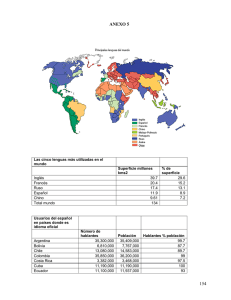
TEMA 1. INTRODUCCIÓN. DISEÑO DE LA INVESTIGACIÓN SOCIOLINGÜÍSTICA Me planteo una pregunta. ¿Existe una respuesta previa? El primer asunto es documentarse para no “reinventar la rueda”. Perdemos tiempo en seguir avanzando por no habernos documentado antes. Causas de la indocumentacion. Si no se encuentra respuesta, pregúntate por qué. Puede ser que el error esté en la forma de plantear esa pregunta, por ser muy general y nadie la ha respondido, o porque se ha descubierto una laguna en el paradigma que hay que rellenar y no existe repuesta. Lo segundo seria las fuentes de internet que son universales, no acaban nunca, son exhaustivas. El problema que conlleva es si tiene criterio de selección o no. Si tenemos documentación, lo ponemos dentro del campo teórico en el que trabajamos; de ideas conceptos y posibles preguntas a nuestras respuestas. Ya nos hemos informado sobre cuál es la forma adecuada de responder a una pregunta que me preocupa. Parte trasera del folio: Las preguntas deben estar planteadas con el nombre de “hipótesis”. Se pueden formular de dos maneras, de dos tipos textuales: - Mediante una hipótesis textual, lo que habitualmente se llama pregunta de investigación. Con lenguaje ordinario. - Mediante una pregunta más precisa que llamamos hipótesis estadística. También con lenguaje ordinario, pero de forma más precisa. Permite hacer medidas en el curso de la investigación y hacer comparaciones. Una hipótesis textual sería, por ejemplo: “En las oraciones ditransitivas del inglés…”. Es más imprecisa. Se puede comprobar con facilidad. Una hipótesis estadística sería, por su parte: “En las oraciones ditransitivas del inglés, la media de longitud silábica es menor en los recipientes…” También se puede hacer de la forma (b); el lenguaje es más complejo. Una hipótesis intenta explicar, predecir o explorar entre dos o más variables. Las hipótesis son predicciones de los resultados esperados de la investigación. Estás predicciones serán puesta a prueba a través del análisis de datos. Un aspecto importante de las hipótesis es que deben poder ser refutadas o rechazadas por los resultados del estudio, sino, la investigación no es científica. Se pueden hacer predicciones sobre la distribucción de elementos de una determinada propiedad. Por ejemplo, la producción de un determinado fenómeno lingüístico como es la elisión de la -s- se producirá más en las clases bajas que en las clases altas. Las hipótesis que formulamos tienen muchas formas diferentes si/entonces… etc. Las hipótesis son de dos grandes formas: - Hipótesis experimental o alternativa(H1). Cuando formulamos una hipótesis tendemos a formularla de manera positiva. Llamamos alternativa a esta hipótesis porque es formulada de manera positiva: formulo una hipótesis y quiero demostrar que es verdadera. La hipótesis experimental es la afirmación o sobre un efecto, una diferencia o una correlación con respecto a una o más variables. Estos elementos sobre los que trabajamos se llaman variables, que no son más que preguntas formuladas de manera precisa y puede ser objeto de medición. Esta hipótesis se transformará en una variable. - Hipótesis nula (H0). Es la contrapartida de H1; la niega. La afirmación que contiene la hipótesis alternativa se debe al azar. Si yo afirmo lo de la elisión de la -s-, la hipótesis nula indica que la diferencia entre estos grupos se debe al azar. Una vez rechazada la hipótesis nula puedo seguir trabajando, puedo plantearme otra pregunta en ese momento. Lo siguiente seria la operalización que consiste en convertir las hipótesis en variables ( H → V) Las variables son estas hipótesis que admiten medición y podemos operar con ellas. Una variable, en una definición poco brillante, sería un elemento real que varía. La primera gran división de variables es: - Continuas, matemáticas o estadísticas � son magnitudes medidas de tipo numérico que se dan en la realidad. o En el ámbito de la ciencia lingüística, una variable continua sería la altura de la frecuencia de F1. o Otro ejemplo podría ser la frecuencia léxica o de ocurrencia (Token F) en una determinada lengua, cuál es el porcentaje de aparición de un elemento léxico. (Silla > camastro). o También tenemos como opción la construcción de variables continuas a partir de variables que no lo son. En el caso de la elisión de la -s- en posición final silábica. Esto en principio no es variable continua, pero la podemos llegar a transformar mediante proporciones. Las variables estadísticas tienen valores infinitos entre cada intervalo, por ejemplo, el peso, porque cada unidad se subdivide en unidades menores, reflejan la distancia relativa entre puntos a lo largo de toda la escala. Un intervalo entre 2 puntos tiene el mismo significado en toda la escala. Si una persona pesa 60 kg y otra 63 kg, la diferencia de peso es la misma. Estos 3 kg se considera tanto si pesan 85-88 o 55-58 kg. Otro ejemplo sería la correlación entre la proporción de mantenimiento y de elisión de /d/ intervocálica. Lo que se relaciona son dos variables muy cercanas: probabilidad de que el hablante diga “ido, pescado” vs. probabilidad de que diga “*io, *pescao”. La relación es negativa porque a un valor determinado en el eje x, le corresponde un valor muy bajo en el eje y. Si mi afirmación fuera perfecta, todos los puntos estarían en orden en una línea. Sin embargo, no es perfecta. Esta línea se llama “línea recta de regresión”. Ahí surge de nuevo una pregunta: ¿por qué no están todos en orden? - Categóricas � frente a las continuas, tenemos a las variables categoricas que clasifican y sirven para dar categoría a la realidad. Por ejemplo, esto se da si categorizamos a los animales por género y sexo. Pueden ser de dos tipos: - Si existe una jerarquía u ordenación ya sea dada por la naturaleza; o bien la puedo establecer yo como investigador sobre una base objetiva. b) En este caso hablamos de variables categóricas ordinales o escalas ordinales. Tiene las mismas propiedades de las nominales, pero Se nos presentan escalas que vienen dadas por la realidad: Las variable ordinales clasifican y ordenan en función de su magnitud. No solo clasifican, sino que presentan un orden lógico, los rangos numéricos nos permite establecer ordenaciones en expresiones de mayor que o menor que, pero sin implicaciones que pueden ser de más a menos o viceversa. - Por ejemplo, una investigación sobre la edad de los informantes de un estudio sociológico, es una escala que se orienta siempre hacia la edad mayor, frente al caso de las variables anteriores, no habrá valores entre los intervalos. Otro ejemplo sería: casta, cahta, cata. Dependiendo de las condiciones de la comunidad podría hacer la escala en un sentido u otro. Esto es muy común, también, en las encuestas de satisfacción. Se llaman escalas de Likert y son variables categóricas ordinales. Pueden llevar número o léxico (nada, poco, bastante…). -Tenemos las variables nominales. Son las menos precisas y clasifican a los objetos según una determinada o determinadas características, las categorías se excluyen mutuamente, ya que un solo objeto solo puede pertenecer a una categoría, una Coca Cola no puede ser un Dr. Peppers . Por otro lado, las categorías de los datos no tienen un orden lógico, una persona puede haber nacido en Londres, Liverpool o Sidney. Las variables nominales pueden ser: o Bicotómicas: si tienen dos valores. Se dan, por ejemplo, en el caso de last � las’ (Las’ guy) otro ejemplo sería Bold � bol’. o Policotómicas: si tienen más de dos valores. Un ejemplo de esto sería la expresión del relativo en inglés, en el que tenemos la alternancia de tres valores: Which, that, o Ø son tres variantes (tres realizaciones o valores de esta variable politómica) de esta variable. La única condición es que estas tres variantes signifiquen lo mismo; haya una identidad o equivalencia. Observación de gráficos: GRÁFICO 1 � escisión de z en /s/ o /ϴ/. Esta es una variable continua, yendo de 0 hasta 1 en el gráfico. Tenemos que observar muy bien el encabezado y el final del gráfico, ya que lo que se presenta es la hipótesis. (Efecto del género y la educación del hablante en la escisión de /ϴ/ en el español de Málaga). Los valores se dividirán conforme a esto en la gráfica. La tendencia es que sean las mujeres de niveles más altos que produzcan este efecto más que los hombres, distinguir /s/ y /ϴ/ es un fenómeno prestigioso. Este es un resumen de varias operaciones previamente hechas. Antes se ha elaborado un gráfico en que se ve cómo, claramente, las mujeres distinguen más que los hombres. GRÁFICO 2 � “Hablar bien. Efecto de la educación (obligatoria/postobligatoria) en las actitudes hacia la lengua”. ¿Qué es para usted hablar bien? En un eje, nivel educacional, en otro, 4 opciones: que me entiendas, expresarme con lógica y sin contradicciones, como las personas instruidas y con estudios universitarios, como los escritores y oradores. DISEÑO DE LA INVESTIGACIÓN SOCIOLINGÜÍSTICA 1. Descubrimiento creativo que se atiene a unos protocolos consolidados y controlados por la comunidad científica (paradigma científico dominante en una época dada). 2. Creación y control: contextos de descubrimiento como una idea nueva sumado a un contexto de justificación, comprobación y defensa de la idea nueva. 3. La tarea es producir teorías (creación, ideas nuevas) y comprobarlas, mediante reglas y control. El proceso es colectivo e implica control y acumulación. 4. Distinguimos dos elementos: la estructura lógica del proceso de investigación y la instrumentación técnica para llevarlo a cabo. 5. Estructura lógica: recorrido cíclico que parte de la teoría, pasa por la fase de colección de datos y análisis y vuelve a la teoría. La ciencia lingüística actual no estaría donde está sino hubiera habido más de un siglo de investigación inductiva que ha conseguido aportar datos y conocimiento de base inductiva sobre los cuales se ha levantado el edificio de la ciencia lingüística.La diferencia entre un método y otro estriba en que el inductivo es el método del rigor, se basa en la observación de casos particulares, y en la clasificación de esos métodos muy preciso y a partir de la cual se elaboran leyes empíricas que reúnen todos los casos observados. Se constituye una ley como fonética o se reconstruye el indoeuropeo, es el método riguroso por definición. Sin embargo, es un método limitado porque la ley que se construye empíricamente solo se aplica a los casos que han servido para construir, NO se puede aplicar a un caso no producido aun no destacada, esa es la máxima: la limitación. Si construimos un corpus. ( Corbetta 2007: 68 y ss.). 6. Se distinguen cinco fases y cinco procesos que las conectan: La organización e interpretación actúa sobre el análisis y produce los Resultados 1 Teoría � 2 Hipótesis � 3 Datos � 4 Análisis � 5 Resultados A deducción B Operacionalización C Organización D Interpretación E Inducción FASES: 1-5 PROCESOS: A-E Organización: puedo organizar esos datos que existen como yo quiero que existan y los organizo de tal modo que yo pueda meterlos en un ordenador. EJEMPLO Integración sociolingüística de los inmigrantes rurales. Variación de (x) en la ciudad de Málaga. La relación en la lengua entre la expresión y el contenido se define como biolivo. Cuando se da esta circunstancia, tenemos un significante que expresa un significado: Significado (1) que expresa el significado (2) Día: 24 horas o el tiempo que dura la luz. Significante (2) que expresa el significado (2): Noche. Otra opción es un determinado significante que expresa distintos contenidos, por ejemplo, el significante vela puede significar varias cosas. Hay variación cuando tenemos un único significado que se expresa a través de diferentes significantes, ej:aquí y acá. Un determinado significante expresa distintos contenidos. Para que se produzca la variación se tiene que cumplir un principio, que sean intercambiables y equivalentes. Hay una pequeña diferencia más allá de la denotacion de las palabras por lo que podemos sospechar e incluso emitir juicio acerca de la posible procedencia del hablante, acá probablemente sea usado por un latinoamericano. Estas cosas interesan en el estudio de la variación. Para eso es necesario que las cosas que se alternan sean equivalente o sean internas, esto se trata en la sociolingüística y la alternancia del significante sobre la base de un mismo significado y cuantas variantes de contenido tiene una expresión. Este se debe cumplir para que podamos hablar de variación. Llamaremos variables a ese conjunto de equivalencias, a esa entidad abstracta (Aquí o acá) Aún así hay una pequeña diferencia que va más allá, podemos saber cual es la procedencia del interlocutor. Esta diferencia es la que interesa en el estudio. Esto lo podemos definir en un principio que definió William Labov: la variación es la alternancia de formas que quieren decir lo mismo. Centrándonos en el plano de la fonología, que nos atañe en este ejemplo: Alternancia entre P y K. Podemos estudiar qué variantes llevan P, y qué tipo de P hay, ya que puede ser aspirada ( apto- aØto) por un proceso de resilabificación. Esto es un fenómeno de variabilidad siempre que P y K no se confundan porque esto puede afectar al proceso. Esto son fenómenos que se excluyen del estudio. EJEMPLO: Proceso que tiene significado social, por ejemplo, “aquí” y “acá”.El fenómeno de variación que se da es el aflojamiento o lenición de esa fricativa del español. (x) � [x] � [xʰ] � [h] � Ø Con frecuencia se abre y se pierde el punto de articulación; con esto surge una aspiración. Este sonido aspirado puede llegar a sonorizarse y parecerse mucho más a una vocal y acabar por desaparecer totalmente. Esto varía dependiendo del hablante. Los de clase alta, tienden a utilizar las variantes de la izquierda que son más parecidos al estándar. Lo de clase baja tienden a los de la derecha. Este caso es un fenómeno complicado. Los inmigrantes cambian su localización y se enfrentan a variedades con las que no están acostumbrados a interaccionar y utilizan variedades fuertemente marcadas, que en muchas ocasiones están mal marcadas. ¿Cómo se integran? ¿Qué problemas tienen? ¿Cómo afecta esto a la variación lingüística? No es lo mismo que entren en contactos dos dialectos que tienen bajo estatus a que entren en contacto dos que tienen mayor reconocimiento. La comunidad de habla, en general, puede representarse como un continuo de variación entre dos puntos en los que hay mucha regularidad, (concentración) una variedad concentrada es una variedad con poca variación interna, muy regulada y de la que los hablantes están muy seguros. Una variedad difusa o dispersa es una variedad en la que existe un alto grado de inseguridad y variación. Las comunidades de habla suelen presentar este dibujo: Mesolecto: clase media y urbana. Compendio que lo reúne todo. Todas las personas vivimos en un conjunto de relaciones informales con 4 sectores: - Familiares - Amigos - Vecinos - Compañeros de trabajo En el sentido moderno, también se puede hablar de Entonces el principal problema que tienen los internet. ACROLECTO (Clase alta) inmigrantes es ¿qué hacen, se mantienen en las redes que tenían o tejen otras nuevas? La conservación de las variedades dialectales tradicionales está muy ligada al tipo de red social. En las que tienen un vinculo muy apretado (lazo apretado) y las personas confían y entregan su confianza (intercambio de bienes, favores, normas internas del grupo, cotilleo…) o laxos. Muchos inmigrantes van a vivir al mismo barrio; esto es un mecanismo de defensa. La primera generación característicamente son campesinos que viven en la ciudad. No conocen a nadie. El individuo de la 3ª generación es, desde el punto de vista lingüístico, un urbanita. Las personas con lazos apretados son las que ves frecuentemente y depositas mucho contenido emocional. Veo a estas personas con más de un papel (compañera de trabajo y vecina). Además, es más fuerte la relación si esta persona conoce a las mismas personas que conozco. Sin embargo, las personas con lazos laxos conocen a muchas personas, pero ninguna se conoce entre sí. La comunidad puede ser: - Con grado alto de contacto externo es una ciudad - Con bajo grado de contacto externo es un ámbito más rural. La comunidad es cerrada y el lazo apretado: Son de redes densas y muy cerradas, no están interesados en la variedad estándar y su lealtad a la variedad linguistica local es tal que si se da el caso de interactuar con otra persona de una variedad diferente puede llegar a llamar la atención, o incluso despertar burlas por parte de los miembros de la comunidad cerrada en caso de que algún miembro intentase adquirir ese habla más proximo al estandar o no, esto es común en las situaciones rurales. La comunidad es abierta y el lazo laxo: típica red ciudadana, urbana, de clase media. Puede ser que esté interesado por algunos aspectos de la lengua estándar. La comunidad es abierta y el lazo apretado: Red abierta al mundo y densa, fuertemente conectadas. Típicamente es la élite social. Los grandes empresarios, banqueros, que viven en redes sociales densas de tipo familiar y amistad en las que confían plenamente. La comunidad es cerrada con redes laxas. Es muy poco común. La variedad vernacular: variedad que los hablantes utilizan cuando se entrevistan o interactúan con miembros de su grupo de pares o iguales. Tendrá un comportamiento alejado de las normas de corriente dominante. ● 1ª FASE � Pregunta y formulación en forma de una hipótesis (limitación de conceptos de la teoría). Hipótesis textual. Existe una correlación positiva entre el uso del dialecto vernacular y la lealtad local. En cuanto a la “correlación positiva”, se da cuando existen dos variables, lo relaciones en medida de los valores de x que pueden predecir los de y, cuando un valor de x sube, también sube el y. Es una relación lineal y positiva entre dos variables. Conviene no confundir correlación con causalidad. Cuando hablamos de casualidad queremos decir que una variable causa otra variable. Es decir, que siempre que se da un valor se va a dar necesariamente otro valor. (Si llueve, se moja la calle, pero que la calle esté mojada no quiere decir siempre que haya llovido). Causalidad � Relación espuria. Es una relación bidireccional entre dos variables. En una relación puede parecer que a causa b, pero puede ser que esto no sea así porque hay una variable que no hemos tenido en cuanta. Puede ser que hayamos observado la relación entre a y b pero no hayamos tenido en cuenta las variables b y c que también operan en el mismo estatus. Si analizamos los datos con mayor detenimiento nos damos cuenta de que hay una relación multivariable. FASE 2. Hipótesis estadísticas. Conceptos específicos. Formulación parcial de la teoría. Limitación de los conceptos teóricos. Cuatro hipótesis (H): H1 � <<El uso de variantes fonológicas no estándar es más frecuente en los hombres que en las mujeres>>. H2 � <<Las variantes fonológicas no estándar son más frecuentes en las clases sociales más bajas>>. H3 � <<Las redes sociales de inmigrantes urbanos con lazos fuertes con la localidad rural de origen favorecen el uso lingüístico no estándar>>. H4 � <<La satisfacción con las redes urbanas de los inmigrantes rurales disminuye el uso de las variantes no estándar>>. Así se limita: 1) Dialecto vernacular a la pronunciación no estándar: - Fonología - Rasgos vernaculares - Concentración dialectal (dialect focusing) 2) La lealtad local a aspectos específicos: - Clase social; género. - Red social de contactos con la comunidad de origen. - Satisfacción con la comunidad local. ● FASE 3. PRODUCCIÓN DE DATOS. Se llega a través de un proceso de operacionalización (= transformación de las hipótesis en afirmaciones observables empíricamente): 1ª transformación de conceptos en variables: a) Uso vernacular = frecuencia de realización no estándar de la variable (V). b) Clase social = índice de ESE (educación, renta, prestigio ocupacional). La clase social es una construcción teórica conflictiva. La sociolingüística es una corriente sociológica que llamamos nacional funcional. La concepción de la clase social en esta corriente es que lo esencial para clasificar los hablantes en la sociedad, es el prestigio. De manera que las personas que desarrollan una afinidad, un conjunto de actos individuales, que se consideran válidos y relevantes para la cohesión social haciendo que esta crezca y se reproduzca, estos individuos serán situados en la parte más alta de la escala, entendiéndose que la posición del sujeto en la escala es la recompensa da al valor que las acciones de esa persona tiene. Esto premia cuestiones que no tienen mucho que ver con la economía, que es lo que precisamente siempre se ha criticado de esta concepción. La concepción más extrema afirma que todo esto es pura ideología, es decir, que realmente la base de toda esa organización social no es el prestigio sino algo más básico como es la economía. Trabajamos habitualmente con el índice de clase socio-económico y nos basamos en tres indicadores parciales: educación, renta y prestigio ocupacional, es decir, el prestigio que tiene la ocupación del individuo. Cada uno de estos indicadores por si mismos es un buen indicador, pero al ser parciales pueden engañar. Por ejemplo, si consideramos que los hablantes universitarios son la clase más alta de una sociedad, nos estaríamos engañando. Con estos indicadores, nos sale una suma en la que los posibles sesgos de cada uno de ellos quedan contrarrestados, y tenemos más o menos una imagen social de cada transformada en número .Basándonos en esos tres básicos, hacemos una cuantificación. Ponemos, por ejemplo, cuatro puntos (como hacía Labov en NY). 0 � hablantes que no tienen estudio o tienen estudios básicos. 1 � secundaria 2 � bachillerato 3 �universidad acabada En cuanto a la renta, lo que hacemos es una escala con 4 intervalos correspondientes a 4 límites en la renta; desde no percibir salario a estar en un sueldo que supera los límites. Si clasificamos el prestigio de la ocupación, hacemos de nuevo una escala de 0 a 3, basándonos en estudios sociolingüísticos que existen en la comunidad. Los simplificamos: 0 � trabajo manual no cualificado 3 � cargo de gran prestigio (banco BBVA). Con todas las características de la persona que estamos analizando, elaboramos una suma de todo. Normalmente tendremos en nuestra muestra una distribución que será similar a la distribución real de la sociedad. Los valores más frecuentes se dan en el centro. Esta distribución será la conocida DISTRUBUCIÓN NORMAL. ¿Hay tantas clases sociales? Labov agrupó las clases sociales de algún modo: De 0 a 2, de 3 a 5 y de 6 a 8, tendríamos entonces clase baja, clase trabajadora, clase media baja y la clase media alta. Normalmente llamamos capas a cada uno de estos intervalos y llamamos clase a la suma de estos 4. c) Red social = número de contactos con la localidad de origen y contenido emocional. d) Satisfacción = grado de satisfacción con los contactos urbanos a través de cuestionario. Si estaba satisfecho con su red social, sus amigos. 2ª Creación de un instrumento de medida de los conceptos = variables 3ª Esto produce un diseño de investigación - Comunidad de habla � Tenemos que saber distinguir entre comunidad de habla y una comunidad lingüística. La comunidad linguistica es un conjunto de hablantes que sin importar el tamaño tienen en común el uso de una lengua, en el caso del español; la comunidad linguistica es transformada por aquellos hablantes que usan el español, cualquier región Hispanoamericana forma parte de esa comunidad. La comunidad de habla es mucho más restringida porque incluye un conjunto de hablantes que usa al menos una variedad lingüística en común. Se pueden dar casos multilingues, podemos pertenecer a la comunidad de una lengua y usar otra como Cataluña. Por ejemplo, el español de España y el de Venezuela; si tomamos la variable de la -d- intervocálica, notamos esa variación. En España es muy frecuente y afecta a todas las clases sociales con muy pocas diferencias de frecuencia. Lo que influye decisivamente es el estilo en el porcentaje de perdida de -d- siendo conservada con mayor frecuencia en los estilos altos. La -d- en España marca el estilo y en Venezuela la clase social, es como si trazásemos una isoglosa interdialectal. - Muestra: tipo, representatividad � La muestra es como un pequeño modelo a escala de la comunidad a la que llamamos universos, dependiendo del cual sea el objetivo de nuestra investigación así será el tamaño de la muestra. Cuando extraemos una muestra de una comunidad de habla, tenemos asegurarnos de que esta sea valida y que ningún detalle se nos escape de ella para producir la diferencia linguistica. El número de muestra depende del objetivo del estudio pero es muy relativo, algunos investigadores establecen un mínimo de 5 hablantes por casilla, aunque el número mínimo que asegura la representatividad no está claro, aunque algunos investigadores lo cifran como el 0.025% del universo. - Cuestionarios � Consiste en preparar un documento con preguntas a los informantes. Esto varía mucho en cuestión del objetivo. Depende de si voy a obtener datos a través de internet o lo voy a hacer mediante individuos cara a cara. [Si se hace un cuestionario como consejo hay que poner los datos en bruto, no en escala]. - Organización de entrevistas y pruebas El objetivo de la investigación determina todo el proceso: proposición teórica general, el diseño (cualitativo, cuantitativo descriptivo…) ● FASE 4. ANÁLISIS DE DATOS El proceso que permite el AD es la organización previa y sistematización de los datos, de tal forma que puedan ser sometidos a análisis. Por ejemplo, los registros orales y su transcripción (información) pasan por un Plan de Codificación a convertirse en una matriz de número filas *columnas o de casos* variables donde cada número = valor de variable = característica o respuesta. La matriz es el punto de partida del AD (=operaciones matemáticas con un programa estadístico SPSS, R, STATA, GOLDVARB, etc.) Plan de codificación V1 hay que hacer un plan de codificación, tener apuntado y guardado lo que significa cada código V2. Variación dependiente, lo que vamos a estudiar, ejemplo de la pérdida del sonido (x): 0 = x, 1 = xh, 2 = h, 3 = h, 4 = Ø. A pesar de estar ordenada como escala es categórica V3. Sexo. 0 H, 1 M. Variable nominal V4. CSE (clase socioeconómica): 0 = Baja, 1 = Trabajadora, 2 = Media Baja, 3 = Media Alta. V5. Red. Densidad (variable continua). V6. Red. Multiplicidad (variable continua). V7. Red. EIR (escala de intensidad reticular) (0-6). Mide la fuerza de los lazos de un individuo con otra u otras personas. V8. Satisfacción (0-3) V1 001 001 … 025 V2 2 0 V3 0 0 V4 0 0 V5 .76 .76 V6 .45 .45 V7 5 5 V8 1 1 4 1 2 .25 .03 2 2 *001 � hablante 1 *En cada fila se analiza una palabra que ha pronunciado el mismo sujeto. *025 � hablante 25 FASE 5. RESULTADOS Para ver los resultados de un manera productiva y útil vamos a necesitar algo de información, que tiene que ver con la fonología del español. Trataremos 2 sistemas fonológicos, uno el estándar y otro sistema en el que encontraremos pequeñas diferencias fonológicas con el que representa a todo el español estándar. Establecemos una diferencia basada en resultados dialectales entre dos sistemas coexistentes, lo llamamos conservador e innovador, entendiendo que estos nombres no son valoraciones, sino que se refieren al estado evolutivo de las variedades que subyacen en los sistemas, es una comparación de hasta qué punto sea distanciado un sistema del sistema que había en el castellano medieval del que procede ambos. En el innovador se encuentra las variedades meridionales: andalúz, canario y buena parte del español de América. El conservador corresponde al español central y septentrional, a lo que llamamos castellano (base del español estándar), así como a las variedades de las tierras altas de América. SESEO /ϴ/ = /S/ p t ts k b d j g f s h CECEO /ϴ/ = /S/ p t b d f ϴ ts k g ʃ h El ceceo supone la pronunciación de la dental no estridente. La palabra poso y pozo tienen la misma pronunciación, pero se hace con una pronunciación no estridente, suena como una z, bastante alejado de la ch fricativa. En el patrón de seseo la única diferencia es que la dental se pronuncia con el alófono estridente. Pozo y poso se pronuncian igual, estridente. Esa s está muy cercana a la ch fricativa, por lo que se llegaría a una reducción. La aparición de la c y z están restringidas, aunque pueden aparecer conjuntos, pero no es lo común. Este fenómeno es el que determina la diferencia entre estos dos patrones en su origen: el de ceceo y el seseo. Por razones sociolingüísticas, el patrón del seseo es el que tiene más prestigio social; no hay ninguna razón lingüística o fonológica para que esto sea así, pero en la sociolingüística eso es así. Hay otros dos patrones minoritarios: 1) De posteriorización o de gegeo/heheo: la consonante dental fricativa se retrasa y se pronuncia como una aspiración. ϴS pasa a ʃ y, después, a h. (Casa, caza, cacha, caha). /ϴ/ = /s/ = /x/ = /ᵭ/ 2) Patrón de seseo extendido o ampliado: aceptar que la restricción de concurrencia entre z y ch no tienen efecto siempre o se guían por la frecuencia. Posho y pocho pueden pronunciarse igual. Cambio en cadena: Posteriorización Dental Palatal ϴ ʃ Velar h �0 > casa, caza cacha caja La fricativa dental pierde el rasgo del punto de articulación, se habla en fonología de desasociación del rasgo del punto de articulación. En el punto laríngeo tendríamos la “s” no sonorante. Rasgos supralaringeos: modo y lugar de articulación (lo que manejamos habitualmente). En modo es continuo, no es interrupto, y en el lugar lo hemos definido como coronal o dental, pero si se produce una desasociación, es decir, que el rasgo de lugar deja de funcionar. Un sonido continuo sordo sin un lugar preciso de constricción no se articula propiamente en ningún sitio, solo el flujo del aire que, si eso roza algo en la laringe o faringe, dando lugar a una aspirada [h]. Un sonido cambia y arrastra otro sonido. Casa, caza, cacha, caja, cuando se produce la posteriorización, se evita la aspiración aunque se mantiene el constante [kaxa] – [kaha]. No sabemos si es un cambio por empuje o por tracción (que se cambia de sitio). H1 y H2. Posteriorización de la fricativa coronal. Efecto de la CSE y el género del hablante. - Fenómeno menos frecuente ( minoritario) - Estratificación por CSE en los dos géneros, especialmente en los hombres - Separación por género en todas las clases sociales menos en las más altas (= ¿efecto de la educación?). Género y clase social (Gráfico). Las mujeres posteriorizan menos y las diferencias de clases entre ellas son menos tajantes. Que en el hombre sea más común la posteriorización de la -s (caja – caha), tiene que ver con el hecho de que la mujer tiende a asemejarse a la norma estándar, al prestigio, pues la realidad social de ambos no es la misma, la mujer siempre ha tenido que esforzarse más que el hombre para poder trabajar en el mismo puesto, por ejemplo. Además, la posteriorización es un marcador masculino y, por lo tanto, las mujeres se van a alejar de esto. Hay diferencia de género en todas las clases, aunque estas diferencias se hacen más pequeñas conforme la clase social va subiendo. La probabilidad de encontrar diferencias de género en las clases altas es muy pequeña. Nos preguntamos entonces, ¿por qué? Una probable respuesta sería que la educación que reciben las clases altas tiene una mejor calidad que la que reciben las clases bajas de modo que supone una desaparición de las diferencias genéricas en el uso linguisticos que se da en las clases bajas. Esto no es más que un reflejo de una situación real. La vida social de las personas en las clases altas y bajas es muy distinta. Se produce una disolución de errores. H3. RURALIDAD. Lugar de origen y satisfacción o insatisfacción con la red social. a) Relación entre la posteriorización de la coronal fricativa y la elisión de la velar fricativa. b) Efecto de la red de contactos rurales. Si esta red es fuerte la probabilidad de realización aspirada de la /ϴ/ será mayor. Lo mismo pasa con la /x/. Esto no es aleatorio, sino que está probado mediante un test estadístico que nos indica que la probabilidad de posteriorización es estadísticamente significativa con una probabilidad de error de 0.También nos damos cuenta de que hay una relación entre las dos variables porque observamos a simple vista que cuando crece la posteriorización, también crece la elisión.