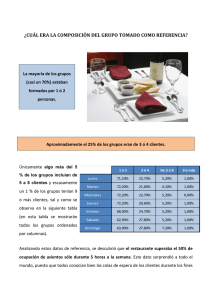
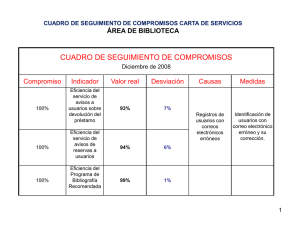
Instituto tecnológico de ciudad guzmán Carrera: Ingeniería en Gestión Empresarial Grado y grupo: 7 ° “C” Alumno: Juárez Seda Juan José Materia: Calidad aplicada a la gestión empresarial. Profesor: Jiménez Martínez Emilio Actividad: Actividad 1: guía-formulario de estadística descriptiva e inferencial Fecha de entrega: 3 de octubre de 2022 índice Pendiente. Introducción. En el presente trabajo se plantean las formulas de las medidas de tendencia central, medidas de dispersión, intervalos de confianza para la medición de muestras grandes y pequeñas, pruebas de hipótesis para una y dos muestras, así como para muestras pareadas. Se pretende que sea más claro el entendimiento de esta a través de una tabla donde se contendrán datos básicos de las fórmulas, desde el significado de cada una de las literales que estas contienen, el procedimiento, su uso y un ejemplo ilustrativo, así como la función en acción dentro del software “Excel”. Nombre. Media aritmética. Media aritmética ponderada. Ecuación. Simbolismo. ∑𝑛𝑖=1 𝑥𝑖 𝑚= 𝑛 m = Muestra. ∑ = Sumatoria. n = Total de datos. xi = Intervalo de enteros (conjunto de datos). i = Límite inferior. La media aritmética es un promedio estándar que a menudo se denomina promedio, se calcula sumando todos los valores a tomar en cuenta y dividir entre el número de valores. Marca la mitad en cuanto a concentración de datos. m = Muestra. ∑ = Sumatoria. wi = Valor ponderado asignado. xi = Intervalo de enteros (conjunto de datos). i = Límite inferior. STE = Suma de todos los números VPA = valor ponderado asignado A veces puede ser útil otorgar pesos o valores a los datos dependiendo de su relevancia para determinado estudio, se calcula asignando un valor numérico ponderado a cada valor de la media, el cual se multiplica por dicho valor. Nos indica la mitad de los nuevos valores en cuanto a concentración, se usa para asignar mayor valor a ciertos resultados que conforman una muestra. 𝑚= ∑𝑛𝑖=1 𝑋𝑖. 𝑤𝑖 ∑𝑛𝑖=1 𝑤𝑖 Descripción. Propósito. Medidas de tendencia central estadística. Excel. z Media generalizada. 𝑛 1 𝑚1 1 𝑚2 𝑚 = ( . ∑ 𝑥𝑖 ) 𝑛 𝑖=1 Mediana de datos no agrupados. 𝑖𝑚𝑝𝑎𝑟 𝑚 = (𝑛 + 1)/2 𝑛 𝑛 (𝑥 2 + (𝑥 2 + 1)) 𝑝𝑎𝑟 𝑚 = 2 𝑚1 → ∞ - máximo. 𝑚1 = 2 – media cuadrática. 𝑚1 = 1 – media aritmética. 𝑚1 → 0 – media geométrica. 𝑚1 = -1 – media armónica. 𝑚1 → −∞ - mínimo. n = número total de datos. i = límite inferior. x = delimitante. 𝑚2 = límite superior. ∑ = Sumatoria. Las medias Sirve como una formula generalizadas, también general donde se agrupan conocidas como medias los 4 tipos de medias. de Hölder, son una abstracción de las medias cuadráticas, aritméticas, geométricas y armónicas, se calcula multiplicando la sumatoria de todos los datos tomados en cuenta por los límites inferior y superior 1 elevado a la 𝑚 donde m es el valor dado por la media que se quiera calcular. n = total de datos. x = valor central. Representa el valor de la variable de posición central en un conjunto de datos ordenados, se encuentra tomando el número total de número de datos y dividirlo entre 2, si es número par se toman los 2 números centrales que conforman el .5 hacía arriba y hacía abajo, se suman y dividen entre dos, si es un número impar, solo se toma el número que se encuentra en medio. Sirve para encontrar en número que se encuentra justo a la mitad de un conjunto de datos no agrupados. Mediana de datos agrupados. 𝑛 2 = 𝐹𝑟𝑒𝑐𝑢𝑒𝑛𝑐𝑖𝑎 𝑎𝑐𝑢𝑚𝑢𝑙𝑎𝑑𝑎 𝑛 − 𝑁𝑖−1 𝑝= 2 ∗ (𝑎𝑖 − 𝑎𝑖−1 ) 𝑁𝑖 − 𝑁𝑖−1 𝑝 = Mediana de datos agrupados. n = total de datos. 𝑁𝑖 = Frecuencia acumulada absoluta. 𝑁𝑖−1 = Frecuencia acumulada absoluta menos uno. 𝑎𝑖 = Extremo exterior. 𝑎𝑖−1 = Extremo interior. Representa el valor de la variable de posición central en un conjunto de datos ordenados y agrupados, se calcula multiplicando la amplitud de los extremos por la cantidad de datos entre dos menos el límite interior, sobre el límite exterior menos el límite interior. Sirve para encontrar dentro de un conjunto de datos agrupados el o los números centrales del mismo. Moda estadística. 𝑛𝜖𝑁 𝑛 = Número que más se repite en un conjunto de datos. 𝑁 = Todos los datos de un conjunto dado. La moda es el valor que aparece con mayor frecuencia en un conjunto de datos. Nos ayuda a identificar el número que más se repite en un conjunto de datos no agrupados. 𝑝= Moda de datos agrupados. 𝑚 = 𝐿𝑖 + ( 𝐷1 )𝐴 𝐷1 + 𝐷2 𝑖 M= moda de datos agrupados. 𝐿1 = Límite inferior. 𝐷1 = Es la diferencia entre la frecuencia absoluta modal y la frecuencia absoluta premodal. 𝐷2 = Es la diferencia entre la frecuencia absoluta modal y la frecuencia absoluta postmodal. 𝐴𝑖 = Amplitud del intervalo modal. La moda es el valor que aparece con mayor frecuencia en un conjunto de datos, se calcula dividiendo la diferencia de frecuencia premodal y absoluta sobre la diferencia de frecuencia premodal más la diferencia de la frecuencia postmodal, multiplicado por la amplitud del intervalo más el límite inferior. Nos ayuda a medir la moda de un conjunto de datos agrupados donde no sería factible contarlos de forma individual. Medidas de dispersión estadística. Desviación estándar. 𝜎 = Desviación de una población completa. 𝑖=1 𝑠 = Desviación de 𝑁 una muestra. 1 2 2 𝑠= √ ((∑ 𝑥𝑖 ) − 𝑁𝜇 ) N = Total de 𝑁−1 muestra o 𝑖=1 población. 𝑥𝑖2 = Valores observados de la muestra o población. 𝑁𝜇 2 = Valor medio al cuadrado de las observaciones. 𝑁 1 𝜎 = √ ( (∑ 𝑥𝑖2 ) − 𝑁𝜇 2 ) 𝑁 Es una medida que se utiliza para cuantificar la variación o la dispersión de un conjunto de datos numéricos, una desviación estándar baja indica que la mayor parte de los datos de una muestra tienden a estar agrupados cerca de su media, mientras que una desviación estándar alta indica que los datos se extienden sobre un rango de valores más amplio. Sirve para saber la concentración de resultados en una muestra o una población total. Varianza. 𝜎 2 = 𝐸((𝑥 − 𝜇)2 ) 𝜎 2 = Varianza. E = Variable aleatoria con media. X = variable aleatoria. 𝜇 = Media aritmética de un conjunto de datos. Es una medida de dispersión definida como la esperanza del cuadrado de la desviación de dicha variable respecto a su media. Su unidad de medida corresponde al cuadrado de la unidad de medida de la variable. Sirve para hacer una aproximación de la dispersión con respecto a una media de un conjunto de datos. Rango. 𝑅 = 𝑥𝑖 − 𝑥𝑖−1 R = Rango. 𝑥𝑖 = Límite superior. 𝑥𝑖−1 = Límite inferior. Es el intervalo entre el valor máximo y el valor mínimo, se calcula restando a el valor mayor el valor menor dentro de un conjunto de datos. Nos ayuda a identificar la cantidad de datos que hay en un cierto grupo de datos. Intervalo de confianza. Intervalo de confianza para pequeñas muestras conociendo la desviación estándar. (𝜇 − 𝑧𝛼 ∗ 𝜎 ; √𝑛 𝜎 𝜇 + 𝑧𝛼 ∗ ) 2 √𝑛 2 𝜇 = Muestra. 𝑧𝛼 = Valor crítico. 2 𝜎 √𝑛 = Error estándar. 𝜎 = Desviación estándar 𝑛 = Toda la población. Es un par o varios pares Sirve para estimar valores de números entre los de una población con cuales se estima que confianza de su suceso. estará cierto valor desconocido respecto de un parámetro poblacional con un determinado nivel de confianza. Intervalo de confianza para pequeñas muestras desconociendo la desviación estándar. Intervalo de confianza para muestras grandes conociendo la desviación estándar. (𝜇 − 𝑧𝛼 2 𝜇 = Muestra. 𝑧𝛼 = Valor crítico. Es un par o varios pares Sirve para estimar valores de números entre los de una población con cuales se estima que confianza de su suceso. estará cierto valor desconocido respecto de un parámetro poblacional con un determinado nivel de confianza. 𝜇 = Muestra. 𝑧𝛼 = Valor crítico. Es un par o varios pares Sirve para estimar valores de números entre los de una población grande cuales se estima que con confianza de su suceso. estará cierto valor desconocido respecto de un parámetro poblacional con un determinado nivel de confianza. 2 1 2 2 𝜎√𝑁 − 1 ((∑𝑁 𝑖=1 𝑥𝑖 ) − 𝑁𝜇 ) 𝑛 = Toda la ∗ ; población. √𝑛 N = Total de 𝜇 + 𝑧𝛼 2 muestra o 1 población. 2 2 𝜎√𝑁 − 1 ((∑𝑁 2 𝑖=1 𝑥𝑖 ) − 𝑁𝜇 ) ∗ ) 𝑥𝑖 = Valores observados de la √𝑛 muestra o población. 𝑁𝜇 2 = Valor medio al cuadrado de las observaciones. 𝜎 ; 𝐸 2 √𝑛 𝜎 𝜇 + 𝑧𝛼 ∗ ) 𝐸 2 √𝑛 (𝜇 − 𝑧𝛼 ∗ 2 𝜎 √𝑛 = Error estándar. 𝜎 = Desviación estándar 𝑛 = Toda la población. E = Variable aleatoria con media. Intervalo de confianza para muestras grandes desconociendo la desviación estándar. (𝜇 − 𝑧𝛼 ∗ 2 𝜇 + 𝑧𝛼 ∗ ∑𝑛𝑖=1(𝑥𝑖 − 𝑥̅ )2 √𝑛 ∑𝑛𝑖=1(𝑥𝑖 − 𝑥̅ )2 √𝑛 2 ; 𝜇 = Muestra. 𝑧𝛼 = Valor crítico. 2 𝜎 ) √𝑛 = Error estándar. 𝜎 = Desviación estándar 𝑛 = Toda la población. 𝑥𝑖 = Límite superior. 𝑥̅ = Media muestral. Es un par o varios pares Sirve para estimar valores de números entre los de una población grande cuales se estima que con confianza de su suceso. estará cierto valor desconocido respecto de un parámetro poblacional con un determinado nivel de confianza. Pruebas de hipótesis para una media. Prueba Z. 𝑍= 𝑥̅ − 𝑢 𝜎 𝑛 √ Prueba t. 𝑡= 𝑥̅ − 𝑢 √ 𝑆2 𝑛 Z = Estadística de prueba. 𝑥̅ = Promedio parcial de la muestra. 𝜎 = Desviación poblacional. 𝑢 = Valor de la hipótesis. 𝑛 = Número de datos. 𝑡 = Estadística de prueba menor a 30. 𝑆 = Desviación de la muestra. 𝑢 = Valor de la hipótesis. 𝑛 = Número de datos. 𝑥̅ = Promedio parcial de la muestra. Es un tipo de prueba paramétrica que se utiliza para determinar el grado de significatividad estadística de las diferencias entre las medias de un conjunto de datos mayor a 30. Se utiliza cuando las muestras son amplias. Es un tipo de prueba paramétrica que se utiliza para determinar el grado de significatividad estadística de las diferencias entre las medias de un conjunto de datos menor a 30. Se utiliza cuando la muestra es pequeña. Sirve para delimitar si un determinado número es rechazado o no de una muestra mayor a 30. Sirve para delimitar si un determinado número es rechazado o no de una muestra menor a 30. Prueba de hipótesis para dos medias. Prueba Z. 𝑥1 − 𝑥2 𝑧= 𝑆2 𝑆2 √ 1+ 2 𝑛1 𝑛2 Prueba t con dos varianzas desiguales. Prueba t con dos varianzas iguales. 𝑥̅1 − 𝑥̅2 𝑡= √ 𝑡1 = 𝑥̅ − 𝑢 2 √𝑆 𝑛 𝑆12 𝑆22 𝑁1 + 𝑁2 ↔ 𝑡2 = 𝑥̅ − 𝑢 2 √𝑆 𝑛 𝑥1 = Promedio de la muestra 1 𝑥2 = Promedio de la muestra 2 𝑆12 = Desviación de la muestra 1 𝑆22 = Desviación de la muestra 2 𝑛1 = Número total del primer conjunto de datos 𝑛2 = Número total del segundo conjunto de datos 𝑥̅1 = Promedio de la muestra 1 𝑥̅2 = Promedio de la muestra 2 𝑆12 = Desviación de la muestra 1 𝑆22 = Desviación de la muestra 2 𝑁1 = Número total del primer conjunto de datos 𝑁2 = Número total del segundo conjunto de datos Es un tipo de prueba paramétrica que se utiliza para determinar el grado de significatividad estadística de las diferencias entre las medias de dos conjuntos de datos menor a 30. Se utiliza cuando las muestras son amplias e independientes. Sirve para delimitar si un determinado número es rechazado o no de dos muestras mayores a 30. Es un tipo de prueba paramétrica que se utiliza para determinar el grado de significatividad estadística de las diferencias entre las medias de un conjunto de datos menor a 30. Se utiliza cuando las muestras son pequeñas. Sirve para delimitar si un determinado número es rechazado o no de dos muestras menores a 30. 𝑡 = Estadística de prueba menor a 30. 𝑆 = Desviación de la muestra. 𝑢 = Valor de la hipótesis. 𝑛 = Número de datos. 𝑥̅ = Promedio parcial de la muestra. No tiene sentido realizar dicha prueba t, ya que la misma se usa para comparar dos muestras distintas, si las varianzas son iguales, se presupone que dichas muestras son idénticas también y por lo tanto no existe un punto de comparación. Realmente solo se puede usar como herramienta de demostración de la igualdad de un tipo de muestra sobre otra, no tiene un uso real practico. Prueba de hipótesis para muestras pareadas o dependientes. 𝑡= 𝑋𝐷 𝑆𝐷 √𝑛 𝑋𝐷 = media de las diferencias 𝑆𝐷 = la desviación estándar de las diferencias 𝑛 = número de pares de observaciones. Es un tipo de prueba paramétrica que se utiliza para determinar el grado de significatividad estadística de las diferencias entre las medias de un conjunto de datos menor a 30, de los cuales son dependientes. Ayuda a comparar de forma efectiva dos conjuntos de datos que dependen uno del otro.