Facultad de Ciencias Económicas
Universidad Nacional de Misiones
Estadística I
Notas de Cátedra
Índice general
1. Estadística Descriptiva
1.1. Introducción y conceptos fundamentales . . . . . . . . . . . . . . . . . . . . . . . .
1.2. Resumen de la información . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1.2.1. Tablas o distribuciones de frecuencia . . . . . . . . . . . . . . . . . . . . . .
1.2.2. Gráco de barras y diagramas circulares . . . . . . . . . . . . . . . . . . . .
1.2.3. Tablas de frecuencias para variables cuantitativas . . . . . . . . . . . . . . .
1.2.4. Histogramas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1.2.5. Polígonos de frecuencias . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1.3. Medidas descriptivas numéricas . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
P
1.3.1. El símbolo sumatoria
. . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1.3.2. Medidas de localización o de posición . . . . . . . . . . . . . . . . . . . . .
1.3.3. Medidas de variabilidad . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1.4. Reglas Empírica y Desigualdad de Chebyshev . . . . . . . . . . . . . . . . . . . . .
1.4.1. Regla empírica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1.4.2. Desigualdad de Chebyshev . . . . . . . . . . . . . . . . . . . . . . . . . . .
1.5. Medidas de localización relativa. Detección de valores atípicos . . . . . . . . . . .
1.6. Medidas de asimetría o sesgo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1.7. Distribuciones bidimensionales . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1.7.1. Tabla para variables discretas. Distribución conjunta . . . . . . . . . . . . .
1.7.2. Tablas para variables cualitativas . . . . . . . . . . . . . . . . . . . . . . . .
1.8. Medidas de asociación. Variables cuantitativas . . . . . . . . . . . . . . . . . . . . .
1.8.1. Diagrama de dispersión . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1.8.2. La covarianza . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
1.8.3. Coeciente de correlación lineal de Pearson . . . . . . . . . . . . . . . . . .
5
5
10
10
11
12
17
18
19
19
21
27
34
34
35
36
40
42
42
44
44
45
46
48
2. Introducción a la Probabilidad
2.1. Denición de probabilidad . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.1.1. Denición clásica de probabilidad . . . . . . . . . . . . . . . . . . . . . . . .
2.1.2. Denición de probabilidad como frecuencia relativa . . . . . . . . . . . . . .
2.1.3. Denición subjetiva de probabilidad . . . . . . . . . . . . . . . . . . . . . .
2.2. Propiedades básicas de la probabilidad . . . . . . . . . . . . . . . . . . . . . . . . .
2.3. Probabilidad condicional. Eventos independientes . . . . . . . . . . . . . . . . . . .
2.3.1. Probabilidad condicional . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.3.2. Eventos independientes . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
53
56
57
57
58
58
60
60
62
3. Variables aleatorias. Distribuciones de probabilidad
65
3
3.1. Variables aleatorias discretas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.1.1. Valor esperado y varianza de una variable aleatoria discreta . . . . . . . . .
3.1.2. Distribución de probabilidad acumulada. Variables aleatorias discretas . .
3.2. Modelos de distribución de probabilidad. Variables aleatorias discretas . . . . . . .
3.2.1. Distribución Binomial . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.2.2. Distribución Hipergeométrica . . . . . . . . . . . . . . . . . . . . . . . . . .
3.2.3. Distribución de Poisson . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.3. Variables aleatorias continuas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.3.1. Valor esperado y varianza de una variable aleatoria continua . . . . . . . .
3.3.2. Densidad de probabilidad acumulada. Variables aleatorias continuas . . . .
3.4. Modelos de densidad de probabilidad. Variables continuas . . . . . . . . . . . . . .
3.4.1. Distribución Normal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.4.2. Distribución Normal Estándar . . . . . . . . . . . . . . . . . . . . . . . . .
3.4.3. Aplicaciones de la distribución Normal . . . . . . . . . . . . . . . . . . . . .
3.5. Funciones de variables aleatorias . . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.6. Propiedades del valor esperado y la varianza de una variable aleatoria . . . . . . .
3.6.1. Propiedades del valor esperado . . . . . . . . . . . . . . . . . . . . . . . . .
3.6.2. Propiedades de la varianza . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.7. Funciones lineales de variables aleatorias . . . . . . . . . . . . . . . . . . . . . . . .
66
68
70
72
73
77
79
80
83
84
85
86
88
91
93
95
95
96
97
4. Distribuciones muestrales. Estimación
101
4.1. Distribuciones muestrales . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
4.2. Muestras aleatorias. Estadísticos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
4.3. Distribución de muestre de la media muestral X̄ . . . . . . . . . . . . . . . . . . . 105
4.3.1. Muestreo de poblaciones nitas . . . . . . . . . . . . . . . . . . . . . . . . . 109
4.4. Estimadores y sus propiedades . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
4.5. Estimación de un parámetro poblacional . . . . . . . . . . . . . . . . . . . . . . . . 114
4.5.1. Intervalo de conanza para estimar µ, población Normal, σ 2 conocida . . . 115
4.5.2. Intervalo de conanza para estimar µ, varianza poblacional desconocida . . 122
4.5.3. Población nita . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
4.6. Inferencia acerca de la proporción de una población . . . . . . . . . . . . . . . . . . 126
4.6.1. Distribución de la proporción muestral P̄ . . . . . . . . . . . . . . . . . . . 126
4.7. Intervalos de conanza para estimar p . . . . . . . . . . . . . . . . . . . . . . . . . 127
4.8. Tamaño de la muestra para estimar la media y la proporción de una población . . 129
4.8.1. Tamaño de la muestra para estimar la media de una población . . . . . . . 129
4.8.2. Tamaño de la muestra para estimar la proporción de una población . . . . 131
4.9. Estimación de la varianza de una población . . . . . . . . . . . . . . . . . . . . . . 133
2
4.9.1. Distribución Chi cuadrado y la distribución de (n−1)S
. . . . . . . . . . . . 133
σ2
4.9.2. Estimación de la varianza poblacional . . . . . . . . . . . . . . . . . . . . . 135
5. Pruebas de hipótesis
139
5.1. Introducción y conceptos fundamentales . . . . . . . . . . . . . . . . . . . . . . . . 139
5.2. Errores en las pruebas de hipótesis . . . . . . . . . . . . . . . . . . . . . . . . . . . 140
5.3. Pruebas de hipótesis bilaterales y unilaterales . . . . . . . . . . . . . . . . . . . . . 147
4
Capítulo 1
Estadística Descriptiva
1.1. Introducción y conceptos fundamentales
Es indudable que la Estadística se ha convertido en una de las herramientas analíticas más importantes para el profesional de las Ciencias Económicas cualquiera sea su rama de actividad
profesional.
Problemas derivados de auditorías a empresas o instituciones, del control de calidad, de la administración de la producción, los análisis micro o macro-económicos en la Economía, etc. pueden ser
abordados y eventualmente resueltos mediante técnicas o modelos estadísticos.
A diario, y en la mayoría de los medios de comunicación, se pueden encontrar informes económicos
sobre variaciones del producto bruto interno, variaciones del índice de precios al consumidor, sobre
el número de personas desocupadas, etc.
Estos informes suelen ir acompañados por tablas, grácos y por alguna medida descriptiva numérica
como un promedio, una proporción, etc.
Aunque estos ejemplos reejan en parte que es y de que se ocupa la Estadística, su campo de acción
es mucho más amplio sobre todo para aquellas personas que la utilizan a diario en sus actividades
laborales y/o de investigación.
Debido al extenso y variado campo abarcado por la Estadística resulta difícil proponer una denición precisa y abarcadora de esta disciplina sin el riesgo de incurrir en alguna omisión importante.
No obstante, proponemos una, sabiendo que será incompleta, con el objetivo de dar una idea
aproximada de que es y de que se ocupa esta disciplina y que además sirva como introducción a
los temas que desarrollaremos en este material.
Denición 1.1 La Estadística es la disciplina que se encarga de la recopilación, organización,
resumen, análisis, interpretación y comunicación de la información.
En la mayoría de los trabajos estadísticos se llevan adelante todas estas acciones.
Cuando se diseña un trabajo estadístico es para alcanzar uno de los siguientes objetivos o ambos:
1. Describir cuantitativamente un grupo de personas, lugares o cosas
2. Dar información de la que se pueda extraer conclusiones acerca de un grupo grande de
personas, lugares o cosas analizando la información de una fracción del conjunto total
Las actividades estadísticas encaminadas a lograr el primer objetivo pertenecen a la rama de la
Estadística Descriptiva, las que se diseñan para alcanzar el segundo, a la rama de la Estadística
Inferencial.
Ambas ramas de la Estadística cumplen funciones complementarias en el análisis de la información.
Analicemos el siguiente ejemplo.
5
Suponga que el jefe de personal de una gran empresa suministra una prueba de aptitud a un grupo
de empleados de la misma.
Algunas de las tareas que puede realizar con las puntuaciones que resulten de la prueba, utilizando
herramientas de la Estadística Descriptiva, son las siguientes:
Tabular las puntuaciones de manera que se pueda lograr una imagen global de sus propiedades
Calcular alguna medida descriptiva numérica como un promedio, una proporción, etc.
Construir grácos
etc.
Las conclusiones de la prueba sólo se aplican al conjunto de empleados seleccionados. No se realizan
generalizaciones al conjunto total de empleados de la empresa ni a los de otras empresas similares.
Si bien es cierto la descripción de los datos recolectados es a veces un n en sí mismo, en la mayoría
de los trabajos estadísticos estamos más bien al comienzo de la tarea que al nal de la misma.
Esto es así porque casi siempre el objetivo último de la actividad estadística es la de extraer
conclusiones sobre todas las observaciones posibles a partir de la información contenida en una
fracción del total.
Es decir, la estadística descriptiva no es más que un trabajo preliminar para la inferencia, entendiéndose por inferencia estadística el proceso de obtener conclusiones acerca de alguna característica
o propiedad de una población a partir de la información contenida en una muestra tomada de esa
población.
Un poco más adelante daremos deniciones más precisas de población y muestra.
Como toda disciplina, la Estadística posee una terminología propia que es necesario conocer para
poder aplicar sus técnicas adecuadamente y comprender sus resultados.
Veremos a continuación una serie de conceptos que se utilizarán extensamente a lo largo de este
material.
La lista será lo más breve posible limitándonos a aquellos que utilizaremos inmediatamente, dejando
para más adelante los restantes, los que serán denidos en la medida que sean necesarios.
Unidad observacional
En todo trabajo de investigación que utilice a la Estadística como herramienta para el análisis de
la información, el analista dirige su atención en un grupo de personas, lugares o cosas. Cada una
de ellas, tomadas de manera individual, recibe el nombre de unidad observacional.
Por ejemplo, para un investigador que estudia las características socio-demográcas de los estudiantes de una universidad, cada uno de los estudiantes, tomados de manera individual, constituye
una unidad observacional.
Para un analista de mercados que estudia las propiedades de la renta mensual de las familias
de una ciudad, cada una de las familias tomadas de manera individual, constituye una unidad
observacional.
Por lo tanto, una unidad observacional es una persona, un lugar o una cosa de la cual se toma
algún tipo de información.
Variable
Es toda característica que toma diferentes valores en distintas unidades observacionales.
Por ejemplo, la altura o el peso de las personas, su lugar de residencia, la renta mensual de las
familias de una ciudad, el estado civil de un grupo de estudiantes de una universidad, etc.
6
Variable cuantitativa
Asume valores numéricos acompañados de una unidad de medida. Por ejemplo, el ingreso mensual
de las familias de una ciudad. El peso o la altura de los estudiantes de una universidad, etc.
El ingreso mensual de una familia puede ser de 150.000 pesos, el peso de un estudiante puede ser
de 80 Kilogramos, su altura puede ser de 1,85 metros, etc.
Las variables cuantitativas se pueden clasicar a la vez en discretas y continuas.
Una variable cuantitativa discreta puede tomar un número nito o innito de valores separados
entre si por alguna cantidad.
Por ejemplo, el número de personas que ingresan por hora a un banco en busca de algún servicio
puede ser 0,1,2,3,...,etc.
El número de hijos por familia en una ciudad puede ser 0,1,2,3,4.
Por lo general las variables cuantitativas discretas se generan en los proceso de contar.
Por otro lado, una variable cuantitativa continua es aquella que al menos en teoría puede tomar
cualquier valor dentro de un intervalo real de valores posibles de la variable.
La altura de de un grupo de personas, el tiempo que se tarda en realizar una tarea son dos ejemplos
de variables cuantitativas continuas.
Por ejemplo, la altura de un grupo de persona puede ser algún valor en el intervalo [1, 50 − 1.90]
metros1
El tiempo en horas necesario para realizar cierta tarea puede ser algún valor en el intervalo
[2, 5 − 8, 0] horas2
Por lo general, las variables continuas se generan en los procesos de medición.
Variables cualitativas o categóricas
Los valores que asume corresponden a categorías de una clasicación como el lugar de nacimiento,
el estado civil de las personas, su lugar de residencia, etc.
Las variables cualitativas se clasican a su vez en nominales y ordinales.
Una variable cualitativa nominal es una variable cuyas categorías no siguen ningún orden, no
existen jerarquías en su valores.
Algunos ejemplos son los siguientes:
Lugar de nacimiento (Posadas, Oberá, Eldorado, etc.)
Estado civil (soltero, casado, viudo, etc.)
Una variable cualitativa ordinal es una variable cuyas categorías siguen un orden, es decir, existen
jerarquía entre sus valores.
Por ejemplo:
Condición académica de un estudiante al nalizar el cursado de una asignatura: libre, regular
o promocionado
Puesto alcanzado en una justa deportiva: primero, segundo, tercer, etc.
En general, las variables se designan con letras mayúscula y su valores con la minúscula respectiva.
Por ejemplo, si
X = Número de clientes que ingresan a un banco por hora a buscar algún servicio
algunos de sus valores pueden ser los siguientes: x1 = 0, x2 = 1, x3 = 2, . . ., etc.
Ahora bien, si
1 Valores teóricos
2 También valores teóricos
7
Y = Lugar de procedencia de los estudiantes de la Universidad
algunos de sus categorías podrían se y1 = Posadas, y2 = Oberá, etc.
Población
En el lenguaje común, la palabra población se utiliza para referirse a un conjunto de personas como
las que habitan una ciudad o un país.
Sin embargo, desde el punto de vista de la Estadística, el término población tiene un signicado
más amplio.
Para la Estadística una población puede estar constituida por:
Un grupo de personas como todos los estudiantes de una universidad
Un grupo de objetos como todas las lámparas de iluminación hogareñas producidas cierto
por una fábrica
Un grupo de medidas como el ingreso mensual de todas las familias de una ciudad
Observe que desde el punto de vista de la Estadística el término población no necesariamente se
reere a un grupo de personas.
Por lo tanto, y desde el punto de vista de la Estadística una población es el conjunto de todos los
posibles individuos, personas, objetos, o mediciones de interés estadístico.
Es importante tener en cuenta que es el analista quien dene la población objetivo jando su alcance
y limitaciones, no existiendo ningún factor o característica predeterminada en su denición.
Muestra
En general, cuando se pretende obtener alguna conclusión acerca de una población se lo hace a
partir de una muestra tomada de esa población.
Podemos armar entonces que una muestra es una parte, una porción de una población seleccionada
de tal manera que resulte representativa de la misma.
¾Por qué tomar una muestra y no analizar directamente todas las unidades observacionales de la
población?
Una muestra de votantes empadronados es necesaria debido al costo prohibitivo de entrevistar a los
millones de votantes registrados con el n de averiguar sus preferencias políticas para las próximas
elecciones.
Sería prácticamente imposible por razones de tiempo y costos entrevistar a todas las familias de
una ciudad con el n de investigar algunas propiedades socio-económicas de las mismas.
Parámetros y estadísticos
Las características numéricas de una población pueden resumirse a partir de ciertas cantidades
numéricas llamadas parámetros.
Por ejemplo, el ingreso mensual promedio de todas las familias de un ciudad es un parámetro,
siempre y cuando la población objetivo haya sido denida como las de todas las familias de esa
ciudad.
Cuando las características numéricas de una población se estudian a partir de una muestra, el
resumen de dicha característica puede realizarse a partir de un estadístico.
Por ejemplo, si se toma una muestra de 100 familias de la ciudad y se registran sus ingresos
mensuales, los 100 ingresos seleccionadas constituyen una muestra y el ingreso mensual promedio
de esas 100 observaciones un estadístico.
Estamos ahora en condiciones de dar una de las deniciones centrales de la Estadística.
Estamos ahora en condiciones de dar una de las deniciones centrales de la Estadística.
8
Denición 1.2 La inferencia estadística se ocupa de obtener conclusiones acerca de algún parámetro poblacional a partir del valor de un estadístico calculado con los datos de una muestra de
esa población
Muestra aleatoria simple
Hemos dicho que la inferencia estadística se encarga de obtener conclusiones acera de alguna
característica poblacional a partir de la información contenida en una muestra tomada de esa
población.
Para que las conclusiones que se obtengan con los datos de una muestra sean signicativos, la
muestra debe ser representativa de la información contenida en la población. Es decir, la información contenida en la muestra debe ser una copia lo más exacta posible de la información existente
en la población.
Obtener una muestra con estas características no es una tarea sencilla, y las técnicas de muestreo
son tantas y de tal complejidad que conforman una disciplina dentro de la Estadística.
Por el momento diremos que, para obtener una muestra representativa de una población, las
unidades que la conforman deben ser seleccionadas de manera aleatoria. Es decir, debe haber
algún mecanismo que garantice una selección aleatoria o al azar de las unidades observacionales,
sin sesgos ni preferencias por parte de quien las selecciona.
De todas las técnicas aleatorias de selección, el muestro aleatorio simple es uno de los métodos que
puede utilizarse para seleccionar una muestra sin sesgos ni preferencias.
Además, el muestreo aleatorio simple sirve de fundamento para otras técnicas más complejas de
selección como el muestreo estraticado, el de conglomerados, sistemático, etc.
Denición 1.3 Una muestra aleatoria simple de tamaño n es una muestra seleccionada de tal
manera que todas las muestras del mismo tamaño tiene la misma probabilidad de ser seleccionada.
El hecho de que todas las muestras de tamaño n tengan la misma probabilidad de ser seleccionada garantiza a su vez que todas las unidades observacionales de la población tendrán la misma
probabilidad de selección.
Por ejemplo, supongamos que se quiera formar un comité de 3 personas a partir de un grupo de 10.
¾Como podemos seleccionar los integrantes del comité utilizando un muestreo aleatorio simple?
Se puede proceder de la siguiente manera:
1. Numerar las personas del 1 al 10
2. Introducir en un bolillero 10 bolitas numeradas de 1 a 10
3. Seleccionar 3 bolitas del bolillero
Supongamos que en la primera selección se obtuvo la bolita que tiene el número 9. Entonces, la
persona identicada con este número es la primera selección.
En general no se repone la bolita con el número 9 (¾por qué?) y se realiza la segunda selección.
Supongamos que en la segunda selección se obtuvo la bolita con el número 2, entonces la persona
que está identicada con el número 2 será nuestra segunda selección.
No se repone la bolita con el número 2 y se realiza la tercera selección. Supongamos que se extrae
la bolita con el número 7.
Entonces nuestro comité estará integrado por las personas identicadas con los números 9, 2 y 7.
En realidad, una muestra aleatoria simple se elije a partir de una tabla de números aleatorios o
mediante programas para computadoras.
No obstante, el principio de selección es el del bolillero.
9
1.2. Resumen de la información
Por lo general, los datos que se obtienen en una investigación estadística no son susceptibles de ser
analizados e interpretados en la forma que se recogen.
Casi siempre, a la etapa de recolección le sigue otra de organización y resumen, previa a la aplicación
alguna técnica estadística más compleja.
Presentaremos a continuación algunos procedimientos tabulares, grácos y numéricos que son utilizados para resumir y organizar las observaciones seleccionadas al inicio de una investigación.
1.2.1. Tablas o distribuciones de frecuencia
Antes de ver que son, y como se construyen las tablas de frecuencias, es necesario introducir algunas
deniciones previas.
Sea n un conjunto de observaciones pertenecientes a una variable, la frecuencia absoluta de una
observación es el número de veces que se repite su valor en el conjunto de datos.
Por ejemplo, supongamos que en cierto grupo de estudiantes de una facultad, 20 cursan al primer
año de su carrera, 30 cursan el segundo año y que 50 cursan materias del ciclo profesional.
Si consideramos la variable
X = Año de cursado de la carrera en una muestra de 100 estudiantes
podemos resumir esta información de la siguiente manera:
La primera categoría (primer año) de la variable tiene una frecuencia absoluta igual a 20 y
escribimos f1 = 20
La segunda categoría (segundo año) de la variable tiene una frecuencia absoluta igual 30 y
escribimos f2 = 30
La tercera categoría (ciclo profesional) de la variable tiene una frecuencia absoluta igual a 50
y escribiremos f3 = 50
Una forma más económica de presentar esta información es mediante la Tabla (1.1):
Año de cursada
Primer año
Segundo año
Ciclo profesional
Total
Frecuencia absoluta fi
20
30
50
100
Tabla 1.1: Tabla de frecuencias absolutas
Las tablas de frecuencias se pueden construir a partir de las observaciones de variables cualitativas
o cuantitativas.
Analicemos otro ejemplo, suponga que un profesor de educación física de una universidad seleccionó
una muestra de 50 estudiantes y a cada uno de ellos le preguntó su preferencia por algún deporte
en particular.
Suponga adicionalmente que del total de 50 estudiantes 19 respondieron que preeren el Fútbol, 8
preeren el Tenis, 5 Rugby, 13 Natación y 5 respondieron que no preeren ningún deporte.
Esta información puede condensarse en una tabla de frecuencias absolutas tal como se muestra en
la Tabla (1.2)
Al analizar la tabla de frecuencias puede verse que el Fútbol es el deporte preferido por un número
mayor de estudiantes (f1 = 19) seguido de la Natación (f4 = 13). Solo 3 alumnos de los 50
encuestados preere el Rugby. Evidentemente pueden realizarse otras lecturas del la Tabla (1.2).
10
Deporte preferido X
Fútbol
Tenis
Rugby
Natación
Ninguno
Total
Frecuencia absoluta fi
19
8
5
13
5
50
Tabla 1.2: Deporte preferido. Muestra de 50 estudiantes
Una tabla de frecuencias para datos de una variable cualitativa es muy fácil de construir.
Pueden seguirse los siguientes pasos:
1. En la primera columna de coloca el nombre de la variable como encabezado y en las las
posteriores sus categorías
2. En la segunda columna se consignan las frecuencias absolutas (fi ) de cada categoría obtenidas
a partir de conteos o de registros previamente confeccionados
Muchas veces interesa conocer, además de las frecuencias absolutas de cada categoría, su proporción
o porcentaje.
Si se tiene un conjunto de n observaciones pertenecientes a una variable categoría , la frecuencia
relativa de la clase o categoría i se dene de la siguiente manera:
fri =
fi
n
(1.1)
donde fri es la frecuencia relativa de la clase i y fi su frecuencia absoluta.
La frecuencia porcentual es la frecuencia relativa de una clase multiplicada por 100.
Se puede completar la Tabla (1.2) con las frecuencias relativas y porcentuales obteniéndose de esta
manera la Tabla (1.3).
Deporte preferido X
Fútbol
Tenis
Rugby
Natación
Ninguno
Total
Frecuencia absoluta fi
19
8
5
13
5
50
fri
0,38
0,16
0,10
0,26
0,10
1,00
100 × fri
38
16
10
26
10
100
Tabla 1.3: Frecuencias relativas y porcentuales. Muestra de 50 estudiantes
Analizando la información de la Tabla (1.3) puede verse que el 38
Además entre el Fútbol y la Natación se cuentan el 64 % de las preferencias. Solo el 10 % de los
encuestados preere el Rugby. Es evidente que pueden realizarse otras lecturas e interpretaciones.
1.2.2. Gráco de barras y diagramas circulares
Un gráco de barras es una forma gráca de presentar los datos de una variable cualitativa cuya
información se he resumido previamente en una tabla de frecuencias.
Para la construcción de una diagrama de barras se pueden seguir los siguientes pasos:
1. Se trazan un par de ejes perpendiculares entre si, uno horizontal
2. Sobre el eje horizontal se registran las distintas categorías de la variable
11
3. Sobre el eje vertical se registran las frecuencias absolutas o relativas de cada categoría
4. A partir de cada categoría registrada en el eje horizontal se levantan barras cuyas alturas
sean las de las frecuencias absolutas o relativas correspondientes
5. Las barras se separan con el n de indicar que las clases son independientes
En la Figura (1.1) se muestra el diagrama de barras correspondiente a las frecuencias absolutas
registradas en la Tabla (1.3).
5
Figura 1.1: Diagrama de barras. Deporte preferido
El gráco de barras para las frecuencias relativas es similar al de las frecuencias absolutas solo que
en el eje vertical se registran las frecuencias relativas y no las absolutas.
Otra herramienta gráca que se utiliza para resumir y describir la información de una variable
categórica son los diagramas circulares.
Supongamos que queremos representar en un diagrama circular las frecuencias relativas de las
categorías de la variable deporte preferido.
Para trazarlo se dibuja primero un círculo y a continuación se divide el círculo en sectores o partes
proporcionales a las frecuencias relativas de cada clase.
Por ejemplo, como en un circulo hay 360º, y en él deberá representarse el 100 % de las observaciones,
a la categoría Fútbol, que representa el 38 % de las observaciones, le corresponderán un sector
circular de
38 % × 360º
= 137º aproximadamente
100 %
El resto de los sectores se determinan de la misma manera.
En la Figura (1.2) se muestra el diagrama circular para los datos del ejemplo sobre las preferencias
deportivas de los estudiantes.
1.2.3. Tablas de frecuencias para variables cuantitativas
Hasta el momento hemos visto algunas herramientas tabulares y grácas que se utilizan para
resumir la información proveniente de una variable cualitativa o categórica.
Varemos como proceder con las variables cuantitativas.
Las tablas de frecuencias también pueden utilizarse para resumir la información proveniente de
una variable cuantitativa.
12
Figura 1.2: Diagrama circular. Deporte preferido
Una tabla de frecuencias para datos cuantitativos, en su forma más simple, es una tabla que resume
observaciones enumerando las clases o intervalos en los cuales se agrupan los valores de la variable
en la primera columna, en la segunda columna se listan los intervalos en los cuales se agrupan
valores similares de la variable, y en la tercera columna el número de observaciones (frecuencias
absolutas) que se contabilizan en cada uno de esos intervalos.
En una tabla de frecuencias para una variable cuantitativa las clases o intervalos en los que serán
agrupados los valores de la variable no son fácilmente identicables.
Presentamos a continuación una tabla de frecuencias para datos cuantitativos con el n de mostrar
cuáles son sus partes. Luego veremos cómo se construyen este tipo de tablas.
En la Tabla (1.4) se presenta la tabla de frecuencias de la variable longitud en pulgadas de una
muestra de 50 barras de acero producidas en una fábrica metalúrgica3 .
Clase o intervalo
1
2
3
4
5
6
7
Total
Longitud
53 55
56 58
59 61
62 64
65 67
68 70
71 73
...
Frecuencia fi
2
5
9
15
12
5
2
50
Tabla 1.4: Longitud rn pulgadas de una muestra de una muestra de 50 barras de acero
En la primera columna de la tabla aparecen enumerados los intervalos o clases en los que serán
agrupados los valores similares de la variable.
En este ejemplo se ha decidido agrupar las 50 longitudes en 7 intervalos o clases.
En la segunda columna se registran los intervalos propiamente dicho y en la tercera columna se
indican el número de observaciones (frecuencia absoluta) que se registran en cada intervalo.
Así, en el intervalo [53 55] pulgadas se registran las longitudes de 2 barras mientras que en el
intervalo [62 - 64] pulgadas se contabilizaron 15 longitudes.
Si bien es cierto, al agrupar las observaciones en una tabla de frecuencias se pierde información en el
proceso de condensación, se logra una mejor aproximación en la identicación de las características
más sobresaliente del conjunto de observaciones.
3 Una pulgadas es aproximadamente igual a 2,5 centímetros
13
Pasamos ahora a describir como se construyen estas tablas de frecuencias.
La primera cuestión que deberá resolverse es decidir cuántos intervalos (clases) se considerarán.
Este número dependerá principalmente de la cantidad de datos a resumir. El número de intervalos
no puede ser muy grande (longitud de los intervalos muy pequeña) pues puede ocurrir que queden
intervalos con muy pocos datos o incluso ninguno. Esto no permitirá apreciar las características
más sobresalientes de las observaciones.
Un número pequeño de intervalos (longitud grande) puede ocultar las propiedades principales de
las observaciones.
Presentamos a continuación algunas recomendaciones que pueden ayudar en la construcción de
una tabla de frecuencias para datos cuantitativos.
Número de intervalos
Hemos dicho que el número de intervalos es recomendable elegirlo de acuerdo con la cantidad de
datos.
En la Tabla (1.5) se muestra la relación entre el número de datos y la cantidad aproximada de
intervalos.
Número de observaciones
Menos de 50
De 50 a 100
De 101 a 500
De 501 a 1.000
De 1.001 a 5.000
Más de 5.000
Número de intervalos
5-7
7-8
8 - 10
10 - 11
11 - 14
14 - 20
Tabla 1.5: Relación aproximada entre el número de datos y la cantidad de intervalos
Otra forma de determinar aproximadamente el número de intervalos de agrupación es utilizando
la fórmula de Sturges.
Si k es el número de intervalos sugeridos, entonces la fórmula siguiente se puede utilizar para
aproximar el valor de k:
k = 1 + 3, 322 log(n)
(1.2)
donde n es el número de observaciones.
Amplitud de los intervalos
Una vez elegido el valor de k, el siguiente paso es determinar la longitud l de cada uno de los
intervalos.
Esto puede lograrse a partir de la siguiente fórmula:
l=
XM − Xm
k
(1.3)
donde XM es el valor mayor y Xm es el valor menor del conjunto de observaciones.
Construcción de la tabla de frecuencias
El primer intervalo debe contener el menor valor y el último el mayor. Todos los intervalos deben
tener la misma longitud.
Se construye una tabla en la cual, en la primera columna se identican las clases (1, 2, ..., k). En la
segunda se identican los intervalos en los cuales se agrupan los valores similares de la variable y
en la tercera columna las frecuencias absolutas.
14
En el ejemplo que sigue pondremos en prácticas estas recomendaciones.
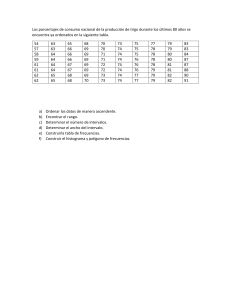
Ejemplo 1.1 Suponga que el administrador de calidad de una fábrica metalúrgica desea analizar
como varían las longitudes, en pulgadas, de las barras de acero producidas cierto día. Para ello toma
una muestra de 50 barras, las mide y decide agrupar la información en una tabla de frecuencias.
Los datos recogidos se presentan en la Tabla (1.6)
65
64
64
63
64
63
65
65
65
64
65
64
64
63
63
63
72
71
70
69
69
68
68
67
67
67
66
66
66
66
53
55
56
57
58
58
57
59
59
60
60
60
61
61
61
61
62
62
62
62
Tabla 1.6: Longitud en pulgadas de una muestra de 50 barras de acero
¾Como debería proceder el administrador si quiere agrupar las observaciones en una tabla de frecuencias?
Solución
En primer lugar debe calcular el número aproximado de intervalos que tendrá la tabla de frecuencias. Puede hacerlo utilizando la Tabla (1.5) o la fórmula de Sturges.
Supongamos que se decide por la fórmula de Sturges. Entonces:
k = 1 + 3, 322 log(50) = 6, 67
Puede tomar k = 7 intervalos.
Seguidamente debe calcular la amplitud de cada intervalo. Analizando la Tabla (1.6) puede verse
que XM = 72 y Xm = 53, por lo tanto
l=
72 − 53
= 2, 7
7
Puede tomar l = 3.
Ahora debe decidir dónde comienza el primer intervalo. Lo que habitualmente se hace es considerar
el comienzo del primer intervalo en el dato menor, es decir 53. Como la longitud de los intervalos
es 3, el primer intervalo es [53 55], el segundo [56 58], etc.
Una vez denidas las dos primeras columnas de la tabla, debe contar cuantas longitudes (frecuencia)
se agrupan dentro de cada intervalo.
En el primer intervalo observan dos longitudes, 53 y 55, por lo tanto, f1 = 2. En el segundo
intervalo se observan las longitudes 58, 57, 56, 57 y 58, por lo tanto,f2 = 5, etc.
Por último, puede colocar toda esta información en una tabla obteniendo como resultado la Tabla
(1.4).
Observe que en esta tabla, los intervalos considerados están separados entre sí por una unidad.
Esto indicaría que la variable longitud da saltos de una unidad de intervalo a intervalo lo cual
parece no tener sentido con la condición de continuidad de la viable.
Con el propósito de construir una tabla que reeje la idea de continuidad de la variable los intervalos
deben estar unidos. Para ello se puede proceder de la siguiente manera:
1. El extremo inferior del primer intervalo se sustituye por 52+53
= 52, 5
2
2. El extremo superior del primer intervalo se reemplaza por 55+56
= 55, 5. Este valor pasa a
2
ser el extremo superior del primer intervalo y el extremo inferior del segundo
3. Se continúa de la misma manera con el resto de los intervalos y el resultado nal se presenta
en la Tabla (1.7)
15
Clase
1
2
3
4
5
6
7
Total
Longitud
52,5 55,5
55,5 58,5
58,5 61,5
61,5 64,5
64,5 67,5
67,5 70,5
70,5 73,5
...
fi
2
5
9
15
12
5
2
50
Tabla 1.7: Intervalos reales. Longitud de 50 barras de acero
Denidos de esta manera los intervalos quedan cerrados dando la idea de continuidad de la variable.
Cuando los intervalos se denen como en la Tabla (1.7) reciben el nombre de intervalos reales. Los
intervalos denido en la Tabla (1.4) reciben el nombre de intervalos cticios.
La Tabla (1.7) puede completarse para obtener más información acerca de las propiedades del
conjunto de observaciones.
Se denomina marca de clase del intervalo i al punto medio del intervalo de clase correspondiente.
Habitualmente se simboliza mi con i = 1, 2, 3, ..., etc.
Así, para el primer intervalo
m1 =
52, 5 + 55, 5
= 54
2
Procediendo de la misma manera con el resto de los intervalos obtendremos: m2 = 57, m3 =
60, · · · , m7 = 72.
Se llama frecuencia acumulada absoluta de la clase i al número que resulta de sumar la frecuencia
absoluta de la clase i con las frecuencias absolutas de las clases que le anteceden.
La frecuencia acumulada absoluta de la clase i se simboliza Fi con i = 1, 2, ...,etc.
Así, F1 = 2; F2 = 5 + 2 = 7; F3 = 9 + 7 = 16, ..., F7 = 50.
Se llama frecuencia relativa de la clase i al cociente entre la frecuencia absoluta de la clase y el
total de datos. La simbolizaremos fri . Es decir:
fri =
fi
n
Se treta de la misma denición de frecuencia relativa que dimos para variables cualitativas.
2
5
Así, para el primer intervalo, fr1 = 50
= 0, 04; para el segundo intervalo fr2 = 50
= 0, 10; etc.
Se llama frecuencia relativa acumulada de la clase i al número que resulta de sumar la frecuencia
relativa de la clase i con la frecuencia relativa de las clases que le anteceden.
La simbolizaremos Fri con i = 1, 2, ..., etc.
Para el primer intervalo de la tabla de frecuencias, Fr1 = 0, 04; para el segundo Fr2 = 0, 14; y así
sucesivamente hasta Fr7 = 1, 00.
Toda esta nueva información se muestra en la Tabla (1.8).
¾Cómo se interpretan las cantidades de la Tabla (1.8)?
Consideremos la cuarta clase o intervalo. Entonces:
Hay 15 barras cuyas longitudes están comprendidas entre 61,5 y 64,5 pulgadas
Hay 31 barras cuyas longitudes son menores o iguales a 64,5 pulgadas
El 30 por ciento de las barras tienen una longitud comprendida entre 61,5 y 64,5 pulgadas
El 62 por ciento de las barras tiene una longitud menor o igual 64,5 pulgadas
El resto de los intervalo puede interpretarse de manera análoga.
16
Intervalo
1
2
3
4
5
6
7
Total
Longitud
52,5 55,5
55,5 58,5
58,5 61,5
61,5 64,5
64,5 67,5
67,5 70,5
70,5 73,5
...
Marca de clase
54
57
60
63
66
69
72
...
fi
2
5
9
15
12
5
2
50
Fi
2
7
16
31
43
48
50
...
Fr
0,04
0,10
0,18
0,30
0,24
0,10
0,04
1,00
Fri
0,04
0,14
0,32
0,62
0,86
0,96
1,00
...
Tabla 1.8: Tabla de frecuencias absolutas, relativas y porcentuales
1.2.4. Histogramas
Un histograma es una representación visual de los datos resumidos previamente en la Tabla (1.8).
Un histograma es similar a un gráco de barras para datos categóricos solo que aquí las barras se
dibujan unidas para dar la idea de continuidad de la variable.
Un histograma se construye de la siguiente manera:
1. Se trazan un par de ejes perpendiculares, uno horizontal
2. La base de las barras se localizan en el eje horizontal. El ancho de las barras representa la
longitud de los intervalos
3. La altura de las barras se registran sobre el eje vertical y corresponden a las frecuencias
(absolutas o relativas) de cada una de las clases o intervalos de la variable
4. Las áreas de las barras son proporcionales a las frecuencias de las clases
Figura 1.3: Histograma de frecuencias absolutas
El histograma muestra algunas de las propiedades más importantes del conjunto de observaciones.
Por ejemplo, los datos están centradas aproximadamente alrededor del valor x = 63 pulgadas.
Además el histograma tiene una conguración casi simétrica con respecto de este valor central.
Un poco más adelante veremos como expresar numéricamente estas importantes propiedades de
un conjunto de observaciones.
17
1.2.5. Polígonos de frecuencias
Otro recurso gráco que sirve para describir un conjunto de observaciones de una variable cuantitativa es el polígono de frecuencias.
Se los construye utilizando un par de ejes perpendiculares al colocar sobre cada marca de clase un
punto a una altura igual a la frecuencia asociada a dicha clase, luego se unen dichos puntos con
segmentos de recta.
Para que el polígono quede cerrado se considera un intervalo más al inicio (con frecuencia cero) y
otro al nal (también con frecuencia cero).
Puede superponerse el polígono de frecuencias con el histograma o no. En la Figura (1.4) se
muestra el polígono de frecuencias para los datos del Ejemplo (1.1) en el cual se han representado
conjuntamente el histograma y el polígono correspondiente.
Figura 1.4: Polígono de frecuencias. Longitud de las barras de acero
El polígono de frecuencias al ser construido a partir de los datos muestrales se puede considerar
como una representación aproximada del comportamiento poblacional, el cual para poblaciones
innitas o muy grandes está dado por una curva continua.
Esta curva suele denominarse gráco o curva de frecuencias.
En la Figura (1.5) se muestra un histograma junto a su curva de frecuencias. En la medida que se
tomen más intervalos la curva de frecuencias se irá pareciendo al histograma.
En el límite, el histograma podrá ser reemplazado por la curva de frecuencias.
Los métodos tabulares y grácos tienen como función principal hacer que se aprecie de manera
rápida las principales propiedades de los datos.
Sin embargo, las técnicas grácas presentan limitaciones en la descripción y análisis de las observaciones.
Por ejemplo, estas técnicas no se pueden utilizar para hacer inferencias (n que generalmente se
persigue) aunque si pueden ser el punto de partida para algunos procesos de este tipo.
Las tablas y los grácos casi siempre son acompañados por medidas descriptivas numéricas las
que complementan el análisis y preparan el camino para la aplicación de técnicas estadísticas más
complejas.
En las secciones siguientes se denirán y estudiarán las propiedades de algunas de las medidas
descriptivas numéricas más utilizadas en la Estadística.
18
Figura 1.5: Gráco o curva de frecuencias
1.3. Medidas descriptivas numéricas
Presentaremos a continuación algunas de las medidas descriptivas numéricas más utilizadas con el
objetivo de obtener conclusiones acerca de las principales propiedades de un conjunto de observaciones.
Se las utiliza, al igual que las tablas y los grácos, para resumir y describir las observaciones
disponibles, solo que ahora la descripción es numérica.
Existen medidas descriptivas numéricas de localización, dispersión, forma, apuntamiento, asociación etc.
Cuando se las calculan a partir de las observaciones de una población reciben el nombre de parámetros, que cuando se calculan a parir de las observaciones de una muestra se las denominan
estadísticos.
Antes de denir y analizar las propiedades de las medidas descriptivas que veremos en este material
es necesario tener presente algunas propiedades del símbolo sumatoria.
1.3.1. El símbolo sumatoria
P
El símbolo sumatoria es muy utilizado en Matemática en general y Estadística en particular. Se lo
emplea con el n de simplicar algunas notaciones matemáticas.
Algunos parámetros y estimadores incluyen en su denición la suma de varios términos.
Por ejemplo, si se tiene una sucesión de observaciones de una variable cuantitativa x1 ,P
x2 , ..., xn
su suma puede expresarse de manera abreviada, utilizando el símbolo de sumatoria ( ) de la
siguiente manera:
x1 + x2 + · · · + xn =
n
X
xi
i=1
que se lee sumatoria de i = 1 hasta n de xi .
Se pueden combinar otras operaciones matemáticas con la sumatoria. Por ejemplo, si se quiere
sumar los cuadrados de cada observación podríamos expresarlo abreviadamente de la siguiente
manera:
x21 + x22 + · · · + x2n =
n
X
x2i
i=1
Algunas propiedades de la sumatoria se presentan a continuación.
19
Primera propiedad
Si k es una constante entonces:
n
X
i=1
k = k + k + · · · + k = nk
{z
}
|
n
Por ejemplo
3
X
2=2+2+2=6
i=1
Como un caso particular de esta propiedad es posible vericar que
n
X
1=n
i=1
Segunda propiedad
n
X
kxi = k
i=1
Demostración
n
X
xi
i=1
Por denición de sumatoria
n
X
kxi = kx1 + kx2 + · · · + kxn
i=1
Pero
n
X
kxi = kx1 + kx2 + · · · + kxn = k(x1 + x2 · · · + xn )
i=1
Por lo tanto
n
X
kxi = k
i=1
n
X
xi
i=1
Como se quería demostrar.
Tercera propiedad
n
n
n
X
X
X
(xi + yi ) =
xi +
yi
i=1
Demostración
i=1
i=1
Por denición de sumatoria
n
X
(xi + yi ) = (x1 + x2 + · · · + xn ) + (y1 + y2 + · · · + yn )
i=1
Por lo tanto
20
n
X
(xi + yi ) =
i=1
n
X
xi +
i=1
n
X
yi
i=1
como se quería demostrar.
Se deja como tarea propuesta demostrar que también se cumple la siguiente propiedad:
n
X
(xi − yi ) =
i=1
n
X
xi −
i=1
n
X
yi
i=1
1.3.2. Medidas de localización o de posición
Media o promedio
La media o promedio es una de las medidas descriptivas numéricas más utilizadas cuando se quiere
describir numéricamente datos provenientes de una variable cuantitativa.
Cuando se la calcula a partir de una población se la simboliza con la letra griega µ (mu). Cuando
se la calcula a partir de los datos de una muestra tomada de una población se la simboliza x̄.
Denición 1.4 Sea x1 , x2 , ..., xn observaciones pertenecientes a una muestra de tamaño n. La
media de la muestra o media muestral se dene de la siguiente manera.
x̄ =
x1 + x2 + · · · + xn
=
n
Pn
i=1 xi
(1.4)
n
Ejemplo 1.2 Suponga que en la Tabla (1.9) se muestra los gastos diarios en alimentos de una
muestra de 12 familias de la ciudad. Calcular la media e interpretar el valor obtenido.
2.210
2.255
2.350
2.380
2.380
2.390
2.420
2.440
2.450
2.550
2.630
2.825
Tabla 1.9: Datos para el Ejemplo 1.2
Solución
Como se trata de una muestra de 12 observaciones, la media muestral se calcula de la siguiente
manera:
x̄ =
2.210 + 2.255 + · · · + 2.825
= 2.440 pesos
12
Es decir, en promedio, estas familias gastan 2.440 pesos diarios en alimentos.
Como puede observarse, el valor obtenido representa bastante bien el conjunto pues no es muy
diferente de los datos de la muestra.
Este es el n que se persigue cuando se calcula la media. Encontrar un número que describa o
resuma de la mejor manera un conjunto de observaciones.
Supongamos que ahora se cambia la última observación por 10.000 pesos y volvemos a calcular x̄
con este nuevo valor.
Obtendremos
x̄ =
2.210 + 2.255 + · · · + 10.000
= 3.038
10
Evidentemente esta cantidad no representa tan bien como la anterior el conjunto de datos.
Hay 11 valores que son menores que el promedio y solo uno mayor, muy distinto del resto.
Un solo valor extremo de la variable, relativamente mayor que el resto de las observaciones, hizo
que el promedio se desplazar hacia los valores mayores de la distribución.
21
Algo similar puede ocurrir si en lugar de una observación muy grande se agrega una relativamente
pequeña. En este caso el valor del promedio puede (no necesariamente) desplazarse hacia valores
pequeños de la distribución y no representarla adecuadamente.
Es importante tener en cuenta que la sola presencia de un valor extremo en el conjunto de observaciones no necesariamente inuirá signicativamente en el valor de la media.
Suponga que en la Tabla (1.10) se muestra la distribución de frecuencias absolutas de una variable
cuantitativa X .
Frecuencia absoluta fi
20
30
40
30
20
1
X
2
3
4
5
6
100
Tabla 1.10: Tabla de frecuencias de X
La media o promedio de X se puede calcular de la siguiente manera:
Pk
x̄ =
i=1 xi fi
k
=
2 × 20 + 3 × 30 + · · · + 100 × 1
660
=
= 4, 68
141
141
Puede verse que la sola presencia de x6 = 100 no ocasionó un desplazamiento signicativo en el
valor del promedio.
La explicación tiene que ver con las frecuencias absolutas de cada una de las observaciones.
Mientras que existen 40 observaciones del valor x = 4, hay una sola observación cuyo valor es
x = 100.
Evidentemente x = 4 tiene mucho más peso o importancia que x = 100 al calcular el promedio.
En aquellos casos en los cuales se tenga acceso a todas las observaciones de una población, la media
poblacional se dene de la siguiente manera:
PN
µ=
i=1 xi
N
=
x1 + x2 + · · · + xN
N
en donde N es el tamaño de la población.
En general, la media µ poblacional es desconocida y hay que estimarla.
Por ejemplo, suponga que un analista de mercados quiera saber cual es la renta promedio de todas
las familias de una gran ciudad.
Entrevistar a todas y cada una de las familias de la ciudad puede resultar imposible por el costo
y el tiempo que insumiría realizar la tarea.
En general lo que se hace es tomar una muestra aleatoria de familias, calcular la media muestral
x̄ y utilizar su valor como una estimación de la media poblacional desconocida.
Esta forma de proceder es la base de la inferencia estadística. Los problema de la estimación de
parámetros serán abordados extensamente a parir del Capítulo 4 de este material
Algunas de las características más importantes de la media son las siguientes:
Fácil de calcular
Fácil de interpretar
Utiliza todos los datos (toda la información) cuando se la calcula
La presencia de valores extremos puede inuir signicativamente en su valor
22
Media ponderada
Suponga que una empresa comercial paga a sus empleados un sueldo básico de 6, 50 7, 50 y 8, 50
dólares por hora de trabajo.
Podemos llegar a la conclusión de que la media de los sueldos por hora es
µ=
6, 50 + 7, 50 + 8, 50
= $7, 50
3
Esto es cierto solo si hay el mismo número de vendedores que perciben esas sumas.
Sin embargo, suponga que 14 vendedores ganan 6,50; que a 10 vendedores se les paga 7,50 y que
solo 2 vendedores cobran 8,50 dólares por hora.
Para calcular la media, 6,50 debe ponderarse (o pesarse) por 14, 7,50 debe ponderarse por 10 y
7,50 se debe ponderar por 2.
Al promedio resultante se lo denomina media ponderada y se la simboliza µw .
La expresión
Es decir
µw =
6, 50 × 14 + 7, 50 × 10 + 8, 50 × 2
= 7, 038
14 + 10 + 2
O sea, en promedio, estos trabajadores ganan 7,038 dolares por hora de trabajo
La expresión
PN
xi w i
x1 w1 + x2 w2 + · · · + xN wN
= Pi=
µw =
N
w1 + w2 + · · · + wN
i=1 wi
(1.5)
recibe el nombre de media poblacional ponderada.
La media poblacional ponderada en general es desconocida y hay que estimarla. Su estimación
recibe el nombre de media muestral ponderada y se dene de la siguiente manera:
Denición 1.5 Sea x1 , x2 , . . . , xn una muestra de tamaño n donde las observaciones tienen ponderaciones o pesos w1 ; w2 , ..., wn respectivamente. La media muestral ponderada se dene de la
siguiente manera:
Pn
xi wi
x1 w1 + x2 w2 + · · · + xn wn
x̄w =
= Pi=1
n
w1 + w2 + · · · + wn
i=1 wi
(1.6)
Ejemplo 1.3 Demostrar que si todas las ponderaciones wi de un conjunto de n observaciones
perteneciste a una muestra son iguales, entonces x̄w = x̄.
Solución
Sean x1 , x2 , ..., xn las n observaciones de una muestra. Sea w el peso o ponderación común de cada
una de las observaciones.
Por lo tanto:
Pn
xi w
x1 w + x2 w + · · · + xn w
w(x1 + x2 + · · · + xn )
x̄w = Pi=1
=
=
n
w + w + ··· + w
nw
i=1 w
|
{z
}
n
Finalmente
Pn
xi w
x1 + x2 + · · · + xn
x̄w = Pi=1
=
= x̄
n
n
w
i=1
como se quería demostrar.
23
Mediana
Cuando en el conjunto de observaciones se detecta algún valor extremo que sospechamos puede
inuir signicativamente en el valor de la media, podemos buscar el centro de los datos con otra
medida descriptiva numérica muy utilizada en la estadística descriptiva. Se trata de la mediana.
La denimos de la siguiente manera:
Denición 1.6 La mediana es el valor intermedio de las observaciones cuando las mismas han
sido ordenadas de manera ascendente.
La mediana se simboliza Me tanto para datos de una población o de una muestra. El contexto del
problema nos dirá si estamos calculando la mediana poblacional o la muestral.
Antes de calcular la medina hay que vericar si se tiene un número par o impar de observaciones.
Veamos como se procede encada caso.
Ejemplo 1.4 Calcular la mediana del siguiente conjunto de observaciones: 46, 54, 42, 46, 32.
Solución
En primer lugar hay que ordenar los datos de manera ascendente. Al hacerlo se obtiene
32
42
46
46
54
Como se trata de un número impar de observaciones hay un único valor central. Ese valor central
se lo asigna a la mediana. Por lo tanto Me = 46.
Ejemplo 1.5 Teniendo en cuenta los datos del Ejemplo (1.2) (gastos diarios en alimentos) calcular la mediana del conjunto de observaciones.
Solución
Los datos que ya están ordenados son los siguientes:
2.210
2.255
2.350
2.380
2.380
2.390
2.420
2.440
2.450
2.550
2.630
2 .825
Como se trata de un número par de observaciones no habrá un único valor central. La mediana se
encuentra promediando los dos valores centrales.
Me =
2.390 + 2.420
= 2.405
2
Si en el conjunto de datos se cambia la última observación, 2.850 por 10.000 la mediana seguirá
teniendo el mismo valor. Por lo tanto, la mediana no se ve afectada por valores extremos de la
variable.
Algunas de las propiedades de la median son las siguientes:
Algunas de las propiedades de la mediana son las siguientes:
Fácil de calcular
Fácil de interpretar
No se ve afectada 0pr valores extremos
No utiliza todos los datos (información) cuando se la calcula
24
Moda
Denición 1.7 La moda o modo es el valor o la categoría de una variable que presenta mayor
frecuencia. Se la simboliza Mo si los datos provienen de una población o de una muestra.
La moda puede calcularse tanto para una variable cuantitativa como cualitativa.
Así, para la distribución de frecuencias presentada en la la Tabla (1.3) la moda es el Fútbol, es
decir Mo = Fútbol con una frecuencia igual a 19.
Para los datos del Ejemplo (1.2) Mo = 2.380 dólares con una frecuencia igual a 2.
Algunas de las características más importantes de la moda son las siguientes:
Fácil de calcular y de interpretar
Puede utilizarse para describir variables cualitativas y cuantitativas
Pueden existir conjuntos de datos que no tengan moda (todas las observaciones con la misma
frecuencia)
Un conjunto de observaciones puede ser multimodal, es decir tener 2 o más modas. En este
caso no se recomienda utilizar la moda como medida descriptiva
Dado un conjunto de observaciones ¾cuál es la mejor medida de posición o de localización para
describirlas? Pues bien, que todo depende del contexto.
Uno de los factores que inuye en la decisión es si se cuenta con datos de una variable cualitativa
o de una cuantitativa.
La media suele ser la medida descriptiva numérica preferida para describir datos provenientes de
una variable cuantitativa.
Sin embargo, no tiene sentido tratar de utilizarla con datos de una variable cualitativa o categórica.
Por ejemplo, si un conjunto de personas se clasican de acuerdo a su estado civil como soltero,
casado, viudo, divorciado, etc. ¾tiene sentido hablar del el estado civil promedio del conjunto de
personas?
En las variables categóricas tiene sentido estadístico encontrar su moda.
Percentiles
A los percentiles se los suele clasicar como medidas descriptivas numérica no centrales.
Un percentil suministra información acerca de cómo se distribuyen los datos sobre ciertos intervalos.
Por ejemplo, el p - ésimo percentil divide el conjunto de datos en dos partes. Más o menos el p
por ciento de las observaciones tiene valores menores al p - ésimo percentil y aproximadamente el
(1 − p) por ciento de las observaciones tienen valores mayores que el p - ésimo percentil.
Las observaciones deben estar ordenadas de manera ascendente.
Denición 1.8 El p - ésimo percentil es el valor tal que aproximadamente un p por ciento de
las observaciones tienen dicho valor o menos y aproximadamente el (100 − p) por ciento de las
observaciones tienen ese valor o más.
Para ver la utilidad práctica de los percentiles analicemos la siguiente situación hipotética.
Suponga que un estudiante ha obtenido una calicación de 8 puntos en una evaluación de Estadística.
Si el profesor desea investigar cuál ha sido el desempeño del estudiante respecto del conjunto total
de calicaciones puede razonar de la siguiente manera: si la calicación 8 se corresponde con el
percentil 70, es decir, P70 = 8, el profesor sabrá que aproximadamente el 70 % de los estudiantes
tuvo una calicación menor o igual que 8 y que aproximadamente el 30 % de los estudiantes obtuvo
una nota superior a este valor.
25
Para calcular el p - ésimo percentil de un conjunto de observaciones se puede proceder de la
siguiente manera:
1. Ordenar las observaciones de manera ascendente
2. Calcular la cantidad i =
ciones
p
100
n donde p es el percentil de interés y n el número de observa-
Si i es un número decimal, se redondea su valor al entero inmediato superior. Este valor
indica la posición del i - ésimo percentil
Si i es un número entero el i - ésimo percentil es el promedio de las observaciones
ubicadas en los lugares i e i + 1 de la serie de datos
Ejemplo 1.6 Utilizando la información del Ejemplo (1.2) calcular el percentil 85 de los gastos
diarios en alimentos para la muestra de las 12 familias.
Solución
Los datos ya están ordenados.
Seguidamente se calcula el valor de i:
i=
p 100
n=
85
100
12 = 10, 2
Como i no es entero se redondea su valor al entero inmediato superior. Por lo tanto, el percentil
85 se encuentra en la posición 11 del conjunto de observaciones.
Luego P85 = 2.630 pesos. ¾Como interpretamos este valor? Podemos decir que aproximadamente el 85 % de las familias de la muestras gastan esa suma o menos por día en alimentos y que
aproximadamente el 15 % gastan esa suma o más.
Supongamos ahora que se quiera calcular el percentil 50. Procedemos como en el caso anterior.
i=
50
100
12 = 6
Como en este caso, i es un número entero, el percentil 50 es el promedio de las observaciones
ubicadas en el sexto y séptimo lugar. Por lo tanto
P50 =
2.390 + 2.420
= 2.405 pesos
2
Observe que el percentil 50 coincide con el valor de la mediana, es decir, P50 = Me .
Cuartiles
Con frecuencia, se busca dividir el conjunto de observaciones en cuatro partes, cada una con el 25
A los puntos de división se los llama cuartiles y se los dene de la siguiente manera:
Q1 = primer cuartil o percentil 25
Q2 = segundo cuartil o percentil 50 (es igual a la mediana)
Q3 =tercer cuartil o percentil 75
Ejemplo 1.7 Utilizando la información del Ejemplo (1.2) calcular e interpretar los cuartiles
Q1 , Q2 y Q3 .
Solución
Se deja como tarea propuesta.
26
Proporción
A continuación denimos y analizamos las propiedades de otra de las medidas descriptivas numéricas muy utilizadas en el análisis estadístico, la proporción.
La proporción muestral simbolizada p̄ se dene como la fracción de una muestra que posee cierta
característica o propiedad.
Por ejemplo, si en un grupo de 80 estudiantes de una facultad, 15 pertenecen al ultimo año de su
carrera, entonces
p̄ =
15
= 0, 1875
80
o el 18,75 % de los estudiantes del grupo están cursado el ultimo año de su carrera.
Si la población estudiada es nita y de tamaño moderado, se podrá calcular la proporción poblacional efectuando el cociente entre todas las unidades que resulten ser un éxito y el número total
de unidades observacionales de la población.
La proporción poblacional se simboliza con la letra p. Es decir:
p=
X
N
(1.7)
donde X es el número de éxitos en la población y N su tamaño.
Si la población objetivo se extrae una muestra de tamaño n y el ella se encuentran x éxitos, entonces
x
n
p̄ =
(1.8)
representa la proporción de individuos de la muestra que poseen la característica de interés.
Como todo parámetro, la proporción poblacional p en general es desconocida.Es común estimarla
por medio de la proporción muestral.
1.3.3. Medidas de variabilidad
Ademas de las medidas de localización o posición, siempre es necesario considerar alguna medida
de dispersión para una completa descripción de un conjunto de observaciones.
Analicemos la siguiente situación hipotética:
Ejemplo 1.8 Dos departamentos de 10 trabajadores cada uno produjeron las siguientes cantidades
de un mismo bien cierto día de trabajo:
Trabajador
Departamento 1
Departamento 2
1
7
3
2
8
4
3
8
5
4
9
6
5
9
9
6
9
9
7
9
12
8
10
13
9
10
14
10
11
15
Tabla 1.11: Datos para el Ejemplo 1.8
Describir y comparar las producciones de los dos departamentos.
Solución
Puede comprobarse que la producción media en los dos departamentos es la misma e igual a 9
unidades, es decir, x̄1 = x̄2 = 9.
Sin embargo, la producción del Departamento 2 está mas dispersa respecto de este valor central.
Para el Departamento 1 la diferencia entre el promedio y los dos valores extremos de la serie de
datos (7 y 11) es igual a 3 unidades mientras que la diferencia entre la media y los dos valores
extremos (3 y 15) para el Departamento 2 es igual a 6 unidades.
27
Evidentemente las observaciones en el primer departamento están más concentradas respecto de
su producción media que en el segundo departamento.
Si solamente nos quedáramos con los valores de las producciones medias de los dos departamentos
estaríamos realizando una descripción incompleta del las observaciones.
Algunas de las razones por las cuales es necesario considerar siempre las medidas de variabilidad
conjuntamente con las de posición son las siguientes:
Las medidas de variabilidad permiten investigar la representatividad del promedio o medida
de localización utilizada. Una dispersión de las observaciones relativamente pequeña respecto
del promedio indicará que se encuentran muy próximas a este valor central. En este caso,
el promedio podrá considerarse representativo del conjunto de datos. Por el contrario, una
dispersión relativamente grande respecto del promedio indicará que las observaciones se encuentran muy dispersas respecto de este valor central. En este caso se dice que el promedio
no es representativo del conjunto de observaciones
Una medida de dispersión permite comparar la variabilidad de dos o más conjunto de observaciones
En general
Una medida de variabilidad es un número que indica el grado de dispersión de un conjunto de
datos. Si el número es pequeño respecto de la unidad de medida de la variable, entonces habrá
una gran uniformidad entre los datos. Por el contrario, un valor relativamente grande indicará
que hay poca uniformidad en las observaciones
A continuación analizaremos algunas de las medidas de dispersión más utilizadas cuando se describe
un conjunto de observaciones.
Rango o amplitud
El rango o amplitud de un conjunto de datos es igual a la diferencia entre el mayor y el menor
valor de las observaciones.
Es decir
A = XM − Xm
(1.9)
donde XM es la mayor y Xm es la menor observación del conjunto de observaciones.
Ejemplo 1.9 Las capacidades de cinco recipientes metálicos son 38, 20, 37, 64 y 27 litros respectivamente. Hallar la amplitud o rango del conjunto de observaciones.
Solución
Como XM = 64 y Xm = 20 entonces A = 64 − 20 = 44 litros
La amplitud es fácil de calcular y es una forma usual de describir la dispersión cuando el objetivo
de la investigación es solamente determinar alcance de las variaciones extremas.
Por ejemplo, la evolución del precio de una acción en la bolsa de valores se suele conocer por la
amplitud de sus valores entre la apertura y cierre de una ronda.
El rango o amplitud también es muy utilizado en el control estadístico de calidad.
De acuerdo con su denición, la amplitud es muy sensible a valores extremos de la variable.
Además, al no tener en cuenta ninguna medida de posición , no informa nada acerca de cómo se
comportan los datos respecto del centro.
Es aconsejable utilizar el rango en conjuntos de pocas observaciones.
28
Rango intercuartílico
El rango intercuartílico (RIC ) mide la dispersión en el 50 por ciento central de los datos.
Se lo dene como diferencia entre la observación correspondiente al tercer cuartil Q3 y la correspondiente al primer cuartil Q1 .
Por lo tanto:
RIC = Q3 − Q1
(1.10)
Ejemplo 1.10 Calcular el rango intercuartílico de los gastos semanales en alimentos de la muestra
de 12 familias de la ciudad del Ejemplo (1.2).
Solución
Calculamos el primer cuartil:
Los datos ya se encuentran ordenados. Por lo tanto:
i=
25
100
12 = 3
Luego
P25 =
2.350 + 2.380
= 2.365 pesos
2
Tercer cuartil
i=
75
100
12 = 9
Por lo tanto
P75 =
2.450 + 2.550
= 2.500 pesos
2
Finalmente:
RIC = 2.500 pesos − 2.365 pesos = 135 pesos
Podemos decir que en un rango de 135 pesos se encuentran los gastos en alimentos del 50 % central
de las familias de la ciudad.
Desviación media
Esta medida de dispersión tiene en cuenta todas las observaciones para su cálculo. Es decir, se
considera toda la información disponible en el conjunto de observaciones.
Se la suele denominar también desviación promedio porque calcula el promedio de las desviaciones
de las observaciones respecto de su media.
Denición 1.9 Sean x1 , x2 , ..., xn observaciones de una muestra de tamaño n tomada de una
población. La desviación media muestral se dene de la siguiente manera
Pn
DM =
i=1 |xi − x̄|
n
donde x̄ es la media de la muestra.
29
(1.11)
Analizando esta denición, cada término |xi − x̄| no es más que la distancia de xi a la media del
grupo.
Por lo tanto, la desviación media puede interpretarse como la distancia promedio de las observaciones respecto de su media.
Si se tienen x1 , x2 , ..., xN observaciones pertenecientes a una población de tamaño N , la desviación
media se dene de la siguiente manera
PN
DM =
i=1 |xi − µ|
N
(1.12)
donde µ es la media de la población.
Como en general la desviación media poblacional no se conoce y habrá que estimarla. Es usual
estimarla por medio de la desviación media muestral.
Ejemplo 1.11 Los pesos de una muestra de 5 cajas listas para embarcarse son los siguientes: 103,
97, 101, 106 y 103 kilogramos. Calcular e interpretar el valor de la desviación media.
Solución
Media de la muestra
x̄ =
103 + 97 + ... + 103
= 102 kilogramos
5
Luego. el peso promedio de las 5 cajas es 102 kilogramos.
Por otro lado
DM =
|103 − 102| + |97 − 102| + ... + |103 − 102|
= 2, 4 kilogramos
5
Podemos armar que los pesos de las cajas se desvían en promedio 2,4 kilogramos respecto de la
media.
Se concluya que existe poca dispersión de las observaciones de la variable respecto de su media.
Varianza
Es otra medida de dispersión que utiliza todas las observaciones de un conjunto de datos.
Denición 1.10 Sea x1 , x2 , ..., xn una muestra aleatoria de n observaciones pertenecientes a una
muestra de una población. La varianza muestral se dene de la siguiente manera:
s2 =
Pn
i=1 (xi − x̄)
2
n−1
=
(x1 − x̄)2 + (x2 − x̄)2 + · · · + (xn − x̄)2
n−1
(1.13)
donde x̄ es la media de la muestra.
Ejemplo 1.12 Considere las siguientes 8 observaciones pertenecientes a una muestra de cierta
población: 2, 3, 3, 5, 5, 8, 10, 12. Calcular la varianza muestral.
Solución
Comenzamos calculando la media de la muestra.
x̄ =
2 + 3 + 3 + · · · + 12
=6
8
Por lo tanto
s2 =
(2 − 6)2 + (3 − 6) + · · · + (12 − 6)2
= 13, 14
8−1
30
Analizando la Fórmula (1.13) puede verse que, exceptuando el hecho de que la división es por
(n − 1) y no por n, la varianza podría interpretarse como promedio de las desviaciones al cuadrado
de las observaciones respecto de la media del grupo.
El denominador n − 1 recibe el nombre de grados de libertad concepto que será denido un poco
más adelante.
La Fórmula (1.13) recibe el nombre de fórmula conceptual o fórmula de denición de la varianza.
A partir de la fórmula de denición se pude deducir la siguiente expresión para calcular la varianza
muestral denominada fórmula de cálculo de s2
2
s =
n
Pn
2
i=1 xi )
Pn
2
i=1 xi − (
(1.14)
n(n − 1)
A modo de ejemplo utilizaremos la Fórmula (1.14) para volver a calcular la varianza de los datos
del Ejemplo (1.12). Los cálculos auxiliares necesarios se disponen en la Tabla (1.12).
Observación
1
2
3
4
5
6
7
8
Total
x2
x
2
3
3
5
5
8
10
12
48
4
9
9
25
25
64
100
144
380
Tabla 1.12: Datos para el cálculo de la varianza
Por lo tanto
s2 =
8(380) − 482
= 13, 14
8×7
Valor que coincide con el calculado con la fórmula de denición.
Ejemplo 1.13 A partir de la fórmula de denición de s2 demostrar que s2 =
n
Pn
2
i=1 xi −
Pn
(
i=1 xi
2
)
n(n−1)
Solución
Pariendo de la fórmula de denición de la varianza muestral s2 tendremos:
Pn
2
2
i=1 (xi − x̄)
s =
n−1
Pn
2
2
i=1 (xi − 2xi x̄ + x̄ )
=
n−1
Por propiedades de la sumatoria se obtiene
Pn
2
i=1 xi − 2x̄
Pn
i=1 xi + x̄
2
Pn
i 1
n−1
Pn
Pn
Pn
xi
Como x̄ = i=1
⇒ i=1 xi = nx̄. Además, i=1 1 = n. Reemplazando estas cantidades en la
n
s2 =
expresión anterior obtendremos:
s2 =
Pn
2
2
2
i=1 xi − 2nx̄ + nx̄
n−1
Realizando un nuevo reemplazo se obtiene
31
Pn
=
2
2
i=1 xi − nx̄
n−1
P
2
( ni=1 xi )
2
2
i=1 xi − n
n
Pn
2
s =
(
2
i=1 xi −
Pn
=
n−1
Pn
i=1 xi
)
2
n
n−1
Finalmente
n
2
s =
Pn
2
i=1 xi −
(
Pn
i=1 xi
)
2
⇒ s2 =
n
n−1
n
Pn
2
i=1 xi − (
2
i=1 xi )
Pn
n(n − 1)
como se quería demostrar.
Desviación estándar
La varianza tiene el inconveniente de que, por su denición, estará medida en unidades de la variable
al cuadrado, como dólares al cuadrado, kilogramos al cuadrado, etc. Esto diculta la interpretación
práctica de su resultado.
Por este y otros motivos que analizaremos más adelante, se dene una medida de variabilidad
derivada de la varianza llamada desviación estándar.
Denición 1.11 Para un conjunto de n observaciones provenientes de una muestra, la desviación
estándar muestral se dene como igual a la raíz cuadrada positiva de la varianza. Se la simboliza
con la letra s.
Es decir
√
s=
Teniendo en cuenta los datos del Ejemplo (1.12) obtenemos s =
La varianza poblacional se dene de la siguiente manera:
σ2 =
(1.15)
s2
PN
2
i=1 (xi − µ)
N
√
13, 14 = 3, 62.
(1.16)
Donde N es el tamaño de la población y µ su media. La letra griega σ recibe el nombre de sigma.
La desviación estándar poblacional se dene como la raíz cuadrada positiva de la varianza.
O sea
√
σ=
σ2
(1.17)
Observe que el denominador de σ 2 es N y el de s2 es n − 1, ¾por qué esta diferencia?
Como todo parámetro, la varianza poblacional en general es desconocida y debe ser estimada.
Suena lógico entonces que se elija el mejor estimador para realizar la estimación.
Bajo ciertas condiciones que analizaremos másP
adelante, puede demostrarse que el mejor estimador
de la varianza poblacional se logra dividiendo ni=1 (xi − x̄)2 por sus respectivos grados de libertad
n − 1.
Téngase siempre presenta que:
Si el objetivo analítico consiste unicamente en describir la variabilidad que presenta las
observaciones de una muestra, es perfectamente satisfactorio calcular s2 dividiendo por n
solamente . Paro si el propósito es estimar σ 2 por medio de s2 debe calcularse la varianza
muestral dividiendo por n − 1
32
Coeciente de variación
Una comparación directa de dos o más medidas de dispersión, por ejemplo, la desviación estándar
de la renta mensual de los empleados de una empresa y la desviación estándar del número de
inasistencias mensuales al trabajo del mismo grupo de empleados no tiene sentido.
¾Se puede decir que la desviación estándar de 1.200 pesos para la variable renta mensual es mayor
que la desviación estándar de 4, 5 días para la variable número de inasistencias al trabajo?
Es obvio que no porque no se pueden comparar directamente unidades monetarias y días de inasistencias al trabajo. Se trata de dos variables diferentes.
Con el n de realizar una comparación signicativa de la variabilidad de las rentas y de las inasistencias manuales al trabajo, es necesario convertir cada una de estas medidas en una expresión
relativa, es decir, en un porcentaje.
Analicemos esta otra situación. Si se comparan las desviaciones estándar de las ventas de los
grandes y pequeños comercios que venden productos similares, casi siempre la desviación estándar
de los grandes comercios será mayor que la de los pequeños, no necesariamente porque exista mayor
variabilidad en las ventas sino simplemente por las diferencias en las escalas de medición.
Las ventas de los grandes comercios pueden medirse en millones de pesos al mes y la de los pequeños
comercios en cientos de miles.
La comparación de la variabilidad de las ventas utilizando solamente la desviación estándar puede
resultar engañosa.
El coeciente de variación de Pearson es una medida de variabilidad relativa que puede utilizarse
para comparar la variabilidad de dos conjuntos de observaciones.
Es una medida de dispersión muy útil cuando:
Los datos están medidos en unidades diferentes
Los datos están en las misma unidades pero en escala muy diferente
El coeciente de variación de Pearson, simbolizado CV, es una medida de dispersión relativa que
expresa la desviación estándar como porcentaje de la media (siempre que la media sea positiva).
El coeciente de variación poblacional se dene mediante la siguiente expresión:
CV =
σ
× 100
µ
(1.18)
Por otro lado, el coeciente de variación muestral se dene así:
CV =
s
x̄
× 100
(1.19)
Supongamos que un conjunto de datos pertenecientes a una muestra de cierta población tiene una
media x̄ = 44 y una desviación estándar s = 8.
Su coeciente de variación muestral vale:
CV =
8
44
× 100 = 18, 2 %
Supongamos otro conjunto de datos con una media x̄ = 2.440 y una desviación estándar s = 165, 65.
Este segundo conjunto de datos parece tener mayor variabilidad que el primero si la comparación
se hace solo con la desviación estándar.
Si calculamos el coeciente de variación para este grupo obtenemos
CV =
165, 65
2.440
100 = 6, 79 %
Evidentemente el segundo conjunto tiene menor variabilidad.
33
1.4. Reglas Empírica y Desigualdad de Chebyshev
La Regla Empírica y la Desigualdad de Chebyshev son dos reglas4 muy utilizadas para describir
conjuntos de datos pertenecientes a variables cuantitativas.
En las dos se combinan la media y la desviación estándar con el n de una mejor caracterización
de la información.
Como se verá, la Regla Empírica es más precisas que la Desigualdad de Chebyshev pero de aplicación mas restringida debido a las características particulares que deben tener las observaciones.
Por otro lado la Desigualdad de Chebyshev es menos precisa que la Regla Empírica, pero más
general pues se aplica a todo conjunto de observaciones, siempre y cuando pertenezcan a una
variable cuantitativa.
1.4.1. Regla empírica
La Regla Empírica arma lo siguiente:
Para un conjunto de observaciones de una variable con una distribución de frecuencias con forma
de campana, el intervalo
µ ± σ = [µ − σ ≤ X ≤ µ + σ] contiene aproximadamente el 68 % de las observaciones
µ ± 2σ = [µ − 2σ ≤ X ≤ µ + 2σ] contiene aproximadamente el 95 % de las observaciones
µ ± 3σ = [µ − 3σ ≤ X ≤ µ + 3σ] contiene aproximadamente el 99 % de las observaciones
En la Figura (1.6) se muestra grácamente las armaciones de la Regla empírica.
Figura 1.6: Interpretación gráca de la Regla empírica
Si bien es cierto hemos enunciado la Regla empírica para datos de una población también se cumple
para las observaciones de una muestra.
Ejemplo 1.14 En una línea de producción se llenan automáticamente envases de plásticos con
detergente líquido. El peso de llenado es una variable que tiene una distribución de frecuencias
con forma de campana con un peso promedio de 16 gramos y una desviación estándar igual a 0,25
gramos. Describir la variable peso de llenado de los envases plásticos con detergente a partir de lo
enunciado por la Regla empírica.
4 En realidad son dos teoremas que daremos sin demostración
34
Solución
Datos:
X =Peso de llenado de los envases de plástico con detergente líquido
Parámetros de la variable: µ = 16 y σ = 0, 25gramos.
Por lo tanto, el intervalo:
µ ± σ = 16 ± 0, 25 = [15, 75 ≤ X ≤ 16, 25] contendrá aproximadamente el 68 % de los pesos
de los envases
µ ± 2σ = 16 ± 2(0, 25) = [15, 50 ≤ X ≤ 16, 50] contendrá aproximadamente el 95 % de los
pesos de los envases
µ ± 3σ = 16 ± 3(0, 25) = [15, 25 ≤ X ≤ 16, 75] contendrá aproximadamente el 99 % de los
pesos de los envases
1.4.2. Desigualdad de Chebyshev
La desigualdad de Chebyshev arma que:
Para todo conjunto de datos,
y para toda constante k > 1, el intervalo µ ± kσ contiene al menos o
por lo menos el 1 − k12 100 % de las observaciones.
Por ejemplo:
Si k = 2, el intervalo µ ± 2σ = [µ − 2σ ≤ X ≤ µ + 2σ] contendrá por lo menos o al menos
1 − 212 = 34 o el 75 % de las observaciones de la variable
Si k = 3 el intervalo µ ± 3σ = [µ − 3σ ≤ X ≤ µ + 3σ] contendrá por lo menos o al menos
1 − 312 = 89 o el 8 % de las observaciones
etc.
La desigualdad de Chebyshev también se cumple para muestras tomadas de poblaciones.
Ejemplo 1.15 Los datos de la Tabla (1.13) representan los porcentajes de la renta mensual familiar asignada a la compra de alimentos en una muestra de 30 familias de cierta ciudad.
26
29
33
40
35
28
39
24
29
26
30
49
34
35
42
37
31
40
44
36
33
28
29
32
37
30
26
41
45
35
Tabla 1.13: Datos para el Ejemplo 1.15
1. Calcular la media, la varianza y la desviación estándar de la variable porcentaje de la renta
mensual familiar destinada a la compra de alimentos por las familias de la ciudad
2. Aplique la desigualdad de Chebyshev para k = 2 y comente los resultados obtenidos
Solución
Primer punto:
En primer lugar se calcula la media de la muestra:
x̄ =
26 + 28 + · · · + 37 + 35
= 34, 10
30
35
Luego estas 30 familias gastan en promedio el 34, 10 % de su renta mensual en la compra de
alimentos.
La varianza de la muestra es:
s2 =
Por lo tanto, s =
√
(26 − 34, 1)2 + (28 − 34, 1)2 + · · · + (35 − 34, 1)2
= 40, 195
3−1
40, 195 = 6, 34
Segundo punto:
Hemos visto que si k = 2 la regla de Chebyshev asegura que por lo menos el 75 % de las observaciones estarán en el intervalo x̄ ± 2(s).
Por lo tanto
x̄ ± 2(s) = 34, 10 ± 2(6, 34) = 34 ± 12, 68
Luego, el intervalo [21, 42 ≤ X ≤ 46, 78] debe contener al menos o por lo menos el 75 % de los
datos.
Si se observa la información de la Tabla (1.13) puede vericarse que solamente x = 49 no pertenece
al intervalo.
O sea , 29
30 = 0, 96 o el 96 % de las observaciones están incluidas en el intervalo [21, 42 ≤ X ≤ 46, 78].
Se cumple holgadamente la regla de Chebyshev.
1.5.
Medidas de localización relativa. Detección de valores
atípicos
En las secciones anteriores se han denido e interpretado algunas medidas de localización y de
dispersión que se utilizan para la descripción de un conjunto de observaciones de una variable
cuantitativa.
La media aritmética o promedio es una de las medidas de localización mas utilizada cuando se trata
de encontrar el centro de un conjunto de observaciones, mientras que la varianza y la desviación
estándar son dos de las más empleadas para estudiar la dispersión de las observaciones respecto
de la media.
En realidad, cuando estas medidas se utilizan conjuntamente puede verse su potencial descriptivo.
Ya lo vericamos cuando estudiamos el coeciente de variación, la Regla empírica y la Desigualdad
de Chebyshev.
Ahora vamos a denir una nueva medida descriptiva cuyo objetivo es el de determinar la posición
relativa de una observación respecto del conjunto de observaciones.
Recibe el nombre de valor z y la denimos a continuación.
Denición 1.12 Sean x1 , x2 , ..., xn , observaciones pertenecientes a una muestra de tamaño n
tomada de una población. El valor zi asociado a la observación xi se dene de la siguiente manera:
zi =
xi − x̄
s
(1.20)
donde x̄ y s son la media y la desviación estándar de la muestra.
Con frecuencia al valor zi se lo denomina valor estándar de xi .
El valor de zi se puede interpretar como la cantidad de desviaciones estándar que dista xi del
promedio x̄.
Por ejemplo, si z1 = 1, 2 esto indica que x1 es 1, 2 desviaciones estándar mayor que la media de la
muestra.
36
O sea, si
x1 − x̄
⇒ x1 = x̄ + 1, 2(s)
s
1, 2 =
Igualmente, si z2 = −0, 5 esto quiere decir que x2 se encuentra 0, 5 desviaciones estándar debajo
de la media.
Es decir, si
−0, 5 =
x2 − x̄
⇒ x2 = x̄ − 0, 5(s)
s
Como puede deducirse de lo expuesto, los valores de z mayores que cero se dan en observaciones
mayores que la media, y los menores que cero en observaciones menores que la media.
Un valor de z igual a cero indica que el valor de la observación es igual a la media.
O sea
x − x̄
= 0 ⇒ x − x̄ = 0 ⇒ x = x̄
s
Ejemplo 1.16 El siguiente conjunto de datos 45, 54, 42, 46, 32 corresponden a una muestra de
tamaño n = 5 tomadas de una población. Calcular los valores z para cada una de las observaciones
xi .
Solución
La media o promedio de las 5 observaciones es:
x̄ =
45 + 54 + · · · + 32
= 44
5
Varianza
s2 =
P5
2
i=1 (xi − x̄)
n−1
=
(46 − 44)2 + (54 − 44)2 + · · · + (32 − 44)2
= 64
4
√
Por lo tanto, s = 64 = 8
Para x1 = 54 su valor z1 es
z1 =
46 − 44
= 0, 25
8
z2 =
54 − 44
= 1, 25
8
Para x2 = 54
Continuando de la misma manera se obtienen los valores z para el resto de las observaciones.
En la Tabla (1.14) se muestran los valores originales de la variable y sus respectivos valores z .
Valores x
46
54
42
46
32
xi − x̄
2
10
-2
2
-12
Valores z
0,25
1,25
-0,25
0.25
-1.50
Tabla 1.14: Valores z para los datos del Ejemplo 1.16
Volvamos nuevamente a la Regla Empírica que fuera analizada anteriormente.
37
Esta regla arma que para una variable con una distribución de frecuencias con forma de campana,
el intervalo
µ ± σ = [µ − σ ≤ X ≤ µ + σ] contiene aproximadamente el 68 % de las observaciones
µ ± 2σ = [µ − 2σ ≤ X ≤ µ + 2σ] contiene aproximadamente el 95 % de las observaciones
µ ± 3σ = [µ − 3σ ≤ X ≤ µ + 3σ] contiene aproximadamente el 99 % de las observaciones
¾Como se modica el enunciado de la Regla empírica si estandarizamos los valores extremos de
cada uno de los intervalos?
Para el primer intervalo, el valor estandarizado del extremos inferior es:
µ−σ−µ
= −1
σ
z1 =
Para el mismo intervalo el valor estandarizado del extremos superior es:
z2 =
µ+σ−µ
=1
σ
Utilizando los valores estandarizados de los extremos del intervalo, el primer punto de la Regla
empírica arma entonces que el intervalo [−1 ≤ Z ≤ 1] contiene aproximadamente el 68 % de las
observaciones de la variable.
Si procedemos de la misma manera para el segundo intervalo obtendremos los siguientes resultados:
El valor estandarizado del extremos inferior es:
z1 =
µ − 2σ − µ
= −2
σ
El valor estandarizado del extremos superior es:
z2 =
µ + 2σ − µ
=2
σ
Utilizando los valores estandarizados de la variable X , el segundo punto de la Regla empírica
armaría entonces que el intervalo [−2 ≤ Z ≤ 2] contiene aproximadamente el 95 % de las observaciones de la variable.
Procediendo de la misma manera con los extremos inferior y superior del tercer intervalo se llega a
la conclusión que el intervalo [−3 ≤ Z ≤ 3] contiene aproximadamente el 99 % de las observaciones
de la variable.
Estos resultados se resumen en la Tabla (1.15).
Intervalo
1
2
3
Extremos no estandarizados
Extremos estandarizados
[µ − σ < X < µ + σ]
[µ − 2σ < X < µ + 2σ]
[µ − 3σ < X < µ + 3σ]
[−1 < Z < 1]
[−2 < Z < 2]
[−3 < Z < 3]
Tabla 1.15: Regla empírica. Extremos estandarizados
La Figura (1.7) se muestra la relación entre los extremos no estandarizados y estandarizados de
una variable cuantitativa X la cual cumple con las condiciones de la Regla empírica.
El valor z de una observación es una valiosa herramienta para determinar si un valor de una variable
puede clasicarse como atípico.
Recordemos que la Regla empírica expresa en uno de su puntos que aproximadamente el 95 % de
las observaciones se encuentran comprendidas en el intervalo [µ−2(σ) ≤ X ≤ µ+2(σ)]. Analicemos
detenidamente este enunciado con la ayuda de la Figura (1.7).
38
Figura 1.7: Regla empírica. Extremos estandarizados
A partir de la gura puede apreciarse que por debajo del valor µ − 2(σ) solo se encuentra el 2,35 %
de las observaciones de la variable y que por encima del valor µ + 2(σ) el 2,35 % restante.
Es tan bajo el porcentaje de observaciones que son menores a µ − 2σ o mayores que µ + 2σ que,
de registrarse un valor en esa región, deberá analizarse como un posible valor extremo. También
puede tratarse de un valor mal registrado.
Recordemos que los valores extremos pueden inuir en el cálculo de algunas medidas descriptivas
numéricas como la media, el rango, la varianza etc.
¾Como se procede si se encuentra una observación que pertenece al 2,35 % superior o inferior del
conjunto de observaciones?
Si se trata de un valor mal registrado se lo corrige. Si se trata de un valor bien registrado puede
optarse por:
Eliminar directamente la observación y realizar el análisis previsto
No eliminarla. Esta observación podría estar reejando alguna característica particular de la
variable analizada
Si en lugar de realizar este análisis con los valores originales de la variable lo hacemos con sus valores
estandarizados, se puede considerar como un posible valor extremo toda aquella observación tal
que zi < −2 o bien zi > 2.
Ejemplo 1.17 A medida que los consumidores tienen más cuidado con los alimentos que consumen, los procesadores de alimentos tratan de ser competitivos en evitar cantidades excesivas de
grasas, colesterol y sodio en los alimentos que procesan. Los datos siguientes muestran las cantidades de sodio, por rebanada, para cada una de 8 marcas líderes de queso regular venidas en
cierto país: 340, 300, 520, 340, 320, 290, 260 y 330 miligramos. A partir de estos datos determine si
exististe algún posible valor atípico.
Solución
De acuerdo con los datos del ejemplo, el valor promedio del contenido de sodio en las rebanadas
de queso es:
x̄ =
340 + 300 + · · · + 330
= 337, 50 miligramos
8
En la Tabla (1.16) se presentan los cálculos auxiliares necesarios para calcula s2 .
Por lo tanto
s2 =
n
P8
2
i=1 xi −
P
n(n − 1)
8
i=1 xi
2
=
8 × 954.600 − 2.7002
646.800
=
= 6.192, 86
8×7
56
39
Observación
1
2
3
4
5
6
7
8
Total
x2i
xi
340
300
520
340
320
290
260
P 330
xi = 2.700
115.600
90.00
270.400
115.600
102.400
84.100
67.600
108.900
P
x2i = 954.600
Tabla 1.16: Cálculos auxiliares para calcular s2 . Ejemplo 1.17
En la Tabla (1.17) se presentan los valores originales de la variable y sus respectivos valores estandarizados.
Observación
1
2
3
4
5
6
7
8
xi
340
300
520
340
320
290
260
330
zi
-0,031
-0,476
2,319
0,031
-0,222
-0,603
-0,984
-0,095
Tabla 1.17: Valores estandarizados
De las 8 observaciones, x3 = 520 miligramos parece ser signicativamente diferentes a las demás.
Su valor estandarizado es:
z3 =
520 − 337, 5
= 2, 32
78, 69
Como z3 > 2 esta observación puede resultar un valor atípico con el criterio del 95 %.
1.6. Medidas de asimetría o sesgo
Como hemos visto anteriormente, la Regla empírica exige que la distribución de frecuencias de la
variable estudiada debe ser simétrica y con forma de campana.
Si embargo, existen variables cuyas distribuciones de frecuencias no son simétrica y que además
presentan algún tipo de sesgo a asimetría.
En la Figura (1.8) se muestra las tres formas características de distribuciones de frecuencias para
variables cuantitativas.
De la distribución ubicada en el extremo izquierdo de la Figura (1.8) se dice que tiene sesgo
negativo o que es sesgada a izquierda. Note que en este tipo de distribuciones la media, la
moda y la mediana guardan la siguiente relación: µ < Me < Mo
De la distribución ubicada en el centro de la gura se dice que es simétrica, insesgada o que
no tiene sesgo. En este tipo de distribuciones la media, la mediana y la moda son iguales, es
decir, µ = Me = M0
Por último, de la distribución ubicada a la derecha de la Figura (1.8) se dice que sesgada a
derecha o que tiene sesgo positivo. En este tipo de distribuciones la moda es menor que la
mediana y esta a su vez menor que la media. Es decir, µ > Me > Mo
40
Figura 1.8: Asimetría o sesgo de variables cuantitativas
Existen varias medidas descriptivas numéricas que son utilizadas para decidir el tipo de sesgo que
pueda tener la distribución de frecuencia de una variable cuantitativa.
Una de las más utilizadas es el coeciente de asimetría de Pearson que se dene de la siguiente
manera:
Denición 1.13 Para una variable cuantitativa de media µ, mediana Me y moda Mo el coeciente
de asimetría poblacional de Pearson se dene de la siguiente manera:
CA =
3(µ − Me )
σ
(1.21)
siendo σ la desviación estándar poblacional.
Por lo tanto:
Si la distribución es sesgada a izquierda µ < Me por lo tanto el coeciente de asimetría es
negativo
Si la distribución es simétrica µ = Me y el coeciente de asimetría será igual a cero
Si la distribución es sesgada a derecha µ > Me por lo tanto el coeciente de asimetría es
positivo
Observación 1.1 Si bien es cierto hemos denido el coeciente de asimetría de Pearson utilizando
la media, moda y mediana poblacionales, también se lo puede denir a partir de datos de una
muestra. En este caso, el coeciente de asimetría se dene de la siguiente manera:
CA =
3(x̄ − Me )
s
(1.22)
El coeciente de asimetría de Pearson es un número real comprendido en el intervalo real [−3, 3],
es decir −3 ≤ CA ≤ 3.
Cuanto más cerca sea su valor a algunos de los extremos del intervalo, más asimétrica (negativa o
positiva) será la distribución de frecuencia de la variable.
Por ejemplo, suponga que un conjunto de observaciones pertenecientes a una muestra tiene una
media x̄ = 2.436, una mediana Me = 2.459 y una desviación estándar s = 76, 7.
Por lo tanto
CA =
3(2.436 − 2.456)
= −0, 91
76, 7
Luego, la distribución es levemente sesgada a izquierda.
41
1.7. Distribuciones bidimensionales
En general, cuando se seleccionan unidades observacionales para algún estudio de interés, se registran valores de varias variables con el objetivo de lograr una descripción más completa de las
unidades.
Suponga que un analista de mercados selecciona un grupo de familias de cierta ciudad con el n de
realizar algún estudio socio-económico de interés para alguna empresa. Lo más probable es que no
solo se interese por los ingresos monetarios de las familias seleccionadas sino que además es muy
posible que registre los valores de otras variables como ser el número de integrantes por familia,
cuantos hijos tiene las familias en la universidad, cuantos adultos mayores residen en la casa, etc.
Existen muchas técnicas estadísticas diseñadas para el análisis de múltiples variables sobre cada
unidad observacional.
En esta sección veremos una de las herramientas más utilizadas para describir unidades observacionales en las cuales se registran los valores de dos variables.
Se trata de tablas de doble entrada. Cuando las dos variables son cualitativas reciben el nombre de
tablas de contingencia . Cuando las dos variables son cuantitativas reciben el nombre de distribución
conjunta.
1.7.1. Tabla para variables discretas. Distribución conjunta
En el caso que se analicen dos variables cuantitativas se llamara tabla de distribución conjunta a
la tabla que muestra los valores observado de las variables y las frecuencias (absolutas o relativas)
asociadas a cada par.
Ejemplo 1.18 Suponga que se recogieron datos sobre la evolución del stock de 40 empresas que si
bien es cierto llevan un control de inventario, tuvieron ruptura de stock en un período determinado.
Las empresas consideradas tienen características similares. En la Tabla (1.18) se presentan las
frecuencias absolutas para cada combinación de los valores de las variables.
Ruptura
1
2
3
Total
Producción en unidades
12.000 13.000 15.000
5
4
3
6
5
2
8
7
0
19
16
5
Total
12
13
15
40
Tabla 1.18: Datos para el Ejemplo 1.18
Analizando la información de la tabla precedente puede verse que:
Hay 5 empresas que producen 12.000 unidades y que han tenido una ruptura de stock
Ninguna empresa que produzca 15.000 unidades ha tenido 3 rupturas
Hay 13 empresas que han tenido 2 rupturas independientemente de las cantidades que producen
Hay 5 empresas que producen 15.000 unidades independientemente del número de ruptura
que hayan tenido
etc.
Si se divide cada una de las frecuencias absolutas de las celdas por 40 (total de empresas analizadas),
se obtienen las frecuencias relativas respecto de gran total.
Para los datos del ejemplo analizado las frecuencias relativas respecto del gran total se muestran
el la Tabla (1.19)
Algunas de las lecturas que pueden hacerse a partir de la Tabla (1.19) son las siguientes:
42
Rupturas
1
2
3
Total
Producción en unidades
12.000 13.000 15.000
0,125
0,10
0,075
0,15
0,125
0,05
0,20
0,175
0
0,475
0,40
0,125
Total
0,30
0,325
0,375
1,00
Tabla 1.19: Frecuencias relativas respectp del gran total
El 12,5 por ciento de las empresas producen 13.000 unidades y han tenido 2 rupturas de stock
El 37,5 por ciento de las empresas han tenido 3 rupturas independientemente de las cantidades
que producen
El 40 por ciento de las empresas produjeron 13.000 unidades independientemente de las
rupturas que hayan tenido
etc.
Los totales que aparecen en los márgenes de una tabla de contingencia reciben el nombre de totales
marginales.
Si cada una de las las se divide por el total de su la se obtienen las frecuencias relativas respecto
de los totales las. La Tabla (1.20) muestra los resultados para nuestro ejemplo.
Total
1
2
3
Total
Producción en unidades
12.000 13.000 15.000
0,42
0,33
0,25
0,42
0,39
0,15
0,53
0,47
0
0,475
0,40
0,125
Total
1
1
1
1
Tabla 1.20: Frecuencias relativas respecto de los totales las
Algunas lecturas que pueden hacerse a partir de la información suministrada por la Tabla (1.20)
son las siguientes:
De las empresas que han tenido 3 rupturas de stock ninguna produce 15.000 unidades
De as empresas que han tenido una ruptura el 33 por ciento produce 13.000 unidades
etc.
Finalmente, si cada una de las columnas de la tabla se divide por el total de la columna se
obtienen las frecuencias relativas respecto de los totales columnas. En la Tabla (1.21) se muestran
los resultados obtenidos para el ejemplo en desarrollo.
Rupturas
1
2
3
Total
Producción en unidades
12.000 13.000 15.000
0,26
0,25
0,60
0,32
0,31
0,40
0,42
0,44
0
1
1
1
Total
0,300
0,325
0,375
1
Tabla 1.21: Frecuencias relativas respecto de los totales columnas
Algunas lecturas que pueden hacerse a partir de la información suministrada por la Tabla (1.21)
son las siguientes:
43
De as empresas que producen 13.000 unidades, el 31 por ciento tuvo dos veces ruptura de
stock
De las empresas que producen 15.000 unidades, el mayor porcentaje de empresas tuvo una
sola ruptura de stock
etc.
1.7.2. Tablas para variables cualitativas
Si el análisis es de dos variables categóricas en forma conjunta, la presentación se hace por medio
de una tabla de contingencia.
En el cuerpo de la tabla se anotan las frecuencias conjuntas y en los márgenes las frecuencias
marginales que no son otra cosa más que las observaciones de una categoría en particular independientemente de la otra variable.
Por ejemplo, en la Tabla (1.22) se presenta una muestra de 40 casas de la ciudad en las cuales
se han registrado el tipo de vivienda (A, B y C) y la capacidad de las cocheras de cada tipo de
vivienda.
Vivienda
A
B
C
Total
Tipo de cochera
Ninguna Un auto Dos autos
2
4
4
2
12
3
5
5
3
9
21
10
Total
10
17
13
30
Tabla 1.22: Tipo de casa vs tipo de cochera
Las tablas de contingencia tienen el mismo tratamiento estadístico que las tablas de distribución
conjunta.
Se deja como actividad propuesta el análisis e interpretación de la información registrada en la
Tabla (1.22)
1.8. Medidas de asociación. Variables cuantitativas
Las secciones precelentes se dedicaron al estudio de algunas de las herramientas y técnicas más
utilizadas en la Estadística Descriptiva.
Se vio como seleccionar una muestra aleatoria simple, cómo organizar los datos recogidos en una
tabla de frecuencias, se emplearon grácos descriptivos para analizar la información contenida en
las tablas de frecuencias y se denieron varias medidas descriptivas numéricas con el n de describir
cuantitativamente las principales características de las observaciones.
En esta sección damos un paso más en la descripción de los datos estudiando la relación entre dos
variables cuantitativas.
Algunos de los problemas que pueden abordarse con las técnicas que estudiaremos en esta sección
son los siguientes:
¾Existe alguna relación entre los años de antigüedad de los empleados en una empresa y sus
ingresos?
¾Existe alguna relación entre los gastos en publicidad y las ventas posteriores en cierta
empresa?
¾Cómo se relacionan las notas de un estudiante en el nivel medio con sus notas en la universidad?
44
En esta sección deniremos tres herramientas estadísticas utilizadas para estudiar la forma y la
intensidad de la relación entre variables cuantitativas.
Ellas son:
Los diagramas de dispersión
La covarianza
El coeciente de correlación lineal de Pearson
1.8.1. Diagrama de dispersión
Supongamos que el administrador de un comercio está interesado en investigar la posible relación
entre la cantidad de comerciales por TV que aparecen los nes de semana en un canal local y las
ventas del comercio durante la semana posterior a la emisión de los comerciales.
En la Tabla (1.23) se presenta los datos de un muestra de 10 semanas donde las ventas se expresan
en miles de pesos.
Semana
1
2
3
4
5
6
7
8
9
10
Cantidad de comerciales X
2
5
1
3
4
1
5
3
4
2
Volumen de ventas Y
50
57
41
54
54
38
63
48
59
46
Tabla 1.23: Número de comerciales vs ventas posteriores
Aún cuando en la Tabla (1.23) se registran pocas observaciones, es muy difícil ver si existe alguna
relación entre las variables X e Y .
Podemos utilizar un diagrama de dispersión para investigar la posible vinculación entre los valores
de estas dos variables.
Un diagrama de dispersión consta de un par de ejes perpendiculares entre si. Vamos a anotar los
valores de la variable X (número de comerciales) en el eje horizontal. El eje vertical registramos
los valores de la variable Y (volumen de ventas).
Los valores de estas variables para la primera semana son x = 2 (dos comerciales) e y = 50 (ventas
por 50.000 pesos). En el diagrama de dispersión se graca un punto con esas coordenadas.
En la segunda semana se tienen los siguientes valores para las variables: x = 5 (cinco comerciales)
e y = 57 (ventas por 57.000 pesos). Se graca otro punto con estas coordenadas.
Con el resto de los valores de las variables X e Y de la Tabla (1.23) se procede de la misma manera
obteniéndose el diagrama de dispersión que se muestra en la Figura (1.9).
Como puede observarse en la Figura (1.9) que a mediada que los valores de la variable X aumentan,
los valares de la variable Y también aumentan.
En este caso se dice que existe una relación positiva entre las variables números de comerciales y
ventas posteriores.
La relación no es perfecta porque no existe una función de fórmula conocida cuyo gráco pase
exactamente por todos los puntos del diagrama de dispersión. Sin embargo el comportamiento
general de los puntos sugieren una tendencia también lineal.
En la Figura (1.10) se muestra una relación negativa donde Y tiende a disminuir a medida que X
aumenta. Tampoco aquí la relación es perfecta pero el comportamiento general de los datos sugiere
una tendencia lineal.
45
Figura 1.9: Diagrama de dispersión comerciales vs ventas
La Figura (1.11) siguiere que no existe una relación entre las variables X e Y . En este caso se dice
que las variables son independientes
Si bien es cierto los diagramas de dispersión son de gran ayuda para estudiar las posibles relaciones entre dos variables cuantitativas, siempre es conveniente acompañarlos de alguna medida
numérica que nos ayude a comprender mejor la naturaleza de la relación y que evite en lo posible
la interpretación subjetiva de un gráco.
A continuación presentamos la covarianza como una medida descriptiva numérica de asociación
lineal entre dos variables cuantitativas.
1.8.2. La covarianza
Para una muestra de n pares ordenados (x1 , y1 ); (x2 , y2 ); ...; (xn , yn ) de valores de las variables X
e Y la covarianza muestral se dene de la siguiente manera:
Pn
i=1 (xi − x̄)(yi − ȳ)
n−1
(1.23)
(x1 − x̄)(y1 − ȳ) + (x2 − x̄)(y2 − ȳ) + · · · + (xn − x̄)(yn − ȳ)
n−1
(1.24)
sxy =
O sea:
sxy =
En la fórmula que dene la covarianza, cada valor xi está apareado con un valor yi . Además, n es
el tamaño de la muestra.
Se calcula a continuación la covarianza entre las variables X e Y del ejemplo que estamos analizando.
30
Puede vericarse sin dicultad que x̄ = 10
= 3 y que ȳ = 510
10 = 51.
Por lo tanto
sxy =
(2 − 3)(50 − 21) + (5 − 3)(57 − 54) + · · · + (2 − 3)(46 − 51)
99
=
= 11
10 − 1
9
La fórmula para calcular la covarianza de una población de tamaño N es la siguiente:
PN
σxy =
i=1 (xi − µx )(yi − µy )
N
46
(1.25)
Figura 1.10: Relación negativa entre las variables X e Y
donde µx es la media de la variable X y µy es la media de la variable Y .
La covarianza poblacional en general se desconoce y si es necesario, se la estima por medio de la
covarianza muestra sxy .
Para ver como se interpreta este valor de la covarianza analizamos la Figura (1.12). Se trata del
mismo diagrama de dispersión de la Figura (1.9) al cual se la ha agregado una recta vertical trazada
x̄ = 3 y una recta horizontal trazada por ȳ = 51.
Figura 1.12: Interpretación de la covarianza
Al proceder de esta manera, el plano en el cual se encuentran los puntos del diagrama de dispersión
queda dividido en 4 partes o cuadrantes identicados como cuadrantes I, II, II y IV.
Los puntos del diagrama de dispersión ubicados en el primer cuadrante tienen la particularidad de que xi > x̄ e yi > ȳ . Por lo tanto, para estos puntos (xi − x̄)(yi − ȳ) > 0
Los puntos del diagrama de dispersión ubicados en el tercer cuadrante tienen la propiedad
de que xi < x̄ e yi < ȳ . Por lo tanto, también para estos puntos (xi − x̄)(yi − ȳ) > 0
47
Figura 1.11: Variables independientes
Los puntos ubicados en el segundo cuadrante tiene la propiedad de que xi < x̄ e yi > ȳ . Por
lo tanto, para estos puntos (xi − x̄)(yi − ȳ) < 0
Finalmente, los puntos ubicados en el cuarto cuadrante tiene la propiedad de que xi > x̄ e
yi < ȳ . Por lo tanto, para estos puntos también (xi − x̄)(yi − ȳ) < 0
Entonces, si el valor de sxy es positivo, esto implica que los puntos que tuvieron mayor peso para
determinar el signo de la covarianza están ubicado en el primer y tercer cuadrante.
Es decir, al aumentar los valores de X también aumentan los valores de Y y el diagrama de
dispersión debe tener una conguración como la de la Figura (1.9). Se dice entonces que las variables
tienen una relación positiva.
Si el signo de de sxy es negativo, los puntos de mayor inuencia en la determinación del signo
de la covarianza estarán en el segundo y cuarto cuadrante. El diagrama de dispersión tendrá una
conguración como el de la gura (1.10) (a), Es decir, a medida que aumentan los valores de X
disminuyen los de Y . En este caso se dice que entre las variables hay una relacinnegativa.
Por ultimo, si los puntos del diagrama de dispersión se distribuyen más o menos de manera uniforme
en los cuatro cuadrantes, los valores de los productos (xi − x̄)(yi − ȳ) con distintos signos se
compensarán y el valor de sxy será cercano a cero, indicando que no existe una asociación lineal
ente las variables X e Y .
Como en nuestro ejemplo el valor de la covarianza sxy = 11, esto indica que existe una relación
positiva entre las variables X e Y .
Un problema que surge con el uso de la covarianza como medida de la intensidad de la relación
lineal entre dos variables, es que su valor depende de las unidades en las que se registran las
variables. Además, valores extremos pueden hacer que aumente articialmente.
Para evitar estas y otras dicultades se dene el coeciente de correlación lineal de Pearson medida
descriptiva numéricas diseñada para cuanticar la intensidad de la relación lineal entre dos variables
cuantitativas.
1.8.3. Coeciente de correlación lineal de Pearson
Denición 1.14 Para los datos de una muestra de pares (xi , yi ) de los valores de las variables
cuantitativas X e Y el coeciente de correlación lineal de Pearson se dene de la siguiente manera:
rxy =
sxy
sx sy
48
(1.26)
donde
sxy es la covarianza de las variables X e Y
sx y sy son las desviaciones estándar muestrales de las variables X e Y respectivamente
Calculemos el coeciente de correlación lineal para los datos del ejemplo que estamos analizando.
Para la variable X :
s2x =
Por lo tanto sx =
q
P10
i=1 (xi − 3)
2
(2 − 3)2 + (5 − 3)2 + · · · + (2 − 3)2
20
=
10 − 1
9
=
10 − 1
20
9 = 1, 4907
Para la variable Y :
s2y =
Por lo tanto sy =
P10
2
i=1 (yi − 51)
10 − 1
q
=
(50 − 51)2 + (57 − 51)2 + · · · (46 − 51)2
566
=
10 − 1
9
566
9 = 7, 9303
Luego
rxy =
sxy
11
= 0, 93
=
sx sy
1, 4907 × 7, 9303
Una forma alternativa de calcular el coeciente de correlación lineal de Pearson es mediante la
Fórmula (1.27) que puede derivarse de la Fórmula (1.26) mediante algunas transformaciones algebraicas.
Pn
i=1 xi yi −
rxy = r
Pn
2
i=1 xi −
Pn
(
i=1 xi
)(
Pn
r n
Pn
2
Pn
( i=1 xi )
i=1 yi
2
i=1 yi −
n
)
(
Pn
i=1 yi
)
2
(1.27)
n
A manera de ejemplo calculamos rxy utilizando la Fórmula (1.28). Los cálculos auxiliares necesarios
se realizan en la Tabla (1.24).
Semana
1
2
3
4
5
6
7
8
9
10
Total
x
2
5
1
3
4
1
5
3
4
2
30
y
50
57
41
54
54
38
63
48
59
46
510
xy
100
285
41
162
216
38
315
144
236
92
1.629
x2
4
25
1
9
16
1
25
9
16
4
110
y2
2.500
3.249
1.681
2.916
2.916
1.444
3.969
2.304
3.481
2.116
26.576
Tabla 1.24: Cálculos auxiliares para determinar rxy
Por lo tanto
1.629 − 30×510
99
q 10
=√ √
rxy = q
= 0, 93
2
2
30
20 566
110 − 100
26.576 − 510
10
49
La expresión para calcular el coeciente de correlación poblacional es la siguiente
ρxy =
σxy
σx σy
(1.28)
donde
ρxy es el coeciente de correlación lineal de Pearson poblacional
σxy es la covarianza poblacional
σx y σy las desviaciones estándar poblacionales de las variables X e Y respectivamente
El coeciente de correlación poblacional generalmente es desconocido y de ser necesario se lo estima
por medio del muestral rxy .
Una vez calculado el coeciente de correlación de Pearson, hay que interpretar su valor. Para ello
analizamos la siguiente situación.
Consideremos las variables X e Y cuyos valores hipotéticos se muestran en la Tabla (1.25).
X
Y
1
2
3
10
30
50
Tabla 1.25: Valores de las variables X e Y
En la Figura (1.13) se muestra el diagrama de dispersión correspondiente a los datos de la Tabla
(1.25).
Figura 1.13: Interpretación del coeciente de correlación rxy
La recta que se trazó y que pasa por cada uno de los tres puntos indica que hay una relación lineal
perfecta entre los valores de las variables X e Y .
Realizando los cálculos correspondientes se obtiene el siguiente valor del coeciente de correlación
lineal para los datos de las variables X e Y :
rxy = p
220 − 6×90
p 3
=1
14 − 62 /3 3.500 − 902 /3
50
Como puede apreciarse, el valor del coeciente de correlación muestral para este conjunto de datos
particular es igual a 1.
En general, si todos los puntos de un conjunto de datos están alineados en una línea recta con
pendiente positiva, el valor del coeciente de correlación es +1.
Esto es, un coeciente de correlación muestral igual +1 corresponde a una relación lineal positiva
perfecta entre las variables X e Y .
Por otro lado, si los puntos de un conjunto de datos están alineados en una recta de pendiente
negativa, el valor del coeciente de correlación muestral será igual a −1.
Es decir, un coeciente de correlación muestral igual a −1 indica una relación lineal negativa
perfecta entre las variables X e Y .
Supongamos ahora que, para cierto conjunto de datos, hay una relación lineal positiva entre X e
Y pero que esta relación no es perfecta. El valor de rxy será menor que uno, lo que implica que los
puntos del diagrama de dispersión no están perfectamente alineados.
A medida que los puntos se desvían más y más de una relación lineal positiva perfecta, el valor del
coeciente de correlación rxy se hace más y más cercano a cero.
Un valor de rxy igual a cero indica que no hay relación lineal entre las variables. Los valores
del coeciente de correlación lineal cercanos a cero señalan una relación lineal débil. En general
−1 ≤ rxy ≤ 1.
En la Figura (1.14) se presentan los puntos del diagrama de dispersión de las variables cantidad
de comerciales y volumen de ventas y la recta que mejor se ajusta a los puntos del diagrama.
Figura 1.14: Recta de mejor ajuste entre el número de comerciales y ventas posteriores
Puede verse que si bien es cierto los puntos del diagrama de dispersión no están perfectamente
alineados, una recta de pendiente positiva puede utilizarse para describir aproximadamente la
relación entre las variables. Más adelante veremos como encontrar la ecuación de esta recta.
Estamos en condiciones de enunciar el siguiente resultado:
Si las variables X e Y son independientes, entonces rxy = 0 . Sin embargo, el enunciado recíproco
no es siempre verdadero pues puede ser rxy = 0 y aun así las variables no ser independientes
Recuerde que el coeciente de correlación lineal de Pearson mide la fuerza de la relación lineal
entre dos variables.
Las variables pueden estar relacionadas de manera no lineal y en ese caso rxy = 0 no porque no
estén relacionadas sino porque la relación no es lineal.
51