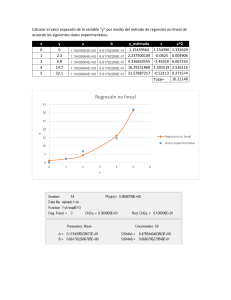
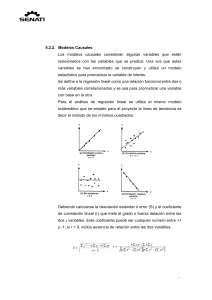
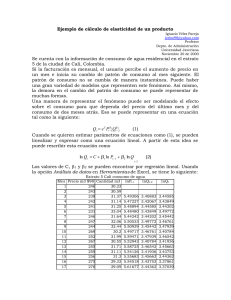
ESTADÍSTICA APLICADA A LA VALUACIÓN INMOBILIARIA ESTADÍSTICA APLICADA A LA VALUACIÓN INMOBILIARIA El proceso de valuar un inmueble así como cualquier otro tipo de activo conlleva la investigación y comparación de elementos de características similares al que se desea valuar. Estos elementos entregan gran cantidad de información que debe ser comparada, analizada y depurada con el fin de obtener datos con alto grado de precisión y credibilidad. El tomar esta información en bruto y convertirlos en datos útiles, de fácil manejo y comparación, le permite al valuador identificar el valor más representativos que debe asignarse al activo valuado. Y esta labor solo es posible con la aplicación de técnicas numéricas de análisis de datos que están contenidas en la estadística. ¿QUÉ ES LA ESTADÍSTICA? La estadística es la ciencia de los datos, la cual implica su recolección, clasificación, síntesis, organización, análisis e interpretación, para la toma de decisiones frente a la incertidumbre. Es una ciencia que facilita la toma de decisiones mediante la presentación ordenada de los datos observados en tablas y gráficos estadísticos, reduciendo los datos observados a un pequeño número de medidas estadísticas que permitirán la comparación entre diferentes series de datos y estimando la probabilidad de éxitos que tiene cada una de las decisiones posibles. LA POBLACIÓN La población es el conjunto total de individuos, objetos o medidas que poseen algunas características comunes observables en un lugar y en un momento determinado. Cuando se vaya a llevar a cabo algunas investigación debe tenerse en cuenta algunas características esenciales al seleccionarse la población bajo estudio como por ejemplo: Homogeneidad – que todos los miembros de la población tengan las mismas características según las variables que se vayan a considerar en el estudio o investigación. Tiempo – se refiere al período de tiempo donde se ubicaría la población de interés. Determinar si el estudio es el momento presente o si se va a estudiar a una población de cinco años atrás o si se van a entrevistar personas de diferentes generaciones. LA POBLACIÓN Espacio – se refiere al lugar donde se ubica la población de interés. Un estudio no puede ser muy abarcador y por falta de tiempo y recursos hay que limitarlo a un área o comunidad en especifico. Cantidad – se refiere al tamaños de la población. El tamaño de la población es sumamente importante porque ello determina o afecta al tamaño de la muestra que se vaya a seleccionar, al igual que la falta de recursos y tiempo también nos limita la extensión de la población que se vaya a investigar. LA MUESTRA La muestra es un subconjunto fielmente representativo de la población. Hay diferentes tipos de muestreo. El tipo de muestra que se selecciona dependerá de la calidad y cuán representativo se quiera sea el estudio de la población. En los avalúos inmobiliarios la muestra se construye de inmuebles que tengan características similares al inmueble valuado tanto físicas como de ubicación geo económicas. La muestra debe tener ciertas características esenciales que permiten un buen nivel de estudio como por ejemplo: ALEATORIA – cuando se selecciona al azar y cada miembro tiene igual oportunidad de ser incluido. ESTRATIFICADA – cuando se subdivide en estratos o subgrupos según las variables o características que se pretenden investigar. Cada estrato debe corresponder proporcionalmente a la población. LA MUESTRA SISTEMÁTICA – cuando se establece un patrón o criterio al seleccionar la muestra. Ejemplo: se entrevistará una familia por cada diez que se detecten. El muestreo es indispensable para el investigador ya que es imposible entrevistar a todos los miembros de una población debido a problemas de tiempo, recursos y esfuerzo. Al seleccionar una muestra lo que se hace es estudiar una parte o un subconjunto de la población, pero que la misma sea lo suficientemente representativa de ésta para que luego pueda generalizarse con seguridad de ellas a la población. El tamaño de la muestra depende de la precisión con que el investigador desea llevar a cabo su estudio, pero por regla se debe usar una muestra tan grande como sea posible de acuerdo a los recursos que haya disponibles. Entre más grande la muestra mayor posibilidad de ser más representativa de la población. A cada uno de los elementos de la muestra se le denomina punto muestral, elemento o punto de investigación. Para el presente curso este será el nombre que se le dará a cada uno de los elementos de la muestra es decir, punto de investigación. MEDIDAS DE TENDENCIA CENTRAL Las medidas de tendencia central son medidas estadísticas que pretenden resumir en un solo valor a un conjunto de valores. Representan un centro en torno al cual se encuentra ubicado en el conjunto de datos. Las medidas de tendencia central más utilizadas son: media, mediana y moda. Media La media o promedio, es una medida de tendencia central. Resulta al efectuar una división entre la sumatoria de las magnitudes de cada unos de los elementos de la muestra dividido entre el número de elemento que constituyen la muestra. Y que, en determinadas condiciones, puede representar por sí solo a todo el conjunto. Existen distintos tipos de medias, tales como la media geométrica, la media ponderada y la media armónica aunque en el lenguaje, tanto en estadística como en matemáticas la más elemental de todas ellas es la llamada generalmente la media aritmética. MEDIDAS DE TENDENCIA CENTRAL Numéricamente la media aritmética está dada por: σ𝑛𝑖=1 𝑋𝑖 𝜇 = 𝑋ത = 𝑛 Que es lo mismo 𝜇 = 𝑋ത = 𝑋1 + 𝑋2 + 𝑋3 + ⋯ + 𝑋𝑛 𝑛 En donde 𝜇 = Media de la población 𝑋ത = Media de la Muestra MEDIDAS DE TENDENCIA CENTRAL La media se calcula de la misma manera tanto para la población como para la muestra y gráficamente se puede representar de la siguiente manera. Figura 1. Representación de la Media Aritmética En donde se puede ver que la media es un valor que se ubica en medio de todos los valores que se utilizan para calcularla tratando de representarlos a todos. MEDIDAS DE TENDENCIA CENTRAL La media para datos agrupados está dada por: σ𝑘𝑖=0(𝑋𝑖 ∗ 𝑓𝑖 ) 𝜇 = 𝑋ത = 𝑛 En donde: 𝑋𝑖 = Marca de intervalo 𝑓𝑖 = frecuencia de intervalo 𝑛 = Número de elementos Todos los conceptos serán aplicados más adelante. MEDIDAS DE TENDENCIA CENTRAL Moda En estadística la moda es el dato que más se repite, o en otras palabras, es el dato con mayor frecuencia. EDIFICIO NÚMERO DE APARTAMENTOS 1 ✓ 4 2 6 Supongamos que en un barrio específico de una ciudad se ha realizado un análisis de cuantos apartamentos tiene cada edificio encontrado y se obtienen los siguientes resultados. 3 ✓ 4 4 8 5 10 6 ✓ 4 7 ✓ 4 En este conjunto de datos (ejercicio1.sav) se puede ver que el dato que más se repite es el número cuatro (4); de tal manera que la moda es cuatro (4). 8 14 9 12 10 ✓ 4 MEDIDAS DE TENDENCIA CENTRAL Debe tenerse claro que en un conjunto de datos puede haber varias modas, no solo una. Las modas son los datos que más se repiten, así que si existen varios datos con frecuencias más altas que el resto, estos serán considerados como modas. En el conjunto de datos mostrado a la derecha (ejercicio2.sav) se observa que los números con mayor frecuencia son el cuatro (4) y el ocho (8), de tal manera que ya no habrá una sola moda sino que habrá dos modas. EDIFICIO NÚMERO DE APARTAMENTOS 1 6 2 ➢ 8 3 ✓ 4 4 ➢ 8 5 10 6 ✓ 4 7 ✓ 4 8 ➢ 8 9 12 10 ✓ 4 MEDIDAS DE TENDENCIA CENTRAL Para los datos agrupados la moda está dada por: 𝑀𝑜𝑑𝑎 𝑀𝑜 = 𝐿𝑖 + (𝑓𝑚 − 𝑓𝑎) ∗𝐴 𝑓𝑚 − 𝑓𝑎 + (𝑓𝑚 − 𝑓𝑠) En donde: fm: es la frecuencia mayor entre los intervalos fa: es la frecuencia del intervalo anterior al que tiene la frecuencia mayor Fs: es la frecuencia del intervalo siguiente al que tienen la frecuencia mayor. A: es la amplitud de los intervalos Li: es el límite inferior del intervalo que tiene la mayor frecuencia. MEDIDAS DE TENDENCIA CENTRAL Mediana La mediana es una medida en virtud de la posición que ocupa un dato en el conjunto de datos. Es decir, es el dato que ocupa la posición central en un grupo de datos. Si se tiene una serie de números ordenados de menor a mayor como se muestra a continuación (ejercicio3.sav) 2,4,5,7,9,12,15,18,21,22,22,25,30 Como el número total de datos es impar (trece datos 13), la mediana será el dato que ocupe la posición (𝑛 − 1) +1 2 En donde n es el número total de datos. Para este caso la mediana será la que ocupe la posición siete (7), es decir, el número quince (15). MEDIDAS DE TENDENCIA CENTRAL Ahora bien, si se tiene una serie de números ordenados de menor a mayor como la siguiente lista (ejercicio4.sav) : 4,5,7,9,12,15,18,21,22,22,25,27 Como el número de datos es par (doce datos, 12), la mediana será el promedio entre los datos que ocupen las posiciones: 𝑛 𝑛 y 2 2 +1 Es decir, que la mediana estaría dada por: (15 + 18) 𝑀𝑒 = = 16.5 2 MEDIDAS DE DISPERSIÓN Las medidas de dispersión (varianza y desviación estándar) en cambio miden el grado de dispersión (separación) de los valores de las variables. Dicho en otros términos las medidas de dispersión pretenden evaluar en qué medida los datos difieren entre sí. De esta forma, ambos tipos de medidas usadas en conjunto permiten describir un conjunto de datos entregando información acerca de su posición y su dispersión. Varianza La varianza de una muestra o de una población se puede definir como el promedio de las diferencias entre cada elemento de la población y su media elevada al cuadrado y se representa por "𝜎 2 ". MEDIDAS DE DISPERSIÓN La definición es mas fácil de lo que parece, a continuación trataremos de explicarla, para que se comprenda más claramente. Supongamos que tenemos los elementos que se muestran en la figura 2. Figura 2. Representación de la Media Aritmética MEDIDAS DE DISPERSIÓN Como se puede ver en la figura los elementos 𝑋1 , 𝑋2 , 𝑋3 , 𝑋4 , … , 𝑋𝑛 se ubican en posiciones distintas los unos con los otros. Al conocer estos datos es posible calcular la media “µ” de los mismos, es decir, un valor numérico que trata de representar a todos los datos. Pero como se puede observar, la media no toca ningún punto, los puntos están separados de la media, unos más separados que otros. Esta separación se puede ver en la figura 3. Figura 3. Representación Gráfica de la diferencia con la Media MEDIDAS DE DISPERSIÓN Como se puede ver, estas diferencias tienen valores diferentes dependiendo de si el elemento está más cerca o más lejos de la media. Pero el objetivo de la varianza 𝜎 2 es saber cuál es la separación promedio, es decir, un valor de la separación que trate de representar a todas las separaciones de los elementos con la media. La separación del elemento 1 está dada por 𝑥1 − 𝜇 ; la del elemento 2 está dada por: 𝑥2 − 𝜇 y así sucesivamente. Como podemos ver, el valor 𝑥1 es mayor que el de la media (está ubicado por encima de la media), luego la diferencia dará como resultado un valor positivo. Pero en cambio el valor 𝑥2 es menor que el de la media (está ubicado por debajo de la media) por tal razón la diferencia dará como resultado un valor negativo. Esto se convierte en un problema ya que no se sumará con los otros valores, sino que se restará. MEDIDAS DE DISPERSIÓN Esto se soluciona elevando al cuadrado cada una de las diferencias ya que todo número elevado al cuadrado se convierte en un número positivo. Por esta razón las diferencias quedarían de la siguiente manera: 𝑥1 − 𝜇 2 + 𝑥2 − 𝜇 2 + 𝑥3 − 𝜇 2 + ⋯ + 𝑥𝑛 − 𝜇 2 Pero como se desea calcular el promedio, esta sumatoria debe dividirse entre el número de elementos de la muestra o de la población y es a este promedio al que se le llama varianza; al realizar las operaciones se tendría: 𝜎2 = 𝑥1 − 𝜇 2 + 𝑥2 − 𝜇 2 + 𝑥3 − 𝜇 𝑛 2 + ⋯ + 𝑥𝑛 − 𝜇 2 Pero esta ecuación se puede reducir a la ecuación que se conoce en la estadística, es decir: σ𝑛𝑖=1 𝑥𝑖 − 𝜇 = 𝑛 2 • 𝜎 es la varianza de la población. • 𝜇 es la media de la población. • 𝑛 es el número de elementos. 𝜎2 2 (𝑨) MEDIDAS DE DISPERSIÓN La ecuación (A) es la varianza poblacional, es decir, cuando se conocen todos los elementos de la población; cuando no se conocen todos los elementos sino tan solo se conoce una muestra, se habla de la varianza de la muestra 𝑆 2 que se expresa de la siguiente manera: 𝑆2 σ𝑛𝑖=1 𝑥𝑖 − 𝑥ҧ = 𝑛−1 • 𝑆 2 es la varianza de la muestra. • 𝑥ҧ es la media de la muestra. • 𝑛 es el número de elementos. 2 MEDIDAS DE DISPERSIÓN Desviación Estándar o Desviación Típica La desviación estándar “σ”, es una medida de dispersión que nos indica que tan separados están los elementos los unos de los otros. Cuando la desviación estándar es muy grande se dice que los elementos tienen valores muy lejanos entre sí, por el contrario, cuando la desviación estándar es pequeña, significa que los valores de los elementos están cercanos los unos de los otros. La desviación estándar se define como la raíz cuadrada de la varianza, por lo que la desviación estándar poblacional está dada por: En donde: 𝜎= σ𝑛𝑖=1 𝑥𝑖 − 𝜇 𝑛 2 𝜎 2 es la varianza de la población. 𝜇 es la media de la población. 𝑛 es el número de elementos. MEDIDAS DE DISPERSIÓN Mientras que la desviación estándar de la muestra “S”, está dada por: 𝑆= σ𝑛𝑖=1 𝑥𝑖 − 𝑥ҧ 𝑛−1 2 En donde: • 𝑆 2 es la varianza de la muestra. • 𝑥ҧ es la media de la muestra. • 𝑛 es el número de elementos. Esta desviación será la que más se usará en los procesos valuatorios ya que normalmente se trabaja con muestras de inmuebles comparables al que se desea valuar no con la población total de inmuebles. MEDIDAS DE DISPERSIÓN La desviación estándar de la población puede obtenerse estimada de la desviación estándar de la muestra con la siguiente ecuación: 𝜎= 𝑆 𝑛 𝑆=𝜎∗ 𝑛 En donde: • 𝜎 es la desviación estándar de la población. • S es la desviación estándar de la muestra. • n es el número de elementos. MEDIDAS DE DISPERSIÓN Gráficamente la desviación estándar puede representarse de la siguiente manera: Figura 4. Representación Gráfica de la Desviación Estándar MEDIDAS DE DISPERSIÓN Coeficiente de Variación El coeficiente de variación “CV”, también llamado coeficiente de variación de Spearman, es una relación estadística que nos permite saber que tan separados o dispersos están los elementos entre si y que tan separados están de la media. Es decir 𝐶𝑉 = 𝐷𝑒𝑠𝑣𝑖𝑎𝑐𝑖ó𝑛 𝐸𝑠𝑡á𝑛𝑑𝑎𝑟 𝑀𝑒𝑑𝑖𝑎 El coeficiente de variación de una población está representado de la siguiente manera: 𝜎 𝐶𝑉 = 𝜇 En donde: • σ es la desviación estándar • μ es la media de la población MEDIDAS DE DISPERSIÓN El coeficiente de variación de una población también puede calcularse con la desviación estándar estimada de una muestra empleando la siguiente ecuación: 𝐶𝑉 = 𝑆 𝑛∗𝜇 En donde: • 𝜇 es la media de la población • S es la desviación estándar de la muestra • n es el número de elementos. Y el coeficiente de variación de una muestra está dado por: MEDIDAS DE DISPERSIÓN Y el coeficiente de variación de una muestra está dado por: 𝐶𝑉 = 𝑆 𝑋ത En donde • S es la desviación estándar de la muestra • 𝑋ത es la media de la muestra Entre mayor sea el coeficiente de variación significa que los puntos están más alejados de la media, entre más pequeño sea el coeficiente de variación significa que los puntos están más cerca de la media. MEDIDAS DE DISPERSIÓN Coeficiente de Asimetría La simetría indica la manera en la que se distribuyen los datos en una población con respecto a la media o si los datos están distribuidos equilibradamente alrededor de la media. Con el coeficiente de asimetría se puede determinar si en la muestra o en la población hay el mismo número de datos de la izquierda o a la derecha de la media. Las distribuciones de datos pueden tener ASIMETRÍA POSITIVA, pueden ser SIMÉTRICAS o pueden tener ASIMETRÍA NEGATIVA. Existe ASIMETRÍA POSITIVA cuando el resultado del coeficiente de asimetría es mayor que cero (CA > 0), entre otras palabras, que sea positivo; en cuyo caso se entiende que la media de la muestra se ubica hacia los valores más grandes de la muestra estudiada. Si se habla específicamente de los avalúos inmobiliarios, se puede afirmar que si se presenta ASIMETRÍA POSITIVA puede tomarse un valor superior al de la media para hacer el cálculo del avalúo. MEDIDAS DE DISPERSIÓN Por otro parte, existe ASIMETRÍA NEGATIVA cuando el resultado del coeficiente de asimetría es menor que cero (CA < 0), en otras palabras, que sea negativo; en cuyo caso se entiende que la media de la muestra se ubica hacia los valores más pequeños de la muestra estudiada. Si se habla específicamente de los avalúos inmobiliarios, se puede afirmar que si se presenta ASIMETRÍA NEGATIVA puede tomarse un valor menor al de la media para hacer el cálculo del avalúo. Cuando el resultado del coeficiente de asimetría es igual a cero (CA = 0), se entiende que la distribución es SIMÉTRICA, es decir, hay igual cantidad de datos mayores y menores que la media, por lo que para un avalúo que cumpla con estás condiciones solo se debe tomar el valor de la media para hacer el cálculo del valor. MEDIDAS DE DISPERSIÓN El coeficiente de asimetría de FISHER (𝐶𝐴𝐹 ) está dada por: 𝐶𝐴𝐹 = 𝑋1 − 𝑋ത 3 + 𝑋2 − 𝑋ത 3 + 𝑋3 − 𝑋ത 𝑛 ∗ 𝑆3 Que es lo mismo que decir: σ𝑛𝑖=1 𝑋𝑖 − 𝑋ത 𝐶𝐴𝐹 = 𝑛 ∗ 𝑆3 En donde: • 𝐶𝐴𝐹 = Coeficiente de Asimetría • 𝑋ത = Media aritmética • S = Desviación Estándar • n= Número de Elementos 3 3 + ⋯ + 𝑋𝑛 − 𝑋ത 3 MEDIDAS DE DISPERSIÓN Para datos agrupados el coeficiente de asimetría de FISHER está dado por: σ𝑛𝑖=1 𝑚𝑖 − 𝑋ത 𝐶𝐴𝐹 = 𝑛 ∗ 𝑆3 En donde: • • • • • • 𝐶𝐴𝐹 = Coeficiente de Asimetría 𝑋ത = Media aritmética S = Desviación Estándar n= Número de Elementos 𝑚𝑖 = Marca de clase 𝑓𝑖 = Frecuencia de intervalo 3 ∗ 𝑓𝑖 MEDIDAS DE DISPERSIÓN Por otro lado, el coeficiente de asimetría de PEARSON (𝐶𝐴𝑃 ) está dado por: 𝑋ത − 𝑀𝑜 𝐶𝐴𝑃 = 𝑆 En donde: • 𝐶𝐴𝑃 = Coeficiente de Asimetría • 𝑋ത = Media aritmética • S = Desviación Estándar • 𝑀𝑂 = Moda De igual manera el coeficiente de asimetría de PEARSON (𝐶𝐴𝑃 ) también puede calcularse con la siguiente expresión: 3(𝑋ത − 𝑀𝑑 ) 𝐶𝐴𝑃 = 𝑆 Cualquiera de los dos métodos puede ser aplicado, pero en Colombia la resolución 620 de 2008 del IGAC, recomienda la aplicación del coeficiente de asimetría de Pearson. Pero si la muestra es relativamente pequeña y no se detecta la moda, sería mucho más práctico la aplicación del coeficiente de asimetría de Fisher. LA REGRESIÓN La Regresión o como es llamada en estadística, el análisis de regresión, es un proceso estadístico que permite determinar una ecuación matemática que explique el comportamiento de una serie de datos que se obtienen del mundo real. Cuando se realizan procesos en nuestro mundo, de los que es posible tomar información, esta información puede ser tabulada y graficada en un plano cartesiano. Luego, con la ayuda de la regresión, es posible obtener una ecuación que muestre el comportamiento de esos datos obtenidos o conocer el comportamiento hacia atrás de esos datos. LA REGRESIÓN Por ejemplo, tomemos el caso de un agricultor que semanalmente mide el crecimiento de una planta que se ha sembrado. El puede realizar una tabla de valores en la que consigne el número de la semana en la que toma la medición y la altura de la planta esa semana; como, por ejemplo, la siguiente tabla: SEMANA No. 4 5 6 7 8 … 20 ALTURA EN (Cms) 45 50 63 75 90 … 176 Luego, con esos datos puede realizar una gráfica de cada punto. Este tipo de gráficas se denomina diagrama de dispersión. Por ejemplo, supongamos que el agricultor obtiene el siguiente diagrama de dispersión: LA REGRESIÓN Figura 5. Diagrama de dispersión de la altura de una planta con respecto a cada semana de crecimiento Ahora bien, como la planta es una planta joven que debe seguir creciendo, el agricultor desea saber cuál será la altura de la planta a las 30 semanas, o a las 40 semanas. LA REGRESIÓN Y es en ese momento que se utiliza el análisis de regresión. Con este análisis, el agricultor puede obtener una ecuación que le permita saber cuánto medirá su planta en cualquier mes. En la figura 6 se muestra cual sería la posible gráfica de la ecuación en este caso podría ser una línea recta y se diría que existe una regresión lineal. Figura 6. Diagrama de dispersión de la altura de una planta con respecto a cada semana de crecimiento LA REGRESIÓN De la misma manera que hizo el agricultor en el ejemplo, lo hace el perito valuador, solo que, en este caso, el valuador usa dos variables diferentes, que normalmente son el valor del inmueble y el área del inmueble. Con estas dos variables, el valuador crea una ecuación de regresión basándose en los datos obtenidos de la investigación de mercado (la muestra) que le permite conocer cuanto costara un inmueble que tiene un área específica en cierto sector de la ciudad. Ahora bien, existen ciertos conceptos básicos que es necesario conocer sobre el análisis de regresión para tener claridad del mismo que se definirán a continuación. VARIABLE INDEPENDIENTE es la variable o el dato cuyo valor no depende de otros datos o de otras variables. También se podrá decir que es el dato conocido o que es difícil de conocer. LA REGRESIÓN Tomemos el caso del perito valuador, cuando el valuador llega a un inmueble que desea valuar, el conoce su tamaño, su área y otras características físicas del mismo, de tal manera que la variable conocida en este caso, sería el tamaño del inmueble y por ende, está sería la variable independiente. La variable independiente siempre se ubica en el diagrama de dispersión sobre el eje horizontal, en el caso del agricultor, su variable independiente era el número de la semana de crecimiento. LA REGRESIÓN VARIABLE DEPENDIENTE: es la variable o el dato cuyo valor si depende de otros datos o de otras variables. También se podrá decir que es el dato desconocido o que se desea encontrar. Tomemos nuevamente el caso del perito valuador, cuando el valuador desea un avalúo, el dato conocido primordial es el área del inmueble (variable independiente), y utilizando la regresión puede calcular cual es el valor de un inmueble con esa área en la zona estudiada. Por tal razón se dice que el valor del inmueble “depende” del área del mismo, ya que un inmueble pequeño tendrá (área menor) tendrá un valor más pequeño y un inmueble más grande (de área mayor) tendrá un valor mayor. La variable independiente en el caso del agricultor, su variable independiente era la altura de la planta. LA REGRESIÓN Al valor de la variable dependiente que se obtiene de la ecuación de regresión se le llama VALOR ESTIMADO. En el caso de la planta se le llamaría ALTURA ESTIMADA. COEFICIENTE DE CORRELACIÓN (r): Se puede definir el coeficiente de correlación como una medida estadística que cuantifica la dependencia entre dos variables, es decir, si se representan en un diagrama de dispersión los valores que toman dos variables, el coeficiente de correlación señalará lo bien o lo mal que el conjunto de puntos representados se aproxima a una curva específica. En otras palabras, como lo muestra las figuras 7 y 8, el coeficiente de correlación indica que tan cercanas entre sí están los datos y que tan cercanos están con la formación de una curva. LA REGRESIÓN En la figura 7 se puede ver una correlación débil, es decir, los puntos están separados entre sí, y al realizar el cálculo de la correlación se obtendrá un valor cercano a cero (0). En la figura 8 por el contrario, se observa que los puntos están más cercanos entre sí, entre otras palabras, el coeficiente de correlación es fuerte y al calcularlo su valor se acerca más a uno (1) o a menos uno (-1). El signo dependerá de la inclinación que tengan los puntos, si se inclinan a la derecha, como en las figuras, tendera a valer uno (1), mientras que si se inclinan a la izquierda tendera a ser menos uno (-1). LA REGRESIÓN Figura 7. Correlación débil Figura 8. Correlación fuerte LA REGRESIÓN Queda claro con lo dicho que el coeficiente de correlación será un número que varía entre menos (-1) y uno (1) pasando por cero (0). Al momento de realizar un análisis de regresión no se conoce a que tipo de curva se aproximan los datos ya que los datos no necesariamente se comportan como una línea recta, los datos de la muestra se comportan de diferentes maneras y es por esa razón que es necesario el realizar el análisis de regresión para diferentes tipos de comportamientos. Los comportamientos más comunes para conjuntos de datos son: • El comportamiento lineal • El comportamiento potencial • El comportamiento exponencial • El comportamiento logarítmico • El comportamiento polinómico LA REGRESIÓN Cada uno de estos comportamientos se expresa con una ecuación específica que debe ser encontrada a partir de los datos de la muestra obtenida y se debe relacionar uno de estos comportamientos para representar el modelo que se usará en los cálculos definitivos del avalúo. La forma más común es la de calcular el coeficiente de correlación para cada uno de estos modelos, y está dado por las siguientes ecuaciones: Para un comportamiento lineal: 𝑟= σ(𝑥𝑖 − 𝑥)(𝑦 ҧ 𝑖 − 𝑦) ത σ(𝑥𝑖 − 𝑥)ҧ 2 σ(𝑦𝑖 − 𝑦) ത 2 Para un comportamiento potencial 𝑁 σ 𝑙𝑛(𝑥) ∗ 𝐿𝑛(𝑦) − σ 𝑙𝑛 𝑥 ∗ σ 𝑙𝑛(𝑦) 𝑟= 𝑁 σ 𝑙𝑛(𝑥) 2 − σ 𝑙𝑛(𝑥) 2 ∗ 𝑁 σ 𝑙𝑛(𝑦) 2 − σ 𝑙𝑛(𝑦) 2 LA REGRESIÓN Para un comportamiento exponencial 𝑟= 𝑁 σ 𝑥 ∗ 𝑙𝑛(𝑦) − σ 𝑥 ∗ σ 𝑙𝑛(𝑦) 𝑁 σ 𝑥2 − σ 𝑥 2 ∗ 𝑁 σ 𝑙𝑛(𝑦) 2 − σ 𝑙𝑛(𝑦) 2 Y para un comportamiento logarítmico 𝑟= 𝑁 σ 𝑦 ∗ 𝑙𝑛(𝑥) − σ 𝑦 ∗ σ 𝑙𝑛(𝑥) 𝑁 σ 𝑦2 − 𝑦 2 ∗ 𝑁 σ 𝑙𝑛(𝑥) 2 − σ 𝑙𝑛(𝑥) 2 Cuando se eleva el coeficiente de correlación al cuadrado se obtiene el coeficiente de determinación (𝑅2 ) que es la forma más utilizada para determinar el modelo que se debe emplear. LA REGRESIÓN COEFICIENTE DE DETERMINACIÓN (𝑹𝟐 ): Hace la comparación de que tanto se aleja el valor estimado de la media aritmética con relación a lo que se aleja el valor real (dato medido) de la media aritmética. σ𝑇𝑡=1 𝑌𝑡 − 𝑌ത 2 𝑅 = 𝑇 σ𝑡=1 𝑌𝑡 − 𝑌ത 2 2 Y está elevada al cuadrado ya que tal y como ocurre en la varianza y en la desviación estándar, cuando el valor estimado o el valor real restante se restan de la media y da resultado negativo, este resultado se vuelve positivo elevándolo al cuadrado. El 𝑅2 se emplea especialmente cuando se realiza el análisis de regresión simple o para una sola variable independiente y su valor varía entre cero (0) y uno (1). El modelo de regresión escogido como representativo de la muestra será el que se acerque más a uno (1). LA REGRESIÓN ഥ 𝟐 ajustado): es el mismo COEFICIENTE DE DETERMINACIÓN AJUSTADO (𝑹 COEFICIENTE DE DETERMINACIÓN solo que con este se analiza el efecto de otras variables independientes en el modelo. Como se analizan varias variables independientes. El 𝑅ത 2 ajustado se emplea especialmente cuando se realiza el análisis de regresión con múltiples variables independientes y al igual que el 𝑅2 , su valor varía entre cero (0) y uno (1) y está dado por: 𝑅ത 2 = 1 − 𝑁−1 1 − 𝑅2 𝑁−𝑘−1 En donde: • • • N: es el número de datos K: es el número de variables independientes ഥ 𝟐 = es el coeficiente de determinación. 𝑹 LA REGRESIÓN ERROR ESTÁNDAR DE LA REGRESIÓN: En la regresión es muy difícil el determinar una desviación estándar de la muestra ya que no se calcula una media constante para todos los elementos. Por esta razón si se quiere medir la dispersión de los datos con la curva generada, además de los coeficientes mencionados con anterioridad, es posible calcular una medida denominada el ERROR ESTÁNDAR DE LA REGRESIÓN que básicamente, es un valor que muestra la diferencia entre los valores reales y los valores estimados (los calculados con la ecuación de regresión). El error de la regresión está dado por la siguiente ecuación: 𝑛 𝜎ො = 1 𝑌𝑖 − 𝑌 𝑛−2 𝑖=1 En donde: los valores estimados 𝑌: 𝑌𝑖 : los valores medidos n: el tamaño de la muestra 2 LA REGRESIÓN Y luego de haber calculado este error, es posible calcular un dato similar al coeficiente de variación con este error de la regresión y cada valor estimado específico. Todos estos coeficiente nos servirán para aceptar o descartar modelos de regresión dependiendo de su valor. REGRESIÓN LINEAL La regresión lineal o el análisis de regresión lineal, es el proceso estadístico que permite determinar una ecuación matemática que tenga la forma de una línea recta para que explique el comportamiento de los datos de una muestra. La ecuación del modelo lineal es: 𝑌 = 𝛽0 + 𝛽1 𝑋 LA REGRESIÓN Donde 𝑌 se denomina “Y estimada”; y gráficamente se representa de la siguiente manera: Figura 9. Modelo de Regresión Lineal Este modelo de regresión es el más utilizado, pero no siempre es el más conveniente, ya que la muestra no necesariamente se comporta de forma lineal. LA REGRESIÓN OTROS MODELOS DE REGRESIÓN Además del comportamiento lineal los datos de una muestra pueden presentar otros tipos de comportamiento. Los comportamientos más comunes diferentes al lineal son: • El comportamiento potencial • El comportamiento exponencial • El comportamiento logarítmico • El comportamiento polinómico Cada uno de estos comportamientos se expresa con una ecuación específica que debe ser encontrada a partir de los datos de la muestra obtenida y a continuación se muestra cada uno de estos modelos y su gráfica respectiva. LA REGRESIÓN REGRESIÓN EXPONENCIAL REGRESIÓN LOGARÍTMICA La ecuación del exponencial es: 𝑌 = 𝛽0 𝑒𝛽1𝑋 modelo La ecuación del modelo logarítmico es: 𝑌 = 𝛽0 + 𝛽1 ∗ 𝑙𝑛 𝑋 Y gráficamente se comporta de la siguiente manera: Y gráficamente se comporta de la siguiente manera: Figura 10. Modelo de Regresión Exponencial Figura 11. Modelo de Regresión Logarítmica. LA REGRESIÓN REGRESIÓN POTENCIAL REGRESIÓN POLINÓMICA La ecuación del modelo potencial es: 𝑌 = 𝛽1 𝑋𝛽0 La ecuación del modelo polinómica es: 𝑌 = 𝛽0 + 𝛽1 𝑋 + 𝛽2 𝑋 2 Y gráficamente se comporta de la siguiente manera: Y gráficamente se comporta de la siguiente manera: Figura 12. Modelo de Regresión Potencial Figura 13. Modelo de Regresión Polinómica LA DISTRIBUCIÓN NORMAL La distribución normal, también llamada distribución Gaussiana (en honor a Carl Friedrich Gauss), es una distribución de elementos continua que tiene forma de campana en la que la media, la moda y la mediana se encuentre en el centro de la campana y la mayor cantidad de elementos se agrupa cerca de ella y este porcentaje de elementos puede definirse en función de la cantidad de desviaciones estándar que se separen del centro de la media. Para comprender la distribución normal comencemos analizando un ejemplo. Supongamos que en una escuela primaria analizamos la edad de la población de los alumnos de los tres cursos de segundo año, segundo A, segundo B y segundo C. LA DISTRIBUCIÓN NORMAL Al agrupar los datos de estos cursos los podemos resumir en las siguientes tablas y haciendo sus histogramas se obtiene lo siguiente (ejercicio5.sav) : EDAD 5 6 7 8 9 TOTAL MEDIA MODA SEGUNDO A CANTIDAD DE ALUMNOS 4 5 3 4 4 20 6.95 6 Figura 14. Histograma Alumnos de Segundo A LA DISTRIBUCIÓN NORMAL ejercicio6.sav SEGUNDO B CANTIDAD DE EDAD ALUMNOS 5 6 6 3 7 1 8 4 9 6 TOTAL 20 MEDIA 7.05 MODA 1 5 MODA 2 9 Figura 15. Histograma Alumnos de Segundo B LA DISTRIBUCIÓN NORMAL ejercicio7.sav SEGUNDO C CANTIDAD DE EDAD ALUMNOS 5 2 6 5 7 8 8 4 9 1 TOTAL 20 MEDIA 6.85 MODA 7 Figura 16. Histograma Alumnos de Segundo C LA DISTRIBUCIÓN NORMAL Si se analiza la información mostrada en los histogramas y las tablas se puede ver que el curso de segundo B tiene dos modas, por lo que se descarta que esta sea una distribución normal. También se puede ver que en el curso de segundo A, la moda es de 6 mientras que la media es 7 (6.95); por lo que se descarta que sea una distribución normal. Si se analiza la información del curso de segundo C se observa que la moda es 7 y la media se puede asumir que también es 7 (6.85). también se observa que la mayor concentración de elementos está en el centro de la distribución; por todas estas condiciones podemos decir que las edades de los alumnos del curso de segundo C siguen una distribución normal y simétrica. Esto significa que la media se encentra en el centro de la distribución y los elementos se reparten relativamente iguales a ambos lados de la curva. LA DISTRIBUCIÓN NORMAL La distribución normal simétrica se representa de la siguiente manera: En ella podemos ver que la media, la moda y la mediana se encuentra en el centro de la distribución. LA DISTRIBUCIÓN NORMAL Pero en ocasiones la distribución normal no es simétrica, es decir, que sus elementos se acumulan más de un lado de la curva que del otro. A este tipo de distribución normal se le llama distribución normal asimétrica o también se le llama distribución normal sesgada. Cuando la media se ubica a la derecha de la moda, se dice que la distribución es asimétrica positiva o que esta sesgada a la derecha. La distribución asimétrica positiva se representa de la siguiente manera: LA DISTRIBUCIÓN NORMAL Por otra parte, cuando la media se ubica a la izquierda de la moda, se dice que la distribución es asimétrica negativa o que esta sesgada hacia la izquierda. La distribución asimétrica negativa se representa de la siguiente manera: LA DISTRIBUCIÓN NORMAL La distribución normal (en ocasiones llamada distribución gaussiana) es la distribución continua que se utiliza más comúnmente en estadística. La distribución normal es de vital importancia en estadística por tres razones principales: • Muchas variables continuas comunes en el mundo de los negocios tienen distribuciones que se asemejan estrechamente a la distribución normal. • La distribución normal sirve para acercarse a diversas distribuciones de probabilidad discreta, como la distribución binomial y la distribución de Poisson. • La distribución normal proporciona la base para la estadística inferencial clásica por su relación con el teorema de límite central. En la distribución normal, uno puede calcular la probabilidad de que varios valores ocurran dentro de ciertos rangos o intervalos. LA DISTRIBUCIÓN NORMAL La Distribución Normal Estandarizada La distribución normal estándar, o tipificada o reducida, es aquella que tiene por media el valor cero, μ = 0, y por desviación estándar la unidad, 𝜎 = 1. La probabilidad de la variable estudiada “X” dependerá del área contenida bajo la curva normal y para calcularla utilizaremos la tabla de la distribución normal. Para poder utilizar la tabla tenemos que transformar la variable X que sigue una distribución 𝑁 𝜇, 𝜎 en otra variable Z que siga una distribución 𝑁 0,1 . Para utilizar la variable en una distribución normal debe tipificarse y convertirse en una variable “Z” lo cual se realiza con la siguiente ecuación: En donde 𝑍= 𝑋−𝜇 𝜎 • X es el dato a tipificar • 𝝈 es la desviación estándar • 𝝁 es la media de la población. LA DISTRIBUCIÓN NORMAL La Distribución Normal Estandarizada En ciertos procesos de muestro, como es el caso de los avalúos, en los que la muestra es muy pequeña debe utilizarse la curva normal estandarizada “t de Student”. Esta distribución surge del problema de estimar la media de una población normalmente distribuida cuando el tamaño de la muestra es pequeño. Cuando el tamaño de la muestra es menor a treinta (30) elementos, se supone que la población tiene una distribución normal y no se conoce la desviación estándar de la población se utiliza la distribución “t de Student” de lo contrario se utiliza la distribución “Z”. LA DISTRIBUCIÓN NORMAL Para los casos en los que la muestra cuenta con menos de 30 datos, la variable se tipifica de la siguiente manera: 𝑡= 𝑥−𝜇 𝜎 𝑛 𝑡= 𝑥 − 𝑥ҧ 𝑠 𝑛 En donde: • • • • • n es el número de datos o el tamaño de la muestra. X es el dato a tipificar 𝝈 es la desviación estándar de la población S es la desviación estándar de la muestra 𝝁 es la media de la población