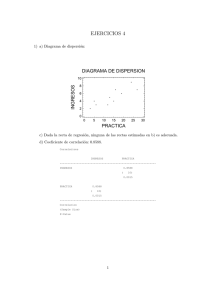
Taller 1 Diseño de experimentos_ANÁLISIS COMPARATIVOS SIMPLES
Anuncio

TRABAJO N°1 DE DISEÑO DE EXPERIMIENTOS ANÁLISIS COMPARATIVOS SIMPLES JESUS RAMON SANCHEZ DURAN CC. 1´090.391.696 de Cúcuta PROFESORA: LUZ MARCELA RESTREPO TAMAYO ING. INDUSTRIAL MAESTRÍA EN INGENIERÍA CIVIL/ENFASIS EN PROFUNDIZACION EN GEOTÉCNIA UNIVERSIDAD DE MEDELLÍN 2020 PRIMER TRABAJO: Análisis Comparativos Simples 2. Ejercicio práctico -1 En Kocaoz, S. Samaranayake, V. A. NanniA. (2005) se presenta un estudio donde se analizan dos tipos de barras de polímero, cuya tensión se refuerza con fibra de vidrio (FRP). Estas barras, en sustitución de las vigas de acero, son utilizadas para reforzar concreto, por lo que su caracterización es importante para fines de diseño, control y optimización para los ingenieros estructurales. Las barras se sometieron a tensión hasta registrarse su ruptura (en Mpa). Los datos para dos tipos de barras se muestran a continuación: - ¿Cuál de los dos tipos de barra prefiere a partir del análisis de los datos? Para responder esta pregunta realice: construcción y análisis de diagrama boxplot, construcción y análisis de pruebas de bondad de ajuste, construcción y análisis de pruebas de hipótesis. - ¿Cuál es el tamaño de muestra que se requiere de cada tipo de barra para asegurar una confianza del 95%? > summary(Barra_1) Min. 1st Qu. Median 815.0 966.8 1015.0 > summary(Barra_2) Min. 1st Qu. Median 843.0 971.8 1007.5 > sd(Barra_1) [1] 73.75333 > sd(Barra_2) [1] 68.14572 Mean 3rd Qu. 980.1 1022.8 Max. 1034.0 Mean 3rd Qu. 986.9 1028.2 Max. 1053.0 Diagrama box-plot: Análisis: La geometría de las cajas induce que hay presencia de outlier. Los datos de la barra_1 tiene un sesgo a la izquierda y los datos de la barra_2 “la caja más larga” confirman que se tratan de unas variables más dispersa. Las medianas de los dos conjuntos de datos están por encima del promedio. Aunque podremos decir que en la barra_1 tiene menor dispersión y a priori sería la mejor opción, hay que resaltar que la barra_2 presenta valores de resistencia más alto en las mediciones. Tabla 1. Pruebas de bondad de ajuste ejercicio practico_1 Prueba bondad de ajuste Nombre del Test Shapiro-Wilk normality test Hipótesis nula Ho= Distribución Normal Nivel de significancia Alpha= 0.05 p-value barra_1= 0.006195 p-Value* p-value barra_2 = 0.1117 Criterio de decisión Si p-value´>0.05 Distribución normal Decisión No rechaza Implicaciones de la decisión Barra_1 La distribución no es normal Barra_2 La distribución es normal Análisis: En general que el p-value para la barra_1 en las pruebas de bondad de ajustes es inferior a 0.05(<5%), esto quiere decir que los valores de resistencia de la barra NO siguen una distribución normal. Por lo contrario, para la barra_2, los datos de resistencia siguen una distribución normal. Tabla 2. Pruebas de hipótesis para el ejercicio practico_1. Varianzas Prueba de hipotesis Nombre del Test F test to compare two variances Hipótesis nula Ho=𝜎12=𝜎22 Nivel de significancia p-Value* Alpha= 0.05 p-value = 0.8401 Criterio de decisión Si p-value´>0.05 Ho se cumple Decisión No rechaza Implicaciones de la decisión Las varianzas poblaciones son iguales Intervalos de confianza. Análisis: Las varianzas poblaciones, aunque son desconocidas son iguales debido a que el intervalo de confianza contiene el 1. L.I: 0.2345084 L. S: 5.8507788 σ12= σ22 Tabla 3. Pruebas de hipótesis para el ejercicio practico_1. Medias Prueba de hipotesis Nombre del Test Two Sample t-test Hipótesis nula Ho=μ y1 =μ y2 Nivel de significancia p-Value* Alpha= 0.05 p-value = 0.8519 Criterio de decisión Si p-value´>0.05 Ho se cumple Decisión No rechaza Implicaciones de la decisión Las medias son iguales Intervalos de confianza. Análisis: El 0 está incluido, por lo tanto, las medias son estadísticamente iguales. L.I = -82.89519, L.S = 69.39519 μ1 = μ2 Conclusión Final; Según análisis de datos los dos tratamientos son iguales o casi parecidos. Es probable que existan otros tratamientos probablemente con datos más cercanos entre ellos 3. Ejercicio práctico -2 Usted compra materia prima a dos diferentes proveedores y usted está preocupado por la variabilidad de las impurezas de un embarque a otro. Si el nivel de impurezas tiende a variar de manera excesiva para una fuente de suministro, podría afectar la calidad del producto terminado. Para comparar el porcentaje de impurezas para los dos proveedores y su variación, el fabricante selecciona diez embarques de cada uno de ellos y mide el porcentaje de impurezas de la materia prima para cada embarque. Los datos obtenidos son los siguientes: ¿Considera usted que son diferentes las variabilidades del porcentaje de impurezas que presentan ambos proveedores? - ¿Cuál de los dos tipos de proveedor prefiere a partir del análisis de los datos? Para responder esta pregunta realice: construcción y análisis de diagrama box-plot, construcción y análisis de pruebas de bondad de ajuste, construcción y análisis de pruebas de hipótesis - ¿Cuál es el tamaño de muestra que se requiere de cada tipo de barra para asegurar una confianza del 95%? > # scrip Comparacion de experimentos Simple > Proveedor_1=c(0.85,0.14,0.25,0.61,0.43,0.42,0.6,0.34,0.83,0.85) > Proveedor_2=c(0.21,0.08,0.44,0.21,0.20,0.29,0.45,0.62,0.47,0.24) > boxplot(Barra_1,Barra_2, horizontal=TRUE,border=c("blue","red"),ylab="M étodo",xlab="Tiempo",names=c("Barra_1","Barra_2")) > summary(Proveedor_1) Min. 1st Qu. Median Mean 3rd Qu. Max. 0.140 0.360 0.515 0.532 0.775 0.850 > summary(Proveedor_2) Min. 1st Qu. Median Mean 3rd Qu. Max. 0.0800 0.2100 0.2650 0.3210 0.4475 0.6200 > sd(Proveedor_1) [1] 0.2570689 > sd(Proveedor_2) [1] 0.1657609 Análisis: La geometría de la caja induce que no hay presencia de outlier, por lo que también podría decirse que la calidad de los datos para este ensayo es alta. Los porcentajes de impurezas del proveedor 1, tiene un sesgo a la izquierda y los datos del provedor_2 “la caja más corta” se presenta un menor rango intercuartil confirman que se tratan de una variable mejor agrupada. Las medianas de los dos conjuntos de datos están por debajo del promedio. Al parecer el proveedor_2, presenta un mejor comportamiento de los datos, además de los valores más bajo del porcentaje de impurezas. ¿Considera usted que son diferentes las variabilidades del porcentaje de impurezas que presentan ambos proveedores? Si, son diferentes, esto se puede inferior por los valores de las desviaciones standar (Sd). Diagrama box-plot: Tabla 4. Pruebas de bondad de ajuste ejercicio practico_2 Prueba bondad de ajuste Nombre del Test Shapiro-Wilk normality test Hipótesis nula Ho= Distribución Normal Nivel de significancia Alpha= 0.05 p-value proveedor A= 0.3607 p-Value* p-value proveedor B = 0.4774 Criterio de decisión Si p-value´>0.05 Distribución normal Decisión No rechaza Implicaciones de la decisión Proveedor A. La distribución es normal Proveedor B. La distribución es normal Análisis: En general que el p-value para los valores de impurezas el proveedor_1 y proveedor_2 en las pruebas de bondad de ajustes son mayores a 0.05(<5%), esto quiere decir que los valores de los dos proveedores siguen una distribución normal. No se rechaza la hipótesis nula. Tabla 5. Pruebas de hipótesis para el ejercicio practico_2. Varianzas Prueba de hipótesis Nombre del Test F test to compare two variances Hipótesis nula Ho=𝜎12=𝜎22 Nivel de significancia p-Value* Alpha= 0.05 p-value = 0.2072 Criterio de decisión Si p-value´>0.05 Ho se cumple Decisión No rechaza Implicaciones de la decisión Las varianzas poblaciones son iguales Intervalos de confianza. Análisis: Las varianzas poblaciones, aunque son desconocidas son igual debido a que el intervalo de confianza contiene el 1. L.I: 0.5973957 L. S: 9.6829645 σ12= σ22 Tabla 6. Pruebas de hipótesis para el ejercicio practico_2. Medias Prueba de hipótesis Nombre del Test Two Sample t-test Hipótesis nula Ho=μ y1 =μ y2 Nivel de significancia p-Value* Alpha= 0.05 p-value = 0.04266 Criterio de decisión Si p-value´>0.05 Ho se cumple Decisión Se rechaza Implicaciones de la decisión Las medias no son iguales Intervalos de confianza. Análisis: El 0 NO está incluido en el intervalo, por lo tanto, las medias no son, SE rechaza la hipótesis nula. L.I = 0.007784129, L.S = 0.414215871 μ1 ≠ μ2 Conclusión; Según análisis el proveedor_2 se prefiere ya que presenta unos menores valores en la medición de impurezas bajos y mejor agrupación de los datos. 4. Diseñar, resolver (preferiblemente en r) y explicar dos ejemplos relacionados con el área de formación, siguiendo los pasos de análisis vistos en clase 4. Ejercicio práctico -3.1 Datos del área Se compara la resistencia al corte no drenado (Su) de arcilla no saturadas con dos ensayos uno de campo y otro de laboratorio sobre el mismo material en un proyecto. Los valores de resistencia al corte no drenado están en kg/cm2. Para comparar el porcentaje resistencias y su variación, se toman diez mediciones en campo mediante equipo de campo y laboratorio. Los datos obtenidos son los siguientes: -Se quiere analizar la resistencia al corte no drenado Su y conocer cuál de los dos métodos tiene un compartimiento más coherente estadísticamente. Tipo de Ensayo R. Campo R. Laboratorio 1.75 2.51 2.20 2.75 3.00 3.2 Resistencia al corte no drenada (Cu) 2.70 1.25 3.00 1.85 2.35 2.61 3.85 2.14 2.30 2.24 - ¿Cuál de los dos tipos de ensayos prefiere a partir del análisis de los datos? 0.75 2.67 3.10 2.54 Min. 1st Qu. 0.750 1.775 > summary(RL) Min. 1st Qu. 2.140 2.390 > sd(RC) [1] 0.7943551 > sd(RL) [1] 0.5045834 Median 2.250 Mean 3rd Qu. 2.190 2.925 Max. 3.100 Median 2.575 Mean 3rd Qu. 2.686 2.730 Max. 3.850 Diagrama box-plot: R.L = Resistencia laboratorio R. C = Resistencia de Campo Análisis: La geometría de las cajas induce que hay presencia de outlier para los ensayos de laboratorio “RL”, y que presenta un sesgo a la derecha, pero presenta menor dispersión de los datos respecto a los ensayos de campo “RC”, los cuales presentan un gran sesgo a la izquierda. Las medianas de los ensayos de laboratorio “RL” casi se ajustan a la media, en cambio para los ensayos de campo “RC”, está por debajo de la media. Podemos inferior que la serie de datos para el ensayo de laboratorio “RL” tiene más congruencia y menor dispersión y que el outlier presente puede ser producto de algún error medición en el ensayo. Tabla 7. Pruebas de bondad de ajuste ejercicio practico_3.1 Prueba bondad de ajuste Nombre del Test Shapiro-Wilk normality test Hipótesis nula Ho= Distribución Normal Nivel de significancia Alpha= 0.05 p-value RC= p-value = 0.4648 p-Value* p-value RL= 0.07958 Criterio de decisión Si p-value´>0.05 Distribución normal Decisión No rechaza Implicaciones de la decisión RC: La distribución es normal RL :La distribución es normal Análisis: En general que el p-value para los dos ensayos tanto de campo “RC” y laboratorio “RL” en las pruebas de bondad de ajustes es mayor a 0.05(>5%), esto quiere decir que los valores de resistencia al corte no drenado de los ensayos siguen una distribución normal. Tabla 8. Pruebas de hipótesis para el ejercicio practico_3.1. Varianzas Prueba de hipótesis Nombre del Test F test to compare two variances Hipótesis nula Ho=𝜎12=𝜎22 Nivel de significancia p-Value* Alpha= 0.05 p-value = 0.1129 Criterio de decisión Si p-value´>0.05 Ho se cumple Decisión No rechaza Implicaciones de la decisión Las varianzas poblaciones son iguales Intervalos de confianza. Análisis: Las varianzas poblaciones, aunque son desconocidas son iguales debido a que el intervalo de confianza contiene el 1. L.I: 0.6155881 L. S: 9.9778396 σ12= σ22 Tabla 9. Pruebas de hipótesis para el ejercicio practico_3.1. Medias Prueba de hipótesis Nombre del Test Two Sample t-test Hipótesis nula Ho=μ y1 =μ y2 Nivel de significancia p-Value* Alpha= 0.05 p-value = 0.1129 Criterio de decisión Si p-value´>0.05 Ho se cumple Decisión No se rechaza Implicaciones de la decisión Las medias son iguales Intervalos de confianza. Análisis: estadísticamente iguales El 0 está incluido, por lo tanto, las medias son L.I = -1.1212156, L.S = 0.1292156 μ1 = μ2 Conclusión; Según análisis de datos las dos mediciones de resistencia son iguales o casi parecidos. Por la dispersión de datos en los valores de la desviación estándar y box-plot, se tiene que los ensayos de campo “RC” son más dispersos y pueden inferir más incertidumbre en las varianzas poblacionales, esto se entiende por qué el ensayo de campo, hay más margen de error en las mediciones comparados con respecto al ensayo de laboratorio “RL”. El mejor ensayo bajo este análisis estadístico es de la medición de las resistencias al corte no drenaje medida en laboratorio “RL”. Ejercicio práctico -3.2 Datos del área Se realiza un experimento con el uso de un aditivo químico que aumentan la resistencia del concreto adicionado por kg de cemento usado. Se miden pruebas o especímenes de concreto a la misma edad y condiciones ambientales Se ensayaron 10 muestras usando el aditivo y otras 10 muestras sin aditivos. Los ensayos fueron hechos a los 28 días de edad. La resistencia se mide en Mpa. # ensayo Con aditivo Sin aditivo 1 2 3 4 5 6 7 8 9 10 20 31 16 22 19 32 25 18 20 19 Mpa 23 34 15 21 22 31 29 20 24 23 Mpa -Concluir si el aditivo ayuda o no para aumentar la resistencia. CA = Con aditivo SA = Sin aditivo > summary(SA) Min. 1st Qu. 16.00 19.00 > summary(CA) Min. 1st Qu. 15.00 21.25 > sd(SA) [1] 5.452828 > sd(RL) [1] 0.5045834 Median 20.00 Mean 3rd Qu. 22.20 24.25 Max. 32.00 Median 23.00 Mean 3rd Qu. 24.20 27.75 Max. 34.00 Análisis: La geometría de las cajas induce que no hay presencia de outlier en los datos analizados. Se presenta un sesgo a la izquierdo para los datos de las resistencias sin aditivo “SA”. Las medianas de los ensayos están por debajo de la media. Tabla 10. Pruebas de bondad de ajuste ejercicio practico_3.2 Prueba bondad de ajuste Nombre del Test Shapiro-Wilk normality test Hipótesis nula Ho= Distribución Normal Nivel de significancia Alpha= 0.05 p-value con aditivo0.6792 p-Value* p-value sin aditivo= 0.07063 Criterio de decisión Si p-value´>0.05 Distribución normal Decisión No rechaza Implicaciones de la decisión CA: La distribución es normal SD :La distribución es normal Análisis: En general que el p-value para los dos datos analizados es mayor a 0.05. La distribución de los datos es normal. Tabla 11. Pruebas de hipótesis para el ejercicio practico_3.1. Varianzas Prueba de hipótesis Nombre del Test F test to compare two variances Hipótesis nula Ho=𝜎12=𝜎22 Nivel de significancia p-Value* Alpha= 0.05 p-value = 0.9243 Criterio de decisión Si p-value´>0.05 Ho se cumple Decisión No rechaza Implicaciones de la decisión Las varianzas poblaciones son iguales Tabla 12. Pruebas de hipótesis para el ejercicio practico_3.1. Medias Prueba de hipótesis Nombre del Test Two Sample t-test Hipótesis nula Ho=μ y1 =μ y2 Nivel de significancia p-Value* Alpha= 0.05 p-value = 0.4304 Criterio de decisión Si p-value´>0.05 Ho se cumple Decisión No se rechaza Implicaciones de la decisión Las medias son iguales Intervalos de confianza. Análisis: estadísticamente iguales El 0 está incluido, por lo tanto, las medias son μ1 = μ2 Conclusión; Con una confianza del 95%, no se concluye que los aditivos químicos aceleran el crecimiento de las resistencias, tiene mayor dispersión en los datos medidos, además que es una solución más costosa, debido al precio del aditivo respecto al cemento. Anexos Ejercicio práctico -1. Código en R CONSTRUCCIÓN Y ANÁLISIS DE PRUEBAS DE BONDAD DE AJUSTE: > shapiro.test(Barra_1) ## Prueba de Shapiro Shapiro-Wilk normality test data: Barra_1 W = 0.73917, p-value = 0.006195 > shapiro.test(Barra_2) Shapiro-Wilk normality test data: Barra_2 W = 0.85686, p-value = 0.1117 > library(nortest) > sf.test(Barra_2) ## Prueba Shapiro-Francia ## Shapiro-Francia normality test data: Barra_2 W = 0.84729, p-value = 0.08017 sf.test(Barra_1) ## Prueba Shapiro-Francia ## Shapiro-Francia normality test data: Barra_1 W = 0.72539, p-value = 0.007761 > ad.test(Barra_1) ## Prueba Anderson-Darling21 ## > ad.test(Barra_2) ## Prueba Anderson-Darling21 ## Anderson-Darling normality test data: Barra_2 A = 0.51695, p-value = 0.1288 Anderson-Darling normality test data: Barra_1 A = 0.92917, p-value = 0.009332 > cvm.test(Barra_2) ## Prueba Cramer-Von Mises ## Cramer-von Mises normality test data: Barra_2 W = 0.08367, p-value = 0.159 > cvm.test(Barra_1) ## Prueba Cramer-Von Mises ## Cramer-von Mises normality test data: Barra_1 W = 0.16107, p-value = 0.01261 > lillie.test(Barra_2) ## Prueba Lilliefors test ## Lilliefors (Kolmogorov-Smirnov) normality test data: Barra_2 D = 0.22733, p-value = 0.2586 > lillie.test(Barra_1) ## Prueba Lilliefors test ## Lilliefors (Kolmogorov-Smirnov) normality test data: Barra_1 D = 0.30684, p-value = 0.02555 > pearson.test(Barra_2) ## Prueba Pearson's chi-square ## Pearson chi-square normality test data: Barra_2 P = 2, p-value = 0.3679 > pearson.test(Barra_1) ## Prueba Pearson's chi-square ## Pearson chi-square normality test data: Barra_1 P = 9.5, p-value = 0.008652 CONSTRUCCIÓN Y ANÁLISIS DE PRUEBAS DE HIPÓTESIS > #Prueba T para diferencia de medias > var.test(x=Barra_1,y=Barra_2,conf.level=0.95)$conf.int #IC para saber s i las varianzas son iguales o son diferentes [1] 0.2345084 5.8507788 attr(,"conf.level") [1] 0.95 > t.test(x=Barra_1,y=Barra_2,conf.level=0.95,var.equal=TRUE)$conf.int #IC para diferencia de medias con varianzas iguales [1] -82.89519 69.39519 attr(,"conf.level") [1] 0.95 Experimento comparativo simple: > #Pruebas de hipótesis para la diferencia de medias > var.test(x=Barra_1,y=Barra_2,conf.level=0.95) #PH para saber si las var ianzas son iguales o son diferentes F test to compare two variances data: Barra_1 and Barra_2 F = 1.1713, num df = 7, denom df = 7, p-value = 0.8401 alternative hypothesis: true ratio of variances is not equal to 1 95 percent confidence interval: 0.2345084 5.8507788 sample estimates: ratio of variances 1.171348 > t.test(x=Barra_1,y=Barra_2,conf.level=0.95,var.equal=TRUE) #PH para dif erencia de medias con varianzas iguales Two Sample t-test data: Barra_1 and Barra_2 t = -0.19013, df = 14, p-value = 0.8519 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -82.89519 69.39519 sample estimates: mean of x mean of y 980.125 986.875 > t.test(x=Barra_1,y=Barra_2,conf.level=0.95,var.equal=FALSE) #PH para di ferencia de medias con varianzas diferentes Welch Two Sample t-test data: Barra_1 and Barra_2 t = -0.19013, df = 13.913, p-value = 0.852 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -82.9397 69.4397 sample estimates: mean of x mean of y 980.125 986.875 Ejercicio práctico -2. Código en R CONSTRUCCIÓN Y ANÁLISIS DE PRUEBAS DE BONDAD DE AJUSTE: > ## Pruebas de normalidad analítica > shapiro.test(Proveedor_1) ## Prueba de Shapiro Shapiro-Wilk normality test data: Proveedor_1 W = 0.92045, p-value = 0.3607 > shapiro.test(Proveedor_2) Shapiro-Wilk normality test data: Proveedor_2 W = 0.93293, p-value = 0.4774 > library(nortest) > sf.test(Proveedor_1) ## Prueba Shapiro-Francia ## Shapiro-Francia normality test data: Proveedor_1 W = 0.94227, p-value = 0.5238 > ad.test(Proveedor_1) ## Prueba Anderson-Darling21 ## Anderson-Darling normality test data: Proveedor_1 A = 0.32709, p-value = 0.451 > cvm.test(Proveedor_1) ## Prueba Cramer-Von Mises ## Cramer-von Mises normality test data: Proveedor_1 W = 0.045525, p-value = 0.5429 > lillie.test(Proveedor_1) ## Prueba Lilliefors test ## Lilliefors (Kolmogorov-Smirnov) normality test data: Proveedor_1 D = 0.17682, p-value = 0.5038 > pearson.test(Proveedor_1) ## Prueba Pearson's chi-square ## Pearson chi-square normality test data: Proveedor_1 P = 3.2, p-value = 0.3618 > library(nortest) > sf.test(Proveedor_2) ## Prueba Shapiro-Francia ## Shapiro-Francia normality test data: Proveedor_2 W = 0.9332, p-value = 0.4231 > ad.test(Proveedor_2) ## Prueba Anderson-Darling21 ## Anderson-Darling normality test data: Proveedor_2 A = 0.40492, p-value = 0.2847 > cvm.test(Proveedor_2) ## Prueba Cramer-Von Mises ## Cramer-von Mises normality test data: Proveedor_2 W = 0.075012, p-value = 0.2151 > lillie.test(Proveedor_2) ## Prueba Lilliefors test ## Lilliefors (Kolmogorov-Smirnov) normality test data: Proveedor_2 D = 0.18746, p-value = 0.4087 > pearson.test(Proveedor_2) ## Prueba Pearson's chi-square ## Pearson chi-square normality test data: Proveedor_2 P = 6.8, p-value = 0.07855 CONSTRUCCIÓN Y ANÁLISIS DE PRUEBAS DE HIPÓTESIS > #Prueba T para diferencia de medias > var.test(x=Proveedor_1,y=Proveedor_2,conf.level=0.95)$conf.int #IC para saber si las varianzas son iguales o son diferentes [1] 0.5973957 9.6829645 attr(,"conf.level") [1] 0.95 > t.test(x=Proveedor_1,y=Proveedor_2,conf.level=0.95,var.equal=TRUE)$conf .int #IC para diferencia de medias con varianzas iguales [1] 0.007784129 0.414215871 attr(,"conf.level") [1] 0.95 Experimento comparativo simple: > #Pruebas de hipótesis para la diferencia de medias > var.test(x=Proveedor_1,y=Proveedor_2,conf.level=0.95) #PH para saber si las varianzas son iguales o son diferentes F test to compare two variances data: Proveedor_1 and Proveedor_2 F = 2.4051, num df = 9, denom df = 9, p-value = 0.2072 alternative hypothesis: true ratio of variances is not equal to 1 95 percent confidence interval: 0.5973957 9.6829645 sample estimates: ratio of variances 2.405111 > t.test(x=Proveedor_1,y=Proveedor_2,conf.level=0.95,var.equal=TRUE) #PH para diferencia de medias con varianzas iguales Two Sample t-test data: Proveedor_1 and Proveedor_2 t = 2.1814, df = 18, p-value = 0.04266 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: 0.007784129 0.414215871 sample estimates: mean of x mean of y 0.532 0.321 Ejercicio práctico -3.1. Código en R CONSTRUCCIÓN Y ANÁLISIS DE PRUEBAS DE BONDAD DE AJUSTE: > shapiro.test(RC) ## Prueba de Shapiro Shapiro-Wilk normality test data: RC W = 0.9317, p-value = 0.4648 > shapiro.test(RL) Shapiro-Wilk normality test data: RL W = 0.86155, p-value = 0.07958 > library(nortest) > sf.test(RC) ## Prueba Shapiro-Francia ## Shapiro-Francia normality test data: RC W = 0.94538, p-value = 0.562 > ad.test(RC) ## Prueba Anderson-Darling21 ## Anderson-Darling normality test data: RC A = 0.27963, p-value = 0.5637 > cvm.test(RC) ## Prueba Cramer-Von Mises ## Cramer-von Mises normality test data: RC W = 0.037488, p-value = 0.6938 > lillie.test(RC) ## Prueba Lilliefors test ## Lilliefors (Kolmogorov-Smirnov) normality test data: RC D = 0.14606, p-value = 0.7889 > pearson.test(RC) ## Prueba Pearson's chi-square ## Pearson chi-square normality test data: RC P = 2, p-value = 0.5724 > library(nortest) > sf.test(RL) ## Prueba Shapiro-Francia ## Shapiro-Francia normality test data: RL W = 0.84966, p-value = 0.05435 > ad.test(RL) ## Prueba Anderson-Darling21 ## Anderson-Darling normality test data: RL A = 0.59497, p-value = 0.08837 > cvm.test(RL) ## Prueba Cramer-Von Mises ## Cramer-von Mises normality test data: RL W = 0.10202, p-value = 0.08984 > lillie.test(RL) ## Prueba Lilliefors test ## Lilliefors (Kolmogorov-Smirnov) normality test data: RL D = 0.24953, p-value = 0.07778 > pearson.test(RL) ## Prueba Pearson's chi-square ## Pearson chi-square normality test data: RL P = 5.6, p-value = 0.1328 CONSTRUCCIÓN Y ANÁLISIS DE PRUEBAS DE HIPÓTESIS > #Prueba T para diferencia de medias > var.test(x=RC,y=RL,conf.level=0.95)$conf.int #IC para saber si las vari anzas son iguales o son diferentes [1] 0.6155881 9.9778396 attr(,"conf.level") [1] 0.95 > t.test(x=RC,y=RL,conf.level=0.95,var.equal=TRUE)$conf.int #IC para dife rencia de medias con varianzas iguales [1] -1.1212156 0.1292156 attr(,"conf.level") [1] 0.95 > t.test(x=RC,y=RL,conf.level=0.95,var.equal=FALSE)$conf.int #IC para dif erencia de medias con varianzas diferentes [1] -1.1294101 0.1374101 attr(,"conf.level") Experimento comparativo simple: > #Pruebas de hipótesis para la diferencia de medias > var.test(x=RC,y=RL,conf.level=0.95) #PH para saber si las varianzas son iguales o son diferentes F test to compare two variances data: RC and RL F = 2.4784, num df = 9, denom df = 9, p-value = 0.1925 alternative hypothesis: true ratio of variances is not equal to 1 95 percent confidence interval: 0.6155881 9.9778396 sample estimates: ratio of variances 2.478354 > t.test(x=RC,y=RL,conf.level=0.95,var.equal=TRUE) #PH para diferencia de medias con varianzas iguales Two Sample t-test data: RC and RL t = -1.6667, df = 18, p-value = 0.1129 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -1.1212156 0.1292156 sample estimates: mean of x mean of y 2.190 2.686 Ejercicio práctico -3.2. Código en R > # scrip Comparacion de experimentos Simple > SA=c(20,31,16,22,19,32,25,18,20,19) > CA=c(231,34,15,21,22,31,29,20,24,23) > boxplot(SA,CA, horizontal=TRUE,border=c("blue","red"),ylab="Prueba",xla b="Mpa",names=c("SA","CA")) > summary(SA) Min. 1st Qu. Median Mean 3rd Qu. Max. 16.00 19.00 20.00 22.20 24.25 32.00 > # scrip Comparacion de experimentos Simple > SA=c(20,31,16,22,19,32,25,18,20,19) > CA=c(23,34,15,21,22,31,29,20,24,23) > boxplot(SA,CA, horizontal=TRUE,border=c("blue","red"),ylab="Prueba",xla b="Mpa",names=c("SA","CA")) > # scrip Comparacion de experimentos Simple > SA=c(20,31,16,22,19,32,25,18,20,19) > CA=c(23,34,15,21,22,31,29,20,24,23) > boxplot(SA,CA, horizontal=TRUE,border=c("blue","red"),ylab="Prueba",xla b="Mpa",names=c("SA","CA")) > summary(SA) Min. 1st Qu. Median Mean 3rd Qu. Max. 16.00 19.00 20.00 22.20 24.25 32.00 > summary(CA) Min. 1st Qu. Median Mean 3rd Qu. Max. 15.00 21.25 23.00 24.20 27.75 34.00 > sd(SA) [1] 5.452828 > sd(RL) [1] 0.5045834 > ## Prueba de normalidad gráfica > datos=as.matrix(SA) > par (mfrow =c(2,1)) > hist(SA,main="Histograma_de_Resistencia_campo") > qqnorm(SA) > qqline(SA,col=1) > datos=as.matrix(CA) > par (mfrow =c(2,1)) > hist(CA,main="Histograma_de_resistencia_labora") > qqnorm(CA) > qqline(CA,col=1) > ## Pruebas de normalidad analítica > shapiro.test(SA) ## Prueba de Shapiro Shapiro-Wilk normality test data: SA W = 0.85324, p-value = 0.06348 > shapiro.test(CA) Shapiro-Wilk normality test data: CA W = 0.9509, p-value = 0.6792 > library(nortest) > sf.test(SA) ## Prueba Shapiro-Francia ## Shapiro-Francia normality test data: SA W = 0.86074, p-value = 0.07063 > ad.test(SA) ## Prueba Anderson-Darling21 ## Anderson-Darling normality test data: SA A = 0.68812, p-value = 0.04943 > cvm.test(SA) ## Prueba Cramer-Von Mises ## Cramer-von Mises normality test data: SA W = 0.11892, p-value = 0.05157 > lillie.test(SA) ## Prueba Lilliefors test ## Lilliefors (Kolmogorov-Smirnov) normality test data: SA D = 0.2567, p-value = 0.06068 > pearson.test(SA) ## Prueba Pearson's chi-square ## Pearson chi-square normality test data: SA P = 4.4, p-value = 0.2214 > library(nortest) > sf.test(CA) ## Prueba Shapiro-Francia ## Shapiro-Francia normality test data: CA W = 0.94678, p-value = 0.5797 > ad.test(CA) ## Prueba Anderson-Darling21 ## Anderson-Darling normality test data: CA A = 0.33839, p-value = 0.4224 > cvm.test(CA) ## Prueba Cramer-Von Mises ## Cramer-von Mises normality test data: CA W = 0.066019, p-value = 0.2855 > lillie.test(CA) ## Prueba Lilliefors test ## Lilliefors (Kolmogorov-Smirnov) normality test data: CA D = 0.21416, p-value = 0.2163 > pearson.test(CA) ## Prueba Pearson's chi-square ## Pearson chi-square normality test data: CA P = 5.6, p-value = 0.1328 > #Prueba T para diferencia de medias > var.test(x=SA,y=CA,conf.level=0.95)$conf.int #IC para saber si las vari anzas son iguales o son diferentes [1] 0.2327313 3.7722550 attr(,"conf.level") [1] 0.95 > t.test(x=SA,y=CA,conf.level=0.95,var.equal=TRUE)$conf.int #IC para dife rencia de medias con varianzas iguales [1] -7.208705 3.208705 attr(,"conf.level") [1] 0.95 > t.test(x=SA,y=CA,conf.level=0.95,var.equal=FALSE)$conf.int #IC para dif erencia de medias con varianzas diferentes [1] -7.2091 3.2091 attr(,"conf.level") [1] 0.95 > #Pruebas de hipótesis para la diferencia de medias > var.test(x=SA,y=CA,conf.level=0.95) #PH para saber si las varianzas son iguales o son diferentes F test to compare two variances data: SA and CA F = 0.93697, num df = 9, denom df = 9, p-value = 0.9243 alternative hypothesis: true ratio of variances is not equal to 1 95 percent confidence interval: 0.2327313 3.7722550 sample estimates: ratio of variances 0.9369748 > t.test(x=SA,y=CA,conf.level=0.95,var.equal=TRUE) #PH para diferencia de medias con varianzas iguales Two Sample t-test data: SA and CA t = -0.8067, df = 18, p-value = 0.4304 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -7.208705 3.208705 sample estimates: mean of x mean of y 22.2 24.2