TABLA DE CONTENIDO
1. BREVE HISTORIA DE LAS BASES DE DATOS
3
2. QUE ES UNA BASE DE DATOS?
6
3. LA INFORMACIÓN COMO RECURSO CORPORATIVO
3
Ventajas y Desventajas de un Sistema de Bases de Datos
Funciones de un Sistema Gestor de Bases de Datos
7
7
4. NIVELES DE ABSTRACCIÓN DE UNA BASE DE DATOS
9
5. PROCESO DE DESARROLLO DE UNA BASE DE DATOS
11
6. LAS BASES DE DATOS Y EL DESARROLLO DE APLICACIONES
13
7. MODELAMIENTO CONCEPTUAL DE DATOS
15
8. ENTIDADES
17
9. RELACIONES
19
10.
MATRIZ DE RELACIONES
22
11.
LOS ATRIBUTOS
23
12.
IDENTIFICADORES UNICOS
25
13.
LA NORMALIZACIÓN
29
14.
RELACIONES JERÁRQUICAS
34
15.
RELACIONES RECURSIVAS
35
16.
GENERACIONES DE BASES DE DATOS
38
1.
Conceptos Básicos
Claudia
Jiménez
Ramírez
Bases
de
Datos
3
LA INFORMACIÓN COMO RECURSO
CORPORATIVO
En los últimos tiempos, se ha empezado a considerar la información como
un recurso estratégico de una organización; pues le facilita su supervivencia
y le permite, además, ser competitiva en el mercado. También le permite
anticiparse a los cambios futuros y adaptarse mucho más rápidamente a
ellos.
De la información que una organización almacene y de cómo esté
organizada esta información, dependen cuáles preguntas se pueden
formular acerca de su gestión actual o pasada, tanto internamente
como en el entorno.
El tratamiento estadístico con datos históricos es factor clave en el
futuro de la organización y vital en su planeación.
La calidad y oportunidad de las decisiones a todos los niveles
depende en gran medida de hacer llegar la información correcta en el
momento adecuado, a las personas que la necesitan.
La información se debe considerar como otro recurso corporativo de la
misma manera que se considera el recurso humano o los recursos físicos.
Por lo tanto, la administración de la información debe implicar:
a) Planear su adquisición por anticipado.
b) Conseguirla y guardarla antes de necesitarla.
c) Protegerla contra la destrucción o el mal uso.
d) Asegurar su calidad.
e) Retirarla de la organización cuando ya no se la requiera.
f) Asignarle un responsable.
2. Breve historia de las bases de datos
La cantidad de información que debe manejar una organización para
sobrevivir es cada vez mayor. Para ello, deben existir métodos eficientes
tanto para el almacenamiento rápido como para la consulta ágil. La
tecnología que actualmente es más utilizada para manejar grandes
volúmenes de datos es la tecnología de Bases de Datos.
Claudia
Jiménez
Ramírez
Bases
de
Datos
4
En los inicios de la computación se elaboraban programas de computador a
los cuales, siempre que se ejecutaban, se les proporcionaban los datos de
entrada y no se veía la necesidad de guardar la información en memoria
secundaria, tanto la resultante como la de entrada, para su uso posterior.
Con el tiempo, el computador adquiere un uso más comercial en las
empresas para llevar la contabilidad, la nómina y otras actividades. Estas
tareas, por lo general, necesitaban una serie de datos iguales para usarlos
en las diferentes corridas de los programas e implicaban un gran esfuerzo
porque había que entrarlos nuevamente, cada vez.
Ante este problema, aparecen los Sistemas de Archivos, donde los datos se
almacenan de manera permanente para sobrevivir a los programas que los
usan; característica conocida como la persistencia.
Aunque el ambiente de archivos representó un avance en su momento,
posteriormente se enfrentaron con tres problemas básicos.
Información de estudiantes
en archivos
nombre, cédula, valor cancelado por matrícula, préstamos, etc.
nombre, carrera, cédula, materias, notas, teléfono, etc.
nombre, carrera, nota promedio, valor préstamo, caducidad, etc.
Programas
Lenguaje
de desarrollo
Ingresos y Egresos
Registro y matrícula
Fortran
Cobol
Préstamo estudiantil
Pascal
Figura 1. Ejemplo hipotético del Sistema de Archivos
El primer problema, consiste en la alta redundancia de datos. El mismo
dato aparece repetido en varios archivos. Las diferentes versiones de un
mismo dato pueden estar con un grado de actualización distinto en cada
lugar. Esto, además de aumentar los costos de almacenamiento y de
reescritura de la información, puede dar lugar a inconsistencias: un directivo
puede estar viendo un informe donde se muestra una cosa y viendo por
pantalla, otra.
El segundo problema es la inflexibilidad porque cuando se quiere agrupar
los datos de cierta manera no se puede hacer, debido a la organización
dada en los archivos que no tienen ninguna clase de vínculos o presentan
formatos diferentes; como en el ejemplo hipotético de la ilustración 1. Esta
inflexibilidad impide resolver rápidamente consultas espontáneas y aunque
Claudia
Jiménez
Ramírez
Bases
de
Datos
5
los datos existan, la información no puede proporcionarse relacionando
datos. Esta es la queja constante de los directivos; que teniendo la
información no tienen acceso a ella, en el momento en que la necesitan.
El tercer problema que se presenta con el sistema de archivos es el costo
de efectuar cambios en las estructuras de los datos porque al cambiar la
representación de un dato, se necesita cambiar el programa para que lo
reciba de la nueva manera. Además, es altamente probable que los mismos
datos se encuentren en otros archivos; entonces los cambios se propagarán
de una manera incontrolable por todos los lugares, aumentando el tiempo
que el personal especializado debe invertir en el mantenimiento de los
programas y, por ende, reduciendo el tiempo que le pudieran dedicar al
desarrollo de nuevas aplicaciones.
Uno de los objetivos de los Sistemas de Bases de Datos es tener la
posibilidad de usar los datos de nuevas maneras sin generar una reacción
en cadena de modificaciones difíciles sobre los otros programas existentes.
El propósito, pues, del ambiente de bases de datos es separar cada
programa de los efectos de los cambios a los otros programas. También,
que todos los programas estén más aislados de los efectos de reorganizar
los datos. Esta característica es conocida como independencia de datos.
La tecnología de bases de datos proporciona los medios, a las
organizaciones para que cumplan con sus objetivos de lograr máximos
beneficios (para las entidades sin ánimo de lucro, a prestar un mejor
servicio) y ocupar una posición de liderazgo por las razones que se
enumeran a continuación.
1. Se logra el desarrollo de aplicaciones más rápidamente porque los
programas reutilizan los datos y procedimientos almacenados en la base
de datos y con lenguajes de programación de más alto nivel.
2. Hay una mayor participación del usuario final en la creación de las
aplicaciones, haciendo el software más tangible y de mayor valor
inmediato.
3. El acceso a los datos es flexible y rápido.
4. Se pueden generar informes y formularios de pantalla sin la
programación convencional.
5. El usuario final puede, él mismo, extraer la información que necesita y
crear nuevos tipos de datos.
Claudia
Jiménez
Ramírez
Bases
de
Datos
6
En otras palabras, permite a las organizaciones implantar el justo a tiempo
para tener mejor y mayor información para la toma de decisiones e
incrementar su productividad.
3. DEFINICION DE UNA BASE DE DATOS
Es una colección de datos (actualmente, también de procedimientos o
funciones) almacenados de una manera permanente, que pueden ser
compartidos y usados con variados propósitos por múltiples usuarios.
Un usuario determinado no tiene que ver todos los datos de la base de
datos, sólo aquellos que necesita o esté autorizado para poder cumplir con
sus funciones dentro de una organización.
No todos los usuarios perciben los datos de la misma manera, a pesar de
que puedan ser extraídos de la misma base de datos. Por ejemplo, la fecha
de compra de un artículo puede ser vista por el asistente de mercadeo con
un formato que no incluye la hora; mientras que el jefe de bodega sí
necesita verla porque, para él, es información valiosa.
Sin embargo, se debe señalar, que la consecución del objetivo de integrar
toda la información de una organización para evitar redundancias, esencial
para superar las limitaciones de los sistemas de archivos, a su vez, puede
generar nuevos problemas o dificultades que se deben resolver. Entre ellos,
está el problema del trabajo concurrente o simultáneo de un grupo de
usuarios o aplicaciones sobre las mismas piezas de información y también el
problema de la seguridad.
Los usuarios de una base de datos se pueden clasificar en tres categorías:
el usuario final que interactúa con la base de datos, por lo general, a
través, de las aplicaciones, el usuario especialista que es el que diseña y
programa las aplicaciones para los usuarios finales y, por último, la persona
encargada de administrar la base de datos llamada en forma abreviada DBA
(database administrator).
No obstante, cualquier persona con cargos administrativos, ingeniero o
profesional cuyo trabajo sea cambiado por los sistemas de bases de datos
debería entender los principios de esta tecnología y lo que ello involucra.
Claudia
Jiménez
Ramírez
Bases
de
Datos
7
3.1 Ventajas y Desventajas de un Sistema de Bases de Datos
3.1.1
Ventajas
1. Economía de escala: esencialmente, la concentración de aplicaciones
en una sola localidad puede reducir costos: menos cantidad de
personas especializadas, en software, etc.
2. Se puede obtener mayor información de la misma cantidad de datos:
existe una mayor facilidad para el análisis y la toma de decisiones.
3. Datos y programas compartidos: la reutilización de los mismos datos y
programas, permiten minimizar o controlar la redundancia.
4. Incentiva la adopción de estándares.
5. Consistencia de los datos: está dada por el control o eliminación de la
redundancia.
6. Integridad: el DBMS debe velar por el grado de validez y de corrección
de los datos. Debe permitir definir reglas que deben cumplir los datos,
en la base de datos. Por ejemplo, que el departamento asociado a un
profesor sea uno de los existentes en la Universidad.
7. Seguridad: se pueden especificar niveles de acceso con una
granularidad más fina, según los perfiles de los usuarios.
8. Flexibilidad y oportunidad: El uso de lenguajes de cuarta generación
hacen más fácil la construcción de los programas por parte de los
usuarios finales.
9. Mayor productividad de los programadores. Las aplicaciones nuevas
pueden desarrollarse en la mitad del tiempo, o menos, que con los
sistemas de archivos tradicionales debido al uso de lenguajes de
tercera generación.
10.Facilidades para el mantenimiento y reingeniería: se puede cambiar la
estructura de los datos sin cambiar los programas que los usan.
3.1.2
Desventajas
1. Tamaño: Un DBMS es un gran conjunto de programas.
2. Mayor susceptibilidad a las fallas: más cantidad de huevos en una
sola canasta.
3. Recuperación a las fallas: la recuperación de un DBMS interactivo y
multiusuario puede ser muy compleja.
Funciones de un Sistema Gestor de Bases de Datos
Un sistema gestor de bases de datos (DBMS o Database Management
System) es el software que sirve de intermediario entre el usuario y la base
de datos. Tiene las siguientes funciones:
Claudia
Jiménez
Ramírez
Bases
de
Datos
8
1. Interactuar en forma transparente con el manejador de archivos del
sistema operativo para la actualización, almacenamiento y recuperación
de los datos. El usuario, a excepción del DBA, no debería preocuparse
por las estructuras internas o por los procedimientos usados para
manipularlos.
2. Optimizar la búsqueda de la información.
3. Ofrecer un catálogo asequible por el usuario (autodescriptivo). Un DBMS
debe ser capaz de responder a preguntas sobre:
i) Los elementos que conforman la estructura de la base de datos.
ii) Las características de los atributos o campos (i.e longitud, tipo de
datos)
iii) Las restricciones.
iv) Los significados de los elementos o datos.
v) Cuáles programas usan cuáles datos y cómo los usan.
4. Manejo de transacciones: para asegurar que todas las actualizaciones se
hagan todas o ninguna. Una transacción es una secuencia de pasos para
cumplir una tarea, según el punto de vista del usuario final.
5. Controlar el acceso concurrente o simultáneo a los mismos datos para
que no existan conflictos por las peticiones de los usuarios o
aplicaciones.
6. Servicios de recuperación ante fallas.
i) Permitir hacer respaldos totales o parciales de la base de datos.
ii) Creación y mantenimiento de archivos log de transacciones o
bitácoras; que deben ser actualizados antes que los datos mismos.
iii) Incluye la identificación de la transacción, hora y fecha de la
misma.
iv) Archivos de imágenes anteriores y posteriores.
v) Permitir la devolución de la base de datos a un estado correcto
conocido.
7. Poner en práctica la seguridad para impedir el acceso a los datos a los
usuarios no autorizados mediante:
i) El encriptamiento de la información.
ii) Los subesquemas o vistas
iii) Privilegios o reglas de autorización: sujeto, objeto, acción y
restricción.
iv) Procedimientos definidos por el usuario que pueden aumentar la
seguridad.
8. Implantar mecanismos para preservar la integridad de los datos mediante
la especificación con:
i) Tipos de datos
ii) Valores válidos
iii) Formatos y valores por defecto
Claudia
Jiménez
Ramírez
Bases
de
Datos
9
iv) Restricciones
9. Servicios para promover la independencia de datos.
10.Otros servicios utilitarios para la administración de los datos.
De lo recién expuesto, se puede apreciar que un sistema gestor de bases
de datos debe realizar muchas tareas bastante complejas y de ahí su
tamaño y costo.
No obstante, en el mercado se pueden encontrar una gran variedad de
sistemas gestores de bases de datos con precios muy disímiles y una de las
razones se debe a que no todos ellos cumplen con las funciones que se
acaban de mencionar.
Funcionamiento de un DBMS
Análisis sintáctico
Error
Verificación de
privilegios y de la
existencia de los
objetos en la base de
datos
Diccionario
de datos
Optimización de la
consulta
Base de
datos
Bitácora
Manejo de
Transacciones
Administración del
almacenamiento
4. Niveles de abstracción de una base de datos
La manera cómo percibimos la base de datos, según seamos usuarios
finales, especialistas o administradores, corresponde con un nivel de
abstracción.
Claudia
Jiménez
Ramírez
Bases
de
Datos
1 0
Por lo anterior, la ANSI/SPARC ha propuesto una arquitectura considerando
tres niveles de abstracción.
Los niveles son tres:
Nivel de visión
(vistas parciales)
1
2
n
Nivel conceptual
(vista comunitaria)
Nivel físico
(almacenamiento)
1. El nivel de visión o externo es el más cercano a los usuarios, esto
significa que se ocupa de la forma cómo los usuarios individuales
perciben la base de datos. A diferencia de los otros dos niveles, existen
múltiples maneras de percibir la base de datos a este nivel; tantas como
grupos de usuarios finales existan en la empresa. Toda vista externa de
la base de datos, se define mediante subesquemas.
2. El nivel conceptual es el nivel mediador entre el nivel físico y el de visión,
se ocupa de cuáles son los datos reales almacenados en la base de
datos y de las relaciones existentes entre ellos. Este nivel, es de interés
primordialmente para el usuario especialista. El esquema lógico,
correspondiente con este nivel de abstracción, está conformado por la
descripción semántica de los datos que conforman la base de datos.
3. El nivel físico o interno es el más cercano a la máquina, es decir, es el
que se ocupa de la forma como se almacenan los datos físicamente en la
memoria secundaria. El nivel físico de la base de datos interesa al
administrador y al usuario especialista. La descripción de este nivel de
abstracción se le denomina esquema físico y está conformado por la
descripción de los datos, sus tipos, su tamaño y dominio de acuerdo con
un DBMS particular.
Claudia
Jiménez
Ramírez
Bases
de
Datos
1 1
Independencia de datos: es una característica de las bases de datos que
permiten modificaciones en la definición de un esquema sin afectar, en la
medida de lo posible, la reescritura del esquema inmediatamente superior.
Independencia física: cuando un cambio en el esquema físico no conduce
a efectuar cambios en el esquema lógico.
Independencia lógica: cuando un cambio en el esquema lógico no conlleva
a un cambio en el nivel de visión. Este tipo de independencia es más difícil
de lograr que la independencia física.
5. Proceso de desarrollo de una base de datos
El desarrollo de una base de datos, es una técnica “arriba-abajo” que
transforma los requerimientos de información en una base de datos en
funcionamiento.
REQUERIMIENTOS DE INFORMACIÓN DE LA ORGANIZACIÓN
Estrategia
Análisis
Diseño
Conceptual de
la Base de Datos
Modelo Entidad-Relación
Diseño
Construcción
Diseño lógico
de la Base de
Datos
Tablas, Índices, Vistas,
Clústeres, Definiciones de
espacios
Implementación
de la Base de Datos
El diseño conceptual parte de la especificación de requerimientos y su
resultado es el esquema conceptual, cuyo propósito es describir el contenido
de información de la base de datos, más que las estructuras de
almacenamiento que se necesitarán para manejar la información. Es una
descripción de alto nivel que es completamente independiente del software
de DBMS que se use, incluso si se pensara en implementar con archivos
tradicionales y con algún lenguaje de programación convencional.
Claudia
Jiménez
Ramírez
Bases
de
Datos
1 2
El diseño lógico parte del esquema conceptual y da como resultado el
esquema lógico. El esquema lógico es una descripción de la estructura de la
base de datos que puede procesar el software DBMS. El modelo lógico más
usado actualmente, es el modelo relacional que ha sido enriquecido con los
modelos orientados por objetos. El modelo lógico no depende del DBMS en
particular, sino del modelo de datos usado por el DBMS.
El diseño físico parte del esquema lógico y da como resultado un esquema
físico. Es una descripción de cómo está almacenada la base de datos en la
memoria secundaria; describe las estructuras de almacenamiento y los
métodos usados para tener un acceso efectivo a los datos. Los esquemas
lógicos y físicos se expresan haciendo uso del lenguaje de definición de
datos del DBMS elegido; la base de datos se crea y se carga, y puede ser
probada. Lo mismo, puede probarse las aplicaciones sobre la base de datos
y de este modo la base de datos se vuelve operacional.
Claudia
Jiménez
Ramírez
Bases
de
Datos
1 3
6. LAS BASES DE DATOS Y EL DESARROLLO DE APLICACIONES
El proceso de desarrollo de la base de datos está estrechamente acoplado
con el proceso de desarrollo de aplicaciones:
Requerimientos de la organización
REQUERIMIENTOS DE INFORMACION
REQUERIMIENTOS DE APLICACIONES
Estrategia
Modelamiento
Conceptual de
Chequeos Cruzados
Análisis
Modelo Entidad-Relación
Diseño
Diseño de la
Base de Datos
Chequeos Cruzados
Tablas, Indices, Vistas,
Clusters, Definiciones de
espacios
Construcción
Construcción
de la Base de
Datos
Modelamiento
de
Funciones
Modelo Jerárquico
Def de Funciones
DFDs
Diseño de las
Aplicaciones
Diseño de módulos
Construcción de
las aplicaciones
APLICACIONES EN OPERACIÓN
BASE DE DATOS EN OPERACIÓN
SISTEMA EN OPERACIÓN
Figura 2 Acoplamiento de la visión orientada a los datos y a las aplicaciones
Un enfoque alternativo en el diseño de los sistemas informáticos llamado
orientado a las funciones se desarrolló en la década de 1960 consiste en
centrarse en las aplicaciones y no en los datos.
Claudia
Jiménez
Ramírez
Bases
de
Datos
1 4
El análisis funcional parte de los requerimientos de aplicaciones que
describen las actividades y los flujos de información dentro de una
organización para llegar a una especificación formal de los procesos y
considera los archivos de datos depósitos de información aislados, utilizados
por cada actividad o intercambiados entre ellas; se pierde la visión de la
información como recurso corporativo de la organización.
Los enfoques orientados a los datos y a las funciones para el diseño de
sistemas informáticos son complementarios, ambos proporcionan
características relevantes y se deben relacionar íntimamente como se
muestra en la ilustración 2.
Lo anterior, también ha originado un el enfoque llamado orientado a objetos
donde se determinan los objetos del dominio del mundo real relevantes en la
solución del problema, con sus características y comportamiento y de esta
manera juntar los dos enfoques anteriores.
Independiente del enfoque utilizado, la tarea más difícil en el proceso de
desarrollo de una base de datos es determinar los datos necesitados por los
usuarios, representarlos en la base de datos y asegurar que ellos son, en
verdad, usados apropiadamente. Esto se dificulta, aún más, debido a los
diferentes nombres que los usuarios dan a un mismo dato, o por el contrario,
el mismo nombre para distintos datos.
De lo expuesto, nace la necesidad adicional de la creación de un diccionario
de datos donde cada término es definido según el lenguaje de la empresa,
buscando una estandarización para los datos y un significado preciso para
cada palabra.
Claudia
Jiménez
Ramírez
Bases
de
Datos
1 5
7. MODELAMIENTO CONCEPTUAL DE DATOS
Los modelos de datos son usados para describir la realidad. Los
diseñadores usan los modelos de datos para construir esquemas que son
representaciones de la realidad. La calidad de los esquemas resultantes
dependerá, no sólo del modelo elegido, sino también de la habilidad del
analista.
Un modelo de datos es una serie de conceptos que se utilizan para describir
un conjunto de datos y de operaciones para manipular los mismos. Cuando
un modelo de datos describe un conjunto de conceptos de una realidad se
llama modelo conceptual.
El bloque de construcción común a todos los modelos conceptuales de
datos es una pequeña colección de mecanismos de abstracción:
clasificación (agrupación de una clase de objetos con características
comunes), agregación (una nueva clase formada por la reunión de varios
objetos) y la generalización o especialización (una relación de subconjunto
entre los elementos de dos o más clases).
La abstracción es un proceso mental que se aplica al seleccionar algunas
características y propiedades de un conjunto de objetos y excluir otras no
pertinentes.
En el modelamiento conceptual, se identifican las propiedades estructurales
(sobre los objetos, sus atributos y relaciones) y dinámicas (operaciones
sobre los objetos) además de ciertas restricciones de integridad, de un
dominio de aplicación con miras a su transformación en un modelo de más
bajo nivel.
Los modelos conceptuales deben ser buenas herramientas para representar
la realidad; por esta razón debe poseer, entre otras las siguientes
características:
1. Expresividad: los modelos más ricos en conceptos son más expresivos.
Por ejemplo, la mayoría de los modelos conceptuales hacen uso
frecuente de la abstracción de generalización lo que permite la
representación de una gran variedad de restricciones de integridad.
2. Simplicidad: un modelo conceptual debe ser simple o fácil de entender
por los diseñadores y por los usuarios finales. Esta propiedad y la
expresividad son objetivos en conflicto; si un modelo es semánticamente
rico, es probable que no sea simple.
Claudia
Jiménez
Ramírez
Bases
de
Datos
1 6
3. Minimalidad: esta característica se consigue si ningún concepto presente
puede expresarse por otros conceptos. Con la minimalidad se persigue
que el modelo abstraiga lo esencial de la realidad, buscando la
parsimonia.
4. Formalidad: todos los conceptos deben tener una interpretación única,
precisa y bien definida.
Los modelos en la ingeniería del software, suelen describirse mediante
representaciones lingüísticas y gráficas. El éxito de un modelo de datos
depende en gran medida de su representación gráfica que debe ser lo más
completa posible (si no requiere complementarse con una representación
lingüística) y facilidad de lectura (si cada concepto se representa con un
símbolo gráfico claramente distinguible del resto).
El modelo Entidad-Relación es el más usado para el modelamiento
conceptual de bases de datos. Fue propuesto por Chen en 1976. En 1988,
la ANSI seleccionó el modelo E-R como el modelo estándar para los
sistemas de diccionarios de recursos de información (IRDS, Information
Resource Dictionary Systems).
Posteriormente, el modelo fue extendido por otros autores, como Richard
Barker en la metodología Case Method, para adicionar una mayor
semántica.
En la figura siguiente, se aprecia un ejemplo de un diagrama entidadrelación, con la notación de Barker.
EMPLEADO
# * carné
* nombre
asignado a
* apellido
responsable
o cargo
de
* fecha enganche
o salario
o comisión
subordinado
de
jefe
de
DEPARTAMENTO
# * número
* nombre
* ubicación
Los conceptos básicos de un modelo Entidad-Relación son:
Claudia
Jiménez
Ramírez
Bases
de
Datos
1 7
• Entidad - representa una clase de objetos de la realidad, de la que se
necesita mantener y conocer información.
• Relación - representa una conexión entre los objetos de una o más
entidades.
• Atributo - representa una propiedad básica que caracteriza a una
entidad o a una relación.
El modelo Entidad-Relación es un medio efectivo para recopilar y
documentar los requerimientos en un formato claro y preciso. Esto es, un
marco de especificación formal, fácil de entender por los usuarios finales,
agilizando la comunicación entre éstos y los usuarios especialistas.
El modelo E-R (Entidad-Relación) se caracteriza, además, porque se puede
refinar con facilidad. Proporciona un claro cuadro del alcance de los
requerimientos de información y sirve de base de integración de múltiples
aplicaciones, proyectos de desarrollo y paquetes comerciales.
Es importante establecer completamente los requerimientos de información
de la organización durante la etapa de modelamiento para evitar cambios en
etapas posteriores del desarrollo, pues siempre implican costos mayores
que los que se detectan en una etapa temprana.
El modelo E-R puede ser transformado una base de datos jerárquica, en
red, relacional u orientada por objetos e, incluso, a un ambiente tradicional
de desarrollo de software. Esto es, puede ser traducido a cualquier modelo
lógico que se desee.
8. ENTIDADES
Una entidad es una clase de objetos de importancia, en el dominio del
problema, sobre la cual se debe guardar o conocer alguna propiedad.
También puede definirse como una categoría. Ejemplos de entidades son:
EMPLEADO
ARTICULO
TIQUETE
Las entidades pueden ser simples si son irreducibles o complejas cuando
están formadas, a su vez, por otras entidades.
Claudia
Jiménez
Ramírez
Bases
de
Datos
1 8
Cada entidad se define por los atributos y sus relaciones que poseen. Por lo
tanto, toda entidad debe poseer dichas propiedades. Algunos atributos
posibles para la entidad EMPLEADO son: su fecha de vinculación, el salario
y cargo.
Convenciones:
ü Para dibujar las entidades en el diagrama E-R se utilizan cajas, con
bordes redondeados, de cualquier dimensión.
ü Cada entidad lleva un nombre único en mayúscula y en singular.
ü Puede ir un nombre sinónimo entre paréntesis. Los sinónimos son útiles
cuando dos grupos de usuarios usan diferentes nombres para referirse a
una misma entidad.
ü Los nombres de los atributos deben ir en minúsculas.
Ejemplos:
EQUIPO
#
¯
¯
¯
referencia
fabricante
marca
fecha de
compra
#
¯
¯
¯
PROYECTO
código
nombre
fecha de inicio
fecha de finalización
Cada entidad suele tener múltiples ocurrencias o instancias; es decir, debe
tener asociada una población de objetos. Toda instancia tiene valores
específicos para los atributos de la entidad.
Cada instancia debe ser identificable de las otras instancias u ocurrencias
de la misma entidad. Un atributo o conjunto de atributos que identifican
inequívocamente a cada instancia es llamado identificador único (IU).
Para los empleados, por ejemplo, el atributo cédula serviría como
identificador único.
Los atributos que identifican a una entidad son marcados con el símbolo #.
Para identificar y modelar las entidades de las notas de las entrevistas, se
recomiendan los siguientes pasos:
Claudia
Jiménez
Ramírez
Bases
de
Datos
1 9
1. Examinar los sustantivos presentes en la descripción verbal de los
requerimientos de información. ¿Son cosas de importancia para
considerarlos como entidades?
2. ¿Hay información de interés que se deba almacenar sobre esa entidad?
3. ¿Es identificable unívocamente cada instancia de esa entidad?
4. Elabore una descripción de cada entidad (será incluida en el diccionario
de datos).
5. Dibuje la entidad y colóquele sus atributos.
No se debe descalificar una entidad muy rápidamente. Posteriormente,
pueden surgir atributos de interés para la organización sobre esa entidad.
9. RELACIONES
Una relación es una asociación bidireccional, significativa, nombrable entre
dos entidades, o de una entidad consigo misma. Cada relación asocia una
instancia de cada una de las entidades involucradas en ella.
La sintaxis de una relación, permite una lectura:
debe
una o varias
Cada entidad1 puede ser o estar nombre-relación una y sólo una entidad2
Ejemplo
La relación entre PROFESOR y CURSO es:
Cada CURSO puede ser dictado por uno y sólo un PROFESOR.
Cada PROFESOR puede ser el docente de uno o más CURSOs.
Cada dirección de una relación tiene ciertas características que se pueden
especificar en el modelo E-R:
• Un nombre - por ejemplo dictado por, asignado a
• Una opcionalidad (una cardinalidad mínima).
• Un grado o cardinalidad máxima.
Para dibujar las relaciones en el diagrama E-R, se siguen las siguientes
convenciones:
• Una línea entre las entidades relacionadas.
Claudia
Jiménez
Ramírez
Bases
de
Datos
2 0
• Los nombres de las relaciones se escriben en minúsculas y se colocan
en los extremos de la línea de la relación.
• La cardinalidad mínima se representa con:
Si es obligatoria (debe ser o estar)
Si es opcional (puede ser o estar)
• El grado o cardinalidad máxima se representa con:
Si la relación se puede dar con una o varias
instancias de la otra entidad
Si la relación se puede dar sólo con una y sólo una
instancia de la otra entidad
Si la cardinalidad, máxima o mínima, tiene una restricción numérica definida,
se le agrega al extremo de la línea conectiva.
Una relación se lee primero en una dirección, y luego en la otra dirección.
Ejemplo
Para leer la relación entre EMPLEADO y DEPARTAMENTO:
EMPLEADO
asignado
a
DEPARTAMENTO
responsable
de
Primero se leerá de izquierda a derecha:
“Cada EMPLEADO debe ser asignado a un, y sólo un, DEPARTAMENTO”.
Ahora, si se lee de derecha a izquierda, sería como se muestra a
continuación.
“Cada DEPARTAMENTO puede ser responsable de uno o varios un
EMPLEADOs”.
Existen tres tipos de relaciones, de acuerdo con su grado:
Claudia
Jiménez
Ramírez
Bases
de
Datos
2 1
• De muchos a uno (n:1) que se caracteriza por tener un grado de uno o
más en una dirección y un grado de uno y sólo uno en la otra dirección.
Es una relación frecuente.
Ejemplo
TIQUETE
comprado
por
PASAJERO
poseedor
de
• De muchos a muchos (n:m) que tienen un grado de uno o más en ambas
direcciones. También es una relación muy común.
Ejemplo
ARRENDADOR
generador
de
originado
por
ALQUILER
• Uno a uno (1:1) tiene un grado uno y sólo uno en ambas direcciones.
Este tipo de relaciones es rara. Es importante tener cuidado ya que
puede que una relación de éstas entre entidades sea realmente una
misma entidad.
Ejemplo
Claudia
Jiménez
Ramírez
OPERARIO
encargado
de
manejada
por
Bases
de
Datos
2 2
MAQUINA
Todas las entidades, relaciones y atributos deben representar los
requerimientos de información y las reglas de la organización.
10. MATRIZ DE RELACIONES
Como ayuda inicial en la recolección de la información acerca de las
relaciones entre un conjunto de entidades se emplea la matriz de relaciones.
Una matriz de relaciones muestra para cada entidad fila sobre el lado
izquierdo si tiene una relación y cómo es ésta, con cada entidad columna.
Todas las entidades son listadas tanto en el lado izquierdo como en la parte
superior de la matriz. Si una entidad fila tiene una relación con una entidad
columna, entonces se coloca el nombre de la relación en la celda que las
intercepta. Si no existe una relación se coloca una raya horizontal.
Cada relación encima de la diagonal es la inversa o el espejo de una
relación por debajo de la diagonal. Las relaciones recursivas (de una entidad
consigo misma) se representan sobre la línea diagonal.
Ejemplo
La siguiente matriz muestra las relaciones entre cuatro entidades.
CLIENTE
ARTICULO
CLIENTE
ARTICULO
ORDEN
BODEGA
Hecha para
ORDEN
el generador
de
comprado
mediante
BODEGA
almacenado
en
Compuesta de
sitio de
almacenamiento
Una vez se tengan definidas las relaciones en la matriz, se pueden llevar al
modelo entidad-relación.
Claudia
Jiménez
ARTICULO
código
descripción
Ramírez
comprado por
almacenado en
compuesta
de
Bases
de
Datos
2 3
ORDEN
número
fecha
originada por
el repositorio de
BODEGA
identificador
dirección
el originador de
CLIENTE
identificador
razón social
dirección
Debemos leer en voz alta las relaciones para validarlas y emplear la matriz
de relaciones para examinar si existe una relación entre cada pareja de
entidades.
No se deben usar los términos "relacionado con" o "asociado a" como
nombres de relaciones, pues estos nombres no definen cuál tipo de relación
se está modelando.
11. LOS ATRIBUTOS
Los atributos son información que se necesita conocer y mantener de una
entidad. Sirven para describir, identificar, cualificar, clasificar, cuantificar o
expresar un estado de una entidad.
Los atributos representan un tipo de descripción o detalle, no una instancia;
los nombres dados a los atributos deben ser claros para el usuario y no
deben incluir el nombre de la entidad; ya que sería redundante como en el
caso de colocar código de curso en la entidad CURSO.
Los nombres de los atributos deben ser específicos y completos. Esto es,
cantidad comprada, fecha de envío en vez de, únicamente, cantidad y fecha.
Las convenciones que rigen para representar los atributos en diagrama E-R,
señalan que siempre deben ir en singular y en minúscula y se colocan
dentro de la caja de la entidad
Se debe descomponer un atributo hasta aquella componente mínima con
significado propio. Así, el nombre de una persona debe ser descompuesto
en nombre y apellidos. Los atributos que contengan fechas no se
Claudia
Jiménez
Ramírez
Bases
de
Datos
2 4
descomponen. No obstante, el nivel de descomposición dependerá de las
necesidades organizacionales.
Se debe verificar que cada atributo tenga un solo valor para cada instancia
de la entidad; pues un atributo con múltiples valores o grupos que se repiten
no son un atributo válido, en este modelo.
Para representarlos, entonces, es necesario ascenderlos a la categoría de
entidad.
Ejemplo
En ESTUDIANTE, el atributo notas es multivaluado:
ESTUDIANTE
carné
nombre
apellido
carrera
notas
Entonces, es preciso crear promover el atributo notas a la categoría de clase
y establecer una relación con estudiante.
Se debe verificar que un atributo no sea calculado o derivado de los valores
existentes de otros atributos. El atributo derivado es redundante y las
redundancias pueden conducir a inconsistencias en los valores de los datos.
Algunas veces se necesita, por cuestiones de eficiencia, tener datos
redundantes; pero se debe tener muy presentes en la etapa de diseño para
que sean, en la medida de lo posible, calculados o recalculados (en el caso
de correcciones) automáticamente por el sistema.
Si un atributo tiene, a su vez, atributos propios; entonces debe modelarse
como otra entidad.
Ejemplo
Claudia
Jiménez
COMPUTADOR
referencia
marca
tarjeta madre
fecha de compra
Ramírez
Bases
COMPUTADOR
referencia
marca
fecha de compra
de
Datos
2 5
TARJETA MADRE
poseedora
de
para
número serie
chip procesador
velocidad procesador
chip coprocesador
Existen atributos obligatorios y otros que pueden ser opcionales. El atributo
obligatorio significa que en todo momento es importante conocer el valor que
toma para cada ocurrencia de la entidad y se marcan con un asterisco.
Cuando el atributo es opcional se marca con la letra “o”.
Ejemplo
PERSONA
* código
* nombre
o profesión
* sexo
o peso
12. IDENTIFICADORES UNICOS
Un identificador único (IU) puede ser cualquier combinación de atributos y/o
relaciones que sirven para identificar inequívocamente una ocurrencia de
una entidad. Cada instancia debe ser completamente identificable.
Puede ocurrir que una entidad sea identificada por medio de una relación.
En las corporaciones financieras, por ejemplo, a cada sucursal se le asigna
un número de identificación y dentro de ellas, cada cuenta tiene un número
único. Entonces, una CUENTA se identifica completamente con su número
más el número de la sucursal.
Claudia
Jiménez
Ramírez
Bases
de
Datos
2 6
Observe cómo, en este caso, se coloca una barra para indicar que la
relación forma parte del identificador único.
Una relación parte de un Identificador Unico debe ser obligatoria y de grado
uno y sólo uno en la dirección que participa en la identificación única.
No es raro, tampoco, que una entidad sea identificada por varias relaciones.
Ejemplo
Para diferenciar una inscripción a un curso de otra, se necesita el carné del
estudiante, el código del curso y de la fecha de inscripción
INSCRIPCION
# * fecha
o nota definitiva
de
para
registrado
en
motivo
para
ESTUDIANTE
CURSO
# * carné
* nombre
# * código
* nombre
Una entidad puede tener más de un identificador único. Este es el caso de
un estudiante que posee un carné y un documento de identificación (cédula
o T.I)
Se debe seleccionar uno, entre los candidatos, para que sea el identificador
único y los otros se dejan como UI secundarios; aunque, lastimosamente, no
se muestran los identificadores únicos alternos en el modelo E-R.
En ocasiones, se usan identificadores artificiales (como pasa en la realidad)
para ayudar en la diferenciación rápida de las instancias de una entidad.
Ejemplo
Claudia
Jiménez
Ramírez
Bases
de
Datos
2 7
ARTICULO
* descripción
* unidad de medida
* marca
* cantidad a la mano
* precio de venta
Para identificar los artículos que vende una tienda, se necesitaría de la
descripción del artículo, de la unidad de medida y de la marca. Para evitar
un identificador único tan largo, es mejor crear un código artificial que será
único para cada instancia.
Claudia
Jiménez
Ramírez
Bases
de
Datos
2 8
NORMALIZACION DEL MODELO DE DATOS
Claudia
Jiménez
Ramírez
Bases
de
Datos
2 9
13. La normalización
La normalización es un concepto de bases de datos relacionales, pero sus
principios se pueden aplicar desde la etapa del modelamiento conceptual.
La ubicación de los atributos se valida, usando las reglas de normalización
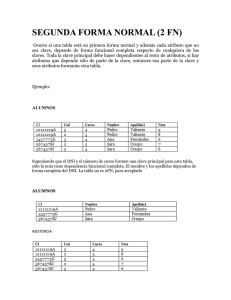
La primera forma normal (1FN) determina que todos los atributos deben
poseer un sólo valor (ser atómicos).
La segunda forma normal enuncia que todo atributo debe ser dependiente
del identificador único de la entidad a la que pertenece.
La tercera forma normal dice que ningún atributo que no sea identificador
único puede depender de otro que tampoco lo sea.
Lo que se persigue con la normalización es evitar redundancia de datos y,
por ende, posibles inconsistencias.
Hasta la tercera forma normal generalmente se acepta que se normalice.
Regla de la primera forma normal: todos los atributos deben poseer un
sólo valor.
Revise que ningún atributo tenga más de un valor para cada instancia de
una entidad.
Ejemplo
PACIENTE
# * identificación
* nombre
* dirección
* teléfono
* fechas citas
El atributo fechas de las citas porque tiene múltiples valores. Por lo tanto, la
entidad PACIENTE, no está en primera forma normal debemos crear una
nueva entidad CITA MEDICA con una relación uno a muchas con
PACIENTE.
Claudia
Jiménez
CITA MEDICA
Ramírez
de
Datos
3 0
PACIENTE
para
# * número
* fecha
Bases
figura
en
# * identificación
* nombre
* dirección
* teléfono
SOLUCION: Si un atributo tiene múltiples valores, cree una entidad
adicional y relaciónela con la original con una relación n:1.
Regla de la segunda forma normal: todo atributo debe ser dependiente
del identificador único de la entidad a la que pertenece.
Para validar si entidad cumple con la segunda forma normal, verifique que
cada identificador único específico determine una sola ocurrencia para cada
atributo. Asegúrese de un atributo no dependa únicamente de una parte del
IU de esa entidad.
Ejemplos
1. Valide si PACIENTE está en segunda forma normal
PACIENTE
# * identificación
* nombre
* dirección
* teléfono
Cada instancia una identificación de paciente determina un valor específico
para nombre, dirección y teléfono. Entonces los atributos están bien
ubicados.
2. Valide la ubicación de los atributos para las entidades
CUENTA
# * número
* fecha apertura
* localización
manejada
por
administrador
de
BANCO
# * número
* nombre
Claudia
Jiménez
Ramírez
Bases
de
Datos
3 1
En el ejemplo anterior, cada instancia de BANCO y de un número de cuenta
determinan una fecha específica de apertura. El atributo localización está
mal ubicado. Depende del BANCO pero no del número de la cuenta. No
debería ser, entonces, atributo de cuenta.
SOLUCION: si un atributo no depende del identificador único entero, está
mal ubicado y debe ser movido a otra entidad.
Regla tercera forma normal: ningún atributo que no sea identificador
único puede depender de otro que tampoco lo sea.
Ejemplo
Verifique si algún atributo no IU depende de cualquier otro que tampoco es
IU
REVISTA
# * número
* codigo editorial
* nombre editorial
* fecha publicación
El atributo nombre de la editorial depende de otro que no es identificador
único: código de la editorial. Luego, se debe crear una nueva entidad
EDITORIAL y se reubican los atributos.
REVISTA
# número
* fecha publicación
EDITORIAL
editada
por
editora
de
# codigo
* nombre
Solución: si un atributo no IU depende de otro que tampoco es IU, mueva
ambos a una nueva entidad relacionada con la original.
Resolución de las relaciones de muchos a muchos (n:m)
Una relación de este tipo no debe aparecer en el modelo E-R. Una relación
de muchos a muchos se resuelve adicionando una entidad de intersección.
Ejemplo
Claudia
Jiménez
Ramírez
Bases
de
Datos
3 2
Considere una relación muchos a muchos entre COMPAÑÍA DE SEGUROS
y SINIESTRO.
SINIESTRO
COMPAÑIA DE
SEGUROS
# Código
* Nombre
# Número
* Nombre
El valor del seguro y la fecha de vencimiento del mismo, son atributos de la
relación entre SINIESTRO y COMPAÑÍA DE SEGUROS. Los atributos sólo
describen a las entidades.
Si los atributos describen una relación, entonces ésta debe ser resuelta. Se
resuelve una relación n:m con una entidad nueva de intersección y dos
relaciones 1:n.
Para el ejemplo, se puede adicionar la entidad de intersección POLIZA.
POLIZA
# número
* fecha inicial
* fecha vencimiento
* valor asegurado
ASEGURADORA
de
encargada
de
# código
* nombre
* dirección
registradora
de
amparado con
SINIESTRO
# código
* nombre
En efecto, los atributos valor del seguro, la fecha inicial y de vencimiento
pertenecen a la entidad POLIZA.
Para resolver una relación muchos a muchos, se ubica la entidad de
intersección de tal manera que las patas de gallina siempre se dirijan hacia
la izquierda o hacia arriba en el diagrama:
Claudia
Jiménez
Ramírez
Bases
entidad de
intersección
de
Datos
3 3
o así
entidades de
referencia
El identificador único de una entidad de intersección casi siempre está
compuesto por las relaciones de las dos entidades que le dieron origen.
Ejemplo
CURSO
# código
* nombre
* créditos
* duración
ESTUDIANTE
tomado por
# carné
inscrito en
* nombre
* teléfono
Para resolver la relación de muchos a muchos, adicionamos la entidad de
intersección INSCRIPCION y dos relaciones 1: m.
INSCRIPCION
* fecha iniciación
* fecha culminación
* nota definitiva
para
de
tomado via
CURSO
# código
* nombre
* créditos
* duración
registrado en
ESTUDIANTE
# carné
* nombre
* teléfono
Una vez se identifique la entidad de intersección, se deben buscar atributos
adicionales que la describan. Puede ocurrir, sin embargo, que obtengamos
una entidad de intersección sin atributos; en este caso tendremos sólo una
referencia cruzada entre las ocurrencias de las entidades y el identificador
único para la entidad de intersección, estará siempre compuesto de las
relaciones de las dos entidades de las cuales se originó.
Claudia
Jiménez
Ramírez
Bases
de
Datos
3 4
Una entidad de intersección sin atributos es la excepción a la regla de que
una entidad siempre debe poseer atributos para poder ser, realmente, una
entidad.
Ejemplo
ACTOR
# código
* nombre artistico
o nombre real
o fecha nacimiento
PELICULA
protagonista
de
protagonizada
por
# identificador
* nombre
* clasificación
Para esta relación de muchos a muchos, no se identifican atributos
asociados. Entonces, se resuelve con una entidad de intersección sin
atributos.
PAPEL ESTELAR
de
en
poseedor de
ACTOR
# código
* nombre artistico
o nombre real
o fecha nacimiento
figurar con
PELICULA
# identificador
* nombre
* clasificación
14. Relaciones jerárquicas
Los identificadores únicos para un conjunto de entidades con una
relación de jerarquía se pueden propagar a través de múltiples
relaciones como se ilustra en el siguiente ejemplo.
Claudia
Jiménez
Ramírez
Bases
de
Datos
3 5
APARTAMENTO
# número
* propietario
situado en
conformado por
PISO
# número
situado en
conformado por
BLOQUE
# número
situado en
conformado por
UNIDAD
# código
* nombre
* dirección
El IU de APARTAMENTO es el número del apartamento y del PISO donde
se localiza.
El IU de PISO es el número del piso y del BLOQUE donde se localiza.
El IU de BLOQUE es el número del bloque y del código de la UNIDAD
donde se localiza.
Cuando las estructuras jerárquicas cambian a menudo, es mejor crear
atributos artificiales para ayudar a identificar las entidades.
15. Relaciones recursivas
Una relación recursiva es aquella que posee una entidad consigo misma.
Claudia
Jiménez
Ramírez
Bases
de
Datos
3 6
Ejemplo
EMPLEADO
# cédula
* nombre
o profesión
* cargo
* fecha ingreso
* salario
bajo ordenes
de
a cargo
de
La convención para dibujar una relación recursiva es conocida con el
nombre de “cola de marrano”. Puede aparecer en cualquier lado de la caja
de la entidad; pero recordando que el lado de muchos siempre va hacia la
izquierda o hacia arriba.
Es recomendable representar una relación jerárquica como una recursiva:
APARTAMENTO
# número
* propietario
situado en
conformado por
PISO
# número
LOCALIZACION
situado en
conformado por
BLOQUE
# número
situado en
conformado por
UNIDAD
# código
* nombre
* dirección
# código
o nombre
o dirección
o propietario
conformada
por
dentro de
Claudia
Jiménez
Ramírez
Bases
de
Datos
3 7
La entidad recursiva debe incluir todos los atributos de cada entidad
individual. La relación recursiva debe ser siempre opcional en ambas
direcciones; puesto que la jerarquía sería infinita.
Claudia
Jiménez
Ramírez
Bases
de
Datos
3 8
16. Generaciones de Bases de Datos
El origen del primer DBMS ocurre a mediados de los años sesenta cuando
IBM y Rockwell International desarrollaron las primeras versiones de un
sistema conocido como DL/I con el propósito de administrar la gran cantidad
de datos del proyecto espacial APOLO [GON96]. Posteriormente, le
adicionan una componente de control de la información, en el sistema (ICS)
para el acceso a los datos en forma concurrente.
El anterior producto se comercializa en 1969, bajo el nombre de IMS/360
(Information Management System para el IBM 360).
Los sistemas manejadores de bases de datos, DBMS, se pueden clasificar
por el método empleado para estructurar los datos internamente. A las
estructuras de datos utilizadas se les llaman también modelos físicos de
datos.
El IMS es un DBMS de tipo jerárquico, es decir, se sustenta sobre una
estructura de datos jerárquica o de árbol; en donde los nodos representan
las entidades y los arcos representan las relaciones.
La arquitectura del IMS se muestra en la figura 3.
Aplicación 1
Programa de
comunicación
Aplicación 2
Aplicación n
Programa de
comunicación
Programa de
comunicación
Descripciones de la base de datos
Figura 3. Arquitectura del DBMS Jerárquico IMS/360.
Claudia
Jiménez
Ramírez
Bases
de
Datos
3 9
Las descripciones de la base de datos, definen una base de datos física que
agrupa la información sobre todos los segmentos (que representan las
entidades) con su longitud y clave, entre otras cosas.
El programa de comunicación define el mecanismo usado para el paso del
modelo lógico al físico.
Finalmente, cada aplicación define el conjunto de procedimientos y de
funciones que requiere un usuario final.
Los desarrolladores de bases de datos jerárquicas se referían a las
relaciones 1:n, como relaciones “padre-hijo” entre los registros; que se
podían implementar por medio de adyacencia física (registro padre + arreglo
de registros hijos) o por medio de punteros. Las bases de datos jerárquicas
se construyen reuniendo múltiples relaciones padre-hijo.
La figura 4, muestra una estructura de árbol cuyo nodo raíz, es Asignatura.
ASIGNATURA
Código
Descripción
REQUISITOS
CURSOS
Fecha
PROFESORES
Cédula
Nombre
Grupo
Aula
ESTUDIANTES
Cédula
Nombre
Figura 4. Estructura de una base de datos académica.
El problema básico de la estructura jerárquica, consistió en que un registro
hijo no podía tener dos registros padres distintos. Esta situación impedía
representar relaciones muchos a muchos, sin tener redundancia.
Considere, por ejemplo, las relaciones siguientes (ver figura 5):
Un estudiante puede matricularse en varios cursos (relación 1:n)
Un curso puede ser tomado por varios estudiantes (relación 1:n)
Claudia
Jiménez
Ramírez
Bases
de
Datos
4 0
Si se quisiera generar el certificado del registro académico de un estudiante,
se tendría que usar la primera relación. Si se quisiera generar la lista de
estudiantes matriculados en un curso dado, se tendría que usar la segunda
relación. El modelo jerárquico obliga a repetir información para dar
respuesta a estos dos tipos de consultas.
REGISTRO
ESTUDIANTE
CURSO
Figura 5. Una relación n: m
Segunda Generación de Bases de Datos
Para resolver el problema de la redundancia en las bases de datos
jerárquicas, con las relaciones de muchos a muchos, surgen las bases de
datos en red. La estructura de un DBMS en red es esencialmente la misma
que en el modelo de datos jerárquico; excepto que un “miembro” (registro
hijo) puede pertenecer a más de un “conjunto” (registro padre).
Los DBMS en red son más generales que un DBMS jerárquico; pues un
árbol siempre podrá ser una red, en cambio una red puede no ser un árbol.
Las redes de conjuntos de una base de datos siempre son implementadas
mediante punteros, como lo ilustra la figura 6.
123 | Juan Pérez
registro 128
registro 146
registro 145
registro 149
Figura 6. Una instancia de Conjunto
A pesar de superar el problema de la redundancia de datos, se originó otro
relacionado con el manejo de punteros; pues además de aumentar la
complejidad, las relaciones que se creaban por medio de ellos hacían que
Claudia
Jiménez
Ramírez
Bases
de
Datos
4 1
se tuviera definir de antemano cómo se consultarían los datos; restando
flexibilidad a los sistemas.
TERCERA GENERACION DE BASES DE DATOS
En 1970, E.F. Codd de la IBM propone el modelo relacional que está basado en la
teoría de conjuntos y en la lógica de predicados de primer orden. La idea de Codd
consistía en evitar el uso de punteros por parte de los usuarios especialistas para
facilitar la gestión de los datos y sus relaciones; el DBMS se debería encargar del
manejo de los punteros de las estructuras de datos físicas. La técnica consistía en
representar los datos como tablas bidimensionales; una manera mucho más
sencilla y comprensible y por ello, este modelo de datos logró la popularidad que
hoy sigue teniendo.
Codd encontraba otro problema básico de los modelos primitivos, además del
manejo de punteros, que era la restricción de procesar sólo un registro a la vez y
por ello el usuario debía controlar condiciones como "fin de archivo". En lugar de
ello, él quería que se pudiera realizar operaciones sobre conjuntos de datos y que
el DBMS controlara los detalles o las condiciones para llevar a cabo estas
operaciones.
Ventajas del modelo relacional
1. Separación clara del nivel lógico y el físico. El usuario no ve para nada el nivel
físico.
2. Simple y fácil de trabajar con él. La representación de los datos por tablas es
intuitiva pues recuerda las hojas electrónicas.
3. Operadores poderosos para la manipulación de datos.
4. Fundamentos teóricos sólidos.
Desventajas:
1. La eficiencia se ve afectada por la prohibición de manejo de punteros en forma
explícita; aunque en algunos manejadores de bases de datos se puede tener
acceso a los objetos mediante su ROWID.
Terminología
Antes de explorar el modelo relacional es importante dar la definición de los
conceptos básicos que éste incluye.
Relaciones y Tablas
La estructura básica del modelo relacional, y de ahí su nombre, es la relación. El
término relación es tomado de la teoría de conjuntos y no tiene que ver para nada
Claudia
Jiménez
Ramírez
Bases
de
Datos
4 2
con el hecho de que los datos puedan estar relacionados. Una relación es un
concepto abstracto de un estructura bidimensional. Una relación se puede definir
por comprensión o por extensión. Así, por ejemplo, podemos definir por
comprensión la relación R:
R = { x / x(identificación, nombre, telefono) es estudiante de la Universidad
Nacional }
La estructura bidimensional que asociamos familiarmente a una relación es la
tabla, entonces estos dos términos se usan indistintamente.
Una relación en este modelo tiene las siguientes propiedades:
•
Cada celda es atómica o univaluada
•
Cada columna tiene un nombre único dentro de la tabla
•
El orden de las columnas o filas es indiferente.
•
Cada fila es distinta e identificable por alguna combinación de sus valores
en los atributos.
Tuplas, Atributos y Cardinalidad
Cada instancia o fila de una relación se le denomina tupla y a cada columna se le
denomina también atributo. Al número de atributos se le denomina el grado de
una relación y al número de tuplas se le denomina cardinalidad o extensión de la
relación.
Dominio
Un dominio es un conjunto aceptable de valores para un atributo. Un dominio
puede ser compartido por varios atributos y se puede restringir para velar por la
integridad de la base de datos.
Clave Primaria
Las claves sirven para la identificación de las tuplas. Se utiliza, entonces, una
colección mínima de atributos como clave primaria para representar los
identificadores únicos del modelo E-R.
Clave candidata:
Claudia
Jiménez
Ramírez
Bases
de
Datos
4 3
Atributo (columna) o atributos que identifican a una tupla (fila) dada. La clave
primaria es la clave candidata elegida por el DBA.
Clave foránea:
Es un atributo que es clave primaria en otra relación. Permite explícitamente
especificar las relaciones entre dos diferentes tablas y es también un mecanismo
para asegurar la integridad.
Terminología Alternativa de términos
Relacional
Relación
Tupla
Atributo
Instancia
Común
Tabla
Fila
Columna
Valor
Sistemas de Archivos
Archivo
Registro
Campo
Valor
DISEÑO DE BASES DE DATOS
El diseño de la base de datos se realiza durante la etapa de diseño del sistema y
se hace al tiempo con el diseño de la aplicación de las aplicaciones que se
piensen desarrollar, en paralelo.
El diseño, produce especificaciones para la implementación de bases de datos
relacionales; incluyendo definiciones para las relaciones, los índices, las vistas
que se deben crear y otras especificaciones sobre el espacio de almacenamiento.
Se debe documentar el sistema, con una tabla de especificaciones para cada
relación en el modelo relacional.
Tabla de Especificación de la Relación EMPLEADOS
Nombre
EMPNO
NOMB
APELL
TBJO
FCHING
SAL
JEFE
DEPNO
CF1
CF2
Columna
Tipo de
CP
Clave
Nulos/
NN, U
NN
NN
NN
NN
7369
Pedro
Hoyos
Dependiente
17-12-80
800
7902
20
7902
Ana
Casas
Analista
03-12-81
3000
7566
50
Unicos
Ejemplos
•
Los tipos de clave válidos, son CP para una columna de clave primaria, y CF
para una columna de clave foránea.
Claudia
•
•
•
•
•
•
Jiménez
Ramírez
Bases
de
Datos
4 4
Se usan sufijos para distinguir entre múltiples columnas de CF en una tabla
simple, por ejemplo, CF1 y CF2. Se rotulan múltiples columnas clave con el
mismo sufijo.
Se usa el rótulo NN para las columnas que deben ser definidas como no
nulas (NOT NULL).
Se usa el rótulo U para una columna que deba ser única (unique).
Si varias columnas deben ser únicas en combinación, se nombran con sufijos,
por ejemplo U1.
Se designa una columna simple que es clave primaria como NN, U.
Se designan múltiples columnas CP como NN, U1 o posiblemente como NN,
U1, U.
El modelo E-R de una institución de educación no formal que se observa en la
figura número 1, se empleará para ilustrar como transformar el modelo E-R en un
modelo relacional.
INSCRIPCION
* Fecha inscripción
o Fecha finalización
o Nota
para
de
tomado
por medio de
CURSO
# Código
* Nombre
o Cuota
o Duración
dictado por
registrado con
ESTUDIANTE
# Identificación
* Nombre
* Apellido
* Teléfono
instructor de
PROFESOR
# Identificación
* Nombre
* Apellido
oTeléfono oficina
Figura 7 Modelo E_R de una institución educativa
Se siguen una serie de pasos para transformar el Modelo E-R a una serie de
relaciones, produciendo un diseño inicial de la base de datos.
PASO 1 - CONVERTIR LAS ENTIDADES SIMPLES A RELACIONES
Claudia
Jiménez
Ramírez
Bases
de
Datos
4 5
Las entidades simples, entidades que no son subtipos o supertipos, ni participan
en una relación exclusiva en el modelo E-R, se transforman en relaciones del
modelo relacional.
Se crea una tabla de especificación para cada entidad simple. Inicialmente se
comienza con el nombre que se le va a dar a esta entidad en el modelo relacional.
El nombre de la tabla debe permitir recordar el nombre de la entidad. Se
acostumbra a utilizar el plural del nombre de la entidad para el nombre de la
relación en el modelo relacional, en especial si éste no es largo.
PASO 2 - CONVERTIR LOS ATRIBUTOS A COLUMNAS
Cada atributo se vuelve una columna de la relación a la cual pertenece. Se debe
especificar que los atributos requeridos son columnas NOT NULL (NN).
Ejemplo: Como los atributos identificación, nombre y apellido son atributos de
entrada obligatoria de la entidad PROFESOR, se transforman en columnas no
nulas. Se debe, entonces, designar sus columnas como NOT NULL.
PROFESOR
Nombre
Columna
ID_PROF
NOMB
APELL
NN
NN
NN
TEL
Tipo de
Clave
Nulos/
Unicos
Ejemplos
Para cada atributo, se sugiere seleccionar un nombre de columna corto pero
significativo. El nombre de la columna debe ser fácil de recordar. Es bueno utilizar
abreviaturas consistentes para evitar confusión al programador y al usuario. Por
ejemplo, Número será abreviado como NO o NUM. Esto es, NODEPTO o
NUMDEPTO?
Los nombres de las columnas cortos reducen el tiempo requerido para la
ejecución de comandos del SQL. Para determinar los tipos de datos adecuados
es útil documentar las tablas de especificaciones, con tuplas ejemplo.
Los datos ejemplo, se pueden obtener de diversas maneras:
• De notas de entrevistas con los usuarios finales.
• De la documentación de sistemas informáticos actuales.
• De conversaciones adicionales con el usuario.
Claudia
Jiménez
Ramírez
Bases
de
Datos
4 6
PASO 3 - CONVERTIR LOS IDENTIFICADORES UNICOS A CLAVES
PRIMARIAS
En este paso, cada atributo que hace parte de los identificadores únicos de la
entidad se convierten en columnas con tipo de clave primaria (CP).
•
Todas las columnas CP deben ser también NN y U.
Un identificador único que incluya varios atributos, se convierte en una clave
primaria compuesta. Estas columnas son NN y U1.
•
Si el identificador único, IU, de una entidad incluye una relación, se deben añadir
las columnas de las claves foráneas a la tabla y marcarlas como parte de la clave
primaria.
Ejemplo: el identificador único de la entidad INSCRIPCION está compuesto por
las relaciones con las entidades CURSO y ESTUDIANTE. Por lo tanto, es
necesario añadir dos columnas claves foráneas, a la tabla INSCRIPCION, para
formar su clave primaria.
Tabla: INSCRIPCION
Columna
Tipo Clave
Nulos/
Unicos
Ejemplos
•
•
•
FCH_INS
FCH_FIN
NOTA
29/09/98
--28/06/98
28/06/98
21/05/98
----4.1
4.2
4.0
NN
20/08/98
05/06/98
14/06/98
08/05/98
05/05/98
COD_CUR ID_EST
CP, CF1 CP, CF2
NN, U1
NN, U1
344
401
717
717
401
47593
15402
51394
94572
51394
Escoger un nombre único para cada columna CF, y rotular la(s) columna(s)
CP, NN y CF.
Si existen múltiples columnas CF en la tabla, usar sufijos para distinguir entre
ellas, por ejemplo, CF1 y CF2. Debemos rotular varias columnas claves con el
mismo sufijo
Una CP compuesta debe ser única en combinación y se debe rotular como
U1.
PASO 4 - CONVERTIR LAS RELACIONES EN CLAVES FORANEAS
Claudia
Jiménez
Ramírez
Bases
de
Datos
4 7
Para una relación 1:n, se debe tomar el IU de la entidad con cardinalidad de uno y
ponerla en la tabla relacional que corresponde a la entidad con cardinalidad de
muchos.
Por ejemplo, se toma la clave primaria Identificación en el lado de uno, y se coloca
en la relación CURSO que está en el lado de "muchos".
instructor
de
dictado
por
CURSO
#Código
* Nombre
o Cuota
o Duración
Nombre
Columna
Tipo de
Clave
Nulos/
Unicos
Ejemplos
•
•
Tabla: CURSO
COD_CUR
NOMBRE
CUOTA
PROFESOR
# Identificación
* Nombre
* Apellido
DUR oTeléfono
ID_PROF oficina
CF
CP
NN, U
NN
344
974
401
717
SQL SERVER
ORACLE
DISEÑO BD
TAREAS DE
UN DBA
1000
400
400
900
5
2
2
3
81
73
95
73
Se debe seleccionar un nombre único para la columna CF y rotularla como
CF.
Para relaciones obligatorias también se debe especificar que la columna es
no nula, NN.
Para una relación 1:1 obligatoria, se debe colocar la clave foránea única en la
tabla al lado de la obligatoriedad y usar la restricción de NOT NULL para hacer
cumplir la relación de obligación.
Ejemplo: la relación entre COMPUTADOR PERSONAL y TARJETA MADRE ES
UNA RELACIÓN 1:1 y es obligatoria hacia tarjeta madre. Entonces, se coloca la
clave foránea de la relación en la tabla COMPUTADOR PERSONAL y se rotula
Claudia
Jiménez
Ramírez
Bases
como NOT NULL. ID_TM es la clavbe foránea añadida.
se rotula como U para hacer cumplir la relación 1:1.
COMPUTADOR_PERSONAL
Nombre
Columna
NO_
INV
TIPO_
CASE
FTE_ ID_TM
ENER
de
Datos
4 8
Esta columna también
TARJETA_MADRE
Nombre
Columna
ID_TM
CHIP_
PRO
VEL_
PRO
CHIP_
COPR
Tipo Clave
CP
CF
Tipo Clave
CP
Nulls/
Unique
NN, U
NN
NN
NN, U
Nulls/
Unique
NN, U
NN
NN
NN
Datos de
1045
Baby AT
150
4579
Datos de
9978
486
33
N
Prueba
0437
Baby AT
200
8731
Prueba
4517
386
40
S
1458
Tower
220
4773
4773
486
25
N
1223
Tower
220
9978
4579
386SX
25
N
1088
Minitower
200
4517
8731
386
33
S
La clave foránea en una relación 1:1 siempre debe ser única, pero puede permitir
valores nulos, en algunos casos.
Si una relación 1:1 es opcional en ambas direcciones, se puede colocar la clave
foránea en la tabla que corresponda a cualquier entidad participante en la
relación.
Cuando exista una relación recursiva 1:n, se debe adicionar una columna CF a la
tabla simple. Esta columna CF remitirá a los valores de la columna CP.
Ejemplo: Para esta relación recursiva 1:M, añadir una columna CF a la tabla
EMPLEADO por cada Jefe de empleado. Nombrar la columna ID_JEFE para
reflejar la relación.
jefe de
bajo órdenes de
Tabla: EMPLEADO
EMPLEADO
Nombre
Columna
#*Id
ID_EMP
*Nombre
*Apellido
NOMBRE
APELL
ID_JEFE
Claudia
Jiménez
Tipo de clave
Nulos/
Unicos
Ejemplos
Ramírez
Bases
CP
NN, U
NN
NN
7450
5579
6714
María
Juana
Susana
Pérez
Mejía
Jiménez
de
Datos
4 9
CF
--7450
5579
Se debe observar que la columna CF se refiere a una fila en la misma tabla. La
columna CF se nombra de tal manera que refleje la relación.
Debe observarse, además, que una CF recursiva nunca será NOT NULL porque
se crearía un ciclo infinito.
Para una relación recursiva 1:1, es necesario añadir una clave foránea única a la
tabla. Esta columna CF remitirá a los valores de la columna CP.
Ejemplo: Para la relación recursiva 1:1 "casado(a) con", se agregó una columna
única, a la tabla PERSONA.
esposo(a)
de
casado(a) con
Tabla: PERSONA
Nombre
Columna
Tipo de Clave
Nulos/Unicos
Ejemplo
•
ID_PERS
CP
PERSONA
NN,
U1
#*Id
7450
*Nombre
*Apellido
5579
6714
9451
3040
NOMBRE
APELL
ID_ESP
NN
María
Juana
Susana
Raúl
Diego
NN
Pérez
Gómez
Jiménez
Tobón
García
CF
U1
--9451
3040
5579
6714
La combinación de las columnas CF y CP siempre debe ser únicas para
asegurar la relación 1:1. Se garantiza que la combinación sea única
rotulándolas ambas columnas como U1.
PASO 5 - ESCOGER OPCIONES DE ARCO
Claudia
Jiménez
Ramírez
OFICINA
#*Id edificio
#*Número oficina
Bases
de
Datos
5 0
Figura 8 . Relación exclusiva
INDIVIDUAL
#*Id
Los arcos representan una clase de clave foránea con varias alternativas. Se
escoge entre dos diseños para llevar los arcos a claves foráneas:
SOCIEDAD
#*Código
# Código
•
•
Diseño de Arco Explícito
Diseño de Arco Genérico
COMPAÑIA
#*Número
# Número
El diseño de Arco Explícito crea una columna, clave foránea, para cada relación
incluida en el arco.
Así, por el ejemplo, el modelo E-R de la figura número 2, el arco se extiende sobre
el final de tres relaciones de "muchos". Entonces, se deben adicionar tres claves
foráneas a la relación de OFICINAS:
OFICINAS
Nombre
Columna
Tipo de Clave
Valores
nulos/únicos
ID_EDIF
NO_OFIC
ID_IND
COD_SOC
NO_COMP
CP
NN, U1
CP
NN, U1
CF1
CF2
CF3
El diseño de Arco Explícito soporta múltiples claves foráneas con diferentes
formatos. Por ejemplo, ID_IND, COD_SOC y NO_COMP pueden tener diferentes
formatos de columna.
Sin embargo, con este tipo de diseño, la aplicación debe hacer cumplir la
exclusividad de la relación entre las claves foráneas.
El diseño de arco genérico, por otro lado, crea una columna de clave foránea
simple y una columna adicional utilizada para indicar cuál de las tablas es
referenciada por la columna clave foránea en cada fila. Como las relaciones son
exclusivas, solamente existe un valor de la clave foránea por cada fila en la tabla.
Claudia
Jiménez
Ramírez
Bases
de
Datos
5 1
Usando el diseño de arco genérico, con el ejemplo, se debe crear una columna de
clave foránea simple y añadir una columna de tipos para indicar cuál de las tres
tablas es la referenciada en cada fila. Por ejemplo, I por INDIVIDUO, S por
SOCIEDAD y C por COMPAÑIA.
OFICINAS
Nombre
Columna
Tipo de Clave
Valores
nulos/únicos
Ejemplos
ID_EDIF
NO_OFIC
ID_RENTADOR
TIPO_RENTADOR
CP
NN, U1
CP
NN, U1
CF
NN
NN
1024
101
30045
I
Si la relación bajo el arco es obligatoria, se deben definir todas las columnas
añadidas como NOT NULL.
Con este tipo de diseño, las claves foráneas deben compartir el mismo formato en
todas las tablas de referencia y la relación de exclusividad queda asegurada
automáticamente.
PASO
6ESCOGER
SUPERTIPO/SUBTIPOS
Las opciones posibles, son las
•
•
•
OPCIONES
PARA
LAS
EMPLEADO
# Número
* Nombre
siguientes:
* Apellidos
DE PLANTA
TEMPORAL
Diseño de los subtipos,
en una sola tabla (el supertipo).
*Salario
* Valor hora
* Valor hora extra
Diseño de los subtipos en tablas separadas.
Como un arco de una relación exclusiva.
Opción 1 - Diseño de los subtipos en una sola tabla.
DEPARTAMENTO
#*Código
EMPRESA
# nit
RELACIONES
Claudia
Jiménez
Ramírez
Bases
de
Datos
5 2
Consiste en diseñar una tabla para el supertipo con toda la información de los
subtipos. Es decir, la tabla resultante contendrá las instancias de todos los
subtipos.
Este diseño es apropiado cuando los subtipos tienen pocos atributos y relaciones
propias y la consulta de los datos suele incluir datos de distintos subtipos.
Pasos de diseño
•
•
•
•
•
•
Crear una tabla para el supertipo
Crear una columna TIPO para identificar a cuál subtipo pertenece cada fila.
Crear una columna para cada uno de los atributos del supertipo.
Crear una columna para cada uno de los atributos de los subtipos.
Crear columnas CF para cada una de las relaciones del supertipo.
Crear columnas CF para cada una de las relaciones de los subtipos.
Como ejemplo, se convertirá el supertipo EMPLEADO y sus subtipos de la figura
3, en una sola tabla.
EMPLEADO
Nombre
Columna
Tipo de
Clave
Nulos/
Unicos
Ejemplos
NUM
NOMB
APELL
TIPO
NN, U
NN
NN
NN
4579
6631
1190
370
800
7147
6794
Jaime
Ana
Juan
Pedro
Luis
Alex
Lili
Pérez
Casas
Hoyos
Díaz
Ruiz
Ríos
Vega
P
P
P
P
P
T
T
SALARIO
VLR_
HORA
VLR_
EXTRA
CP
NUM_
EMP
CF1
COD_
DEP
CF2
NN
29000
25000
42700
44050
38450
8.50
6.75
12.75
11.50
201
150
40
35
40
30
35
35
30
El diseño de en una sola tabla requiere siempre que se cree una nueva columna
(tipo) para identificar el subtipo correspondiente en cada fila.
Ventajas de este diseño
•
•
El acceso al supertipo es directo. Si en la organización se debe consultar
frecuentemente el supertipo, esta opción es apropiada.
Se puede tener acceso a los subtipos mediante vistas.
Desventajas de este diseño
Claudia
•
•
Jiménez
Ramírez
Bases
de
Datos
5 3
Los requerimientos de atributos no nulos, en cada subtipo, no se pueden
hacer cumplir desde la definición de la base de datos.
La lógica de la aplicación debe proveer distintos atributos, dependiendo del
tipo.
Opción 2 - Diseño de los subtipos en tablas diferentes
Esta opción consiste en convertir los subtipos en tablas diferentes -una para cada
subtipo. Cada tabla contendrá instancias solamente de ese subtipo.
Pasos de diseño
•
•
•
•
•
Crear una tabla para cada subtipo
TABLA para cada atributo
En cada tabla de un subtipo, crear las columnas
B
A
subtipo.
B
En cada tabla de un subtipo, crear las columnas para los atributos
supertipo.
TABLA
C
C para cada relación
En cada tabla de un subtipo, crear columnas CF
subtipo.
En cada tablas del subtipo, crear columnas CF para cada relación
supertipo.
del
del
del
del
Empleando este método de diseño, la relación supertipo/subtipo de la figura 3,
conduce a convertir el supertipo EMPLEADO en dos tablas -una por cada subtipo
como se muestra a continuación.
Tabla: EMPLEADO DE PLANTA
Nombre
Columna
NUM_ESC
NOMB
APELL
SALARIO
COD_DEP
NN
NN
NN
Tipo Clave
CP
Nulls/Unique
NN, U
NN
Ejemplos
CF
4579
Jaime
Pérez
29000
40
6631
1190
Ana
Juan
Casas
Hoyos
25000
42700
35
370
Pedro
Díaz
44050
30
40
Claudia
Jiménez
Ramírez
800
Luis
Bases
Ruiz
38450
de
Datos
5 4
35
Tabla: EMPLEADO TEMPORAL
Nombre
Columna
NUMERO
NOMB
APELL
VLR_HORA VLR_EXTRA NUM_EMP COD_DEP
CF1
CF2
NN
NN
NN
NN
NN
Tipo Clave
CP
Nulls/
Unique
NN, U
NN
Ejemplos
7147
Alex
Ríos
8.50
12.75
201
35
6794
Lili
Vega
6.75
11.50
150
30
941
Saúl
Mejía
12.00
18.00
201
45
Se usa el diseño de subtipos en tablas diferentes cuando los subtipos tienen
muchos atributos y relaciones específicas o particulares.
Ventajas de este diseño
•
•
La opcionalidad de los atributos del subtipo se hace cumplir desde la
definición de la base de datos.
La lógica de la aplicación no requiere comprobaciones para los subtipos
Desventajas de este diseño
• El acceso al supertipo requiere del operador UNION o una vista creada con
este operador.
• Las vistas que unen las dos tablas son solamente de lectura.
• El mantenimiento de identificadores únicos a través de los subtipos es más
difícil de implementar, cuando los subtipos son excluyentes.