inversionista posea acciones y bonos? c) ¿Cuál es la probabilidad de que un inversionista posea acciones o bonos? d) ¿Cuál es la probabilidad de que posea otro documento diferente a los dos anteriores? 9.10.4 Medición de la eficacia de un procedimiento aduanero para detectar sustancias alucinógenas. Un procedimiento aduanero a través de un proyecto de la instalación de una planta bioelectrónica analiza su eficacia en detectar el tráfico de sustancias alucinógenas en los cargamentos de exportación de flores y frutas tropicales. La probabilidad de que la prueba sea positiva dado que el cargamento posee sustancia alucinógena es de 0,99. La probabilidad de que la prueba sea positiva dado que el cargamento no posee la sustancia alucinógena es de 0,05. La probabilidad de que un cargamento posea sustancia alucinógena es de 0,10. Calcular la probabilidad de que un cargamento posea sustancia alucinógena dado que la prueba resultó positiva. Estadística para educación superior 9.10.5 Almacenes distribuidores de electrodomésticos. De un grupo de 127 almacenes: 60 venden neveras. 52 venden lavadoras. 62 venden equipos de sonido. 22 venden neveras y lavadoras. 20 venden neveras y equipos de sonido. 17 venden lavadoras y equipos de sonido. 5 no venden ninguno de los tres electrodomésticos anteriores. Calcular: a) Probabilidad de que venda los tres electrodomésticos. b) Probabilidad de que venda neveras. c) Probabilidad de que venda únicamente neveras. d) Probabilidad de que venda lavadoras y equipos de sonido. e) Probabilidad de que venda lavadoras o equipos de sonido. f) Probabilidad de que venda sólo lavadoras y equipos de sonido. g) Probabilidad de que venda sólo equipos de sonido. h) Probabilidad de que no venda ninguno de los tres electrodomésticos. 9.10.6 Población adulta clasificada según lectores de prensa y votantes en elecciones. La siguiente tabla recoge las proporciones de adultos en áreas no metropolitanas de Antioquia, clasificadas en aquellos que leen o no la prensa y aquellos que votaron o no en las elecciones anteriores: Votaron Lectores No lectores Sí 0,63 0,13 No 0,14 0,10 a) ¿Cuál es la probabilidad de que un adulto de esta población elegido al azar votase? b) ¿Cuál es la probabilidad de que un adulto de esta población elegido al azar lea la prensa? Estadística para educación superior c) ¿Cuál es la probabilidad de que vote dado que lee la prensa? d) ¿Cuál es la probabilidad de que vote y lea la prensa? 9.10.7 Transporte de mercancía: Embarque de cajas con juguetes y ropa para bebé. Un embarque contiene 10 cajas, tres de ellas, con juguetes para niños menores de un año y siete con ropa de bebé. Si se seleccionan aleatoriamente dos cajas del embarque, ¿cuál es la probabilidad de que las cajas seleccionadas contengan ropa para bebé? Calcular esta probabilidad para el caso de: a) Selección con reposición. b) Selección sin reposición. 9.10.8 Solicitudes de afiliación a una organización para estudiantes universitarios. Un estudiante de una organización universitaria distribuyó solicitudes de afiliación a nuevos estudiantes durante una reunión de orientación. El 40% de los que recibieron estas solicitudes eran hombres, y el 60%, mujeres. Posteriormente, el 7% de los hombres y el 9% de las mujeres que recibieron la solicitud se afilió a la organización. a) ¿Cuál es la probabilidad de que un nuevo estudiante elegido al azar, que recibe la solicitud, se afilie a la organización? b) Calcular la probabilidad de que un nuevo estudiante elegido al azar, que se afilie a la organización después de recibir la solicitud, sea mujer. 9.10.9 Comerciantes y distribuidores de amplificadores de sonido, botiquines y cosméticos. De un grupo de 108 comerciantes, 53 exportan amplificadores de sonido; 46 exportan botiquines para baños; 78 exportan cosméticos; 23 exportan amplificadores y botiquines; 35 Estadística para educación superior exportan amplificadores y cosméticos; 15 exportan los tres productos anteriores; 7 no exportan ninguno de los tres productos anteriores. Si seleccionamos aleatoriamente un comerciante, cuál es la probabilidad de que: a) Exporte únicamente amplificadores. b) Exporte únicamente botiquines y cosméticos. c) Exporte amplificadores o botiquines o cosméticos. 9.10.10 Firma manufacturera y calidad del as piezas suministradas por los proveedores. Una firma manufacturera recibe embarques de dos proveedores. El 70% de las piezas adquiridas provienen del proveedor A y el 30% restante del proveedor B. La calidad de las piezas adquiridas varía con la fuente de suministro. Con base en datos históricos, las probabilidades condicionales de recibir piezas buenas y malas de los proveedores están dadas por: La probabilidad de que la pieza esté buena, dado que fue enviada por el proveedor A es de 0,98. En otras palabras, el 98% de las piezas enviadas por el proveedor A son buenas. La probabilidad de que la pieza esté mala dado que fue enviada por el proveedor A es de 0,02. La probabilidad de que la pieza esté buena dado que fue enviada por el proveedor B es de 0,95. La probabilidad de que la pieza este mala dado que fue enviada por el proveedor B es de 0,05. Si se selecciona una pieza al azar y resultó ser mala: Estadística para educación superior a) ¿Cuál es la probabilidad de que dicha pieza mala provenga del proveedor A? b) ¿Cuál es la probabilidad de que dicha pieza mala provenga del proveedor B? 9.10.11 Estudiantes de educación superior con teléfono celular, beeper y fijo inalámbrico. De un grupo de 123 alumnos de una institución de educación superior, 71 poseen en sus casas teléfono fijo inalámbrico; 58 tienen teléfono celular; 51 tienen beeper; 33, teléfono fijo inalámbrico y celular; 31 teléfono fijo inalámbrico y beeper; 23 tienen los tres (inalámbrico, celular, beeper); 12 no poseen ninguno. Si se selecciona un alumno aleatoriamente: a) ¿Cuál es la probabilidad de que posea sólo beeper? b) ¿Cuál es la probabilidad de que posea sólo celular y beeper? c) ¿Cuál es la probabilidad de que posea beeper o celular? d) ¿Cuál es la probabilidad de que posea inalámbrico y beeper? 9.10.12 Control de calidad en una empresa manufacturera. En el departamento de producción de una empresa se seleccionan en forma aleatoria tres artículos de un proceso de manufactura. Se examina cada uno de ellos y se clasifica como defectuoso y bueno. a) ¿Cuál es la probabilidad de que los dos primeros artículos sean buenos? b) ¿Cuál es la probabilidad de que los tres artículos examinados sean buenos? Estadística para educación superior 9.10.13 Amas de casa consumidoras de detergentes para el aseo del hogar. Se tomó una muestra de 115 amas de casas consumidoras de detergentes para el aseo en el hogar, se encontró que: 15 no consumen Arielly ni Fabe; 45 consumen Arielly; 60 consumen Fabe. Si seleccionamos aleatoriamente un ama de casa, cuál es: a) La probabilidad de que consuma Arielly. b) La probabilidad de que consuma sólo Arielly. c) Probabilidad de que consuma Arielly y Fabe. d) Probabilidad de que consuma Arielly o Fabe. e) Probabilidad de que no consuma ninguno de los dos detergentes anteriores. 9.10.14 Distribución de vuelos en una aerolínea. Una aerolínea estudia la distribución de sus vuelos en época de vacaciones con destino a tres ciudades (Armenia, Bogotá, Cartagena). Se toma una muestra de 146 pasajeros, a los cuales se les hace un seguimiento sobre sus viajes, encontrándose los siguientes resultados: 53 visitan la ciudad de Armenia; 60 visitan la ciudad de Bogotá; 100 visitan la ciudad de Cartagena; 25 visitan Armenia y Bogotá; 35 visitan Armenia y Cartagena; 40 visitan Bogotá y Cartagena; 18 no visitan ninguna de las tres ciudades anteriores. Si se elige al azar un pasajero, calcular: a) Probabilidad de que visite las tres ciudades anteriores. b) Probabilidad de que visite la ciudad de Cartagena. c) Probabilidad de que visite sólo Cartagena. d) Probabilidad de que visite Bogotá o Cartagena. e) Probabilidad de que visite Bogotá y Armenia. f) Probabilidad de que visite Bogotá o Armenia. Estadística para educación superior g) Probabilidad de que visite sólo Bogotá y Armenia. 9.10.15 Estudiantes universitarios con becas y vinculación laboral de medio tiempo. Un grupo de 120 estudiantes de la universidad a los cuales se les concedieron becas el semestre actual, mostró que 53 de ellos poseen vinculación laboral de medio tiempo; 30 de ellos solicitaron beca el semestre anterior y 18, al mismo tiempo, solicitaron beca el semestre anterior y poseen vinculación laboral de medio tiempo. Si se selecciona un estudiante al azar dentro de este grupo: a) ¿Cuál es la probabilidad de que haya solicitado beca el semestre anterior? b) ¿Cuál es la probabilidad de que posea vinculación laboral de medio tiempo? c) ¿Cuál es la probabilidad de que sólo posea vinculación laboral de medio tiempo y no haya solicitado beca el semestre anterior? d) ¿Cuál es la probabilidad de que haya solicitado beca el semestre anterior y posea vinculación laboral de medio tiempo? 9.10.16 Evaluación de un producto por parte de los consumidores, y grado de aceptación del mismo en el mercado. El departamento de mercadeo de una compañía desea analizar la incidencia de la buena evaluación hecha a sus productos por parte de los consumidores en relación con los productos que han tenido mucho éxito en el mercado, moderado éxito y baja aceptación. El 97% de los productos con mayor éxito en el mercado recibieron buenas evaluaciones. El 70% de los productos con moderado éxito en el mercado recibieron buenas calificaciones. El 12% de los productos con baja aceptación en el mercado recibieron buenas calificaciones. El estudio también muestra que: El 45% de los productos han tenido mucho éxito en el mercado; Estadística para educación superior El 40% de los productos han tenido éxito moderado en el mercado; El 15% de los productos son de baja aceptación en el mercado. Si se selecciona aleatoriamente un producto: a) ¿Cuál es la probabilidad de que obtenga buena calificación? b) Si el producto obtuvo buena evaluación, ¿cuál es la probabilidad de que sea un producto con alto éxito en el mercado? c) Si el producto obtuvo buena evaluación, ¿cuál es la probabilidad de que sea un producto con bajo éxito en el mercado? 9.10.17 Producción de muebles modulares y control de calidad en el ensamblaje. El departamento de producción de una compañía dedicada a la fabricación de muebles modulares desea efectuar control de calidad respecto al ensamble e instalación de los muebles. Un mueble modular tiene 20 tornillos. Por diagnósticos preliminares, se ha detectado que generalmente, cinco de ellos no están bien apretados. Si se seleccionan aleatoriamente y sin remplazo, cuatro tornillos para efectuar la auditoría en el control de la calidad del ensamblaje, para determinar si están bien apretados: a) ¿Cuál es la probabilidad de que los cuatro tornillos estén bien apretados? b) ¿Cuál es la probabilidad de que el primer tornillo seleccionado este flojo y los otros tres, bien apretados? c) ¿Cuál es la probabilidad de que los dos primeros tornillos estén bien apretados y los otros dos, flojos? d) ¿Cuál es la probabilidad de que los tres primeros tornillos estén apretados y el último, flojo? e) ¿Cuál es la probabilidad de que el primer tornillo esté bien apretado y los otros tres, flojos? Estadística para educación superior 9.10.18 Producción y comercialización de maletines escolares. La tabla siguiente presenta un resumen de las características solicitadas en 315 órdenes de maletines escolares: Característica Estampado Fondo entero Con cierre 30 85 Sin cierre 50 150 Si se selecciona aleatoriamente una orden de maletines escolares: a) ¿Cuál es la probabilidad de que la solicitud sea de maletines estampados? b) ¿Cuál es la probabilidad de que la orden sea de maletines con cierre? c) ¿Cuál es la probabilidad de que la orden sea de maletines fondo entero y con cierre? d) ¿Cuál es la probabilidad de que la orden sea de maletines fondo entero? e) ¿Cuál es la probabilidad de que la orden sea de maletines estampados y sin cierre? 9.10.19 Mercadeo y lanzamiento de un nuevo producto. El departamento de mercadeo de una empresa está promocionando un evento para el lanzamiento de su nuevo producto. Se distribuyen tarjetas de invitación a diferentes empresarios de la ciudad. El director de mercadeo efectúa auditoría al proceso de distribución de volantes y tarjetas, para tal efecto, selecciona aleatoriamente tres empresarios para analizar si la invitación llegó a tiempo o tarde. a) ¿Cuál es la probabilidad de que al primer empresario seleccionado le haya llegado tarde y a los otros dos a tiempo? b) ¿Cuál es la probabilidad de que los tres empresarios hayan recibido la información a tiempo? Estadística para educación superior c) ¿Cuál es la probabilidad de que al segundo empresario seleccionado le haya llegado a tiempo y al primero y al tercero, tarde? 9.10.20 Perfil de clientes de un reconocido restaurante. El propietario de un reconocido restaurante ubicado en una ciudad capital desea construir el perfil de sus clientes para desarrollar una campaña publicitaria que atraiga a clientes potenciales típicos de quienes actualmente prefieren este restaurante. El 40% de los usuarios actuales son mujeres, el 75% de ellas es menor de 30 años. El 25% de los hombres son menores de 30 años. Determine cuál es la probabilidad de que un usuario seleccionado aleatoriamente: a) Sea una mujer menor de 30 años. b) Sea un hombre. c) Sea un hombre mayor de 30 años. d) Sea una mujer. e) Sea una mujer mayor de 30 años. f) Sea un usuario menor de 30 años. 9.10.21 Secretaría de Desarrollo Comunitario y proyecto para jóvenes. La secretaría de desarrollo comunitario de un municipio, inicia un estudio en la población de jóvenes de 18 años, para analizar la distribución respecto de los bachilleres y los que actualmente laboran, con el objetivo de presentar un proyecto académico-laboral de ayuda a este sector de la población. De 1.500 jóvenes de 18 años se encontró que 400 tienen empleo y 1.200 son bachilleres. De los bachilleres, 285 tienen empleo. Estadística para educación superior Determine cuál es la probabilidad de que un joven seleccionado aleatoriamente sea: a) Un bachiller. b) Un bachiller empleado. c) Un bachiller desempleado. d) Un joven sin culminar el bachillerato. e) Un joven sin culminar el bachillerato y desempleado. f) Un joven sin culminar el bachillerato y empleado. 9.10.22 Distribución y comercialización de teléfonos. Un distribuidor de teléfonos vende teléfonos Panic y Solevy. De acuerdo a estudios preliminares en las ventas se ha diagnosticado que: El 35% de los clientes compran teléfonos Panic; El 53% de los clientes adquieren teléfonos Solevy; El 15% de los clientes adquieren los dos teléfonos. Determine cuál es la probabilidad de que un cliente: a) No compre ninguna de las dos marcas de teléfono anteriores. b) Compre sólo teléfonos Panic. c) Compre teléfonos Panic o Solevy. d) Compre teléfonos Panic y Solevy. e) Compre únicamente teléfonos Solevy. Estadística para educación superior PARTE III 10. Distribuciones de probabilidad 10.1 Asociación de probabilidad con conceptos de estadística descriptiva. La variable dentro de un estudio estadístico, hace referencia a lo que se desea medir sobre cada unidad o elemento de investigación. Cuando cada valor de la variable (o intervalos de la variable) pueden ser asociados con un respectivo valor de probabilidad, se habla de variable aleatoria. En estadística descriptiva se elaboran tablas de frecuencia, existe una columna que identifica los respectivos valores de la variable (marcas de clase o intervalos) y otra columna con frecuencias relativas (hi) las cuales pueden ser interpretadas en términos probabilísticos. Las frecuencias relativas son valores entre 0 y 1, además, la sumatoria de las frecuencias relativas siempre es igual a 1. Esta distribución de frecuencias se refiere a datos reales y se denomina distribución empírica o simplemente distribución de frecuencias. Existen casos en que no se conoce la totalidad de datos reales, pero con base en los reales se puede construir la distribución de probabilidad, se conoce como una distribución de probabilidad teórica referida a una variable aleatoria o variable estocástica. En estadística descriptiva se construye el gráfico del polígono para visualizar la forma de la distribución real de los datos de la variable, este polígono (curva o línea) tiene una función matemática específica que lo identifica, dependiendo de su forma. El polígono es una curva elaborada en un plano cartesiano, en el eje X (abscisa) se ubican los valores de la variable aleatoria, y en el eje Y (ordenada) se ubican los respectivos valores de probabilidad. Bajo estas circunstancias se habla de función de densidad de probabilidad. Estadística para educación superior En la misma forma que las distribuciones de frecuencia, las distribuciones de probabilidad pueden analizarse mediante algunas medidas estadísticas como la media y la varianza, las cuales se identificarán de ahora en adelante como parámetros de la distribución de probabilidad, siendo la media conocida con el nombre de esperanza matemática. Las variables aleatorias pueden ser discretas o continuas, dependiendo de si sólo admiten valores enteros o expresiones decimales. 10.2 Función de densidad de probabilidad. Para que una función matemática f(X) pueda ser definida como función de densidad de probabilidad, debe cumplir las siguientes condiciones, para cada valor de X que forme parte del dominio de la función. Es importante recordar que una función matemática puede estar definida para valores de X infinitos, o para determinados valores de X, lo que se conoce como el dominio de la función. En este tema, el rango de la función esta dado por los valores de probabilidades, los cuales se ubican en el eje Y. Cuadro 8. Función de densidad de probabilidad Variable aleatoria discreta Variable aleatoria continua ( )≥0 ∑ ( 𝑖) = 1 𝑖=1 Con ( 𝑖) = ( 𝑖) ( )≥0 +∞ ( ) 𝑑𝑥 = 1 ∞ Esto significa que toda el área bajo la función de densidad de probabilidad es igual a 1. Estadística para educación superior 10.3 Función de distribución acumulativa de probabilidad. La función de densidad de probabilidad se identifica con f(X). La función de distribución acumulativa de probabilidad se identifica con F(X). La probabilidad puntual P(X = xi) de que X tome un valor particular de xi sólo es posible calcularla para el caso de la variable aleatoria discreta, para la variable aleatoria continua no existen valores de probabilidad puntuales. Cuadro 9. Probabilidad puntual Variable aleatoria discreta ( = 𝑥𝑖 ) = (𝑥𝑖 ) Variable aleatoria continua ( = 𝑥𝑖 ) = 𝑥𝑖 ( )𝑑𝑥 = 0 𝑥𝑖 La probabilidad acumulativa, de que X sea menor o menor o igual que un valor respectivo de xi se denomina función de distribución acumulativa F(X). Estadística para educación superior Cuadro 10. Probabilidad acumulativa Variable aleatoria discreta Variable aleatoria continua ( ≤ 𝑥) ≠ ( < 𝑥) Se acumula con el operador sumatoria los valores de f(X) arrojados por todos los X ≤x ( ≤ 𝑥) = ( < 𝑥) = 𝐹(𝑥) Se acumula con el operador integral desde el menor valor que puede tomar la X hasta el valor particular de x. Esta operación significa hallar un área bajo la función de densidad de probabilidad f(X) a la izquierda de x. =𝑥 ( ≤ 𝑥) = ∑ ( ) = ∞ 𝑡𝑒 𝑖 ( < 𝑥) = ( ≤ 𝑥) = ( )𝑑𝑥 = 𝐹(𝑥) ∞ ( ) ∑ 𝑥 = ∞ Nota: se acumula sin incluir el valor de x, hasta el anterior. La probabilidad de que X se encuentre entre dos valores a y b (Incluyéndolos), se calcula de la siguiente manera, dependiendo si es el caso de una variable discreta o una variable continua, así: Cuadro 11. Cálculo de probabilidad de X entre a y b Variable aleatoria discreta Variable aleatoria continua ( ≤ =𝑏 ≤ 𝑏) = ( )𝑑𝑥 = =𝑏 ( ≤ ≤ 𝑏) = ∑ ( ) = Significa hallar un área entre dos valores de X, a y b, bajo la función de densidad de probabilidad. ( ≤ ≤ 𝑏) = ( ≤ 𝑏) ( ≤ ) ( ≤ ≤ 𝑏) = 𝐹(𝑏) 𝐹( ) La probabilidad de que X se encuentre entre dos valores puede ser expresada como la diferencia de dos valores arrojados por la función de distribución acumulativa. Estadística para educación superior 10.4 Parámetros en las distribuciones de probabilidad. La media (esperanza matemática) y la varianza, se calculan de manera diferente dependiendo si se trata de una variable aleatoria discreta o una continua. Cuadro 12. Cálculo de parámetros Variable aleatoria discreta Media o esperanza matemática µ= ( )=∑ 𝑖 ( 𝑖) 𝑖=1 Con ( 𝑖 ) = ( = Fórmula (40) Variable aleatoria continua Media o esperanza matemática µ= ( )= =∑ 𝑖 𝑖) ( 𝑖) ( )𝑑𝑥 Fórmula (42) ∞ Varianza ( )= 2 2 +∞ Varianza Fórmula (41) 2 +∞ = ( µ)2 ( )𝑑𝑥 Fórmula (43) ∞ 𝑖=1 10.5 Cálculo de probabilidades. Dependiendo del tipo de variable aleatoria discreta o continua, el cálculo de las probabilidades presenta algunas diferencias. Para la variable aleatoria discreta. ( )≠ ( ( ) ( ( ) ( ) ( ( ) ( ( ≤ ≤ 𝑏) ( ) ( ≤ ) ) ≤ ( ≤ ) ) ( ≥ ) ( ≤ ( ≤ ) ≤ ) ( ≤ 𝑏) ( ≤ ) ( ≥ ) ) 𝐹( ) 𝐹( ) 𝐹(𝑏) 𝐹( ) ) ( ≤ ) Estadística para educación superior Para la variable aleatoria continua. ( ) No existe ( ≤ ) ( ( ≤ ≤ 𝑏) ( ( 𝑏) ( ( ) ( ≥ ) 𝐹( ) ( ≤ ) ≤ 𝑏) ≤ ≤ 𝑏) ) ( ≤ ) ( ( 𝑏) ( ) ) 𝐹(𝑏) 𝐹( ) 𝐹( ) 10.6 Distribuciones de probabilidad discretas. 10.6.1 Distribución binomial. Es una distribución de probabilidad para una variable discreta X, la variable X representa el total de “éxitos” dentro de n ensayos. La palabra éxito siempre estará asociada con la característica de interés que se esté analizando dentro de la ocurrencia del evento. Es una distribución de probabilidad con aplicaciones en inspección de calidad, ventas, mercadeo, investigación de opiniones, entre otras. Nomenclatura. n = Total de casos posibles, o total de ensayos. X = Total de éxitos dentro de los n ensayos. p = Probabilidad de éxito, en otras palabras, es la probabilidad de que ocurra la característica de interés. El valor de p es una proporción, siempre se encuentra entre 0 y 1. La probabilidad p es conocida con estudios preliminares y se calcula como la relación entre el total de casos favorables para la característica de interés sobre el total de casos posibles. Fórmula (44) Estadística para educación superior Con a = total de casos favorables para la característica de interés. 0 ≤ p ≤ 1. q = probabilidad de fracaso, en otras palabras, la probabilidad de que no se presente la característica de interés. También es una proporción y se puede calcular como la relación entre el total de casos que no son favorables para la característica de interés (b) dividido por el total de casos posibles, o simplemente utilizando la siguiente fórmula: Fórmula (45) 𝑏 Fórmula (46) Nota: Siempre, la unión de p con q representa el 100%, en términos relativos 1, por lo tanto, se cumple que: Fórmula (47) De donde q = 1 – p, o también, p = 1–q Función de distribución de probabilidad binomial. f(X) = Probabilidad de que se presenten X éxitos dentro de los n ensayos. ( ) ( ) ≤ Fórmula (48) X = 0, 1, 2, 3,…, n. La variable X toma valores positivos y enteros (variable discreta). Parámetros de la binomial. Fórmula (49) Estadística para educación superior √ Fórmula (50) ( ) Representa combinaciones de n en X, se calcula de la siguiente forma: ( ) ( ) n! se lee n factorial. El factorial de un número se calcula así: ( ) Por definición, 0! = 1 Nota: Por tratarse de una función de distribución de probabilidad, se tiene que la sumatoria de todos los valores de f(X) es igual a 1: ∑ ( ) Representación gráfica de la binomial. No existe un único gráfico que identifique la distribución binomial, existen tantos cuantos valores de n, p y q diferentes se tengan, cada caso particular posee su respectivo gráfico estadístico. El gráfico se elabora en un plano cartesiano, pero recordando que en el eje X sólo se toman valores enteros, en el eje Y se ubican los valores de las probabilidades, se desplaza una línea continua que una cada valor de X con el cruce donde se ubica su respectiva probabilidad. Para su gráfico se recomienda efectuar con anterioridad las respectivas tabulaciones, tal como se presenta en el ejemplo a continuación (ver figura 45). Estadística para educación superior Figura 45. Tabulaciones para el caso particular de una binomial con n = 7, p = 0,30 𝑥 ( )=( ) X f(X) Probabilidad 0,082354 7 (0) = ( ) (0,300 )(0,707 ) 0 7 (1) = ( ) (0,301 )(0,706 ) 1 7 (2) = ( ) (0,302 )(0,705 ) 2 7 (3) = ( ) (0,303 )(0,704 ) 3 7 (4) = ( ) (0,304 )(0,703 ) 4 7 (5) = ( ) (0,305 )(0,702 ) 5 7 (6) = ( ) (0,306 )(0,701 ) 6 7 (7) = ( ) (0,307 )(0,700 ) 7 0 1 2 3 4 5 6 7 0,247063 0,317652 0,226895 0,097241 0,025005 0,003572 0,000219 Probabilidad f(X) Binomial para n = 7, p = 0,30 0,360000 0,340000 0,320000 0,300000 0,280000 0,260000 0,240000 0,220000 0,200000 0,180000 0,160000 0,140000 0,120000 0,100000 0,080000 0,060000 0,040000 0,020000 0,000000 0 1 2 3 4 5 6 7 8 Valores de X 10.6.2 Distribución Poisson. La variable aleatoria en la distribución Poisson representa el número de éxitos por unidad de medición. Cada éxito que se presente es independiente de la ocurrencia de otro. Estadística para educación superior El número de éxitos hace referencia al número de veces de la ocurrencia de un evento, entendiéndose por evento como llegada de personas, clientes, documentos, unidades defectuosas, piezas examinadas, solicitudes, fallas en una máquina, accidentes, llamadas telefónicas, entre otras. La unidad de medición se define dependiendo de las necesidades específicas y particulares de la situación, algunas unidades de medición que se adoptan son el tiempo (segundos, minutos, horas, días, semanas, meses), la longitud (centímetros, metros, kilómetros), el área (cm2, m2, km2), el volumen (cm3, m3, onza, litro, galón). La distribución Poisson es muy utilizada dentro de la teoría de colas o líneas de espera para analizar el comportamiento de una variable definida como el número de clientes que llegan para ser atendidos en determinada unidad de tiempo. Función de densidad de probabilidad para la Poisson. La función de densidad de probabilidad para la Poisson está dada por: ( ) 𝑒 ( 𝑡) para K ≥ 0, y valores enteros Fórmula (51) Siendo: λ = Promedio de éxitos (llegadas, clientes) por unidad de tiempo. t =Unidad de tiempo. K = Número de éxitos (llegadas, clientes) en el tiempo t. Parámetros de la distribución Poisson. 𝑡 Fórmula (52) Estadística para educación superior 𝑡 Fórmula (53) Para t = 1 Una unidad de tiempo, se tiene: µ = λ y σ2 = λ Representación gráfica de la Poisson. La representación gráfica de la distribución Poisson depende de los valores particulares que tomen λ y t. Por tal motivo, no existe una forma única que represente a esta distribución. A continuación se muestra la representación gráfica de la Poisson para un caso particular en que: Número de éxitos: Llegada de clientes. Unidad de medición: El tiempo en horas. λ = Número de éxitos por unidad de tiempo. λ = 20 clientes/hora. t = Tiempo en horas. t = 10 minutos. Como t en este caso particular se expresa en horas, se tiene: 𝑡 La función de densidad de probabilidad viene dada por: ( )( ) ( ) ( ) ( ) ( ) Con K ≥ = 0, además, valores enteros. A continuación se muestra la tabla con los cálculos de las respectivas probabilidades utilizando la función de densidad de probabilidad dada para la distribución Poisson (ver figuras 46 y 47). Estadística para educación superior Figura 46. Cálculo de probabilidades de Poisson para K 0 1 2 3 4 5 6 7 8 9 10 11 12 13 ; f(K) (0) = (1) = (2) = (3) = (4) = (5) = (6) = (7) = (8) = (9) = (10) = (11) = (12) = (13) = 𝑒 𝑒 𝑒 𝑒 𝑒 𝑒 𝑒 𝑒 𝑒 𝑒 𝑒 𝑒 𝑒 𝑒 20 6 Probabilidad 0 20 ) 6 0! 20 20 1 6 ( ) 6 1! 20 20 2 6 ( ) 6 2! 20 20 3 6 ( ) 6 3! 20 20 4 6 ( ) 6 4! 20 20 5 6 ( ) 6 5! 20 20 6 6 ( ) 6 6! 20 20 7 6 ( ) 6 7! 20 20 8 6 ( ) 6 8! 20 20 9 6 ( ) 6 9! 20 20 10 6 ( ) 6 10! 20 20 11 6 ( ) 6 11! 20 20 12 6 ( ) 6 12! 20 20 13 6 ( ) 6 13! ( 0,035673993 0,118913311 0,198188852 0,220209835 0,183508196 0,122338797 0,067965999 0,032364761 0,013485317 0,004994562 0,001664854 0,000504501 0,000140139 0,000035933 Estadística para educación superior Figura 47. Gráfica de probabilidades de Poisson para ; Probabilidad f(K) Poisson para λ = 20; t = 1/6 0,2375 0,2250 0,2125 0,2000 0,1875 0,1750 0,1625 0,1500 0,1375 0,1250 0,1125 0,1000 0,0875 0,0750 0,0625 0,0500 0,0375 0,0250 0,0125 0,0000 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 K éxitos 10.6.3 Distribución hipergeométrica. La variable aleatoria X representa el número de éxitos presentes en una muestra de tamaño n. La palabra éxito hace referencia a la característica de interés estudiada, al suceso o evento de interés, el cual se denota con la letra mayúscula A. Se tiene una población de tamaño N, dentro de la cual NA elementos poseen la característica de interés y el resto poseen otra característica diferente a la de interés, denominada B. Para calcular la probabilidad de que se encuentren X éxitos en la muestra, se utiliza la función de densidad de probabilidad hipergeométrica. Estadística para educación superior Función de densidad de probabilidad hipergeométrica. ( ) ( )( ) ( ) N, n, NA, X, NB, nB enteros positivos X = 0, 1, 2, 3, 4, . . . , NA X ≤ NA nB ≤ NB n≤N Fórmula (54) Siendo: N = tamaño de la población. n = tamaño de la muestra. NA = número de éxitos en la población, número de elementos que poseen la característica de interés en la población. X = número de éxitos en la muestra, número de elementos que poseen la característica de interés en la muestra. NB = número de fracasos en la población, número de elementos que no poseen la característica de interés dentro de la población. nB = número de fracasos en la muestra, número de elementos que no poseen la característica de interés A dentro de la muestra. De acuerdo a la nomenclatura presentada con sus respectivas definiciones, se tiene que: Las diferentes combinaciones que definen la función de densidad de probabilidad de la hipergeométrica, se calculan así: Estadística para educación superior ( ) ( ) ( ) ( ( ) ) ( ) Para efectos de calcular la función de densidad de probabilidad f(X) es adecuado expresar ésta en términos de X, así: ( ) ( )( ) Fórmula (55) ( ) Parámetros de la distribución hipergeométrica. Fórmula (56) ( ( )( ) ) Fórmula (57) Representación gráfica de la distribución hipergeométrica. La representación gráfica de la distribución hipergeométrica cambia dependiendo de los valores particulares que asuman los tamaños N, NA, NB y n; por tal motivo no existe una sola forma de la distribución hipergeométrica. A continuación se muestra un caso en el cual N = 12, NA = 8, NB = 4 y n = 5, la variable X puede asumir los valores de 0, 1, 2, 3, 4 y 5. Efectuando la tabulación respectiva e indispensable para efectuar el gráfico, se tiene (ver figura 48): Estadística para educación superior Figura 48. Cálculo de probabilidad de la distribución hipergeométrica para N = 12, NA = 8, NB = 4 y n = 5 y gráfica X f(X) 8 4 ( )( ) (0) = 0 5 12 ( ) 0 0 5 4 No existe porque ( ) no está definido, es imposible 5 calcularlo 8 4 ( )( ) (1) = 1 4 1 0,0101010 12 ( ) 5 8 4 ( )( ) (2) = 2 3 2 0,1414141 12 ( ) 5 8 4 ( )( ) (3) = 3 2 3 0,4242424 12 ( ) 5 8 4 ( )( ) (4) = 4 1 4 0,3535354 12 ( ) 5 8 4 ( )( ) (5) = 5 0 5 0,0707071 12 ( ) 5 Observar que la sumatoria de las f(X) con X desde 0 hasta 5 vale 1: ∑5 =0 ( ) = 1 Poisson para N = 12; NA = 8; NB = 4; n = 5 0,45 0,4 Probabilidad 0,35 0,3 0,25 0,2 0,15 0,1 0,05 0 0 1 2 3 4 Número de éxitos en la muestra 5 6 Estadística para educación superior 10.7 Distribuciones de probabilidad continuas. 10.7.1 Distribución normal. Conocida también con el nombre de distribución Gaussiana. Es una de las distribuciones de probabilidad más importantes y utilizadas, su campo de aplicación es muy amplio, en comercio, economía, mercadotecnia, medicina, entre otras ramas; también es indispensable para el análisis de la estadística inferencial. Tiene forma de campana (campana de Gauss), es simétrica, sus sesgos se extienden a través del eje X sin llegarlo a cortar, es por ello que el eje X es una asíntota horizontal. Función de densidad de probabilidad para la normal. La función f(X) que representa a la distribución de probabilidad normal está dada por: ( ) √ 𝑒 ( ) Fórmula (58) µ = media de la variable X σ = desviación típica o estándar de la variable X e = base de los logaritmos naturales (ln), equivale a 2, 71828 π = valor de “pi”, equivale a 3,14159265... ─∞≤X≤+∞ La forma que toma la campana de Gauss, depende de los valores respectivos de µ y de σ dentro de la función f(X), siendo su forma simétrica apuntada, achatada o normal. Estadística para educación superior Los sesgos, donde existen áreas representativas bajo la curva de la normal, se extienden más o menos a tres desviaciones estándar de la media, sin embargo éstos sesgos continúan infinitamente acercándose al eje X pero sin tocarlo, las áreas bajo la curva de la normal por fuera de éste rango de X constituyen áreas demasiado pequeñas y por lo tanto no muy representativas. Parámetros de la distribución normal. Media µ Varianza σ2 Representación gráfica de la distribución normal. La representación gráfica de la distribución normal se muestra en la figura a continuación: Figura 49. Distribución normal Frecuencia Distribución normal µ - 3σ µ - 2σ µ - σ µ 68,3% 95,5% 99,7% µ + σ µ + 2σ µ + 3σ X Estadística para educación superior Las áreas bajo la curva de la distribución normal representan valores de probabilidades, toda el área bajo la curva de la normal vale 1. Para calcular áreas bajo la función de la normal se debe desarrollar la integral de la función respectiva, sin embargo, existe una tabla que puede ser utilizada independientemente de los valores que tome X, con el único requisito de que la variable X se distribuya normalmente con una media de µ y una desviación típica o estándar de σ. La tabla que se puede utilizar recibe el nombre de Tabla de la Normal Estandarizada. Siempre, antes de buscar el valor de probabilidad dentro de la tabla, se debe haber efectuado con antelación el proceso de estandarización de la variable X. Estandarización. Estandarizar la variable X, consiste en transformarla en otra que recibirá el nombre de Z, mediante la siguiente operación algebraica: Fórmula (59) Los parámetros de la nueva serie de datos Z, están dados por: La media de Z siempre es igual a cero: La varianza de Z siempre es igual a uno: 0 Por lo tanto, la desviación típica o estándar de Z siempre es igual a 1: Estadística para educación superior Representación gráfica de la normal estandarizada. Siempre que se grafique una función de densidad de probabilidad, es recomendable tabular la serie de datos para facilitar el gráfico en el plano cartesiano. En este caso, la función de densidad de probabilidad a graficar está dada por la siguiente expresión matemático-estadística: ( ) √ 𝑒 Para el gráfico se ubican en la abscisa los valores de Z, y en la ordenada, los valores arrojados por la función de densidad de probabilidad f(Z), la tabulación está dada por: Figura 50. Tabulación de la función de densidad de probabilidad f(Z) Z -3,5 -3,4 -3,3 -3,2 -3,1 -3 -2,9 -2,8 -2,7 -2,6 -2,5 -2,4 -2,3 -2,2 -2,1 -2 -1,9 -1,8 -1,7 -1,6 -1,5 -1,4 -1,3 -1,2 f (Z ) 0,00087268 0,00123222 0,00172257 0,00238409 0,00326682 0,00443185 0,00595253 0,00791545 0,01042093 0,01358297 0,0175283 0,02239453 0,02832704 0,03547459 0,0439836 0,05399097 0,06561581 0,07895016 0,09404908 0,11092083 0,1295176 0,14972747 0,17136859 0,19418605 Z -1,1 -1 -0,9 -0,8 -0,7 -0,6 -0,5 -0,4 -0,3 -0,2 -0,1 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 1,1 1,2 f (Z ) 0,21785218 0,24197072 0,26608525 0,28969155 0,31225393 0,3332246 0,35206533 0,36827014 0,38138782 0,39104269 0,39695255 0,39894228 0,39695255 0,39104269 0,38138782 0,36827014 0,35206533 0,3332246 0,31225393 0,28969155 0,26608525 0,24197072 0,21785218 0,19418605 Z 1,3 1,4 1,5 1,6 1,7 1,8 1,9 2 2,1 2,2 2,3 2,4 2,5 2,6 2,7 2,8 2,9 3 3,1 3,2 3,3 3,4 3,5 f (Z ) 0,17136859 0,14972747 0,1295176 0,11092083 0,09404908 0,07895016 0,06561581 0,05399097 0,0439836 0,03547459 0,02832704 0,02239453 0,0175283 0,01358297 0,01042093 0,00791545 0,00595253 0,00443185 0,00326682 0,00238409 0,00172257 0,00123222 0,00087268 Estadística para educación superior Figura 51. Representación gráfica de la normal estandarizada Probabilidades f(Z) Normal estandarizada Valores de Z Tabla de la distribución normal estandarizada. Existen tres tabulaciones o diseños de tablas de normal estandarizada, dependiendo si los valores de probabilidades que se hallan dentro de la tabla corresponden a áreas a la izquierda de un valor de Z, área a la derecha de un valor de Z o a un área entre dos valores de Z. A continuación se presenta la tabla de la normal estandarizada, con el cálculo para áreas a la izquierda de un valor de Z determinado, esto significa encontrar la probabilidad de que Z sea menor o igual a un valor particular o específico de ZP, se escribe P(Z ≤ ZP). Estadística para educación superior Figura 52. Tabla de la Distribución Normal Estandarizada P(Z ≤ ZP) ( ≤ ( ≤ Z -3,5 -3,4 -3,3 -3,2 -3,1 -3 -2,9 -2,8 -2,7 -2,6 -2,5 -2,4 -2,3 -2,2 -2,1 -2 -1,9 -1,8 -1,7 -1,6 -1,5 -1,4 -1,3 -1,2 -1,1 -1 -0,9 -0,8 -0,7 -0,6 -0,5 -0,4 -0,3 -0,2 -0,1 -0,0 0 0,0002 0,0003 0,0005 0,0007 0,0010 0,0013 0,0019 0,0026 0,0035 0,0047 0,0062 0,0082 0,0107 0,0139 0,0179 0,0228 0,0287 0,0359 0,0446 0,0548 0,0668 0,0808 0,0968 0,1151 0,1357 0,1587 0,1841 0,2119 0,2420 0,2743 0,3085 0,3446 0,3821 0,4207 0,4602 0,5000 ) ( )𝑑 ) 0,01 0,0002 0,0003 0,0005 0,0007 0,0009 0,0013 0,0018 0,0025 0,0034 0,0045 0,0060 0,0080 0,0104 0,0163 0,0174 0,0222 0,0281 0,0351 0,0436 0,0537 0,0655 0,0793 0,0951 0,1131 0,1335 0,1562 0,1814 0,2090 0,2389 0,2709 0,3050 0,3409 0,3783 0,4168 0,4562 0,4960 0,02 0,0002 0,0003 0,0005 0,0006 0,0009 0,0013 0,0018 0,0024 0,0033 0,0044 0,0059 0,0078 0,0102 0,0132 0,0170 0,0217 0,0274 0,0344 0,0427 0,0526 0,0643 0,0778 0,0934 0,1112 0,1314 0,1539 0,1788 0,2061 0,2358 0,2679 0,3015 0,3372 0,3745 0,4129 0,4522 0,4920 0,03 0,0002 0,0003 0,0004 0,0006 0,0009 0,0012 0,0017 0,0023 0,0032 0,0043 0,0057 0,0075 0,0099 0,0129 0,0166 0,0212 0,0268 0,0336 0,0418 0,0516 0,0630 0,0764 0,0918 0,1093 0,1292 0,1515 0,1762 0,2033 0,2327 0,2643 0,2981 0,3336 0,3707 0,4090 0,4483 0,4880 0,04 0,0002 0,0003 0,0004 0,0006 0,0008 0,0012 0,0016 0,0023 0,0031 0,0041 0,0055 0,0073 0,0096 0,0125 0,0162 0,0207 0,0262 0,0329 0,0409 0,0505 0,0618 0,0749 0,0901 0,1075 0,1271 0,1492 0,1736 0,2005 0,2297 0,2611 0,2946 0,3300 0,3669 0,4052 0,4443 0,4840 0,05 0,0002 0,0003 0,0004 0,0006 0,0008 0,0011 0,0016 0,0022 0,0030 0,0040 0,0054 0,0071 0,0094 0,0122 0,0158 0,0202 0,0256 0,0322 0,0401 0,0495 0,0606 0,0735 0,0885 0,1056 0,1251 0,1469 0,1711 0,1977 0,2266 0,2578 0,2912 0,3264 0,3632 0,4013 0,4404 0,4801 0,06 0,0002 0,0003 0,0004 0,0006 0,0008 0,0011 0,0015 0,0021 0,0029 0,0039 0,0052 0,0069 0,0091 0,0119 0,0154 0,0197 0,0250 0,0314 0,0392 0,0485 0,0594 0,0721 0,0869 0,1038 0,1230 0,1446 0,1685 0,1949 0,2236 0,2546 0,2877 0,3228 0,3594 0,3974 0,4364 0,4761 0,07 0,0002 0,0003 0,0004 0,0005 0,0008 0,0011 0,0015 0,0021 0,0028 0,0038 0,0051 0,0068 0,0089 0,0116 0,0150 0,0192 0,0244 0,0307 0,0384 0,0475 0,0582 0,0708 0,0853 0,1020 0,1210 0,1423 0,1660 0,1922 0,2206 0,2514 0,2843 0,3192 0,3557 0,3936 0,4325 0,4721 0,08 0,0002 0,0003 0,0004 0,0005 0,0007 0,0010 0,0014 0,0020 0,0027 0,0037 0,0049 0,0066 0,0087 0,0113 0,0146 0,0188 0,0239 0,0301 0,0375 0,0465 0,0571 0,0694 0,0838 0,1003 0,1190 0,1401 0,1635 0,1894 0,2177 0,2483 0,2810 0,3156 0,3520 0,3897 0,4286 0,4681 0,09 0,0002 0,0002 0,0003 0,0005 0,0007 0,0010 0,0014 0,0019 0,0026 0,0036 0,0048 0,0064 0,0084 0,0110 0,0143 0,0183 0,0233 0,0294 0,0367 0,0455 0,0559 0,0681 0,0823 0,0985 0,1170 0,1379 0,1611 0,1867 0,2148 0,2451 0,2776 0,3121 0,3483 0,3859 0,4247 0,4641 Estadística para educación superior Z 0,0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0 1,1 1,2 1,3 1,4 1,5 1,6 1,7 1,8 1,9 2,0 2,1 2,2 2,3 2,4 2,5 2,6 2,7 2,8 2,9 3,0 3,1 3,2 3,3 3,4 3,5 0 0,5000 0,5398 0,5793 0,6179 0,6554 0,6915 0,7257 0,7580 0,7881 0,8159 0,8413 0,8643 0,8849 0,9032 0,9192 0,9332 0,9452 0,9554 0,9641 0,9713 0,9772 0,9821 0,9861 0,9893 0,9918 0,9938 0,9953 0,9965 0,9974 0,9981 0,9987 0,9990 0,9993 0,9995 0,9997 0,9998 0,01 0,5040 0,5438 0,5832 0,6217 0,6591 0,695 0,7291 0,7611 0,791 0,8186 0,8438 0,8665 0,8869 0,9049 0,9207 0,9345 0,9463 0,9564 0,9649 0,9719 0,9778 0,9826 0,9864 0,9896 0,992 0,994 0,9955 0,9966 0,9975 0,9982 0,9987 0,9991 0,9993 0,9995 0,9997 0,9998 0,02 0,5080 0,5478 0,5871 0,6255 0,6628 0,6985 0,7324 0,7642 0,7939 0,8212 0,8461 0,8686 0,8888 0,9066 0,9222 0,9357 0,9474 0,9573 0,9656 0,9726 0,9783 0,9830 0,9868 0,9898 0,9922 0,9941 0,9956 0,9967 0,9976 0,9982 0,9987 0,9991 0,9994 0,9995 0,9997 0,9998 0,03 0,5120 0,5517 0,5910 0,6293 0,6664 0,7019 0,7357 0,7673 0,7967 0,8238 0,8485 0,8708 0,8907 0,9082 0,9236 0,9370 0,9484 0,9582 0,9664 0,9732 0,9788 0,9834 0,9871 0,9901 0,9925 0,9943 0,9957 0,9968 0,9977 0,9983 0,9988 0,9991 0,9994 0,9996 0,9997 0,9998 0,04 0,5160 0,5557 0,5948 0,6331 0,6700 0,7054 0,7389 0,7703 0,7995 0,8264 0,8508 0,8729 0,8925 0,9099 0,9251 0,9382 0,9495 0,9591 0,9671 0,9738 0,9793 0,9838 0,9875 0,9904 0,9927 0,9945 0,9959 0,9969 0,9977 0,9984 0,9988 0,9992 0,9994 0,9996 0,9997 0,9998 0,05 0,5199 0,5596 0,5987 0,6368 0,6736 0,7088 0,7422 0,7734 0,8023 0,8289 0,8531 0,8749 0,8944 0,9115 0,9265 0,9394 0,9505 0,9599 0,9678 0,9744 0,9798 0,9842 0,9878 0,9906 0,9929 0,9946 0,9960 0,9970 0,9978 0,9984 0,9989 0,9992 0,9994 0,9996 0,9997 0,9998 0,06 0,5239 0,5636 0,6026 0,6406 0,6772 0,7123 0,7456 0,7764 0,8051 0,8315 0,8554 0,8770 0,8962 0,9131 0,9279 0,9406 0,9515 0,9608 0,9686 0,9750 0,9803 0,9846 0,9881 0,9909 0,9931 0,9948 0,9961 0,9971 0,9979 0,9985 0,9989 0,9992 0,9994 0,9996 0,9997 0,9998 0,07 0,5279 0,5675 0,6064 0,6443 0,6808 0,7157 0,7486 0,7794 0,8078 0,8340 0,8577 0,8790 0,8980 0,9147 0,9292 0,9418 0,9525 0,9616 0,9693 0,9756 0,9808 0,9850 0,9884 0,9911 0,9932 0,9949 0,9962 0,9972 0,9979 0,9985 0,9989 0,9992 0,9995 0,9996 0,9997 0,9998 0,08 0,5319 0,5714 0,6103 0,6480 0,6844 0,7190 0,7517 0,7823 0,8106 0,8365 0,8599 0,8810 0,8997 0,9162 0,9306 0,9429 0,9535 0,9625 0,9699 0,9761 0,9812 0,9854 0,9887 0,9913 0,9934 0,9951 0,9963 0,9973 0,9980 0,9986 0,9990 0,9993 0,9995 0,9996 0,9997 0,9998 0,09 0,5359 0,5753 0,6141 0,6517 0,6879 0,7224 0,7549 0,7852 0,8133 0,8389 0,8621 0,8830 0,9015 0,9177 0,9319 0,9441 0,9545 0,9633 0,9706 0,9767 0,9817 0,9857 0,9890 0,9916 0,9936 0,9952 0,9964 0,9974 0,9981 0,9986 0,9990 0,9993 0,9995 0,9997 0,9998 0,9998 10.7.2 Distribución exponencial. La variable X representa el tiempo transcurrido entre dos eventos, sucesos, llegadas, por tal motivo se refiere a una variable cuantitativa continua. La distribución exponencial es muy Estadística para educación superior utilizada dentro de la teoría de colas o líneas de espera, para analizar el comportamiento de la variable tiempo, entre dos llegadas (éxitos). Función de densidad de probabilidad para la exponencial. La función de densidad de probabilidad está dada por: ( ) 𝑒 Fórmula (60) ( ) 𝑒 ≥ θ = tiempo promedio entre llegadas La función de densidad de probabilidad acumulativa se utiliza para calcular la probabilidad de que X sea menor o igual a determinado tiempo t: P(X ≤ t). ( ≤ 𝑡) ( ≤ 𝑡) ( )𝑑𝑥 𝑒 ( ≤ 𝑡) ( ) 𝑑𝑥 𝑒 Fórmula (61) 𝑒 Se presenta relación entre el número promedio de llegadas en la unidad de tiempo y el tiempo promedio entre llegadas (ver figura 53), siendo: λ = promedio de llegadas (clientes, éxitos) por unidad de tiempo. θ = tiempo promedio entre llegadas. Estadística para educación superior Figura 53. Relación entre el número promedio de llegadas y el tiempo promedio entre llegadas, de la función de densidad para la exponencial 1ª llegada 2ª llegada 3ª llegada λª llegada Unidad de tiempo t = 1 Si se toma la unidad de tiempo t = 1 y se divide por el tiempo promedio entre llegadas θ, se obtiene el número promedio de llegadas λ: Si se toma el tiempo promedio entre llegadas θ y se multiplica por el número de llegadas, se obtiene el tiempo total es decir la unidad de tiempo t = 1: Si se toma la unidad de tiempo t = 1 y se divide por el número promedio de llegadas, se obtiene el tiempo promedio entre llegadas θ: Parámetros de la distribución exponencial. Fórmula (62) Fórmula (63) Representación gráfica de la distribución exponencial. La forma que toma la distribución exponencial cambia dependiendo del valor que asuman λ y θ. Se grafica, a manera de ejemplo un caso particular (ver figura 54), donde: λ = 1 éxito/2 minuto (Se presenta 1 éxito cada dos minutos) Estadística para educación superior θ = 2 minutos (tiempo entre éxitos o llegadas). X = tiempo (en minutos) ( ) 𝑒 Sustituyendo el valor de θ se tiene: ( ) 𝑒 Figura 54. Representación gráfica de la distribución exponencial f (X ) 0,5 0,4412485 0,3894004 0,3436446 0,3032653 0,2676307 0,2361833 0,208431 0,1839397 0,1623262 0,1432524 0,1264198 0,1115651 0,0984558 0,086887 0,0766775 0,0676676 Distribución exponencial con θ = 2 Probabilidad X 0,00 0,25 0,50 0,75 1,00 1,25 1,50 1,75 2,00 2,25 2,50 2,75 3,00 3,25 3,50 3,75 4,00 X (tiempo) 10.7.3 Distribución uniforme continua. La variable aleatoria toma valores dentro de un intervalo finito, distribuyéndose uniformemente dentro de éste, es decir, el valor de densidad de probabilidad para cualquier valor X dentro del intervalo siempre es la misma. El límite inferior se identifica con un valor específico a y el límite superior con b, de tal forma que a ≤ X ≤ b. Esta distribución también se conoce con el nombre de distribución rectangular. Estadística para educación superior La función de densidad de probabilidad de la distribución uniforme está dada por: ( ) para a ≤ X ≤ b 𝑏 Fórmula (64) La forma que toma la distribución uniforme es una línea recta paralela al eje X, toda el área bajo función a través de todo el recorrido de X vale uno (1); esto es: ∫ ( )𝑑𝑥 a: valor más pequeño posible de X (límite inferior). b: valor más grande posible de X (límite superior). La función de distribución de probabilidad acumulativa viene dada por: ( ≤ 𝑥) ∫ (𝑡)𝑑𝑡 𝑑𝑡 ∫ ( ≤ 𝑥) 𝑥 𝑏 Fórmula (65) La probabilidad de que X se encuentre entre los valores a1 y b1, es: ( ≤ ≤𝑏 𝑏 𝑏 Fórmula (66) Parámetros para la uniforme continua. Los parámetros, media y varianza, para la distribución uniforme, vienen expresados por: Estadística para educación superior 𝑏 (𝑏 Fórmula (67) ) Fórmula (68) Representación gráfica de la distribución uniforme continua. Un ejemplo de representación gráfica para la distribución uniforme, a través del caso particular en que la variable tome valores entre 3 y 10. ( ) Se tabula la función f(X) para diferentes valores de X dentro del intervalo, arrojando siempre el mismo resultado, así: Figura 55. Representación gráfica para la distribución uniforme X 3,0 4,0 5,0 6,0 7,0 8,0 9,0 10,0 f (X ) 0,1429 0,1429 0,1429 0,1429 0,1429 0,1429 0,1429 0,1429 Valores de f(X) Distribución uniforme con a = 3 y b = 10 Valores de X Estadística para educación superior 10.7.4 Distribución Chi-cuadrado. La distribución Chi-cuadrado es muy utilizada para probar o analizar la forma como se comportan los datos en un proceso, esto se efectúa a través de la prueba para la bondad de ajuste, la cual se explica y analiza en el acápite sobre de Pruebas de hipótesis. Definición de la Chi-cuadrado. Sean X1, X2, X3,..., Xv variables aleatorias independientes que se distribuyen normalmente con una media de cero (0) y una desviación típica o estándar de uno (1), es decir variables que se distribuyen como normales estandarizadas; la sumatoria de cada una de estas variables normales estandarizadas al cuadrado recibe el nombre de Chi-cuadrado (ji-cuadrado) con v grados de libertad. La Chi-cuadrado se identifica con el símbolo . Fórmula (69) ∑ Sumatoria de normales estandarizadas al cuadrado. La función de densidad de probabilidad de la Chi-cuadrado, está dada por: ( ) ( ) ( ) 𝑒 ( ) Para X > 0 Fórmula (70) Estadística para educación superior Parámetros de la distribución Chi-cuadrado. La media y la varianza de la distribución Chi-cuadrado, se expresan en términos de los grados de libertad, así: Fórmula (71) Fórmula (72) El símbolo Г es la función Gamma definida en cálculo como: ( ) 𝑒 ∫ 𝑑𝑥 En caso de desear ampliar información sobre Г(n), remitirse al tema de la distribución tstudent, donde se visualizan algunas explicaciones al respecto. Representación gráfica de la Chi-cuadrado. La curva de la función de densidad de probabilidad de la Chi-cuadrado cambia dependiendo del valor específico que asuma v. Ejemplo: Para la Chi-cuadrado con v = 4 grados de libertad, la función queda definida así: ( ) 𝑒 ( ) ( ) ( ) ( ) ( ) 𝑒 ( ) ( ) ( 𝑒 ) 𝑒 Estadística para educación superior Se tabula esta función para diferentes valores de X y se obtienen los respectivos valores de f(X), puntos que se ubican en el plano cartesiano, dando forma a la curva de densidad de probabilidad de la Chi-cuadrado, así: Figura 56. Representación gráfica de la densidad de probabilidad de la Chi-cuadrado f (X ) 0,02378074 0,04524187 0,0645531 0,08187308 0,0973501 0,11112273 0,12332042 0,13406401 0,14346633 0,15163267 0,18393972 0,16734762 0,13533528 0,10260625 0,0746806 0,05284542 0,03663128 0,02499524 0,01684487 0,01123862 0,00743626 0,00488618 0,00319159 0,00207407 Distribución Chi-cuadrado para v = 4 Valores de f(X) X 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Valores de X La función de distribución de probabilidad acumulativa para la distribución Chi-cuadrado, se utiliza para calcular áreas bajo la curva a la izquierda de un valor específico de X, las cuales representan probabilidades, se expresa así: ( ) ( ≤ ) ∫ ( ) 𝑒 𝑑𝑥 Estadística para educación superior La tabla de la Chi-cuadrado se desprende de la función de distribución de probabilidad acumulativa y hace referencia específicamente a: ( ≤ ) ( ≤ ) Fórmula (73) Donde (1 – α) representa el valor de la probabilidad acumulativa o el valor del área bajo la curva de la Chi-cuadrado a la izquierda del valor específico de χ2. En la tabla de la Chi, el encabezado de las columnas representa diferentes valores de (1 α), el encabezado de las filas representa diferentes valores de v grados de libertad y cada cruce al interior de la misma representa el valor de una Chi-cuadrado ; datos éstos importantes para utilizarla acertadamente. Por ejemplo: ( ≤ ( ≤ ) ) Figura 57. Diseño de la tabla de la Chi-cuadrado ( ≤ ( ≤ ) ) Estadística para educación superior Figura 58. Tabla de la distribución de la Chi-cuadrado Estadística para educación superior 10.7.5 Distribución t-student. La distribución t-student se utiliza para analizar pruebas de hipótesis y calcular intervalos de confianza. (Para visualizar detalles al respecto, remitirse al acápite sobre pruebas de hipótesis e intervalos de confianza). La variable aleatoria t-student se define como el cociente entre la variable aleatoria normal estandarizada y la raíz cuadrada de la variable aleatoria Chi-cuadrado, dividida en sus grados de libertad. 𝑡 Fórmula (74) √ La siguiente es la función de densidad de probabilidad de la variable aleatoria t-student, para t que toma valores desde menos infinito hasta más infinito y v valores mayores que cero: ─∞ < t < +∞, v > 0. (𝑡 ) ( √ ) ( ) ( 𝑡 ( ) ) Fórmula (75) Parámetros de la distribución t-student. La media y la varianza para esta distribución están dadas por: para v > 1 Fórmula (76) para v > 2 Fórmula (77) En la función dada el símbolo Г identifica a la función Gamma, definida en cálculo como: Estadística para educación superior ( ) 𝑒 ∫ 𝑑𝑥 Otras fórmulas útiles para calcular Г(n), el valor gamma de un número n, son: ( ) ( ) ( ( ) ( ) ( ) √ ( ) ( ) ) ( para n entero para 0 < n < 1 ) Para calcular ( ) se aplica la fórmula para 0 < n < 1, así: ( ) ( ( ) ( ) ) ( ) ( ) [ ( )] [ ( )] [ ( )] ( ) √ Representación gráfica de la t-student. La forma que toma la función de densidad de probabilidad de la t-student se asemeja a la forma de una normal, existen muchas curvas de la t-student dependiendo del valor que asuma v en un caso específico, y de los valores de Z. Esta función es simétrica respecto a t = 0, punto de referencia que constituye el punto donde la función se maximiza. Estadística para educación superior Ejemplo: Caso particular de la forma que toma la función de densidad de probabilidad de la tstudent, para v = 5 grados de libertad. De igual manera se puede trabajar para cualquier valor de v. Se tiene la función definida: ( (𝑡 ) ( ) ( ) √ ( ) ) Para v = 5, se tiene: ( ) ( ) ( ) ( ) ( ) ( ( ) ( ) √ √ ( ) ) ( ) ( ) ( ) ( ) √ En resumen, la función t-student a graficar queda definida así: (𝑡 ) (√ ) ( ) Se tabula la función para diferentes valores de t; los valores de t se ubican en el eje X del plano cartesiano, y los valores que arroje f(t,5) se ubican en el eje Y. Estadística para educación superior Figura 59. Tabulación de la función t-student para diferentes valores de t y para v = 5 t -10 -9 -8 -7 -6 -5 -4 -3 -2 -1 -0,8 -0,6 -0,4 -0,2 0 0,2 0,4 0,6 0,8 1 2 3 4 5 6 7 8 9 10 f (t ) 0,00010798 0,00019652 0,00038051 0,00079383 0,00181367 0,00462963 0,01349746 0,04555394 0,17146776 0,5787037 0,69674314 0,81173756 0,90983137 0,97637894 1 0,97637894 0,90983137 0,81173756 0,69674314 0,5787037 0,17146776 0,04555394 0,01349746 0,00462963 0,00181367 0,00079383 0,00038051 0,00019652 0,00010798 El gráfico respectivo se observa a continuación, luego de ubicar las coordenadas indicadas (X, Y). Estadística para educación superior Figura 60. Gráfica de la función t-student para diferentes valores de t y para v = 5 F(t) con v = 5 Distribución t-student Valores de t Figura 61. Tabla de la t-student Estadística para educación superior 10.8 Ejercicios resueltos. 10.8.1 Producción de empaques (unidades defectuosas). El 20% de los empaques producidos por una máquina son defectuosos. Determinar la probabilidad de que de cuatro empaques tomados al azar: a) Exactamente uno sea defectuoso. b) Ninguno sea defectuoso. c) Por lo menos uno sea bueno. d) Entre uno y tres sean buenos. Solución Distribución binomial a) Característica de interés: defectuosos ( ) ( ) ( )( ) ( ) La probabilidad de que de cuatro empaques tomados al azar, exactamente uno sea defectuoso es de 0,4096. Si se toman cuatro empaques al azar, el grado de certeza de que exactamente uno sea defectuoso es del 40,96%. b) Característica de interés: defectuosos ( ) ( ) ( )( ) ( ) Si se toman cuatro empaques al azar producidos por esta máquina, la probabilidad de que ninguno sea defectuoso es de 0,4096. Si se toman cuatro empaques al azar producidos por esta máquina, el grado de certeza de que ninguno sea defectuoso es del 40,96%. c) Característica de interés: buenos Estadística para educación superior ( ≥ ) ( ) ( ≥ ) ( ) ( ) ( ) ( ) ( ) ( )( ) ( ) ( ≥ ) Si se toman cuatro empaques al azar producidos por esta máquina, la probabilidad de que por lo menos un empaque sea bueno es de 0,9984. Si se toman cuatro empaques al azar producidos por esta máquina, el grado de certeza de que por lo menos un empaque sea bueno es del 9,84%. d) Característica de interés: buenos ( ≤ ≤ ) ( ) ( ) ( ) ( )( ) ( ) ( ) ( )( ) ( ) ( ) ( )( ) ( ) ( ≤ ≤ ) ( ) ∑ (𝑥) Si se toman cuatro empaques al azar producidos por esta máquina, la probabilidad de que entre uno y tres empaques sean buenos es de 0,5888. Si se toman cuatro empaques producidos por esta máquina, el grado de certeza de que entre uno y tres empaques sean buenos es de 58,88%. 10.8.2 Venta de seguros de vida. Un vendedor de seguros vende pólizas a cinco hombres, todos de la misma edad (48 años) y en buen estado de salud. La probabilidad de que un hombre de esa edad viva 30 años más es de 2/3. Hallar la probabilidad de que dentro de 30 años: a) Vivan solamente dos de los hombres. b) Vivan al menos tres de los hombres. Estadística para educación superior Solución Distribución binomial a) ( ) ( ) ( )( ) ( ) Si se venden pólizas de seguro de vida a cinco hombres, todos de la misma edad y en buen estado de salud, la probabilidad de que dentro de 30 años vivan solamente dos hombres es de 0,161321; el grado de certeza de que dentro de 30 años vivan solamente dos hombres es del 16,13%. b) ( ≥ ) ( ) ( ) ( ) ( )( ) ( ) ( ) ( )( ) ( ) ( ) ( )( ) ( ) ( ≥ ) ( ) ∑ ( ) Si se venden pólizas de seguro de vida a cinco hombres, todos de la misma edad y en buen estado de salud, la probabilidad de que dentro de 30 años vivan como mínimo tres hombres es de 0,795037; el grado de certeza de que dentro de 30 años vivan por lo menos tres hombres es del 79,5%. Estadística para educación superior 10.8.3 Pago de facturas por parte de los usuarios de una compañía de teléfonos celulares. Los clientes de una compañía de teléfonos celulares llegan a la caja registradora para pagar sus facturas con una rapidez promedio de 15 clientes cada media hora. a) ¿Cuál es la probabilidad de que lleguen más de nueve clientes en 15 minutos? b) ¿Cuál es la probabilidad de que lleguen entre cinco y ocho clientes en 10 minutos? Solución Distribución Poisson 𝑖𝑒 𝑡𝑒 𝑚𝑖 𝑡 Al definir la unidad de tiempo “minuto”, el valor de λ queda expresado así: 𝑖𝑒 𝑡𝑒 𝑚𝑖 𝑡 La conversión de λ se obtiene a través de una regla de tres: Clientes Minutos 15 30 1 𝑥 a) ( 0 ) 1 2 3 4 5 6 7 8 9 10 11 12 ( ≤ ) La probabilidad pedida es ( 13 ( ) también puede expresarse como ( 14 15 ) ≥ ) Metodología 1: Evaluar la función de densidad de probabilidad para 10, 11, 12, 13, 14 y 15 éxitos, efectuar la sumatoria para obtener la probabilidad pedida. ( ) ∑ ( ) ( ) ( ) ( ) ( ) ( ) ( ) Metodología 2: Tener presente que la sumatoria de todas las ( ) vale 1, ∑ ( ) , por tal motivo ( ) ( ≤ ). En este caso, se debe calcular la probabilidad Estadística para educación superior ( ≤ ) de la siguiente manera: ( ≤ ) ∑ ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) El resultado obtenido al aplicar cada una de éstas metodologías es el mismo, por tal motivo se puede elegir trabajar con cualquiera de las dos, generalmente se elige la más corta, en este caso sería la metodología 1, sin embargo se muestra el procedimiento de la metodología 2, así: ( 𝑒 ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) 𝑒 ( ) 𝑒 ( ) 𝑒 ( ) 𝑒 ( ) 𝑒 ( ) 𝑒 ( ) 𝑒 ( ) 𝑒 ( ) 𝑒 ( ) ) 𝑒 ( ) Se obtiene la sumatoria: ∑ ( ) ( ( ( ( ≤ ) ) ) ) ( ≤ ) La probabilidad de que lleguen más de nueve clientes en 15 minutos es de 0,22359. El grado de certeza de que lleguen más de nueve clientes en 15 minutos es del 22,4% b) ( ≤ ( ≤ ≤ ) ≤ ) Con un 𝑡 ( ) ( ) minutos y un ( ) ( ) Estadística para educación superior ( ) ( ) ( ) ( ) ( 𝑒 𝑒 ( ) 𝑒 ( ) 𝑒 ( ) ( ≤ ≤ ) ( ≤ ≤ ) ) 𝑒 ( ) ∑ ( ) La probabilidad de que lleguen entre cinco y ocho clientes en 10 minutos es de 0,49141. El grado de certeza de que lleguen entre cinco y ocho clientes en 10 minutos es del 49,14%. 10.8.4 Importación de chapas para puertas de seguridad e inspección de calidad. Una compañía importadora de chapas para puertas de seguridad recibió un pedido de 25 chapas de las cuales siete son defectuosas. Cada que se recibe un pedido de 25 unidades se toma una muestra de cinco unidades para inspeccionar la calidad en que llegan. El pedido sólo es aceptado si la muestra de chapas trae como máximo dos unidades defectuosas. Cuando llega un lote de 25 unidades, calcular la probabilidad de que éste sea aceptado. Solución Distribución hipergeométrica. Unidad defectuosa se asocia con un éxito. Tamaño de la población: chapas. Número de éxitos en la población: Número de “no éxitos” en la población: Tamaño de la muestra: Se pide calcular ( ≤ ) Estadística para educación superior ( ≤ ) ∑ ( ) ( ≤ ) ( ) ( ) ( ) ( ) ( )( ) ( )( ) ( )( ) ( ) ( ) ( ≤ ) ( ≤ ) La probabilidad de que un lote de 25 unidades sea aceptado es de 0,8869565. El grado de certeza de que un lote de 25 chapas sea aceptado es del 88,70% 10.8.5 Volumen de exportación mensual de una compañía de electrodomésticos. El volumen de exportación mensual (en millones de pesos) de una compañía de electrodomésticos presenta un comportamiento normal, con una media de $22.500 y una desviación típica o estándar de $2.250. Calcular la probabilidad de que: a) El volumen de exportación mensual sea mayor a $21.000 millones. b) El volumen de exportación mensual se encuentre entre $24.000 y $26.000 millones. c) El volumen de exportación mensual no sea superior a $19.000 millones. Estadística para educación superior Solución a) ( ≤ ) ( ≤ ( ≤ ) ( ≤ ( ≤ ) ( ≤ ( ≤ ( ≤ ) ) ) ) ) La probabilidad de que el volumen de exportación mensual sea mayor o igual a $21.000 millones es de 0,7486. El grado de certeza de que el volumen de exportación sea mayor o igual a $21.000 millones es del 74,86%. b) ( ( ( ( ≤ ≤ ≤ ≤ ≤ ≤ ≤ ≤ ) ) ) ) ( ≤ ( ≤ ) ) ( ≤ ( ≤ ) ) Estadística para educación superior La probabilidad de que el volumen de exportación mensual se encuentre entre $24.000 y $26.000 millones es de 0,1920. El grado de certeza de que el volumen de exportación mensual se encuentre entre $24.000 y $ 26.000 millones es del 19,20%. c) ( ≤ ( ≤ ) ) ( ≤ ) La probabilidad de que el volumen de exportación mensual se encuentre por debajo (menor o igual) de $19.000 millones es de 0,0594. El grado de certeza de que el volumen de exportación sea como máximo de $19.000 millones es del 5,94%. 10.8.6 Vida útil de las pilas de una cierta marca. La vida útil de las pilas de una cierta marca está distribuida normalmente. Si el 6,68% de las pilas duran más de 56 horas y el 30,85% duran menos de 52 horas, ¿cuál es la media y la desviación estándar? Solución Distribución normal vida útil de las pilas (en horas). ( ≥ ) ( ≤ ( ≤ ) ) Estadística para educación superior Estandarizando, se obtienen las siguientes expresiones estadísticas: ( ≤ ) ( ≤ ( ≤ ( ≤ ) ) ) Se busca en la tabla de la normal estandarizada, el valor de la probabilidad 0,9332 y se extrae el valor de , de igual manera se busca la probabilidad 0,3085 y se encuentra un . Plantear el siguiente sistema de ecuaciones de 2x2, las dos incógnitas son precisamente µ y σ . Primera ecuación: Segunda ecuación: Se resuelve simultáneamente el sistema por algún método algebraico (igualación, sustitución, reducción o determinantes) o por métodos de álgebra lineal (eliminación Gaussiana, Jordan Gauss, pivoteo, entre otros). Por el método de igualación: se despeja la misma variable en ambas ecuaciones, se iguala quedando una ecuación en términos de una sola variable, se despeja la variable, el valor encontrado se sustituye en alguna de las ecuaciones para hallar el valor de la otra variable. Igualando se tiene: Se despeja el valor de σ, así: Estadística para educación superior Se sustituye el valor de σ en alguna de las ecuaciones, así: ( ) La vida útil media de las pilas y su desviación típica o estándar es de horas. horas y La representación gráfica se muestra a continuación: 10.8.7 Llegada de clientes a un banco. Los clientes llegan a un banco con una rapidez promedio de 20 clientes por hora. Si un cliente acaba de llegar: a) ¿Cuál es la probabilidad de que el siguiente cliente llegue dentro de 10 minutos? b) ¿Cuál es la probabilidad de que el siguiente cliente llegue en el lapso de tiempo entre tres y siete minutos? Estadística para educación superior Solución Distribución exponencial a) clientes/hora minutos Se expresa el valor de λ y de X en la misma unidad de tiempo. Para pasar el valor de X dada en minutos, a horas, se puede resolver la siguiente regla de tres simple: Hora Minutos 1 60 10 ( ≤ ) 𝑒 ( ≤ ) 𝑒 La probabilidad de que el siguiente cliente llegue dentro de 10 minutos es de 0,966. El grado de certeza de que el siguiente cliente llegue dentro de 10 minutos es de 96,6%. b) ( 𝑚𝑖 ≤ ≤ 𝑚𝑖 ) Utilizando regla de tres simple se pasa lo expresado en minutes, a horas. ( ≤ ≤ ) ( ≤ ≤ ) ( ≤ ( ≤ ≤ ) [ 𝑒 ( ≤ ≤ ) ( 𝑒 ) ( ( ≤ ) ) ] ( 𝑒 [ ( ) 𝑒 ) ] ) La probabilidad de que el siguiente cliente llegue en el lapso de tiempo entre tres y siete minutos es de 0,2706. El grado de certeza de que el siguiente cliente llegue en el lapso de tiempo entre tres y siete minutos es del 27,06%. Estadística para educación superior 10.8.8 Producción de circuitos electrónicos y su vida útil. El departamento de producción de una compañía efectúa un experimento para analizar la vida útil (en horas) de un circuito electrónico, para ello somete los circuitos de varios lotes de producción bajo las mismas condiciones, encontrando que la vida útil se encuentra distribuida uniformemente entre 2.500 y 3.000 horas. Si se selecciona de manera aleatoria un circuito electrónico: a) ¿Cuál es la probabilidad de que dure menos de 2.670 horas? b) ¿Cuál es la probabilidad de que su vida útil se encuentre entre 2.800 y 2.950 horas? Solución Distribución uniforme continua a) ( ≤ ) Si se selecciona un circuito electrónico de manera aleatoria, el grado de certeza de que éste dure menos de 2.670 horas es del 34%. b) ( ≤ ≤ ) Si seleccionamos un circuito electrónico de manera aleatoria, el grado de certeza de que dure entre 2.800 y 2.950 horas es del 30%. 10.9 Ejercicios de aplicación propuestos. 10.9.1 Unidades defectuosas en un proceso de manufactura. Todos los días se seleccionan de manera aleatoria, seis unidades de un proceso de manufactura, con el propósito de verificar el porcentaje de unidades defectuosas en la Estadística para educación superior producción. Con base en información pasada, la probabilidad de tener una unidad defectuosa es de 0,12. La gerencia ha decidido detener la producción cada vez que una muestra de seis unidades tenga dos o más defectuosas. ¿Cuál es la probabilidad de que en cualquier día, la producción se detenga? 10.9.2 Campaña de mercadeo para un club nacional de automovilistas. Un club nacional de automovilistas comienza una campaña telefónica con el propósito de mercadear y aumentar el número de personas afiliadas al club. Con base en experiencia previa se sabe que una de cada 20 personas que reciben la llamada, se une al club. Si en un día 14 personas reciben la llamada telefónica, ¿cuál es la probabilidad de que por lo menos tres personas de ellas se unan al club? 10.9.3 Pago de compras con tarjeta de crédito en un almacén. El 38% de los clientes de un almacén pagan sus compras con tarjeta de crédito, si se selecciona una muestra aleatoria de 25 clientes: a) ¿Cuál es la probabilidad de que exactamente cinco clientes paguen con tarjeta de crédito? b) ¿Cuál es la probabilidad de que por lo menos ocho clientes paguen con tarjeta de crédito? c) ¿Cuál es la probabilidad de que entre cinco y nueve clientes no paguen con tarjeta de crédito? d) ¿Cuál es la probabilidad de que a lo sumo (como máximo) dos clientes no paguen con tarjeta de crédito? Estadística para educación superior 10.9.4 Control de calidad en cajas de bombillas. Supóngase que en una caja con bombillas, el 10% son defectuosas. Cuál es la probabilidad de que una muestra al azar de cinco bombillas contenga: a) Por lo menos una defectuosa. b) Por lo menos tres defectuosas. c) Exactamente una defectuosa. d) Como máximo, una defectuosa. 10.9.5 Asistencia tarde al trabajo por parte de empleados. El 30% de los empleados de una compañía llegan tarde al trabajo. Si se eligen 10 personas al azar, cuál es la probabilidad de que: a) Tres lleguen tarde. b) Como mínimo, tres lleguen tarde. c) Como máximo, cinco lleguen tarde. 10.9.6 Preferencias por determinado candidato a la presidencia. El 70% de los antioqueños creen en el candidato A para la presidencia. Si seleccionamos nueve antioqueños al azar, cuál es la probabilidad de que: a) Crean tres o menos. b) Crean más de cuatro. c) Crean menos de dos. 10.9.7 Hogares con televisión por cable. El 75% de los hogares del área metropolitana de Medellín tienen televisión por cable. Si se analizan 18 hogares, cuál es la probabilidad de que el número de ellos que tenga cable sea: Estadística para educación superior a) Mayor que uno. b) Cinco o menos. c) Entre siete y ocho, inclusive. d) Diecisiete o más. 10.9.8 Tiempo de llegada de estudiantes a una biblioteca. Los alumnos llegan a la biblioteca con una rapidez promedio de 50 alumnos por hora. Si un alumno acaba de llegar, cual es la probabilidad de que el siguiente usuario llegue: a) Dentro de 15 minutos. b) Dentro de 10 minutos. c) Después de 12 minutos. d) Entre en el lapso de tiempo de ocho a 13 minutos. 10.9.9 Número de estudiantes que llegan a una biblioteca. Los alumnos llegan a la biblioteca con una rapidez promedio de 50 alumnos por hora. Cuál es la probabilidad de que lleguen: a) Tres alumnos en los próximos 15 minutos (es decir, dentro de 15 minutos). b) Dos alumnos en los próximos 10 minutos. c) Entre Tres y seis alumnos en los próximos 10 minutos. c) Entre 20 y 30 alumnos en los próximos 30 minutos. d) Menos de tres alumnos en los próximos 12 minutos. 10.9.10 Tiempo de llegada de clientes a la caja registradora. Los clientes de un supermercado llegan a la caja registradora con una rapidez promedio de dos clientes por minuto. Si un cliente acaba de llegar, cuál es la probabilidad de que el siguiente cliente llegue: Estadística para educación superior a) En medio minuto (es decir, dentro de medio minuto). b) Dentro de un minuto. c) Dentro de minuto y medio. d) Dentro de dos minutos y medio. e) Entre el lapso de tiempo de uno a 2,5 minutos. 10.9.11 Número de clientes que llegan a la caja registradora. Los clientes de un supermercado llegan a la caja registradora con una rapidez promedio de dos clientes por minuto. Cuál es la probabilidad de que lleguen: a) Tres clientes en el próximo minuto. b) Cuatro clientes en el próximo minuto. c) Tres clientes en los próximos dos minutos d) Cinco clientes en el próximo minuto y medio. e) Entre uno y tres clientes por minuto. 10.9.12 Tiempo y número de clientes que llegan a una compañía de teléfonos celulares. Los clientes de una compañía de teléfonos celulares llegan a la caja registradora para pagar sus facturas con una rapidez promedio de 15 clientes cada media hora. a) ¿Cuál es la probabilidad de que lleguen más de nueve clientes en 15 minutos? b) ¿Cuál es la probabilidad de que lleguen entre cinco y ocho clientes en 10 minutos? c) Si acaba de llegar un cliente, ¿cuál es la probabilidad de que el siguiente cliente llegue dentro de 5 minutos? d) Si acaba de llegar un cliente, ¿cuál es la probabilidad de que el siguiente cliente llegue en el lapso de tres a 10 minutos? Estadística para educación superior 10.9.13 Proceso de selección y contratación de personal en una entidad financiera. El jefe de personal de una entidad financiera debe contratar ocho personas entre 35 candidatos para el cargo de analista de cartera, 24 de los candidatos tienen título profesional y el resto son estudiantes de los últimos semestres. ¿Cuál es la probabilidad de que cinco de los contratados tengan título profesional? 10.9.14 Firma de asesores en comercio internacional para nuevos proyectos. De los 20 ejecutivos de una firma de asesores en comercio internacional, se seleccionan 12 para ser enviados a Francia a estudiar nuevos proyectos con empresas de ese país. Ocho de los ejecutivos ya tienen experiencia con casos similares. ¿Cuál es la probabilidad de que cinco de los enviados tengan experiencia previa en proyectos similares? 10.9.15 Cálculo de áreas bajo la curva de la distribución normal estandarizada. Hallar el área bajo la curva normal: a) Entre b) Entre y y c) Entre y d) A la izquierda de e) A la derecha de Nota: graficar cada numeral. 10.9.16 Ventas anuales a crédito. Las ventas anuales a crédito (por club) de un almacén se distribuyen normalmente, con una media y una desviación típica o estándar de: (millones de pesos). Calcular las siguientes probabilidades: (millones de pesos) y Estadística para educación superior a) Probabilidad de que las ventas anuales por club estén por debajo de $38,7 millones. b) Probabilidad de que las ventas anuales por club sean superiores a $ 31,5 millones. c) Probabilidad de que las ventas anuales por club se encuentren entre $30,2 y $37,5 millones. Nota: graficar cada numeral y analizar resultados obtenidos. 10.9.17 Gasto semanal en loncheras para niños. Si el gasto semanal en loncheras para niños de preescolar se encuentra distribuido normalmente con una media de $10 mil y una desviación estándar de $2 mil, emplear la tabla y calcular las siguientes probabilidades: a) ( ) b) ( ) c) ( d) ( e) ( ) ) ) Nota: graficar cada numeral y analizar los resultados obtenidos. 10.9.18 Estatura de los alumnos de un colegio. Suponiendo que las estaturas X de los alumnos de un colegio se encuentran distribuidas normalmente con una media igual a 169 cm y una desviación estándar igual a 3 cm, calcular las siguientes probabilidades (empleando la tabla): a) Probabilidad de que un estudiante tenga una estatura inferior a 165 cm. b) Qué porcentaje de alumnos tendrá una estatura entre 165 y 170 cm. Nota: graficar y analizar resultados. Estadística para educación superior 10.9.19 Peso promedio de las frutas de un cargamento a transportar. El peso promedio de las frutas de un gran cargamento es de 15 lb. Con una desviación estándar de 1,62 lb.; si sus pesos están distribuidos normalmente, ¿qué porcentaje de frutas tendrá un peso entre 15 lb y 18 lb? Graficar. 10.9.20 Duración de las baterías de una cierta marca. Si la vida media de cierta marca de baterías es de 30 meses, con una desviación estándar de seis meses, ¿qué porcentaje de estás baterías puede esperarse que tengan una duración de 24 a 36 meses? Se supone que su duración tiene una distribución normal. Graficar. 10.9.21 Salario medio mensual. En cierto negocio, el salario medio mensual es de $386.000 y la desviación estándar es de $4.500. Si se supone que los salarios tienen una distribución normal, ¿qué porcentaje de empleados percibe salarios entre $380.000 y $385.000? Graficar. 10.9.22 Notas en un examen de legislación. Dos estudiantes fueron informados de que habían recibido referencias tipificadas de 0,8 y –0,4 respectivamente, en un examen de legislación. Si sus puntuaciones fueron 88 y 64 respectivamente, hallar la media y la desviación típica (o estándar) de las puntuaciones del examen. Estadística para educación superior 10.9.23 Peso de un grupo de deportistas. La media del peso de 500 deportistas (mayores de edad) es de 75,5k y la desviación típica es de 6k. Suponiendo que los pesos se distribuyen normalmente, hallar cuántos deportistas pesan: a) Entre 60 y 75,5k. b) Más de 92,5k. 10.9.24. Gasto semanal en transporte por parte de un grupo de empleados. El gasto promedio semanal en transporte de un grupo de empleados es de $15.000 y la desviación estándar es de $3.500. Se sabe que 647 empleados tienen un gasto mayor de $16.300 ¿Cuál es el número total de empleados? 10.9.25 Publicación sobre los salarios mensuales de contadores. Una revista publicó un estudio donde se indica que los salarios mensuales para contadores titulados presenta un comportamiento normal con una media de $2.800.000 y una desviación típica o estándar de $435.000. Cuál es la probabilidad de que: a) Un contador titulado gane entre $1.500.000 y $3.000.000. b) Un contador titulado gane más de $2.598.000. Graficar cada caso e interpretar. 10.9.26 Fabricación de neumáticos y su vida útil. Una fábrica de neumáticos produce llantas con una vida útil media de 85.000 Km y una desviación estándar de 6.800 Km. La vida útil se encuentra distribuida normalmente. a) ¿Cuál es la probabilidad de que una llanta dure más de 91.000 Km? Estadística para educación superior b) Hallar el valor del Kilometraje límite donde el 7,3% de los neumáticos duran menos de dicho valor (en Km). c) ¿Cuál es la probabilidad de que un neumático dure entre 80.000 Km y 93.000 Km? Graficar cada caso e interpretar. 10.9.27 Comisión mensual obtenida por un grupo de vendedores. El nivel de comisión mensual obtenida por un grupo de vendedores se encuentra distribuido normalmente. El 3,15% ganan por concepto de comisión, más de $980.000; el 85,3% obtienen menos de $574.000. Determinar la comisión promedio y la desviación estándar. Graficar. 10.9.28 Vida útil de circuitos electrónicos. La vida útil media de un circuito electrónico es de 1.200 horas, y la desviación típica o estándar es de 250 horas. Si la vida útil se distribuye normalmente, ¿cuál es la probabilidad de que el circuito dure más de 1.300 horas? Graficar e interpretar. 10.9.29 Producción de arandelas: unidades aceptables y defectuosas. La media de los diámetros de una muestra de arandelas producidas por una máquina es de 0,502 pulgadas, y la desviación típica, de 0,005 pulgadas. Las arandelas se consideran buenas o aceptables si su diámetro se encuentra entre 0,496 y 0,508 pulgadas. Determinar el porcentaje de arandelas defectuosas producidas por la máquina, si se sabe que los diámetros presentan una distribución normal. Graficar e interpretar. Estadística para educación superior 10.9.30 Costo de trascripción e impresión de trabajo de tesis. Un digitador estima que el costo de transcribir e imprimir una tesis para obtener título profesional es una variable aleatoria que se distribuye normalmente con una media de $1.700.000 y una desviación típica de $95.000. ¿Cuál es la probabilidad de que el costo de transcribir e imprimir una tesis se encuentre entre $1.320.000 y 1.900.000? Graficar. 10.9.31 Puntaje en proceso de admisión para laborar en una empresa. El puntaje obtenido en un examen por un grupo de personas durante el proceso de admisión para laborar en una empresa se distribuye normalmente con una media de 700 puntos y una desviación típica de 120 puntos. Se decide no tener como referencia de posibles alternativas de elección al 5% de personas con puntaje más bajo. ¿Cuál es ese puntaje mínimo necesario para ser tenido en cuenta dentro del proceso de admisión? Graficar. 10.9.32 Tiempo de servicio en una compañía de reparación de fotocopiadoras. Una compañía de reparación de fotocopiadoras sabe que el tiempo invertido en hacer un servicio se puede representar como una variable aleatoria normal con una media de 75 minutos y una desviación típica de 20 minutos. ¿Qué proporción de servicios se hacen en menos de una hora? Graficar. 10.9.33 Tiempo de espera en un restaurante. El tiempo que tardan en recibir su orden después de hacerla, en un prestigioso restaurante de la ciudad, promedia 10 minutos. De acuerdo a estudios previos, se sabe que la distribución del tiempo de espera en ser atendido se distribuye exponencialmente. a) Calcular la probabilidad de que el tiempo de espera sea mayor de 12 minutos. b) Probabilidad de que el tiempo de espera sea menor o igual a 10 minutos. Estadística para educación superior 10.9.34 Tiempo de servicio en una agencia de viajes. El tiempo de servicio en una agencia de viajes se distribuye exponencialmente con una media de cuatro minutos. Cuál es la probabilidad de que el tiempo de servicio sea: a) Mayor de cuatro minutos. b) Menor de cuatro minutos. c) Menor de dos minutos. d) Entre dos y cinco minutos. 10.9.35 Control de calidad en producción de bombillas eléctricas. El departamento de control de calidad de una empresa productora de bombillas eléctricas efectúa un análisis de la duración del producto que fabrica, encuentra que la vida útil se distribuye exponencialmente con una media de 1000 horas. a) ¿Cuál es la probabilidad de que la bombilla falle dentro de 500 horas? b) Probabilidad de que la bombilla falle dentro de 1000 horas. c) Probabilidad de que la bombilla falle dentro de 1500 horas. d) Probabilidad de que la bombilla falle dentro de 2000 horas. 10.9.36 Vida útil de transistores importados por una firma nacional. Los transistores importados por una firma nacional distribuidora de productos afines tiene una vida útil media de 25 horas. El jefe de compras de esta empresa desea saber: a) Cuál es la probabilidad de que un transistor dure más de 30 horas. b) Si el jefe de compras adquiere 1.720 transistores, ¿cuántos de ellos duran menos de 20 horas? Estadística para educación superior 10.9.37 Transporte de mercancía en camiones hacia una bodega. A una bodega llegan en promedio cuatro camiones durante una hora para ser descargados, hallar: a) El tiempo promedio en minutos entre la llegada de cada camión. b) Suponga que acaba de llegar un camión. ¿Cuál es la probabilidad de que el tiempo que transcurra para la llegada del próximo camión sea menor de 10 minutos? 10.9.38 Servicio de taxis en un aeropuerto local. La empresa “Súper-Taxis” programa la llegada de sus taxis al aeropuerto local con una tasa media de llegada de 12 taxis por hora. El gerente de una multinacional acaba de arribar al el aeropuerto y tiene que ir al centro de la ciudad para cerrar un gran negocio, ¿cuál es la probabilidad de que no tenga que esperar más de cinco minutos para tomar un taxi? 10.9.39 Inducción y entrenamiento a un nuevo empleado. El tiempo promedio para entrenar a un nuevo empleado como asesor de servicio al cliente es de dos semanas. ¿Cuál es la probabilidad de que el empleado pueda ser formado como máximo, en una semana y media (1,5 semanas)? 10.9.40 Tiempo de llegada de clientes para pago de servicios públicos. Los clientes llegan a pagar sus cuentas de servicios públicos en una caja registradora a razón de 10 clientes por hora. Si acaba de llegar un cliente, ¿cuál es la probabilidad de que el siguiente llegue dentro de los próximos 15 minutos? Estadística para educación superior 10.9.41 Contenido de cerveza envasada por botella. El contenido promedio de cerveza envasado por botella en una compañía es de 17,4 onzas, su contenido se considera aceptable si se encuentra entre 16,3 onzas y 18,5 onzas, siguiendo una distribución uniforme. Si se selecciona aleatoriamente un envase, ¿cuál es la probabilidad de que su contenido esté entre 16,8 y 17,2 onzas? 10.9.42 Empaque de leche en polvo en una compañía de procesamiento de lácteos. Una compañía dedicada al procesamiento de lácteos y sus derivados empaca bolsas de leche en polvo para la venta, el contenido de las bolsas se encuentra distribuido uniformemente entre 1,9 y 2,2 libras. a) ¿Cuál es el peso promedio de la bolsa de leche en polvo? b) Si se selecciona aleatoriamente una bolsa de leche en polvo, ¿cuál es la probabilidad de que su peso se encuentre entre 2 y 2,13 libras? c) Probabilidad de que su peso sea inferior a 2,15 libras. Estadística para educación superior PARTE IV 11. Muestreo básico El muestreo es una técnica estadística a través de la cual se trabaja con una parte representativa de la población, con el objetivo de hacer inferencias para toda la población. Surgen interrogantes básicos por solucionar como: ¿cuántos elementos de la población se deben tomar para que conformen la muestra?, ¿cuáles elementos de la población deben ser elegidos?, ¿cómo debe hacerse el proceso de selección de los elementos?; todos estos interrogantes se analizan dentro de las técnicas de muestreo para tomar decisiones al respecto. 11.1 Tamaño de muestra. Al iniciar una investigación aplicando muestreo, una decisión fundamental es determinar el tamaño óptimo de la muestra, denotado por n, de tal forma que los costos de recolección de información no sean demasiado altos, y al mismo tiempo, asegurando cierto grado de confianza en las inferencias o pronósticos para la población elaborados a partir de dicha muestra. El tamaño de la muestra también se ve afectado por el tiempo predeterminado durante el cual se debe llevar a buen término los resultados de la investigación, por el recurso humano (encuestadores) de que se disponga, así como por el recurso económico destinado a la investigación. Cálculo del tamaño de muestra. Fórmula (78) Fórmula (79) Estadística para educación superior Cálculo de Z. Se toma de la tabla de la distribución normal estandarizada acumulativa. El valor de Z cambia dependiendo de la confianza con que se desee trabajar la investigación. Los pasos a seguir antes de extraer el valor correspondiente de Z son: Cuadro 13. Pasos para hallar el valor de Z, para el tamaño de la muestra Paso 1: Definir la confianza, la cual se denota como (1 ) Paso 2: Despejar α (Grado de incertidumbre) Paso 3: Calcular 2 Paso 4: Calcular 1 2 Paso 5: Buscar el valor de esta probabilidad (1 ) por dentro de la tabla y mirar cuál es 2 el valor de Z correspondiente (los valores de Z están en el borde de la tabla). En caso de no encontrarse el valor exacto de (1 ) se ubica el más aproximado, para 2 identificar luego el valor de Z, sin embargo, para una mayor precisión, se aplica la técnica de interpolación de datos para calcular el Z. Interpolación. La interpolación de datos es un procedimiento basado en el cálculo de distancias y de regla de tres proporcional. Se busca dentro de la tabla de la normal estandarizada, el valor de ( ) que corresponde a una probabilidad, en caso de no encontrarse el valor exacto, ubicamos dos valores de probabilidades con sus respectivos valores asociados de Z, la única condición es que dentro del rango de estos dos valores de probabilidades esté el valor de ( ). Estadística para educación superior Cuadro 14. Procedimiento para aplicar interpolación para hallar el valor de Z a través de un ejemplo 𝜶 Dado el valor de( ) = , 𝟗𝟕𝟑𝟒𝟑, hallar el valor de Z correspondiente, de tal forma que la probabilidad 𝑷(𝒁 ≤? ) = , 𝟗𝟕𝟑𝟒𝟑. Solución Paso 1: Se busca en la tabla de la distribución normal estándar acumulativa, el valor de 0,97343 (probabilidad), al no encontrarse, se extraen los siguientes dos valores de probabilidades con sus respectivos valores de Z: Z Probabilidad 0,9732 0,97343 0,9738 1,93 ? 1,94 Paso 2: Calcular las distancias. Z 0,01 1,93 ? 1,94 d Probabilidad 0,9732 0,97343 0,9738 0,00023 Paso 3: Aplicar la regla de tres proporcional a las distancias y solucionarla. Distancias Z 0,01 d Dist. Probabilidades 0,0006 0,00023 Se puede leer: 0,01 es a 0,0006, como d es a 0,00023. Al solucionarla, se encuentra el valor de d, así: 𝑑= (0,01)(0,00023) 0,0006 = 0,003833 Paso 4: Calcular el valor de Z pedido, así: = 1,93 + 0.003833 = 1,933833 0.0006 Estadística para educación superior Cálculo de S2. El cálculo de S2 (varianza muestral o cuasivarianza), se efectúa de manera diferente, dependiendo del tipo de variable (cuantitativa o cualitativa) que se considere más importante o relevante dentro de la investigación. Si existen estudios preliminares, éste valor se puede sacar del estudio anterior, pero en caso de no existir, se debe tomar una muestra piloto que sirva de referencia para el cálculo respectivo de S2. El tamaño de la muestra piloto (npilot) es generalmente menor o igual al 4% del tamaño de la población (N), es decir, un porcentaje pequeño del tamaño poblacional. Para variable cuantitativa: En datos sin agrupar: En datos agrupados: ∑( ∑( ̅) ̅) Fórmula (80) (𝑖) Fórmula (81) El S2 puede ser calculado a través del Excel o también con la utilización de las calculadoras científicas, ingresando previamente los datos en el modo SD. Para variable cualitativa. Fórmula (82) Fórmula (83) p = proporción de elementos que poseen la característica de interés. Es un valor entre 0 y 1: ≤ ≤ a = total de elementos que poseen la característica de interés. Estadística para educación superior Fórmula (84) 𝑏 q = proporción de elementos que no poseen la característica de interés: Fórmula (85) ≤ ≤ b = total de elementos que no poseen la característica de interés. 𝑏 Fórmula (86) Cálculo de E. El margen de error E, se calcula de manera diferente, dependiendo del tipo de variable (cuantitativa o cualitativa) que se considere más importante o relevante dentro de la investigación. Para variable cuantitativa: ̅ En datos sin agrupar: En datos agrupados: ̅ = promedio ̅ ̅ ∑ ∑ Fórmula (87) Fórmula (88) Fórmula (89) Para variable cualitativa: Fórmula (90) Nota: En las Fórmulas anteriores se trabaja inicialmente el n como npilot, porque el tamaño de muestra n es precisamente lo que se está calculando a partir de los datos recolectados en la muestra piloto. Estadística para educación superior 11.2 Relación entre el tamaño poblacional y el muestral. Se tiene la creencia de que el tamaño de la muestra n crece indefinidamente a medida que aumenta el tamaño poblacional, simbolizado por N, esta creencia es errónea, ya que existe un punto en el cual el tamaño de la muestra permanece constante, aunque el tamaño de la población aumente. A continuación, se visualiza el comportamiento del tamaño de la muestra en relación con el tamaño poblacional, a través de un ejemplo particular. Estadística para educación superior Cuadro 15. Comportamiento del tamaño de la muestra en relación con el tamaño poblacional: Ejemplo Calcular los diferentes tamaños de muestra dependiendo del tamaño poblacional, para una confianza del 95% y un error de estimación del 5%, en una investigación de la cual no existen estudios preliminares y donde la variable más relevante es cualitativa. Solución En este caso se tienen los siguientes valores: 2 = 1,96 = (0,5)(0,5) = 0,25 = = 5% = 0,05 2 2 0 1+ 0 0 = 2 Se sustituyen estos valores en las fórmulas para el cálculo del tamaño de muestra, y se obtienen los resultados siguientes: Relación entre el tamaño poblacional y el muestral Para el caso de un nivel de confianza del 95%. Tamaño poblacional N 1.000 2.000 3.000 4.000 5.000 10.000 20.000 50.000 100.000 500.000 o más Tamaño de muestra n 278 322 341 350 357 370 377 381 383 384 El análisis matemático-estadístico del motivo por el cual el tamaño de la muestra se estabiliza aunque el tamaño de la población aumente, es el siguiente: = 2 2 0 1+ 0 0 = 2 Cuando N tiende a ser muy grande o tiende a infinito, la división 0 tiende a cero. Por tal motivo se estabiliza el tamaño de la muestra precisamente en = 0 , porque al efectuar operaciones siempre se estaría dividiendo 0 para obtener el valor de n. 1 Estadística para educación superior 11.3 Relación entre nivel de confianza, margen de error y error de estimación. Figura 62. Relación entre nivel de confianza, margen de error y error de estimación El nivel de confianza ( ) se refiere a la confianza, probabilidad o grado de certeza de que la muestra permita estimar el parámetro poblacional. El margen de error α se refiere al grado de error o probabilidad de que las muestras no permitan estimar el parámetro poblacional. Conocido también como error de tipo 1, nivel de significación o probabilidad de rechazar la hipótesis dado que es verdadera, siendo la hipótesis en este caso, una proposición donde se afirma que el parámetro poblacional esta dado por el estimador obtenido con la muestra, α es una probabilidad establecida con el objetivo de minimizar el error de tipo 1, la región α bajo la curva de la distribución normal se denomina región crítica o zona de rechazo. Existen muchas posibles muestras que pueden ser seleccionadas de una misma población, por tal motivo se habla de distribuciones muestrales. Una muestra puede arrojar resultados diferentes a los obtenidos por otra muestra de la misma población, bajo éstas Estadística para educación superior circunstancias es posible pensar en muestras que sí estimen el parámetro poblacional y otras que tal vez no estimen adecuadamente el parámetro poblacional. El valor de α se refiere al margen de error de las muestras que no permiten estimar el parámetro poblacional. El error de estimación (E) se refiere a la precisión con que el estimador refleja el verdadero valor del parámetro poblacional. El estimador es un cálculo estadístico realizado con la información obtenida en la muestra y es utilizado para estimar el valor del parámetro poblacional, por ejemplo: para una variable cuantitativa, la media muestral ̅ es el estimador de la media poblacional µ (parámetro); para una variable cualitativa, la proporción muestral ̅ es el estimador de la proporción poblacional p (parámetro). En términos generales, se denota al estimador con el símbolo ̂ y al parámetro poblacional con el símbolo θ. Cuanto más cercanos se encuentren entre sí los valores del estimador y del parámetro, mayor es la precisión, y por lo tanto, menor el error de estimación E, de tal forma que al restarlos entre sí, esta diferencia tienda a cero. ̅ o también ̅ ̅ o también ̅ De manera general, se tiene: ̂ La unidad de medida del error de estimación es diferente dependiendo si se trata de una variable cuantitativa o una cualitativa. Para el caso de variable cuantitativa, la unidad de medida para E, se expresa en la misma unidad de medición que tenga la variable ($, Kl, Km, tiempo, horas, entre otras). Para el caso de variable cualitativa, la unidad de medida para E, se expresa en términos porcentuales (%). Estadística para educación superior El nivel de confianza ( ) y el margen de error (α) se complementan (el uno es el complemento del otro). El nivel de confianza ( ) y el error de estimación (E) no son el complemento el uno del otro. 11.4 Total de muestras posibles a extraer de una población. Todas las posibles muestras de tamaño n extraídas de una población de tamaño N, tienen igual probabilidad de ser seleccionadas. El total de posibles muestras al emplear muestreo sin reposición (no se repone el elemento seleccionado) está dado por ( ) muestra sea seleccionada, está dada por ( ) , en este caso, la probabilidad de que una . ( ) El total de posibles muestras al emplear muestreo con reposición (se repone el elemento seleccionado) está dado por dada por , en este caso, la probabilidad de seleccionar una muestra, está . 11.5 Clases de muestreo. 11.5.1 Muestreo aleatorio simple. Una muestra de tamaño n extraída de una población de tamaño N, es aleatoria cuando todas las muestras posibles tienen igual probabilidad de ser seleccionadas. Hay dos aspectos básicos a tener en cuenta, estos son: el tamaño de la muestra n y la forma de extraer de la población N este tamaño de muestra. Estadística para educación superior El tamaño de la muestra hace referencia al número de elementos que se han de extraer de la población. La forma de extraer los elementos hace referencia al proceso de selección, éste ha de ser aleatorio, que todos y cada uno de los elementos de la población tengan igual probabilidad de ser seleccionados para formar parte de la muestra, para esto puede utilizarse una tabla de números aleatorios o generarlos a través del sistema; se recomienda tener a mano un listado codificado de la población para poder extraer del listado poblacional, el elemento indicado por la generación de números aleatorios. El muestreo aleatorio simple puede hacerse con reposición o sin reposición, dependiendo del caso particular y de las necesidades del investigador. 1. Muestreo aleatorio simple con reposición. Significa que al extraer un elemento de la población para que forme parte de la muestra, éste vuelve de nuevo a ser incluido dentro del gran total poblacional (se repone) teniendo la posibilidad de ser seleccionado en otra oportunidad. El total de posibles muestras es , todas las posibles muestras tienen igual probabilidad de ser seleccionadas, ésta probabilidad es de . Durante el proceso de selección de las unidades, cada unidad tiene igual probabilidad de ser seleccionada, cada vez que se extrae una unidad, la probabilidad de ser seleccionada viene dada por . 2. Muestreo aleatorio simple sin reposición. Significa que al extraer un elemento de la población para que forme parte de la muestra, éste no se incluye de nuevo en el gran total poblacional (no se repone), perdiendo la posibilidad de ser seleccionado en otra oportunidad. Estadística para educación superior El total de posibles muestras es ( ) ( ) , se lee: combinaciones de N en n. Todas las muestras tienen igual probabilidad de ser seleccionadas, ésta probabilidad está dada por ( ) . Durante el proceso de selección de las unidades, cada que se extrae de la población una unidad para que forme parte de la muestra, la probabilidad de que una unidad sea seleccionada dentro de las que quedan va cambiando, así: Figura 63. Cambio de probabilidad de selección de una unidad para la muestra Momento de selección o extracción de la unidad Total de elementos existentes en la población Probabilidad de que una unidad sea seleccionada Momento 1. MO1 Momento 2. MO2 Momento 3. MO3 𝟑 Momento 4. MO4 𝟑 … … Momento n-ésimo. MOn ( ) ( ) 11.5.2 Muestreo estratificado. Se identifica también como muestreo aleatorio estratificado. Una muestra estratificada es la obtenida mediante la separación de los elementos de la población en grupos que presentan ciertas características comunes. Estadística para educación superior Generalmente, dentro de los estratos se presenta homogeneidad y entre estratos, heterogeneidad. Se utiliza el procedimiento de afijación proporcional, que fracciona el tamaño de la muestra n en forma proporcional al tamaño de los estratos en la población. L = total de estratos N = tamaño de la población n = tamaño de la muestra Ni = tamaño poblacional del estrato i ni = tamaño muestral del estrato i Wi = peso o ponderación del estrato i ∑ Fórmula (91) ∑ Fórmula (92) ( ) Fórmula (93) Fórmula (94) Estadística para educación superior 11.5.3 Muestreo por conglomerados. Una muestra por conglomerados es una muestra aleatoria en la cual cada unidad de muestreo es un grupo de elementos (llamado conglomerado), los elementos dentro de un conglomerado generalmente están juntos físicamente. Una muestra por conglomerados se obtiene seleccionando aleatoriamente un conjunto de m colecciones muestrales llamados conglomerados y posteriormente, llevando a cabo un censo en cada uno de los conglomerados. El tamaño m se calcula siguiendo la misma metodología del cálculo del tamaño de muestra, con la única diferencia de que M es el total poblacional. M = número de conglomerados de la población o tamaño poblacional de conglomerados. m = número de conglomerados de la muestra o tamaño muestral de conglomerados. ni = número de elementos del i-ésimo conglomerado. 11.5.4 Muestreo sistemático (muestreo tipificado). La metodología empleada para seleccionar los elementos de la muestra inicia con una unidad de arranque que es seleccionada de forma aleatoria o al azar, a partir de ésta, los elementos se seleccionan por intervalos regulares, cada K elementos; por tal motivo se denomina muestra sistemática de 1 en K. 11.6 Cálculo de estimativos poblacionales. El objetivo de utilizar el muestreo es precisamente inferir hacia la población, calcular estimativos de los parámetros poblacionales utilizando los datos muestrales para describir el comportamiento de la población. Estadística para educación superior 11.6.1 Estimación puntual. La estimación puntual hace referencia a un valor específico (un punto) y no a un rango de valores. El estimador se distingue porque en la parte superior se le coloca el símbolo ˆ, para indicar que fue calculado a través de una muestra y que infiere o habla de la población. Figura 64. Estimación puntual Estimación de la media poblacional Fórmula (95) ̂ ̅ = media poblacional ̂ = media poblacional estimada, estimador de la media poblacional ̅ = media muestral ̅ Estimación del total poblacional ̂ ̅ Fórmula (96) = total poblacional ̂ = total poblacional estimado, estimador del total poblacional = tamaño de la población ∑ = tamaño de la muestra La media poblacional se estima con la media muestral. Parámetro = media poblacional Estadístico = media muestral 11.6.2 Estimación por intervalos. Un intervalo de confianza es un rango de valores dentro del cual se encuentra incluido el valor del parámetro estimado. Cuenta con un límite inferior y un límite superior, identificados como los límites de confianza. Estadística para educación superior Figura 65. Intervalos para estimar la media poblacional Para n ≤ 30 ̅ √ √ Para n > 30 ̅ Fórmula (97) 𝒁 √ √ Fórmula (98) t = valor de la tabla de la distribución de probabilidad t-student Z = valor de la tabla de la distribución de probabilidad normal estandarizada f = fracción de muestreo f = fracción de muestreo n = tamaño de la muestra n = tamaño de la muestra N = tamaño de la población N = tamaño de la población S2 = cuasivarianza, varianza muestral El valor de Z corresponde a ∑( ̅) ∑ ̅ El valor de la t-student corresponde a Ejemplo: 𝑡 Z = ?, confianza del 95%. Solución Ejemplo: t = ?, confianza del 95% y n = 28 Solución 𝒁 𝟗𝟕 𝟗𝟕 𝟗 Estadística para educación superior Figura 66. Intervalos para estimar el total poblacional Para n ≤ 30 ̂ √ Para n > 30 ̂ Fórmula (99) 𝒁 √ Fórmula (100) ̂ = Estimador del total poblacional ̂ = Estimador del total poblacional S2 = cuasivarianza, varianza muestral S2 = cuasivarianza, varianza muestral N = tamaño de la población N = tamaño de la población n = tamaño de la muestra n = tamaño de la muestra Z = valor de la tabla de la distribución de probabilidad normal estandarizada t = valor de la tabla de la distribución de probabilidad t-student 11.6.3 Estimación puntual y por intervalos para la proporción poblacional. Estimación puntual. ̂ Fórmula (101) = total de elementos en la muestra que poseen la característica de interés. Estimación por intervalo de confianza. ̂ ̂ ( ̂) ̂ ̂ Fórmula (102) ( ̂) √ ( ̂ ̂ )( Fórmula (103) ) Fórmula (104) Estadística para educación superior Fracción de muestreo Fórmula (105) 11.7 Ejercicios de aplicación resueltos. 11.7.1 Tamaño de muestra para una población de padres de familia. Para una investigación efectuada a padres de familia con hijos cursando secundaria, de los ocho colegios de una comunidad religiosa, la madre superiora de la comunidad ha contratado un equipo de investigadores para que apliquen técnicas de muestreo, debido a que no dispone del suficiente tiempo como para encuestar a todos los padres de familia (censo), porque ha de tomar una decisión a nivel administrativo en el corto plazo. Colegios de secundaria de una comunidad religiosa Colegio 1 2 3 4 5 6 7 8 Total padres de familia 500 1200 900 3000 1600 800 725 1520 Se toma el 0,1952% de la población como muestra piloto, con el objetivo de calcular el tamaño de muestra definitivo. ( ) ( ) Se eligen aleatoriamente 20 padres de familia como muestra piloto. Estadística para educación superior Calcular el tamaño de muestra necesario en caso de que la variable más relevante dentro de la investigación sea: el ingreso quincenal (en miles de pesos). ¿Cuántos padres de familia se deben seleccionar en cada uno de los ocho colegios? Nota: trabajar con un nivel de confianza del 95,56% Solución Se recolecta la información necesaria de los 20 padres de familia seleccionados aleatoriamente, estos 20 padres de familia suministraron los siguientes datos respecto al ingreso quincenal (miles de $): 1 2 3 4 5 Ingreso quincenal ($miles) 532 600 1.200 700 500 6 7 8 9 10 931 605 938 625 734 11 12 13 1.129 935 1.350 14 15 16 980 820 700 17 620 18 19 535 670 20 820 Padre de familia Nivel de confianza 95.56% Estadística para educación superior Con los valores de la muestra piloto, calcular , ̅ y . Se obtienen los siguientes resultados: ̅ ̅ ( )( ) Los valores calculados se reemplazan en ( El valor de ) ( ( ) ) se sustituye en la fórmula para , así: El tamaño de muestra ha de ser de padres de familia. Para especificar cuántas unidades van en cada estrato, es decir, cuántos padres de familia se deben encuestar de cada colegio, se calculan las ponderaciones que permitan realizar una afijación proporcional. Cada ponderación viene dada por: Colegio No. de padres de familia Ponderaciones 1 2 500 1.200 0,0488 0,1171 Estadística para educación superior 3 4 900 3.000 0,0878 0,2928 5 6 1.600 800 0,1562 0,0781 7 8 725 1.520 0,0708 0,1484 Total 10.245 1,0000 Aplicar como factor de ponderación, cada una del las , con el objeto de obtener la repartición adecuada de los 179 elementos que conforman la muestra, entre cada uno de los colegios. Colegio 1 0,0488 9 2 3 4 5 0,1171 0,0878 0,2928 0,1562 21 16 52 28 6 7 8 Total 0,0781 0,0708 0,1484 1,0000 14 13 27 179 El tamaño de la muestra padres de familia, queda distribuido de la siguiente manera: Colegio 1 2 No. padres de familia 9 21 3 4 5 16 52 28 6 7 14 13 8 Total 27 179 Estadística para educación superior 11.7.2 Estimativo puntual y por intervalo de confianza para la media del ingreso poblacional. Con base en el ejemplo anterior, alusivo a la investigación en padres de familia con hijos estudiando en colegios pertenecientes a una comunidad religiosa, el Investigador ha de recolectar información necesaria que sea de utilidad para que la madre superiora del centro educativo pueda tomar decisiones acertadas, para esto se vale de encuestas y entrevistas dirigidas a los respectivos padres de familia, sin olvidar que los padres de familia encuestados han de ser seleccionados de manera aleatoria sin reposición, utilizando la metodología descrita en el numeral 11.4 de la Parte IV del texto. La encuesta realizada a padres de familia cuenta con varias preguntas que ayudan a recolectar la información necesaria para alcanzar los objetivos de la investigación. Si dos de las preguntas de la encuesta son: Señale con una X la respuesta que considere adecuada: 1. Su ingreso quincenal en miles de pesos se encuentra entre: a. De 500 a 700 inclusive ⃝ De 700 a 900 inclusive ⃝ De 900 a 1.100 inclusive ⃝ De 1.100 a 1.300 inclusive ⃝ De 1.300 a 1.500 inclusive ⃝ 2. Hace uso del contrato de transporte escolar para su(s) hijo(s): a. Sí ⃝ b. No ⃝ Utilizando la información recolectada a través de la primera pregunta, se pide: a) Estimación puntual de la media poblacional para el ingreso quincenal. Estadística para educación superior b) Intervalo de confianza del 97% para el estimador de la media poblacional referente al ingreso quincenal. Solución Variable: Ingreso quincenal (miles de $) – Variable cuantitativa Variable: Uso del transporte escolar por parte de los hijos – Variable cualitativa La información recolectada queda consignada en una base de datos de la investigación, al procesar y organizar las dos variables anteriores se obtuvieron las siguientes tablas de frecuencia: Ingreso quincenal padre de familia Ingreso quincenal (miles de $) 500 – 700 700 – 900 900 – 1.100 1.100 – 1.300 1.300 – 1.500 No. de padres de familia 20 48 65 31 15 Total 179 Transporte escolar hijos Contratan transporte Sí No Total a) No. de padres de familia 125 54 179 Estimación puntual de la media poblacional para el ingreso quincenal: ̂ ̅ Ingreso quincenal (miles de $) 500 – 700 700 – 900 900 – 1.100 600 800 1.000 20 48 65 12.000 38.400 65.000 Estadística para educación superior ̅ 1.100 – 1.300 1.300 – 1.500 1.200 1.400 31 15 37.200 21.000 Total - 179 173.600 ∑ ̅ ̂ El promedio del ingreso quincenal estimado de los padres de familia con hijos estudiando en esa comunidad es de $969.830. b) Intervalo de confianza del 97% para el estimador de la media poblacional referente al ingreso quincenal: Ingreso quincenal (miles de $) 500 – 700 700 – 900 900 – 1.100 1.100 – 1.300 1.300 – 1.500 Total ( 600 800 1.000 1.200 1.400 - 20 48 65 31 15 179 12.000 38.400 65.000 37.200 21.000 173.600 ̅) 2735520,11 1384466,15 59155,46 1642290,81 2775662,43 8597094,97 Confianza del 97% ̂ √ Se sustituyen los valores encontrados en la fórmula del intervalo de confianza para calcular de este modo el límite inferior y superior del intervalo de confianza pedido. Estadística para educación superior ( √ )√ ( )√ 𝑖𝑚 𝑖𝑚 Intervalo de confianza para la media poblacional: [ ] ≤̂≤ Se estima con una confianza del 97%, que el ingreso quincenal de los padres de familia se encuentra entre $934.500 y $1.005.160. Otra forma de interpretar el anterior resultado en términos probabilísticas es: La probabilidad de que el ingreso quincenal se encuentre entre $934.500 y $1.005.160 es de 0,97. ( ≤̂≤ ) 11.7.3 Estimación puntual y por intervalo de confianza para la proporción del uso de transporte escolar. Utilizando la información recolectada a través de la segunda pregunta planteada en el ejemplo anterior, se pide: a) Estimación puntual de la proporción poblacional para la utilización de transporte escolar. b) Intervalo de confianza del 95% para la proporción poblacional en cuanto al uso del transporte escolar. Solución a) Estimación puntual de la proporción poblacional para la utilización de transporte escolar: ̂ Estadística para educación superior Contratan transporte Sí No. padres de familia 125 No Total 54 179 Característica de Interés: Contratar servicio de transporte escolar para sus hijos. Total de elementos en la muestra con la característica de interés. ̂ La proporción estimada de padres de familia que contratan transporte escolar para sus hijos es de 0,70. Se estima que el 70% de los padres de familia contratan transporte escolar para sus hijos. b) Intervalo de confianza del 95% para la proporción poblacional en cuanto al uso del transporte escolar: ̂ ̂ ̂ ( )( ) ̂ ̂ Intervalo de confianza para la proporción poblacional: ( )( ) 𝑖𝑚 𝑖𝑚 Intervalo: [ ] Estadística para educación superior Se puede estimar con una confianza del 95%, que la proporción de padres de familia que contratan transporte escolar para sus hijos se encuentra entre 0,6988 y 0,7012. Con una confianza del 95%, se puede estimar que el porcentaje de padres de familia que contratan transporte escolar para sus hijos se encuentra entre 69,88% y 70,12%. La proporción poblacional se encuentra entre 0,6988 y 0,7012, esto es: ≤ ̂≤ La probabilidad de que la proporción poblacional se encuentre entre 0,6988 y 0,7012 es de 0,95. ≤̂≤ ( ) 11.7.4 Tamaño de muestra para un nivel de confianza del 95% y diferentes errores de estimación. Dado un tamaño poblacional, un nivel de confianza del 95% y diferentes errores de estimación, calcular el tamaño de muestra respectivo, suponiendo que no existen estudios preliminares y que la variable más importante dentro del estudio es cualitativa. Se pide llenar la siguiente tabla: Tamaño de muestra para un nivel de confianza del 95% y diferentes errores de estimación Tamaño de la población 1.000 2.000 3.000 4.000 5.000 10.000 20.000 50.000 100.000 500.000 y más Error de estimación (E) 1% 2% 3% 4% 5% Estadística para educación superior Solución Nivel de confianza: ( )( ) Para un error de estimación del 4%: ( ) ( ( ) ) ⇒ ⇒ ⇒ ⇒ ⇒ ⇒ ⇒ ⇒ Estadística para educación superior ⇒ De igual manera, se obtienen los restantes tamaños de muestra para cada uno de los diferentes errores de estimación, quedando así: Tamaño de la población Error de estimación (E) 1% 2% 3% 4% 5% 1.000 Más de 1/2 1/2 1/2 375 278 2.000 1/2 1/2 696 462 322 3.000 1/2 1.344 787 500 341 4.000 1/2 1.500 842 522 350 5.000 1/2 1.622 879 536 357 10.000 4.899 1.936 964 566 370 20.000 6.489 2.144 1.013 583 377 50.000 8.057 2.291 1.045 593 381 100.000 8.763 3.245 1.056 597 383 500.000 y más 9.423 2.390 1.065 600 384 Nota: ½ significa la mitad de la población 11.7.5 Tamaño de muestra para adelantar un proyecto a cargo de la secretaría de planeación de un municipio. La Secretaría de Planeación de un municipio determinado efectúa un estudio en cuatro zonas rurales (veredas del municipio), respecto a la distribución de familias que viven en casa propia o arrendada, bajo el supuesto de que en cada casa vive una familia. Zona rural Total familias A 52 B 85 C 93 D 24 Estadística para educación superior Calcular el tamaño de muestra si se desea trabajar con un nivel de confianza del 95% y un error de estimación del 3%. La característica de interés es poseer vivienda propia, además no existen estudios preliminares al respecto. Solución Cuando no existen estudios preliminares al respecto, se trabaja con una muestra piloto para calcular inicialmente los valores de p y de q, aunque también es permisible trabajar asignando para y . En este caso particular se opta por utilizar una muestra piloto del 5% de la población. ( ) La muestra piloto indica que se ha de seleccionar aleatoriamente, 13 familias, para los cálculos de p y de q. La información recolectada en la muestra piloto es la siguiente: Familia 1 2 3 4 Vivienda propia Sí Sí No Sí 5 6 No No 7 8 Sí Sí 9 10 11 12 Sí Sí No No 13 No Con la información recolectada se calculan las proporciones respectivas, así: Estadística para educación superior Los valores de Z, S2 y E son los siguientes: ( )( ) Se sustituyen estos resultados en la fórmula definida para n (tamaño de muestra): ( ) ( ( ) ) Se ha de tomar una muestra de 205 familias, para efectuar la distribución de este tamaño de muestra en cada una de las cuatro zonas establecidas, se calculan las ponderaciones Wi respectivas, que constituyen el factor para la repartición proporcional. Población Ponderaciones Zona rural No. familias Wi A B 52 85 0,2047 0,3346 C D Total 93 24 254 0,3661 0,0945 1 Aplicando cada uno de los factores de ponderación sobre el tamaño de muestra se obtiene la siguiente distribución: Estadística para educación superior Muestra Zona rural No. familias A B 42 69 C D 75 19 Total 205 11.8 Ejercicios de aplicación propuestos. 11.8.1 Proyecto de capacitación académica para dirigentes gubernamentales. El gobierno actual de un país está sumamente preocupado por el nivel educativo de sus dirigentes y líderes políticos. Para adelantar un proyecto de capacitación académica, se pretende desarrollar una investigación para detectar el porcentaje de profesionales y no profesionales que ejercen cargos públicos y sus respectivas necesidades de capacitación. Se tiene una población de 3.785 dirigentes políticos. Calcular el tamaño de muestra utilizando un nivel de confianza del 97% y un margen para el error de estimación del 4%. a) ¿Cuál es el procedimiento a seguir en caso de existir estudios preliminares que contengan la proporción de profesionales? b) Especificar y efectuar el procedimiento en caso de no existir estudios preliminares al respecto y de optar por no extraer una muestra piloto. c) Especificar y efectuar el procedimiento en caso de no existir estudios preliminares al respecto y de optar por extraer inicialmente una muestra piloto. Estadística para educación superior 11.8.2 Estimación puntual e intervalo de confianza para la proporción de dirigentes profesionales. Con base en el ejercicio anterior, efectuar la estimación puntual para la proporción de dirigentes profesionales y calcular el intervalo de confianza del 95.5%. Especificar el procedimiento completo. 11.8.3 Plan de mercadeo y ayuda solidaria por parte de una empresa procesadora de leche: Tamaño de muestra de familias. Uno de los varios planes de mercadeo de una empresa procesadora de leche y lácteos consiste en suministrar gratuitamente, litros de leche a familias de estrato 1 con población infantil. Se dona un litro de leche diario por cada dos niños que existan en la familia. Con este proyecto, al mismo tiempo se contribuye con programas de solidaridad y aporte alimenticio a la población más necesitada de la región. Existe un convenio con una cadena de supermercados reconocida en el medio, dependiendo de la cantidad de leche donada, se comprometen a distribuir y vender entre la población con poder adquisitivo, el triple de lo donado. La población ubicada en el estrato 1 del municipio, está distribuida así: Nororiental No. familias con población infantil 120 Suroriental Noroccidental Suroccidental 89 150 115 Región La donación se hará a toda la población, sin embargo, para efectos de planeación en la producción dentro de la planta procesadora de leche, se requiere calcular un tamaño de Estadística para educación superior muestra de las familias con población infantil. Se pide: Calcular el tamaño de muestra con una confianza del 96% y un margen para el error de estimación del 3%, ¿cuántas familias cada región forman parte de la muestra? 11.8.4 Estimativo del promedio de litros de leche a donar semanalmente por familia. Utilizar el tamaño de muestra calculado en el ejercicio anterior para estimar el número promedio de litros semanales que se donarían por familia, y calcular el intervalo de confianza del 97%. ¿Qué información se necesita recolectar para obtener éstos cálculos? ¿Cuál es el estimativo para el total de litros a donar semanalmente en la población? Especificar el procedimiento. 11.8.5 Tamaño de muestra de ejecutivos en diferentes empresas multinacionales. Una empresa organiza viajes vía aérea para ejecutivos de tres empresas multinacionales diferentes que requieren desplazarse a otros países para asistir a seminarios y juntas de negocios. Cada ejecutivo efectúa en promedio, tres viajes semestrales, el gasto promedio por viaje de cada ejecutivo, en cuanto a pasaje y estadía, es de $2.800.000,00 dinero que ingresa a la agencia de viajes por concepto de prestación de servicios. El total de la población de ejecutivos de las tres multinacionales es el siguiente, de los cuales algunos tienen asignadas labores dentro de la misma ciudad y otros viajan al extranjero: Empresa multinacional No. ejecutivos A B C 320 125 238 Calcular el tamaño de muestra de ejecutivos con un nivel de confianza del 95% y un margen para el error de estimación del 3%. Estadística para educación superior 11.8.6 Estimativo de la proporción poblacional de ejecutivos que viajan. Haciendo uso del cálculo del tamaño de muestra hallado en el ejercicio anterior, estimar la proporción poblacional de ejecutivos que viajan frecuentemente como una de sus actividades laborales. ¿Cuál es el número estimado de ejecutivos que efectúan viajes laborales? Especificar el estimativo por empresa multinacional. 11.8.7 Intervalo de confianza para la proporción poblacional de ejecutivos que viajan. Con base en el ejercicio anterior, se pide: Calcular el intervalo de confianza del 98% para la proporción poblacional de ejecutivos que viajan por cuestiones laborales. 11.8.8 Estimativo del gasto total por concepto de viajes y estadía. Con base en el ejercicio anterior, se pide: ¿Cuál es el gasto total estimado semestralmente para toda la población en cuanto al rubro de viajes y estadía? Especificar qué cantidad del gasto total le corresponde a cada una de las empresas multinacionales. 11.8.9 Tamaño de muestra para una población de empresas de una región determinada. Para una investigación en el área económico-administrativa se requiere calcular el tamaño de muestra de las empresas de una región clasificadas en grandes, medianas y microempresas. Es de anotar que no existen estudios preliminares en esa región respecto a la temática. La población de empresas de la región es la siguiente: Estadística para educación superior Clasificación Grande No. empresas 140 Mediana Micro 520 1.743 a) Justifique si se recomienda trabajar con una muestra piloto para calcular el tamaño de muestra, ¿qué aspectos se necesita conocer para tal fin? ¿Cuál sería el procedimiento a seguir, en caso de que la variable más importante dentro del estudio fuese el nivel de exportación semestral? ¿Cuál sería el procedimiento a seguir, en caso de que la variable más importante dentro del estudio fuese el atributo de existencia de buen clima laboral en la empresa? b) En caso de optar por calcular el tamaño de muestra sin utilizar una muestra piloto, ¿cómo se calcularía el tamaño de muestra? ¿Qué cantidad de empresas forman parte de la muestra dentro de cada clasificación? 11.8.10 Tamaño de muestra para una población universitaria. En una institución universitaria se sabe, por estudios preliminares, que el 75% de las personas (entre empleados y alumnos) asisten a los eventos programados por Bienestar Institucional. Para adelantar una investigación con el objetivo de analizar los logros de cada uno de los eventos culturales, así como las sugerencias a tener en cuenta para futuras programaciones, se requiere calcular un tamaño de muestra con un nivel de confianza del 96% y un margen para el error de estimación del 5%. La población universitaria cuenta con 130 empleados y 2.415 alumnos. 11.8.11 Tamaño de muestra de televidentes para mercadear un producto. Una empresa de utensilios plásticos para el hogar contrata los servicios de una empresa publicitaria para analizar si se justifica o no, mercadear su producto a través de la televisión en el canal regional, durante las horas de la noche entre las 7:00 p.m. y las 10:00 p.m. Estadística para educación superior La investigación se delimita físicamente a toda la zona de cobertura del canal regional, esta zona se encuentra divida en siete sectores, el número de viviendas por sector es el siguiente: Sector No. viviendas S1 S2 68 95 S3 S4 158 67 S5 S6 S7 256 147 93 a) Tomar una muestra piloto y calcular la proporción de viviendas en las cuales existe un adulto responsable viendo la televisión en el canal regional durante ese lapso de tiempo. b) Utilizar el resultado de esa proporción como herramienta para calcular el tamaño de muestra para la investigación definitiva con un nivel de confianza del 95% y un margen para el error de estimación del 3%. ¿Cuántas viviendas dentro de cada sector forman parte del tamaño de la muestra? Estadística para educación superior 12. Pruebas de hipótesis Una hipótesis estadística es una afirmación que se hace en la cual se involucra un parámetro poblacional o la distribución de una serie de datos, para probar a través de cálculos estadísticos y haciendo uso de la muestra si la hipótesis es verdadera o falsa. La decisión de aceptar o rechazar una hipótesis se toma dependiendo de la probabilidad calculada para el caso específico. Se plantean dos hipótesis, la una recibe el nombre de hipótesis nula y la otra, hipótesis alternativa, generalmente se identifican con H0 y H1 (en algunas ocasiones, como H1 y H2). H0: hipótesis nula H1: hipótesis alternativa La hipótesis nula (H0) es aquella afirmación donde se plantea que el valor del parámetro poblacional es igual (=) a un valor específico. La hipótesis alternativa (H1) es aquella afirmación donde se plantea que el valor del parámetro poblacional es diferente (≠), mayor (>) o menor (<) que un valor específico. Dentro del análisis de pruebas de hipótesis, interviene como criterio de decisión el estadístico de la prueba, el cual es un valor resultado de operaciones aritméticas donde intervienen términos o factores hallados preliminarmente con cálculos estadísticos. Se plantea la región de rechazo, ésta es un área bajo una función de densidad de probabilidad definida (en su dominio) por un intervalo de valores (abscisa) que se utiliza como marco de referencia para analizar si el estadístico se encuentra incluido en dicho intervalo o no. Se asumen los siguientes criterios de decisión: Estadística para educación superior Si el estadístico de la prueba cae en la región de rechazo, la decisión es rechazar H0 (hipótesis nula). Si el estadístico de la prueba no cae en la región de rechazo, se deduce que cae en la región de aceptación, en este caso la decisión es aceptar H0 (hipótesis nula). En el análisis de prueba de hipótesis existe la probabilidad de cometer errores como los siguientes: Error de tipo I. Rechazar H0 dado que H0 es cierta o verdadera. Rechazar H0 / H0 es cierta. Error de tipo II. Aceptar H0 dado que H0 es falsa. No rechazar H0 / H0 es falsa. La probabilidad de cometer el error de tipo I se denota con α, también llamado nivel de significación de la prueba. El nivel de significancia generalmente es menor o igual al 5%, es decir, α ≤ 0,05, valor de probabilidad que se fija con el objeto de minimizar el error de tipo I. La probabilidad de cometer el error de tipo II se denota con β. 12.1 Prueba de hipótesis para la media. Nomenclatura. Hipótesis nula Hipótesis alternativa Procedimiento. 1. Calcular el estadístico de la prueba. 2. Analizar si el estadístico cae en la región de rechazo. Estadística para educación superior 3. Tomar la decisión: Si el estadístico cae en la región de rechazo: rechazar H0 y aceptar H1. Si el estadístico no cae en la región de rechazo significa que el estadístico cae en la región de aceptación: aceptar H0 y rechazar H1. Descripción de la prueba. Región de rechazo ≠ Estadístico: ̅ √ ⇒ ≤ ⇒ ≥ ⇒ ≤ ≥ Estadística para educación superior Figura 67. Representaciones gráficas Estadística para educación superior 12.2 Prueba de hipótesis para la proporción. Nomenclatura. Hipótesis nula Hipótesis alternativa Procedimiento. 1. Calcular el estadístico de la prueba. 2. Analizar si el estadístico cae en la región de rechazo. 3. Tomar la decisión: Si el estadístico cae en la región de rechazo: rechazar H0 y aceptar H1. Si el estadístico no cae en la región de rechazo significa que el estadístico cae en la región de aceptación: aceptar H0 y rechazar H1. Descripción de la prueba. Región de rechazo Estadístico: ̂ √ ̂̂ ⇒ ≤ ⇒ ≥ ⇒ ≤ ≥ Estadística para educación superior 12.3 Prueba Chi-cuadrado para la bondad de ajuste. La prueba Chi-cuadrado es utilizada para analizar la forma como se distribuye una serie de datos, certificando si los datos se ajustan a una distribución supuesta. Este procedimiento estadístico busca probar la hipótesis de que una variable aleatoria X presenta una distribución específica como la normal, Poisson, exponencial, entre otras; aceptando o rechazando la hipótesis al final del estudio. Para esto, se hace indispensable comparar las frecuencias observadas o reales, con las frecuencias teóricas o esperadas. El siguiente cuadro muestra el procedimiento para la aplicación de la prueba Chicuadrado: Cuadro 16. Pasos a seguir para aplicar la prueba Chi-cuadrado. Paso 1: Establecer la hipótesis de la distribución de probabilidades que se va a ajustar a los datos. Los valores de cada parámetro de la distribución (media, varianza) se deben colocar como hipótesis, o estimarlos con datos reales. Así: Hipótesis 1: La variable aleatoria X (escribir nombre de la variable), se distribuye como una (escribir nombre de la distribución de probabilidad), con una media de (escribir el valor de µ) y una desviación de (escribir el valor de σ). Hipótesis 2: La variable aleatoria X (escribir nombre de la variable), no se distribuye como una (escribir nombre de la distribución de probabilidad), con una media de (escribir el valor de µ) y una desviación de (escribir el valor de σ). Paso 2: Utilizar la distribución de probabilidad hipotética específica para calcular las probabilidades Pj, para cada intervalo. Paso 3: Calcular las frecuencias teóricas ftj, para cada intervalo, utilizando la siguiente fórmula: Con j 𝑡 ∑ … m Con foj = frecuencia real u observada Siendo m el número de intervalos, y n el total de datos reales u observaciones. Es importante tener en cuenta que la sumatoria de las frecuencias teóricas debe ser aproximadamente igual a la sumatoria de las frecuencias reales. Estadística para educación superior ∑ 𝑡 ∑ También hay que tener presente para aplicar esta prueba, que las frecuencias teóricas de cada intervalo sean mayores o iguales a cinco (5), de lo contrario, se deben agrupar con aquellos intervalos consecutivos que cumplan la condición. Paso 4: Obtener el estadístico Chi-cuadrado “calculado” de la prueba de la siguiente manera: ∑ ( ) ( ∑ 𝑡) Fórmula (106) 𝑡 Siendo k = número de intervalos resultantes después de analizar la condición de las frecuencias teóricas. Paso 5: Obtener el estadístico Chi-cuadrado “tabulado” de la prueba, buscando el valor correspondiente en la tabla de la distribución Chi-cuadrado. Este estadístico se identificará como ( ) . Los grados de libertad = k – p – 1 p = número de parámetros estimados con los datos. α error que se est dispuesto a tolerar al tomar una decisión sobre aceptar o rechazar alguna hipótesis. Confianza = (1 – α) Paso 6: Utilizar el criterio o regla de decisión que posee la prueba Chi-cuadrado de bondad de ajuste, para seleccionar la hipótesis adecuada, así: Si ( ) Si ( ) ≤ ( ) ⇒ Aceptar la H1 y rechazar H2. ( ) ⇒ Rechazar la H1 y aceptar H2. Gráficamente: Estadística para educación superior 12.4 Ejercicios de aplicación resueltos. 12.4.1 Proceso de producción: Prueba de bondad de ajuste. En un proceso de producción de un artículo para piezas interiores de rodamiento, se toman las medidas del diámetro interior en mm. para efectuar un mejor control de calidad. Se hace indispensable analizar si presenta un comportamiento normal con una media de 3,476mm. y una desviación típica de 0,065mm. Trabajar con una confianza del 95%. A continuación se muestran los datos reales u observados durante el proceso de producción del lote: Intervalo (Diámetro en mm.) 3,275 – 3,325 3,325 – 3,375 Frecuencias reales 3 3 3,375 – 3,425 9 3,425 – 3,475 3,475 – 3,525 3,525 – 3,575 3,575 – 3,625 32 38 10 3 3,625 – 3,675 3,675 – 3,725 1 1 Total 100 Solución: Paso 1: Establecer las hipótesis. H1 = El diámetro de las piezas se distribuye normalmente con una media de µ = 3,476mm. y una desviación de σ = 0,065. H2 = El diámetro de las piezas no se distribuye normalmente con una media de µ = 3,476 mm. y Estadística para educación superior una desviación de σ = 0,065. Paso 2: Utilizar la distribución hipotética, en este caso, la distribución normal, para calcular las diferentes probabilidades Pj, para cada intervalo. Para el primer intervalo se tiene: ( ≤ ≤ ) ( ≤ ) ( ≤ ( ≤ ( ≤ ) ( ≤ ) ) ( ≤ ) ( ≤ ) ) Luego, Para el segundo intervalo se tiene: ( ≤ ≤ ) ( ≤ ( ≤ ( ≤ ) ( ≤ ) ) ( ≤ ) ) Luego, Para el resto de los intervalos se sigue la misma metodología. Paso 3: Calcular las frecuencias teóricas para cada intervalo. ( ) 𝑡 ( ) 𝑡 De igual manera para los intervalos siguientes, siendo ∑ Se revisa que la sumatoria de las frecuencias reales sea aproximadamente igual a la sumatoria de las frecuencias teóricas. Señalar aquellas frecuencias teóricas ft ≤ 5, y agruparlas con las frecuencias vecinas, de tal forma que se cumpla la condición, de esta manera surge una nueva tabla con un menor número de intervalos (k intervalos). Intervalos 3,275 - 3,325 fo 3 Pj 0,0092 ft 0,92 3,325 - 3,375 3 0,0504 5,04 3,375 - 3,425 3,425 - 3,475 9 32 0,1571 0,2743 15,71 27,43 3,475 - 3,525 38 0,2814 28,14 No condición * Estadística para educación superior 3,525 - 3,575 3,575 - 3,625 10 3 0,1623 0,0533 16,23 5,33 3,625 - 3,675 3,675 - 3,725 1 1 0,0099 0,0011 0,99 0,11 Total 100 * * 99,90 Intervalos fo Pj ft 3,275 - 3,375 3,375 - 3,425 6 9 0,0596 0,1571 5,96 15,71 3,425 - 3,475 3,475 - 3,525 32 38 0,2743 0,2814 27,43 28,14 3,525 - 3,575 3,575 - 3,725 Total 10 5 100 0,1623 0,0643 16,23 6,43 99,9 Paso 4: Obtener el estadístico Chi-cuadrado “calculado”. ∑ ( ) 𝑡) ( ∑ 𝑡 ( ) Intervalos 3,275 - 3,375 3,375 - 3,425 3,425 - 3,475 3,475 - 3,525 3,525 - 3,575 fo 6 9 32 38 10 ft 5,96 15,71 27,43 28,14 16,23 (fo – ft)2 0,002 45,024 20,885 97,220 38,813 3,575 - 3,725 5 6,43 2,045 Total 100 99,9 203,988 Paso 5: Obtener el estadístico Chi-cuadrado “tabulado”. Grados de libertad = k – p – 1 = 6 – 2 – 1 = 3 Confianza (1 – α) = 0,95 Se busca en la tabla y se obtiene: Paso 6: Utilizar el criterio o regla de decisión de la prueba de bondad de ajuste de la Chicuadrado. Si ( ) ≤ ( ) ⇒ Aceptar H1 Estadística para educación superior ≤ Decisión: Se acepta H1. Se puede asegurar con una confianza del 95%, que los diámetros tienen una distribución normal con una µ = 3,476mm. y una desviación σ = 0,065mm. 12.4.2 Prueba de hipótesis para el promedio de exportación semestral. Se efectúa una investigación en una población de empresas de un departamento determinado del país, destinadas a la producción y exportación de ropa interior para dama, el nivel de exportación semestral (en millones de pesos) de cada una de las empresas que conforman la muestra se visualiza a continuación: Código empresa E-014 E-236 E-025 E-526 E-087 E-189 E-358 E-249 E-731 E-825 Exportación 120 235 113 381 187 309 126 335 103 380 Código empresa E-991 E-803 E-484 E-132 E-047 E-101 E-329 E-575 E-229 E-275 Exportación 343 250 164 335 281 288 304 228 249 284 Código empresa E-329 E-574 E-206 E-759 E-464 E-673 E-485 E-160 E-688 E-827 Exportación 284 306 328 200 183 209 364 387 129 296 Código empresa E-026 E-609 E-610 E-034 E-796 E-310 E-143 E-298 E-876 E-154 Exportación 295 145 338 163 268 184 240 213 160 252 Elaborar la siguiente prueba de hipótesis con un nivel de significancia del 4%: Estadística para educación superior H0: µ = 215 H1: µ > 215 Solución ̅ ̅ √ √ ≥ ≥ El estadístico de la prueba cae en la región de rechazo (RR). Decisión: Rechazar H0 y aceptar H1. El promedio de exportación semestral de las empresas del departamento es mayor a $215 millones. 12.4.3 Prueba de hipótesis para la proporción poblacional de cajas de CD-ROM en un proceso de producción. Por estudios preliminares, se sabe que el porcentaje de artículos defectuosos de un proceso de producción de cajas para CD-Room, es del 16%, el jefe de producción implantó medidas más drásticas para el control del proceso de producción con el objeto de disminuir este porcentaje. Se efectúa una investigación para analizar si la proporción poblacional de artículos defectuosos es menor a 0,10, con un nivel de significancia del 5%. Se tomó una muestra de 370 unidades y se detectó que de éstas, 32 presentaban defectos. Estadística para educación superior Solución H0: p = 0,10 H1: p < 0,10 (pasado) ̂ Estadístico: ̂ √ ̂ ̂ √( RR: )( ) ≤ ≥ El estadístico no cae en la región de rechazo (RR). Decisión: Como el estadístico no cae en la RR, se acepta H0 y se rechaza H1. La proporción de cajas de CD-Room defectuosas en el proceso de producción es igual a 0,10. Gráficamente: Estadística para educación superior 12.5 Ejercicios de aplicación propuestos. 12.5.1 Número de empleados con trabajo pendiente para el día siguiente: Prueba de bondad de ajuste. Los empleados de una empresa han presentado quejas frente al director de personal, argumentando que la cantidad de actividades diarias es extremadamente alta, por tal motivo se efectúa una investigación para analizar la proporción de empleados por día que se ven obligados a dejar trabajo pendiente para el día siguiente. Cada día se toma una muestra aleatoria de 15 empleados, y al finalizar el día se observa el número de empleados con trabajo pendiente. Los datos reales se visualizan a continuación: 1 No. empleados con trabajo pendiente 5 2 3 4 4 3 10 Día Estadística para educación superior 5 6 5 4 7 8 3 3 9 10 4 9 11 12 13 14 7 3 3 4 15 2 Contrastar la siguiente prueba de hipótesis: H1: El número de empleados con trabajos pendientes para el día siguiente se distribuye binomialmente con un promedio de tres empleados y una desviación típica o estándar de 0,36. H2: El número de empleados con trabajos pendientes para el día siguiente no se distribuye como una binomial con un promedio de tres empleados y una desviación típica o estándar de 0,36. 12.5.2 Prueba de hipótesis para la proporción de población potencial que rechaza un nuevo producto. Una compañía de gaseosas pretende sacar al mercado un producto nuevo, con un alto contenido de nutrientes y zumos naturales, bebida destinada especialmente para jóvenes entre ocho y 18 años. Se efectúa un estudio preliminar para detectar el porcentaje de consumidores entre ocho y 18 años que no les agrada por algún motivo (sabor, diseño del empaque, olor, color, precio, entre otros). El porcentaje de jóvenes que no aceptaron la bebida fue alto, por tal motivo, los aspectos negativos consignados en las encuestas, se tomaron como punto de referencia para iniciar un plan de mejoramiento en el proceso de la producción. El gerente ha Estadística para educación superior decidido lanzar definitivamente el producto sólo si el porcentaje máximo de rechazo es inferior al 8% de la población joven con edad entre ocho y 18 años. Se tomó una muestra de 278 jóvenes del área metropolitana y se encontró que 25 jóvenes no aceptaron el producto. Se pide: Elaborar un estudio de prueba de hipótesis para determinar si el porcentaje de no aceptación es menor al 8%. Utilizar un nivel de significancia del 4%. 12.5.3 Prueba de hipótesis para el contenido promedio de latas de atún. Una empresa procesadora de atún enlatado ha sido demandada bajo el supuesto de que sus latas presentan un contenido inferior al impreso en el empaque. La compañía detiene la producción y con la ya existente, pretende demostrar que es falsa la acusación, conjuntamente con un grupo de auditores, inicia una investigación. Se toma una muestra de 400 latas con un contenido impreso en el empaque de 380gr cada una. Con la muestra recolectada se calculó el peso promedio y la desviación típica o estándar, siendo X = 382 y S = 5,3. a) Probar la hipótesis de que el peso promedio de las latas producidas por la empresa es igual a 380gr. Trabajar con un nivel de significancia del 5%. b) Probar la hipótesis de que el peso promedio de las latas producidas por la empresa es superior a 380gr. Trabajar con un nivel de significancia del 5%. 12.5.4 Prueba de hipótesis para el tiempo promedio de duración de velones especiales. Una industria productora de velas con aroma destinadas para estudios de velomancia detecta que la demanda de su producto ha aumentado en los últimos años. Los consumidores Estadística para educación superior prefieren velas con duración superior a cinco horas. El gerente de producción inicia una investigación con el propósito de analizar si su producto cumple con las expectativas del cliente en cuanto a tiempo de duración y en caso de no ser así, optar por medidas correctivas en el proceso. Se toma una muestra de 90 velones medianos para mirar el tiempo de duración: Probar la hipótesis de que el tiempo promedio de duración de los velones es superior a cinco horas. Trabajar con un nivel de significancia del 3%. Estadística para educación superior PARTE V 13. Análisis de regresión y correlación El objetivo principal de la regresión y correlación es identificar el tipo de relación y asociación entre variables. La regresión se encarga de determinar el tipo de relación entre las variables y la correlación determina qué tan intensa es dicha relación. 13.1 Conceptos básicos. Regresión. Es una técnica estadística que estudia la relación entre variables cuantitativas. Con base en el número de variables que se relacionan dentro del estudio, la regresión se clasifica en simple (dos variables) o múltiple (más de dos variables). La regresión múltiple también se conoce como análisis multivariante. Con base en el tipo de asociación existente entre las variables tratadas, la regresión puede ser lineal, parabólica, exponencial, logarítmica, entre otras. Diagrama de dispersión. (Nube de puntos). Es la representación gráfica de la información original en un plano. Cuando se estudia la relación entre dos variables, se utiliza el plano cartesiano, dentro del cual se ubican los puntos, cada uno con sus respectivas coordenadas (X, Y), los puntos que se localizan en el plano constituyen los datos reales u originales, siendo X la variable independiente y Y la variable dependiente, identificadas como la abscisa y la ordenada. Estadística para educación superior El objetivo de elaborar la nube de puntos es visualizar la tendencia que siguen los datos originales, y de esta forma, decidir cuál de los tipos de asociación utilizar para el cálculo de la función de ajuste. Función de ajuste. Corresponde a la función matemática empleada para el ajuste o representación matemática de la relación existente entre las variables. La función de ajuste es utilizada para efectuar pronósticos, los cuales se identifican como los datos pronosticados. Los datos reales y los pronosticados deben ser semejantes, parecidos, con valores muy cercanos, porque de lo contrario, no tiene sentido utilizar la función de ajuste hallada para pronosticar, debido a que los pronósticos no presentarían alta confiabilidad. 13.2 Ajuste lineal. Es utilizada cuando la tendencia que presentan los datos reales u originales es una línea recta, tendencia no significa que todos y cada uno de los puntos reales ubicados en el plano formen exactamente una línea recta, sino que mirándolos de manera conjunta o global, se pueda determinar un comportamiento lineal, de tal forma que pueda ser calculada la función de una línea recta que pase muy cerca de la mayoría de datos originales, quedando algunos puntos sobre la línea ajustada, otros por debajo, e incluso, algunos sobre la misma línea. Algunas nubes de puntos que representan tendencia lineal se presentan a continuación: Estadística para educación superior Figura 68. Ejemplos de nubes de puntos con tendencia lineal En el análisis de la regresión lineal se calcula la función de ajuste Y = a + bX, hallando los valores de los parámetros a y b a partir de los datos reales u originales. La función Y = a + bX, es conocida en cálculo como la función lineal. Luego de hallar los valores de a y de b, se escribe estadísticamente: ̂ 𝑏 Fórmula (107) a = Término independiente. Intercepto con el eje Y. Es aquel valor que toma la variable dependiente Y cuando la variable independiente X se hace cero. b = Pendiente de la línea recta. Es el grado de incremento o de disminución de la variable dependiente Y, cuando la variable independiente X se incrementa en una unidad. La pendiente es positiva (+) cuando la relación entre las variables X y Y es directamente proporcional; es decir, al aumentar el valor de la variable X también aumenta el valor de la variable Y. Estadística para educación superior La pendiente es negativa (─) cuando la relación entre X y Y es inversamente proporcional; es decir, al aumentar el valor de la variable X el valor de la variable Y disminuye. 13.2.1 Estimación de los parámetros. Para estimar o calcular los parámetros a y b, se utiliza el método de los mínimos cuadrados, de la siguiente manera: 𝑏 𝑏 ) ∑ ∑ 𝑏 ∑ ∑( 𝑏 ∑ ∑ ∑𝑏 ∑ ∑ ∑𝑏 ∑ ∑ 𝑏∑ ∑ ∑ 𝑏∑ Se llega a un sistema de dos ecuaciones con dos incógnitas, siendo las incógnitas los valores de a y de b: Ecuación 1: ∑ Ecuación 2: ∑ ∑ 𝑏∑ ∑ 𝑏∑ Para encontrar los valores de a y de b, se soluciona simultáneamente este sistema por alguno de los métodos de solución simultánea de ecuaciones, igualación, sustitución, reducción, determinantes o con la utilización de álgebra lineal como eliminación Gaussiana, Gauss-Jordan, pivoteo, entre otros. Por ejemplo, si utilizamos determinantes, llegamos a los siguientes valores de a y de b: Estadística para educación superior | ∑ ∑ ∑ | ∑ ∑ | ∑ | ∑ | 𝑏 (∑ )(∑ ∑ ∑ ∑ ∑ ∑ ∑ | ∑ | | ) ∑ ∑ (∑ )(∑ ) (∑ )(∑ ) (∑ )(∑ ) (∑ )(∑ ) (∑ )(∑ ) ∑ ∑ ∑ (∑ )(∑ ) (∑ ) (∑ )(∑ ) (∑ ) Fórmula (108) Fórmula (109) Otra alternativa que agiliza el cálculo, es hallar el valor de b mediante determinantes y luego el de a, despejándolo de la Ecuación 1, así: ∑ ∑ Todo lo que se necesita conocer para calcular los valores de a y de b, es obtenido a partir de los puntos (X, Y) reales u originales, siendo n el total de datos o puntos originales que han sido recolectados para el estudio. Se recomienda elaborar una tabla que facilite la obtención de los valores necesarios para el cálculo de los parámetros de a y b; ésta puede ser diseñada con las siguientes columnas: Figura 69. Diseño de tabla para el cálculo de los parámetros de a y b, para el ajuste lineal X Y XY X2 ∑X ∑Y ∑XY ∑X2 Estadística para educación superior Luego de conocer los valores respectivos de a y de b, se concluye que la función de ajuste está dada por: ̂ 𝑏 Este ajuste es considerado óptimo porque hace mínima la suma de los cuadrados de los errores. 13.2.2 Cálculo del pronóstico. El cálculo del pronóstico ( ̂ ) para la variable Y, dado (conociendo) un valor de X, se obtiene sustituyendo los valores respectivos de a, b y X en la función de ajuste hallada: ̂ 𝑏 13.3 Error residual (ei). Es cada una de las distancias verticales entre el dato real y el dato pronosticado. Todos los datos pronosticados caen sobre la recta ajustada y los datos reales algunos se ubican por encima, por debajo o sobre la línea de ajuste; entre más pequeña sea esta distancia, el pronóstico será más confiable. 𝑒 ( ̂) Fórmula (110) Ésta distancia debe ser mínima para que exista un buen ajuste o una buena bondad de ajuste; la sumatoria de todos los residuales debe ser igual a cero o muy cercana a cero: ∑ 𝑒 Un error es positivo cuando el dato real se ubica por encima de la función de ajuste, es decir, el dato real es mayor al dato pronosticado: ̂ Estadística para educación superior Un error es negativo cuando el dato real se ubica por debajo de la función de ajuste, es ̂ decir, el dato real es menor al dato pronosticado: Un error es igual a cero cuando el dato real se ubica exactamente sobre la función de ajuste, es decir, cuando el dato real es igual al dato pronosticado: ̂ La recta ajustada minimiza la sumatoria de los errores residuales cuadráticos, en otras palabras: la función ̂ ̂) 𝑏 minimiza ∑( ∑𝑒 La figura a continuación ilustra lo mencionado: Figura 70. Representación gráfica de error residual 13.4 Coeficiente de correlación (r). Definición y características. El coeficiente de correlación se denota con la letra r. Es aquel valor que se encarga de dar el grado de asociación entre la variable dependiente Y y la variable independiente X. El rango de valores dentro del cual siempre se encuentra el coeficiente de correlación es: límite inferior ─ 1 y límite superior 1, así: ≤ ≤ Estadística para educación superior El signo del coeficiente de correlación debe coincidir siempre con el signo del parámetro b. El signo del coeficiente de correlación indica si la relación entre las variables es inversamente o directamente proporcional. El valor en absoluto del coeficiente de correlación indica el grado de asociación entre las variables, es la fuerza de la relación entre las variables y la confiabilidad en los pronósticos. Si r = 1, la relación entre X y Y es directamente proporcional en un 100%. En este caso, todos los datos reales caen sobre la línea ajustada, todos los datos reales son idénticos a los pronosticados, por lo tanto, al utilizar la función de ajuste para efectos de pronósticos, la confiabilidad es del 100%. Si r = ─ 1, la relación entre X y Y es inversamente proporcional en un 100%. En este caso, todos los datos reales caen sobre la línea ajustada, todos los datos reales son idénticos a los pronosticados, por lo tanto, al utilizar la función de ajuste para efectuar pronósticos, la confiabilidad es del 100%. Si r = 0, no existe relación lineal entre las variables, la función lineal de ajuste no puede ser utilizada para pronosticar. Entre más cercano se encuentre el valor de r de ─ 1 o de 1, implica un grado mayor de asociación y relación entre las variables, y entre más cercano se encuentre a cero menor será el grado de relación. Cálculo del coeficiente de correlación: Método 1. ( √ ( ) ) ( ) Fórmula (111) Estadística para educación superior Cov (XY) = covarianza de XY Var (X) = varianza de X Var (Y) = varianza de Y Las varianzas siempre son valores positivos, la covarianza puede ser positiva o negativa, por tal motivo, el signo de r depende del signo que tenga la covarianza. La covarianza se calcula como el promedio del producto de las desviaciones respecto a la media para cada variable, así: ( ̅ )( ∑( ) ̅) Fórmula (112) ̅ = media de la variable X ̅ = media de la variable Y Otra forma de calcular la covarianza es: ( ) ( ) ( ) ( ) Fórmula (113) ( ) ̅̅̅̅ ̅ ̅ La covarianza de X, Y es igual a la media de (XY) menos la media de X por la media de Y. ( ∑ ) ( ) ∑ ( ) ∑ Las varianzas para cada variable se calculan así: Estadística para educación superior ( ) ( ) ( ) ( ) ̅) ∑( ( ) [ ( )] ̅) ∑( ( ) [ ( )] Cálculo del coeficiente de correlación: Método 2. Para este método, se hace necesario conocer las medidas de variación en la regresión. Estas son: la variación total, la variación no explicada y la variación explicada. VT = variación total VNE = variación no explicada VE = variación explicada √ √ Fórmula (114) Fórmula (115) Al utilizar este método, el signo del coeficiente de correlación se le asigna dependiendo del signo que tenga el parámetro b. 13.5 Medidas de variación en la regresión. Existen tres medidas de variación básicas dentro del estudio de la regresión, éstas son: variación total, variación no explicada y variación explicada. Estadística para educación superior 13.5.1 Variación total (VT). Es la suma de cuadrados totales (SCT). Es la sumatoria de las desviaciones cuadráticas respecto a la media, para la variable Y. ̅) ∑( Fórmula (116) Figura 71. Representación gráfica de la variación total 13.5.2 Variación no explicada (VNE). Es la suma de los cuadrados del error (SCE). Es la sumatoria de las desviaciones cuadráticas de los valores reales con respecto a los valores pronosticados, para la variable Y. ∑( ̂) ∑𝑒 Fórmula (117) Estadística para educación superior Figura 72. Representación gráfica de a variación no explicada 13.5.3 Variación explicada (VE). Es la suma de los cuadrados de la regresión (SCR). Es la sumatoria de las desviaciones cuadráticas de los valores pronosticados respecto a la media de los valores reales, para la variable Y. ∑( ̂ ̅) Fórmula (118) 13.5.4 Propiedades de las medidas de variación en la regresión. Propiedad 1. Las medidas de variación en la regresión siempre son valores positivos. ≥ , ≥ , ≥ Propiedad 2. La variación total es igual a la sumatoria de la variación no explicada con la variación explicada. Estadística para educación superior ∑( ̅) ̂) ∑( ∑( ̂ ̅) Fórmula (119) Nota: , por lo tanto, De aquí se tiene que: 13.6 Coeficiente de determinación (D). Es el coeficiente de correlación cuadrado. Fórmula (120) Este coeficiente determina la bondad de ajuste, es decir, determina si la función matemática aplicada representa en forma adecuada los datos originales. El rango de valores dentro del cual siempre se encuentra el coeficiente de determinación es: límite inferior, cero (0), y límite superior, uno (1); siempre es un valor positivo menor o igual a uno (1), así: ≤ ≤ 𝑅 ∑( ̂ ∑( ̅) ̅) Fórmula (121) Nota: El coeficiente de correlación es la raíz cuadrada del coeficiente de determinación, así: Estadística para educación superior √ √ Fórmula (122) Mientras que el coeficiente de correlación mide el grado de asociación lineal, el coeficiente de determinación es aquel valor que determina la bondad del ajuste (ajustes no lineales), determina si la función matemática aplicada representa en forma adecuada los datos originales, determina el grado de representatividad del ajuste efectuado. 13.7 Ajuste parabólico. El ajuste de regresión parabólico es utilizado cuando la nube de puntos o diagrama de dispersión presenta una tendencia parabólica. El ajuste parabólico esta dado por la función cuadrática: ̂ 𝑏 Fórmula (123) Con los datos originales o reales (X, Y) se plantea el siguiente sistema de tres ecuaciones con tres incógnitas: (1) ∑ (2) ∑ (3) ∑ 𝑏∑ ∑ ∑ ∑ 𝑏∑ ∑ 𝑏∑ ∑ Se soluciona simultáneamente por algún método: igualación, sustitución, reducción, determinantes o algún método de algebra lineal. Para facilitar el planteamiento del anterior sistema, se puede optar por elaborar una tabla con las siguientes columnas, de tal forma que se puedan obtener las sumatorias necesarias. Estadística para educación superior Figura 73. Diseño de tabla para el cálculo de valores del sistema de ecuaciones para el ajuste parabólico X Y X2 X3 X4 XY X2Y ∑X ∑Y ∑X2 ∑X3 ∑X4 ∑XY ∑X2Y Luego de encontrar los respectivos valores de a, b y c, se sustituyen en la función de ajuste ̂ 𝑏 Se concluye que esta función representa de manera adecuada a los datos originales, y por tal motivo, puede ser utilizada para pronosticar Y dado un valor respectivo de X, el cálculo del pronóstico se efectúa sustituyendo X en la función de ajuste para hallar el valor de ̂ . Cuando el valor de c, coeficiente en X2 es negativo (─), la función de ajuste parabólica abre hacia abajo, y en caso de ser positivo (+) la parábola abre hacia arriba. Figura 74. Representación gráfica del ajuste parabólico Estadística para educación superior 13.8 Ajuste exponencial. El ajuste de regresión exponencial es utilizado cuando el comportamiento de la nube de puntos o diagrama de dispersión presenta una tendencia exponencial. La función de ajuste exponencial está dada por: ̂ 𝑏 En esta función se tiene: a = es el intercepto en el eje Y b = indica si la función es creciente o decreciente, siempre b ≠ 1 Si 0 < b < 1 la función es decreciente Si b > 1 la función es creciente Figura 75. Representación gráfica del ajuste exponencial Para encontrar los valores de a y de b, se toma como base la serie de datos original con los valores respectivos de X y de Y, para plantear un sistema de dos ecuaciones con dos incógnitas. Estadística para educación superior 𝑏 Se parte de: log( 𝑏 ) Se saca logaritmo a ambos lados de la igualdad: log Se aplican propiedades de los logaritmos, y se obtiene: og log og log log 𝑏 log 𝑏 Se plantean las dos ecuaciones con dos incógnitas, utilizando el método de los mínimos cuadrados. og log log 𝑏 ∑ log ∑(log ) ∑ log ∑ log ∑ log log log 𝑏 ∑ log 𝑏 log 𝑏 ∑ log (log log log log 𝑏) log 𝑏 ∑ log ∑( log ∑ log ∑ log ∑ log log ∑ log 𝑏) ∑ log 𝑏 log 𝑏 ∑ Las dos ecuaciones resultantes son: (1) ∑ log (2) ∑ log log log ∑ log 𝑏 ∑ log 𝑏 ∑ Las dos incógnitas son: log a y log b, por tal motivo, luego de solucionar simultáneamente el sistema de ecuaciones, se debe sacar antilogaritmo a ambos resultados para hallar los valores de a y de b, respectivamente. Estadística para educación superior Se recomienda elaborar una tabla a partir de los datos originales, que contenga las siguientes columnas, para efecto de facilitar el cálculo de las sumatorias necesarias para el planteamiento del sistema de ecuaciones. Figura 76. Diseño de tabla para el cálculo de valores del sistema de ecuaciones para el ajuste exponencial X Y X2 log Y X ⋅ log Y ∑X - ∑X2 ∑log Y ∑X ⋅ log Y 13.9 Análisis de regresión en una serie de tiempo. Una serie de tiempo nos muestra el comportamiento de una variable a través del tiempo. Utilizando la regresión como aplicación dentro de las series temporales se cuenta con dos variables, donde una de ellas es el tiempo. La variable X siempre se asocia con el tiempo, y la variable Y es aquella que se desea analizar a través del tiempo. Como el tiempo es identificado en este tema con días, meses, semestres, bimestres, años, entre otros; es en este sentido que se hace indispensable asignarle a cada identificación del tiempo un número, y de ahí en adelante, consecutivos. Es muy importante tener en cuenta los consecutivos de X en el momento de efectuar un pronóstico. Estadística para educación superior A continuación se muestran varios ejemplos de asignación de valores consecutivos para X, dado una identificación de tiempo mensual; de igual manera se aplica para las otras identificaciones del tiempo. Figura 77. Ejemplos de asignación de valores consecutivos para el análisis de regresión en una serie de tiempo Tiempo (meses) X X X X X Enero 0 -3 0 1 -4 Febrero 1 -2 3 2 -2 Marzo 2 -1 6 3 0 Abril 3 0 9 4 2 Mayo 4 1 12 5 4 Junio 5 2 15 6 6 Julio 6 3 18 7 8 Agosto 7 4 21 8 10 Septiembre 8 5 24 9 12 … … … … … … 13.10 Ejercicios de aplicación resueltos. 13.10.1 Ajuste de regresión entre el precio y la demanda de un producto. El departamento de investigaciones económicas de una compañía desea realizar un estudio sobre los precios y la demanda de su principal producto. Para ello cuenta con la siguiente información: Variable X: Precio (miles de $) Variable Y: Demanda (número de unidades) Estadística para educación superior X Y 5 100 7 90 9 86 12 72 17 60 23 55 30 43 Se pide: a) Elaborar el diagrama de dispersión o nube de puntos. ¿Qué tendencia se visualiza en el gráfico? b) Calcular la función de ajuste y graficarla sobre el diagrama. c) Pronosticar el número de unidades demandadas para un precio de $15.000. d) Calcular el coeficiente de correlación e interpretarlo. Solución a) Diagrama de dispersión: Unidades demandadas Nube de puntos Precio (miles $) Los datos originales o reales presentan una tendencia lineal, por tal motivo, el análisis de regresión y correlación se efectúa con ajuste lineal. Estadística para educación superior b) Cálculo de la función de ajuste: X Y X2 XY 5 100 25 500 7 90 49 630 9 86 81 774 12 72 144 864 17 60 289 1.020 23 55 529 1.265 30 43 900 1.290 103 506 2.017 6.343 El sistema de ecuaciones que se plantea es el siguiente: Ecuación 1. ∑ 𝑏∑ Ecuación 2. ∑ ∑ 𝑏∑ 𝑏 𝑏 Se soluciona simultáneamente el sistema de ecuaciones y se encuentra que el valor de las incógnitas esta dado por: a = 104,64 y b = -2,2; por lo tanto, la función de ajuste que representa de manera adecuada a los datos originales está dada por la siguiente expresión matemática: ̂ Gráfica de la función de ajuste sobre el diagrama de dispersión: Unidades demandadas Nube de puntos Precio (miles $) Estadística para educación superior c) Pronóstico del número de unidades demandadas para un precio de $15.000: ̂ , para un valor de ̂ ̂ ̂ ( ) unidades d) Coeficiente de correlación: ( ) ( ) √ ( ) Se elabora una tabla con las columnas necesarias para calcular la covarianza y las varianzas respectivas. ( ̅) ( ̅ )( 100 94,37 768,08 -269,22 7 90 59,51 313,80 -136,65 9 86 32,65 188,08 -78,37 12 72 7,37 0,08 0,78 17 60 5,22 150,94 -28,08 23 55 68,65 298,80 -143,22 30 43 233,65 857,65 -447,65 103 506 501,43 2.577,43 -1.102,43 Var(X): 71,63 Var(Y): 368,20 Cov(XY): -157,489796 Coeficiente de correlación: -0,97 ̅ ( 5 Media de X: 14,71 Media de Y: 72,29 ̅ ̅) ∑ ∑ ( ) ̅) Estadística para educación superior ( ) ( ) 𝟕 𝟒𝟗 √𝟕 𝟑 𝟑 𝟗𝟕 La relación entre el precio y el número de unidades demandadas es inversamente proporcional en un 97%. Los pronósticos que se efectúen utilizando la función de ajuste hallada, tendrán un grado de confiabilidad del 97%, ya que el grado de asociación lineal entre las variables es del 97%. Otra forma de calcular el coeficiente de correlación: √ √ Para calcular el coeficiente de correlación utilizando el coeficiente de determinación, se debe tener presente que al resultado hallado siempre se le pone el signo que tenga el parámetro b (coeficiente en X) de la función de ajuste hallada. Se elabora una tabla que sea de utilidad para hallar la variación explicada (VE) y la variación total (VT). ̂ ̅ ̅) (̂ ̅) 5 100 93,643305 768,08 456,15 7 90 89,246154 313,80 287,66 9 86 84,849003 188,08 157,84 12 72 78,253276 0,08 35,61 17 60 67,260399 150,94 25,25 23 55 54,068946 298,80 331,85 30 43 38,678917 857,65 1.129,42 103 506 - ∑ ∑( ̂ ( ̅) 2.577,428571 2.423,772446 Estadística para educación superior ̅) ∑( √ √ El coeficiente de correlación lleva el signo de b, en este caso, negativo (-), por lo tanto, se concluye que 13.10.2 Comportamiento de la captación de una cooperativa a través del tiempo: Enfoque de regresión y correlación. Analizar el comportamiento de la captación anual en millones de pesos de una cooperativa, utilizar el ajuste que se considere adecuado, para tal fin, visualizar a través del diagrama de dispersión cuál es la tendencia de la nube de puntos. Año Captación (millones $) 1996 1,3 1997 3,5 1998 14,5 1999 27,1 2000 41,3 2001 70,3 2002 87,1 2003 130,5 2004 150,3 a) Elaborar el diagrama de dispersión, visualizar la tendencia de los datos originales, ¿Cuál tipo de ajuste es conveniente efectuar? Estadística para educación superior b) Efectuar un ajuste lineal y graficar la función de ajuste sobre el diagrama. Calcular pronósticos y compararlos con el valor original o real. Calcular el coeficiente de correlación y el de determinación e interpretar resultados. c) Efectuar un ajuste parabólico y graficar la función de ajuste sobre el diagrama. Calcular pronósticos y compararlos con el valor original o real. Calcular el coeficiente de determinación e interpretarlo. d) Efectuar un ajuste exponencial y graficar la función de ajuste sobre el diagrama. Calcular pronósticos y compararlos con el valor original o real. Calcular el coeficiente de determinación e interpretarlo. e) Luego de realizar los numerales b), c) y d), ¿cuál ajuste elige dentro del análisis de esta serie de datos como representativo? Comparar la elección realizada con el ajuste propuesto en el numeral a). Solución a) Diagrama de dispersión o nube de puntos: Año 1996 X 0 Y 1,3 1997 1 3,5 1998 2 14,5 1999 3 27,1 2000 4 41,3 2001 5 70,3 2002 6 87,1 2003 7 130,5 2004 8 150,3 Estadística para educación superior Captación Diagrama de dispersión Año Al visualizar el gráfico, la tendencia de los puntos originales parece ser lineal, sin embargo también se asemeja a la mitad derecha de una parábola que abre hacia arriba, o también a una exponencial creciente. ¿Qué decisión tomar, si los tres ajustes se acercan a la tendencia? A continuación se efectúan los tres ajustes para analizar resultados y poder tomar la decisión sobre el tipo de ajuste adecuado que se ha de aplicar en esta serie de datos en particular. Nota: Cuando se tienen dudas respecto a la tendencia de los datos originales en una serie de tiempo, se puede suavizar la serie utilizando el método de los promedios móviles, a través del cual se seleccionan períodos de determinada longitud y luego se calculan medias aritméticas sucesivas, posteriormente, se grafican y se puede mirar con mayor claridad cuál es la tendencia. Si los datos son pocos no se recomienda este método, además, con este método se pierden datos al principio y al final de la serie. b) Ajuste lineal: Año 1996 X 0 Y 1,3 XY X2 0 0 1997 1 3,5 3,5 1 1998 2 14,5 29 4 1999 3 27,1 81,3 9 2000 4 41,3 165,2 16 2001 5 70,3 351,5 25 2002 6 87,1 522,6 36 2003 7 130,5 913,5 49 2004 8 150,3 1.202,4 64 Total 36 525,9 3.269 204 Se plantea el siguiente sistema de ecuaciones: Estadística para educación superior (1) ∑ (2) ∑ 𝑏∑ ∑ 𝑏∑ 𝑏 𝑏 Al solucionar simultáneamente este sistema de ecuaciones se obtiene: y𝑏 La función de ajuste lineal está dada por: ̂ Gráfica de la función de ajuste lineal sobre el diagrama de dispersión: Captación Ajuste lineal Año Cálculo de los pronósticos utilizando la función de ajuste lineal: Año X Y ̂ ̂ 1996 0 1,3 -19,26 20,56 422,7136 1997 1 3,5 0,16333333 3,336666667 11,1333444 1998 2 14,5 19,5866667 -5,086666667 25,8741778 1999 3 27,1 39,01 -11,91 141,8481 2000 4 41,3 58,4333333 -17,13333333 293,551111 2001 5 70,3 77,8566667 -7,556666667 57,1032111 2002 6 87,1 97,28 -10,18 103,6324 2003 2004 Total 7 8 - 130,5 150,3 - 116,703333 136,126667 - 13,79666667 14,17333333 - 190,348011 200,883378 1447,08733 Estadística para educación superior Los valores reales no tienen similitud con los datos pronosticados. La sumatoria de los errores residuales cuadráticos es ∑ 𝑒 , no tiende a ser un valor pequeño. Más adelante se comparan las sumatorias de los errores residuales cuadráticos para mirar cuál es el menor. Coeficiente de correlación lineal: Año X Y ̂ 1996 0 1,3 -19,26 6.036,254044 3.264,217778 1997 1 3,5 0,16333333 3.395,3929 3.017,671111 1998 2 14,5 19,5866667 1.509,063511 1.930,137778 1999 3 27,1 39,01 377,2658778 981,7777778 2000 4 41,3 58,4333333 4,54384 293,5511111 2001 5 70,3 77,8566667 377,2658778 140,8177778 2002 6 87,1 97,28 1.509,063511 821,7777778 2003 2004 Total 7 8 - 130,5 150,3 525,9 116,703333 136,126667 - 3.395,3929 6.036,254044 22.635,95267 5.193,604444 8.439,484444 24.083,04 (̂ ̅) ( ̅) Media de Y: 58,4333333 Coeficiente de determinación D = 0,9399126 Coeficiente de correlación r = 0,9694909 Más adelante se comparan los coeficientes de determinación para analizar cuál de los tres ajustes presenta el coeficiente D más alto, es decir, el más cercano al valor de 1. En este ajuste, el coeficiente de correlación lineal es r = 0,9694909, lo que significa que la función de ajuste hallada tiene un grado de representatividad del 96,9% para efectuar los pronósticos, sin embargo, aunque este porcentaje parezca alto, no es confiable, porque como se detectó anteriormente, los valores pronosticados son muy diferentes a los datos reales. c) Ajuste parabólico: Año X Y X2 X3 X4 XY X2Y 1996 0 1,3 0 0 0 0 0 1997 1 3,5 1 1 1 3,5 3,5 1998 2 14,5 4 8 16 29 58 1999 3 27,1 9 27 81 81,3 243,9 2000 4 41,3 16 64 256 165,2 660,8 2001 5 70,3 25 125 625 351,5 1.757,5 Estadística para educación superior 2002 6 87,1 36 216 1.296 522,6 3.135,6 2003 7 130,5 49 343 2.401 913,5 6.394,5 2004 8 150,3 64 512 4.096 1.202,4 9.619,2 Total - 525,9 204 1.296 8.772 3.269 21.873 Se soluciona simultáneamente el siguiente sistema de 3x3: (1) ∑ (2) ∑ (3) ∑ 𝑏∑ ∑ ∑ ∑ 𝑏∑ 𝑏∑ ∑ ∑ 𝑏 𝑏 𝑏 La solución de este sistema está dada por: 𝑏 La función de ajuste parabólica está dada por: ̂ ̂ 𝑏 Gráfico de la función de ajuste parabólico sobre el diagrama de dispersión: Captación Ajuste parabólico Año Al visualizar este gráfico se detecta que los puntos reales se encuentran más cercanos a la función de ajuste parabólica que en el caso anterior, del ajuste lineal. Estadística para educación superior Cálculo de los Pronósticos utilizando la función de ajuste parabólica: Año X Y ̂ ̂ 1996 0 1,3 -0,18727276 1,487272758 2,21198026 1997 1 3,5 4,93151514 -1,431515144 2,04923561 1998 2 14,5 14,137316 0,362683974 0,13153967 1999 3 27,1 27,4301299 -0,330129889 0,10898574 2000 4 41,3 44,8099567 -3,509956732 12,3197963 2001 5 70,3 66,2767966 4,023203445 16,186166 2002 6 87,1 91,8306494 -4,730649359 22,3790434 2003 2004 Total 7 8 - 130,5 150,3 - 121,471515 155,199394 - 9,028484856 -4,899393909 - 81,5135388 24,0040607 160,904346 Los pronósticos calculados con el ajuste parabólico se encuentran más cercanos a los datos originales que en el caso del ajuste lineal, también se puede observar que la sumatoria de los errores residuales cuadráticos es menor a la arrojada en el ajuste lineal. Cálculo del coeficiente de Determinación en el ajuste parabólico: Año X Y ̂ 1996 0 1,3 -0,18727276 3.436,37546 3.264,21778 1997 1 3,5 4,93151514 2.862,44455 3.017,67111 1998 2 14,5 14,137316 1.962,13715 1.930,13778 1999 3 27,1 27,4301299 961,198624 981,777778 2000 4 41,3 44,8099567 185,59639 293,551111 2001 5 70,3 66,2767966 61,5199153 140,817778 2002 6 87,1 91,8306494 1.115,38072 821,777778 2003 2004 Total 7 8 - 130,5 150,3 525,9 121,471515 155,199394 - 3.973,81237 9.363,67048 23.922,1356 5.193,60444 8.439,48444 24.083,04 (̂ ̅) ( ̅) Media de Y = 58,4333333 Coeficiente de determinación D = 0,99331877 En el presente ajuste parabólico, el coeficiente de determinación es más alto que el hallado en el ajuste lineal, por lo tanto, este ajuste representa mucho mejor a la serie de datos original. Estadística para educación superior d) Ajuste exponencial: X2 0 Y 1,3 0 0,11394335 1997 1 3,5 1 0,54406804 0,54406804 1998 2 14,5 4 1999 3 27,1 9 1,43296929 4,29890787 2000 4 41,3 16 1,61595005 6,46380021 2001 5 70,3 25 1,84695533 9,23477663 2002 6 87,1 36 1,94001816 11,6401089 2003 2004 Total 7 8 - 130,5 150,3 525,9 49 64 204 2,11561051 14,8092736 2,17695898 17,4156718 12,9478417 66,7293431 Año 1996 X 1,161368 0 2,322736 Se plantea el siguiente sistema de ecuaciones: (1) ∑ log (2) ∑ log log log 𝑏 ∑ log ∑ log 𝑏 ∑ log log log 𝑏 log 𝑏 Al solucionar simultáneamente el sistema, se obtiene como resultado: log log 𝑏 Para hallar los valores de a y de b, se aplica antilogaritmo: 𝑏 Recordar que el logaritmo de un número es el exponente al cual hay que elevar la base para que dé dicho número, es decir: log log 𝑏 𝑏 La función de ajuste exponencial está dada por: ̂ ̂ 𝑏 ( ) La función de ajuste exponencial también puede ser expresada como: Estadística para educación superior ̂ 𝑒 Para hallar el valor de c y poder expresarla con la base (e) de los logaritmos naturales (ln), tenemos presente el siguiente análisis matemático: 𝑏 𝑒 ⇩ 𝑏 𝑒 ln 𝑏 ln 𝑒 ln 𝑏 ln 𝑒 ln 𝑏 ln 𝑏 ln 𝑏 En este caso específico, se tiene que: ln Por tal motivo, la función de ajuste exponencial también puede quedar expresada así: ̂ 𝑒 Gráfica de la función de ajuste exponencial sobre el diagrama de dispersión: Captación Ajuste exponencial Año Estadística para educación superior Cálculo de los pronósticos utilizando la función de ajuste exponencial: ̂ ̂ Año X Y 1996 0 1,3 2,77194109 -1,471941086 2,16661056 1997 1 3,5 4,91756678 -1,417566783 2,00949558 1998 2 14,5 8,72401769 5,775982311 33,3619717 1999 3 27,1 15,4768584 11,62314163 135,097421 2000 4 41,3 27,4567468 13,84325317 191,635658 2001 5 70,3 48,7096883 21,59031173 466,141561 2002 6 87,1 86,4135051 0,686494939 0,4712753 2003 2004 Total 7 8 - 130,5 150,3 - 153,302025 -22,80202516 519,932351 271,965718 -121,6657176 14.802,5469 16.153,3632 Los datos pronosticados utilizando la función de ajuste exponencial indican que ésta no es adecuada, porque no presentan semejanza o similitud con los datos reales u originales, además, la sumatoria de los errores residuales cuadráticos es alta. Cálculo del Coeficiente de determinación en el ajuste exponencial: Para calcular el coeficiente de determinación en un ajuste exponencial se debe elaborar preliminarmente la siguiente tabla: ̂ ̅̅̅̅̅̅ log ̂ ̅̅̅̅̅̅ log ̂ ( ̂ ̅̅̅̅̅̅̅ ̂) ( ̅̅̅̅̅̅̅) 2,77194109 0,442784 4,91756678 0,69175027 8,72401769 0,94071654 15,4768584 1,18968281 0,11394335 0,54406804 1,161368 1,43296929 0,991747265 0,557857836 0,247936816 0,061984204 1,754845263 0,800275228 0,076884796 3,226E-05 27,4567468 48,7096883 86,4135051 153,302025 271,965718 1,43864908 1,68761535 1,93658162 2,18554789 2,43451416 1,61595005 1,84695533 1,94001816 2,11561051 2,17695898 0 0,061984204 0,247936816 0,557857836 0,991747265 0,031435635 0,16671399 0,25137095 0,458276781 0,54510151 Total 12,9478417 12,9478417 3,719052243 4,084936413 Estadística para educación superior ∑(log ̂ ̅̅̅̅̅̅ log ̂ ) ∑(log ̅̅̅̅̅̅ log ) El valor de este coeficiente de determinación es inferior a los arrojados en los dos anteriores ajustes. d) Decisión del tipo de ajuste: El ajuste más adecuado para esta serie de datos es el ajuste parabólico. 13.11 Ejercicios de aplicación propuestos. 13.11.1 Análisis de regresión entre el precio de entrada a una sala de videos y el número de estudiantes que entran. La junta de estudiantes de una institución educativa intenta determinar si el precio de entrada a la sala de videos ejerce algún efecto sobre el número de estudiantes que utilizan la instalación. Se cuenta con la siguiente información sobre el precio (en miles de pesos por hora) y el número de estudiantes que entran al recinto: Precio No. Estudiantes 1,25 1,5 1,75 2 2,1 1 2,5 1,1 95 83 75 72 69 101 65 98 a) Graficar el diagrama de dispersión (probar visualmente que los datos originales presentan una tendencia lineal). b) Calcular la función de ajuste y graficarla sobre el diagrama de dispersión. c) Calcular el coeficiente de correlación. d) Pronosticar cuál es el número de estudiantes que ingresan al recinto si el precio es de $1.900. Interpretar resultados. Estadística para educación superior 13.11.2 Análisis de regresión entre la utilidad y el gasto en publicidad. Una empresa descubre que sus utilidades netas (en millones de $) se incrementan al aumentar la cantidad gastada en publicidad (en millones de $) del producto. La empresa dispone de los siguientes registros: Gasto en publicidad 10 11 12,3 13,5 15 15,5 17 Utilidades netas 50 63 68 73 75 77 83 a) Graficar el diagrama de dispersión y probar visualmente que la nube de puntos presenta una tendencia lineal. b) Calcular la función de ajuste lineal y graficarla sobre el diagrama. c) Pronosticar de cuánto es la utilidad si el gasto en publicidad es de $14 millones. d) Calcular el coeficiente de correlación. Interpretar resultados. 13.11.3 Análisis de regresión entre el nivel de ahorro y el ingreso. El departamento de personal de una compañía desea analizar el comportamiento del ahorro mensual de sus empleados en relación con el salario devengado por los mismos, para ello cuenta con la siguiente información: Ingreso mensual (miles $) Ahorro mensual (miles $) 500 100 600 80 550 90 700 200 720 120 730 150 800 200 Estadística para educación superior 820 180 830 210 850 220 a) Graficar el diagrama de dispersión y visualizar cuál es la tendencia que siguen los datos originales. b) Elaborar diferentes tipos de ajuste, para cada uno de ellos: calcular la función de ajuste y graficarla sobre el diagrama; calcular pronósticos; errores residuales; coeficiente de determinación. 13.11.4 Análisis de regresión: Utilidad a través del tiempo en una compañía distribuidora de computadores. La utilidad de una compañía dedicada a distribuir equipos de computador para oficinas presenta las siguientes utilidades en cada uno de los años respectivos: Año Utilidades (millones $) 2000 2001 2002 2003 2004 2005 2006 2007 2008 6 6,5 7 7,2 7,3 7,6 8 8,1 7,9 a) Graficar el diagrama de dispersión y analizar visualmente cuál es la tendencia que siguen estos datos. b) Elaborar el ajuste lineal y el parabólico, ¿cuál considera más adecuado?, explicar. Para cada uno de los dos tipos de ajuste analizar: función de ajuste y gráfica de la función de ajuste; cálculo de pronósticos; coeficiente de correlación lineal; coeficiente de determinación. Estadística para educación superior 13.11.5 Análisis de regresión: Ventas versus espacio asignado. Un comerciante desea analizar si las ventas semanales (en miles de $) tienen relación alguna con el espacio asignado para vender (en metros cuadrados). De acuerdo a eventos pasados se recopiló la siguiente información: Ventas semanales Espacio disponible m2 635 7 528 6 456 4,5 654 6,3 498 5 539 5,2 580 7 620 8 472 6 587 6,8 a) Graficar el diagrama de dispersión, analizar visualmente cuál es la tendencia de esta serie de datos. b) Analizar dos tipos de ajuste diferentes y justificar cuál de ellos elige. 13.11.6 Análisis de regresión: Pasivo pensional a través del tiempo. El pasivo pensional de una entidad estatal viene presentando el siguiente comportamiento: Año 2003 2004 2005 2006 2007 Semestre I II I II I II I II I II Pasivo pensional (millones $) 7 8 10,8 13 14,8 21,1 26,5 30 30,2 31 Estadística para educación superior a) Graficar el diagrama de dispersión. Analizar visualmente la tendencia que siguen los datos. b) Efectuar el ajuste lineal, el parabólico y el exponencial. Analizar cada uno de ellos y justificar cuál de éstos considera más adecuado. Para cada uno de los ajustes se pide: calcular la función de ajuste y graficarla sobre el diagrama de dispersión; calcular pronósticos; errores residuales; coeficiente de determinación y en el caso del ajuste lineal, el coeficiente de correlación lineal. 13.11.7 Análisis de regresión: Presupuesto ejecutado de egresos a través del tiempo. El presupuesto ejecutado de egresos de una caja de compensación familiar viene mostrando el siguiente comportamiento en los últimos años: Año 2001 2002 2003 2004 2005 2006 2007 2008 Presupuesto ejecutado de egresos (millones $) 114 144 177,2 191 311,5 314,1 426 555 a) Graficar el diagrama de dispersión, analizar visualmente la tendencia de los datos originales. b) Efectuar ajuste lineal, parabólico y exponencial. Analizar y justificar cuál de ellos considera de mayor pertinencia. Para cada uno de los ajustes se pide: calcular la función de ajuste y graficarla sobre el diagrama de dispersión; calcular pronósticos; errores residuales; coeficiente de determinación y en el caso del ajuste lineal, el coeficiente de correlación lineal. 13.11.8 Análisis de regresión: Crecimiento de la población a través del tiempo. La población (en millones de habitantes) de una zona determinada del país viene presentando el siguiente comportamiento a través del tiempo: Estadística para educación superior Año Población (millones de habitantes) 2001 2002 2003 2004 1,7 5,95 20,83 72,89 2005 2006 255,11 892,87 2007 2008 3.125,05 10.937,68 a) Graficar el diagrama de dispersión y visualizar cuál es la tendencia que sigue la población a través del tiempo. b) Efectuar diferentes tipos de ajuste y analizar cuál de ellos es el más adecuado. Para cada uno de los ajustes aplicados, calcular: función de ajuste y graficarla sobre el diagrama de dispersión; calcular pronósticos; errores residuales; coeficiente de determinación. 13.11.9 Análisis de regresión: Utilidad semestral. Los siguientes datos se refieren al comportamiento de la utilidad semestral (millones de pesos) de una empresa dedicada a la fabricación de artículos de cuero: Año Semestre Pasivo pensional (millones $) 2005 2006 2007 2008 2009 I II I II I II I II I II 2,07 2,14 2,23 2,34 2,57 2,63 2,85 3,01 3,67 4,1 a) Graficar el diagrama de dispersión y visualizar cuál es la tendencia que siguen las utilidades a través del tiempo. b) Efectuar ajuste lineal, parabólico y exponencial. Analizar y justificar cuál de ellos considera de mayor pertinencia. Para cada uno de los ajustes se pide: calcular la función de ajuste y graficarla sobre el diagrama de dispersión; calcular pronósticos; errores residuales; coeficiente de determinación y en el caso del ajuste lineal, el coeficiente de correlación lineal. Estadística para educación superior Referencias David R., A. (2005). Estadística para administración y economía. México: Editorial Thomson. Douglas, L. (2008). Estadística aplicada a los negocios y la economía. México: Editorial McGrawHill. Canavos, G. C. (1987). Probabilidad y estadística. México: Editorial McGraw-Hill. Levine, D. M. (2006). Estadística para administración. México: Editorial Pearson. Martínez Bencardino, C. (2008). Estadística y Muestreo. Bogotá, Colombia: Editorial ECOE. Stevenson, W. J. (2006). Estadística para administración y economía. México: Alfaomega Grupo Editor OXFORD University Press. Wackerly, D. (2007). Estadística matemática con aplicaciones. México: Editorial Thomson.